
3,4章
- 内置函数
第三章:内置函数,控制语句
(python中的变量赋值改变以后,内存会给变量一块新的地址空间)
-
- int(x,[,base]):将数值或字符串,转换成十进制。base有参数时,x必须是字符串而且得是base进制。print int('12345',8) # 5349
- all():函数全都不为0时,或者元素为空时返回ture。否则返回false
- range()函数生成的只是一个可以迭代的对象,打印出来不是列表。用list(range())将range返回的对象迭代成一个列表。
- format(value[,format_spec]):
- format(x,'6.3f') :其中6.3f 输出格式中规定浮点数是以总宽度6位、3位小数输出。
- 如实际小数位数不足3位,则补0;如小数位数超过3位,则多余部分四舍五入。
- print()函数里面 “ ”要和变量名用 , 隔开
2.语句结构
- 单分支(if 语句),双分支(If,else语句),多分支(if,elif,else)。多分支只执行第一个为true的语句,所以多分支的条件顺序会影响程序执行结果
- 循环结构:遍历循环(for ),条件循环(while,不知道循环多少次用这个方法)。
判断语句中常用的运算符==是判断两个对象是否相等,不是数值是否相等字母w=w。 条件循环是依靠一个条件来进行,循环体里面要给一个处理使得循环可以结束,条件计算结果不能一直是true,否则陷入死循环。
3. 循环结构的嵌套:
也要注意语句或者语句锻的所属层次,认清是外层循环还是内层。
break语句:break语句可以中断循环,一般需要和if一起使用,当遇到break语句时立刻跳出break所在 的循环,break之后在循环结构内的语句全都不执行。(循环结构语句和break不一定同一级)
for s in "python": for i in range(1,4): if s=="h": break print(s,end='/')
输出是p/p/p/y/y/y/t/t/t/o/o/o/n/n/n/
continue语句循环中断,后面语句不执行,判断下一次循环判断。
第四章 Python 组合数据类型
4.1 组合类型
基本数据类型:整型,字符串,逻辑型
组合类型:
- 序列(元素向量,元素之间存在先后关系)str list tuple
- 映射(键值对) dict
- 集合(无序不重复,固定数据类型)整型,字符串,元组
4.2列表
列表的每个元素可以不一样,可以是基本的,可以是组合数据类型。列表给列表赋值,是两个列表公用一个存储地址,改变其中一个值另一个也会变
l=list("北邮"),则list是['北','邮']
列表推导式:list=[表达式 for 变量 in 序列]
【0,1,2,3,4,5】北京邮电大学,逆向序【-6,-5,-4,-3,-2,-1】
list[:-4]从左边开始索引到序号-4(不包含)
- 根据列表的某一列大小删除整个一行(FPgrowth算法里面需要删除迭代字典,只能转成列表删除):
import numpy as np A = [[1, 2, ], [2, 3], [2, 2], [5, 4], [7, 7]] l = len(A) #取二维listA里面的第二列 countlist = [countl[1] for countl in A] for i in range(0,l): if countlist[i]<3: A=np.delete(A,[i],axis=0) print(A)
其中:函数取列表中的几列:
for i in range(num_feature):
feat_list = [example[i] for example in data_ch]
删除多维数组的行或列:np.delete。
参考https://blog.csdn.net/lanchunhui/article/details/65935814
https://blog.csdn.net/Chirszzz1/article/details/80340487
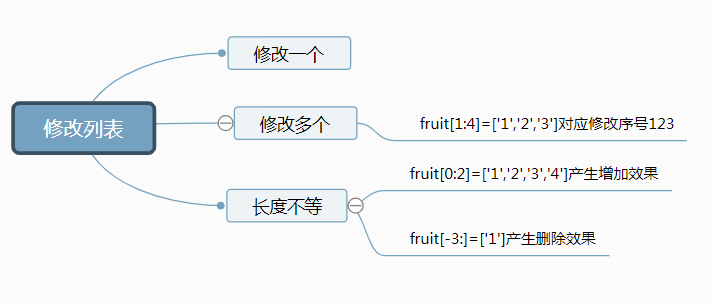
列表里面的序号操作【:2】是0,1。但是【-3:】是-3,-2,-1
增加,删除列表:表.insert 表.append() ,删除:del ,remove
列表生成表达式与生成器:https://www.cnblogs.com/jiangshitong/p/6700919.html
······················································
列表的生成表达式一直记不住,因为for语句里面会有一个i,暂时记忆为比for语句多一个变量,然后再把这个变量,这个变量有可能是for语句变量的一部分(即表达式),存到列表里面
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)]
这里面的v[0]就是v的第一个元素。v是一个字典中的Item
·························································
4.3 元组
- 定义:元素不可变,类型相同。(5,)单个元素的元组逗号不能少
- 生成器:元组的生成器是一种一次性的生成器算法。用tuple(g)把结果转化成元组
- 元组的元素不可变,但是元组的元素是列表时,二维元素是可变的
4.4 字典
(要对字典进行遍历删减的时候,千万不能直接遍历删减原字典,可以讲遍历语句的字典转换成list)
- 定义:赋值;dict()函数,{}fromkeys函数;字典的产生有一种dict1['a']=dict.get('a',0)+1:当字典里面没有a健的时候,会自动加一个a健。这个是字典的产生的同时完成计数。不只是计数。
x={i:(i+3)**2 for i in range(5)}:用列表的推导式产生字典。{0: 9, 1: 16, 2: 25, 3: 36, 4: 49}
- dict[item]取出的是对应的val值
- 删除:
pop(key[,default])删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
del dict['Name']; # 删除键是'Name'的条目。把name和对应的value都删除。
- 遍历字典:
遍历字典中的键:for key in dict或者for key in a.keys()。但是在“遍历中删除特定元素”这种特例,keys() 不再返回列表,而是被迭代对象的 dict_keys 属性,考虑 list 转换、待迭代结束后再 pop 或者使用字典推导式。
遍历字典项:for k,v in a.items():
- 排序
sorted(dic,value,reverse)
dic为比较函数,value 为排序的对象(这里指键或键值),经常用ambda函数
reverse:注明升序还是降序,True--降序,False--升序(默认)
sorted(dic.iteritems(), key = lambda asd:asd[1])中,第一个参数传给第二个参数“键-键值”,第二个参数取出其中的键([0])或键值(1])
- 字典转化成二维数组:
def dict(dic:dict): keys=dic.keys() vals=dic.values() L=[(key,val) for key,val in zip(keys,vals)] return L
- 字典根据val删键值对:
headerTable={'q': 2, 'w': 3, 'e': 2, 'p': 4, 's': 7} headertable={} l = len(headerTable) for k in headerTable.keys(): if headerTable[k] > 0.6 * l: headertable[k] = headerTable[k] print(headertable)for k in list(headerTable): #此处headerTable要取list,因为字典要进行删除del操作,字典在迭代过程中长度发生变化是会报错的 if headerTable[k] < minSup: del (headerTable[k])
4.5 集合
- 定义:赋值{},set(),frozenset()
- 删除:remove,discard,
4.6 字符串
判断子串是否在字符串里面,或者判断某个字母出现的次数,这时区分大小写
第六章 函数 模块
6.3 函数的参数
实参传递给形参,是将地址传递给形参。所以实参必须是不变对象(数值,字符,元组)
位置参数:多个参数时,要按照顺序赋值;关键字参数:赋值的时候带有形参关键字。
默认值参数:实参少于形参
可变数量参数:用*形参名来接受可变数量的参数(元组)
**:字典(for i in 字典:
print(i+":"+str(y[i]))) 就能输出键:值
实参是列表,字典,元组,集合时,在传递参数之前先给实参解包:*
dic={1:"x",2:"y",3:"z"}
print(*dic)
list1=[1,2,3]
print(*list1)
tup=(1,2,3)
print(*tup)
set_1={1,2,3}
print(*set_1)
输出都是1,2,3
返回值
函数内部用return返回函数结果,都是调用函数时要以表达式或者print调用,不然值显示不出来。
6.4 变量的作用域

局部变量和全局变量同名也没有影响,在函数体里面作变化的,或者print的是局部变量;在函数体之外的主程序里面做变化的,print的是全局变量
global可以在函数体内声明全局变量,这个时候global在函数内部一旦声明了同名全局变量,就是说可以在局部对全局变量进行更改。
同时:出现函数嵌套时,全局变量和局部变量变成外部函数和内部函数的对应,即现在外部函数相当于主程序。
6.5 lambda函数:就是def return的缩写
6.6 递归
在函数内部调用自己叫做递归。(核心思想:把大问题分解成小规模,与原问题有相同解法的问题)
特点:可以通过递归缩小问题的规模,而且新的小问题和原问题有相同的形式;必须存在使得递归结束的条件)
递归的思想是:
- 先递推:将复杂的问题一步步推到小规模的问题,自上而下逐渐调整参数,一直到达到终止条件
- 再回归,由已知 的终止条件返回值,一层一层直到得到初始问题的解
def Lf(n):#求斐波拉契数 if n==1: return 0 elif n==2: return 1 else: return Lf(n-1)+Lf(n-2) print(Lf(9))
虽然递归的思想是先递推再回归,但是在写程序时,先判断终止条件是否满足,回归初始值,然后再给出递推公式
蓝色字体重要,难理解的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号