


词嵌入
复习的时候可以看这个博客:https://blog.csdn.net/haoyutiangang/article/details/81213697
2.5 学习词嵌入
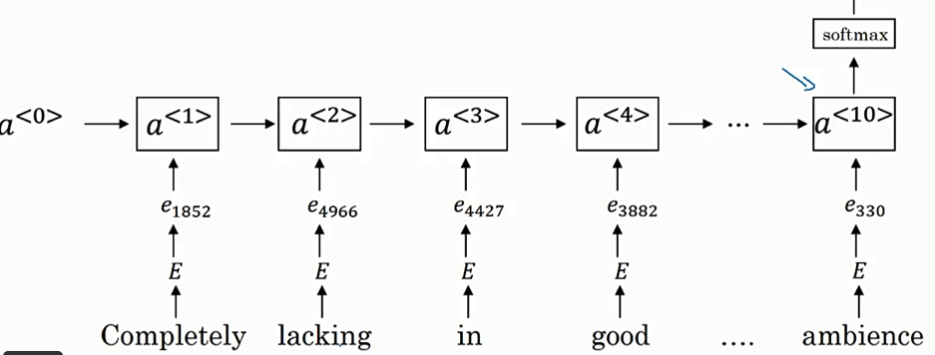
在构造语言模型里面:往往不是由一句话里面所有的词来预测下一个词,而是有一定的历史窗口(窗口的大小是一个超参数)
当窗口是4的时候:输入神经网络的向量大小是:4X300,
算法的参数是词嵌入矩阵,和隐层W,b,softmax的参数W,b
这个算法是让相似的词得到的词嵌入相似。词嵌入矩阵可以先初始化,算法想得到好的结果就需要不断地让相似的词的嵌入矩阵也相似。
如果要学习语言模型本身就可以选取目标词的上下文,如果要学习词嵌入可以用其他的上下文:
有三种方法选取上下文:前后n个词:
前一个词;
邻近词(并不是前一个词)
2.6 world2vc
分析句子做监督学习:在预料库里面选取一些词作为上下文,目标词在这些上下文的前后词距为10的这些单词里面
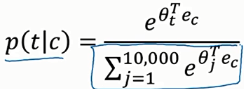
注意这个概率算出来是一个向量。
解决这个求和过大的问题(加速softmax的分类):使用一个分级的softmax滤波器
上下文的选取并不是随机的,而是采用某些方法来平衡常见词和非常见词
2.7 负采样
在词库里面随机选择一些词对来做标记,做一个监督学习的集合
2.8 Glove词向量
定义Xij为单词i出现在单词j前后的次数;如果定义上下文是词的前后十个单词之内的话,就有Xij和Xji对称

f(xij)是为了平衡log0的时候,让0 log0=0;且还可以衡量在英文中出现频率很高的词(停止词)一些适当又不是很大的权重,还有一些不常见的词给予一些相对小的权重。
这里的
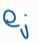 是等价的,所以在用梯度下降来让上面式子最小的时候,求两者的平均
是等价的,所以在用梯度下降来让上面式子最小的时候,求两者的平均
2.9 情绪分类
挑战:训练集不够多,但是词嵌入可以解决这个问题
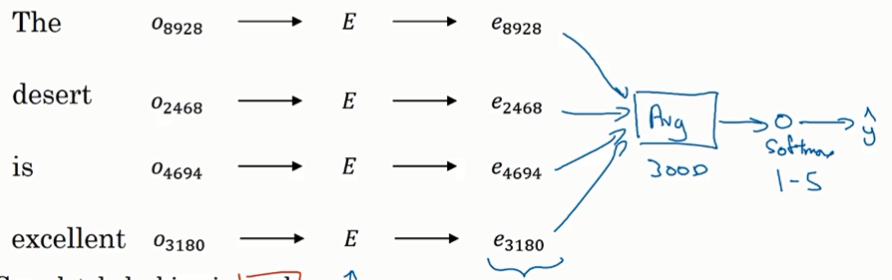
词嵌入矩阵E就是从大量文本中提取的。
这个算法的一个缺点就是没有考虑词序,只是考虑到了词出现的次数
改进:不用平均词嵌入,用RNN(多对一的模型)
2.10 减少偏见
减少机器学习算法所学到的一些社会上常见的偏见
第一:
第二步:中和步,把一些带有偏见的词做处理
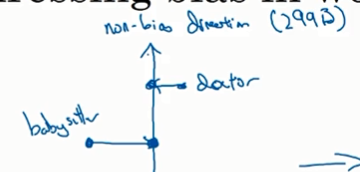
第三步:平衡步
保证像father ,mother这种带性别的词,和一些别的词有相同的相似度(距离)
将这两个词移动到中间轴对称位置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号