


序列模型
第一周
1.2
命名实体识别,符号
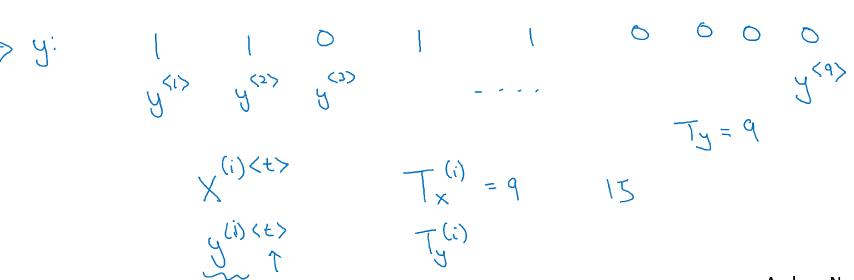
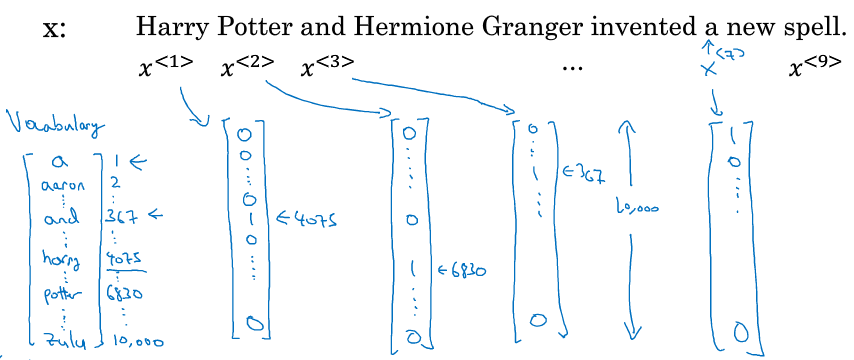
1.3 循环神经网络模型
注意前向传播公式和之前的不一样了。
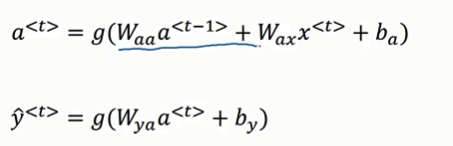
前向传播公式简写:
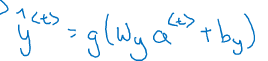
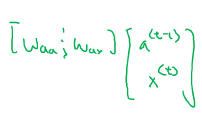
1.4 反向传播
![]()
这里的y是一种概率?y<t>的值就是0和1,但是y`的值是0-1中一个概率值,这里用交叉熵主要是让y`的值要么接近于1,要么接近于0??
总的损失函数不用求平均了直接相加:![]()
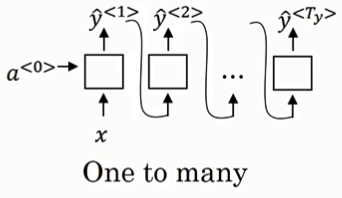
1.5 不同类型的循环神经网络
一对多结构:音乐生成,输入为类型输出为类型
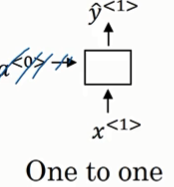
一对一结构:
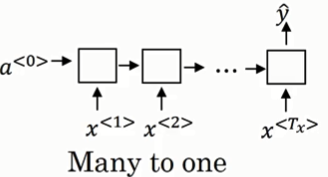
多对一结构:电影描述为输入,评价星级为输出
多对多(输入输出不同):
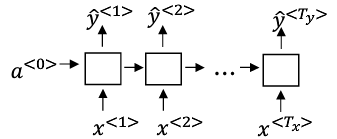
翻译“”:
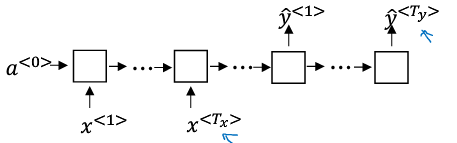
1.6 语言模型
给定一个句子序列,语言模型给出单词出现的概率
training set:很多很长的句子;将句子转化为onehot编码的一系列序列:(怎么感觉和通信里面的编解码很像) ,加入eos标志在句子后面表示一个句子的结束,
如果句子中出现词典里面没有的词,可以用UNK代替。
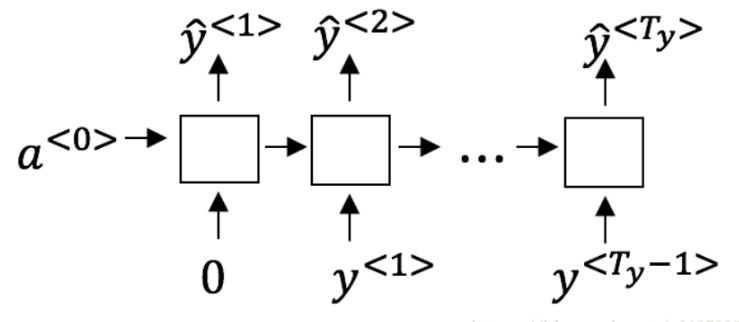
构建RNN:这个模型第一个时间步的x<1>输入的单词是0,第二个时间步输入的是y,所以和之前的不太像,这个第一时间步是为了计算一个单词在没有条件下是cat这个单词的概率。
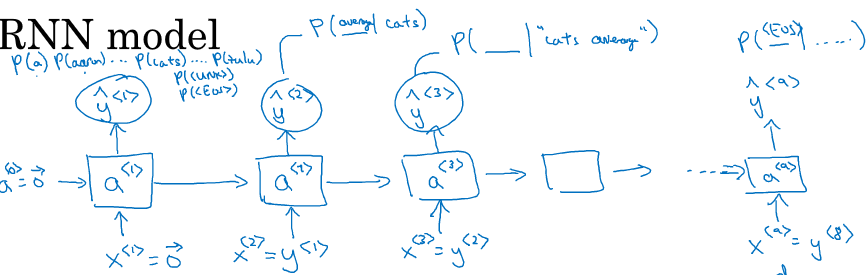
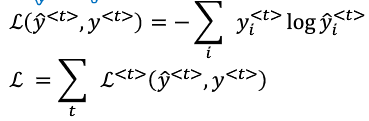 这里的 y^是一些概率但是y取值是0或1
这里的 y^是一些概率但是y取值是0或1
最后求单个单词同时出现的概率利用条件概率公式
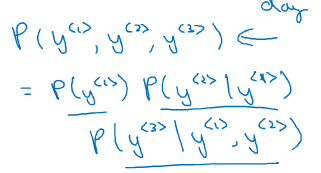
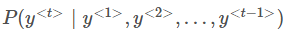
这个语言模型正在试着根据前面所有的知识来预测下一步
1.7 新序列采样(当训练模型结束之后看看模型学到了什么)
· 新序列采样和之前的创建模型又不一样:新序列的输入是前面的输出y^,而且这个y^是一个onehot的编码表示的随机函数选择的结果。而不是正在的单词y
输入a(0),X(1),输出值y1^,进行随机选择编码成onehot;再输入编码之后的值,输出值y2^
基于字符的模型:字典中就是大小写字母和数字;句子序列就变成了以字母为单了;
基于字符的模型不会出现未知词,但是基于单词的模型更能捕获前后单词之间的依赖
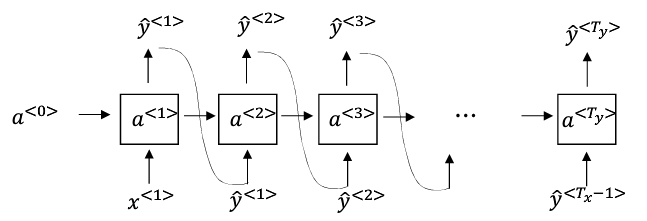
和上面那个手绘图不一样
1.8 梯度消失(导数呈指数级下降)
对于很深的神经网络,训练的时候后面的输出误差对前面的权重影响很小;所以在rnn中就会出现很难捕捉到很长的依赖关系。解决办法:GRU
对于梯度爆炸:用梯度修剪的方法来进行。
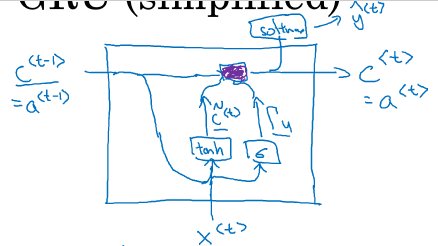
1.9 GRU单元
GRU和LSTM能够更好地捕捉到长范围的依赖,
GRU的示意图:
公式:
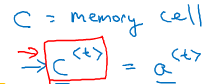
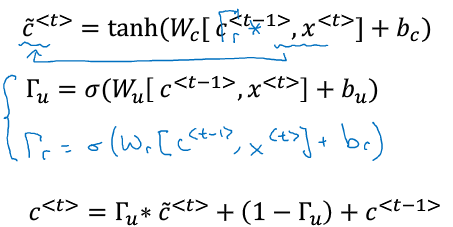
用c(t-1)和c(t)~来计算C(t),Tr是衡量下一个候选值与前面的关系、要使信号反向传播而不消失,我们需要 c<t>c<t>高度依赖于c<t−1>c<t−1>。
这里的sigmoid函数接近于0或1 ,所以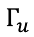 大多数都是很小的接近0的数,或者接近1的数
大多数都是很小的接近0的数,或者接近1的数
而且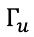 可以是一个向量,如果c(t)是一个向量,
可以是一个向量,如果c(t)是一个向量,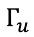 和c(t)维度相同是一个向量,而且
和c(t)维度相同是一个向量,而且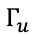 不同的元素对应不同的位置
不同的元素对应不同的位置
1.10 LSTM
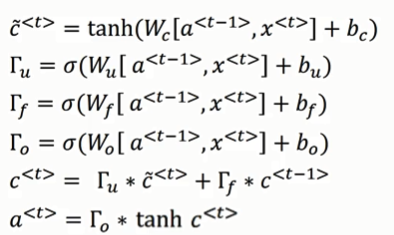
对于GRU来说,记忆门和遗忘门(1-),但是对于LSTM来说遗忘门和记忆门是相互独立的,且还有一个输出门
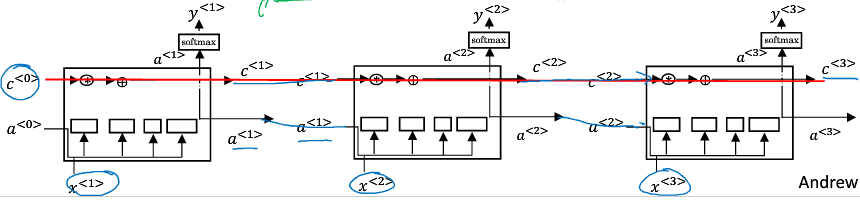
1.11 双向RNN
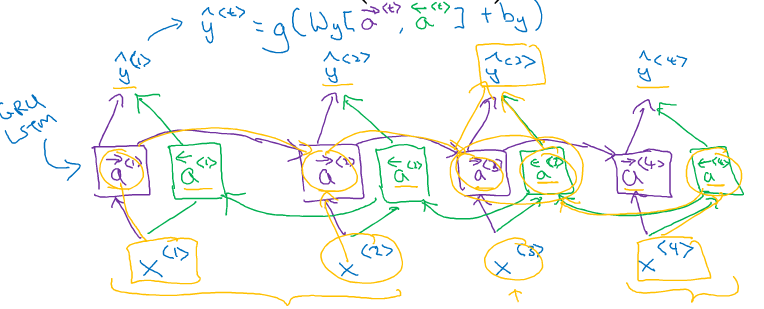
双向RNN,在预测的时候会考虑到前向信息和后向信息。在双向RNN里面的每一个单元都可以任意使用LSTM或者GRU和简单的RNN
1.12 深度神经网络
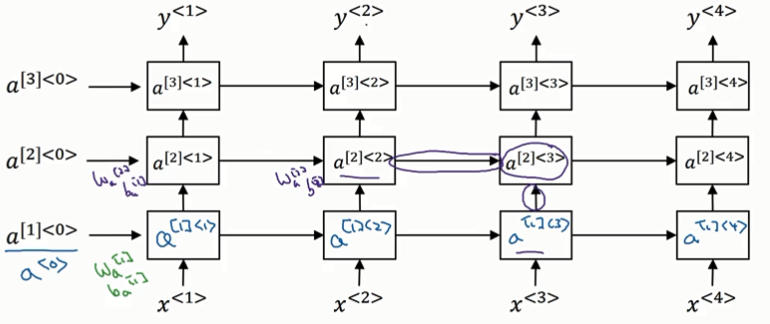
为什么每一层的w,b都一样??

 浙公网安备 33010602011771号
浙公网安备 33010602011771号