
卷积神经网络(第二周:深度神经网络;第三周:目标检测)
2.1 -2.2 实例分析
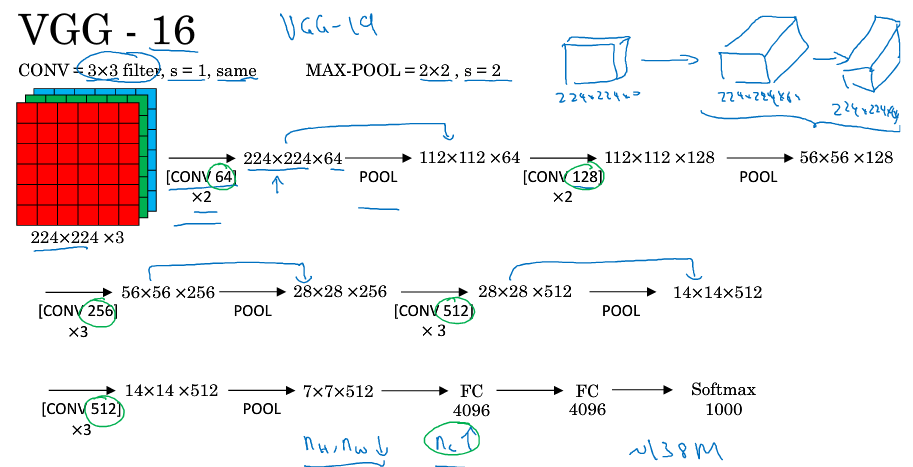
经典实例:LeNet-5;AlexNet;VGG;ResNet;Inception
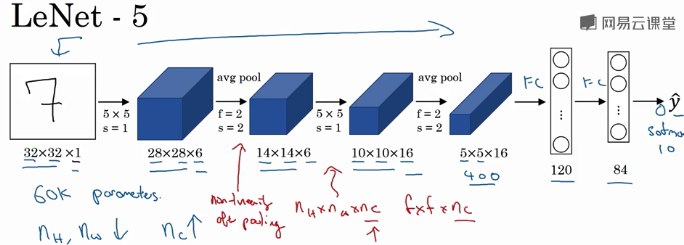
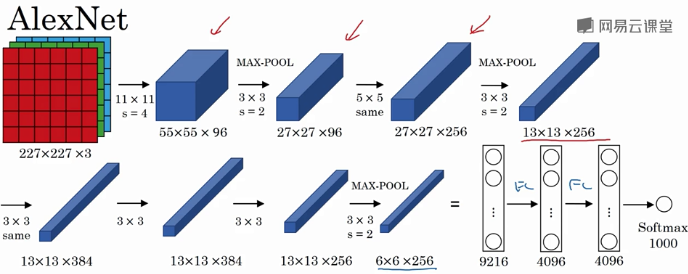
LRN现在都不用了
池化可以减小图片的像素,把某一点附近的最大匹配值留下。这样就做到不是逐一像素匹配,而是大概的区域匹配
卷积之后的relu非线性,感觉是为了让没有匹配上的区域值更小。
2.3--2.4 残差网络
将某一个激活值通过捷径送到深层神经网络里的某一层激活函数之前。
残差块:
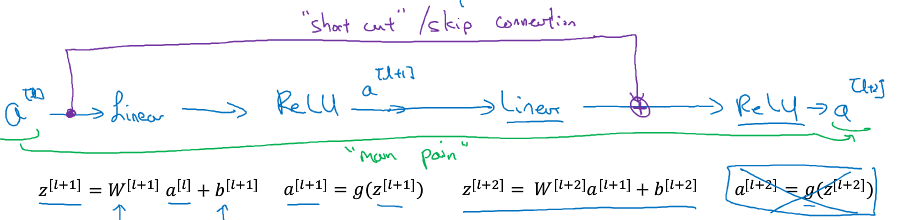
残差网络:就是每两层增加一个捷径。普通网络层数越多训练误差反而越来越大,而残差网络层数越多误差是越小的,可以解决梯度爆炸和梯度消失问题,
就像电路上引入误差的概念。
笔记:L2正则化的解释
https://www.cnblogs.com/yxwkf/p/5268577.html
为什么用学习恒等函数容易,可以提升神经网络的效率??
为什么捷径画出来是一条直线,这里面为什么要加一个ws???

2.5 1x1滤波器
二维矩阵乘以1x1的矩阵就是乘上一个数;但是三维的张量通过1x1xnc的滤波器,就是针对张量里面的一个1x1xnc的切片通过了一个全连接层(权重对应的是滤波器的值)
池化可以压缩宽高,但是1x1可以ya
还要注意的是我们说的通过滤波器其实之后一般还有一步是需要通过激活函数的。
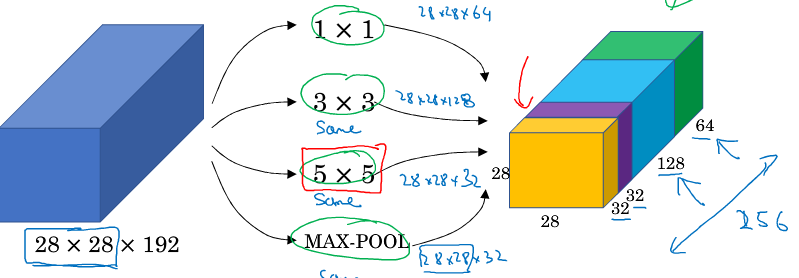
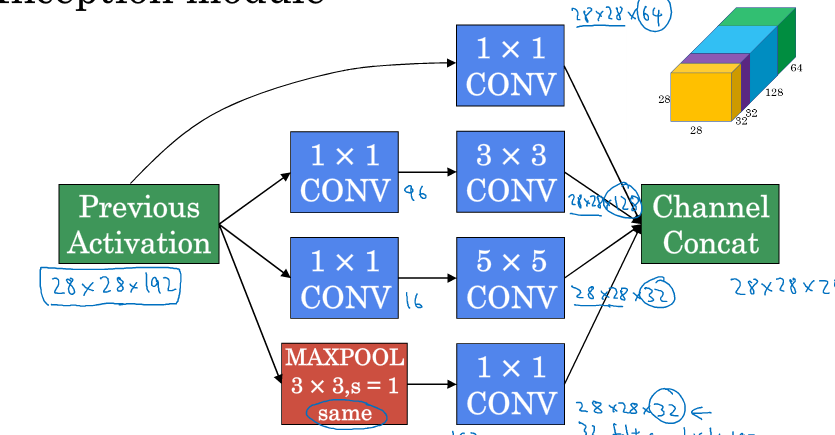
2.6 -2.7Inception
Inception来决定卷积层,池化层是否需要,滤波器的维度大小。(为什么用5x5的滤波器会提升网络性能)。可以把所有的滤波器可能性
参数都加上最后看输出。网络会自己学习
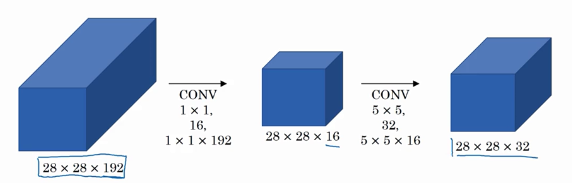
1x1卷积的作用:减少计算量。输入的128x128x192的张量---32个5x5x192滤波器需要计算的乘法数将近120亿
将大的输入层压缩成小通道的瓶颈层(网络中最小的),再扩大到输出层
但是这样不会在中间1x1卷积运算的时候丢失东西吗?为什么池化层是在池化之后加入1x1的滤波器
在进行5x5或者3x3滤波器之前都可以先通过一个1x1来减少通道数。
2.9迁移学习
用别人的代码和参数;把别人的参数当做初始参数,神经网络在迁移的时候把最后的softmax换成自己的softmax。
把中间层的参数当做冻结层,只训练softmax
2.10
垂直镜像对称,随机剪裁,旋转,剪切图像,局部弯曲
色彩转换:给rgn信道一定的失真;pca颜色增强。
第三周:目标检测
3.1 目标分类与定位
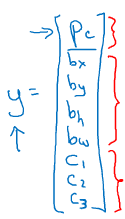
图片分类;分类与定位;目标检测(多个对象)。动作识别的输出会有一个softmax输出各种概率,还有坐标位置。(bx,by)是中心点坐标位置,pc是有无对象;bh,bw,c1,c2,c3就是输出的某一种种类的概率。

 ,
,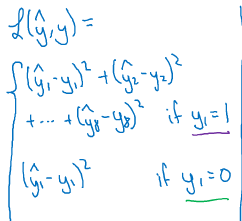
3.2特征点检测
例如:人脸识别中,在人脸上设置各种特征点。在数据集里面,特征点的含义要一致。
(x,y)输入卷积神经网络,x是一张图片;y是【有无人脸,各特征点的坐标值】
3.3 -3.4 目标检测,卷积滑动窗口的实现
滑动窗口目标检测算法:,标签训练集一开始要使用一些占大部分图片的汽车图像,判断有无汽车,输出为0或1训练完标签训练集之后,然后把要检测的图片按着滑动窗口分出一小块输入,然后移动再分割。遍历完整张图片之后,再用一个稍微大一点的窗口继续检测。
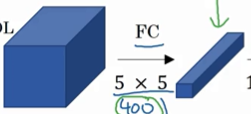
全连接层改成卷积层,这个跟之前讲的1x1的滤波器原理是一样的,只是1x1的滤波器会产生很多个,这里只需要一个所以滤波器的维度要和前面相同。
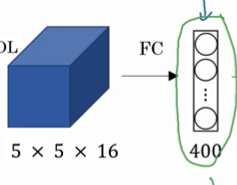 ------
------ 
直接用滑动窗口检测,会重复很多次的卷积运算,所以把全连接层换成卷积层;因为在卷积神经网络的运算中,之后的结果是成比例缩小像素,所以我们按着一开始的切割图像比列;来切割最后的结果就可以得到,滑动窗口检测很多次的结果。
不需要把图片切分成不同的部分来进行前向传播,可以一起进行卷积这样共享公共部分的计算。切割得到的份数可以用那个公式算,但是要注意的是那个公式算出来 的只是一个维度,这个份数应该是()/2+1 X ()/2+1
缺点:边界框的位置不太准确,
3.5 bounding box(获得准确的边界框)
有可能没有一个窗口可以准确匹配汽车的位置。Yolo比上一个滑动窗口更能准确获得边界框。上一个滑动窗口算法也只是输出了很多个0,1来判断哪一个窗口有对象。
yolo算法:将图片分割成若干份,每一份都运用目标分类与检测算法,将对象归于对象中心所在的格子;如果有格子存在两个中心点,则看做木有任何对象;就上一个例子而言则每一个分割格子输出都是一个8维的向量。这样经过卷积神经网络之后 就得到了精确的坐标。定义每一个方格的左上角是(0,0)点,右下角是(1,1)中心点坐标<1。但是宽高不小于1.
以下的课程都是用来优化yolo
3.6 并交比
判断对象的定位检测是否准确

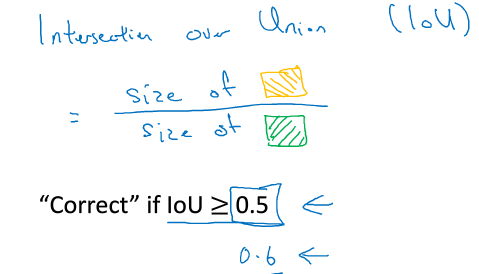
3.7 非最大值抑制(对象被多次检测)
输出pc值最大的框:先去掉pc<0.6的,留下pc值最大的,;再这个最大pc的边框有很大的lou的边框的输出都会受到抑制。
多个测试对象:车,人,摩托车时独立运用三次非最大值抑制

3.8 anchor box(可以检测多个对象的算法)
需要改变一下训练输出结果
 :
:
把每个格子和哪一个box交并比大,其输出结果判断是anchorbox中的哪一个;人工选择5-10个anchorbox,也可以用k-means选出一组;
有几个box,这里的定位检测的输出就会有几x(5+类别个数)维度,这

对于每一个小格子,都有2个被预测出来的bounding box;舍弃比较小的预测概率;对每一个种类使用非最大值抑制来做最好的判断。(这样可以判断出到底哪个框有哪一个种类
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号