

作业3.Spark设计与运行原理,基本操作
1.Spark生态系统的组成及各组件的功能(图文)
Spark大数据计算平台包含许多子模块,构成了整个Spark的生态系统,其中Spark为核心。
伯克利将整个Spark的生态系统称为伯克利数据分析栈(BDAS),其结构如图1-1所示。
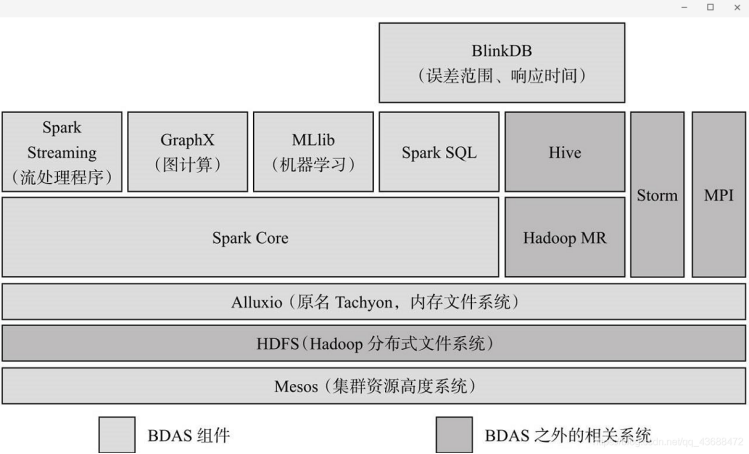
以下简要介绍BDAS的各个组成部分。
1. Spark Core
Spark Core是整个BDAS的核心组件,是一种大数据分布式处理框架,不仅实现了MapReduce的算子map函数和reduce函数及计算模型,还提供如filter、join、groupByKey等更丰富的算子。
Spark将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。其底层采用Scala函数式语言书写而成,并且深度借鉴Scala函数式的编程思想,提供与Scala类似的编程接口。
2. Mesos
Mesos是Apache下的开源分布式资源管理框架,被称为分布式系统的内核,提供了类似YARN的功能,实现了高效的资源任务调度。
3. Spark Streaming
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。其吞吐量能够超越现有主流流处理框架Storm,并提供丰富的API用于流数据计算。
4. MLlib
MLlib是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。MLlib目前支持4种常见的机器学习问题:二元分类、回归、聚类以及协同过滤,还包括一个底层的梯度下降优化基础算法。
5. GraphX
GraphX是Spark中用于图和图并行计算的API,可以认为是GraphLab和Pregel在Spark (Scala)上的重写及优化,与其他分布式图计算框架相比,GraphX最大的贡献是,在Spark上提供一栈式数据解决方案,可以方便、高效地完成图计算的一整套流水作业。
6. Spark SQL
Shark是构建在Spark和Hive基础之上的数据仓库。它提供了能够查询Hive中所存储数据的一套SQL接口,兼容现有的Hive QL语法。熟悉Hive QL或者SQL的用户可以基于Shark进行快速的Ad-Hoc、Reporting等类型的SQL查询。由于其底层计算采用了Spark,性能比Mapreduce的Hive普遍快2倍以上,当数据全部存储在内存时,要快10倍以上。2014年7月1日,Spark社区推出了Spark SQL,重新实现了SQL解析等原来Hive完成的工作,Spark SQL在功能上全覆盖了原有的Shark,且具备更优秀的性能。
7. Alluxio
Alluxio(原名Tachyon)是一个分布式内存文件系统,可以理解为内存中的HDFS。为了提供更高的性能,将数据存储剥离Java Heap。用户可以基于Alluxio实现RDD或者文件的跨应用共享,并提供高容错机制,保证数据的
可靠性。
8. BlinkDB
BlinkDB是一个用于在海量数据上进行交互式SQL的近似查询引擎。它允许用户在查询准确性和查询响应时间之间做出权衡,执行相似查询。
2.请详细阐述Spark的几个主要概念及相互关系:
Spark:高速的同意分析引擎
特点
Speed(在批处理和流处理都有很好的表现)
Easy of Use(可以使用Java、Scala、Python、R、SQL开发应用)
Generality(集成了SQL、Streaming、复制的分析)
Runs Everywhere(可以在Hadoop、Apache Mesos、standlone、或者cloud上运行)
RDD
弹性分布式数据集,是Spark的一个基本抽象;代表一个不可变的,可并行操作的,分区的元素集合
1.弹性:如果其中一个RDD计算失败,会从父RDD创建恢复计算
2.分布式: 支持分区,并行计算
五大特点
1.一个分区集合(A list of partitions)
2.计算每个分片的函数(A function for computing each split)
3.一个依赖于其它RDDS的列表(A list of dependencies on other RDDs)
4.键值RDD分区器(例如说RDD是hash分区的)(Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned))
5.计算每个每个分割的首选位置列表(例如块位置)(Optionally, a list of preferred locations to compute each split on (e.g. block locations for
an HDFS file)
Spark Context
1.是Spark 功能的主要入口
2.代表了一个Spark 集群的连接
3.可以在集群上创建RDD、累加器、广播变量
4.每个JVM上只有一个active的SparkContext
SparkConf
1.Spark应用程序的配置
2.以键值对设置Spark 参数
3.通过 New SparkConf 创建,然后以spark.*加载(load)数据
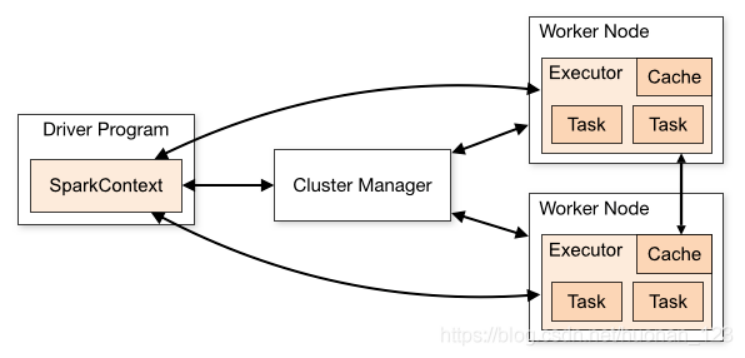
Spark 执行流程 如下图
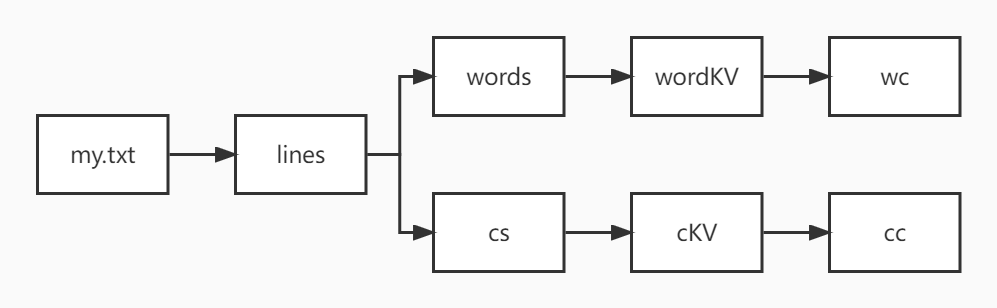
3.理解sc,RDD,DAG。请画出相应的RDD转换关系图。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号