
LLaMA大型语言模型
LLaMA (Large Language Model Meta AI)是Meta公司发布的大型语言模型系列,近日LLaMA种子文件被合并到了GitHub 上,同时一些项目维护者给予了批准,目前该项目在 GitHub 已收获 7k+ 个星。Meta 宣称LLaMA 规模仅为竞争对手 ChatGPT 的“十分之一”,但性能却优于 OpenAI 的 GPT-3 模型。
有网友认为这次泄露事件是 Meta 方有意为之,另外一些网友认为只是单纯地被泄露。目前,Meta 方面暂未对此事做出回应。有 Meta 员工表示:“Meta 员工可能没有注意到或仍在思考如何做出反应,因此 PR 仍在进行中。”
事实上,无论此事是否是 Meta 有意为之,在部分网友看来,LLaMA 原本的设定就是申请之后即可下载,“被公开是迟早的事情”。
什么是LLaMA
LLaMA是Meta(前脸书)于2月25日首次推出的大型语言模型,相当于超快超小型GPT-3,参数量只有后者的10%,只需要单张GPU就能运行。
公司 CEO 扎克伯格表示,LLaMA 旨在帮助研究人员推进研究工作,LLM(大型语言模型)在文本生成、问题回答、书面材料总结,以及自动证明数学定理、预测蛋白质结构等更复杂的方面也有很大的发展前景。能够降低生成式 AI 工具可能带来的“偏见、有毒评论、产生错误信息的可能性”等问题。

与 OpenAI 的 GPT-3 相比,Meta 在一开始就将 LLaMA 定位成一个“开源的研究工具”,该模型所使用的是各类公开可用的数据集(例如 Common Crawl、维基百科以及 C4)。项目组成员 Guillaume Lample 在推文中指出,“与 Chinchilla、PaLM 或者 GPT-3 不同,我们只使用公开可用的数据集,这就让我们的工作与开源兼容且可以重现。而大多数现有模型,仍依赖于非公开可用或未明确记录的数据内容。”
早在上周发布时,Meta 就曾表示,LLaMA 可以在非商业许可下提供给政府、社区和学术界的研究人员和实体工作者,正在接受研究人员的申请。此外,LLaMA 将提供底层代码供用户使用,因此用户可以自行调整模型,并将其用于与研究相关的用例。也就是说,各方贡献者也能参与进来,让这套模型变得越来越好。LLaMA 的官方博文也提到,“后续还需要更多研究,以解决大语言模型中的偏见、有害评论和捏造事实等风险。”
此次非正式开源,或将标志着这些科技巨头们最优秀的大语言模型,正以前所未有的速度进入全球千行百业中,未来将以更丰富的产品形式让用户享受到先进的 AI 技术。
超越 ChatGPT,LLaMA 强在哪里?
根据 Meta 官方发布的消息,LLaMA 是一种先进的基础语言模型,旨在协助研究人员在 AI 相关领域迅速开展工作。
据悉,LLaMA 跟 OpenAI 的 GPT-3 模型差不多,LLaMA 模型是根据世界上二十种最流行的拉丁语和西里尔字母语言文本训练而成的。论文《LLaMA:开放且高效的基础语言模型》(LLaMA:Open and Efficient Foundation Language Models)就将该模型与 GPT、Gopher、Chinchilla 及 PaLM 等同类成果做出了比较。后面这几种模型都用到了广泛的公共数据,但也引入了某些非公开可用或未记录在案的文本数据。LlaMA 则仅使用公开可用的数据集进行训练,所以虽然自身尚未开源,但该模型与开源原则完全兼容。
从某种意义上讲,LLaMA 是对 2022 年 3 月发表的 Chinchilla 模型及其论文《训练计算优化型大模型》(Training Compute-Optimal Large Models)的直接反应。通过加州大学伯克利分校、哥伦比亚大学、芝加哥大学和伊利诺伊大学在 2021 年 1 月合作进行的大规模多任务语言理解(MMLU)基准测试,这篇论文探讨了模型大小、算力预算、令牌数量、训练时间、推理延迟和性能等问题。
论文中的核心观点是,AI 训练与推理的最佳性能未必由大模型的参数量直接决定。相反,增加训练数据并缩小模型体量才是达成最佳性能的前提。这样的训练可能需要更多时间,但也会带来有趣的意外收获 —— 在推理新数据时,小模型的速度更快。为了证明这一点,Chinchilla 的创建者一年前曾建议在 2000 亿个令牌(一个令牌代表一个单词片段)上训练一套具有 100 亿参数的模型。与之对应,LLaMA 的创建者称自己的模型只有 70 亿个参数,且仍在“继续优化中”,但令牌量已经高达 1 万亿。
LLaMA 模型还分别使用 67 亿、130 亿、320 亿和 652 亿几种参数组合进行训练,其中体量较小的两种使用 1 万亿个令牌,后两种较大的使用 1.4 万亿个令牌。Meta Platforms 采取了 2048 个英伟达 Ampere A100 GPU 加速器配合 80 GB HBM2e 内存,使用 1.4 万亿个令牌对规模最大的 LLaMA-65.2B 模型进行了测试,且训练周期为 21 天(每 GPU 每秒 380 个令牌)。
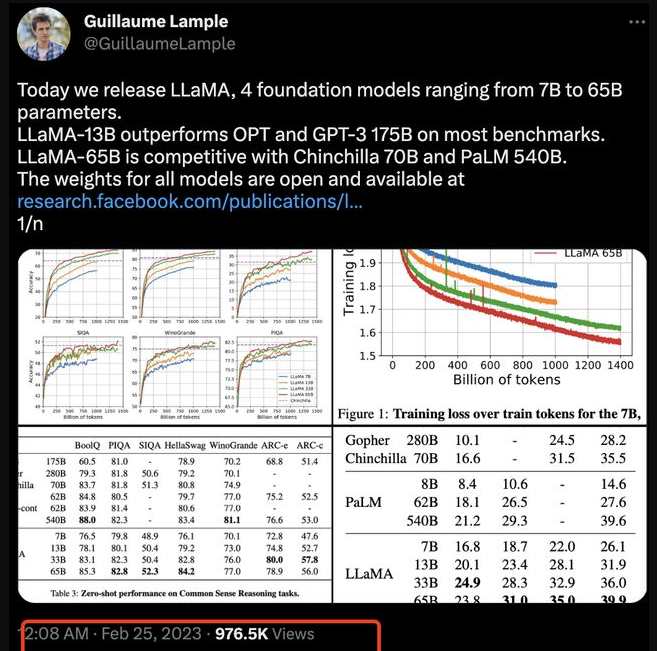
这样的速度并不算快,但 Meta AI 的研究人员表示,LLaMA-13B 模型“在大多数基准测试中都优于 GPT-3,且体积仅相当于后者的 1/139。”而且重点在于,“我们相信该模型有助于推动大语言模型的大众化普及,因为它完全能够在单 GPU 上运行。而且在规模化模型层面,我们的 65B 参数模型也完全能够与 Chinchilla 或者 PaLM-540B 等顶尖大语言模型相媲美。”
与其他同类大模型的性能对比
论文中列出大量性能比较,这里我们挑出几条来感受一下。下图展示了各模型在“常识推理”任务中的零样本性能表现:

零样本意味着利用一种数据训练而成的模型,对另外一种数据类型进行处理,且无需专门针对新类别做重新训练。(这也是大语言模型的强大之处,其具备自动扩展能力。)从表中的粗体部分可以看到,650 亿参数的 LLaMA 达成或超越了除 PaLM-540B 两个实例以外的其他所有模型,而且跟冠军的表现也相当接近。GPT-3 也在其中,其 1750 亿参数的版本虽然表现不错,但准确率也没有特别明显的优势。而且需要注意,GPT-3 的 1750 亿参数相当于 LLaMA-65B 的 2.7 倍。
在另一轮有趣的比较中,Meta Platforms 展示了 LLaMA 在人文、科学、技术与数学、社会科学及其他各领域的多选测试结果。我们来看以下图表:
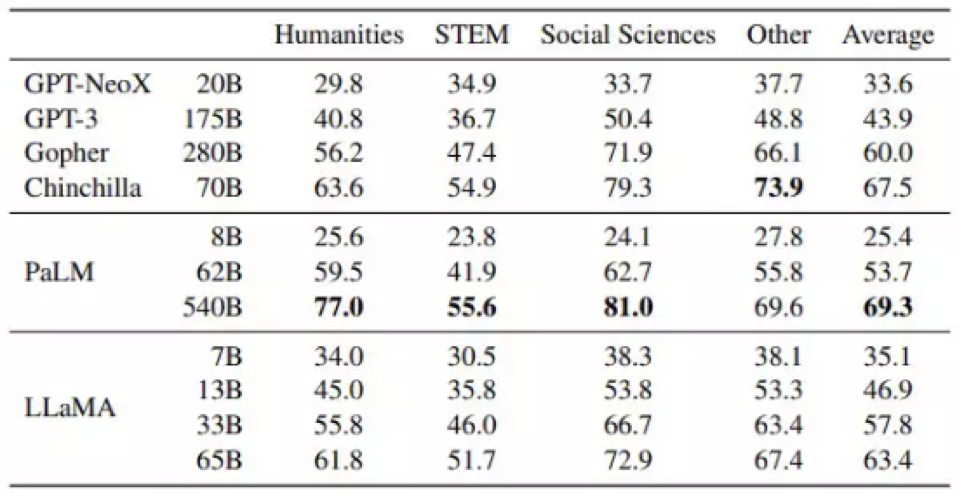
这里测试的是所谓 5-shot 准确率,也就是对于任何特定问题,源材料都至少对其提及 5 次,(随着每次提及,答案的确定性水平都会提高,这与人类推理的过程非常相似。这反映的是除了确切知晓之外,我们也往往能从多选题中推断出正确答案。)
下图也很重要,展示的是 LLaMA 在不同参数规模下,与 Chinchilla 模型之间的常识推理与问答基准测试差异:

如图所示,LLaMA-33B 和 LLaMA-65B 已经可以与 Chinchilla-70B 模型正面对抗,当令牌数量达到 1 万亿时甚至能够反超。
值得一提的是,在 NaturalQuestions 和 SIQA 问答测试中,这些基础模型都及不了格——准确率过低,甚至距离及格线还有一段距离。各模型在 TriviaQA 测试中的得分在 D+ 到 C- 之间,在 WinoGrande 测试中得到 C- 至 C,在 HellaSwag 测试中得到 C 至 B,在 PIQA 测试中得到 C+ 至 B-。单从成绩来看,现有大语言模型还算不上班里的“尖子生”。
Meta 的目标是在未来发布更大的模型,这些模型在更广泛的预训练数据集上进行训练,同时它观察到随着规模的扩大,性能也在稳步提高。
在这场争夺 AI 霸主地位的竞赛中,OpenAI 率先发布了 ChatGPT,谷歌很快以其 "实验性 "聊天机器人 Bard 紧随其后,而中国科技巨头百度正计划以 Ernie Bot- ERNIE 3.0 进入战场。更不用说微软声称正建立在 "新的下一代 OpenAI 大型语言模型 "基础上的 Bing Chat(又名Sydney),它比 ChatGPT 更先进,而且还与 Bing 搜索整合。
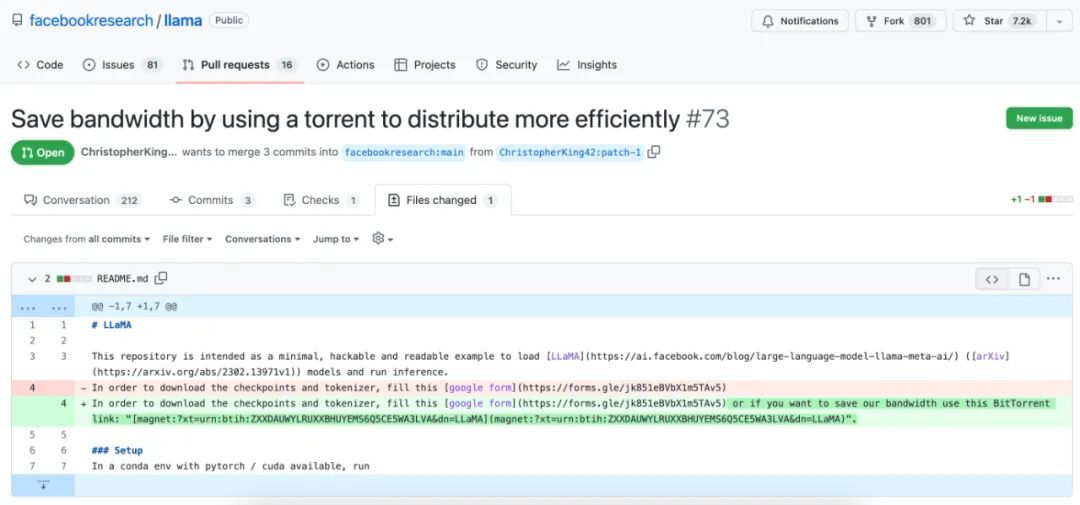
LLaMA地址
https://github.com/faceb**kresearch/llama/pull/73/files
参考资料
https://news.cnblogs.com/n/737746/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号