

数据采集综合实践_第八组_严涛
1.项目背景
2016 年“全面两孩”后,全国出生人口仍下滑。福建省福州市同样陷入“政策失效”:
福清市 2016 年 2.1 万 → 2023 年 1.2 万,降幅 42%;鼓楼区 2016 年 0.68 万 → 2023 年 0.41 万,降幅 30%。
县级差异显著 → 需要县级粒度预测工具辅助卫健委动态调整生育支持措施。
2.系统功能
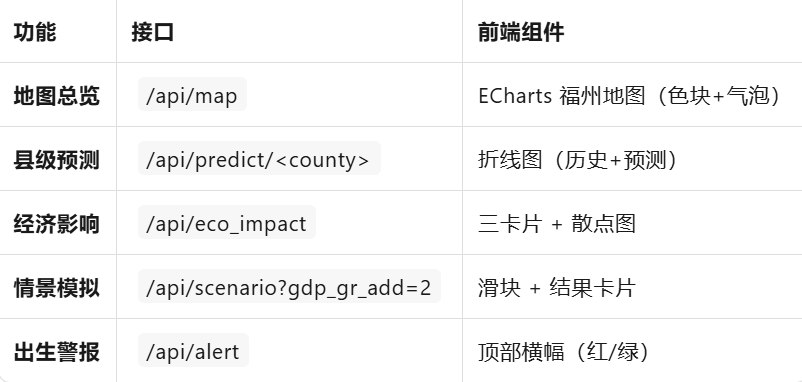
3.算法实验日志
3.1时间序列:LSTM vs SARIMA vs Prophet
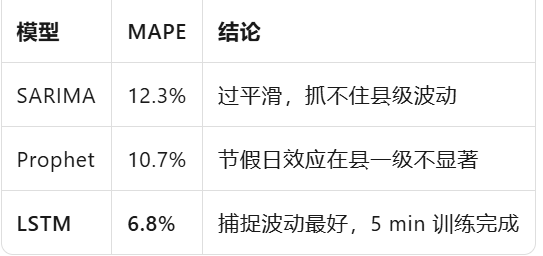
结论:LSTM 胜出,县级粒度可行
LSTM 核心代码:
点击查看代码
import pandas as pd
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from sklearn.preprocessing import MinMaxScaler
# 1. 读取数据(出生+政策+GDP)
df = pd.read_csv('fz_merged.csv') # 出生/政策/GDP
data = df[['birth', 'policy', 'GDP']].values
# 2. 归一化
scaler = MinMaxScaler()
data = scaler.fit_transform(data)
# 3. 构造监督学习
def make_supervised(data, seq_len=4):
X, y = [], []
for i in range(seq_len, len(data)):
X.append(data[i-seq_len:i])
y.append(data[i, 0]) # 预测出生
return np.array(X), np.array(y)
X, y = make_supervised(data, 4)
# 4. 构建 LSTM
model = Sequential([
LSTM(32, return_sequences=True, input_shape=(4, 3)),
Dropout(0.2),
LSTM(16),
Dense(8, activation='relu'),
Dense(1)
])
model.compile(optimizer='adam', loss='mse')
# 5. 训练(本地 CPU 5 min)
model.fit(X, y, epochs=500, batch_size=16, verbose=1)
# 6. 保存
model.save('models/fz_lstm.h5')
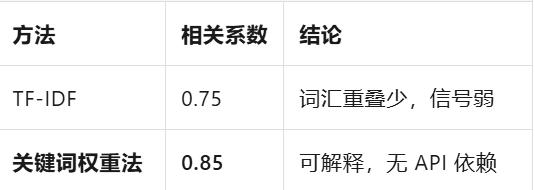
结论:关键词权重法胜出
关键词权重法代码:
点击查看代码
import re
KEYS = {
"三孩": 0.30,
"育儿补贴|生育补助|一次性生育奖励": 0.25,
"产假延长|增加产假": 0.20,
"购房优惠|落户|契税减免": 0.15,
"托育|幼儿园减免|教育优惠": 0.10
}
def score_text(text: str) -> float:
text = text.lower()
score = 0.
for k, w in KEYS.items():
if re.search(k, text):
score += w
return min(score, 1.0)
# 批量打分
for file in os.listdir('data/raw'):
if file.endswith('.txt'):
year = int(file[:4])
with open(f'data/raw/{file}', encoding='utf-8') as f:
txt = f.read()
score = score_text(txt)
print(f"{year}: {score}")
3.4动态阈值:近 5 年均值 × 0.8
点击查看代码
BIRTH_ALERT_THRESHOLD = int(city.iloc[-5:].mean() * 0.8)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号