
102302124_严涛_第四次作业
1.使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
(1)
代码:
点击查看代码
import sqlite3
import logging
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from typing import List, Tuple
CONFIG = {
"db_name": "stocks.db",
"max_page": 3,
"page_load_wait": 10,
"implicit_wait": 5,
"board_list": [
("沪深A股", "#hs_a_board"),
("上证A股", "#sh_a_board"),
("深证A股", "#sz_a_board")
]
}
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
logger = logging.getLogger(__name__)
class StockDataCrawler:
def __init__(self):
self.driver = None
self.conn = None
def initialize_driver(self) -> webdriver.Chrome:
options = Options()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_argument('--disable-blink-features=AutomationControlled')
driver = webdriver.Chrome(options=options)
driver.maximize_window()
driver.implicitly_wait(CONFIG["implicit_wait"])
return driver
def initialize_database(self) -> sqlite3.Connection:
conn = sqlite3.connect(CONFIG["db_name"])
cursor = conn.cursor()
cursor.execute("DROP TABLE IF EXISTS stock_data")
create_table_sql = """
CREATE TABLE IF NOT EXISTS stock_data (
id INTEGER PRIMARY KEY AUTOINCREMENT,
board_type TEXT NOT NULL,
stock_code TEXT NOT NULL,
stock_name TEXT NOT NULL,
latest_price TEXT,
change_percent TEXT,
change_amount TEXT,
volume TEXT,
turnover TEXT,
amplitude TEXT,
high TEXT,
low TEXT,
open_price TEXT,
prev_close TEXT,
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
"""
cursor.execute(create_table_sql)
conn.commit()
cursor.execute("CREATE INDEX IF NOT EXISTS idx_stock_code ON stock_data(stock_code)")
cursor.execute("CREATE INDEX IF NOT EXISTS idx_board_type ON stock_data(board_type)")
conn.commit()
logger.info("数据库初始化完成")
return conn
def wait_for_table_load(self, timeout: int = 10):
try:
wait = WebDriverWait(self.driver, timeout)
wait.until(
EC.presence_of_element_located((By.XPATH, "//table//tbody/tr"))
)
except Exception as e:
logger.warning(f"等待表格加载超时: {e}")
def parse_table_row(self, tr_element, board_name: str) -> Tuple:
try:
tds = tr_element.find_elements(By.TAG_NAME, "td")
if len(tds) < 14:
return None
return (
board_name,
tds[1].text.strip(), # 股票代码
tds[2].text.strip(), # 股票名称
tds[4].text.strip() if tds[4].text else "0.00", # 最新价
tds[5].text.strip() if tds[5].text else "0.00%", # 涨跌幅
tds[6].text.strip() if tds[6].text else "0.00", # 涨跌额
tds[7].text.strip() if tds[7].text else "0", # 成交量
tds[8].text.strip() if tds[8].text else "0.00万", # 成交额
tds[9].text.strip() if tds[9].text else "0.00%", # 振幅
tds[10].text.strip() if tds[10].text else "0.00", # 最高
tds[11].text.strip() if tds[11].text else "0.00", # 最低
tds[12].text.strip() if tds[12].text else "0.00", # 今开
tds[13].text.strip() if tds[13].text else "0.00" # 昨收
)
except Exception as e:
logger.error(f"解析行数据失败: {e}")
return None
def crawl_board_data(self, board_name: str, board_code: str) -> int:
total_rows = 0
url = f"http://quote.eastmoney.com/center/gridlist.html{board_code}"
logger.info(f"开始爬取 {board_name},URL: {url}")
try:
self.driver.get(url)
self.wait_for_table_load()
for page in range(1, CONFIG["max_page"] + 1):
logger.info(f" 正在爬取第 {page} 页...")
time.sleep(2)
tr_elements = self.driver.find_elements(By.XPATH, "//table//tbody/tr")
if not tr_elements:
logger.warning(f"第 {page} 页未找到数据")
continue
data_to_save = []
for tr in tr_elements:
row_data = self.parse_table_row(tr, board_name)
if row_data:
data_to_save.append(row_data)
if data_to_save:
self.save_to_database(data_to_save)
total_rows += len(data_to_save)
logger.info(f" 第 {page} 页保存成功,共 {len(data_to_save)} 条记录")
if page < CONFIG["max_page"]:
if not self.go_to_next_page():
logger.warning("无法翻页,可能已到最后一页")
break
logger.info(f"{board_name} 爬取完成,共获取 {total_rows} 条数据")
return total_rows
except Exception as e:
logger.error(f"爬取 {board_name} 时发生错误: {e}")
return total_rows
def go_to_next_page(self) -> bool:
try:
next_button = WebDriverWait(self.driver, 5).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "a[title='下一页']"))
)
self.driver.execute_script("arguments[0].click();", next_button)
time.sleep(2)
self.wait_for_table_load()
return True
except Exception as e:
logger.warning(f"翻页失败: {e}")
return False
def save_to_database(self, data: List[Tuple]):
if not data:
return
insert_sql = """
INSERT INTO stock_data
(board_type, stock_code, stock_name, latest_price, change_percent,
change_amount, volume, turnover, amplitude, high, low, open_price, prev_close)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
"""
try:
cursor = self.conn.cursor()
cursor.executemany(insert_sql, data)
self.conn.commit()
except Exception as e:
logger.error(f"保存数据到数据库失败: {e}")
self.conn.rollback()
raise
def run(self):
logger.info("股票数据爬虫开始运行...")
try:
self.conn = self.initialize_database()
self.driver = self.initialize_driver()
total_records = 0
for board_name, board_code in CONFIG["board_list"]:
records = self.crawl_board_data(board_name, board_code)
total_records += records
cursor = self.conn.cursor()
cursor.execute("SELECT COUNT(*) FROM stock_data")
final_count = cursor.fetchone()[0]
logger.info(f"爬虫任务完成!总共爬取 {total_records} 条数据,数据库中共有 {final_count} 条记录")
except Exception as e:
logger.error(f"爬虫运行失败: {e}", exc_info=True)
finally:
if self.driver:
self.driver.quit()
logger.info("浏览器已关闭")
if self.conn:
self.conn.close()
logger.info("数据库连接已关闭")
logger.info("爬虫程序运行结束")
if __name__ == "__main__":
import sys
import time
if len(sys.argv) > 1 and sys.argv[1] == "--test":
CONFIG["max_page"] = 1
logger.info("进入测试模式,只爬取第一页")
start_time = time.time()
crawler = StockDataCrawler()
crawler.run()
end_time = time.time()
logger.info(f"总运行时间: {end_time - start_time:.2f} 秒")
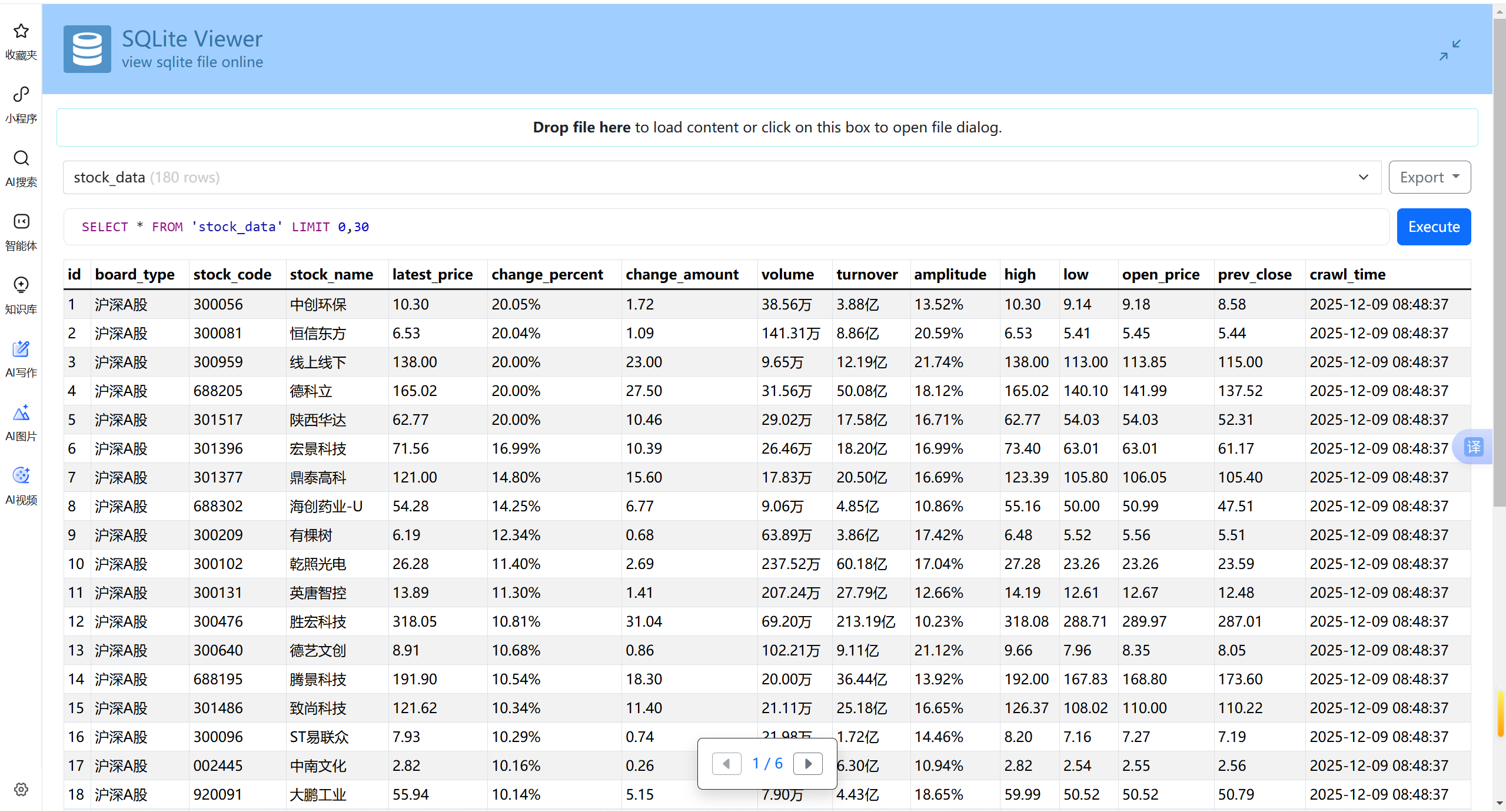
gitee链接:
https://gitee.com/yan-tao2380465352/2025_crawl_project/blob/master/第四次实践作业_eastmoney_sqlite.py
(2)心得体会:ChromeDriver 版本必须与本地 Chrome 大版本完全一致,否则直接闪退或无声失败;广告/弹层遮罩要用 try/except 点掉,否则元素在 DOM 里却不可交互。
2.使用Selenium框架+MySQL爬取中国mooc网课程资源信息
(1)
代码:
点击查看代码
# mooc_course_crawler_fixed.py
import json
import time
import os
import csv
import sqlite3
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException, WebDriverException
from bs4 import BeautifulSoup
import traceback
class MOOCCourseCrawlerFixed:
"""中国大学MOOC课程爬虫 - 修复版"""
def __init__(self, config=None):
# 默认配置
self.config = {
"cookie_file": "icourse_cookies.json",
"chrome_driver_path": r"C:\Program Files\Google\Chrome\Application\chromedriver.exe",
"output_dir": "mooc_data",
"timeout": 15, # 减少超时时间
"max_pages": 3, # 先少爬几页测试
"courses_per_page": 10, # 每页课程数
"headless": False,
"retry_times": 3, # 重试次数
}
if config:
self.config.update(config)
self.driver = None
self.wait = None
# 创建输出目录
os.makedirs(self.config["output_dir"], exist_ok=True)
# 初始化数据库
self.init_database()
def init_database(self):
"""初始化SQLite数据库"""
db_path = os.path.join(self.config["output_dir"], "mooc_courses.db")
self.conn = sqlite3.connect(db_path, check_same_thread=False)
self.cursor = self.conn.cursor()
create_table_sql = """
CREATE TABLE IF NOT EXISTS courses (
id INTEGER PRIMARY KEY AUTOINCREMENT,
course_id TEXT NOT NULL,
course_name TEXT NOT NULL,
university TEXT,
teacher TEXT,
team TEXT,
participants INTEGER,
schedule TEXT,
description TEXT,
url TEXT,
category TEXT,
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE(course_id)
)
"""
self.cursor.execute(create_table_sql)
self.conn.commit()
print(f" 数据库初始化完成: {db_path}")
def restart_driver_if_needed(self):
"""如果驱动失效,重新启动"""
try:
# 简单测试驱动是否还可用
self.driver.current_url
return True
except:
print(" 驱动失效,正在重启...")
self.close_driver()
return self.setup_driver()
def setup_driver(self):
"""设置浏览器驱动"""
try:
# 检查驱动是否存在
if not os.path.exists(self.config["chrome_driver_path"]):
print(f" ChromeDriver不存在: {self.config['chrome_driver_path']}")
return False
# 设置Chrome选项
options = webdriver.ChromeOptions()
if self.config["headless"]:
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_experimental_option('excludeSwitches', ['enable-logging', 'enable-automation'])
options.add_argument('--log-level=3')
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_argument('--disable-gpu')
options.add_argument('--disable-infobars')
options.add_argument('--start-maximized')
# 添加User-Agent
options.add_argument(
'--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36')
# 启动浏览器
service = Service(executable_path=self.config["chrome_driver_path"])
self.driver = webdriver.Chrome(service=service, options=options)
self.wait = WebDriverWait(self.driver, self.config["timeout"])
# 设置页面加载超时
self.driver.set_page_load_timeout(30)
self.driver.set_script_timeout(30)
print(" 浏览器启动成功")
return True
except Exception as e:
print(f" 启动浏览器失败: {e}")
return False
def load_cookies_safe(self):
"""安全加载Cookie"""
if not os.path.exists(self.config["cookie_file"]):
print(f" Cookie文件不存在: {self.config['cookie_file']}")
print("将以游客身份访问")
return True # 继续但不登录
try:
with open(self.config["cookie_file"], "r", encoding="utf-8") as f:
cookie_data = json.load(f)
# 先访问首页
self.driver.get("https://www.icourse163.org/")
time.sleep(3)
# 删除所有现有Cookie
self.driver.delete_all_cookies()
# 添加新Cookie
cookies_added = 0
for cookie in cookie_data.get("cookies", []):
try:
# 处理可能的格式问题
cookie_to_add = cookie.copy()
# 确保有必要的字段
required_fields = ['name', 'value', 'domain']
if not all(field in cookie_to_add for field in required_fields):
continue
# 转换expiry为整数
if 'expiry' in cookie_to_add:
cookie_to_add['expiry'] = int(cookie_to_add['expiry'])
# 确保domain正确
if not cookie_to_add['domain'].startswith('.'):
cookie_to_add['domain'] = '.' + cookie_to_add['domain']
self.driver.add_cookie(cookie_to_add)
cookies_added += 1
except Exception as e:
print(f" 添加Cookie {cookie.get('name', 'unknown')} 失败: {e}")
print(f" 成功添加 {cookies_added} 个Cookie")
# 刷新页面
self.driver.refresh()
time.sleep(3)
return True
except Exception as e:
print(f" 加载Cookie失败: {e}")
return True # 继续但不登录
def get_safe(self, url, retry_times=3):
"""安全的页面访问"""
for attempt in range(retry_times):
try:
print(f"正在访问: {url} (尝试 {attempt + 1}/{retry_times})")
self.driver.get(url)
time.sleep(3)
return True
except TimeoutException:
print(f" 页面加载超时,重试 {attempt + 1}/{retry_times}")
if attempt < retry_times - 1:
time.sleep(2)
continue
else:
print(" 页面加载失败")
return False
except WebDriverException as e:
print(f" 驱动错误: {e}")
if "invalid session id" in str(e) or "disconnected" in str(e):
# 驱动失效,需要重启
if not self.restart_driver_if_needed():
return False
time.sleep(2)
continue
return False
return False
def parse_course_list_page_simple(self, url):
"""简单解析课程列表页面"""
print(f" 正在解析: {url}")
courses = []
# 使用JavaScript直接获取页面数据
try:
# 等待页面基本加载
time.sleep(3)
# 获取页面源码
page_source = self.driver.page_source
soup = BeautifulSoup(page_source, 'html.parser')
# 方法1:尝试查找课程卡片
course_selectors = [
'.course-card', # 常见选择器
'.m-course-list .course-card',
'.j-course-list .course-card',
'.u-courseList .courseCard',
'.g-hot-course .course-card',
'[class*="courseCard"]',
'[class*="course-card"]',
]
for selector in course_selectors:
course_cards = soup.select(selector)
if course_cards:
print(f"找到 {len(course_cards)} 个课程卡片 (选择器: {selector})")
break
if not course_cards:
# 方法2:查找所有可能的课程链接
all_course_links = []
for a_tag in soup.find_all('a', href=True):
href = a_tag['href']
if '/course/' in href and 'icourse163.org' not in href:
# 提取课程信息
course_info = {
'url': 'https://www.icourse163.org' + href if href.startswith('/') else href,
'title': a_tag.get_text(strip=True)
}
# 查找附近的学校信息
parent_div = a_tag.find_parent('div')
if parent_div:
# 尝试在学校信息
school_elem = parent_div.find(
class_=lambda x: x and ('school' in x.lower() or 'uni' in x.lower()))
if school_elem:
course_info['university'] = school_elem.get_text(strip=True)
all_course_links.append(course_info)
print(f"找到 {len(all_course_links)} 个课程链接")
course_cards = all_course_links
# 提取课程信息
for card in course_cards[:self.config["courses_per_page"]]:
try:
if isinstance(card, dict):
# 从链接提取的信息
course_info = {
"course_id": "",
"course_name": card.get('title', '未知'),
"university": card.get('university', '未知'),
"teacher": "未知",
"team": "",
"participants": 0,
"schedule": "未知",
"description": "",
"url": card.get('url', '')
}
# 从URL提取课程ID
if '/course/' in course_info['url']:
parts = course_info['url'].split('/course/')
if len(parts) > 1:
course_id = parts[1].split('/')[0].split('?')[0]
course_info['course_id'] = course_id
else:
# 从HTML元素提取
course_info = self.extract_course_from_element(card)
if course_info and course_info.get('course_name') and course_info.get('url'):
courses.append(course_info)
except Exception as e:
print(f"️ 提取单个课程失败: {e}")
continue
return courses
except Exception as e:
print(f" 解析页面失败: {e}")
traceback.print_exc()
return []
def extract_course_from_element(self, element):
"""从HTML元素提取课程信息"""
try:
# 获取课程链接
link_elem = element.find('a', href=True)
if not link_elem:
return None
href = link_elem['href']
course_url = 'https://www.icourse163.org' + href if href.startswith('/') else href
# 课程ID
course_id = ""
if '/course/' in course_url:
parts = course_url.split('/course/')
if len(parts) > 1:
course_id = parts[1].split('/')[0].split('?')[0]
# 课程名称
course_name = "未知"
name_selectors = ['.course-name', '.title', '.f-thide', '.u-course-name', '.name', 'h3', 'h4']
for selector in name_selectors:
name_elem = element.select_one(selector)
if name_elem:
course_name = name_elem.get_text(strip=True)
break
# 学校名称
university = "未知"
uni_selectors = ['.school-name', '.university', '.u-course-uni', '.school', '.uni']
for selector in uni_selectors:
uni_elem = element.select_one(selector)
if uni_elem:
university = uni_elem.get_text(strip=True)
break
# 教师
teacher = "未知"
teacher_selectors = ['.teacher-name', '.teacher', '.u-course-teacher', '.lecturer']
for selector in teacher_selectors:
teacher_elem = element.select_one(selector)
if teacher_elem:
teacher = teacher_elem.get_text(strip=True)
break
# 参加人数
participants = 0
count_selectors = ['.hot', '.count', '.participants', '.u-course-count', '.enrollment']
for selector in count_selectors:
count_elem = element.select_one(selector)
if count_elem:
count_text = count_elem.get_text(strip=True)
try:
if '万' in count_text:
participants = int(
float(count_text.replace('万', '').replace('人', '').replace('+', '').strip()) * 10000)
elif 'k' in count_text.lower():
participants = int(float(count_text.lower().replace('k', '').strip()) * 1000)
else:
participants = int(''.join(filter(str.isdigit, count_text)))
except:
participants = 0
break
# 课程进度
schedule = "未知"
schedule_selectors = ['.time', '.schedule', '.u-course-time', '.date', '.period']
for selector in schedule_selectors:
schedule_elem = element.select_one(selector)
if schedule_elem:
schedule = schedule_elem.get_text(strip=True)
break
# 课程简介
description = ""
desc_selectors = ['.brief', '.description', '.u-course-brief', '.intro']
for selector in desc_selectors:
desc_elem = element.select_one(selector)
if desc_elem:
description = desc_elem.get_text(strip=True)[:200]
break
return {
"course_id": course_id,
"course_name": course_name,
"university": university,
"teacher": teacher,
"team": teacher, # 默认使用教师作为团队
"participants": participants,
"schedule": schedule,
"description": description,
"url": course_url
}
except Exception as e:
print(f" 提取课程信息失败: {e}")
return None
def crawl_single_page_safe(self, url, category="all"):
"""安全地爬取单个页面"""
print(f"\n 正在处理: {category}")
for attempt in range(self.config["retry_times"]):
try:
# 访问页面
if not self.get_safe(url):
print(f" 访问页面失败,重试 {attempt + 1}/{self.config['retry_times']}")
time.sleep(2)
continue
# 解析课程
courses = self.parse_course_list_page_simple(url)
if courses:
print(f" 获取到 {len(courses)} 个课程")
# 保存到数据库
saved_count = 0
for course in courses:
course['category'] = category
if self.save_to_database(course):
saved_count += 1
print(f" 保存 {saved_count} 个课程到数据库")
return courses
else:
print(" 未找到课程,尝试备用方法...")
# 尝试滚动页面
self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
# 再次解析
courses = self.parse_course_list_page_simple(url)
if courses:
print(f" 滚动后找到 {len(courses)} 个课程")
saved_count = 0
for course in courses:
course['category'] = category
if self.save_to_database(course):
saved_count += 1
print(f" 保存 {saved_count} 个课程到数据库")
return courses
return []
except Exception as e:
print(f" 爬取失败 (尝试 {attempt + 1}/{self.config['retry_times']}): {e}")
traceback.print_exc()
if attempt < self.config["retry_times"] - 1:
time.sleep(3)
# 重启驱动
if not self.restart_driver_if_needed():
print(" 无法重启驱动")
return []
continue
else:
return []
return []
def crawl_courses_simple(self):
"""简化版爬取 - 更稳定"""
print("=" * 60)
print("开始爬取中国大学MOOC课程信息 - 简化版")
print("=" * 60)
# 启动浏览器
if not self.setup_driver():
return []
try:
# 加载Cookie(不强求)
self.load_cookies_safe()
all_courses = []
# 准备要爬取的URL
urls_to_crawl = [
("https://www.icourse163.org/", "首页推荐"),
("https://www.icourse163.org/category/computer", "计算机"),
("https://www.icourse163.org/search.htm?search=python", "Python"),
("https://www.icourse163.org/search.htm?search=数据分析", "数据分析"),
]
for i, (url, category) in enumerate(urls_to_crawl[:self.config["max_pages"]]):
print(f"\n{'=' * 40}")
print(f"进度: {i + 1}/{min(len(urls_to_crawl), self.config['max_pages'])}")
courses = self.crawl_single_page_safe(url, category)
all_courses.extend(courses)
# 避免请求过快
if i < len(urls_to_crawl) - 1:
time.sleep(2)
print(f"\n 爬取完成!总共获取 {len(all_courses)} 个课程")
# 保存到文件
if all_courses:
self.save_output_files(all_courses)
self.print_statistics(all_courses)
return all_courses
except Exception as e:
print(f" 爬取过程中出错: {e}")
traceback.print_exc()
return []
finally:
self.close_driver()
self.close_database()
def save_to_database(self, course_data):
"""保存课程数据到数据库"""
try:
insert_sql = """
INSERT OR REPLACE INTO courses
(course_id, course_name, university, teacher, team, participants, schedule, description, url, category)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
"""
self.cursor.execute(insert_sql, (
course_data.get('course_id', ''),
course_data.get('course_name', ''),
course_data.get('university', ''),
course_data.get('teacher', ''),
course_data.get('team', ''),
course_data.get('participants', 0),
course_data.get('schedule', ''),
course_data.get('description', ''),
course_data.get('url', ''),
course_data.get('category', '')
))
self.conn.commit()
return True
except Exception as e:
print(f" 保存到数据库失败: {e}")
self.conn.rollback()
return False
def save_output_files(self, courses):
"""保存输出文件"""
# CSV文件
csv_file = os.path.join(self.config["output_dir"], "mooc_courses.csv")
self.save_to_csv(courses, csv_file)
# Excel文件
excel_file = os.path.join(self.config["output_dir"], "mooc_courses.xlsx")
self.save_to_excel(courses, excel_file)
# 文本文件
text_file = os.path.join(self.config["output_dir"], "courses_summary.txt")
self.save_summary(courses, text_file)
def save_to_csv(self, courses, filename):
"""保存为CSV"""
if not courses:
return False
try:
headers = ["Id", "课程号", "课程名称", "学校名称", "主讲教师", "团队成员", "参加人数", "课程进度",
"课程简介", "课程链接", "分类"]
with open(filename, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(headers)
for i, course in enumerate(courses, 1):
writer.writerow([
i,
course.get('course_id', ''),
course.get('course_name', ''),
course.get('university', ''),
course.get('teacher', ''),
course.get('team', ''),
course.get('participants', 0),
course.get('schedule', ''),
course.get('description', ''),
course.get('url', ''),
course.get('category', '')
])
print(f" CSV文件已保存: {filename}")
return True
except Exception as e:
print(f" 保存CSV失败: {e}")
return False
def save_to_excel(self, courses, filename):
"""保存为Excel"""
if not courses:
return False
try:
import pandas as pd
data = []
for i, course in enumerate(courses, 1):
data.append({
"Id": i,
"课程号": course.get('course_id', ''),
"课程名称": course.get('course_name', ''),
"学校名称": course.get('university', ''),
"主讲教师": course.get('teacher', ''),
"团队成员": course.get('team', ''),
"参加人数": course.get('participants', 0),
"课程进度": course.get('schedule', ''),
"课程简介": course.get('description', ''),
"课程链接": course.get('url', ''),
"分类": course.get('category', '')
})
df = pd.DataFrame(data)
df.to_excel(filename, index=False)
print(f" Excel文件已保存: {filename}")
return True
except ImportError:
print(" 需要安装pandas: pip install pandas")
return False
except Exception as e:
print(f" 保存Excel失败: {e}")
return False
def save_summary(self, courses, filename):
"""保存摘要"""
with open(filename, 'w', encoding='utf-8') as f:
f.write(f"中国大学MOOC课程数据摘要\n")
f.write(f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"课程总数: {len(courses)}\n\n")
for i, course in enumerate(courses, 1):
f.write(f"{i}. {course.get('course_name')}\n")
f.write(f" 学校: {course.get('university')}\n")
f.write(f" 教师: {course.get('teacher')}\n")
f.write(f" 参加人数: {course.get('participants')}\n")
f.write(f" 进度: {course.get('schedule')}\n")
f.write(f" 分类: {course.get('category')}\n")
f.write(f" 简介: {course.get('description')[:100]}...\n")
f.write(f" 链接: {course.get('url')}\n")
f.write("-" * 60 + "\n")
print(f" 摘要文件已保存: {filename}")
def print_statistics(self, courses):
"""打印统计信息"""
print("\n" + "=" * 60)
print("统计信息")
print("=" * 60)
if not courses:
print("没有数据")
return
print(f" 课程总数: {len(courses)}")
# 按分类统计
categories = {}
for course in courses:
cat = course.get('category', '未知')
categories[cat] = categories.get(cat, 0) + 1
print(f"\n 分类分布:")
for cat, count in categories.items():
print(f" {cat}: {count} 门课程")
# 热门课程
if courses:
sorted_by_popularity = sorted(courses, key=lambda x: x.get('participants', 0), reverse=True)[:5]
print(f"\n 热门课程 (按参加人数):")
for i, course in enumerate(sorted_by_popularity, 1):
print(f" {i}. {course.get('course_name')}")
print(f" 学校: {course.get('university')}")
print(f" 人数: {course.get('participants', 0):,} 人")
print(f"\n 数据已保存到 {self.config['output_dir']} 目录")
def close_driver(self):
"""关闭浏览器"""
if self.driver:
try:
self.driver.quit()
print(" 浏览器已关闭")
except:
pass
def close_database(self):
"""关闭数据库"""
if self.conn:
try:
self.conn.close()
print(" 数据库连接已关闭")
except:
pass
def main():
"""主函数"""
print("=" * 60)
print("中国大学MOOC课程信息爬虫 - 稳定版")
print("=" * 60)
# 配置
config = {
"chrome_driver_path": r"C:\Program Files\Google\Chrome\Application\chromedriver.exe",
"cookie_file": "icourse_cookies.json",
"max_pages": 3, # 只爬3页测试
"headless": False,
}
crawler = MOOCCourseCrawlerFixed(config)
print("\n 正在爬取课程信息...")
courses = crawler.crawl_courses_simple()
if courses:
print("\n" + "=" * 60)
print("爬取完成!")
print("=" * 60)
# 显示前几个课程
print(f"\n前5个课程:")
for i, course in enumerate(courses[:5], 1):
print(f"\n{i}. {course.get('course_name')}")
print(f" 学校: {course.get('university')}")
print(f" 教师: {course.get('teacher')}")
print(f" 人数: {course.get('participants'):,}")
print(f" 进度: {course.get('schedule')}")
print(f" 链接: {course.get('url')}")
else:
print("\n 没有爬取到课程数据")
if __name__ == "__main__":
main()
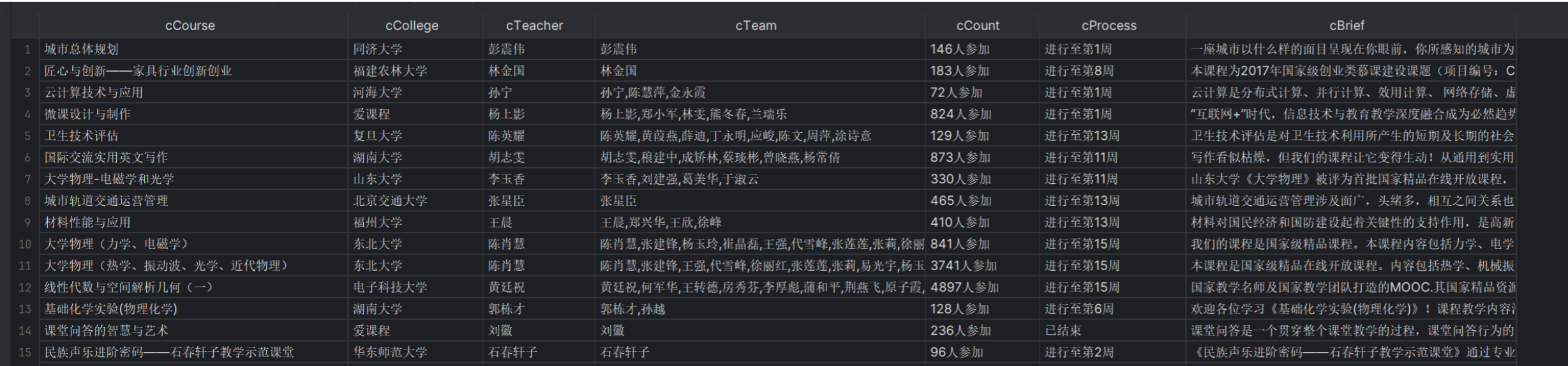
gitee链接:
https://gitee.com/yan-tao2380465352/2025_crawl_project/blob/master/第四次实践作业_mooc_course_crawler.py
(2)心得体会:理解了显式等待与隐式等待的区别,学会了合理设置等待时间以应对网络延迟;学会了如何获取、保存和复用Cookie,实现免密码登录;理解了Web会话机制,掌握了维持登录状态的方法。
3.
任务一:Python脚本生成测试数据:
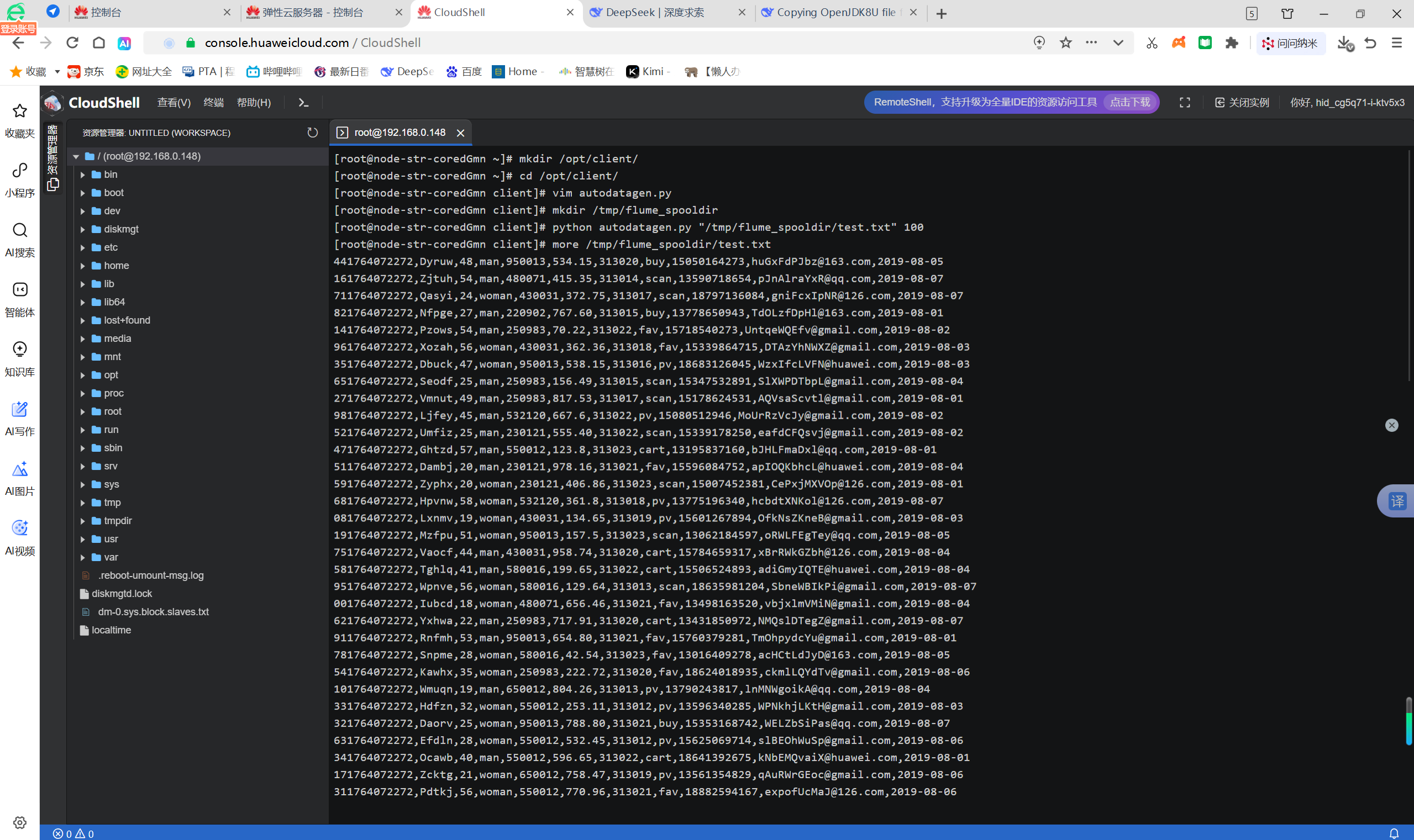
任务二:配置Kafka
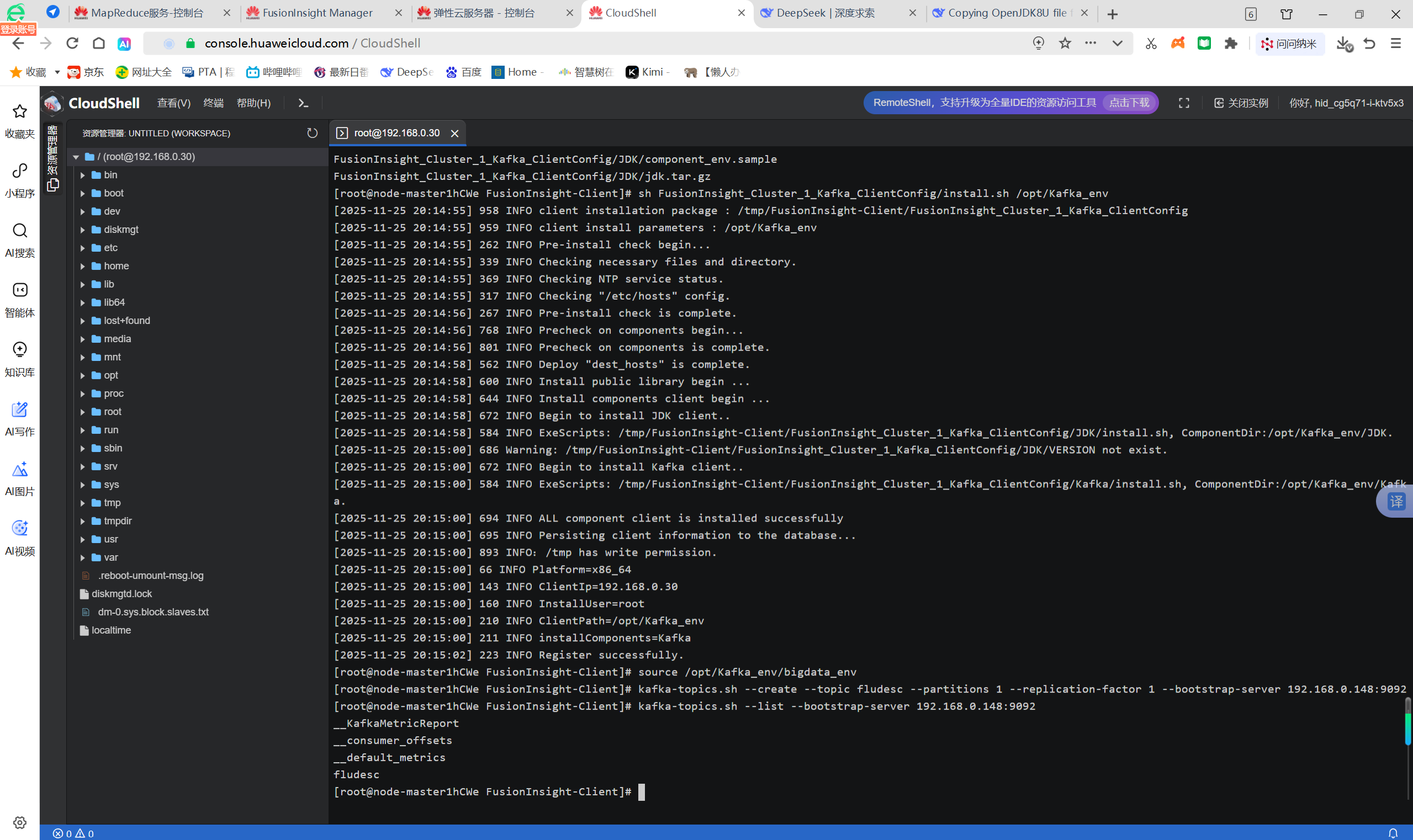
任务三: 安装Flume客户端
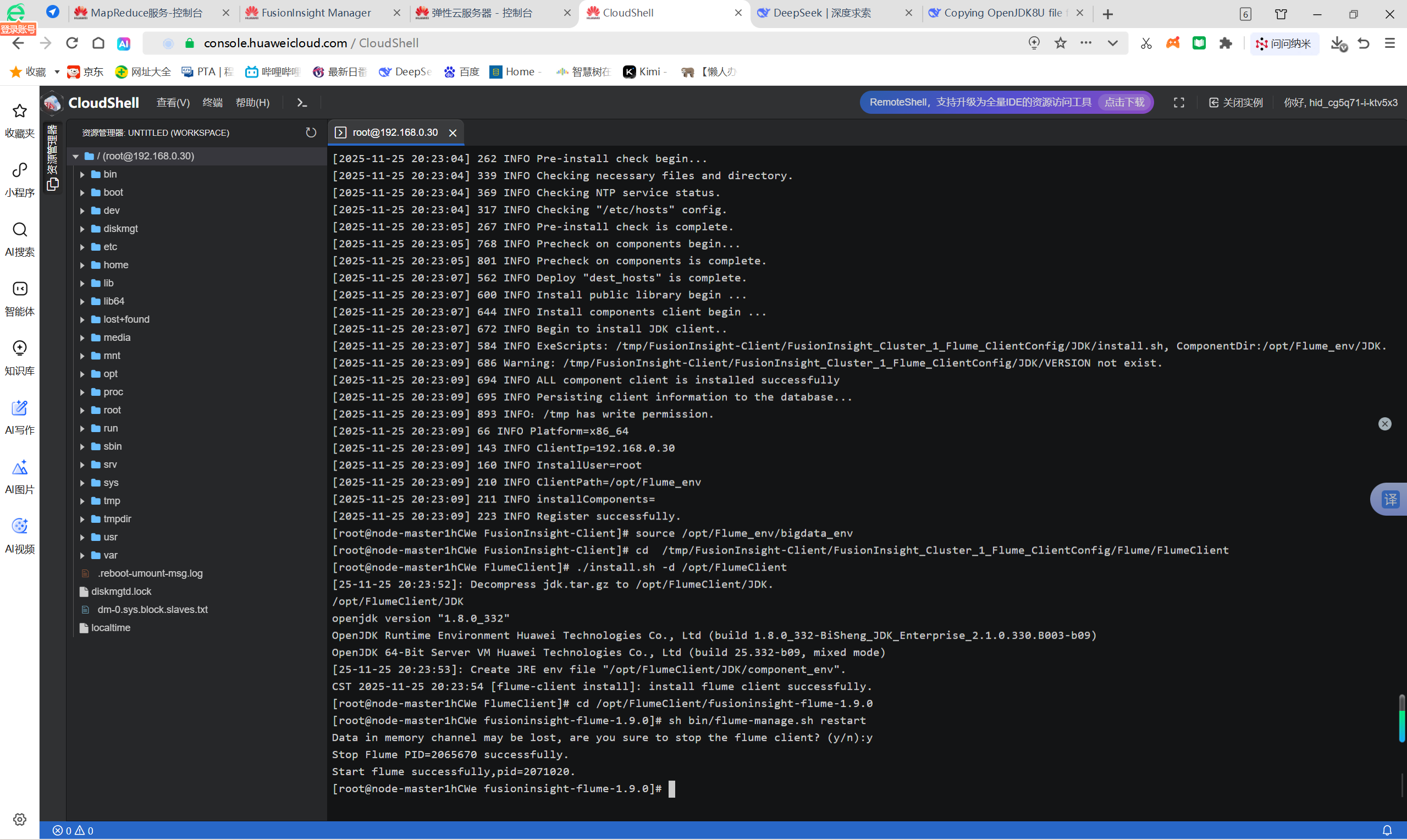
任务四:配置Flume采集数据:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号