Flink场景分析与比较【事件驱动、数据分析、数据管道】
一.事件驱动
提到事件驱动应用,首先讲什么是事件驱动的应用程序?事件驱动的应用程序是有状态的应用程序,它从一个或多个事件中提取事件,并通过触发计算,状态更新或外部操作来对传入的事件做出反应。
事件驱动的应用程序是传统应用程序设计的发展,具有分离的计算和数据存储层。在这种体系结构中,应用程序从远程事务数据库读取数据并将数据持久化到远程事务数据库。相反,事件驱动的应用程序基于状态流处理应用程序。在这种设计中,数据和计算位于同一位置,从而可以进行本地【内存或磁盘】的数据访问。通过定期将检查点写入远程持久化存储来实现容错。下图描述了传统应用程序结构和事件驱动的应用程序之间的区别。
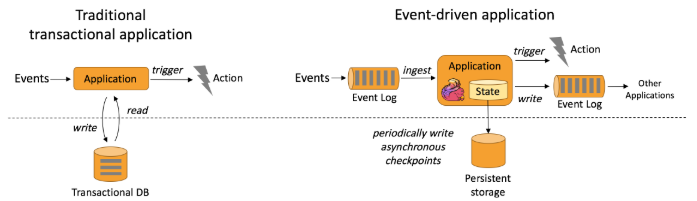
说白了,区别主要在一下两点:
1.程序与数据的位置
传统应用程序不要求程序和程序使用的数据位于相同的机器上,数据的位置对程序来说无关紧要【排除网络传输】,而且一般数据在远端。而事件驱动程序则要求数据本地性,这有利于数据的快速计算,特别对于大批量数据来说效果更加明显。
2.容错
传统应用程序一般不依赖容错机制,因处理逻辑链条较短且同一个程序内部并发较少,因此一般使用事务来限制数据异常。而事件驱动程序,需要7*24不间断执行,且增量计算比较常见,因此使用容错和检查点就显得尤为重要了。
事件驱动的应用程序有哪些优势?
1.事件驱动的应用程序不是访问远程数据库,而是在本地访问去数据,从而在吞吐量和延迟方面都产生了更好的性能。
2.远程持久性存储的定期检查点可以异步和增量方式完成。因此,对事件处理的影响很小。
3.在分层体系中,多个应用程序共享同一数据库是很常见的。因此,需要协调数据库的任何修改。而由于每个事件驱动的应用程序都只负责自己的数据,因此更改数据的表示形式或缩放应用程序需要较小的协调。
Flink如何支持事件驱动的应用程序?
1.事件驱动的应用程序的限制由流处理器处理时间和状态的能力来定义。Flink的许多杰出功能都围绕这些概念。其提供了一组丰富的状态原语,可以通过一次精确的一致性保证来管理非常大的数据量【最多几个TB】。
2.Flink对事件时间的支持,高度可定制的窗口逻辑以及对时间的细粒度控制【通过ProcessFunction启用高级业务逻辑的实现】提供了支持。
3.Flink具有用于复杂事件处理【CEP】的库,可检测数据流中的模式。
4.Flink对于事件驱动的应用程序的突出功能是保存点。保存点是一致的状态映像,可用作兼容应用程序的起点。给定一个保存点,可以更新应用程序或调整其规模,或者可以启动应用程序的多个版本进行A/B测试。
什么是典型的事件驱动应用程序?
1.欺诈识别
2.异常检测
3.基于规则的警报
4.业务流程监控
5.Web应用程序【社交网络】
二.数据分析
什么是数据分析应用程序?
1.分析工作从原始数据中提取信息和见解。传统上,分析是作为批处理查询或应用程序对已记录事件的有限数据集执行的。为了将最新数据合并到分析结果中,必须将其添加到分析数据集中,然后重新运行查询或应用程序。结果被写入存储系统或作为报告发出。
2.借助完善的流处理引擎,还可以以实时方式执行分析。流查询或应用程序不读取有限的数据集,而是吸收实时事件流,并随着事件的使用不断产生和更新结果。结果要么写入外部数据库,要么保持内部状态。仪表板应用程序可以从外部数据库读取最新结果,也可以直接查询应用程序的内部状态。
Flink支持流以及批处理分析应用程序,如下图所示:
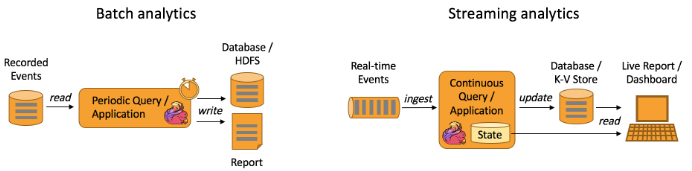
流分析应用程序的优点是什么?
与批处理分析相比,连续六分析的优势不限于消除了定期导入和查询执行,因此从事件到洞察的延迟都大大降低。与批处理查询相反,流查询不必处理输入数据中的人为边界,后者由定期导入和输入的有界性质引起的。
另一方面是更简单的应用程序体系结构。批处理分析管道由几个独立的组件组成,用于定期计划数据提取和查询执行。可靠地操作这样的管道并非易事,因为一个组件的故障会影响管道的后续步骤。相比之下,在像Flink这样的复杂处理器上运行的流分析应用程序则包含了从数据提取到连续结果计算的所有步骤。因此,它可以依靠引擎的故障恢复机制。
Flink如何支持数据分析应用程序?
Flink为连续流以及批处理分析提供了很好的支持。具体来说,它具有符合ANS的SQL接口,具有用于批处理和流查询的统一语义。无论是在记录的事件的静态数据集上还是在实时事件流上运行,SQL查询都会计算相同的结果。对用户定义函数的丰富支持确保可以在SQL查询中执行自定义代码。如果需要更多的自定义逻辑,则Flink的DataStream API或DataSet API可以提供更多的底层控制。此外,Flink的Gelly库提供了用于批处理数据集上的大规模和高性能图形分析的算法和构建。
什么是典型的数据分析应用程序?
1.电信网络的质量监控
2.移动应用中的产品更新分析和实验评估
3.临时分析消费消费中的实时数据
4.大规模图分析
三.数据管道
什么是数据管道?
提取转换加载【ETL】是在存储系统之间转换和移动数据的常用方法。通常,会定期触发ETL作业,以将数据从事务数据库系统复制到分析数据库或数据仓库。数据管道的用途和ETL作业类似。它们可以转换和丰富数据,并且可以将其从一个存储系统转移到另一个存储系统。但是,它们以连续模式运行,不是定期触发。因此,它们能够从连续产生数据的源中读取记录,并以低延迟将其移动到目的地。例如,数据管道可能会监视文件系统目录中是否有新文件,并将其数据写入事件日志。另一个应用程序可以将事件流具体化到数据库中,或者以增量方式构建和完善搜索索引。
下图描述了定期ETL作业和连续数据管道之间的区别:
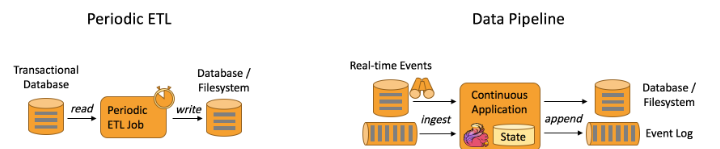
数据管道的优势是什么?
与周期性ETL作业相比,连续数据管道的明显优势是减少了将数据移至其目的地的等待时间。此外,数据管道更通用,可以用于更多用例,因为它们能够连续使用和发出数据。
Flink如何支持数据管道?
Flink的SQL接口【或Table API】及其对用户定义函数的支持可以解决许多常见的数据转换或扩充任务。使用更通用的DataStream API可以实现具有更高级要求的数据管道。Flink为各种存储系统【例如Kafka、Kinesis、Elasticsearch和JDBC数据库系统】提供了丰富的连接器集。它还具有用于文件系统的连续源,这些源监视目录和接收器以时间存储方式写入文件。
什么是典型的数据管道应用程序?
1.电子商务中的实时搜索索引构建
2.电子商务中的持续ETL
四.典型案例
1.搜索引擎 2.流计算 3.特征提取和ETL



4.云计算 5.实时流处理 6.互联网




 浙公网安备 33010602011771号
浙公网安备 33010602011771号