Spark Shuffle原理分析及性能优化
一.HashShuffle
普通机制:产生磁盘小文件的数量为:M(map task number)*R(reduce task number)
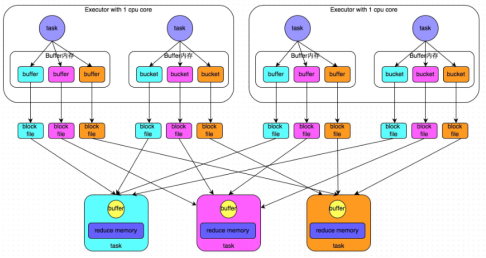
过程:
1.map task处理完数据之后,写到buffer缓冲区,buffer的大小为32k,个数与reduce task个数一致
2. 每个buffer缓存区满32k后会溢写磁盘,每个buffer最终对应一个磁盘小文件
3.reduce task拉取数据
问题:
1.shuffle write,read 频繁
2.占用内存过多,容易造成gc以及出现OOM
3.磁盘小文件多,会造成频繁I/O,效率降低
合并机制:产生磁盘小文件的数量为:C(core number)*R(reduce task number)
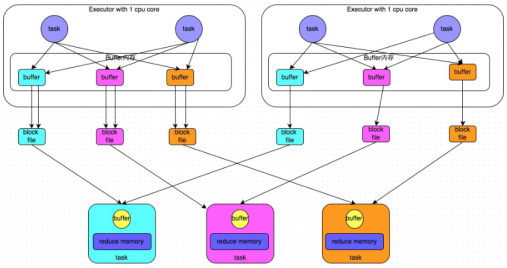
过程:
1.map task处理完数据之后,写到buffer缓冲区,buffer的大小为32k,个数与reduce task个数一致
2.Executor中每个core中的task共用一份buffer缓冲区
3.每个buffer缓存区满32k后会溢写磁盘,每个buffer最终对应一个磁盘小文件
4.reduce task拉取数据
二.SortShuffle
普通机制:产生磁盘小文件数量:2*M(map task number)
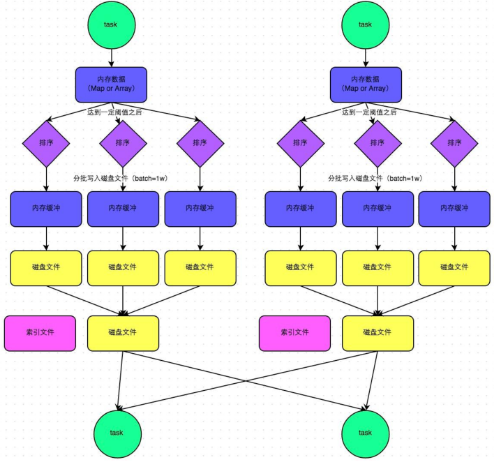
步骤:
1.map task处理完数据之后,首先写入一个5M的数据结构
2.sortShuffle有不定期估算机制,来估算这个内存结构的大小,当估算超过真实的大小,会申请内存:2*估算大小-当前大小
3.申请到内存继续写入内存数据结构,申请不到会溢写磁盘
4.溢写磁盘过程中有排序,每批1万条数据溢写,最终对应两个磁盘文件:一个索引文件,一个数据文件
5.reduce task拉取数据首先读取索引文件,再拉取数据
bypass机制:产生磁盘小文件数量:2*M(map task number)
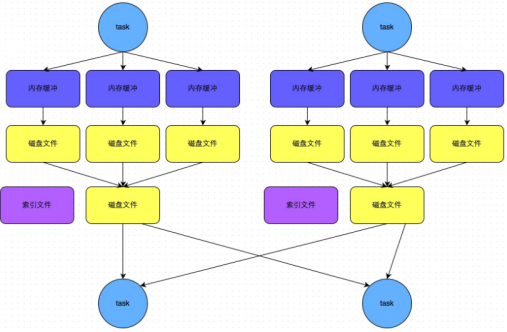
步骤:
1.map task处理完数据之后,首先写入一个5M的数据结构
2.sortShuffle有不定期估算机制,来估算这个内存结构的大小,当估算超过真实的大小,会申请内存:2*估算大小-当前大小
3.申请到内存继续写入内存数据结构,申请不到会溢写磁盘
4.溢写磁盘过程中没有排序,每批1万条数据溢写,最终对应两个磁盘文件:一个索引文件,一个数据文件
5.reduce task拉取数据首先读取索引文件,再拉取数据
三.Shuffle文件寻址
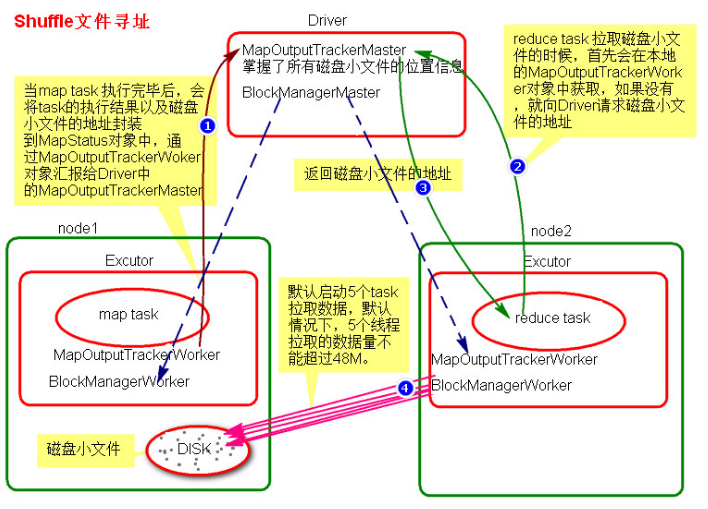
1.当map task执行完成后,会将task的执行情况和磁盘小文件的地址封装到MapStatus对象中,通过MapOutputTrackerWorker对象向Driver中的MapOutputTrackerMaster汇报。
2.在所有的map task执行完毕后,Driver中就掌握了所有的磁盘小文件的地址。
3.在reduce task执行之前,会通过Executor中MapOutputTrackerWorker向Driver端的MapOutputTrackerMaster获取磁盘小文件的地址。
4.获取到磁盘小文件的地址后,会通过BlockManager中的ConnectionManager连接数据所在节点上的ConnectionManager,然后通过BlockTransferService进行数据的传输。
5.BlockTransferService默认启动5个task去节点拉取数据。默认情况下,5个task拉取数据量不能超过48M。
四.Shuffle性能优化
1.spark.shuffle.file.buffer,默认值:32k,该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写到磁盘文件之前,会先写入buffer缓冲区中,待缓冲区写满之后,才会溢写到磁盘。适当增加这个参数的大小,从而减少shuffle write过程中溢写磁盘文件的次数,减少磁盘的I/O,进而提升性能。实践表明,合理调节该参数可以带来1%~5%的性能提升。
2.spark.reducer.maxSizeInFlight,默认值:48M,该参数用于设置shuffle read task的buffer缓冲区大小,而这个buffer缓冲决定了每次能够拉取多少数据。适当增加这个参数的大小可以减少拉取数据的次数,从而减少网络传输的次数,进而提升性能。实践表明,合理调节该参数,也会带来1%~5%的性能提升。
3.spark.shuffle.io.maxRetries,默认值:3,该参数用于设置shuffle read task从shuffle write task所在节点拉取数据时,若因网络异常而导致失败时的重试次数,在重试次数之内,会自动进行重试。若超过这个次数,可能导致作业执行失败。对于包含了特别耗时的shuffle操作的作业,建议增加重试次数,以避免由于JVM的full gc或网络不稳定等因素导致的数据拉取失败。实践表明,对于大数据量的shuffle过程,调节该参数可以大幅度提升稳定性。
4.spark.shuffle.io.retryWait,默认值:5s,该参数代表了每次重试拉取数据的等待间隔。适当调大间隔时长可以增加shuffle操作的稳定性。
5.spark.shuffle.memoryFraction,默认值:0.2,该参数代表在Executor内存中,分配给shuffle read task进行聚合操作的内存比例。当很少使用持久化操作时,可以调高这个比例,给shuffle read聚合操作更多的内存,以避免由于内存不足导致聚合过程中频繁读写磁盘。实践表明,合理调节该参数可以带来10%的性能提升。
6. spark.shuffle.mamager,默认值:sort|hash,该参数用于设是置shuffleManager的类型。在spark1.5以后,有三个可选项:hash/sort/tungsten-sort。HashShuffleManager是Spark1.2之前的默认配置。在1.2版本之后默认都是SortShuffleManager。tungsten-sort与sort类似,但是使用了tungsten计划【钨丝计划】中的堆外内存管理机制,内存使用效率更高。由于SortShuffleManager默认会对数据进行排序,因此如果需要排序机制的话,则使用默认的SortShuffleManager即可;而如果不需要对数据进行排序,那么建议通过bypass机制或优化的HashShuffleManager来避免排序操作,同时也提供较好的磁盘读取性能。此外,使用tungsten-sort需要特别注意,其在使用中还存在一些bug。
7.spark.shuffle.sort.bypassMergeThreshold,默认值:200,当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值,则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成为一个文件,并会创建单独的索引文件。当使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大,大于shuffle read task的数量。那么此时就会自动启用bypass机制,map侧就不会进行排序,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能还有待提高。
8.spark.shuffle.consolidateFiles,默认值:false,如果使用HashShuffleManager该参数有效。如果设置为true,那么就会开启consolidate机制,会大幅度合并shuffle write 的输出文件,对于shuffle read task数量特别多的情况下,这个方法可以极大地减少磁盘I/O开销,提升性能。如果不需要SortShuffleManager的排序机制,那么除了使用bypass机制,还可以尝试将spark.shuffle.manager参数手动指定为hash,使用HashShuffleManager同时开启consolidate机制。实践表明,其性能比开启了bypass机制的SortShuffleManager要提高10%~30%。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号