基于决策树算法的贷款风险预警研究
1 背景
现在个人贷款越来越多,有风险,现在防范风险的手段,引出决策树
随着我国经济高速发展,贷款业务也随之快速发展,而贷款业务的发展对提高内需,促进消费也有拉动作用。有好处就会有坏处,个人贷款量持续增长,但信用违约等风险问题也在增加,部分限制了我国信用市场的健康发展。
近年来,个人贷款类型发生了变化,从最初的单一信贷类型转变为今天的各种各样的信贷类型。我国具体实施了汽车贷款、教育贷款、耐用消费品贷款(家电、电脑、厨具等)、结婚贷款等。违约风险是指债务人因各种原因不能及时偿还信用债务的风险,对于商业银行来说,违约风险主要是指由于贷款人偿付能力或信用水平下降而导致的违约。
在我国个人贷款建立之初,担保+贷款+保险的模式得到了广泛应用,银行将其视为低风险信贷产品。然而,随着借款人贷款数量的增加,不良贷款率也逐年上升,定期贷款数量也呈上升趋势。以贷款为名的欺诈行为正在增加。与此同时,个人贷款信息系统也发展迅速,收集了大量数据,覆盖面广,指标多。然而,对这些数据的分析、集成、提取、挖掘和呈现方法还不够。因此,银行经理和信贷工作人员的分析和预测数据很少,有效的决策信息也很少。
商业银行的信贷活动,包括个人贷款,都有各种各样的风险评估任务,虽然数据挖掘技术已经在这些方面得到了应用,但这些应用大多是基于聚类算法、神经网络或传统的统计方法,主要用于确定金融欺诈。同时信息熵和决策树作为归纳分类的重要方法之一,已被应用于风险预测和分类预测,但在利用信息熵和决策树构建评估模型方面几乎没有应用。本文有效地提取了个人贷款体系中的数据信息,揭示了相关知识,并延续了个人贷款审批的信用技巧模型,为信用风险管理提供投资解决方案。
决策树是最重要的分类和预测技术,主张是由一系列不规则情况得出决策树表示形式的分类规则。此功能比较决策树中节点的属性值,根据每个属性评估节点到下一个节点的分支,并从决策树的叶节点得出结论。因此,从根节点到叶节点,整个树都有一套对应于表达式规则的合理规则。决策树是一种广泛而重要的数据分析技术,可用于数据分析和预测。基于决策树的算法的最大优点之一是在学习过程中不需要了解很多背景知识。只要训练案例能够以属性或结论的形式表达,算法就可以用于学习。
2 研究意义
2.1 对银行的意义
对于银行来说,银行贷款风险管理具有十分重要的现实意义。在竞争激烈的市场环境下,银行贷款风险管理不到位,就可能导致贷款资金无法及时收回甚至直接成为坏账,轻者导致银行蒙受一定的经济损失,重者甚至造成银行破产。而加强银行贷款的风险管理,从贷款的条件审核到贷款的跟踪都有一定的科学化规范化的预测,有利于促进银行内部管理的规范化和正规化,有利于确保银行贷款及时收回,并最终提高信贷管理效率,而只有确立了明晰、科学的管理目标才能合理组织其他环节,建立起完善的管理机制,取得最佳管理绩效。2.2 对社会的意义
加强银行贷款风险管理涉及到社会生产的各个方面,一方面有利于形成诚信的社会风气,另一方面有助于促进国民经济的进步,推动社会的进一步发展。
2.2.1加强银行贷款风险管理的措施
银行贷款风险管理是一门艺术。本着对风险早发现、早预防、早化解的宗旨,一方面要建立快速预警预控系统,做到对风险及时发现、及时预防、及时化解,最大限度地降低风险系数;另一方面要建立快速的风险处置系统。从各个方面加强银行贷款的风险管理,就要从以下几个方面入手:
(1)建立健全银行贷款风险管理机制——完善的银行贷款风险管理机制是银行规范经营行为的前提,也是银行稳健经营的重要的保障。银行贷款风险管理需要银行内部各个部门的相互配合,会计部门、法律部门、内控部门、计划部门以及资金部门等协调沟通,积极配合才能够营造出良好的风险防范氛围。银行应该加强对银行信贷风险管理机制建设,从整体上计量、把握、监控及限制风险,保证商业银行的稳健经营。另外,随着我国经济的不断发展,银行业务也越来越多元化,银行推出各种各样的金融产品越来越多,利用投资组合和投资产品的多元化有利于降低银行的整体的风险,可以作为银行贷款风险管理的一个补充。
(2)做好贷款前的风险评估工作——贷款前了解贷款人的信息是十分必要的,包括贷款人的道德品质、资本实力、还款能力、担保条件等都是重要的评估考察方面。银行可以通过贷款人以往的还款情况,有无不良记录了解贷款人的信用状况;至于贷款人的资本实力、还款能力等都可以对贷款人的实际情况进行走访调查,全面分析贷款人的还款能力。一般情况下,贷款人都会有贷款担保。贷款担保的作用在于为银行贷款提供一种保护,即在借款人无力还款时,银行可以通过处分担保品或向保证人追偿而收回贷款本息,从而使银行少担风险,少受损失,保证贷款本息的安全。这是一项重要的保障措施,一定要对贷款担保进行仔细的评估预测,尽量减少银行的损失。
(3)加强贷款后的监管工作——对于银行贷款业务来说,将贷款收回才算是贷款业务的最终完成,也就是说,在贷款收回之前银行是有风险的,尤其是将贷款发放出去之后。在新的社会环境下,一定要加强贷款后的监管工作,增加贷款“三查”内容,除了要关注贷款企业经营情况、节能环保情况、担保情况、现金流情况等常规内容外,还要重点关注企业是否存在拖欠工资、拖欠税费、拖欠货款、职工是否放假或轮岗、是否有高利贷融资、结算是否正常,股东关系是否和谐,合作伙伴是否稳定等等,并将其作为判断贷款是否形成隐性风险的主要依据。如果是个人贷款,一定要随时关注贷款人的动态,银行也要定期回访贷款资金的使用情况,随时掌握贷款人的基本状况,做好贷款后的监管工作。
该数据集共有252000个样本,每个样本包含13个特征,首先使用pandas读取数据,得到dataframe格式的数据,然后调用info接口查看每个字段的基本信息,包括字段非空个数,字段类型。
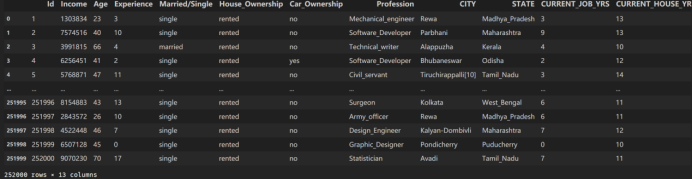
机器学习模型只能处理数值型数据,因此对于部分非数值型数据需要进行转换,编码成数值型数据,本实验主要使用encoder类来对object类型数据进行编码,变成数值型。同时删除无用特征,这些特征对模型分类结果没有起到作用。处理好的数据如下图所示:
数据集处理好后,分析了各个特征的和标签之间的相关性,并进行可视化展示,如下图所示:
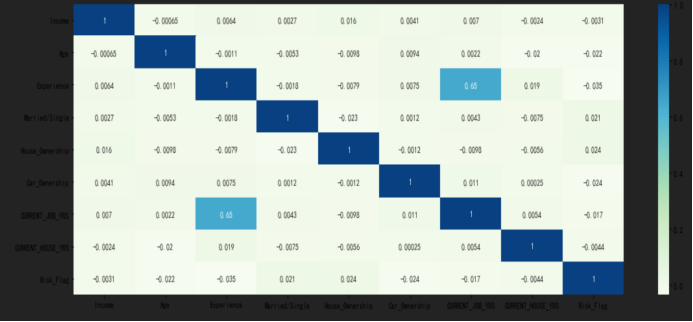
从上图可以看出,标签和特征CURRENT_JOB_YRS相关性最强,达到了0.65,这里的相关系数使用的是皮尔森相关系数。
从数据中分离出训练数据和对应标签,如下图所示:
划分训练集和测试集。
模型在测试集上的精度如下图所示:
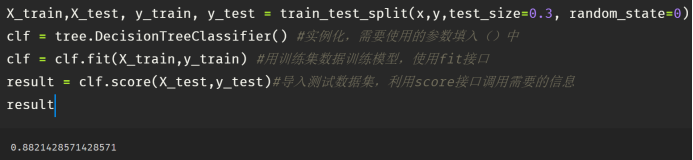
精度为88.21%,验证了决策树模型的有效性,可以很好的对贷款风险与否进行分类判断。
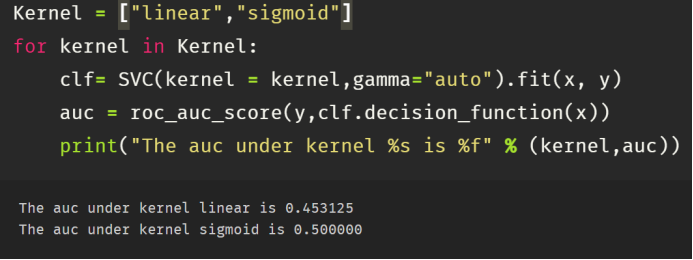
使用SVM在测试集上的AUC如上图所示。
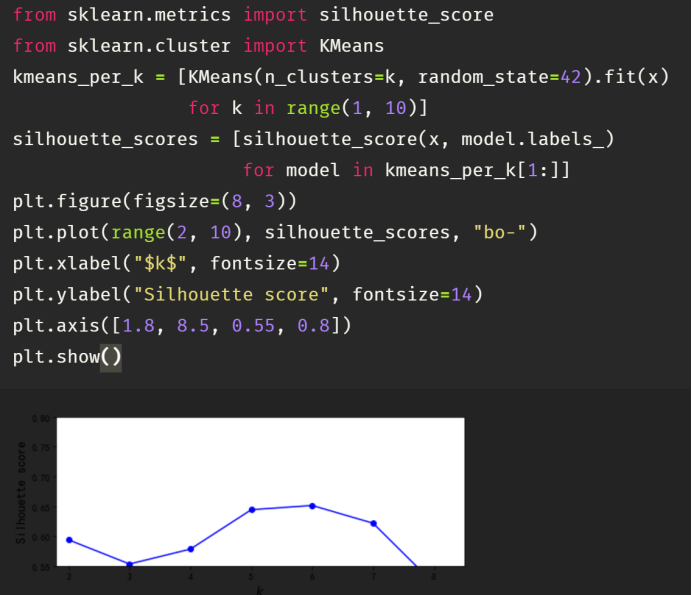
使用k-means聚类算法得到的布里尔分数如上图所示,先减小,后增大。
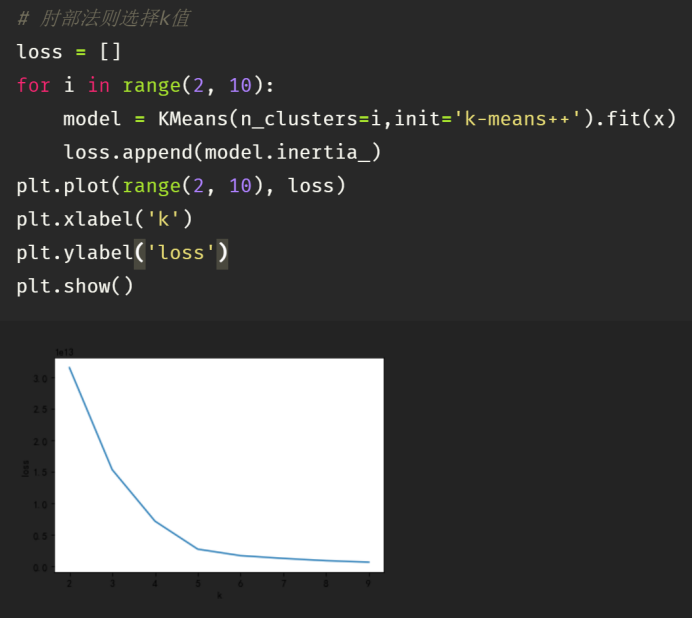
从上图可以看出,K在5时聚类效果比较好。
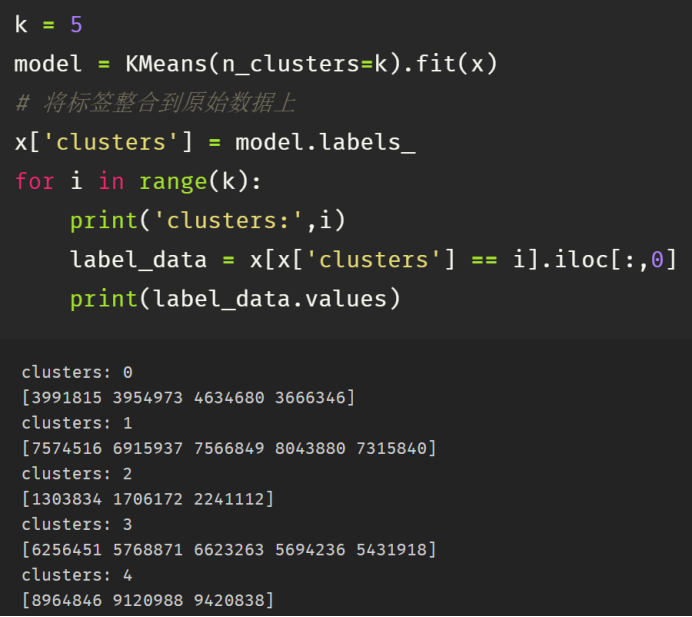
聚类中心如上图所示。
3 原理及应用
决策树(Decision Tree)是机器学习中一种常见的算法,它的思想非常朴素,就像我们平时利用选择做决策的过程。决策树是一种基本的分类与回归方法,当被用于分类时叫做分类树,被用于回归时叫做回归树。决策树是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。该算法容易理解,适用各种数据,在解决各种问题时都有良好表现,尤其是以树模型为核心的各种集成算法,在各个行业和领域都有广泛的应用。 决策树算法的本质是一种图结构。
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量。熵越大表示不确定性越大,要明白某件事需要的信息量更大,设X是一个取有限个值的离散随机变量,其概率分布为:
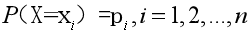
随件变量X的熵可以定义为:
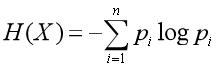
随机变量条件熵的定义:
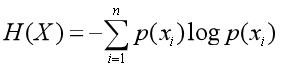
定义为X给定条件下,Y的条件概率分布的熵对X的数学期望,条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。随机变量X给定的条件下随机变量Y的条件熵H(Y|X)
信息增益(information gain)可以定义为:信息增益 = 熵-条件熵,其相减得到的值为信息量的变化,在某个条件下,信息量的变化情况。信息增益越大,说明某个条件是越重要的。
信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。
4 收获
机器学习是一门多领域的交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科,专门研究计算机如何模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。未来将使用更多的机器学习技术,像随机森林,Bagging,SVM等机器学习技术,已解决更多的实际生活中的问题。
5 全部程序代码
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 from sklearn.model_selection import StratifiedShuffleSplit 5 from sklearn.model_selection import GridSearchCV 6 from sklearn.svm import SVC 7 from sklearn.preprocessing import OneHotEncoder 8 from sklearn.linear_model import LogisticRegression 9 from sklearn.metrics import roc_auc_score 10 import seaborn as sns 11 from sklearn.metrics import confusion_matrix 12 from sklearn.preprocessing import LabelEncoder 13 plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置默认字体,显示中文 14 plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是符号‘-’显示为方块的问题 15 df = pd.read_csv('基于用户行为的贷款预测训练集.csv') 16 df 17 18 df.info() 19 20 df.describe() 21 22 le = LabelEncoder() 23 df['Married/Single'] = le.fit_transform(df['Married/Single']) 24 df['House_Ownership'].value_counts() 25 26 df['House_Ownership'].value_counts().values.tolist() 27 28 df['House_Ownership'].value_counts().index.tolist() 29 30 x = np.array(df['House_Ownership'].value_counts().values.tolist()) 31 plt.pie(x, 32 labels=df['House_Ownership'].value_counts().index.tolist(), 33 autopct="%1.1f%%" 34 ) 35 plt.title("所占比例") 36 plt.show() 37 38 le = LabelEncoder() 39 df['House_Ownership'] = le.fit_transform(df['House_Ownership']) 40 le = LabelEncoder() 41 df['Car_Ownership'] = le.fit_transform(df['Car_Ownership']) 42 df.drop(['Id','Profession','CITY','STATE'],axis=1,inplace=True) 43 df 44 45 df.corr()#皮尔森相关系数 46 47 plt.figure(figsize=(19,6)) 48 sns.heatmap(df.corr(), annot=True,cmap='GnBu') 49 50 plt.scatter(df['Experience'][:100],df['CURRENT_JOB_YRS'][:100]) 51 52 y = df['Risk_Flag'] 53 x = df.iloc[:,:-1] 54 x 55 56 from sklearn.feature_selection import SelectFromModel 57 from sklearn import tree #导入需要的模块 58 sfm_selector = SelectFromModel(estimator = tree.DecisionTreeClassifier()) 59 sfm_selector.fit(x, y) 60 x.columns[sfm_selector.get_support()] 61 62 x = x[['Income', 'Age']] 63 from sklearn.model_selection import train_test_split 64 X_train,X_test, y_train, y_test = train_test_split(x,y,test_size=0.3, random_state=0) 65 clf = tree.DecisionTreeClassifier() #实例化,需要使用的参数填入()中 66 clf = clf.fit(X_train,y_train) #用训练集数据训练模型,使用fit接口 67 result = clf.score(X_test,y_test)#导入测试数据集,利用score接口调用需要的信息 68 result 69 70 from tensorflow.keras.utils import to_categorical 71 from tensorflow.keras.layers import Input, Dense, Multiply 72 from tensorflow.keras.models import Model 73 from tensorflow.keras.optimizers import SGD, Adam 74 from tensorflow.keras.layers import * 75 y_test = to_categorical(y_test, num_classes=2) 76 y_train = to_categorical(y_train,num_classes=2) 77 X_test = X_test.values 78 np.random.seed(1160) 79 np.random.shuffle(X_test) 80 np.random.seed(1160) 81 np.random.shuffle(y_test) 82 # 划分训练集,验证集,测试集 83 x_val = X_test[100:] 84 y_val = y_test[100:] 85 x_test = X_test[:100] 86 y_test = y_test[:100] 87 88 # Build model 89 input_shape = (100,) 90 model_input = Input(shape=input_shape) 91 O_seq = Embedding(3000, 300, input_length=300, name="embedding")(model_input) 92 93 #自注意力机制 94 import tensorflow.keras.backend as K 95 import tensorflow as tf 96 class Self_Attention(Layer): 97 98 def __init__(self, output_dim, **kwargs): 99 self.output_dim = output_dim 100 super(Self_Attention, self).__init__(**kwargs) 101 102 def build(self, input_shape): 103 # 为该层创建一个可训练的权重 104 # inputs.shape = (batch_size, time_steps, seq_len) 105 self.kernel = self.add_weight(name='kernel', 106 shape=(3, input_shape[2], self.output_dim), 107 initializer='uniform', 108 trainable=True) 109 110 super(Self_Attention, self).build(input_shape) # 一定要在最后调用它 111 112 def call(self, x): 113 print(self.kernel[0]) 114 print(self.kernel[1]) 115 print(self.kernel[2]) 116 WQ = K.dot(x, self.kernel[0]) 117 WK = K.dot(x, self.kernel[1]) 118 WV = K.dot(x, self.kernel[2]) 119 print(WQ) 120 print(WK) 121 print(WV) 122 print("WQ.shape", WQ.shape) 123 print('----------------') 124 print(x) 125 print('----------------') 126 print("K.permute_dimensions(WK, [0, 2, 1]).shape", K.permute_dimensions(WK, [0, 2, 1]).shape) 127 128 QK = K.batch_dot(WQ, K.permute_dimensions(WK, [0, 2, 1])) 129 130 QK = QK / (64 ** 0.5) 131 132 QK = K.softmax(QK) 133 134 print("QK.shape", QK.shape) 135 136 V = K.batch_dot(QK, WV) 137 print("V.shape",V.shape) 138 return V 139 140 def compute_output_shape(self, input_shape): 141 print(input_shape[0], input_shape[1], self.output_dim) 142 return (input_shape[0], input_shape[1], self.output_dim) 143 144 X_train = X_train[:5000] 145 y_train =y_train[:5000] 146 batch_size = 32 147 S_inputs = Input(shape=(2,), dtype='int32') #(None,600) 148 O_seq = Embedding(5000, 128)(S_inputs) #(None,600,128) 149 # O_seq = Self_Attention(128)(embeddings) #(None,600,128) 150 151 cnn1 = Conv1D(256, 3, padding='same', strides=1, activation='relu')(O_seq) 152 cnn1 = MaxPooling1D(pool_size=1)(cnn1) 153 cnn2 = Conv1D(256, 4, padding='same', strides=1, activation='relu')(O_seq) 154 cnn2 = MaxPooling1D(pool_size=1)(cnn2) 155 cnn3 = Conv1D(256, 5, padding='same', strides=1, activation='relu')(O_seq) 156 cnn3 = MaxPooling1D(pool_size=1)(cnn3) 157 # 合并三个模型的输出向量 158 cnn = concatenate([cnn1, cnn2, cnn3], axis=-1) 159 160 O_seq = GlobalAveragePooling1D()(cnn) #(None,128) 161 O_seq = Dropout(0.5)(O_seq) 162 outputs = Dense(2, activation='softmax',kernel_regularizer = tf.keras.regularizers.L2())(O_seq) 163 model = Model(inputs=S_inputs, outputs=outputs) 164 opt = Adam(learning_rate=0.002, decay=0.00001) 165 loss = 'categorical_crossentropy' 166 model.compile(loss=loss, 167 168 optimizer=opt, 169 170 metrics=['categorical_accuracy']) 171 print('Train...') 172 173 feature_name = x.columns.tolist() 174 import graphviz 175 dot_data = tree.export_graphviz(clf 176 ,feature_names= feature_name 177 ,class_names=["有风险","无风险"] 178 ,filled=True 179 ,rounded=True 180 ) 181 graph = graphviz.Source(dot_data) 182 183 feature_name 184 185 def naive_classify(train,test): 186 labels = ['0', '1'] 187 avg =[] 188 std =[] 189 res = [] 190 for i in labels: 191 value = train.loc[train.iloc[:,-1]==i,:] 192 m = value.iloc[:,:-1].mean() 193 s = np.sum(np.power((value.iloc[:,:-1]-m),2))/(value.shape[0]) 194 avg.append(m) 195 std.append(s) 196 means = pd.DataFrame(avg,index=labels) 197 print(means) 198 std_ = pd.DataFrame(std,index=labels) 199 for j in range(test.shape[0]): 200 iset = test.iloc[j,:-1].tolist() 201 iprob = np.exp(-1*np.power((iset-means),2)/(std_*2))/(np.sqrt(2*np.pi*std_)) 202 pro = 1 203 for k in range(test.shape[1]-1): 204 pro *= iprob[k] 205 cla = pro.index[np.argmax(pro.values)] 206 res.append(cla) 207 test['predict']=res 208 acc = (test.iloc[:,-1]==test.iloc[:,-2]).mean() 209 return test,acc 210 x = x.head(20) 211 y = y.head(20) 212 Kernel = ["linear","sigmoid"] 213 for kernel in Kernel: 214 clf= SVC(kernel = kernel,gamma="auto").fit(x, y) 215 auc = roc_auc_score(y,clf.decision_function(x)) 216 print("The auc under kernel %s is %f" % (kernel,auc)) 217 218 gamma_range = np.logspace(-10,1,20) 219 coef0_range = np.linspace(0,5,10) 220 param_grid = dict(gamma = gamma_range,coef0 = coef0_range) 221 cv = StratifiedShuffleSplit(n_splits=5, test_size=0.3, random_state=420) 222 grid = GridSearchCV(SVC(kernel = "rbf",degree=1,cache_size=5000), param_grid=param_grid, cv=cv) 223 grid.fit(x, y) 224 225 clf= SVC(kernel = 'rbf',coef0=0.0,gamma=0.1832).fit(x, y) 226 auc = roc_auc_score(y,clf.decision_function(x)) 227 y_pred = clf.predict(x) 228 c = confusion_matrix(y, y_pred) 229 sns.heatmap(c,fmt="d",annot=True) 230 231 from sklearn.ensemble import RandomForestClassifier 232 from sklearn.model_selection import GridSearchCV 233 from sklearn.model_selection import cross_val_score 234 scorel = [] 235 for i in range(0,200,10): 236 rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1,random_state=90) 237 score = cross_val_score(rfc,x,y,cv=10).mean() 238 scorel.append(score) 239 param_grid = {'max_depth':np.arange(1, 20, 1)} 240 rfc = RandomForestClassifier(n_estimators=111,random_state=90) 241 GS = GridSearchCV(rfc,param_grid,cv=10) 242 GS.fit(x,y) 243 244 SEED = 2019 245 import torch 246 import torch.nn as nn 247 import pickle 248 import torch.nn.functional as F 249 import bz2 250 import torch.optim as optim 251 import warnings 252 warnings.filterwarnings("ignore") 253 torch.manual_seed(SEED) 254 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') 255 256 class MLP(nn.Module): 257 def __init__(self, num_hidden, output_dim): 258 super().__init__() 259 self.fc1 = nn.Linear(num_hidden, 200) 260 self.fc2 = nn.Linear(200, 100) 261 self.fc3 = nn.Linear(100, output_dim) 262 def forward(self, x): 263 x = self.fc1(x) 264 x = F.relu(x) 265 x = self.fc2(x) 266 x = F.relu(x) 267 out = self.fc3(x) 268 return out 269 270 num_hidden = 2 271 num_output = 2 272 model = MLP(num_hidden, num_output) 273 optimizer = optim.Adam(model.parameters(), lr=0.1) 274 criterion = nn.CrossEntropyLoss() 275 model = model.to(device) 276 criterion = criterion.to(device) 277 train_loss = 0.0 278 num_samples = len(y_train) 279 280 for epoch in range(1, 100): 281 ytrain = y_train 282 train_acc = 0.0 283 batch_loss = [] 284 optimizer.zero_grad() 285 predictions = model(x_train).squeeze() 286 loss = criterion(predictions, y_train) 287 batch_loss.append(loss.item()) 288 loss.backward() 289 optimizer.step() 290 with torch.no_grad(): 291 l = loss.cpu().detach().numpy() 292 train_loss += l * (len(ytrain) / num_samples) 293 y_hat = torch.argmax(predictions, dim=1) 294 ytrain = torch.argmax(ytrain, dim=1) 295 correct = (y_hat == ytrain).sum().cpu().detach().numpy() 296 train_acc += correct / num_samples 297 avg_loss = np.array(batch_loss).mean() 298 299 from sklearn.metrics import silhouette_score 300 from sklearn.cluster import KMeans 301 kmeans_per_k = [KMeans(n_clusters=k, random_state=42).fit(x) 302 for k in range(1, 10)] 303 silhouette_scores = [silhouette_score(x, model.labels_) 304 for model in kmeans_per_k[1:]] 305 plt.figure(figsize=(8, 3)) 306 plt.plot(range(2, 10), silhouette_scores, "bo-") 307 plt.xlabel("$k$", fontsize=14) 308 plt.ylabel("Silhouette score", fontsize=14) 309 plt.axis([1.8, 8.5, 0.55, 0.8]) 310 plt.show() 311 312 # 肘部法则选择k值 313 loss = [] 314 for i in range(2, 10): 315 model = KMeans(n_clusters=i,init='k-means++').fit(x) 316 loss.append(model.inertia_) 317 plt.plot(range(2, 10), loss) 318 plt.xlabel('k') 319 plt.ylabel('loss') 320 plt.show() 321 322 k = 2 323 model = KMeans(n_clusters=k).fit(x) 324 # 将标签整合到原始数据上 325 x['clusters'] = model.labels_ 326 for i in range(k): 327 print('clusters:',i) 328 label_data = x[x['clusters'] == i].iloc[:,0] 329 print(label_data.values)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号