唯一标识符漫谈
标识符在许多领域主要用于标记用途。可以根据环境条件等因素随机的生成一个ID,也可以使用哈希算法或者消息摘要算法对对象生成一个唯一的固定长度的标记符。前者主要用于区分身份的标记,后者可以用于比较文件数据的一致性和重复数据的检测。
三种标识符
UUID
uuid即通用唯一标识符(Universally Unique Identifier),是一种软件构建的标准,目的是让分布式系统中的元素都能有唯一辨识信息。
其由4个连字号(-)连接32个字节的字符串构成,总共36个字节长。如:UUID('c5c11029-8c99-400e-a7a5-d741f6aaf3e3')。
GUID
guid是UUID的一种实现,目前最广泛应用的UUID,是MS的全局唯一标识符(GUID)。
VS中通过Tools->Create GUID生成:
// {8403C5C0-7F0C-4933-BE85-0E2A90E888AB}
DEFINE_GUID(<<name>>,
0x8403c5c0, 0x7f0c, 0x4933, 0xbe, 0x85, 0xe, 0x2a, 0x90, 0xe8, 0x88, 0xab);
ObjectID
objectid则是用于MongoDB的主键,12-byte的bson类型字符串:
An ObjectId is a 12-byte unique identifier consisting of:
- a 4-byte value representing the seconds since the Unix epoch,
- a 3-byte machine identifier,
- a 2-byte process id, and
- a 3-byte counter, starting with a random value.
>>> from bson import objectid as objectid >>> objectid.ObjectId() ObjectId('5c6921b65846b70514ebf839')
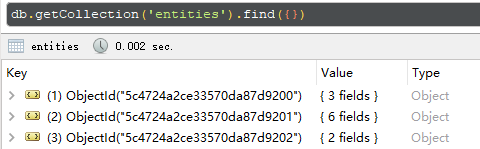
上面是MongoDB中产生的若干条记录
这些随机生成算法产生的ID重复的概率可以小到忽略不计,通常可以认为是唯一的。
消息摘要算法
上面是我们主动生成一个全局唯一标识符,用于标记信息数据对象等。被标记对象与标记符之间没有必然关系,两者之间通常通过key-value的形式关联,通过key来索引得到value。
那么能不能用一个算法对给定的信息生成一个唯一的标识符?且满足下面的条件:
func(data_1) = identifier_1 func(data_2) = identifier_2 if data_1 == data_2 then identifier_1 == identifier_2 if data_1 != data_2 then identifier_1 != identifier_2
其实这就是消息摘要算法:
- 结果一致性:相同的输入应该产生相同的结果;
- 结果唯一性:不同的输入的结果应该不同;
- 不可逆性:已知算法的生成过程和产生结果,但不能推断出输入值。
消息摘要算法的应用是很广泛的,其本质是对数据进行摘要计算以得到一个固定长度的hash值,目前比较常用的有MD5和SHA1.
MD5
信息-摘要算法Message-Digest Algorithm 5简称MD5,是广泛使用的一种散列函数。
能将任意字符串加密成固定长度为128bit的MD5值,且该过程不可逆,安全性较高。能对文件进行散列计算得到一个"数字指纹”,用于校验文件的一致性。
SHA1
安全哈希算法Secure Hash Algorithm简称SHA1 。SHA1基于MD5,它对长度小于264的输入,产生长度为160bit的hash值。
由于加密后的数据长度更长,SHA1的运算速度要比MD5慢,但是更安全。
散列计算和上面介绍的随机算法一样均可能产生重复值,因为将任意的输入转换到一个固定格式和长度的元素构成的集合中,必然会出现多对一的映射关系。
但是实际应用中重复的概率非常小,可以忽略不计。
因此实际使用时如果两个输入a和b产生相同的hash值,我们便认为a和b是相同的。这也是数字签名和文件一致性校验等应用的一个基础。
动手实践
由于python有丰富的库,而且操作较为方便,下面通过python来简单的了解实践一下。
UUID的生成算法
python提供了RFC 4122标准中uuid 1, 3, 4, 和5版本的生成算法,分别对用uuid模块中的uuid1、uuid3、uuid4和uuid5四个函数。
- uuid1:该函数使用host ID和序列数以及当前的时间来生成UUID,由于包含有网络地址,因此该算法可能会暴露隐私;
- uuid3:使用一个命名空间的UUID的MD5值和一个字符串来生成一个UUID;
- uuid4:直接生成一个随机的UUID;
- uuid5:使用一个命名空间的UUID的sha-1值和一个字符串来生成一个UUID;
实际例子如下:
# uuid1(node=None, clock_seq=None) >>> uuid.uuid1() UUID('27751551-34cf-11e9-ac82-54bf64938e35') # uuid3(namespace, name) >>> uuid.uuid3(uuid.NAMESPACE_DNS, 'cnblogs/alpha_panda') UUID('585ccea7-3560-3af5-a265-456e5944a39e') # uuid4() >>> uuid.uuid4() UUID('72148b42-eec8-4109-80e8-b157134c94d7') # uuid5(namespace, name) >>> uuid.uuid5(uuid.NAMESPACE_DNS, 'cnblogs/alpha_panda') UUID('a8fa1c8d-bff6-5df4-839b-7787b9094863')
通过str将其装换成字符串,也可通过.bytes属性得到16字节的编码。
>>> uobj = uuid.uuid4() >>> uobj UUID('d172a1ed-71bb-4cb5-ac00-4d0dd6041128') >>> str(uobj) 'd172a1ed-71bb-4cb5-ac00-4d0dd6041128' >>> uobj.bytes '\xd1r\xa1\xedq\xbbL\xb5\xac\x00M\r\xd6\x04\x11(' >>> uuid.UUID(bytes=uobj.bytes) UUID('d172a1ed-71bb-4cb5-ac00-4d0dd6041128')
ObjectID
python中可以通过bson库生成objectid,下面是我们封装的一个用于生成和处理objectid的类:
import bson.objectid as objectid class ObjectIDMgr(object): @staticmethod def genid(): return objectid.ObjectId() @staticmethod def id2str(obj_id): return str(obj_id) @staticmethod def str2id(id_str): return objectid.ObjectId(id_str) @staticmethod def id2bytes(obj_id): return obj_id.binary @staticmethod def bytes2id(id_bytes): return objectid.ObjectId(id_bytes)
hash算法
python中有内置函数hash和库hashlib中提供接口可供计算hash值。下面来一一介绍一下。
1.内置hash函数
内置hash函数的函数原型为:hash(object) -> integer
该函数主要用于程序运行时通过计算hash值来区分不同的对象,其散列的结果和对象的值以及id(内存中的地址)有关。
要想保证跨进程的结果一致性,可以使用hashlib库中提供的函数。
2.hashlib
hashlib中包括md5和sha1的实现,以md5为例。
Python 2.x
import hashlib m1 = hashlib.md5('cnblogs/alpha_panda') m2 = hashlib.md5() m2.update('cnblogs/') m2.update('alpha_panda') hd1, hd2 = m1.hexdigest(), m2.hexdigest() print hd1, hd2, hd1 == hd2
结果:
fb9e9f0f84773f74587f2f05ae0e55d2 fb9e9f0f84773f74587f2f05ae0e55d2 True
Python 3.x
>>> import hashlib >>> print(hashlib.md5('cnblogs/alpha_panda'.encode('utf-8')).hexdigest()) fb9e9f0f84773f74587f2f05ae0e55d2
hashlib.md5算法对同一字符串计算必能得到相同的md5值,由于该函数计算的md5值可重现,因此可以进行保存和传输。
文件一致性校验
对于文本文件和二进制文件均可以通过hashlib.md5进行计算。
def cal_file_md5(file_path): m = hashlib.md5() with open(file_path, 'rb') as fobj: for segment in iter(lambda : fobj.read(4096), b""): m.update(segment) return m.hexdigest()
上面的函数可以对较大的文件进行md5的值进行计算
明文转密文
为安全考虑,防止用户的密码泄露,一般公司都不会直接存储用户的密码明文,而是将密码转换成密文存放到后台数据库中。
用户登录的时候,将密码转换成密文和数据库中的存储的密文进行比较以进行身份认证。
该过程要求不能有密文反推到出明文,而且明文和密文应该是一一对应的关系。消息摘要算法恰好可以满足需求。
hash值可用作数据库中用户密码的密文。下面是一个简单的例子:
DB = { 'zhangsan':'305e4f55ce823e111a46a9d500bcb86c', 'lisi':'7c6a180b36896a0a8c02787eeafb0e4c', } def check_valid(user_name, pwd): cipher = hashlib.md5(pwd).hexdigest() valid_cipher = DB.get(user_name, None) return valid_cipher == cipher def login_request(user_name, pwd): if check_valid(user_name, pwd): # do_login() return True else: return False login_queue= (('zhangsan', 'password0'), ('zhangsan', 'hello'), ('lisi', 'password1')) for user, pwd in login_queue: is_suc = login_request(user, pwd) print is_suc
即使服务器端DB中的用户账号信息泄露,但是由于很难伪造一个明文使其md5值恰好等于密码密文,因此有较高的安全性。
目前网络上有传言说md5已被破解,实际无从验证。但是破解简单密码的暴力破解是可以实现的。
预先计算一些常见的字符串的密文,然后将密文作为key,明文作为value存放到数据库中,这样可以使用密文查询得到明文。
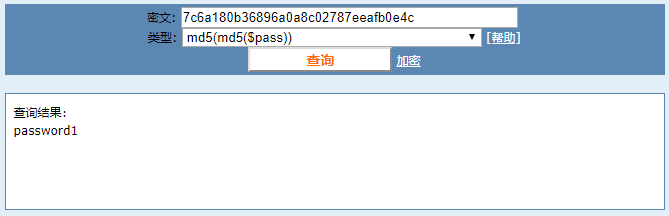
重复文件检测与引用
使用消息摘要算法计算文件的md5值,可以将改值作为文件的ID。
比如某网盘上传文件的秒传功能,我们将一个几G大小的操作系统的镜像文件上传至网盘服务器,可能只需要几秒钟的时间。
客户端或者浏览器先去读文件,这个过程实际上是计算待上传文件的hash值,然后将改值上传到服务器,查找改值对应的文件是否在网盘中;
如果已经存在,则直接将服务端网盘文件的引用计数加一,然后将文件添加到在当前用户的文件列表中,便完成上传。如果没有,这需要将文件上传至服务器。
这样如果几万个用户网盘中存储一个相同的文件,网盘服务器只需存放一份文件,分别被几万个用户引用。当删除一个文件而导致其引用计数为零时,便可真正删除该文件。
此外,一些本地检测重复文件的软件同样可以分别计算硬盘上文件的md5值,通过md5值来判断文件是否重复。
消息摘要算法的有很广泛的用途,限于篇幅就先介绍到这里。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号