

TCP/IP 笔记 - 用户数据报协议和IP分片
关于本章中的IP分片部分,参考第五章IP分片头部知识点。需要注意的是,TCP有超时重传,UDP的超时重传则依赖上层应用程序实现。
用户数据报协议(UDP)
UDP是一个简单的面向无连接、不可靠的数据报的传输协议(它把应用程序传给IP层的数据发送出去,但并不保证它们能够到达目的地)。它不提供差错纠正、队列管理、重复消除、流量控制和拥塞控制;它提供差错检测,包含传输层真实的端到端检验和。[RFC0768]是UDP的正式规范。
在IPv4中,协议字段值为17标识UDP;IPv6则在下一个头部字段使用相同的值17。
UDP头部如下图所示:
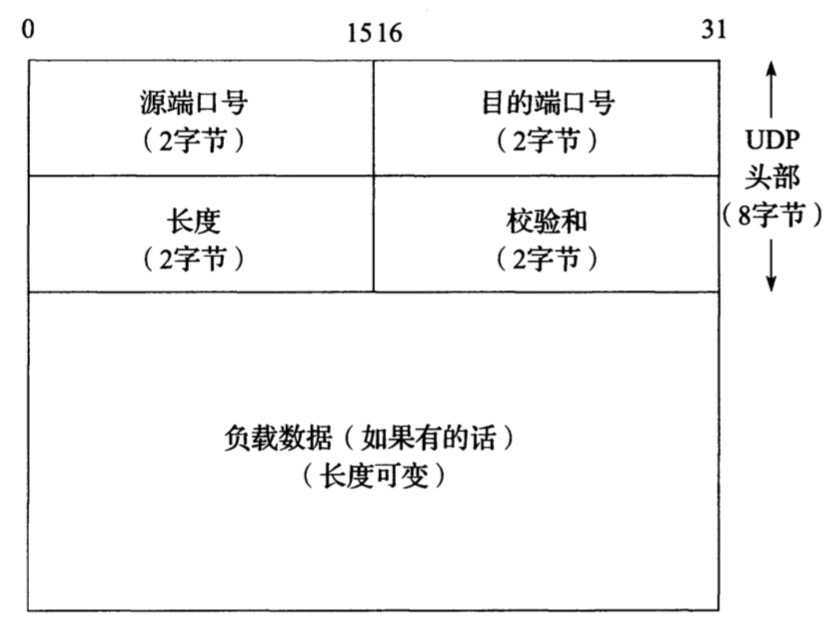
端口号帮助协议辨认发送和接收进程,纯属抽象概念(不与主机上的任何物理实体相关)。在UDP中,端口号是正的16比特数字,源端口号是可选的。
目的端口号以帮助分离从IP层进入的数据,IP层根据IPv4头部的协议字段或者IPv6的下一个头部字段值将进入IP的数据报分离到特定的传输协议,这意味着端口号在不同传输协议之间是独立的。
长度字段是UDP头部和UDP数据的总长度,以字节为单位,最小值为8(这个字段可以是冗余的,基于IP头部有数据报总长度字段)。
校验和字段是端到端的,是对包含了IP头部中的源和目的IP地址字段的UDP伪头部计算得到的,因此想要修改源或目的IP地址字段就需要对检验和进行修改。
校验和的计算和第五章的Internet校验和计算方法类似(16位自己的反码和的反码),但需要注意2个细节:
1. UDP数据报长度可以是奇数个字节,而校验和算法只相加16位字(总是偶数个字节),所以UDP的处理过程会在奇数长度的数据报尾部追加一个值为0的填充字节。
2. UDP计算它的校验和时包含了衍生自IPv4头部的字段的一个12字节的伪头部或者衍生自IPv6头部字段的一个40字节的伪头部。这个伪头部也是虚的,目的只是用于校验和的计算,实际上确从不会被传送出去。伪头部包含了来自IP头部的源和目的地址以及协议或者下一个头部字段(值为17),目的是让UDP层验证数据是否已经到达正确的目的地。
如下是一个包含伪头部、头部、数据的UDP/IPv4数据报结构:
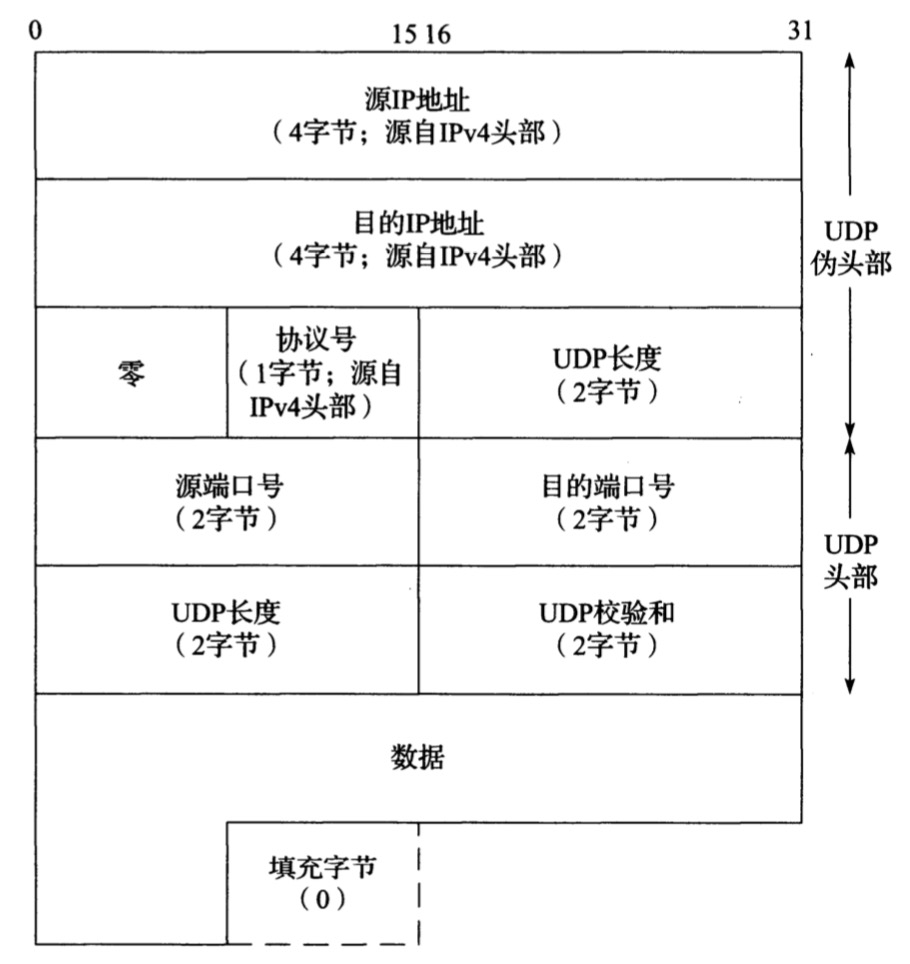
伪头部和填充字段仅供UDP层处理应用,不会与数据报一起传输。
IPv6相对IPv4,对于UDP来说,改动很小。两者最明显的不同在于IPv6使用128位地址和由此产生的的对伪头部结构带来的影响,更细致的不同是IPv6里不存在IP层头部校验和。如果UDP不使用校验和去运行,就没有端到端检测任何IP层地址信息的正确性,因此IPv6的UDP伪头部检验和是必需的(TCP也是)。

当遇到IPv6超长数据报情况时,由于IPv6长度是32位,而UDP是16位,这时候UDP的长度字段会被设置为0。
UDP协议被修改产生一种称为UDP-Lite的协议,该协议允许UDP数据里存在指定的比特差错且能够通过校验。UDP-Lite协议算是一种独立的协议,用一个"校验和覆盖范围"字段取代了"长度"字段。该字段给出校验和覆盖的字节数,特殊值0表示数据报全覆盖,最小值为8(UDP头部)。
结构如下:

理论上来说,一个IPv4数据报的最大长度是65535,由16位总长度字段决定,除去20字节不带选项的IPv4头部和一个8字节的UDP头部,剩下的65507字节就是UDP/IPv4数据。对于IPv6,除去超长数据报外,允许65527字节的数据负载(IPv6的16位负载长度字段65535减去8字节的UDP头部)。
API套接字[UNP3]提供一组函数让应用程序能够调用以设置或查询接收和发送缓存的大小(协议实现给应用程序提供API以选择一些缓存大小来进行数据的发送和接收)。对于一个UDP套接字,这个大小与应用程序可读写的最大UDP数据报大小直接关联,典型的默认值是8192或65535字节,一般可以调用setsocketopt() API设置值。
UDP/IP能发送和接收一个给定大小的数据报并不意味着接收应用程序就能够读取这种大小的数据报。UDP编程接口允许应用程序指定每次一个网络的读操作完成时返回的最大字节数。对于超过部分,大多数情况下执行API截断数据报以丢弃超额数据,然后给出通知调用者数据报截断信息;也有一些系统会将这些数据报的超额数据放到后续的读操作中。
对于UDP/IPv4和UDP/IPv6的转换,如果校验和为"0"(IPv4允许,IPv6不允许),从IPv4到IPv6的转换则可能产生结果:生成一个带有完整进行了计算的伪头部校验和的UDP/IPv6数据报;丢弃到来的数据报。转换器应该提供一个配置项来选择数据的取舍,且转换计算校验和的开销可能无法接受。另外一点是,对于无状态的转换器,被分片的带有"0"校验和的UDP/IPv4数据报不能转换,这些数据将被丢弃;有状态的转换器可以重组多个分片和计算要求的校验和,被分片的带有已计算校验和的UDP/IP数据报在转换的两边都被当作普通分片处理。
UDP的路径MTU发现
IP层经常基于每个目的地址缓存一个路径MTU发现机制(PMTUD)信息,当没有更新时就让它超时。
以UDP/IPv4为例,针对一台没有路径MTU路径历史的主机发起请求,UDP的路径MTU发现过程如下:
1. 第一次发送数据报,由于ICMPv4 PTB消息,程序返回错误信息;
2. 延时进行第二次发送数据报,延时是为了主机接收PTB消息,也让错误环境能传回给发送方去处理,这时路径MTU被发现且记录;
3. 第二次发送的数据报根据路径MTU决定是否被分片或分片大小,以作传输;
4. 如果路径MTU超时时间到,则重复路径MTU发现机制。
UDP对服务器设计的影响
在典型的客户机/服务端场景中,客户机启动后立即与一台服务器通信,然后就完成了。而针对服务端而言,启动后进入睡眠,等一个客户机请求的到达后被唤醒,这时候需要服务器来评估这个请求以及可能要进行更进一步的处理。本章并未涉及到UDP服务器的详细程序实现,而是针对UDP服务器的设计和实现有影响的UDP协议特性。
IP地址和UDP端口号
当一个应用程序接收到一个UDP消息时,它的IP和UDP头部已经被剥离;如果想要给予回复,应用程序必须由操作系统以其他方式告知是谁(源IP地址和端口号)发送的消息。这个特点允许UDP服务器去处理多个客户机请求。有些服务器还需要知道数据报是发送给谁的,即IP目的地址,但由于如因为多址、IP地址别名、IPv6多范围使用,一台主机可能有多个IP地址,单个服务器可使用它们中的任何一个来接收进入的数据报。如果目的地址是广播或者组播的,那么有些服务则可能会有不同的回应。
针对以上得出结论,即使一个API可能得到传输层数据报里的所有数据,但是额外的来自各层的信息(一般指地址信息)也可能是使服务器更有效地进行操作所需的。设计同时使用IPv4和IPv6的UDP服务器必然要考虑着两种地址类型由明显不同的长度以及需要不同的数据结构。另外,用IPv6地址来给IPv4编码的交互操作机制可能允许使用IPv6套接字同时处理IPv4和IPv6寻址。
限制本地IP地址
大多数UDP服务器在创建UDP端点时都使其本地IP地址具有通配符的特点,也就是说如果进入的UDP数据报的目的地是一个服务器的端口,那么在该服务器上的任何本地接口均可接收到它(包含本地回路地址)。当服务器建立它的端点,它可以指定主机的一个本地IP地址(包括一个广播地址),作为该端点的本地IP地址。在这种情况下,只有目的IP地址与指定的本地地址匹配时,进入的UDP数据报才会被转到这个端点。
如 linux 系统下的sock程序(百度文库sock小程序介绍),执行命令: sock -u -s 127.0.0.1 7777 (-u 使用UDP,-s 作为一个服务器),限制了服务器只能接收到达本地回路接口127.0.0.1:7777的数据报,这时候尝试以另外一台主机发送UDP数据报是服务器收不到的。
使用多地址
有可能会存在一种情况,在同一个端口号开启几个不同的服务器,每个服务器使用一个不同的本地IP地址(这种情况的套接字API需使用SO_REUSEADDR)。在同个端口加多个地址的场景中(IPv4为例),只有直接广播、受限广播(255.255.255.255)或本地回路地址(127.0.0.1)的数据报才能到达带通配符本地地址的服务器。带指定IP地址的端点会越过通配符地址被优先选择。
限制远端IP地址
默认情况下,服务器接收来自所有地址和端口号的数据报,但也可以选择限制远端地址,只接收来自指定地址和端口号的UDP数据报。如果指定远端地址而没选择本地地址的话,那么本地地址会被自动选择,它的值是由IP路由选择的能到达那个指定的远端IP地址的网络接口的地址。
如执行命令:sock -u -s -f 10.0.0.12:3333 5555,使得服务器端口5555的UDP服务只接收来自10.0.0.12:3333发送的数据报。
每端口多服务器的使用
默认情况下,给定的地址族(IPv4/IPv6)同一时间只允许一个应用程序端点与任何一个(本地IP地址,UDP端口号)对关联。但为了支持组播,可允许多个端点使用相同的(本地IP地址,UDP端口号)对,但是应用程序一般要告诉API允许这样做(sock使用-A,或者套接字API SO_REUSEADDR)。
当一个UDP数据报到达的目的IP地址是一个广播或组播地址,同时这个目的IP地址和端口号有多个端点时,每个端点都会收到这个数据报的一个拷贝。然而如果一个UDP数据报到达其目的IP是一个单播地址时,只有唯一的端点会收到这个数据报的拷贝(哪个端点收到依赖于具体实现)。
跨越地址族:IPv4和IPv6
即UDP的IPv4和IPv6之间的端口空间是共享的。如果一个服务绑定在一个使用IPv4的UDP端口上,它同时也被分配在IPv6空间里的同一个端口,反之亦然。然而具体情况仍需根据系统的具体实现来判定。
流量和拥塞控制缺失
大多数UDP服务器是迭代服务器,也就是说单个服务器线程(或进程)在单个UDP端口处理所有客户请求。通常一个应用程序使用的每个UDP端口均有一个大小有限的队列与之对应,来自不同客户机的、几乎同时到达的请求会被UDP自动排入列队里。接收到的UDP数据以它们到达的顺序被传送给应用程序。
然而这个队列可能会溢出,使得UDP实现丢弃进入的数据报。UDP本身不提供流量控制,且是个无连接协议,自身没有可靠机制,应用程序无法得知什么时候UDP输入队列发生溢出。这导致一个问题,发送方和接收方之间的IP路由器里也有个列队,当这些列队满了,流量可能被丢弃,于是发生了网络的拥塞。当网络处于拥塞状态,无法通知通信方降低发送率,这就是拥塞控制缺失。
相关攻击
经常与UDP相关的一种更复杂的Dos攻击类型是放大攻击,通常涉及一个攻击者发送小部分流量,而导致其他系统产生更多流量。比如以下步骤:
1. 一个恶意的UDP发送方伪造源IP地址成一个受害者的地址,并且设置目的地为广播类型的一种;
2. UDP分组被发送到一个能对进入数据报做回应的服务;
3. 服务回应时把消息导向包含在达到的UDP分组的源IP地址字段里的IP地址;
4. 受害者主机因有多个UDP流量对其回应而处于超负载。
而针对IP分片的攻击,比如泪滴攻击,涉及使用可使某些系统奔溃或严重受影响的重叠分片偏移字段来构造一系列的分片(重叠分片在IPv6中被禁止使用[RFC5722]);又比如Ping of Death,通过产生一个在重组时超过最大限制的IPv4数据报(因为分片偏移字段可设置的值最大只能到8191,代表65528字节的偏移,任何长度超过7字节的这样的分片如果没有保护措施的话都会导致产生超过65535字节的重组数据报)。
参考:
《TCP IP 详解卷1:协议》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号