

1. 作业①:
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)
的数据,屏幕打印爬取的大学排名信息。
点击查看代码
import urllib.request
from bs4 import BeautifulSoup
target_url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
# 发送请求并获取响应
web_response = urllib.request.urlopen(target_url)
# 检查请求是否成功(状态码200)
if web_response.getcode() == 200:
# 读取并解码网页内容
page_html = web_response.read().decode('utf-8')
soup_obj = BeautifulSoup(page_html, 'lxml')
# 定位排名表格容器(class为'rk-table-box'的div)
table_containers = soup_obj.find_all('div', class_='rk-table-box')
# 提取表格中的所有行(tr标签)
table_rows = table_containers[0].find_all('tr')
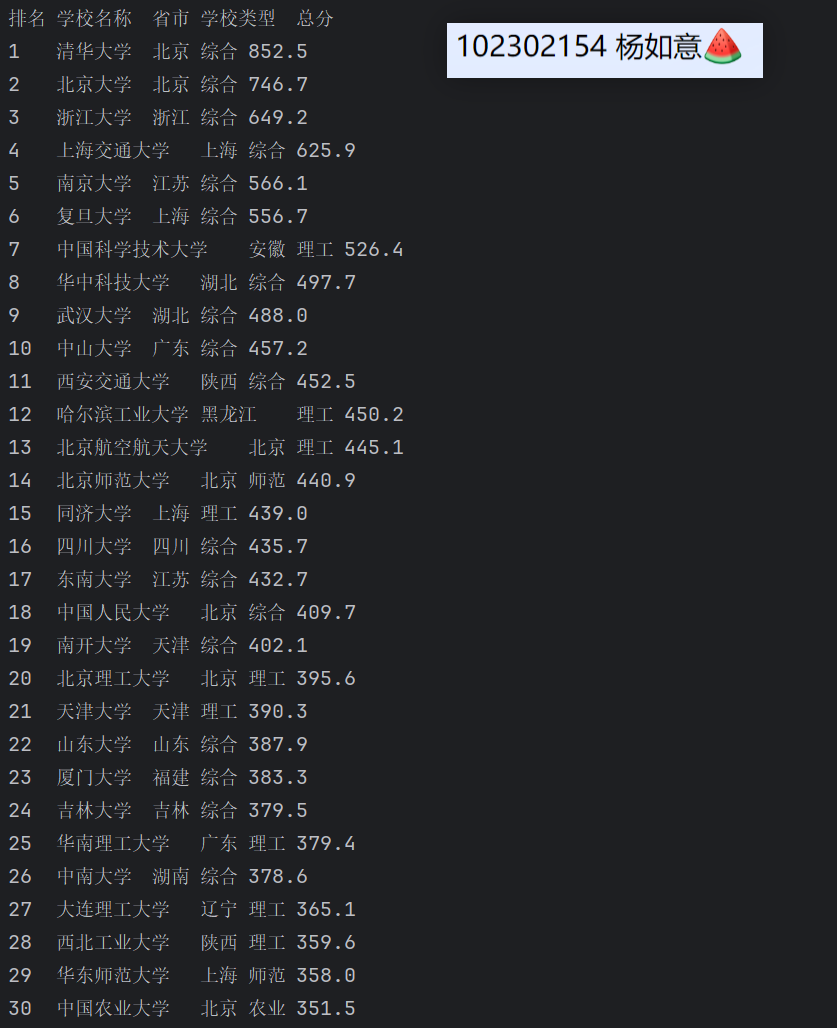
print('排名\t学校名称\t省市\t学校类型\t总分')
# 遍历数据行(跳过表头行)
for data_row in table_rows[1:]:
# 提取排名(class为'ranking'的div)
rank_info = data_row.find('div', class_='ranking').text.strip()
print(rank_info, end='\t')
# 提取学校名称(class为'name-cn'的span)
school_name = data_row.find('span', class_='name-cn').text.strip()
print(school_name, end='\t')
# 提取省市、学校类型(倒数第4到倒数第2个td)
for attr in data_row.find_all('td')[-4:-1]:
print(attr.text.strip(), end='\t')
print()
心得体会:
这次写这个爬虫代码,真是有点小曲折。一开始照着思路写,结果运行就报错,说找不到表格。后来才发现,网页里的 class 名跟我想的不一样,得一点点对着网页源码找正确的标签。
2.作业②:
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
点击查看代码
import urllib3
import re
http = urllib3.PoolManager()
target_url = "https://www.imaijp.com/auc/aucCategory!newSearch?query=%E4%B9%A6%E5%8C%85&is_user_input=1"
max_items = 60 # 限定爬取60项
all_products = [] # 存储商品信息
# 构造请求头(模拟浏览器,避免反爬)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36",
"Referer": "https://www.imaijp.com/",
"Host": "www.imaijp.com",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
}
try:
response = http.request("GET", target_url, headers=headers)
if response.status != 200:
print(f"请求失败,状态码:{response.status}")
exit()
page_html = response.data.decode("utf-8", errors="ignore")
# 4. 正则提取商品名和价格(关联匹配,排除非书包商品。商品名多含 “ランドセル”(日语 “书包”))
product_pattern = r'(?s)(.*?ランドセル.*?|.*?书包.*?)(¥\d+(?:,\d+)*)'
products = re.findall(product_pattern, page_html)
# 筛选有效商品并去重(避免重复匹配)
seen_products = set()
for name_raw, price_raw in products:
# (去除HTML标签、多余空格和特殊字符)
clean_name = re.sub(r'<.*?>|\s+|[^\u4e00-\u9fa5a-zA-Z0-9ランドセル]', ' ', name_raw)
clean_name = re.sub(r'\s+', ' ', clean_name).strip()
# 清理价格(保留¥、数字和逗号)
clean_price = re.sub(r'[^\¥\d,]', '', price_raw).strip()
# 排除空名称、空价格和重复商品
if clean_name and clean_price and (clean_name, clean_price) not in seen_products:
seen_products.add((clean_name, clean_price))
all_products.append({"名称": clean_name, "价格": clean_price})
# 达到60项则停止
if len(all_products) >= max_items:
break
print("=" * 95)
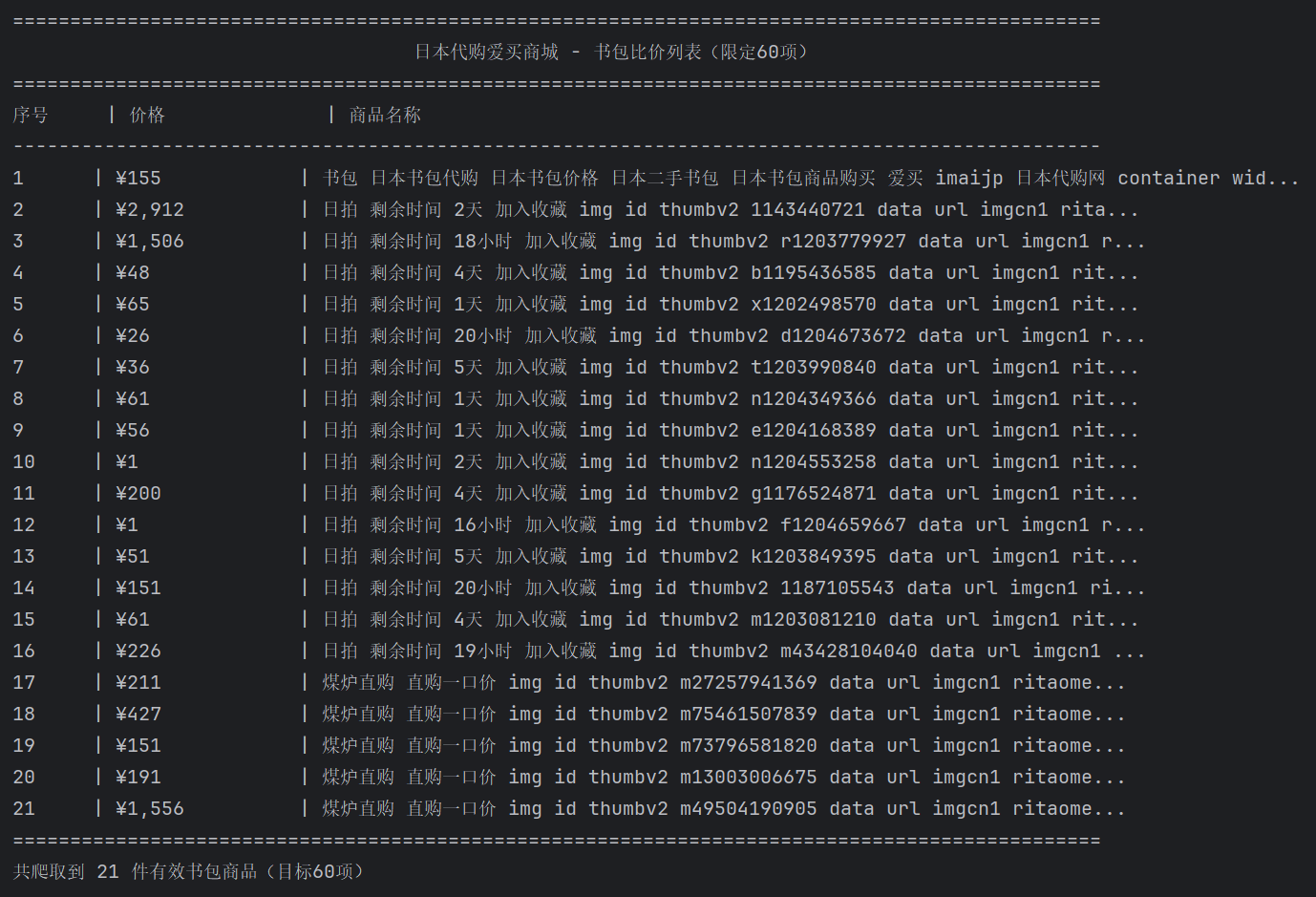
print(f"{'日本代购爱买商城 - 书包比价列表(限定60项)':^95}")
print("=" * 95)
print(f"{'序号':<6} | {'价格':<15} | {'商品名称':<65}")
print("-" * 95)
# 遍历输出商品
for idx, product in enumerate(all_products, 1):
# 商品名过长时截断(65字符内)
display_name = product["名称"][:62] + "..." if len(product["名称"]) > 65 else product["名称"]
print(f"{idx:<6} | {product['价格']:<15} | {display_name:<65}")
print("=" * 95)
print(f"共爬取到 {len(all_products)} 件有效书包商品(目标60项)")
except Exception as e:
print(f"爬取过程出错:{str(e)}")
心得体会:我爬取的是一个日本代购网站,查看了页面源码,class 的文本块中没有商品信息,通过 “商品名 + 价格” 的关联关系匹配。并且该页面为单页加载。而且还因为是日文网站,借助大模型去修改了代码中的错误。不过最后爬取成功了
3.作业③:
要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)
或者自选网页的所有JPEG、JPG或PNG格式图片文件
点击查看代码
# 网页 URL
url = "https://news.fzu.edu.cn/"
# 创建请求对象
req = urllib.request.Request(url=url, headers=headers)
try:
with urllib.request.urlopen(req) as response:
html_content = response.read().decode("utf-8")
# 定义正则表达式匹配 jpg 图片链接
pattern = r'<img.*?src="(.*?\.jpg)".*?>'
# 查找所有匹配的 jpg 链接
img_urls = re.findall(pattern, html_content)
if not os.path.exists("images"):
os.makedirs("images")
# 下载每张图片
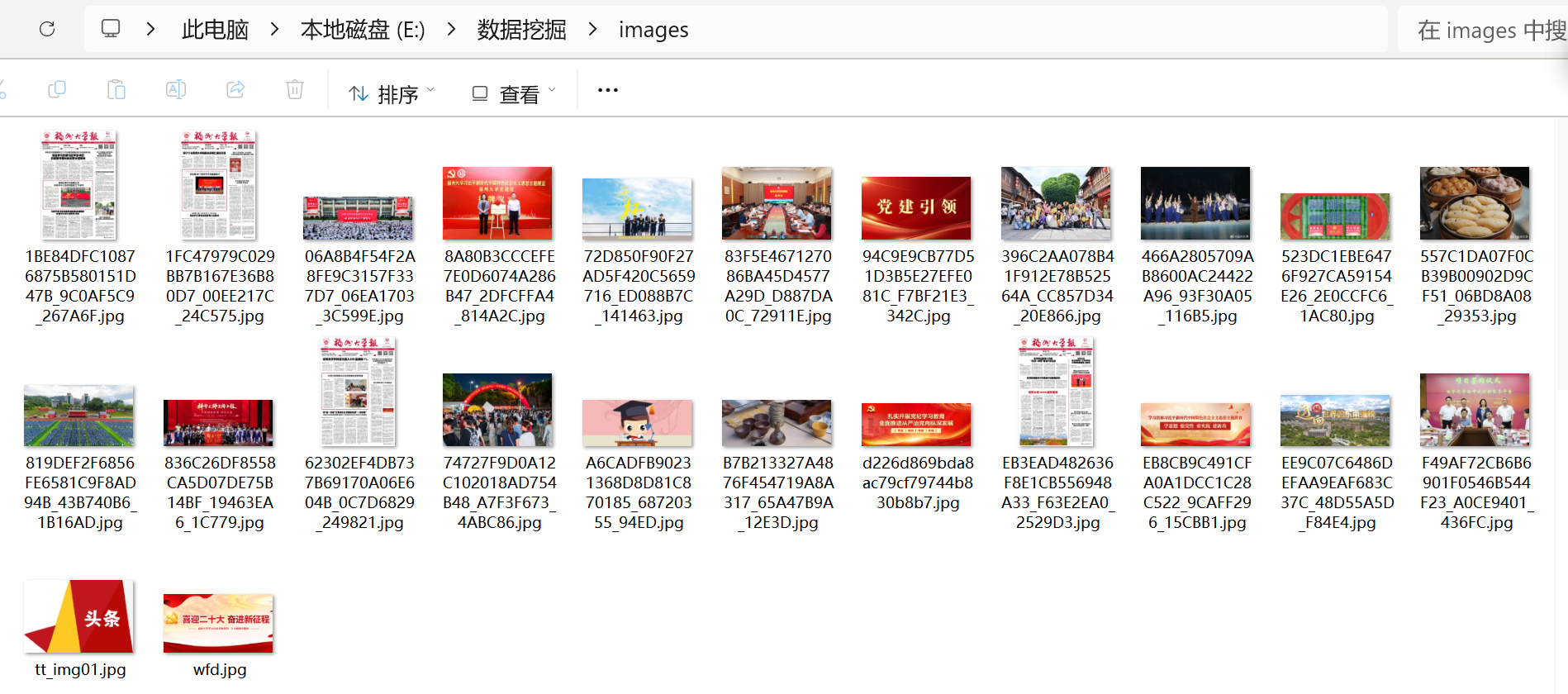
for i, img_url in enumerate(img_urls):
# 处理相对路径,转换为绝对路径
if not img_url.startswith("http"):
img_url = url + img_url
# 提取图片文件名
img_name = img_url.split("/")[-1]
save_path = os.path.join("images", img_name)
try:
urllib.request.urlretrieve(img_url, save_path)
print(f"成功下载图片:{img_name}")
except Exception as e:
print(f"下载图片 {img_name} 失败:{e}")
except Exception as e:
print(f"获取网页内容失败:{e}")
心得体会:
我爬的是福大网站其中一个页面中的所有图像,在爬过程中发现有的图片链接有的是相对路径,直接下载肯定失败,得手动拼上主网址才行。还有正则表达式那块,试了好几次才写出能准确匹配 jpg 链接的 pattern,少个问号都可能漏抓。这边借助了大模型去找修改错误,然后完成的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号