

垃圾回收算法GC
垃圾回收GC
垃圾收集算法
复制算法
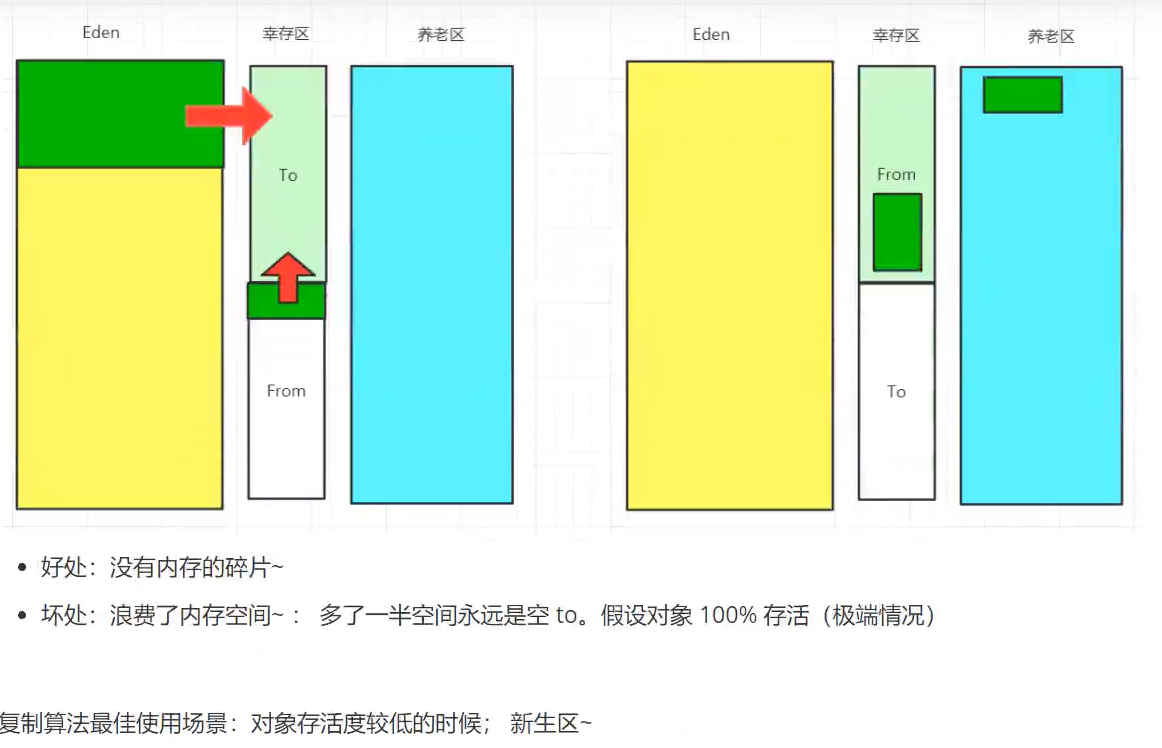
将可用内存按容量,划分为等量大小相等的两块,每次使用其中的一块。将幸存区分为from区和to区,每次将from区的对象复制到to区,将from区回收。from区和to区是相对的,复制的目标区始终是to区,被复制区始终是from区。这样使得每次都是对整个半区进行内存回收,内存分配时不用再考虑内存碎片等复杂情况,只需要移动堆顶指针即可。
将堆内存划分为较大的Eden区和两块较小的survivor区。
HotSpot虚拟机默认Eden和Survivor的比例是8:1,每次新生代可用内存空间是(80%+10%),另一10%的区域将会被浪费,当Survivor区存活的对象过多,内存不够用时,会依赖老年代进行分配担保。
复制算法的最佳使用场景是新生代
标记清除
最基础的算法是标记清除算法,分为标记和清除两个阶段。
首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。
不足:
- 效率:标记和清除两个过程的效率都不高;
- 空间:标记清除后会产生大量不连续的内存碎片。
标记-整理
标记整理算法的过程和标记清除算法一样,在后续的步骤中,不是直接对可回收对象进行清理而是让左右存活的对象都向一端进行移动,然后直接清理端边界以外的内存。
分代垃圾回收算法
根据对象存活周期的不同将内存划分为几块。把Java堆分为新生代和老年代,根据各个年代的特点采用适当的收集算法。
新生代:大批对象死去,少量存活,采用复制算法。
老年代:对象存活率高,没有额外空间对它进行分配担保,使用标记-清理或者标记-整理算法进行回收。
总结
内存效率:复制算法>标记整理>标记清除
内存整齐度:复制算法=标记整理>标记清除
内存利用率:标记整理=标记清除>复制算法
年轻代:
- 存活率低
- 适用复制算法
老年代
- 区域大,存活率较高
- 适用标记清除+标记整理
本文来自博客园,作者:依然学不会,转载请注明原文链接:https://www.cnblogs.com/yrxbh/p/15626960.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号