结对作业1
| 这个作业属于哪个课程 | 2021春软件工程实践 | W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对作业一 |
| 结对学号 | 221801312 & 221801337 |
| 这个作业的目标 | 原型设计 |
| 其他参考文献 | Axure官网 |
PSP表格和效能分析
PSP表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | ||
| • 估计这个任务需要多少时间 | 5 | 10 |
| 开发 | ||
| • 需求分析 | 60 | 90 |
| • 学习使用原型设计工具 | 60 | 60 |
| • 原型具体设计 | 600 | 720 |
| • 设计复审 | 30 | 45 |
| 报告 | ||
| • 设计报告 | 60 | 90 |
| • 计算工作量 | 20 | 20 |
| • 总结 | 20 | 20 |
| 合计 | 855 | 1055 |
效能分析
经过总结后,我们发现了实际耗时和预估耗时出入较大的有一下几个部分:
- 需求分析阶段
- 我们发现在需求分析阶段是最容易产生分歧的,而解决分歧统一双方的意见是很耗时的,这就导致了我们花费了更多时间在需求分析上。但我们认为这是十分值得花费的时间,因为有效的沟通解决分歧肯定比项目开始后再重新讨论需求要省时省力得多。
- 原型设计阶段
- 因为是第一次设计完整的项目原型,所以我们都还是在一边学习一边设计,在学习方面更多地看了一些其他平台的UI设计,所以我们花费了很多的时间在学习和设计上。
- 因为对Axure这个软件的不熟悉,所以在设计过程中也出现了很多效率低下的操作,这导致了我们不断地返工浪费了很多时间,但经过这一次地学习使用,对Axure应该有了更熟悉的掌握
- 设计报告阶段
- 首先我们有一部分的时间是花在了截图上,因为我们想让博客更加生动形象,所以想用gif的形式展示我们的原型,但又因为使用的图床有对图片大小的限制,所以为了解决这个问题花费了很多时间,最终只能在gif的画质上做出部分妥协,以及录制了完整的使用视频。
- 写报告时,我们两个人也有可能遇到部分分歧,所以还是有部分时间花在了解决分歧上。
原型地址
原型介绍
因为我们的目标用户是需要查询论文的所有大学生,其中不乏一些对电脑不是那么熟悉的人。所以我们主要目标是让用户容易上手,在没有人协助的情况下可以很容易的使用我们的系统。
而要实现上述目标,我们参考了可以让所有人轻易上手的网页--搜索引擎。搜索引擎的主页大多都是一个简洁的搜索框,甚至可以让没有任何电脑基础的人都可以明白要如何使用。
论文查询和论文爬取页面
- 论文查询页面支持用户上传文件搜索,支持用户模糊搜索。
- 论文爬取页面根据用户输入的内容直接进行爬取,所以需要提示用户等待一定时间,爬取成功后会提示用户是否直接跳转到搜索页。


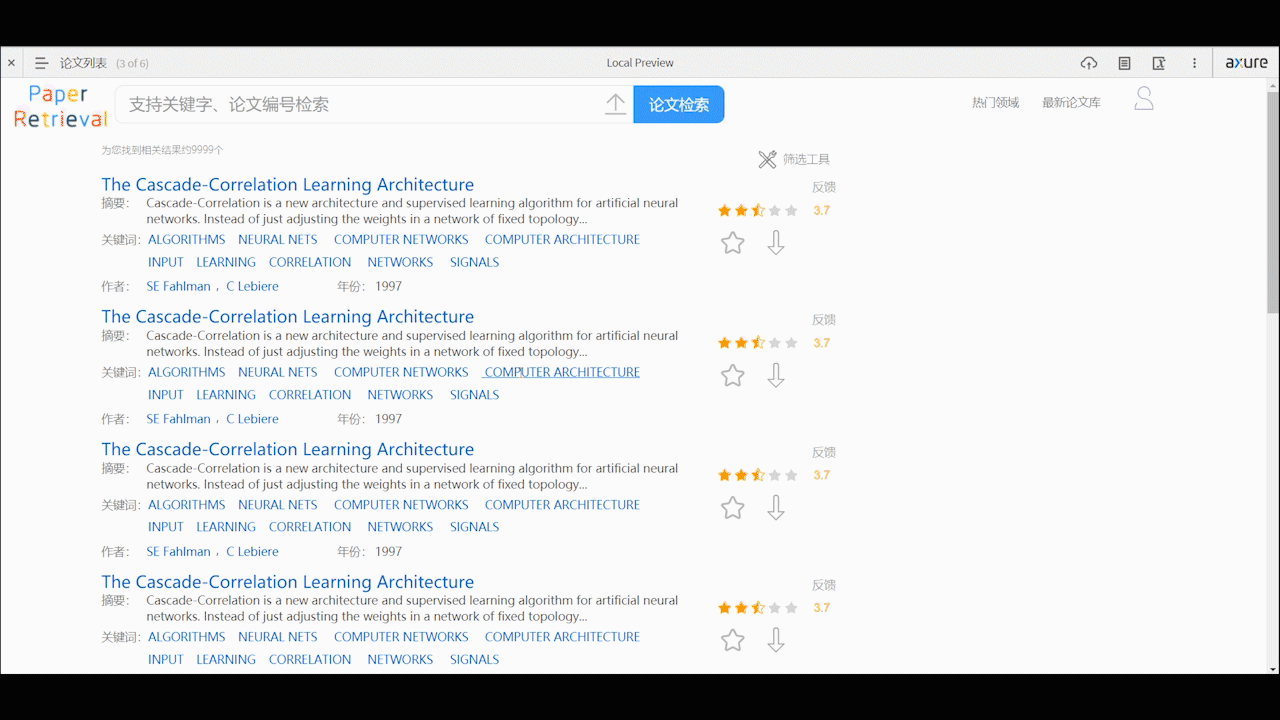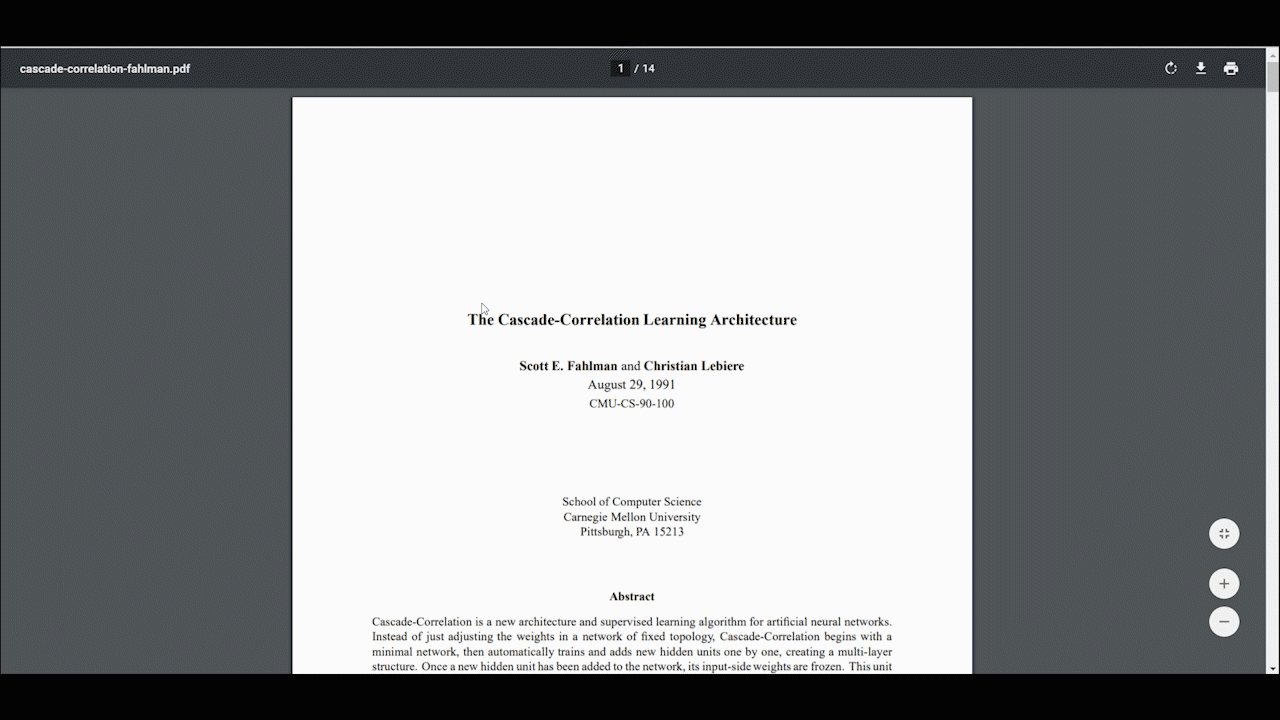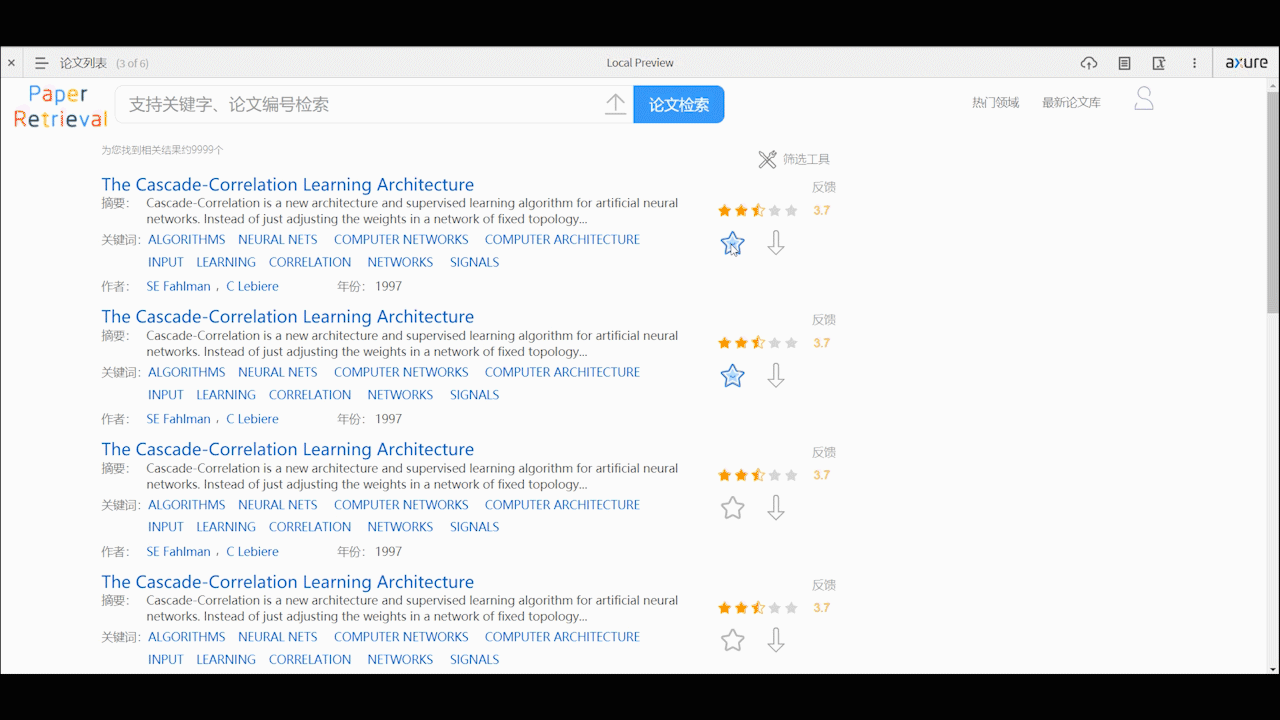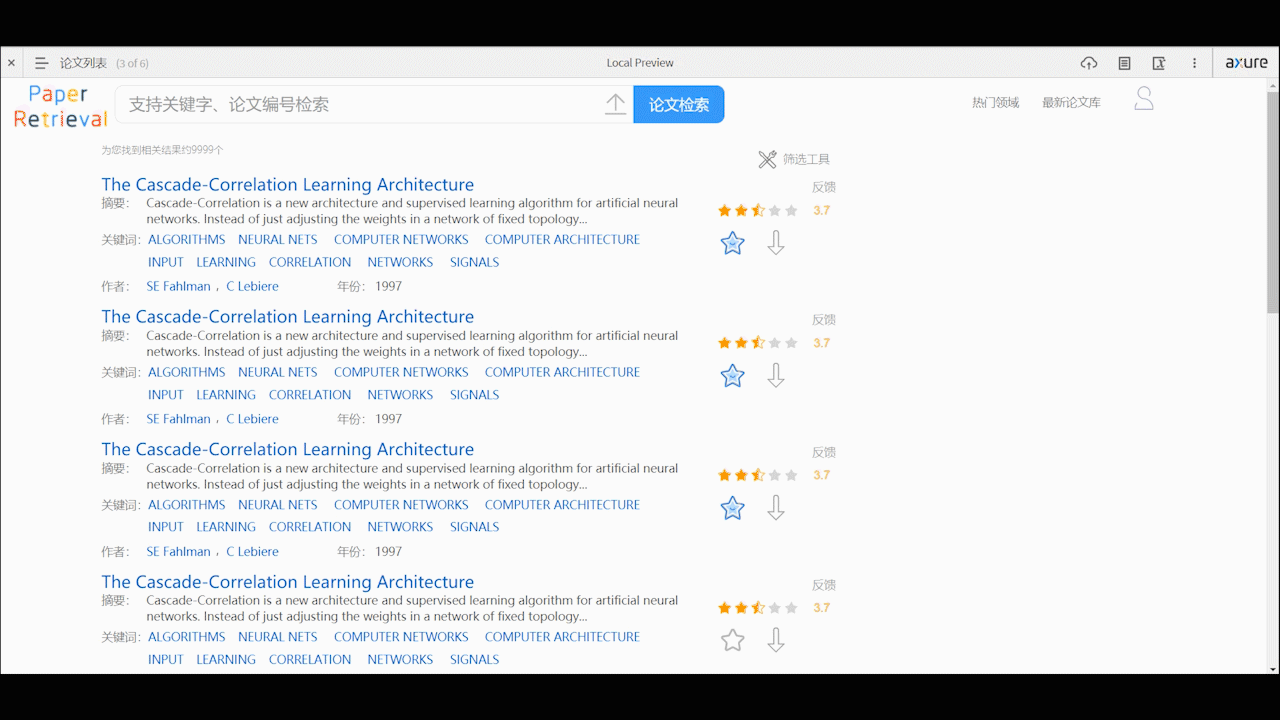
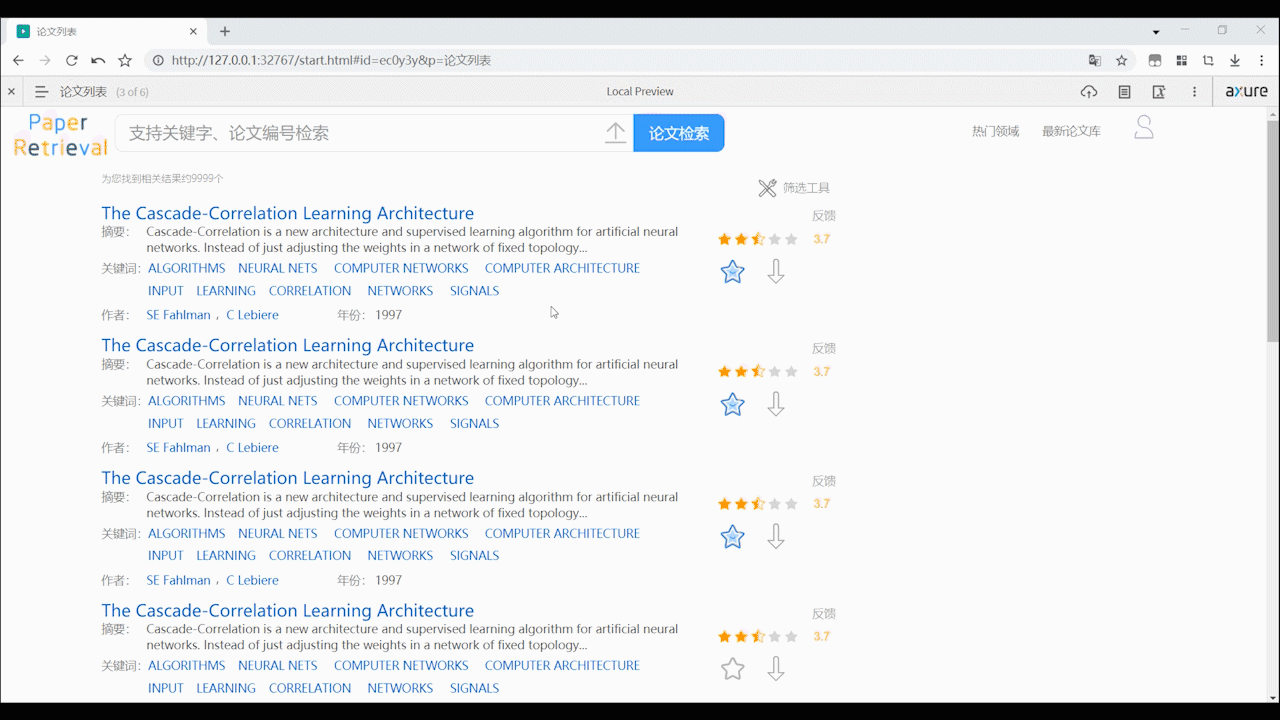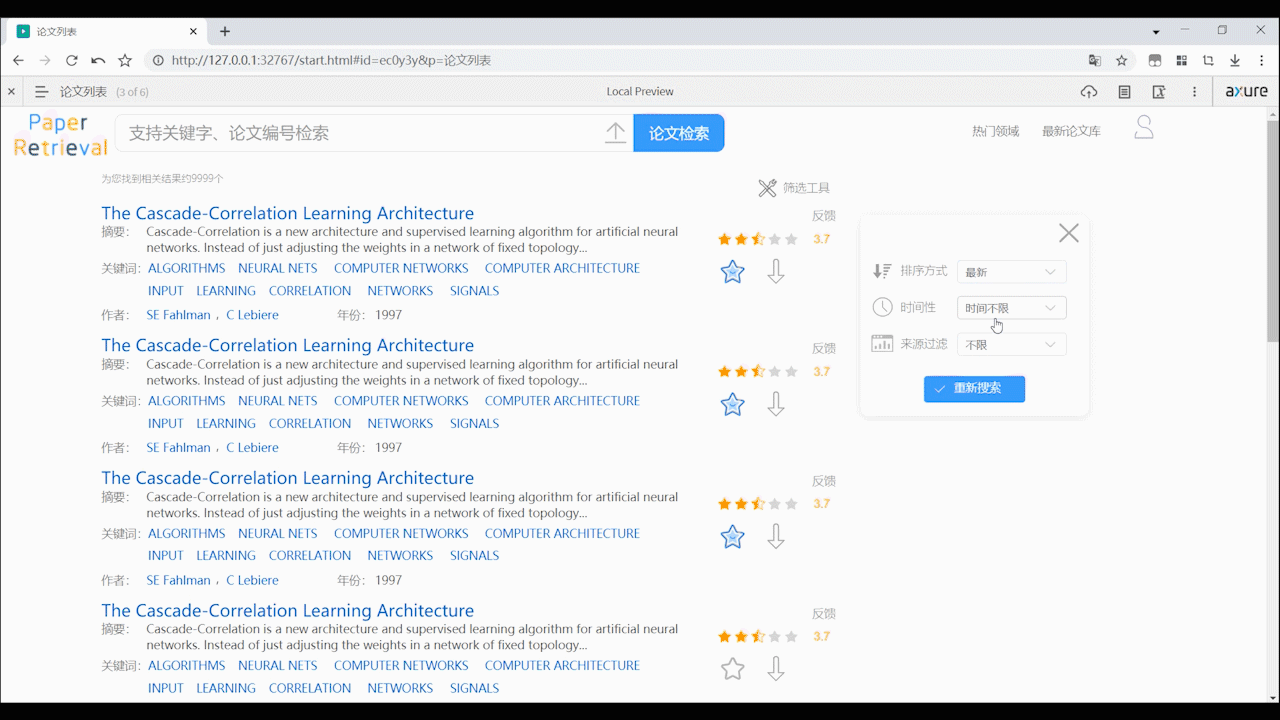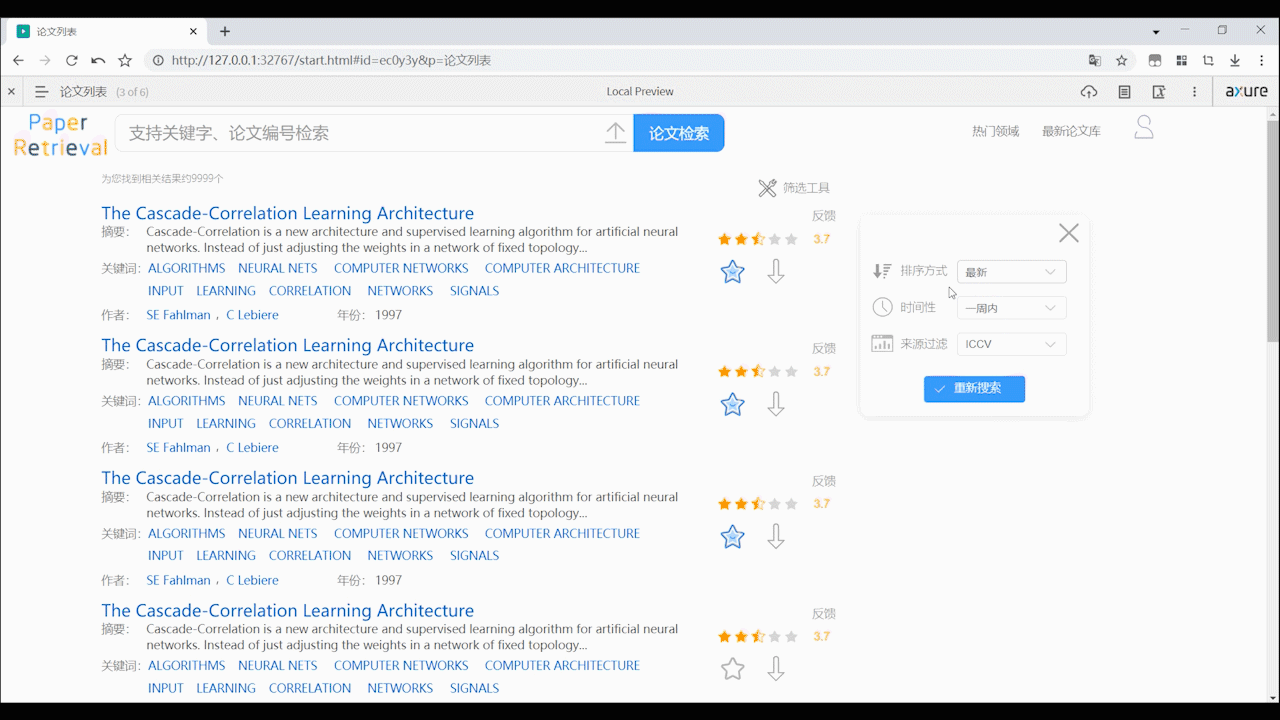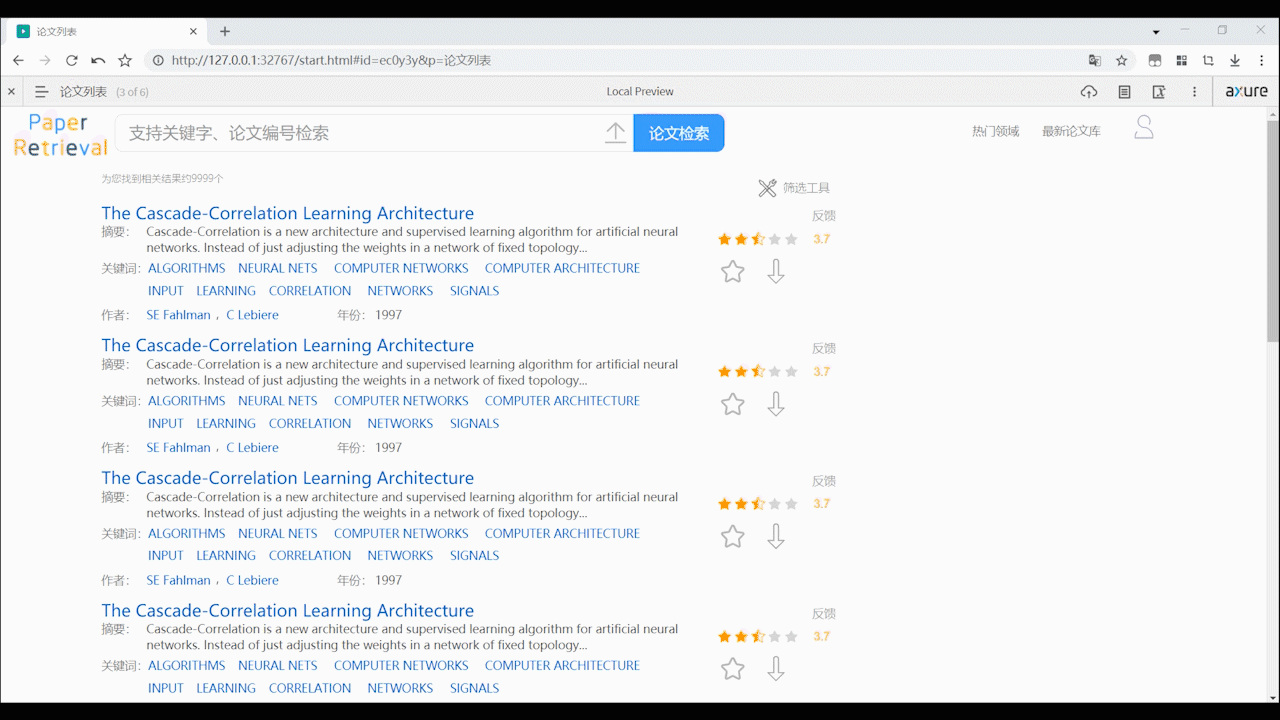
论文列表页面
- 论文的列表支持用户点击标题直接在线阅读pdf,可以看到论文的部分摘要、作者、关键词、年份等基本信息,以及可以看到论文的评分,收藏、下载论文。反馈按钮可以让用户对错误的数据或格式进行反馈。
- 支持用户通过高级筛选过滤论文,可根据相关性、最新、影响因子来排序,可根据论文时间性和影响因子来过滤搜索出的论文,过滤后会重新加载页面。
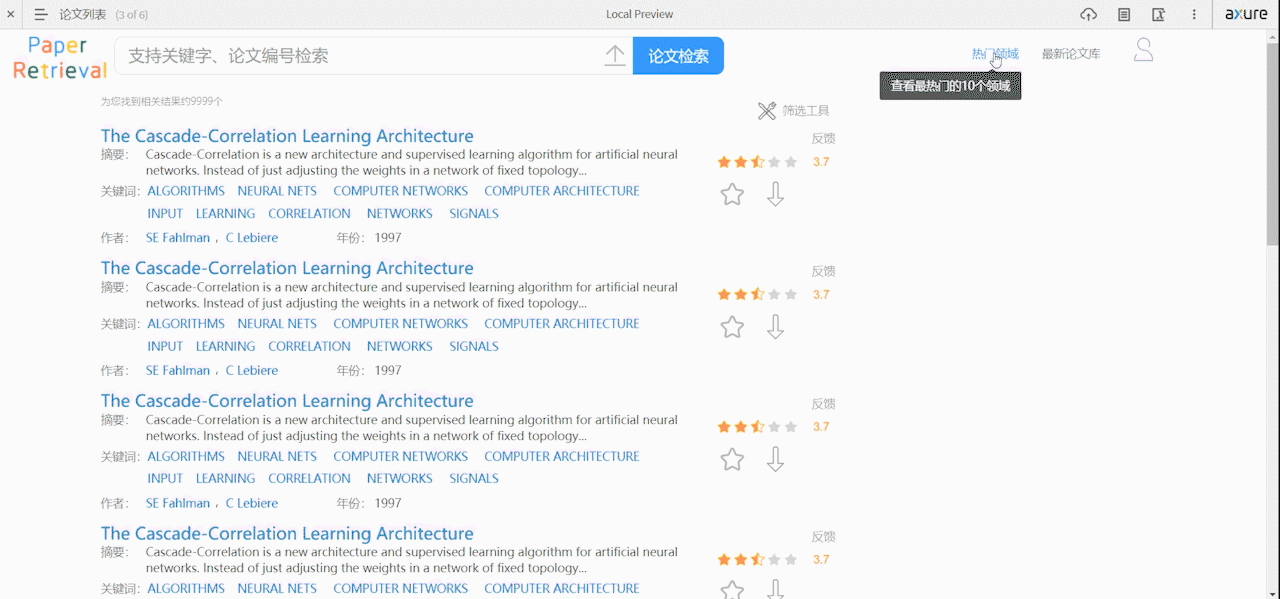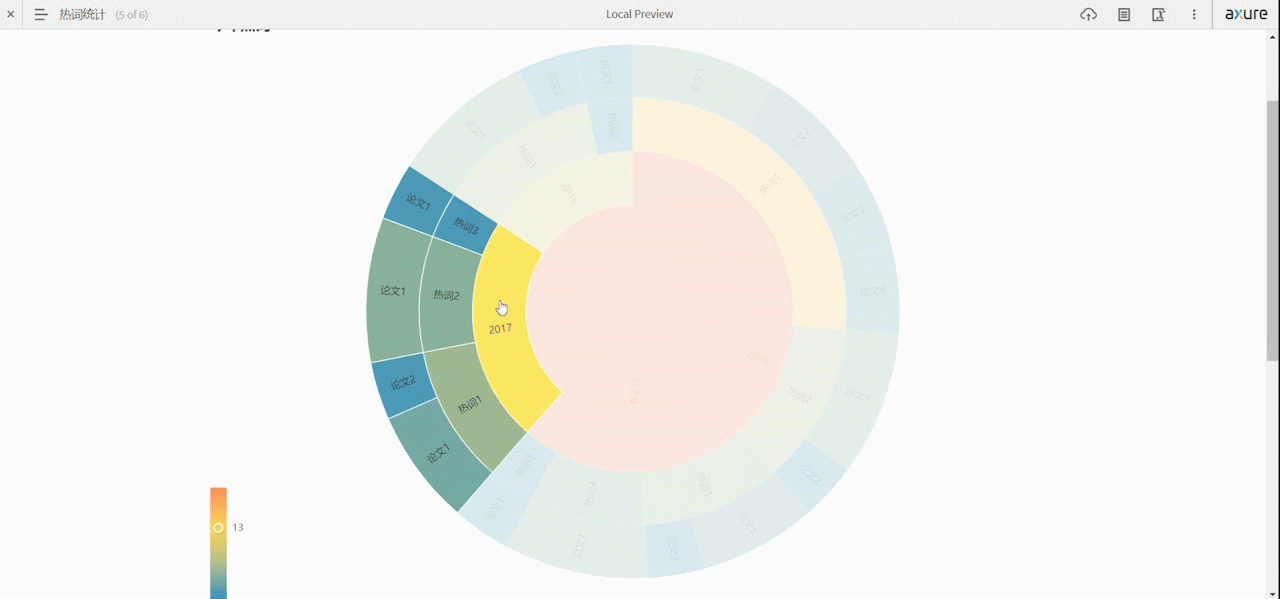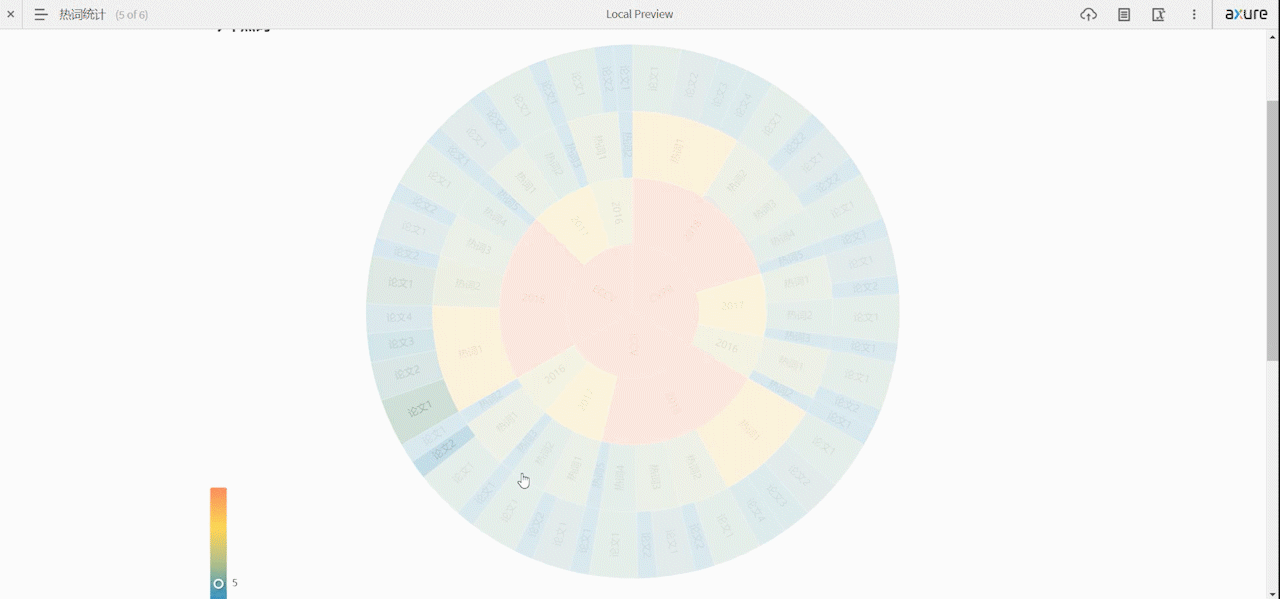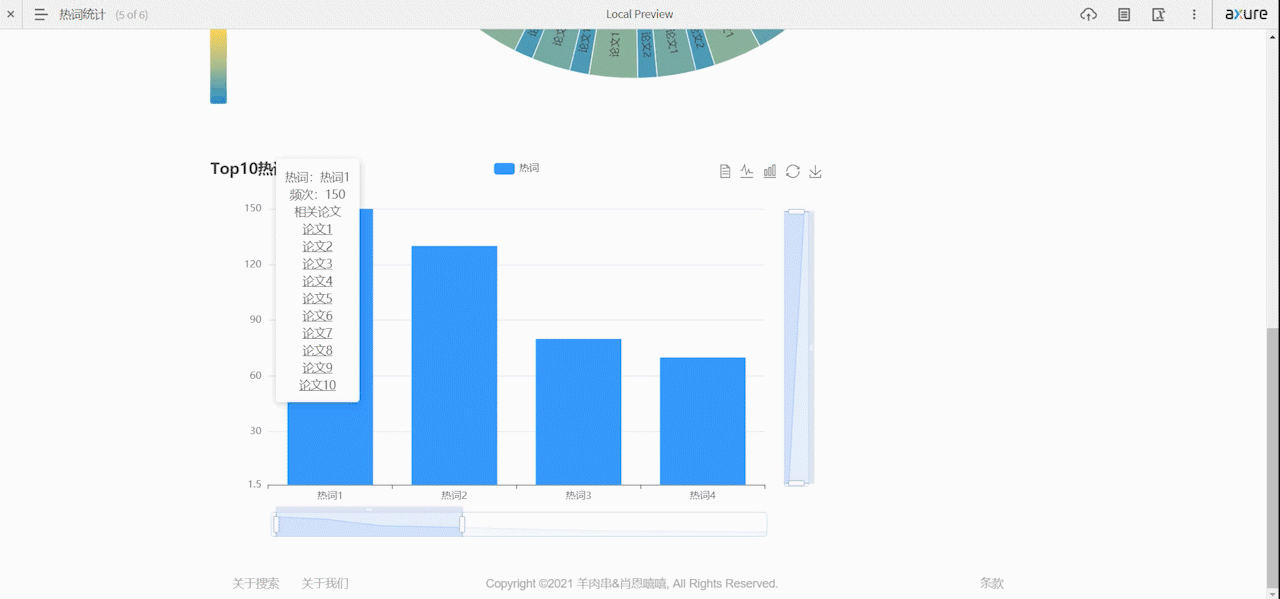
Top10热门领域和词条分析页面
登录注册页面

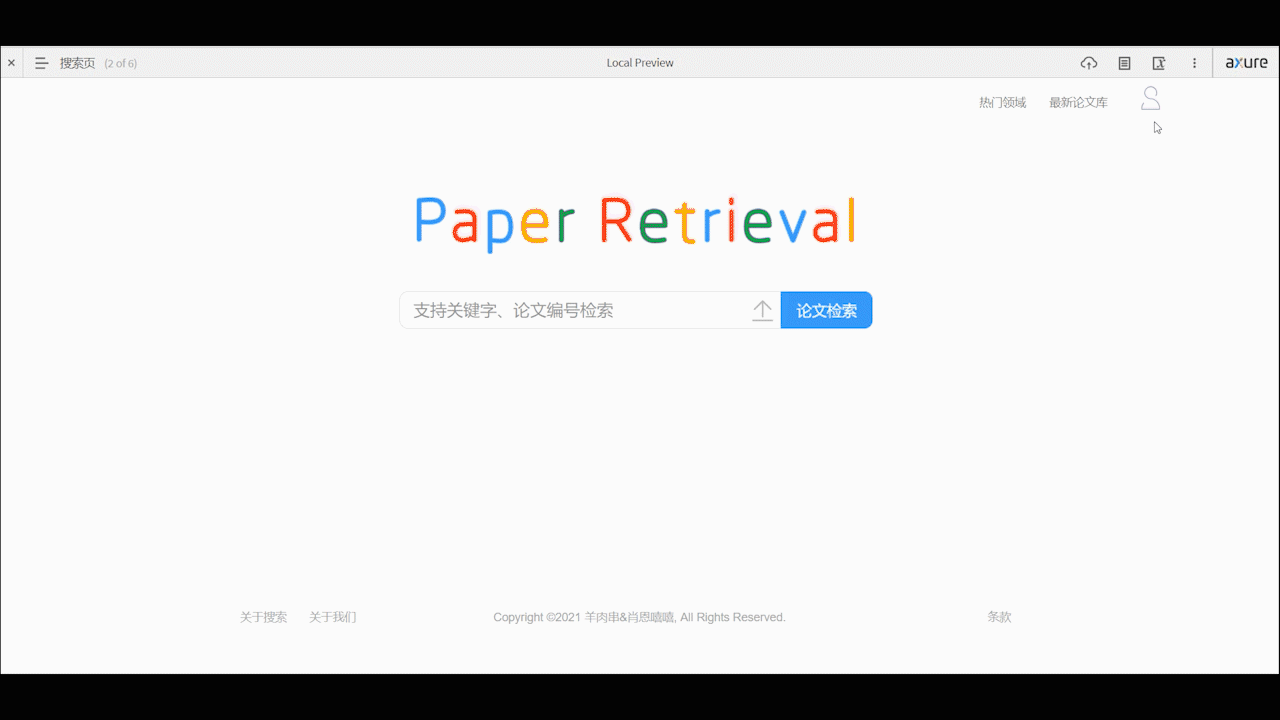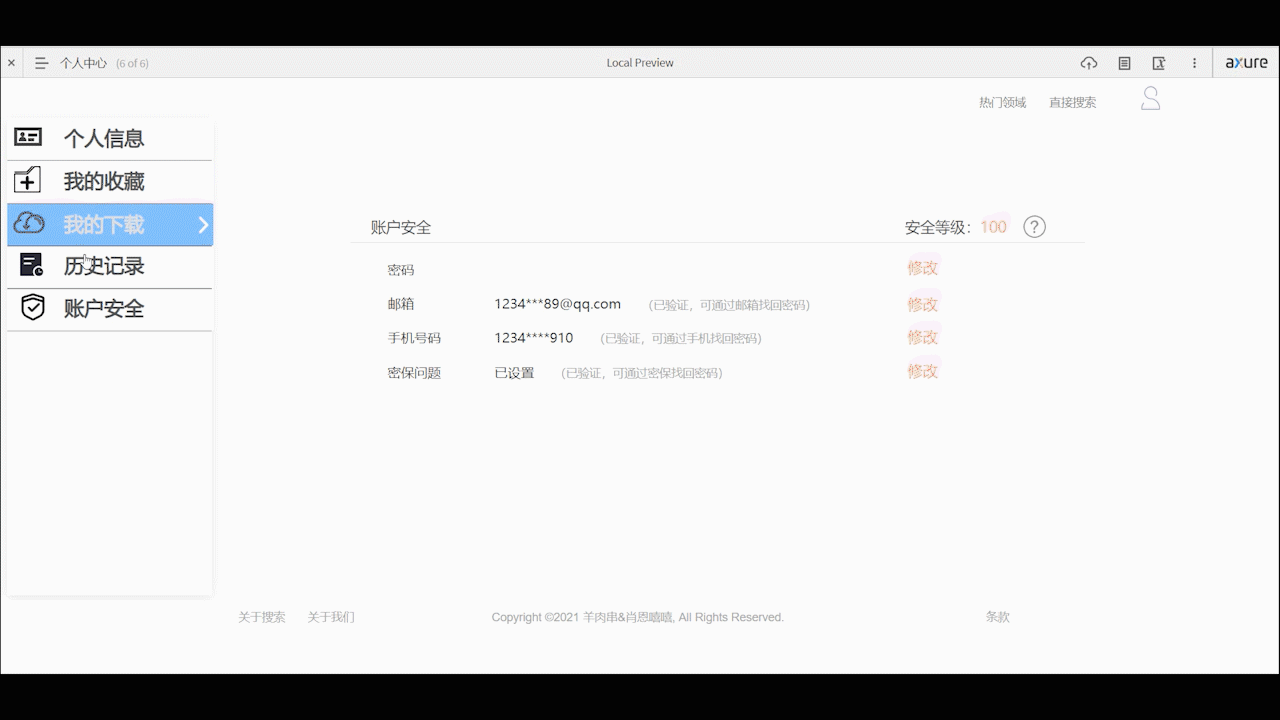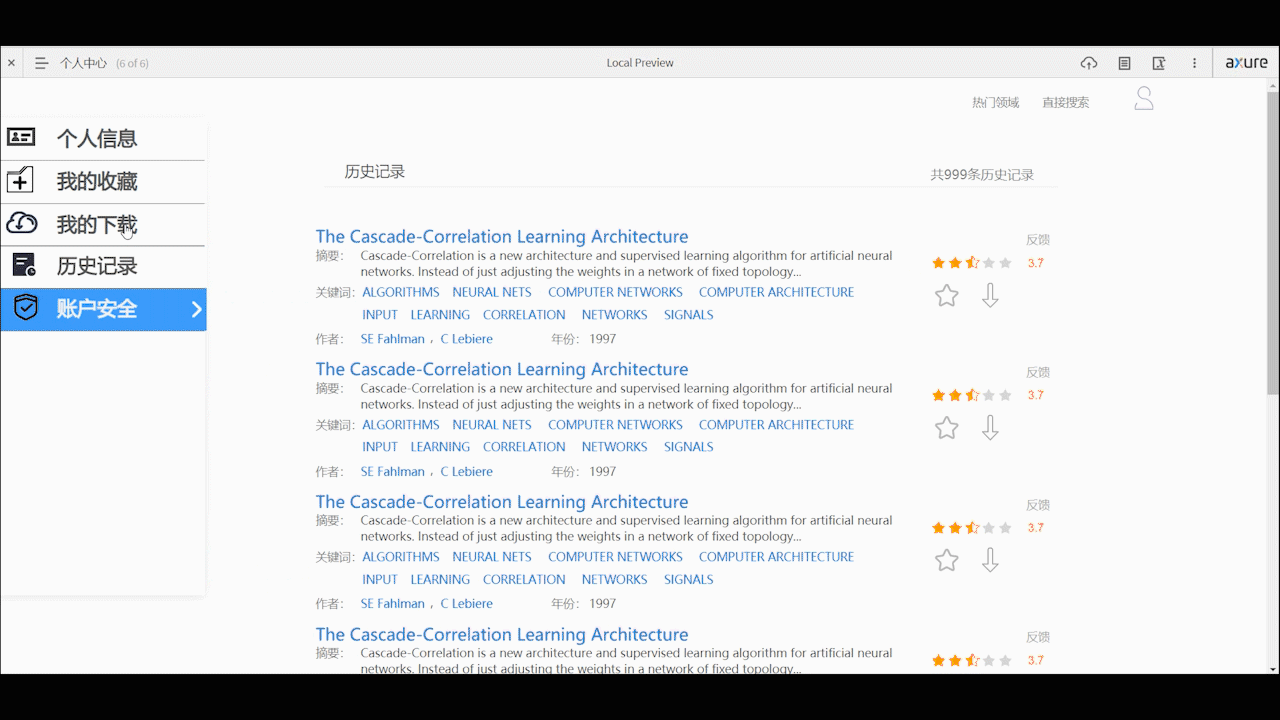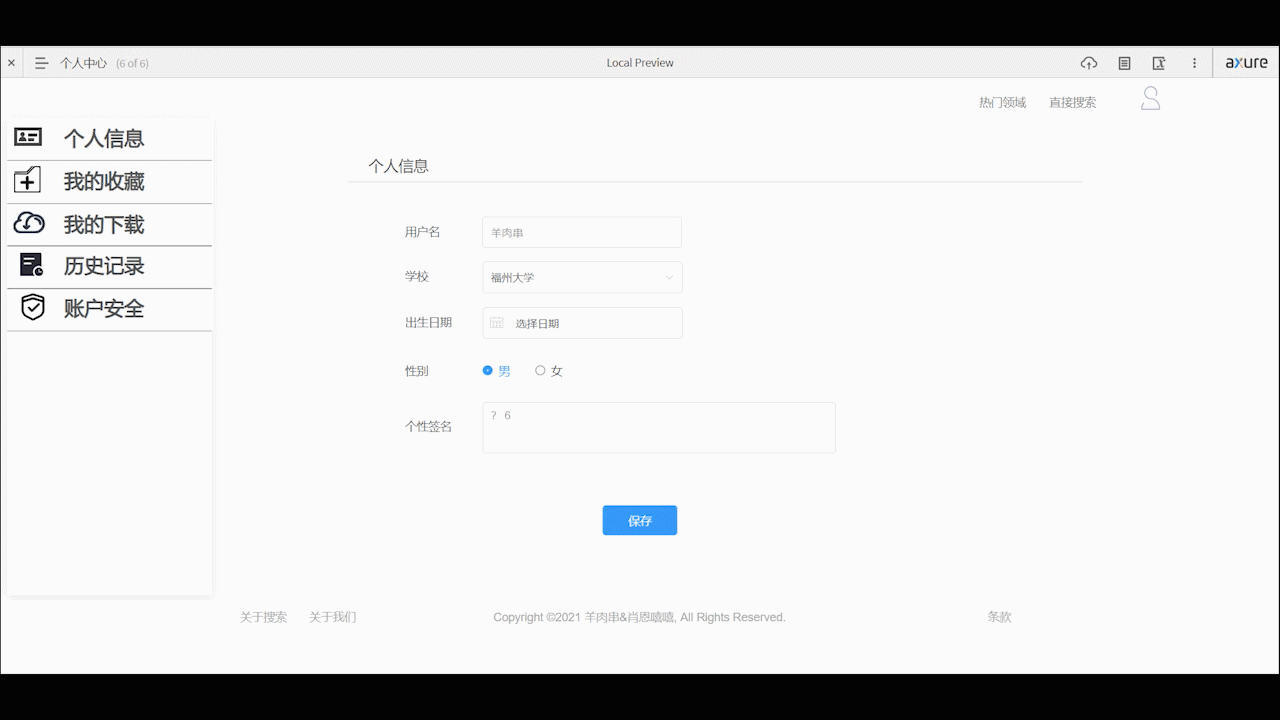
个人中心页面
- 个人中心支持用户对自己的基本个人信息的编辑、账户安全的设置,以及查看自己收藏、下载和历史浏览记录。
顶栏和底栏设计
- 顶栏支持用户跳转到热词分析页面,论文爬取页面,以及个人中心。
- 底栏包括一些基本的版权信息和条款等。

完整使用视频
因为使用的图床有对GIF大小的限制,我们录制了完整的使用视频。
困难解决
- 对于要实现什么功能存在困惑
- 通过画思维导图统一了意见
- 发现了思维导图可以很快速直观地统一双方地意见

- 由于对于爬取和查询的整体流程存在困惑,阻碍了后面的设计
- 通过一起画了部分的流程图、交流了思路


-
对需求的一些困惑,我们认为需求所说的对爬取论文列表的修改和删除是不合理的,因为即使爬取的数据或格式出现了错误,那应该是平台的错误,不应该由用户来对论文列表进行修改和删除。
- 所以我们在每个搜索项添加了一个反馈的按钮,当论文出现错误时,由用户反馈给平台,由平台处理错误。
-
因为我们这次是模仿搜索引擎式的原型设计,所以我们参考了Google、百度等一些在搜索引擎方面做的比较好的企业的UI,我们发现这些大厂设计的UI总是能够恰到好处,能够设计好每一个小细节,而我们仅仅只是模仿设计就应该遇到了很多困难,比如有的交互效果难以实现,UI设计没办法非常好看,因为我们不是专业的UI设计师,可能对颜色、图片、icon不是特别敏感,一系列的问题让我们意识到那些大厂的UI也是有很多巧妙之处的。
NABCD模型
Need|需求
-
获取待爬取论文列表及论文信息爬取
- 通过论文列表,爬取论文的摘要、关键词、原文链接
- 通过输入框输入单个爬取的关键信息
- 批量导入论文列表,通过表格
-
对已爬取的论文列表进行操作
- 可对论文列表进行查询(输入论文题目,也支持模糊查询:输入论文编号、关键词等基本信息)
- 若在论文列表中不存在所要检索的论文,则提示进行爬取(相当于增)
- 通过最新、相关性或者影响因子排序
- 通过时间、论文来源过滤(相当于删)
- 缓存历史记录
- 批量导入论文列表,通过表格
- 通过表格上传列表的查询,可以通过列表项过滤
-
分析已爬取到的论文信息,提取top10个热门领域或热门研究方向
- 可对多年间、不同顶会的热词呈现热度走势对比,以动图的形式呈现
- 通过图表展示top10热门领域
- 点击领域显示相关文章及其链接
-
用户系统
- 收藏
- 保存浏览历史
Approach|做法
技术
- 对于在数据库里搜得到的论文,用户可以直接搜索
- 搜索不到的论文,用户可以使用爬取功能去爬取,但是有爬取次数限制,以降低服务器负载
- 定时爬取最新的论文,降低用户搜不到论文的概率
用户体验
- 用户可以在个人中心很方便地找到自己收藏、下载、曾经浏览的文章。
- 网页简介、操作简单。
人脉
- 我们认识很多大学生
Benefit|好处
- 简洁、突出重点,参考了Google等搜索引擎的页面设计
- 有强大的过滤器,实现了对查询结果的增删改的功能
- 操作简单,只要会使用搜索引擎的用户都可以轻松使用我们的系统,所以用户迁移成本极低
Competitors|竞争
- 实际上,如果是想要运营一个只有大学生运营的论文查询平台是非常困难的。最重要的就是版权问题,而要大学生要支付昂贵的版权费是一个不现实的方法,而要因此收费,也会导致用户数量下降。
- 所以还是要依靠学校或者其他平台,要有一个相对丰富的论文库,才能吸引用户。有了用户,才能有更多的投资,来丰富论文库和提升技术力。
- 竞争的对手有很多,如百度学术、知网、维普网等,他们的优势就在于已经有一大部分用户量,以及解决了论文版权问题。我认为我们的优势就在于简洁,没有广告,没有VIP,没有推荐等可能会降低用户体验感的因素,如果要在前期吸引用户,可以采用全平台免费的形式暂时运营,因为对大学生来说,一个好用的平台是很容易互相推荐的,让用户成为我们产品的“自来水军”,可以让我们的用户基数快速增长。
Delivery|推广
- 通过熟人推荐方式传播
- 通过推荐码的方式来保证注册用户的高质量,可以间接降低运营成本
- 可以与学校合作
原型工具的使用
- 使用了Axure RP 9来进行了这次原型设计
结对过程
- 通过qq共享屏幕进行讨论

- 通过聊天进行讨论

队友评价
- 221801312=>221801337
因为我与我的队友有过几次合作的经历,所以在讨论、协同等方面都很熟悉,我觉得他是一位自律的人,能够按时完成团队分配的任务,也能够提出很多合理的需求以及自己独特的见解,有很强的专业性。
第一次结对,我意识到了两个人的团体的互补与多人团体的不同,结对不需要进行很复杂的工作分配,也更容易解决分歧。
- 221801337=>221801312
由于我审美能力不足,所以这次的原型设计的制作基本上都是由队友进行制作的,我只原型设计部分我只做了一个登录页面和用echarts制作了图表。我主要是在编写文档和讨论原型设计的大体思路。
我觉得结对编程的好处就是可以互补,相互在自己擅长的部分发挥作用,来提升效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号