聚类算法 Clustering
此系列笔记来源于
Coursera上吴恩达老师的机器学习课程
聚类算法Clustering(无监督学习)
K均值算法 K-Means
步骤:
1、随机生成两点
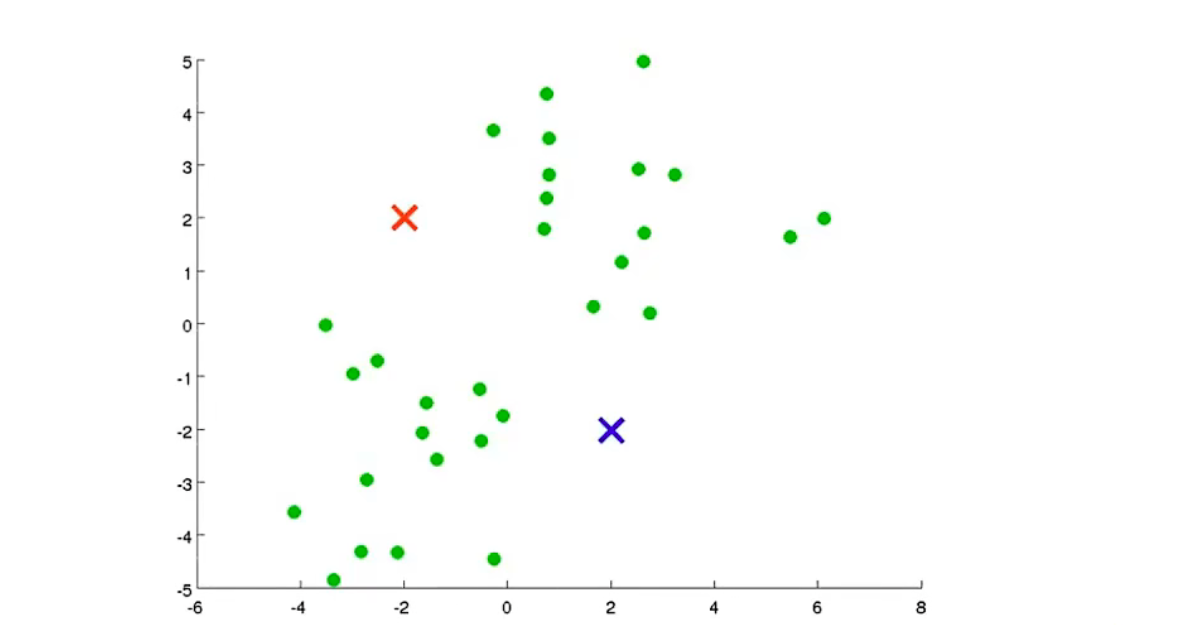
这两点叫做聚类中心,选择两点是因为这里想把数据分成两类
2、迭代
在内循环中的第一步是 簇分配
这里将每个绿点根据距离谁最近分成红蓝两部分
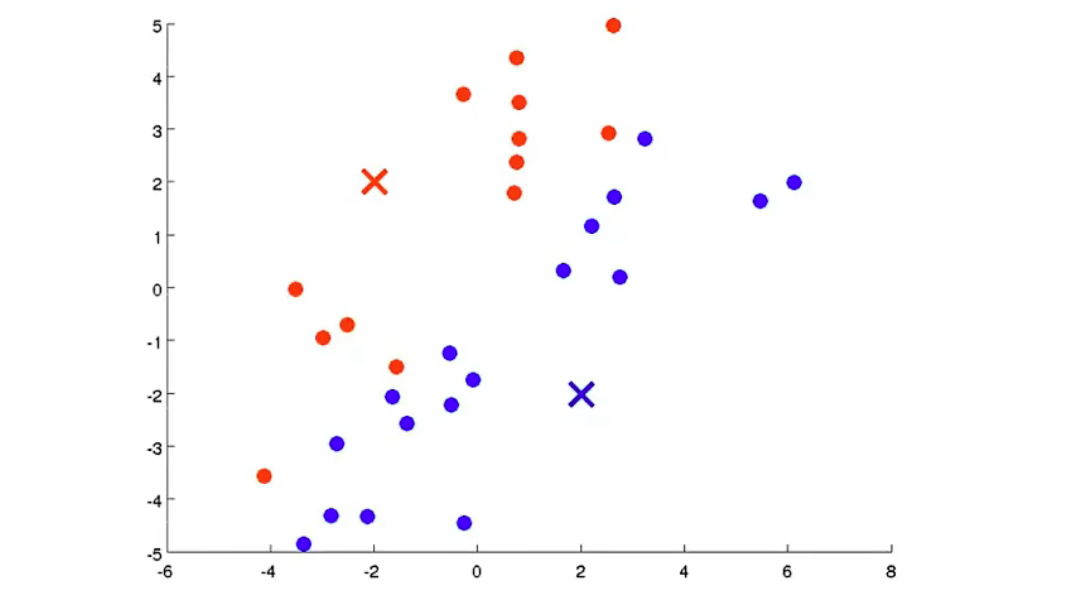
即计算\(c^{(i)}=min_k||x^{(i)}-\mu_k||^2\),k表示第k个聚类中心
第二步是 移动聚类中心
对于第k个聚类中心,计算所有\(c^{(i)}=k\)的点的平均值,并令该聚类中心,即\(\mu_k\)等于这个平均值点
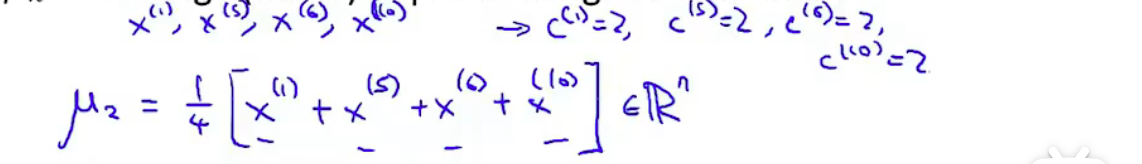
代价函数
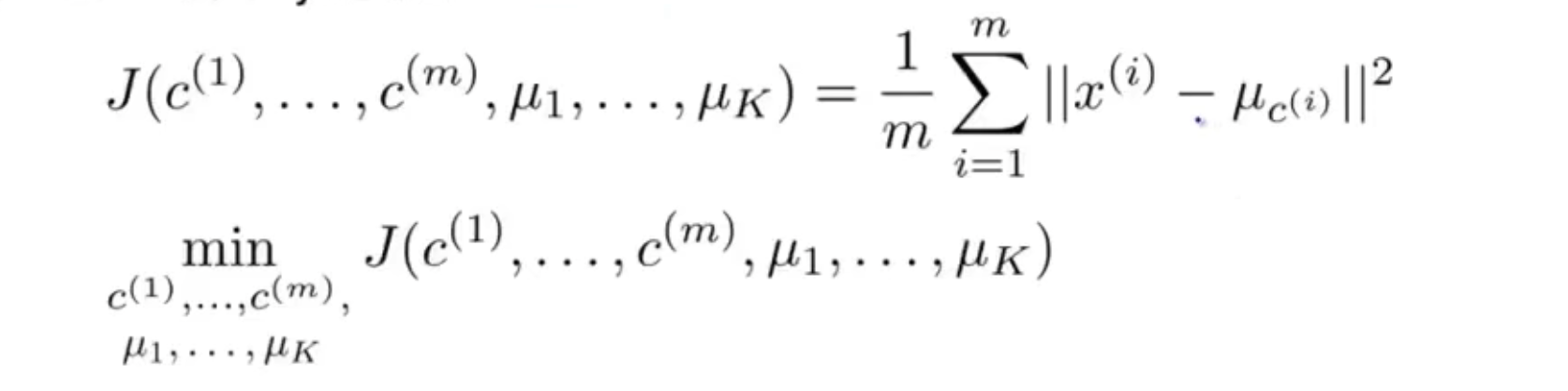
随机初始化
运行K均值算法前我们需要先初始化,选取几个初始的聚类中心。
由于一次的随机初始化,效果可能不太好,会导致局部最优解,因此我们会进行多次K均值算法。

初始化时,令\(\mu_i=x^{(i)}\)
另外这个算法在k较小时,如\(2-10\)会有比较好的效果,当聚类中心数量较大时,未必有非常好的效果。
选择聚类数量
1、最常见的是根据图像手动选择聚类数量
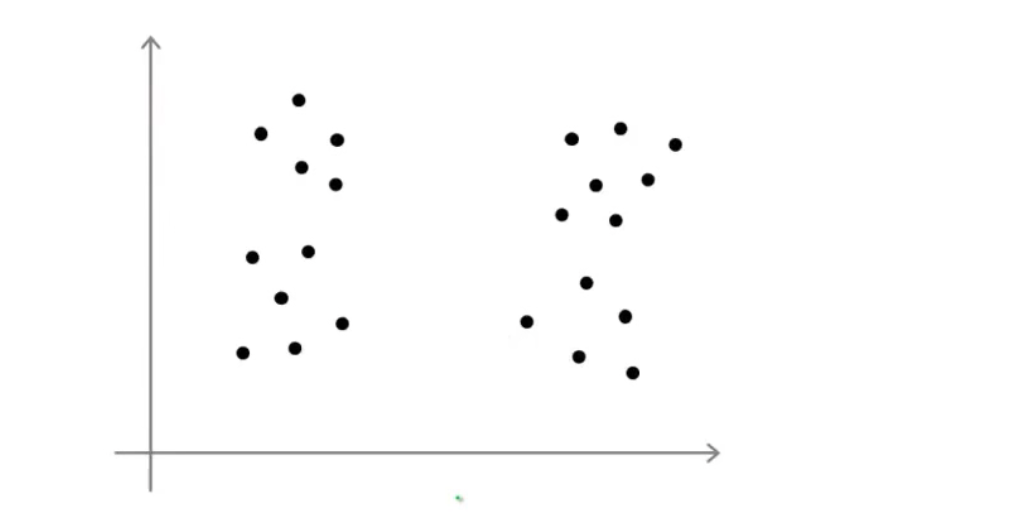
可以是两个也可以是三个四个
2、运用肘部法则
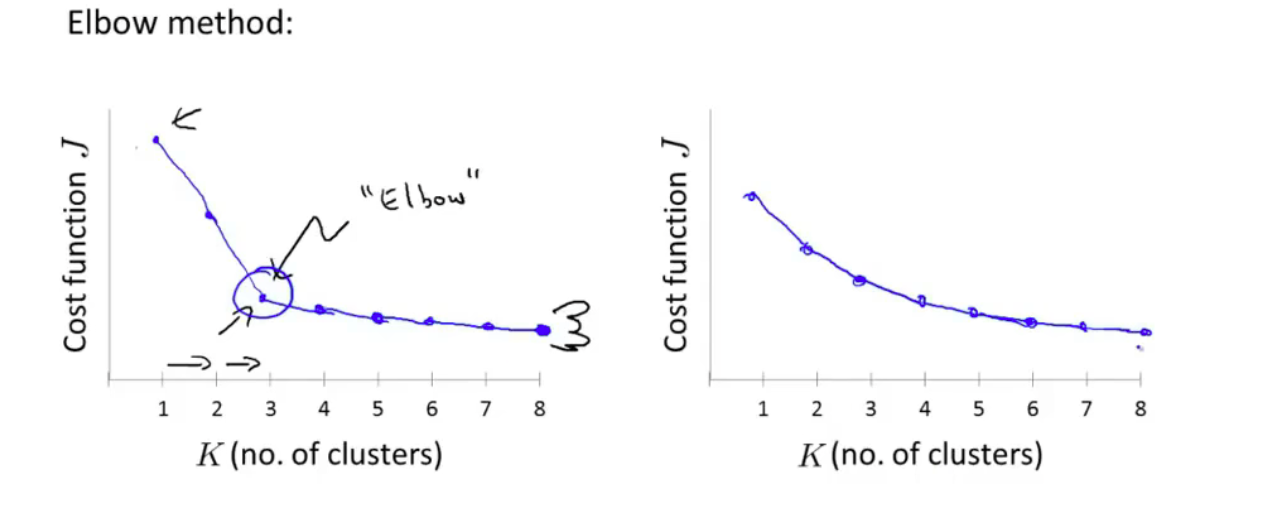
如左图,我们做出曲线后,可以选择这个拐点
但当图像如右图时,用肘部法则便是十分困难的
3、根据实际目的
比如卖T恤
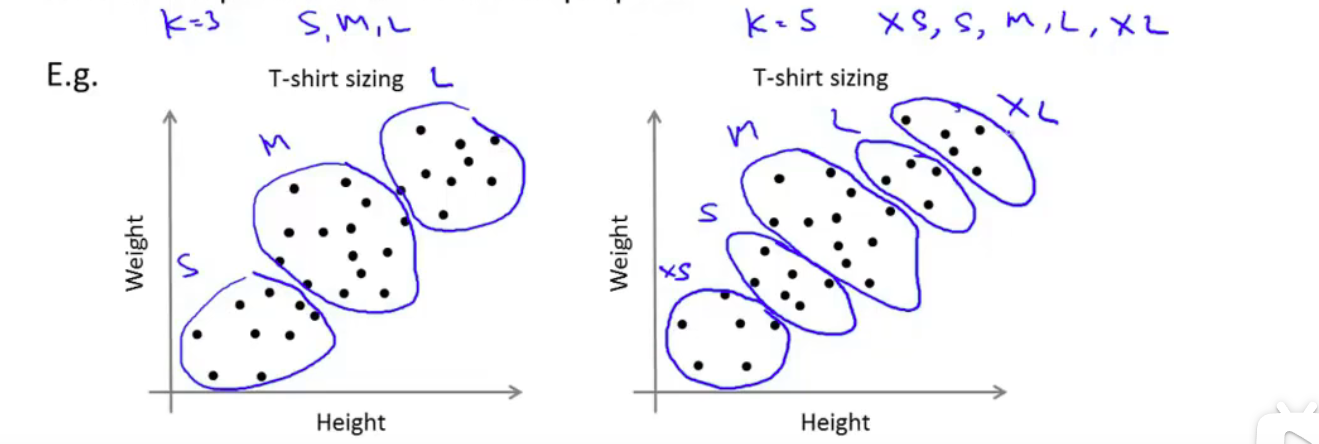
我们要提供多种尺寸的T恤,那么就根据目的选择K的种数即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号