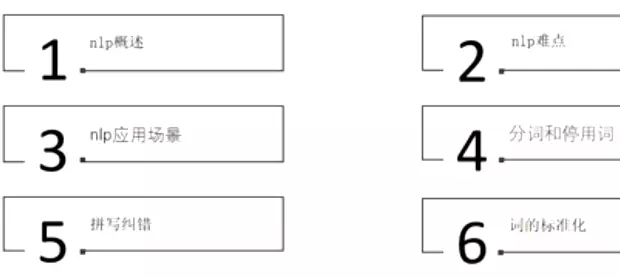
NLP概述及文本预处理
![]()
![]()
![]()
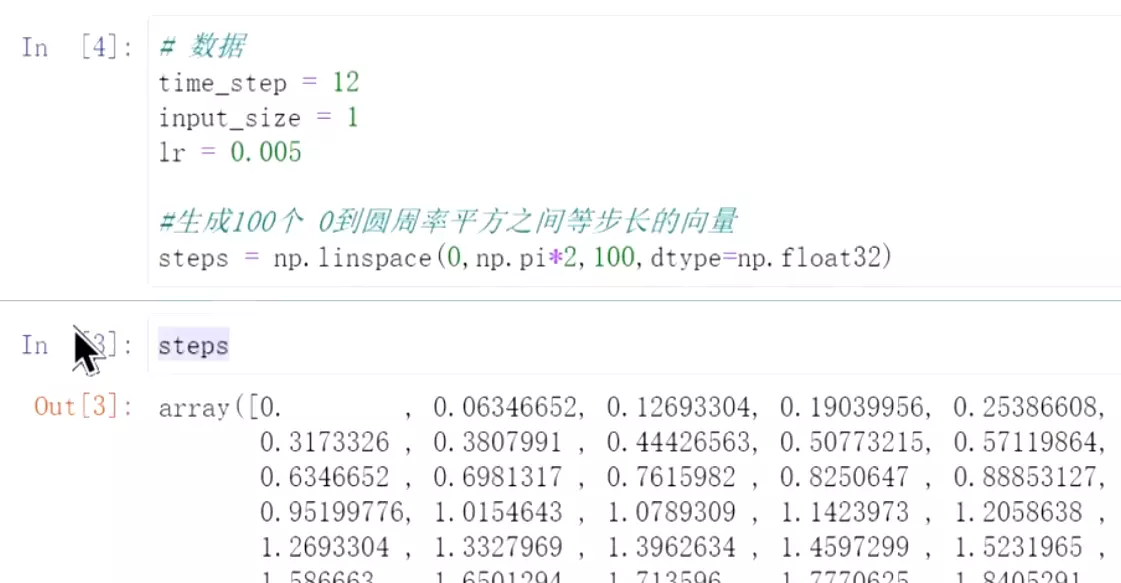
#可否直接用语言和设备进行交流?就是NLP发展的初衷。![]()
![]()
![]()
![]()
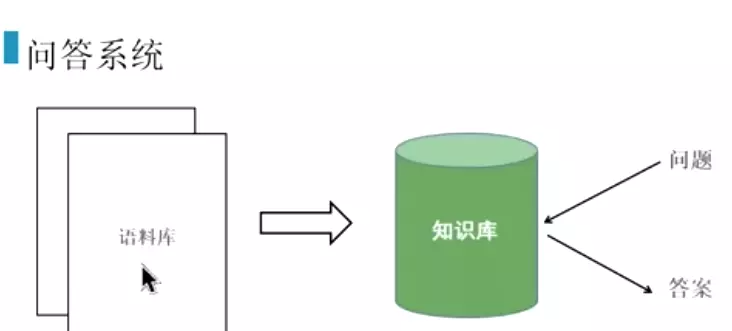
#问答系统添加一些功能,就会变成智能客服。添加非常规的问题。![]()
#加入语音技术,就变成语音助手。
![]()
![]()
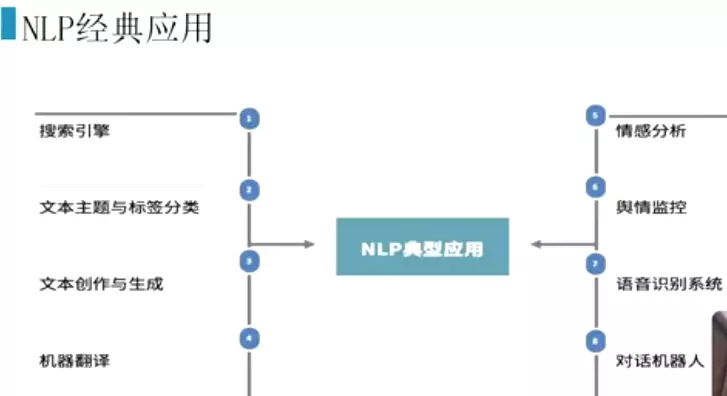
#公司负面评论多(先爬虫爬下来),舆情监控,做公关处理,某个时间或某个产品。联系媒体或发布者进行处理。![]()
![]()
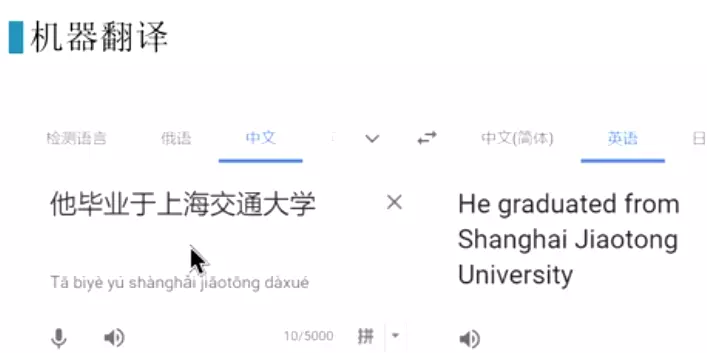
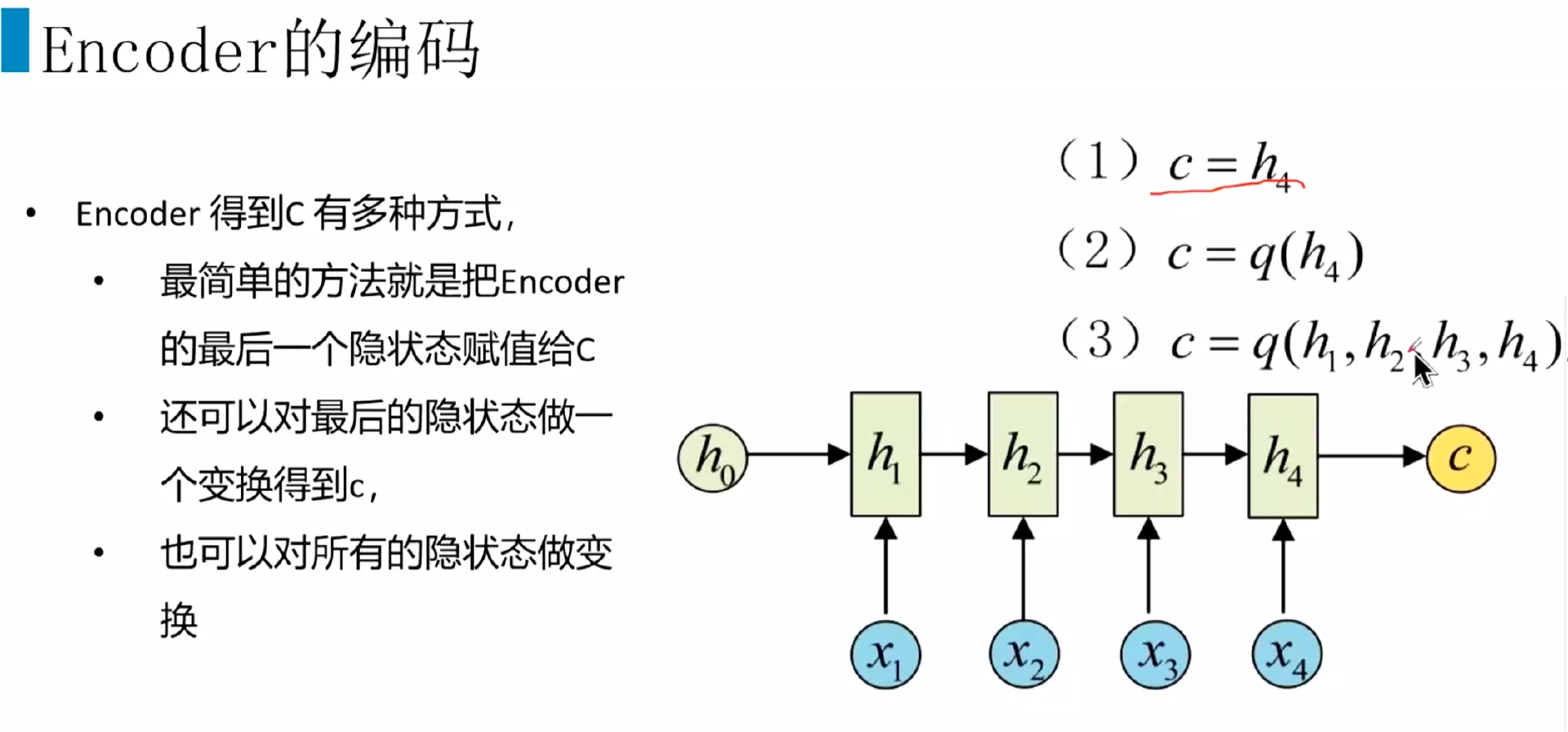
#编程层和解码层。![]()
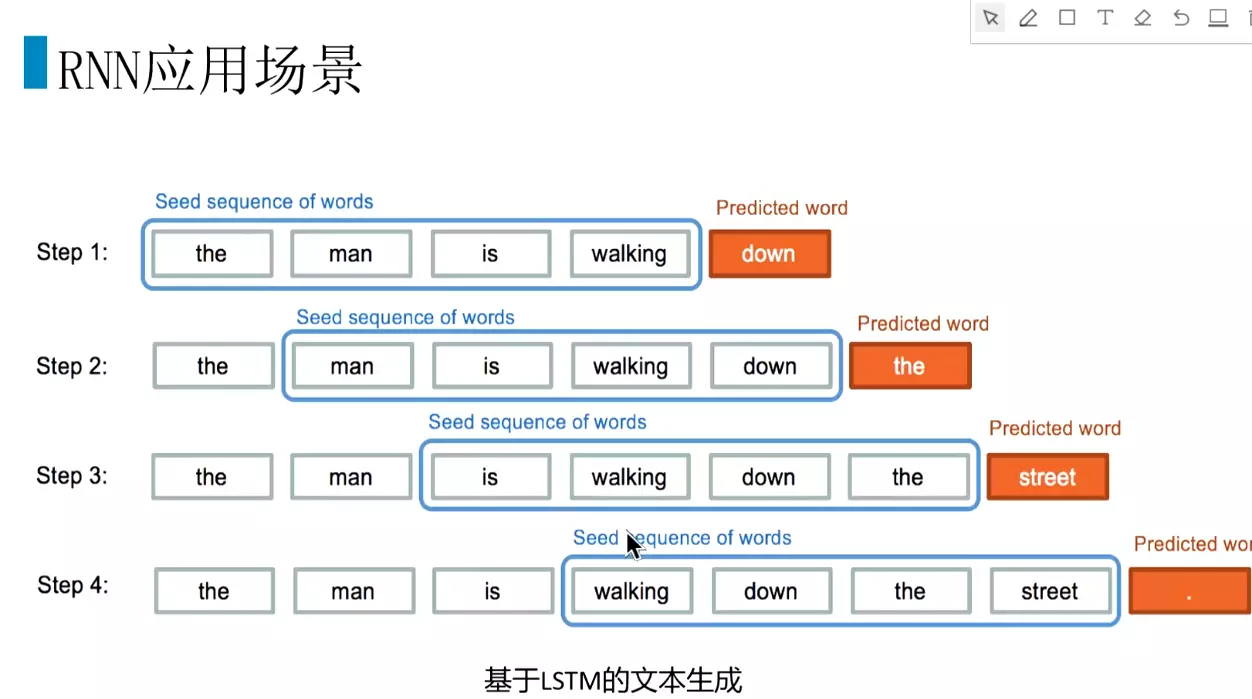
#文本生成。GPG3可以写论文。商业应用不太靠谱。不太可控。![]()
![]()
![]()
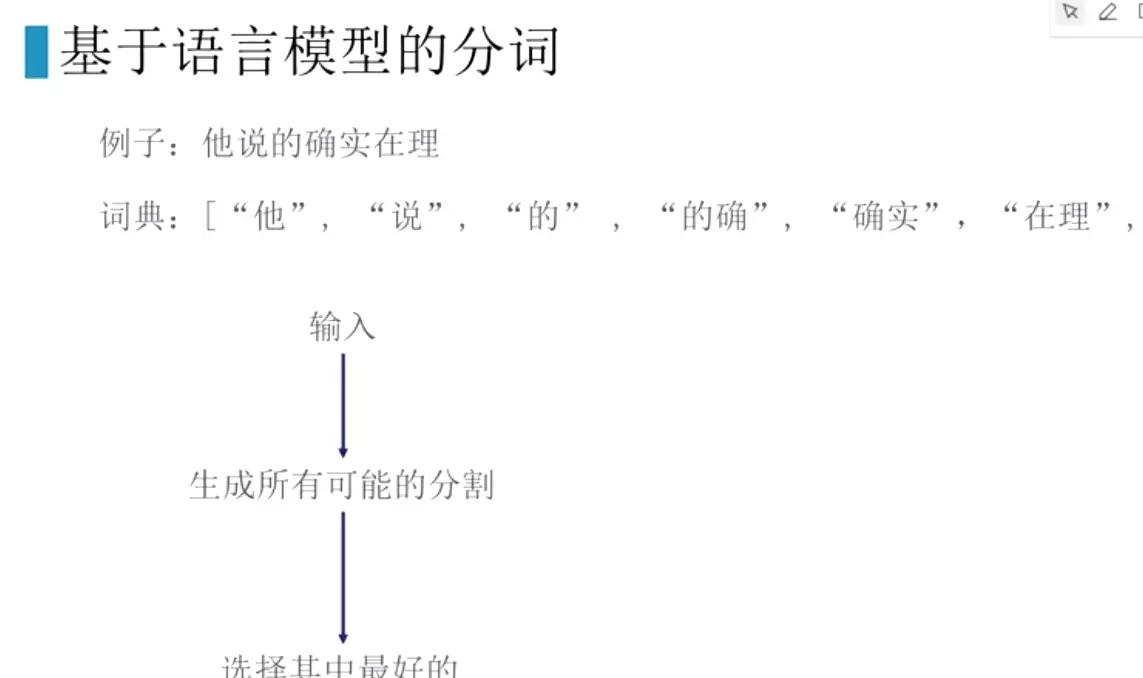
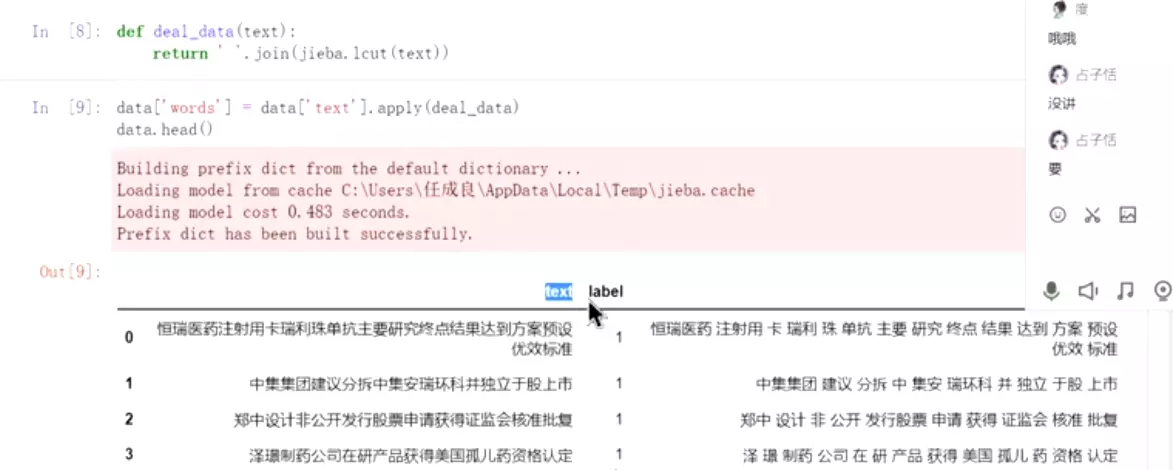
#pipeline:原始文本-预处理(分词、清洗、标准化)-特征提取-建模。常规的pipeline,如果深度学习nb的话,可以减少部分
![]() 中文里一般没有词的标准化,拉丁语系有
中文里一般没有词的标准化,拉丁语系有![]()
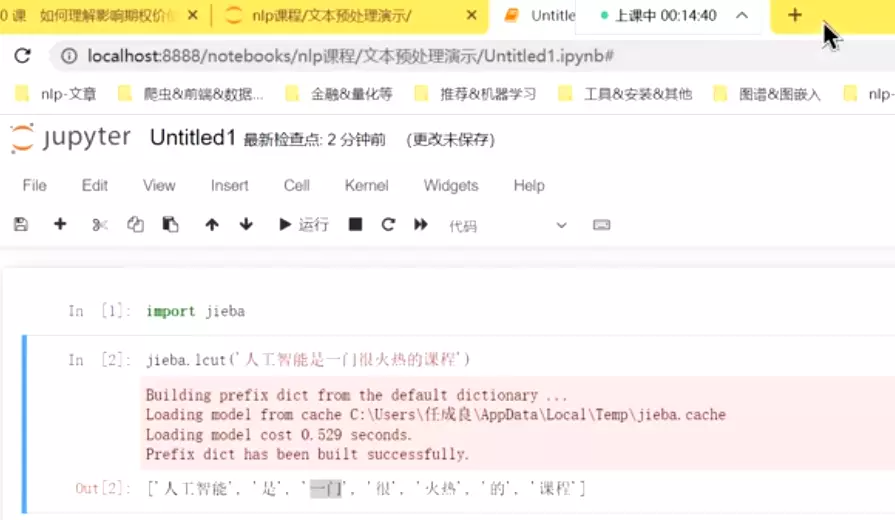
#jieba速度最快,可以加载自己的专有词汇。![]()
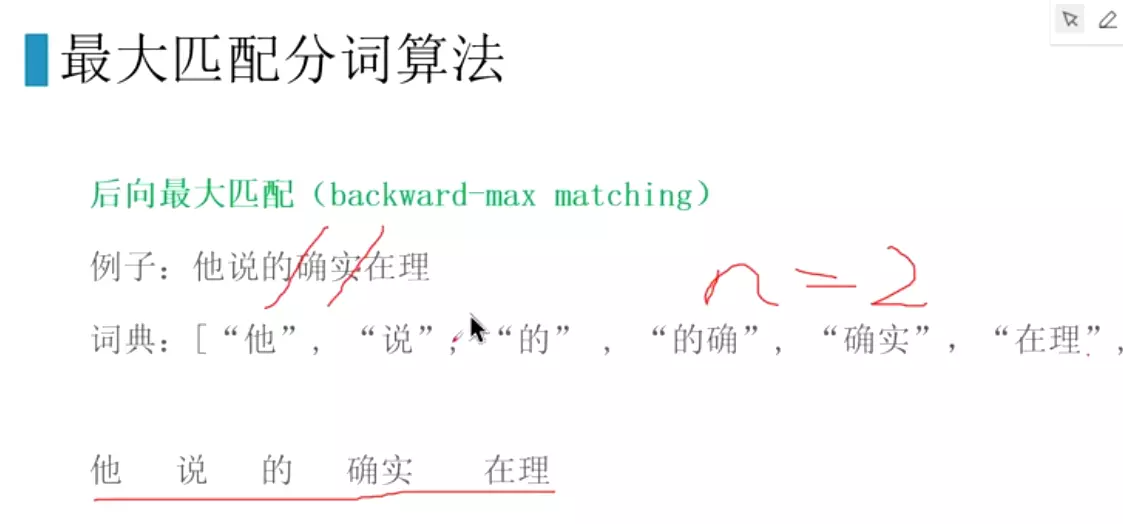
#原理:向前最大匹配。n=2,先切,再去词典里匹配,匹配上就拿出来,匹配不上就在减小n。
![]()
![]()
#后向最大匹配表现的比前项最大匹配稍微强一点。错误率前向1/169,后项1/245![]()
![]()
![]() #在出现w2词的时候w1的个概率
#在出现w2词的时候w1的个概率
#二阶马尔科夫假设:假设这个词只跟前面两个单词有关系。极端情况下是所有词都独立。![]()
#两种分割,选择计算概率最大的。
![]()
![]()
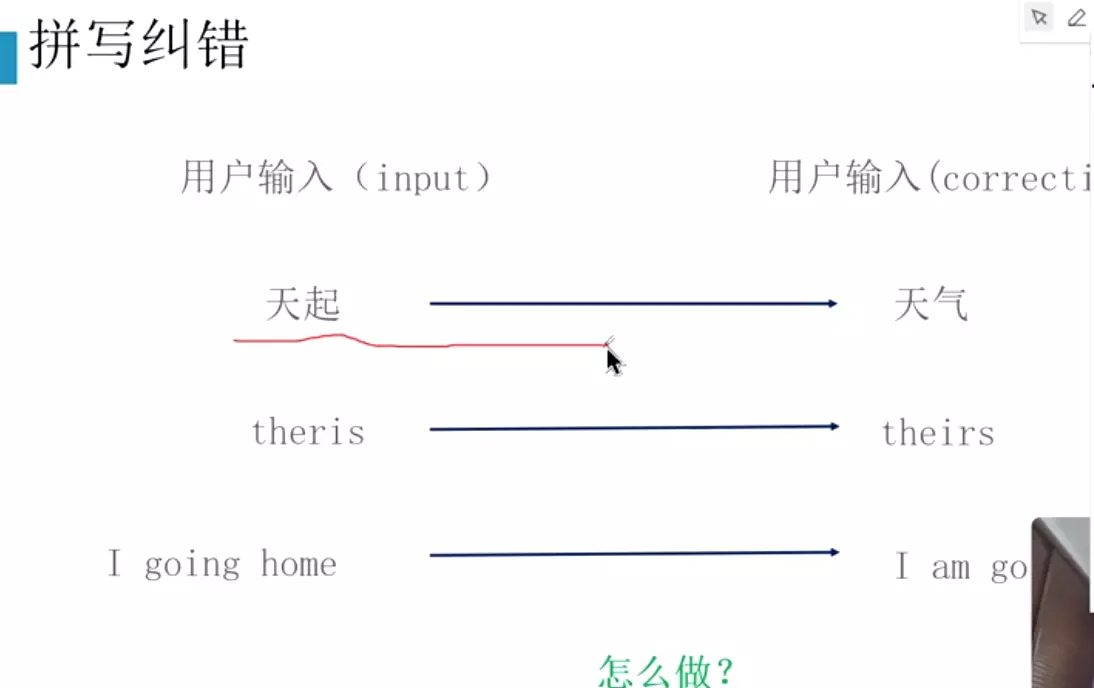
#拼写纠错:常用的是英文环境中,在英文中比较重要一些
![]()
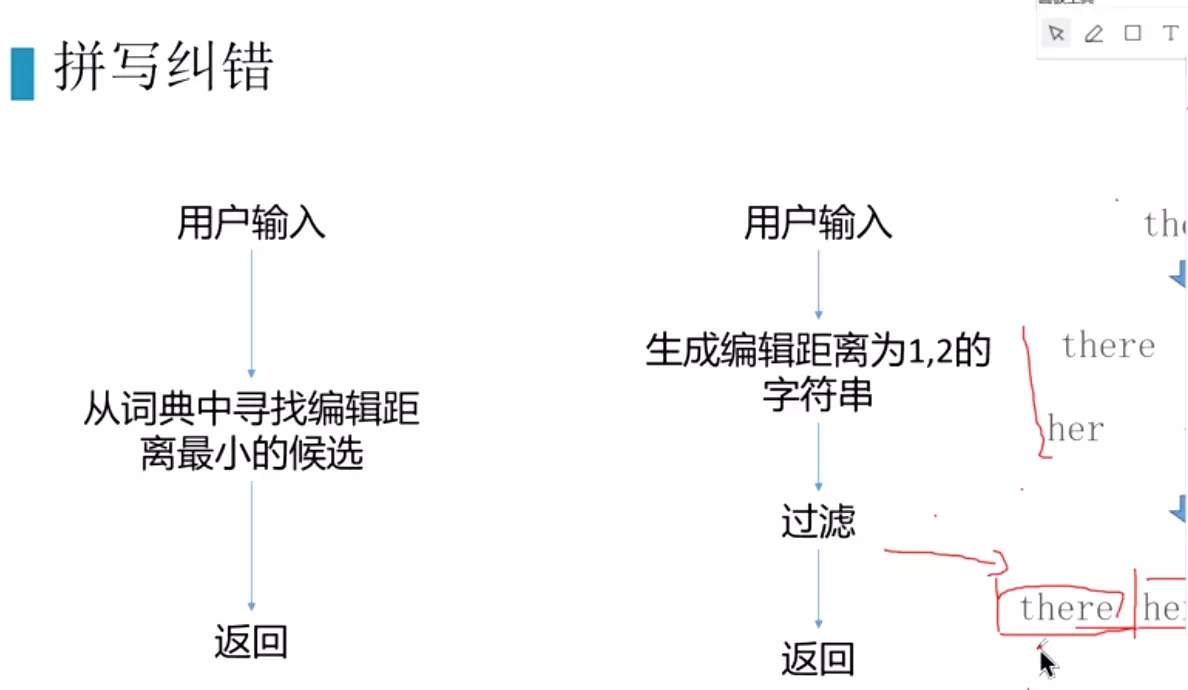
#编辑距离:就是两个词的距离。只能用插入、删除、替换。选择候选词![]()
#通过语言模型判断一句话是人话的概率。
![]()
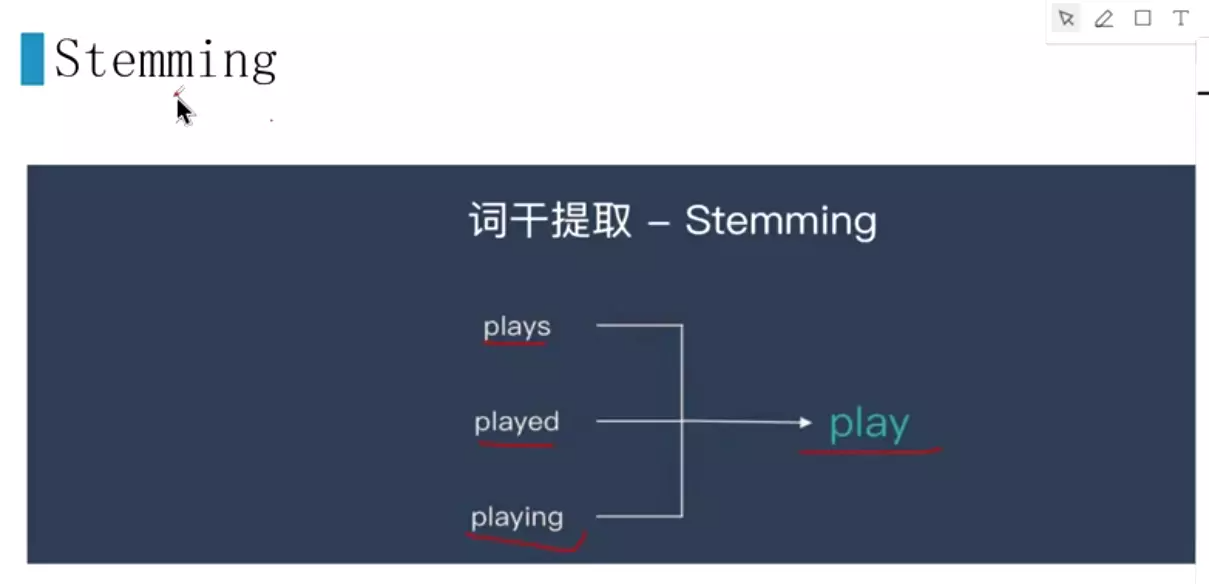
#词干提取![]()
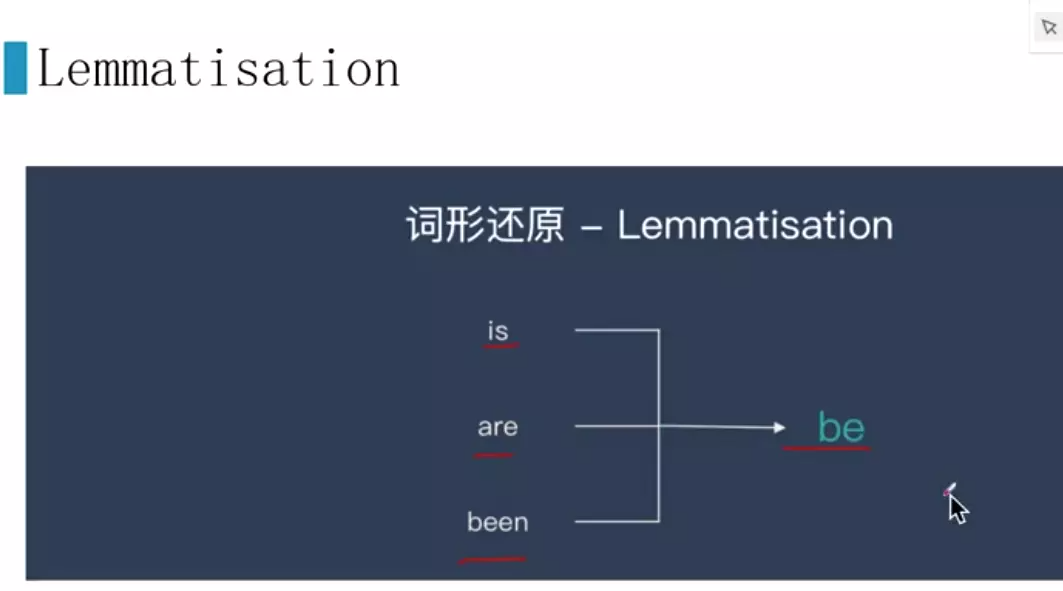
#词形还原。
上面是词的标准化。
![]()
![]()
#这些词保留下来还影响计算,停用后好一些。
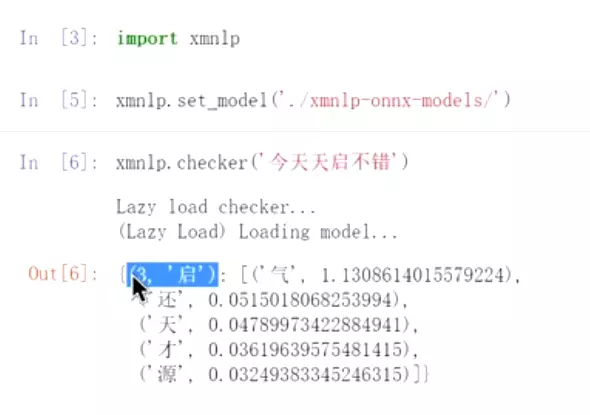
#文本纠错包:xmnlp
![]()
![]()
#纠错:第三个字‘启’错了。给出分数,后面最可能是‘气’
![]()
#文本表示:就是特征提取
![]()
#会把文本的数据搞成数字型的数据
![]()
![]()
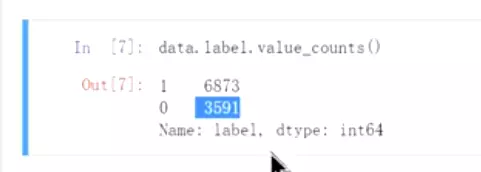
#1表示正面评论;0表示负面评论。
![]()
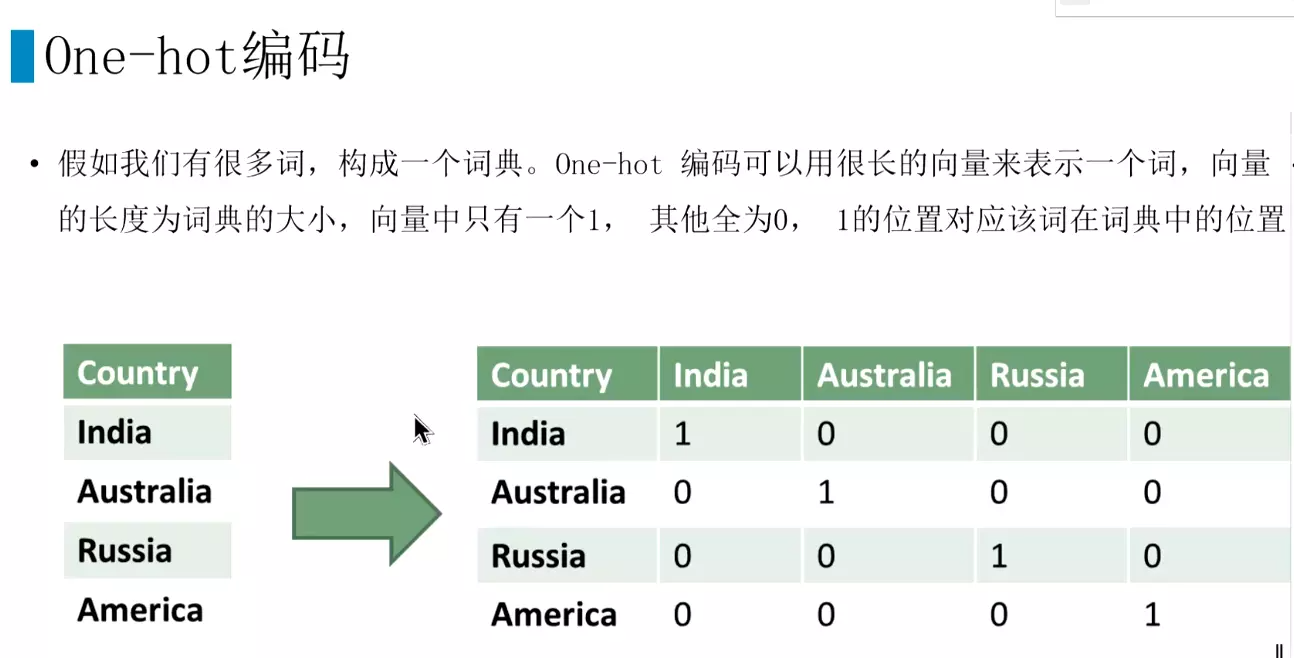
#最基本的是one-hot;词袋法和TF-IDF是基于one-hot
#基于主题模型方法:LSA、LDA 用的不多
#词向量
![]()
![]()
![]()
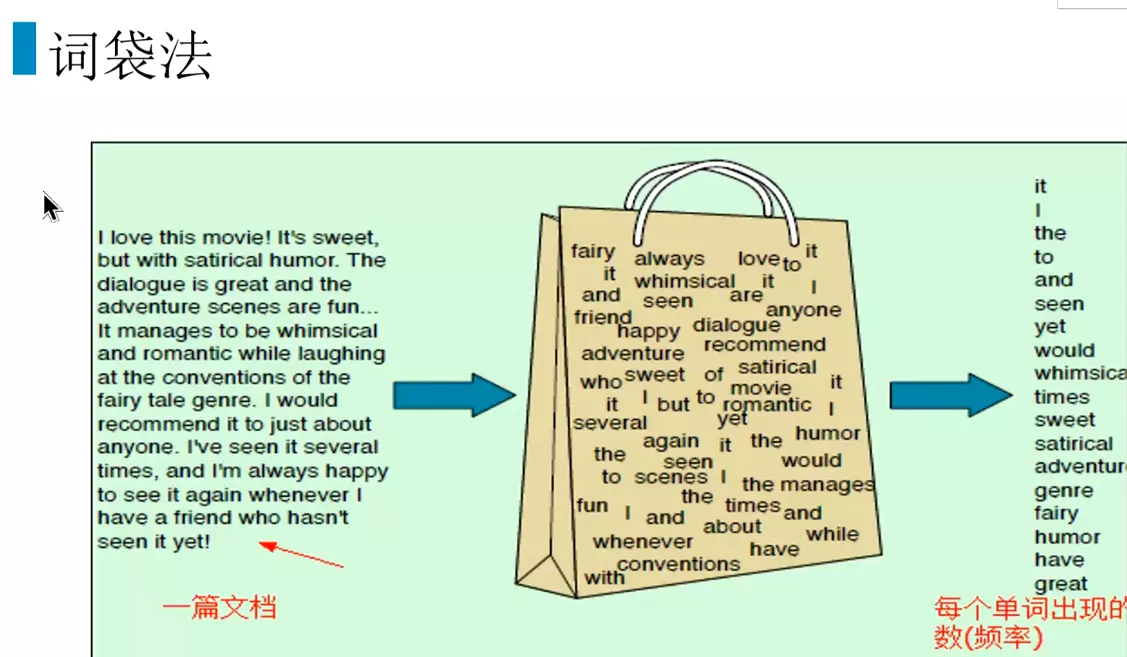
#词袋子,打散![]()
#按照词典里的顺序排序。把词典位置的相加。比较浅的统计的信息。统计词语在一段话里出现次数排序。![]()
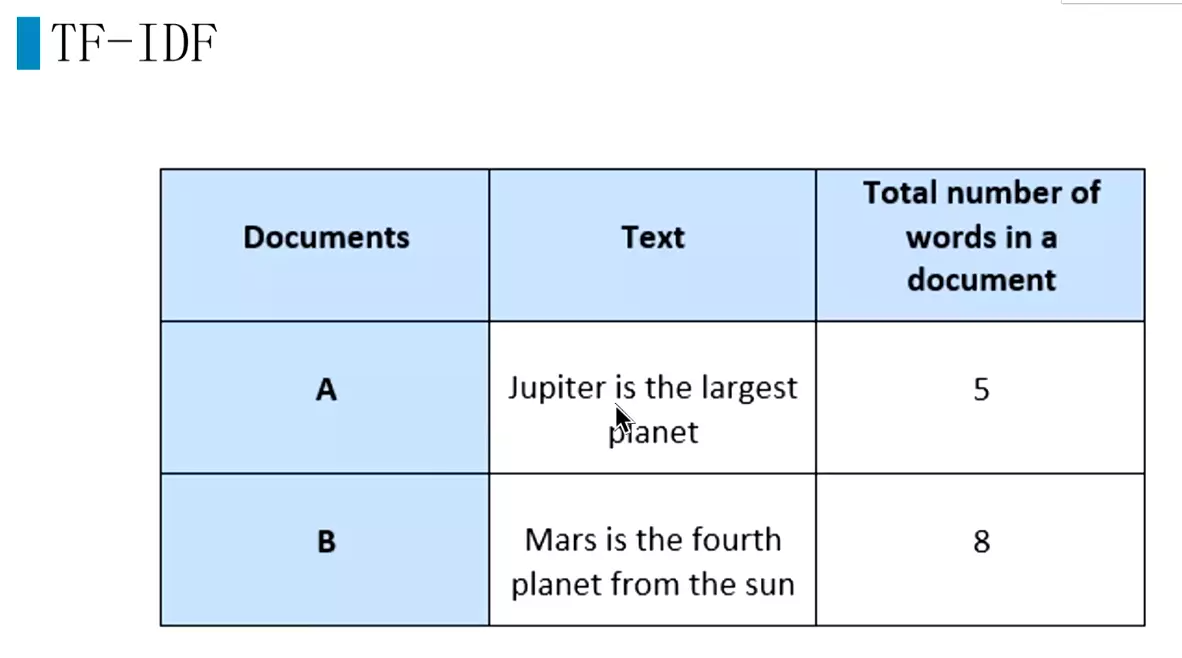
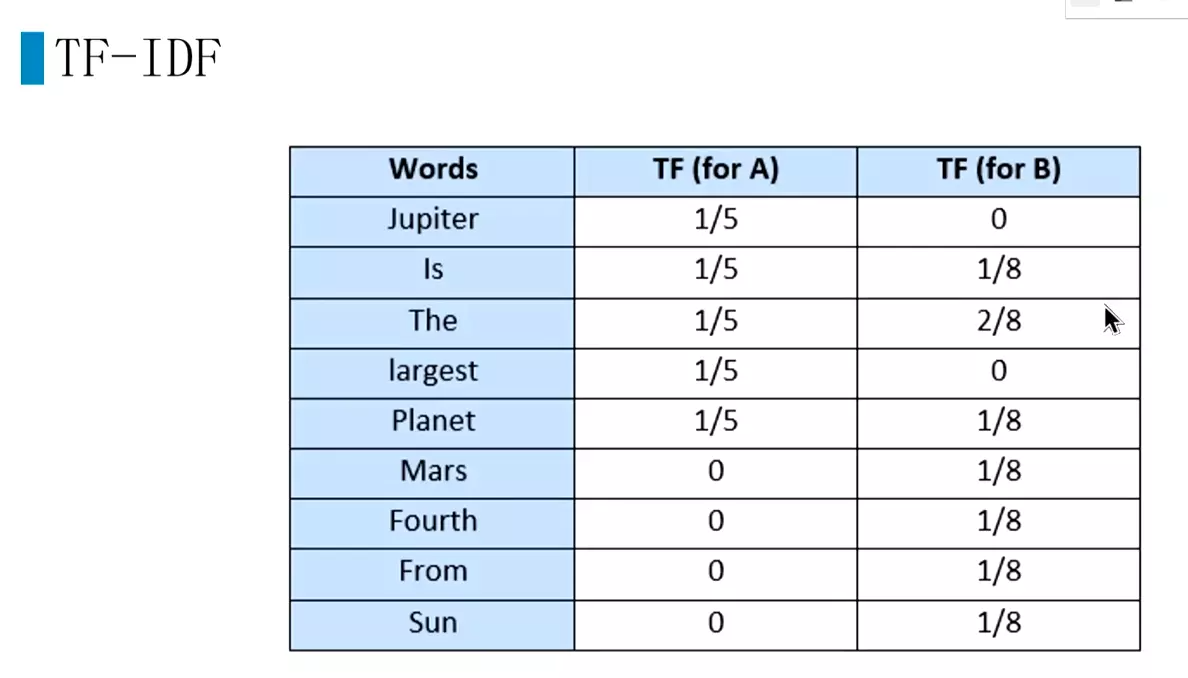
#TF-IDF还在用,效果还不错。![]()
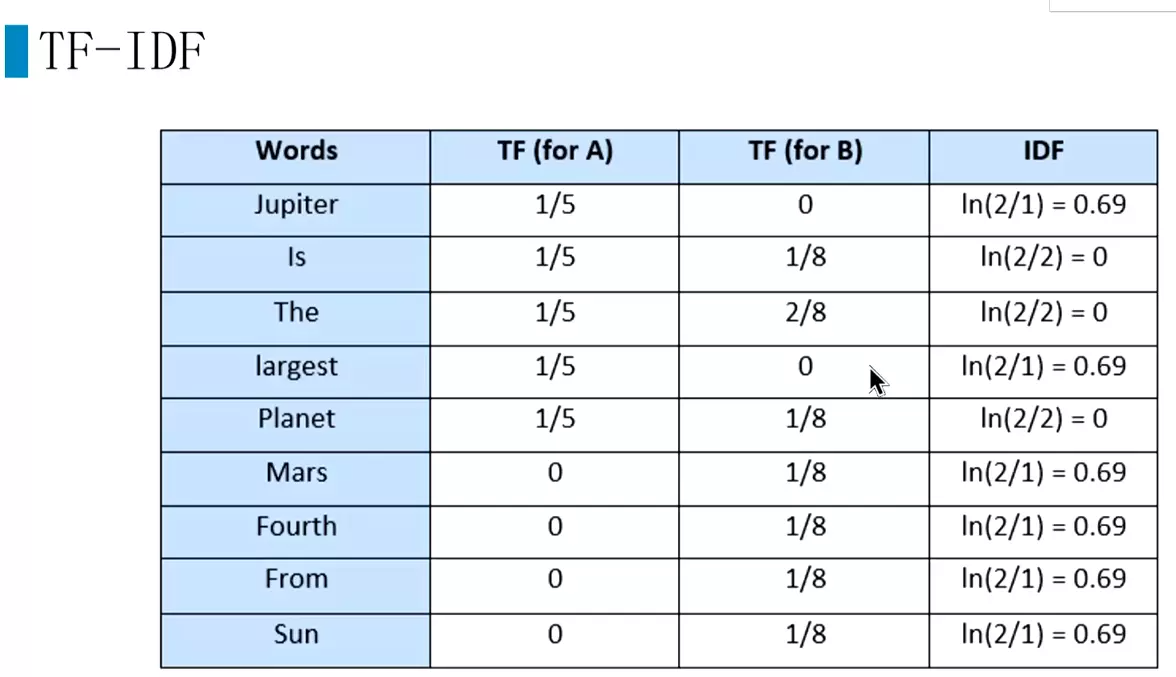
#语料库中有多少文档,![]()
![]()
#两个文章A和B,就是2;jupiter在A文章重现,就是1,所以就是2/1
![]()
#再用TF乘以IDF。就是TF-IDF,简单粗暴,好用。因为有些文本只需要用统计信息的,而用深度学习会处理文本会产生一些问题。![]()
#文本离散表示缺点:维度灾难(利用率很低)、无法表示语义信息(两个词之间的关系没有)
![]()
##代码实例:金融领域,正面的新闻,有利于做多![]()
![]()
![]()
#去掉标题。
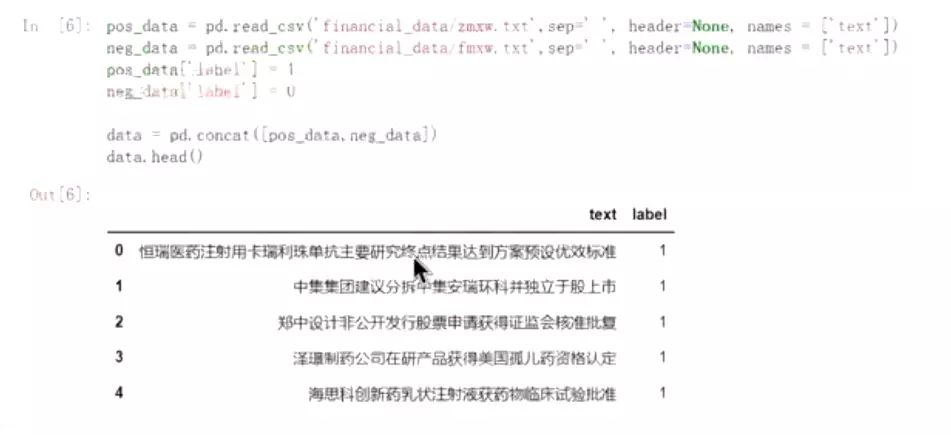
![]()
#负面信息给标签0,正面数据给标签1
![]()
#上面是停用词。有的话给它去掉
![]() #实例化词袋法
#实例化词袋法
![]()
#取5条数据变成词袋
![]()
![]()
#用空格拼接起来,这种形式才能用词袋
![]()
#是个对象![]()
#转换成向量,词袋向量
![]()
#词袋的顺序。
![]()
#实例化TFIDF
![]()
#直接把词给过来
![]()
#给5条数据,每条数据有29个维度
![]()
#用所有数据进行idf![]()
![]()
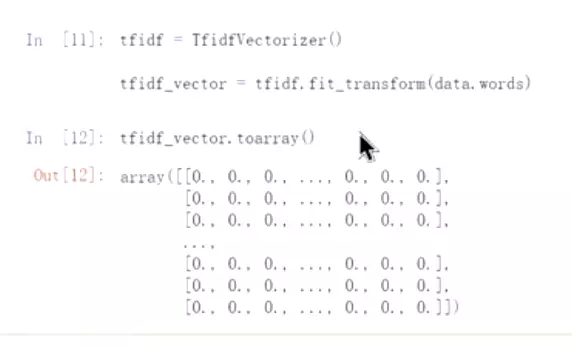
#很稀疏的数据,这就是维度灾难。离散表示。
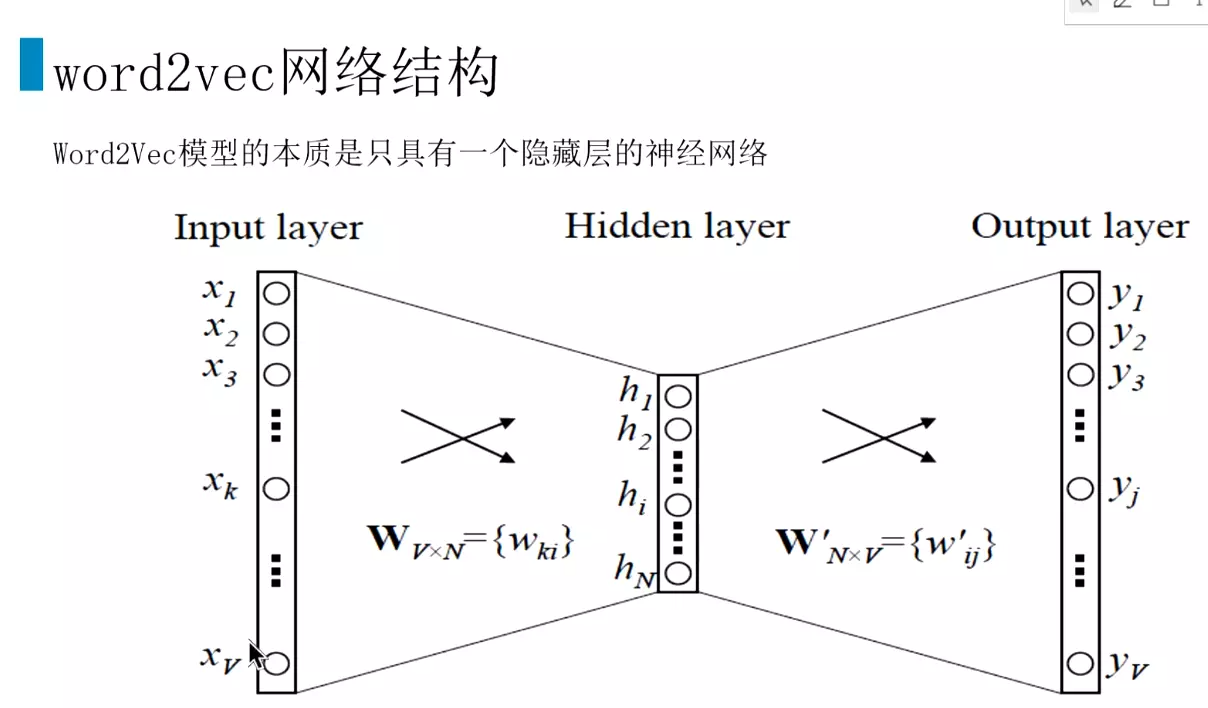
##词向量:一般用二进制的方式存储
![]()
#截取了2000个词向量:![]()
#上面是‘的’的词向量,是用神经网络优化的。维度是300,可以调整。自己定义。
![]()
#如何用词向量:
![]()
![]()
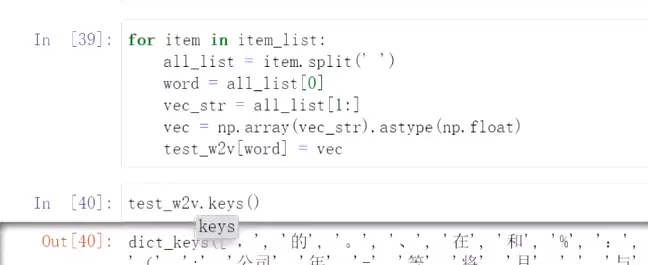
#拿出一个词向量,是一个字符串,需要转换成词向量:
![]()
#转换成向量![]()
![]()
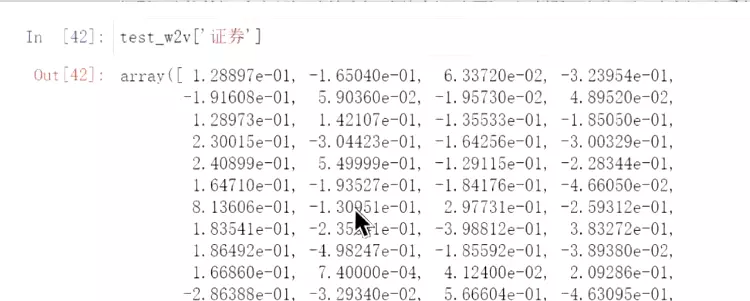
![]()
#‘证券’的词向量,固定是一个300的维度。
![]()
#上面的词向量Wv*n就是通过一个浅层的神经网络训练出来的。![]()
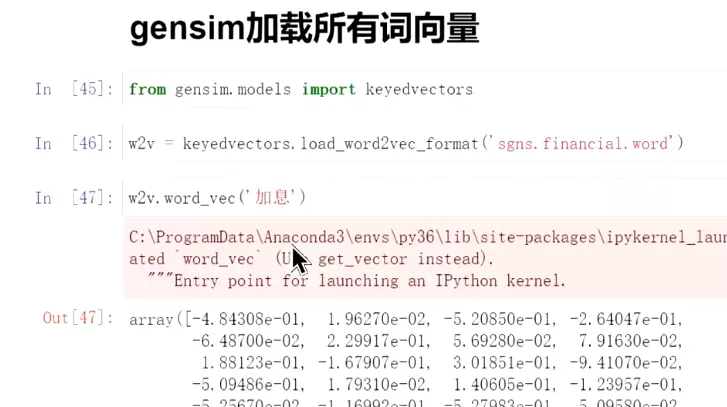
#加载所有的词向量(二进制模式储存)
![]()
#查找某个词向量,如‘加息’
![]()
#是否有该词向量。
![]()
#寻找,和‘加息’相近的词,后面是余弦距离。就可以通过语义做一定的相似性判断
![]()
#相似度判断
![]()
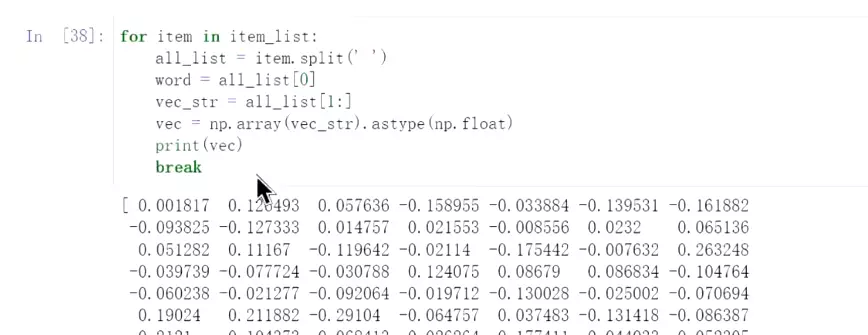
#如何进行向量化?例,用上面五句话
![]() 把所有词相加取平均,只有一些语义信息,但是没有顺序的信息。所以后面的RNN和bert会去处理顺序信息。
把所有词相加取平均,只有一些语义信息,但是没有顺序的信息。所以后面的RNN和bert会去处理顺序信息。![]() #把第一句话向量化。看出短文本还不错,效果比TF-IDF要好一些。
#把第一句话向量化。看出短文本还不错,效果比TF-IDF要好一些。
##现在的w2v是别人训练好的模型。
![]()
![]()
![]()
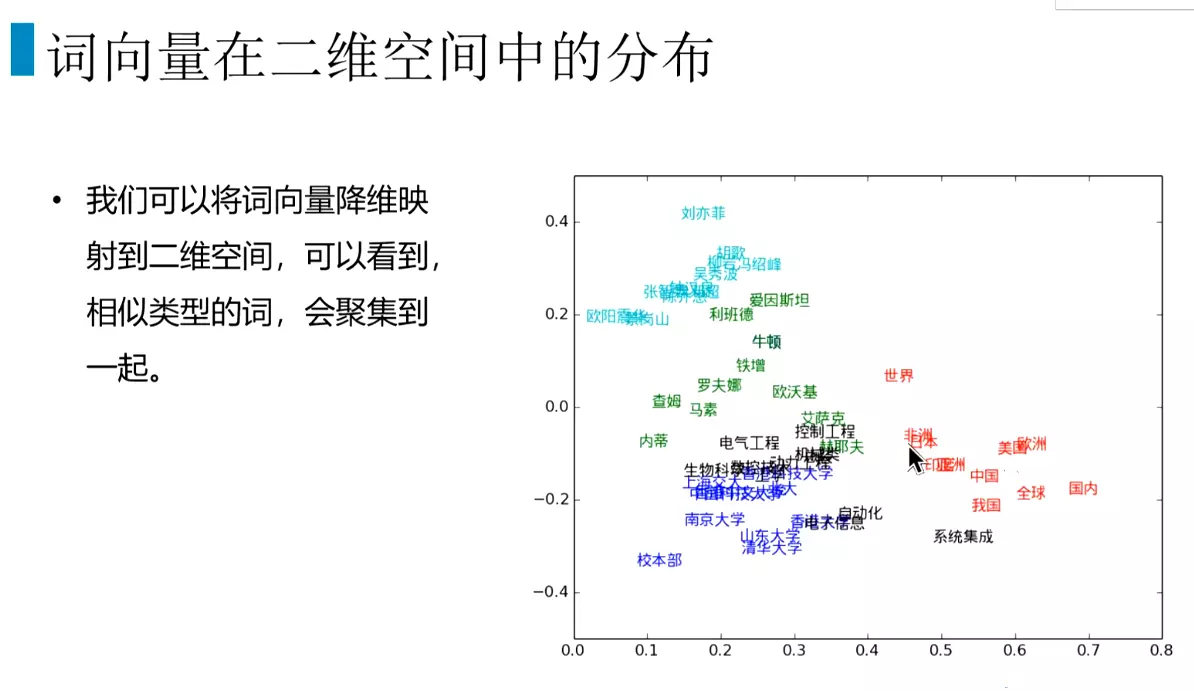
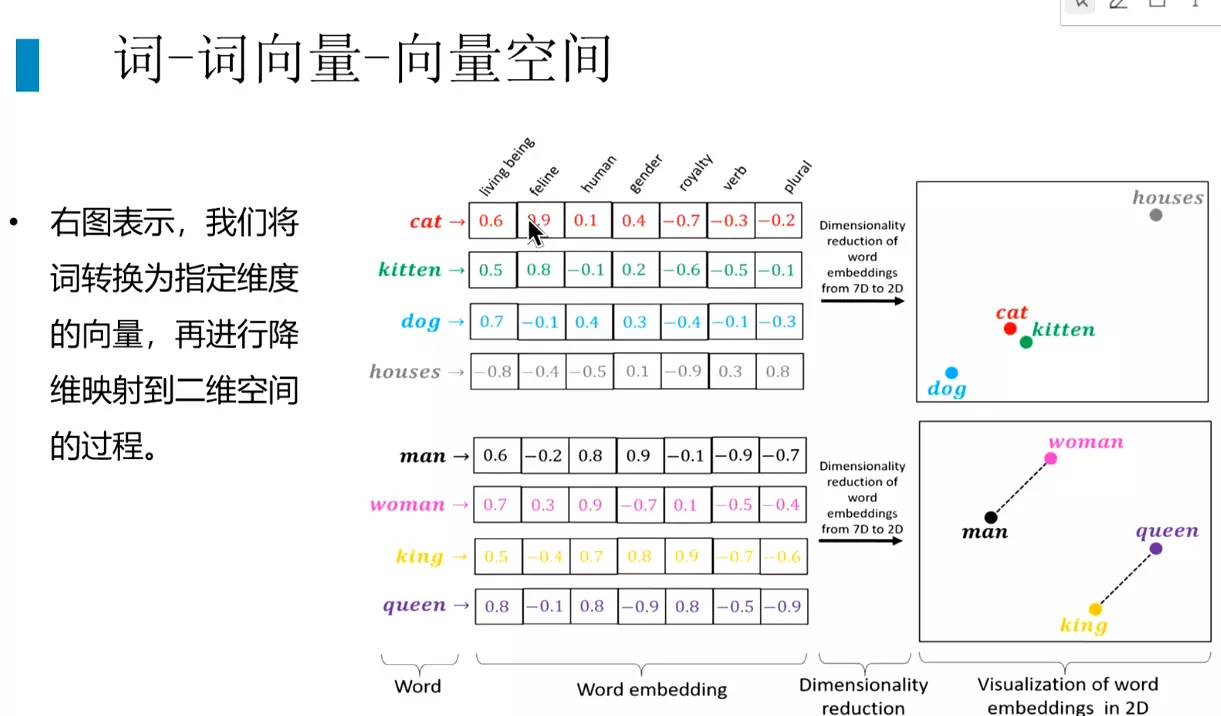
#假设每个维度上都有意义,图片是转化为7维的词向量。再转化为2维空间,右图。
#词向量是NLP中很有意义的技术,但是对于多义词没有办法。两个词距离的远近可以表示两个词的关系。![]()
#推荐第三个论文,由浅入深。有时间去读一下。![]()
#语言模型,就是函数,可以判断一句话是否符合语法,是否是人话。
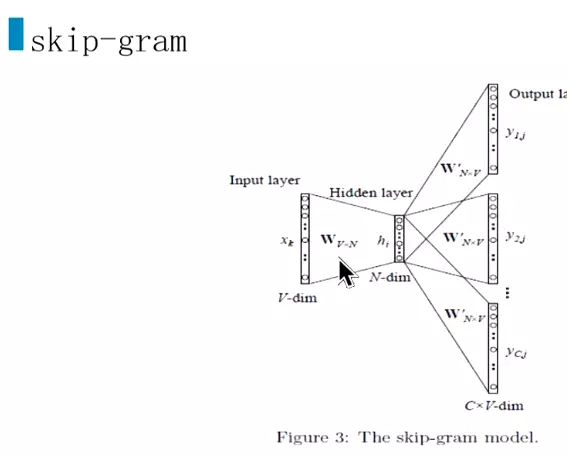
#word2vec是为了找到参数![]()
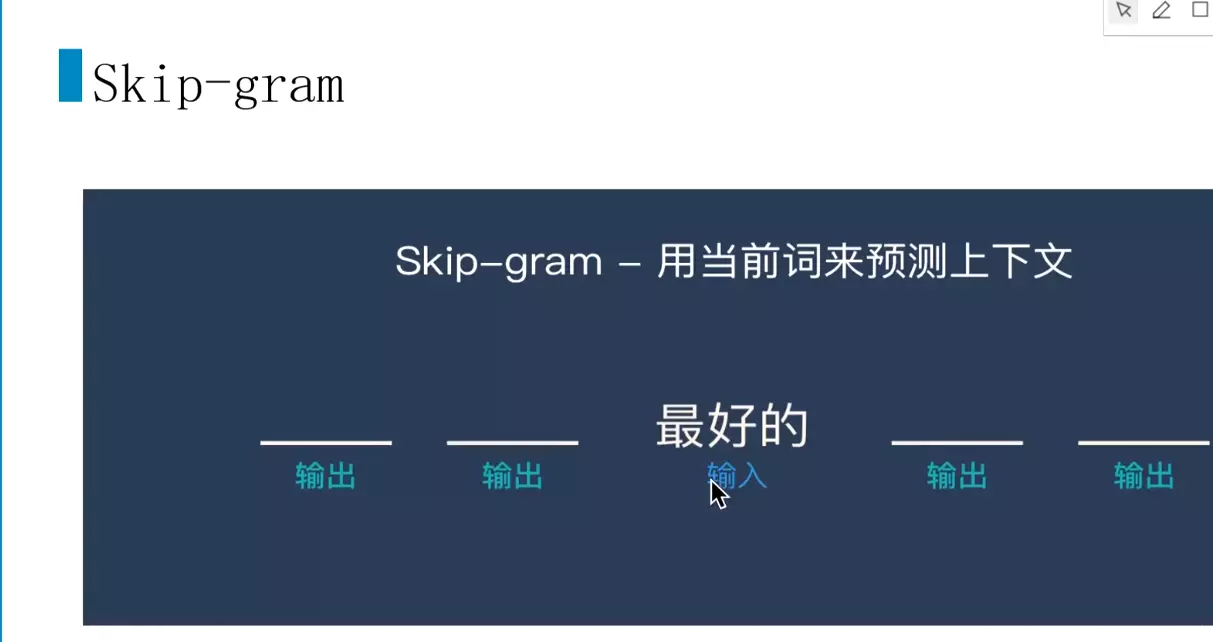
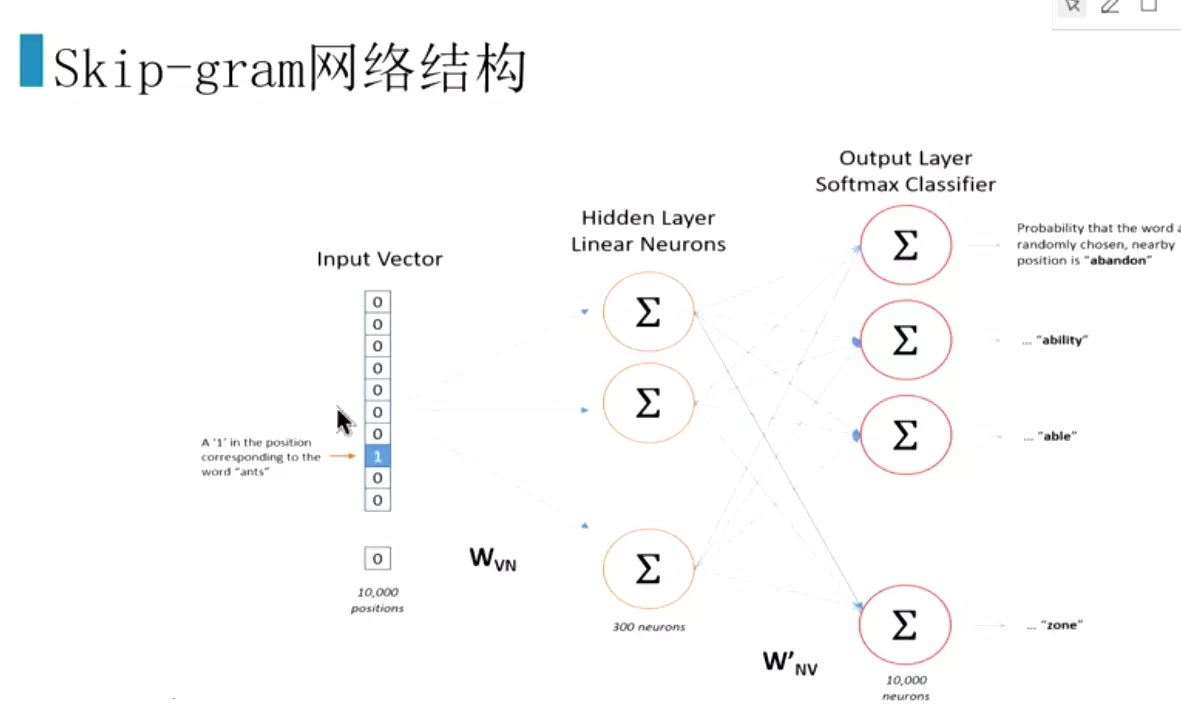
![]() skip-gram用的比较多
skip-gram用的比较多![]()
![]()
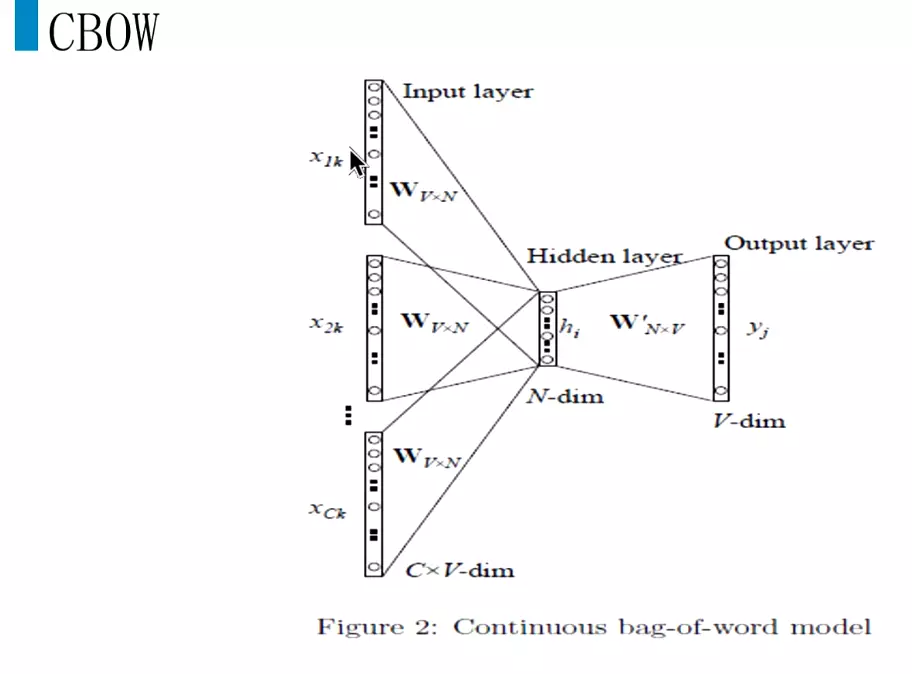
#x1k是第一个词的one-hot编码![]()
#需要更新多,效果好一些,一般会用skip-gram![]()
#输入也是one-hot编码。隐层、输出每个词的概率,最大的就是我们需要的词。
基于word2vec算法原理应用实例![]()
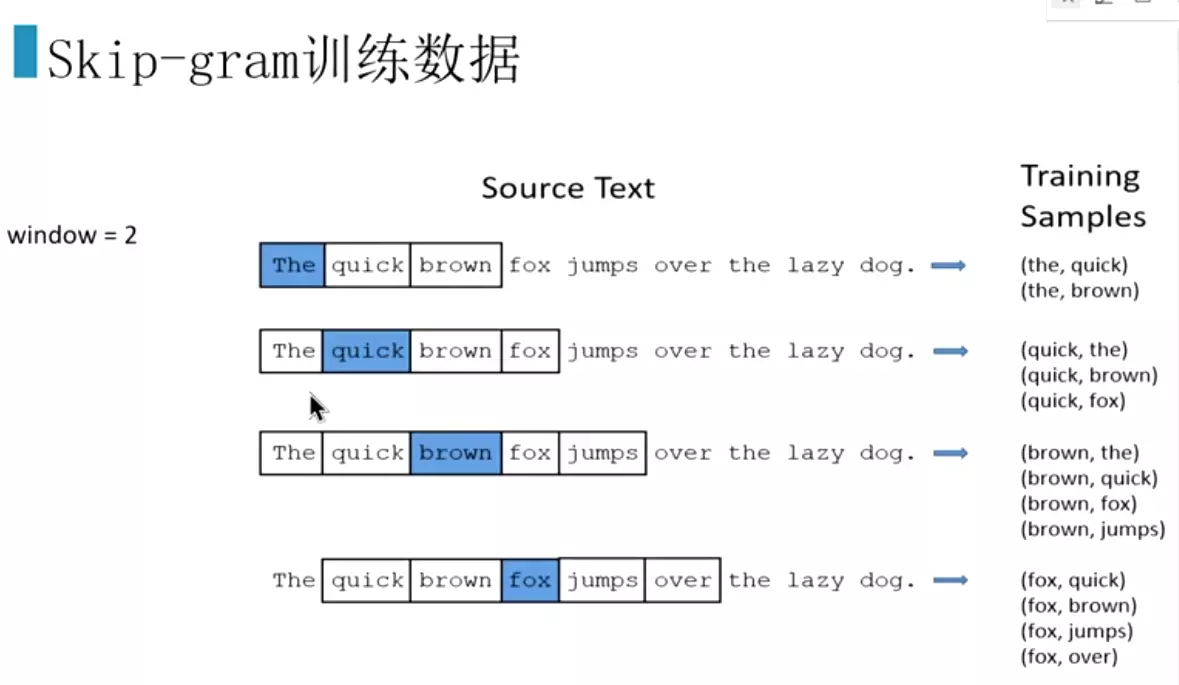
#skip-gram自己会构建数据。有一个重要的参数是window,如果设为2.就是预测上面两个词和下面两个词。中心词周围的2*2个词就是正样本,词典里的其他的词全部是负样本。再去滑动。通过滑动窗口,去构建正样本。![]()
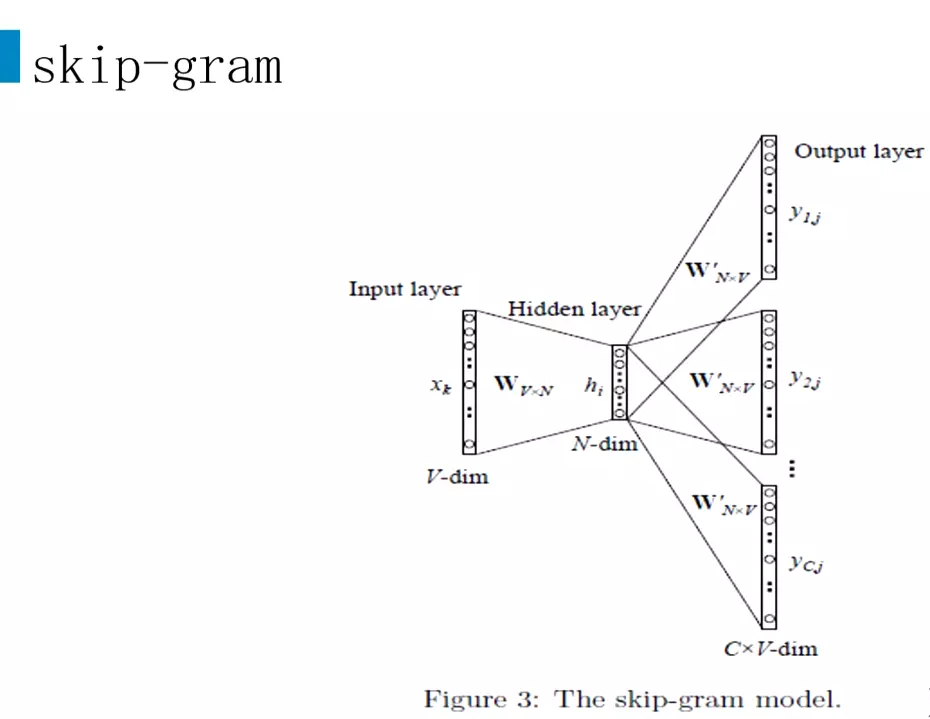
#假设是10000维的向量,给它预测300维,![]()
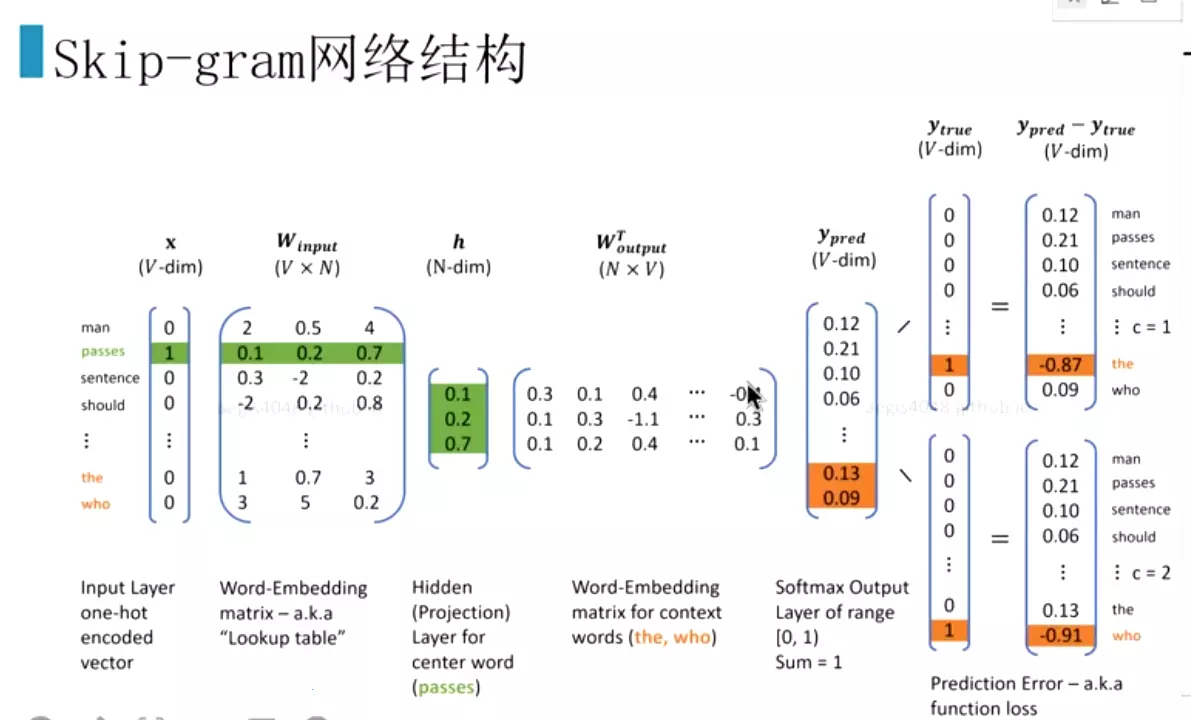
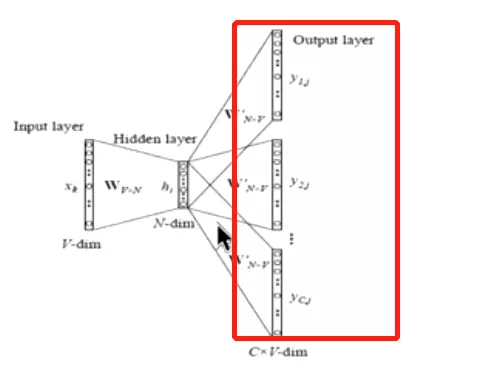
#Wvn是每一个词的词向量,就是训练为了得到的东西;h是小向量;橘黄色的就是预测值得概率。最右侧是计算交叉熵损失。![]()
#这是概率![]()
![]()
![]()
![]()
#得到损失函数![]()
![]()
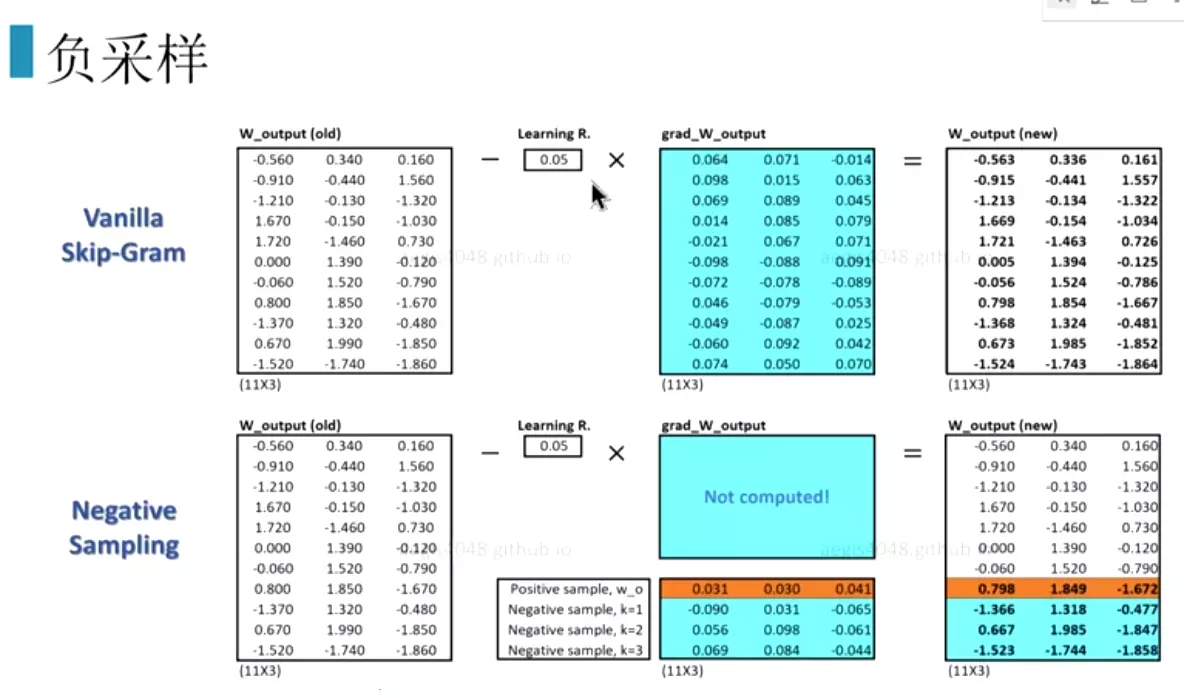
#两个训练方法,一个是负采样,一个是层次softmax。都能大幅度提升训练速度。![]()
![]()
#其他的词不更新权重,只更新选择的样本。如更新所有的词的话开销非常大。
![]()
![]()
![]()
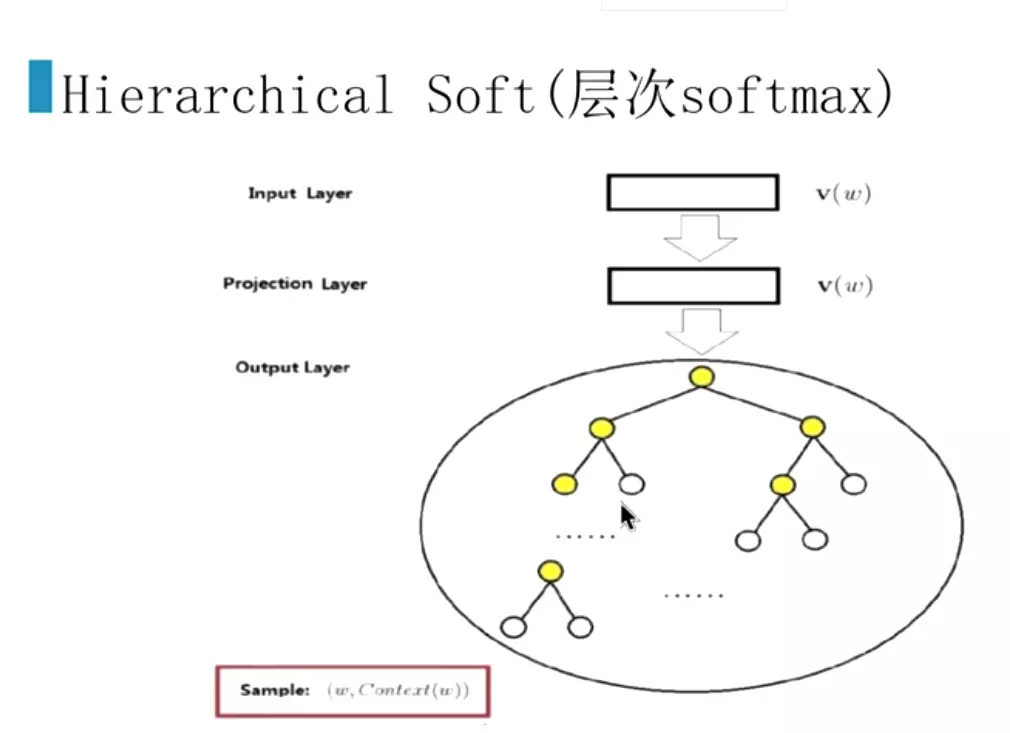
#层次softmax,就是频率低的词放下面,再合并。对节点进行二分类。预测为1就是白色的球,就是预测的词。这样就把n分类的问题,改为了logn2分类的问题,这样训练词向量就会非常快。![]()
#红线就是预测走法,哪个分支概率大,就往哪里走!![]() 就是右边输出部分,直接接一个哈夫曼树。
就是右边输出部分,直接接一个哈夫曼树。
#上面是理论内容。
![]()
![]()
![]()
![]()
#合并![]()
![]()
#生成一列,tf-idf需要的这一列![]()
#实例化一个tf-idf向量![]()
#写的标准一下:![]()
#用svm做分类:
![]() 在训练数据集上做训练。
在训练数据集上做训练。
![]()
![]()
#在测试集上做预测
![]()
![]() #用word2vec,加载向量,
#用word2vec,加载向量,
![]()
#把所有的语句全部转化为word2vec向量
![]()
#看一下长度
![]() shuffle=True打乱
shuffle=True打乱
#分成训练数据和测试数据
![]()
#实例化一个svm,看一下分数
![]()
#预测一下测试数据
![]()
#打印准确率。比上面的用tf-idf的强一些,尤其是在0的数据上。
原因是文本已经处理的很好的![]() 是一个纯粹的文本。
是一个纯粹的文本。
![]()
#看一下这种质量不好的文本,工作中,大部分是这种不好的文本。
上面就是对文本做分类的任务。
###如何训练一个词向量?
上面的例子词向量已经训练好了。下面是训练词向量例子:最简单的例子
![]()
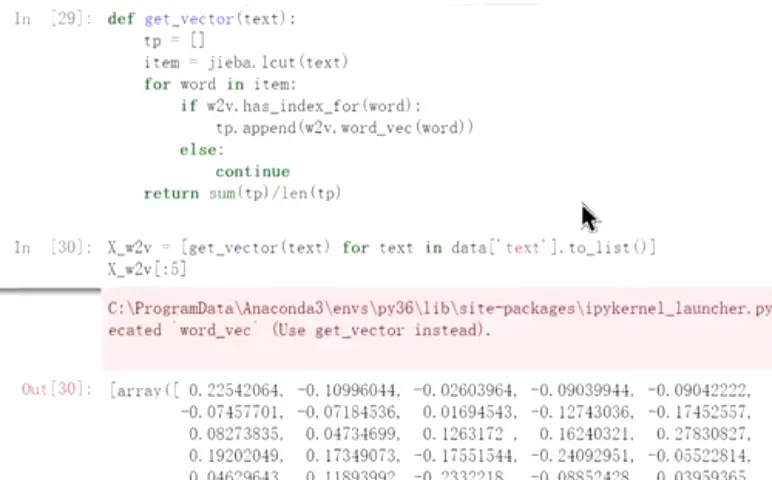
#分词是中文中很重要的任务。训练好的词向量存储在一个KeyedVectors实例 ![]()
#用于不是做分类,所以不用标签了,直接concat
![]()
#打乱数据,就是去采样。打乱的比例,设为1就是是所有的数据都进行采样
![]()
#先分词,然后直接可以去训练
![]()
#变成可迭代的数据,方便节省内存。变成迭代器
![]()
#hs表示用哈夫曼树。上面就是训练词向量
![]()
#查看词向量
![]()
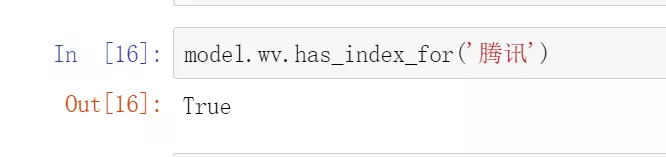
#查询是否有‘腾讯’这个词
![]()
![]()
#保存方式一:保存词向量和模型结构。后面读取后还可以继续训练![]()
#加载模型结构
![]()
![]()
#保存方式二:只保存词向量。读取后没有办法再进行训练
![]()
#用上次的方法加载
![]()
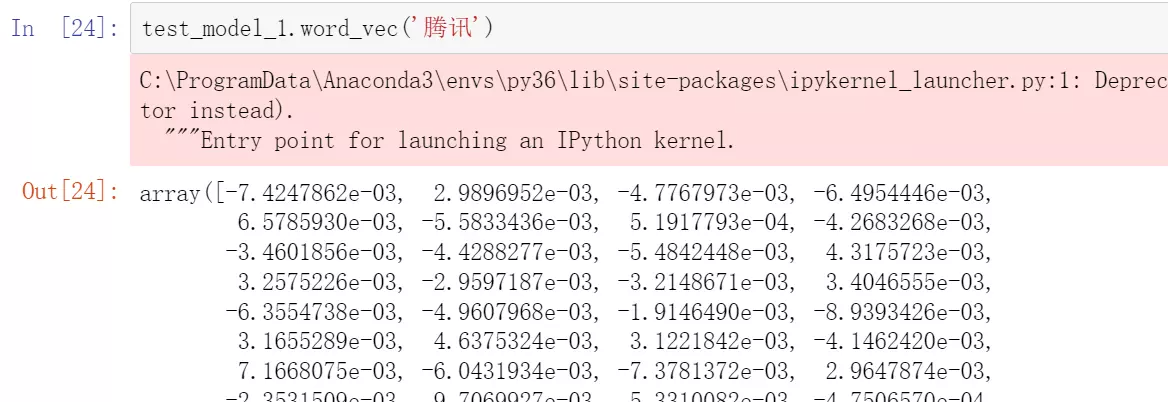
#使用词向量
##以后工作中需要自己去训练词向量可以安装上面方法搞
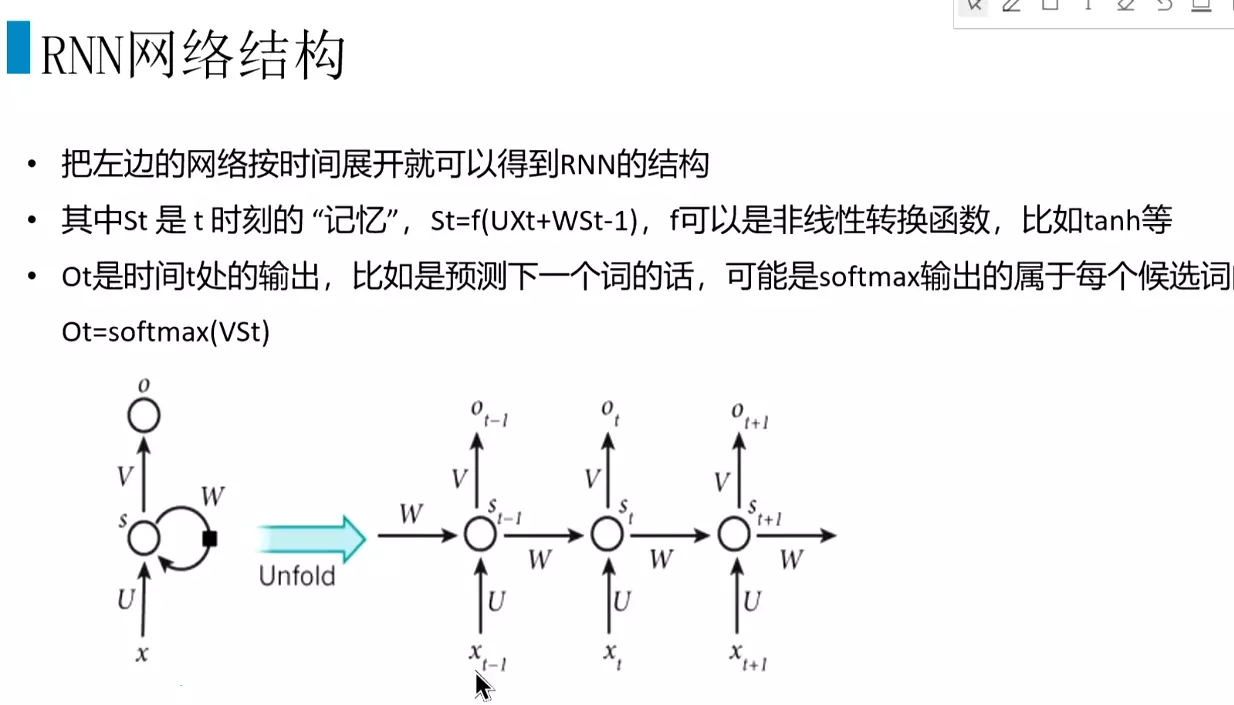
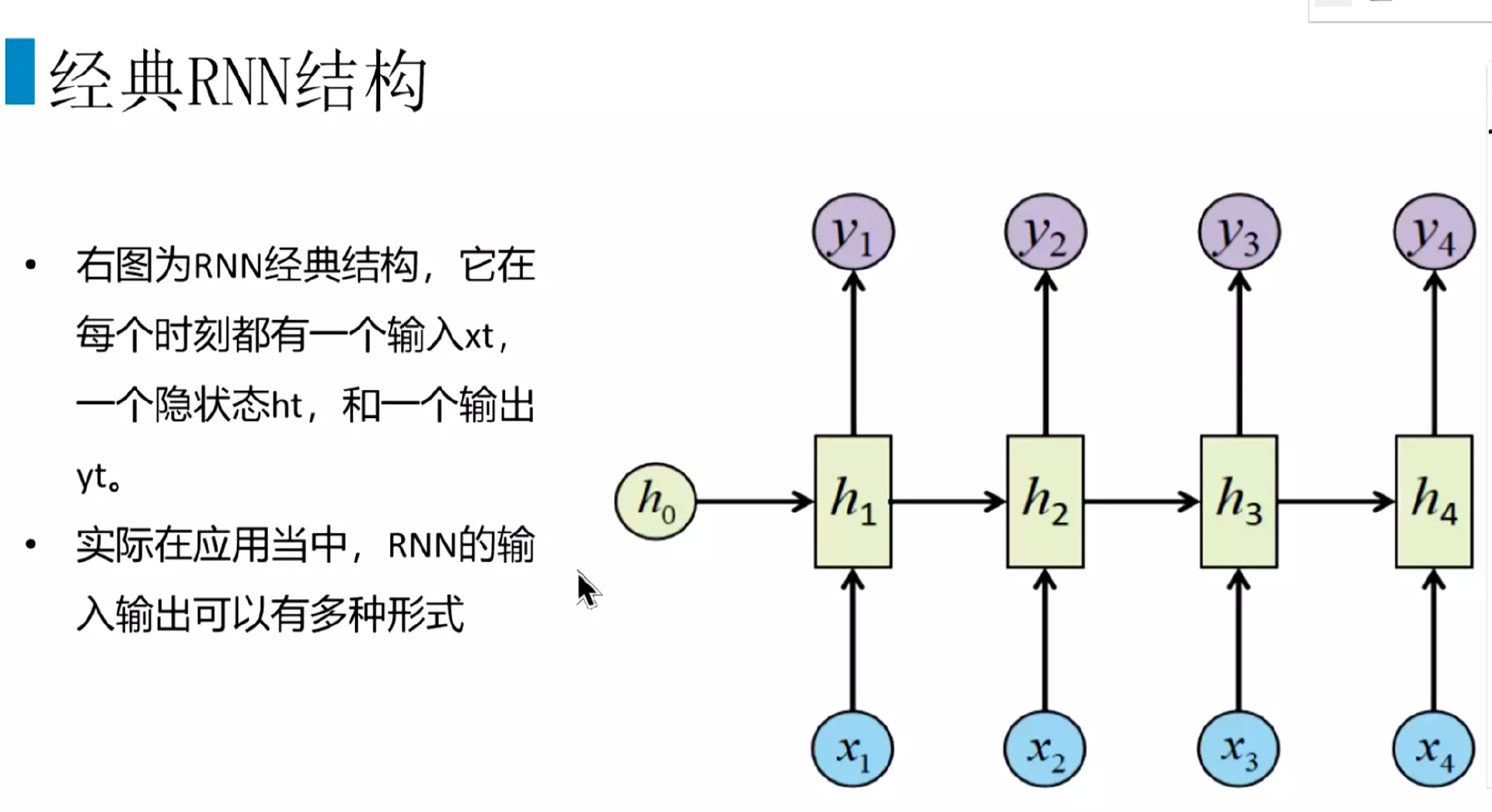
RNN模型、BPTT及梯度问题
![]()
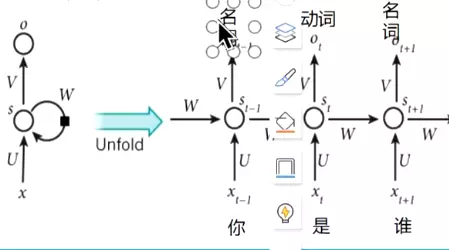
#为什么有了CNN还需要RNN?答:因为有些数据有顺序特征,CNN没有办法训练;前一时刻的输出对后一时刻的输出也有影响,例如词性关系,前一个词名词,后一个词是动词。
#语言识别、视频分类也需要用RNN![]()
#应用场景:文本生成, 后面有了更强的模型去替代。![]()
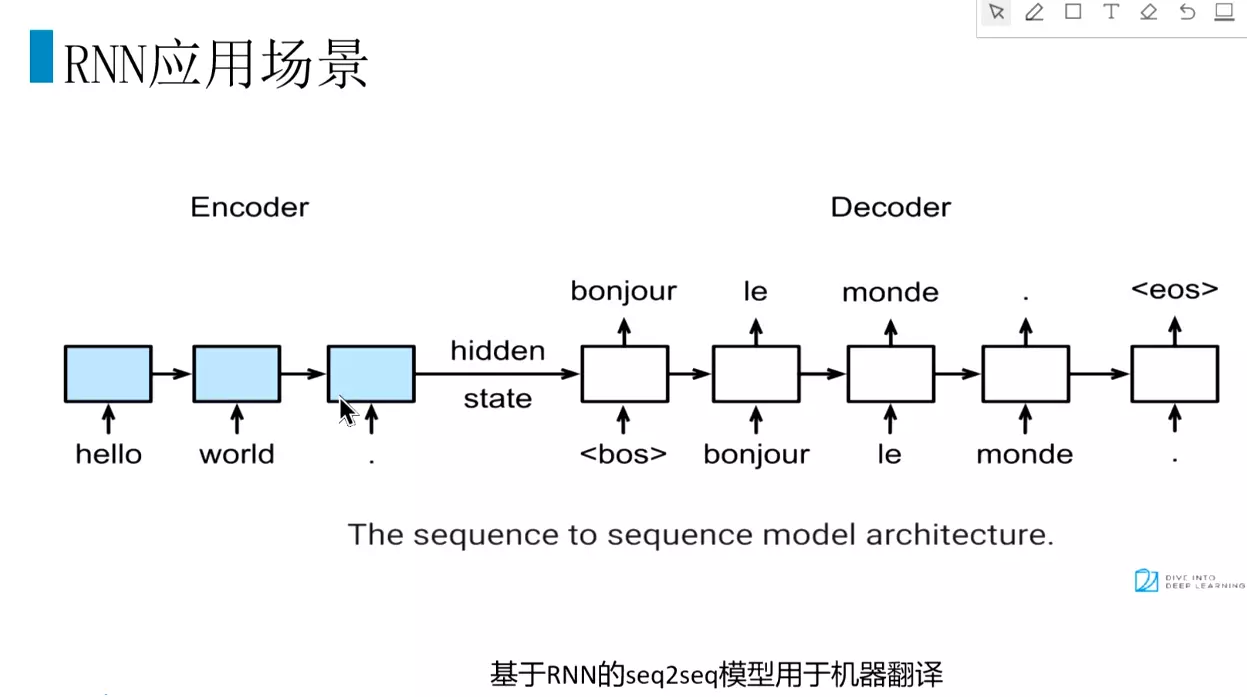
#RNN应用:机器翻译,seq2seq,读sikun2sikun![]() ,就是先把词分开,然后再组合。在机器翻译领域把错误率减少了?%。
,就是先把词分开,然后再组合。在机器翻译领域把错误率减少了?%。
![]()
#应用:词性标注、命名实体识别,用lstm+crf处理,现在用bert处理的更好
![]()
#命名实体识别![]()
#应用:做分类。大部分场景深度学习的效果比较好。#输入向量化,传入RNN结构。
![]()
#应用:语音识别,错误率减少30%
![]()
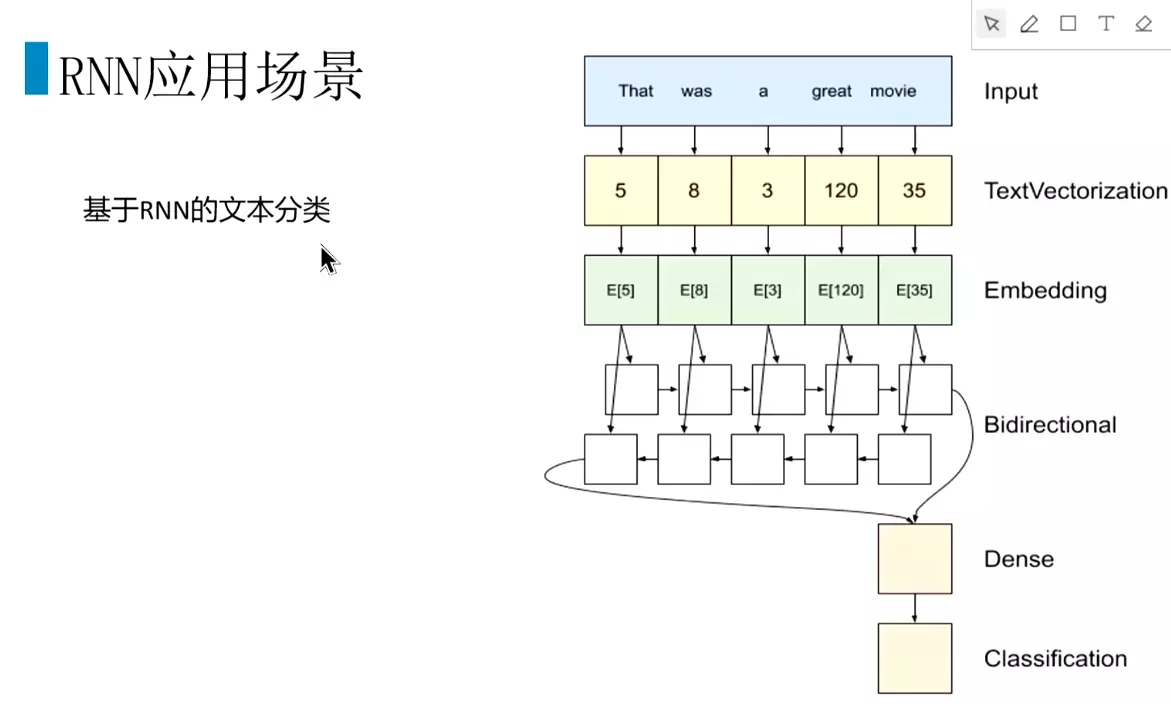
#回顾神经网络结构
![]()
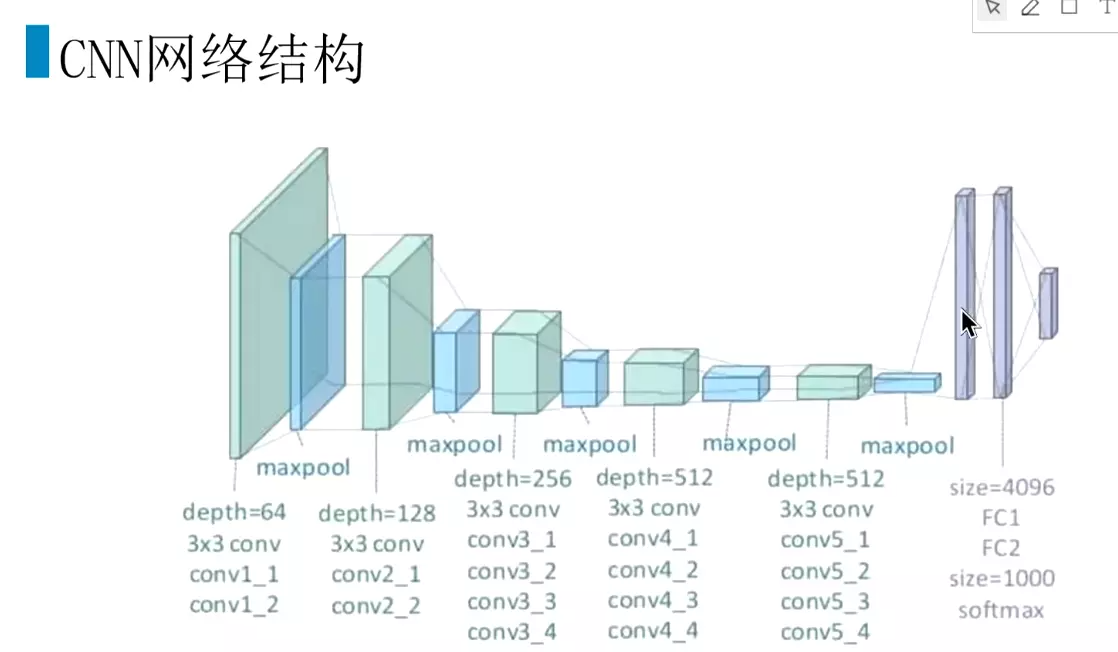
#CNN结构
![]()
![]()
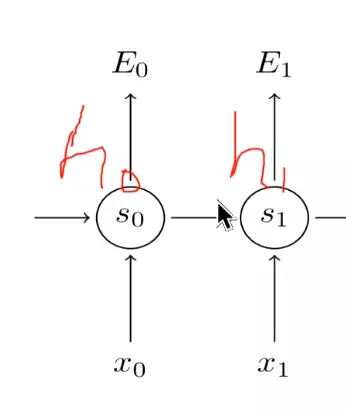
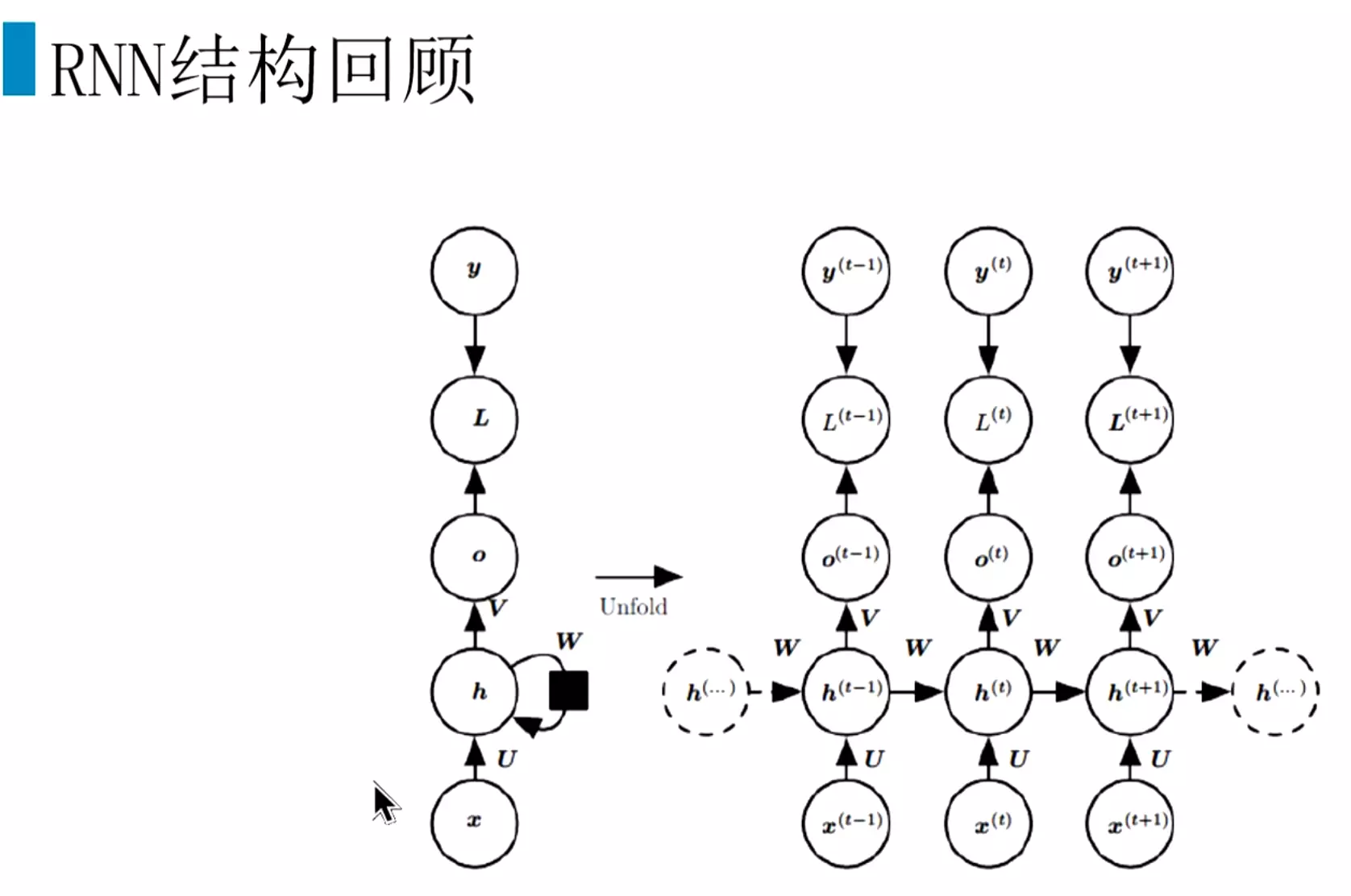
#RNN结构:分为很多时间步,每个时间步有很多隐层。输入是x,参数是u,隐层是s,输出权重是v。ot接一个softmax给出一个预测值。
![]()
#正向传播![]()
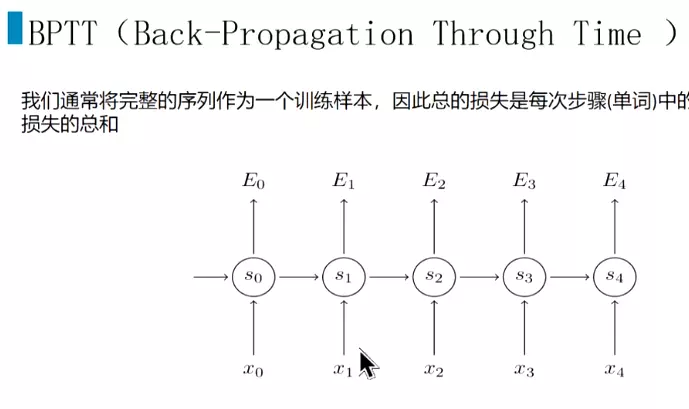
#交叉熵作为损失函数
![]()
#损失加在一起,计算梯度![]()
![]()
![]()
![]()
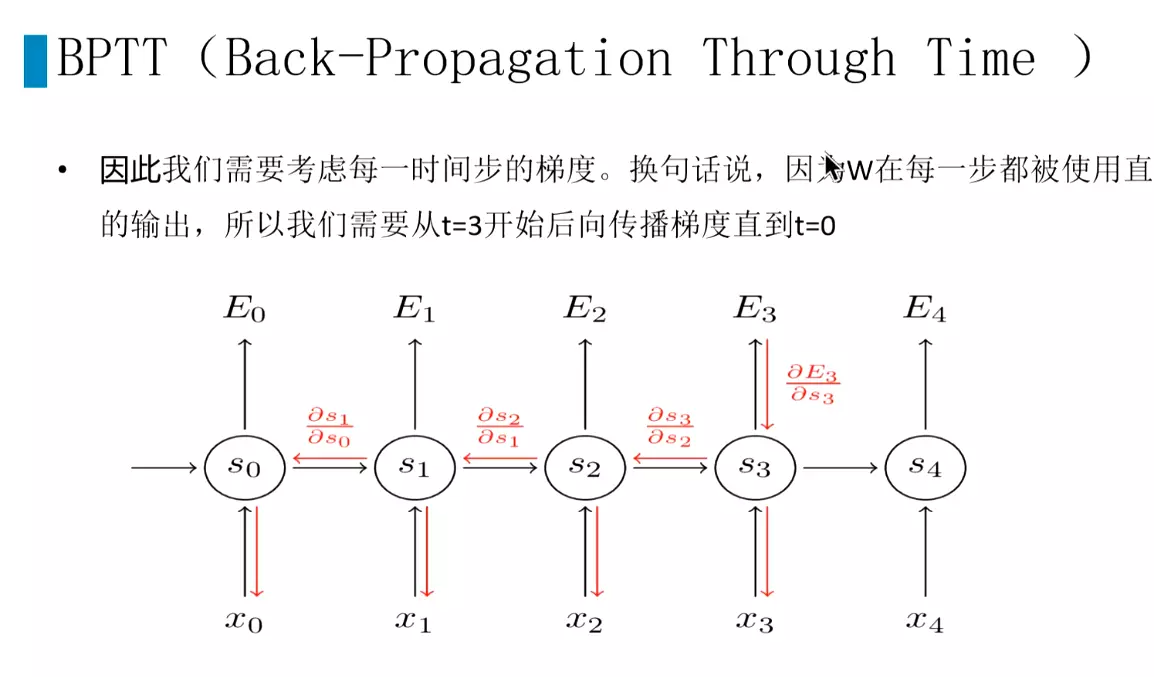
#因此计算s3的梯度需要一直传到s0,计算梯度,导致梯度爆炸和梯度消失。![]()
#RNN的梯度爆炸和梯度消失特别明显,几乎无法用在长文本中。
![]()
![]()
#RNN代码实例:
![]()
![]()
#先加载,词向量,这个是向量单独存储,没有词。注意:这里是300维,是word2vec训练出来的。![]()
#加载词表。每一个词给了一个id。查找词向量是会根据id在embedding里面查。
![]()
![]() #构建一个RNN,Rnn的层数,
#构建一个RNN,Rnn的层数,![]() ,这里用1层,也可以用两层,后面就改为2。
,这里用1层,也可以用两层,后面就改为2。
![]()
#查看输出![]()
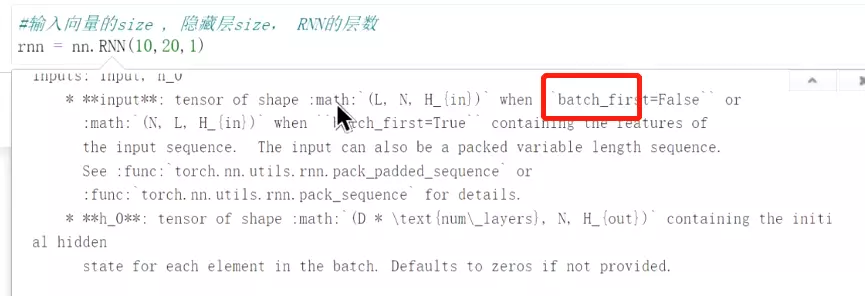
#举例说明RNN的数据结构:第一位是输入向量的size,第二位是隐藏层数,第三位是RNN的层数。![]()
#构建一个输入,5是batchsize,3是序列长,10是向量![]()
#看输入
![]()
看第一个数值![]() ,3是指这个序列有三个,比如输入是‘你是谁’
,3是指这个序列有三个,比如输入是‘你是谁’![]()
#这里有三个向量,相当于每一个字的向量。这里距离是每个字向量是10维。但是上面embedding的维度是300维。
问:![]() ,答:需要把训练的数据进行embedding,类似文本分类,先用word2vec或seq2seq把文本变成向量,再去传给分类器里,可以把RNN理解成分类器。
,答:需要把训练的数据进行embedding,类似文本分类,先用word2vec或seq2seq把文本变成向量,再去传给分类器里,可以把RNN理解成分类器。
![]()
#隐藏层构建
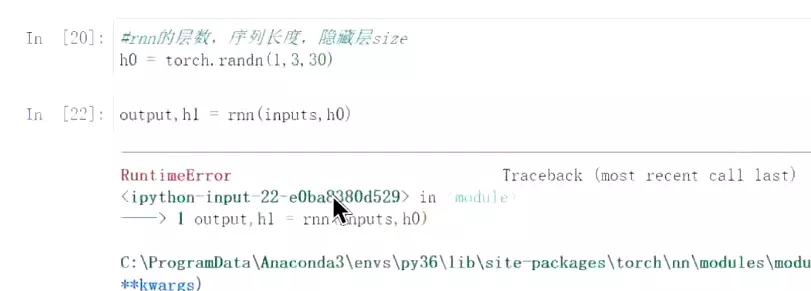
![]()
#讲input和h0输入到RNN里,报错。
![]() #修改为20
#修改为20
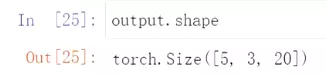
![]() #查看output的size。5对应batchsize,3对应序列长度,20对应隐藏层大小,因为隐藏层是20,
#查看output的size。5对应batchsize,3对应序列长度,20对应隐藏层大小,因为隐藏层是20,![]()
#h1 size可知,隐藏层大小不变。而输入经过隐藏层之后,变成【5,3,20】大小。![]() #上面的h0,h1相当于隐层。
#上面的h0,h1相当于隐层。
问:RNN传参过程中,隐藏层的大小始终保持不变吗?答:对
![]()
#下面是文本分类。首先讲embedding转换成torch的tensor格式,用32位浮点型
#output_path = './model/LSTM' #训练好的结果保存路径
embedding_len 的维度是300;
padding_len就是句子的最大的长度,超过这个长度就截断;不超过就用特殊字符padding.设置成32。因为![]() 就像例子中的输入是3个字,这个长度需要固定住,不能变来变去。
就像例子中的输入是3个字,这个长度需要固定住,不能变来变去。
batch_size设置成32
num_epochs = 5因为电脑不一定跑得动
学习率lr设为0.001,小了学不动
hidden隐藏层大小设为128
num_layers设为2
随机失活设为0.5
class_num 分类的类别设为2,就是上面文本分类![]() #重新展示这个参数,bidirection表示是否是双向RNN
#重新展示这个参数,bidirection表示是否是双向RNN![]() 就是反向也传
就是反向也传
weigh_decay反写率?给0
注意:Rnn不太好并行。因为这一时刻需要用到上一时刻计算结果。也就是说GPU不如CPU好使。所以RNN任务训练天然比较慢。
![]()
![]()
![]()
![]() #导进要用的包,Dataloader加载数据,再喂到模型里面去。
#导进要用的包,Dataloader加载数据,再喂到模型里面去。
![]()
#读取数据
![]()
![]() #上面给错了;再拼接数据
#上面给错了;再拼接数据
![]()
#针对data数据处理数据。![]() 把label变成list;tokens用于接收向量。
把label变成list;tokens用于接收向量。
![]()
#先看一下词表的keys,里面有两个特殊的字,一个是'UNK'就是列表中没有的字,一个是'PAD'用于填充。
![]()
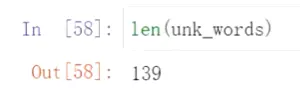
![]() #看一下没有在wordtoid词表中的词,这些词就用‘UNK’替代
#看一下没有在wordtoid词表中的词,这些词就用‘UNK’替代![]()
![]() #如果在词列表中没有的词用unk对应的value填充;
#如果在词列表中没有的词用unk对应的value填充;
![]() #如果不够长度,用pad的value填充。
#如果不够长度,用pad的value填充。
#继续处理数据
![]() #get用法,没有取到的,给一个新值,如200
#get用法,没有取到的,给一个新值,如200
![]()
#先试一下数据加载
![]()
#这是第一句话,就是一个个的index![]() 就是把第一句话所有的字找到对应的index。
就是把第一句话所有的字找到对应的index。![]()
![]() 例如‘强’、‘力’
例如‘强’、‘力’
##转化成tensor:![]()
![]()
#放到gpu或者cpu里
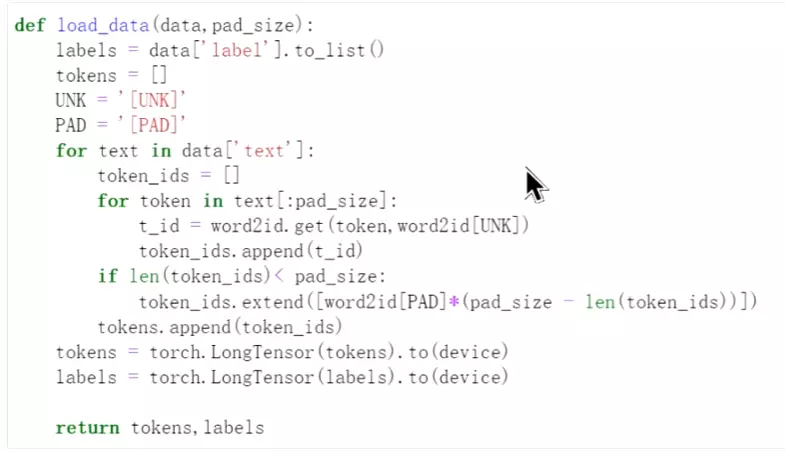
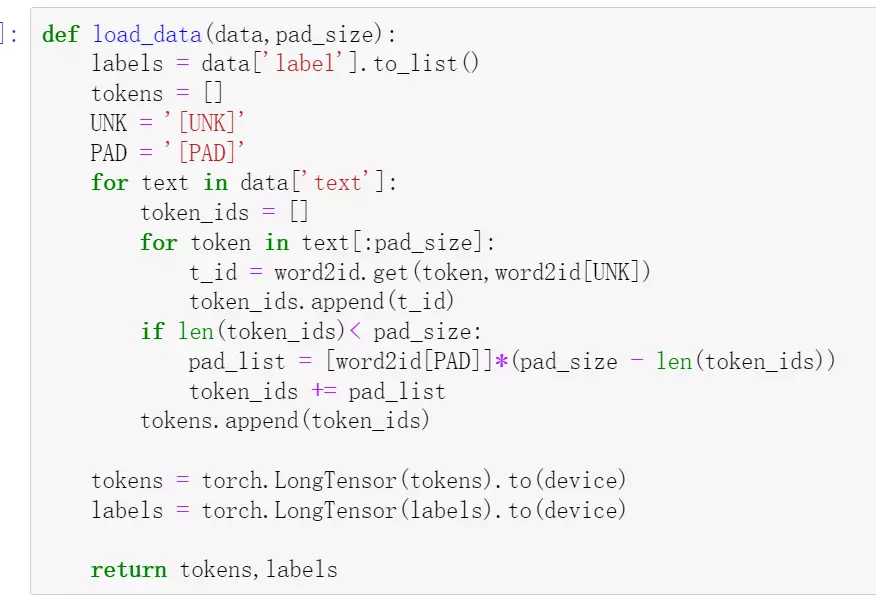
#检查,出错了,重新修改![]()
#可能是extend错了,可以改成extend([word2id[PAD]]*(pad_size - len(token_ids))
![]()
#或者改成这个
![]()
#加载数据
![]()
#标准化的加载数据方法:放在NewsDataset中,加载时直接
![]()
#训练
#hidden_size = hidden隐藏层数
#num_layers = num_layers RNN的层数
#bidirectional = True用一个双向RNN
#nn.Linear(hidden*2, class_num) 给一个全连接层,由于是双向RNN输出维度有两个,所以隐层是128*2,输出是2,就是类别数量
#self.embedding = nn.Embedding.from_pretrained(embedding_pretrained,freeze=False)把刚才加载的embedding_pretrained加载进来,就是去这里embedding_pretrained找,例如![]() 就是去embedding_pretrained找到第153向量、98的向量作为输入向量。freeze=False是不冻结参数,跟着训练embedding向量还会继续调整。
就是去embedding_pretrained找到第153向量、98的向量作为输入向量。freeze=False是不冻结参数,跟着训练embedding向量还会继续调整。
#x,_ = self.rnn(embedding) _是隐藏层不要
#x = self.fc(x[:,-1,:]) 是取最后一个时刻输出的向量,所以是-1。例如输出是![]() “你 是 谁”,我们就要最后一个时间步长的向量,就是‘谁’
“你 是 谁”,我们就要最后一个时间步长的向量,就是‘谁’
![]()
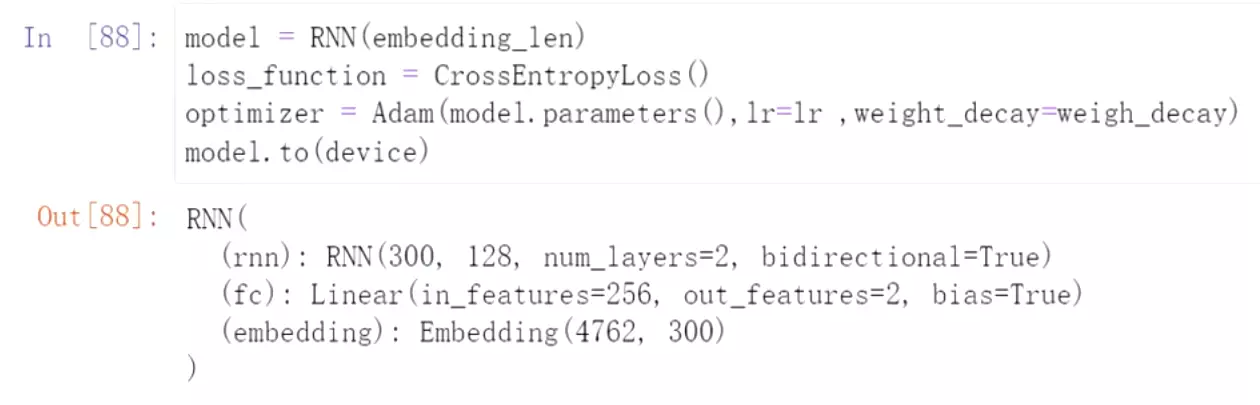
#先实例化,看一下模型参数
![]()
#添加一个优化器,重新训练,weight_decay=weigh_decay是给一个衰减的意思
![]()
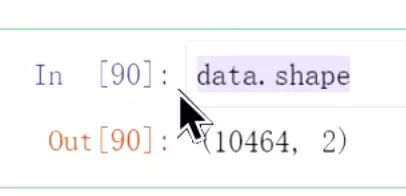
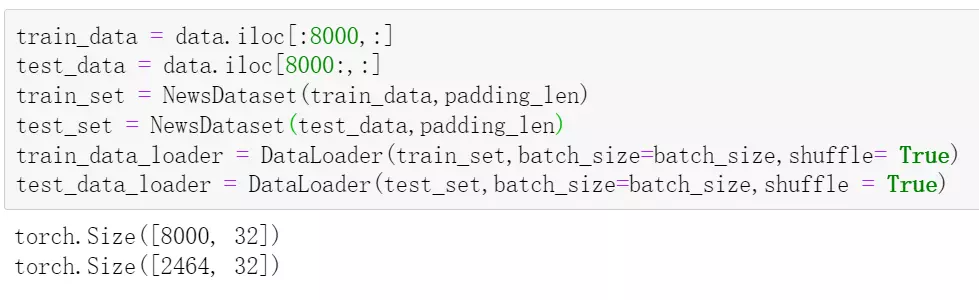
#先看一下数据,有1万多条,分两千多条出来测试![]()
#train_data_loader = DataLoader(train_set,batch_size=batch_size,shuffle= True)每次送进来batch_size为32个数据,就是32个句子;shuffle= True打乱操作
#加载数据,train和test加载进来,就可以训练了
![]()
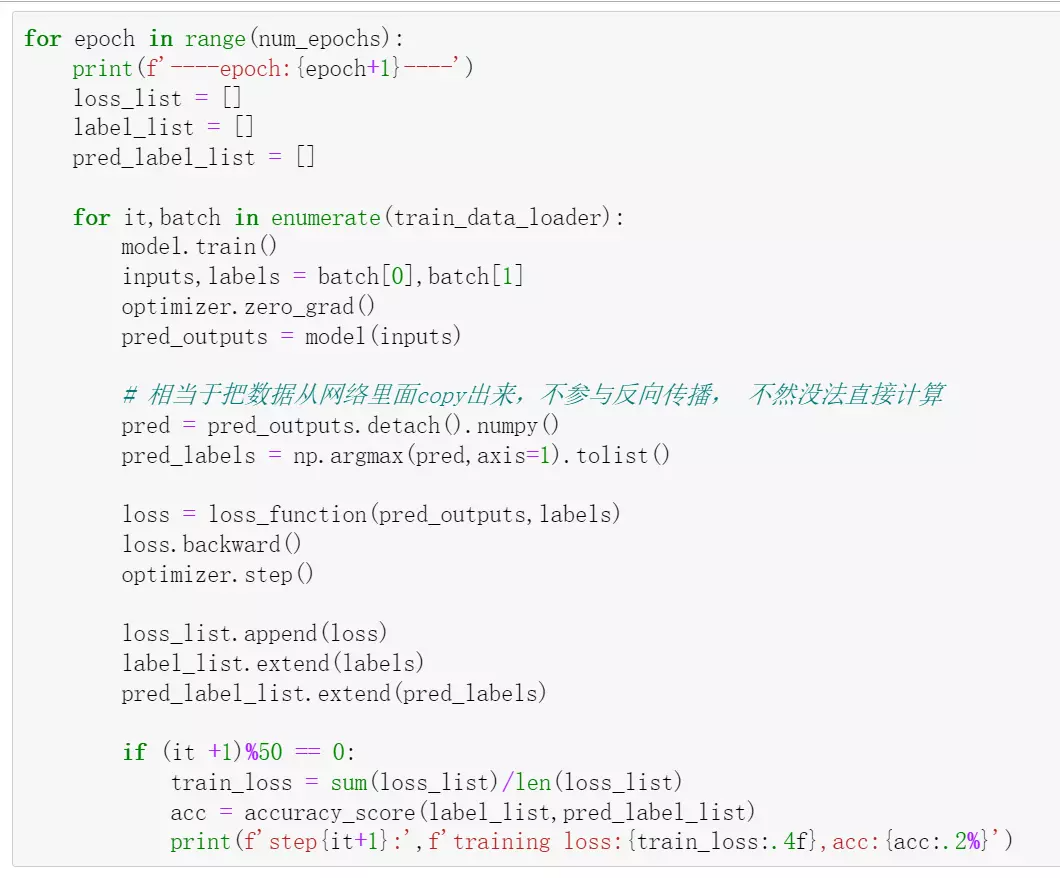
# loss_list = [] 存平均损失
label_list = [] 存样本label,用于计算准确率召回率等
pred_label_list = [] 用于存预测的labels
#for it,batch in enumerate(train_data_loader): 迭代数据
#model.train()调成train模式
#optimizer.zero_grad()每一个batch的梯度设为0,就是每一个batch之间的batch没有关系
# pred = pred_outputs.detach().numpy() 相当于把数据从网络里面copy出来,不参与反向传播, 不然没法直接计算。转化成numpy格式
#pred_labels = np.argmax(pred,axis=1).tolist() 在1的维度上求argmax。“np.argmax是用于取得数组中每一行或者每一列的的最大值。常用于机器学习中获取分类结果、计算精确度等”
#注:pred和pred_labels是为了copy数据出来,自己计算损失。
#loss = loss_function(pred_outputs,labels)让模型自己计算损失
#loss.backward()反向传播
#optimizer.step(),用优化器去学习
#loss_list.append(loss)把损失放到列表中
#label_list.extend(labels)
#pred_label_list.extend(pred_labels)预测的label放到列表
#train_loss = sum(loss_list)/len(loss_list)打印出来,把列表中所有的损失求平均
#f'training loss:{train_loss:.4f}显示后面4位小数;,acc:{acc:.2%}准确率百分比
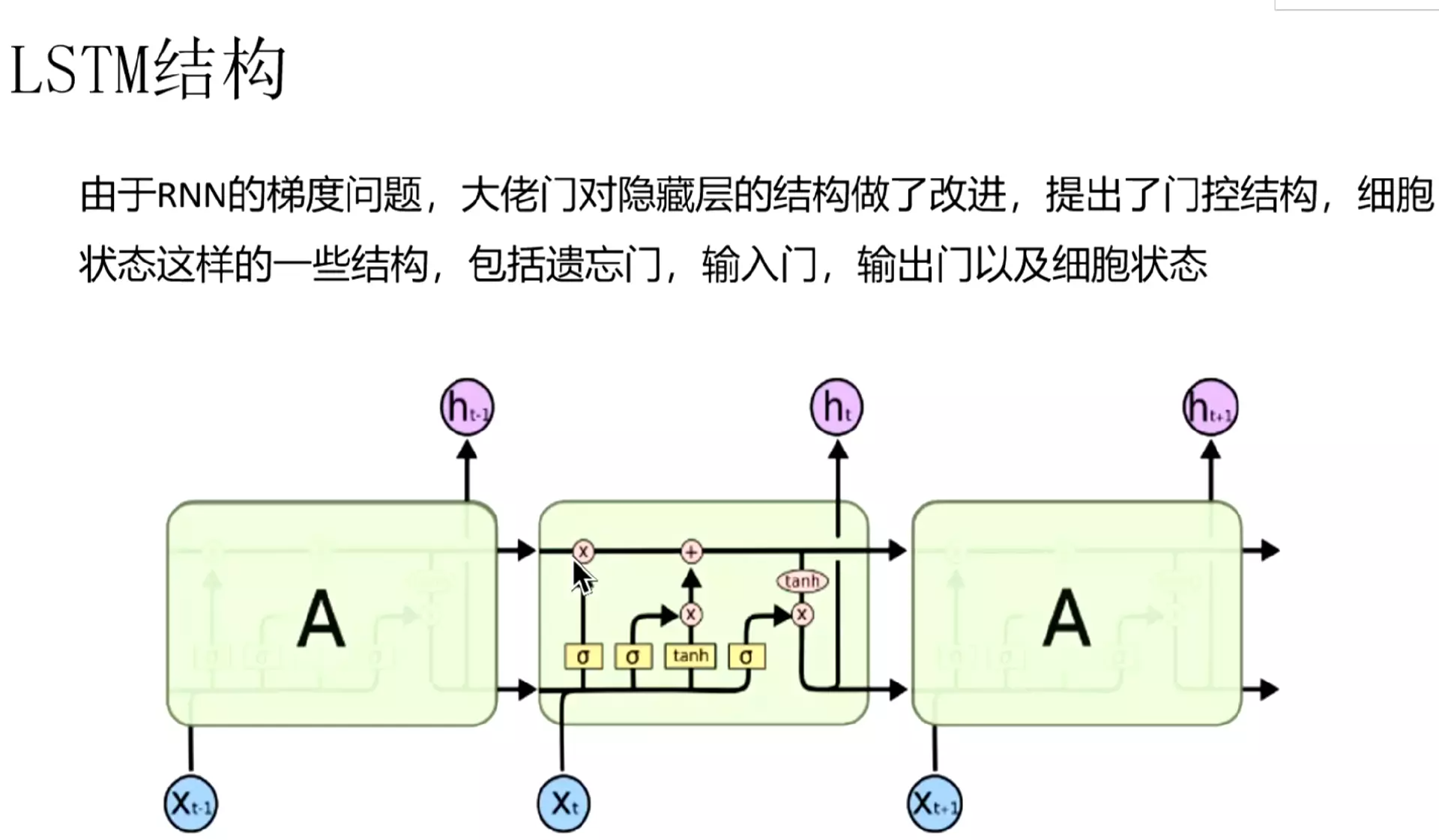
LSTM及GRU
![]()
#LSTM和RNN结果差不多,上面是RNN结构:![]() 每个时间步有一个输入;
每个时间步有一个输入;![]() 有一个隐藏层;
有一个隐藏层;![]() 输出层;
输出层;![]() 这里计算损失
这里计算损失
![]()
#把损失和输出去掉,它的结构如上,前一时刻的输出和这一时刻的输入,一起输入对tanh函数中。h是隐层状态![]()
#LSTM有一些门结构:包括遗忘门、输入门、输出门以及细胞状态
![]()
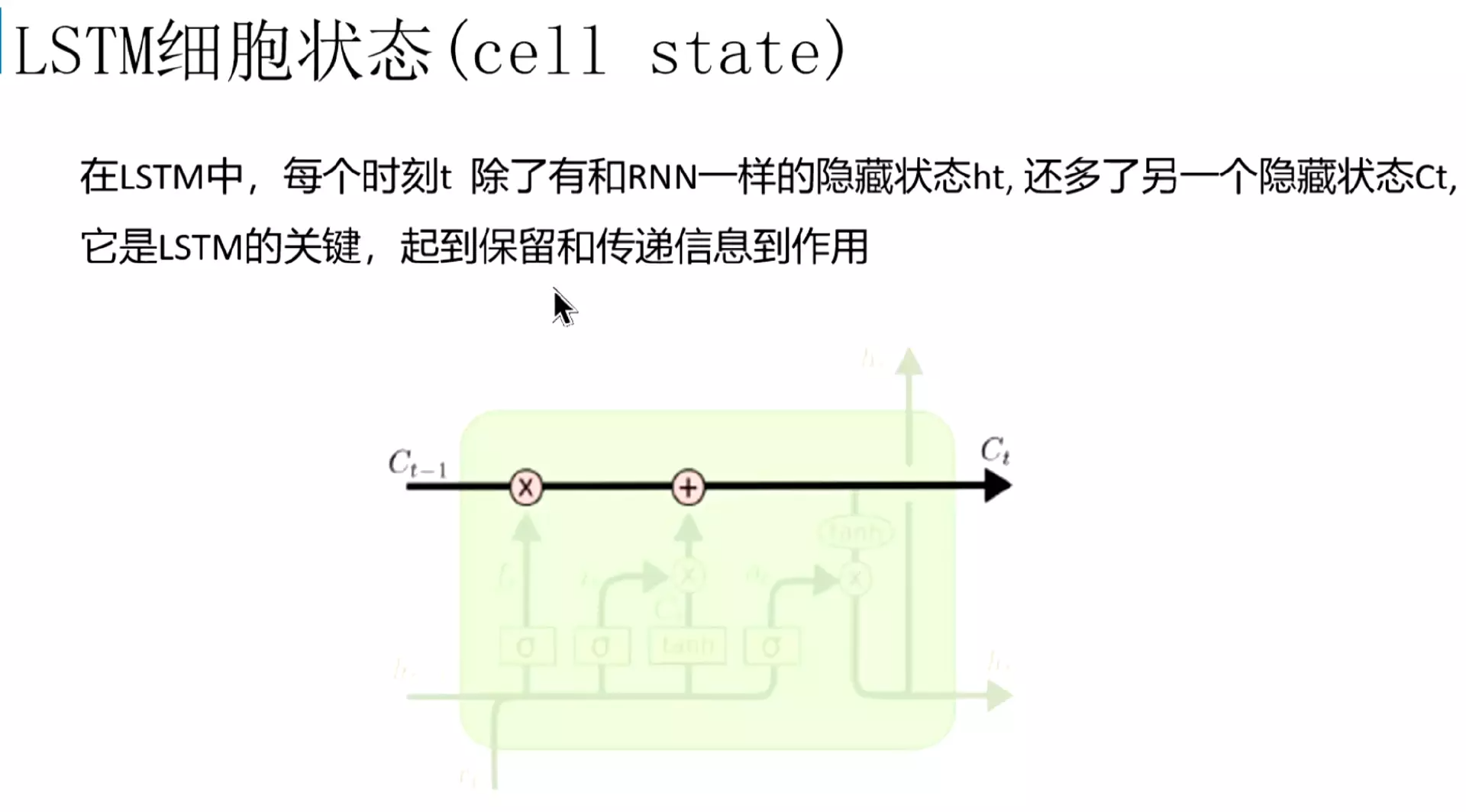
#细胞状态是关键,起到了保留和传递信息的作用
![]()
#遗忘门,是否遗忘上一层细胞状态;把上一层的隐层状态和当前的输入,传到sigmoid里面,就是映射对0~1的取值空间里面;如果结果和0接近,就把它遗忘掉,如果结果和1接近,这个信息就保留。![]()
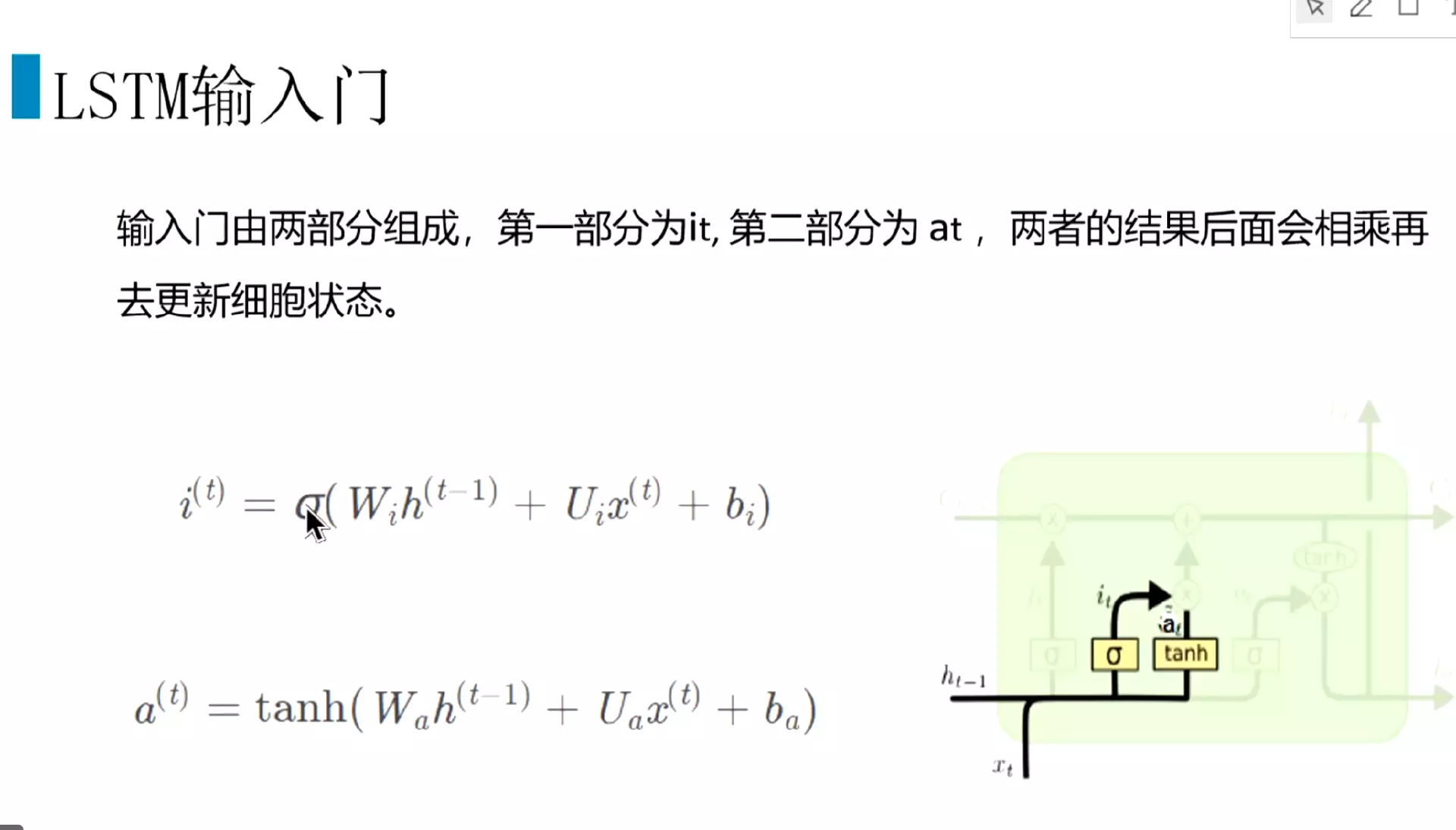
#输入门: 分两部分,第一部分是很遗忘门一样,得到i(t);a(t)是新的输入,把上一层的隐藏状态和这一层的输入通过tanh函数组合成一个新的输入。
![]()
#遗忘门和输入门得到后,就去更新细胞状态:上一时刻的细胞状态C(t-1)和当前遗忘门的输出f(t)进行点乘,由于遗忘门的输出都是一些0~1的值,跟上一时刻的细胞状态C(t-1)进行点乘,那么跟0点乘的信息就给它丢弃;跟1点乘的信息就给它保留。然后再把输入门得到的两个数值点乘。把两个点乘的结果相加更新到细胞中来,就得到当前时刻的细胞状态C(t)
![]()
#输出门,也和隐藏门一样,上一时刻的隐藏状态和输入一起放到sigmoid中来,得到o(t);然后再把当前细胞状态C(t)送进一个tanh,再和o(t)点乘,就得到了当前时刻隐藏状态h(t);
#这个h(t)就可以用来计算,跟RNN一样,加softmax做分类,也可以做回归
![]()
#首先是更新遗忘门的输出。![]() #然后是更新门两部分的输出。然后通过遗忘门和更新门把细胞状态进行更新。
#然后是更新门两部分的输出。然后通过遗忘门和更新门把细胞状态进行更新。![]()
#然后输出门通过计算得到输出。然后就可以计算当前时刻预测的舒输出,把隐藏状态过一个sigmoid和softmax
#上面就是整体的前向传播过程。![]()
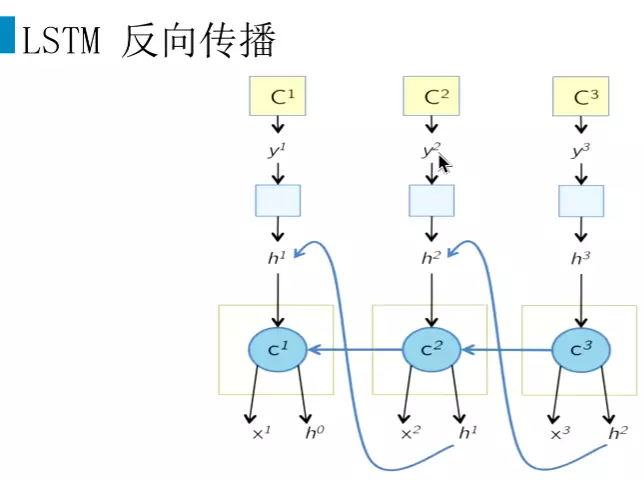
#在lstm中,我们有两个隐藏状态ht和Ct,损失为L,就要分别这两个隐藏状态求偏导。![]() #课后自己推导一下,这里省略了很多步骤。
#课后自己推导一下,这里省略了很多步骤。![]()
#我们可以认为H当前时刻只由当前时刻的输出来决定,不参与上一时刻或下一时刻的计算。![]()
![]()
![]()
#这样求梯度时把连乘变成了连加。这样就解决了梯度的问题。就使用当前时刻的Ct+1对上一个时刻的Ct求偏导的时候,得到遗忘门,![]()
可以通过设置遗忘门的参数来控制梯度。不至于消失的很快,或者让梯度平坦,梯度爆炸的问题在这个门不会产生。![]()
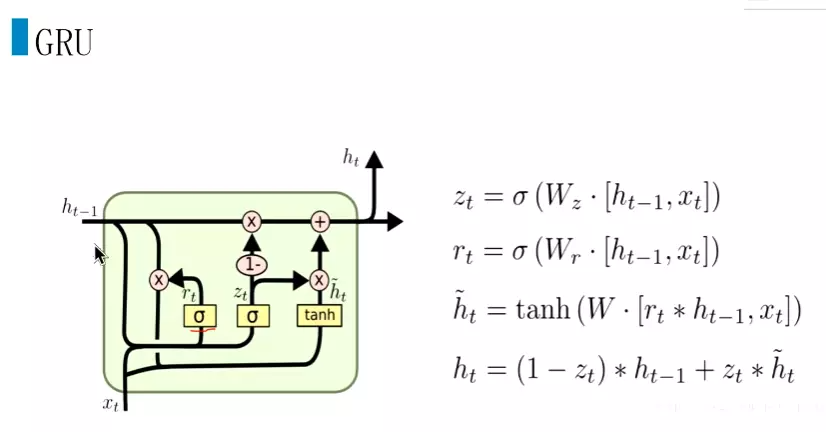
#除了LSTM外,还有一个经典的模型GRU。是一个效果很好的变体。比lstm结构更加简单。计算更加快。效果也比较好。在LSTM中有三个门,输入门、遗忘门和输出门。而在GRU中只有两个门,更新门zt和重置门rt。![]()
#这个rt也是跟一个sigmoid,同样把xt和ht-1输出到sigmoid中,再跟ht-1去进行一个点乘。就是控制前一时刻的隐藏层状态有多大程度更新到当前候选隐藏层状态。
#然后更新门会zt会先和前面计算的重置门和xt加起来再经过tanh函数的结果进行点乘,再1-更新门zt再和ht-1点乘。
#GRU和LSTM相比参数量更少一些。运行更快一些。在一些比较长的文本中会用GRU进行一个替代。当然lstm在长文本依赖的任务会表现得更好一些。
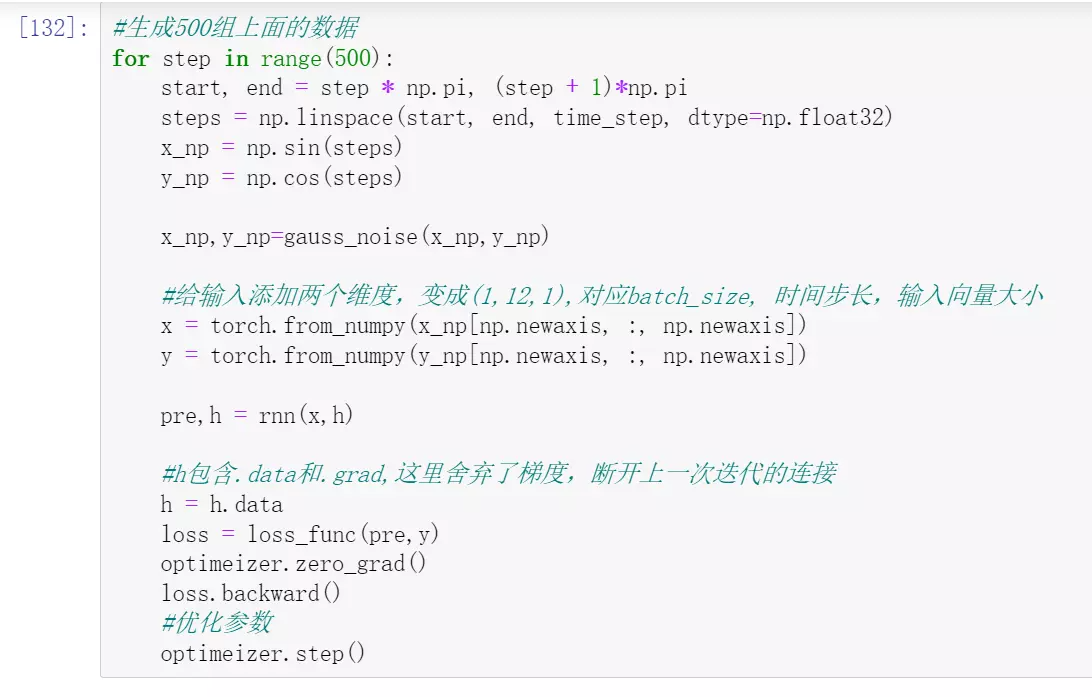
##代码实例:用长文本来预测长文本的任务。数据是自己构造,用生成的序列来预测另外一个序列。
![]()
#因为任务是一个回归类的问题,所以用均方误差损失
![]() #时间步长等于12。输入向量给1;
#时间步长等于12。输入向量给1;![]()
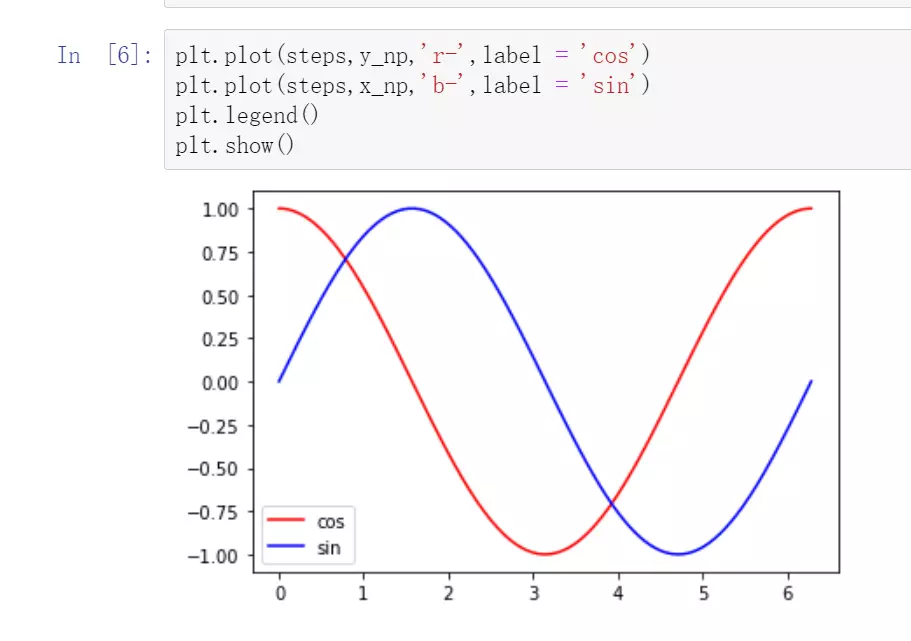
#构造一个输入x,sin,然后去预测y,cos
![]()
#数据样子,没有实际意义,只是演示
![]()
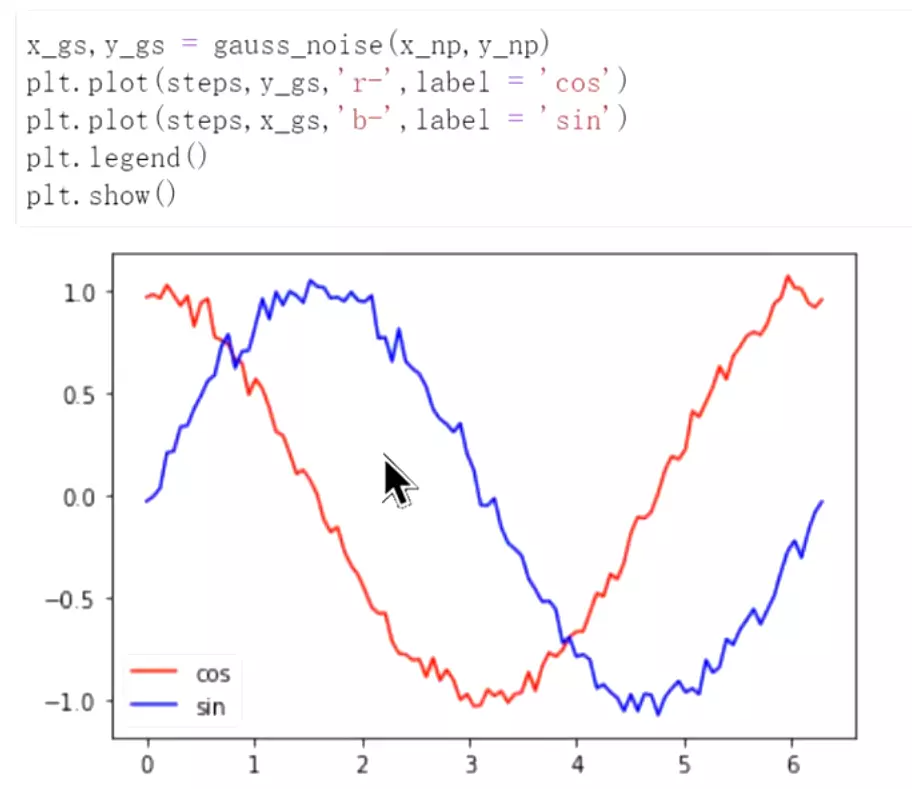
#增加一些噪声,否则太平滑了
![]()
![]() #加入噪音之后再去预测,先用RNN然后再用LSTM
#加入噪音之后再去预测,先用RNN然后再用LSTM
#input_size = input_size,前面设置过,是1
#batch_first = True # 表示输入形状为[batch_size,time_step, featrue_size]featrue_size是向量的大小,就是input_size=1
#self.out = nn.Linear(32,1)输出是1,就是把隐藏层32维度映射为1
#o,h = self.rnn(x,h)输出和隐藏层都拿到
#outs = []输出建好列表,储存输出
![]()
![]()
![]()
![]()
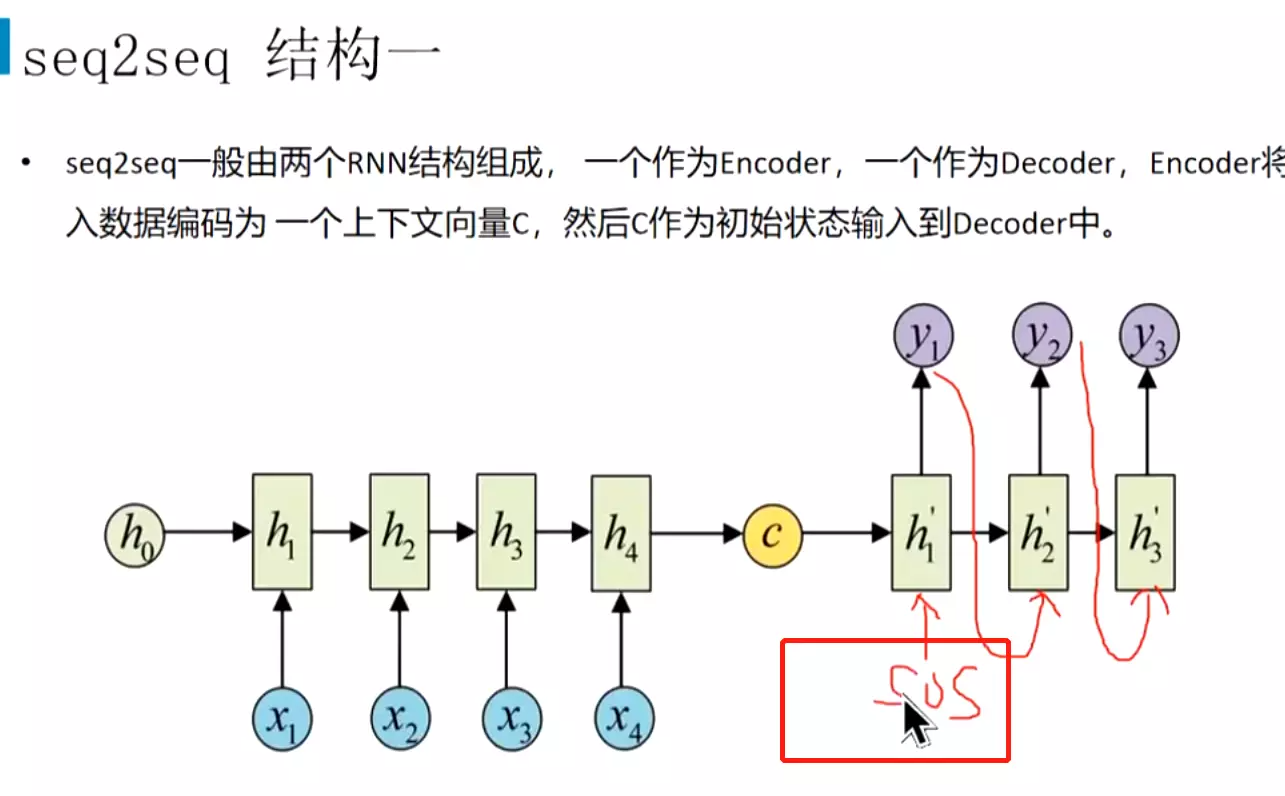
seq2seq及attention机制
![]()
#seq2seq是很经典的模型,里面提出的注意力机制。
![]()
#每一个时刻有一个数据、隐藏状态、输出
![]()
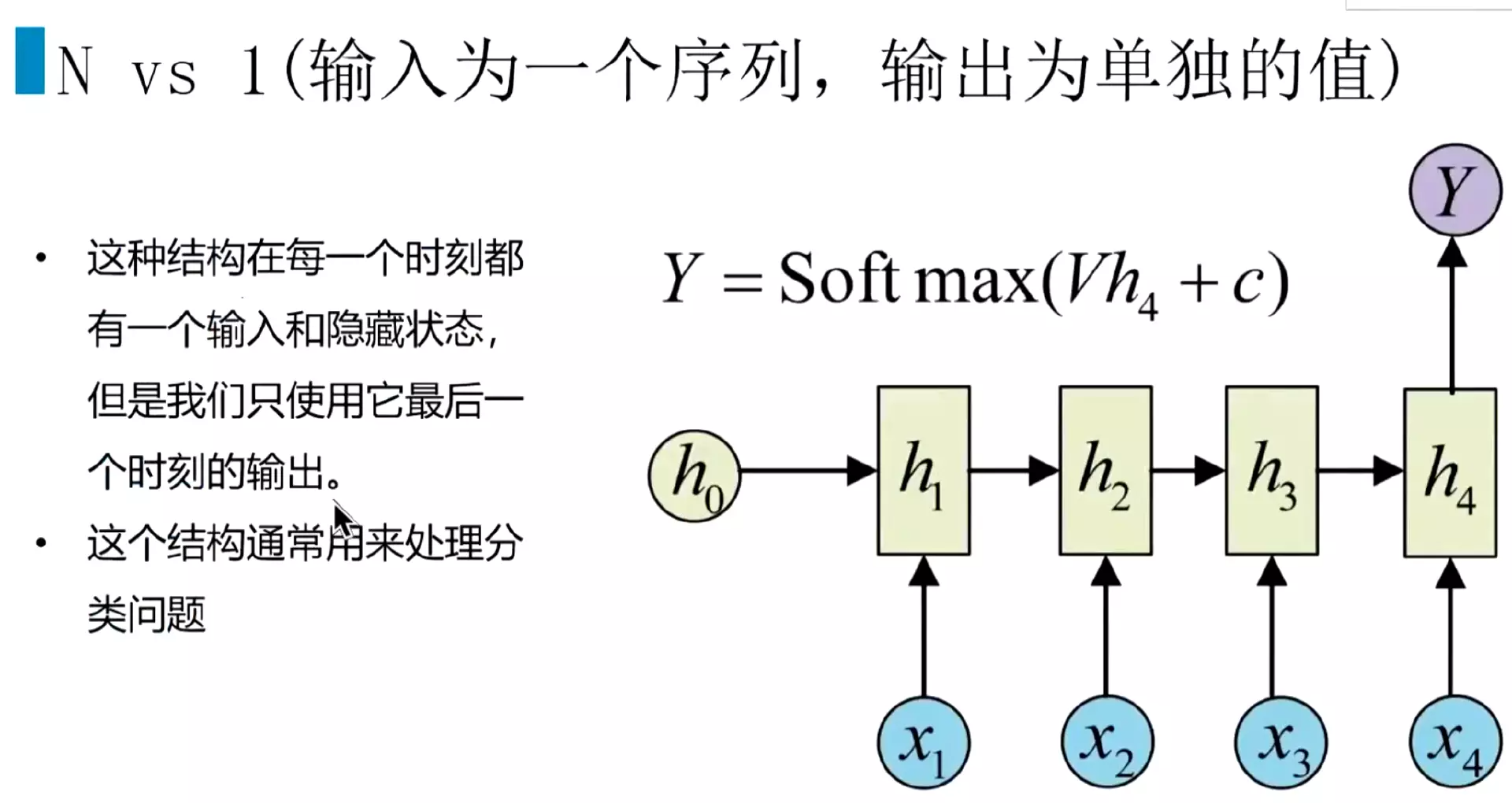
#N vs 1结构:文本分类就是前面的输出不要,只拿最后一个输出作为文本分类
![]()
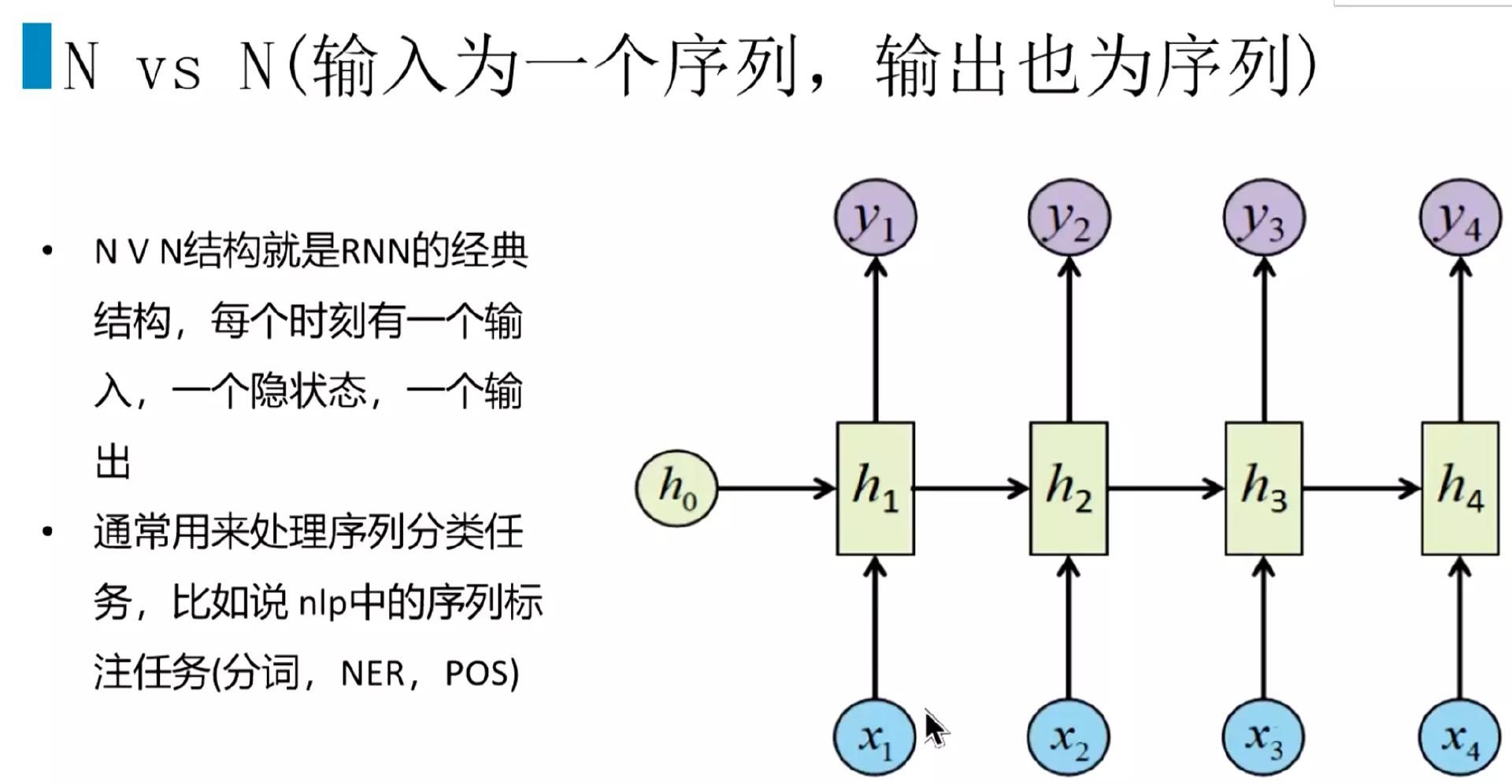
#n v n结构:分词、序列标注
![]()
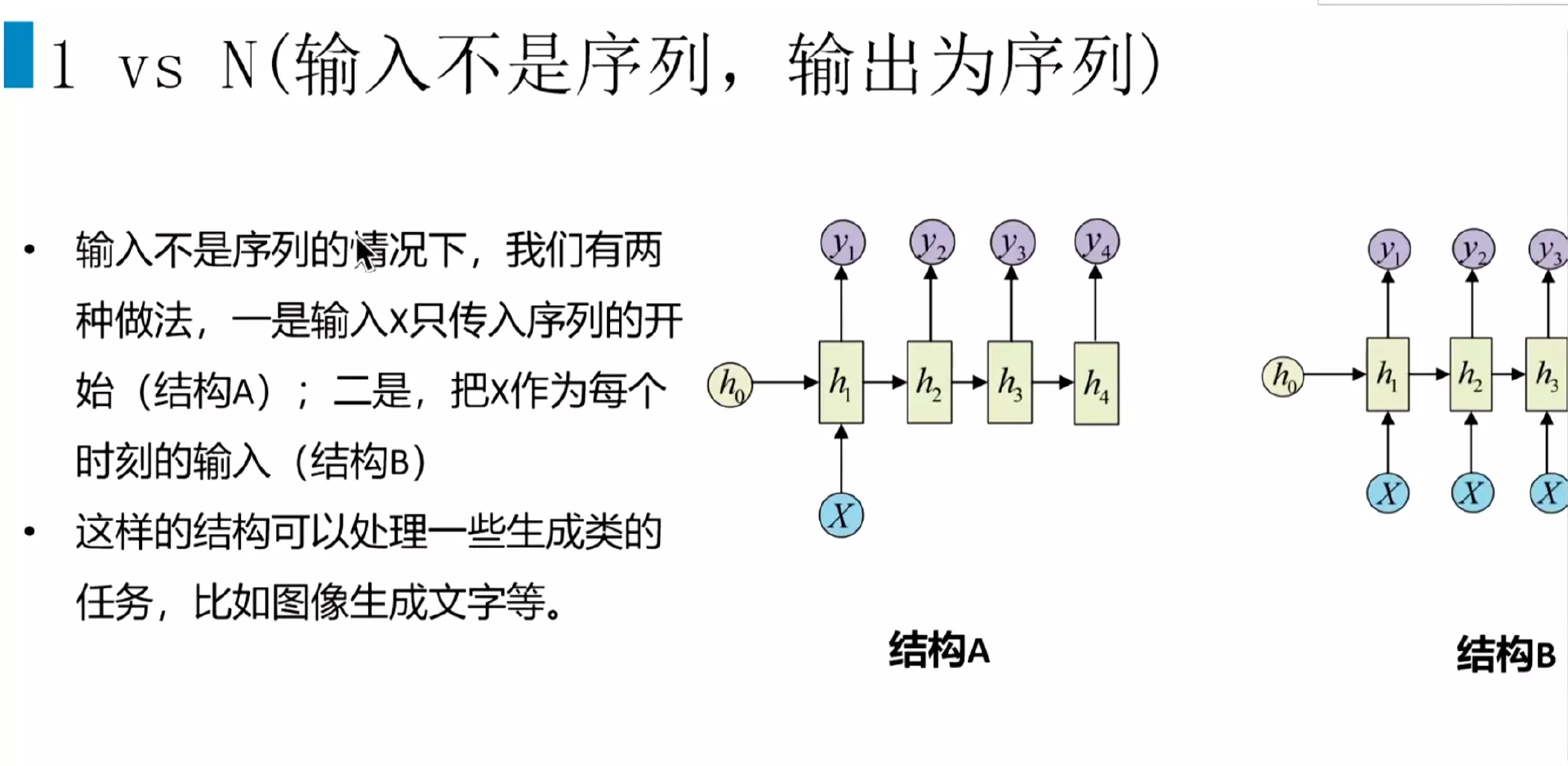
#1 v N结构:图像生成,生成类
![]()
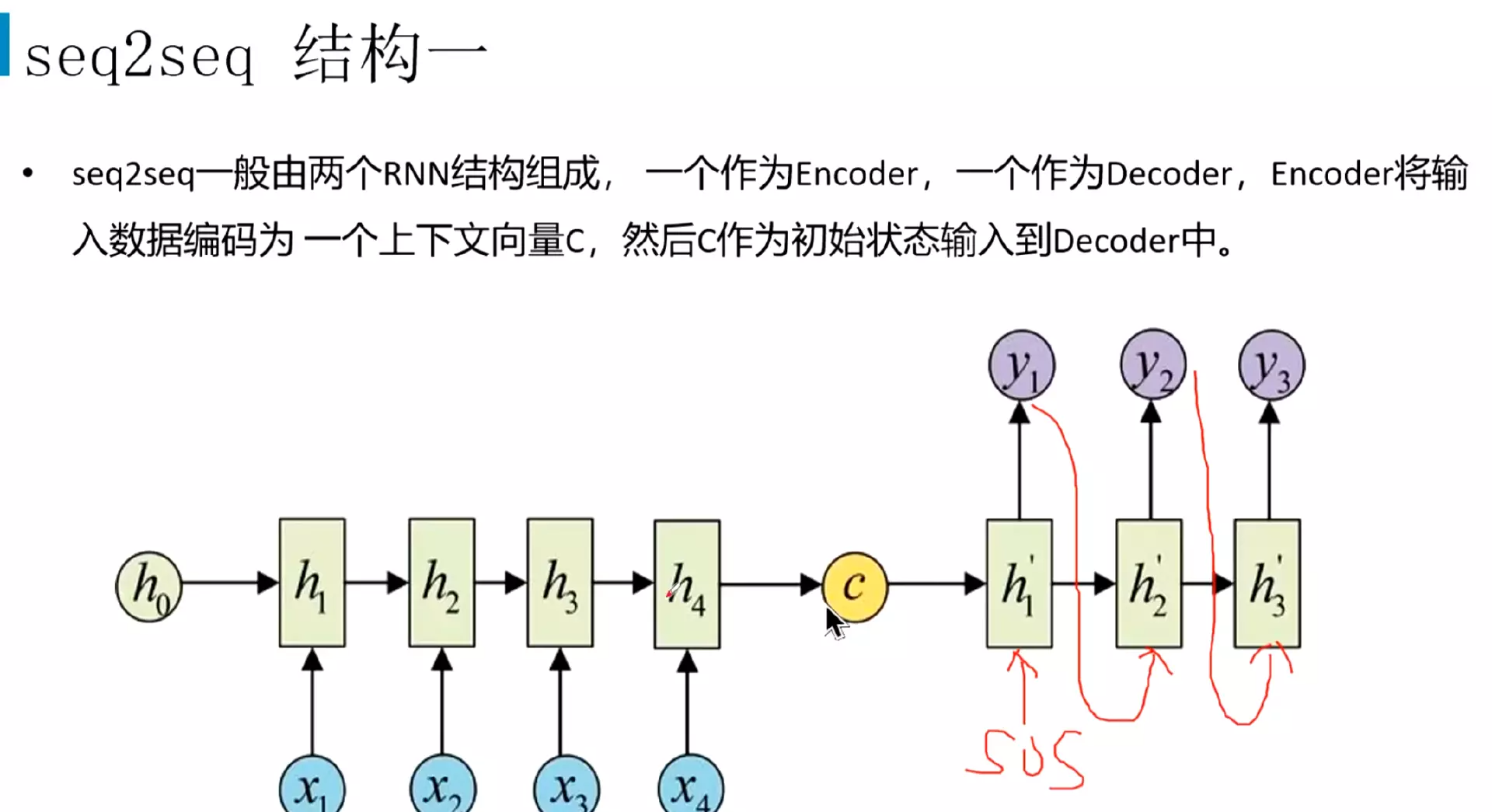
#NvM就是输入和输出不一样长度:seq2seq,机器翻译、文本摘要、阅读理解、语音识别![]()
#由两个RNN组成,也可以是LSTM或GRU;左边叫encoder编码器,右边叫decoder解码器
#编译成语义向量c![]()
![]()
![]()
#例如RNN的结构,靠前的文本的信息会有损失,靠后的文本的信息会多一些;不同位置的单词贡献是一样的,这不符合语言学规律
![]()
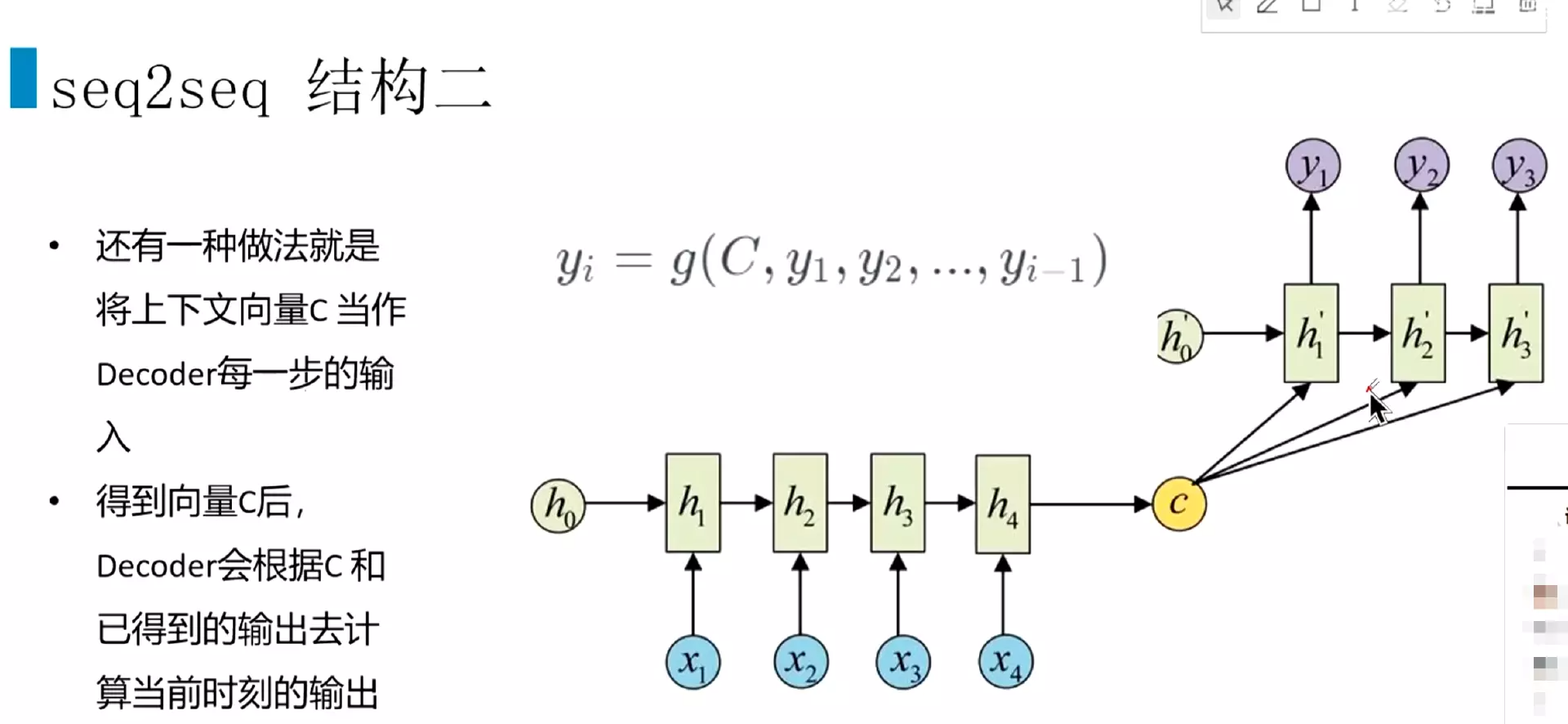
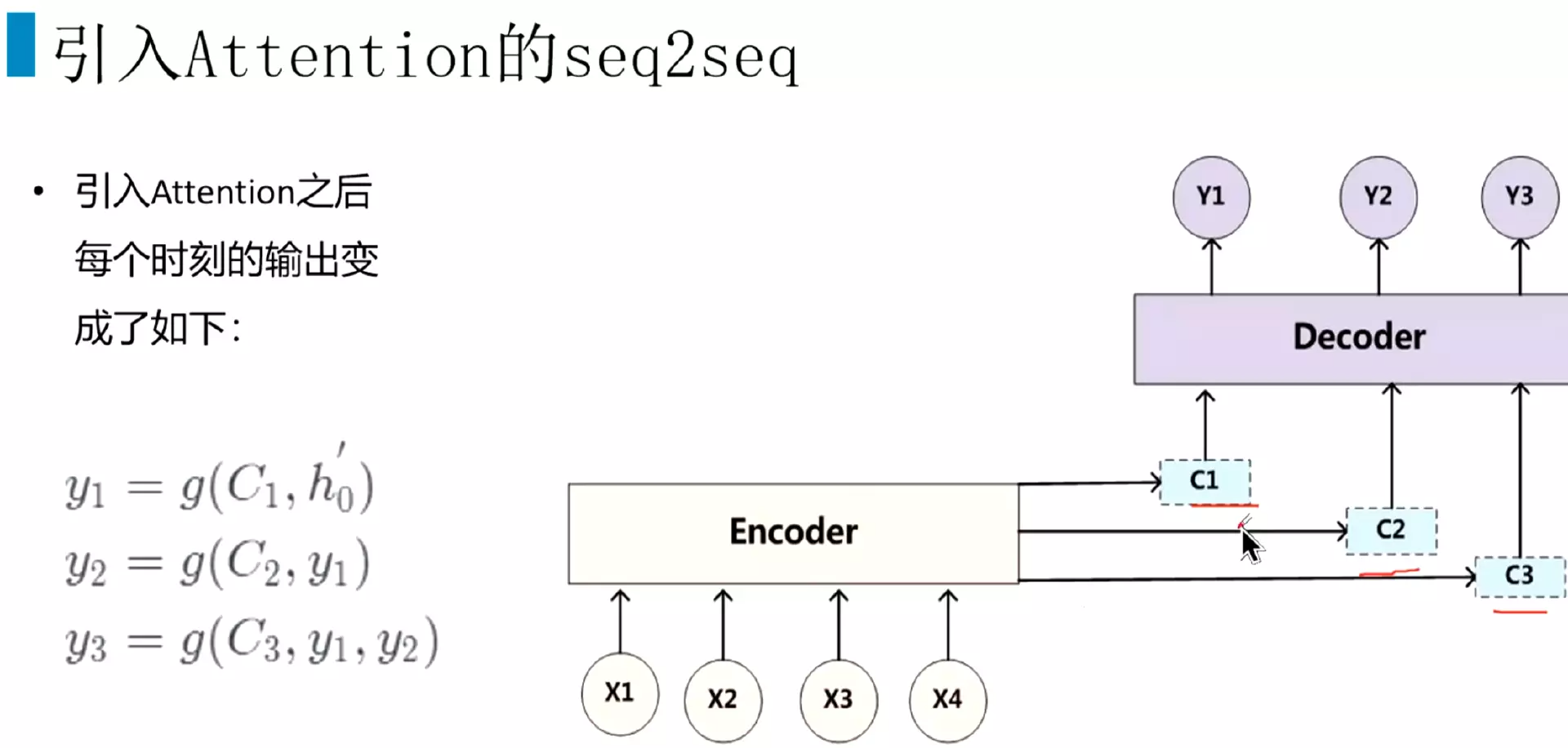
#注意y1、y2、y3里面都有C,C对每一时刻都是一样的。这样就导致上面两个问题。每个单词的语言路线是一样的,不能很好的表达。所以引入attention机制,特点是不在将整个输入序列编码为固定长度的中间语义向量,每一个时刻都有不同的![]()
#attention机制的核心思想:每一个时刻计算一个语义向量![]()
![]()
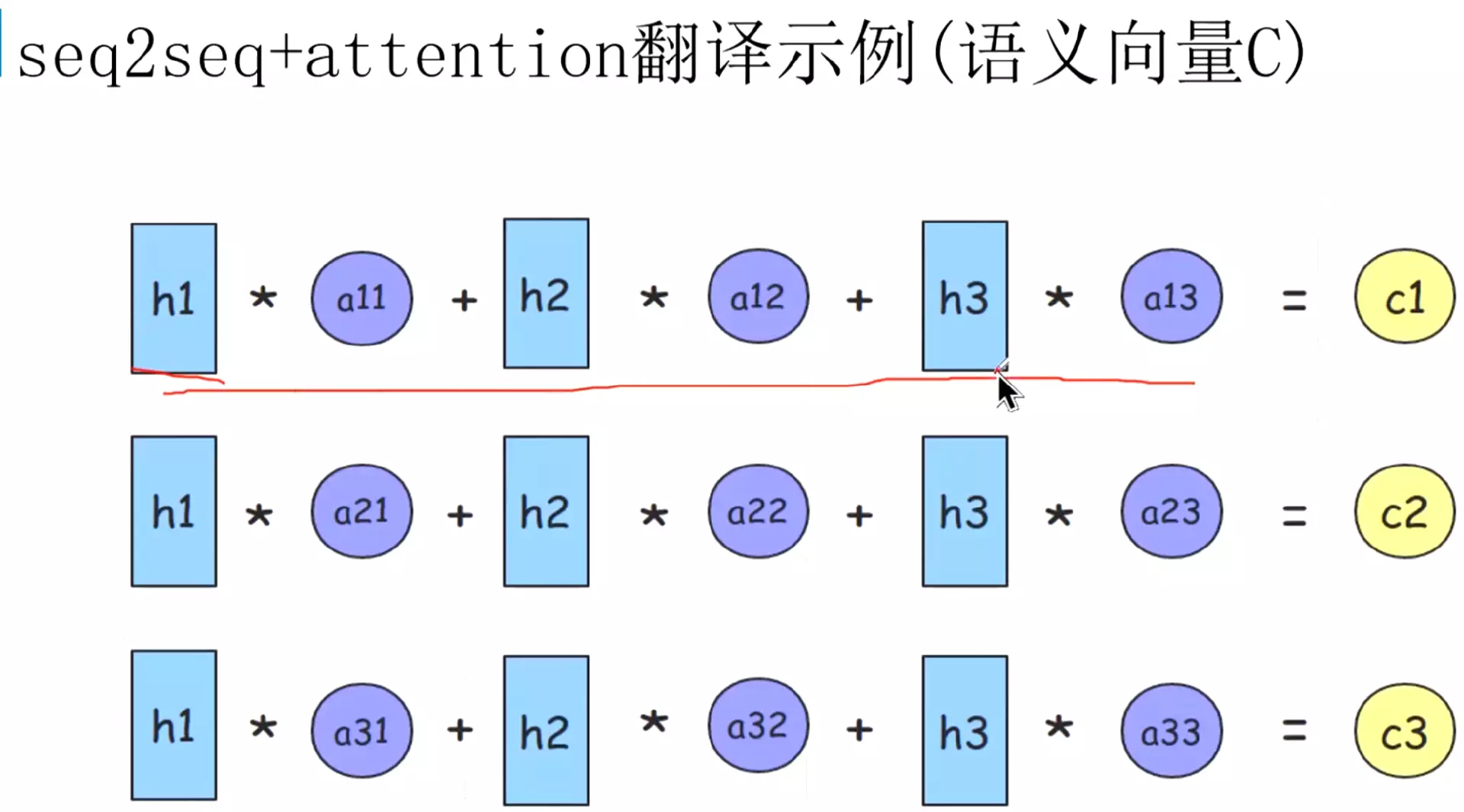
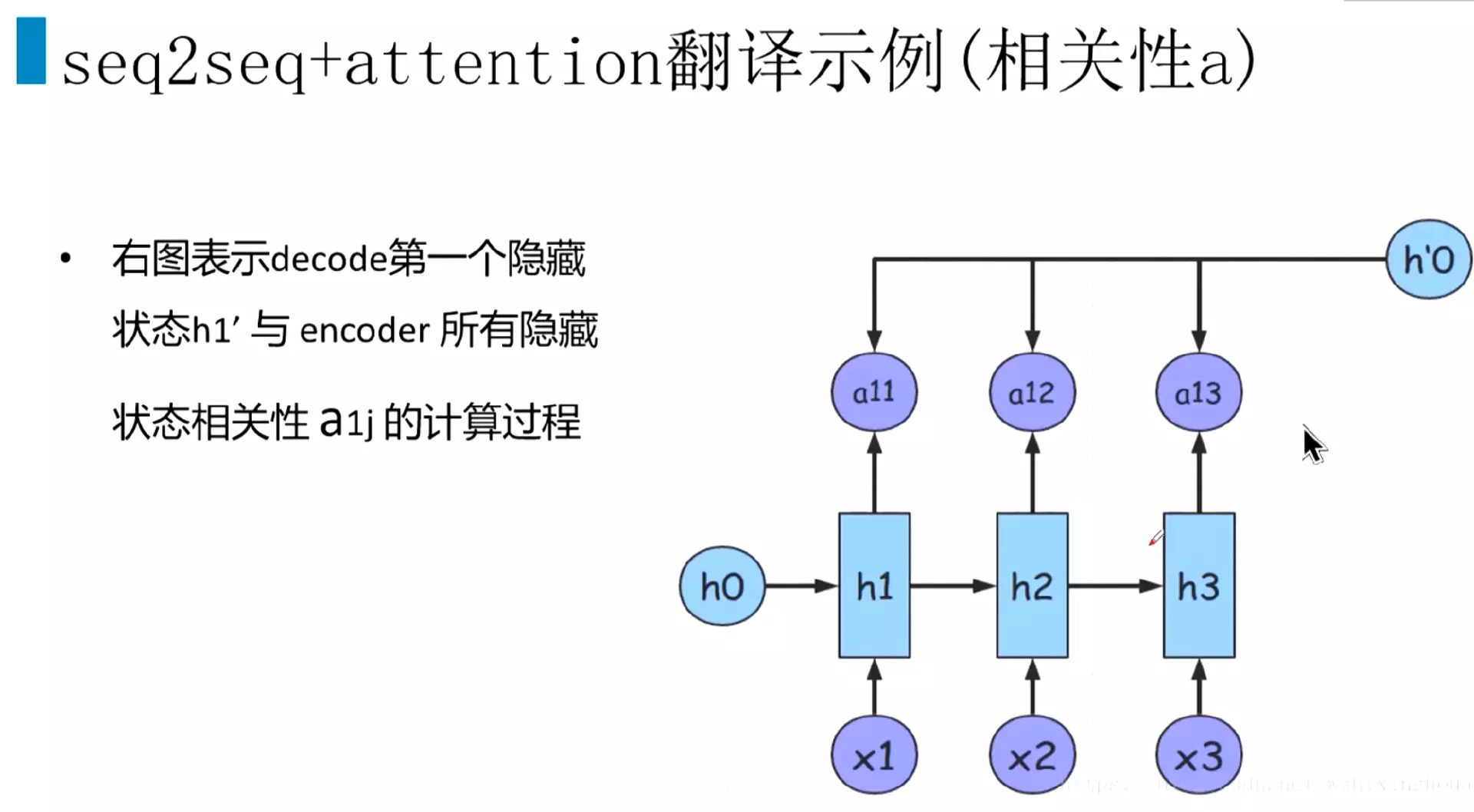
#h1、h2、h3就是编码层的隐藏状态。a就是相关系数,比较关键。a21,中的2表示解码器的第二个时刻,会跟编码层的每一个隐藏状态做一个加权计算
![]()
![]()
#decoder的h'0
![]()
![]()
#s是decoder的隐藏状态;h是encoder的隐藏状态![]()
![]()
#beam search设置一个参数,叫beam size设为2,将英文翻译中文,第一步是预测,候选词2个;第二部根据语义C以及第一次的两个词,重复预测两个词,每一步都重复预测;
#如果有1000个词,第二部算的时候,计算1000*1000次,一直这样最后再找到概率最大的的话导致计算量非常大,所以用beam search
#但是seq2seq经常会预测最短的句子
#seq2seq在工作中遇到的并不多。
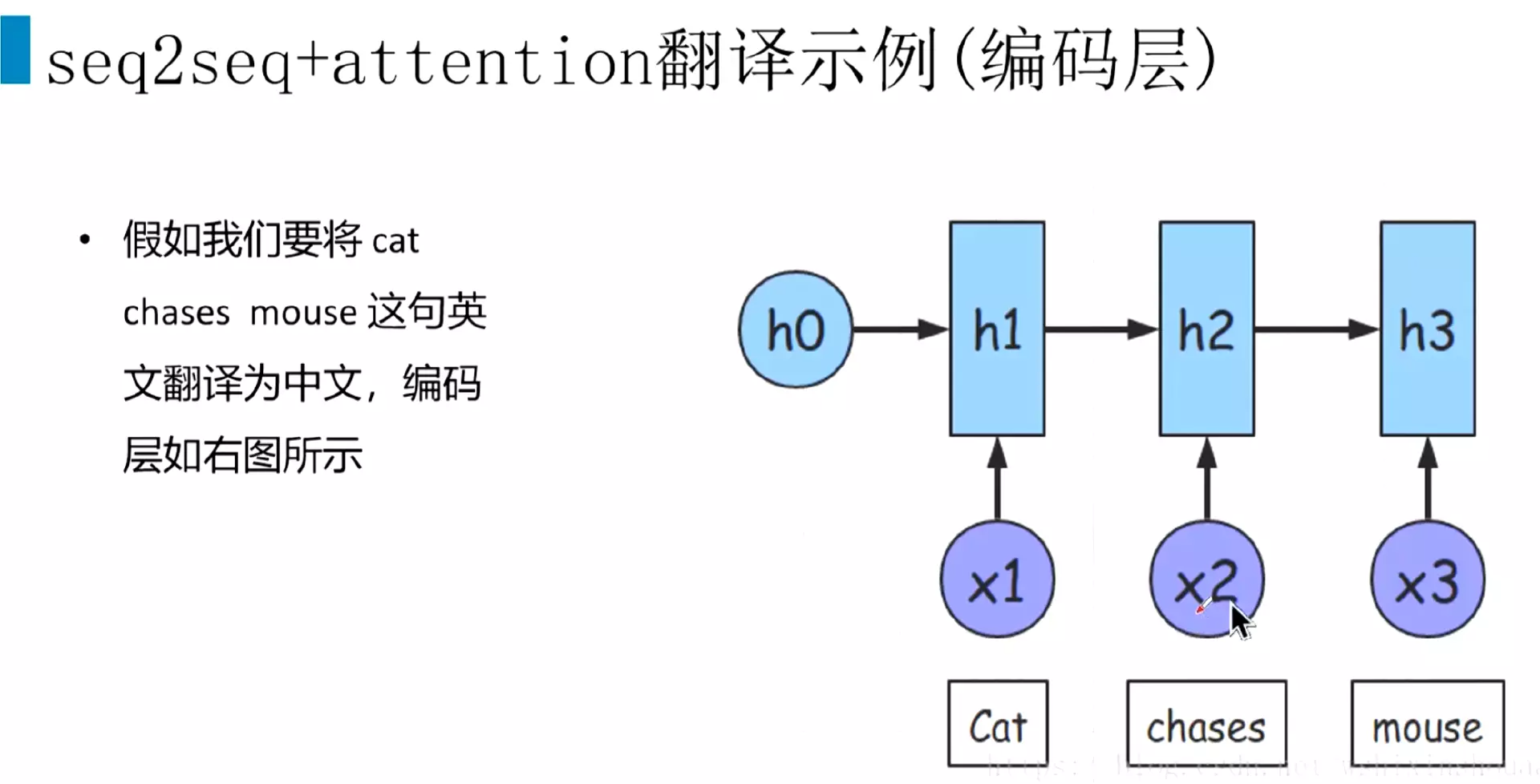
##代码实例:机器翻译任务
![]()
#unicodedata处理编码问题,处理字符的计算,不是一种语言的有英文、法文、中文
#from torch.autograd import Variable把数据变成可以反向传播的节点
![]()
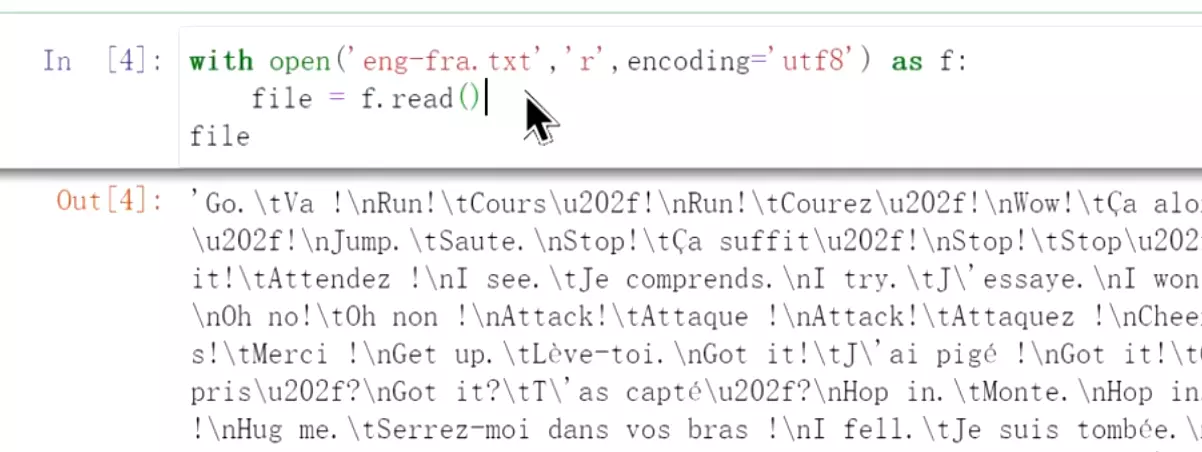
#先看一下数据,encoding='utf8'用编码限制。数据到处是回车和空格![]()
![]()
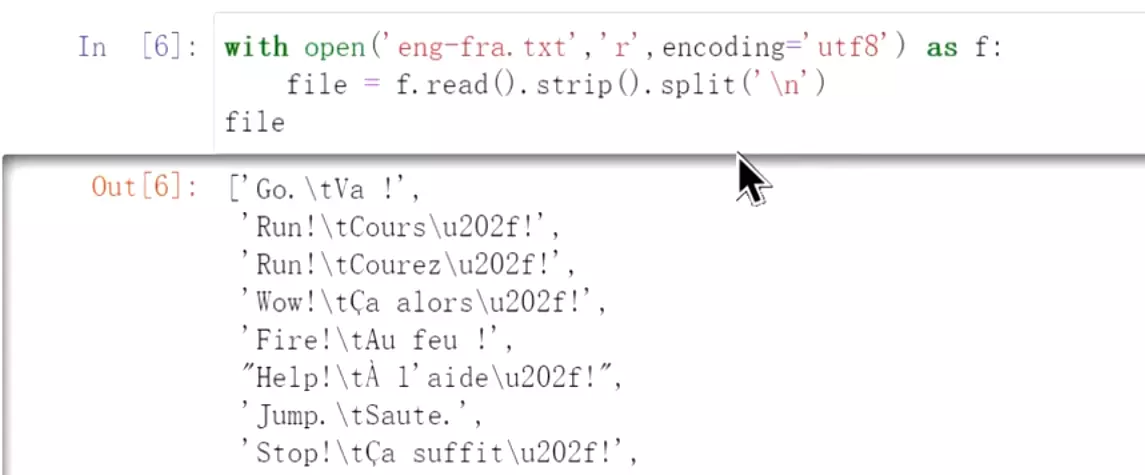
![]() #处理一下数据,左边是英文,右边是法语
#处理一下数据,左边是英文,右边是法语
#if unicodedata.category(char) != 'Mn':判断字符的类型,如果类型=Mn,就是很复杂的字符。#Mn 表示在编码中一些奇怪的字符,容易报错。需要过滤掉。''.join(char_list)最后再组合起来
#sen = re.sub(r'[^a-zA-Z.!?]+',r' ',sen) ^表示不在后面这里的字符
![]()
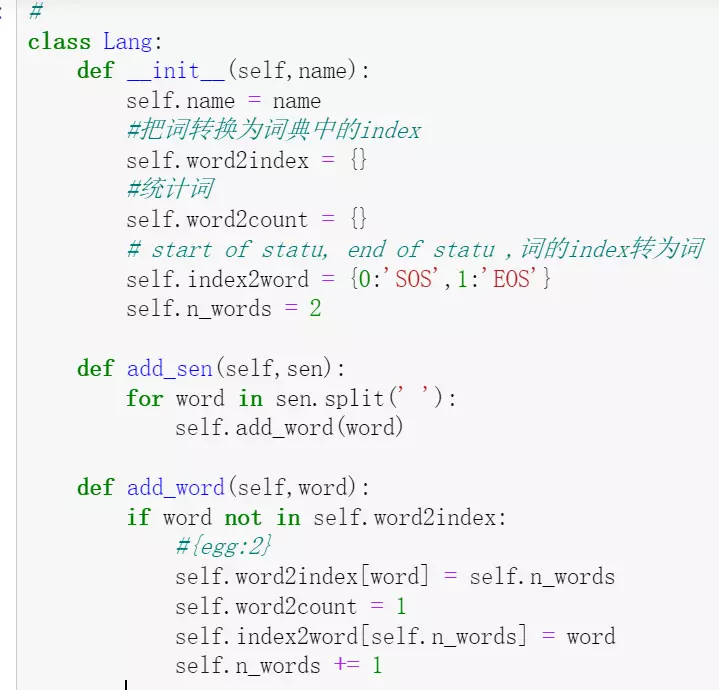
#构建一个词典的类,去实例化
#先给一个名字name,因为有两套词典,英文和法文,所以命名一下;再给一个类![]() 开始的字符就是SOS作为输入的开始字符
开始的字符就是SOS作为输入的开始字符
#self.n_words = 2记录词的个数,已经有两个词了SOS、EOS
![]() #实例化
#实例化
![]()
![]()
![]() #构建每个语言的词
#构建每个语言的词
![]() #词比较多,有2万个
#词比较多,有2万个
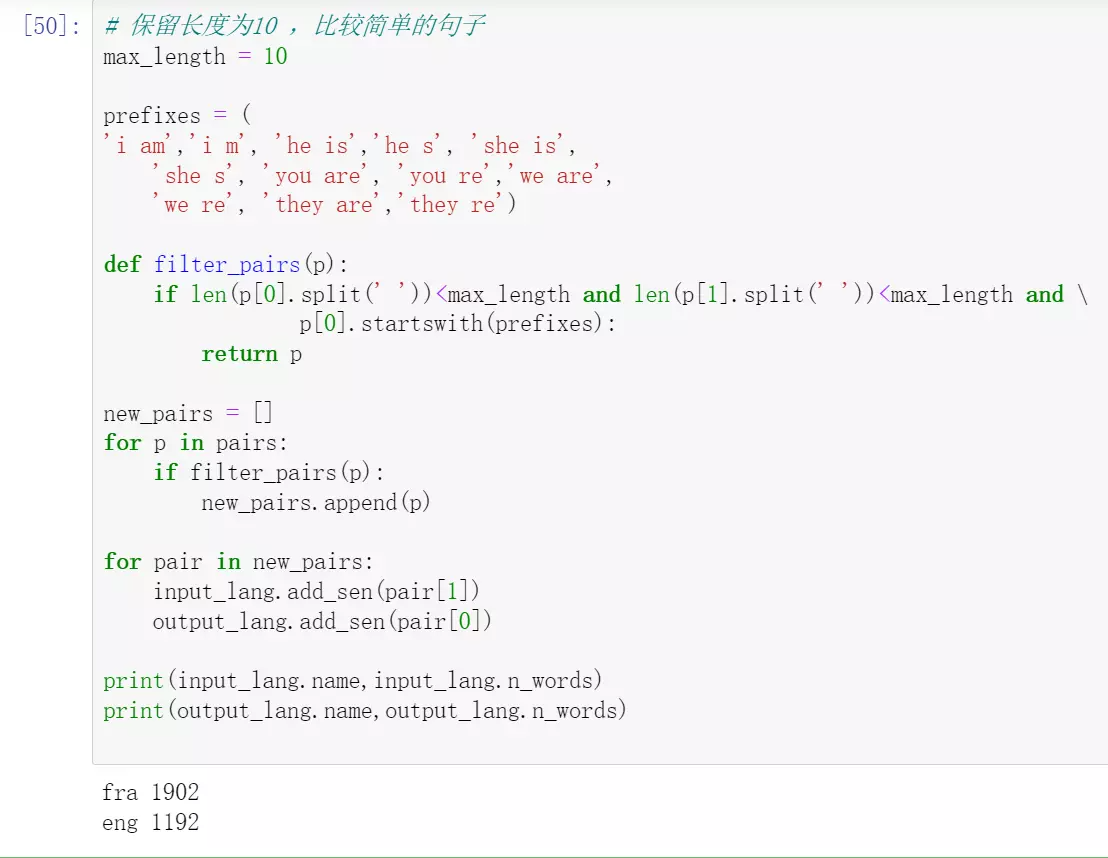
#prefixes = (
'i am','i m', 'he is','he s', 'she is',
'she s', 'you are', 'you re','we are',
'we re', 'they are','they re')找一些开头比较简单的语句
#因为是句子对,所以p[0]就是第一个英文的句子,p【1】是法语
#if filter_pairs(p):如果符合筛选条件,就加进来new_pairs
#构建完,每个语言词典的大小只有1000多个
![]()
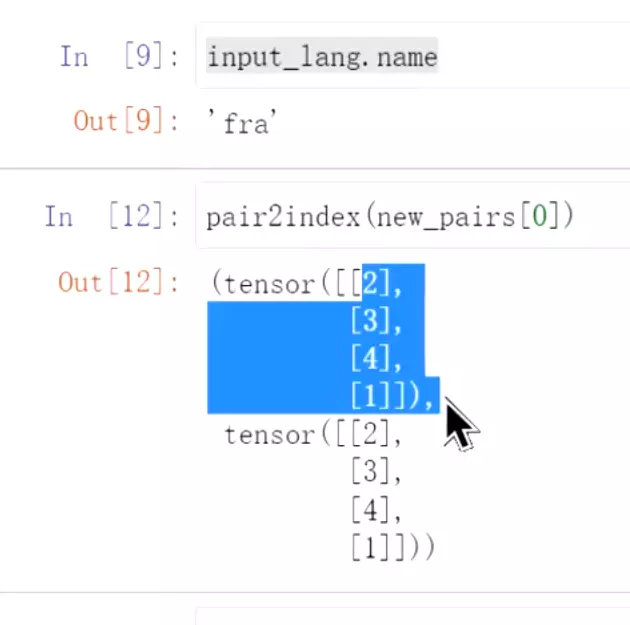
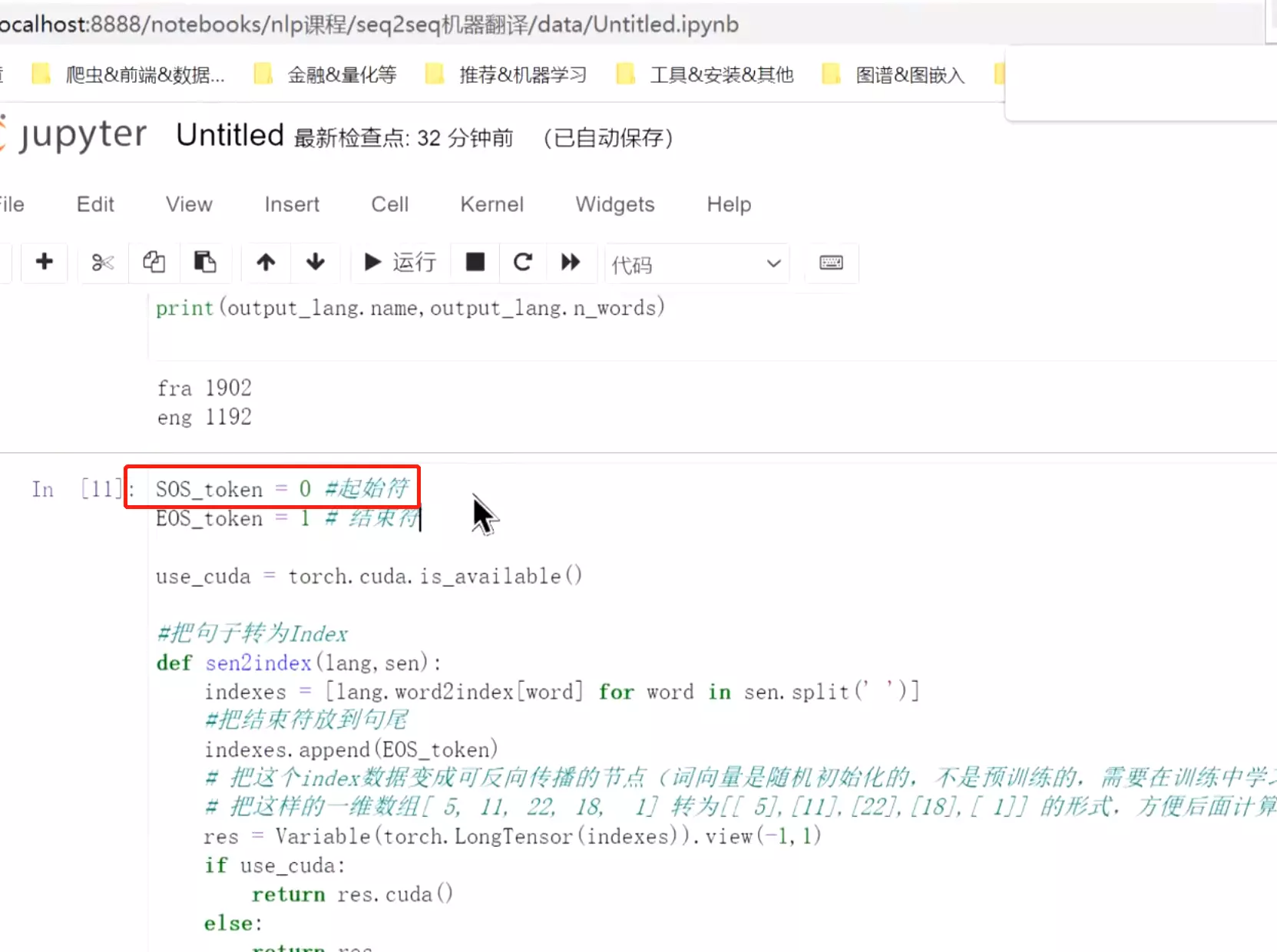
#res = Variable(torch.LongTensor(indexes)).view(-1,1)# 把这个index数据变成可反向传播的节点(词向量是随机初始化的,不是预训练的,需要在训练中学习)#view(-1,1)是把它拉平
![]()
#这就是在词典里的index。上面就是处理数据,后面还会用encoder和decoder时用到
![]()
![]()
![]()
#embedding后的效果,变成上面这样的数组。这个embedding是随机初始化的,没有经过预训练的![]()
#128就是隐藏层的size,4是有4个单词
![]()
#先encoder
#self.embedding = nn.Embedding(input_size,hidden_size)是随机初始化的词向量
#前向传播时需要embedded = self.embedding(inputs).view(1,1,-1)把input进行embedding一下
#initHidden(self):初始化一个隐藏状态, Variable(torch.zeros(1,1,self.hidden_size))是变成一个可以反向传播的节点
![]()
#重新导一些包
![]()
#再decoder
#self.out = nn.Linear(hidden_size, output_size)与encoder不同的地方,有一个linear,是输出词表的大小,就是把隐藏层大小的向量映射为英语词表的大小
#self.softmax = nn.LogSoftmax(dim=1),就是让预测错的损失越大越好#维度是两维的,类似于[[1,2,3,4,5]],所以dim设置为1,如果是[1,2,3,4,5] dim设置为0
#后面还要加attention的decoder,AttnDecoderRNN。
attention的计算没有那么复杂。经常是用几个向量看concat一下,然后过几个线性层,让他们做一个交叉计算,然后就有了attention。
##待补充attention代码
transformer及bert系列模型
#现在基本上很多场景一上来就上bert模型,然后觉得不行再换其他模型,一个一个测试。因为他在各个Nlp任务里面表现的相当好。像之前复旦秋季红团队做的Hanlp自然语言包之前是用很多机器学习去做。然后bert模型出来之后用bert去做。出了2.0版本,效果非常好。
![]()
#是谷歌的vaswani提出的,现在离开谷歌了。他只基于attention结构来处理序列模型相关的问题,比如机器翻译。像我们之前的seq2seq它是有一个编码器和解码器,中间再加一个attention的结构进行处理的。但是transformer只基于Attention的结构进行处理,效果相当的棒。而且他的结构摆脱了rnn序列的结构,他就可以并行的计算,速度也更快。像梯度消失和梯度爆炸的问题也解决的更好了。他就可以高度的并行工作,RNN和lstm每一时刻的输出都要前一时刻的隐藏状态,他就没有办法去很好的并行计算。
#注意力机制出来之后除了在nlp在CV领域也广泛应用了,效果比较好。
#论文地址的可以去下。需要的话自己看。
#Transformer提出了一年之后,bert就出现了。![]()
#bert都是用了以前的模型,但是对输入向量和预训练任务处理的很巧妙。他是在谷歌上的数据进行训练。然后针对少量数据的任务进行微调。就能获得比较好的效果。Bert相当于开了一个先河。![]()
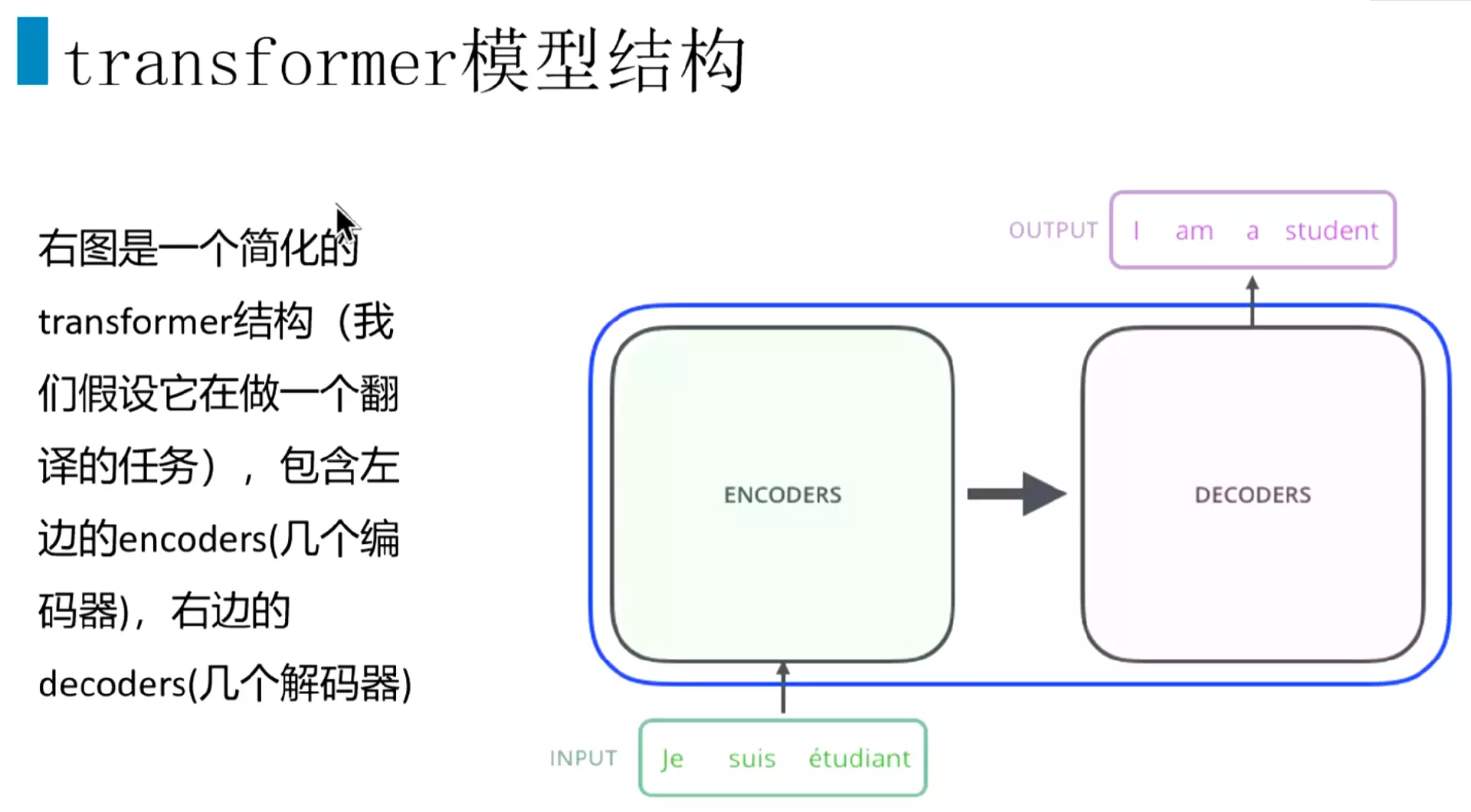
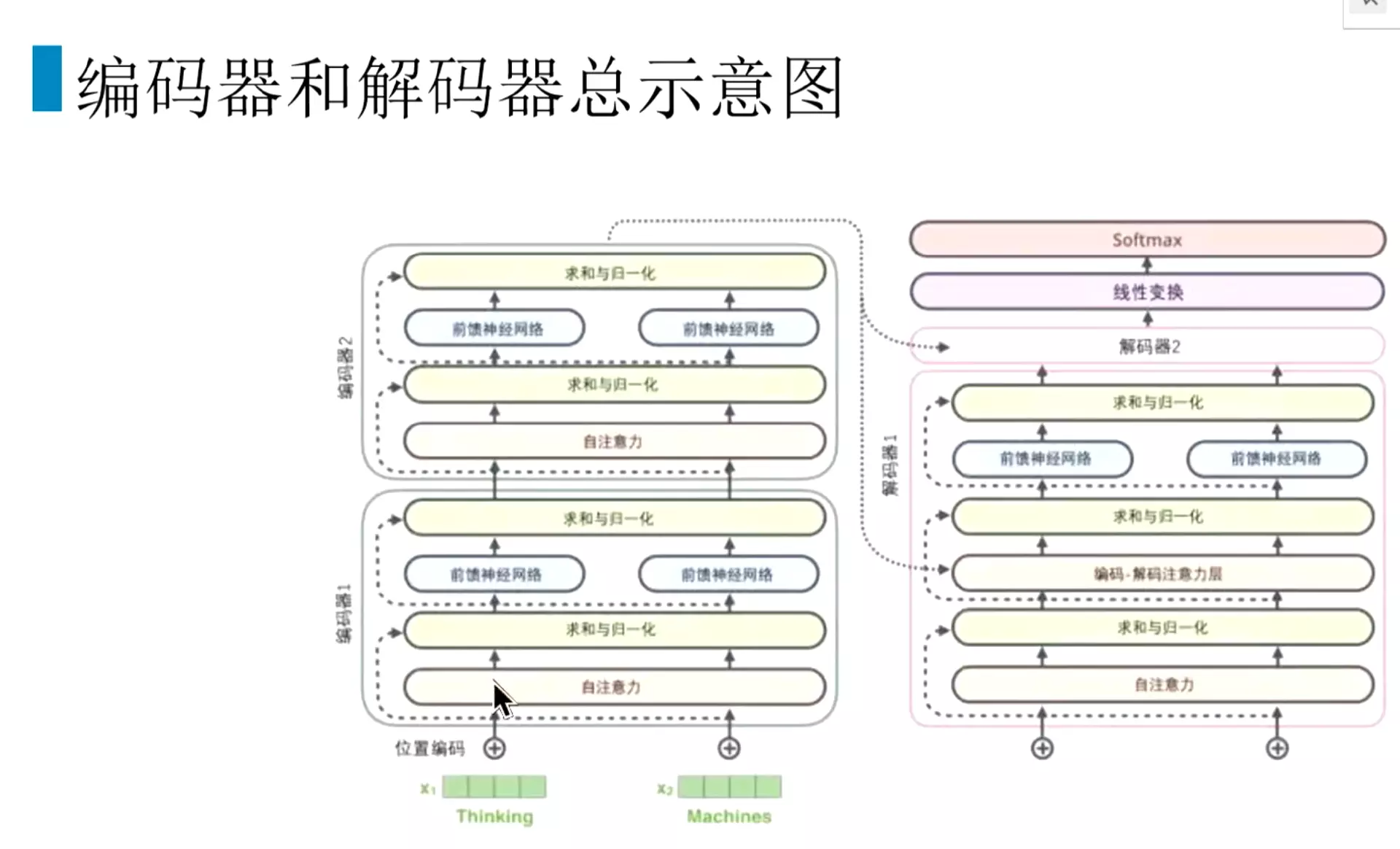
#Transformer的结构:前面有一个Encoder。后面有个Decoder![]()
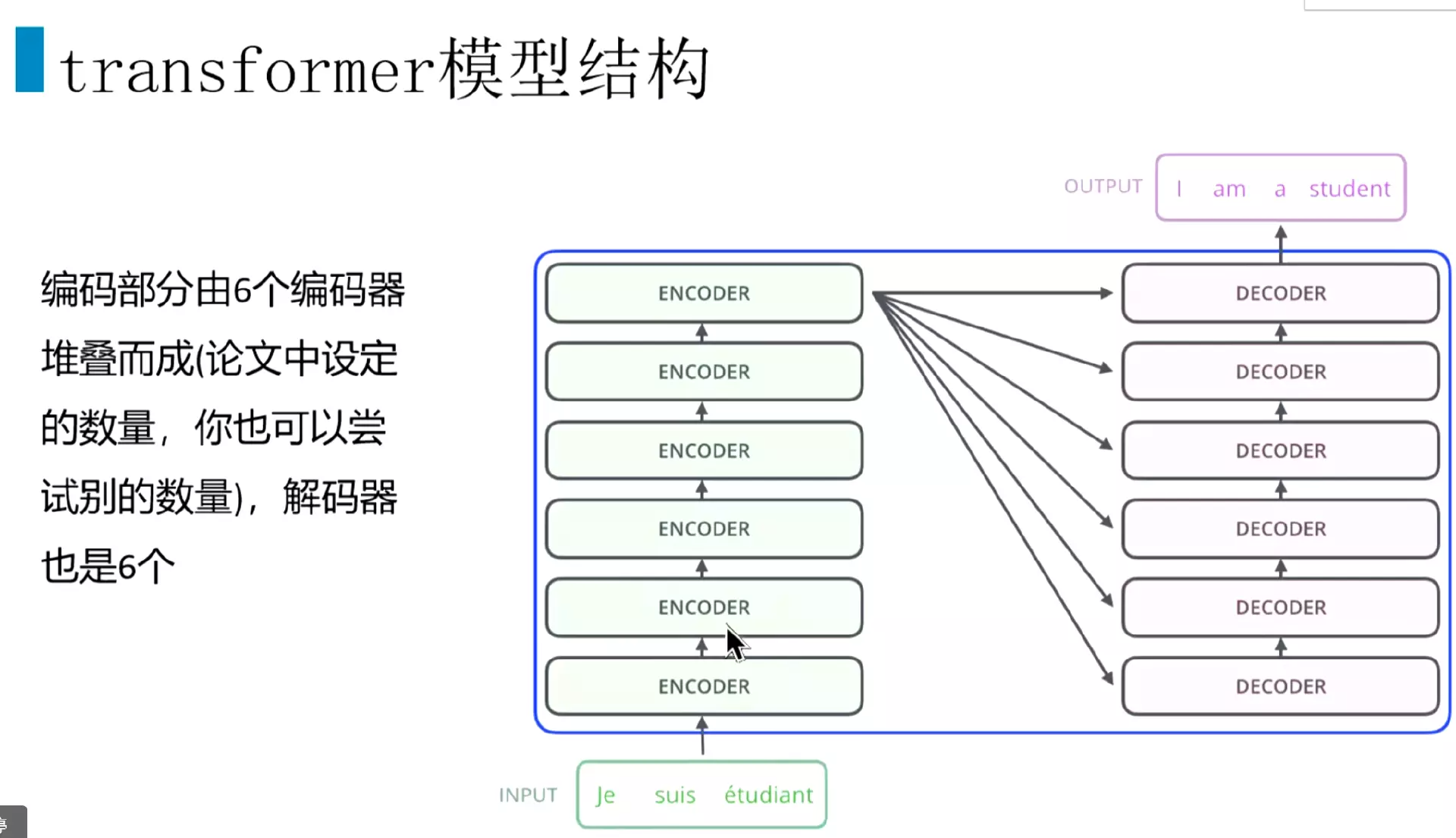
#但是把它拆开了。可以看到encoder有六个encoder块堆叠而成。Decoder也有六个decoder块堆叠而成。6是论文中设定的数量,也可以尝试其他的数量。![]()
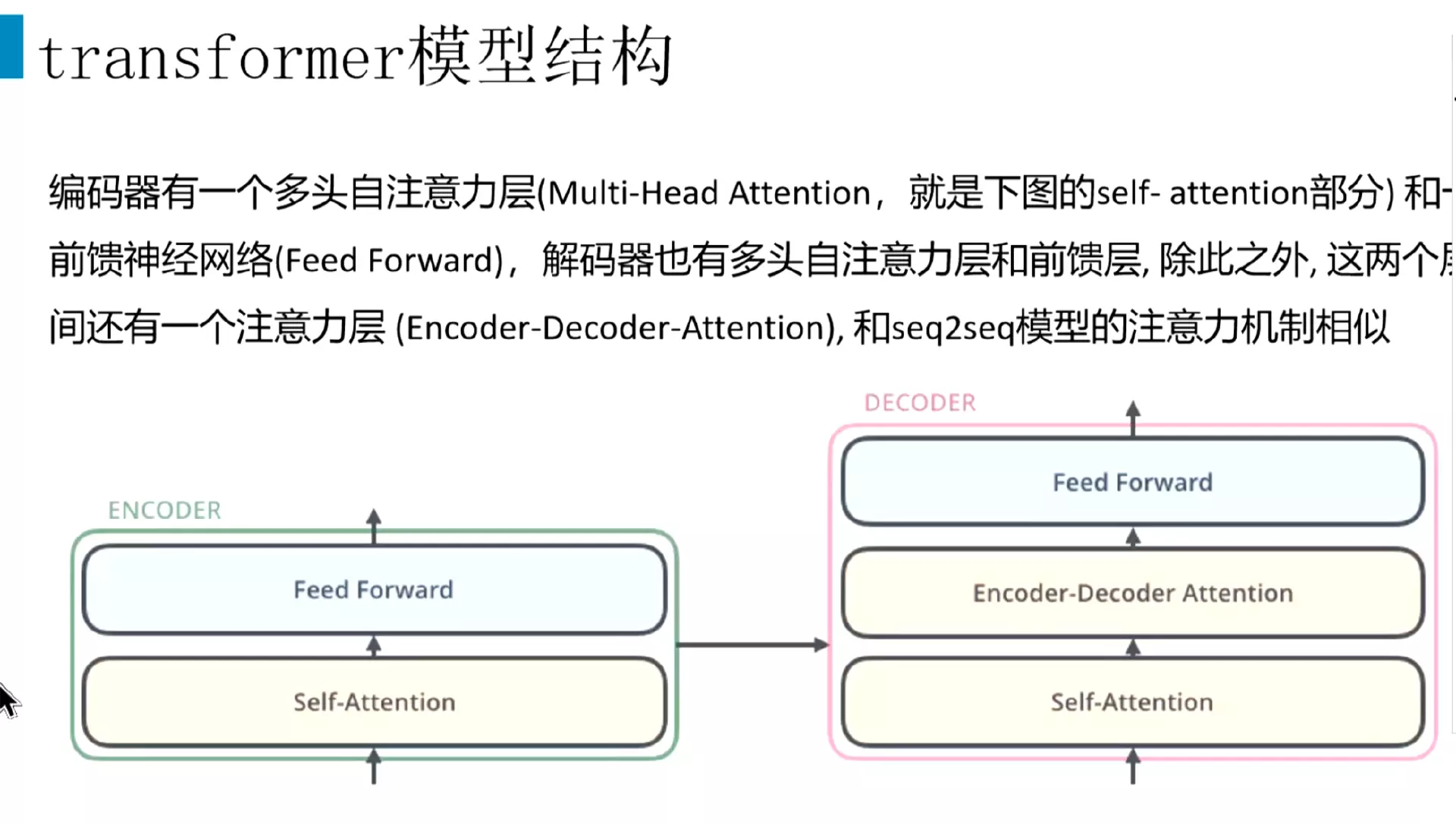
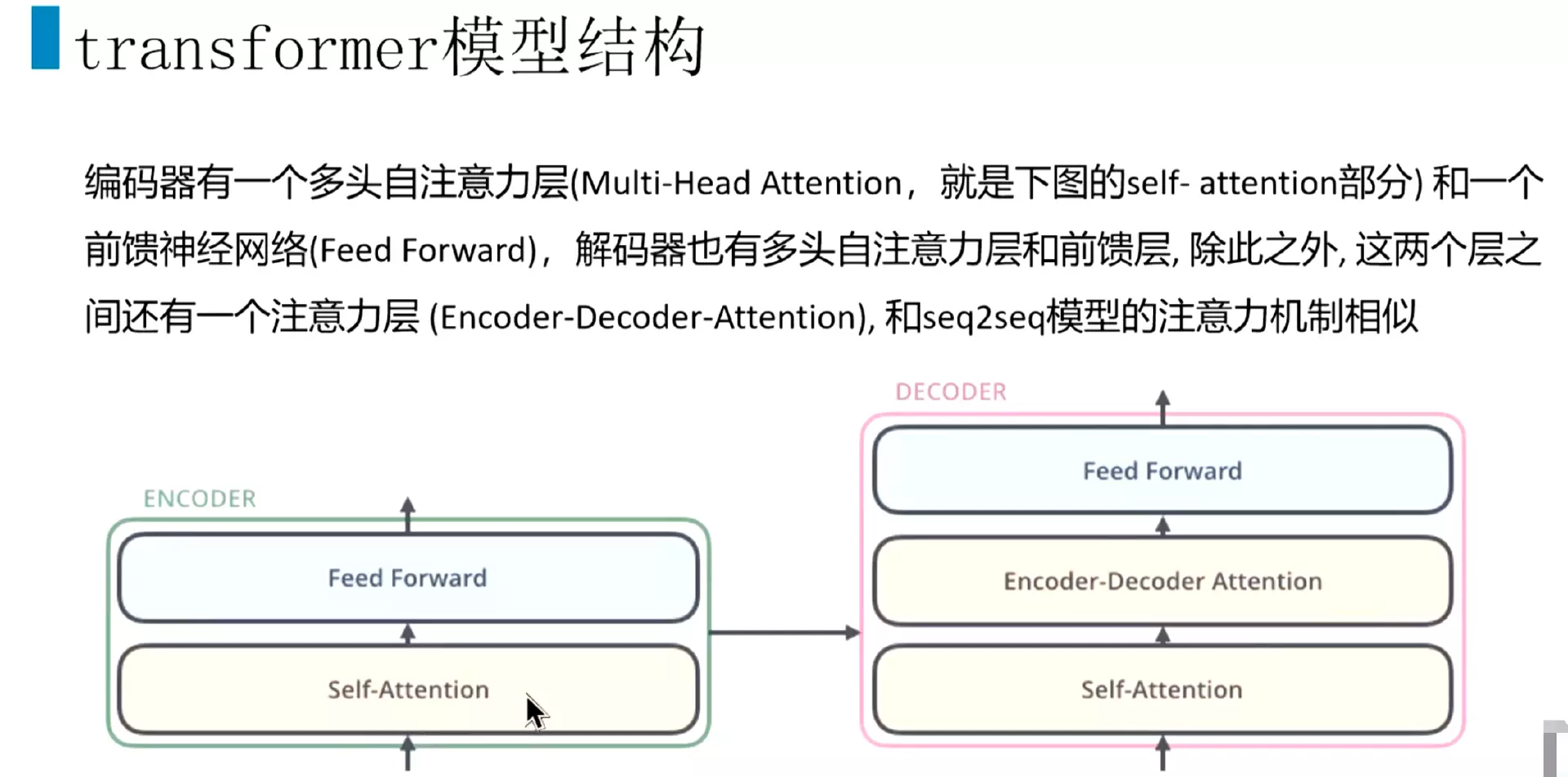
#先看Encoder内部的结构:Encoder里面包含一个self-attention,其实是一个multi-Head-Attention多头注意力机制,后面接一个前馈神经网络,就是两个线性层。
#解码器也包含一个self-attention,然后第二层是一个Encoder decoder attention.然后后面接一个前馈神经网络。
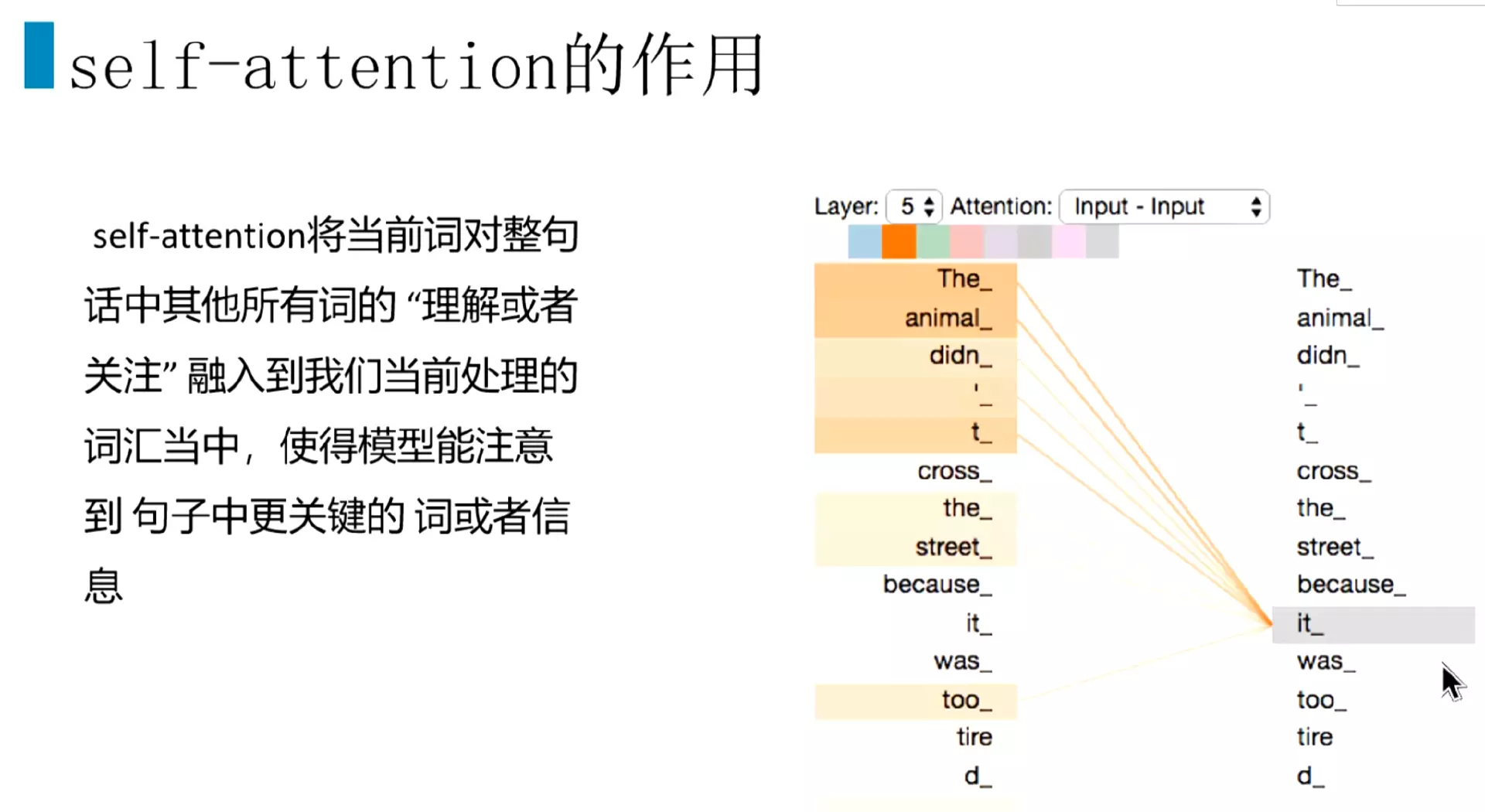
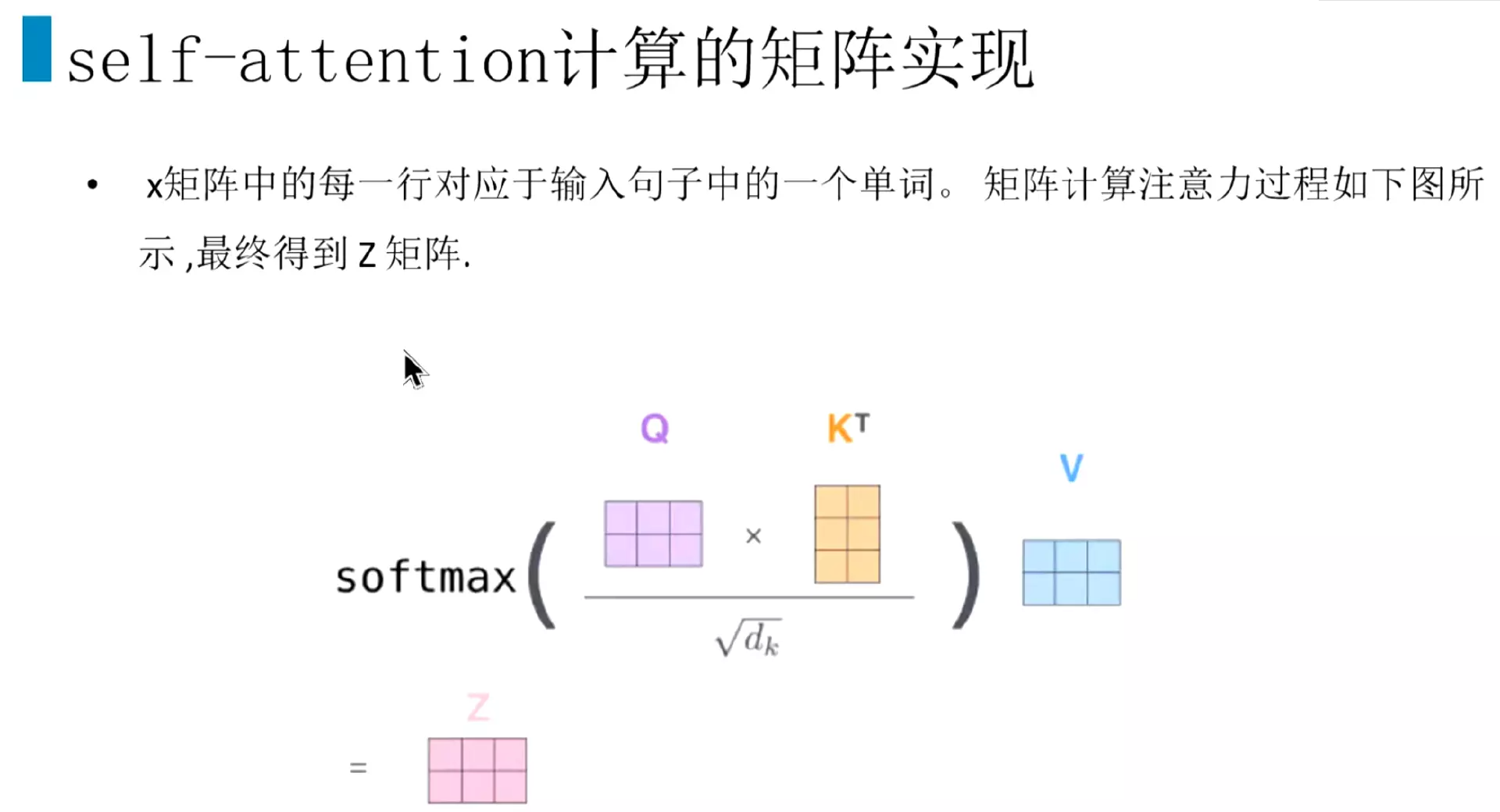
#先讲一下self-Attention,这个结构面试频率非常高。![]()
#Self attention的作用,当模型计算到当前词,会把当前词对其他所有词的关注度或者理解或者重要性,相关性,汇入到当前词的计算当中。使模型能够注意到句子中最关键的词或信息。比如说计算到it。他和The和animal的关注度或相关性更高一些。Self attention注意力就能够关注这样的信息。实际上的做法就是把权重的加权计算得到的,本质上就是矩阵的加权计算。
![]()
![]()
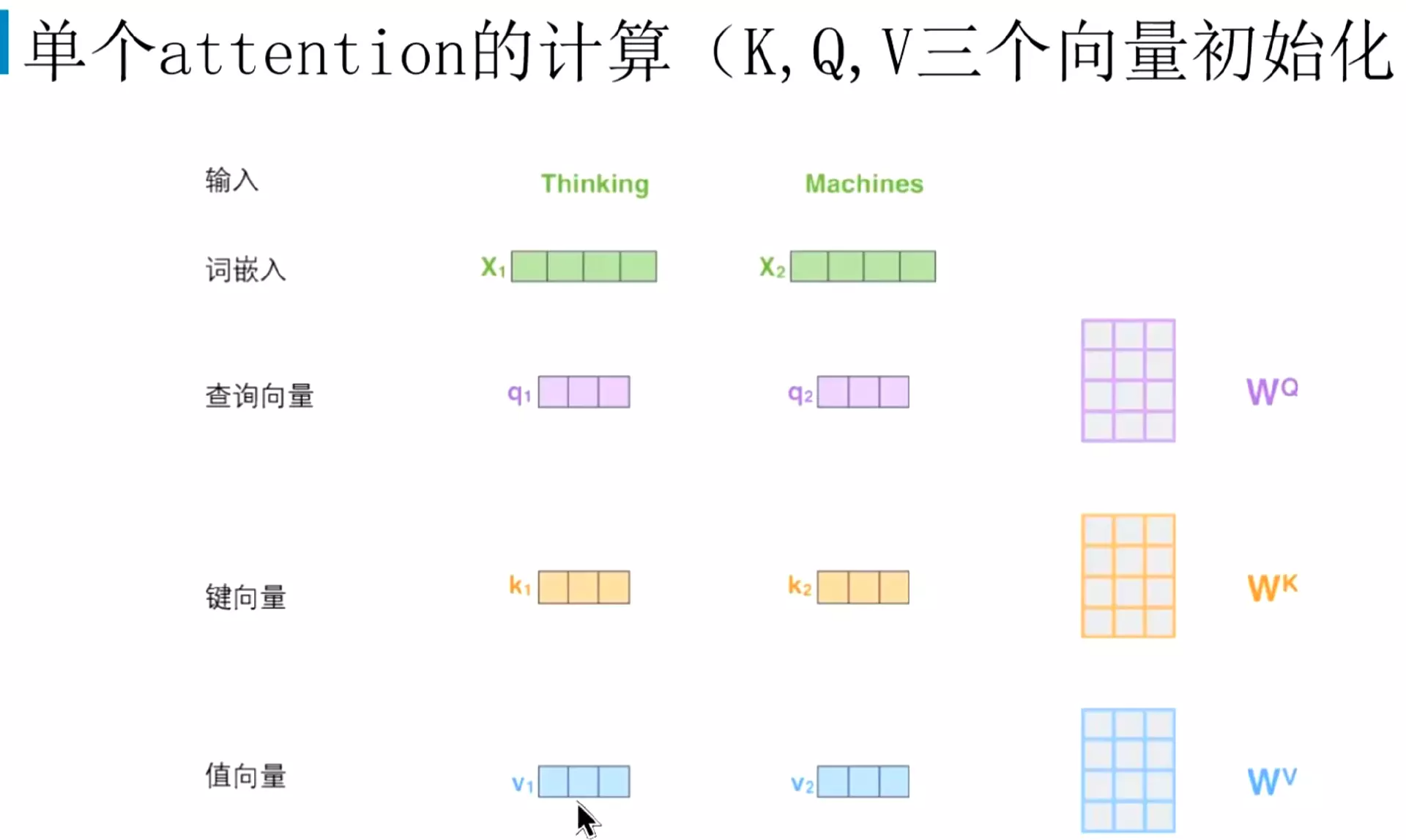
#第一步就是给每个编码器的输入向量生成三个向量:一个是查询向量q,一个是键向量k,一个是值向量v。然后比如我们输入两个词,分别是thinking和machine,然后这两个词就分别和查询向量,键向量,值向量进行相乘。得到Q、K和v
#w矩阵是什么?答:是我们初始化的权重矩阵。类似于seq2seq时的我们会初始化一个隐藏状态h0。然后这个权重矩阵和输入向量进行点乘。就得到了三个向量。![]()
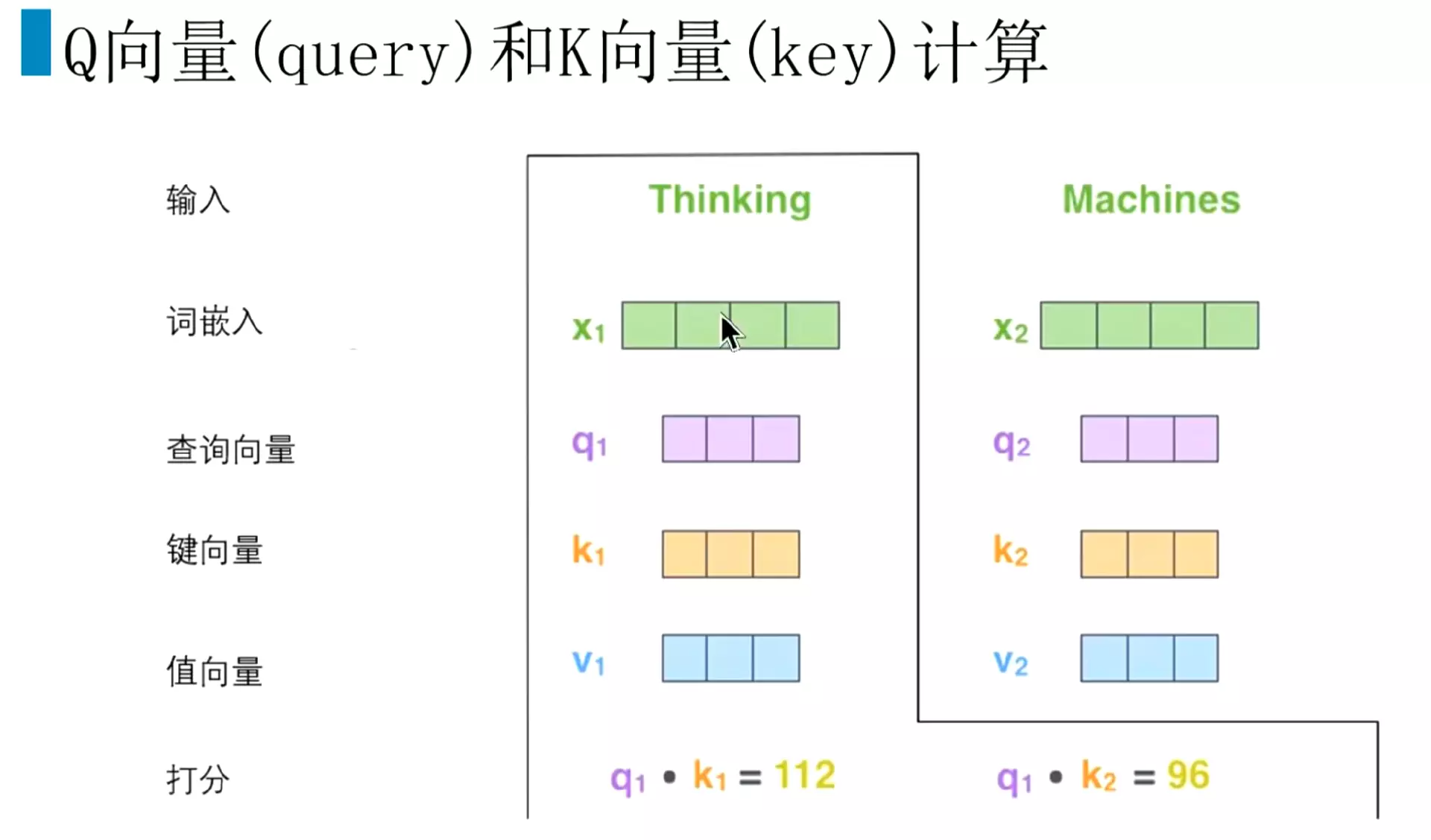
#得到三个限量之后,我们就计算得分相当于注意力分数或者说是相关性分数。![]()
#比如Thinking的计算过程,首先拿查询向量q1去和所有词的键向量进行一个点乘。Q1首先跟自己的k1进行计算;然后再和Machines的K2进行计算。得到一个分值。这个分数代表了当前词对其他词的关注程度、这个词对其他词的相关性是怎么样的。可以这样理解这个分数。
#这几个向量的维度是64,论文里设定的维度。![]()
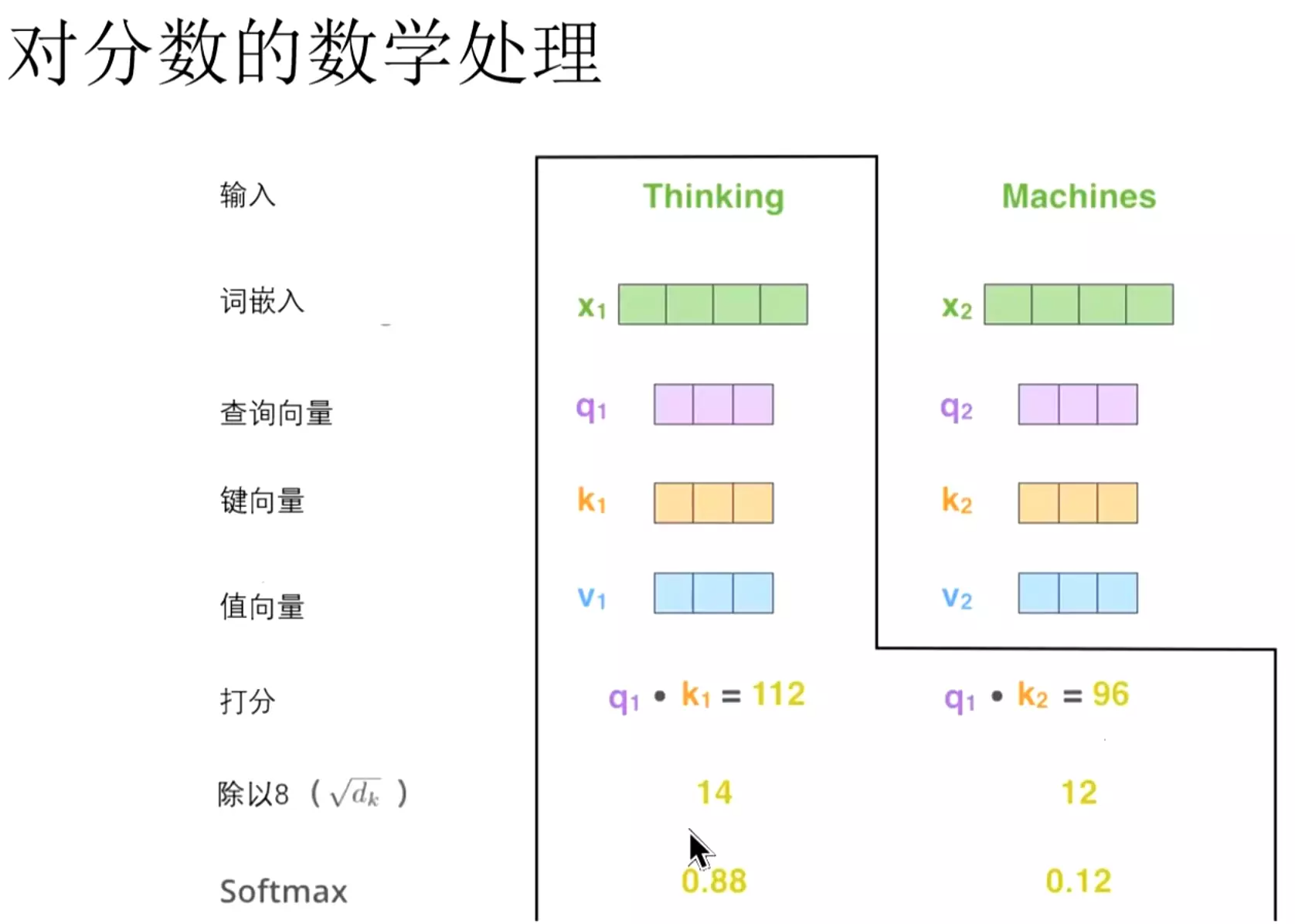
#把分数除以8。8就是论文里使用的键向量的维度64的平方根。说是会让梯度更稳定。但是这样的做法比较玄学。没有理论进行支撑,只能说实验结果比较稳定一些。![]()
#除以8之后,再接一个soft max进行归一化。归一化之后值更小一些,更好计算。值太大了会让梯度不稳定。
#在当前的位置。用这个词跟所有的词进行计算分数。肯定是和自己的词做计算是分数是最高的。就是Thinking和thinking自己进行计算得到的分数是最高的。![]()
#然后再把值向量乘以soft max,这样做法是希望关注语义上相关的单词,弱化不相关的单词。比如Thinking和machine计算完之后soft max的值是0.12,然后他跟值向量相乘之后的值是非常小的。把不相关的词更加的弱化一些。
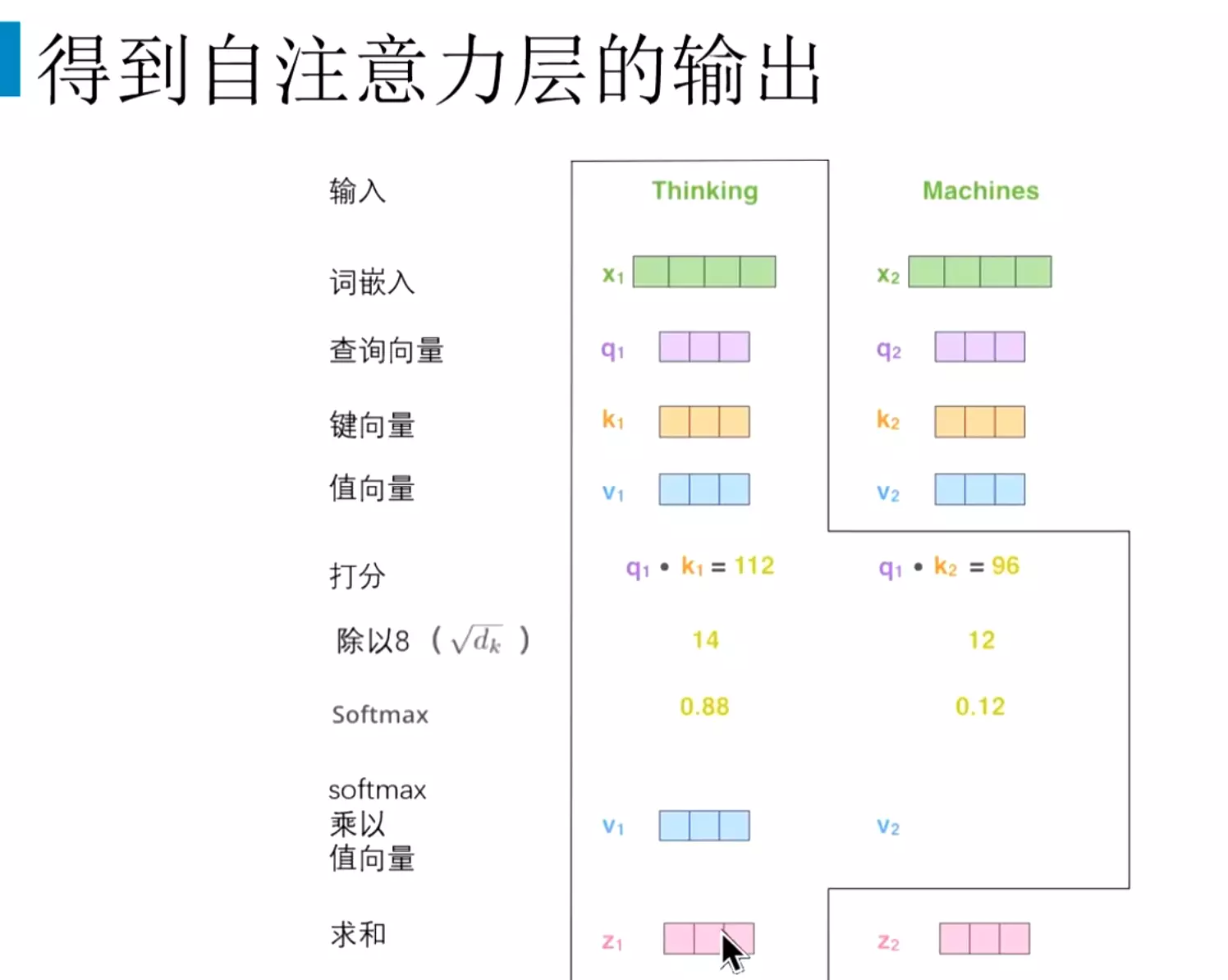
![]() #用thinking和每一次词得到的归一化结果,像0.88、0.12这些softmax再和v向量相乘之后,再去把v向量都求和。得到z,z就是注意力机制的输出。
#用thinking和每一次词得到的归一化结果,像0.88、0.12这些softmax再和v向量相乘之后,再去把v向量都求和。得到z,z就是注意力机制的输出。![]()
#实际计算时用矩阵来进行计算。首先是输入的向量矩阵X去乘以几个初始化的权重矩阵q\k\v,得到Q\K\V这三个矩阵向量。![]()
#然后Q向量乘以所有的K向量,除以k维度的平方根,再进行一个softmax,再乘以v值向量,就得到的注意力的输出Z。上面就是单个注意力机制的实现方式。一个头的计算
![]()
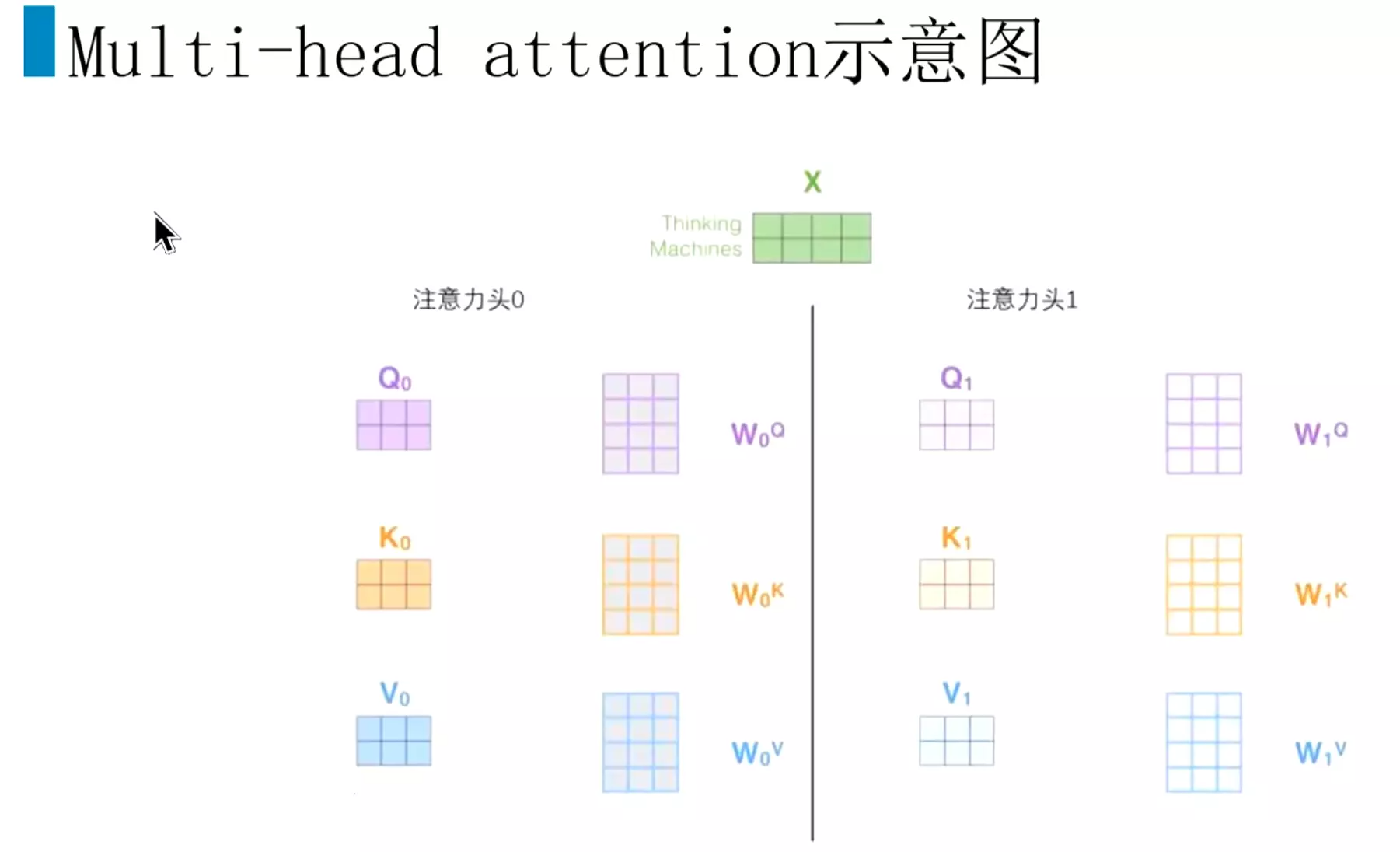
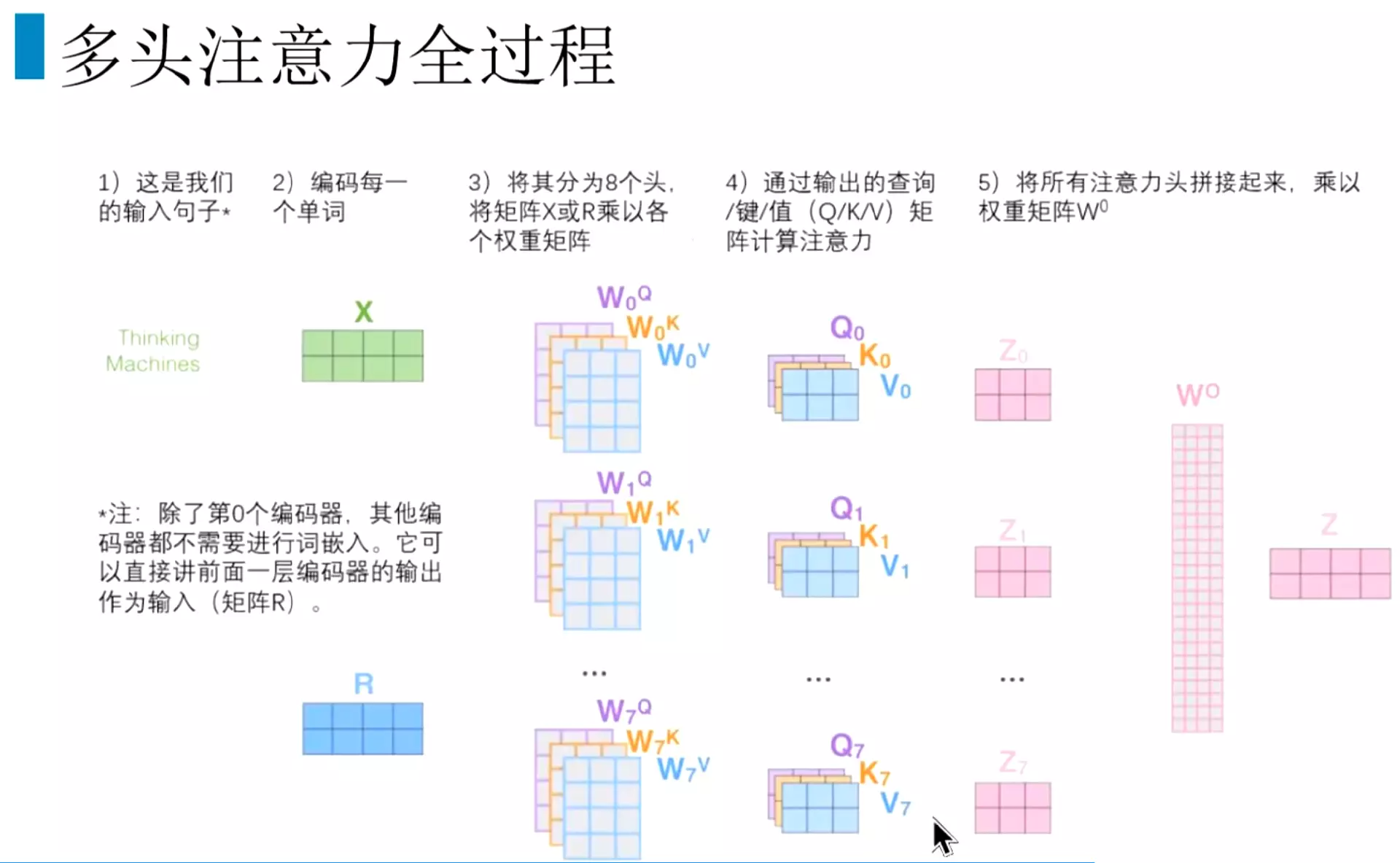
#多头注意力机制在两个方面提高了注意力层的性能。一个它扩展了模型专注于不同位置的能力,或者说是不同信息的能力。比如说第一个attention可能会关注句子中名词和动词之间的关系;另一个attention可能会更加关注代词和名词之间的关系。可能关注的数据层面不同,获取更多的特征。当然这个东西比较玄学,也第二个是他给出了注意力层的多个表示子空间,因为有八个头,所以在集成之后能起到防止过拟合的作用。![]()
#分开计算。注意力头0进行得到q\k\v;然后注意力头1进行得到q\k\v;![]()
#比如我们有8个头,一共会得到8个输出;每个头的计算都是独立的。![]()
#一共有八个头,每个头都是独立计算q k v矩阵,最后得到八个输出Z0到Z7。
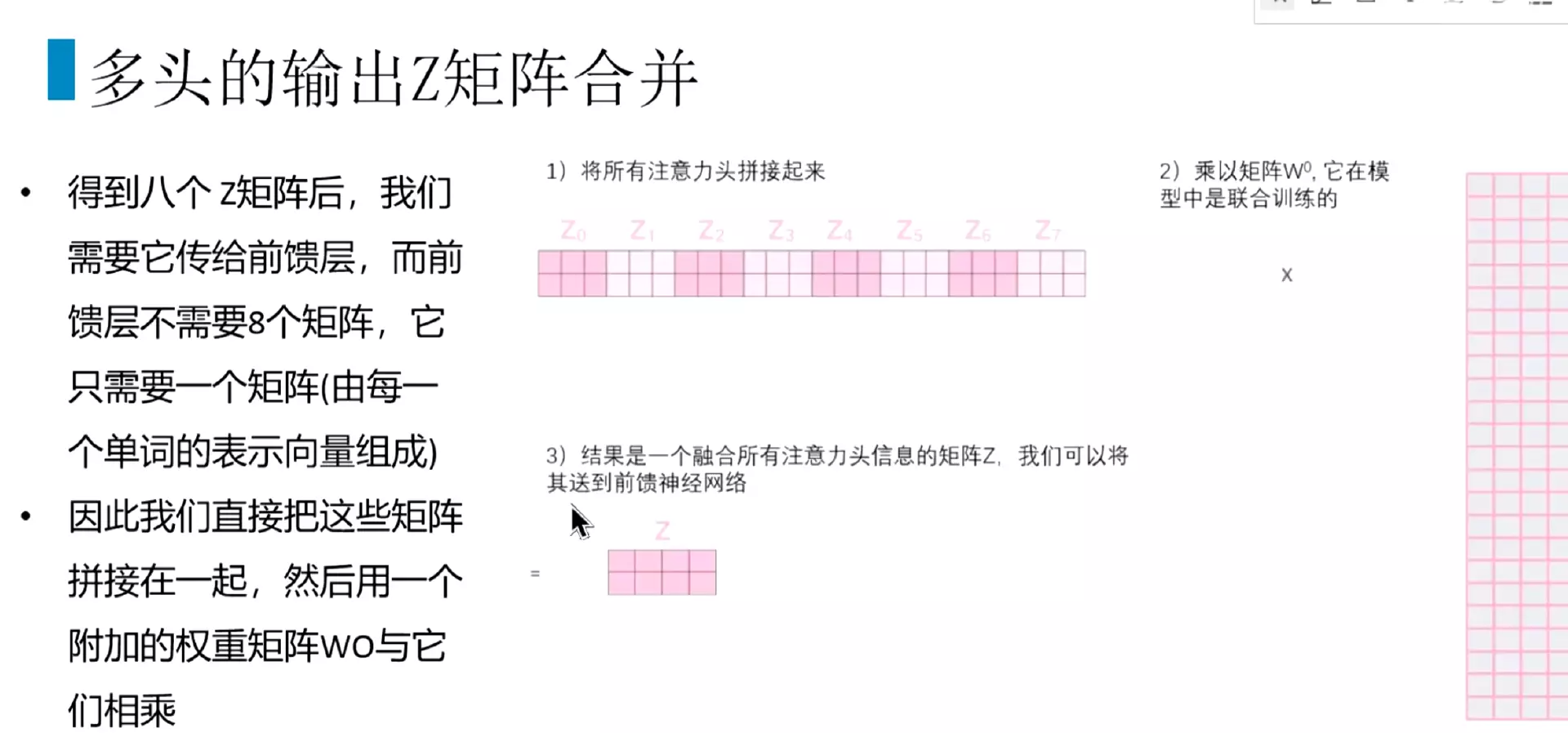
#我们肯定不想要8个头,要一个头就可以了。
![]()
#把八个头得到的输出z拼接起来。![]() 然后再去乘以一个权重矩阵W0,把它映射回一个单个输出Z。相当于一个attention的计算。
然后再去乘以一个权重矩阵W0,把它映射回一个单个输出Z。相当于一个attention的计算。
![]()
#多头注意力全过程。输出矩阵,然后向量化,每个单词进行编码,编码之后得到向量跟8个头的参数,分别得到qkv向量,通过计算得到8个输出z,然后拼接起来和w进行计算,返回一个z。![]()
![]()
#这里需要注意,不是每一个encoder都需要输入input;第二个encoder的输入就是第一个encoder的输出。这样一个过程。
![]()
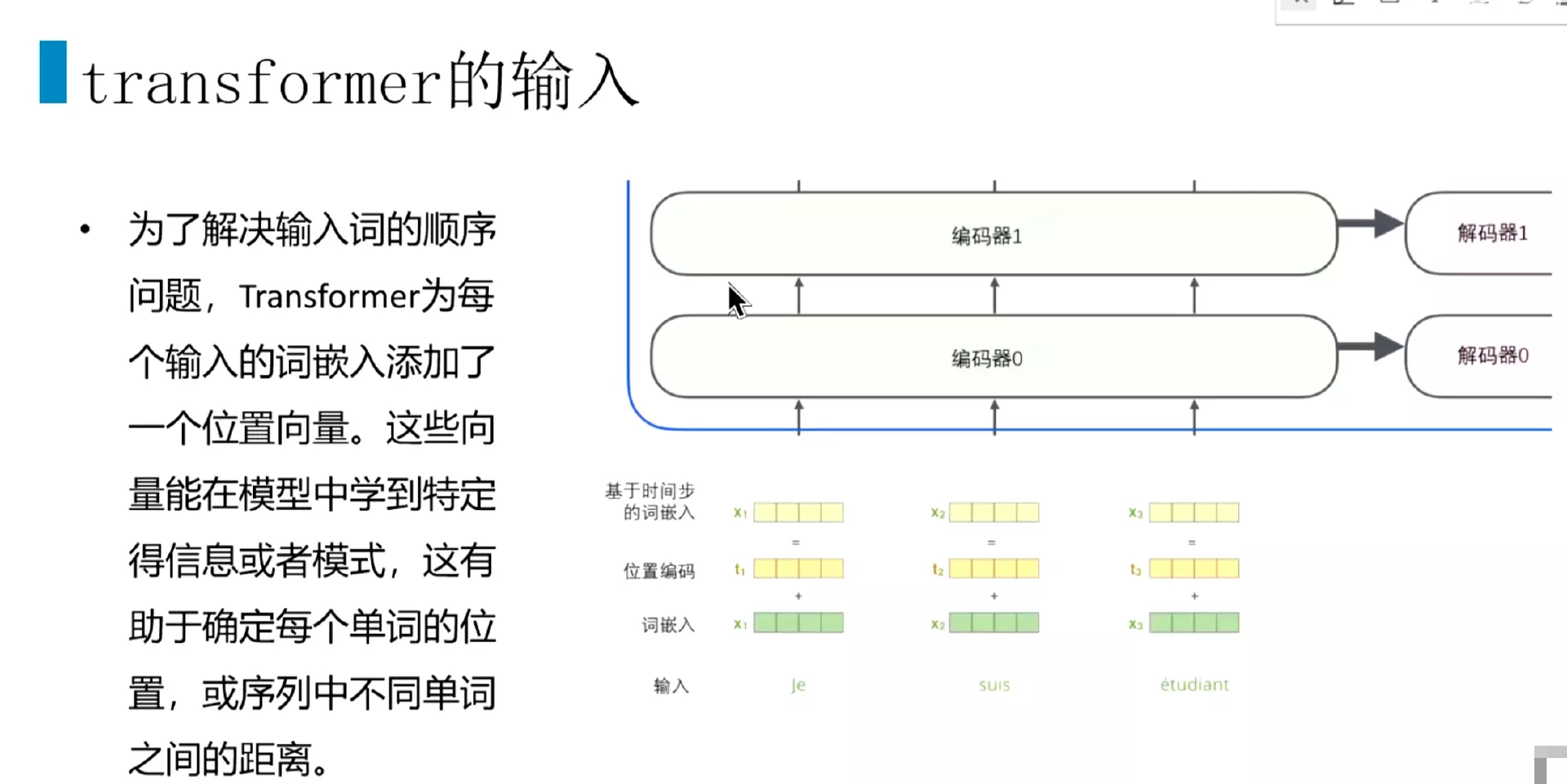
#再返回来看transformer的输入,它的输入会加入位置编码。之前的RNN和seq2seq的词嵌入都是比较简单粗暴,没有加位置信息。但是transformer的输入加了位置编码。就把原始的词嵌入和位置编码相加,得到了基于时间步的词嵌入;也就是说transformer在训练的时候能关注到位置或者序列的信息。这个设计比较巧妙,后面bert的输入也是借鉴了这个方法。![]()
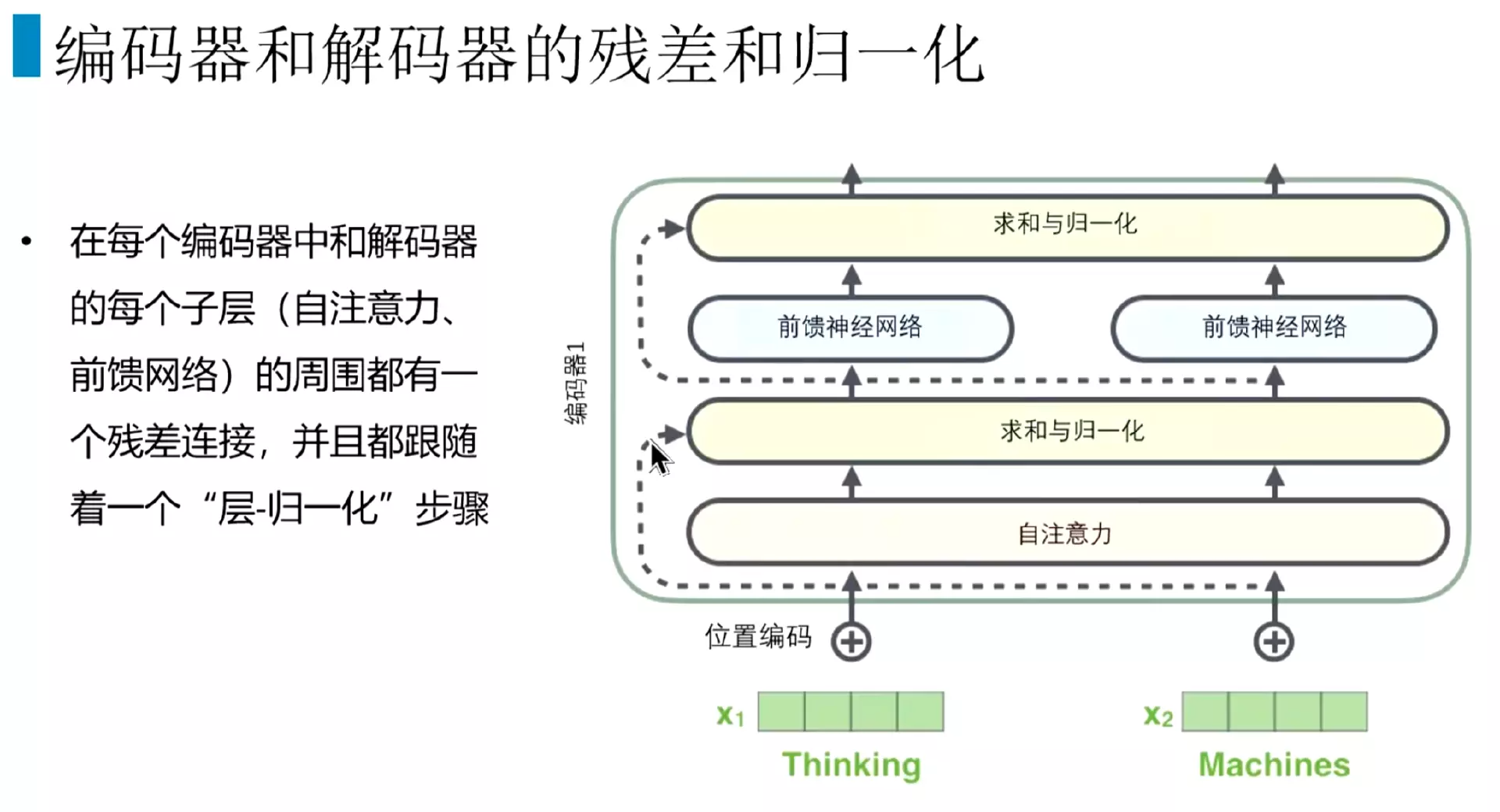
#在每一个解码器和解码器里面除了注意力外,还有求和与归一化;分两块,自注意力机制和前馈神经网络,每一块都有一个求和与归一化。![]()
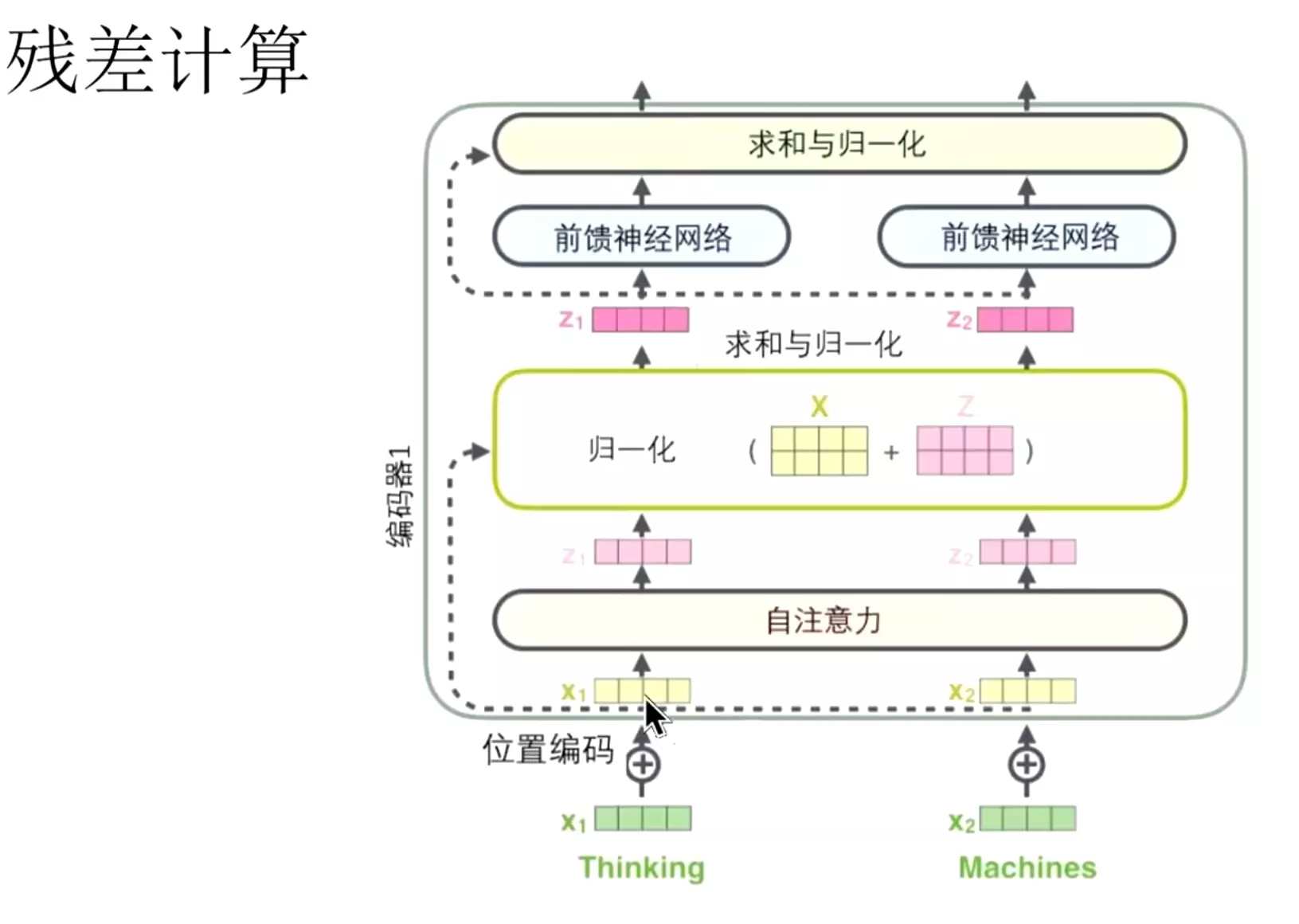
#就是输入的词向量。然后过一个自注意力机制,得到Z1,它的归一化就是用残差去计算,会把x和和Z相加,然后去进行一个归一化。这个做法和图像领域的ResNet的做法是一样的,输入和输出相加一下,然后在进行归一化。在前馈神经网络也有一个求和与归一化,类似于残差的模块。![]()
#整体的编码器和解码器做法。编码器都是自注意力加上求和与归一化、然后是前馈神经网络加上求和与归一化;在解码器有一点区别:前面的注意力机制是一样的, 但是会mask掉一些信息,第二个![]() 是一个编码解码注意力层,他会利用到编码器的输出也会用到它上一层的输出,然后再过一个求和和归一化。然后是前馈神经网络加上求和与归一化。然后过一个线性层
是一个编码解码注意力层,他会利用到编码器的输出也会用到它上一层的输出,然后再过一个求和和归一化。然后是前馈神经网络加上求和与归一化。然后过一个线性层![]() 再做一个softmax
再做一个softmax
![]()
#看一想解码器的第二个注意力层,它的query来自于前一个层decoder的输出,key和value来自编码器的输出。![]()
#它的query来自于前一个层decoder的输出;然后它的k和v来自于encoder的输出,这个就是encoder-decoder attention layer编码-解码注意力层,也就是同时利用编码和解码的注意力。![]() #输出的话就比较简单的,就是一般都是过一个线性层,映射到分类的类别的数量,然后过一个softmax,就得到概率。
#输出的话就比较简单的,就是一般都是过一个线性层,映射到分类的类别的数量,然后过一个softmax,就得到概率。
##以上就是transformer的结构。以及输入输出和attention机制。attention也是内容最多的一块。
![]()
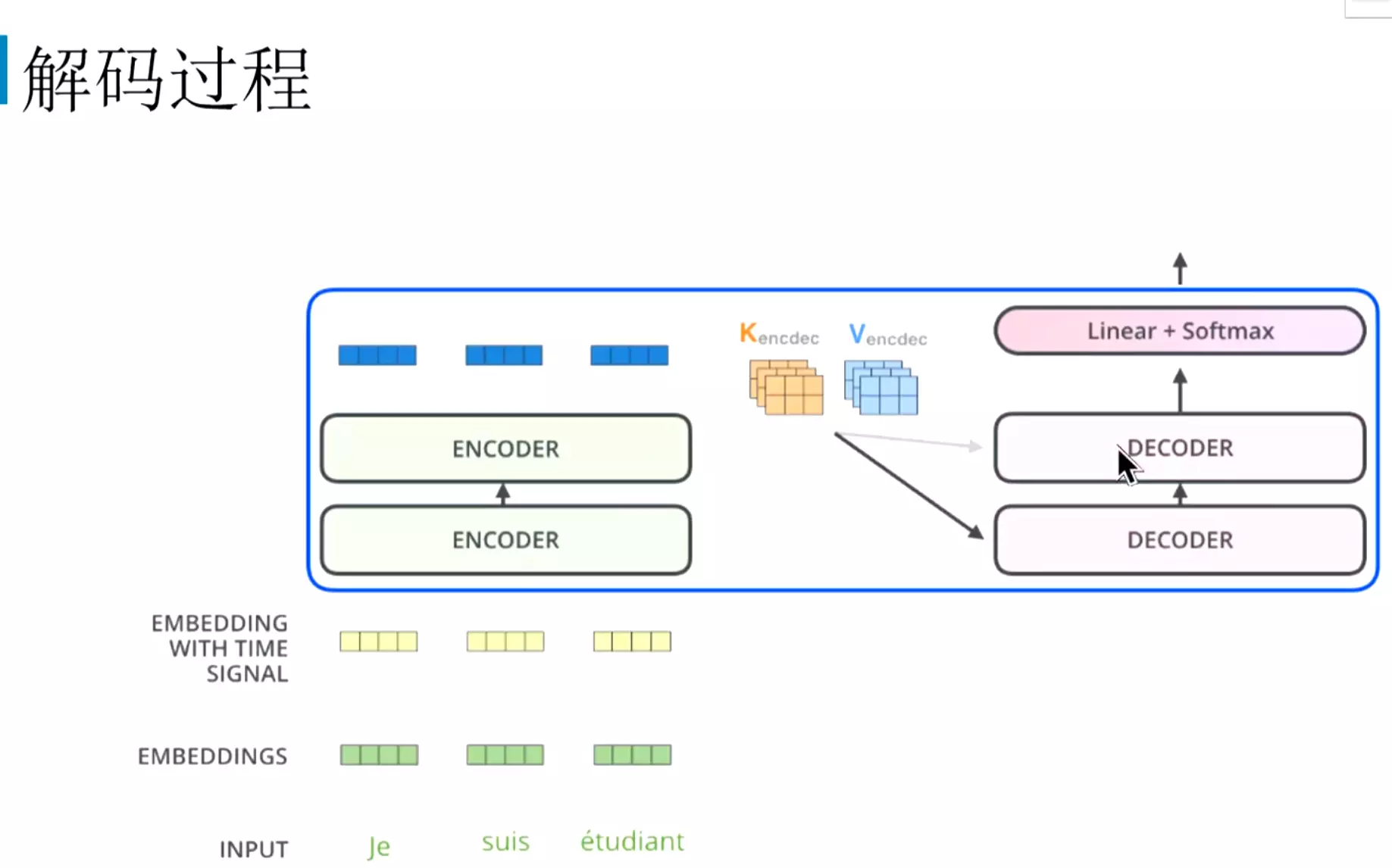
#问:![]() ?答:如果是生成是的任务。会有一开始的token,一般做生成,会给一个起始符。然后到第二个时间步的话输入就是上一个时间步的输出
?答:如果是生成是的任务。会有一开始的token,一般做生成,会给一个起始符。然后到第二个时间步的话输入就是上一个时间步的输出![]()
#bert模型结构
#Bert是基于transformer的双向编码器。双向表示在处理一个词的时候,能同时考虑前面和后面的单词的信息,从而能获取上下文的一个语义。论文当中有两种模型,一种是那个base,有三个比较重要的参数l h a,不是我们经常去调整的。L是层数,就是使用了12个transformer块,然后H是隐藏层,隐藏层的尺寸就是transformer内部的一个维度,也算是一个尺寸;A就是上面讲的多头注意力机制的头。
![]()
#具体结构是这样![]() 这个Tm就是transformer模块;经常和bert对比就是GPT也是transformer模块;还有一个是ELMO,它是双向的LSTM拼接而成,企图同时获取上下文的语义信息。
这个Tm就是transformer模块;经常和bert对比就是GPT也是transformer模块;还有一个是ELMO,它是双向的LSTM拼接而成,企图同时获取上下文的语义信息。
#看bert和gpt的区别:bert其中同时跟前面的transformer和后面的transformer能链接起来,也就是能关注到上下文的语义;而GPT只能关注对前面的已经出现的文本信息,![]() ;双向transformer在文献中通常称为transformer编码器。而只关注左侧语境的版本,经常会用来做文本生成,像这个GPT就是transformer解码器。写小说的就是用GPT3写的。
;双向transformer在文献中通常称为transformer编码器。而只关注左侧语境的版本,经常会用来做文本生成,像这个GPT就是transformer解码器。写小说的就是用GPT3写的。![]()
#bert比较巧妙的预训练任务。在word2vec里有一个任务是用中心词预测周围的词,训练收敛后拿到权重矩阵可以使用。而bert里设置了两个任务:一个是同时处理词级别的标注任务,一个是处理句子级别的任务,比如说问答。就是这两个任务:![]() 。第一个是MLM任务。
。第一个是MLM任务。
#之前的语言模型,比如在某个时刻要预测这个单词只能根据前面出现的单词计算它的概率,但是它后面也是有文本数据的,后面的数据用不上,没有办法同时利用双向的信息。而上面提到的ELMo只是用两个单向的RNN构成语言模型的拼接,用两个目标函数拼接的,一个是前面词一个是后面词的信息,只能分别进行计算,再拼接,这样就没有办法同时处理上下文信息,只是号称能处理而已。![]()
#bert模型预训练一
#而bert是这样训练的:他会在中间抠掉一个词,P(wi|w1...wi-1,wi+1,...wn)再去训练这个语言模型。具体是怎么做的呢?就是随机去掉句子当中的一些词,然后用模型来预测被去掉的词是什么,随机操作是随机把语料这种15%的这个词覆盖掉,然后预测这个被覆盖的词。然后去进行一个编码后,把mask token位置的隐藏层输出的向量,送进softmax就可以进行一个预测,预测是哪个词的概率最大。当然这样做是有一定问题的,直接去把这个词mask掉,这是在训练的时候,但是在做任务时在别的任务上预测和微调的时候,是不匹配的,因为我们没有这个mask标志。
![]()
#原来是将选中15%的词给他mask掉;现在采取的策略是选中的词的80%mask掉,选中的词的10%用任意词来代替,选中的词的10%不发生变化
![]()
#bert模型预训练二
#还有一个比较鸡肋的任务就是Next Sentence Prediction。就是输入的是两句话,需要去判断这两句话是不是正常的顺序,就是在训练的语料当中,第二句话是否是第一句话的下一句。如果是,它就是一个正样本,如果不是,它就是负样本。
#现在好多模型不用这个方法了,因为太过简单和低效,模型学不到东西。
![]()
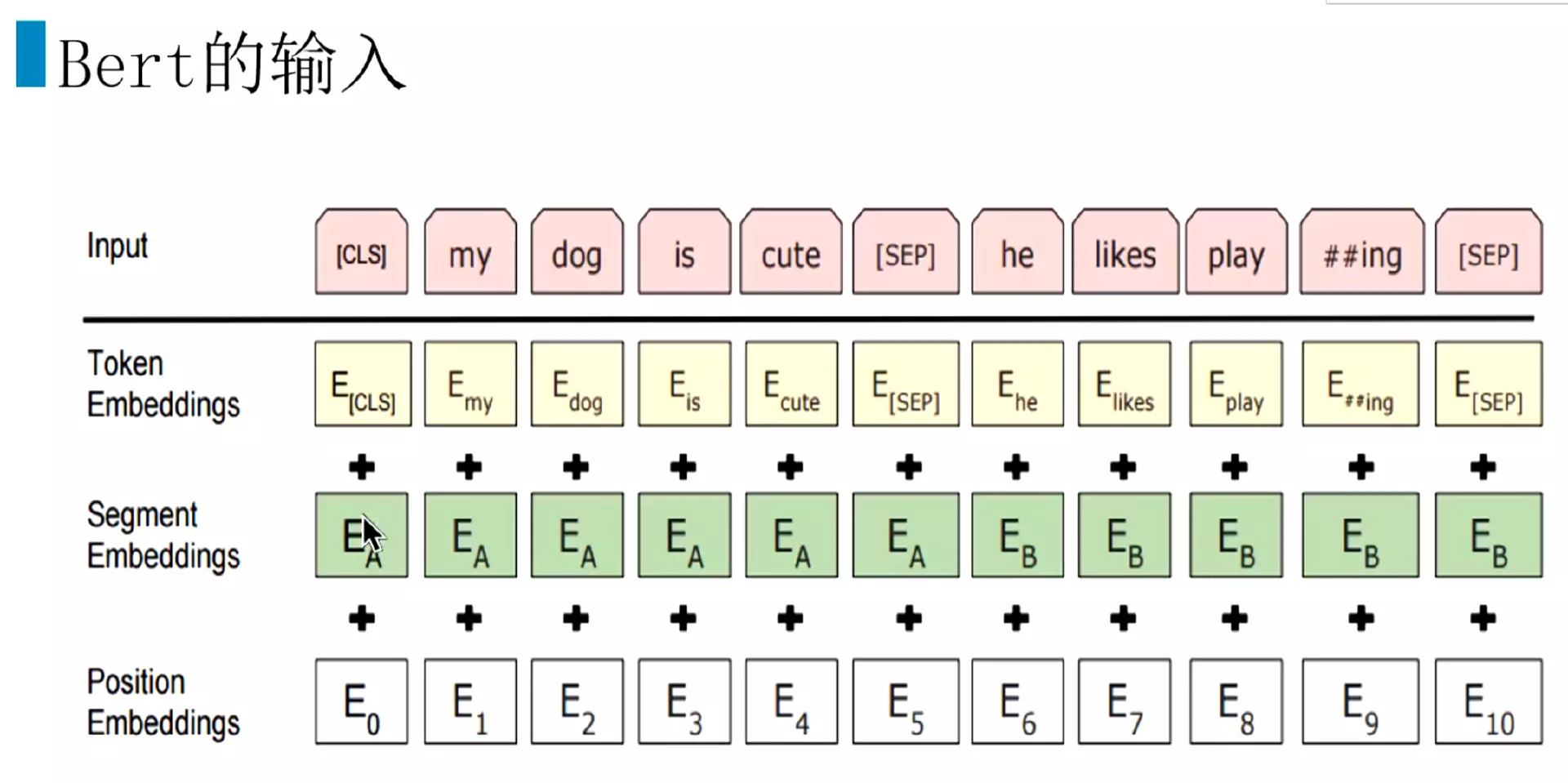
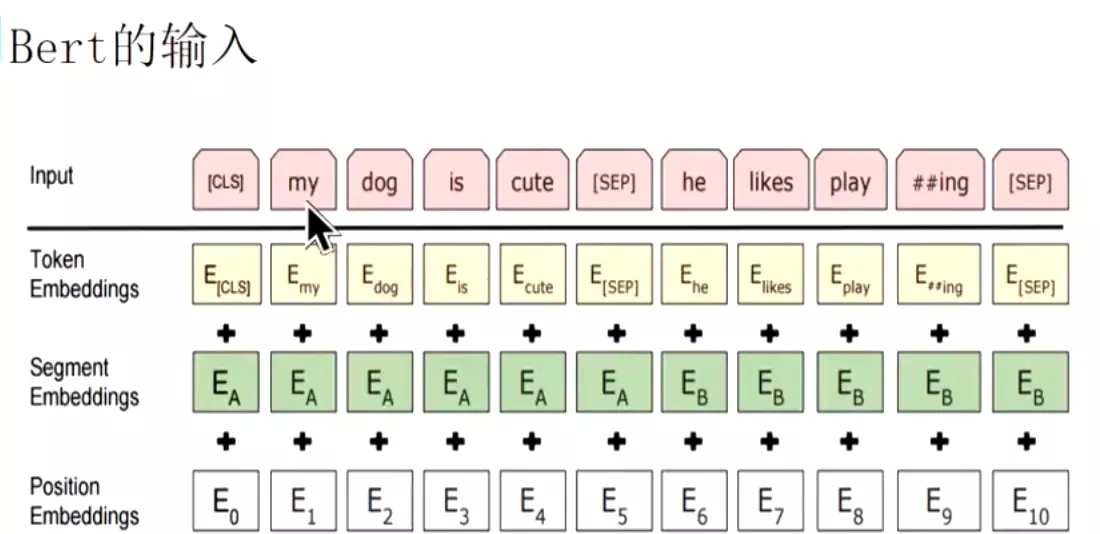
#下面讲一下bert的输入,做的比较好。transformer的输入是词向量加上他的位置编码。而bert的输入是由两个句子用【sep】这个符号拼接起来的,但是在微调的时候可以输入一个句子。第一个输入是词向量,第二个是在输入的时候也要区分两个句子,所以加了一个断向量;第三个就是位置向量。
![]()
#输入,先是词向量Token Embeddings,然后是断向量Segment Embeddings比如Ea表示第一个句子,Eb表示第二个句子。然后在加上位置向量Position Embeddings。
![]()
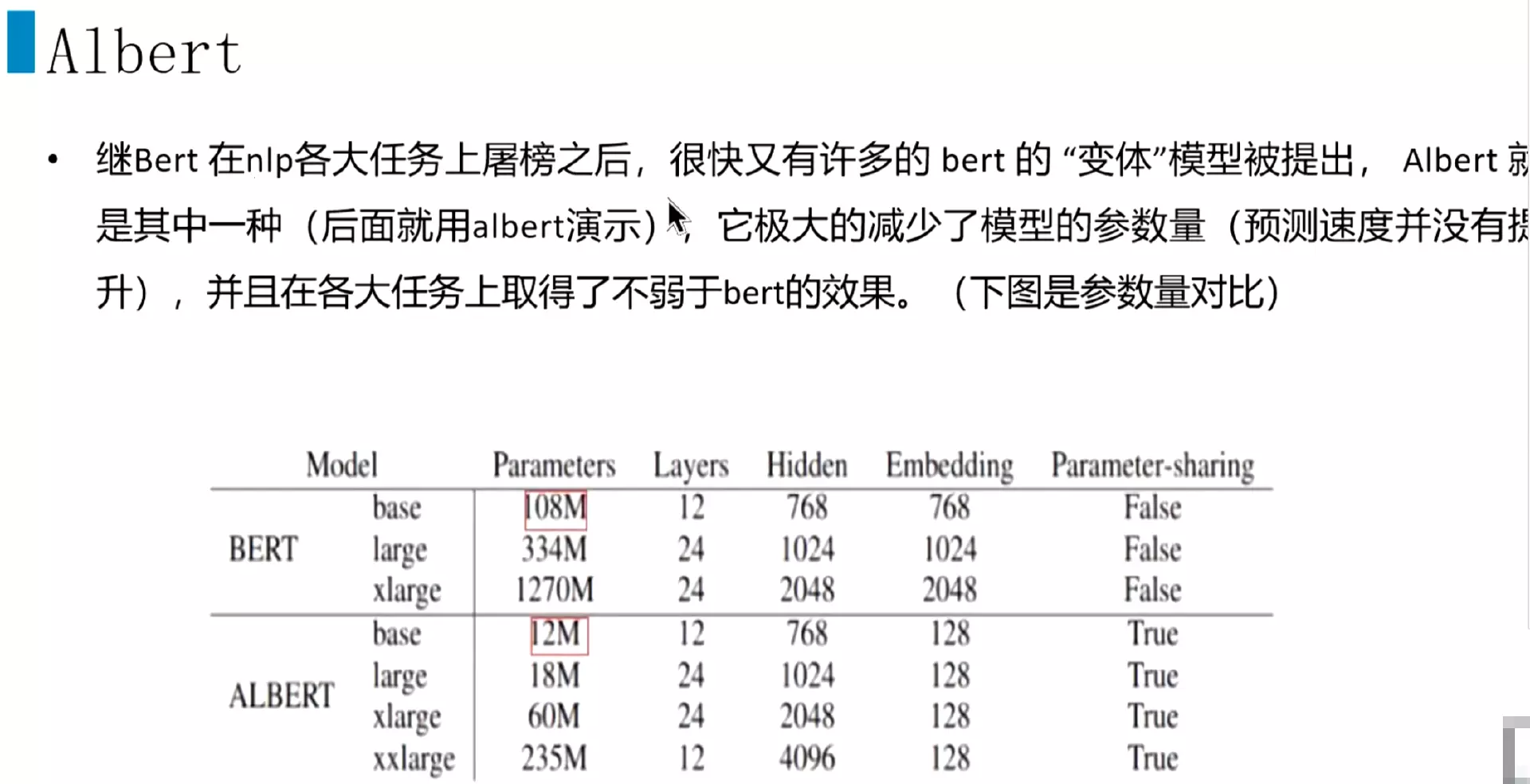
#继bert在各大任务上屠榜之后,就有很多魔改的一些模型被提出来,有的时候在有些任务方面更牛逼。像这个Albert就是其中一种,因为这个bert的参数量比较大,参数大小应该有300多兆,电脑加载到内存里面的话就会更大一些。所以Albert就是首先这个参数量降下来,结构不改的情况,参数确实降下来了,只是说他的预测速度并没有提高。这个Albert在各种任务上面的效果也还不错,并不比bert差,看一下对比图。
#bert的base版本是108M,用的很少。基本上都是用的是334M的版本;xlarge是1270M,可能你的电脑就扛不住了。然后看Albert就相当的袖珍,base版本只有12M,large版本也才18M,xlarge版本也就60M,这个大小的版本是比较好的,内存占用不那么大了。
#Albert在bert基础上做了几个改动。第一个是矩阵分解。
![]()
先看代码里面做embedding的时候,在做训练是会初始化一个embedding就是把词表的大小乘以一个隐藏层的大小,得到一个矩阵,这个矩阵就比较大。然后把输入乘以这个矩阵,映射到隐藏层的大小。我们还做了过滤,这个词就3W多条过滤到1000多条。但是实际上在做的时候维度往往是几十万的维度。![]() 实际上可能是30万*768,对机器的性能要求是相当高的。
实际上可能是30万*768,对机器的性能要求是相当高的。
![]()
#Albert通过矩阵分解讲大的矩阵改成一个小的矩阵。它加了一个E去分解矩阵,先把V*E把V映射到一个更小的维度,然后再把这个E映射到H上,如果E远远小于H,例如![]() 这样就减少了很多参数。比如词汇表是2万,20000*768就是1536万,比如用128去拆解矩阵,这样就变成265万左右,降低了很大参数量。
这样就减少了很多参数。比如词汇表是2万,20000*768就是1536万,比如用128去拆解矩阵,这样就变成265万左右,降低了很大参数量。 ![]()
#光有矩阵拆解是不够的,还有一个操作是跨层参数贡献。
#bert模型的base版本是有12个transformer块,每一个transformer块参数都不是共享的,每个参数都是不一样的。而Albert就是把所有块的参数进行共享,有三种共享方式。
#第一种共享是只共享attention的相关参数;还有一种是只共享前馈层FFN的参数;第三种是共享所有参数。
#所有层的参数都去共享,E=128是拆解的矩阵。
#所有参数贡献时的参数是12M,![]() 这是一些任务,
这是一些任务,![]() 这些是机器阅读理解,还有MNLI。后面是平均分数,可以看到最小的模型第一行的平均分数是80.1,还可以。第二个是贡献注意力的参数,它的大小是64M,平均分数是81.7,是最高的。第三个只贡献前馈层,效果就不明显。第四个参数不共享时参数大小是89M,参数量最大,效果和共享注意力的差不多。
这些是机器阅读理解,还有MNLI。后面是平均分数,可以看到最小的模型第一行的平均分数是80.1,还可以。第二个是贡献注意力的参数,它的大小是64M,平均分数是81.7,是最高的。第三个只贡献前馈层,效果就不明显。第四个参数不共享时参数大小是89M,参数量最大,效果和共享注意力的差不多。
![]()
#还有一个改进是,上次讲BERT有一个Next Sentence Prediction任务,就是NSP任务,是一个比较简单的任务,模型很难通过这个任务去学到一些东西,因为在某些任务上NSP任务还有伤害,损失函数没有贡献。很多bert模型在预训练过程中放弃了NSP任务,因为他对下游任务效果没有带来提升。改用SOP任务作为预训练任务。
#SOP任务正样本和NSP任务一样,就是两句话的顺序是否是对的,反例就是判断这两句话是否是颠倒过来了。看一下性能对比,None是不加句子顺序判断的任务,平均分数大概是79%,加了NSP任务后只提升了0.2%点,加了SOP之后提升了1个点。一个点的提升就是非常不错了。
##Albert就在bert基础上做了上面两个改动,模型结构都差不多。
###补充之前的RNN的dataset:![]()
#dataset会把数据处理做成一个统一的方式,便于更方便的去读代码。
#dataloader能在内存是读取数据上有一个优化,能并行的去读。
![]()
#数据处理,一个是 UNK = '[UNK]'就是处理数据时一句话每一个字的去词典里找它的index,没找到的话,就用UNK的index来替代。PAD = '[PAD]'由于数据时不同长度的,我们设定的是一个句子的长度,例如869这个句子,如果下一个句子的长度不够,就要PAD的index去填充;如果290这句话超过了限定的长度,就给它截断。![]()
#pad_size是设定的最大长度,超过这个长度的句子就截断
#然后遍历每一个字,从word2id词表中找到它的index,这里是字典的get用法, t_id = word2id.get(token,word2id[UNK]) #如果找到了,就用这个词的index,如果一个词的index没在词表中找到,就用UNK token的index替代
#if len(token_ids)< pad_size:如果小于设定的pad_size,就用[PAD]的index填充。
###Albert实例:![]()
transformers会把很多注意力机制的模型集成到这个包里面,非常好用。BertTokenizer是分词的包。AlbertModel是Albert包。
![]()
#hugging face里搜索模型,可以找到model。![]()
#打开后可以看到简单的介绍。![]()
#可以看到它的一些模型结构,可以下载下来。
![]() 这是pytorch的模型,
这是pytorch的模型,![]() 这是tensorflow的模型。
这是tensorflow的模型。![]() 这是参数。
这是参数。![]() 这是词表。
这是词表。
![]() #再去加载dataset和data loader
#再去加载dataset和data loader
![]()
![]()
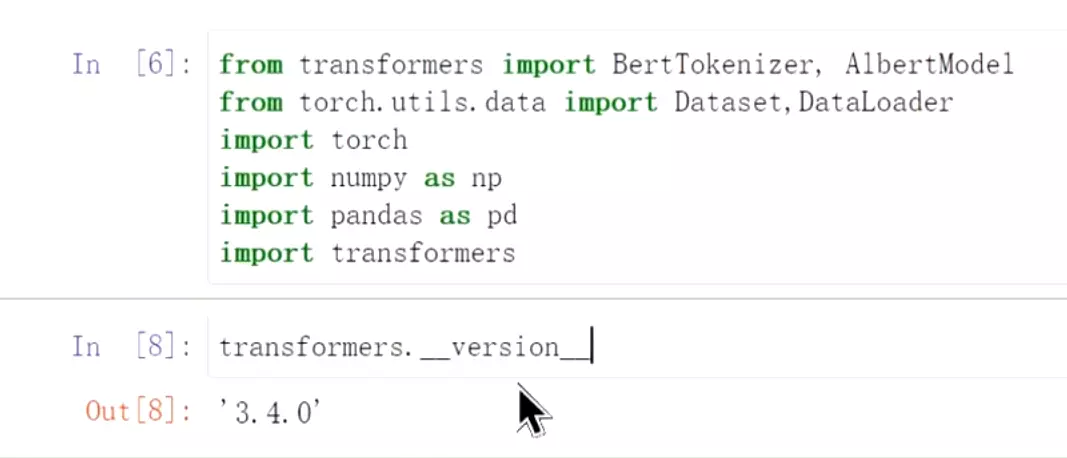
#数据还是之前的股票的新闻。正面和负面新闻的分类做演示。transformers比较大的版本可能会存在一些bug,t用的是3.4.0;![]() 如果新版本报错的话,可以把版本退到3.4.0,比较稳定一些。
如果新版本报错的话,可以把版本退到3.4.0,比较稳定一些。![]()
首先从预训练的模型中加载模型,已经下载了![]() ,一个是albert_chinese_small一个是albert_chinese_tiny。
,一个是albert_chinese_small一个是albert_chinese_tiny。
![]() 一个是模型参数、一个是模型词表
一个是模型参数、一个是模型词表
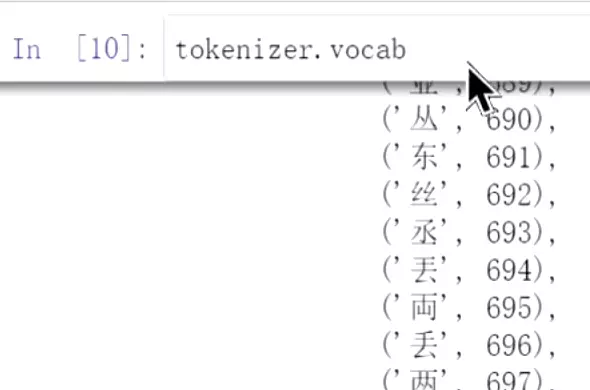
#可以看到词表的词,跟我们之前自己做的词表没什么区别。
![]()
![]() 我们就不用之前一样费力写很多词表了。预训练模型里面就包含这些词表。
我们就不用之前一样费力写很多词表了。预训练模型里面就包含这些词表。
![]()
#看一下,总共有21128个词。
#如何使用?和之前的jieba不一样,jieba是给他分成词。这个tokenizer是给他分成单个单个字。![]()
#看一下分词后的效果![]()
#分完词之后要给他转换为index![]() #用t1 = tokenizer(sen1) 直接调用它。
#用t1 = tokenizer(sen1) 直接调用它。
#input_ids就是在词表中index。这里注意原来是7个词,这里的input_ids是9个词,多了两个词。多的两个词是?101和102.可以看一下bert输入和输出![]() ,多出来的两个就是前面一个[CLS]后面一个[SEP]。[CLS]表示分类,就是分类的标签,一般那第一个[CLS]做分类,当然效果不是很好,以后还有几种做法会将。[SEP]表示两句话的间隔。
,多出来的两个就是前面一个[CLS]后面一个[SEP]。[CLS]表示分类,就是分类的标签,一般那第一个[CLS]做分类,当然效果不是很好,以后还有几种做法会将。[SEP]表示两句话的间隔。
#token_type_ids就是区分两句话的;attention_mask就是需要关注的词,1就是需要关注的,不需要关注的例如PAD填充的就是0![]()
#看一下是什么,一个句子输入进来前面会加一个[CLS]后面加一个[SEP]![]()
#看一下attention_mask的作用,它是按照最长的一句话来填充其他句子的。所以后面两句话不够长的地方就是用0来填充的,所以attention_mask就是0.![]()
![]()
#看一下,tokenizer可以直接编码两个句子。输入两句话,判断是否是相似,就像它的预训练任务一样![]() ,会把两句话拼接起来一起放到模型里去训练。我们在做模型微调的时候也可以同时把两句话放进去,然后用token_type_ids来做区分。
,会把两句话拼接起来一起放到模型里去训练。我们在做模型微调的时候也可以同时把两句话放进去,然后用token_type_ids来做区分。
![]() #用t1进行Albert测试,先加载模型
#用t1进行Albert测试,先加载模型![]()
#报错![]()
#所以重新加载,让它返回的是tensor
![]()
#然后把t1直接放到模型中,得到这样一个向量输出。
![]()
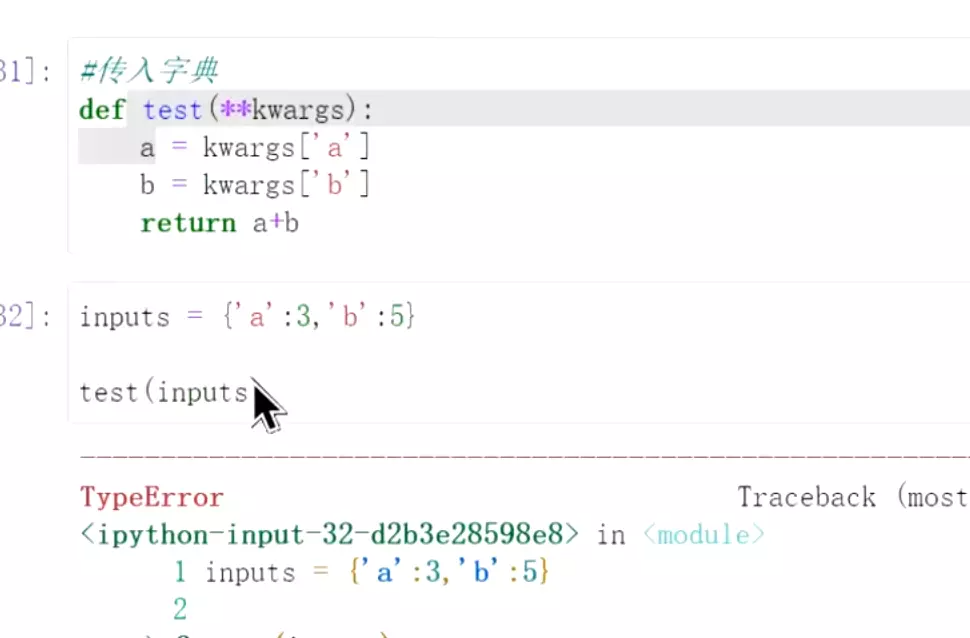
#让输出的返回一个字典;
#**t1用法:这个就是python函数里的超参数。![]() #直接传过去这个inputs字典是不行的,
#直接传过去这个inputs字典是不行的,![]() 用**去分配就可以传过去。这是使用的一个技巧。
用**去分配就可以传过去。这是使用的一个技巧。
![]()
#看一下output返回的key值。last_hidden_state是最后一层隐藏层状态,pooler_output是池化后的输出。![]() #看一下shape,1表示batchsize,9表示训练的长度,384就是向量的大小
#看一下shape,1表示batchsize,9表示训练的长度,384就是向量的大小![]()
#看一下第一个,这是一个token的向量![]()
#看一下大小是384;我们一般用的bert向量的维度是768,这个是其他大佬自己定义的形状,所以他的维度是384。
![]() #再看一下pooler_output的向量,它表示最后一层隐藏层向量的第一个向量(CLS token的向量),经过一层线性层和一个tanh 得到。它是通过nsp训练得到
#再看一下pooler_output的向量,它表示最后一层隐藏层向量的第一个向量(CLS token的向量),经过一层线性层和一个tanh 得到。它是通过nsp训练得到
#在直觉上我们用pooler_output效果应该会好一些,但是实际上它的效果是比较一般的。一般会直接去拿最后一层隐藏层last_hidden_state的第一个向量去做下游的任务。或者说把最后一层隐藏层的向量加起来取平均再做下游的任务。pooler_output一般用的是比较少的。![]()
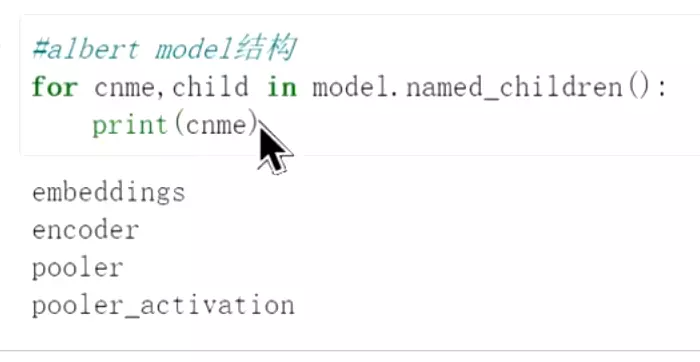
#看一下model的结构![]()
#model的结构一共分为这几个:一个是embeddings层,一个是encoder层,一个是pooler层,是线性层;一个是pooler_activation激活层。其中最关键的是encoder层。之前讲的bert是transformer的编码器,所以它取得是encoder。
![]()
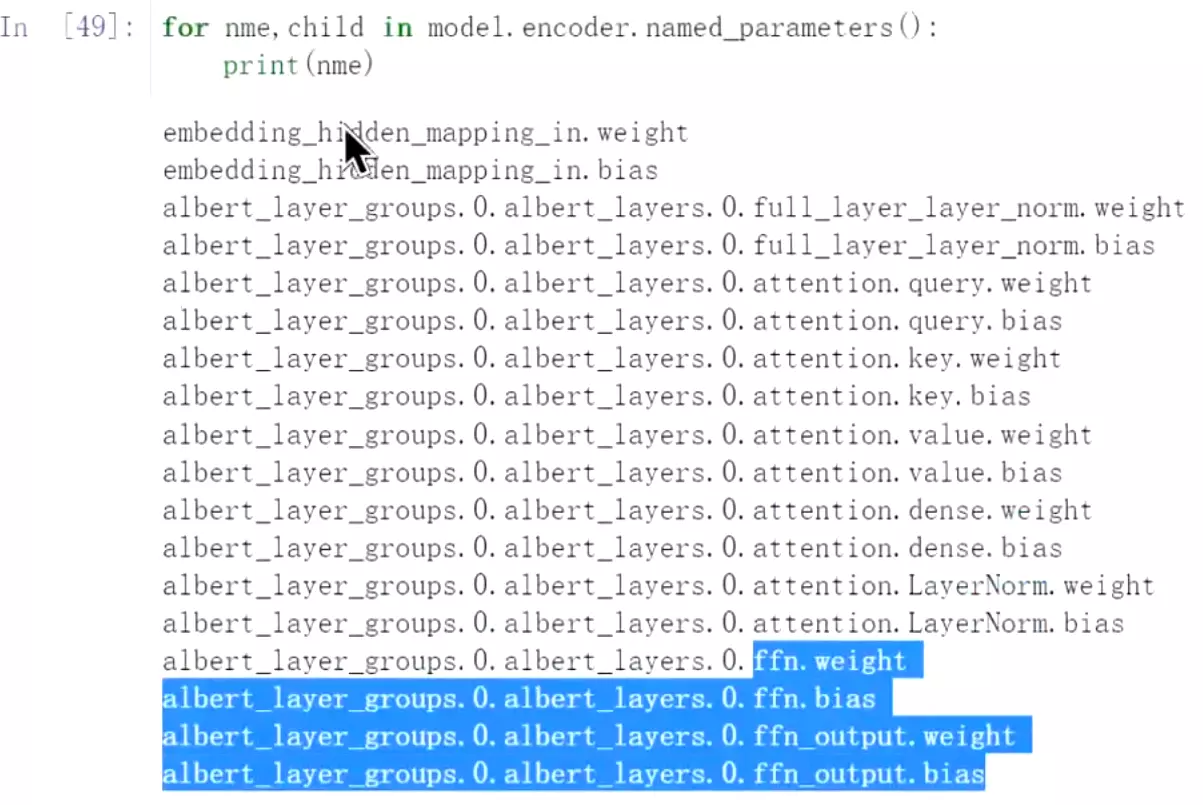
#看一下参数![]() 这个是隐藏层的初始化的向量w,下面是bias
这个是隐藏层的初始化的向量w,下面是bias![]() 这个是全连接层的w和b
这个是全连接层的w和b![]() #下面是q、k、v的w和b
#下面是q、k、v的w和b![]() dense是有一个前馈神经网络,是两个线性层堆叠起来的,就是dense
dense是有一个前馈神经网络,是两个线性层堆叠起来的,就是dense![]() 这个是层归一化的参数
这个是层归一化的参数![]() 这个是前馈层的参数。要更新的就是这些。
这个是前馈层的参数。要更新的就是这些。
#其实![]() embedding也可以更新,在做文本匹配任务的时候要去更新embedding层。
embedding也可以更新,在做文本匹配任务的时候要去更新embedding层。
![]() #sample(frac=1)用sample的方式打乱,frac=1就是所有的数据都进行采样。
#sample(frac=1)用sample的方式打乱,frac=1就是所有的数据都进行采样。
![]()
#构建一个新的dataset类,继承一下Dataset。self.texts = data['text'].values是因为读入数据是用pandas读入的做的dataframe,所以data['text'].values是把pandas一列数据变成numpy数组。
#一般这个类有两个方法:一个方法是返回数据的长度;第二个是__getitem__通过index获取文本和label。![]()
#再去构建一个Albert![]() 重新导入nn。def __init__(self, bert_model, hidden_size, num_class):把bert_model通过外边传进来hidden_size是隐藏层的大小。num_class是类别,我们需要把隐藏层的大小映射到类别上来。这里只放了model,也可以把tokenizer放进来,现在的写法比较随意一点。
重新导入nn。def __init__(self, bert_model, hidden_size, num_class):把bert_model通过外边传进来hidden_size是隐藏层的大小。num_class是类别,我们需要把隐藏层的大小映射到类别上来。这里只放了model,也可以把tokenizer放进来,现在的写法比较随意一点。
self.dropout=nn.Dropout(0.2)加一个dropout,给个0.2
self.fc1=nn.Linear(hidden_size,64)为了映射到2类, 先平滑处理一下,先把384维映射到64.
self.fc2=nn.Linear(64,num_class)再把64映射到2类
self.relu=nn.ReLU()然后给个激活函数。
#然后是前向传播。
bert_out=self.bert_model(**inputs)[1]先拿输出的pooler_out层的向量
bert_out=self.fc1(bert_out) 先过一个全连接层。
bert_out=self.relu(bert_out)再激活函数
bert_out=self.dropout(bert_out)再dropout一下,这个都是组合使用,顺序也可以打乱试试。
bert_out=self.fc2(bert_out)
#如果是之前的做法会加一个softmax,然后再映射。这里暂时不这么用,拿出来输出的值后面直接去处理。
![]() #然后设置参数,去把数据和模型加载进来:
#然后设置参数,去把数据和模型加载进来:
hidden_size = 384首先是隐藏层向量的大小是384
num_class = 2分类的数量是2
max_length = 32 就是最大的长度embedding
batch_size = 24
然后![]() 一共有1万多数据,拆分成训练和测试数据。
一共有1万多数据,拆分成训练和测试数据。
然后把两个数据灌到dataset里面来。数据就处理好了。
![]()
后面num_class是设置进程,如果是比较大的话,就会比较快;如果数据小的话,没有必要。
![]()
#加载模型
![]()
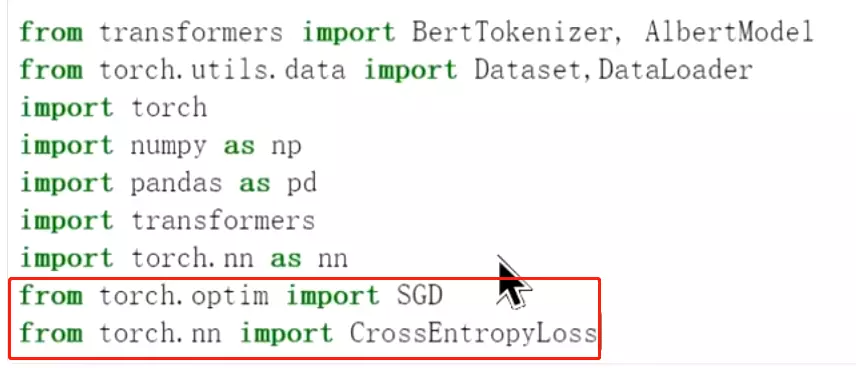
#看一下Albert的参数。![]() #在导入优化器和交叉熵损失包
#在导入优化器和交叉熵损失包
![]() #优化一下模型,把参数送到SGD优化器中。待查询SGD?
#优化一下模型,把参数送到SGD优化器中。待查询SGD?
#学习率是0.001,后面是动量和衰减等是对学习率进行优化的参数。待查询?
![]()
![]()
![]()
![]()
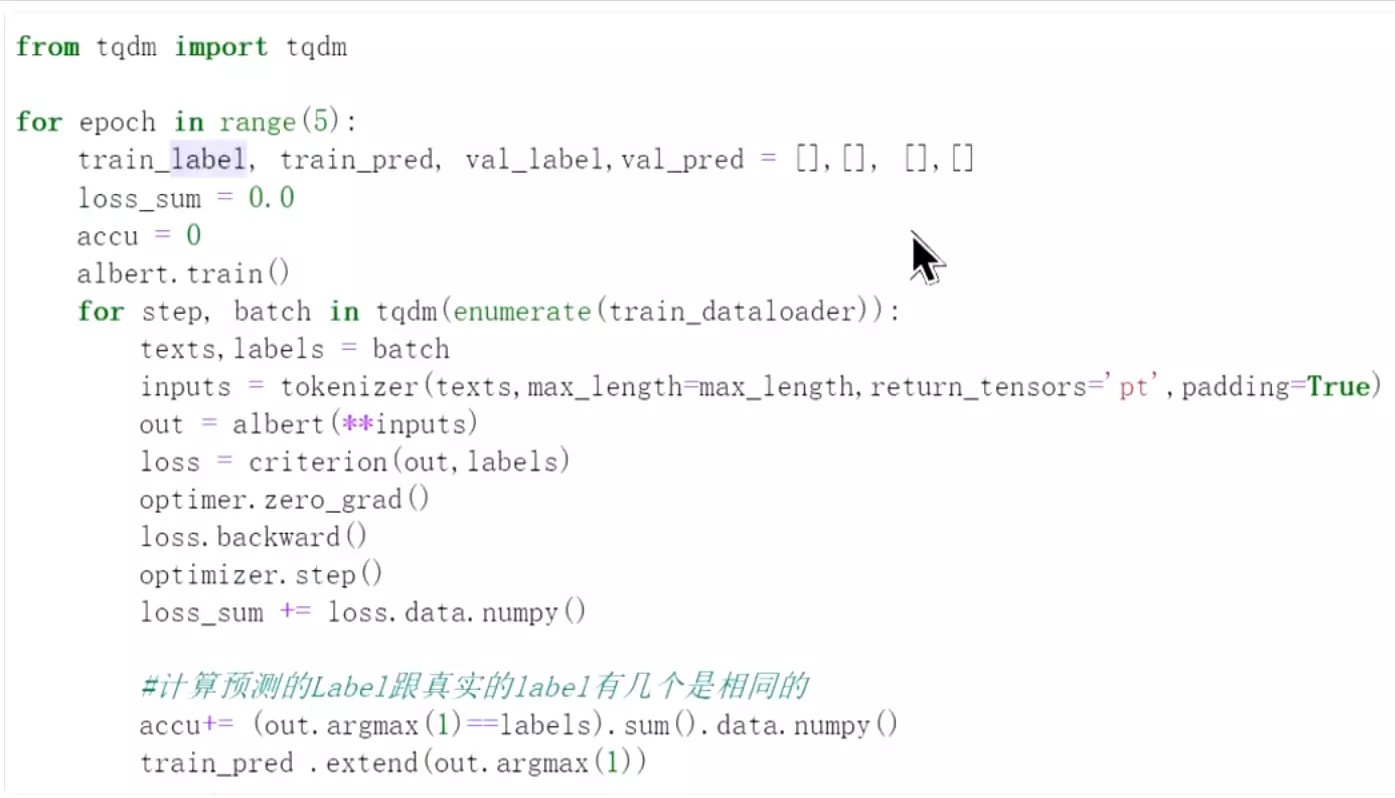
#开始训练,准备5个批次训练
![]() 这个是进度条,可以直观看一下进展
这个是进度条,可以直观看一下进展![]() 设置成训练的模式;
设置成训练的模式;![]() 通过batch拿到文本和label。
通过batch拿到文本和label。![]() 返回的类型指定一下。
返回的类型指定一下。![]() padding设为True。
padding设为True。![]() input经过tokenizer之后就是字典
input经过tokenizer之后就是字典![]() 直接计算交叉熵;
直接计算交叉熵;![]() 梯度进行初始化、重置
梯度进行初始化、重置![]() 损失进行反向传播。
损失进行反向传播。![]() 数据进行更新;
数据进行更新;![]() 由于loss是参与反向传播的,所以要把他的data拿出来,再转化成numpy格式。
由于loss是参与反向传播的,所以要把他的data拿出来,再转化成numpy格式。![]() #这里有一个技巧,是统计输出最大值,1表示只取最大的值。求和再去data再转化为numpy。这里就是统计输出值和label相同的有多少。
#这里有一个技巧,是统计输出最大值,1表示只取最大的值。求和再去data再转化为numpy。这里就是统计输出值和label相同的有多少。![]()
#可以看一下比较之后的结果是布尔值的列表。![]()
#求和之后就是2。![]() 损失和准确率都是是总的损失/准确率除以预测出来多少个数值
损失和准确率都是是总的损失/准确率除以预测出来多少个数值
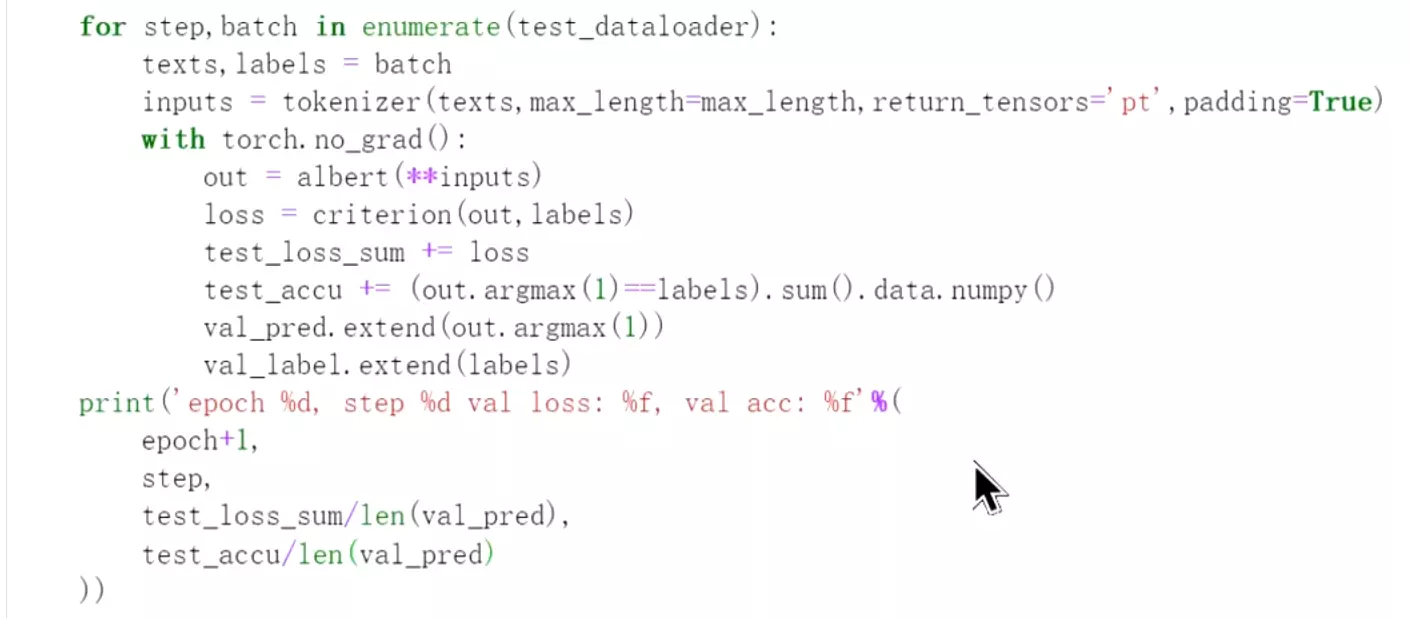
#训练完就在测试数据上评估:![]() 设置损失、准确率和测试模式。
设置损失、准确率和测试模式。![]() 在测试数据集上评估的话不用反向传播了。
在测试数据集上评估的话不用反向传播了。![]() 下面是计算损失、损失求和、准确率求和。
下面是计算损失、损失求和、准确率求和。![]() 把预测值也放进来
把预测值也放进来![]() 损失和除以预测的值得大小
损失和除以预测的值得大小
![]()
#运行,出现了一些bug,后面会补充正确的代码。上面的代码是整体熟悉一些bert模型的使用。











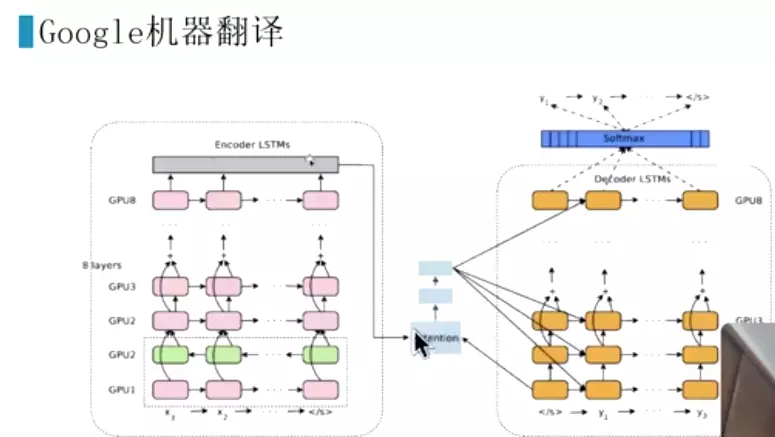



 中文里一般没有词的标准化,拉丁语系有
中文里一般没有词的标准化,拉丁语系有



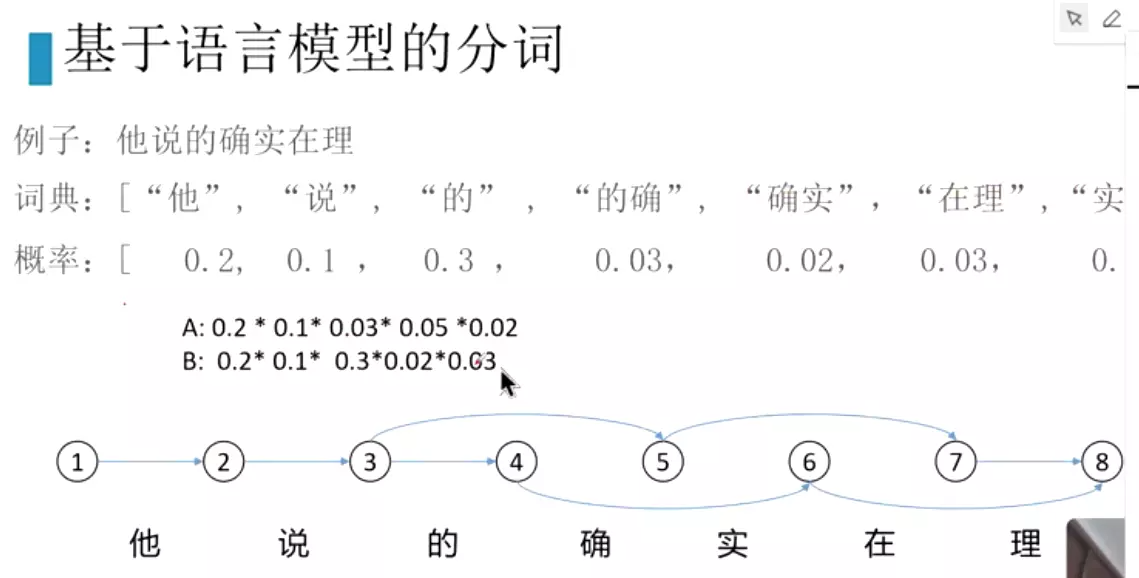

































 把所有词相加取平均,只有一些语义信息,但是没有顺序的信息。所以后面的RNN和bert会去处理顺序信息。
把所有词相加取平均,只有一些语义信息,但是没有顺序的信息。所以后面的RNN和bert会去处理顺序信息。 #把第一句话向量化。看出短文本还不错,效果比TF-IDF要好一些。
#把第一句话向量化。看出短文本还不错,效果比TF-IDF要好一些。


 skip-gram用的比较多
skip-gram用的比较多









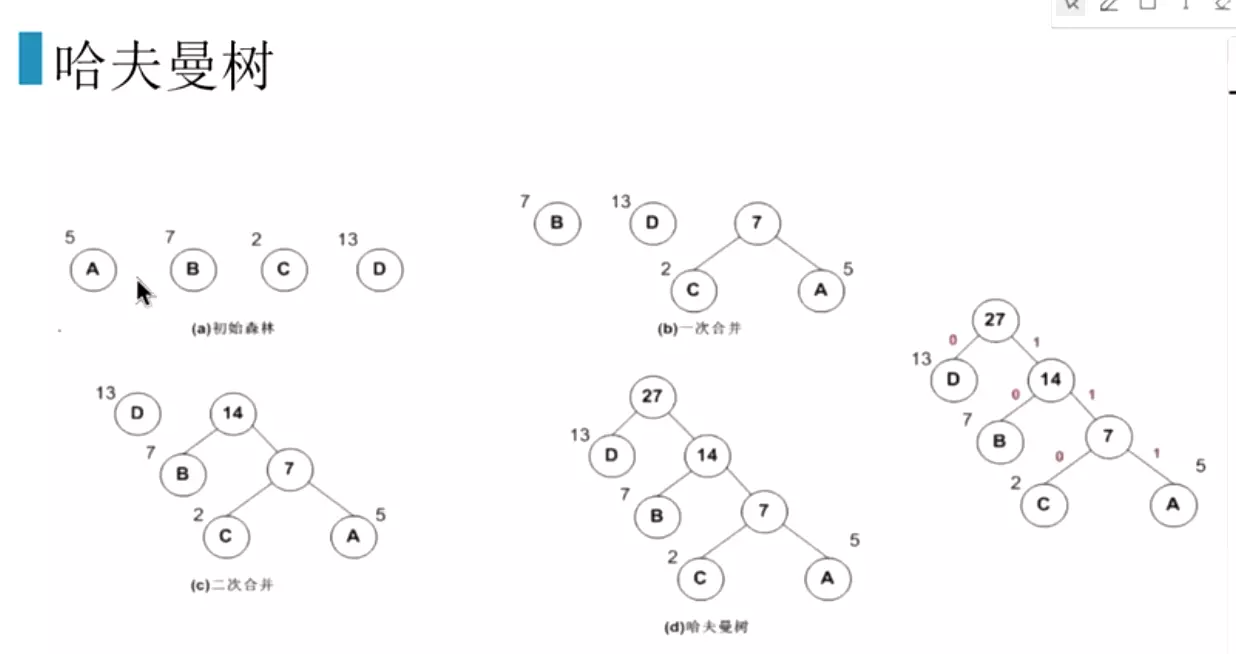

 就是右边输出部分,直接接一个哈夫曼树。
就是右边输出部分,直接接一个哈夫曼树。




 在训练数据集上做训练。
在训练数据集上做训练。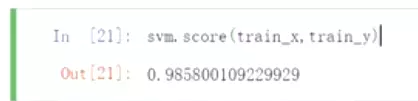
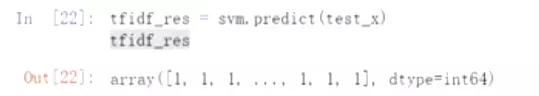



 shuffle=True打乱
shuffle=True打乱


 是一个纯粹的文本。
是一个纯粹的文本。










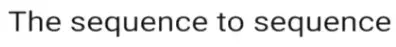 ,就是先把词分开,然后再组合。在机器翻译领域把错误率减少了?%。
,就是先把词分开,然后再组合。在机器翻译领域把错误率减少了?%。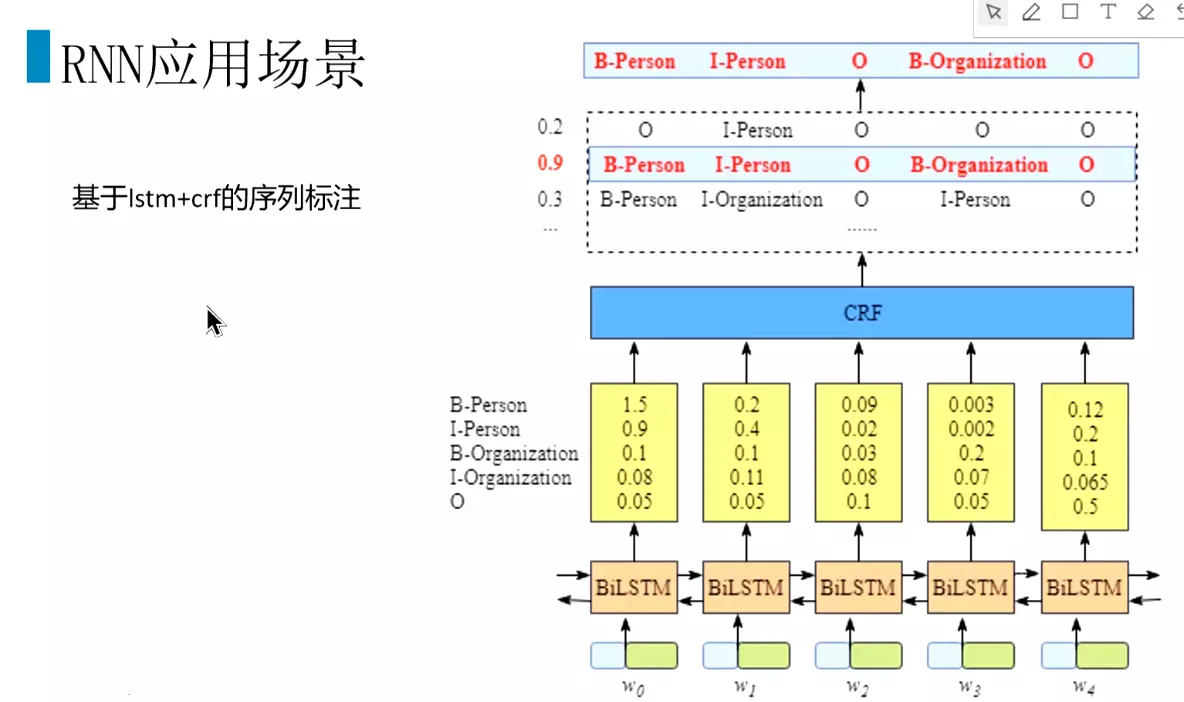













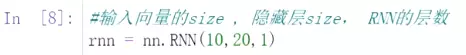 #构建一个RNN,Rnn的层数,
#构建一个RNN,Rnn的层数,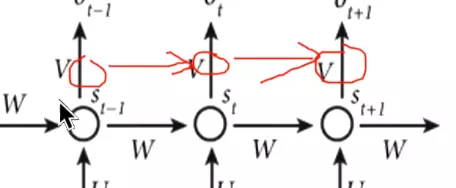 ,这里用1层,也可以用两层,后面就改为2。
,这里用1层,也可以用两层,后面就改为2。



 ,3是指这个序列有三个,比如输入是‘你是谁’
,3是指这个序列有三个,比如输入是‘你是谁’
 ,答:需要把训练的数据进行embedding,类似文本分类,先用word2vec或seq2seq把文本变成向量,再去传给分类器里,可以把RNN理解成分类器。
,答:需要把训练的数据进行embedding,类似文本分类,先用word2vec或seq2seq把文本变成向量,再去传给分类器里,可以把RNN理解成分类器。

 #查看output的size。5对应batchsize,3对应序列长度,20对应隐藏层大小,因为隐藏层是20,
#查看output的size。5对应batchsize,3对应序列长度,20对应隐藏层大小,因为隐藏层是20,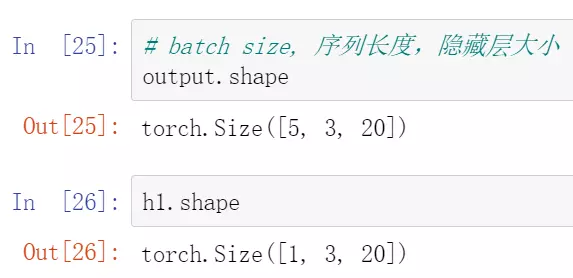
 #上面的h0,h1相当于隐层。
#上面的h0,h1相当于隐层。
 就像例子中的输入是3个字,这个长度需要固定住,不能变来变去。
就像例子中的输入是3个字,这个长度需要固定住,不能变来变去。 #重新展示这个参数,bidirection表示是否是双向RNN
#重新展示这个参数,bidirection表示是否是双向RNN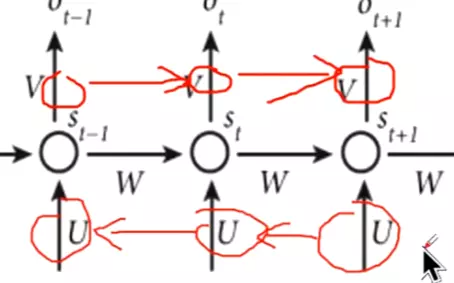 就是反向也传
就是反向也传





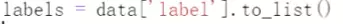 把label变成list;tokens
把label变成list;tokens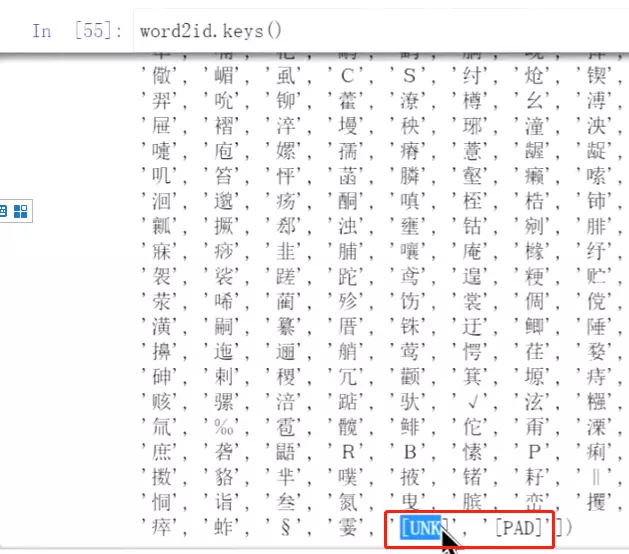

 #看一下没有在wordtoid词表中的词,这些词就用‘UNK’替代
#看一下没有在wordtoid词表中的词,这些词就用‘UNK’替代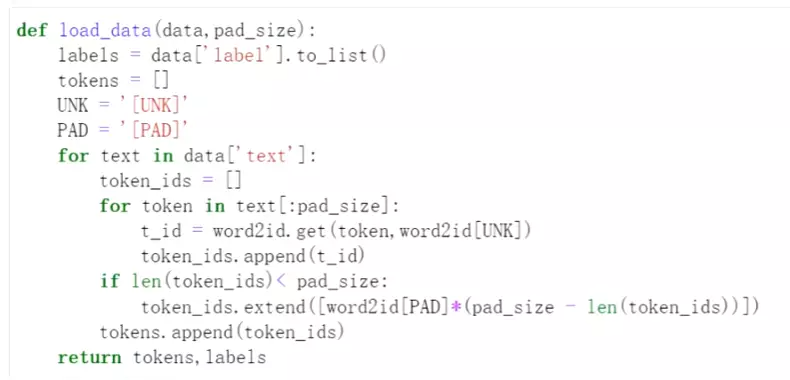
 #如果在词列表中没有的词用unk对应的value填充;
#如果在词列表中没有的词用unk对应的value填充; #如果不够长度,用pad的value填充。
#如果不够长度,用pad的value填充。 #get用法,没有取到的,给一个新值,如200
#get用法,没有取到的,给一个新值,如200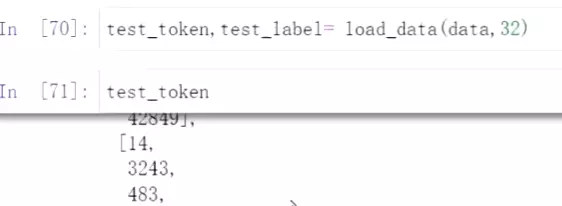
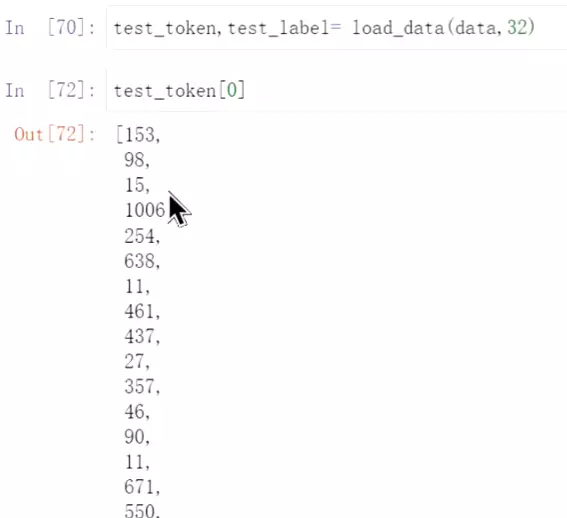
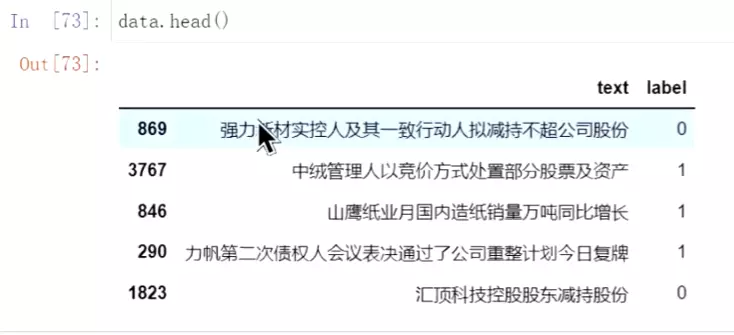 就是把第一句话所有的字找到对应的index。
就是把第一句话所有的字找到对应的index。





 就是去
就是去

 每个时间步有一个输入;
每个时间步有一个输入;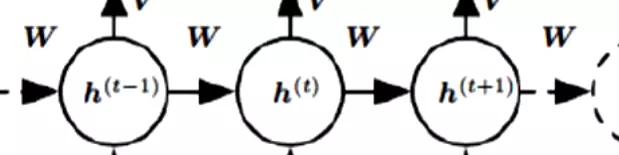 有一个隐藏层;
有一个隐藏层;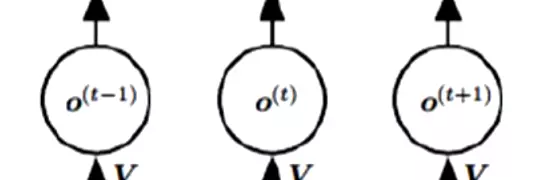 输出层;
输出层; 这里计算损失
这里计算损失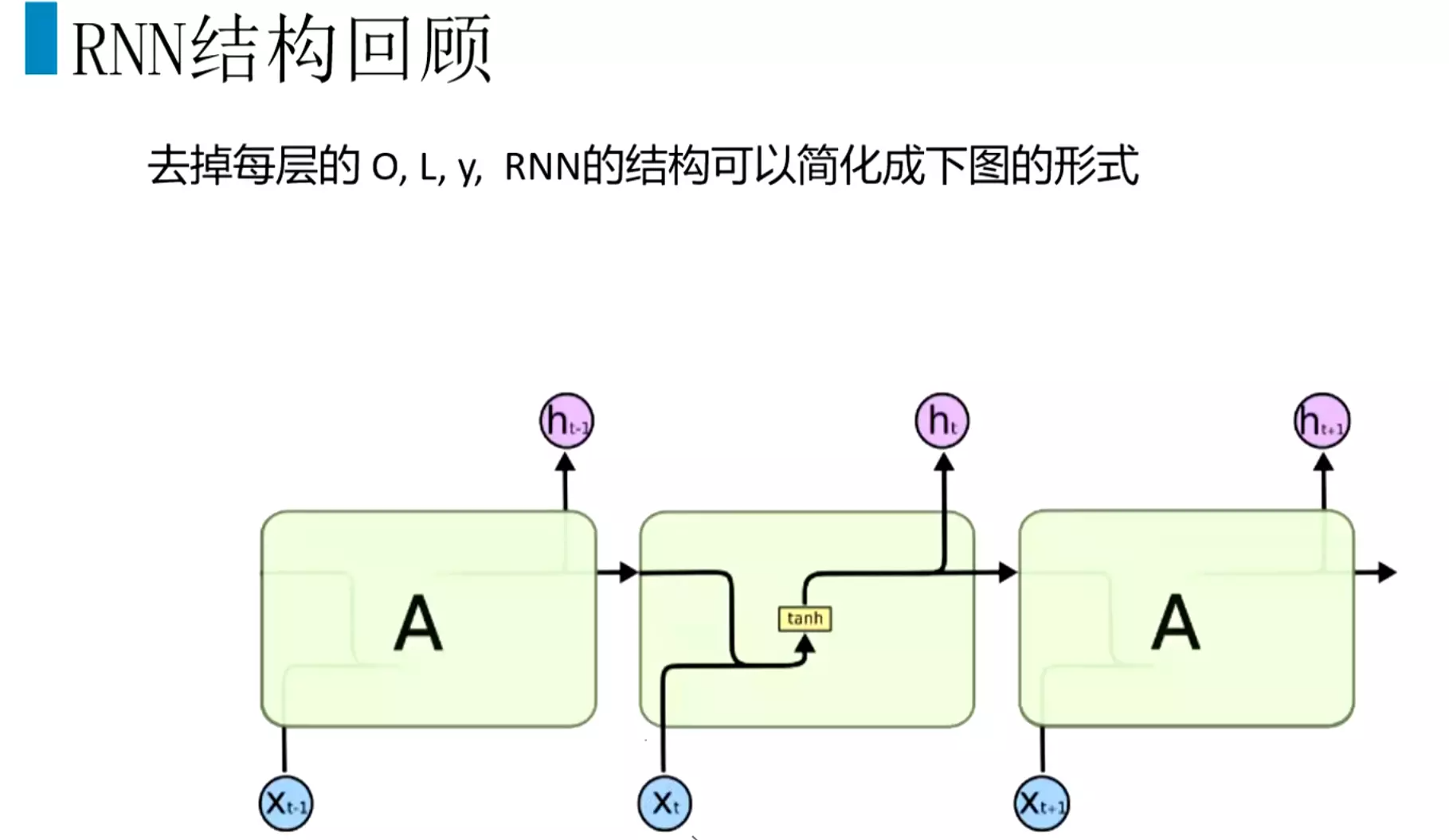




 #然后是更新门两部分的输出。然后通过遗忘门和更新门把细胞状态进行更新。
#然后是更新门两部分的输出。然后通过遗忘门和更新门把细胞状态进行更新。

 #课后自己推导一下,这里省略了很多步骤。
#课后自己推导一下,这里省略了很多步骤。




 #时间步长等于12。输入向量给1;
#时间步长等于12。输入向量给1;
















 开始的字符就是SOS作为输入的开始字符
开始的字符就是SOS作为输入的开始字符


 #词比较多,有2万个
#词比较多,有2万个













 #用thinking和每一次词得到的归一化结果,像0.88、0.12这些softmax再和v向量相乘之后,再去把v向量都求和。得到z,z就是注意力机制的输出。
#用thinking和每一次词得到的归一化结果,像0.88、0.12这些softmax再和v向量相乘之后,再去把v向量都求和。得到z,z就是注意力机制的输出。



 是一个编码解码注意力层,他会利用到编码器的输出也会用到它上一层的输出,然后再过一个求和和归一化。然后是前馈神经网络加上求和与归一化。然后过一个线性层
是一个编码解码注意力层,他会利用到编码器的输出也会用到它上一层的输出,然后再过一个求和和归一化。然后是前馈神经网络加上求和与归一化。然后过一个线性层

 #
#
 ?答:如果是生成是的任务。会有一开始的token,一般做生成,会给一个起始符。然后到第二个时间步的话输入就是上一个时间步的输出
?答:如果是生成是的任务。会有一开始的token,一般做生成,会给一个起始符。然后到第二个时间步的话输入就是上一个时间步的输出
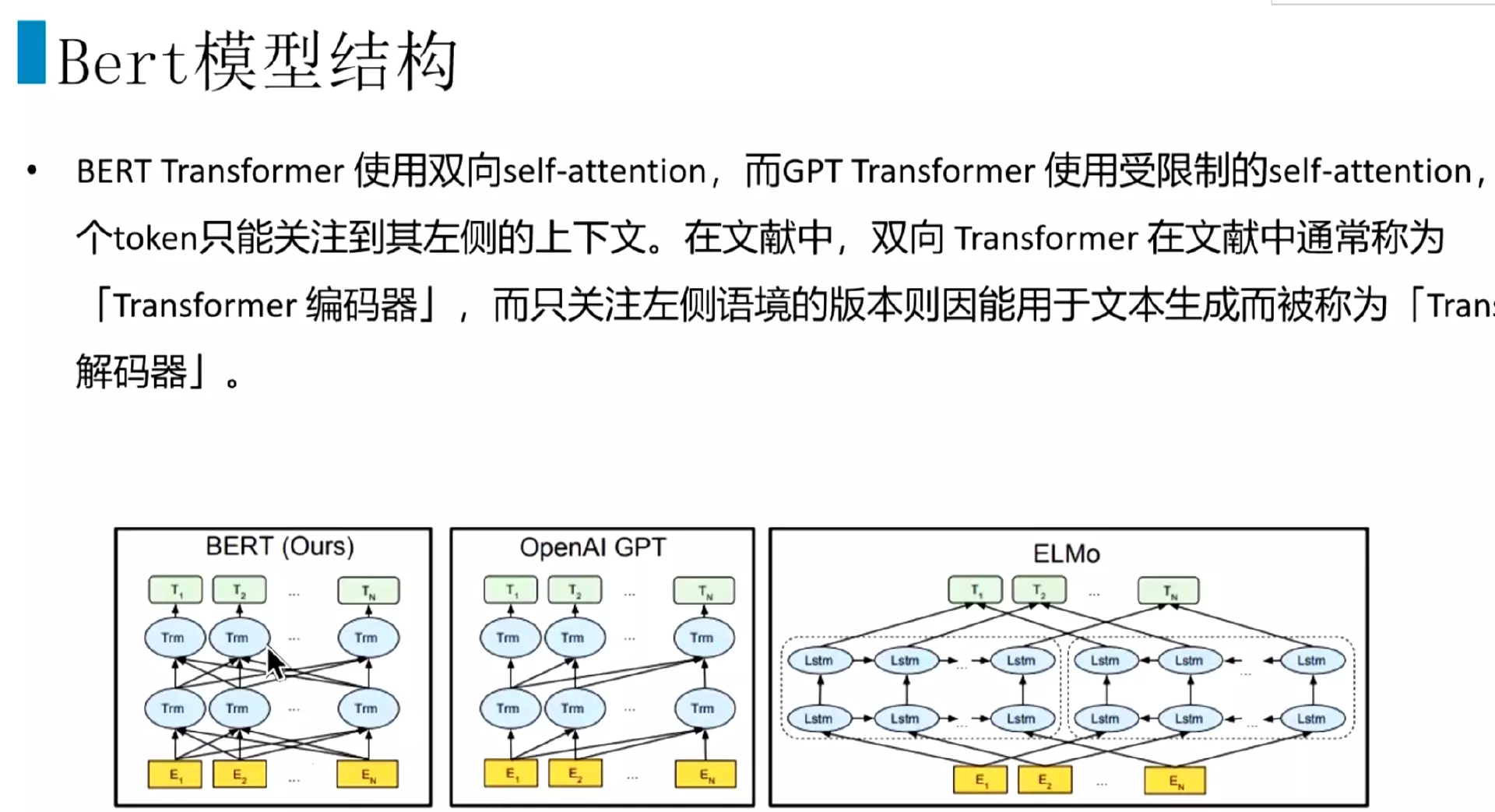
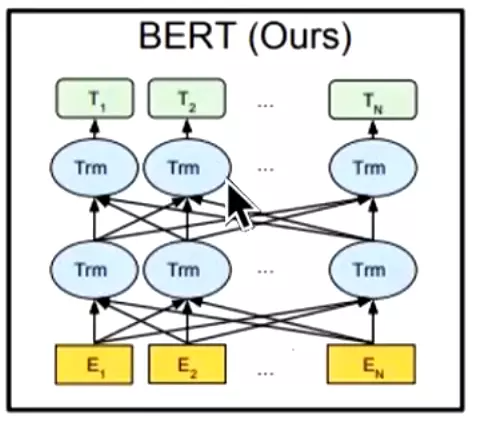 这个Tm就是transformer模块;经常和bert对比就是GPT也是transformer模块;还有一个是ELMO,它是双向的LSTM拼接而成,企图同时获取上下文的语义信息。
这个Tm就是transformer模块;经常和bert对比就是GPT也是transformer模块;还有一个是ELMO,它是双向的LSTM拼接而成,企图同时获取上下文的语义信息。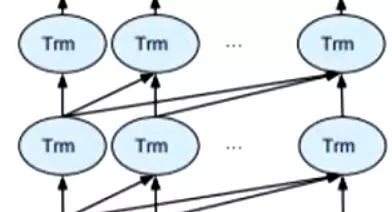 ;双向transformer在文献中通常称为transformer编码器。而只关注左侧语境的版本,经常会用来做文本生成,像这个GPT就是transformer解码器。写小说的就是用GPT3写的。
;双向transformer在文献中通常称为transformer编码器。而只关注左侧语境的版本,经常会用来做文本生成,像这个GPT就是transformer解码器。写小说的就是用GPT3写的。
 。第一个是MLM任务。
。第一个是MLM任务。




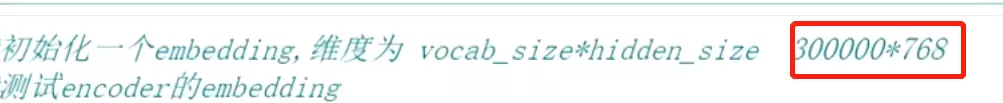 实际上可能是30万*768,对机器的性能要求是相当高的。
实际上可能是30万*768,对机器的性能要求是相当高的。
 这样就减少了很多参数。比如词汇表是2万,20000*768就是1536万,比如用128去拆解矩阵,这样就变成265万左右,降低了很大参数量。
这样就减少了很多参数。比如词汇表是2万,20000*768就是1536万,比如用128去拆解矩阵,这样就变成265万左右,降低了很大参数量。 
 这是一些任务,
这是一些任务, 这些是机器阅读理解,还有MNLI。后面是平均分数,可以看到最小的模型第一行的平均分数是80.1,还可以。第二个是贡献注意力的参数,它的大小是64M,平均分数是81.7,是最高的。第三个只贡献前馈层,效果就不明显。第四个参数不共享时参数大小是89M,参数量最大,
这些是机器阅读理解,还有MNLI。后面是平均分数,可以看到最小的模型第一行的平均分数是80.1,还可以。第二个是贡献注意力的参数,它的大小是64M,平均分数是81.7,是最高的。第三个只贡献前馈层,效果就不明显。第四个参数不共享时参数大小是89M,参数量最大,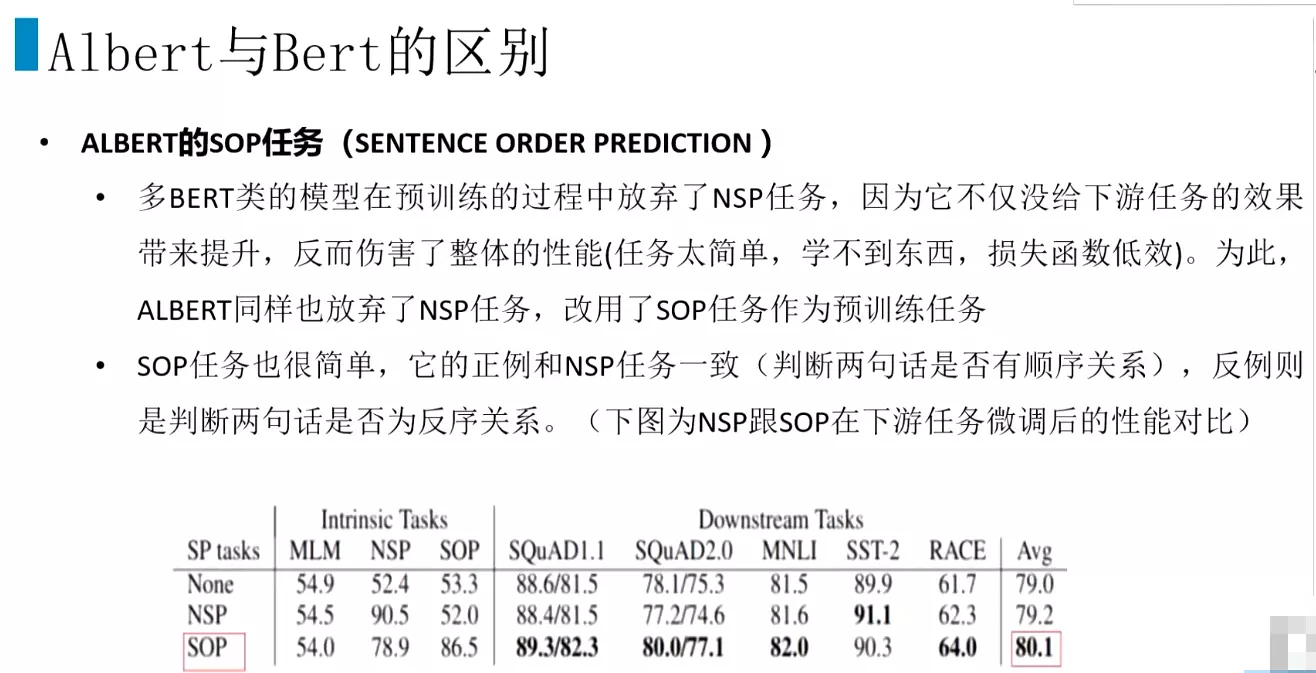




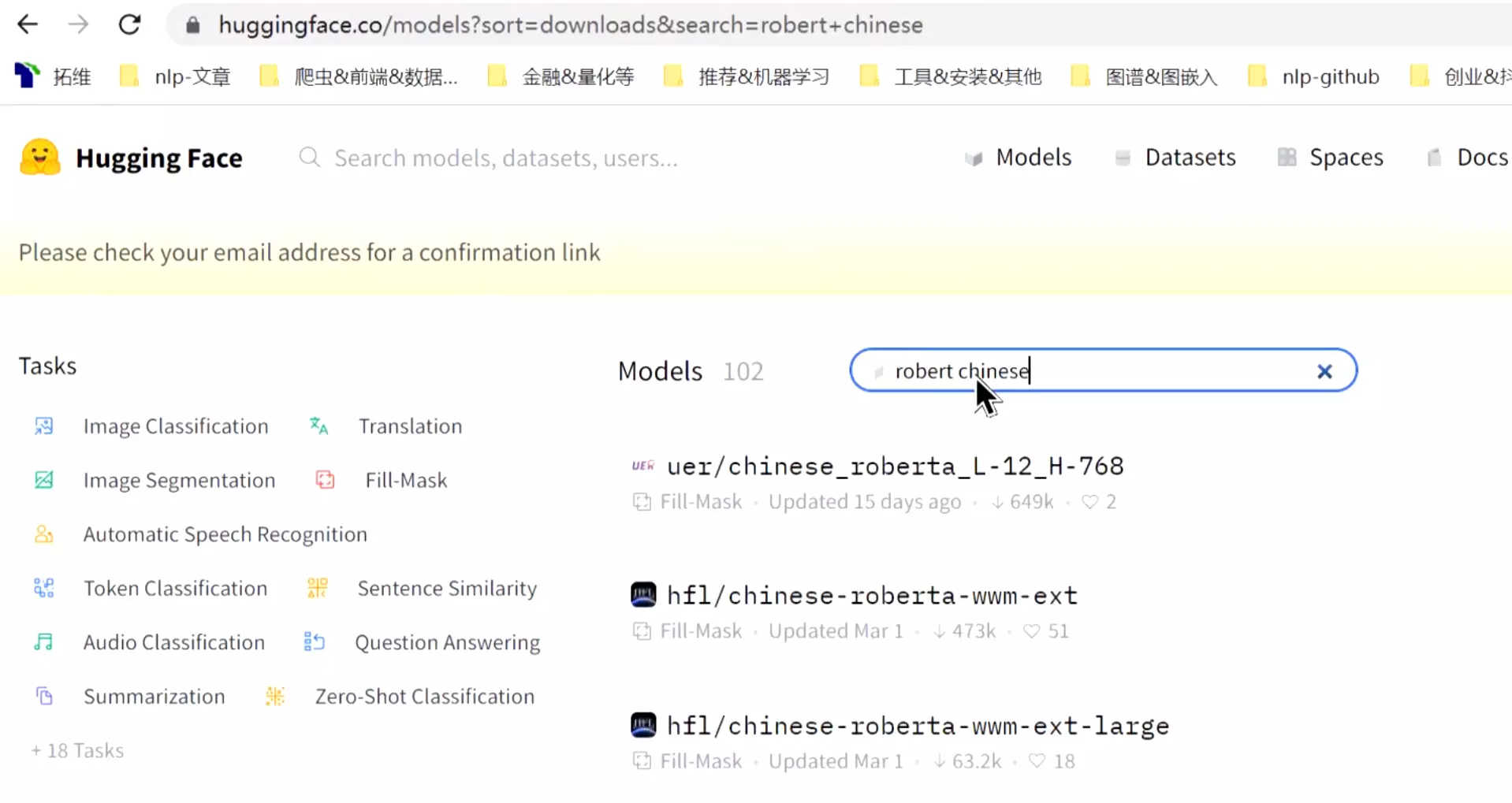
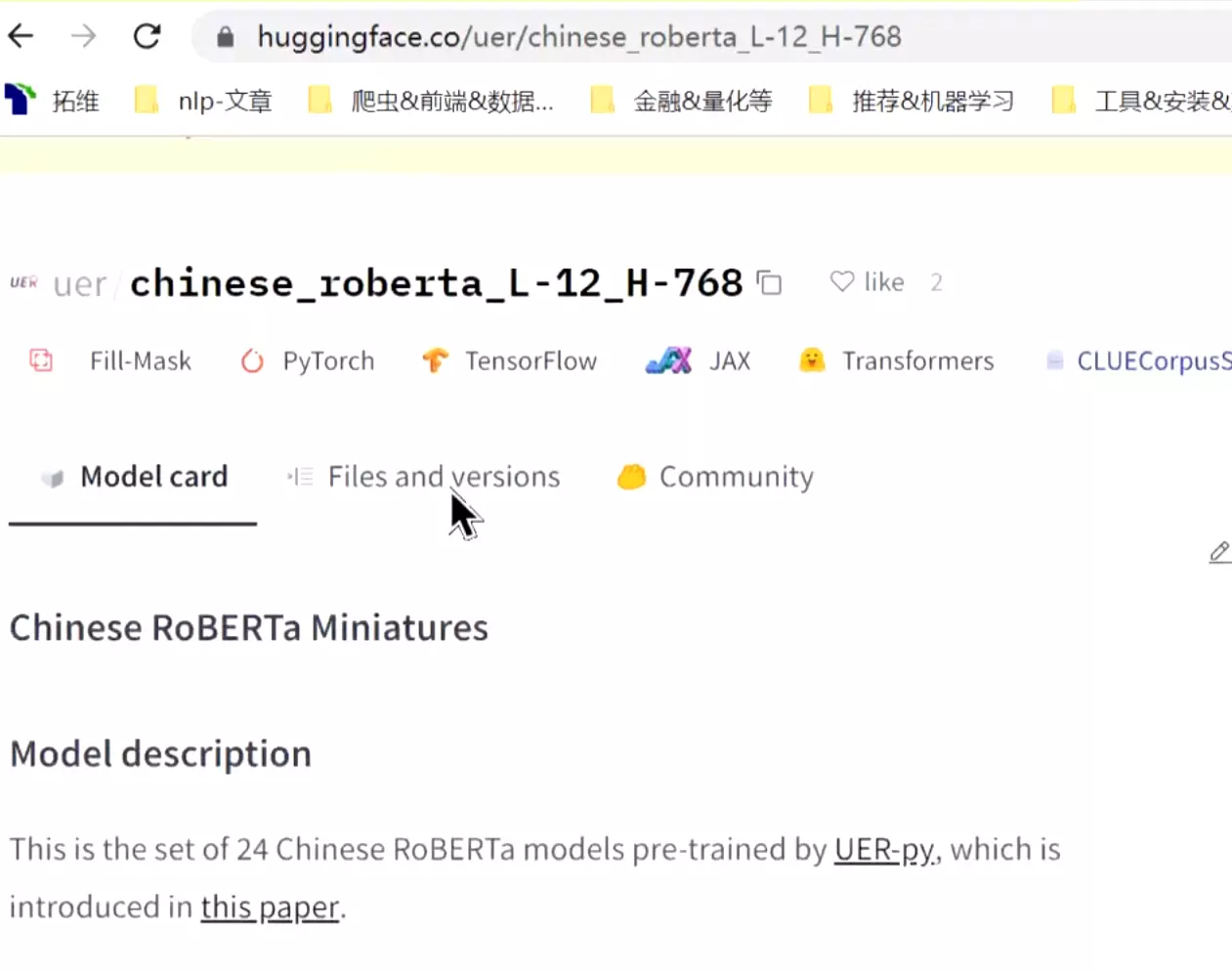
 这是pytorch的模型,
这是pytorch的模型, 这是tensorflow的模型。
这是tensorflow的模型。 这是参数。
这是参数。 这是词表。
这是词表。
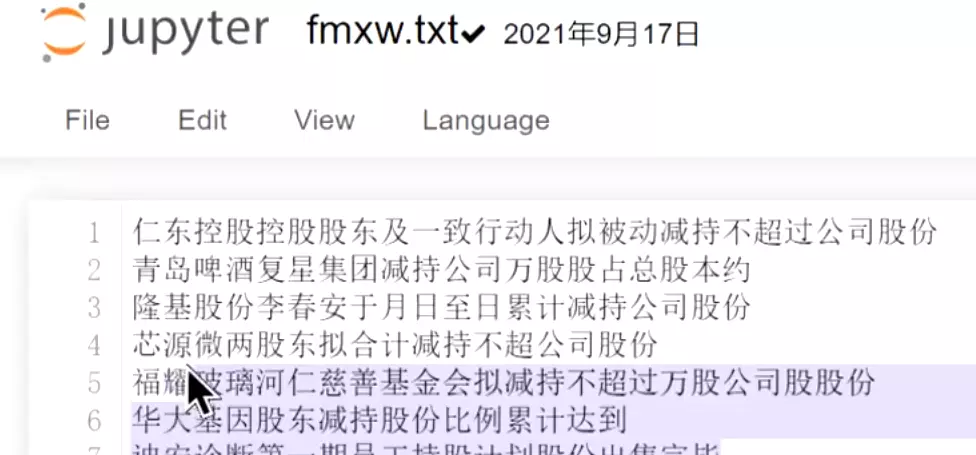
 如果新版本报错的话,可以把版本退到3.4.0,比较稳定一些。
如果新版本报错的话,可以把版本退到3.4.0,比较稳定一些。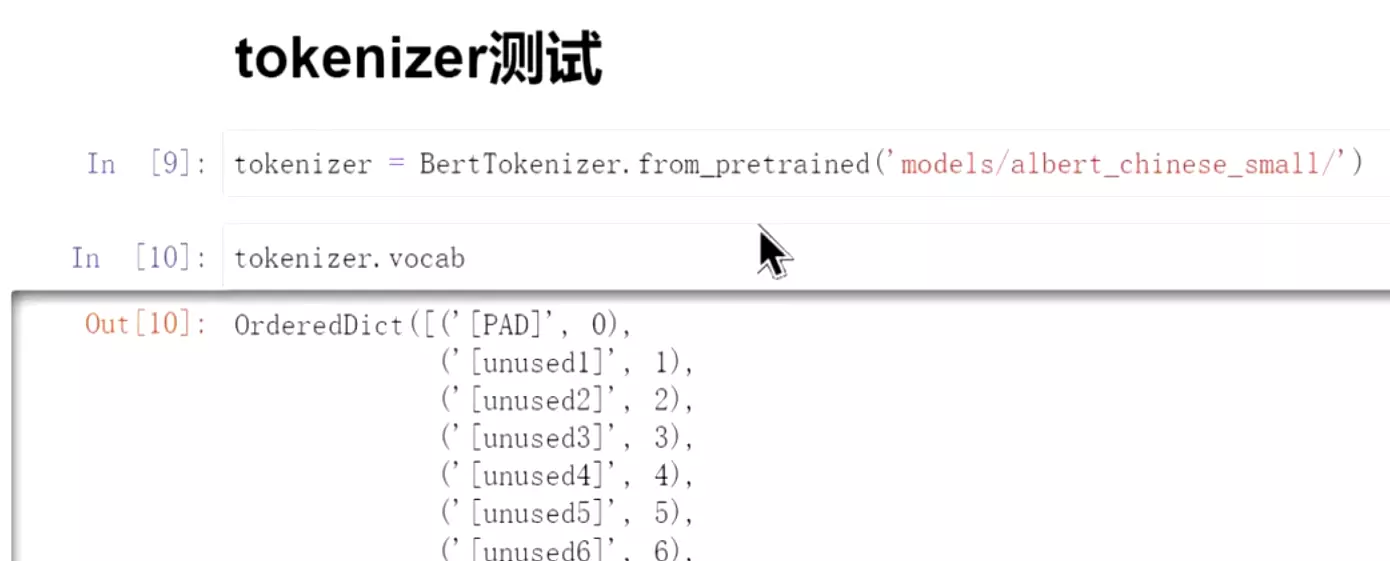
 ,一个是
,一个是 一个是模型参数、一个是模型词表
一个是模型参数、一个是模型词表
 我们就不用
我们就不用


 #用
#用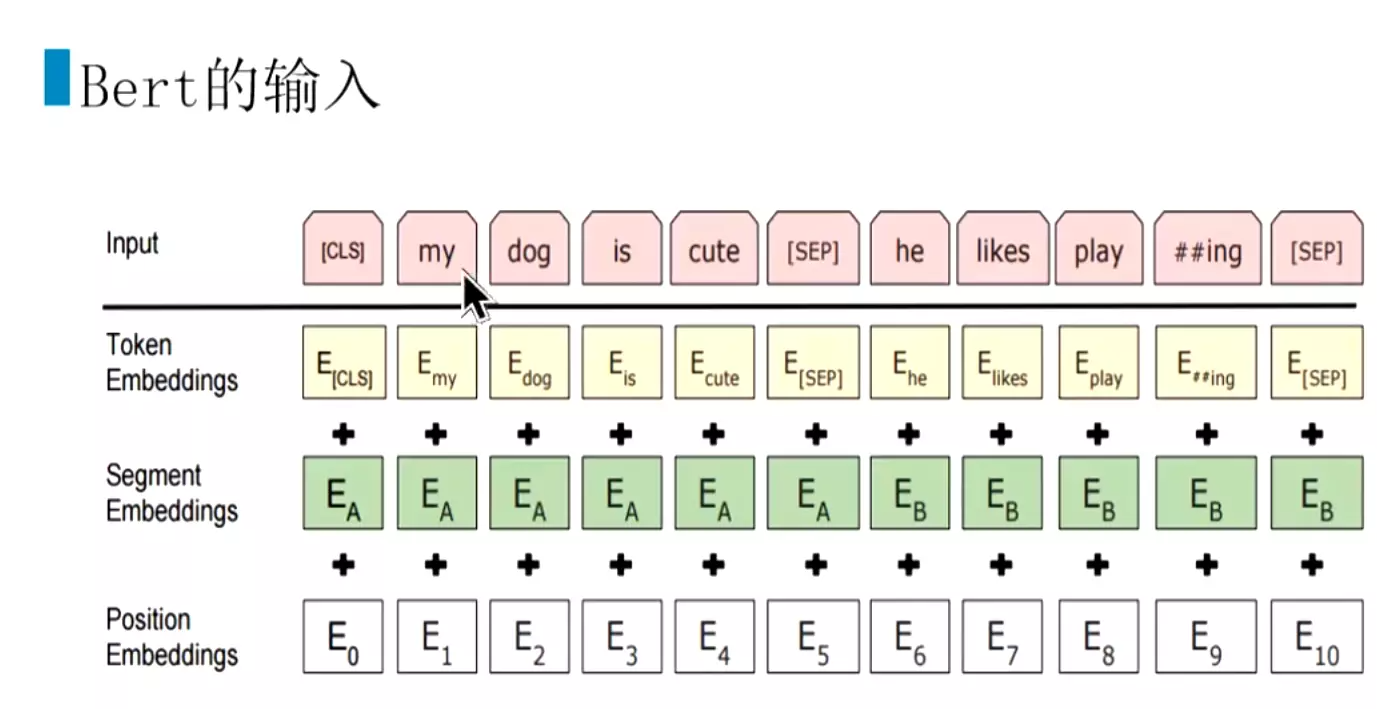 ,多出来的两个就是前面一个[CLS]后面一个[SEP]。
,多出来的两个就是前面一个[CLS]后面一个[SEP]。



 ,
, #用t1进行Albert测试,先加载模型
#用t1进行Albert测试,先加载模型



 #直接传过去这个inputs字典是不行的,
#直接传过去这个inputs字典是不行的, 用**去分配就可以传过去。这是使用的一个技巧。
用**去分配就可以传过去。这是使用的一个技巧。
 #看一下shape,1表示batchsize,9表示训练的长度,384就是向量的大小
#看一下shape,1表示batchsize,9表示训练的长度,384就是向量的大小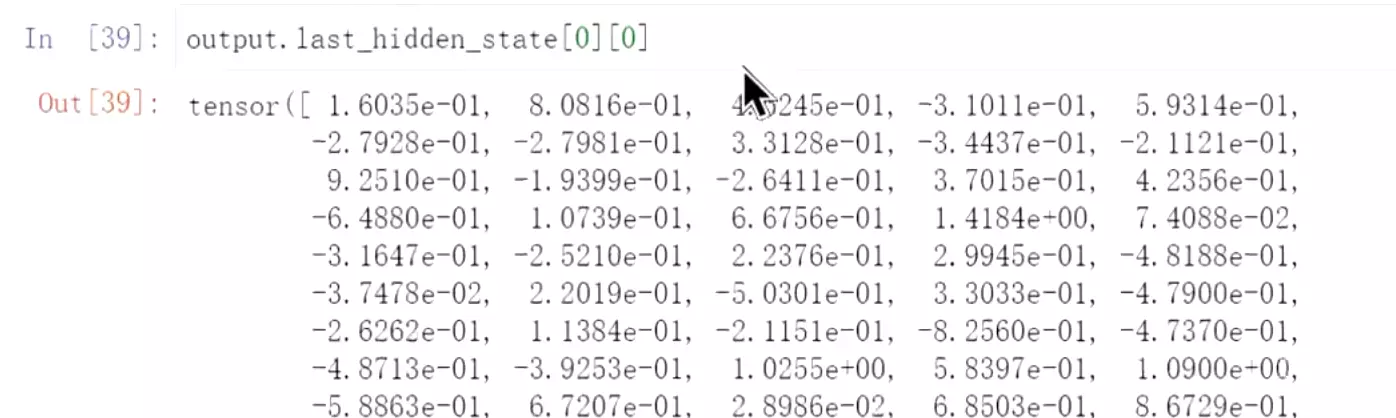



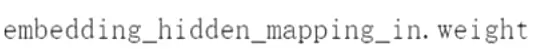 这个是隐藏层的初始化的向量w,下面是bias
这个是隐藏层的初始化的向量w,下面是bias 这个是全连接层的w和b
这个是全连接层的w和b #下面是q、k、v的w和b
#下面是q、k、v的w和b dense是有一个前馈神经网络,是两个线性层堆叠起来的,就是dense
dense是有一个前馈神经网络,是两个线性层堆叠起来的,就是dense 这个是层归一化的参数
这个是层归一化的参数 这个是前馈层的参数。要更新的就是这些。
这个是前馈层的参数。要更新的就是这些。 embedding也可以更新,在
embedding也可以更新,在


 重新导入nn。
重新导入nn。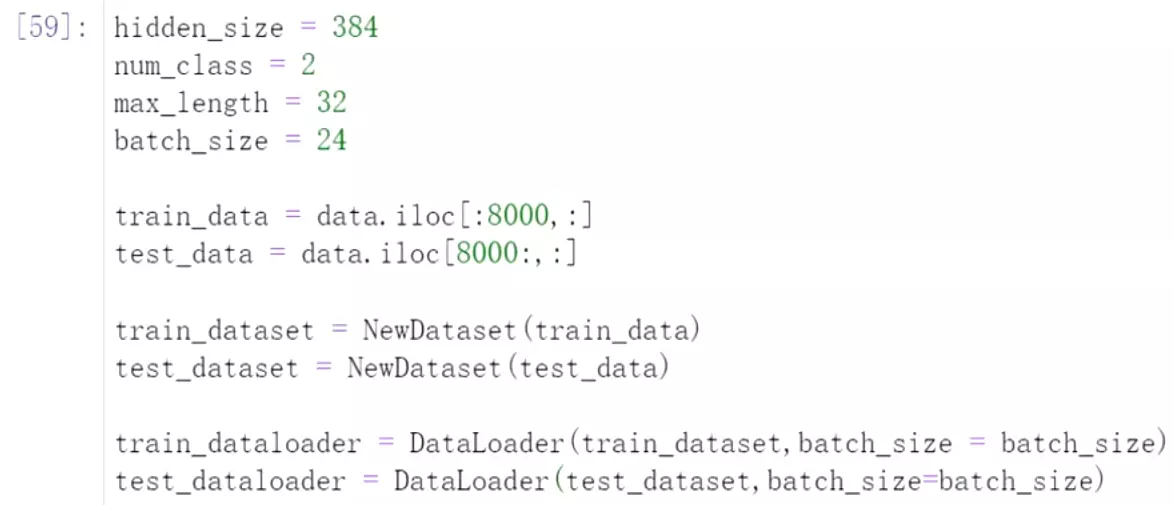
 一共有1万多数据,拆分成训练和测试数据。
一共有1万多数据,拆分成训练和测试数据。


 #
#


 这个是进度条,可以直观看一下进展
这个是进度条,可以直观看一下进展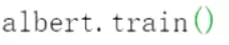 设置成训练的模式;
设置成训练的模式;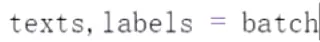 通过batch拿到文本和label。
通过batch拿到文本和label。 返回的类型指定一下。
返回的类型指定一下。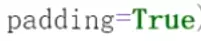 padding设为True。
padding设为True。 input经过tokenizer之后就是字典
input经过tokenizer之后就是字典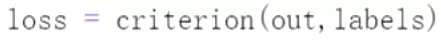 直接计算交叉熵;
直接计算交叉熵;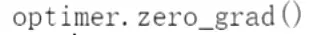 梯度进行初始化、重置
梯度进行初始化、重置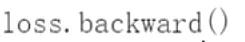 损失进行反向传播。
损失进行反向传播。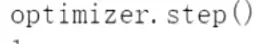 数据进行更新;
数据进行更新;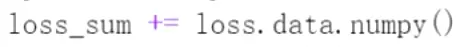 由于loss是参与反向传播的,所以要把他的data拿出来,再转化成numpy格式。
由于loss是参与反向传播的,所以要把他的data拿出来,再转化成numpy格式。 #这里有一个技巧,是统计输出最大值,1表示只取最大的值。求和再去data再转化为numpy。这里就是统计输出值和label相同的有多少。
#这里有一个技巧,是统计输出最大值,1表示只取最大的值。求和再去data再转化为numpy。这里就是统计输出值和label相同的有多少。


 设置损失、准确率和测试模式。
设置损失、准确率和测试模式。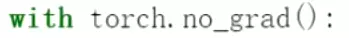 在测试数据集上评估的话不用反向传播了。
在测试数据集上评估的话不用反向传播了。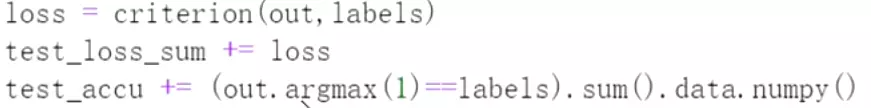 下面是计算损失、损失求和、准确率求和。
下面是计算损失、损失求和、准确率求和。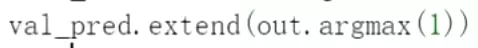 把预测值也放进来
把预测值也放进来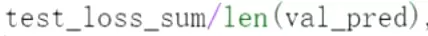 损失和除以预测的值得大小
损失和除以预测的值得大小


 浙公网安备 33010602011771号
浙公网安备 33010602011771号