。![]()
#首先对图像进行预处理![]()
#然后实例化一下刚才搭建的新版的alexnet![]()
#然后加载一下你的权重,因为我是要查看你的featuremaps的,其实你的网络时已经被训练好的,因为只有被训练好的,他卷积计算得到的特征图才是有意义的。所以这里要加载一个权重,这个权重要有一个地址的,可以改成自己的。![]()
![]() 然后通过torch.load的方法,加载进来。
然后通过torch.load的方法,加载进来。
![]()
#然后要加载一张图像。![]() 用之前设定的预处理方式进行预处理。
用之前设定的预处理方式进行预处理。![]() 然后将图像用unsqueeze去扩展一个batch维度,在第0维的地方,这是为了能送进我们的模型里面。
然后将图像用unsqueeze去扩展一个batch维度,在第0维的地方,这是为了能送进我们的模型里面。
#然后送进我们的模型里面![]() ,他会返回一个结果。这个结果是什么?这个结果是我们刚才的outputs。它里面放的是我们三次卷积之后得到的featuremap,如下图是之前的训练脚本。
,他会返回一个结果。这个结果是什么?这个结果是我们刚才的outputs。它里面放的是我们三次卷积之后得到的featuremap,如下图是之前的训练脚本。![]()
#这时候我们就可以查看它长成什么样子了:![]()
#通过for循环的方式去遍历featuremaps他是一个列表——out_put
#首先会将它取出来,用detach()方法。这个方法就是说,这跟pytorch底层原理有关:pytorch是能实现底层求导的,因为在训练过程中,你只需要调用backward函数就可以实现梯度下降算法以及他的参数更新。所以它在底层已经把倒数或者偏导球求好了。它之所以能做这个事情,是因为它将这些节点都通过计算图的方式![]() 给它在底层有一个逻辑关系的链接。如果现在我们不是做网络训练的话,我们想用到这些中间产物;我们必须就他从中间图里面分离出来。因为如果你不分离的话如果你对featuremap做一些操作,你可能会影响到底层的计算图,这时候就可能会影响到模型的训练。所以这里面我们安全起见,会将网络的中间产物通过detach这个方法从他底层的计算图里面给它拿出来。这样就不会影响网络的梯度、传播等等 的东西。
给它在底层有一个逻辑关系的链接。如果现在我们不是做网络训练的话,我们想用到这些中间产物;我们必须就他从中间图里面分离出来。因为如果你不分离的话如果你对featuremap做一些操作,你可能会影响到底层的计算图,这时候就可能会影响到模型的训练。所以这里面我们安全起见,会将网络的中间产物通过detach这个方法从他底层的计算图里面给它拿出来。这样就不会影响网络的梯度、传播等等 的东西。
![]() 拿出来后再将featuremap转化成一个车numpy的形式,这是为了用plt这个库做一个可视化。
拿出来后再将featuremap转化成一个车numpy的形式,这是为了用plt这个库做一个可视化。
#然后将第一维度给它挤压掉:![]() 因为第一维度是一个batch维度,这里只有一张图像,所以这里batch维度只有1,N=1,没啥用,给它挤压掉。
因为第一维度是一个batch维度,这里只有一张图像,所以这里batch维度只有1,N=1,没啥用,给它挤压掉。
#然后我们再做一个transpose,将Channel维度,从第0维调换到最后一位。就办成了高度、宽度、通道这种格式[H, W, C]。这种格式是因为我们在做可视化的时候plt要求我们的图像维度是这种排列的。![]()
#然后实例化一个画布![]() ,
,
然后去遍历一下,这里我们只去前12张featuremap,因为我们的网络结构经过卷积之后,得到的featuremap是很多的,你像第一次卷积得到是48个featuremap,他的特征图是很多的。这里我们只取前十二个就够了,去那么多没啥意义,只是做一个展示。然后给它画到我们刚才的画布里面。做一个展示。
![]()
#可以看一下长成这个
样子:![]()
这是我们第一次卷积之后得到的featuremap他的可视化结果我们的原图张这个样子。
![]()
大家可以观察,是不每一个特征图它都不一样啊?也就是每一个特征图他都去尝试提取不同的模式或特征。像这个![]() 可能是提取白色花瓣这个特征。
可能是提取白色花瓣这个特征。![]() 这个不好说,这就是神经网络里面不好解释的地方。就是他在干嘛不好理解。但是每张featuremap都不一样。
这个不好说,这就是神经网络里面不好解释的地方。就是他在干嘛不好理解。但是每张featuremap都不一样。![]() 问:为什么这个featuremap这么黑? 大家可以思考一下。答:我们zfnet已经给大家解释过了,没有学的特征。
问:为什么这个featuremap这么黑? 大家可以思考一下。答:我们zfnet已经给大家解释过了,没有学的特征。![]() 在这里,他可视化alexnet的网络结构,他发现有些featuremap值特别大,有些值特别小,这些featuremap实际上是没有学到特征。是学习失败的一种现象,所以他才对alexnet做了一些改进,他讲出现这个现象的原因是你在做第一次卷积的时候,他的卷积核的尺寸太大了,步幅太大了,所以ZFNet才将第一次卷积、那个11*11步幅为4的卷积,给它变成了7*7步幅为2的卷积。
在这里,他可视化alexnet的网络结构,他发现有些featuremap值特别大,有些值特别小,这些featuremap实际上是没有学到特征。是学习失败的一种现象,所以他才对alexnet做了一些改进,他讲出现这个现象的原因是你在做第一次卷积的时候,他的卷积核的尺寸太大了,步幅太大了,所以ZFNet才将第一次卷积、那个11*11步幅为4的卷积,给它变成了7*7步幅为2的卷积。
![]() 这是啥看paper的软件?答:棵岩阅读。pdf阅读器gooood。
这是啥看paper的软件?答:棵岩阅读。pdf阅读器gooood。
#第二次卷积之后得到的featuremap,看不到它提取的什么了。![]()
#第三次卷积之后提取的featuremap,压根看不出他在干嘛了。所以也是ZFNet提到的一个现象。![]()
![]() ZFNet说大多数可视化都被限制在了第一层,因为第二层以后都看不出来在干嘛了。所以他才提出来一些技术,通过反操作,把featuremap映射回原始的像素空间。但是老师这里给展示的features并没有映射回原始的像素空间。
ZFNet说大多数可视化都被限制在了第一层,因为第二层以后都看不出来在干嘛了。所以他才提出来一些技术,通过反操作,把featuremap映射回原始的像素空间。但是老师这里给展示的features并没有映射回原始的像素空间。
GoogleNet 总结
#以博文的形式讲解吓:
#googlenet博文https://blog.csdn.net/qq_39297053/article/details/123717625
前言
2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名、VGG获得了第二名,这两类模型结构的共同特点是层次更深了。VGG继承了LeNet以及AlexNet的一些框架结构,而GoogLeNet则做了更加大胆的网络结构尝试,虽然深度只有22层,但大小却比AlexNet和VGG小很多,GoogleNet参数为500万个,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍,因此在内存或计算资源有限时,GoogleNet是比较好的选择;从模型结果来看,GoogLeNet的性能却更加优越。
小知识:GoogLeNet是谷歌(Google)研究出来的深度网络结构,为什么不叫“GoogleNet”,而叫“GoogLeNet”,据说是为了向“LeNet”致敬,因此取名为“GoogLeNet”
#googlenet 参数量非常小,VGG你可能训练不起来,但是googlenet你是可以的。
一、GoogLeNetV1
1、Motivation
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,或者输入数据的大小;这也就意味着网络训练种巨量的参数。但这种方式存在以下问题:
(1)参数太多,如果训练数据集有限,很容易产生过拟合;
(2)网络越大、参数越多,计算复杂度越大,难以应用;
(3)网络越深,容易出现梯度弥散问题(梯度越往后穿越容易消失),难以优化模型。
所以,有人调侃“深度学习”其实是“深度调参”。
文章认为解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。一方面现实生物神经系统的连接也是稀疏的,另一方面有文献表明:对于大规模稀疏的神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。这点表明臃肿的稀疏网络可能被不失性能地简化。
##稀疏连接。全连接和卷积哪个是稀疏的?答:卷积。因为卷积关注的是局部,而全连接是所有的都送进去了。
早些的时候,为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接例如Droupout。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。
#因为dropout导致网络结构不均衡,对计算不友好。
所以,现在的问题是有没有一种方法,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,据此论文提出了名为Inception 的结构来实现此目的。
2、Architectural Details
#通过调整padding和步长,使featuremap的输出结果是一样尺寸的。
对上图做以下说明:
卷积核的大小在神经网络里是一种超参数,没有一种严格的数学理论证明那种尺寸的卷积核更适合提取特征,因此GoogLeNet选择了大人的方式:我全都要
采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,采用1x1卷积核来进行降维。
#1*1的卷积非常重要,mobilenet就用了很多1*1的卷积。
![]()
#这是3*3的卷积核
![]()
#这是1*1的卷积核,卷积核的数量不同就可以随意的对channel进行升降维。而且还顺便做了通道的交互,因为每一个结果都是对rgb三通道做了数据交互。
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
改进后的网络模型子结构如下:
![]()
![]()
#这个模型里首次有了BLOCK和stage 块,通过改变BLOCK和stage 块的大小就可以改变模型的网络结构,非常简便。
红色框的是stage
1 . 显然GoogLeNet采用了模块化的结构,如上图红黄绿圈出来的方框,方便增添和修改;
2 . 网络最后采用了average pooling来代替全连接层 ,事实证明可以将TOP1 accuracy提高百分之0.6,而且,这样就允许网络接收不同大小的图片输入了,但是,实际在最后还是加了一个全连接层,主要是为了方便以后大家finetune;
3 . 虽然移除了全连接,但是网络中依然使用了Dropout ;
4 . 为了避免梯度消失,网络额外增加了2个softmax辅助分类器,用于向前传导梯度。文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。此外,实际测试的时候,这两个额外的softmax会被去掉。
![]()
#圈起来的是stage;一般来讲,有block和stage的网络架构,它每个stage里面的featuremap都会是相同大小的。通道数增多。如上,习惯一个stage后面跟一个maxpooling
![]()
#不管是blok还是vgg都给了一个表格,可以根据表格很好的搭建网络架构。
这里给出网络的详细参数,红黄蓝三个模块与上图相对应。
小结:#三个贡献
提出inception块增加网络宽度,在卷积操作时可以提取不同尺度的特征。
提出辅助分类器,为网络训练提供更多梯度信息。
将网络模块化三个阶段(stage)每个stage内部的feature map不变,结束后下采样送入下个stage,这种模式在之后的模型中经常出现:例如resnet,mobilenet,shufflenet等等
![]()
![]()
#像VGG就通过不同阶段层的做分类;而googlnet就用来三个分类器。但是后面研究发现这样对于分类没有帮助,但是可以对梯度弥散有帮助,有利于梯度的回传,并不是对分类精度一个提升。
二、GoogLeNetV2
GoogLeNetV2最大的贡献就是提出了BatchNormalization数据归一化方法。
#就是BN,之前有一个数据的归一化,将像素值归一化,得到均值为0,方差为1的像素分布。
![]()
#BatchNormalization就是对channel维度的数据做归一化。
1、Motivation
首先,GoogLeNet V1出现的同期,性能与之接近的大概只有VGGNet了,并且二者在图像分类之外的很多领域都得到了成功的应用。但是相比之下,GoogLeNet的计算效率明显高于VGGNet,大约只有500万参数,只相当于Alexnet的1/12(GoogLeNet的caffemodel大约50M,VGGNet的caffemodel则要超过600M)。
而且,二者的发展方向不同;从某种角度可以这样理解:Vgg追求的是网络深度;GoogLeNet追求的是网络宽度
GoogLeNet的表现很好,但是,如果想要通过简单地放大Inception结构来构建更大的网络,则会立即提高计算消耗。 为了提升GoogLeNetv1训练速度,提出对模型结构的部分做归一化处理,也就是对每个训练的mini-batch做归一化,叫做Batch Normalization(BN)。BN在之后的网络模型中频繁出现,成为神经网络中必不可少的一环BN的好处如下:
BN使得模型可以使用较大的学习率而不用特别关心诸如梯度爆炸或消失等优化问题;
降低了模型效果对初始权重的依赖;
可以加速收敛,一定程度上可以不使用Dropout这种降低收敛速度的方法,但却起到了正则化作用提高了模型泛化性;
即使不使用ReLU也能缓解激活函数饱和问题;
能够学习到从当前层到下一层的分布缩放( scaling (方差),shift (期望))系数。
作者认为:网络训练过程中参数不断改变导致后续每一层输入的分布也发生变化,而学习的过程又要使每一层适应输入的分布,因此我们不得不降低学习率、小心地初始化。作者将分布发生变化称之为internal covariate shift。
解决这个问题的方法是在训练网络的时会将输入减去均值,目的是为了加快训练。为什么减均值可以加快训练呢,这里做一个简单地说明:
首先,图像数据是高度相关的,相似的图像分布接近。假设其分布如下图a所示(一个点代表一个图像,简化为2维)。由于初始化的时候,我们的参数一般都是0均值的,因此开始的拟合y=Wx+b,基本过原点附近,如图b红色虚线。因此,网络需要经过多次学习才能逐步达到如紫色实线的拟合,即收敛的比较慢。如果我们对输入数据先作减均值操作,如图c,显然可以加快学习。
![]()
再举一个可视化的解释:BN就是对神经网络每层的输入数据的数据分布,做了下面左图不规律的数据分布到右图规则的数据分布的归一化操作。箭头表示模型寻找最优解的过程,显然有图的方式更方便,更容易。
#C图,就是BN效果,找的比较容易,只需要旋转不需要平移,就能找到。
再举一个可视化的解释:BN就是对神经网络每层的输入数据的数据分布,做了下面左图不规律的数据分布到右图规则的数据分布的归一化操作。箭头表示模型寻找最优解的过程,显然有图的方式更方便,更容易。
#对比VGG,VGG是追求网络深度,而googlnet是追求网络宽度。
小结
- 提出了batch normalization数据归一化操作。
三、GoogLeNetV3
GoogLeNet Inception V3在《Rethinking the Inception Architecture for Computer Vision》中提出(注意,在这篇论文中作者把该网络结构叫做v2版,我们以最终的v4版论文的划分为标准),该论文的亮点在于:
提出通用的网络结构设计准则
引入卷积分解提高效率(空间可分离卷积)
引入高效的feature map降维
平滑样本标注
1、Motivation
在V1版本中,文章也没给出有关构建Inception结构注意事项的清晰描述。因此,在文章中作者首先给出了一些已经被证明有效的用于放大网络的通用准则和优化方法。这些准则和方法适用但不局限于Inception结构。
2 、General Design Principles
#作者总结的炼丹技巧。
避免特征表示上的瓶颈,尤其在神经网络的前若干层(准则一)
神经网络包含一个自动提取特征的过程,例如多层卷积,直观并符合常识的理解:如果在网络初期特征提取的太粗,细节已经丢了,后续即使结构再精细也没法做有效表示了;
#例如Alexnet ,前几层用来kernerl11步长为4的卷积层,这样featuremap尺寸就会快速的下降,这是不合理的。网络的细节被丢掉了。
所以feature map的大小应该是随着层数的加深逐步变小,但为了保证特征能得到有效表示和组合其通道数量会逐渐增加。
#比如224-》112-》56》7
举个例子,刚开就始直接从35×35×320被抽样降维到了17×17×320,特征细节被大量丢失,即使后面有Inception去做各种特征提取和组合也没用,因此,再对feature map进行降维的同时,一般会对channel通道进行升维。
#为了防止空间维度丢失,我会把空间部分降下来的转移到channel中,一般会35×35×320-》17×17×640
特征的数目越多收敛的越快 (准则二)
相互独立的特征越多,输入的信息就被分解的越彻底,分解的子特征间相关性低,子特征内部相关性高,把相关性强的聚集在了一起会更容易收敛。规则2和规则1可以组合在一起理解,特征越多能加快收敛速度,但是无法弥补Pooling造成的特征损失,Pooling造成的representational bottleneck要靠其他方法来解决。
![]()
对于神经网络的某一层,通过更多的激活输出分支可以产生互相解耦的特征表示,从而产生高阶稀疏特征,从而加速收敛,注意下图的1×3和3×1激活输出:
合理的压缩特征维度数,来减少计算量(准则三)
inception-v1中提出的用1x1卷积先降维再作特征提取就是利用这点。不同维度的信息有相关性,降维可以理解成一种无损或低损压缩,即使维度降低了,仍然可以利用相关性恢复出原有的信息。
#1*1先降维,和 通道融合,将冗余特征压缩!!
![]()
整个网络结构的深度和宽度(特征维度数)要做到平衡(准则四):
#挖了一个坑,自己读EfficientNet!github上有链接。
只有等比例的增大深度和维度才能最大限度的提升网络的性能。很有道理,也很模糊,没有给出具体的参数指导,后期的模型如 EfficientNet(V1, V2)就填了这个坑。
---以上是V3版本第一个贡献(4个准则)
3、Architectural Details
![]()
#下面讲如何高效的降维? 有两种方式,一是:(35*35*320)一是卷积之后做一个池化maxpooling,特征图会减一半(17*17*320),然后再做一个卷积将 通道数上升到2倍(17*17*640);二是,先做一个卷积将 通道数上升到2倍(35*35*640)
,再做池化,特征图会减一半(17*17*640)。
#但是上面两种方式都有不好的地方,第一种方式会遇到特征瓶颈,就是刚才讲的第准则一,避免特征表示上的瓶颈,尤其在神经网络的前若干层。第二种会带来很大的计算量——特征维度没有减小,而且channel维度翻倍。
#有没有一个两全其美的方法呢? V3作者提出并行操作;卷积步长调为2,这样(35*35*320)-》(17*17*320);而池化也是(17*17*320)。最后讲卷积和池化合并,就能得到(17*17*640)。
#但是这个方法不常用,并没有流行起来!
优化标签
深度学习用的labels一般都是one hot向量,用来指示classifier的唯一结果,这样的labels有点类似信号与系统里的脉冲函数,或者叫“Dirac delta”,即只在某一位置取1,其它位置都是0。
Labels的脉冲性质会引发两个不良后果:一是over-fitting,另外一个是降低了网络的适应性。
一种解决方法是加正则项,即对样本标签给个概率分布做调节:
在网络实现的时候,令 label_smoothing = 0.1,num_classes = 1000。Label smooth提高了网络精度0.2%。
Label smooth 把原来很突兀的one_hot_labels稍微的平滑了一点,避免了网络过度学习labels而产生的弊端。
小结
- 提出了通用的网络设计准则,慎用
- 优化了辅助分类器
- 优化了池化操作
- 优化了标签
![]() #例如1是蒲公英,但是0.9我也希望是蒲公英,不要一个数字,而是一个标签的抖动范围。这样做也能提升网络精度。
#例如1是蒲公英,但是0.9我也希望是蒲公英,不要一个数字,而是一个标签的抖动范围。这样做也能提升网络精度。![]() 2就是去掉了。
2就是去掉了。
![]()
#V4的贡献,一是改进网络架构
#ResNet很厉害,必须会,以后讲。
四、GoogLeNetV4
《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》一文中的亮点是:提出了效果更好的GoogLeNet Inception v4网络结构;与残差网络融合,提出效果不逊于v4但训练速度更快的GoogLeNet Inception ResNet结构。
1、 GoogLeNet Inception V4网络结构
略
#就是带残差链接的网络结构
GoogLeNet 讲解
![]()
#google写的论文两个特点,1、不好懂 2、质量高
#老师领读的都是不好懂得,如VGG
#分三遍读:
#一题目、摘要。
#更深的卷积、(如果你是图像领域的,这篇文章要好好读一下。)获得14年图像大赛的冠军。好处是提升资源利用率。设计理解和赫夫法则、另一是多尺度处理。
#赫布理论: 赫布理论 ( 英语 :Hebbian theory)描述了 突触可塑性 的基本原理,即 突触 前神经元向突触后神经元的持续重复的刺激可以导致突触传递效能的增加。
#两个神经元或者神经元系统,如果总是同时被激发,就会形成一种组合,其中一个神经元的激发会促进另一个神经元的激发。
#后面讲网络是22层的神经网络,比VGG19层还深一些,在图片分类和目标检测做的都不错。
#然后直接看结论:
![]()
#结果提供了证据:我们可以近似期望最优的稀疏结构,通过相对密集的块block,可以提升神经网络视觉上的帮助。
##读第二遍:
![]()
#介绍部分:讲了深度学习领域的三驾马车,一架马车是更强的硬件支持,第二驾是更大的数据集以及更大的模型,第三个是新颖的idea和改进的网络架构。No new data sources were used, for example, by the top entries in the ILSVRC 2014 competition besides the classification dataset of the same competition for detection purposes例如,除了用于检测目的的同一竞赛的分类数据集外,ILSVRC 2014竞赛中的顶级参赛者没有使用新的数据源。#就是说即使没有扩展数据集,通过新的算法和架构也能获得更好的结果。比如我们的模型比AlexNet有更高的准确率。
#我们自己的算法讲究的是效率,模型深度是考虑计算效率。还说:如果我们设计的深度框架如果不去考虑计算效率的话,相当于一种纯粹的学术好奇。这里讲我们并不是一个纯粹的学术好奇,我们的模型可以被用于真实世界里面,因为它可以算的很快。 ![]()
#在我们论文里,有效的深度神经网络,叫做inception。我们的网络架构有两个灵感来源,一个是Network in network 的paper;这个paper很重要!!!第二个思想是著名的“we need to go deeper” internet mem网络梗,引用放到第一位,盗梦空间里经典的台词。这个在写论文里面是很少见的。两个意思:一是新的小网络架构,二网络模型要比较深一些。
![]() 小李子的一个台词,
小李子的一个台词,![]()
Network in network paper 的两个贡献:一、1*1的卷积conv;二、全局平均池化GAP:global average pooling很好理解:![]()
两个阶段之间有一个flatten打平,用GAP替代flatten。一个feature map经过GAP就是一个元素,长度为100的feature map 就是[x1,x2,... ] 100个元素的向量,这样再送进全连接里面,这就是全局平均池化。
#这样才有道理,我们得到的结果其实是融合前面feature map得到的所有特征的,他将前面得到的feature map 融合到一起在输出。
#这么做的好处,大量减少参数量,尤其是全连接的参数量;不管是Alexnet还是ZFNet它全连接的参数量都占到整个模型的百分之90多,而且这么多参数量是非常冗余的、没有必要的,可能会影响模型的过拟合,因此他们才考虑在全连接里面接我们的dropout正则。
在这里如果用GAP,我们得的节点、送进全连接神经网络的输入信息就没有那么多,可以大量的减少我们的参数量。
自从GAP提出以后,用flatten的操作在模型中就比较少了,基本上都是在最后一个featuremap上用GAP(全局平均池化)得到一个向量再送进全连接。这是一个技术发展路线。
## a logical culmination 一个逻辑上的最高点,就是说我们讲network思想用到了极致。
还用了Arora et a论文的思想——用稀疏、分散的网络结构去取代一个密集、臃肿的网络是比较好的,能够得到一个好的性能,本质上讲了稀疏性。
![]()
##相关工作
#lenet5是一个比较小的数据集MNIST手写数据集,如果迁移到比较大的数据中,像ImageNet,模型就需要改进,最常见的改进方式就是提升层数量和层尺寸已经dropout;
maxpooling会损失一些空间信息,但是种种证明了对模型不会有太大影响。
#多尺度的事情,Serre等人。[15]使用一系列不同大小的固定Gabor滤波器,它的作用和卷积一样;获得不同尺度的特征,这个是比较好的,和我们Inception的模型很相似,但是我们有不同的地方,我们所有的过滤核都是可以学习的,我们Inception块可以堆叠很多次,可以随机调解网络大小。
#1*1卷积可以降维,也可以升维,用多个1*1的卷积核。
#下面将目标检测的,当前研究是分类,所以第二遍先不读。
![]() 我们可以提升网络的深度(网络的层数)和宽度(每一次操作的产物——得到的featuremap更多),宽度就是1*1的卷积核。通过卷积核提升宽度的方式是比较安全和高效的。尤其是有大量带标注的数据时。但是有两个缺点:1)比较大的尺寸会提升非常多的参数,引起过拟合,尤其是训练数据集不够多的时候;而获得更大的数据集是比较贵的。比如ImageNet里面得有些图是人类的专家才能区分的。例如两个犬:
我们可以提升网络的深度(网络的层数)和宽度(每一次操作的产物——得到的featuremap更多),宽度就是1*1的卷积核。通过卷积核提升宽度的方式是比较安全和高效的。尤其是有大量带标注的数据时。但是有两个缺点:1)比较大的尺寸会提升非常多的参数,引起过拟合,尤其是训练数据集不够多的时候;而获得更大的数据集是比较贵的。比如ImageNet里面得有些图是人类的专家才能区分的。例如两个犬:![]() 正常人类是很难区分的——大数据集并不是很好收集的。
正常人类是很难区分的——大数据集并不是很好收集的。![]() 2)这么大的参数是会影响训练资源的提升;他说一个有效的计算资源的分别,比不分青红皂白的扩大规模更重要。就是我们在扩大规模的同时还要考虑怎么去合理的分布计算资源。他倡导服务显示生活。
2)这么大的参数是会影响训练资源的提升;他说一个有效的计算资源的分别,比不分青红皂白的扩大规模更重要。就是我们在扩大规模的同时还要考虑怎么去合理的分布计算资源。他倡导服务显示生活。
#现在不一样的,不管是transformer还是比较大的模型,现在的趋势是大的模型了,都是比较大的公司搞的。
![]() #ALexNet全连接层的参数量占了所有的参数的93%。他将生物学里在思考问题时,只有少数神经元是被激活的,大多数神经元 没有被激活,思考不同的事情,不同的神经元被激活。而全连接是每一个神经元都参与计算了。我需要训练每一个神经元的权重,所以说全连接是一个密集的,而生物学里面人类的思考方式是稀疏的,讲了这么一个灵感来源。第二个灵感来源是一篇paper—— Arora et al.给了一个数学理论支持,就是我这样做(用稀疏取代密集)是可行的。生物学灵感来源是赫布理论的。
#ALexNet全连接层的参数量占了所有的参数的93%。他将生物学里在思考问题时,只有少数神经元是被激活的,大多数神经元 没有被激活,思考不同的事情,不同的神经元被激活。而全连接是每一个神经元都参与计算了。我需要训练每一个神经元的权重,所以说全连接是一个密集的,而生物学里面人类的思考方式是稀疏的,讲了这么一个灵感来源。第二个灵感来源是一篇paper—— Arora et al.给了一个数学理论支持,就是我这样做(用稀疏取代密集)是可行的。生物学灵感来源是赫布理论的。
#non-uniform sparse data structures非均匀稀疏数据结构,比如dropout是不利于计算资源做并行计算的,不管是CPU还是GPU。
#我们的卷积这个操作本身就是一个稀疏的:参照全连接去想,![]()
#ConvNets have traditionally used random and sparse connection tables in the feature dimension:ConvNets传统上在特征维度上使用随机和稀疏的连接表
#跟lenet比,lenet并不是讲全部的feature map都送入下一层去做计算,而是随机的选一些featuremap送到下一层。但是杨立坤这么做的原因是当时的硬件计算能力太差了,它搞那么多featuremaps下一次处理不了,所以他随机的送。但是从另一个角度讲,他这做也是一个网络的随机性, 是计算内部的随机性。
#但是Alex以后,你这么随机的送进下一次这么做是不利于网络的并行加速的。所以自2012年之后就把得到的featuremaps全部送进下一层了。
##有没有一种中间操作,既能保证架构上的稀疏性,即使是在卷积核这种级别上,有理论支撑的,还可以使用现阶段的硬件加速能力【灵魂拷问】
#我们的这种方法就能得到这两种好处。用稀疏替代密集
![]()
#用【2】的数据理论,实验得到了好的结果。
![]()
由于我们的1*1、2*2、3*3卷积得到的featuremaps都是全部送到下一层的,所以我们Inception里的子操作就近似出一个稀疏的最优的结构;--Inception的解释,理论支撑就是文献【2】;这种方法在计算机视觉领域不管是分类还是目标检测的效果都是比较好的。但是它背后的理论(用相对密集的块去近似一个最优的稀疏的结构)是值得探讨的。以后可能会被验证,如果将来有一个自动的构建网络架构的工具,跟我们设计的Inception比较相似的话,证明了我们模型的设计是比较合理的。这么技术叫自动机器学习
#the Inception architecture is based on finding out how an optimal local sparse structure in a convolutional vision network can be approximated and covered by readily available
#什么是用相对密集的网络组件来近似一个最优的稀疏结构?答:密集和稀疏是哲学思想。相对传统的卷积lenet来讲,1*1,2*2,3*3是比较稀疏的,就是相对于全连接来讲,我们的组件是稀疏的。Inception的稀疏是相对于全连接讲的。我们的结构可以得到很好的精度——所以是最优的,相对于AlexNet、VGG来说Inception是最优的。![]()
#上面左图是密集的,但是右边卷积就是稀疏的。
##赫布法则:一个神经元激活,相关的神经元也被激活。这是我们人脑记忆和识别的基础。比如识别猫咪,我们脑中一个识别猫耳朵、一个识别猫眼睛、一个识别猫尾巴等等的神经元同时被激活。——用Inception块的结构给了一个生物学的解释。
![]()
#就是把每个尺寸的卷积核得到的不同数量的featuremaps都堆叠在一起。这个子块类似于机器学习里的集成学习:三个臭皮匠顶一个诸葛亮。
。
![]()
#在网络的浅层它处理的就是局部相关性,在这种情况下可以用尺寸比较小的卷积核,如1*1、3*3就可提取到这种特征;但是在网络的深层,However, one can also expect that there will be a smaller number of more spatially spread out clusters that can be covered by convolutions over larger patches, and there will be a decreasing number of patches over larger and larger regions.空间信息是不一样尺寸的,1*1、3*3并不能完全覆盖,所以用5*5的卷积核来提取;也可以预见空间范围比较大的信息相较于见空间范围比较小的信息是比较少的, 所以用比较少5*5的卷积核。
#造成featuremaps不同的大小,用padding填充一下![]()
#由于我们的池化操作被证明是非常有效的,因此在Inception结构里面也添加了池化操作。
#我们需要知道它的思想,并不是只知道这个模型结构。!
##Inception 块在网络结构的顶部,应该遵循随着更高层捕捉到更高级的特征,会提升3*3和5*5的卷积核的数量。#为什么捕捉更高级的特征需要更大的感受野? 答:回忆ZFNet,底层是空间特征,高层是抽象特征,例如草地。为了提取抽象特征,需要关注全局的信息,就需要比较大的卷积核。
【随着更高层捕捉到更高级的特征,他们的空间集中度预计会降低,这表明随着我们向更高层移动,3*3和5*5协同进化的比例叠加】【Inception理解:有多重结构,类似于人脑不同区域有不同的能力】
#所以Inception块就大概长成什么样子了
#用5*5的卷积核会提升计算量,所以需要进行改进。尤其是使用了maxpooling后计算量更会提升:假设原始图像有256个通道,通过maxpooling后,通道数有多少?答:还是256,只会在图像尺寸上有改变,通道数不变。
经过一个Inception后,maxpooling得到的通道数量和其他卷积核得到的通道数量进行相加,所以我们的通道数会变得越来越大。所以需要改变通道数。通过1*1的卷积来控制通道的数量。
![]()
![]()
如上 如果觉得图片数量通道数太多了,就用1*1的卷积核降维;同理如果maxpooling后通道数太多了,也用1*1的卷积核换成比较少的通道数送进网络里。
![]()
#如果浅层用正常的卷积,网络的中层、顶层用Inception块。这种方法是比较好的,不管是在计算资源上讲还是结果上讲都是。这个操作并不是严格遵从的,只是一个现象。![]()
#可以看到第一次卷积和第二次卷积都是正常的卷积,在之后的才用的Inception块。
![]()
#我们架构的另一个好处:可以非常灵活的更改每一个stage里的block,就是更改每一阶段子结构堆叠的次数,这样可以随意控制网络的大小、深度和宽度。!!后期的模型都是基于block和stage进行搭建的,因为这样比较方便。
#另外需要注意的是 这种多尺度的信息融合在计算机视觉里是非常重要的。就是不同尺寸的卷积核提取不同尺度的特征,然后融合。
#最后讲模型的计算资源,比传统的架构(不用Inception)快两到三倍。
###下面是讲架构。
#先看图,如果看图能看懂,就不用读文字了。![]()
![]()
#列代表网络的stage,就是网络的阶段。Inception3就是第3阶段,Inception4就是第4阶段,Inception5就是网络的第5阶段。上面的第一行就是第一阶段;第4行,maxpooling的作用就是对特征图做尺寸的减少,顺便在channel维度上做一些改变。因为步长为2【patch size/stride】为3 × 3/2;
最后倒数第四行,avg pool 就是Network in Network文章里提到的全局池化。经过全局池化后得到一个向量,送进dropout里再送进一个全连接。这里为什么还跟了一个全连接?答:是为了做模型的迁移学习用的。例如我们model在ImageNet训练好了,当我们想换一个数据集例如kaffee,我们可以讲ImageNet训练好的模型参数拿出来,在avg pool 及以上的层的参数都固定住,不会在训练的过程中被改变。然后只训练我们的全连接层,用这一层去训练新的任务,这种操作叫迁移学习。这个迁移学习的效果是非常好的,可以自己试一试!
如果没有这一层的话,迁移学习的时候去训练什么?就没有参数可以训练了。迁移学习主要看两个数据集分布距离是否远。
#【patch size/stride】指kernel size卷积核的尺寸和步长 例如第一次卷积,尺寸是7*7步长是2的操作。【output size】是卷积之后得到的featuremap 的尺寸。是112*112*64的。【depth】是指卷积操作的个数,例如第一行是1个卷积操作,第三行是指用两个卷积操作。
后面列就是卷积的具体参数,例如第5行3a里面,#1× 1 是64,是1*1之后卷积得到的featuremap的channel维度的数值,会有64个channel。 #3× 3 reduce 是指先1*1reduce![]()
#3× 3 就是1*1reduce之后的3*3;#5× 5 reduce也是指1*1reduce; pool proj 指全局池化![]() ;params参数量; ops计算复杂度。
;params参数量; ops计算复杂度。
![]()
#在池化之后接了一个全连接是为了适应微调的任务;
#用全局平均池化可以提升大概0.6%个百分比,而且可以减少参数量。
#辅助分类器,对最终结果给了0.3的权重,最后一个分类器是1的权重。但是在test阶段预测时,并不使用辅助分类器。辅助分类器只是在训练时用。在以后证明了,并不能对网络分类精度有帮助,更多的是为网络回传提供梯度。--网络是需要反向传播,如果距离比较远,可能引起梯度弥散和梯度爆炸,但是如果用辅助分类器,能传播比较近。 注:在V3版本,把辅助分类器删掉了!
![]()
#但是,只是针对分类问题,用中间结果帮助分类没有用;但是用目标检测和语义分割会经常用的中间结果的。![]()
#在读第二遍的时候不需要读参数设计。
![]()
#ImageNet比赛,我们为了在比赛中得到更高的精度,1、训练7个版本模型,再集合预测。用来相同的初始化和learning rate,只有什么不同?它们只在采样方法和它们看到输入图像的随机顺序上有所不同。2、第2个技巧:先将一张图像resize成4个尺寸,256, 288, 320 and 352 。然后在每个尺裁成左中右三个小图,再取中间、4个角和原图,这样一个图片变成144个。![]()
![]()
4*3*6*2=144:4是每张图片resize成4张,3是指每个尺寸裁成左中右三个小图,6指每个小图取4个角+中心+原图,2是指最后取了镜像。mirrored versions就是翻转。
#所以一张图像得到144个不同的版本,就是不同的观察角度。在预测时,会对144个版本都进行预测,然后将这些预测结果统一到一起。###以前我们在训练的时候是也可以对图像进行裁剪,但是这里是预测,预测也可以裁剪了。#这里不是简单的做数据增强,这里是为了预测的更精准一些。所以我从1 张图像变成了144张图像。比如我去动物园看一个动物,我从一个角度看一张图像,还有从另外144个角度看144张图像哪一个更加精确?? ,哪种方式判断的更准确? 肯定是多个角度,多个方向看,更加准确。他这里讲在真实的生活中,这里是没有必要的。,他主要是为了打比赛, 准确率刷错误,所以就无所不用其极。![]()
#这里能说明情况,用一张图它的错误率是10.07%,用144张图它的错误率降低为6.67%。看第5行如果要把一张图变成10张图的话,它的错误率是7.62%。但是我要变成144张图的时候,我的成本很大,但是我的收益却是很小的,我的收益和我的付出是不平衡的。因此这里讲我们在现实生活中没有必要用这么极端的方式。#他这里挺好的,给大家点出来了,不会误导大家。
![]()
#这里讲做分类的时候用了 softmax。 他也用了其他的方法,比如最大池化平均操作都没有 max表现好。
###上面就是预测时的小技巧:一个是softmax,一个是多尺度预测,一个是集成学习。![]()
#然后讲我们的模型如何如何好,这里讲的非常艺术。他首先讲我们的错误率是6.67%,做了对比。因为你单看这个错误率,你不懂这个大赛的话,你是不知道所以然的。你甚至还觉得6%挺高的。但是他对比了,我们比12年的AlexNet,错误率降低了56.5%。这个多夸张。可以看table2,他做了个对比是AlexNet错误率是15.3%,他们是6.67%。
他没有这么说,我们是6%,Alex是15%,我们降低了9%, 他如果这么说9%和56%,哪个更加吓人?所以他这样描述,显得更加有艺术。
#他们还比较了ZFNet,他们比ZFNet有40%的错误率的下降。
# both of which used external data for training the classifiers. 他讲嗯next night和light都是先在ImageNet 22k进行训练,然后再进行一个迁移学习,你们用了迁移学习都没有我没有用迁移学习效果好。如下。他们都是用迁移学习训练22k之后再去用来训练ImageNet 1k。
![]()
#googlnet没有用迁移学习。
![]()
下面是检测模型上的结果是实验。由于我们关心的分类,所以第二遍时不看。
然后就是结论。
#第三遍不领读了,自己读。
###再讲一个事,googlenet是一个非常值得学习的模型,而且它是一系列模型。而且他并不止是4版,它还有第5版,他还有一个X,最终版。![]()
#这里强烈建议,回去把V1到指好好读一读.
#XGoogLeNet等讲完mobilenet再讲。因为这里有两个技术,一个是ResNet残差神经连接,是ResNet里面的,一个叫深度可分离卷积,是mobile net里面的。
作业:1、VGG 80多行的模型敲一遍;2、googlenet论文回去好好读一读:V1,和V2的batch normalization。3、读一读VGG论文
#########总结googlnet v1~v5################
![]()
#Googlenet和VGG都是里程碑式的模型。
![]()
#拼接不同尺寸的卷积核:思想:1、集成学习(上课的学生,学同一个问题,每个人不同思考方式,交作业时把每个人合到一起)2、不同的感受野可以识别出不同大小的对象。
#问题:V1版本有5*5计算量很大。还有一个maxpooling,没有办法对channel维度降维,造成维度越来越大。![]()
#引入1*1卷积:作用:1、进行升维或降维,2、融合channel维度的信息--》深度可分离卷积 (卷积的变体)就用了1*1卷积,以后看。
![]()
#模块化结构:Inception块堆叠的,有block和stage;每一个stage有很多block,block就是Inception块。有block和stage的好处非常简单清晰明了的可以控制模型的大小。例如可以将stage里的block等比例的增大。![]()
###下面讲googlenet代码:首先记得里面的组件,有一个辅助分类器,用了帮助模型分类,他底层也是卷积层,所以第一步搭建辅助分类器。
def __init__(self, input_channels, num_classes): 初始化一些成员变量,看原文![]() 辅助分类器的结果:首先是一个Inception得到的结果作为辅助分类器的输入,送进来后,先经过一个AveragePool平均池化,在送入一个1*1的卷积,再送入两个全连接,最后接一个softmax作为分类的函数。所以模型也这么搭。
辅助分类器的结果:首先是一个Inception得到的结果作为辅助分类器的输入,送进来后,先经过一个AveragePool平均池化,在送入一个1*1的卷积,再送入两个全连接,最后接一个softmax作为分类的函数。所以模型也这么搭。
![]()
![]()
![]()
#看另一个脚本:
BasicConv2d(nn.Module): #讲卷积操作和激活函数绑定到一起,这样做一般是卷积后面都会跟一个激活函数;def __init__(self, in_channels, out_channels, **kwargs): #接受一个输入维度,吐出一个输出维度;**kwargs作用是我当前的类可以接受一个不定长的参数;如果没有它,只能有两个参数传进来;有了它可以传很多。因为conv2D函数里面有很多参数,常用的是input和output但是还有一些其他参数,像步长、padding,这些就以不定长的参数传进来
![]() #然后就是Inception块的搭建。将4个分支当做成员送进来:第一个分支是1*1,第二个分支是1*1加3*3;第三个分支是1*1加5*5,第四个分支是3*3加1*1;
#然后就是Inception块的搭建。将4个分支当做成员送进来:第一个分支是1*1,第二个分支是1*1加3*3;第三个分支是1*1加5*5,第四个分支是3*3加1*1;
![]()
#in_channels首先指定输入维度, ch1x1是第一个分支里的参数, ch3x3red指channel3*3reduce指的是第二个分支里面1*1的输出的通道维度, ch3x3第二个分支里的参数, ch5x5red, ch5x5, pool_proj
#pool_proj最后一个maxpooling输出维度的设定
#注意每一个分支的输入维度是不是都一样的啊?都是in_channels。所以Inception块会将输入copy成4份,从forward也能看出来,xui copy成4份分别送进4个分支里面,outputs = [branch1, branch2, branch3, branch4]然后将4个分支的结果放进列表里面。
![]()
从256最后到64通道;googlenet v3准则之一:避免特征表示上的瓶颈![]()
#池化会尽可能保留原有的特征,所以先池化再1*1降维
![]()
#然后是辅助分类器,前面讲到。
#然后就是搭建模型了,里面的名字和论文里的table1是一一对应的。
![]()
![]()
![]()
#这里每一Inception块都接一个maxpooling,用于做特征图的尺寸减半的。
#看一下代码,同理先看Inception。self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32) #Inception上面搭建的Inception类 这里和表格里的参数是一一对应的。192是上一次输出的维度,上一层是maxpooling,他channel维度输出的数量,作为下一个stage输入的特征数量。
#self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)每一个maxpool都是大小3×3÷2的设置;ceil_mode=True 是指步长为2,滑动时超出边界,要不要滑动?如果滑的话,这些填充为0,如果不滑的话就直接滑到第2行。![]()
![]()
#第78~82行,就是在stage前,要堆叠三个卷积,一个是self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3) 是7*7步长为2;另一个 self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)是3×3步长为1.
#只不过这里还跟了一个1×1的卷积,但是表格里没有写。self.conv2 = BasicConv2d(64, 64, kernel_size=1) 第81行在第2个卷积前面跟了一个1×1的卷积。但是这个卷积既没有改变特征图的大小,也没有改变特征图数量 。思考一下这是什么作用?答:跟准则二有关。为了进一步提取信息。就是后面Inception模块,不管多么精妙,它的输入信息都是前面的,如果多了一层的话,就是多了一个映射,给网络更多的可能性。因为多了一层的话,就会多很多参数,可以学习更多的东西。
![]()
#stage后面就会跟非常常规的分类头。这里跟VGG不一样的是不再用打平操作。如AlexNet和VGG
![]()
![]()
#googlenet后面用的是全局平均池化。就是对featuremap里面的值求和/featuremap的元素数量,相当于做了一个信息的融合。融在一起就得到一个值,这一个值就能表征原featuremap的含义。相当于长度为1的向量。好处是大量减少全连接层的参数量。一个经典的网络结构大部分参数量都在全连接层,一个很大的原因就是做flatten后得到的结果太多了。中间映射的节点也多,所以最后分类的参数就很多。注意:以后不要用flatten了,直接用全局平均池化。![]()
###googlenet v1贡献就是两点:一个是全局平均池化,另一个就是1*1的卷积。![]()
![]() #后面就是跟了一个dropout、一个linear 线性层、一个softmax
#后面就是跟了一个dropout、一个linear 线性层、一个softmax
#后面就是前向传播。
![]()
#他在第二个stage里面,有两个辅助分类器![]()
#下面辅助分类器是通过if语句判断的。if self.training and self.aux_logits: 辅助分类器只是在训练过程中才会被执行,在预测时就扔掉了。aux_logits这个是指如果要的话才加载这个辅助分类器。aux1 = self.aux1(x)得到一个结果。![]()
#这里为什么还有一个flatten?答:就是扔掉后两个维度。也可以用x = x.squeeze(-1).squeeze(-1)
![]()
#x = self.fc(x) 送进一个全连接。注意如果有辅助分类器的话时输出三个值。
# x = 0.3 * aux2 + 0.3 * aux3 建议不要用,并不能提高网络性能,在v3版本给它删掉了
![]()
#深度可分离卷积![]()
#回忆一下常规卷积:![]()
#如果上面的卷积,1张RGB图,卷积之后,得到的尺寸是[1, 4, H, W] 就是1个batch,4张featuremaps,高度和宽度。
###卷积操作的参数量:重要!>卷积核高度* 卷积核宽度*输入通道数*输出通道数
###计算量。
深度可分离卷积可以大量减少计算量。![]()
#逐通道卷积:每一个卷积核只负责处理一个通道,所以输入有几个通道就意味着有几个卷积核。所以有三个卷积核,每一个卷积核去卷一个通道。![]()
#问:他也什么问题?正常卷积是对每一个通道都做计算得到一个featuremap,对通道信息有一个融合;而逐通道卷积就不行了,每一张featuremap并不是由原始数据里面全部通道整合来的,只能看到某个通道。所以需要第二步——1*1的卷积。
#逐点卷积:逐通道卷积的featuremap并不能做通道的信息交互,如果在maps后面接一个1*1的卷积,在得到一个featuremap,就有信息交互了。
![]()
#为什么这样做?可以节省大量的参数。##回去理解一些卷积操作的计算量公式,对理解卷积操作有很大意义。
#计算量指在卷积过程中一共做了多少次的计算。![]()
#参数量39,比原始卷积108下降了很多,只是之前的1/3
![]()
#计算量只有351是常规卷积的972的1/3
![]()
#1*1的卷积核作用:1、信息融合 2、升降维。
##XGoogLeNet![]()
#V2提出了batch normalization
#在V3提出了网络设计的四个准则,所以V3里Inception块变得更加复杂了:![]()
#V4里面提出了复杂的两个架构
![]()
![]()
#只不过每一个stage中的Inception 的结构不一样。网络变得越来越复杂。![]()
#V4里面还提出了残差神经网络结构。
#问:搞这么复杂有效吗?V4确实比V1效果好,但是它这么设计主要是把人为的先验知识安在网络里了,有没有更简洁更有效的表达方式呢?这是一个非常值得探讨的问题,这是我们Inception块最终版本XGoogLeNet的思路。
![]()
![]()
![]()
#算法层次的概念:不管是VGG还是GoogLeNet,都指明一个事情,两个3×3的卷积核等同于一个5×5的感受野。右图两个3*3的感受野能看到25的面积,等同于一个5*5。既然我用这两种方式得到的感受野都是一样的,那么我为什么不用两个3×3呢?因为两个3×3,有更多的映射在里面,每一个卷积后面都会跟一个非线性激活函数ReLU,如果你网络是两层的话,那么你做的映射就会更多。他就说,用这种更深的结构,能得到更大的潜能,模型的上限会更多,因为它有更多的变换可能。在VGG里就看不到大的卷积核了,像5*5,,11*11,他就说用小尺寸的卷积和的叠加,就能够得到大的感受野,这是VGG的一个思想。##这里不仅从映射的角度讲,还有一个从参数的角度,两个3×3堆叠起来的参数量比 5*5 是要少的。如果默认通道数是1,两个3×3的参数量9+9=18, 而一个5×5的参数量是25。既然我的映射多,参数还少,我为什么不用这种简单有效的方式呢?
#但是这是10年前的事情。那时候人们普遍认为堆叠小卷积核是有效的,这种思想引导大家有十年之久,但是现在2022年开始提倡大卷积核。有多大?31×31。清华大学有一个paper就讲这种超大的卷积核,在大型数据集中是更有效的,它的作者是丁霄汉,一个大神。而去年的VNN模型,它的卷积核是21*21的。但是这么大的卷积核参数量是非常多的,不可能直接用一个常规的卷积。比较常见的就是用DW深度可分离卷积,或者是扩张卷积都可以减少参数;但是他们的感受野是越来越大的。到底是大卷积核好还是小卷积核好使,就跟百家争鸣差不多。##总结:
小卷集合更能提取纹理特点,假设你做的是图像分类任务,可以根据目标的纹理去将目标进行分类,这时候我的网络结构里面是3×3的卷积核就更加有效一些。但是大的卷积核的好处是有更大的感受野,它的鲁棒性就更好一些,这时候我就可以用它去检测一些空间特征了。所以说如果我的任务是跟目标检测有关的,那么实验证明了大卷积核是有效的。 所以说算法或模型到底要长什么样子,是根据的任务问题相关的,并没有一条公理,告诉你网络要怎么设计。如果有的话,我们的深度学习也不会那么有魅力,那就没有意思了。正因为生活中有这么多问题,深度学习有这么多参数可调深度学习才这么火热。所以在看任何一篇论文时,都要有一个批判的思想在里面,不要觉得他讲的就是真理。当然,像VGG、GoogLeNet,你也不要把他看得一无是处 ,你也要有一个敬畏的思想在里面。 人家确实是大佬,确实比我们强, 我们要虚心一些。
![]()
![]() #所以在v3里面,他两个3×3就等效于V1里面的5*5;V3的Inception第2层都变成3×3了,第1层都变成1×1了。用1×1来控制通道的位数。每一层的结构都越来越相似了,就这么一个趋势。
#所以在v3里面,他两个3×3就等效于V1里面的5*5;V3的Inception第2层都变成3×3了,第1层都变成1×1了。用1×1来控制通道的位数。每一层的结构都越来越相似了,就这么一个趋势。
![]()
#X版本做了简化,十分规整。第2层都变成3×3了,第1层都变成1×1了,没有第三层。比V4的Inception好看多了。![]()
#下一步:既然第1层都是1*1,那么我们就把他们合并,共享一个1*1。这是把1*1得到的featuremaps切开分组,然后把每一组分别送进不同的分支中,这样参数量就没那么多了。【对比V1版本forward函数是将数据分别copy进四个分支里去,如下图】![]()
#这里有三个分支,而不是合并?就是希望我有不同的思考方式,这是一个集成学习的思想。
#想一下如果不是三个分支,分支数量是c(通道数),那么就成了逐通道卷积了。所以XGoogLnet的终极版本就是逐通道卷积。而这三个分支这个状态就是组卷积(G conv),回想AlexNet,他硬件有效,送进两个GPU里,就是组卷积。组卷积的核心思想就是集成学习,通过不同的角度做分析处理。
#XInception的终极版本就是深度可分离卷积。大家并不用关注XInception怎么设计的,你只需要用深度可分离卷积就可以了,如果将来你要做模型轻量化的话。
#XInception跟深度可分离卷积只有一点细节不一样。对于DW卷积来讲,他是先做逐通道卷积,再做1*1卷积的,但是在XInception里,是先做1*1卷积,在做逐通道卷积的。但是如果把Inception块堆叠起来的话就完全一样了。![]()
![]()
![]()
#Inception的网络结构:
![]()
#整体上X与之前V1的差不多,有XInception和relu,但是有一个残差,这根连起来的线就是残差神经网络,后面讲。
#很多实验都证明了深度可分离卷积他的参数量少,计算量少,而且网络精度还高,所以这个思想很厉害。
#作业:1、卷积操作的参数量和计算量是如何算的?底层原理2、搞懂DW卷积,这里面有两个自操作,逐层卷积和点卷积,点卷积更重要。3、至于googleNet一系列文章,如果感兴趣建议到X版本都读一读;4、回去做实验,用torch_summary包把VGG和googleNet网络打印出来,对比参数量,你就明白GoogLeNet有多厉害了。VGG是往深度走,GoogLeNet是往广度走。
5、GoogLeNet V1版本代码手敲一下
深度解析神经网络
复习:
![]()
#神经网络根本上可以说是一种线性模型。![]()
#这个线性模型等价于一个单层神经网络。
![]()
#训练的目的是最小化损失函数:预测值与真值的距离最小。
#怎么求导?梯度下降![]()
#梯度的作用:如果某点沿着梯度的方向前进会是当前函数值增大最快的方向。有求出极小值,只需要沿着梯度的反方向前进就可以了。梯度下降就是沿着梯度反方向前进,总会有一天下降到极值点。这里需要更新梯度:就是学习率lr,不断更新梯度。选择学习率,不能太小,每次只挪一点模型训练不动,不能太大,容易挪走,会产生梯度震荡或梯度爆炸。所以lr是一个超参,一个好的lr,不希望是一个静态的,所以刚开始训练时可以把lr设的大一些,因为网络刚开始训练时现在值和最小值是有很大距离的,而训练到离最小值比较近的时候就设置小一些。一种lr设定方案是以阶梯的方式每隔一段时间就把lr设定下一点。
![]()
#小批量随机梯度下降:是DeepLearning里默认的梯度下降方式。一般来讲深度学习数据集都是很大的,全部用来求导,训练是很贵的。所以我们对原始数据集随机采样,因为随机采用b个样本与原样本分布应该是一样的,我们就用b个样本做梯度下降。batch size 如果选的太小了,近似原数据集误差大,又不利于GPU并行计算;b不能选的太大,浪费计算资源、不利于近似。
#为什么要做反向传播?只需要记住是为了求梯度。
![]()
#广义线性模型。预测值逼近y的衍生物。加了一个g-1,g就加连续函数,要求单调可微的。可广义线性模型以解决非线性问题。线性模型——红线,衍生物——黑线,就是加了联系函数,就是原始线性模型值做了一个映射。
#线性模型输出是连续的,可以做预测和分类。只需要找到一个单调可微的联系函数,例如单位阶跃函数,就可以解决二分类问题。
#思考:单位阶跃函数是否可作为联系函数?不可,因为不可导。需要改进成sigmoid![]()
![]()
#分类是离散的,回归是连续的
![]()
![]()
#回归任务一般一个输出;分类任务有多个输出,每一个节点表示预测为该类别预测的一个置信度。
#思考:回归是一个连续,如何将一个连续的输出映射成一个概率呢?答:用联系函数,找一个函数映射一下,例如softmax
![]()
#softmax特征:一、相加等于1,相当于概率;二、映射后的结果变得更分明。例如4和1差距不大,但是映射后变成0.64和0.3,就是让大的更大,小的更小,他们之间的差距更明显,更容易做分类了,让界限变得清晰了。
![]() #感知机
#感知机
![]()
#sigema的作用是对线性模型做了一个映射。
#问:感知机与回归和softmax不同之处?答:对于回归输出是实数,对于感知机,输出是一个二分类;对于softmax输出是概率,感知机是二分类。
#问:感知机是否是一个线性模型?答:不是
#问:感知机是否是一个广义的线性模型?答:不是。联系函数是单调可微,它不单调。不要纠结感知机是啥,模糊讲归类为一个广义的线性模型没有问题。
#问:感知机是否是一个回归?答:不是。回归要求输出是一个连续值,而感知机输出是离散的。
#如何训练感知机?1)参数初始化2)重复步骤:判断感知机的输出和真值相乘是否小于等于0,如果小于等于0,说明真值和预测值不一样,预测值是错误的,所以要更新权重。作为更新后出来,再repeat,直到所以的分类都正确。其实感知机等价于一个梯度下降。对于损失函数关于w求导,后面就剩下一个-y*x,w- -y*x,相当于w + y*x做了一次梯度下降。
#感知机有一个缺陷,感知机不能解决异或问题,让当年的神经网络的研究陷入了一个冰河期。![]()
#感知机拟合的一个线性模型,一个分界面无法在平面分开异或。解决办法是多加一层。![]()
#MLP:可以拟合任何一个连续的复杂函数。![]()
#用两个分界面解决异或问题。异或问题:同号输出为正,异或输出为负。
#每个节点都可以拟合一个平面,现在需要两个平面,就需要两个节点,这就是为什么需要一个隐层。右图,两个线之间就是+,中间之外就是-,就解决了异或问题。
![]()
#什么叫MLP?现在大火的transformer每一层都用了MLP。MLP叫多层感知机。
#对于感知机,只有输入层有权重的,可以看成是单层神经网络。MLP一般指![]() 只带一个隐层的神经网络。也有人叫两层神经网络,因为只有输入层和中间层有权重参数。
只带一个隐层的神经网络。也有人叫两层神经网络,因为只有输入层和中间层有权重参数。
#灵魂拷问二:一层就能拟合任意函数,为什么需要多层级结构?答:一、减少参数量。假设有一个隐层,有10个节点;现在有两个隐层也能代表10个节点,单只需要7个节点就能拟合原单隐层。![]() 二、可以减少维度诅咒
二、可以减少维度诅咒![]()
![]()
![]()
#当一组数据在当前的特征空间里不可分的时候,通常可以对当前的特征空间映射到更高维度的空间,就有可能分开。例如支持向量机SVM。
#加入三个特征,三维特征空间可以想象成一个带隐藏层的神经网络,2维不可分时,升级为三维,用分界面就可以分开。但是这种情况不是完美的,如果继续增加特征维度,将原始数据映射到更高维的空间,是不是更有利于分类? 答:过拟合。![]()
![]()
随便找一个平面就可以分开,对模型来说太小儿科了,能找到很多平面很多解;如果一个平面很完美的分开了,当把平面投影到二维时,发现这两个猫咪是个特例,这个区域狗是多的。其实更合理的是红线。
#模型去学习了训练样本中的特例——就是过拟合。所以更多的特征容易轻易的过拟合。![]() 过拟合就是泛化能力不强;更希望得到一个泛化能力强的模型,因为人的泛化能力就比较强。
过拟合就是泛化能力不强;更希望得到一个泛化能力强的模型,因为人的泛化能力就比较强。
过拟合的原因就是维度诅咒。维度诅咒最根本的原因是数据量不够大。假设样本是无限大的,就可以拟合真实的世界,所以不存在特例了。相对于真实的世界不叫特例,![]()
#trade off权衡数据集容量和特征数量,如果数据大可以采取很多特征,数据集小不能采取很多特征。
#灵魂拷问三:为什么激活函数需要非线性?
![]()
![]()
#工作中默认的是如果增加特征,必须增加训练数据。
#为什么nn层级结构从开始一般是降维的?就是为什么节点会减少?![]() 答:神经神经网络的输入一般是高维数据,例如输入图像和文字。这么高维的空间样本的相似性难以挖掘,所以会用神经网络做特征维度的压缩;隐层从宽到窄,经过压缩的特征的空间维度它的数据分布就是比较稠密的,利于寻找空间相似性和做一个分类。
答:神经神经网络的输入一般是高维数据,例如输入图像和文字。这么高维的空间样本的相似性难以挖掘,所以会用神经网络做特征维度的压缩;隐层从宽到窄,经过压缩的特征的空间维度它的数据分布就是比较稠密的,利于寻找空间相似性和做一个分类。
所以有两个原因:一是输入数据一般是高维的;二是高维度的空间样本之间相似性难以被挖掘。
#降维是为了更好的挖掘空间相似性。增加样本是为了防止过拟合。--这两个方式都有利于网络训练。
#神经网络有升维的吗?答:有,例如生成图像,图像一般都是高维的。从10维生成256,就需要reshape图像。如果任务期望得到一个低维的输出,就用降维,如果任务需要一个高维的输出,就用升维。升维和降维是跟任务有关的。
#梯度下降是需要到所有的样本进行计算吗?如果做全批量是的,如果做批量的话ninibatch,就需要取样本计算就可以。
#作业:回去用python实现一个MLP,不用pytorch,网上有很多教程。为了真正理解MLP——搭一个单隐藏层就可以。
###
![]()
#衡量预估质量:用真实值和预测值的距离。例如平方损失。模型训练的目的是让距离尽可能的减小=求损失函数的最小值。
#星号是最优的意思。![]()
#更新参数,更新方式是梯度下降。对损失函数求导,得到梯度,乘以-lr,就是学习速率,就是更新方式为梯度的反方向。![]()
#深度学习网络是默认的是小批量随机梯度下降。
#原始的梯度下降需要对梯度求导, 是对数据集全部的计算再求平方损失。但是现在数据集太大,比较贵,所以在数据集里做随机采样,b样本近似为原始数据集。
#反向传播是为了求梯度,求梯度是为了求损失函数最小值。
ResNet
![]()
#讲特别有名的文章,ResNet,是计算机视觉里面引用量第一的文章。
#读第一遍时题目摘要和结论,看题目知道这个算法是图像识别的,看是否与自己相关。
![]()
#看摘要,说一个比较神的神经网络是不好训练的。他们显示的构造一个层级结构可以去学习残差功能,去代替原本的层级结构。后面讲结果多么多么好。学VGG或GooGLeNet发现这些网络都是20层左右,ResNet是152层,相当于深了8倍。而且错误率是下降的,效果非常好的,并且获得了ImageNet大赛2015年的冠军。#冠军算法就非常值得读了。像2012年冠军AlexNet,13年ZFNet,14年是GoogLeNet第二名是VGG,15年就是ResNet
#他们还去分析了CIFAR-10数据集,这个数据集是100分类,5万张图片,比ImageNet 120万张图片是要少很多的,所以它相较而言是一个比较小的数据集。但是他可以在这个小数据集上构造一个100层的神经网络,这就很吓人了。
#第二段说了一个要点,网络的深度表征,对于视觉识别任务来讲是非常重要。 用残差表示,可以把网络构造的很深,得到了一个相对来讲比较准确的性能,这个性能是在目标检测任务上,不是分类了。就是说不仅在检测任务上表现的很好,在分类任务上表现得也很好。
#然后看结论,这里没有结论的原因是他做了大量实验,他的实验结果写不开,所以他把结论讨论给去掉了,用来展示他的结果。不过这个写法不推荐。
#读第二遍:核心了解一下算法,但是细节问题,比如网络怎么调参和具体的一些结构、包括训练配置可以不读--第三遍再读。
![]()
#简要:介绍深度学习网络浅层是提取的low level级别的特征,而网络的高层提取的是high level语义特征。
#end-to-end的概念:对照机器学习。端到端,就是数据进去直接出结果;而常规的机器学习是需要特征工程,比如PCA降维,主成分分析,送进模型的不是数据而是处理过的特征。深度学习是自动提取特征,例如卷积。
#深度神经网络可以简单的通过堆叠层的方式做的很深、深度对于网络是非常重要的。举例了之前的工作都是增加网络的深度。
![]()
#灵魂拷问:简简单单增加网络深度真的有利于网络训练吗?获得更好的网络和更容易训练吗?我们可以观察一个现象,可以回答这个问题,就是梯度弥散或梯度爆炸。网络很深联程。一个深层的网络就是矩阵的连城,而梯度也是一个连城,如果值比较小容易造成梯度弥散或梯度爆炸。这样就不是很容易得到一个好的网络。上图他做了一个实验,针对同一个问题做了一个实验,一个是20层,一个是56 层,当我们去实验的时候,20层得到的错误率比较低。所以网络如果更深有更多的参数,理应由很大的潜能,但是为什么学不出来呢?
#尝试解答,会不会是梯度弥散/爆炸呢?不是,因为这个问题已经被一些技术比较好的解决了,例如GoogleNet V2里提到的batch normalization,以及一些比较好的初始化方法。既然不是梯度弥散/爆炸,又是什么造成的这一现象呢?![]()
#这个现象他叫网络退化degrades,这个现象是不符合预期的,也不是过拟合导致的。他提出了另一种解释:当网络比较深的时候,深的那几层可以什么都不学,只把浅层学过的东西原封不动的传下去。如果这样做,深的网络的学习效果理论上不应该比浅的网络效果差,最起码可以保证一致。#是否理解?这就是他说的identity mapping,自我映射,就是自己传给自己,不做任何学习。所以效果不应该比浅层的差,所以他很不理解这个现象。
#他们显示的构造了这种结构,允许网络在后层什么也不干,只负责传递。他说好像对于神经网络而言什么都不干是最难学到的。![]()
#他们隐士的构造出来:![]() 常规的网络结构是构造一个映射,再传到下一层。我现在隐士的构造一个残差学习来,希望我的学习并不是在原始数据上,希望学到H(x)-x
常规的网络结构是构造一个映射,再传到下一层。我现在隐士的构造一个残差学习来,希望我的学习并不是在原始数据上,希望学到H(x)-x![]() 就是x是前几层学到的,到深层时希望学到的x不丢,只学跟之前不一样的东西,而不是全部给他改变。#是否理解?
就是x是前几层学到的,到深层时希望学到的x不丢,只学跟之前不一样的东西,而不是全部给他改变。#是否理解?
#我们希望中间的block学的是H(x)-x,如果将开头的x直接传过来,最后的输出结果是H(x),那中间这块肯定是H(x)-x,我学的东西就是刚才的残差。
![]() 像机器学习里面树模型里的boast;
像机器学习里面树模型里的boast;
前面是正常的神经网络传播过程。只有把x映射过去,中间才有可能学的是H(x)-x。
#正常的网络学到的是H(x),但是我把x传过来,网络学到的就是H(x)-x。--》目的为了后几层什么都不学,目的就是直接传x,这么学我的网络至少不会太差。
![]()
![]()
#我们的残差结构也可以叫捷径分支,这个结构有一个非常大的好处,就是没有任何可学习的参数,不会增加网络的复杂度,因为只是把网络的结果传过来了,不会增加网络的复杂性。
#在ImageNet上做实验,当增加了残差结构网络退化的问题就会得到很好的解决,而且模型会非常容易的被优化,就是它收敛的很快。而且可以通过残差神经结构很容易的得到很深的网络。
#在CIFAR-10数据集上,图片是23*23尺寸的,类似于头像的数据集,在这个数据集上,他们可以达到1000层的网络深度。然后说实验结果和比赛效果都很好。。。
###可以看到他的Introduction写的是非常好的,首先它是摘要的扩写,首先解释了什么叫reshazour、什么叫显示得构造一个残差结构。而且进一步讲了我们的实验结果怎么样。这个Introduction写的是非常不错,如果能读懂就能掌握ResNet的核心思想了。非常值得借鉴的一种写作方式。
![]()
![]()
#相关工作:介绍了Residual Representations残差表示和Shortcut Connections捷径分支/捷径链接。这两个说的都是上面讲的残差结构,有人叫Residual有人叫Shortcut。这个相关工作就是介绍之前在机器学习里面有人用的残差链接和短路链接。这说明:这条连线并不是何凯明的原创,之前有很多的工作都已经有这个东西了。包括树模型里面,并行树和串行树里面就有这个链接。所以他不是一个新东西。由于是机器学习这里不仔细讲了。
#一篇经典的文章,像ResNet并不代表的里面的工作是原创,你可以是引用以前人的技术。像这里的技术都是90年代的事情了。只要我能把之前的技术挪过来可以解决当前你的领域比较严重的问题,比如他说的网络退化的问题,即便你不是原创,也是一个里程碑式的文章。意思是原创虽然很重要,但并不是一个写论文必备的要求。千万不要明明知道有这么一个工作,但是我就不提他我就不说不引用,就说是我自己新出来的,这样如果以后你被发现了,可能会有学术上的纠纷。所以以后写文章时我要大胆的写出来。#你引用过来后,还有表征一个事情:我的方法跟之前的方法究竟有没有不一样的地方。that these solvers converge much faster than standard solvers that are unaware of the residual nature of the solutions.比如他说我的方法可以收敛的更快比之前的方法。
#短路链接里讲的神经网络里之前的工作,例如MLP和googlenet v4里也有残差链接,比如highway networks高速网络。On the contrary, our formulation always learns residual functions; our identity shortcuts are never closed, and all information is always passed through, with additional residual functions to be learned与他们相比,我们的公式总能学的残差功能。因为他是显示的接过来了。
#highway networks高速网络也可以学到残差,只不过他的残差更复杂。简单说highway networks的思想,他传过来的x并不是一个完整的x,而是一个百分比,可能传1%的x,也可能不传x。但是残差永远传一个线,所以highway 更复杂一些o。
![]()
#第三节讲的是算法,是Introduction的扩写,就是上面残差结果的扩写。描述了什么H(x)是什么,不重读了。是递进式的写作风格。
![]()
![]()
![]()
![]()
![]()
#网络设计:对照网络时的两条准测:1)每一个的feature map的尺寸都是保持一致的,包括每一层卷积层的数量2)如果feature map的size减半,会增加卷积核的数量。这个是默认准则,在增加对特征图减半时一定要增加卷积核的数量。我们希望将空间上的特征转移到channel维度上,我们空间上的特征都是一些位置、纹理、颜色等low level低级的特征,而转移到channel维度上,能表征一些比较高级的特征。这里将特征图减半,将通道数翻倍,其实在做特征提取。
#直接将卷积步长调为2,最后借一个全局平均池化。
#下面讲了一些VGG的参数,为了对比。这里太细了,读第二遍时不用读。
![]()
![]()
![]()
#左边时VGG,中间时VGG改的跟残差结构一样的,希望做一个对照,他对照的时中间和右边两个。
#上图右边注意有一个虚线,![]() 这是因为每一个stage之间特征图的维度是不一样的。这就不能直接相加了,所以虚线是做了一个处理,就是1*1的卷积,可以改变通道数量。
这是因为每一个stage之间特征图的维度是不一样的。这就不能直接相加了,所以虚线是做了一个处理,就是1*1的卷积,可以改变通道数量。![]()
#这种stage变换有两种方式:一种是1*1的卷积,另一种是在channel维度padding一些空的featuremap进去来保证两个featuremap的维度是相等的。但是经过实验发现第一种方式更好,所以舍弃了第二种方式。![]()
#3。4实现:这里先不详细读;他说初始化权重的方式和论文12是一样的,不建议这么写。他这么写是因为12是他自己的论文工作。
#没有用dropout,因为它没有用全连接,一般只有全连接才会跟一个dropout;注意最后一个全连接是做分类的不会跟dropout。AlexNet和ZFNet的最后一个全连接也不会跟一个dropout。
#测试时将一张图裁成10张小图,把10个小图都送进模型里都做一个预测,将预测结果统一决定预测是什么,相当于做了一个集成学习。一般刷榜都会用非常夸张的测试来提高一点精度。它是要达到训练 。 这就是为什么图像大赛,从12年办到17年,17年之后就不再举办的原因了。因为已经跑偏了,大多数团队都会尝试怎么用一些非常复杂的,没有道理的操作来提高一丁点的精度,没有必要。这就是很多人不愿意打比赛的原因,没有必要。ImageNet里程碑12年AlexNet,然后14年GoogLnet和VGG,这两个模型首次达到了跟人类是同等级别的分类任务;再往下是15年ResNet 它的分类水平已经超过人类了。然后16、17走了两年,主办方觉得好像 趋势不对,大家都尝试用很贵的模型很贵的设备,去搞那么一丁点的精度。 已经违背了搞科研的初衷了,所以就把比赛停掉了,当然这5年涌现的模型都是非常经典的,值得学习。
![]()
#先介绍ImageNet
#测试:对比的模型写在了table2和fig4里面。![]()
#左图是没有加残差的,右图是加残差的。,可以看到没加残差的图有一个网络退化在里面,就是说更深的模型达到的网络效果更差。但是加了残差模型就没有退化的问题了,更深的模型就会得到更好的精度,这是我们所期望的。VGG就说过就说过,如果将来网络做得更深的话,模型的精度会更高。这是符合正常现象的,所以Resnet会有助于解决网络退化的问题。
#这里可以发现一个现象:红色细线是模型训练的精度,红色粗线是测试时的网络精度,可以发现,网络在训练时的错误率比测试的错误率要高的。 问:为什么训练的是网络的精度比测试的网络精度要高? 答:因为在训练模型时做过大量的数据增强,做完数据增强以后的数据是有很多噪音的。做完数据增强,比如说正常一张图像,我们的目标在下面,但是我做随机裁剪,可能减不到这个目标。 也就是说,做完数据增强后的图像、数据集是一个更难的数据集。但是做预测的时候,并不会做那么多的数据增强,就造成了两个数据集的难度不一样。 所以在最开始训练的错误率肯定是要更高一些的。
#曲线为什么有一个陡然的下降?答:因为在训练中用的一个策略,叫做学习率阶段性下降。在基础的脚本里,学习率是一个数值,比如0.002。之前讲理论的时候也讲了,这样一个固定的学习率并不是一个最优的策略,我们希望学习率,随网络的训练是一个下降的状态,他可以递减,比如说从0.02一直降到0.01。可以是阶梯递减,也可以是按照曲线递减。这个学习率也是一个小方向,里面有很多学习曲线。 以后可以看一些关于学习率的论文。
#这里采用一个策略,有一个人在守着模型训练。 如果错误率不降了,这说明当前的学习率有些大,当前的状态一直在震荡,他就手动把学习率乘以一个0.1。 然后错误率就一下子降下来,然后再训练。 然后错误率曲线又不动了,学习率就再给他乘一个0.1,又降下来了。 这是他的训练方式,这种训练方式有些古老了,需要一个人在那里盯着看,现在基本上不用了。而且这样也有一个不好的地方。 错误率虽然不降了,但是从何时乘以0.1好呢??
![]() 其实都是一个主观的事情,即便你这样搞,他也不是一个最优解。而且在我看来,这里就是说降的确实有点早了,就是说,你如果过早,对后期模型收敛不利 。应该往后训训练再讲也是没有问题的,所以这就比较主观了。
其实都是一个主观的事情,即便你这样搞,他也不是一个最优解。而且在我看来,这里就是说降的确实有点早了,就是说,你如果过早,对后期模型收敛不利 。应该往后训训练再讲也是没有问题的,所以这就比较主观了。
#训练的时候还可以改参数吗?? 答:当然可以。比如说训练到这里,我可以把我的网络停掉,然后在这里的参数我是保存的,我可以在代码里把我的学习率手动改成0.1。 然后在重新开启训练的时候,不用随机初始化了,就用我之前停下来的时候存的那些权重作为初始化,那么我们的网络不就重新跑吗? 所以说可以停下来的。
#右边就是加了残差之后的结果,可以明显看到网络越深,效果越好。 table2跟上图说的是一个事情,可以发现,加了残差之后的网络越深的错误率是越低的。
#还有一点需要注意,加了残差之后,网络的收敛是越来越快的。可以看到10和20之间模型不动的时候,没加残差的错误率是54%左右, 但是加了茶的错误率是45%,说明加了之后还有利于帮助模型去收敛。![]()
#所以残差有两个好处 :一个好处是可以帮助模型搭建更深,解决网络退化问题;第2个好处是,残差可以帮助网络更快的收敛。
#下面就是对图表的描述,如果你能看懂图表,下面的描述可以先不看,尤其是在你读第2遍的时候。读第3遍你想看也可以看。
#再往下走就是整个模型的残差结构:
![]()
![]()
#说的是不同的调整channel的方式,有三个方式,一个是可以通过padding, 另一个1*1的卷积;最后一个是可以在每一个层级结构后面都跟一个1×1的卷积。这就是network in network的思想,,他用了大量的1* 1去增加网络的深度,给网络赋予更多的非线性可能,这样子我们的网络他的潜能就会更大。他说这三种方式做了一个实验,看哪种方式更好。首先他发现去padding维度它的效果是不太好,它的错误率是有上升的,然后第2个比第1个要好一些,第3个比第2个要好一些。这里我们的作者他选用的是我们第2种方式。所以我们在本文的其余部分不使用选项C,以减少内存/时间复杂性和模型大小。
。![]()
#在ImageNet上的错误率展示,随着网络更深,错误率是不断下降的,这就符合网络正常的状态:网络越深状态越好。![]()
#对比之前的网络结构:像VGG、GoogLeNet。比他们都好,看到,比GoogLeNet的精度要高了两个多点,所以效果是非常非常好,非常惊人。
#Deeper Bottleneck Architectures瓶颈结构。先看这个表table1![]()
这个表和GoogLeNet里面讲参数的表格一样的,就是给大家去复现模型时详细的参数表格。![]()
#这张表非常重要,你甚至可以不读文章,看这个表就可以把resnet网络结构给搭建出来。、
![]()
#这张表,每一行都是一个stage,共有4个stage,每一个stage里面的block可以重复堆叠多次,![]() 这个乘号就是重复堆叠的次数。block里面就是层级结构的集合,像上面的block里面有两个3*3的结构,后面跟着是64是channel维度的值,这个block就是前面讲的那个结构图:
这个乘号就是重复堆叠的次数。block里面就是层级结构的集合,像上面的block里面有两个3*3的结构,后面跟着是64是channel维度的值,这个block就是前面讲的那个结构图:![]()
#看到50层、101和152这三个比较深的网络结构里面用的block结构是不太一样的——这就是刚才提到的瓶颈结构。
#这4个stage上下都有一些不一样的东西:上面是有一个比较经典的卷积结构的,和GoogLeNet一样,用来做下采样的,用了一个7*7步长为2,channel是64的一个卷积,然后在跟一个最大池化。这是在stage之前做的操作;之后是GAP,global average pooling 接全连接FC fully connected layer 接一个softmax。整个网络结构用一个表画出来了。
#总共有几层网络?上面写的18、34、50等
#问:block里面的步长是多少?答:论文里有描述,就是中间的block里面的步长都是等于1的。只有虚线这里![]() 就是新stage第一个卷积的步长是等于2的其他地方的步长都等于1。
就是新stage第一个卷积的步长是等于2的其他地方的步长都等于1。
#之后的目标检测都会用到很深的网络吗?答:会用到,像yolo v5用213层。
#层数是怎么看的?算一下,看18层的,中间有8个block,8*2=16层,前面一个卷积层,后面有一个全连接层,加起来18层
#池化不算层,池化里面没有可学习的参数,所以这里指的层数,是说带参的层。
#细心的可以观察,网络从34层增加到50层,他的FLOPs只增加了一点点,网络计算量只有一点点提升。他就是用瓶颈结构达到的。
![]()
看到从18层到34层翻了两倍,50到101也翻了两倍,都是正常的,只是34到50增加了一点点。![]()
#左图是原本的一个残差结构,右图是瓶颈结构。可以看出来,瓶颈结构就是多了两个1*1。首先3*3是一个,上面下面各加了一个1*1,足以见得1*1多好用。这个1*1就是控制channel维度的数量的。想升就升,想降就降。在深层网络里面,每一层的featuremap是比较多的。不降维,正常往下走,例如256,下面也是256,就是网络参数量会多特别多。右图,首先把256的channel降维64,这么做是降低网络参数的计算量;第二个1*1的作用是什么,为什么我又要给它升回去?考虑一下?通过这个问题可以进一步把残差的结构掌握明白。答:为了维度匹配,因为残差传过来的维度是256,如果输出不是256,就加不起来,给网络又回到了256,这样就又保证我的残差网络结构了。
#所以这里用两个1*1做升降维,这个结构可以给网络省非常多的参数量和计算量。
#这个瓶颈就是3*3比较宽,1*1比较窄,就跟一个瓶子一样。
#再往下走就是一些结果的比较,在读第二遍的时候你就简单看一看,说我的网络参数比VGG有多少下降,所以这里略读。而不是不读,第二遍你就读到这样做参数量可以降很多就够了。
#第三遍的时候,你再去和其他模型对比降了多少。![]()
![]()
#下面是CIFAR-10 and Analysis,只需要知道CIFAR-10是比较小的数据集,ResNet可以在CIFAR-10上搭建一个1000层的网络。当然1000层的深度是一个没有必要的,他是冗余的不是最优的结构,只不过他能达到1000层已经很吓人了。就是说为什么我1000层都没有梯度弥散呢?就是模型还能训练出来,尽管模型的精度赶不上100层的。这里强调一个是:残差确实有用!好用![]()
![]()
#下面是在CIFAR-10上的训练图,比如左边是不带残差的,右边是带残差的对照组等![]()
#后面讲了他们可以达到1000层的深度![]()
![]() #讲一下这个,但是这个有点不公平。上面图表是不带残差很深的模型,下面图表是带残差很深的模型,纵轴是网络参数的标准差——可以代表,如果我的网络深层真的什么东西都没有学到的话,那么我深层的权重那些参数应该是比较平滑的,应该是接近于0的,以为啥都没学到,所以就搞了一个实验。上图,不带残差是后面权重还是有东西的,但是带了残差之后曲线就比较平滑了。
#讲一下这个,但是这个有点不公平。上面图表是不带残差很深的模型,下面图表是带残差很深的模型,纵轴是网络参数的标准差——可以代表,如果我的网络深层真的什么东西都没有学到的话,那么我深层的权重那些参数应该是比较平滑的,应该是接近于0的,以为啥都没学到,所以就搞了一个实验。上图,不带残差是后面权重还是有东西的,但是带了残差之后曲线就比较平滑了。
#为什么说是不公平的?因为两个模型的结构是不一样的,你从原本的模型加了一个残差结构,虽然你只改变了一点,但是对于网络而言,你改了一点结构,他的本质是有巨大的改变的在里面的。所以你用同一个,就出我们的训练配置是适用于带残差的网络结构的,你用这个训练配置当然可以训练出一个不错的网络模型了。但是如果你用这个训练配置去训练另一个模型,首先这个训练配置就对这个模型是不适用的,而且在我看来,上图后面是模型没有训练好。就是用这个训练配置去训练这个模型是一个失败的结果,用来对比没有太大参考价值,看看就好。
##4.3节讲了在目标检测的结果,这块本来应该写结论的,但是他写了在目标检测上的结果,大家不要学他。也能理解作者为什么这么搞,首先何恺明是一个大神,他完全可以把目标检测不写在这里面,他在写一篇paper,用我的残差再写一篇paper。因为我的精度也是刷榜的,所以他完全可以写两篇paper的。但是他感觉我没有必要去水论文,我这两篇paper虽然效果都好,但是我的idea相差不大,他就写到一起了。但是换一个人的话,他极有可能去水两篇paper。
#在我看来,你的效果已经这么好了,所以你目标检测这个东西写不写完全不影响,完全都可以发顶刊的。所以4.3如果能写总结的话,写自己对模型的理解,对以后这么技术该用到那个方向,在我看来是更好的。
##探讨:残差到底有多有效?
#先总结:何开明当时写残差时,他为什么觉得残差有效?说的这些都是表象,问为什么会有这个效果?用残差弥补信息的缺失。
#首先作者认为用残差可以保留之前学的东西不被丢掉,我进一步学习不会丢掉之前学的东西,我永远都给他加过来,我永远都在学新东西。就是网络越来越深,我永远都在学习新东西,这就是网络不会变差的原因。这是作者当时提出的解释。但是现在很多研究人员不买账,他们觉得网络效果好是因为我们残差结构可以很好的帮助网络梯度很好的传下去。就是你的网络特别深的时候,由于你的数值不稳定,所以你的梯度会越传越小。
#讲正则时讲过,正则的一种手段就是把连乘变成加号,现在去理解一下:假设原始数据是x,经过一层有一层,其实就是对x做映射,首先一个前向传播的过程就是连乘,而反向传播也是一个连乘,比如求导的时候,先对f(g(x))求导,在对g(x)求导,所以求梯度过程是一个连乘。但是加一个残差就不同了,就是f(g(x))+g(x),就是说先对f对x求导再加上g(x)对x求导,所以加了一个残差之后,不仅仅是连乘了,连乘后面还加了一项,所以梯度就不会出现因为连乘而弥散的现象了。![]() 这是从梯度角度讲,所以现在有人说ResNet之所以有效是因为梯度传播比较有效,因为有一个加号在里面。
这是从梯度角度讲,所以现在有人说ResNet之所以有效是因为梯度传播比较有效,因为有一个加号在里面。
#现在已经读了两边,有没有必要读第三遍?没有必要,因为读到这里已经能把模型搭建起来了,所以说这篇文章写作是非常好的。唯一不要学的是两点:第一点是没有结论不要学,第二点是引用[12]那一块。这篇文章的写作方式是是否值得学习的。
#自15年以后所有的模型都用到了残差。大道至简,说了那么多,就是那条线。深度学习里面从来不缺复杂的模型,缺的就是ResNet这种简单的模型,工业里面也在用。
ResNeXt
###讲ResNet代码之前讲一个模型——ResNet的变体,其次他是2016年图片分类大赛的亚军ResNeXt,ResNest。讲了它之后,只剩下17年的冠军没有讲了。16年的冠军的算法没有开源。冠军是中国公安团队,但是源码没有公开,大家猜是集成学习的算法。17年的冠军是SENet,稍微带点attention的意思在里面,不过他是计算机视觉领域的注意力机制,跟nlp不一样。
#ResNeXt这个算法很简单,https://blog.csdn.net/qq_39297053/article/details/123850155?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167050117916782429727756%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=167050117916782429727756&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-2-123850155-null-null.nonecase&utm_term=ResNet&spm=1018.2226.3001.4450
前言
由于ResNet在神经网络里的地位实在是无可撼动,其paper引用量在CV界位居第一。
因此,基于ResNet也有很多变体,单单其变种就有几十种,其中最知名的当属ResNeXt, SENet, GENet, SKNet,CBAM等等。其中尤以ResNeXt, SENet与SKNet最为人知。而亚马逊出品的这篇ResNeSt一经开源同样引起了不小的轰动。 这个博文的目的就是介绍这些变体,这将会是一个持续更新的博文
另外,有很多经典的网络也是受到ResNet的启发提出的,比如DenseNet,又或是FractalNet等等
一、ResNeXt
1. Motivation
问题背景:
传统的提高模型的准确率时,都是加深或加宽网络,但是随着超参数数量的增加(人为设定调节的参数,比如channels数,filter size等等),调参难度、网络设计难度和计算开销也会增加,超参数很多时很难保证每个超参数最优。
#怎么样去搞一个模型他的参数量降下来而且模型的性能是有提高的?他的扩展性很好?ResNet就是从另一个角度,如深度可分离卷积,和组卷积。
网络超参数的针对性比较强(特定数据集需要的超参往往不一样),当应用在别的数据集上时需要修改许多参数,因此可扩展性一般。
ResNeXt要在提高准确率的同时,基本不改变或降低模型的复杂度,同时还减少了超参数的数量。使用的方法是分组卷积,关于分组卷积我在MobileNet系列文章中有详细讲解(传送门)关于如何减少参数量请移步上述链接,下面将在第三小节解释一下分组卷积的有效性。
ResNeXt的可扩展性更强,更简单、更模块化、超参数更少,相同参数下的结果更好,ResNeXt-101的准确度相当于ResNet-200的,而且计算量减半。
2. Model Architecture
非常的简单:将resnet中3*3的卷积,替换为分组卷积。然后就没有了。。。。
#震惊,只改了一点就发了一个很好的paper。
说实话就这个点换我是发不出来paper的,可见讲好故事有多重要。
论文里增加了一个cardinality的概念(就是group),并讨论了相较于增加网络的宽度和深度,简单的增加group会更好。一句话就是,split-transform-merge。
上图是正常的残差快;下图是ResNeXt的残差块。可以看出ResNeXt先对1X1的卷积进行了一个分组(groups=32);注意:ResNeXt残差块经过第一个1X1卷积后的维度是32X4=128,相比原始残差块64的维度来说,是有一个上升的。由于分组卷积可以减少很多参数量,所有这里即便维度上升了,总参数量也是下降的。
####
![]()
#上面是普通卷积:上图为普通卷积示意图,为方便理解,图中只有一个卷积核,此时输入输出数据为:
输入feature map尺寸: W×H×C ,分别对应feature map的宽,高,通道数;
单个卷积核尺寸: k×k×C ,分别对应单个卷积核的宽,高,通道数;
输出feature map尺寸 :W’×H’ ,输出通道数等于卷积核数量,输出的宽和高与卷积步长有关,这里不关心这两个值。
参数量 : k2×C
运算量 : k2×C×W’×H’ (这里只考虑浮点乘数量,不考虑浮点加)。
![]()
将图一卷积的输入feature map分成组,每个卷积核也相应地分成组,在对应的组内做卷积,如上图2所示,图中分组数,即上面的一组feature map只和上面的一组卷积核做卷积,下面的一组feature map只和下面的一组卷积核做卷积。每组卷积都生成一个feature map,共生成个feature map。
输入feature map尺寸: W×H×C/g ,分别对应feature map的宽,高,通道数, 共有g组(上图g=2);
单个卷积核尺寸: k×k×C/g ,分别对应单个卷积核的宽,高,通道数,一个卷积核被分成g组;
输出feature map尺寸 :W’×H’×g ,共生成g个feature maps。
参数量 : k2×C/g×g = k2×C
运算量 : k2×C/g×W’×H’×g = k2×C×W’×H’
对比普通卷积来看,虽然参数两和运算量相同,但是,我们得到了g倍的feature map数量。
所以group conv常用在轻量型高效网络中,因为它用少量的参数量和运算量就能生成大量的feature map,大量的feature map意味着能提取更多的信息。
从分组卷积的角度来看,分组数g就像一个控制旋钮,最小值是1,此时的卷积就是普通卷积;最大值是输入feature map的通道数,此时的卷积就是depthwise sepereable convolution,即深度分离卷积,又叫逐通道卷积。
#组卷积就是将一组featuremap切开分组进行卷积,这个东西和alexnet的模型一样![]() 当时并没有组卷积这回事,只是当时的硬件不达标而已。
当时并没有组卷积这回事,只是当时的硬件不达标而已。![]() 还有这张图,表示不同的卷积学到的东西是不一样的,比如上半部分是gpu1学到的图,他是一种偏黑白的纹理特征,下半部分是gpu2学到的图,他是一种偏色彩的颜色特征。所以分组卷积有一个好处,每一组都能学到不一样的特征。这就跟上学一样,班级里每一个同学都是查不多,每一个都可以看成是分组卷积的卷积核,每一个同学学到的都是同一个东西,但是每一人学到的东西的事不一样,这就类似于集成学习或多尺度处理,总之我们可以学对不同的模式,这就是组卷积的核心。如果不分组,相当于一个人学,就没有一样不一样了。
还有这张图,表示不同的卷积学到的东西是不一样的,比如上半部分是gpu1学到的图,他是一种偏黑白的纹理特征,下半部分是gpu2学到的图,他是一种偏色彩的颜色特征。所以分组卷积有一个好处,每一组都能学到不一样的特征。这就跟上学一样,班级里每一个同学都是查不多,每一个都可以看成是分组卷积的卷积核,每一个同学学到的都是同一个东西,但是每一人学到的东西的事不一样,这就类似于集成学习或多尺度处理,总之我们可以学对不同的模式,这就是组卷积的核心。如果不分组,相当于一个人学,就没有一样不一样了。
#没分组之前,![]() ,例如这个结构他自己想学成什么样子就什么样子,没有对比了,但是分组之后,送进不同的分支里面,AlexNet也讲了,每一组都能学到不同的模式。
,例如这个结构他自己想学成什么样子就什么样子,没有对比了,但是分组之后,送进不同的分支里面,AlexNet也讲了,每一组都能学到不同的模式。
![]()
#回来看ResNeXt,a图像什么?像GoogLeNet多分支处理。归纳偏置:是transformer里的概念,指当一个模型造出来之后就已经把人们的先验知识加进来了。将神经网络最开始将MLP,她为什么处理图像不好呢?因为她参数太多,所以发明了CNN卷积,卷积为什么效果好?因为我们把跟图像相关的先验知识加进来了,有两个先验知识,一个先验知识加图像局部相关性,另一个叫仿射不变形。就是因为我们人为的把这两个先验知识给他加到了神经网络里面,所以她训练起来更容易。就想一个小孩成长过程中有大人给他指引方向哪些能获得成功,跟一个小孩自己去悟,那个更好呢?
所以以后设计算法时,首先要想的是我要处理什么问题,例如对于图像,就要先总结对于图像有哪些先验知识去赋予给我这个算法,当年Yann LeCun就发现了图像有两个性质,一个是局部相关性,一个仿射不变形,就把这两个性质通过模型设计赋予给了卷积神经网络,因此卷积在处理图像时效果很好。那么他怎么赋予的呢?#首先局部相关性怎么赋予的?是不因为卷积是一个小尺寸的kernel他每次只能观察一个局部,所以他符合了图像的局部相关性;放射不变形怎么赋予的?是不他通过滑动的方式,不管同一个特征出现在图像的哪一个位置,我都可以通过滑动的方式,划到你脑袋上面给你做一个识别。这是他卷积为什么这么设计的原因。
所以归纳偏置就是模型在设计过程中给模型赋予的先验知识。
#MLP也有归纳偏置,不过MLP的偏置,她觉得如果是层级结构的话,他能够对数据做更好的映射。所以层级结构就是MLP的归纳偏置。
#RNN也有他的归纳偏置,就是处理他的时序信息;transformer也有归纳偏置,就是全局建模。
#归纳偏置就是讲每一个算法都有自己建模偏好。
![]()
所以这个特别想googlenet,回忆GoogLeNet为什么要搞多分支?或者这时候他的归纳偏置又是什么?是不说多分支多尺度的处理是更合理的。
resnet的归纳偏置是什么?原作者认为是网络应该有恒等映射的能力,所以他显示的去构造了一个结构出来。让网络去学恒等映射,这就是他的归纳偏置。
#归纳偏置无法量化,但是可以通过网络设计隐士的赋予进去。
#能不能通过参数的方式归纳偏置?有,例如初始化时将参数初始化成均值0,方差1,他觉得这样初始化对数值稳定性有帮助。![]()
![]()
#这三个图的操作是等效的。a图送进32个支路,每个支路都用1*1的卷积处理,例如256,1*1,4左边256是指接收到的channel维度大小,中间是1*1卷积,右边4是指1*1卷积后输出的featuremap数量,等于4。再往下走,就更原始的ResNet一样,是接一个1*1的卷积输入通道和输出通道数是不变的是4,再往下走就是接一个1*1的卷积,就是输入维度是4,输出维度是升维到256,最后他们在256每一通道上相加,最后就得到一个256通道的输出。
![]() 这就和原始的ResNet输出一样,只不过在第一个1*1就开始分组了。
这就和原始的ResNet输出一样,只不过在第一个1*1就开始分组了。
b是前两步与a是一样的,然后得到3*3卷积的结果给它concat到一块,相当于googlnet里面每个分支得到的featuremap都给它concat成一块,给它叠到一起。可以算一下,每个分支都会得到4个featuremap一个有32个分支,concat起来,一共得到4*32=128,再用1*1的卷积将这128个featuremap给它升维到256,这是另一种操作形式。宏观上也是256个进256个出。
c是先用1*1的卷积将256个维度降到128,然后在3*3的操作上做分组卷积,拆成32个支路,每个支路都有4个featuremap,做完之后再将他们concat一起输出也是256.
#作者也说了一个事,既然我这三种方式 宏观表现都是相同的效果,都是256输入,256输出。, 那么他做实验就说明哪种方式效果好呢。 就是他也不知道,这是她做实验之前设计的三种结构。但是他经过实验发现,这三种方式的效果都差不多。,所以他就选择了c这种最简单的方式。 去做整RESNEXT里的block。 C图就是整个ResNeXt里面最小的unit。
#ResNeXt跟原始的ResNet有两点不一样:第1个不一样就是原始的做1 *1时候降到了64维,降的挺狠的,但是ResNeXt只降了一半,降到了128;第二点不一样的就是原始的是3*3的卷积,但是在ResNeXt就变成了分组的卷积。其他的都一模一样。
#googlenet x里面只有一个1*1的卷积,而ResNeXt又两个,是一个瓶颈结构。而残差都是有的所以区别不是很大。
#
![]() 这个就是2016年分类大赛的亚军模型。
这个就是2016年分类大赛的亚军模型。
#看代码:![]() ,BasicBlock就是原论文里的
,BasicBlock就是原论文里的![]() 左边的结构。
左边的结构。![]()
#设计两个3*3的卷积核,输入维度和输出维度通过传参的方式指定
#注意第二次卷积后面只跟了一个batchnormalization,relu而是放到了forward函数中
#第二次卷积是把残差加过来之后再经过一个ReLU输出的
![]()
#至于为什么这么搞,原作者发现这样会得到一个更高的性能。也是一一个以结果为导向的操作。
self.downsample = downsample #是一个下采样,这里只残差过来时那条线的下采样。因为在每一个stage过渡的时候都是一个虚线,虚线的原因是因为传过来的featuremap的channel维度是不匹配的
就是我传过来的channel是64维度的数据,但是传过来我会经过卷积变成128维。这时候去cancat的话是没有办法把残差直接拿过来、逐通道加起来的。
![]() 所以这里我通过下采样的方式去改变残差的数据维度。所以下采样并不是每一个block所必须的,只是在stage过度的时候做一个下采样。
所以这里我通过下采样的方式去改变残差的数据维度。所以下采样并不是每一个block所必须的,只是在stage过度的时候做一个下采样。
![]()
#Bottleneck就是论文里的![]() ,所以和他相比就是里面的成员不一样了。原本是两个3*3,现在变成一个1*1,一个3*3和一个1*1。整体的思路是一样的。
,所以和他相比就是里面的成员不一样了。原本是两个3*3,现在变成一个1*1,一个3*3和一个1*1。整体的思路是一样的。
![]()
#注意里面的expansion = 4 #扩张因子。这个是根据网络结构有关的,最后一个1*1在输出的channel维度上是256,但是上一个3*3的时候是64,这里相当于乘以了4,所以扩张因子就干了这么一个事。出现在最后一个1*1卷积上,会在channel维度上乘以4,self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion, kernel_size=1, stride=1, bias=False)。这里是方便修改的意思
#还有一个是width:![]() 指的是每一卷积之后输出的channel维度的数量,为什么不直接传?是因为要适配ResNeXt
指的是每一卷积之后输出的channel维度的数量,为什么不直接传?是因为要适配ResNeXt![]()
通过 groups=groups,比如groups如果指定成为32的话,他相当于把一个正常的卷积分成32个支路,做一个组卷机,所以实现起来非常简单,指定一个参数就可以。width就决定每次卷积后得到的通道的数量。例如如果啥也不改的话,groups=1一组就是一个正常的卷积,不分组了。这些默认参数不改,计算一下,width_per_group=64除以64=1,所以后面的东西等于啥也没有。相当于宽度就等于out_channel,所以这时候就等于一个正常的网络结构![]() 。如果给他制定参数的话,
。如果给他制定参数的话,![]() 制定32组,每组的成员是4,width = int(out_channel * (width_per_group / 64.)) * groups =64*4/64*32=128,这个时候的通道数量,就跟
制定32组,每组的成员是4,width = int(out_channel * (width_per_group / 64.)) * groups =64*4/64*32=128,这个时候的通道数量,就跟![]() 结构的通道数量是一致的。如果不做分组卷积的话,width 就等于channel=64,就是原始的卷积结构。
结构的通道数量是一致的。如果不做分组卷积的话,width 就等于channel=64,就是原始的卷积结构。
这里就是为了适配ResNeXt。
#BatchNorm2d是在Batch维度上做的归一化,而在channel维度上做归一化的也有,叫layernorm和instancenorm,可以搜一搜;还有一个叫groupnorm的。
#论文中,第三遍读到批量归一化,![]() #关于BN操作,只需要记住,以后的网络肯定是有BN的,这已经成为了设计模型的默认的一个操作了!!!
#关于BN操作,只需要记住,以后的网络肯定是有BN的,这已经成为了设计模型的默认的一个操作了!!!
##把这两个block搭建之后,就可以搭建整个网络结构了,这里有一个好处,就是block和stage的概念,如果你有这个概念在实现深度学习模型时,你就会由小到大一点点去实现这个模型。所以我们要先写block,跟砖一样盖房子,再搭建一个模型出来,所以写模型要有一个宏观的概念。
![]()
#self.include_top = include_top #网络最顶层,分类头,这个top是可要可不要的。因为只有在做分类时才这么搞,接一个全局平均池化接一个·全连接,但是如果不做分类的话是没有必要要这个top的。只需要用前面这些网络架构都数据进行特征提取,至于提取到的特征接下来干什么用就是其他任务要考虑的事情了,比如要做目标检测、语义分割啊,那就不是这么一个套路。所以用用一个参数指定要不要这个top。![]()
#self.in_channel = 64 #第一次卷积之后得到的通道数量。如果看模型,就是
![]()
#下面是第一层卷积后面跟一个BN、relu、和maxpooling
![]() 回去可以背一下常见的参数配置。如果kernelsize=7,stride=2,padding=3的话,这里s=2,说明这里的卷积做了一个二倍下采样,他的特征图尺寸会减半,因为步长翻倍了。然后maxpooling,nn.MaxPool2d(kernel_size=3, stride=2, padding=1) 跟3 1 1比步长也变成2,所以特征图也减半。所以前两层相当于一个4倍下采样
回去可以背一下常见的参数配置。如果kernelsize=7,stride=2,padding=3的话,这里s=2,说明这里的卷积做了一个二倍下采样,他的特征图尺寸会减半,因为步长翻倍了。然后maxpooling,nn.MaxPool2d(kernel_size=3, stride=2, padding=1) 跟3 1 1比步长也变成2,所以特征图也减半。所以前两层相当于一个4倍下采样
#常规的特征图不变的参数配置: k=3 s=1 p=1; k=5 s=1 p=2;k=7 s=1, p=3; k=9 s=1 k=4; k=11 s=1 p=4
#再往下就是创建4个stage,每一个stage都有block前面已经搭建好了,block是叠加的![]() #这里建stage是通过函数的方式,和VGG一样,现在只需要知道这里他是4个stage就可以了。
#这里建stage是通过函数的方式,和VGG一样,现在只需要知道这里他是4个stage就可以了。![]() 再往下走就是include_top。初始化讲完了。这个模型初始化就结束了。
再往下走就是include_top。初始化讲完了。这个模型初始化就结束了。
#看一下他的信息流动:依次送进前两个网络结构做4倍下采样、送进4个stage、送进top里得到一个结果
![]()
#然后看_make_layer到底怎么搭建stage的。十分巧妙。
![]()
#判断步长是否等于1或者,input和output是否相等,不等就做一个下采样。为什么?观察虚线,每个虚线都有一个特点![]() 是不是步长变成2了?其他block里的步长都是1呀。所以说每次我需要下采样的时候步长是变成2的。也就是说我是通过步长等于2每一个stage里第一个block的第一个卷积层,让他的步长等于2,这样子去实现一个下采样的。所以就判断到底是否等于2,如果等于2的话,我相对而言也会对indentity里的数据做一个处理,这是第一个判断。后面还有一个or,就是inchannels和outchannels做一个比较,可以观察一下,如果需要处理的话,通道数也是不对等的。当不需要做下采样时,通道数都是一样的,每一个stage里面通道数传递的时候它的通道数都是一样的。所以这里是通过ifstride != 1orself.in_channel != channel * block.expansion:这两个条件来判断是否需要对残差过来的indentity数据做downsample的。#下采样的方式是用1*1的卷积,channel是通过 self.in_channel, channel * block.expansion,这两个参数来调整的。
是不是步长变成2了?其他block里的步长都是1呀。所以说每次我需要下采样的时候步长是变成2的。也就是说我是通过步长等于2每一个stage里第一个block的第一个卷积层,让他的步长等于2,这样子去实现一个下采样的。所以就判断到底是否等于2,如果等于2的话,我相对而言也会对indentity里的数据做一个处理,这是第一个判断。后面还有一个or,就是inchannels和outchannels做一个比较,可以观察一下,如果需要处理的话,通道数也是不对等的。当不需要做下采样时,通道数都是一样的,每一个stage里面通道数传递的时候它的通道数都是一样的。所以这里是通过ifstride != 1orself.in_channel != channel * block.expansion:这两个条件来判断是否需要对残差过来的indentity数据做downsample的。#下采样的方式是用1*1的卷积,channel是通过 self.in_channel, channel * block.expansion,这两个参数来调整的。
#layers = [] #用来存放每一个block,这个列表就是用来存放每一个block的。比如![]() ,所以这里初始化一个列表来放这些block。首先会 把每一个block写出来。每一个stage里面第一个个block和其他的长得都不一样。
,所以这里初始化一个列表来放这些block。首先会 把每一个block写出来。每一个stage里面第一个个block和其他的长得都不一样。![]() 所以把它拿出来之后,后面的block就可以通过一个for循环写出来了。所以整个代码看起来很简洁,所以这里先把不一样的写出来。downsample=downsample, #只会出现在第一个block
所以把它拿出来之后,后面的block就可以通过一个for循环写出来了。所以整个代码看起来很简洁,所以这里先把不一样的写出来。downsample=downsample, #只会出现在第一个block
in_channel这些都是通过参数传过来的。相对于后面的for循环里的block,这里面多了两个参数,就是downsample=downsample和 stride=stride,其他的都是一样的
后面是用循环的方式把后面的block实现:是从1到block_num的,这是因为第一个block已经写好了。![]()
#问:第一个个block不是都要下采样吗,好要传downsample吗?答:第一个stage里面的第一个block是不需要做下采样的,所以需要判断。
![]() 这时候怎么判断?就是根据步长和通道数量。
这时候怎么判断?就是根据步长和通道数量。
#返回nn.Sequential(*layers) #把列表放进一个sequential容器里,由于是一个列表,前面需要有一个*
![]()
![]()
#先向传播上面讲了
#下面是如何搭建一个ResNet的。![]() 这里是参数的意义:block, #指当前构建的block里面的结果是什么样的,是下面哪种。
这里是参数的意义:block, #指当前构建的block里面的结果是什么样的,是下面哪种。![]() blocks_num, #每一个stage里的block的数量,对应2 2 2 2或3 4 6 3
blocks_num, #每一个stage里的block的数量,对应2 2 2 2或3 4 6 3
##把ResNet搭建成一个函数:
![]()
#先搭建resnet34,就是![]()
blocks_num传的参数是[3, 4, 6, 3]就是上面通过会通过索引列表的方式传过来。![]()
105到108行拿到的就分别是3 4 6 3。后面是分类数量和是否要索引头。#有一个细节,就是_make_layer的传参,之前没讲,现在讲:![]()
#第一参数block是说要用哪一种block用basicblock还是瓶颈block,这个参数就是搭建resnet里传的block #然后在搭建stage时还会将它的通道数和维度传进来。这个 64 128 256 512它等于什么?它等于原始论文里面的第一个stage里面是不所有的features是不都是64个呀,第二个stage是128个,第3个stage是256个,第4个stage是512个。瓶颈结构也是一样的,例如50layer里面![]() 的这里不是64是256?没关系有一个扩张因子,会给它变成256,所以整个网络结构是没有任何问题的。
的这里不是64是256?没关系有一个扩张因子,会给它变成256,所以整个网络结构是没有任何问题的。
#这里讲一个写函数的思路,例如你就要写这个stage,![]() 你要想你搭建stage要写什么东西。想,你要搭stage要想这里面都是哪一个种类的block,所以肯定要有一个参数是控制block属于那个种类的——block。又要想这个stage里面通道数量都是几,所以肯定有一个参数去控制通道数量的——64。又要想每一个stage里的block的数量是几,所以有一个参数去控制blcok数量——blocks_num[0]。然后你就可以搭了,这时候还没有讲步长,当搭建的时候发现,stage在切换的时候,通道数需要改变,这时候脑中要有思路,要么通过池化的方法,要么通过调整步长的方法。当要用调整步长的方法时,发现刚才的参数不够用,所以要增加一个参数过来——stride=2。
你要想你搭建stage要写什么东西。想,你要搭stage要想这里面都是哪一个种类的block,所以肯定要有一个参数是控制block属于那个种类的——block。又要想这个stage里面通道数量都是几,所以肯定有一个参数去控制通道数量的——64。又要想每一个stage里的block的数量是几,所以有一个参数去控制blcok数量——blocks_num[0]。然后你就可以搭了,这时候还没有讲步长,当搭建的时候发现,stage在切换的时候,通道数需要改变,这时候脑中要有思路,要么通过池化的方法,要么通过调整步长的方法。当要用调整步长的方法时,发现刚才的参数不够用,所以要增加一个参数过来——stride=2。![]()
这里发现第一个没传stride,但是第二、三、四都传了。因为只需要在第二个、第三个、第4个stage做下采样![]() ,而第一个stage不需要。
,而第一个stage不需要。
#resnet50的搭建方法:
![]()
#只不过50就不用BasicBlock、而是用一个Bottleneck。下面是resnet101
![]()
#下面两个是ResNeXt,只是指参时你发现你要多指定一个groups和每一个group要卷的多少个卷积数量,他们这两个模型是写到一起了,是一个很巧妙的方法。![]()
#上面就是整个模型的搭建
#这个图怎么画的?![]() 答:最好的方式就是PPT,如果你是大神的话可以干很多事。也有一个叫draw io
答:最好的方式就是PPT,如果你是大神的话可以干很多事。也有一个叫draw io![]() 是一个非常简洁的画流程图的软件。
是一个非常简洁的画流程图的软件。
![]()
DensNet
ImageNet从2012年举办到2017年一共5年。15年冠军是ResNet,16年亚军ResNeXt,18年SENet
#DenceNet叫密集块,效果比ResNet还好,只不过有一个缺点,就是非常占显存。就是做计算的时候非常占计算空间。这点对项目落地是不太友好的。像有些硬件里面的计算空间是有限的。所以整个模型就跑步起来。参考:https://blog.csdn.net/qq_39297053/article/details/123765554
#是CVPR2017年的Best Paper。基本不会出现梯度消失的情况。模型对features的复用是非常厉害的。优点
- 1、减轻了vanishing-gradient(梯度消失)
- 2、加强了feature的传递,更有效地利用了feature
- 3、网络更易于训练,并具有一定的正则效果.
- 4、一定程度上较少了参数数量
一、Motivation
卷积神经网络在沉睡了近20年后,如今成为了深度学习方向最主要的网络结构之一.从一开始的只有五层结构的LeNet, 到后来拥有19层结构的VGG, 再到首次跨越100层网络的Highway Networks与ResNet, 网络层数的加深成为CNN发展的主要方向之一; 另一个方向则是以GoogLeNet为代表的加深网络宽度.
#两种趋势:一种是像VGG这种向着深度去发展的;另一个方向是做网络的宽度,或多尺度,这种分叉的,包括组卷积、甚至说深度可分离卷积也是这个方向,要做这个多尺度的类似于集成学习的这种。
随着CNN网络层数的不断增加,gradient vanishing和model degradation问题出现在了人们面前,BatchNormalization的广泛使用在一定程度上缓解了gradient vanishing的问题,而ResNet和Highway Networks通过构造恒等映射设置旁路,进一步减少了gradient vanishing和model degradation的产生.Fractal Nets通过将不同深度的网络并行化,在获得了深度的同时保证了梯度的传播,随机深度网络通过对网络中一些层进行失活,既证明了ResNet深度的冗余性,又缓解了上述问题的产生(失活操作对应网络的影响与DenseNet还挺相似). 虽然这些不同的网络框架通过不同的实现加深的网络层数,但是他们都包含了相同的核心思想,既将feature map进行跨网络层的连接.
#网络退化是不是因为搞得太深,如果我的网络不够深的话,我通过什么去提升他的性能呢?这都是大家考虑一个问题啊,那么这个DensNet是第二个。他的网络一点都不深,很浅,但是他通过一个很巧妙的对特征图的使用来提升了网络的性能。我们看这个图吧。
何恺明同学在提出ResNet时做出了这样的假设:若某一较深的网络多出另一较浅网络的若干层有能力学习到恒等映射,那么这一较深网络训练得到的模型性能一定不会弱于该浅层网络.通俗的说就是如果对某一网络中增添一些可以学到恒等映射的层组成新的网路,那么最差的结果也是新网络中的这些层在训练后成为恒等映射而不会影响原网络的性能.同样DenseNet在提出时也做过假设:与其多次学习冗余的特征,特征复用是一种更好的特征提取方式.
二、Model Architecture
假设输入为一个图片X0, 经过一个L层的神经网络, 第l层的特征输出记作 Xl.
那么残差连接的公式如下所示:
对于ResNet而言,l层的输出是l-1层的输出加上对l-1层输出的非线性变换。
对与DensNet而言,I层的输出是之前所有层的输出集合,公司如下所示:
其中[]代表concatenation(拼接),既将 [公式] 到 [公式] 层的所有输出feature map按Channel组合在一起.这里所用到的非线性变换H为BN+ReLU+ Conv(3×3)的组合。所以从这两个公式就能看出DenseNet和ResNet在本质上的区别,下面放一张DenseBlock的图片帮助理解公式:
![]() 这个图我们就可以看出来,先在这个图上面画什么叫reset,如果是reset的话,它长这个样子:如果单看我画的连线的话,它是一个ResNet
这个图我们就可以看出来,先在这个图上面画什么叫reset,如果是reset的话,它长这个样子:如果单看我画的连线的话,它是一个ResNet![]()
那么DensNet怎么做呢?它希望每一个网络结构,就是每一层卷积都得到丰富的利用。这是干嘛呀?我不仅说我传给就是做一个残差,我会传给网络里边的每一个阶段。那这有什么好处?首先。我们是不是讲,网络前面讲ZFNet的时候说过,网络浅层提取的是一些细节方面的是纹理特征。网络的深层次呢提到的是一些语义级别的特征,那些高级别特征。ResNet为什么要有残差?有残差是因为网络前几个阶段他学到这些特征容易在前向过程中给他丢掉。就是这个恒等映射很难保持下来,就是我前面有什么东西,可能结果后面的计算就得慢慢的忽视掉了。相当于一种特征的丢失,所以我要做恒等映射。那么这里DenseNet就说了,既然你想用这个之前你学到的特征,为什么非要说一层一层往下传呢?为什么不能直接传给你吗?当然可以啊,所以说他这里前一层比较浅的特征,输出的feature map就会直接传给最后一层,他会有这种连线——直接传过来。比如说要在最后一层做分类的时候,或者做识别的时候,能用到的feature map就不仅仅是网络通过这种层级结构提到的这种比较高级语义的特征了,还有什么?还有我浅层网络提到这种纹理特征。可以拿过来一起用。这就叫特征复用。它这样来提高网络性能的。
#那这样子有什么不好的地方?就是内存,如果是一个正常的前向传播计算的话,网络传到哪里,只需要保存当前的状态就可以了。前面的东西可以丢掉,因为不需要在后面再用到它。所以它占用的这个计算空间是比较小的,因为之前计算过的东西都可以不保留,只需要算当前时刻的一个中间状态就可以。但是DensNet不一样,前面计算的featuremap不能丢,因为后面要用到前面的东西,所以说前面计算完的featuremap不能丢,要存下来。包括每个阶段、都要存下来,然后后面用的时候再拿过来。这就造成整个网络在计算过程中它要消耗很大的内存。
#这个模型里面也是有stage和block的。每一个stage里面也有block只不过block之间是密集链接的。![]() 这个特征图有非常复杂的复用关系。
这个特征图有非常复杂的复用关系。
Down-sampling Layer
由于在DenseNet中需要对不同层的feature map进行cat操作,所以需要不同层的feature map保持相同的feature size,这就限制了网络中Down sampling的实现.为了使用Down sampling,作者将DenseNet分为多个Denseblock,如下图所示:
![]()
在同一个Denseblock中要求feature size保持相同大小,在不同Denseblock之间设置transition layers实现Down sampling, 在作者的实验中transition layer由BN + Conv(1×1) +2×2 average-pooling组成.
注意这里1X1是为了降维;池化才是为了降低特征图的尺寸。
详细解释一下1X1卷积:因为每个Dense Block结束后的输出channel个数很多,需要用11的卷积核来降维。以上图的DenseNet-169的Dense Block(3)为例,包含32个11和33的卷积操作,也就是第32个子结构的输入是前面31层的输出结果,每层输出的channel是32(growth rate),第32层的33卷积操作的输入就是31*32 +(上一个Dense Block的输出channel),近1000了。因此这个transition layer有个参数reduction(范围是0到1),表示将这些输出缩小到原来的多少倍,默认是0.5,这样传给下一个Dense Block的时候channel数量就会减少一半,这就是transition layer的作用。文中还用到dropout操作来随机减少分支,避免过拟合,毕竟这篇文章的连接确实多。
#与ResNet不一样的地方是:每一个stage之间不是通过控制步长等于2做下采样的方式,而是通过pooling层做下采样。![]()
Growth rate
在Denseblock中,假设每一个卷积模块的输出为K个feature map, 那么第i层网络的输入便为K0+(i-1)×K, 这里我们可以看到DenseNet和现有网络的一个主要的不同点:DenseNet可以接受较少的特征图数量作为网络层的输出,具体从网络参数如下图所示:
![]()
#注意先看ResNet再看DensNet,因为DenseNet不是那么好理解。
值得注意的是这里每个dense block的3X3卷积前面都包含了一个1X1的卷积操作,就是所谓的bottleneck layer,目的是减少输入的feature map数量,既能降维减少计算量,又能融合各个通道的特征。
详细说下bottleneck。以上图的DenseNet-169的Dense Block(3)为例,包含32个11和33的卷积操作,也就是第32个子结构的输入是前面31层的输出结果,每层输出的channel是32(growth rate),那么如果不做bottleneck操作,第32层的33卷积操作的输入就是3132 +(上一个Dense Block的输出channel),近1000了。而加上11的卷积,代码中的11卷积的channel是growth rate4,也就是128,然后再作为33卷积的输入。这就大大减少了计算量,这就是bottleneck。
三、Model Compare
![]()
但是,DenseNet在实际训练中是非常占用内存的!原因是在计算的过程中需要保留浅层的feature map为了与后面的feature map就行拼接。简单说,虽然DenseNet参数量少,但是训练过程中的中间产物(feature map)多;这可能也是为什么DenseNet没有ResNet流行的原因吧。
上图是DenseNet与ResNet的对比图,在相同的错误率下,DenseNet的参数更少,计算复杂度也越低。
#参数量增加不到3倍。那再看准确度,如果固定这个参数量。flops是计算复杂度。固定一个计算复杂度例如都等于1×10的10次方,会发现DenseNet的错误率也是比ResNet的更低。
##通过这个模型做进一步更深的理解,到底是什么东西才是对计算机视觉里边最重要的网络结构?是深度最重要还是说,特征的复用是更重要的。还是像GoogLeNet一样,就是多尺度,多分叉的这种集成学习啊是更重要的。这些都是不同的归纳偏置。
像DenseNet的归纳偏置是认为特征复用是最重要的。说白了,这是你对计算机视觉,对这个深度学习去处理图像的一个自己的看法,你的眼光是什么?就是你的一个处理问题的一个偏置。
#看DenseNet源码,看不懂不要纠结啊,说明你当前对代码的理解不是特别深刻,可以放一放,因为这个代码写的就不是特别好懂。再过两个月你再回过头来看。说不定就看懂了,不要说钻牛角尖儿,看不懂,非要看啊。
用的不是sequential,而是有序字典。![]()
#作业:ResNet和ResNext模型理解和代码敲一下。 对CV太重要了。
MobileNet(V1,V1,V3)
#之所以把这几个模型把这几个系列模型放到一起讲,是因为这些模型都属于轻量级的模型。一边讲就比较,为了让我们的深度学习模型可以嵌入到一些硬件设备里边,所以说像现在的这个汽车里边或者手机里边,甚至耳机里边运行模型,因为它非常的轻量,这个模型它的参数量是非常非常少的,他是一个很小巧。
#MobileNet做轻量化的一个手段就是DW卷积。里面有两个操作一个加逐层卷积,一个讲逐点卷积。
##参考:https://blog.csdn.net/qq_39297053/article/details/123793236
#如果没有搞明白常规卷积、逐层卷积、逐点卷积的参数量回去一定算一下。
二、MobileNetV1
1.深度可分离卷积
MobileNetV1之所以轻量,与深度可分离卷积的关系密不可分。
如上图所示,模型推理中卷积操作占用了大部分的时间,因此MobileNetV1使用了深度可分离卷积对卷积操作做了进一步的优化,具体解释如下:
常规卷积操作
![]()
对于5x5x3的输入,如果想要得到3x3x4的feature map,那么卷积核的shape为3x3x3x4;如果padding=1,那么输出的feature map为5x5x4,如下图:
卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算(即:卷积核W x 卷积核H x 输入通道数 x 输出通道数):
N_std = 4 × 3 × 3 × 3 = 108
计算量:
(即:卷积核W x 卷积核H x (图片W-卷积核W+1) x (图片H-卷积核H+1) x 输入通道数 x 输出通道数):
C_std =3*3*(5-2)*(5-2)*3*4=972
深度可分离卷积 深度可分离卷积主要分为两个过程,分别为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。
逐通道卷积(Depthwise Convolution)
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积,这个过程产生的feature map通道数和输入的通道数完全一样。
![]()
一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。(卷积核的shape即为:卷积核W x 卷积核H x 输入通道数)
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下(即为:卷积核Wx卷积核Hx输入通道数):
N_depthwise = 3 × 3 × 3 = 27
计算量为(即:卷积核W x 卷积核H x (图片W-卷积核W+1) x (图片H-卷积核H+1) x 输入通道数)
C_depthwise=3x3x(5-2)x(5-2)x3=243
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。简而言之,虽然减少了计算量,但是失去了通道维度上的信息交互。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
逐点卷积(Pointwise Convolution)
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。
![]()
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为(1 x 1 x 输入通道数 x 输出通道数):
N_pointwise = 1 × 1 × 3 × 4 = 12
计算量(1 x 1 特征层W x 特征层H x 输入通道数 x 输出通道数):
C_pointwise = 1 × 1 × 3 × 3 × 3 × 4 = 108
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同。
参数对比
回顾一下,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
计算量对比
回顾一下,常规卷积的计算量为:
C_std =33(5-2)*(5-2)34=972
Separable Convolution的参数由两部分相加得到:
C_depthwise=3x3x(5-2)x(5-2)x3=243
C_pointwise = 1 × 1 × 3 × 3 × 3 × 4 = 108
C_separable = C_depthwise + C_pointwise = 351
相同的输入,同样是得到4张Feature map,Separable Convolution的计算量是常规卷积的约1/3。因此,在计算量相同的情况下,Depthwise Separable Convolution可以将神经网络层数可以做的更深。
2.MBconv
前面讲述了depthwise separable convolution,这是MobileNet的基本组件,但是在真正应用中会加入batchnorm,并使用ReLU激活函数,所以depthwise separable convolution的基本结构如下图右面所示:
#这个是V1的block的设计。这里对比了VGG的block,它里面就是不断地重复叠加3*3的卷积,后面更一个bn和relu。对于mobilenet v1来讲,他就是换成了逐层卷积以及逐点卷积。当然它的逐层卷积和逐点卷积后面都跟着BN和relu,下面右图就是mobilenet v1的block。
![]()
整体网络就是通过不断堆叠MBconv组件组成的,另外值得提一句的是深度可分卷积并不是 MobileNet 首次提出的,仅仅是利用这一变换来达到减少参数量和计算量的目的。
3.Model Architecture
MobileNet的网络结构如表1所示。首先是一个3x3的标准卷积,然后后面就是堆积depthwise separable convolution,并且可以看到其中的部分depthwise convolution会通过strides=2进行down sampling。经过 卷积提取特征后再采用average pooling将feature变成1x1,根据预测类别大小加上全连接层,最后是一个softmax层。
如果单独计算depthwise convolution和pointwise convolution,整个网络有28层(这里Avg Pool和Softmax不计算在内)。我们还可以分析整个网络的参数和计算量分布,如下面第二张图所示。
![]()
#它的结构很简单。整体的模型架构就可以发现。很简单,他的第一层就是一个正常3*3的卷积。![]() 往后走就是逐层加逐点,
往后走就是逐层加逐点,![]() 逐层加逐点,逐层加逐点。。。就这样一直一直跟盖房子一样,一直做下去,到最后跟一个全局平均池化加上一个全连接,然后跟一个softmax做一个分类,这就是整个的模型架构。是不是很简单。
逐层加逐点,逐层加逐点。。。就这样一直一直跟盖房子一样,一直做下去,到最后跟一个全局平均池化加上一个全连接,然后跟一个softmax做一个分类,这就是整个的模型架构。是不是很简单。
可以看到整个计算量基本集中在1x1卷积上,如果你熟悉卷积底层实现的话,你应该知道卷积一般通过一种im2col方式实现,其需要内存重组,但是当卷积核为1x1时,其实就不需要这种操作了,底层可以有更快的实现。对于参数也主要集中在1x1卷积,除此之外还有就是全连接层占了一部分参数。
![]()
#可以看到参数量,table2里统计的是mobilenet v1里面每一个结构占得参数量的比例。我们可以发现大部分的这个参数大都集中在1×1的卷积上,大概占了75%的这么一个比例;这个逐层卷积占1%非常少;这里一个3×3卷积占的格外少,这是因为什么?就是因为我们这个模型里边只用了一个3*3,就是在我们的第一层,所以说他占这么点儿的参数量是很正常的。然后还有一个大头,是在我们的全链接上面。所以对于mobilenet v1这个模型来讲,它大多数的参数都是集中在1×1的卷积以及这个全连接层上。之后会看一些其他模型会对比和优化,尤其是我们等下讲那个shuttleNet。
#1*1是逐点卷积吗?是
MobileNet到底效果如何,这里与GoogleNet和VGG16做了对比,如Table8所示。相比VGG16,MobileNet的准确度稍微下降,但是优于GoogleNet。然而,从计算量和参数量上MobileNet具有绝对的优势。
![]()
#首先我没有看表的话,会发现啊,这个V1它的精度比GoogleNet好一些的,然后比VGG16要差一点点,但是对比参数量很夸张,他的数量比GoogleNet还少,比VGG差了一个数量级,MobileNet是百万级的,但是VGG是千万级。中间是一个运行时间,它的这个时间也是比较短的,就可以看出来MobileNet模型相对而言是一个既小巧又轻量,精度还高的这么一个模型。
小结
本文简单介绍了Google提出的移动端模型MobileNet,其核心是采用了可分解的depthwise separable convolution,其不仅可以降低模型计算复杂度,而且可以大大降低模型大小。另外,值得一提的是,文中将激活函数从Relu替换成Relu6。在真实的移动端应用场景,像MobileNet这样类似的网络将是持续研究的重点。
三、MobileNetV2
Andrew G. Howard 等于 2018 年在 MobileNet V1 的基础上又提出了改进版本 MobileNet V2。具体可以参考原始论文 MobileNetV2: Inverted Residuals and Linear Bottlenecks。
从标题我们就可以看出,V2 中主要用到了 Inverted Residuals 和 Linear Bottlnecks。
#两个改进:1、翻转残差 2、线性瓶颈结构
1. Inverted Residuals
上一篇我们看到 V1 的网络结构还是非常传统的直桶模型(没有分支),但是 ResNet 在模型中引入分支并取得了很好的效果,因此到了 V2 的时候,作者也想引入进来,这就有了我们要探讨的问题了。
首先我们看下 Residual block。下图可以看到,采用 1x1 的卷积核先将 256 维度降到 64 维,经过 3x3 的卷积这后,然后又通过 1x1 的卷积核恢复到 256 维。
![]() #这是正常的残差,引入到mobilenet会出现问题,因为逐层卷积是不会改变feature map。上面层本身得到了这个feature map的维度就不是很多。如果这时候我们还要先对它压缩的话,那么一个问题是会让我们的模型变得比较小,第二个问题就是说大GoogLeNet v3里边提到了四个设计网络架构的建议准则。第一个准则就是模型每一次操作不能将信息压缩的太狠。压缩太狠会丢失很多细节。这些细节即便后面的模型架构设计再精密,也是没有办法把细节重建回来的。本来的featuremap就不多,如果压缩的话,那这个模型就太小了,而且channel维度也太少了,对于提特征不是一个好事儿。那么这里作者就讲了一个他的这个改进:不做压缩,反而做一个扩展。这就是反转残差的这么一个名字的原因。a图是feature map刚进来的时候,这是一个正常的残差,他会做一个下采样,从256变成64。但是b图mobilenet,会做一个乘,而不是除,他会先将featuremap扩大6倍。然后再做一个映射,然后再给它减回原本的通道数量,为了去做残差。
#这是正常的残差,引入到mobilenet会出现问题,因为逐层卷积是不会改变feature map。上面层本身得到了这个feature map的维度就不是很多。如果这时候我们还要先对它压缩的话,那么一个问题是会让我们的模型变得比较小,第二个问题就是说大GoogLeNet v3里边提到了四个设计网络架构的建议准则。第一个准则就是模型每一次操作不能将信息压缩的太狠。压缩太狠会丢失很多细节。这些细节即便后面的模型架构设计再精密,也是没有办法把细节重建回来的。本来的featuremap就不多,如果压缩的话,那这个模型就太小了,而且channel维度也太少了,对于提特征不是一个好事儿。那么这里作者就讲了一个他的这个改进:不做压缩,反而做一个扩展。这就是反转残差的这么一个名字的原因。a图是feature map刚进来的时候,这是一个正常的残差,他会做一个下采样,从256变成64。但是b图mobilenet,会做一个乘,而不是除,他会先将featuremap扩大6倍。然后再做一个映射,然后再给它减回原本的通道数量,为了去做残差。
![]()
那如果我们要把 residual block 运用到 MobileNet 中来的话,如果我们还是采用相同的策略显然是有问题的,因为 MobileNet 中由于逐通道卷积,本来 feature 的维度就不多,如果还要先压缩的话,会使模型太小了,所以作者提出了 Inverted Residuals,即先扩展(6倍)后压缩,这样就不会使模型被压缩的太厉害。 下图对比了原始残差和反转残差(截取自原论文):
2. Linear Bottlnecks
Linear Bottlnecks 听起来很高级,其实就是把上面的 Inverted Residuals block 中的 bottleneck 处的 ReLU 去掉。通过下面的图片对比就可以很容易看出,实际上就是去掉了最后一个 1x1 卷积后面的 ReLU。整体的网络模型就是由堆叠下图右图的Bottlenecks搭建成的
![]()
#线性瓶颈结构,就是把上面的 Inverted Residuals block 中的 bottleneck 处的 ReLU 去掉或者换成一个线性的激活函数。
#b图是原本的mobilenet v1它是先经过逐层卷积,再经过这个逐点卷积,这个驻点卷积会经过一个relu激活函数。而这个线性瓶颈结构里d图就没有relu了,它变成了一个线性的激活函数。就是如果送进去是1的话,吐出的还是1。这是送你什么,他就给我什么,就是一个线性,这就是区别。这么做也是有目的的:在训练DW卷积时候会发现,最后DW卷积的部分卷积核会容易训练失效。就跟最开始讲的AlexNet里边那个第一层卷积核里面的失效是一个道理。失效的卷积核一般都会出现一个值比较大或者比较小这种情况。那么他在经过一个relu的话就容易出现值是0这个状况,如果这值比较小的话,那么他就不会激活,它就是一个零。作者发现这时候用relu对dw卷积后得到的featuremap做映射的时候,会造成非常多的信息损失。因此,执行降维卷积层后一般不会接这种relu激活函数。就是说1×1的卷积,它本身就会丢失一部分信息,那么再加上relu以后,就是一个雪上加霜的状态,所以就把它去掉,缓一缓。把这relu改成一个线性的映射。让它进来什么出来什么就可以了。
![]()
那为什么要去掉呢?而且为什么是去掉最后一个1X1卷积后面的 ReLU 呢?因为在训练 MobileNet V1 的时候发现最后 Depthwise 部分的 kernel 训练容易失去作用,最终再经过ReLU出现输出为0的情况。作者发现是因为ReLU 会对 channel 数较低的张量造成较大的信息损耗,因此执行降维的卷积层后面不会接类似于ReLU这样的非线性激活层。说人话就是:1X1卷积降维操作本来就会丢失一部分信息,而加上 ReLU 之后那是雪上加霜,所以去掉 ReLU 缓一缓。
3. Model Architecture
完整的MobileNetV2的网络结构参数如下:
t代表反转残差中第一个1X1卷积升为的倍数;c代表通道数;n代表堆叠bottleneck的次数;s代表DWconv的幅度(1或2),不同的步幅对应了不同的模块,详见上图(d)MobilenetV2。
![]()
#网络架构很v1差不多,先经过一个正常的卷积,再经过7个stage(bottleneck),stage里面是block是网络操作层的集合。后面再跟一个全局平均池化,再跟一个全连接层,就得到结果了。细心的可以发现,最后一个不是用的全连接层用的不是那个nn.linear,他用的是一个1×1的卷积。这里是完全没有问题的,不是他写错了,因为1×1的卷积本身就等价于一个全连接层。
![]()
左图是一个神经网络,就是一个全连接层去处理图像的样子,用FC就是那个a去处理图像的样子。那么1×1怎么做?1×1也是卷积核每次只计算一个元素,只乘以这一个元素,然后拿过来,然后下面再乘一个元素,滑动一下,再拿过来。所以说他也是对图像里边的所有元素都做完乘法,之后再求和加起来。所以说跟FC是一个等同的概念。这样就理解为什么1×1的卷积核和等于一个全连接了。#而pytorch在底层给卷积做了一个加速了,所以以后要用全连接,建议直接换成一个1*1的卷积!!!
标准的FC:先打平,再做![]() 与每个节点做连接。这是一个的fc啊,但是如果你用1*1的卷积的话,你就不用打平了,就跟刚才图
与每个节点做连接。这是一个的fc啊,但是如果你用1*1的卷积的话,你就不用打平了,就跟刚才图![]() 上边展示的一样,所以它其实更像是一个1*1的卷积,因为不用对这个图像数据做打平,只需要每次计算一个节点,然后滑动去做这个计算,最后给他加起来就行了。
上边展示的一样,所以它其实更像是一个1*1的卷积,因为不用对这个图像数据做打平,只需要每次计算一个节点,然后滑动去做这个计算,最后给他加起来就行了。
![]()
#总结:flatten可以换成GAP全局平均池化,而FC(fully connection)可以换成1*1的卷积。这是两个等效的操作。
![]()
#看下V2版本的效果怎么样啊?V2比V1的精度是有所提升的。这个精度提升其实就是刚才讲的那两点:一个是反转的残差结构,另一个就是一个线性的瓶颈映射。这两点是他的精度有所提高,在参数量上面还是要稍微大一些的、稍微多一点儿,运行速度也是会慢一些,不过它的精度是有很大提升的。
小结
MobileNetV2最大的贡献就是改进了通道数较少的网络运用残差连接的方式:设计了反转残差(Inverted Residuals)的结构。
四、MobileNetV3
V3 保持了一年一更的节奏,Andrew G. Howard 等于 2019 年又提出了 MobileNet V3。文中提出了两个网络模型, MobileNetV3-Small 与 MobileNetV3-Large 分别对应对计算和存储要求低和高的版本。具体可以参考原始论文 Searching for MobileNetV3。
这回的标题(Searching for MobileNetV3)说的不是 V3 里面有什么,而是说的 V3 是怎么来的。Searching 说的是网络架构搜索(NAS),即 V3 是通过搜索和网络优化而来。
这里我们不详细讨论 NAS网络搜索计算,虽然这是论文的一大亮点。原因是这个技术不是一般人玩得起的…它相当于训练的不是模型参数,而是模型架构。说白了就是设计一个网络模型结构的集合,通过不同网络层的排列组合可以组合出许多许多的模型,再通过NAS搜索技术搜索出最佳的网络结构。这相当于大力出奇迹嘛,将调参工作交给NAS技术去做,实属一种降维打击。
#能干出这事的公司,都是把显卡当做白开水买的公司。有很大的财力,这个公司愿意投钱去搞科研,才能去搞这么一个搜索。所以说我们自己是很难这门技术的,那么这个V3版本对这些网络结构做了一个搜索,所以说如果问为什么V3这个网络跑的又快又准?其实很简单,就是他找出来的,用一个很笨的方法去搜索出来的。
#V3用了一门技术,但是我们没有能力去复现的,最主要的一个问题是我们没有计算资源。这门技术叫做NAS网络搜索技术,其实跟我们之前提到一个叫做AutoML(machine learning)是一个东西,就是一个自动机器学习。神经网络里边是不是有许多参数?这些参数是一个超参可以供我们去调整。像kernel size这个尺寸,这个kernel的数量等,还有输进去图像的大小、网络的层数等,这些都是可以调整的一个超参数。然后人去训练模型的时候,其实是去调整这些参数。就跟炼丹一样,那么现在这个网络搜索技术,他调的不再是超参了,他升了一个维度——调的是一些网络结构。比如说我们的这个网络结构里边,激活函数里面可以选relu函数,可以选sigmoid函数,那么到底哪个对网络效果比较好呢,需要试,对吧。再比如我们可以做残差连接,residual,可以像DenseNet一样去做一个特征复用,那个非常密集的连接,这也是网络架构方面的,那么到底哪个有效呢?也需要去试。你再比如block结构,我们讲ResNet的时候有一个basicblock,那还有一个瓶颈的block,那么到底哪个在模型里边效果好呢?我们也不知道也要试,总之这里去调整的参数不再是那个传统意义上的那些网络超参,而是一个网络架构。我们会把这一堆网络架构给他放进一个集合里边,这个集合就是操作库。然后NAS就从这个集合里边去选这些网络架构,只选这些架构,相当于是这个集合里面是盖房子这些材料,砖头,水泥,我们这个nas就自己的把这些材料拿过来盖房子,他试一试看看哪个房子盖出来既大有稳固又漂亮还安全稳固。这个叫做网络搜索。
当然,随之而来的缺点也很明显,这需要大量的计算资源才能完成,恐怕只有想GoogLe,Baidu这种可以买显卡当买白开水的公司才有财力去搞这些研究。而且,由于搜索过程中最关注网络的性能,因此最优的的网络结构可能长得五花八门,换一种说法就是层级结构的排列比较混乱。
这就导致了两个缺点:
一:网络的可解释性更差,没办法说为啥这么排列性能好,这能说实验得出…
二:这种不规律的模型层级排列也不利于模型的部署。因此经过NAS搜索后的模型一般需要人为的进行进一步调整,让它长的规矩一些…
#mobilenet v2的两个缺点一个是V2版本网络结构最后几层比较冗余。删掉几层后,少了计算参数量、计算速度也会有提升、。因此做了精简。
1. 对 V2 最后几层的修改
作者发现 V2 网络最后一部分结构可以优化,如Figure5所示,原始的结构用 1x1 的卷积来调整 feature 的维度,从而提高预测的精度,但是这一部分也会造成一定的延时,为了减少延时,作者把 average pooling 提前,这样的话,这样就提前把 feature 的 size 减下来了(pooling 之后 feature size 从 7x7 降到了 1x1)。这样一来延时减小了,但是试验证明精度却几乎没有降低。
![]()
#V3版本效果最好,但是工业上常用的还是v2。因为它的网络结构的可解释性是比较差的,就是说我们说不出来为什么网络以这种形式去排列的性能就好。只能说这是经过搜索,经过实验得出来的这样的一个结构,所以这是一个缺点。那第二个缺点就是网络搜索出来的这个模型一般长得不是特别的规矩。Resnet的网络图如果画出来的话,规规矩矩的,而nas一般每个操作组合可能都不一样,每个stage里边的情况可能也不一样,长得五花八门,所以说这种结构是不太利于模型去部署——部署就是讲怎么将模型去搞到一个硬件上、搞到工业里面。所以说经过NAS搜索搜索之后的这个模型,一般还需要人为的进一步调整,让他规律一些。
##V3的改进一个是刚才讲的最后几个阶段做了一个精简,第二个是它还搜到了一个比较好的激活函数,叫h-swish函数,它长的样子右图。可以发现如果跟relu比的话,有两个好处,一个好处就是relu函数在x=0的时候就等于0了,它后边就没值了。但是这个函数稍微还有那么点值,都不等于0。他的整个域都不等于0。另一个好处就是它显得比较平滑,所以说这个结果函数经过实验效果证明是比较好。有利于网络得到一个更高的精度。#所以以后你在你的模型搭建里边就可以把它用上。用起来很简单,因为pytorch已经集成了这个函数,叫GeLU
#第三个改进就是用了SE是用到了一个叫做senet这个东西,它其实就是17年图像分类大赛的winner冠军模型,SENet,这就是v3版本的改进。后面讲SENet
2. h-swish
这个得先说说 swish(也是 google 自家人搞出来的),说是这个激活函数好用,替换 ReLU 可以提高精度,但是这个激活函数(主要是 σ ( x ) \sigma(x)σ(x) 部分)在移动端设备上显得太耗资源,所以作者又提出了一个新的 h-swish 激活函数来取代 swish,效果跟 swish 差不多,但是计算量却大大减少。
![]()
3. squeeze-and-excite(SE)
Squeeze-and-Excitation Networks(SENet)是由自动驾驶公司Momenta在2017年公布的一种全新的图像识别结构,它通过对特征通道间的相关性进行建模,把重要的特征进行强化来提升准确率。这个结构是2017 ILSVR竞赛的冠军,top5的错误率达到了2.251%,比2016年的第一名还要低25%,可谓提升巨大。SE也被一下研究人员成为基于通道的注意力机制。
与MobileNetV2相比,MobileNetV3 中增加了 SE 结构,并且将含有 SE 结构部分的 expand layer 的 channel 数减少(为原来的 1/4 以减少延迟,但是时间查看模型,貌似只是减少了1/2),试验发现这样不仅提高了模型精度,而且整体上延迟也并没有增加。
![]()
![]()
##三个改进:第一个对最后几层做了精简;第二是搞了一个比较好用的激活函数;第三个把s e这个思想用到了模型里面
#将SE加在了反转的残差block里边。在这个反转的参差block里面,3×3的逐层卷积之后跟一个senet,然后对featuremaps做一个权重的充分配。然后再经过一个1*1得到一个结果,就是这么给se嵌在里边了。可以嵌在任何一个block里面
Model Architecture
Table1对应着MobileNetV3_Large版的网络结构参数;Table1对应着MobileNetV3_Small版;
![]()
![]()
值得注意的是:对比 V3 和 V2 还可以发现模型开始的 conv2d 部分的输出 size 减少为原来的一般了,试验发现延迟有所降低,精度没有下降。
至于效果,相比 V2 1.0 来说, V3-Small 和 V3-Large 在性能和精度上各有优势。但是在工程实际中,特别是在移动端上 V2 用的更为广泛,因为 V2 结构更简单,移植更方便,速度也更有优势。
#工业里会权衡,所以他们更喜欢用v2.
小结 mobile net v3三个优化:
- 利用NAS网络搜索结构优化了网络架构
- 使用h-swish激活函数
- 加入SE模块
#代码:
V1:逐层和逐点![]() ;V2翻转残差模块(先升维再逐层逐点在降回去)和线性瓶颈结构(讲最后的relu换成一个线性的激活,相当于什么也不做,relu可以进一步丢失的信息
;V2翻转残差模块(先升维再逐层逐点在降回去)和线性瓶颈结构(讲最后的relu换成一个线性的激活,相当于什么也不做,relu可以进一步丢失的信息![]() );V3延续V2两个技巧,
);V3延续V2两个技巧,![]() 用来NAS网络搜索和SE模块,
用来NAS网络搜索和SE模块,![]() SE就是对通道重要程度做了一个重分配,增加attention map。SE不是在每一个blcok都有,这是NAS网络搜索的结果,整个模型架构不太规范。HS是更好的激活函数,
SE就是对通道重要程度做了一个重分配,增加attention map。SE不是在每一个blcok都有,这是NAS网络搜索的结果,整个模型架构不太规范。HS是更好的激活函数,![]() ,这里由于是nas网络搜索出来的,所以每一层用的激活函数也不一样,有的是relu,有的是hs。这个模型不太规则,因此在代码实现中就会有一个专门配置网络超参数的configure的这么一个类,把每一层的这些超参数给他配置好。
,这里由于是nas网络搜索出来的,所以每一层用的激活函数也不一样,有的是relu,有的是hs。这个模型不太规则,因此在代码实现中就会有一个专门配置网络超参数的configure的这么一个类,把每一层的这些超参数给他配置好。
![]()
#typing代码提示包,可回调、list、可选 包 ![]() 目的是防止看代码时,不记得当初指定的超参是什么属性的超参。
目的是防止看代码时,不记得当初指定的超参是什么属性的超参。![]()
![]()
#partial是python语法包,为了为传进来的类提前指定一些超参,像eps和momentum都是BatchNorm2d里面的超参数,![]() 例如eps默认值是0.00001,这里给它指定为0.001,partial就是提前给一个函数或者类指定一些超参数,这样将来再去用这个函数的时候,就不用再给它指定这些东西了。更便捷、更方便,这样的用法叫做partial。
例如eps默认值是0.00001,这里给它指定为0.001,partial就是提前给一个函数或者类指定一些超参数,这样将来再去用这个函数的时候,就不用再给它指定这些东西了。更便捷、更方便,这样的用法叫做partial。
![]() #utils放的是训练脚本的工具,其中distrubute_utils.py是这个多GPU训练时启动脚本的工具,里面放了一些函数和类;lr_methods.py是学习率的一种方式,将来如果有新的学习率的方式,也可以放到里边;train_engin.py这个是一个训练的引擎,将每一轮训练的步骤放到这里边。将来做训练的时候,可以直接调用这个包儿里边的函数。
#utils放的是训练脚本的工具,其中distrubute_utils.py是这个多GPU训练时启动脚本的工具,里面放了一些函数和类;lr_methods.py是学习率的一种方式,将来如果有新的学习率的方式,也可以放到里边;train_engin.py这个是一个训练的引擎,将每一轮训练的步骤放到这里边。将来做训练的时候,可以直接调用这个包儿里边的函数。![]()
#def _make_divisible(ch, divisor=8, min_ch=None): #channel调整函数,调整为最近的8的倍数,最小为8这个函数,它叫整除函数。就是说一般会让这个channel的维度调整为是八的倍数,这样是比较有利于硬件加速的。然后模型里边又有大量的对channel维度的调整,不管是那个反转的残差模块里边会升维、还是se net里边会先做降维等等,总之整个模型会对channel做一些调整,那么这个时候就不一定说是八的倍数,所以专门写了这个函数,将接受的参数ch,第二个参数就是一个整除的倍数,这里是默认等于8,将这个channel调整成这个8的一个倍数,然后还有一个最小的才默认8。这里还有一个判断,就是要给它调整成离8最近的一个通道数字,而有的时候比如说除完之后=5,这其实是不希望的,因为是0没有意义,所以会指定一个最小的8,如果指定的话,它就默认是8,就是即便它等于5,有一个最小的让它等于八的,保证这个最后这个channel出完以后不要于零。
![]()
#继承Sequential会自动执行forward函数,就是不需要指定这个forward函数,只需要把这个init里边成员指定处理就好了。但是如果继承于nn.Modules就必须要实现一个init函数、实现一个forward函数,才知道信息应该从哪里流动到哪里。
in_planes: 输入的channel维度;out_planes:输出的channel维度, kernel_size: kernel_size:;stride:步长;groups:组数,就是分组卷积的参数,如果组数等于1,说明当前是一个正常的卷积、普通的卷积,如果组数跟inchannel数是相等的话,是一个什么卷积?逐通道卷积=逐层卷积。所以说这个组数就是逐通道卷积与普通卷积的一个折中;norm_layer: 确定batchnormalization的操作,Optional可选的,就是在实例化Sequential类的时候,这个参数可以填也可以不填,[Callable[..., nn.Module]] = None, activation_layer确认当前卷积后面接的是什么激活函数: Optional[Callable[..., nn.Module]] = None),上面两个操作都是可填可不填的Optional,因为如果不填,第28和30行,如果norm_layer和activation_layer等于None,会手动指定一下,就默认当前用于去做归一化的方式是BN、用于做激活函数的方式是relu。这样子就可以完成整个函数的搭建了。
![]()
#bias不指定的话默认是false,注意31行用的是ReLU6,是relu的升级版本,待搜其函数形式。
![]() #这个se模块很短,不到10行代码,所以有时候一篇很优秀的paper工作,拿代码实现出来的话,可能就很短,se就是非常典型的案例。这个SE模块你可以把它加在任何一个卷积或者全连接后边,作为一个升级操作。
#这个se模块很短,不到10行代码,所以有时候一篇很优秀的paper工作,拿代码实现出来的话,可能就很短,se就是非常典型的案例。这个SE模块你可以把它加在任何一个卷积或者全连接后边,作为一个升级操作。
#回忆SE block样子![]() 第一步做一个全局平均池化GAP,然后将空间信息打掉,会将featuremap变成一个标量,就是对里面的所有元素做一个相乘求和,这时候变成一个1*1*C的向量,C就是channel维度没有变,相当于每一个featuremap都用一个变量表征了,后面在接两个全连接层,对得到的向量做映射,我们希望这两层会学到一个attention map,学到之后就变成色彩不同的向量,颜色深浅代表了重要程度,然后再用这个向量把原本的feature map乘回来,这样对原本的每一个feature做了一个重要程度的重分配。
第一步做一个全局平均池化GAP,然后将空间信息打掉,会将featuremap变成一个标量,就是对里面的所有元素做一个相乘求和,这时候变成一个1*1*C的向量,C就是channel维度没有变,相当于每一个featuremap都用一个变量表征了,后面在接两个全连接层,对得到的向量做映射,我们希望这两层会学到一个attention map,学到之后就变成色彩不同的向量,颜色深浅代表了重要程度,然后再用这个向量把原本的feature map乘回来,这样对原本的每一个feature做了一个重要程度的重分配。
#第42、43行,![]() 两个全连接,第一个全连接会对原本的特征向量做降维,然后第二个连接再升回去。这个缩放因子,就是给它缩减成一个长度、最后再重建回去了这样一个因子。#为什么要降维?答:降维参数量肯定少了,之前讲AlexNet或ZFNet时,全连接是非常占参数的,中间层比较短的话,参数是比较小的。作者应该试过,中间搞一样长的全连接和搞短一些的全连接,效果差不多,所以为什么不选一个参数量少的呢?
两个全连接,第一个全连接会对原本的特征向量做降维,然后第二个连接再升回去。这个缩放因子,就是给它缩减成一个长度、最后再重建回去了这样一个因子。#为什么要降维?答:降维参数量肯定少了,之前讲AlexNet或ZFNet时,全连接是非常占参数的,中间层比较短的话,参数是比较小的。作者应该试过,中间搞一样长的全连接和搞短一些的全连接,效果差不多,所以为什么不选一个参数量少的呢?
#squeeze_factor这个缩放因子,默认=4,就是对那个长度为c的特征向量做四倍下采样,在第一个全连接层里。
queeze_c = _make_divisible(input_c // squeeze_factor, 8) #压缩以后的channel,先经过一个整除的函数,因为我们对C做了下采样,之后得到的通道的数量有可能不会被8整除,对硬件加速不友好,所以套了一个整除函数_make_divisible,变成离8的倍数最近的通道数量。
#scale = F.adaptive_avg_pool2d(x, output_size=(1, 1)) #经过全局平均池化,由特征图变成特征向量
#scale = self.fc1(scale) #送进第一个全连接里。注意第一个全连接层实现的手段是卷积self.fc1 = nn.Conv2d(input_c, squeeze_c, 1),kernel为1的卷积,等价于一个全连接。好处就是,在经过GAP后,虽然得到的是一个向量,但是它高度和宽度维度并没有被打掉,如果写完整的话,长这个样子,第一个维度是batch维度。第二个维度是C,第三个维度是宽度=1,第四个维度是高度=1维度。![]() ,如果用全连接需要打平,虽然pytorch会自动实现只接入最后一个维度做全连接。所以用卷积就可以保留空间维度,如果用卷积代替一个全连接的话,就不需要对空间维度做任何的操作。这是一个好处。
,如果用全连接需要打平,虽然pytorch会自动实现只接入最后一个维度做全连接。所以用卷积就可以保留空间维度,如果用卷积代替一个全连接的话,就不需要对空间维度做任何的操作。这是一个好处。
scale = F.relu(scale, inplace=True) #再送进一个relu
scale = self.fc2(scale) #送进第二个全连接,输出维度和原featuremap inputchannel维度相等
scale = F.hardsigmoid(scale, inplace=True) #经过一个激活函数,叫sigmoid,变成[0,1]的权重/概率。
return scale * x 最后#将attention map乘回原数据,做重要程度的重分配
#sigmoid可以换成softmax吗?答:没有必要,softmax是sigmoid升级版,多分类,但是更复杂,增加计算量。
![]() #因为网络不规整,
#因为网络不规整,![]() 所以用了一个配置类,形成参数列表:
所以用了一个配置类,形成参数列表:
use_se:决定是否用SE;width_multi扩张因子;那这里这这就是一个扩张因子,用于将它乘到每一次卷积之后输出的通道数量上,来决定当前的卷积要输出多少通道。
初始化一些成员变量:调用了一个静态方法adjust_channels调整通道数量的函数,用扩张因子把input_channels调整一下![]() (转置残差)这一步就是先扩张通道数。
(转置残差)这一步就是先扩张通道数。
![]() InvertedResidualConfig函数就是一个文件配置类。去实现模型的时候,会把这个文件配置给写好,这里第一个参数就是配成类里面的input channel,第二个就是kernel size,第三个就是卷积输出的通道数量,第四个就是每个block的输出通道数量,第五个就是用不用SE,第六个用哪个激活函数,第七个用不用步长。这里给他配置好,而且这个表其实和论文里边这个表
InvertedResidualConfig函数就是一个文件配置类。去实现模型的时候,会把这个文件配置给写好,这里第一个参数就是配成类里面的input channel,第二个就是kernel size,第三个就是卷积输出的通道数量,第四个就是每个block的输出通道数量,第五个就是用不用SE,第六个用哪个激活函数,第七个用不用步长。这里给他配置好,而且这个表其实和论文里边这个表![]() ,这样就可以把论文工作复现出来。
,这样就可以把论文工作复现出来。
![]() cnf: InvertedResidualConfig, norm_layer: Callable[..., nn.Module]): #接收上面的config类InvertedResidualConfig,norm_layer是是否需要归一化;
cnf: InvertedResidualConfig, norm_layer: Callable[..., nn.Module]): #接收上面的config类InvertedResidualConfig,norm_layer是是否需要归一化;
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c) #判断在block里是否用残差连接,是之前讲resnet里的残差。这里先判断步长是否等于1,如果不等于1意味着卷积会让featuremap的尺寸变小,如果featuremap尺寸一旦变小就不符合做残差的前提了;第二个判断条件,inputchannel是否等于outputchannel保证维度匹配
![]()
![]() if cnf.expanded_c != cnf.input_c: #如果不相等提升通道数,这个参数就是升维
if cnf.expanded_c != cnf.input_c: #如果不相等提升通道数,这个参数就是升维![]() ,
,
# depthwise #逐层卷积
layers.append(ConvBNActivation(cnf.expanded_c, cnf.expanded_c, kernel_size=cnf.kernel, stride=cnf.stride, groups=cnf.expanded_c,
norm_layer=norm_layer, activation_layer=activation_layer))逐层卷积的通道数量groups就是等于input的通道数,kernel_size和stride是通过cnf类传进来的
![]() 上面把所有组件建好了,下面就是搭建模型了。
上面把所有组件建好了,下面就是搭建模型了。
![]()
#如何搭建?如果刚才没有把各组件写成类的话,每一个参数都![]() 要传进来,整个要传进来的参数会很长很长。这里把block参数封装成一个配置文件:inverted_residual_setting
要传进来,整个要传进来的参数会很长很长。这里把block参数封装成一个配置文件:inverted_residual_setting
所以这里只需要把配置文件传进来,传的参数就很短,显得很简洁。![]() 还需要告诉模型block长什么样子,是翻转的残差block还是正常的block,还是用的VGG的block,所以用block参数传参。last_channel是最终输出channel,后面跟全连接相关。num_classes共分多少类,ImageNet默认是1000类别。norm_layer每一次用的归一化的方法。
还需要告诉模型block长什么样子,是翻转的残差block还是正常的block,还是用的VGG的block,所以用block参数传参。last_channel是最终输出channel,后面跟全连接相关。num_classes共分多少类,ImageNet默认是1000类别。norm_layer每一次用的归一化的方法。
![]() 这里不是冗余,而是代码的优雅。
这里不是冗余,而是代码的优雅。
![]()
![]() 所以先搭建第一层:
所以先搭建第一层:
![]()
#这里3是指输入的是RGB彩色图。激活函数是HS
![]() for循环能完成这么多层的搭建,添加到空列表里。
for循环能完成这么多层的搭建,添加到空列表里。![]()
#在往下走就是top层![]()
会先跟一个1*1的卷积。用于扩大输出的channel维度的数量。上一次输出的160,这一层的输出是960,做了升维。这其实是为了提取更深的特征。让模型有更多的可学习参数。有更大的潜能。在处理一些更大的问题更有优势。因为最后是有1000个类别,现在只有160维度,差距比较大。
![]() 分成feature部分和top部分,分别搭建。
分成feature部分和top部分,分别搭建。
![]()
![]()
![]()
![]() #给使用者提供一个功能:reduced_tail是否对模型后半部分做缩减
#给使用者提供一个功能:reduced_tail是否对模型后半部分做缩减
![]()
202行last_channel最后去指定一下,就是对最后一个![]() 全连接指定是多少,可以任意指定。他指定了1280。
全连接指定是多少,可以任意指定。他指定了1280。
179行width_multi = 1.0,是缩放因子。他可以放大每个卷积输出channel的数量。
![]()
#这是一个小版本的V3。
![]() #这个细节,这里是7*7的卷积。因为到pool这层的时候,经过几次下采样
#这个细节,这里是7*7的卷积。因为到pool这层的时候,经过几次下采样![]() ,图片尺寸就等于7*7,再用一个kernel size是7*7的池化,他就等同于全局平均池化。
,图片尺寸就等于7*7,再用一个kernel size是7*7的池化,他就等同于全局平均池化。
##作业:V3代码写一遍,因为他的写作方式是很巧妙和优雅的值得学习。
SENet
参考:https://blog.csdn.net/qq_39297053/article/details/123848298
#SENet启发于attention。什么叫做注意力啊?自己先考虑考虑,你对注意力是一个怎样的理解啊?注意力机制是指对全局信息的重视程度是不同的。比如说对这块儿可能更重视一些,对那块儿就不太重视一些,对这块可能就比较重一些,总之对不同的区域有一个不同的重视程度。这个叫做注意力。每个区域都有不同的重视程度,通过什么方式?权重,权重的含义就是对的输入数据做一个重要程度的重分配,如果想对一张图像或者对一个数据去做一个注意力机制的话,需要为他生成一个attention map,就是注意力图。通过权重矩阵,权重矩阵里边的值,就是一些相应的权重,然后会对这个attentionmap跟数据做一个乘法。
前言
SENet,胡杰(Momenta)在2017.9提出,通过显式地建模卷积特征通道之间的相互依赖性来提高网络的表示能力,SE块以微小的计算成本为现有的最先进的深层架构产生了显著的性能改进,SENet block和ResNeXt结合在ILSVRC 2017赢得第一名。
一、Motivation
提出背景:现有网络很多都是主要在空间维度方面来进行特征通道间的融合(如Inception的多尺度)。卷积核通常被看做是在局部感受野上,将空间上和特征维度上的信息进行聚合的信息聚合体。
channel维度的注意力机制:通过学习的方式来自动获取到每个特征通道的重要程度(即feature map层的权重),以增强有用的特征,抑制不重要的特征。
与1X1卷积相比,SE是为每个channel重新分配一个权重(即重要程度);而逐点卷积只是在做channel的融合,顺带进行升维和降维。
二、SE模块
Squeeze:全局信息嵌入,全局平均池化成1*1
Excitation:自适应调整,用两个全连接,训练参数W,得到每通道的权重s
![]()
#回忆神经网络里边经过每一次卷积操作都会得到很多的featuremap特征图,这些特征图如果在做下次卷积的时候,其实这些特征图是对下一层卷积的贡献程度是相同的。这是原始的卷积方式。这种方式不存在attention。但这么多featuremap其实肯定是有的比较重要,有的太重要,所以这里是希望把这个重要程度赋予到channel这个维度上。就是对我们每次卷积之后得到的这一堆featuremaps做一个重要程度的重分配,就是SENet。
#上图左边第一个第一个卷积之后得到的特征图,第一个c'是featuremaps的数量,channel维度,然后正常的卷积会对左图的featuremaps做特征处理,然后得到一组新的featuremaps(中间图),而注意力机制是,首先对一组featuremaps做全局平均池化GAP,这样就打掉了一张featuremap的空间信息,就会得到1*1*C的向量。做GAP时对这个一张featuremap上全部元素做了一次平均,![]() 所以得到的一个值就可以一定程度上去表征原始的这张featuremap的信息。所以这个向量就表征了原本一组featuremap的信息,只不过是作为一个精简。然后再把这个向量送进一个全连接神经网络去做映射。就是后面会跟一个全连接神经网络,最后也会得到1*1的向量。做映射的目的就是让网络自己去学习当前的attention。就是让网络自己去学习,这个channel,就是这一张featuremap哪个重要程度更多一些,哪个重要程度更少一些,学完他就是长这个样子
所以得到的一个值就可以一定程度上去表征原始的这张featuremap的信息。所以这个向量就表征了原本一组featuremap的信息,只不过是作为一个精简。然后再把这个向量送进一个全连接神经网络去做映射。就是后面会跟一个全连接神经网络,最后也会得到1*1的向量。做映射的目的就是让网络自己去学习当前的attention。就是让网络自己去学习,这个channel,就是这一张featuremap哪个重要程度更多一些,哪个重要程度更少一些,学完他就是长这个样子![]() 。
。
##问:不知道怎么学是吧?答:其实你不知道怎么学是很正常的。这就跟大家不理解那个卷积神经网络,他是怎么学到一个合理的卷积核是一个道理。比如说卷积核,它是提特征的,那它怎么自己去学习的?怎么自己学去提这个特征的呀,咱也不知道,撑死那个像ZFNet一样可以做一些可视化。但是咱们也不知道他怎么学的,其实这里是一样的,一个意思,我们就是希望通过全连接,让网络自己去学权重,但是我们也不知道他怎么学的。只不过结果表明了我们加这么一个结构,它确实有效,所以它确实好像可以学到这个权重。这就是深度学习的魅力。就是我们也不知道他为什么能成这个目的,但是他确实就能。
#问:怎么知道他能学,是实验出来的吗?答:对啊,就是说其实是加了这个结构之后,这个se之后所有的实验结果都证明了模型的性能是有提高的。因此作者就尝试去解释这是怎么一回事儿。然后这个channel通道上的注意机制就是他搬出来解释的一套说辞。他认为我们的网络是由这个原理去达到了这个效果。
深度学习这个领域确实是这样子,有很多时候都是无意间搞了一些操作,发现网络的性能真的很好。然后就想办法去解释这个事情,如果你能解释的通顺,挺有道理的话,那就是一片不错paper。所以说DeepLearning是这种以结果为导向的一种开发形式。所以我们就希望通过这个全链接的映射可以让网络自己去学习这个attention。
#问:为什么用两个卷积层,而不是一个,好像gap也可以学参数?答:这个没有办法给一个特别精准的解释,因为可能作者也不知道。就是作者也是试,就用了两个卷积层,发现效果就是好,就比一个卷积好。就这么个原因。可能是两个卷积层做的映射更多,能学到更多东西,所以说他的上限/潜能就会更大一些,它的效果会更好。
#然后再把原始的featuremap乘回去。![]()
就对原始的这一组特征图做了一个重要度的重分配,这就是NENet的思想。
四、代码
这里给出模型搭建的python代码(基于pytorch实现)。完整的代码是基于图像分类问题的(包括训练和推理脚本,自定义层等)详见我的GitHub: 完整代码链接
class SqueezeExcitation(nn.Module):
def __init__(self, pervious_layer_channels, scale_channels=None, scale_ratio=4):
super().__init__()
if scale_channels is None:
scale_channels = pervious_layer_channels
# assert input_channels > 16, 'input channels too small, Squeeze-Excitation is not necessary'
squeeze_channels = make_divisible8(scale_channels//scale_ratio, 8)
self.fc1 = nn.Conv2d(pervious_layer_channels, squeeze_channels, kernel_size=1, padding=0)
self.fc2 = nn.Conv2d(squeeze_channels, pervious_layer_channels, kernel_size=1, padding=0)
def forward(self, x):
weight = F.adaptive_avg_pool2d(x, output_size=(1,1))
weight = self.fc1(weight)
weight = F.relu(weight, True)
weight = self.fc2(weight)
weight = F.hardsigmoid(weight, True)
return weight * x
![]()
weight = F.adaptive_avg_pool2d(x, output_size=(1,1)) #送进全局平均池化,得到1*1*C的向量,可以一定程度上表征一组featuremap
fc1(weight) fc2(weight) #通过两个全连接层,做一个映射,希望在计算的过程中,这个1*1的向量自己能学到一个attention、featuremap。
return weight * x把学到的featuremap再乘回那一组featuremap。就做了一个重要程度的重分配
#注意这里乘以一个sigmoid![]() 会把输入给它归成一个0~1的范围。相当于对这些值做了一个重要程度的划分。最重要的话就是1,不太重要的话,就把Channel维度上的信息抑制一下,乘上一个小数,这是为什么要有一个sigmoid的一个原因。
会把输入给它归成一个0~1的范围。相当于对这些值做了一个重要程度的划分。最重要的话就是1,不太重要的话,就把Channel维度上的信息抑制一下,乘上一个小数,这是为什么要有一个sigmoid的一个原因。
#senet的归纳偏置有没有跟ResNet还挺像。都是先保留一下原有的这个数据,然后做一些映射,然后再跟原有数据合到一起来,只不过一个是乘一个是加。那个加号就是ResNet的归纳偏置,就是那个恒等映射。但是当你换到SENet以后,那么归纳偏置是什么?就是注意力机制。
#注意:由于se它处理的是featuremaps,是对特征图做处理,因此它可以放到任何一个网络结构里边,只要这个结构它可以产出featuremaps,后面都可以跟SE。这个se叫做压缩和扩展。压缩Squeeze就是GAP,扩展Excitation就是最后要乘回去。任何网络结构都可以加SE,做一个通道维度上的注意力机制。
总流程:
X经过一系列传统卷积得到U,对U先做一个Global Average Pooling ,输出的1x1xC数据
(即上图梯形短边的白色向量)。
再经过两个全连接后 ,用sigmoid限制到[0, 1]的范围,这时得到的输入可以看作每个通道的权重(即上图梯形短边的彩色向量)。
把这个1x1xC的值乘到U的C个通道上,这时就对channles进行了重要程度的重新分配。
Squeeze:
顺着空间维度来压缩特征,就是在空间上做全局平均池化,每个通道的二维特征变成了一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的通道数相匹配。用全局平均池化是因为scale是对整个通道作用的,利用的是通道间的相关性,要屏蔽掉空间分布相关性的干扰。
Excitation:
用2个全连接来实现 ,第一个全连接把C个通道压缩成了C/ratio 个通道来降低计算量(后面跟了RELU,增加非线性并减少计算量),ratio是指压缩的比例一般取r=16;第二个全连接再恢复回C个通道(后面跟了Sigmoid归一化到0~1),Sigmoid后得到权重 s。s就是U中C个feature map的权重,通过训练的参数 w 来为每个特征通道生成权重s,其中参数 w 被学习用来显式地建模特征通道间的相关性。用全连接是因为全连接层可以融合全局池化后各通道的feature map信息。
三、效果
与SE 模块可以嵌入到现在几乎所有的网络结构中,而且都可以得到不错的效果提升,用过的都说好。
在所有的结构上SENet要比非SENet的准确率更高出1%左右,而计算复杂度上只是略微有提升(增加的主要是全连接层,全连接层其实主要还是增加参数量,对速度影响不会太大)。在MobileNet上提升更高。而且SE块会使训练和收敛更容易。CPU推断时间的基准测试:224×224的输入图像,ResNet-50 164ms,SE-ResNet-50 167ms。
ShuffleNet
为了纪念孙健博士,何凯明他的赐作也是孙健
可以看做是mobilenet的升级版本。
前言
ShuffleNet v1是由旷视科技在2017年底提出的轻量级可用于移动设备的卷积神经网络。
该网络创新之处在于,使用 group convolution还有channel shuffle,保证网络准确率的同时,大幅度降低了所需的计算资源。
在近期的网络中,pointwise convolution(1X1conv)的出现使得所需计算量极大的增多,于是作者提出了pointwise group convolution来降低计算量,但是group与group之间的几乎没有联系,影响了网络的准确率,于是作者又提出了channel shuffle来加强group之间的联系。在一定计算复杂度下,网络允许更多的通道数来保留更多的信息,这恰恰是轻量级网络所追求的。
一、Group Convolution
就想解读MobileNet不得不说深度可分离卷积一样,解读ShuffleNet就不得不说组卷积了。这里对比着普通卷积和深度可分离卷积来说说组卷积:
#首先mobilenet里面用的是深度可分离卷积,dw conv;ShuffleNet 用的是组卷积
![]()
![]()
#组卷积的c加起来也是C,和普通卷积是一样的,但是产出的featuremaps是两个。
#就是说:组卷积可以保证和普通卷积是相同参数量的情况下,有几个组,就可以产生几张feature map。
上图为普通卷积示意图,为方便理解,图中只有一个卷积核,此时输入输出数据为:
输入feature map尺寸: W×H×C ,分别对应feature map的宽,高,通道数;
单个卷积核尺寸: k×k×C ,分别对应单个卷积核的宽,高,通道数;
输出feature map尺寸 :W’×H’ ,输出通道数等于卷积核数量,输出的宽和高与卷积步长有关,这里不关心这两个值。
参数量 : k2×C
运算量 : k2×C×W’×H’ (这里只考虑浮点乘数量,不考虑浮点加)。
将图一卷积的输入feature map分成组,每个卷积核也相应地分成组,在对应的组内做卷积,如上图2所示,图中分组数,即上面的一组feature map只和上面的一组卷积核做卷积,下面的一组feature map只和下面的一组卷积核做卷积。每组卷积都生成一个feature map,共生成个feature map。
输入feature map尺寸: W×H×C/g ,分别对应feature map的宽,高,通道数, 共有g组(上图g=2);
单个卷积核尺寸: k×k×C/g ,分别对应单个卷积核的宽,高,通道数,一个卷积核被分成g组;
输出feature map尺寸 :W’×H’×g ,共生成g个feature maps。
参数量 : k2×C/g×g = k2×C
运算量 : k2×C/g×W’×H’×g = k2×C×W’×H’
对比普通卷积来看,虽然参数两和运算量相同,但是,我们得到了g倍的feature map数量。
#可以把group看成一个控制旋钮,当他等于1的时候,就是一个普通的卷积;当组数等于输出数据的channel维度的时候,就等价于一个深度分离卷积(逐通道卷积)。所以感觉组卷积是一个更好的平衡
所以group conv常用在轻量型高效网络中,因为它用少量的参数量和运算量就能生成大量的feature map,大量的feature map意味着能提取更多的信息。
从分组卷积的角度来看,分组数g就像一个控制旋钮,最小值是1,此时的卷积就是普通卷积;最大值是输入feature map的通道数,此时的卷积就是depthwise sepereable convolution,即深度分离卷积,又叫逐通道卷积。
![]()
如上图所示,深度分离卷积是分组卷积的一种特殊形式,其分组数,其中是feature map的通道数。 这种卷积形式是最高效的卷积形式,相比普通卷积,用同等的参数量和运算量就能够生成个feature map,而普通卷积只能生成一个feature map。
所以深度分离卷积几乎是构造轻量高效模型的必用结构,如Xception, MobileNet, MobileNet V2, ShuffleNet, ShuffleNet V2, CondenseNet等轻量型网络结构中的必用结构。 关于逐层卷积的具体解释详见我关于MobileNet系列的文章。
二、ShuffleNetV1
1. Channel Shuffle
对于上述的Group Convolution,很容易想到一个问题就是在卷积的时候,仅仅是将这一个Group的特征图进行了融合,但是不同的组别之间缺没有充分的连接,长此以往,不同的特征图对于对方的了解就越来越少,虽然网络的全连接层会帮助不同特征图相互连接,但是可以预想的是这样的连接融合的次数较少,不如不分组的情况。
基于上述的情况,作者提出把每个组的特征图分为一定组在每一层都进行一定程度的乱序结合,以这样的方式增加特征图的连接融合次数,过程如下图所示:
![]()
#组卷积的一个问题:每一组自己做自己的卷积,组合组之间没有交互。回忆深度可分离卷积,为什么逐层卷积后面跟一个逐点卷积?为什么要跟一个1×1的卷积?就是因为逐层卷积得到Feature map的没有交互。所以后面要跟一个1×1的卷积做交互。这里组卷积也是一样的,如果我们不去做交互的话,他也是自己玩自己的。结果可想而知,不是那么好的。即便是最后有一个top分类头。有一个全连接去给不同组之间做一个融合,其实也是不太够用的。这是组卷积一个明显的缺点。所以我们就要考虑如何改进他?
#Shuffle net就给他做了一个改进。就是说每一组卷积得到的feature map。不要着急往下送。先给他做一个Shuffle,就是A组得到的Feature map拿出一些给b组和c组,给他shuffle一下。Shuffle是打散的意思。打散完之后再分组。再做计算搞下去。这样子效果就很好。就做了不同组之间Feature map的信息融合或者叫信息交互。
#这个东西也不新,AlexNet在拆开的时候,也搞了一个。如果把feature map搞到两个设备。自己搞自己的。最后做融合可能会有问题。因为自己玩自己的,没有交互。因此当初AlexNet也讲了他会在不同的设备里也做一个交互。这其实就是一个shuffle。这是12年的思想。所以这个东西也不新。
![]()
如上图(a)是正常的组卷积模式,不同分组(不同颜色表示不同分组)几乎没有信息交流;(b)和(c)描述的是channel shuffle的方式。
2. ShuffleNet unit
整个单元其实比较好理解,直接上图如下:
如同所示(a)是MobileNet系列网络中的DWconv(详见我之前的博文)
![]() #首先左边的a是哪一个结构?是不是Mobile net里面的block。
#首先左边的a是哪一个结构?是不是Mobile net里面的block。![]() 然后Shuffle net就是说将1×1的卷积先做一个分组卷积,这里做分组卷积有一个目的。就是分组卷积可以比正常的卷积减少参数量。以前讲过不管是分组卷积还是分组卷积的最终版逐层卷积都是可以减少参数量的。之前还讲过。Mobile net你的参数量75%都集中在1×1的卷积里。这里shuffle net为了进一步的降低参数量,把1×1的卷积变成了1×1的分组卷积。然后为1×1的卷机有个交互做了一个channel shuffle。再送进一个正常的3×3的DW卷积,再送进一个1×1的分组卷积然后出来。这是他的改进。也是Shuffle net的Block。
然后Shuffle net就是说将1×1的卷积先做一个分组卷积,这里做分组卷积有一个目的。就是分组卷积可以比正常的卷积减少参数量。以前讲过不管是分组卷积还是分组卷积的最终版逐层卷积都是可以减少参数量的。之前还讲过。Mobile net你的参数量75%都集中在1×1的卷积里。这里shuffle net为了进一步的降低参数量,把1×1的卷积变成了1×1的分组卷积。然后为1×1的卷机有个交互做了一个channel shuffle。再送进一个正常的3×3的DW卷积,再送进一个1×1的分组卷积然后出来。这是他的改进。也是Shuffle net的Block。
#c图还有另一种,这种就是在做下采样的时候的block。回忆一下。resnet有两种block。就是在stage有更迭的时候,他的第一个block和其他的Block长得不一样。![]() 。同理在shuffle net里面也有两种block。C图就是他在做下采样的时候那种block,这里就是对残差过来的这条线做了一个pooling操作。这个跟resNet里不一样,resNet里面是做一个一乘一卷积步长为2。Shuffle net做了一个池化操作,步长为2。都可以达到一个相同的目的。
。同理在shuffle net里面也有两种block。C图就是他在做下采样的时候那种block,这里就是对残差过来的这条线做了一个pooling操作。这个跟resNet里不一样,resNet里面是做一个一乘一卷积步长为2。Shuffle net做了一个池化操作,步长为2。都可以达到一个相同的目的。
(b)和(c)是本文中提出的shuffle unit,(b)是3X3卷积步幅等于1的情况,可以看出与DWconv非常像,只是为了进一步减少参数量将1X1卷积优化成1X1组卷积,而且添加channel shuffle来确保不同组之间的信息交互。注意:Channel Shuffle操作在1×1的卷积操作之后,也就是先对通道进行了收缩,随后进行通道调整,最后卷积在调整回原来的通道数;(c)是步幅等于2的情况,输出特征图尺寸减半,channel维度增加为原先的2倍,为了保证最后的concat连接,需要保证两个分支的输出特征图尺寸相同,因此,在捷径分支上添加步幅为2的3X3全局池化。
3. Model Architecture
下图Table1是网络的结构的详细参数。
stride表示步幅,不同步幅有自己不同的shuffle unit;repeat代表重复次数,例如stage3的意思是重复stride=2的shuffle unit一次,重复stride=1的shuffle unit单元7次。
![]()
#按照整体的网络架构图的超参设计也能够很轻松的把网络搭建出来。后面讲。Mobile net和shuffle net的代码。
从上表的最后一行可以看到,随着分组的增加,最终的复杂度(论文中以FLOPS作为衡量标准)相应的减少,这和我们对于Group Convolution操作的期望相同;随之而来的一个问题是,采用了这样的方式会对准确率有影响吗?出人意料的,该改进也比传统的网络优秀一些,如下图所示。
![]()
#这里有一个问题,降了那么多参数量会对精度有影响吗?答:这种改进比传统的网络能达到更高的性能。看论文里的结果。ShuffleNet相对于vgg相对于Google net相对于alex net他的精度都是有提升的。而且它的参数量都是有很大下降的。
#不仅是mobile net和shuffle net都证明了一件事。就是之前讲的那些经典的模型里面的参数都是冗余的。这就证明了深度学习模型其实很强大。这么一个简单结构就能完成生活中很复杂的一个问题。而且你的参数还是一个冗余的状态。这就很厉害了。
除了标准网络,作者也按照MobileNetV1的思路,对于网络设置了一些超参数s,表示通道数的多少,例如s=1,即标准的网络结构,通道数如上图Table1所示;s=0.5表明每个stage的输出和输入通道数都为上图中通道数的一半,其他的类似。通过通道缩放s倍,整个计算复杂度和参数均下降s2 倍。下表是作者的一些实验数据。
![]()
![]()
#G代表组数,一组就是普通的卷积,一直到8组。下面是错误率。可以看出一个问题。随着group组数的提升错误率是在逐步下降的。从33降到32。也就是说,他是一点一点的下降的。参数变得更少了,但是效果变得更好了。这个原因是为什么?为什么分组这么有效? 答:![]() 其实是为了提取不同的模式。左图是alexnet送进两个设备,发现每一个设备提取到的模式都不一样。当时这个小哥儿还不知道为什么。但是现在我们知道了。因为现在我们把组卷积技术做了详细的研究。就是我们分组之后,每一组都可以学到不同的模式。这相当于一种集成学习的思想。就相当于班级学习时有好多同学一起在学。到时候回答问题的时候一起举手表决一个道理。所以随着组数的提升,相应的精度也是会慢慢提高的。
其实是为了提取不同的模式。左图是alexnet送进两个设备,发现每一个设备提取到的模式都不一样。当时这个小哥儿还不知道为什么。但是现在我们知道了。因为现在我们把组卷积技术做了详细的研究。就是我们分组之后,每一组都可以学到不同的模式。这相当于一种集成学习的思想。就相当于班级学习时有好多同学一起在学。到时候回答问题的时候一起举手表决一个道理。所以随着组数的提升,相应的精度也是会慢慢提高的。
二、ShuffleNetV2
1. Motivation
论文发现,作为衡量计算复杂度的指标,FLOPs实际并不等同于速度。FLOPs相似的网络,其速度却有较大的差别,只用FLOPs作为衡量计算复杂度的指标是不够的,还要考虑内存访问消耗以及GPU并行。基于上面的发现,论文从理论到实验列举了轻量级网络设计的5个要领,然后再根据设计要领提出ShuffleNet V2。
#参数量实际上并不等同于模型的计算速度。这个不是等同的。这个非常重要。工业里面最关心的是模型跑得快不快。而不是参数量多不多。V2版本发现有一些操作看上去减少了很多参数量。但是耗时很严重。
#这个版本提出了五个准则。如果以后要开发轻量级的模型,一定要参考。这五个准则就是说如果这样做会对模型跑的速度是有提升的。
2. Practical Guidelines for Efficient Network Design
G1: Equal channel width minimizes memory access cost (MAC).
#第一、在一个操作集合里面,尽可能的保证一个相同的维度。就是说每一个block里面都有一个input channels。和output channels。这时候如果保证他俩相等的时候,运算速度是最快的。
相同维度的通道数将最小化内存访问成本,如下图所示,当input channles = output channels时,每秒处理的照片数量越多。
![]()
#Batches/second是指每秒钟处理多少个图像。Inchannel和outchannel是1:1的时候。每秒钟可以处理1000多张。但是当他们不相等的时候,每秒钟处理的图像会逐渐减少。这就意味着模型计算的时间在逐渐增加。
G2: Excessive group convolution increases MAC
#分组卷积虽然会降低参数量,但是他也会增大内存访问的成本。就是分组越多的话,模型的计算速度是有所下降的。尤其是在GPU上非常严重。可以理解。DW卷积虽然参数量下降了很多,但是跟正常的卷积相比,他的运算时间是差不多的。甚至Dw卷积还会更慢一些。这是因为pytorch底层对3*3卷积做了很多优化处理,所以他的计算速度会很快。因为自14年开始Vgg就倡导一个小卷积核。所以这么多年下来,这些底层框架也会对小卷积核做一个非常夸张的加速。但是对dw卷积就没有做优化,所以他的运行时间相对慢一些。
![]()
#当分组数g越来越多的时候,我能计算的图像数量也是慢慢变少的。这里如果要用八个分组卷积计算的话,速度会下降四倍。很夸张。所以要明白分组和速度是一个check off权衡。需要去选择,并不是说参数越少越好。你的参数越少,计算速度反而会上升。这是一个权衡问题。
过多的分组卷积会加大内存访问成本,如下图所示,越多的分组会导致速度急速下降,特别是在GPU上,下降的十分严重,一个显卡跑的话,8个Group Convolution会使得速度下降4倍!(这一这里作者依旧是在不同的条件下使用不同的通道数保证FLOPs是一样的)
G3: Network fragmentation reduces degree of parallelism
#碎片化的网络结构。
碎片操作将减小网络的平行度,这里的碎片操作指的是将一个大的卷积操作分为多个小的卷积操作进行。作者这里使用自己搭建了一些网络进行验证,网络的结构如下:
![]()
#Abcde哪种结构它的速度计算更快?不用看,a是最快的。因为a是最简单的。他做了这么一个实验,其他结构到底是加速还是减速呢?直观上的理解好多人会认为e更快一些。因为他是一个并行的结构。GPU对并行的结构单元有一个很强的加速能力。作者发现并不是这样的。
![]()
#首先A是最快的。每秒钟可以做2446张图片。看到b和d串型的和并行的两个块儿都有减速。而且并行的减速是更多的。串起来可以每秒预测1700多张图片。但是并行只能预测1500多张图片。所以并行对速度的影响是更大的。![]() 同理串四个和并四个运行也是一样的结果。进行的速度是最慢的。这里通过实验就做了一个证明。e反而是最慢的。
同理串四个和并四个运行也是一样的结果。进行的速度是最慢的。这里通过实验就做了一个证明。e反而是最慢的。
#注意:这里的慢是有争议的。并不一定是因为并行结构引起的。也可能是因为这个加操作![]() ,而串行没有加操作,是一直往下走的。所以不好讲,到底是因为并行结构引起的,还是加操作引起的。总之从现象展开并行结构是最慢的,所以作者倡导在搭建网络结构时,尽量不要搭建碎片化的网络结构。
,而串行没有加操作,是一直往下走的。所以不好讲,到底是因为并行结构引起的,还是加操作引起的。总之从现象展开并行结构是最慢的,所以作者倡导在搭建网络结构时,尽量不要搭建碎片化的网络结构。
在实际设备上进行对比,在固定FLOPs情况下,分别对比串行和并行分支结构的性能。结果如上图所示,这里有一个比较有趣的结果,就是我们认为可能增加并行度的平行结构,最后居然减低了速度,不过这里由于还有下一个guide line的实验说到了元素级的操作也会对速度有一定的影响,因此这里还不能下定论到底是因为平行还是因为最后的相加拉低了时间。
G4: Element-wise operations are non-negligible
#第四个讲了一个元素级别的操作其实就是加操作。像Relu,TensorAdd,BiasAdd等等的矩阵元素级操作。是加减操作,不是乘除。这些加减操作其实基本没有被算到FLOPs中,因为我们默认他很快。我们只会算一些乘法操作嗯。但是加减操作也需要访问内存的,所以他还是会消耗计算时间的。到底消耗的多不多,是不是真的像我们想的理论一样不需要考虑呢?他就做了这么一个实验。
不要忽略元素级操作, 这里元素级操作指的就是Relu,TensorAdd,BiasAdd等等的矩阵元素级操作,可以推测到这些操作其实基本没有被算到FLOPs中,但是对于内存访问成本(MAC)这个参数的影响确实比较大的。
作者为了验证这个想法,对bottleneck这个层级进行了相应的修改,测试了是否含有Relu和short-cut两种操作的情况,对比如下:![]()
#看第一行,既有relu又有残差的时候。跟有relu没有残差的时候做比较,肯定是第二行没有残差的时候速度更快一些。每秒要计算出来的图像要多一些。跟没有relu有残差的时候做比较也是第三行速度较快。既没有relu也没有残差的时候(第四行),速度是最快的。这就是shufflenet v2四个网络设计的准则。
结论一目了然,没有两种操作的时候,更快一些。而且一个有意思的现象是,去掉short-cut对于速度的提升比Relu快一些,可以想到的是Relu只是对一个tensor进行操作,而short-cut是对两个tensor进行的操作。
![]()
#先看这张图,最直观。不论是Shufflenet还是mobilenet,首先,卷积消耗的时间是最多的。因为网络里面基本上都是卷积结构。Elemwise这个模块指的是元素级别的操作。看mobile net v2里面有23%的时间,都是在做元素级别的操作。 Shufflenet里面也有,15%少一些是因为他在刻意优化。大家要有一个印象。这些加减操作也是占用我们的时间的。
如上图所示,作者还分析了mobilenet和本文模型中具体操作的时间占用。Elemwise指的就是激活函数,残差连接等非线性操作,可以看到其时间占用并不能像计算FLOPS那样被忽略。
随后作者分析道最近的一些比较火的网络结构:
ShuffleNetV1违反了G2,bottleneck的结构违反了G1,而MobileNetV2使用的inverse bottleneck的结构违反了G1,其中夹杂的DWconv和Relu都违反了G4,自动生成结构(auto-generated structures)高度碎片化违反了G3。
#G2是分组卷积过多影响计算时间。在v1里面就是通过分组卷积来搞的模型,所以违反了g2。
#resnet里的瓶颈结构、MobileNetV2使用的反瓶颈结构都违反了g1
#G1是说输入通道和输出通道应该尽可能的相等。回忆不管是残差的block还是反转残差的block里面的input channel和outputChannel都是不相等的。要么做了压缩,要么做了扩张,也影响计算时间。
#DWconv和Relu都违反了G4,像dw里面由于拆成了逐层或者逐点,所以逐层或者逐点里面每一个都会跟一个relu。相当于又多了一个relu;向用NAS技术去搜出来的结构非常的不稳定,五花八门的,违反了这种高碎片化的G3。
3. Model Architecture
作者首先复盘了ShuffleNetV1,认为目前比较关键的问题是如何在全卷积或者分组卷积中维护大多数的卷积是输入通道与输出通道相等的。针对这个目标,作者提出了Channel Split的操作,同时构建了ShuffleNetV2 的unit,如下图所示:
![]()
#C和d就是对V1版本的a和b做了改进。
#先看从a到c的结构。首先把1×1的组卷积又换回了1×1的卷积。这样做的目的是为了不违反g2。但是这样子就没有了不同的组卷积去获得不同模式的能力了。他想了一个办法去模拟组卷积。就是在送进的时候把feature map分成两组。一种送进右边的分支,另一种送进残差的分支,这样就模拟了组卷积group=2。而且在送进dw卷积的时候,由于分组是2,通道数量刚刚好,不需要做通道维度的扩张或压缩,就不会违反g1。![]() 所以送进去的c维度是不会做任何改变的,然后再cancat一起。
所以送进去的c维度是不会做任何改变的,然后再cancat一起。
#也是相同的道理。只不过在左分支下面多了一个1×1的卷积。
如上图所示:(a)(b)对应shufflenetV1是uints; (c),(d)对应改进后的V2版units。
这里结合个人看法说说这么做的好处:
split channel把整个特征图分为两个组了(模拟分组卷积的分组操作,接下来的1X1卷积又变回了正常卷积),这样的分组避免了像分组卷积一样增加了卷积时的组数,符合G2;
小疑问?分组卷积看似在减少运算参数,但是却影响了运行速度;那么究竟怎么权衡?#![]() #分开送,只送进去1/2,这样就破坏了残差网络结构恒等映射的归纳偏置,学到的是其他东西了。深度学习每个人都有自己的归纳偏置,怎么解释都对,所以要敢于质疑权威,形成自己的理解模型的眼光,这样才有可能开发出自己的一套模型。如果你能提高精度,就可以把自己的理解写到paper里。是深度学习里面的论文大多描写如何实验、结果如何好,所以我的理解有可能是有道理。
#分开送,只送进去1/2,这样就破坏了残差网络结构恒等映射的归纳偏置,学到的是其他东西了。深度学习每个人都有自己的归纳偏置,怎么解释都对,所以要敢于质疑权威,形成自己的理解模型的眼光,这样才有可能开发出自己的一套模型。如果你能提高精度,就可以把自己的理解写到paper里。是深度学习里面的论文大多描写如何实验、结果如何好,所以我的理解有可能是有道理。
split channel之后,一个小组的数据是通过short-cut通道,而另一个小组的数据经过bottleneck层;这时,由于split channel已经降低了维度,因此bottleneck的1X1就不需要再降维了,输入输出的通道数就可以保持一致,符合G1;
小疑问?既然不需要降维,那么第一个1X1的conv还是否有存在的必要?![]() #既然C不变。还有必要要1×1的卷积?人说加了一层。会使网络有更多的参数空间。但是从实际的调整的效果看的话啊,有没有它都可以。
#既然C不变。还有必要要1×1的卷积?人说加了一层。会使网络有更多的参数空间。但是从实际的调整的效果看的话啊,有没有它都可以。
同时,由于最后使用的concat操作,没有用TensorAdd操作,符合G4;
小疑问?对于残差结构来说,concat操作和add操作到底哪个更好用?另外,由于捷径分支不在是空集操作,那么这样的结构是否还符合short-cut的初衷(即bottleneck学到的是残差Residual部分)?但是可以想到的是经过后面的Channel Shuffle的乱序之后,每个通道应该都会经过一次bottleneck结构。
#在resnet里面残差会和计算得到的结果做一个add,如图a。但是shufflenet会在channel维度上做一个cancat,将feature map堆起来。这两个到底哪个更好呢?在resNext里也做了这样的实验,结果好像是add与concat对性能影响差不多。你到底有什么道理?需要自己去理解。
![]()
最后, 给出ShuffleNetV2的网络结构详细参数:
![]()
#按照这个表就可以把shufflenet V2整个模型结构搭建起来。![]()
6值得注意的是:channel数都比较的小, 这里作者并没有特别的解释这个现象(按照MobileNetV2中对于Relu的分析,这种数量的通道设计不太适合relu激活函数)。五、总结
ShuffleNetV1:提出使用组卷积优化1X1卷积,来降低Flops;同时提出channel shuffle的概念来增加不同组间数据的交互;
ShuffleNetV2:提出了设计轻量快速模型的四个准则;并根据准则重新优化了shufflenet网络结构,具体讨论和分析见上文。
EifficientNet
自己看:https://blog.csdn.net/qq_39297053/article/details/123804502?spm=1001.2014.3001.5502
![]()
#EifficientNet 主要讲了当去放大网络的时候,可以放大网络的宽度。也可以放大网络的深度。
当想去放大网络的时候,有几种方式?三种。可以选择放大网络的宽度,也就是说去增加每一次卷积得到的feature map的数量(a\b图),这就相当于放大你网络的宽度;可以选择去放大网络的深度,就是用更多的层级结构进行堆叠(c);还可以选择送进去一个更高清的图像进去,使数据更清晰了,这是三种放大网络的结构。每一种都会对网络的性能有提升。![]()
#通过实验结果对比左图是放大网络的宽度,中间的是放大网络的深度,右图是用更高清的图像。结果发现网络性能都有所提升。只不过这三种提升都有一个饱和。到后期越来越大的时候,对性能的提升是逐渐饱和的。而且由于网络退化的存在,甚至网络搞得更大的时候,准确率会下降。因此在放大模型的时候啊,如果单独的使用某一种方式,其实并不是一个最优解。那么究竟应该怎么去合理的放大模型?
很简单,去放大这三个因素,这是作者的想法。所以说eifficientnet讲的就是炼丹,讲了怎么去搭建一个比较好的模型,想要回答如何调参,就是读这篇论文,里边都有非常多的这个实战经验。
#在这篇文里边作者提到了一个缩放因子——这个希腊字母ϕ叫什么?![]()
#说将来只要给这样一个参数就可以实现网络的自动放大和缩小。这个阿尔法、贝特、伽马就是网络的深度,宽度、和送进图像的尺寸的超参数。所以他的贡献就是找到了一个ϕ,可以很方便的对模型进行合理的缩放。
![]()
#它试出来了,Alpha beta gama等于1.2 1.1 1.15是最合理的。
#V2版本:主要讲等比例放大每一个阶段是不合理的。resnet里的stage![]() ,对上面的stage少发大一些,对下面的stage多放大一些,这样得到的模型准确率会更高。
,对上面的stage少发大一些,对下面的stage多放大一些,这样得到的模型准确率会更高。![]() 引入改进的渐进式学习的策略这个有时间可以去学一学。
引入改进的渐进式学习的策略这个有时间可以去学一学。
##3D点云用的是什么模型啊?底层也是一个卷积,只不过它的模型非常复杂,他处理的数据跟图像都不太一样啊,因为图像是一个2D的,这个3D点云有一个三维的这个空间的里边,所以这块儿还还是要另讲。
计算机视觉任务
五中:图像分类、图像识别、目标检测、语义分割和图像生成。![]()
#识别比分类多做了一个事情。把置信度最高的类别作为识别。
![]() #目标检测:输入是图像,输出是三类,1是bounding box边界框;2是识别任务;3是置信度;
#目标检测:输入是图像,输出是三类,1是bounding box边界框;2是识别任务;3是置信度;
![]()
#前两维是中心点的坐标,后两维是宽度和高度。
#边界框分为真实框和预测框,这和有监督训练的标签有关。标签是任务的真值,检测的真值就真是框。预测框是模型预测的结果,真事框和预测框的差距就是边界框对于位置的属性预测的准不准。![]()
#送进模型的不是完整的图像,而是随机裁剪裁剪的子图,裁剪的图就叫锚框。![]()
#整体的目标检测分为两个分支。一个叫1-阶段检测,包括SSD、YOLO;这部分模型优点是推理速度很快,所以可以适用于自动驾驶、行人检测,人脸检测等等。
![]()
#另一类是两阶段检测。是一个多任务,一步是生成锚框,另一步是针对锚框进行分类识别并且调整锚框的位置。![]()
#一阶段的优点是检测速度快。二阶段的优点是检测更准确。![]()
开山鼻祖:他是第一个用深度学习处理目标检测任务这的工作。当时比传统的目标检测精度要高20个点。![]()
#第一步操作其实就是生成锚框,用的方法是machine learning的方法。
#第二步就是用卷积提取特征。
#第三步类似于用softmax做分类。第二步部和第三其实就是图像识别任务。
#第四步是用回归器修正锚框的位置。回归器也是机器学习里面的方法。![]() 这个步骤就是调整随机生产的锚框的大小。
这个步骤就是调整随机生产的锚框的大小。
#可见目标检测任务比较复杂。而且四个步骤中只有第二步是用到深度学习的,其他都用的是机器学习。RCNN算法的精度和耗时在现在看都比较落后了,一般工业里都不会选择用它了。#空洞卷积——一个卷积的变体![]() #类似逐层卷积和逐点卷积合起来话叫做深度可分离卷积;卷积的变体有20多种。空洞卷积右图,就是为了扩大感受野。
#类似逐层卷积和逐点卷积合起来话叫做深度可分离卷积;卷积的变体有20多种。空洞卷积右图,就是为了扩大感受野。![]()
#多尺度的感受野在图像检测任务是很重要的,决定了网络能检测到的尺寸上限。
#卷机是做特征提取的,池化是做特征聚合,最后接一个全连接。但是在检测和分割任务上,感受野决定了网络能检测的尺寸上限。例如检测一个公交车,占了1000个像素。但是你模型的感受野经过网络堆叠只能达到500个像素,这时候检测是一件很麻烦的事。所以这时就想有没有办法来提升感受野?最简单的办法是堆叠网络层级结构让网络变得更深,会带来很多问题:如网络退化、数值不稳定性、梯度弥散、梯度爆炸、参数量也变大。但是空洞卷积会在不提升参数量的情况下提高感受野。
![]()
#普通卷积可以看成是空洞卷积的特殊形式。普通卷积的空洞率等于一,意味着kernel里每一个元素之间是没有间隔的,如a。空洞率为2就是元素之间间隔为1,如图b,而图c代表空洞率为4,卷积核元素之间间隔是3;图b间隔是1,中间就填0,等价于一个7*7的普通卷积。而c空洞率为4,间隔是3,等价于一个15*15的卷积。
![]()
#信息损失:虽然有,但是图像数据本身就是一个非常冗余的数据。假设一个图像它是384×384,给他隔点下采样层256×256,或者隔点采样层128×128,甚至你隔点采样成64*64,其实我们依然可以看明白这个图像里边都表征的是什么东西。说明图像本身就很冗余的。
#空洞卷积会存在一个问题:如果始终使用同一个空洞率去做空洞卷积的话,就会导致图像里边有一些像素值永远都不会参与计算。这个问题很大,就不是丢特征的事儿,就等价于本来的图像,是一个64×64大小的图像。但是对这个图像去做特征提取的时候,只用了一个32×32大小。这个问题怎么解决呢? 答:改变空洞率。
![]() 这样改是否可以? 答:不行,不能让空洞率是倍数的关系。
这样改是否可以? 答:不行,不能让空洞率是倍数的关系。
![]()
#分割是检测的升级版本。目标检测的输出,它是用bounding box把我们的感兴趣的这个目标给框出来的,但是框的有些粗糙。我们希望一个更细致的框,就跟抠图一样,这种任务就叫做语义分割。分割其实也是一个分类。这个怎么理解啊?这个就是说我们当前还是做分类,只不过分类的力度不一样,我们之前的分类粒度是目标是物体。现在的分割任务里边,分类的粒度是像素值。我们会对图像里边的每一个像素值都做一个分类,比如说这个像素值给它归为背景类别,这个像素值可以归为狗这个类别。实例分割:是语义分割的终极任务,将不同的个体也分出来、![]() 比如现在的远程会议,当前这个人就是保留一下前景,把背景做一个模糊,做一个虚化,甚至做一个改变,这个任务首先要区分前景和背景,其实就是一个语义分割任务。
比如现在的远程会议,当前这个人就是保留一下前景,把背景做一个模糊,做一个虚化,甚至做一个改变,这个任务首先要区分前景和背景,其实就是一个语义分割任务。![]()
#叫做骑车的可行驶区域分割,最后告诉成那部分是能开的区域,那部分是不能开的区域。![]()
#或者地图标注,也可以用语义分割去搞。![]()
#医学辅助计算。
![]()
#分割任务,输入是图像,输出也是一个图像。模型整体呈现一个先下采样,再上采样的一个过程。原因是,输出结果其实相较于原始的输入是丢了很多细节的,像这个狗的毛发纹理特征,这个小动物的眼睛,还有背景,都丢掉,只是一个大框这样一个结构化的信息。所以下采样的过程就是去丢掉这些我们不感兴趣的特征的。换言之,可以讲下采样的过程中就是去原图中提取这些结构化的特征。然后上采样,再把提到的这些结构化的特征重建回原始的空间。这是上采样和小采样的目的。![]()
#下采样就是用那些经典的模型如,Alexnet、VGG,砍掉分类头。
![]()
#做上采样:用卷积的另一种变体:转置卷积。右边这个就是转置卷积。输入和输出,对于卷积任务来讲,我们会在原始的数据上做特征提取,最后得的得这个输出就是经过提取之后的结果,肯定会小。而转置卷积就是正好相反,它的输入是比较小的,输出是比较大的。目的是去做信息的重建。![]()
#计算过程如上。上面步长是1.![]()
#转置卷积不等同于反卷积。因为,反卷积是逆运算。![]()
#图像生成
#生成对抗网络,2016年提出。16年Image大赛冠军是闭源的,大家也没关注,反而去关注GAN了,gan模型才是真正意义上的智能!![]() #首先GAN模型是做图像生成,图像生成分为很多子任务,例如风格迁移,生成人脸,改变发型,改变衣服等等。上图中展示的大部分是一些风格迁移的任务。可以看左上就是语音分割里面的一个迁移,就是会有一个模型输入是一些语音分割的这个结果,输出给你还原回真实的一个街景,现在我还能给他重建回去,重建回去用的就是一个干网络。左中图,,图像标注,这个地图是gan生成的,语言分割能做地图标注,其实干网络里边也可以用风格迁移的方法,把这个街景变成一个地图风格。中中图是白天转黑夜。中右图是草稿填色,gan网络都可以做。
#首先GAN模型是做图像生成,图像生成分为很多子任务,例如风格迁移,生成人脸,改变发型,改变衣服等等。上图中展示的大部分是一些风格迁移的任务。可以看左上就是语音分割里面的一个迁移,就是会有一个模型输入是一些语音分割的这个结果,输出给你还原回真实的一个街景,现在我还能给他重建回去,重建回去用的就是一个干网络。左中图,,图像标注,这个地图是gan生成的,语言分割能做地图标注,其实干网络里边也可以用风格迁移的方法,把这个街景变成一个地图风格。中中图是白天转黑夜。中右图是草稿填色,gan网络都可以做。![]()
![]()
上左图输入是一个正常的马,视频;输出是斑马。
![]()
#卷积的发明者:leNet杨立坤。如何评价干模型?他说对抗训练是一个非常酷的事,自从切片面包开始。这个其实是英语的一个俗语,在美国人看来,切片面包是一个非常伟大的发明,因为它非常便利,便于携带。![]()
#生成器就是一个自编码器,或者说他跟刚才讲的语义分割任务的模型是一模一样的。他会先下采样再上采样;或者没有下采样直接上采样。
#判别器就是一个非常普通的分类网络。
#GAN目的是去学习数据集的数据分布的。![]()
#一个图像数据集放在一个文件夹里面,如果将这个数据集升维成一个高维空间的话,在这个高维空间里边,每一个点儿代表一张图像。先理解这个事情,我们本身是处在三维空间里边的,那个文件夹,可以把它看作是一个二维空间的世界,里边的每张图像都是一种二维空间的。现在要给它抽象到高维的空间里面去。这个时候的一张图像,在高位空间里边的表示就是一个点儿。那肯定能用一个曲线把数据分布描绘出来。GAN模型其实就是去学右图的数据分布的。
举个例子,在这个数据分布里边,长得比较像的图像肯定是扎堆儿的。像这个红色区域可能就是一堆杯子,然后从这个红色区域里边随机取一个点,它就代表比如可以表征左上图这个杯子。然后这个蓝色区域可能就是一个蝴蝶,数据分布里面的每一个点儿都是一个蝴蝶,比如说这个点儿,可能表征的就是这一张蝴蝶图像。由于这个杯子和蝴蝶离得比较远,所以他们在这个图像数据分布里边理应也是隔得比较远的——红色和蓝色区域。
#他们学完有什么用呢?学习数据分布的时候,肯定不可能采集到真实世界里边的全部图像,或者说在学习一个数据集时,数据集都是对真实数据的一个采样,不可能讲每一个数据都收集。这就造成了我们再去学习这个数据分布的时候,学的是比较粗糙的。比如说在这个数据分布里边,原始的训练数据里边,可能就四个点,一个是马克杯,一个是玻璃杯,一个是小酒盅,一个是纸杯,可能是就这四个样本,就是在真实的里边采样的,用来训练数据的样子。但是如果把这个分布学到了那么神奇地方出现了,可以从这些其他的位置随机采一些点出来,这些点其实就是一张又一张的图像。然后当人们把这些图像可视化时,就会发现这个点也是一个杯子,而且是数据集里从来没有见过的杯子。这就是模型生成的一个杯子。
#学习数据集数据的目的就是为了生成其他数据样本。![]() 生成器就是一个神经网络。在最原始的干模型里,生成器就是一个最原始的神经网络,它的输入是一个随机向量,可以把它看作是一个长度为100的一个vector。然后再接一些隐藏层,最后搞成一个长度为1000的输出向量。再把这个1000的向量再reshape成一个10*10的像素矩阵,这个东西就是一张图像,所以可以有一个随机向量经过上采样得到很多点,然后再reshape成一个图像。
生成器就是一个神经网络。在最原始的干模型里,生成器就是一个最原始的神经网络,它的输入是一个随机向量,可以把它看作是一个长度为100的一个vector。然后再接一些隐藏层,最后搞成一个长度为1000的输出向量。再把这个1000的向量再reshape成一个10*10的像素矩阵,这个东西就是一张图像,所以可以有一个随机向量经过上采样得到很多点,然后再reshape成一个图像。
#如果做风格迁移,就不太一样。风格迁移是由图像变图像的,例如刚才展示的那个斑马,它是由马变斑马的,所以对于风格迁移,我们的输入就不是一个随机向量了,而是一张图像。这个时候采用的一个图像分割,所以这时候生成器其实跟分割是一模一样的。就是会通过一些卷积层先对原始的图像做下采样,然后丢掉原始图像里边的风格,最后得到一些结构化特征,然后再通过转置卷积做上采样,在这部分去重建想要的一个目标风格,最终生成一个图像。这种图像生成是一种分割的网络结构。
#总之,生成器是去生成一种高维向量。而且它不仅可以生成图像,它还可以去生成文本!!![]() #判别器就是分类头,去接收到的这个图像。目的就是给当前接受到的图像打分。如果图像比较真,判决器就会给一个比较高的分值,如果这个图像不太真,就给他一个比较低的分值。可以看成一个分类任务。
#判别器就是分类头,去接收到的这个图像。目的就是给当前接受到的图像打分。如果图像比较真,判决器就会给一个比较高的分值,如果这个图像不太真,就给他一个比较低的分值。可以看成一个分类任务。![]()
#甚至可以生成语音。
![]()
![]()
#非常有意思,你会觉得非常的奇妙。你可以把这个生成器和判别器看成两个小孩子。为什么先讲为什么看小孩子啊?因为是生成器和判别器,他们都是一个深度学习模型,就意味着他们需要被训练,由于他的权重是随机初始化的,因此他们对数据的处理能力是很弱的。那么这时候他们就相当于一个孩童的能力,只不过啊这两个小孩儿他俩的职业规划不一样,生成器这个小孩儿的职业规划是一个画家。这个任务来讲判别这个小孩儿他的职业规划是一个打假人,或者说是鉴画师,然后他们就开始对抗了,怎么对抗的?首先生成器的小朋友,会把他的画作送到判别器这个小朋友这里,然后这个判别器的小朋友,他就会拿着生成器的朋友生成的一个画作跟真实世界里边存在的东西所比较。然后他的目的就是去区分这两种东西,看能不能分开,由于一开始小朋友,说话能力肯定不强,就把结果反馈给生成器,那我画的不够好。回去想想怎么给他生成一个更真实的好,那么经过训练,他又产生了第二批作品,这个时候就变得比较真实一下。然后再送给我们的判别器啊。判别器不去训练的话,那意味着他始终是一个孩童能力啊?这个时候他把这个比较真实的图像送进判别机器判别的时候,和真实的这个图像比较像,这个时候这个小孩儿可能分不出来了,他就懵了,所以判别器也需要被训练。那么判别器被现在过程中他的判别能力就会越来越强,那这时候啊,他可能还是能看出来生成这个东西,跟我真的是这里边这个东西还是有一点儿差别的,再几代,再训练,直到生成器生成的这个结果跟我们真实世界里边这个结果足够相似的时候,直到判决器,这个判别器这个小孩儿再也判别不出来,当前接收到这个图像,它是来自于真实世界的,还是来自于生成器生成的,这时候我们就可以停止整个训练过程。这个对抗思想就结束了。
#上图画的是生物领域例子,原来生物是没有眼睛的,眼睛是跟环境不断对抗的结果。环境就相当于是一个判决器,生物就相当于是一个生成器。
![]()
#强化学习和对抗思想是非常类似的;生成对抗网络就是实现强化学习目标的一种手段。二人零和博弈,就是没有双赢。生成对抗网络就是一个二人零和博弈。
![]()
#在训练判别器的时候,首先会将这个生成器给它固定住,然后先让生成器去生成一些图像,我们会往这个生成器里边送一些随机向量,然后这个生成器会生成一些图像,然后手动将这个生成器生成的图像给上标签儿0,这第一步。第二步是真实数据集,这个数据集就是真实世界的采集到了一些图像。然后在这个数据集里面做随机抽样,给这批随机抽样图片打上标签儿1,这是第二步。第三步,从这两批图像里边随机的选一张图片送进判别器里,让这个判别器去分类,分类结果和这个标签做一个比较,就相当于分类去训练一个二分类模型,这个就是判别器的训练过程。最后生成器给的是一个概率,比如0.7![]() ,看成是图像真实度的打分。
,看成是图像真实度的打分。![]() #先去固定判别器,接收的是一组随机向量,生成一个图像,然后把这个图像送进判别器里边跟他打分。训练生成器的目的就是说让他根据这个分数进行返工。生成一张更真实图像,这个更真实的图像可以在判别器里边得到一个更高的评分,这就是一个生成器训练目的。
#先去固定判别器,接收的是一组随机向量,生成一个图像,然后把这个图像送进判别器里边跟他打分。训练生成器的目的就是说让他根据这个分数进行返工。生成一张更真实图像,这个更真实的图像可以在判别器里边得到一个更高的评分,这就是一个生成器训练目的。
#如果让你去评判图像是否真实,如何评判?答:这些指标不太好定义。
#其实生成器的损失函数就是判别器。因为判别器就是对生成器的结果打分;相当于对当前模型的这个prediction和一个真值对比,很巧妙。以前的损失是MSE,现在把损失变成模型了,而且这个模型可以被训练。是一个动态的损失,意味着随着训练,模型越来越强。![]()
#只有数据集没有标签:例如生成猫任务,只需要给一些喵咪的图片。![]() 这里只有数据集没有标签,从这个角度看GAN模型是无监督训练。但是从判别器角度看,因为会打上标签,所以是有监督任务。整体GAN,生成器是无监督,判别器是有监督。
这里只有数据集没有标签,从这个角度看GAN模型是无监督训练。但是从判别器角度看,因为会打上标签,所以是有监督任务。整体GAN,生成器是无监督,判别器是有监督。
#生成的图像也可以做数据扩充。![]()
#训练GAN模型,需要同时训练生成器和判别器。所以目标有两个。因为是零和博弈,所以我们要最大化判别器,最小化生成器。
#先看优化D:判别器![]() x是来自真实样本,希望打高分D(x);
x是来自真实样本,希望打高分D(x);![]() z是生成器生成的假样本,希望答低分。
z是生成器生成的假样本,希望答低分。
#再看生成器。![]()
生成器的目标是尽可能的生成真实图像,打高分骗过判别器。maxG是生成一个假图,希望得到高分。转换一下,求最小。![]()
![]()
当固定判别器时,目标函数第一个项相当于常数,可以干掉。后面项就等于上面的值。![]()
![]()
#GAN网络,GS散度,不容易训练。GAN模型的变体有100多个,是个大家庭。针对于不同的任务,都可以找到相应的一个干模型、干网络的。其实称生成对抗网络为一个新的网络并不合理,因为他的生成器里边是一个上采样的神经网络,或者像语义分割一样的是一个先下采样再上采样的过程,而判决器里边就是一个卷积,在网络搭建方面并没有什么创新。
GAN的创新点是什么呀?是训练策略,是这种对抗的思想,这才是他的创新。而且这个对抗思想可以把它添在任何一个任务里边。对抗思想可以把它归属于损失函数这个领域里,它是可以放在任何一个任务里边的。这就造成为什么有这么多变体,因为它是一个很通用的思想。是对的损失函数做一个改进,或者可以把它看看成巧妙的损失,这个损失可以被训练。把这个损失看成是一个模型,而不是一个数学式。








 用之前设定的预处理方式进行预处理。
用之前设定的预处理方式进行预处理。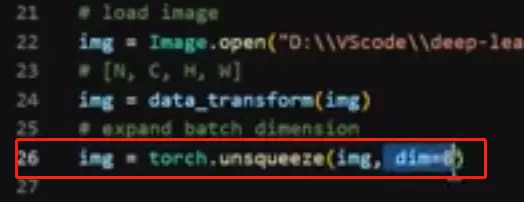
 ,他会返回一个结果。这个结果是什么?这个结果是我们刚才的outputs。它里面放的是我们三次卷积之后得到的featuremap,如下图是之前的训练脚本。
,他会返回一个结果。这个结果是什么?这个结果是我们刚才的outputs。它里面放的是我们三次卷积之后得到的featuremap,如下图是之前的训练脚本。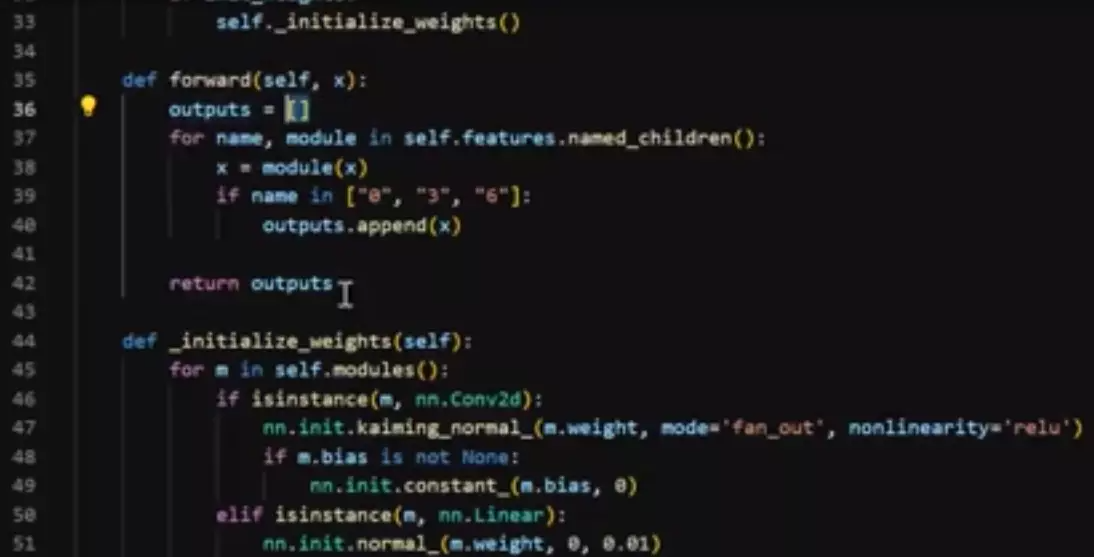
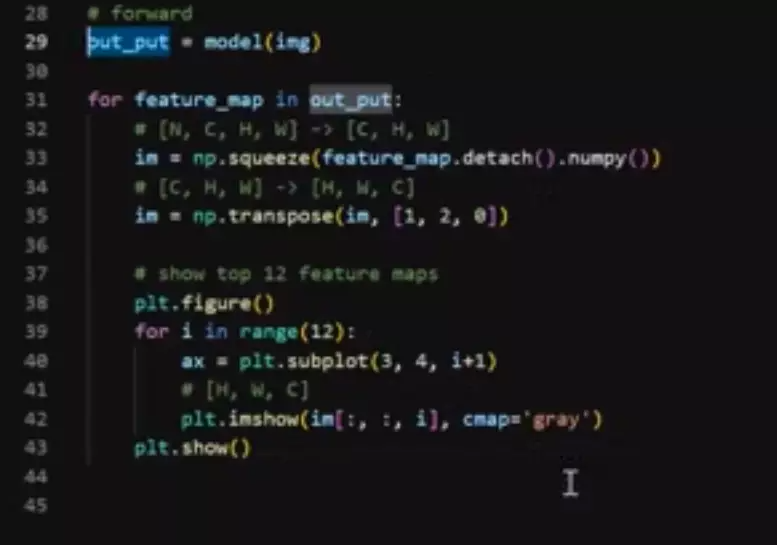




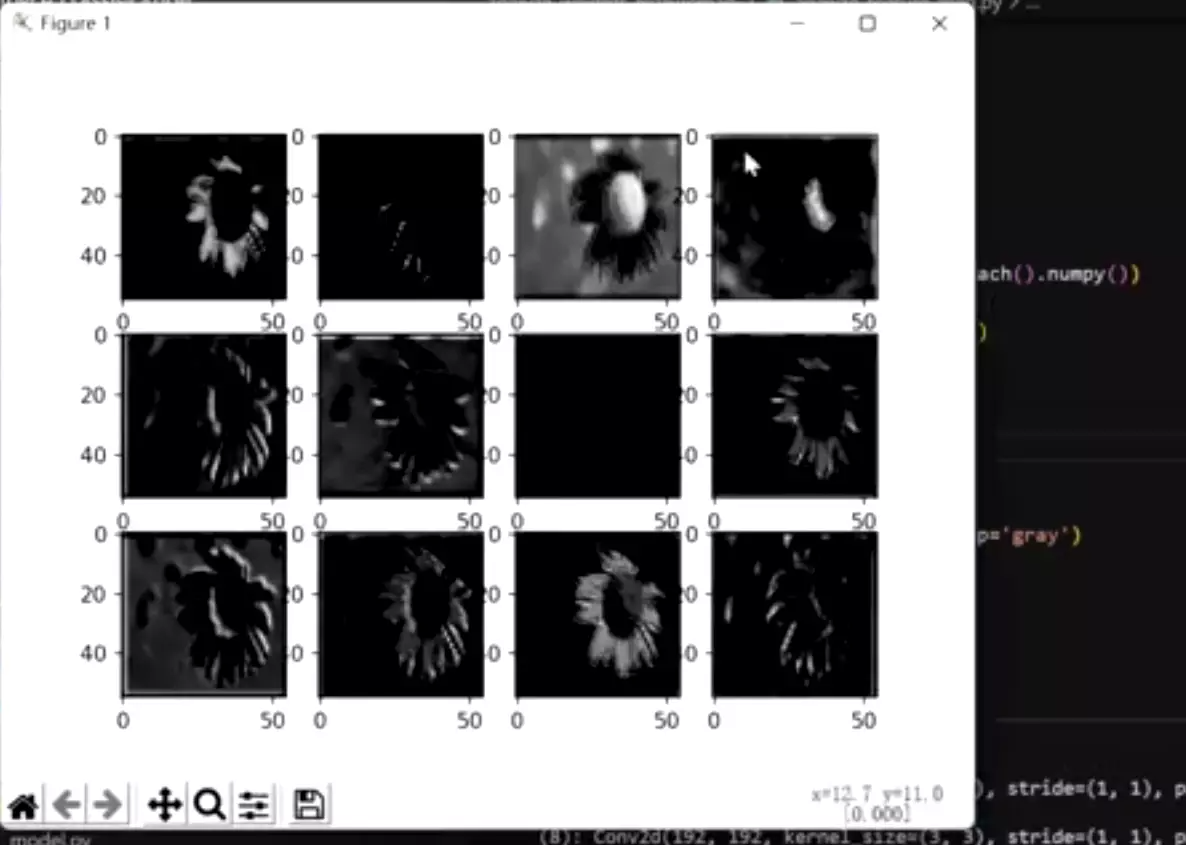
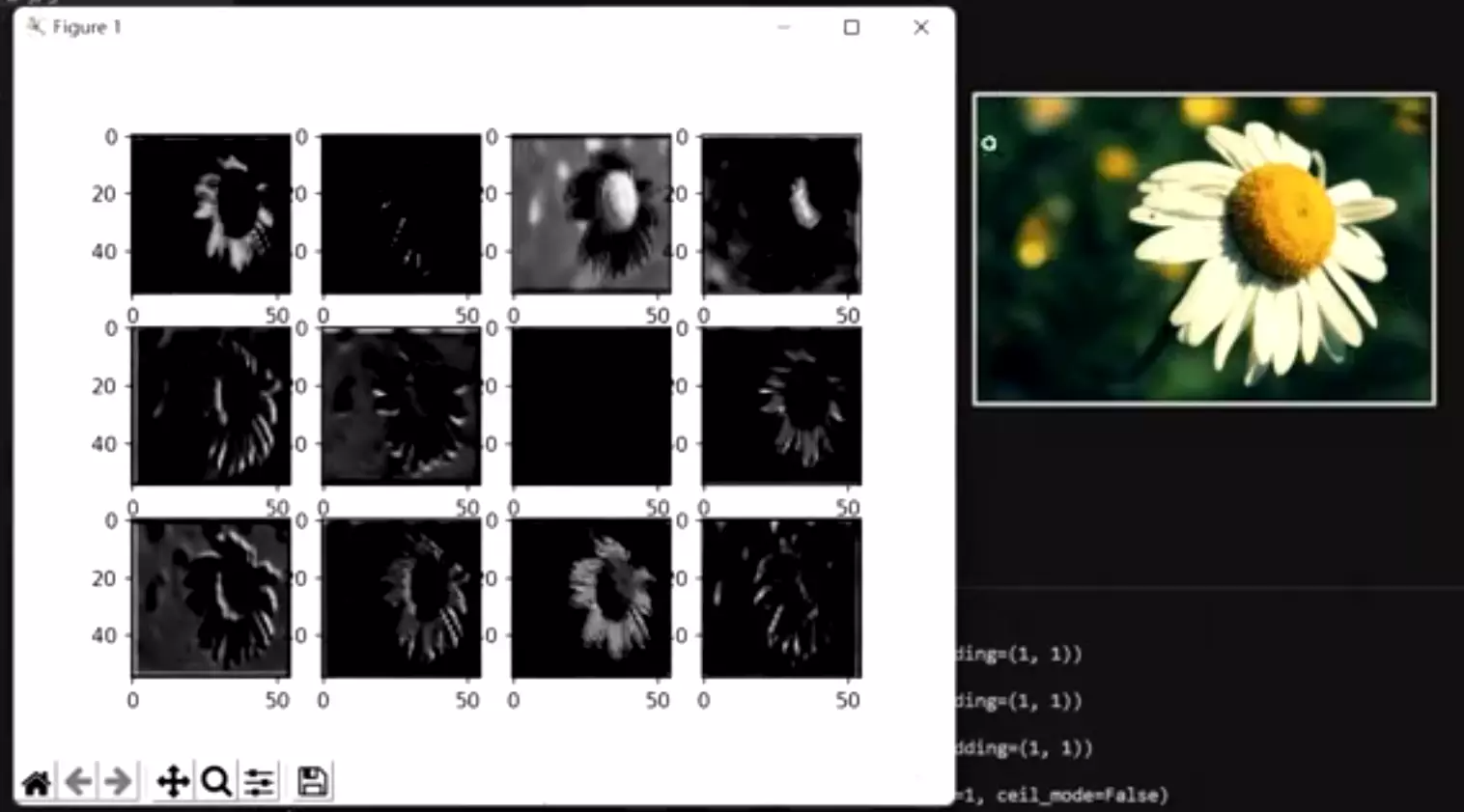
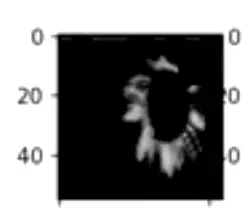 可能是提取白色花瓣这个特征。
可能是提取白色花瓣这个特征。 这个不好说,这就是神经网络里面不好解释的地方。就是他在干嘛不好理解。但是每张featuremap都不一样。
这个不好说,这就是神经网络里面不好解释的地方。就是他在干嘛不好理解。但是每张featuremap都不一样。 问:为什么这个featuremap这么黑? 大家可以思考一下。答:我们zfnet已经给大家解释过了,没有学的特征。
问:为什么这个featuremap这么黑? 大家可以思考一下。答:我们zfnet已经给大家解释过了,没有学的特征。

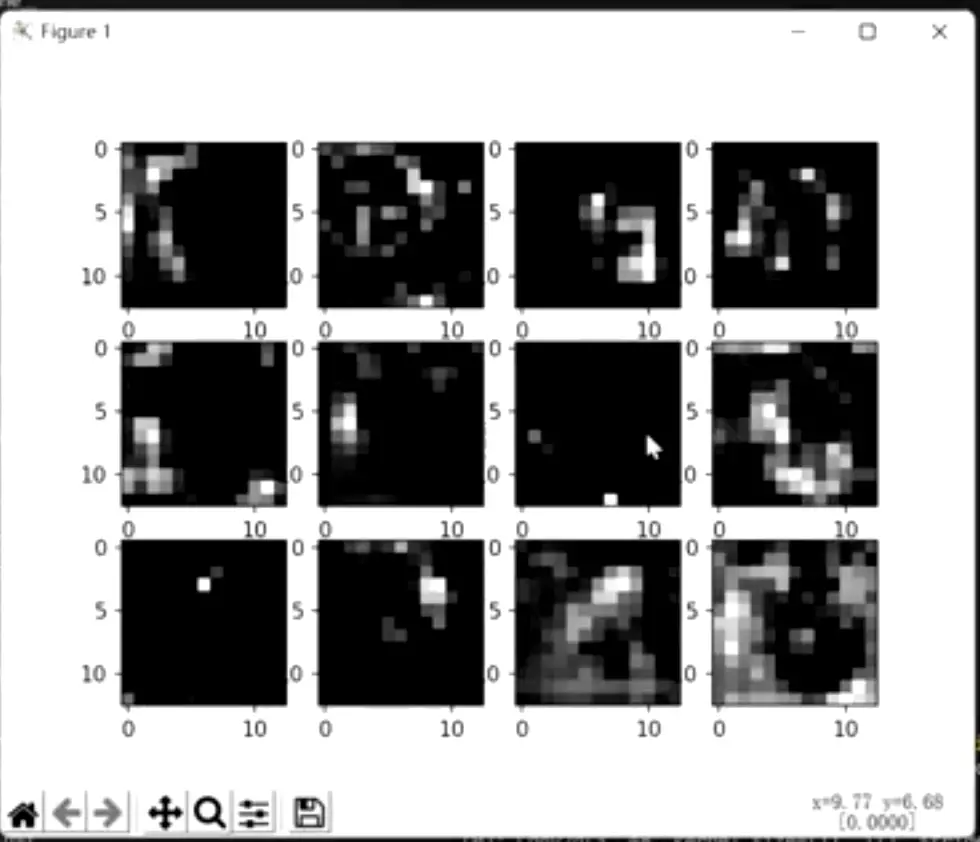

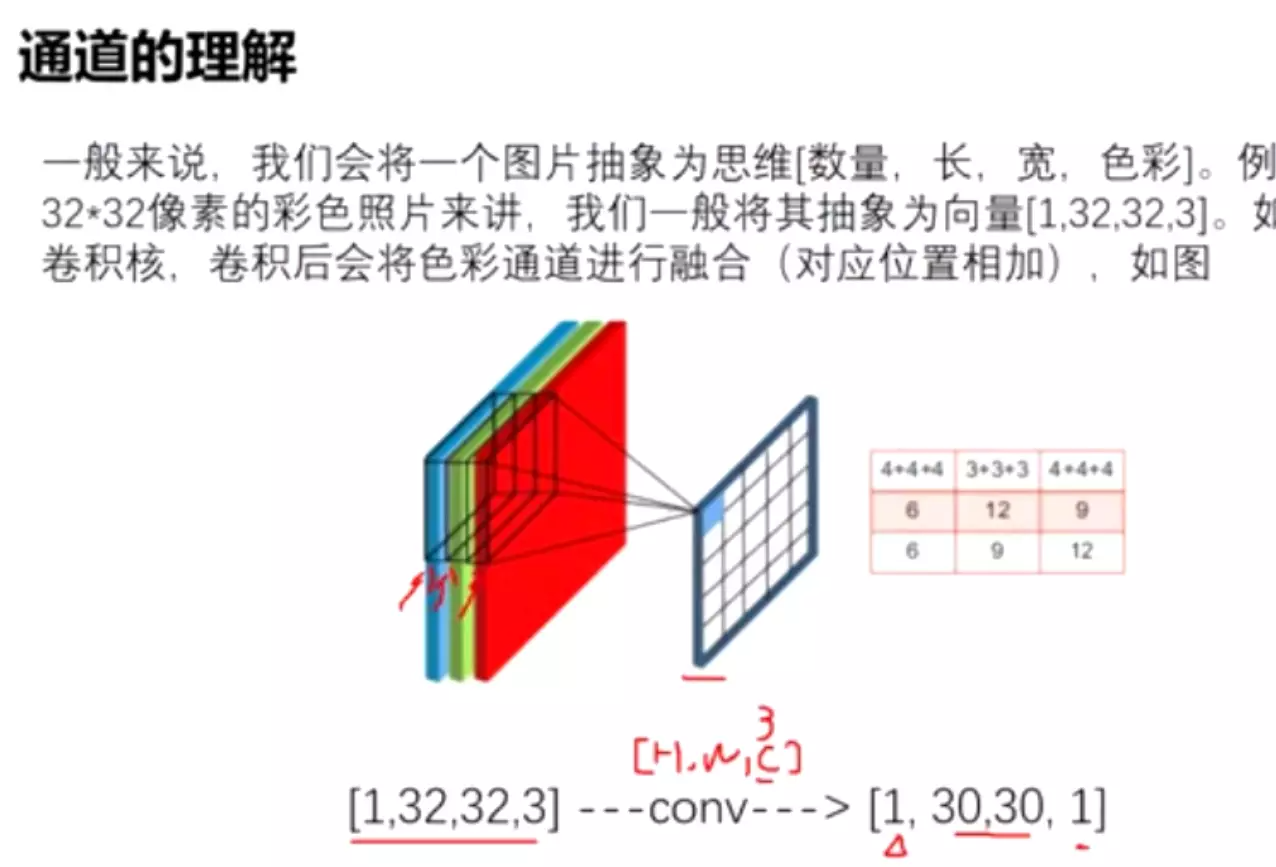
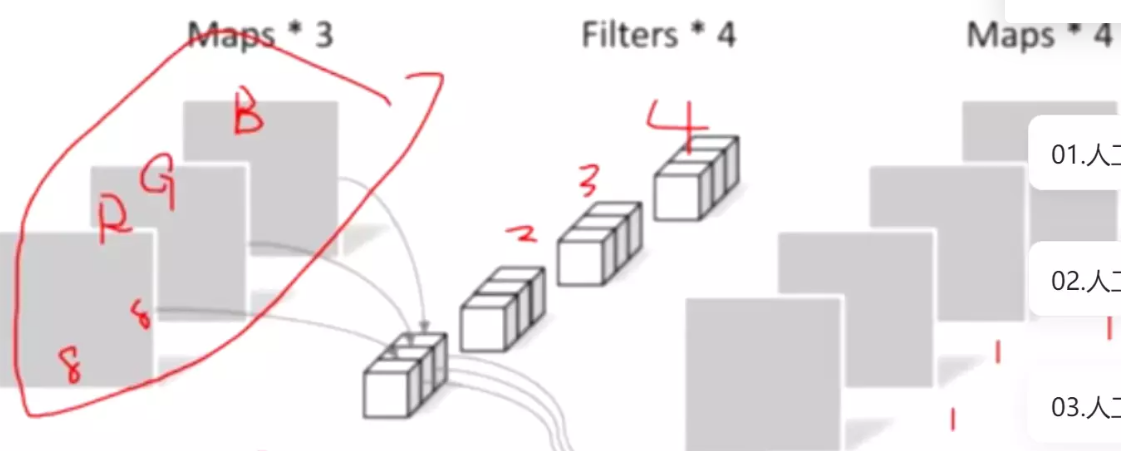
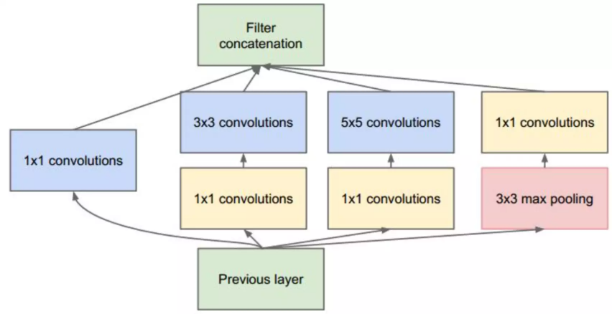
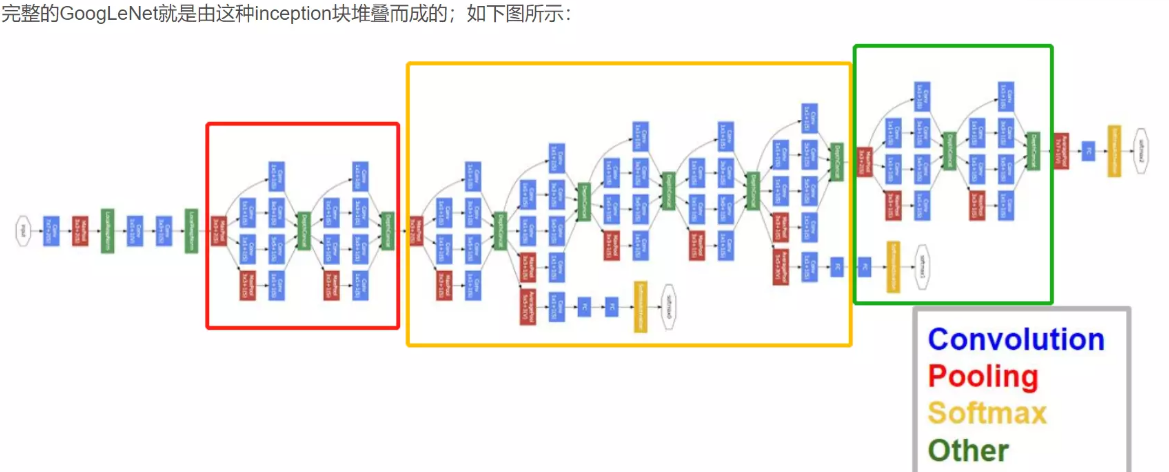
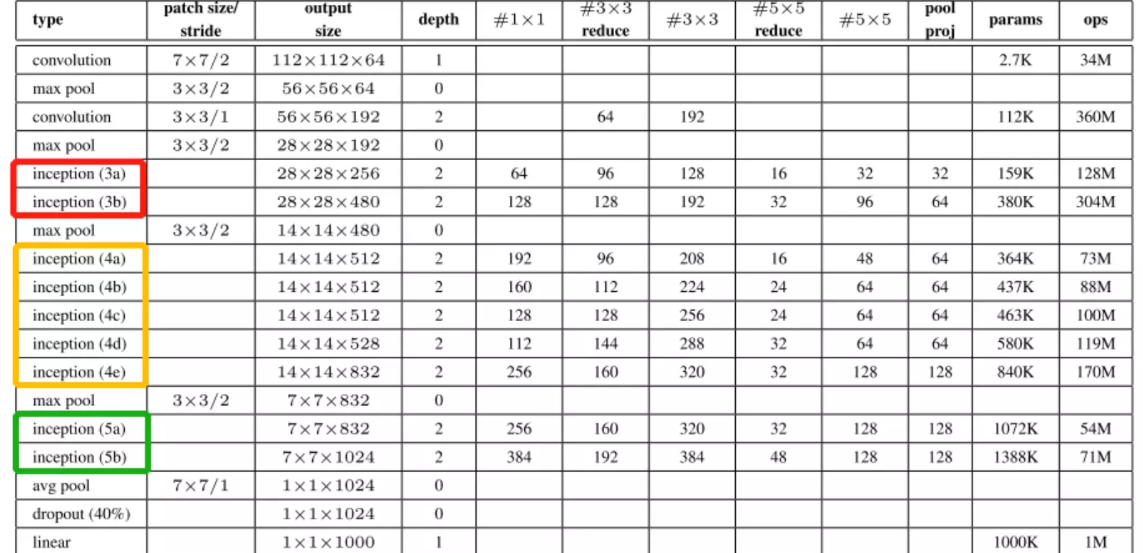
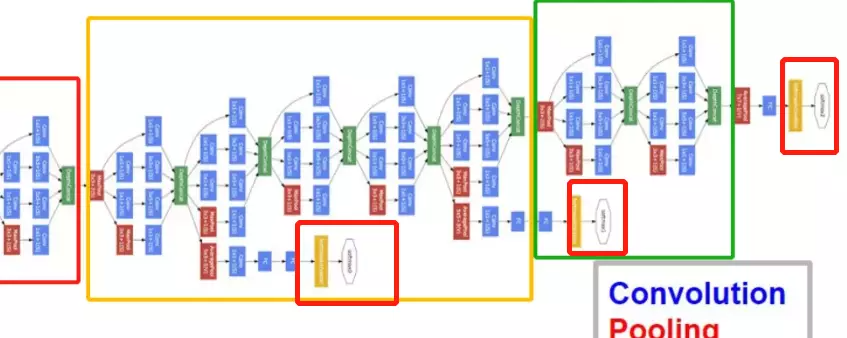
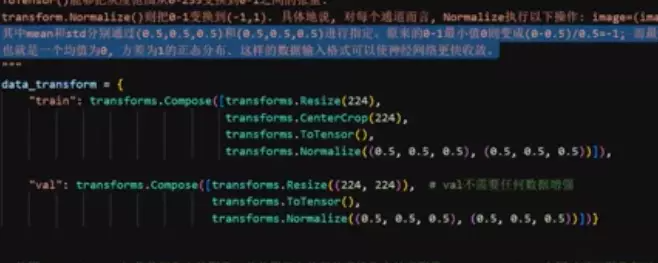
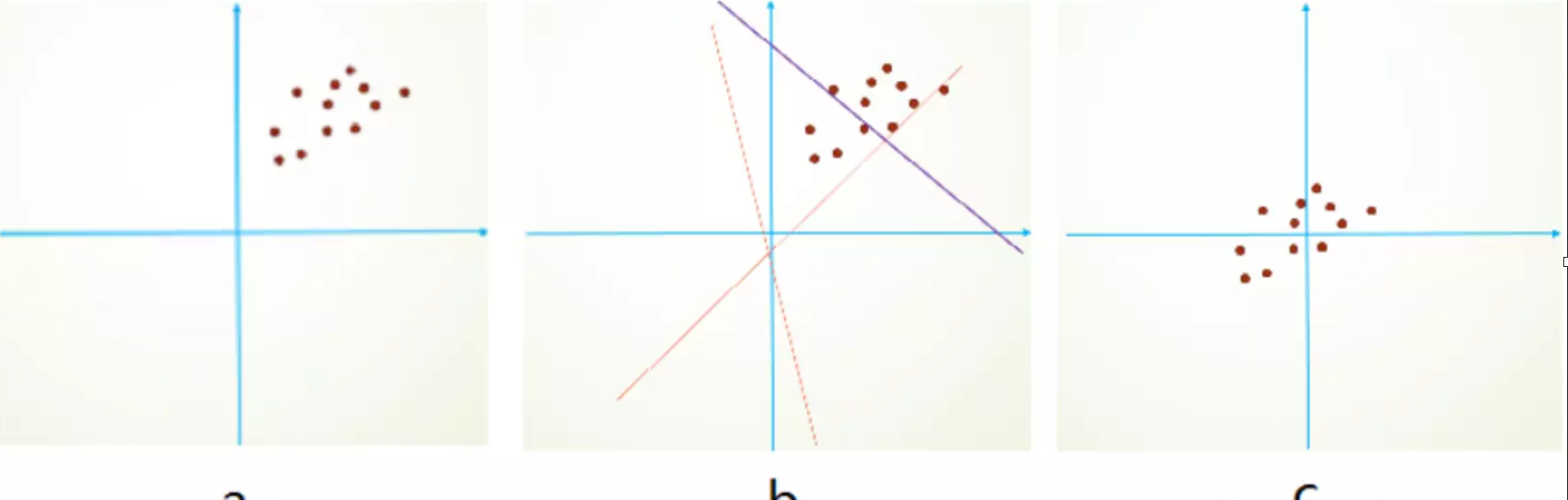


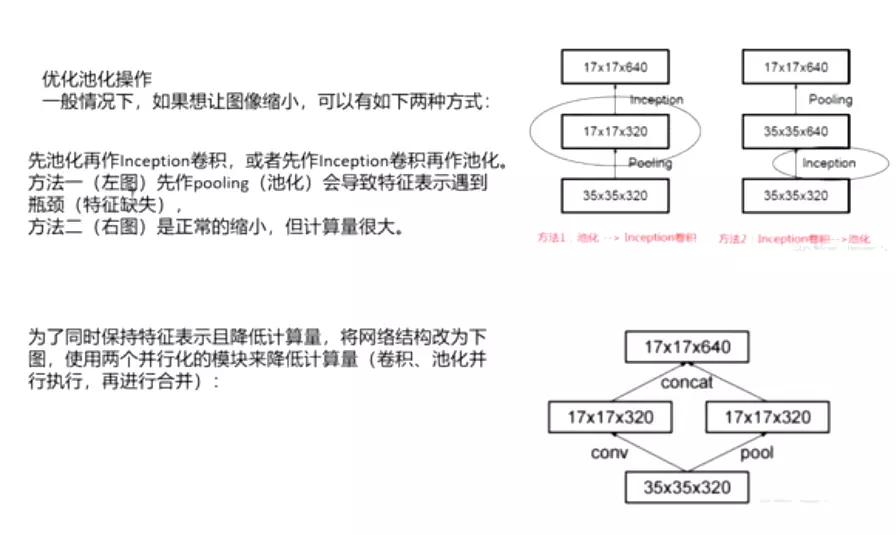
 #例如1是蒲公英,但是0.9我也希望是蒲公英,不要一个数字,而是一个标签的抖动范围。这样做也能提升网络精度。
#例如1是蒲公英,但是0.9我也希望是蒲公英,不要一个数字,而是一个标签的抖动范围。这样做也能提升网络精度。 2就是去掉了。
2就是去掉了。




 小李子的一个台词,
小李子的一个台词,
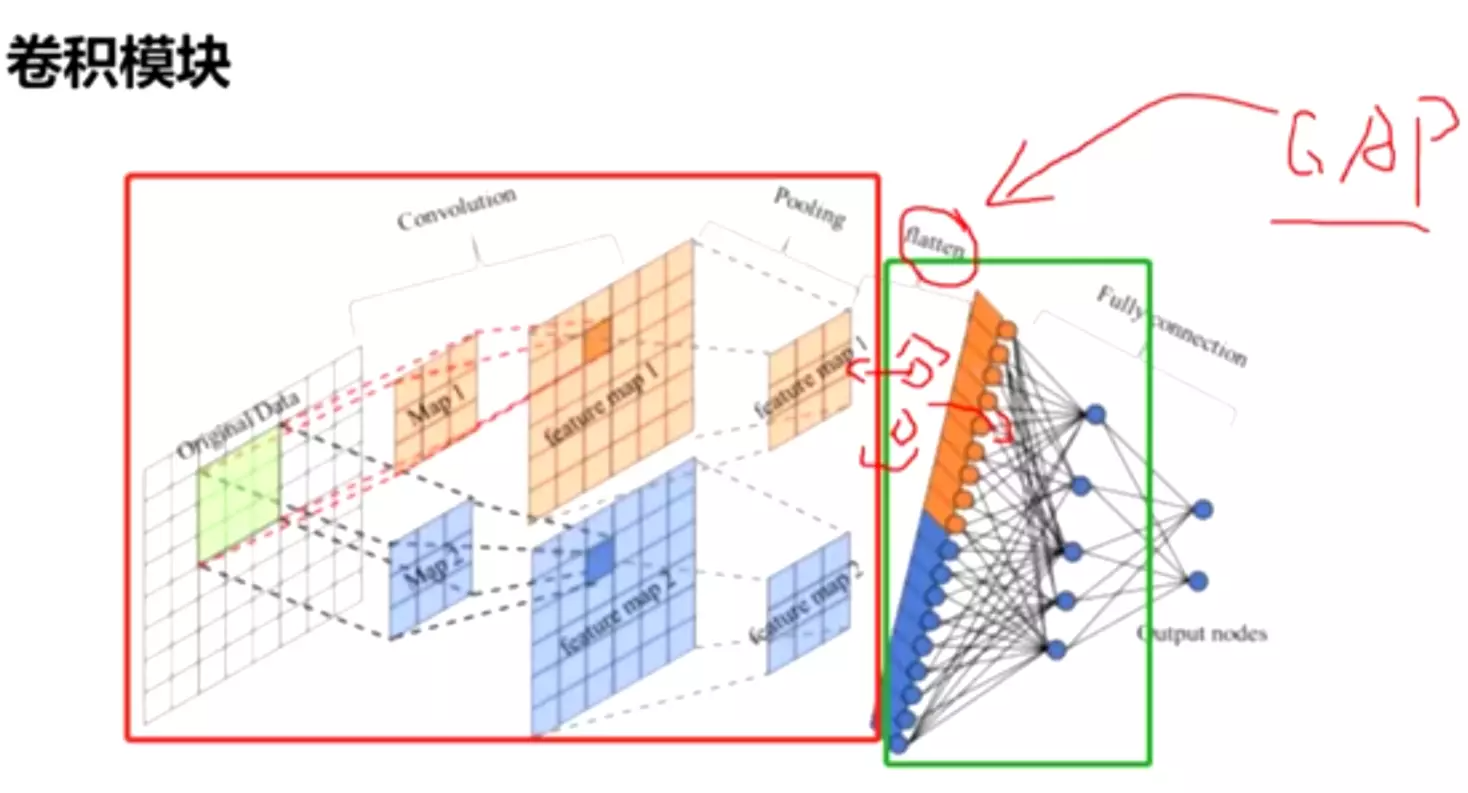

 我们可以提升网络的深度(网络的层数)和宽度(每一次操作的产物——得到的featuremap更多),宽度就是1*1的卷积核。通过卷积核提升宽度的方式是比较安全和高效的。尤其是有大量带标注的数据时。但是有两个缺点:1)比较大的尺寸会提升非常多的参数,引起过拟合,尤其是训练数据集不够多的时候;而获得更大的数据集是比较贵的。比如ImageNet里面得有些图是人类的专家才能区分的。例如两个犬:
我们可以提升网络的深度(网络的层数)和宽度(每一次操作的产物——得到的featuremap更多),宽度就是1*1的卷积核。通过卷积核提升宽度的方式是比较安全和高效的。尤其是有大量带标注的数据时。但是有两个缺点:1)比较大的尺寸会提升非常多的参数,引起过拟合,尤其是训练数据集不够多的时候;而获得更大的数据集是比较贵的。比如ImageNet里面得有些图是人类的专家才能区分的。例如两个犬: 正常人类是很难区分的——大数据集并不是很好收集的。
正常人类是很难区分的——大数据集并不是很好收集的。

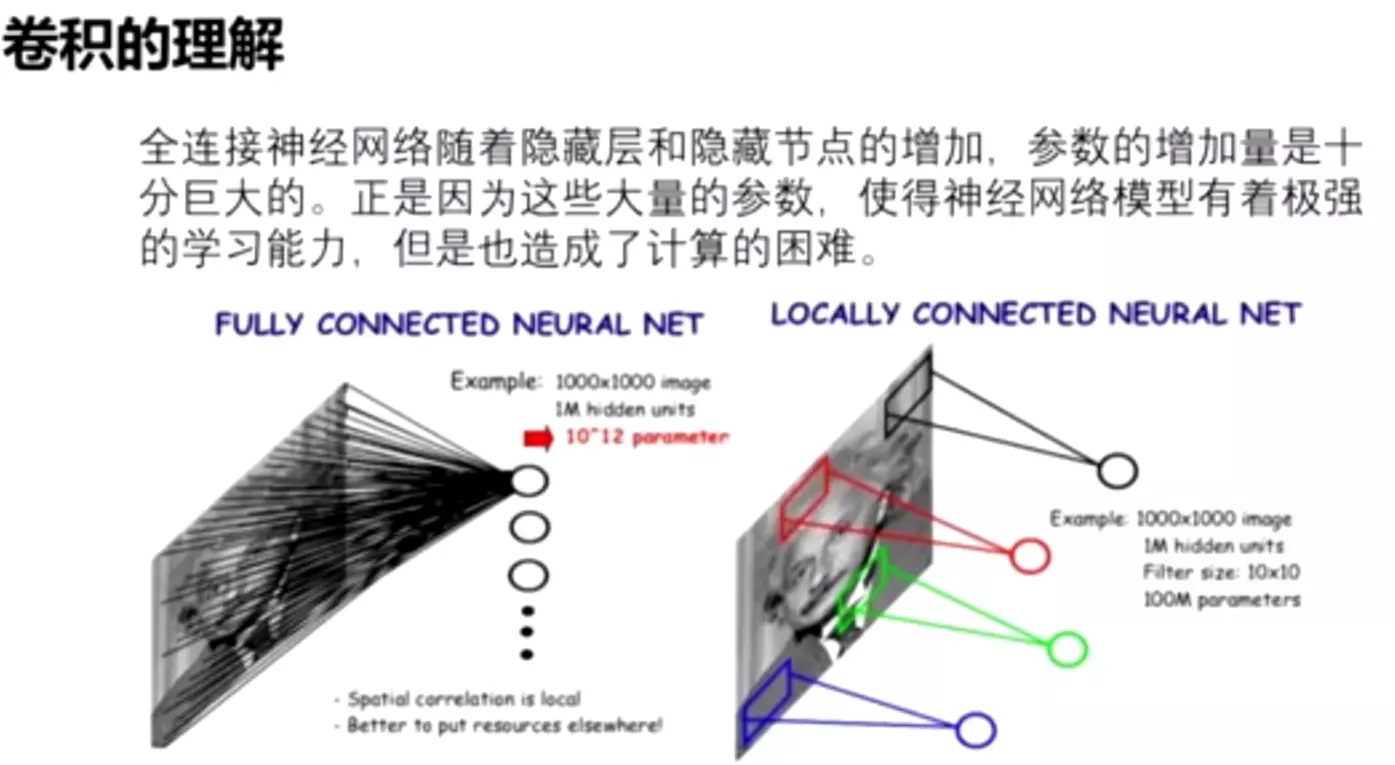

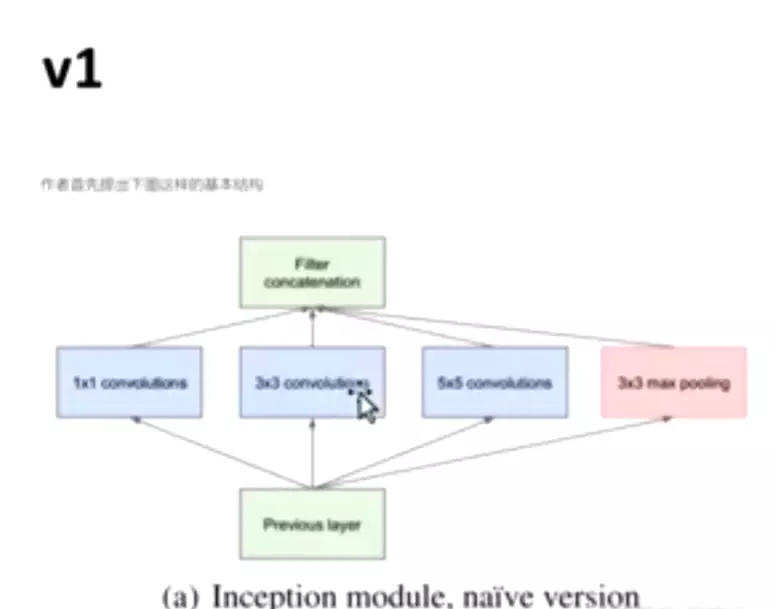
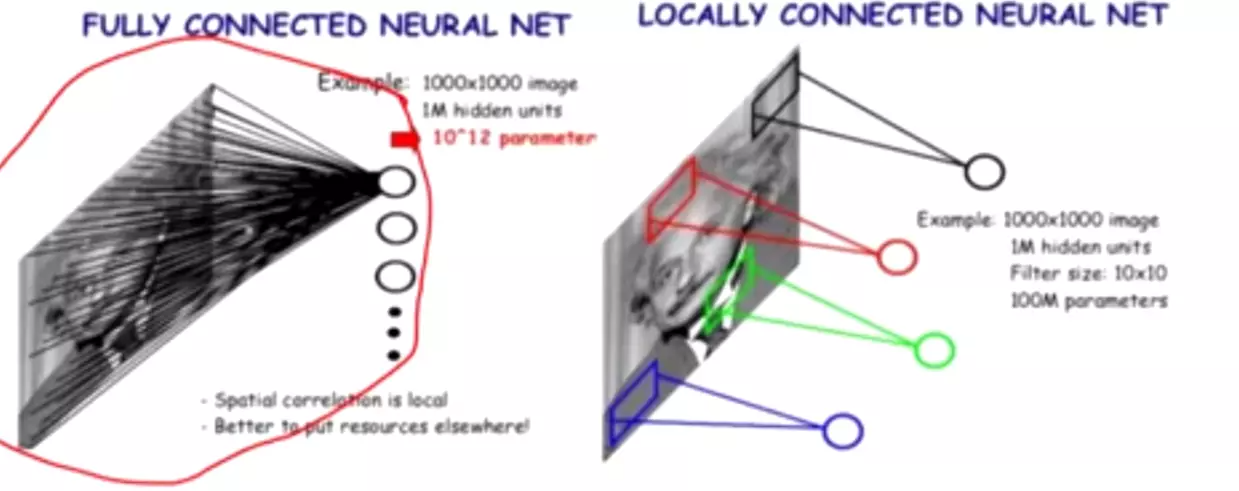
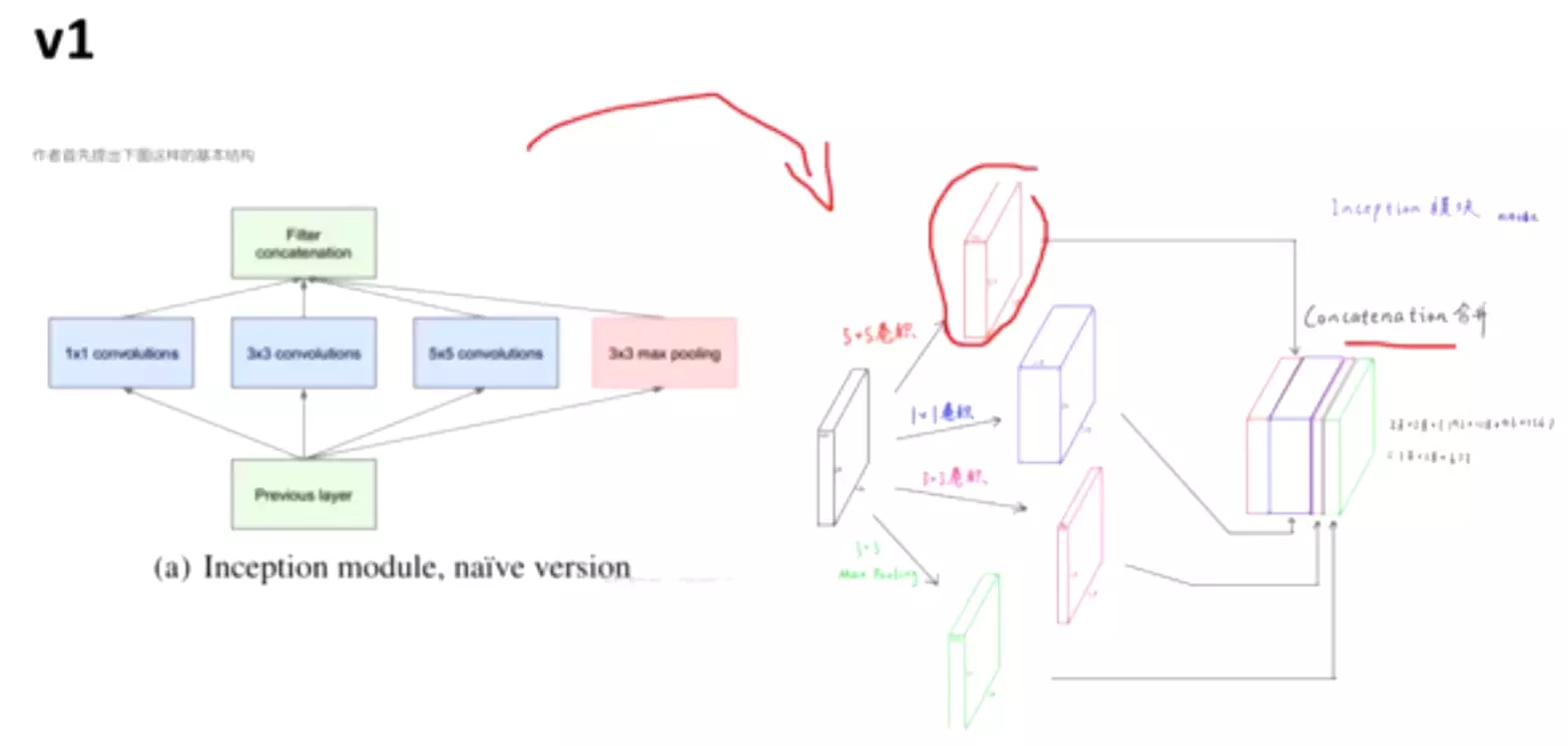

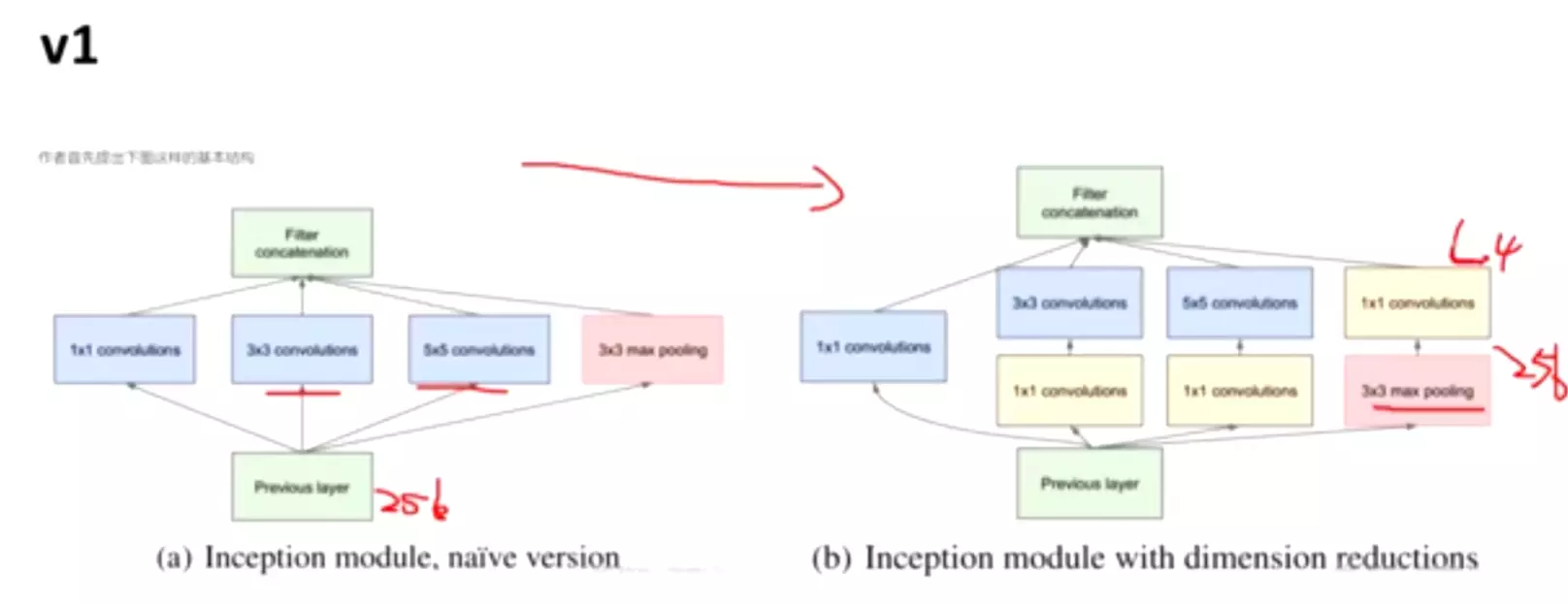
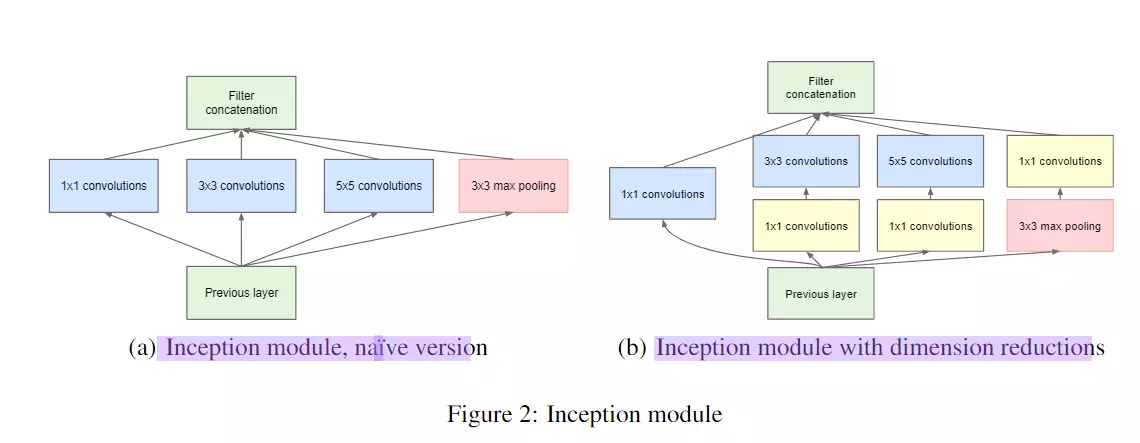

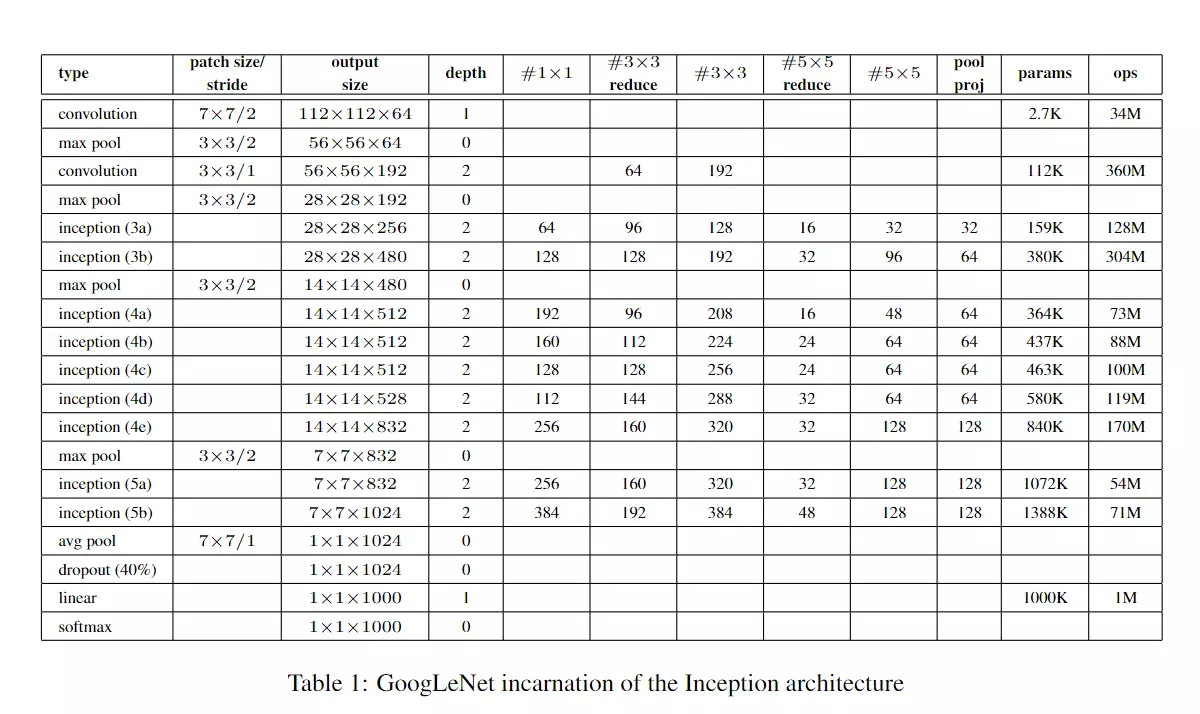


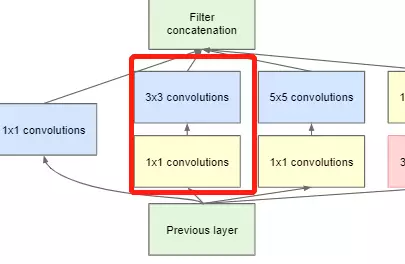



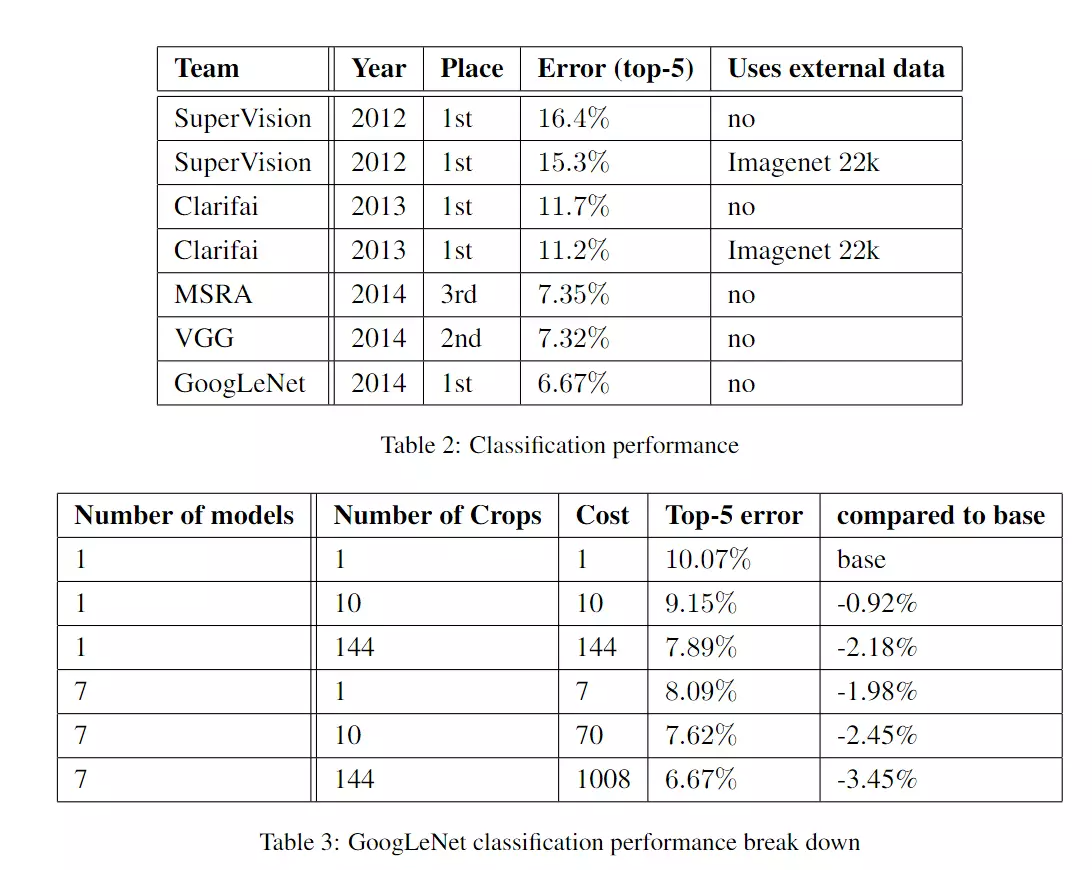

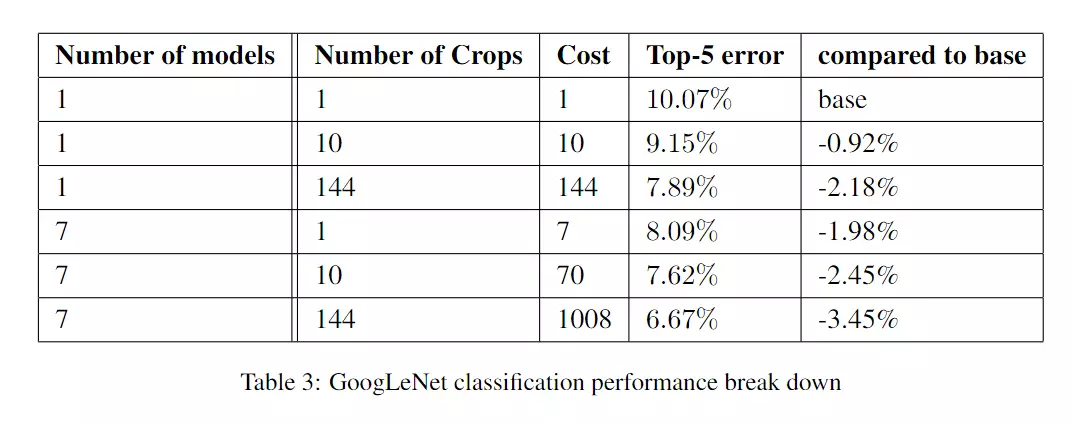


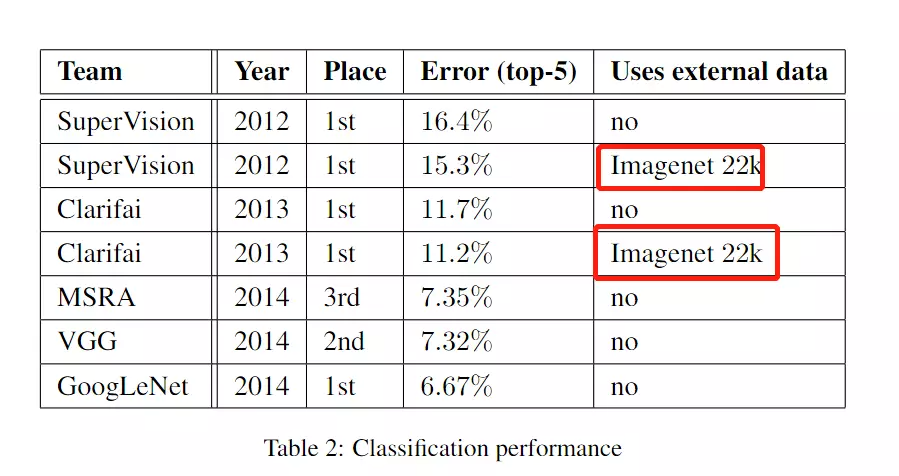


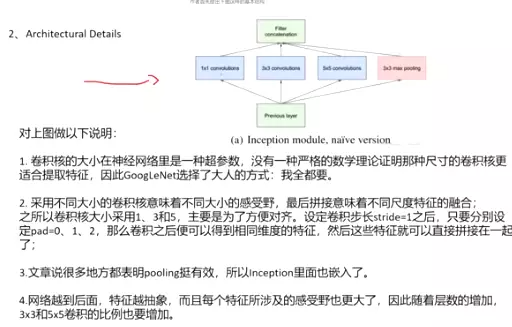
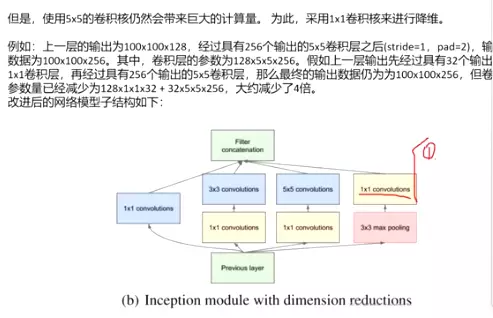
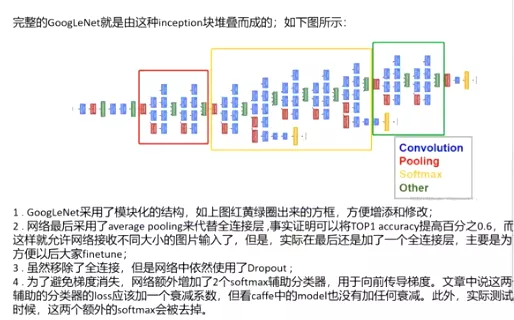
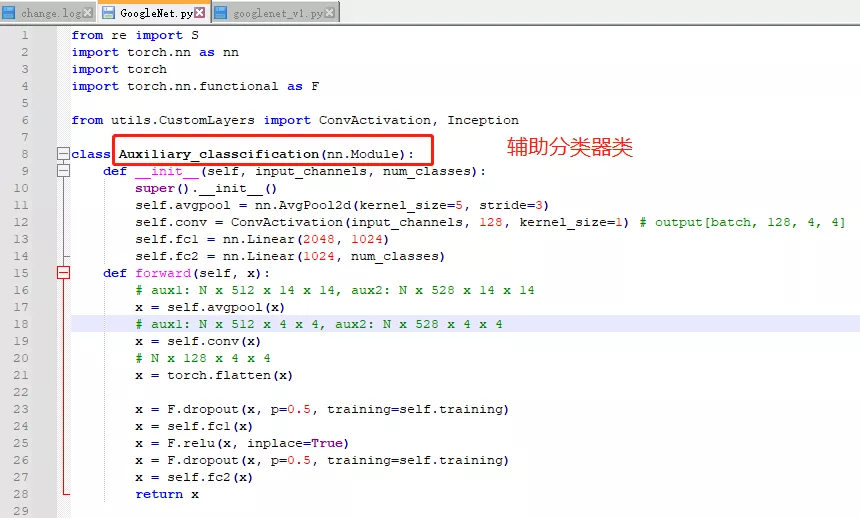
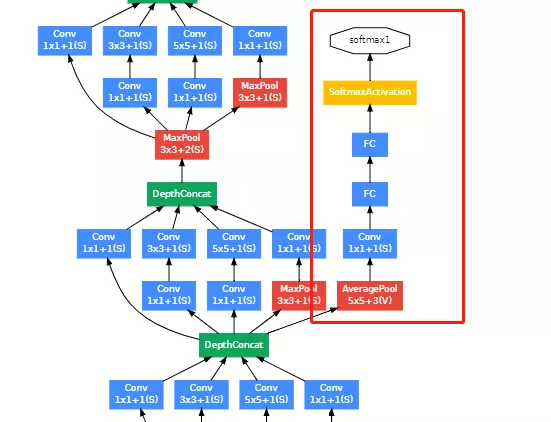 辅助分类器的结果:首先是一个Inception得到的结果作为辅助分类器的输入,送进来后,先经过一个AveragePool平均池化,在送入一个1*1的卷积,再送入两个全连接,最后接一个softmax作为分类的函数。所以模型也这么搭。
辅助分类器的结果:首先是一个Inception得到的结果作为辅助分类器的输入,送进来后,先经过一个AveragePool平均池化,在送入一个1*1的卷积,再送入两个全连接,最后接一个softmax作为分类的函数。所以模型也这么搭。
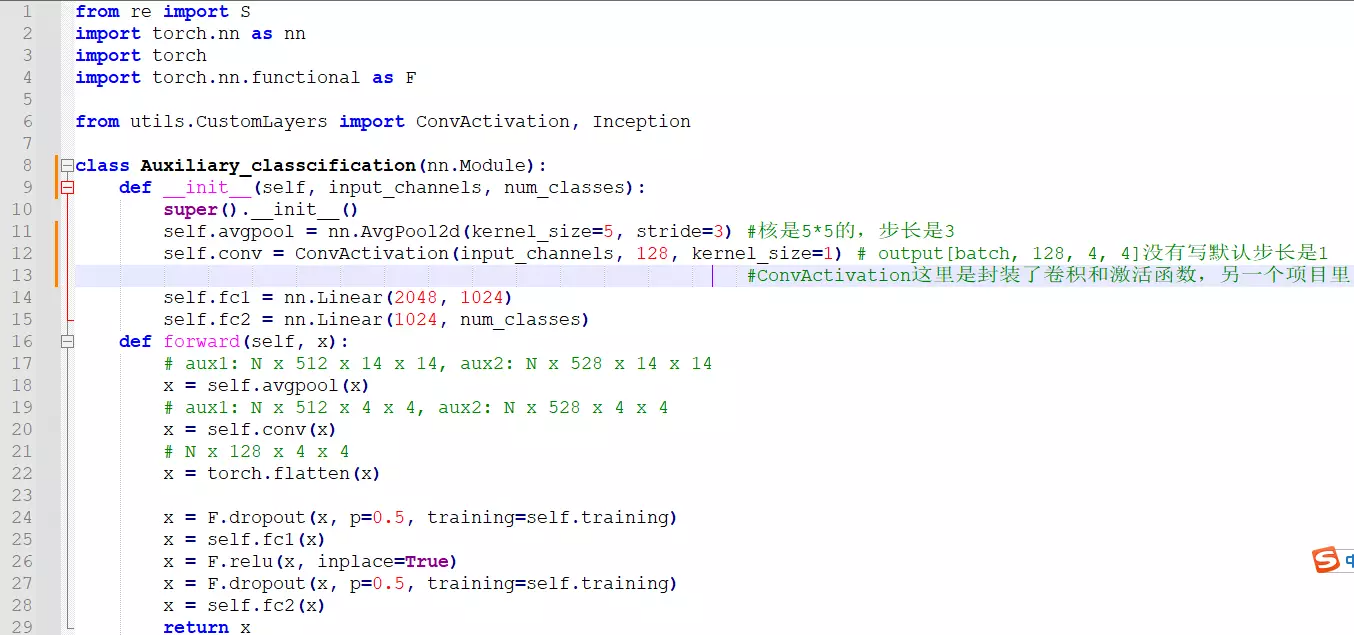
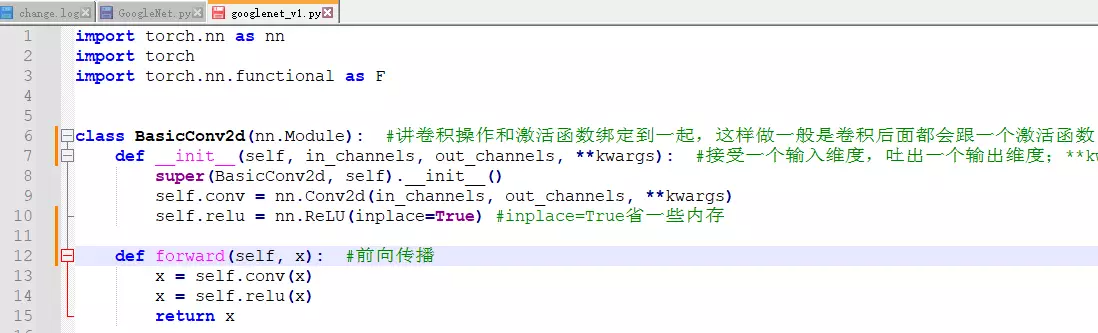
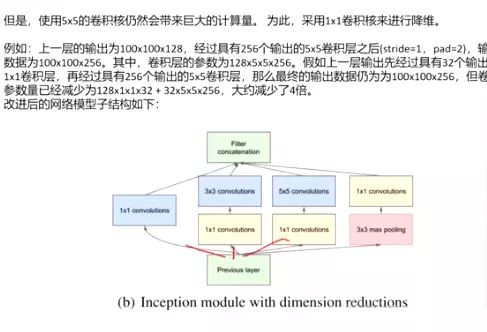 #然后就是Inception块的搭建。将4个分支当做成员送进来:第一个分支是1*1,第二个分支是1*1加3*3;第三个分支是1*1加5*5,第四个分支是3*3加1*1;
#然后就是Inception块的搭建。将4个分支当做成员送进来:第一个分支是1*1,第二个分支是1*1加3*3;第三个分支是1*1加5*5,第四个分支是3*3加1*1;


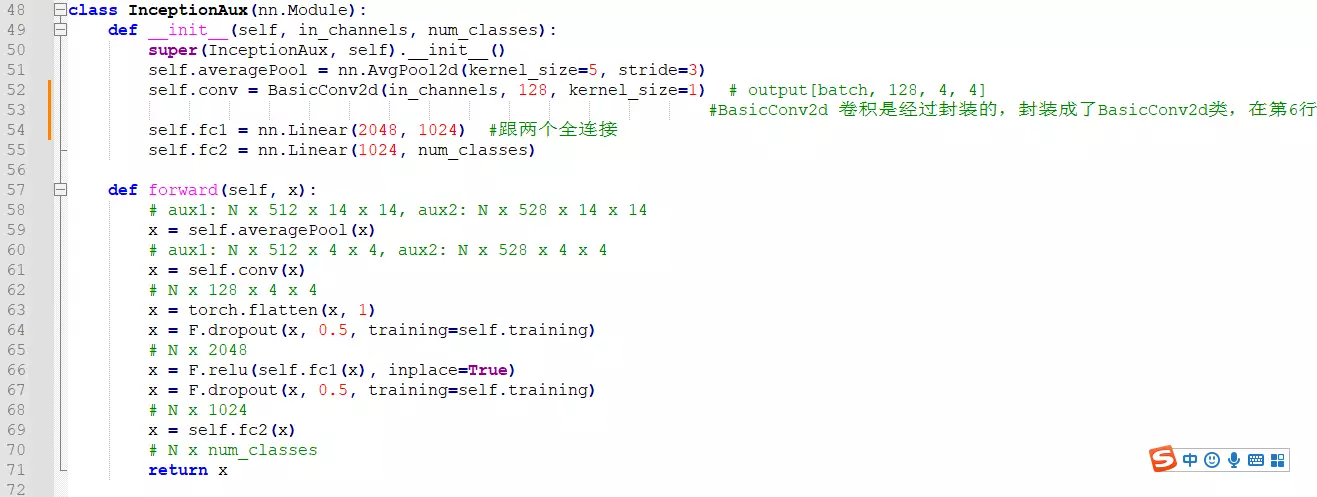


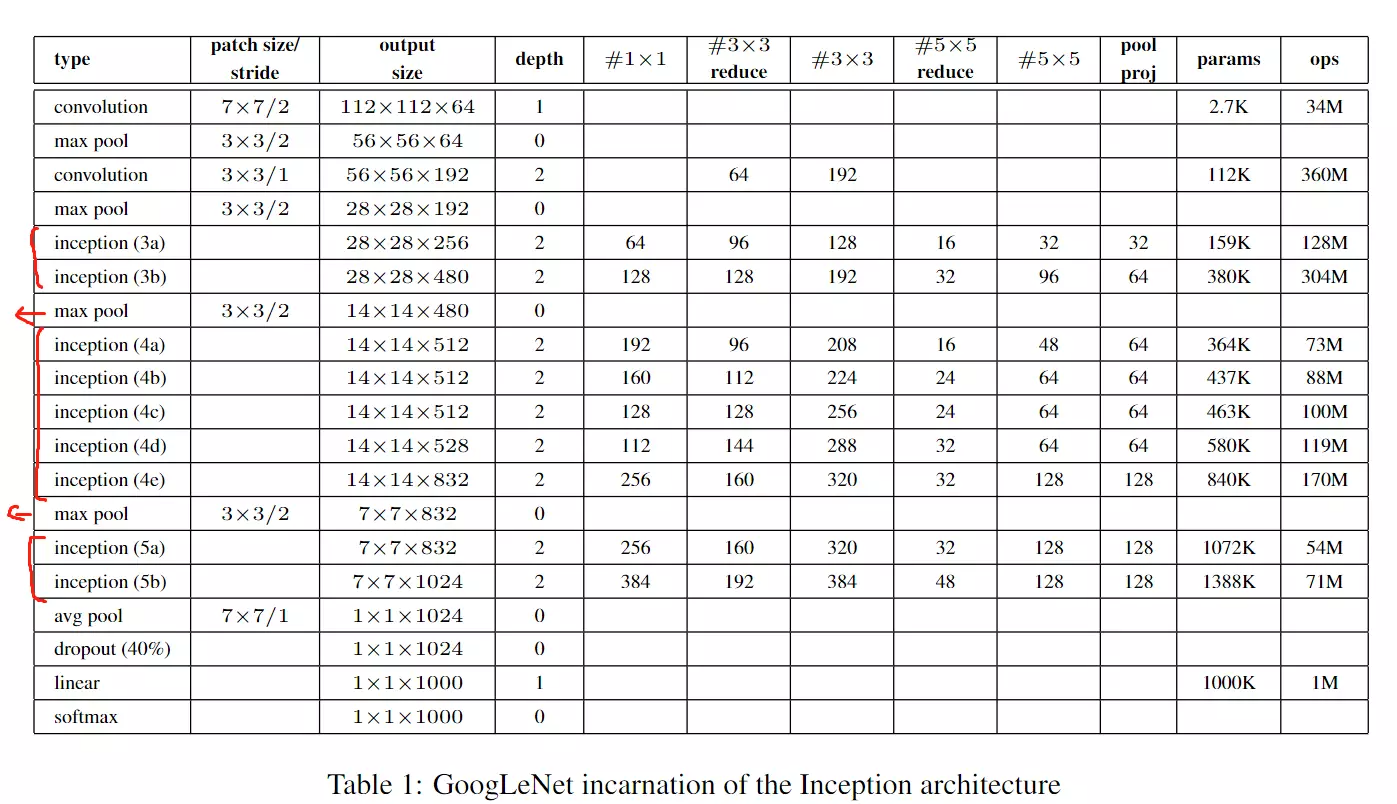
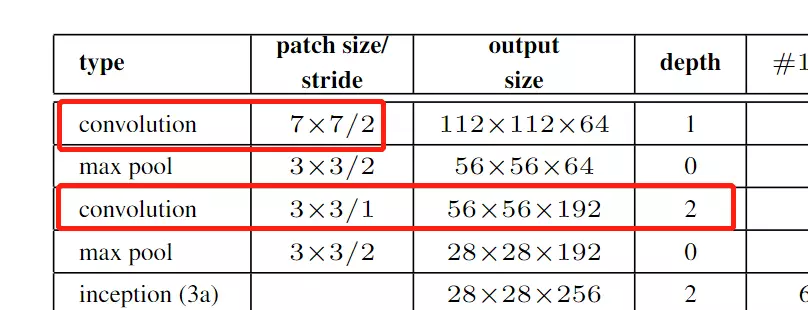

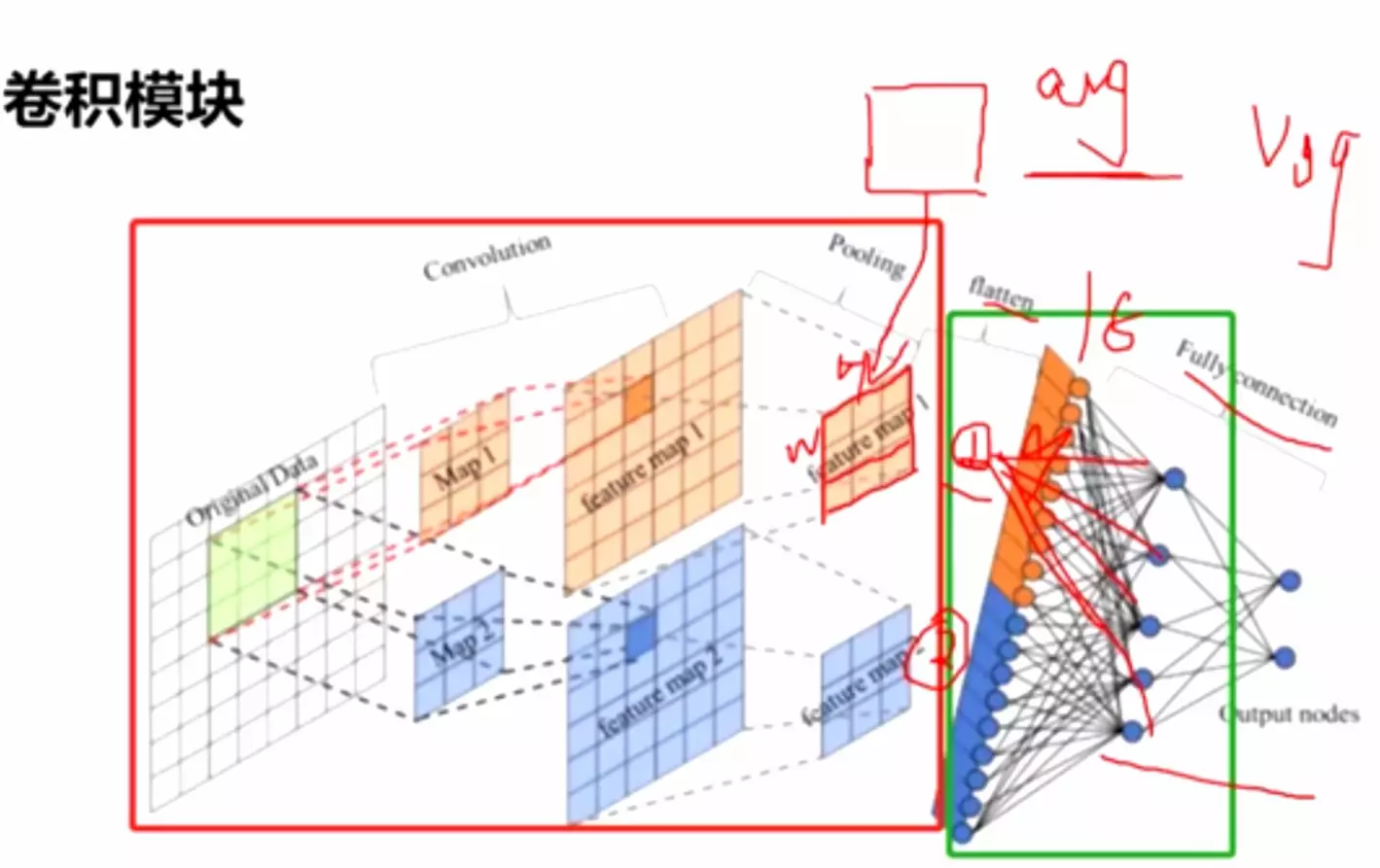


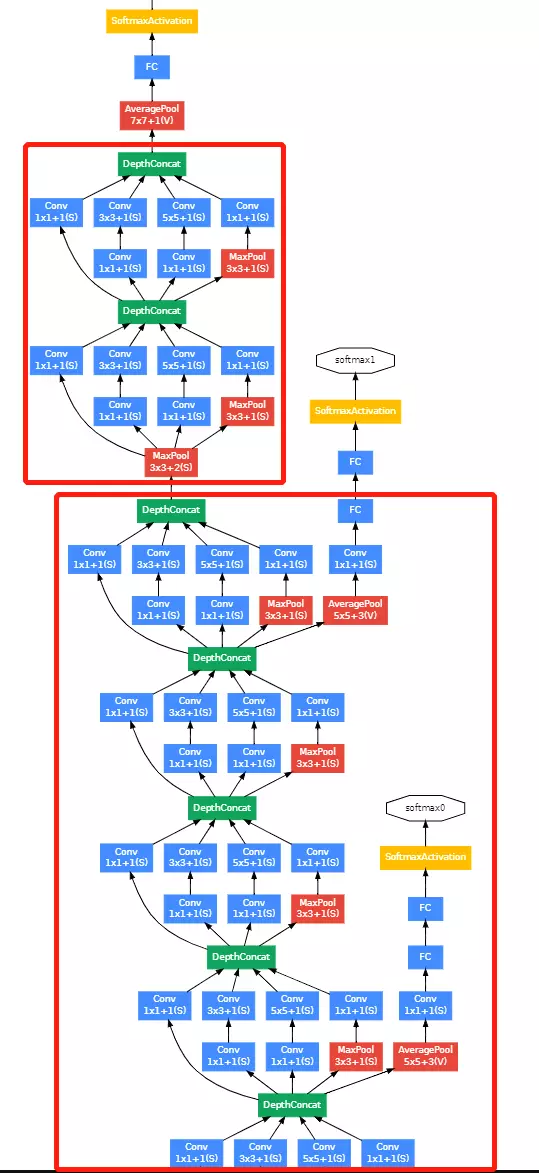
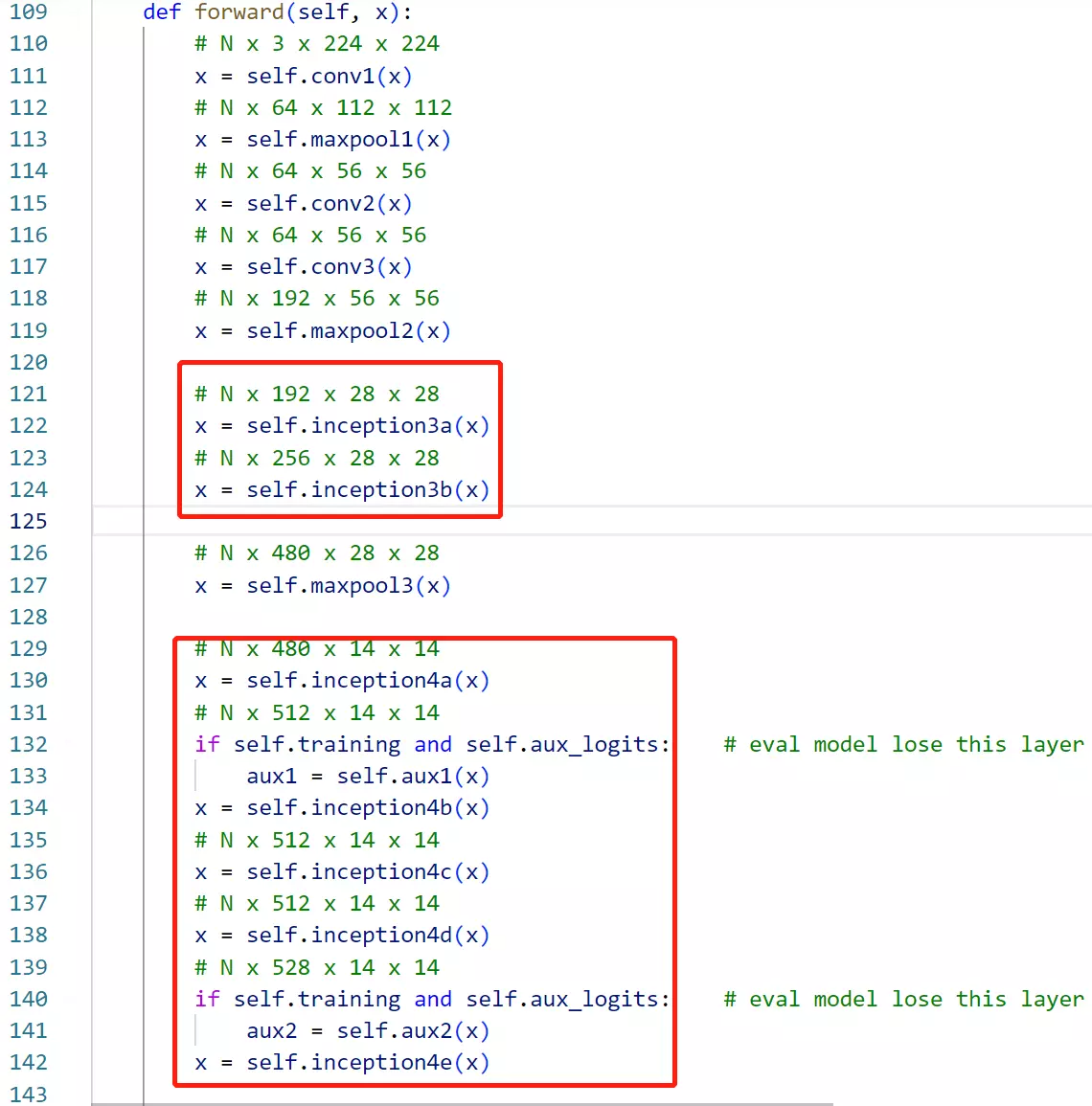


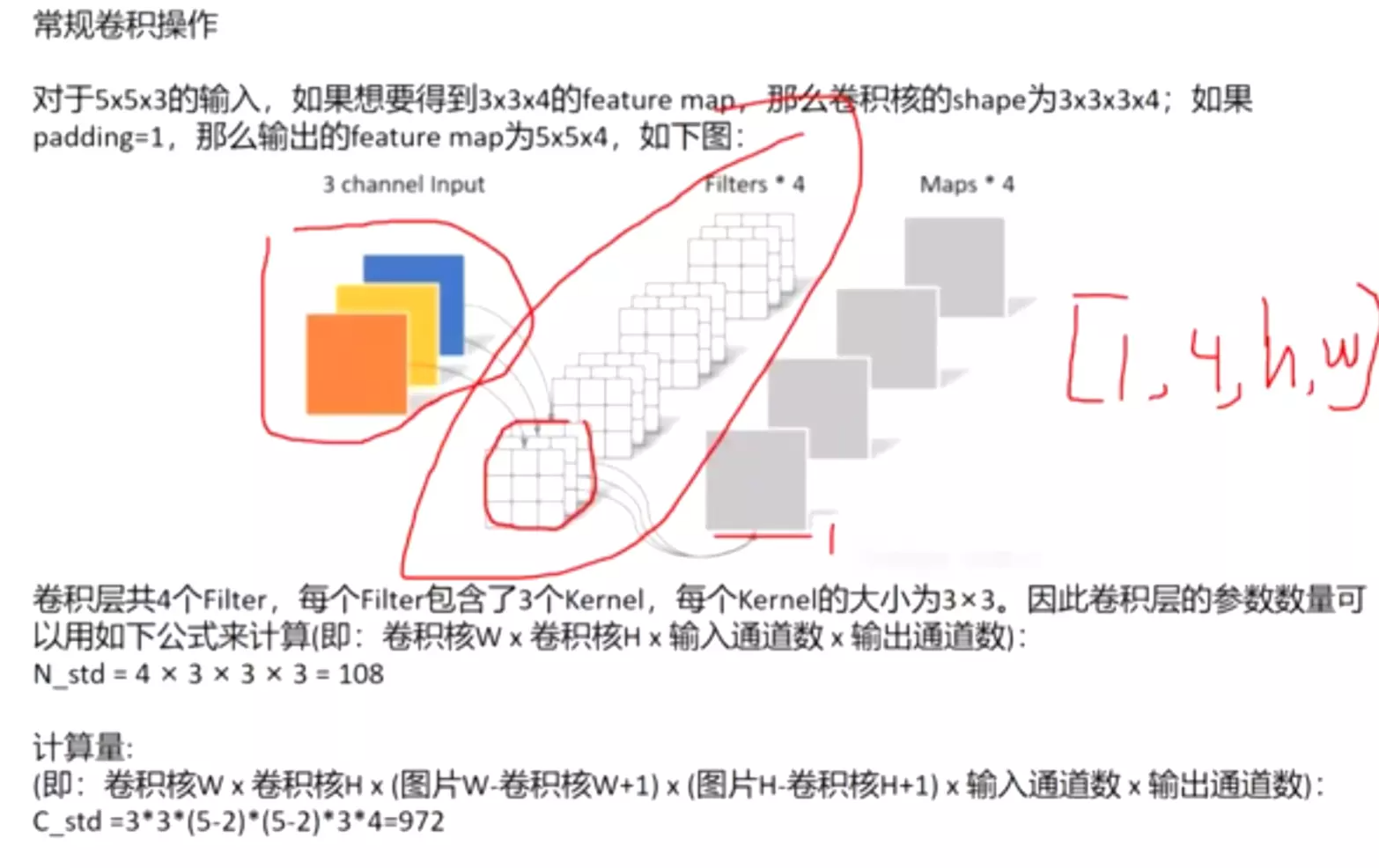

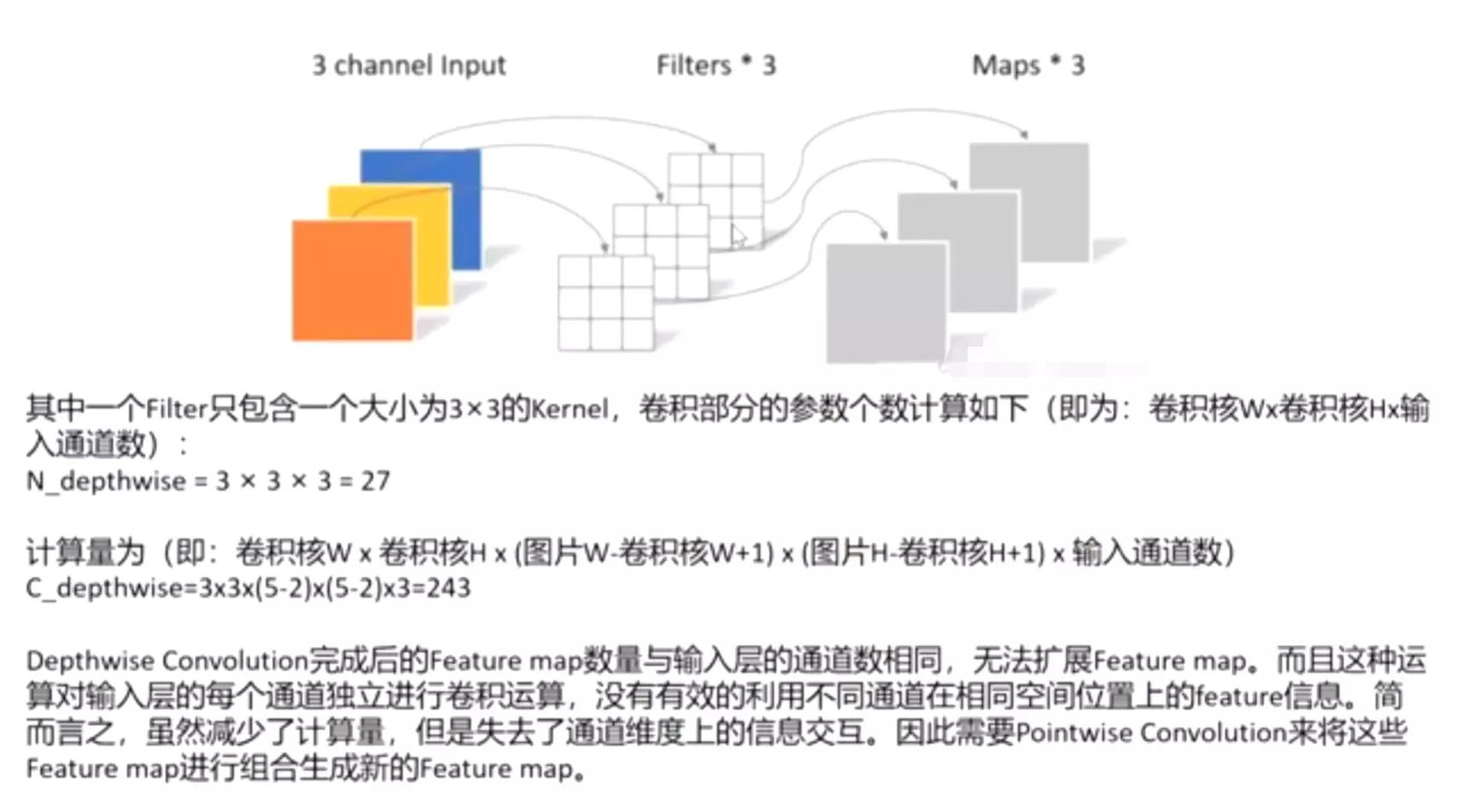
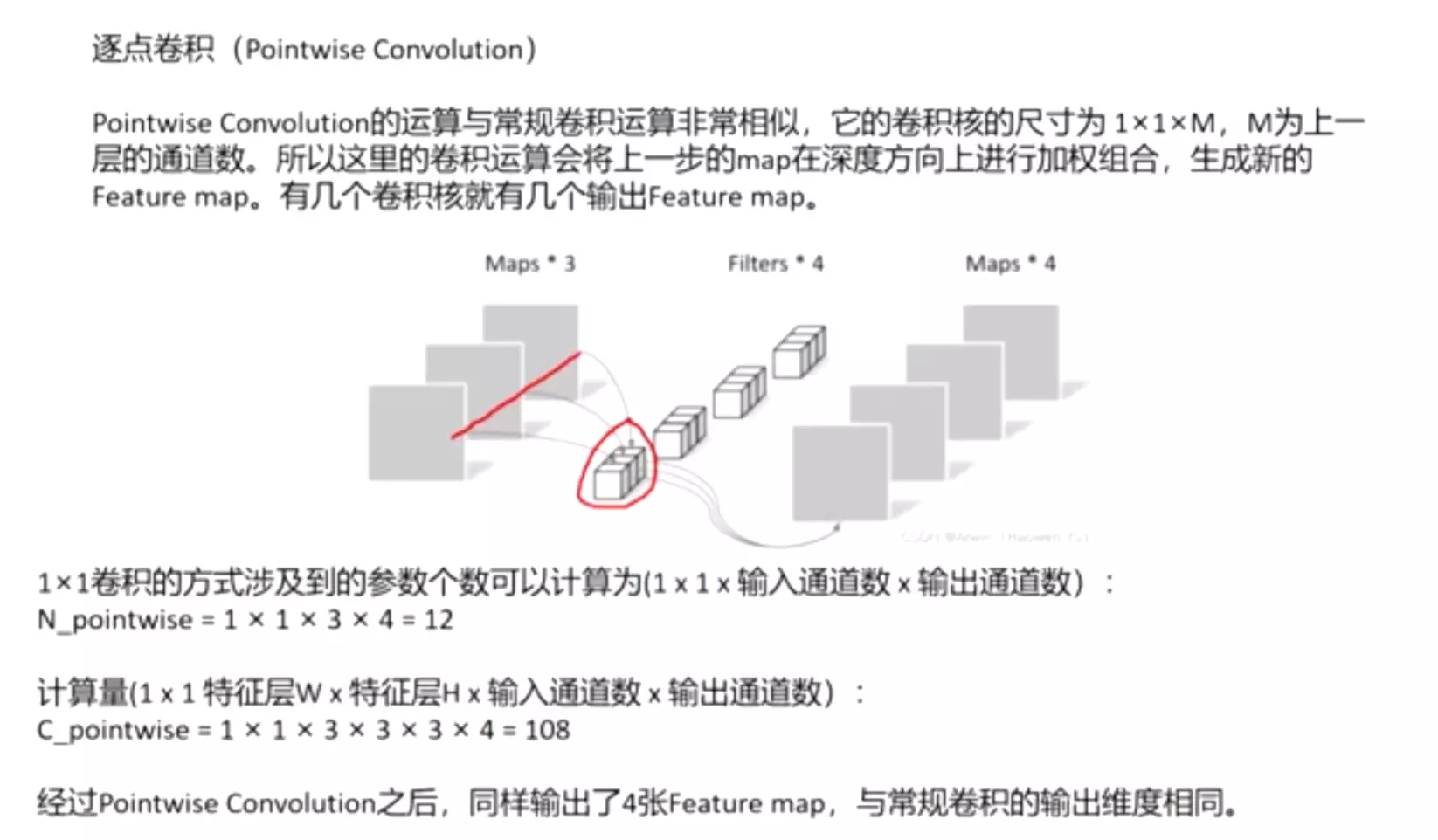


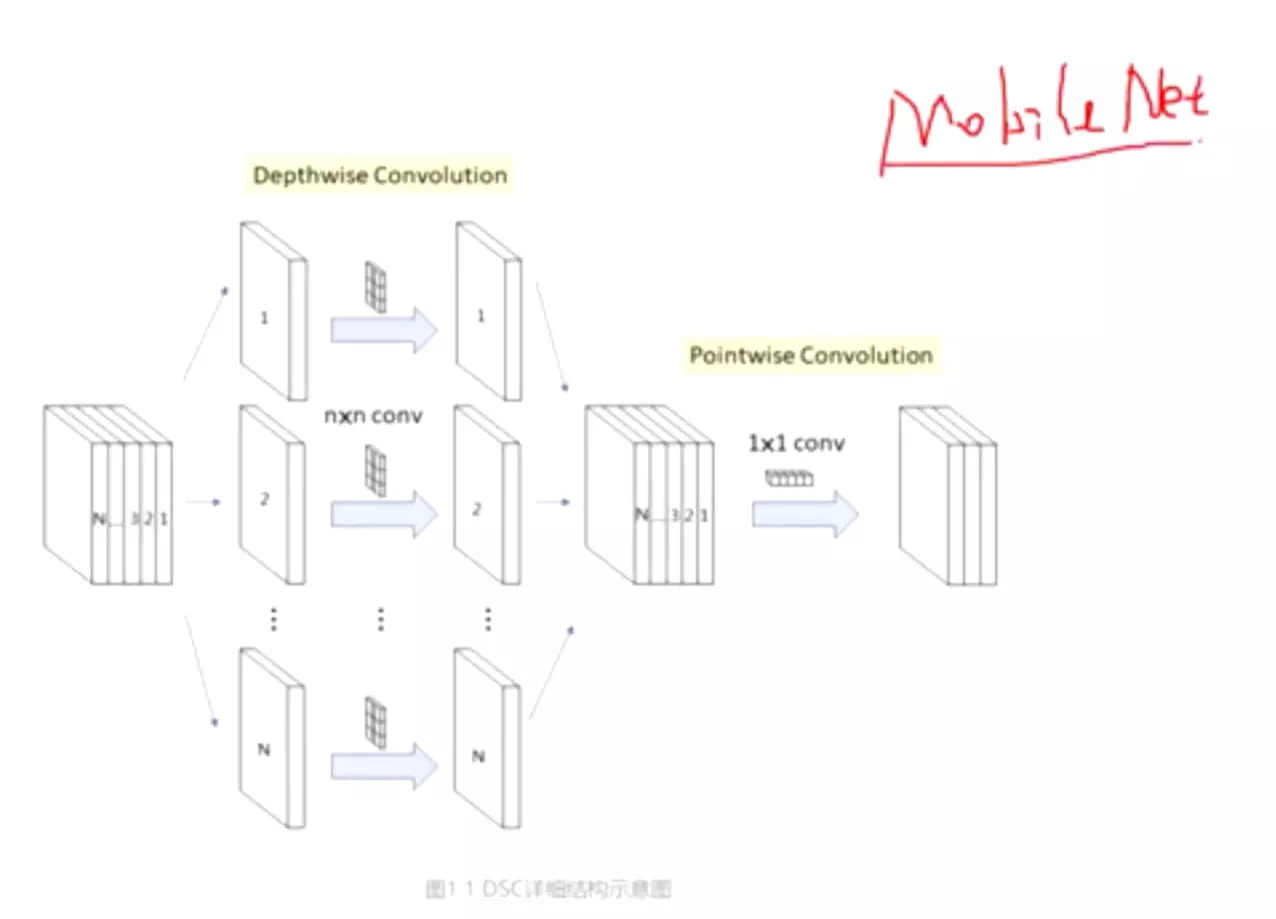

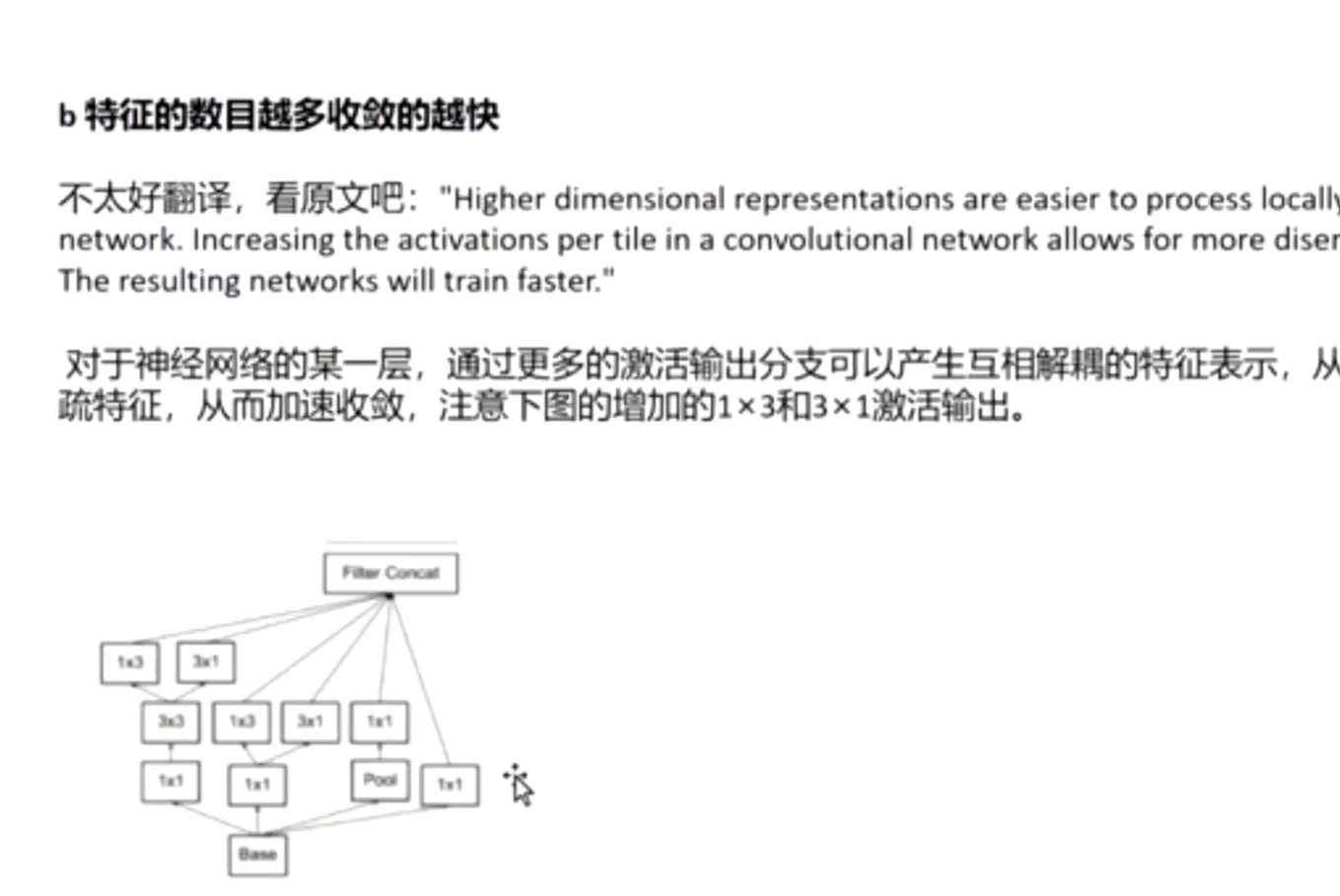

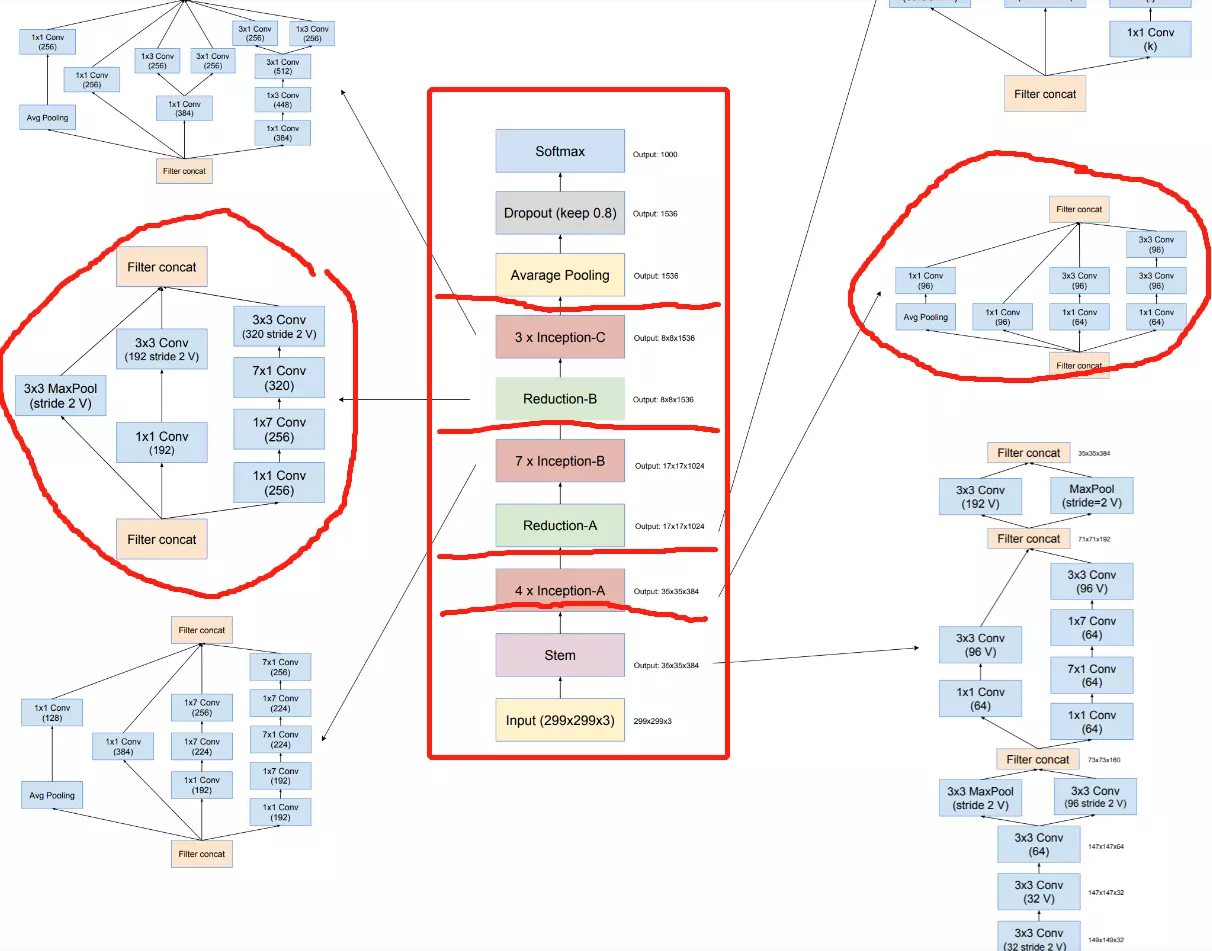
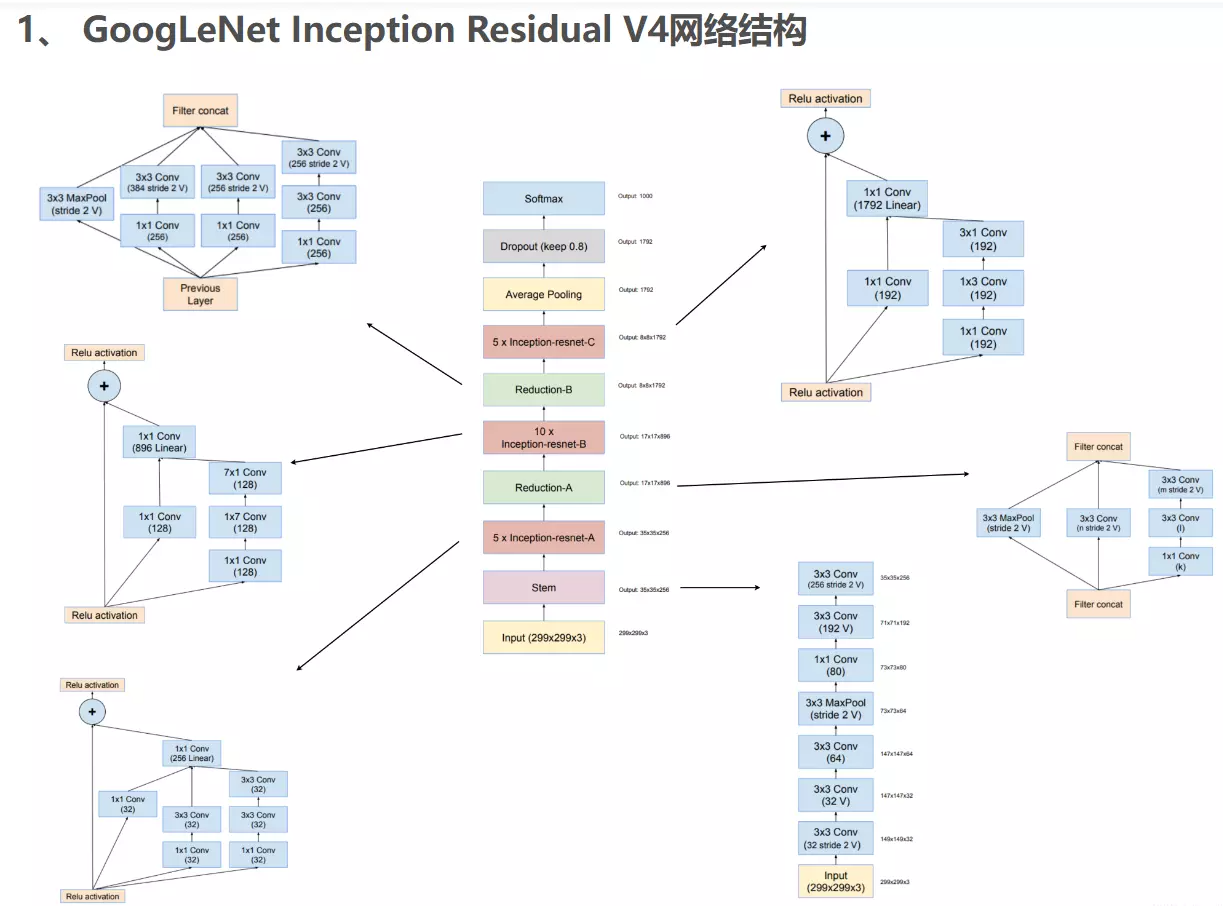
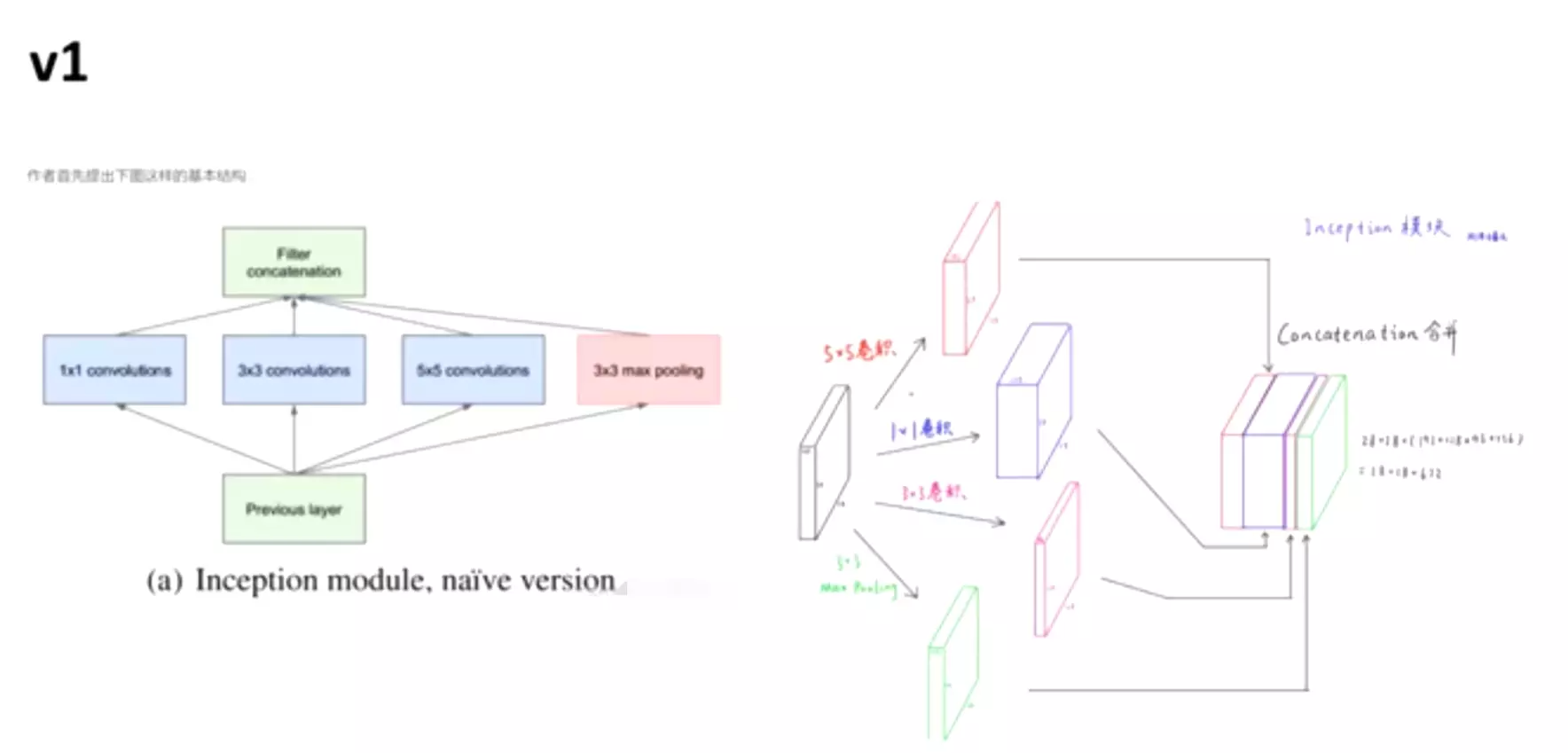
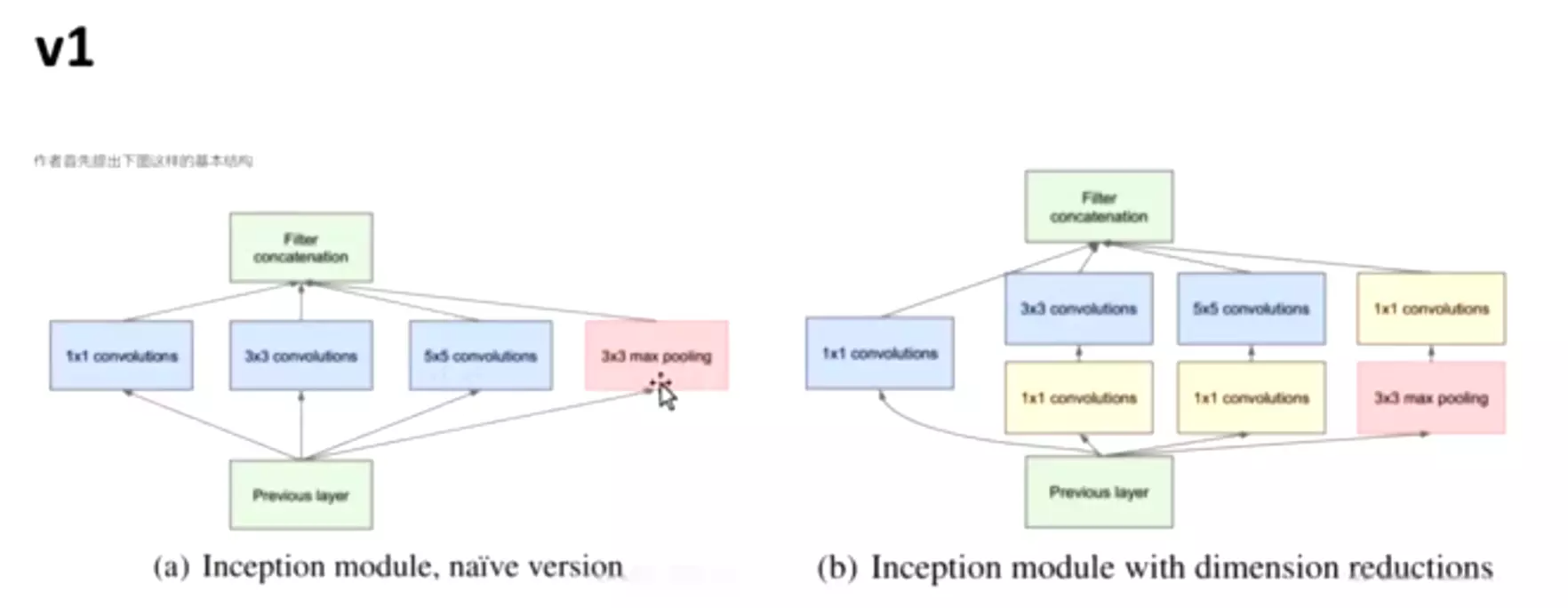
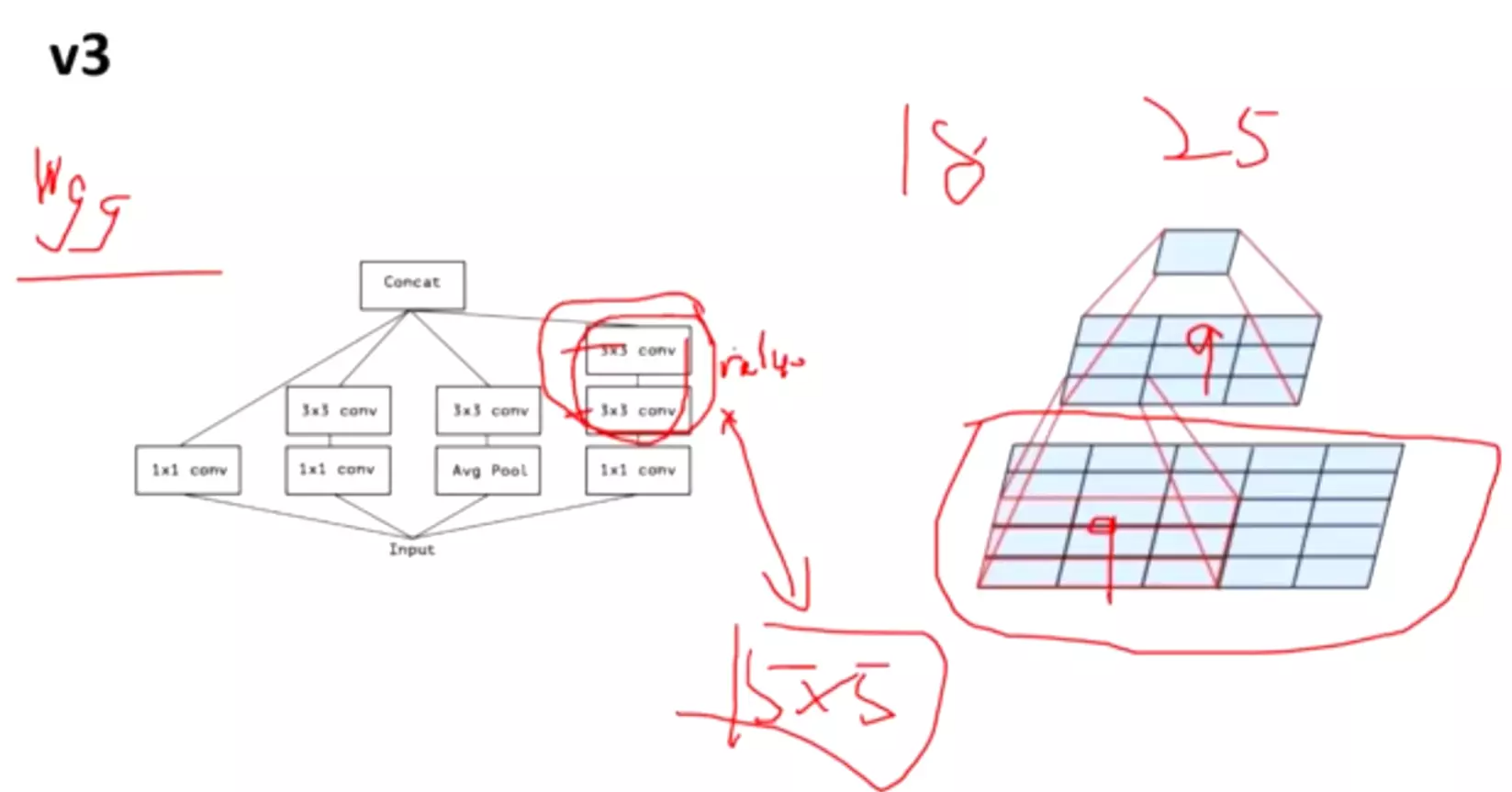
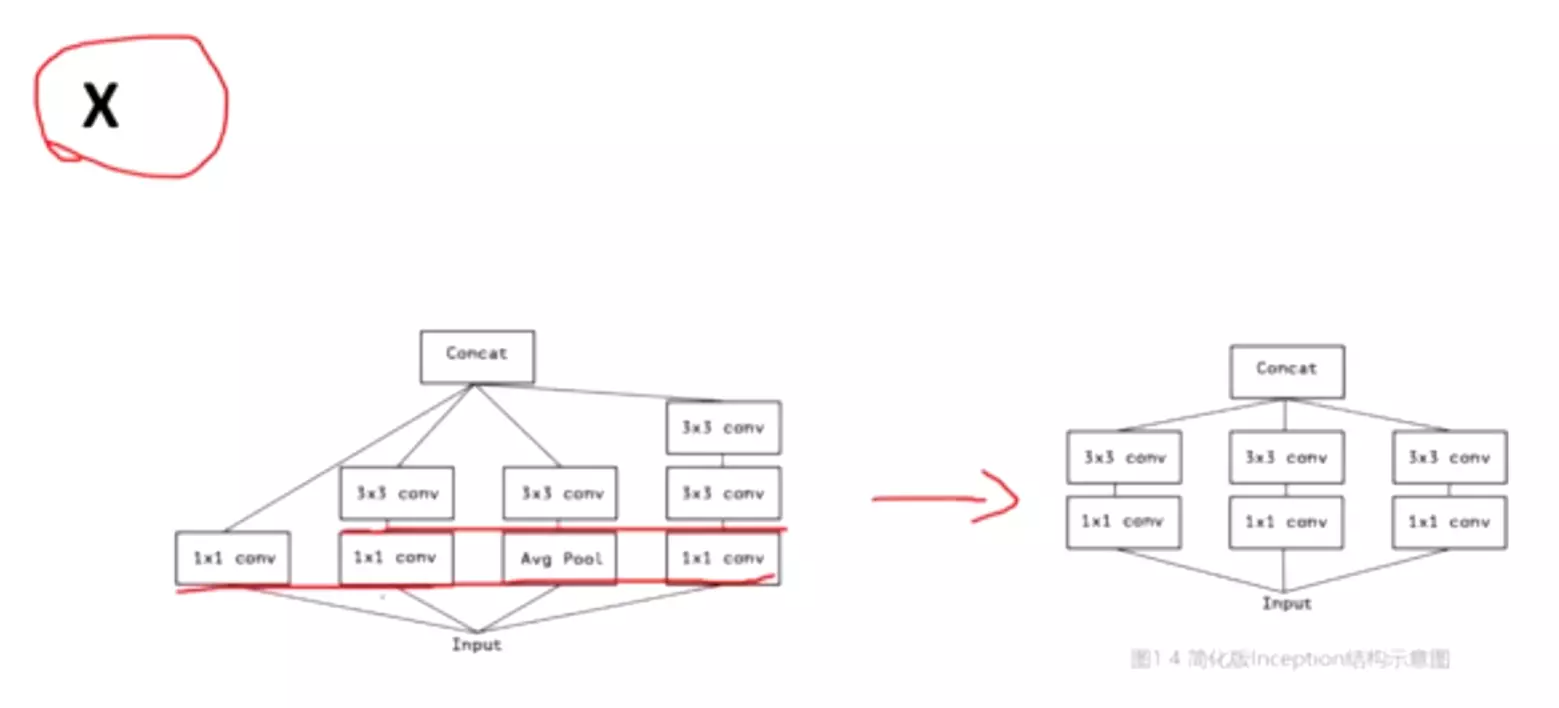
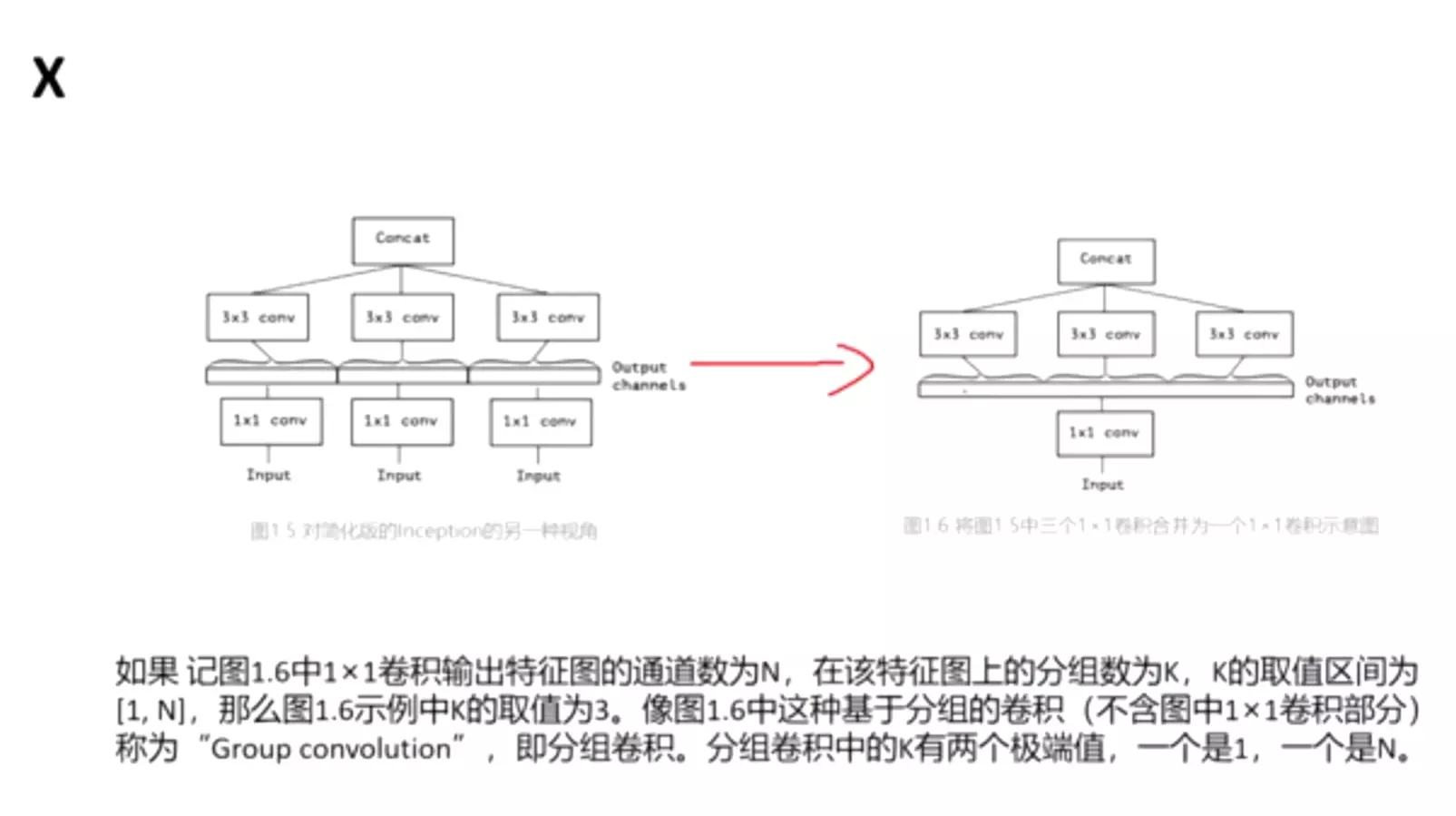
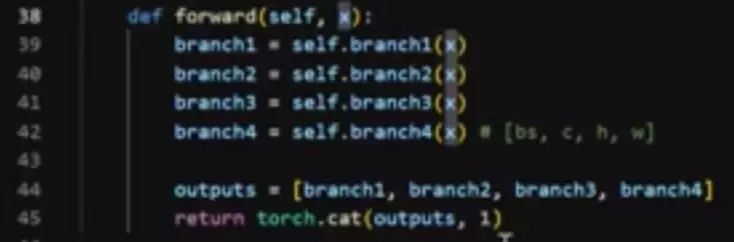
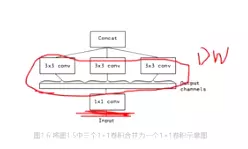
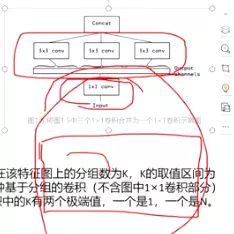
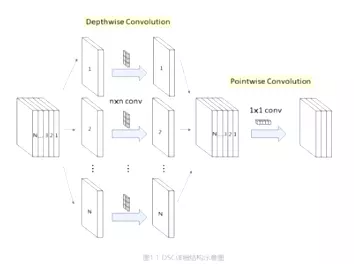
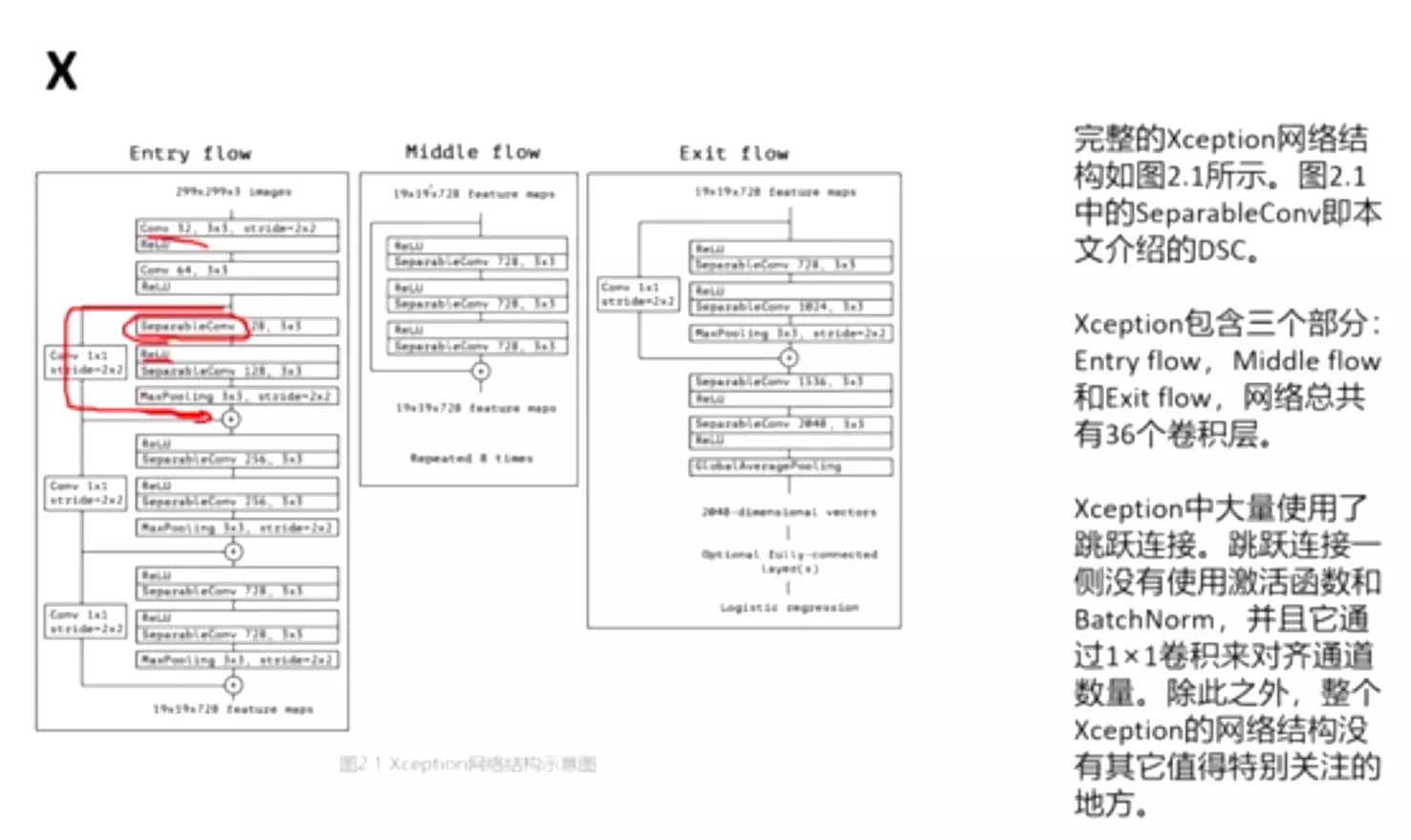

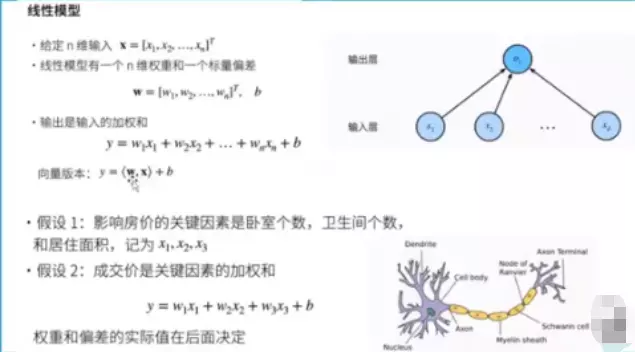

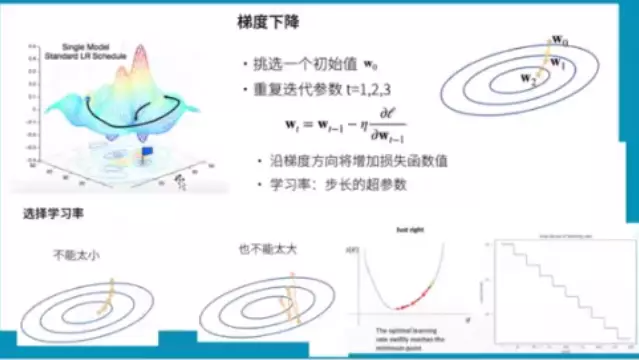


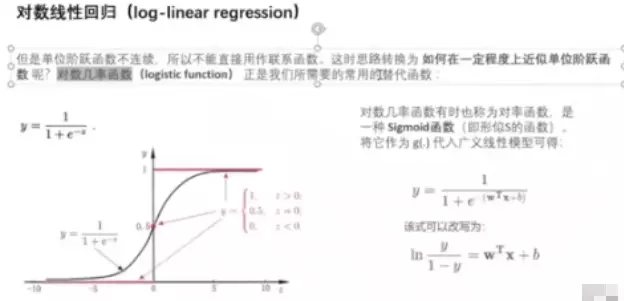

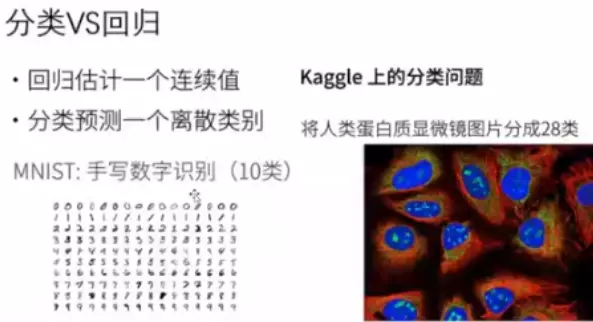
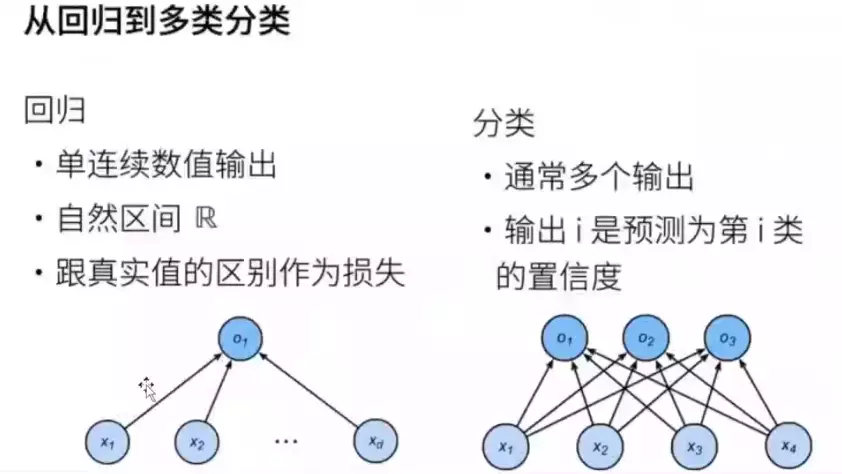

 #感知机
#感知机
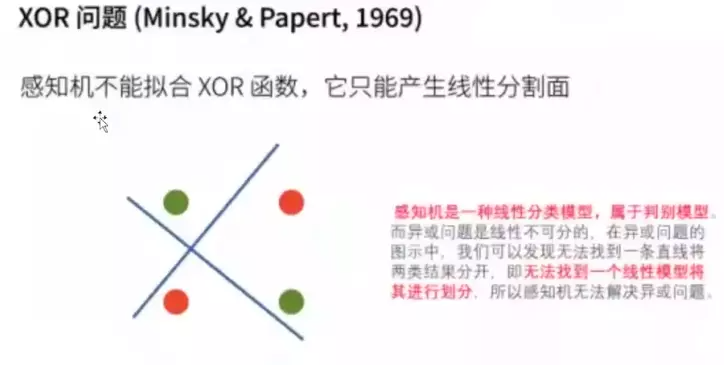
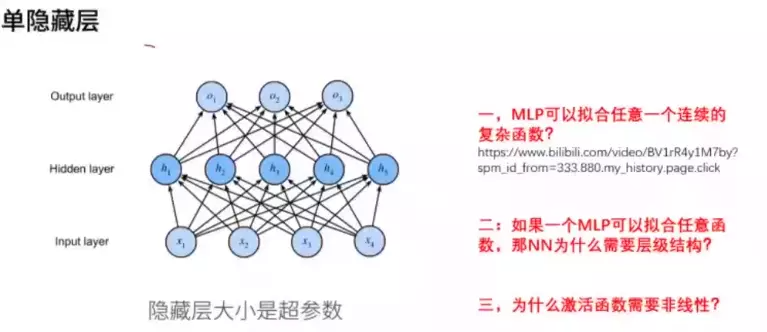
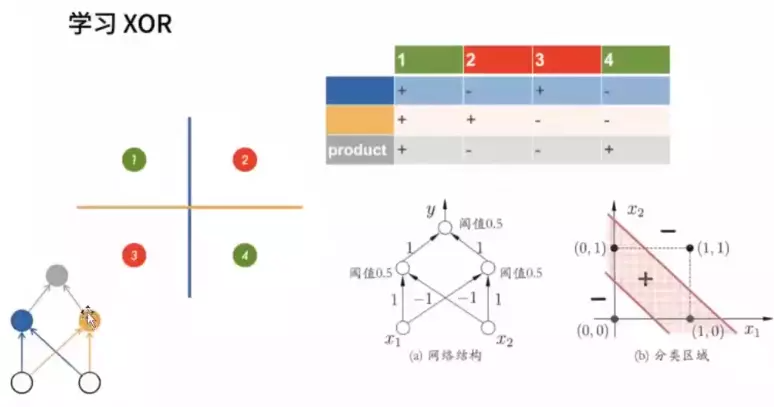

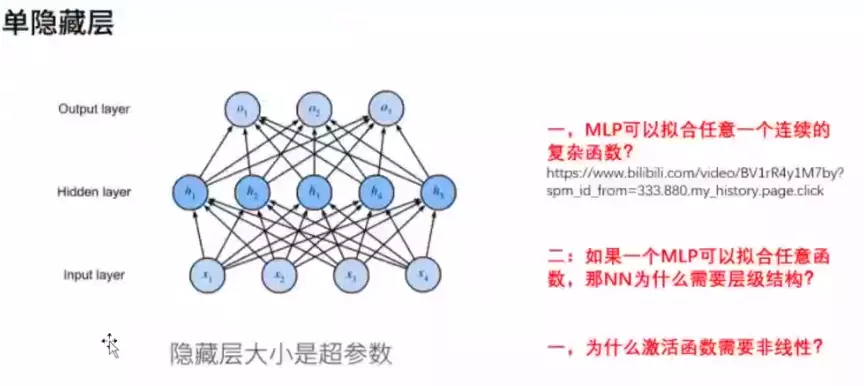
 二、可以减少维度诅咒
二、可以减少维度诅咒
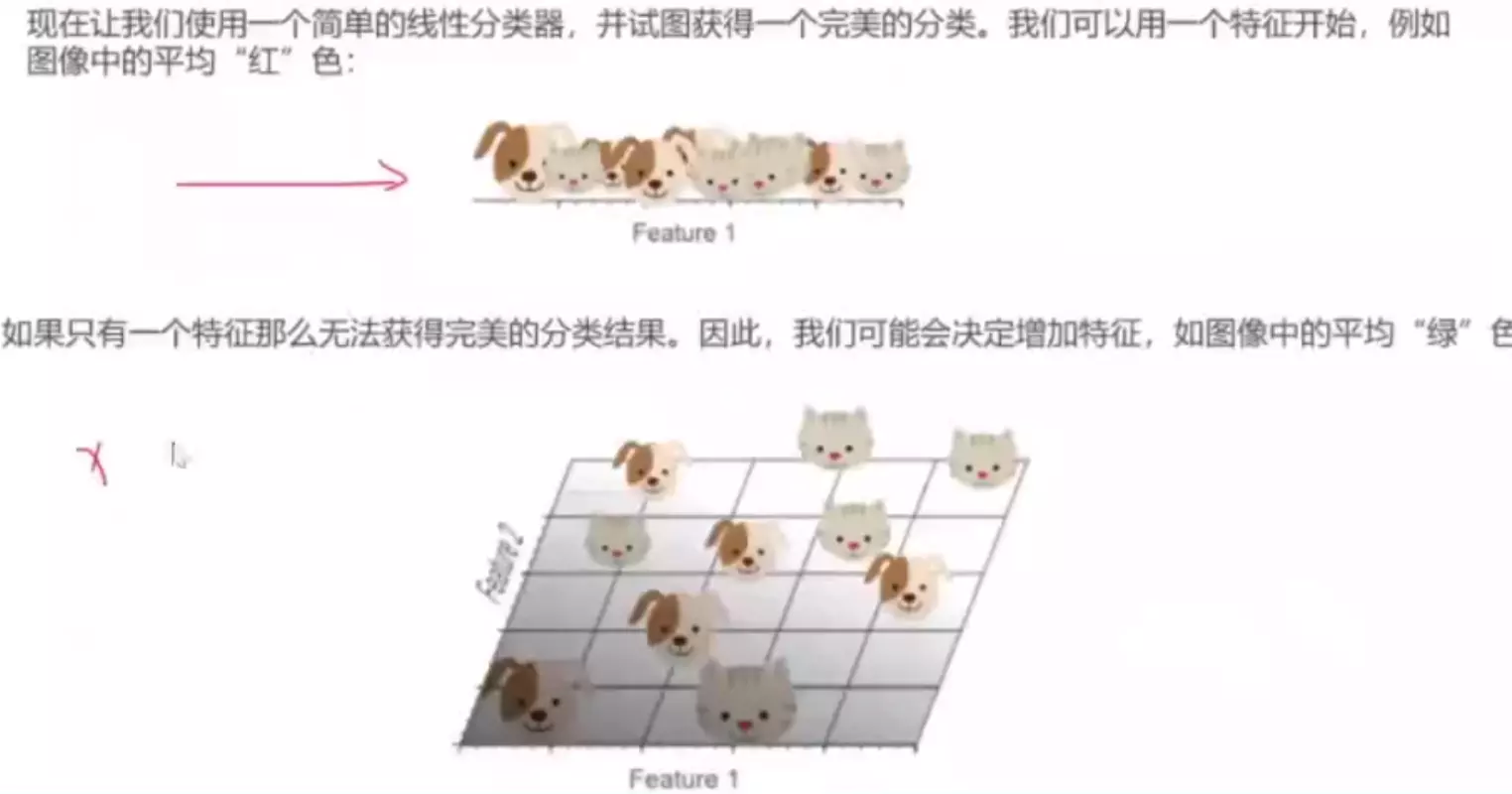
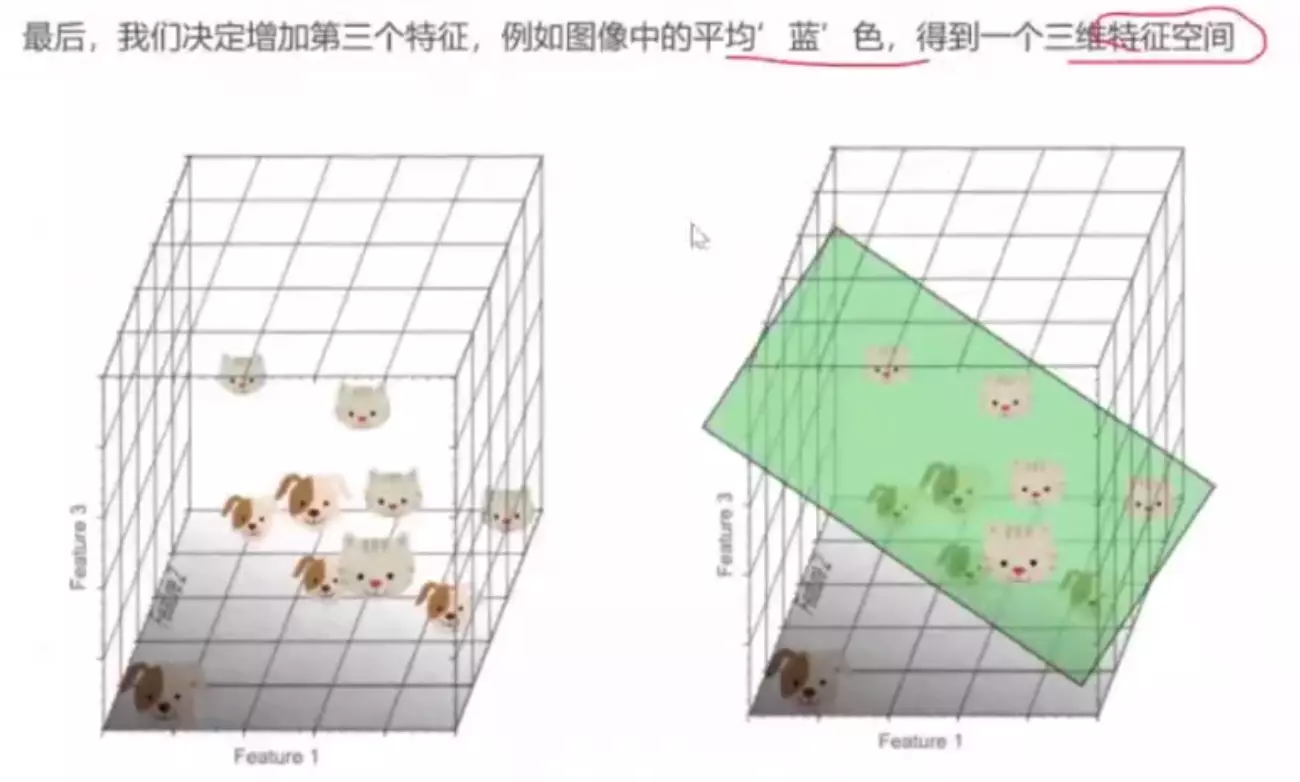
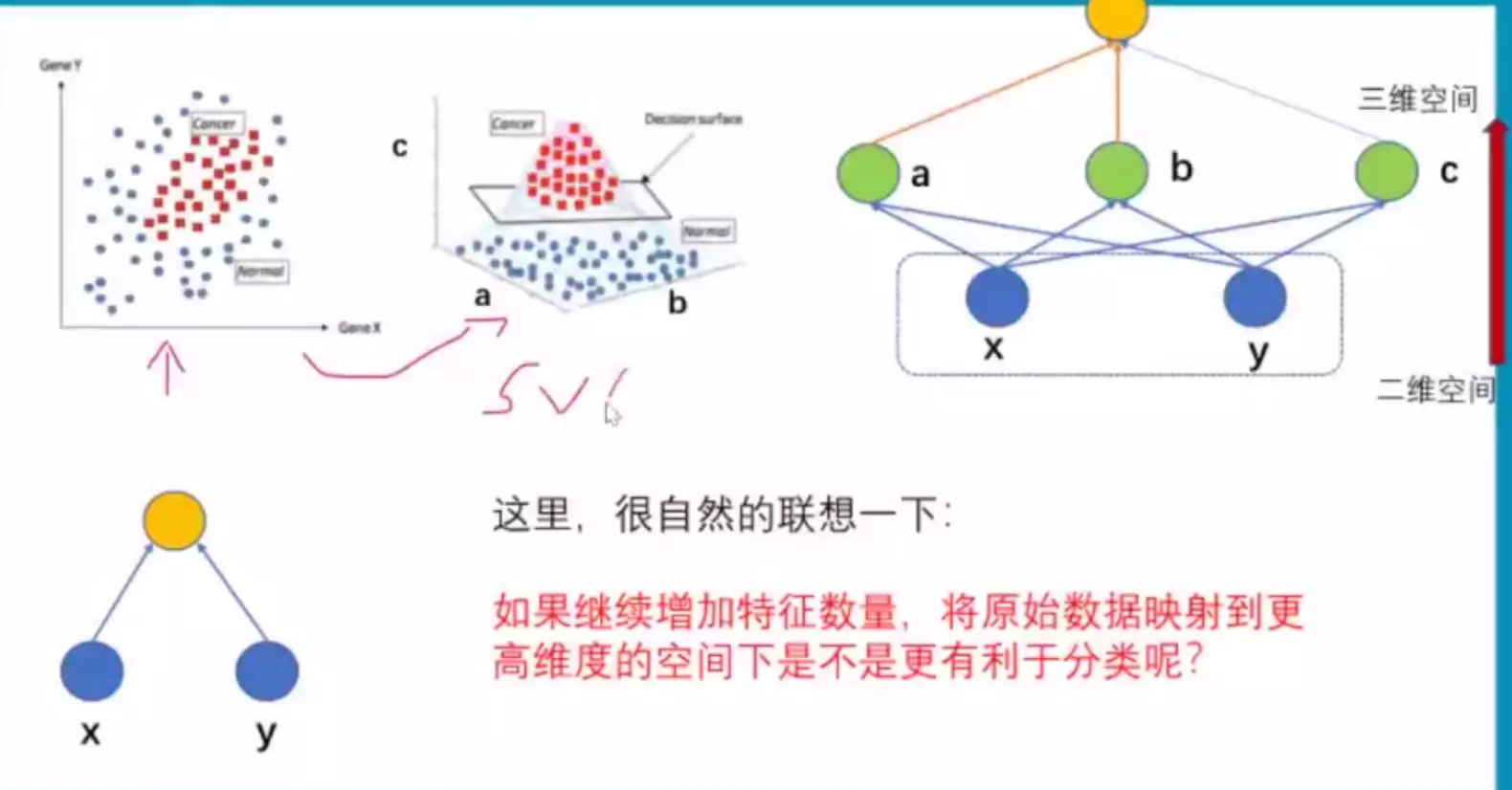

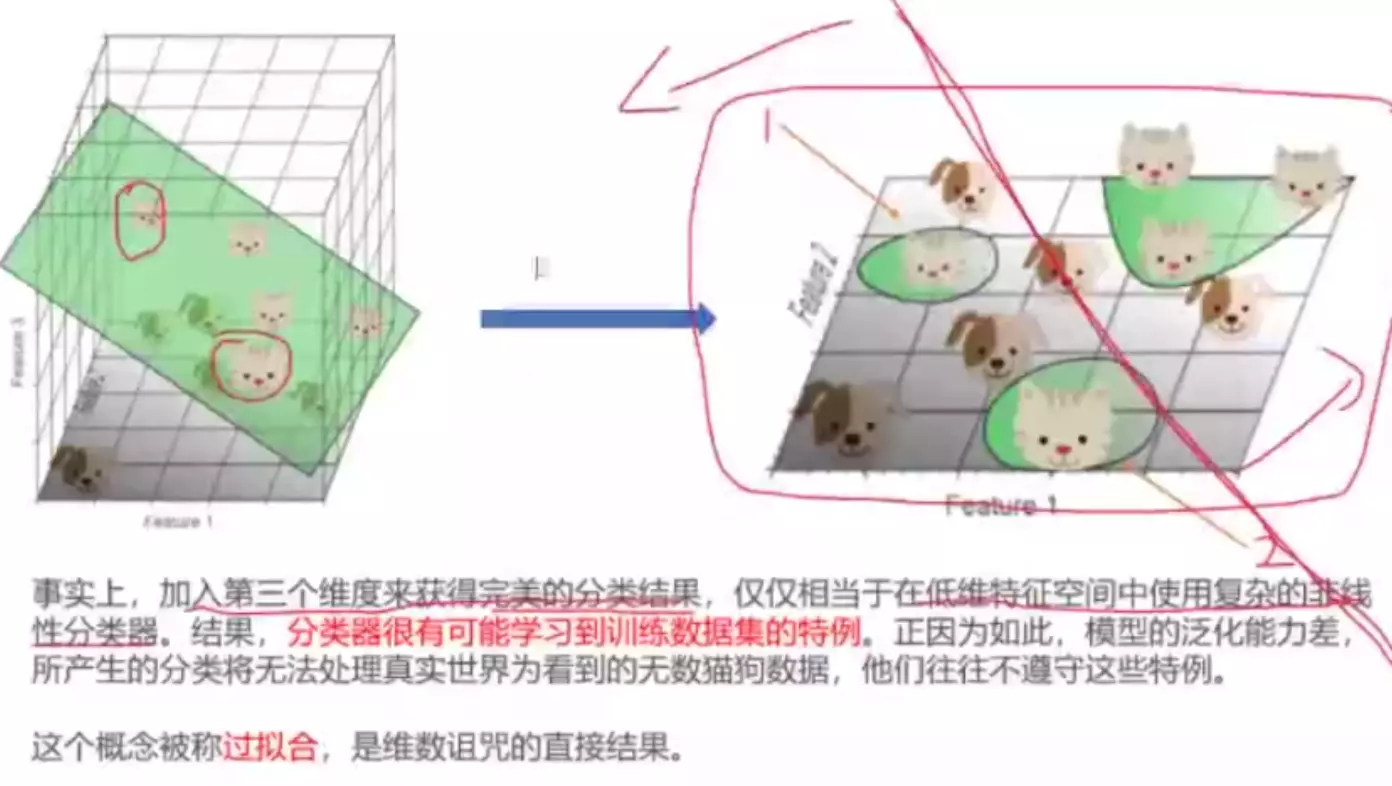 过拟合就是泛化能力不强;更希望得到一个泛化能力强的模型,因为人的泛化能力就比较强。
过拟合就是泛化能力不强;更希望得到一个泛化能力强的模型,因为人的泛化能力就比较强。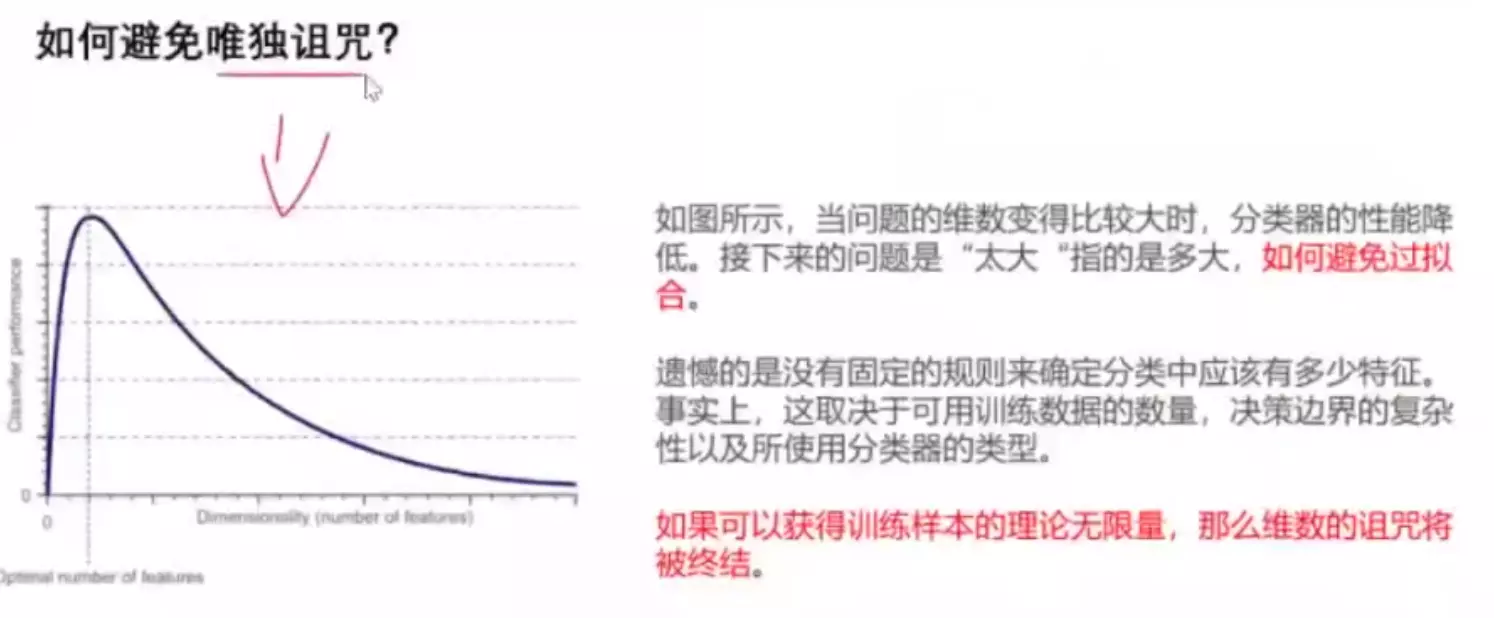


 答:神经神经网络的输入一般是高维数据,例如输入图像和文字。这么高维的空间样本的相似性难以挖掘,所以会用神经网络做特征维度的压缩;隐层从宽到窄,经过压缩的特征的空间维度它的数据分布就是比较稠密的,利于寻找空间相似性和做一个分类。
答:神经神经网络的输入一般是高维数据,例如输入图像和文字。这么高维的空间样本的相似性难以挖掘,所以会用神经网络做特征维度的压缩;隐层从宽到窄,经过压缩的特征的空间维度它的数据分布就是比较稠密的,利于寻找空间相似性和做一个分类。
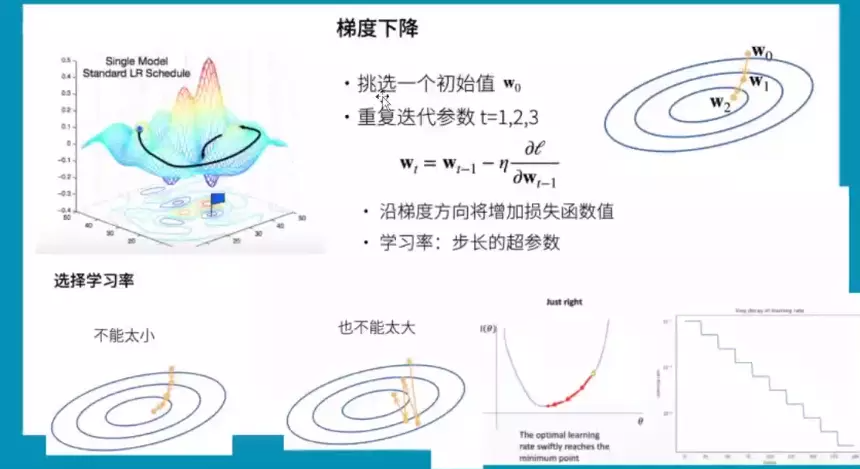




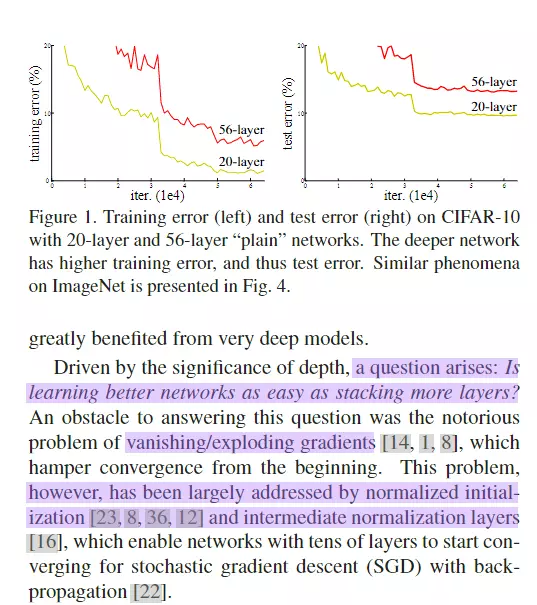


 常规的网络结构是构造一个映射,再传到下一层。我现在隐士的构造一个残差学习来,希望我的学习并不是在原始数据上,希望学到H(x)-x
常规的网络结构是构造一个映射,再传到下一层。我现在隐士的构造一个残差学习来,希望我的学习并不是在原始数据上,希望学到H(x)-x 就是x是前几层学到的,到深层时希望学到的x不丢,只学跟之前不一样的东西,而不是全部给他改变。#是否理解?
就是x是前几层学到的,到深层时希望学到的x不丢,只学跟之前不一样的东西,而不是全部给他改变。#是否理解?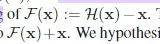 像机器学习里面树模型里的boast;
像机器学习里面树模型里的boast;









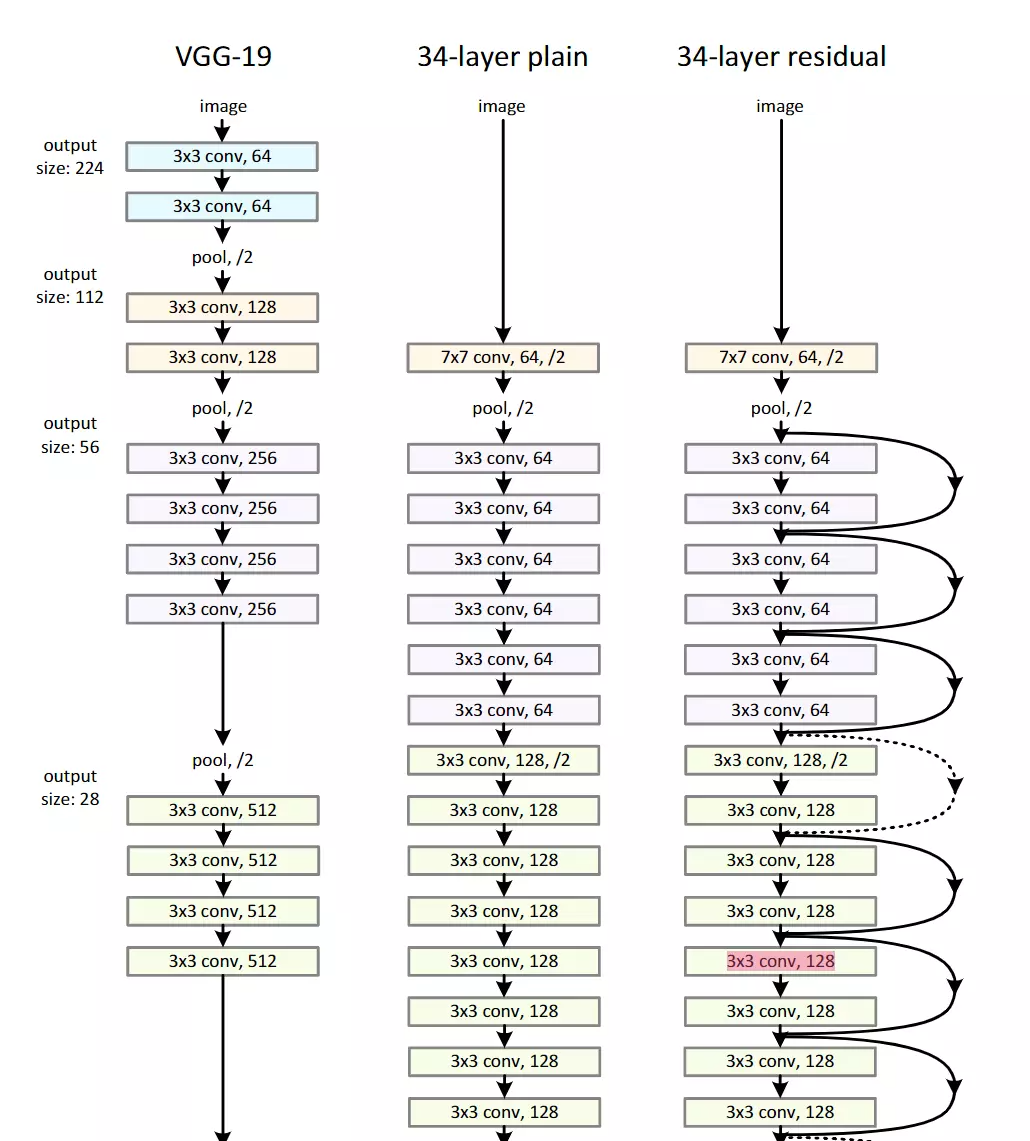
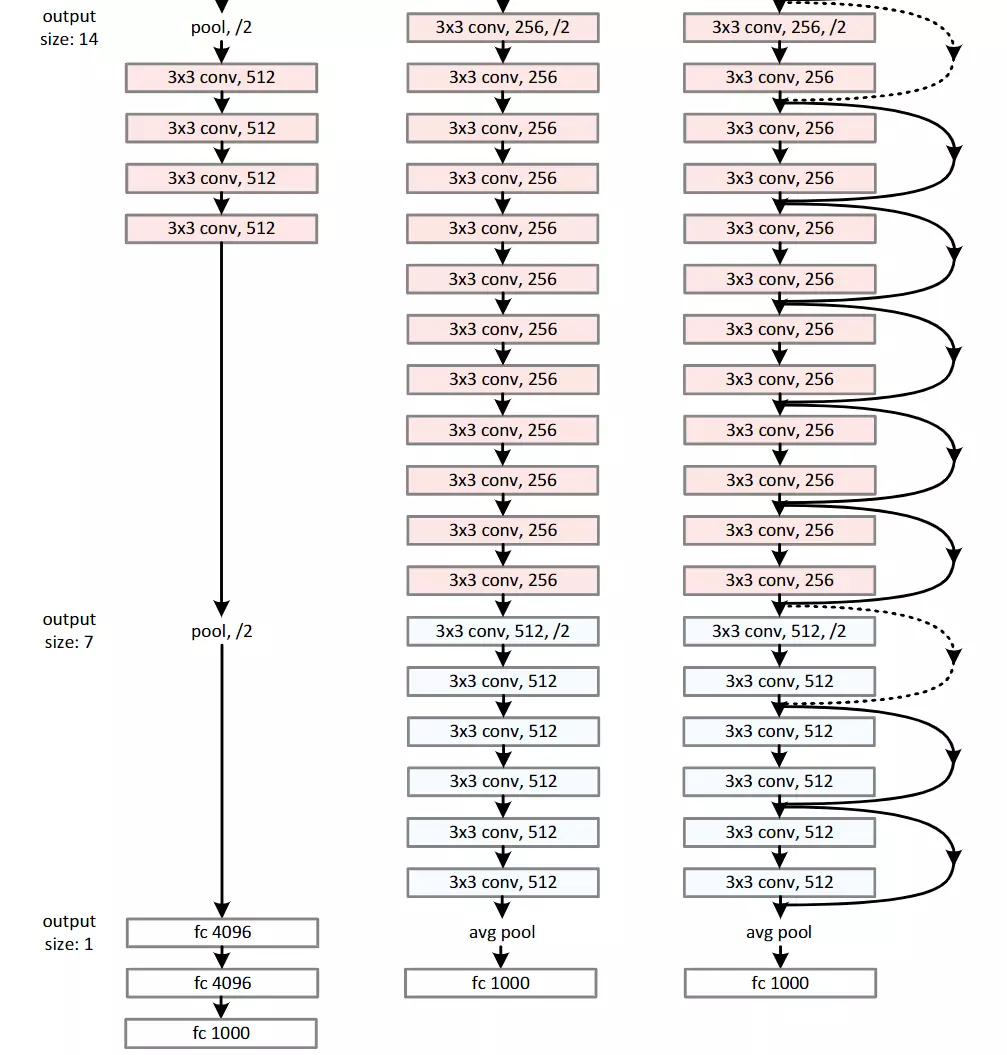

 这是因为每一个stage之间特征图的维度是不一样的。这就不能直接相加了,所以虚线是做了一个处理,就是1*1的卷积,可以改变通道数量。
这是因为每一个stage之间特征图的维度是不一样的。这就不能直接相加了,所以虚线是做了一个处理,就是1*1的卷积,可以改变通道数量。


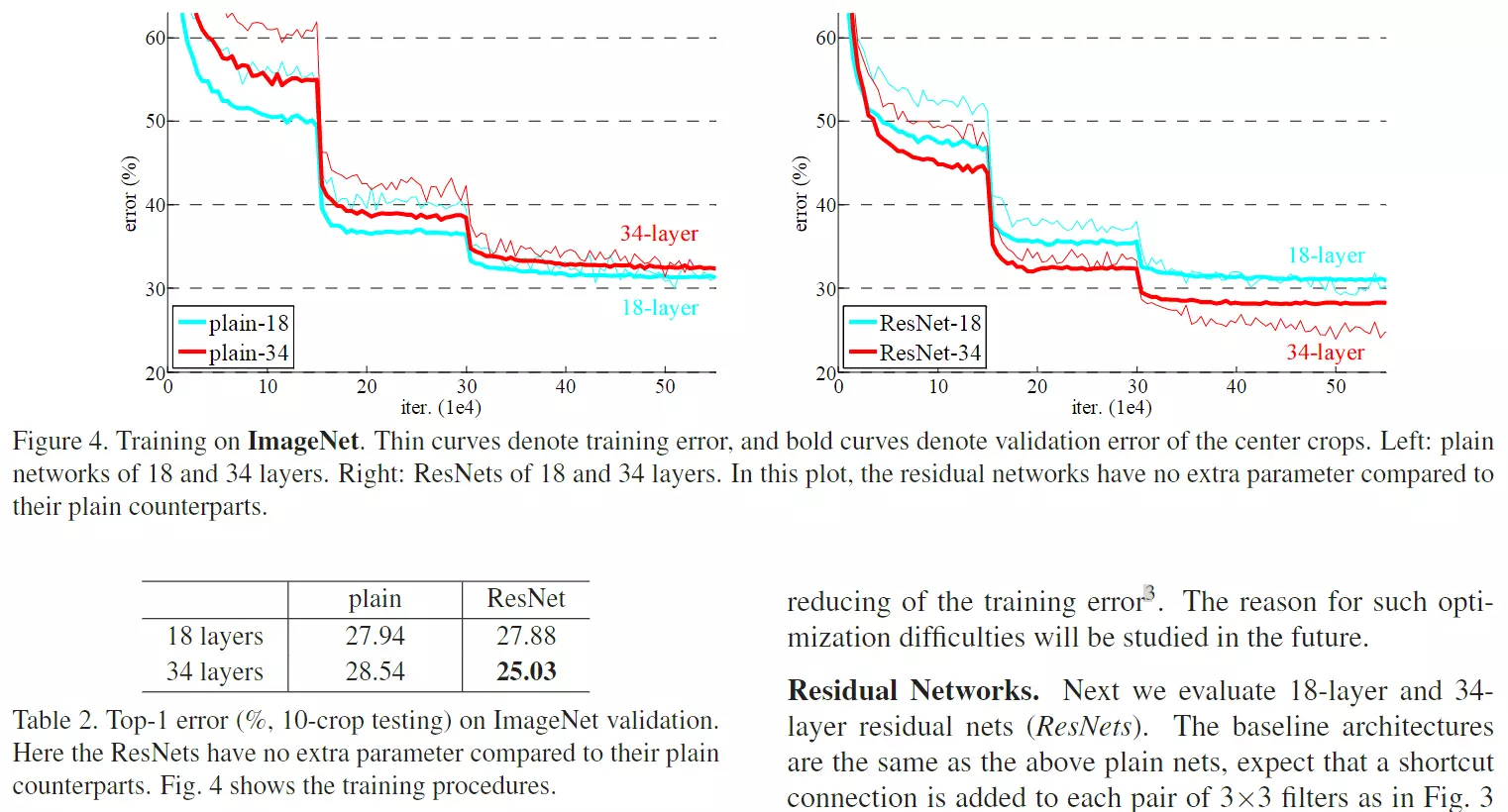
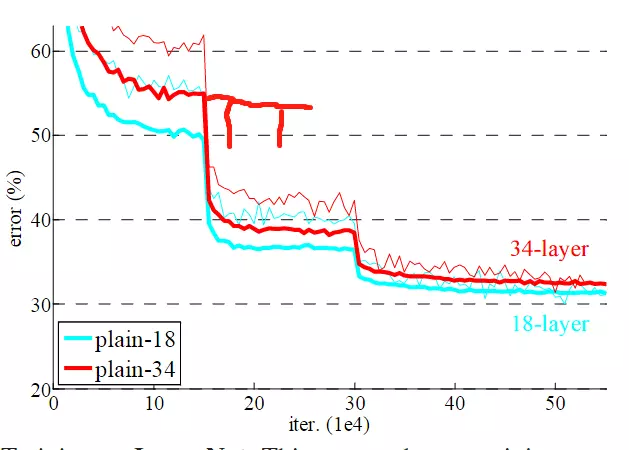
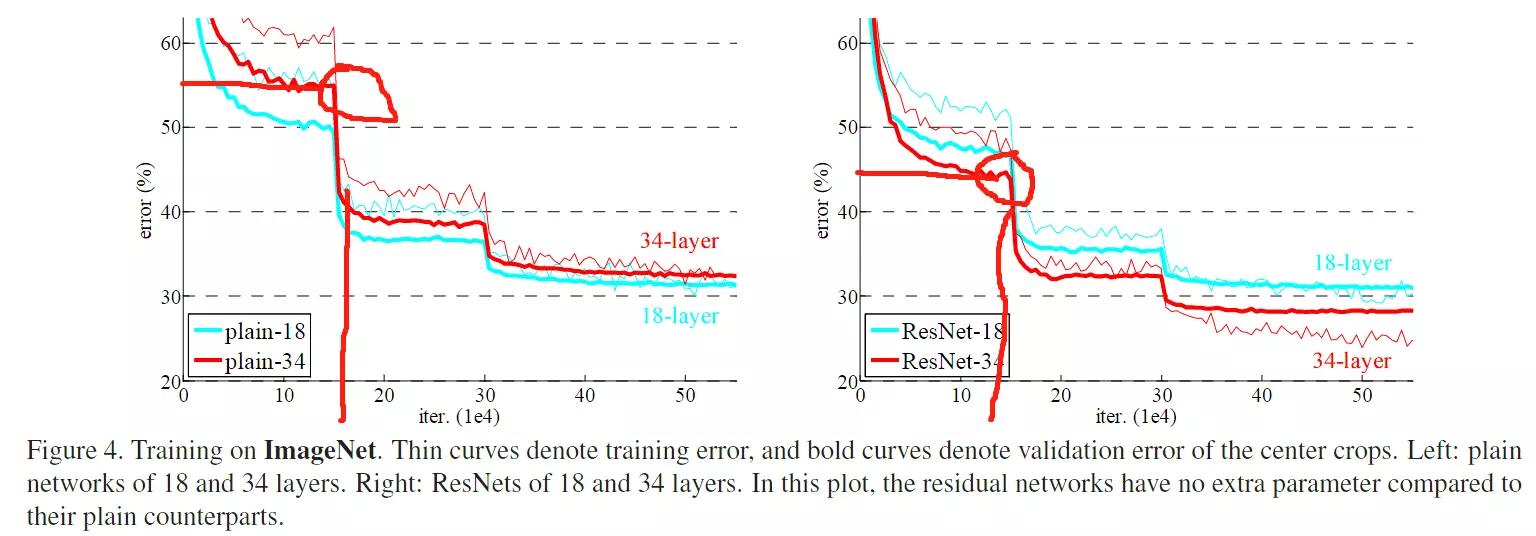

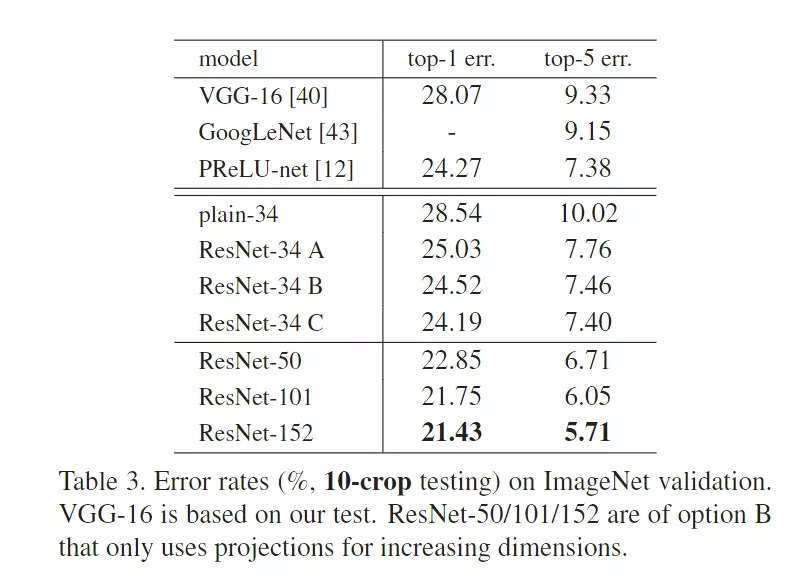
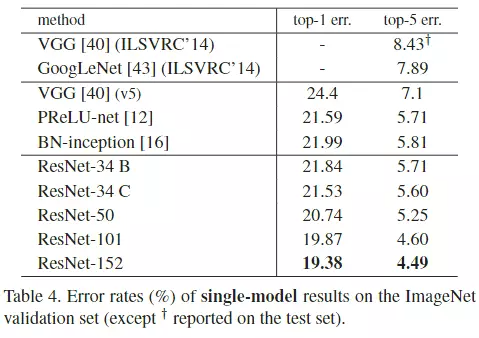
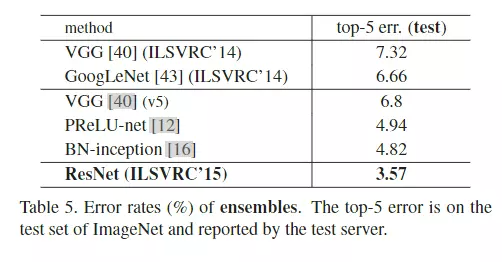
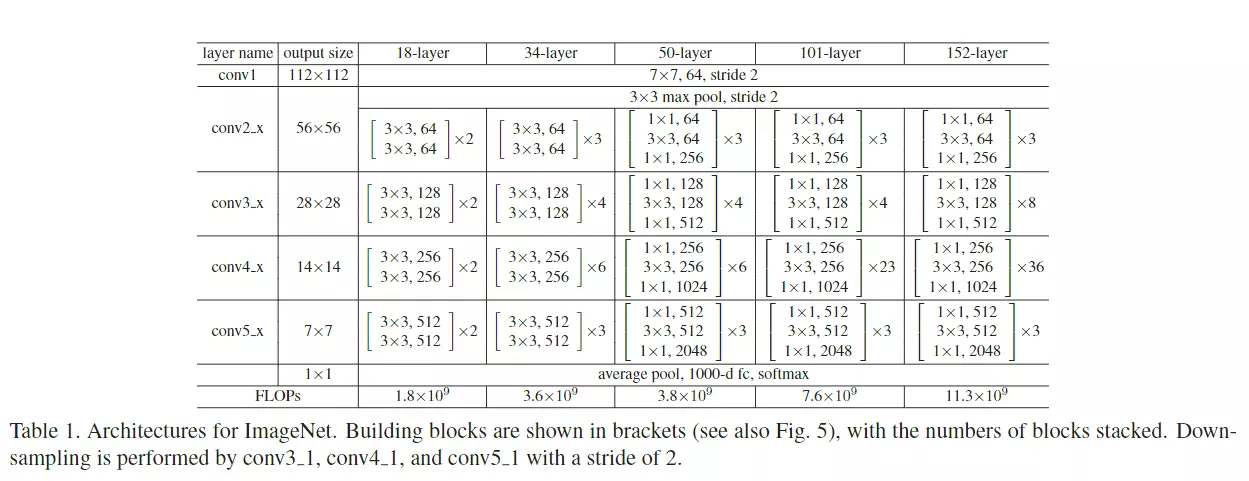
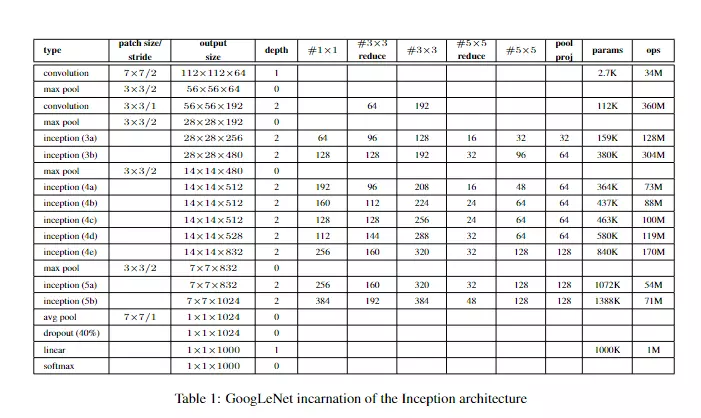
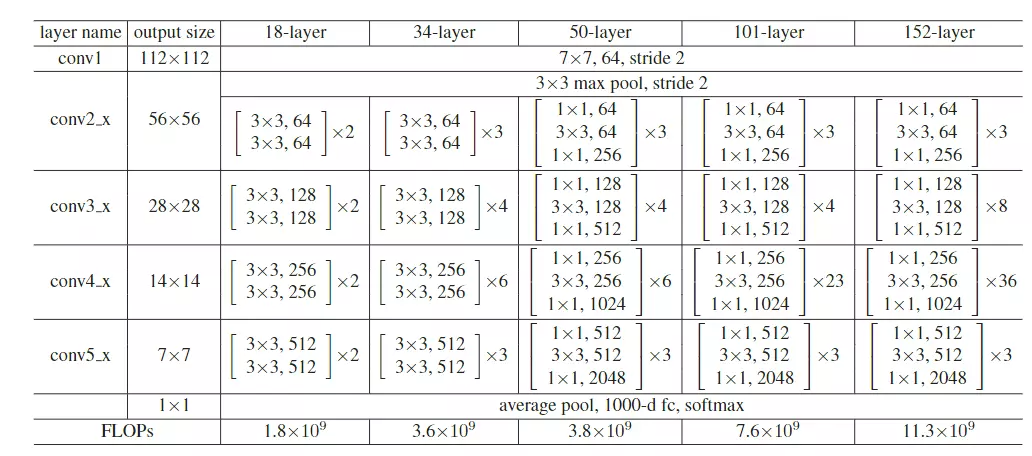
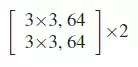 这个乘号就是重复堆叠的次数。block里面就是层级结构的集合,像上面的block里面有两个3*3的结构,后面跟着是64是channel维度的值,这个block就是前面讲的那个结构图:
这个乘号就是重复堆叠的次数。block里面就是层级结构的集合,像上面的block里面有两个3*3的结构,后面跟着是64是channel维度的值,这个block就是前面讲的那个结构图: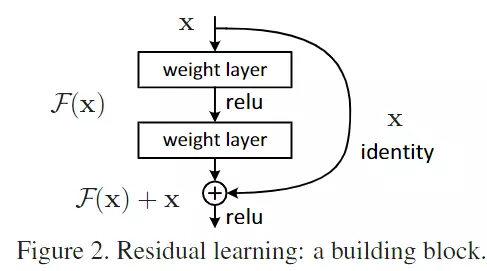
 就是新stage第一个卷积的步长是等于2的其他地方的步长都等于1。
就是新stage第一个卷积的步长是等于2的其他地方的步长都等于1。
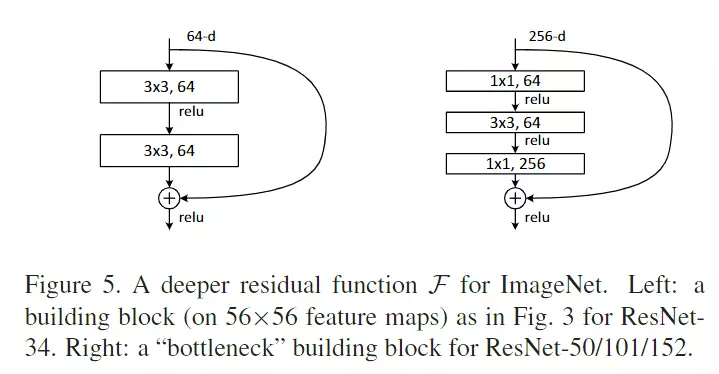




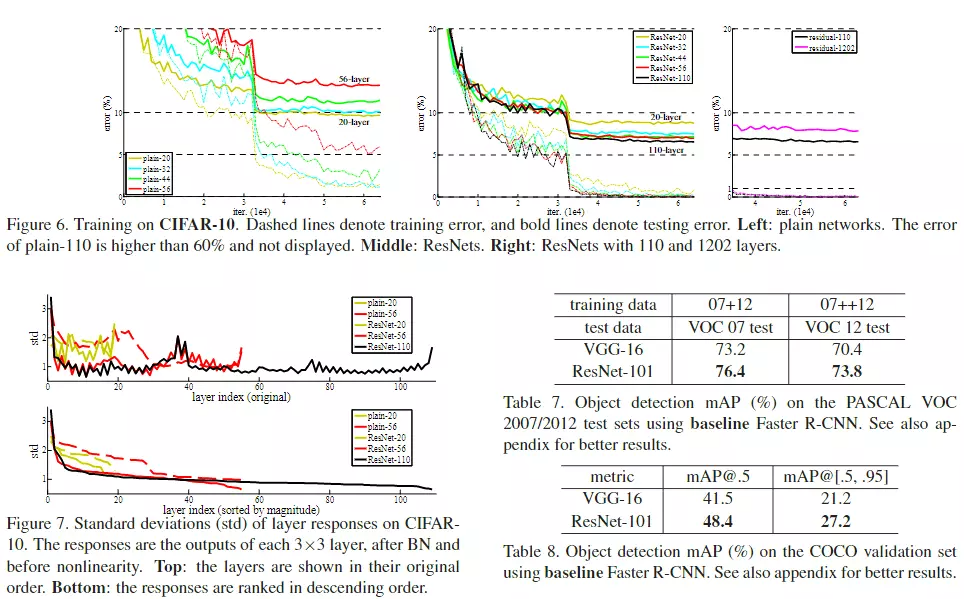

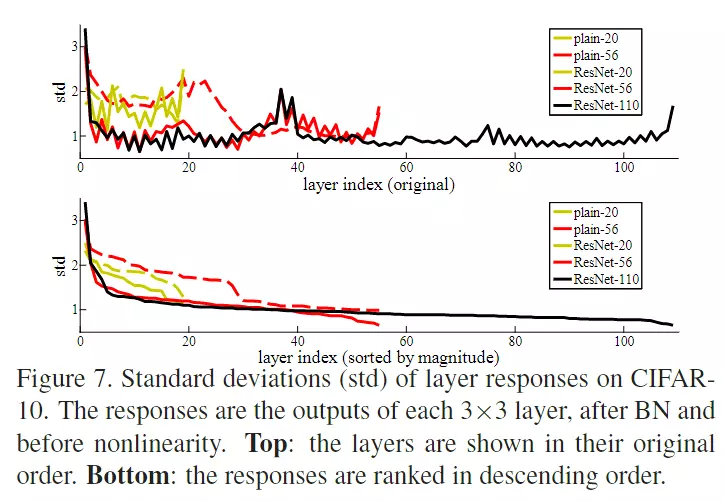 #讲一下这个,但是这个有点不公平。上面图表是不带残差很深的模型,下面图表是带残差很深的模型,纵轴是网络参数的标准差——可以代表,如果我的网络深层真的什么东西都没有学到的话,那么我深层的权重那些参数应该是比较平滑的,应该是接近于0的,以为啥都没学到,所以就搞了一个实验。上图,不带残差是后面权重还是有东西的,但是带了残差之后曲线就比较平滑了。
#讲一下这个,但是这个有点不公平。上面图表是不带残差很深的模型,下面图表是带残差很深的模型,纵轴是网络参数的标准差——可以代表,如果我的网络深层真的什么东西都没有学到的话,那么我深层的权重那些参数应该是比较平滑的,应该是接近于0的,以为啥都没学到,所以就搞了一个实验。上图,不带残差是后面权重还是有东西的,但是带了残差之后曲线就比较平滑了。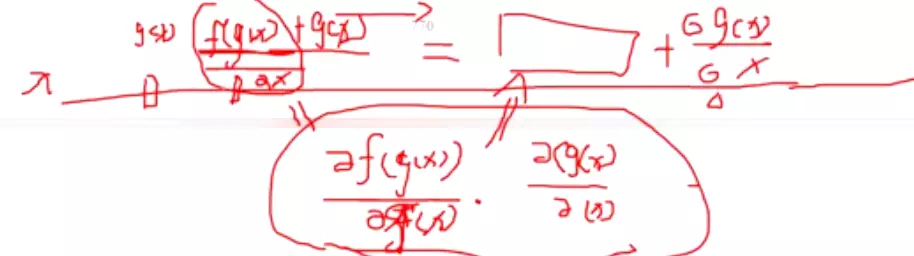 这是从梯度角度讲,所以现在有人说ResNet之所以有效是因为梯度传播比较有效,因为有一个加号在里面。
这是从梯度角度讲,所以现在有人说ResNet之所以有效是因为梯度传播比较有效,因为有一个加号在里面。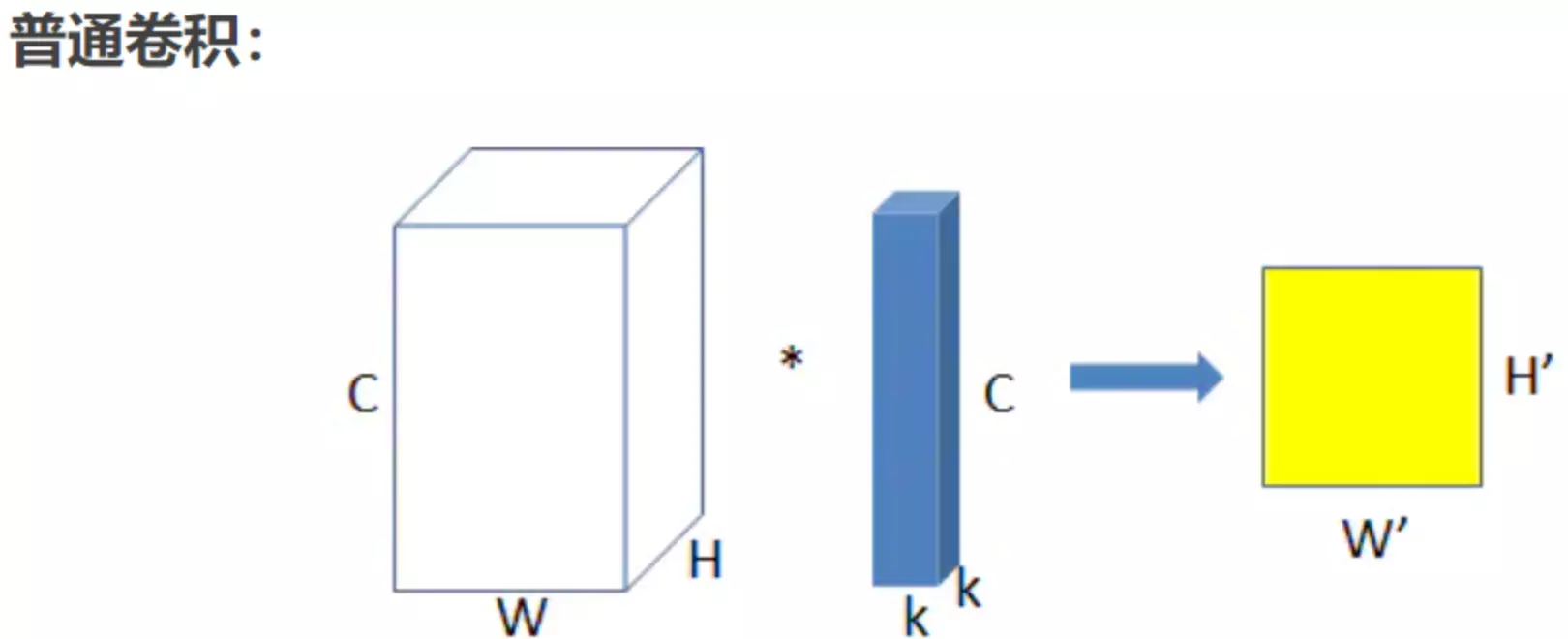
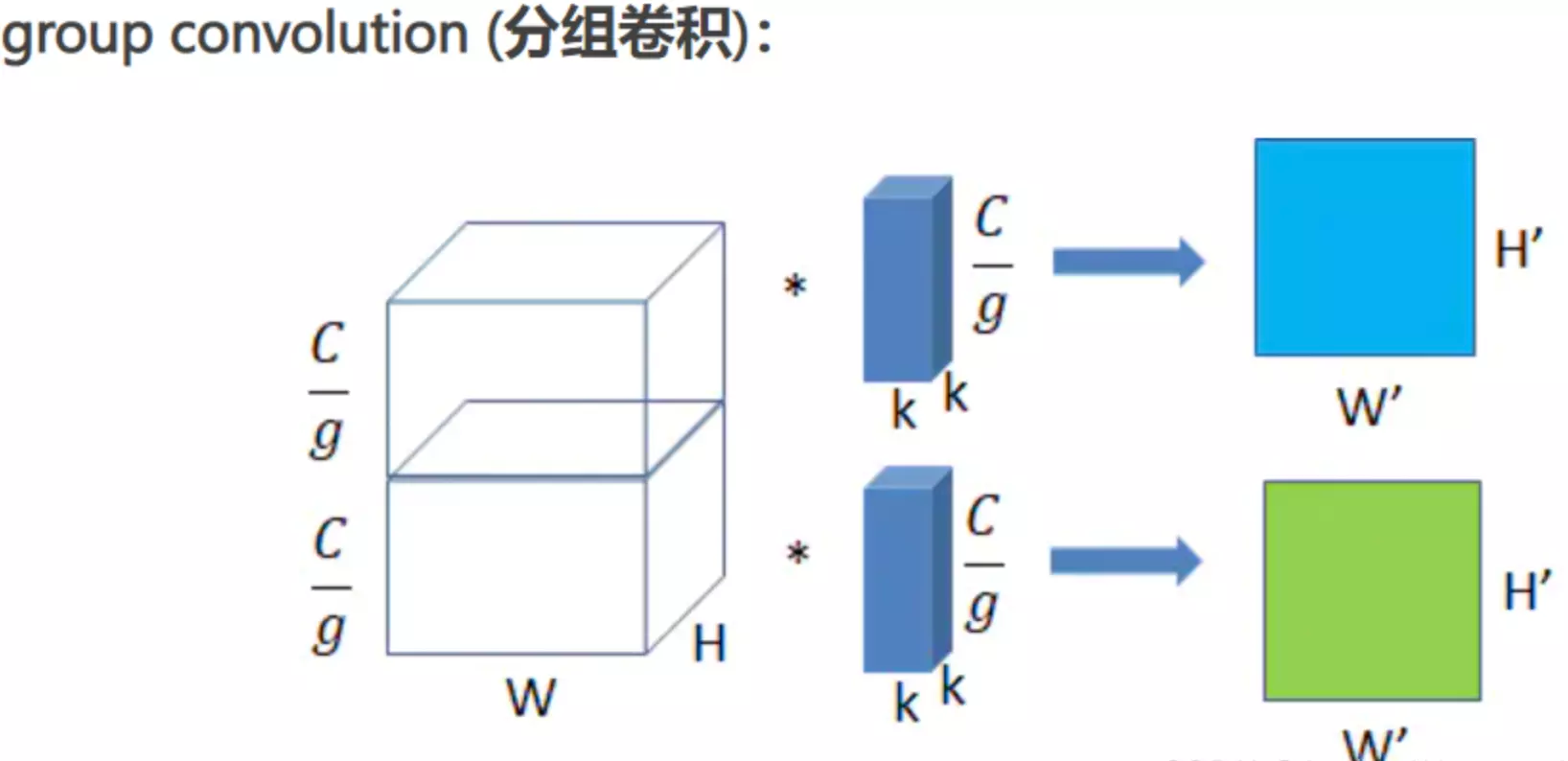
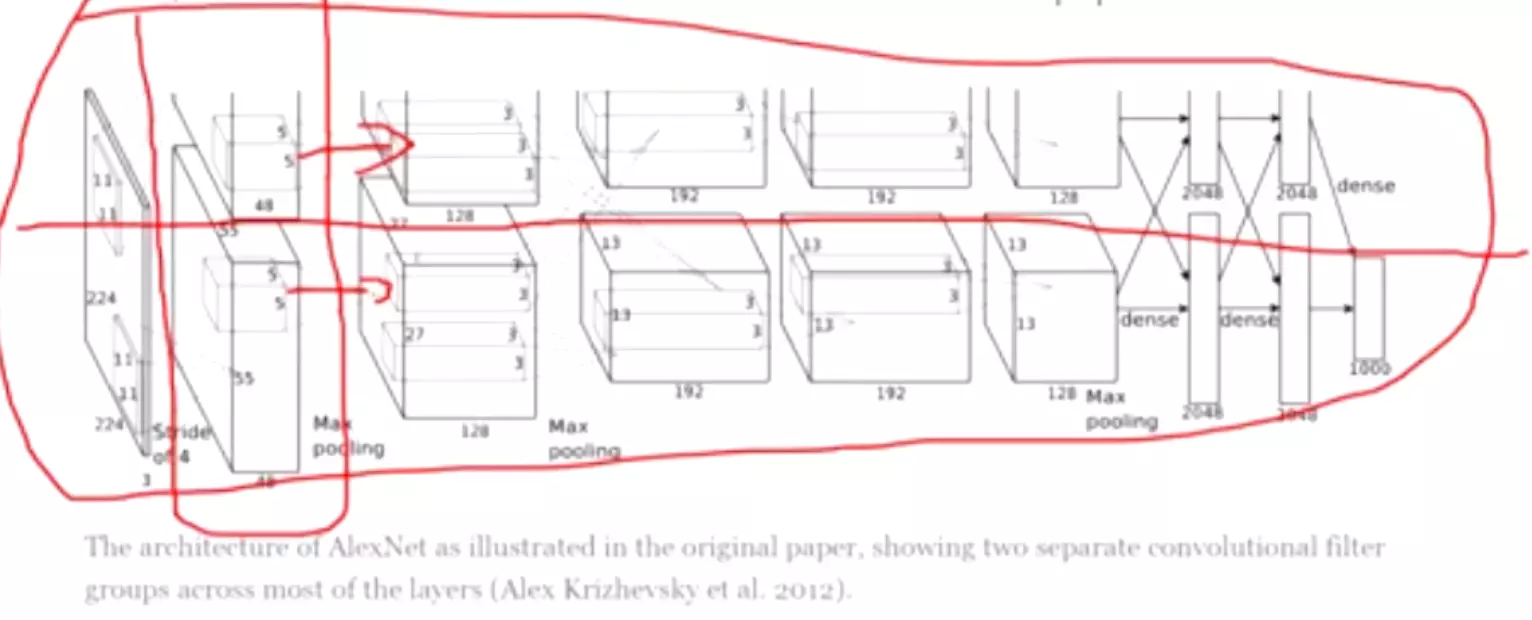 当时并没有组卷积这回事,只是当时的硬件不达标而已。
当时并没有组卷积这回事,只是当时的硬件不达标而已。 还有这张图,表示不同的卷积学到的东西是不一样的,比如上半部分是gpu1学到的图,他是一种偏黑白的纹理特征,下半部分是gpu2学到的图,他是一种偏色彩的颜色特征。所以分组卷积有一个好处,每一组都能学到不一样的特征。这就跟上学一样,班级里每一个同学都是查不多,每一个都可以看成是分组卷积的卷积核,每一个同学学到的都是同一个东西,但是每一人学到的东西的事不一样,这就类似于集成学习或多尺度处理,总之我们可以学对不同的模式,这就是组卷积的核心。如果不分组,相当于一个人学,就没有一样不一样了。
还有这张图,表示不同的卷积学到的东西是不一样的,比如上半部分是gpu1学到的图,他是一种偏黑白的纹理特征,下半部分是gpu2学到的图,他是一种偏色彩的颜色特征。所以分组卷积有一个好处,每一组都能学到不一样的特征。这就跟上学一样,班级里每一个同学都是查不多,每一个都可以看成是分组卷积的卷积核,每一个同学学到的都是同一个东西,但是每一人学到的东西的事不一样,这就类似于集成学习或多尺度处理,总之我们可以学对不同的模式,这就是组卷积的核心。如果不分组,相当于一个人学,就没有一样不一样了。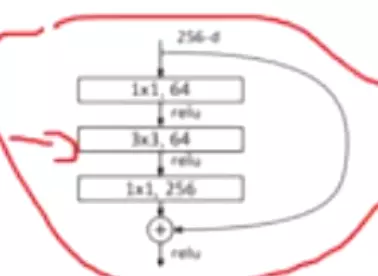 ,例如这个结构他自己想学成什么样子就什么样子,没有对比了,但是分组之后,送进不同的分支里面,AlexNet也讲了,每一组都能学到不同的模式。
,例如这个结构他自己想学成什么样子就什么样子,没有对比了,但是分组之后,送进不同的分支里面,AlexNet也讲了,每一组都能学到不同的模式。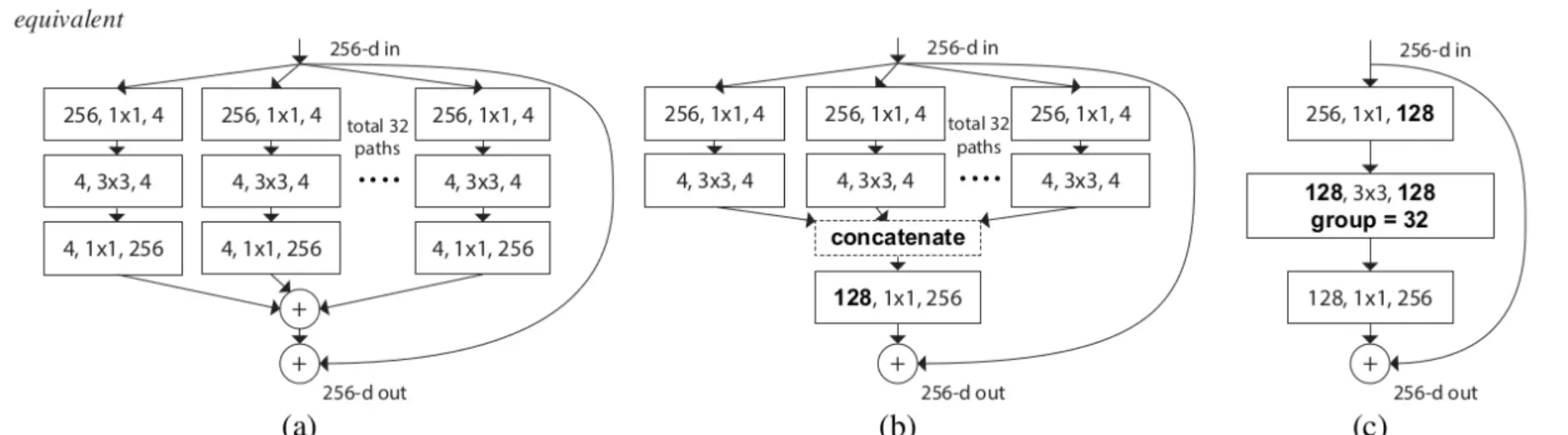
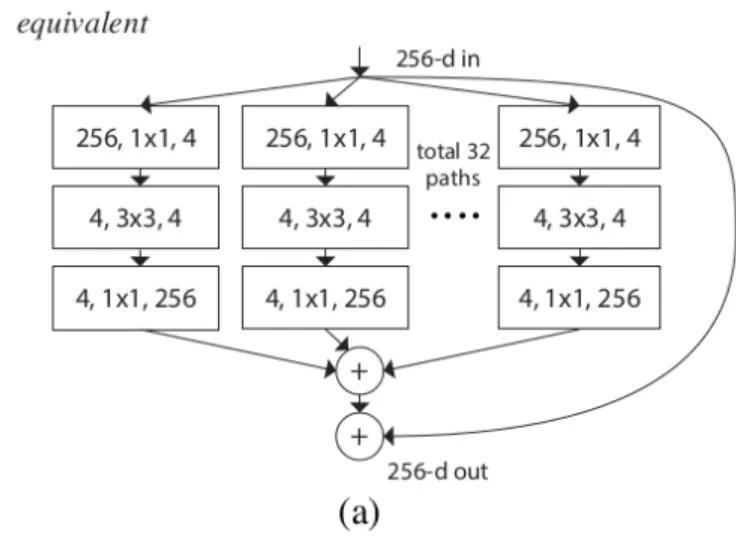
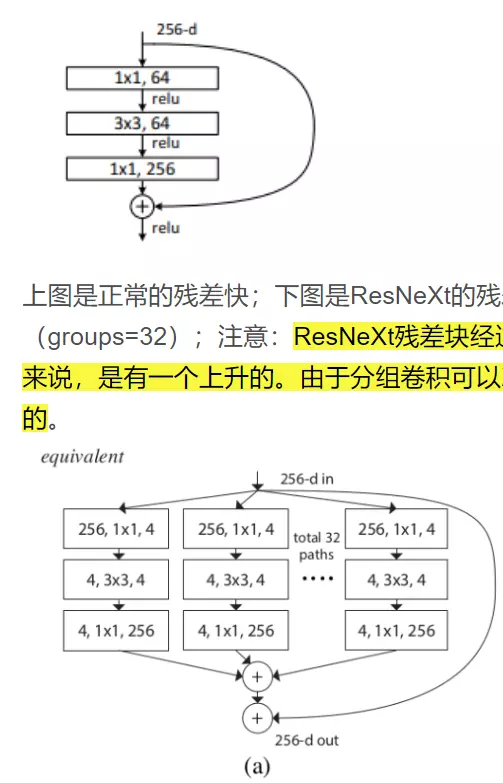 这就和原始的ResNet输出一样,只不过在第一个1*1就开始分组了。
这就和原始的ResNet输出一样,只不过在第一个1*1就开始分组了。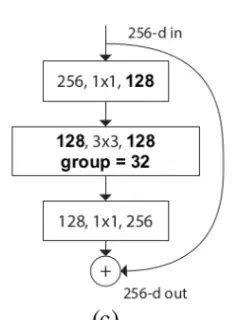 这个就是2016年分类大赛的亚军模型。
这个就是2016年分类大赛的亚军模型。 ,BasicBlock就是原论文里的
,BasicBlock就是原论文里的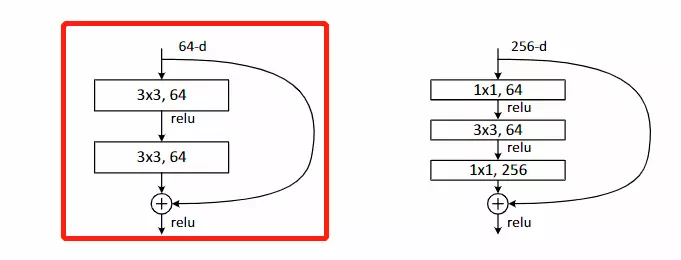 左边的结构。
左边的结构。

 所以这里我通过下采样的方式去改变残差的数据维度。所以下采样并不是每一个block所必须的,只是在stage过度的时候做一个下采样。
所以这里我通过下采样的方式去改变残差的数据维度。所以下采样并不是每一个block所必须的,只是在stage过度的时候做一个下采样。
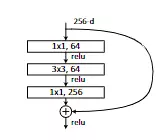 ,所以和他相比就是里面的成员不一样了。原本是两个3*3,现在变成一个1*1,一个3*3和一个1*1。整体的思路是一样的。
,所以和他相比就是里面的成员不一样了。原本是两个3*3,现在变成一个1*1,一个3*3和一个1*1。整体的思路是一样的。
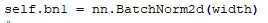 指的是每一卷积之后输出的channel维度的数量,为什么不直接传?是因为要适配ResNeXt
指的是每一卷积之后输出的channel维度的数量,为什么不直接传?是因为要适配ResNeXt
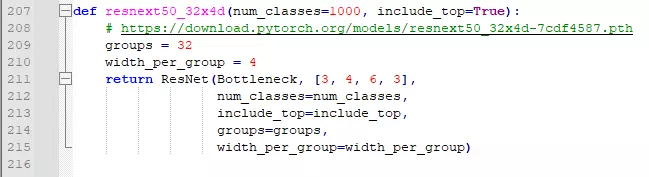 制定32组,每组的成员是4,width = int(out_channel * (width_per_group / 64.)) * groups =64*4/64*32=128,这个时候的通道数量,就跟
制定32组,每组的成员是4,width = int(out_channel * (width_per_group / 64.)) * groups =64*4/64*32=128,这个时候的通道数量,就跟 #关于BN操作,只需要记住,以后的网络肯定是有BN的,这已经成为了设计模型的默认的一个操作了!!!
#关于BN操作,只需要记住,以后的网络肯定是有BN的,这已经成为了设计模型的默认的一个操作了!!!
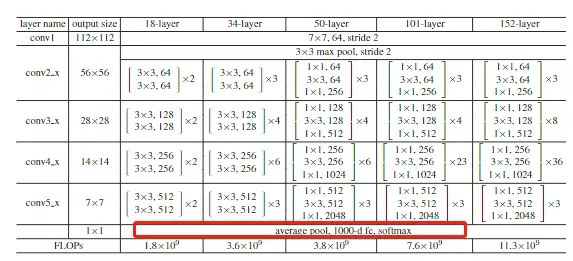

 回去可以背一下常见的参数配置。如果kernelsize=7,stride=2,padding=3的话,这里s=2,说明这里的卷积做了一个二倍下采样,他的特征图尺寸会减半,因为步长翻倍了。然后maxpooling,
回去可以背一下常见的参数配置。如果kernelsize=7,stride=2,padding=3的话,这里s=2,说明这里的卷积做了一个二倍下采样,他的特征图尺寸会减半,因为步长翻倍了。然后maxpooling, #这里建stage是通过函数的方式,和VGG一样,现在只需要知道这里他是4个stage就可以了。
#这里建stage是通过函数的方式,和VGG一样,现在只需要知道这里他是4个stage就可以了。


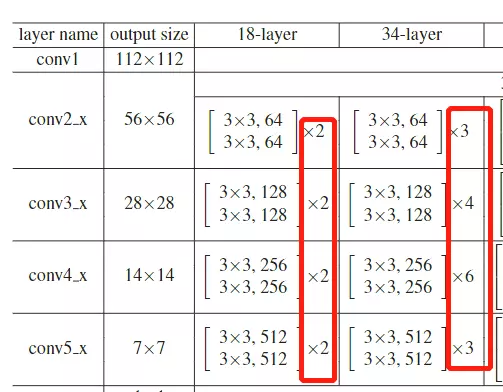 ,所以这里初始化一个列表来放这些block。首先会 把每一个block写出来。每一个stage里面第一个个block和其他的长得都不一样。
,所以这里初始化一个列表来放这些block。首先会 把每一个block写出来。每一个stage里面第一个个block和其他的长得都不一样。 所以把它拿出来之后,后面的block就可以通过一个for循环写出来了。所以整个代码看起来很简洁,所以这里先把不一样的写出来。
所以把它拿出来之后,后面的block就可以通过一个for循环写出来了。所以整个代码看起来很简洁,所以这里先把不一样的写出来。
 这时候怎么判断?就是根据步长和通道数量。
这时候怎么判断?就是根据步长和通道数量。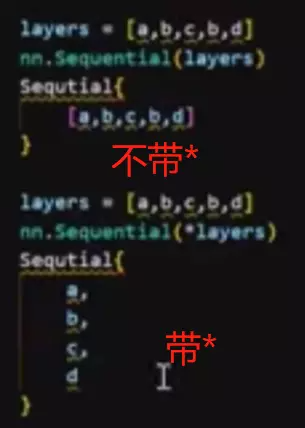

 这里是参数的意义:block, #指当前构建的block里面的结果是什么样的,是下面哪种。
这里是参数的意义:block, #指当前构建的block里面的结果是什么样的,是下面哪种。
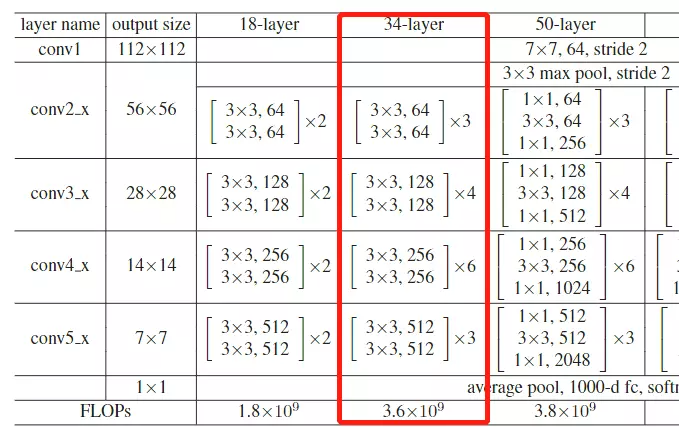


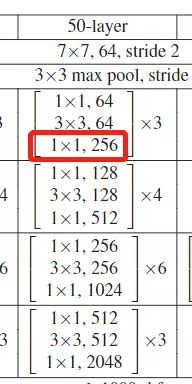 的这里不是64是256?没关系有一个扩张因子,会给它变成256,所以整个网络结构是没有任何问题的。
的这里不是64是256?没关系有一个扩张因子,会给它变成256,所以整个网络结构是没有任何问题的。 你要想你搭建stage要写什么东西。想,你要搭stage要想这里面都是哪一个种类的block,所以肯定要有一个参数是控制block属于那个种类的——block。又要想这个stage里面通道数量都是几,所以肯定有一个参数去控制通道数量的——64。又要想每一个stage里的block的数量是几,所以有一个参数去控制blcok数量——blocks_num[0]。然后你就可以搭了,这时候还没有讲步长,当搭建的时候发现,stage在切换的时候,通道数需要改变,这时候脑中要有思路,要么通过池化的方法,要么通过调整步长的方法。当要用调整步长的方法时,发现刚才的参数不够用,所以要增加一个参数过来——stride=2。
你要想你搭建stage要写什么东西。想,你要搭stage要想这里面都是哪一个种类的block,所以肯定要有一个参数是控制block属于那个种类的——block。又要想这个stage里面通道数量都是几,所以肯定有一个参数去控制通道数量的——64。又要想每一个stage里的block的数量是几,所以有一个参数去控制blcok数量——blocks_num[0]。然后你就可以搭了,这时候还没有讲步长,当搭建的时候发现,stage在切换的时候,通道数需要改变,这时候脑中要有思路,要么通过池化的方法,要么通过调整步长的方法。当要用调整步长的方法时,发现刚才的参数不够用,所以要增加一个参数过来——stride=2。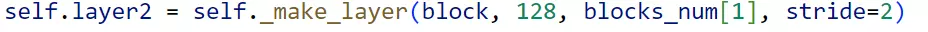
 ,而第一个stage不需要。
,而第一个stage不需要。

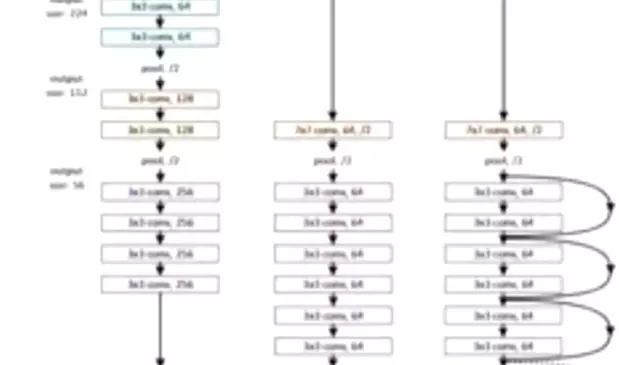 答:最好的方式就是PPT,如果你是大神的话可以干很多事。也有一个叫draw io
答:最好的方式就是PPT,如果你是大神的话可以干很多事。也有一个叫draw io 是一个非常简洁的画流程图的软件。
是一个非常简洁的画流程图的软件。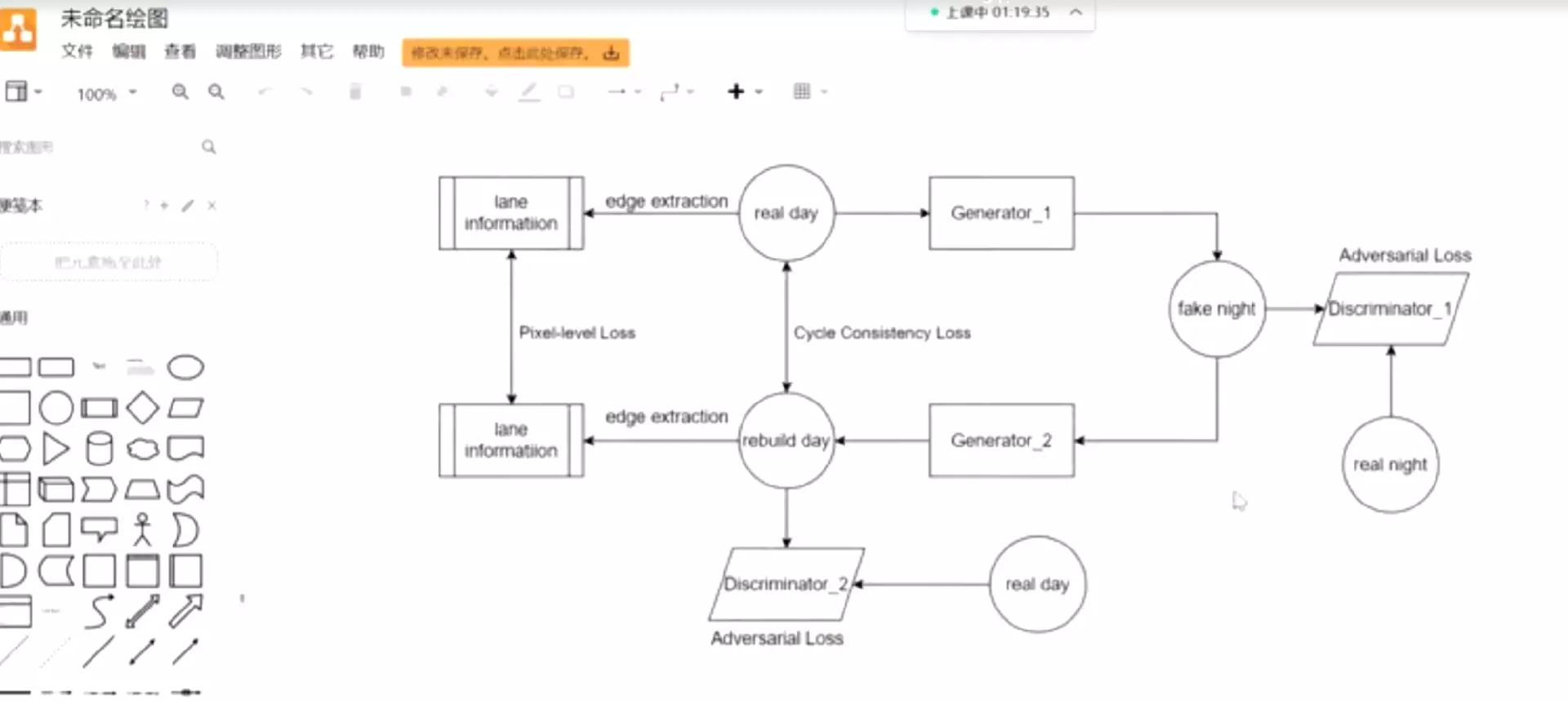
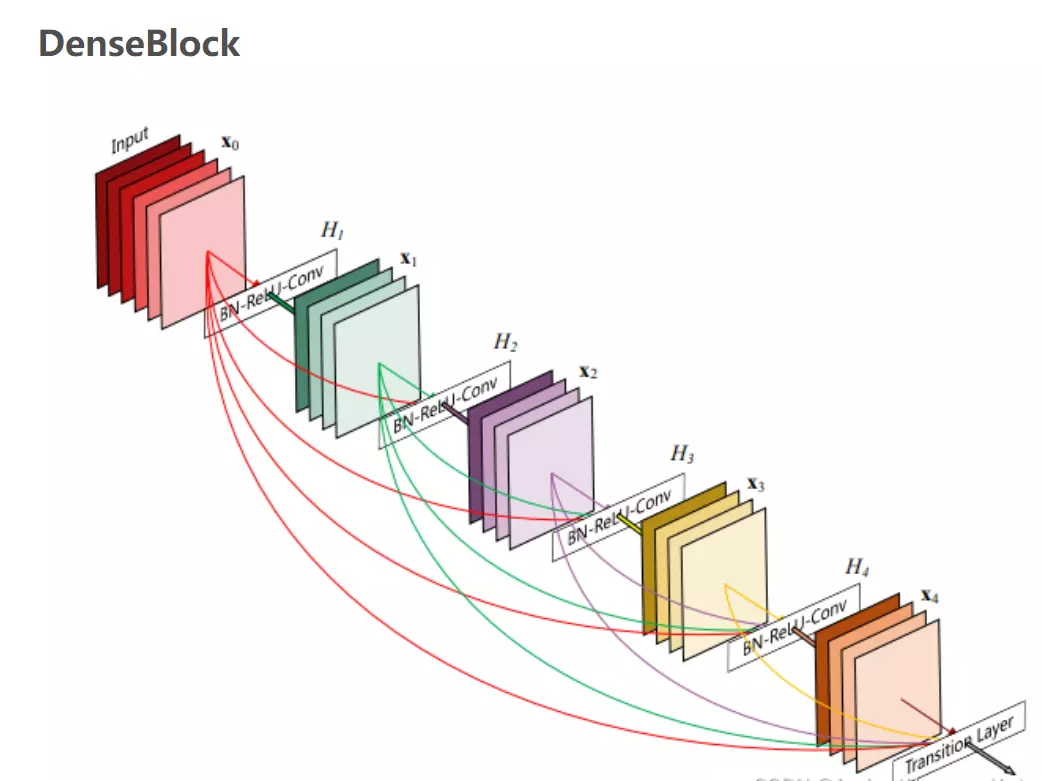 这个图我们就可以看出来,先在这个图上面画什么叫reset,如果是reset的话,它长这个样子:如果单看我画的连线的话,它是一个ResNet
这个图我们就可以看出来,先在这个图上面画什么叫reset,如果是reset的话,它长这个样子:如果单看我画的连线的话,它是一个ResNet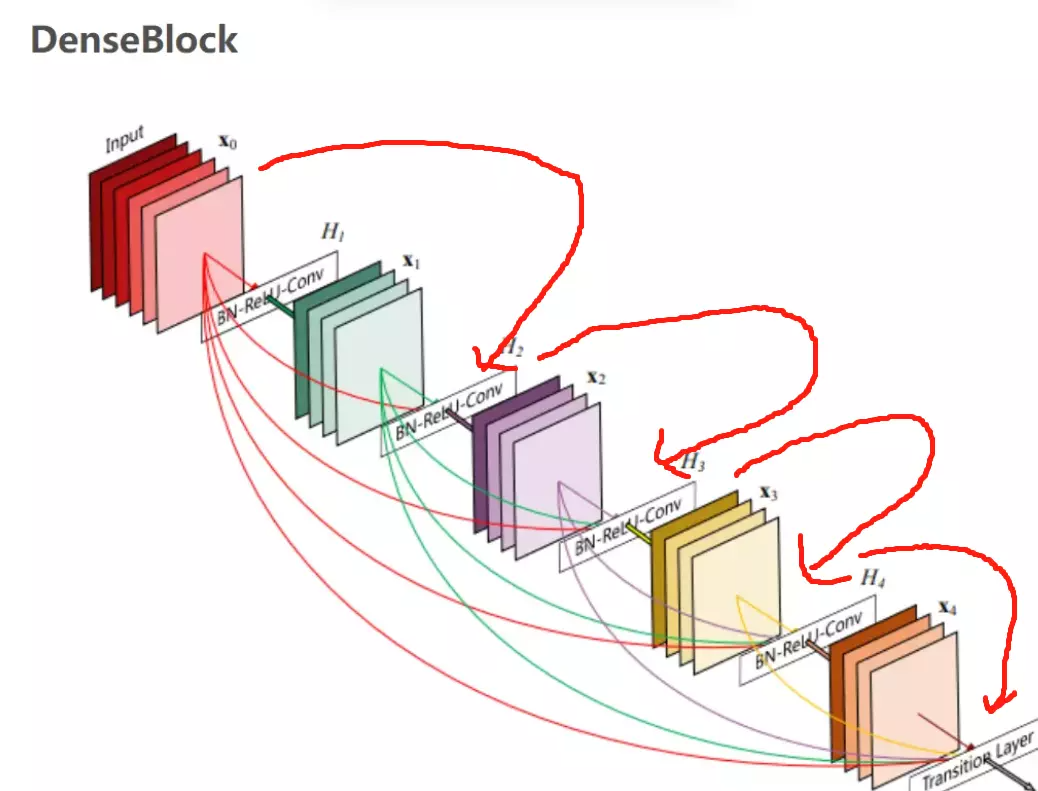
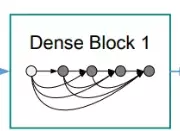 这个特征图有非常复杂的复用关系。
这个特征图有非常复杂的复用关系。
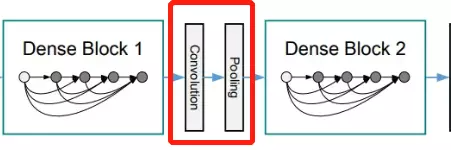

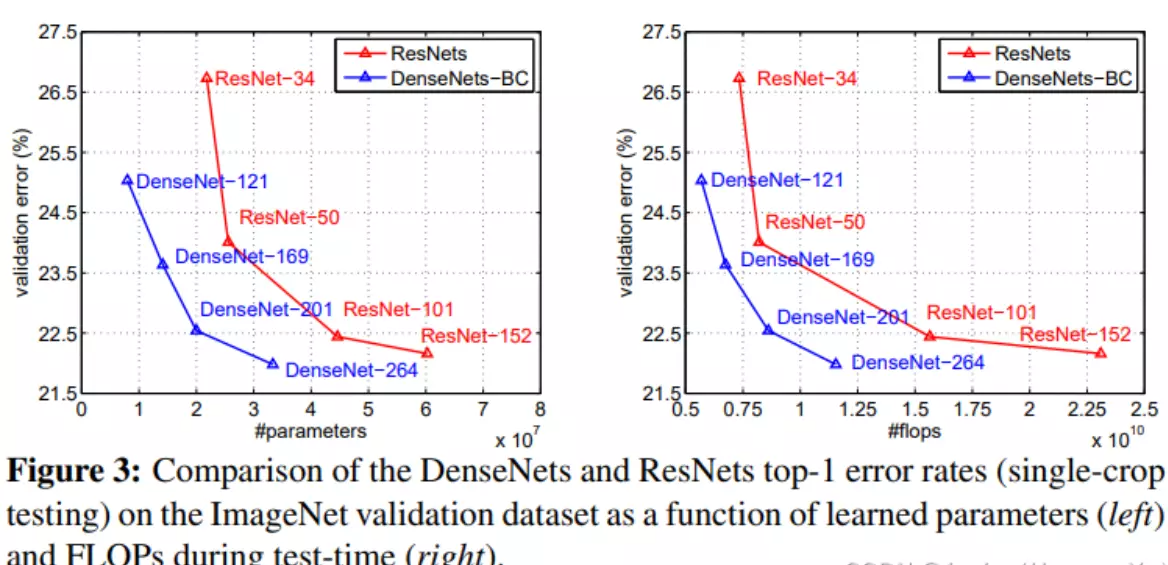
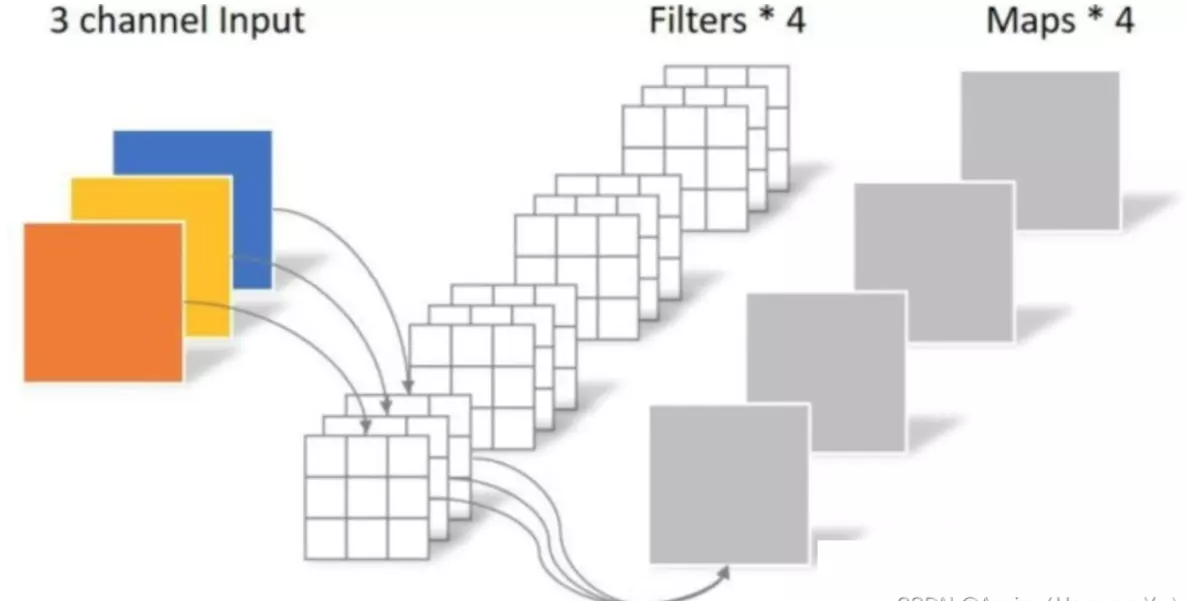
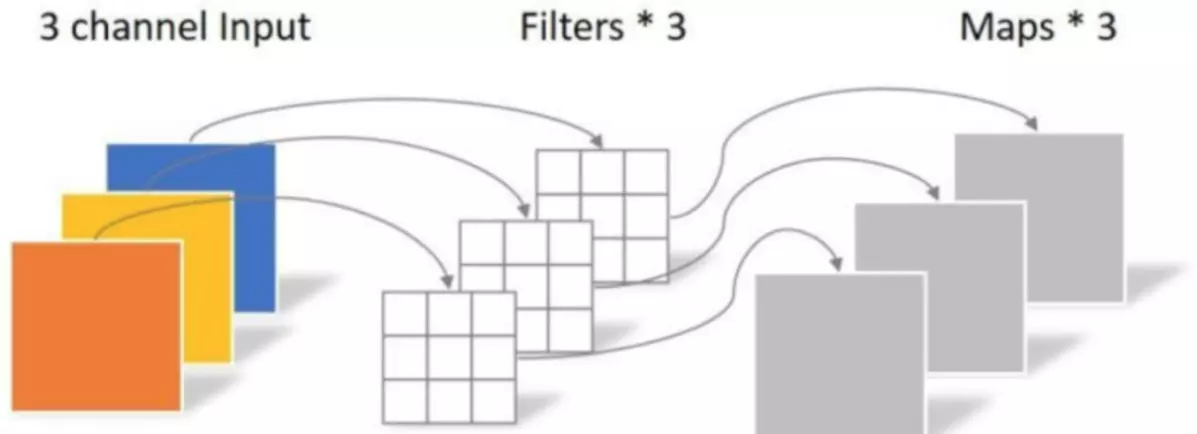
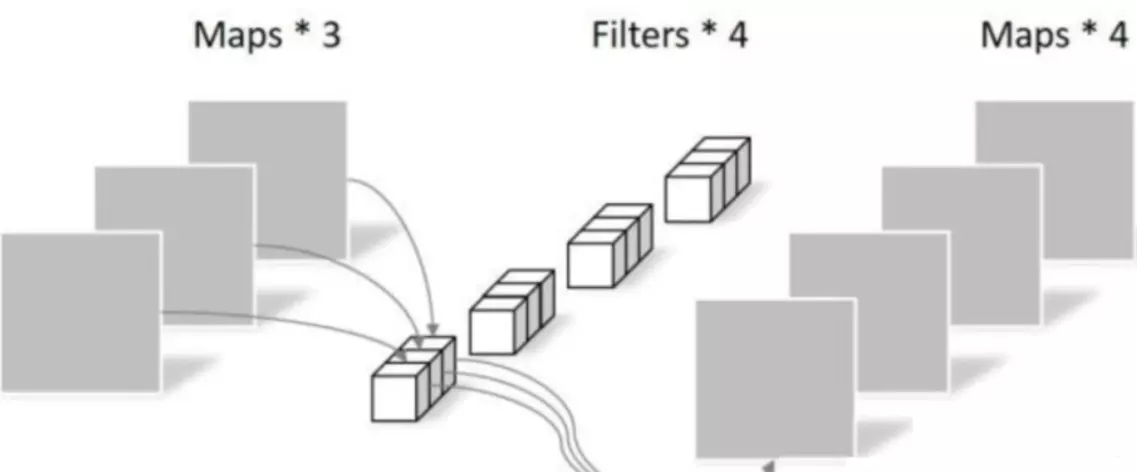

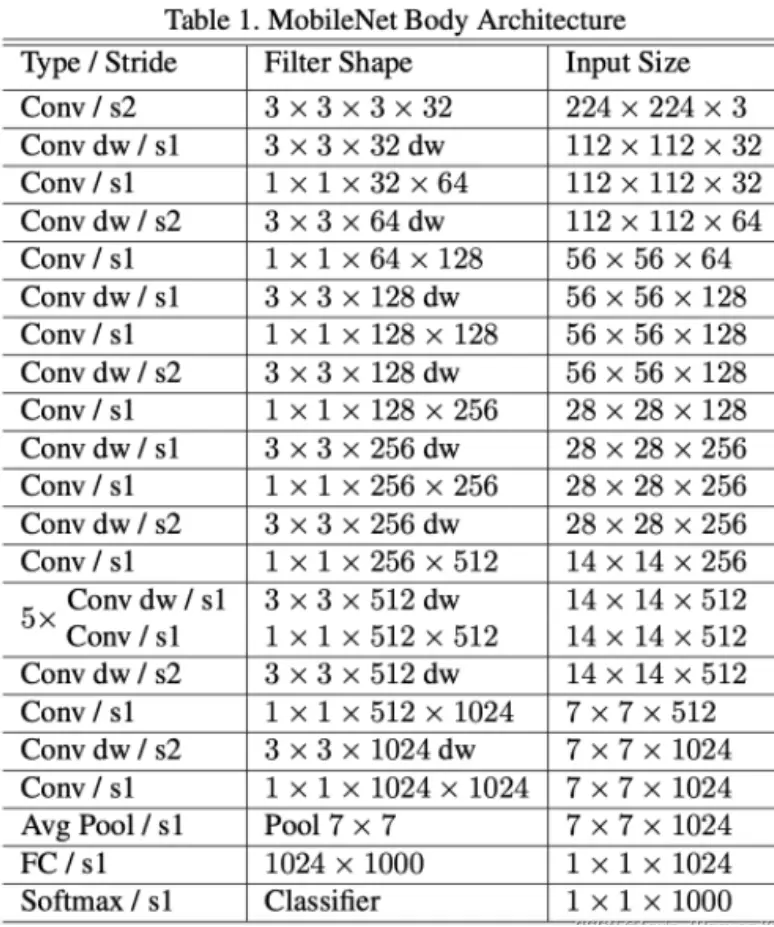
 往后走就是逐层加逐点,
往后走就是逐层加逐点,
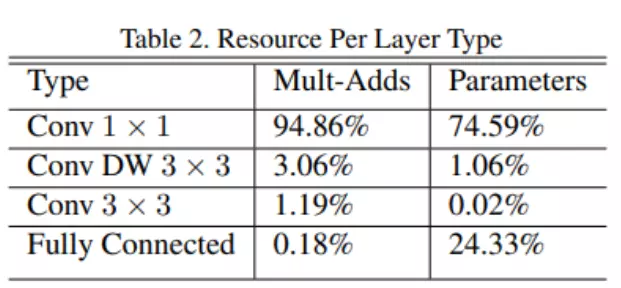
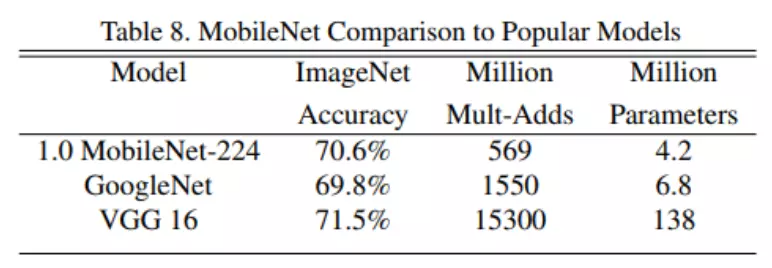
 #这是正常的残差,引入到mobilenet会出现问题,因为
#这是正常的残差,引入到mobilenet会出现问题,因为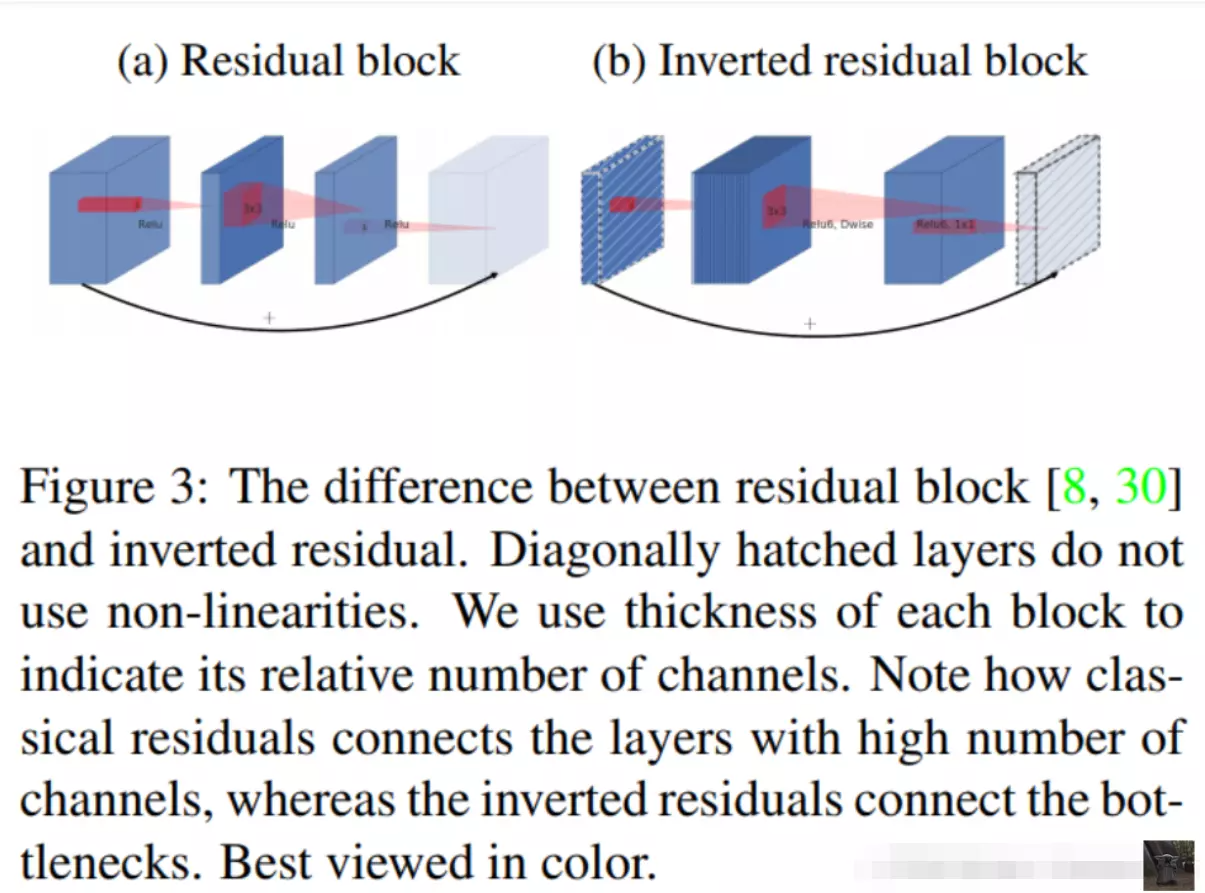
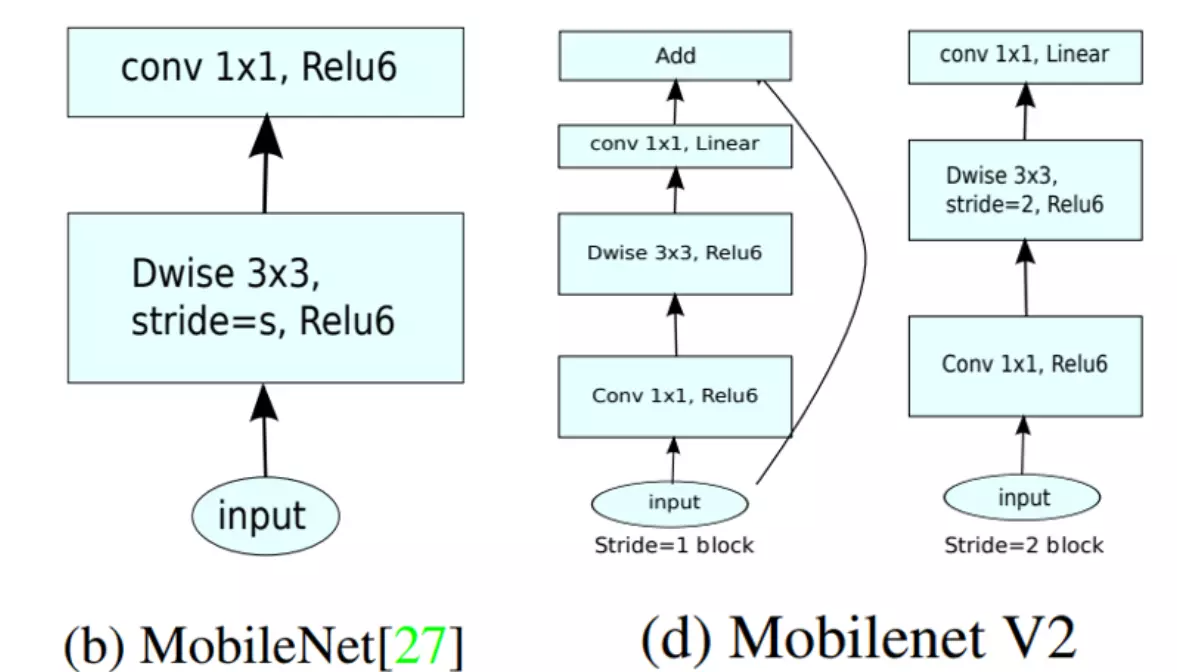
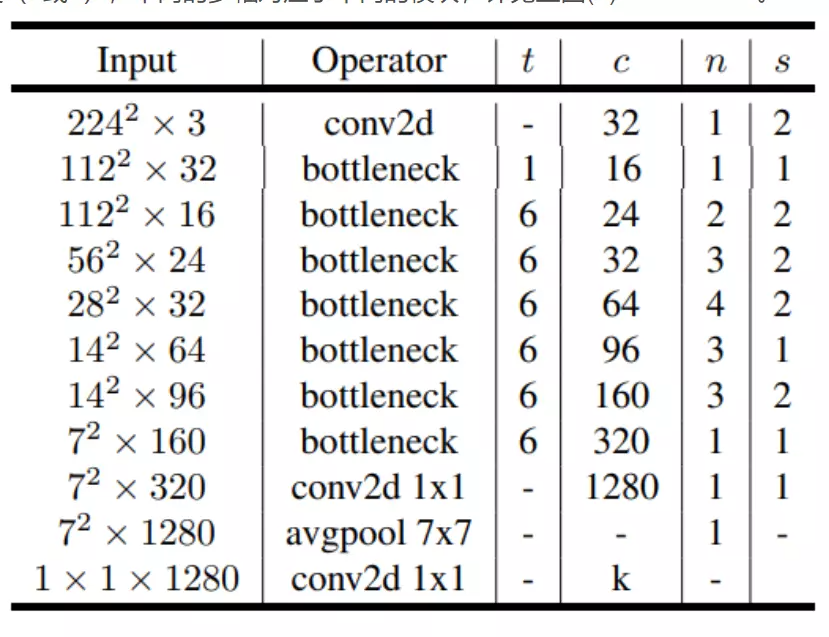
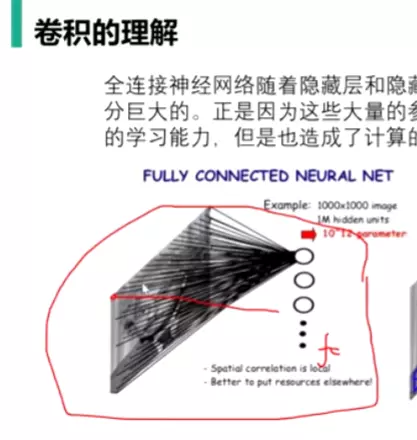
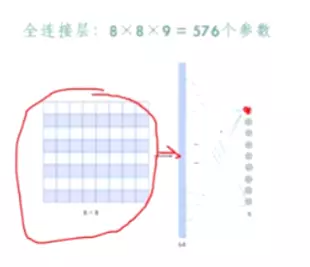 与每个节点做连接。这是一个的fc啊,但是如果你用1*1的卷积的话,你就不用打平了,就跟刚才图
与每个节点做连接。这是一个的fc啊,但是如果你用1*1的卷积的话,你就不用打平了,就跟刚才图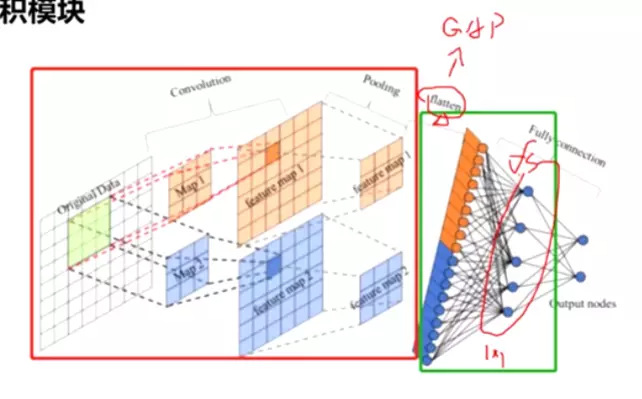
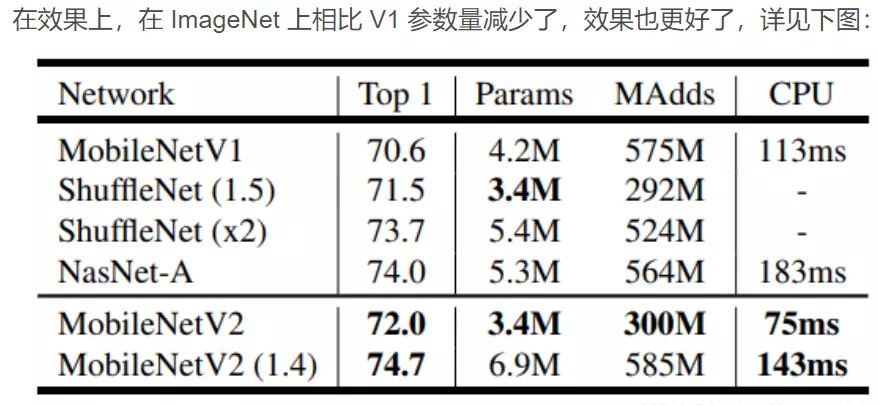
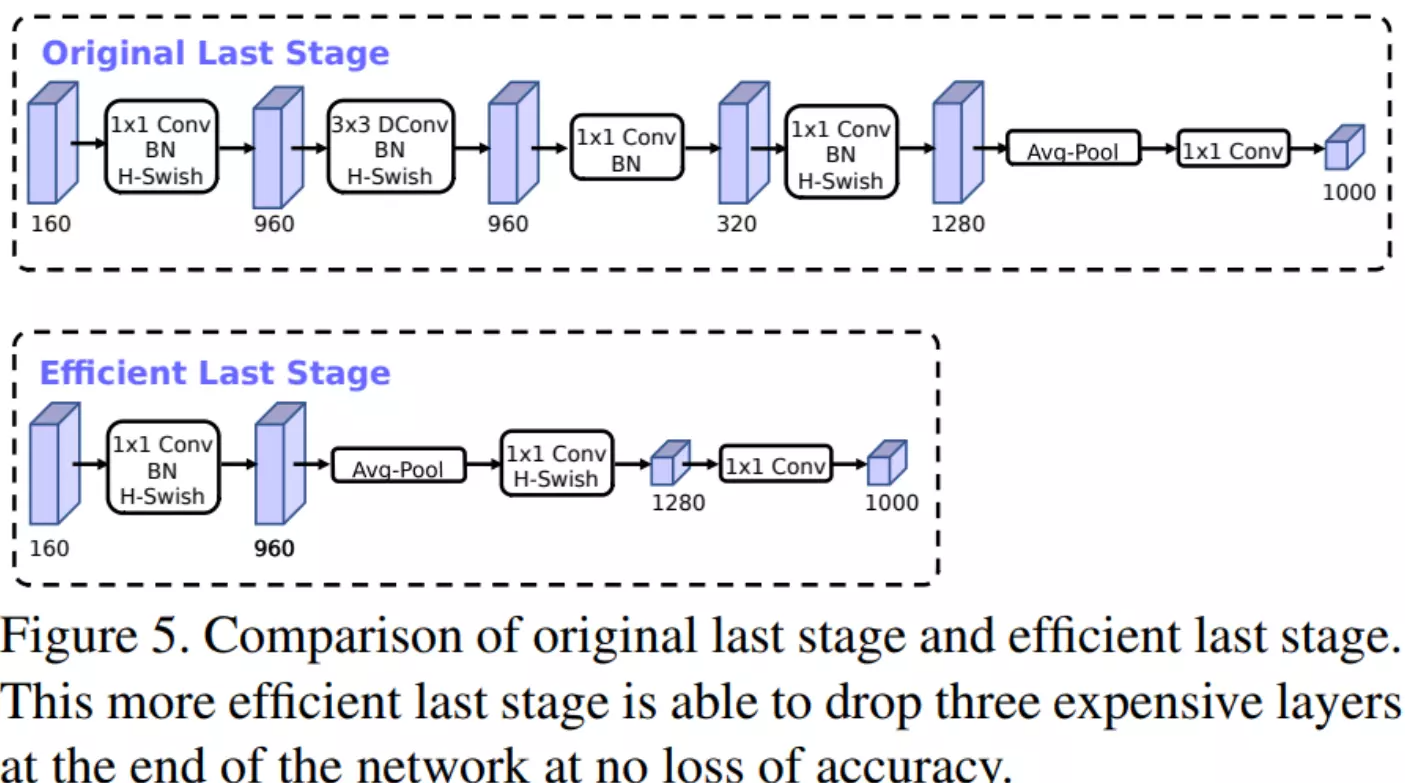
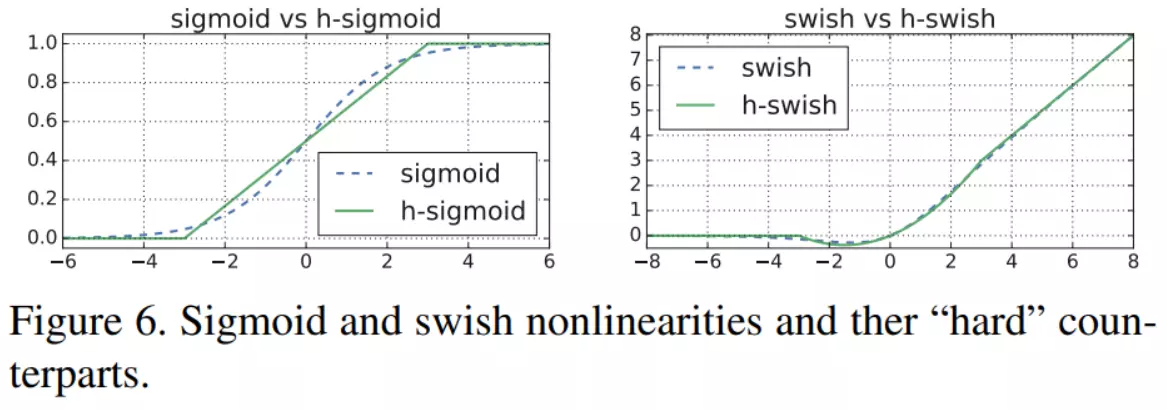
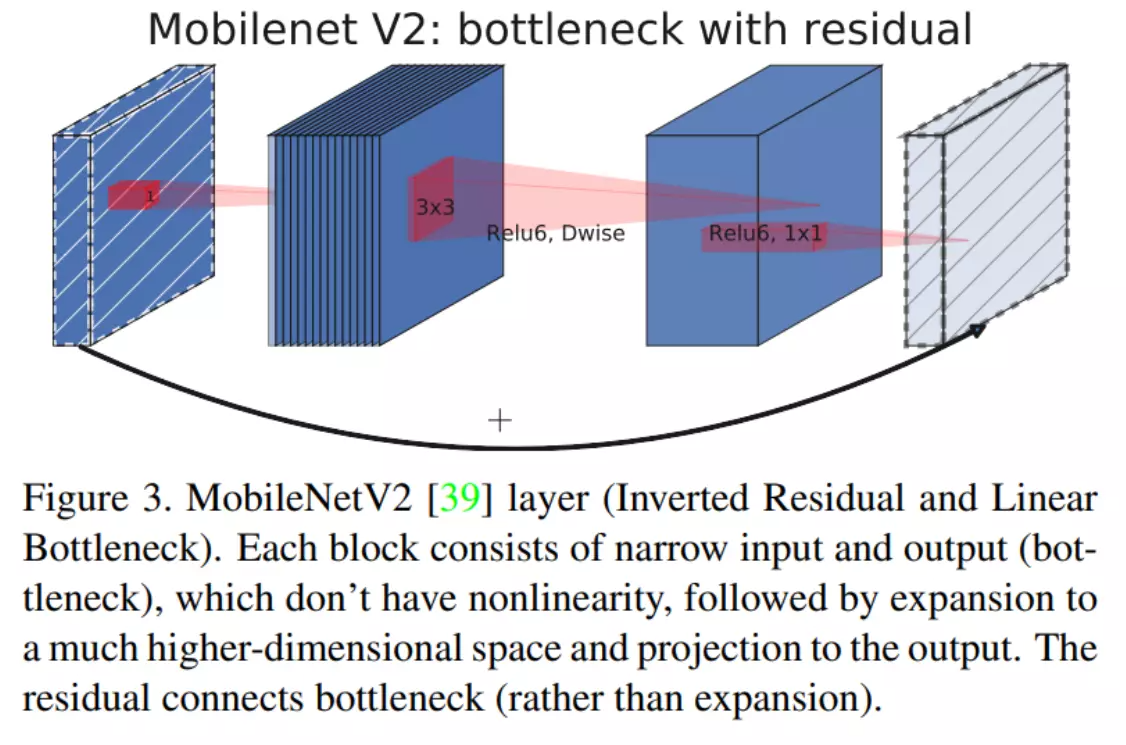


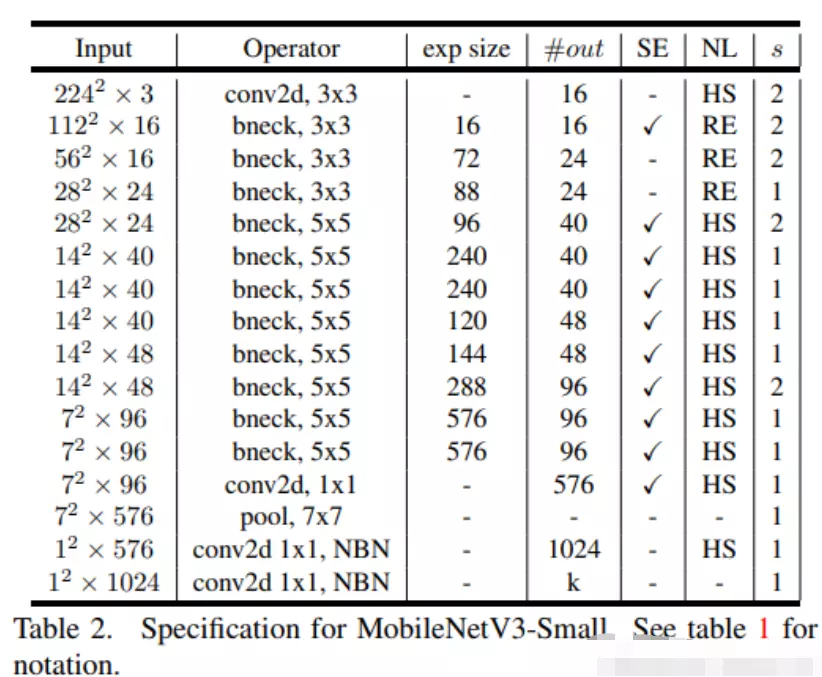
 ;V2翻转残差模块(先升维再逐层逐点在降回去)和线性瓶颈结构(讲最后的relu换成一个线性的激活,相当于什么也不做,relu可以进一步丢失的信息
;V2翻转残差模块(先升维再逐层逐点在降回去)和线性瓶颈结构(讲最后的relu换成一个线性的激活,相当于什么也不做,relu可以进一步丢失的信息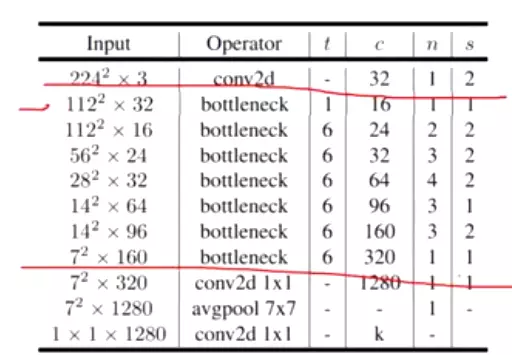 );V3延续V2两个技巧,
);V3延续V2两个技巧,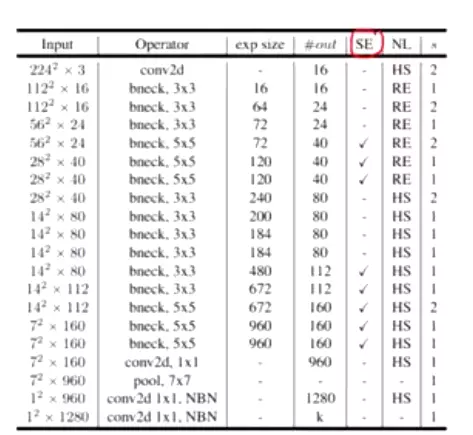 用来NAS网络搜索和SE模块,
用来NAS网络搜索和SE模块,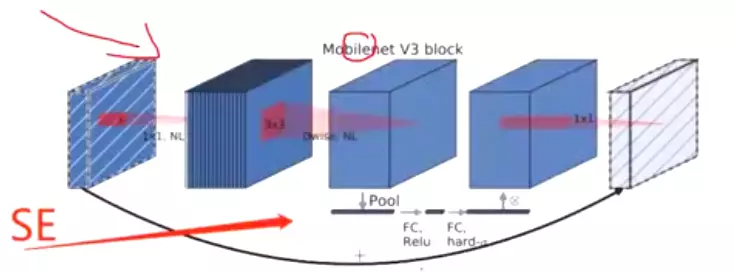 SE就是对通道重要程度做了一个重分配,增加attention map。SE不是在每一个blcok都有,这是NAS网络搜索的结果,整个模型架构不太规范。HS是更好的激活函数,
SE就是对通道重要程度做了一个重分配,增加attention map。SE不是在每一个blcok都有,这是NAS网络搜索的结果,整个模型架构不太规范。HS是更好的激活函数,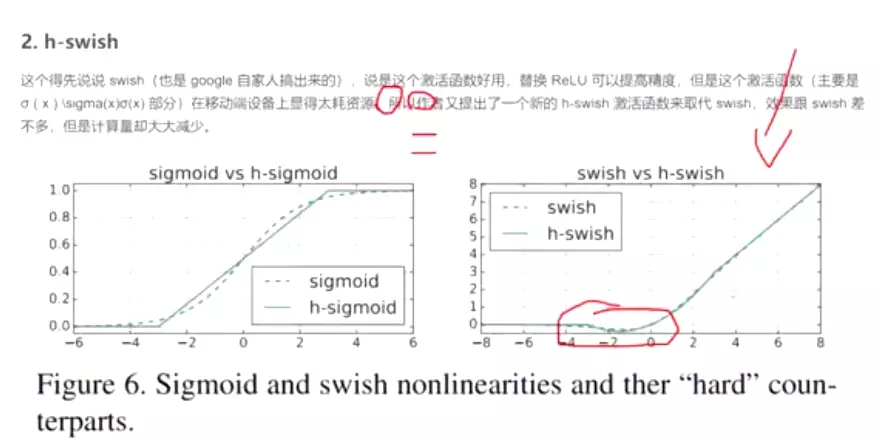 ,这里由于是nas网络搜索出来的,
,这里由于是nas网络搜索出来的,
 目的是防止看代码时,不记得当初指定的超参是什么属性的超参。
目的是防止看代码时,不记得当初指定的超参是什么属性的超参。

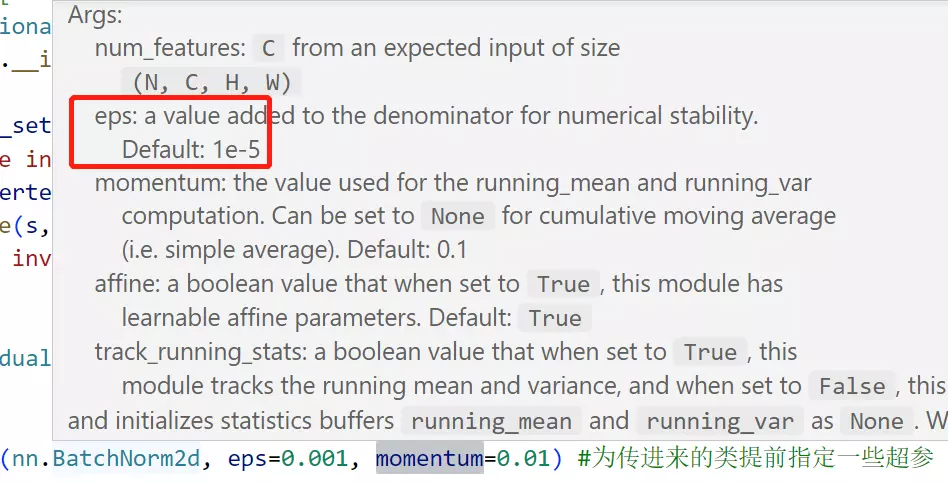 例如eps默认值是0.00001,这里给它指定为0.001,
例如eps默认值是0.00001,这里给它指定为0.001, #utils放的是训练脚本的工具,其中distrubute_utils.py是这个多GPU训练时启动脚本的工具,里面放了一些函数和类;lr_methods.py是学习率的一种方式,将来如果有新的学习率的方式,也可以放到里边;train_engin.py这个是一个训练的引擎,将每一轮训练的步骤放到这里边。将来做训练的时候,可以直接调用这个包儿里边的函数。
#utils放的是训练脚本的工具,其中distrubute_utils.py是这个多GPU训练时启动脚本的工具,里面放了一些函数和类;lr_methods.py是学习率的一种方式,将来如果有新的学习率的方式,也可以放到里边;train_engin.py这个是一个训练的引擎,将每一轮训练的步骤放到这里边。将来做训练的时候,可以直接调用这个包儿里边的函数。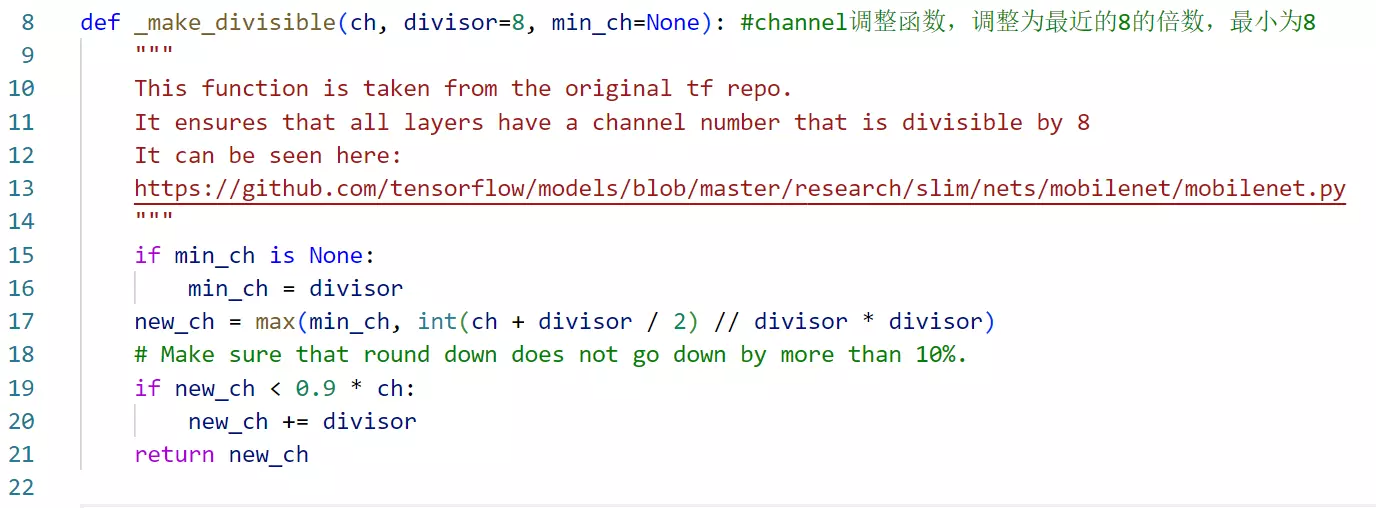



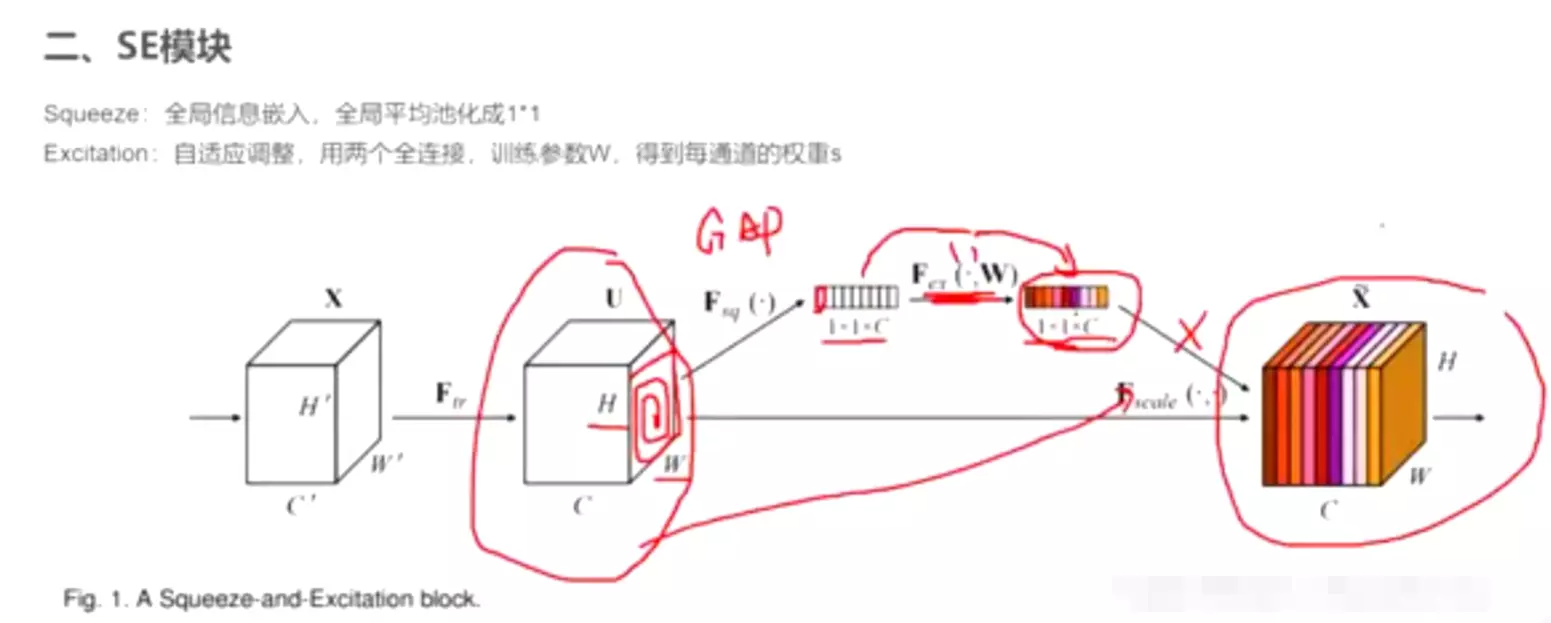
 #因为网络不规整,
#因为网络不规整,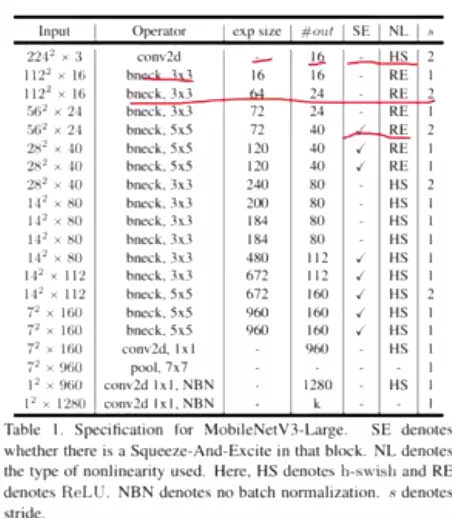 所以用了一个配置类,形成参数列表:
所以用了一个配置类,形成参数列表: (转置残差)这一步就是先扩张通道数。
(转置残差)这一步就是先扩张通道数。 InvertedResidualConfig函数就是一个文件配置类。去实现模型的时候,会把这个文件配置给写好,这里第一个参数就是配成类里面的input channel,第二个就是kernel size,第三个就是卷积输出的通道数量,第四个就是每个block的输出通道数量,第五个就是用不用SE,第六个用哪个激活函数,第七个用不用步长。这里给他配置好,而且这个表其实和论文里边这个表
InvertedResidualConfig函数就是一个文件配置类。去实现模型的时候,会把这个文件配置给写好,这里第一个参数就是配成类里面的input channel,第二个就是kernel size,第三个就是卷积输出的通道数量,第四个就是每个block的输出通道数量,第五个就是用不用SE,第六个用哪个激活函数,第七个用不用步长。这里给他配置好,而且这个表其实和论文里边这个表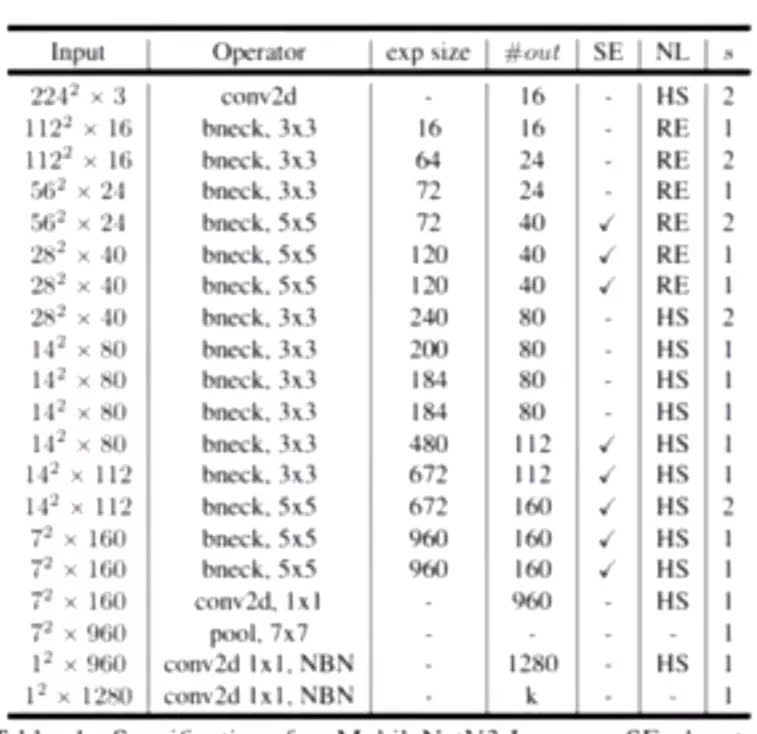


 if cnf.expanded_c != cnf.input_c: #如果不相等提升通道数,这个参数就是升维
if cnf.expanded_c != cnf.input_c: #如果不相等提升通道数,这个参数就是升维 ,
,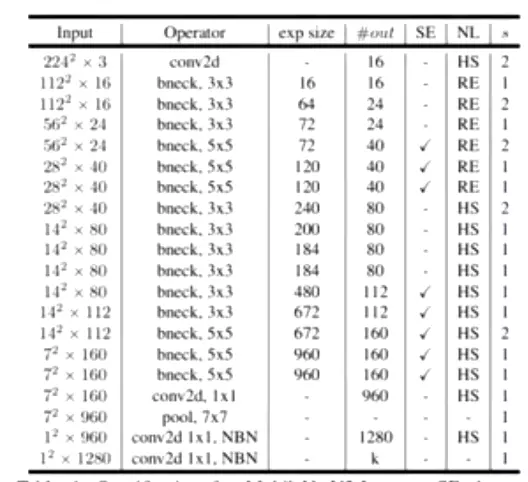 上面把所有组件建好了,下面就是搭建模型了。
上面把所有组件建好了,下面就是搭建模型了。
 要传进来,整个要传进来的参数会很长很长。这里把block参数封装成一个配置文件:
要传进来,整个要传进来的参数会很长很长。这里把block参数封装成一个配置文件: 还需要告诉模型block长什么样子,是翻转的残差block还是正常的block,还是用的VGG的block,所以用
还需要告诉模型block长什么样子,是翻转的残差block还是正常的block,还是用的VGG的block,所以用 这里不是冗余,而是代码的优雅。
这里不是冗余,而是代码的优雅。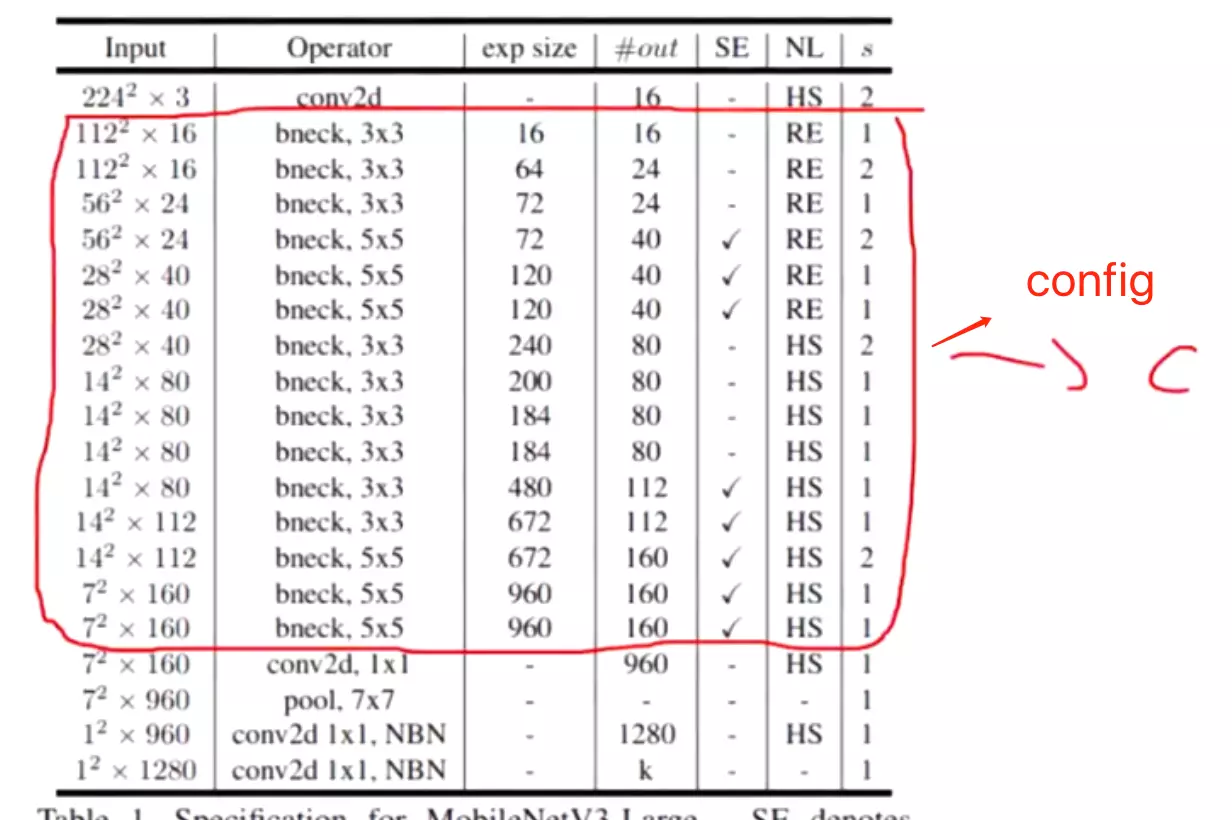
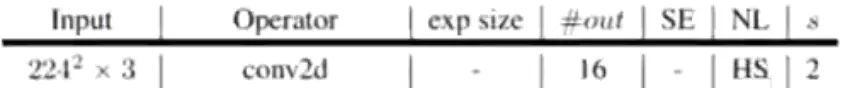 所以先搭建第一层:
所以先搭建第一层:
 for循环能完成这么多层的搭建,添加到空列表里。
for循环能完成这么多层的搭建,添加到空列表里。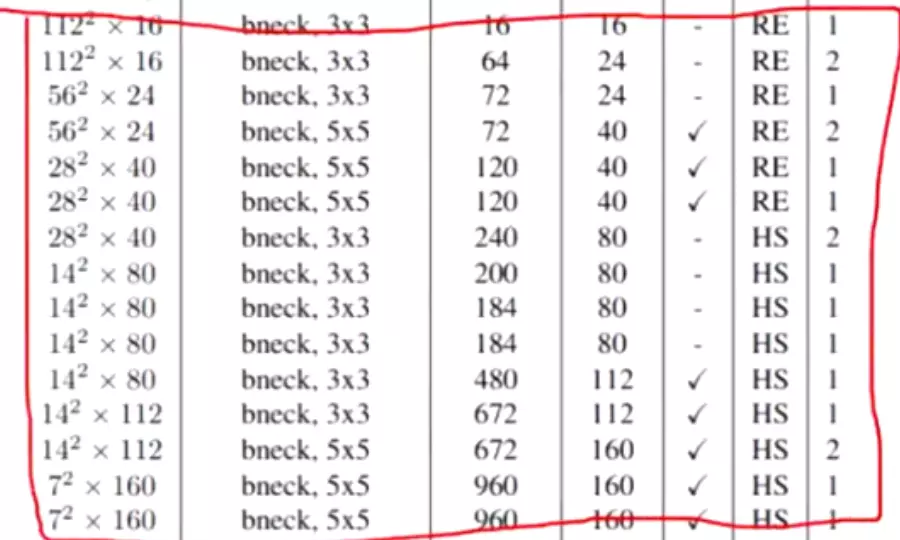

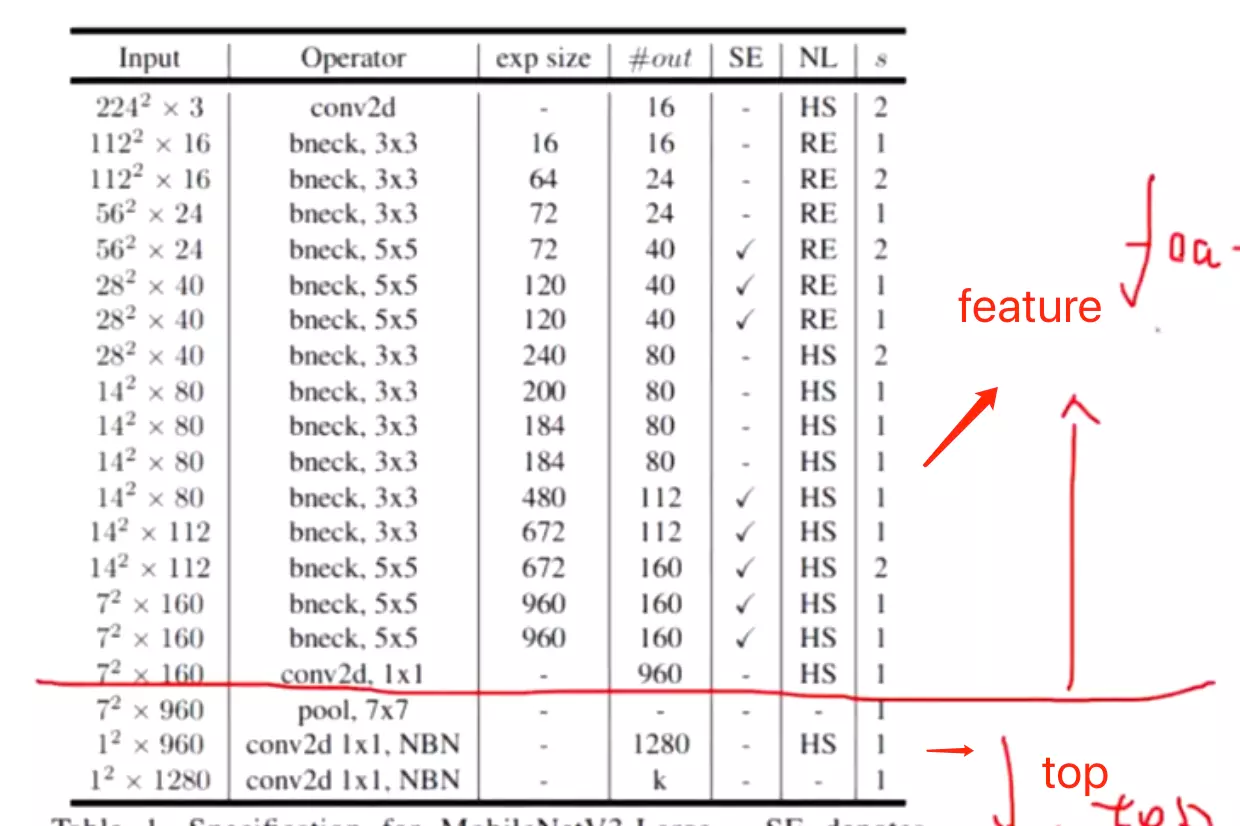 分成feature部分和top部分,分别搭建。
分成feature部分和top部分,分别搭建。

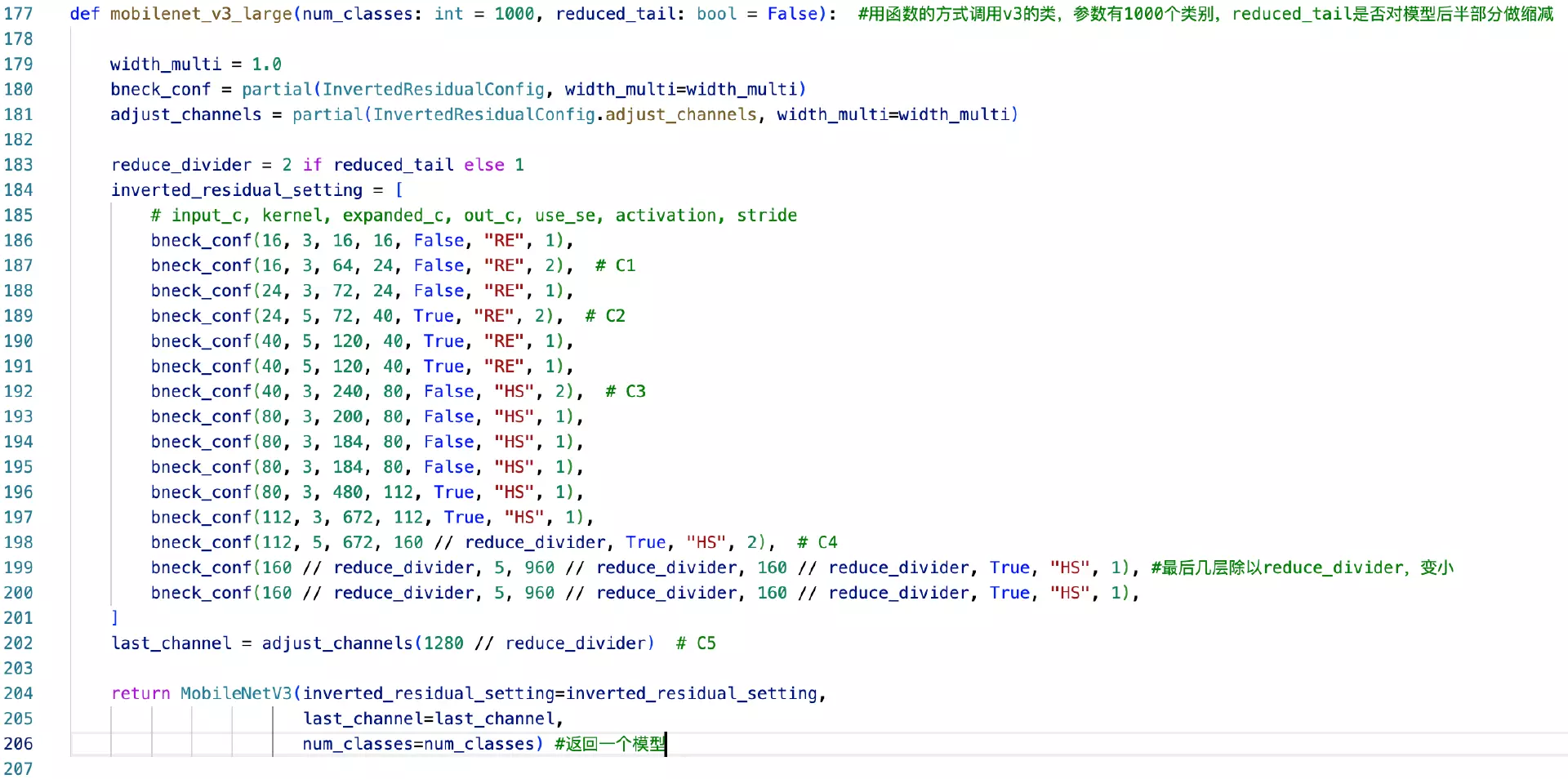
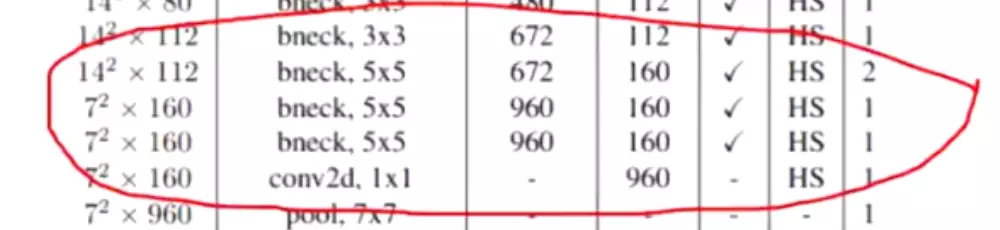
 全连接指定是多少,可以任意指定。他指定了1280。
全连接指定是多少,可以任意指定。他指定了1280。
 #这个细节,这里是7*7的卷积。因为到pool这层的时候,经过几次下采样
#这个细节,这里是7*7的卷积。因为到pool这层的时候,经过几次下采样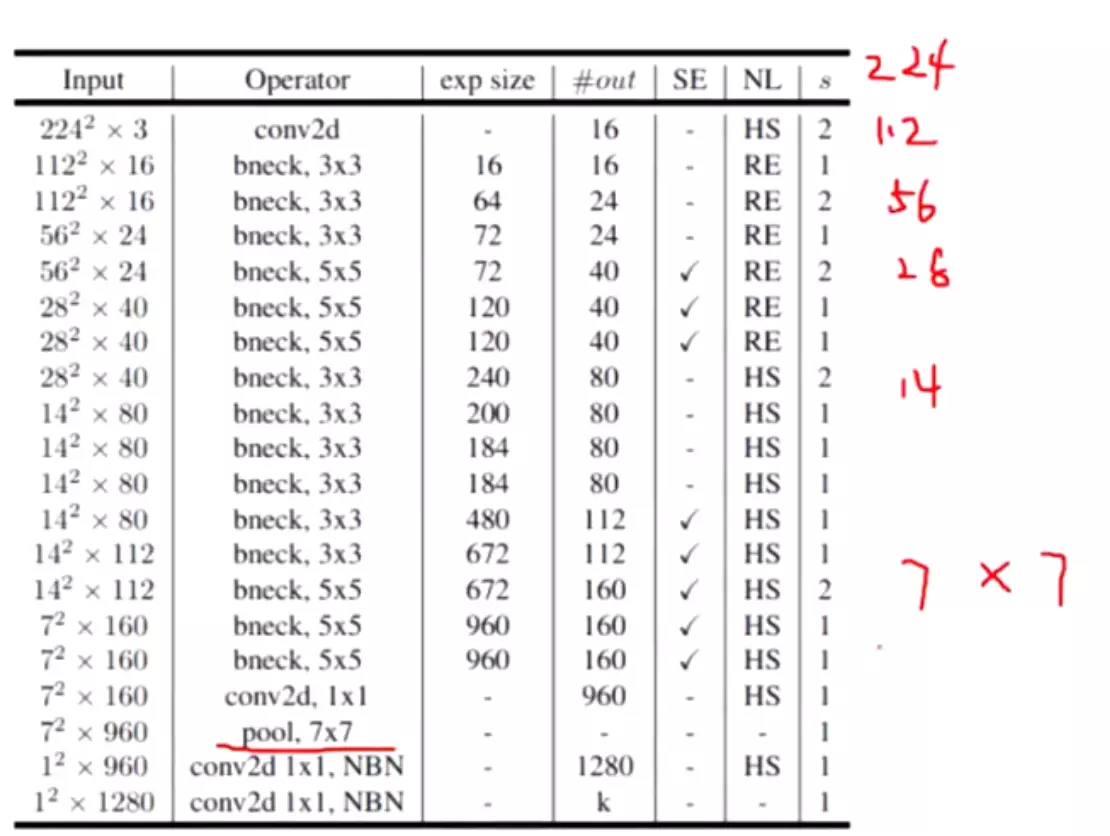
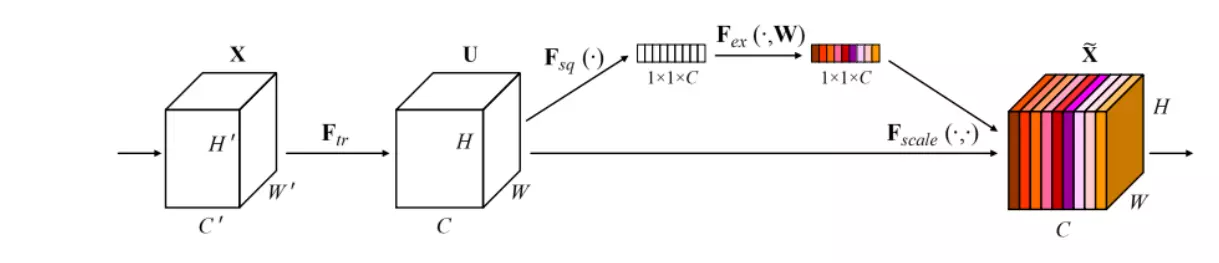
 所以得到的一个值就可以一定程度上去表征原始的这张featuremap的信息。所以这个向量就表征了原本一组featuremap的信息,只不过是作为一个精简。然后再把这个向量送进一个全连接神经网络去做映射。就是后面会跟一个全连接神经网络,最后也会得到1*1的向量。做映射的目的就是让网络自己去学习当前的attention。就是让网络自己去学习,这个channel,就是这一张featuremap哪个重要程度更多一些,哪个重要程度更少一些,学完他就是长这个样子
所以得到的一个值就可以一定程度上去表征原始的这张featuremap的信息。所以这个向量就表征了原本一组featuremap的信息,只不过是作为一个精简。然后再把这个向量送进一个全连接神经网络去做映射。就是后面会跟一个全连接神经网络,最后也会得到1*1的向量。做映射的目的就是让网络自己去学习当前的attention。就是让网络自己去学习,这个channel,就是这一张featuremap哪个重要程度更多一些,哪个重要程度更少一些,学完他就是长这个样子

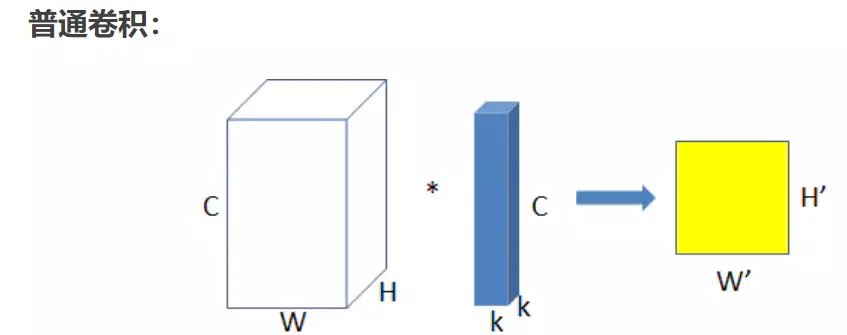
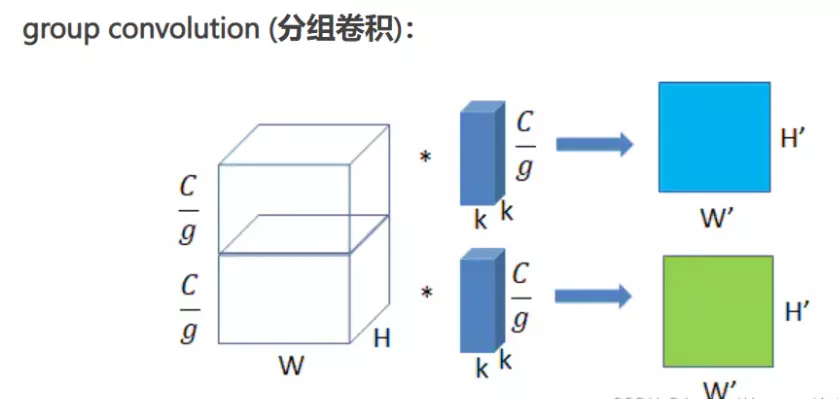
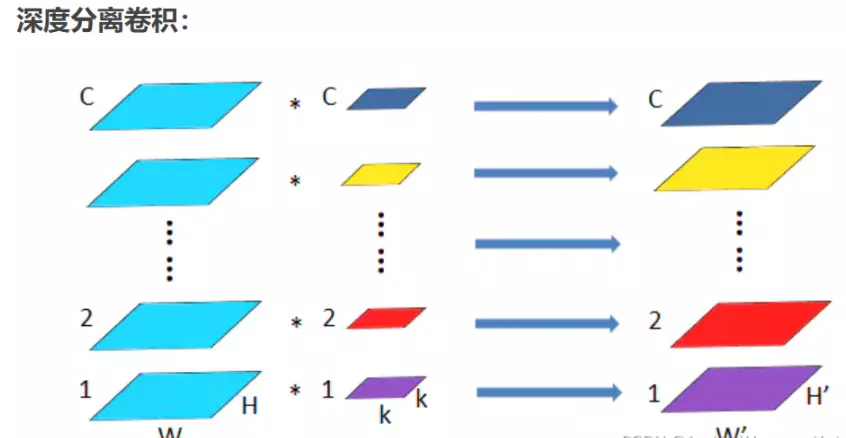
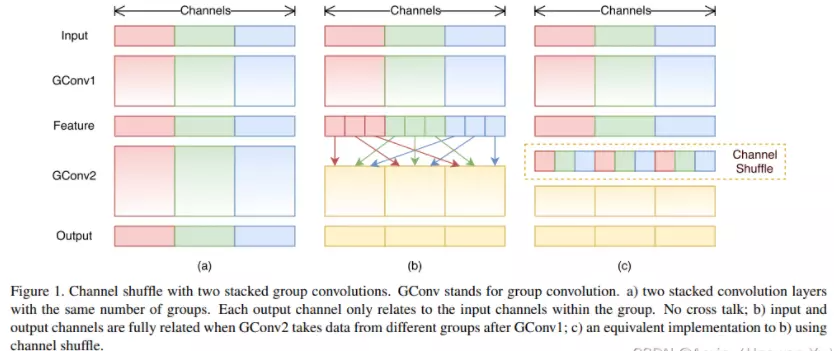
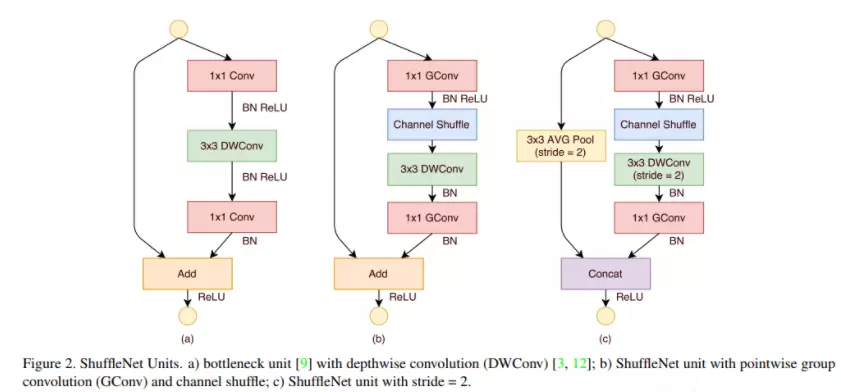 #首先左边的a是哪一个结构?是不是Mobile net里面的block。
#首先左边的a是哪一个结构?是不是Mobile net里面的block。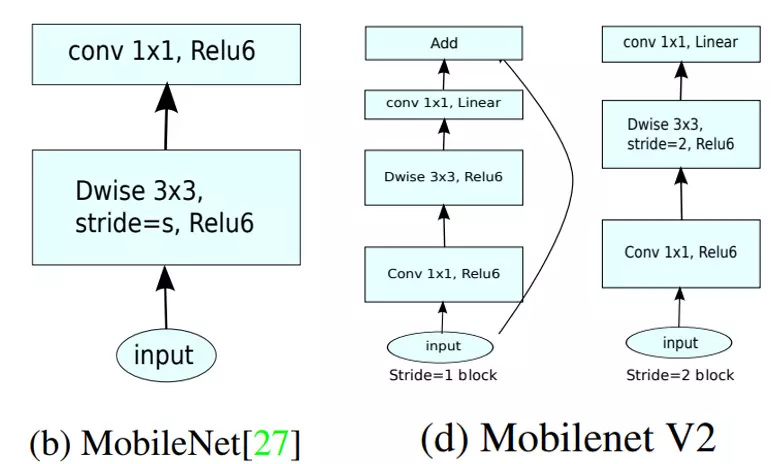
 。
。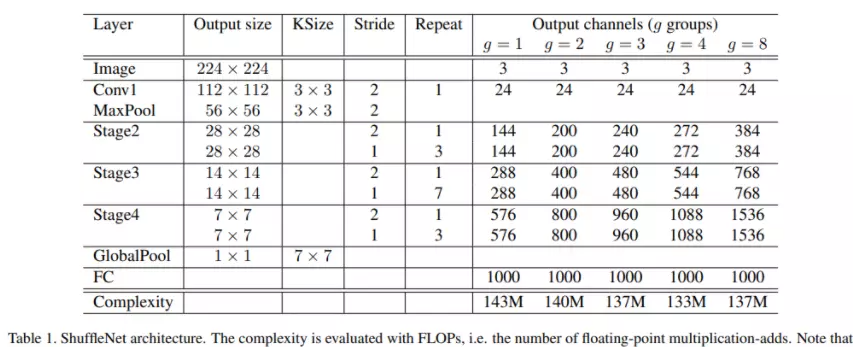
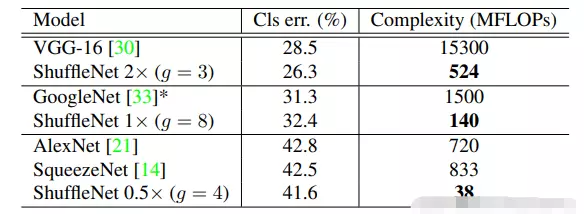


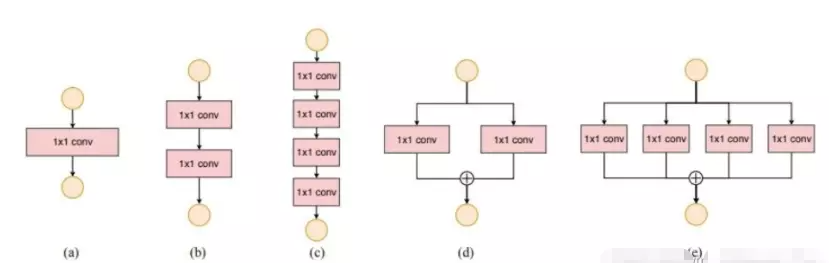

 ,
,
 #
#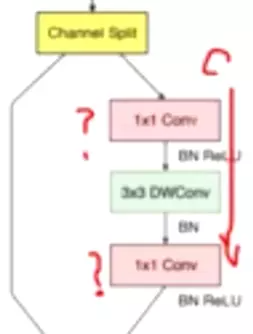 #
#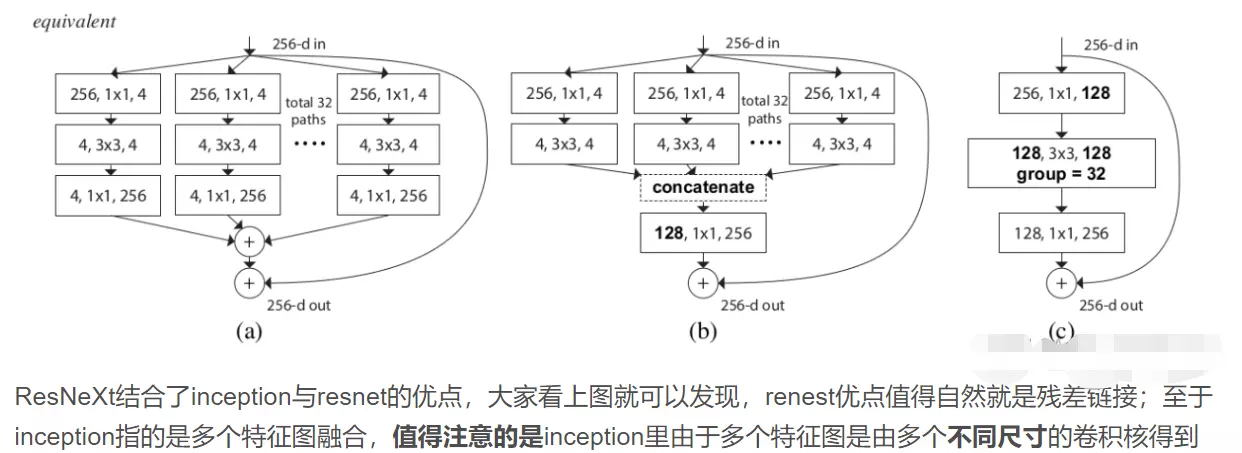
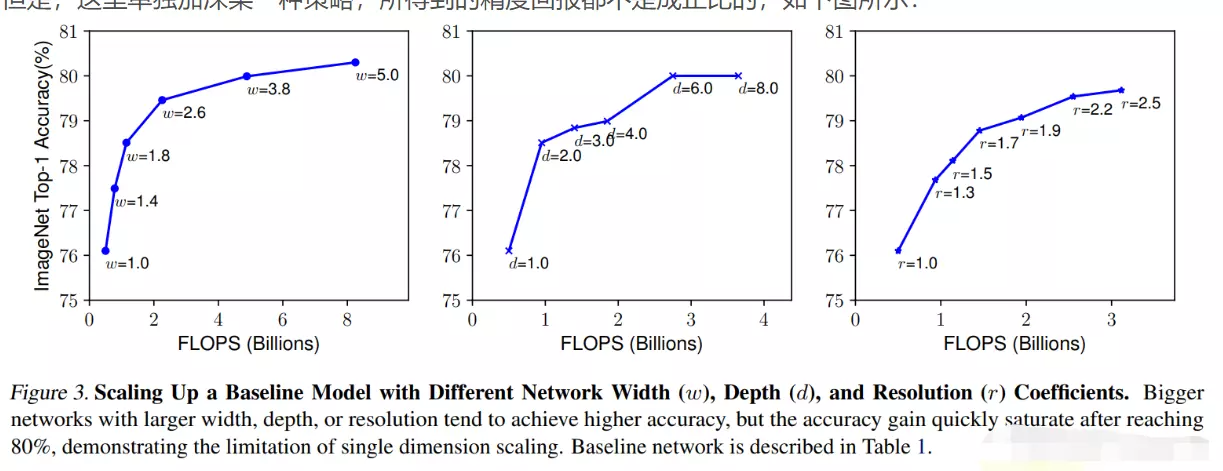
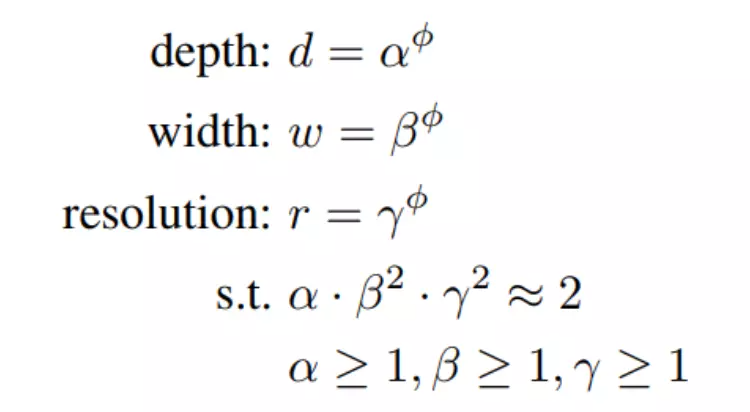

 ,对上面的stage少发大一些,对下面的stage多放大一些,这样得到的模型准确率会更高。
,对上面的stage少发大一些,对下面的stage多放大一些,这样得到的模型准确率会更高。 引入改进的渐进式学习的策略
引入改进的渐进式学习的策略
 #目标检测:输入是图像,输出是三类,1是bounding box边界框;2是识别任务;3是
#目标检测:输入是图像,输出是三类,1是bounding box边界框;2是识别任务;3是





 这个步骤就是调整随机生产的锚框的大小。
这个步骤就是调整随机生产的锚框的大小。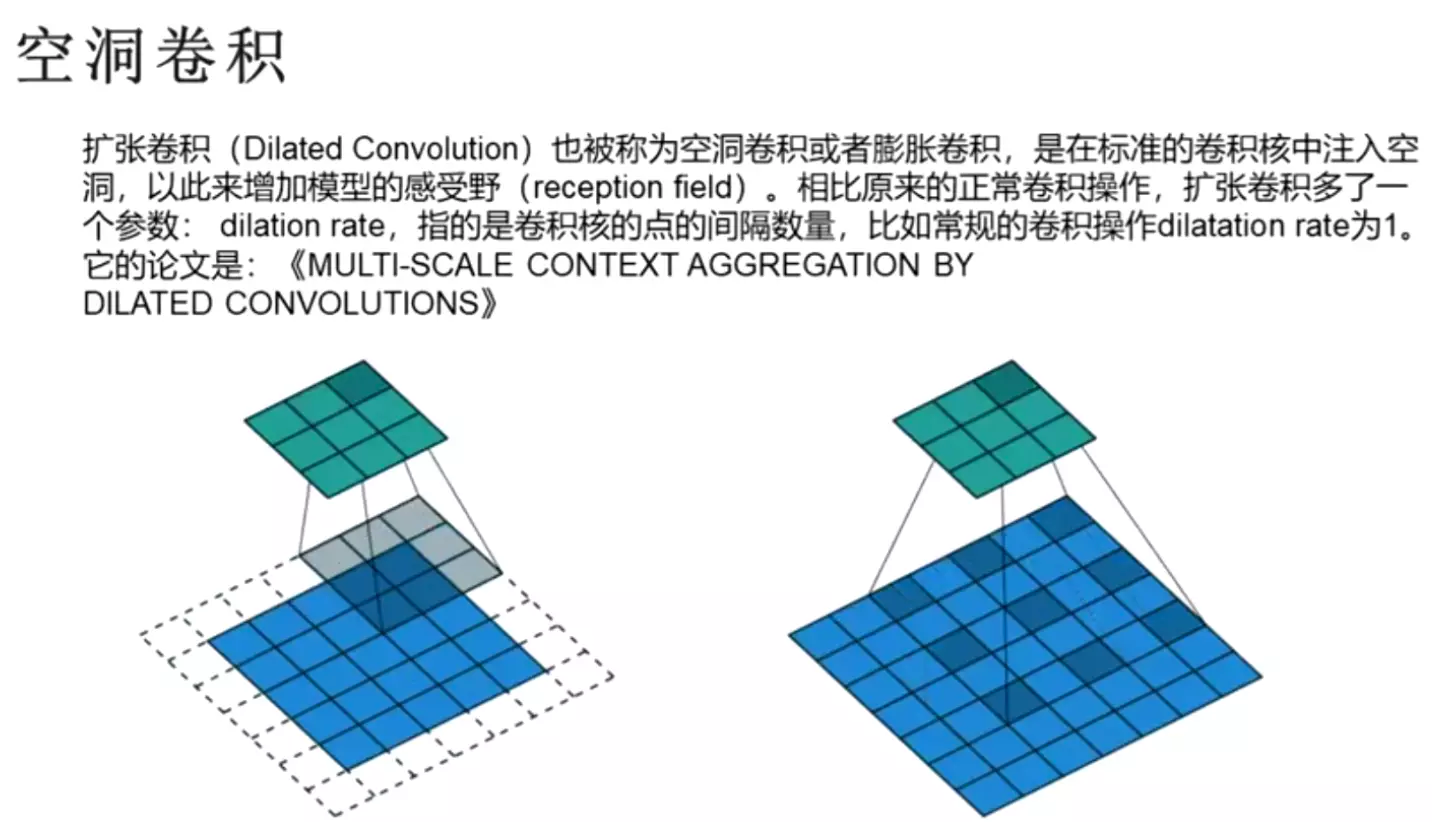 #类似逐层卷积和逐点卷积合起来话叫做深度可分离卷积;卷积的变体有20多种。空洞卷积右图,就是为了扩大感受野。
#类似逐层卷积和逐点卷积合起来话叫做深度可分离卷积;卷积的变体有20多种。空洞卷积右图,就是为了扩大感受野。


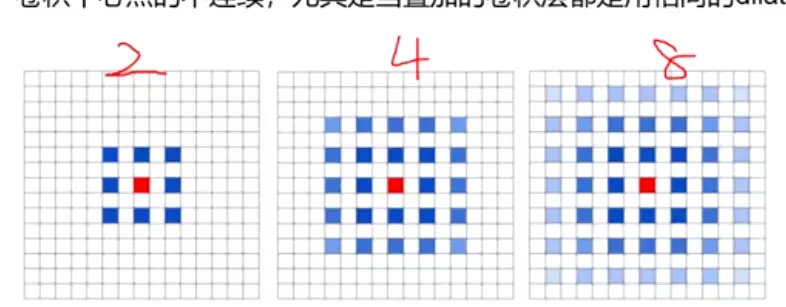 这样改是否可以? 答:不行,不能让空洞率是倍数的关系。
这样改是否可以? 答:不行,不能让空洞率是倍数的关系。
 比如现在的远程会议,当前这个人就是保留一下前景,把背景做一个模糊,做一个虚化,甚至做一个改变,这个任务首先要区分前景和背景,其实就是一个语义分割任务。
比如现在的远程会议,当前这个人就是保留一下前景,把背景做一个模糊,做一个虚化,甚至做一个改变,这个任务首先要区分前景和背景,其实就是一个语义分割任务。

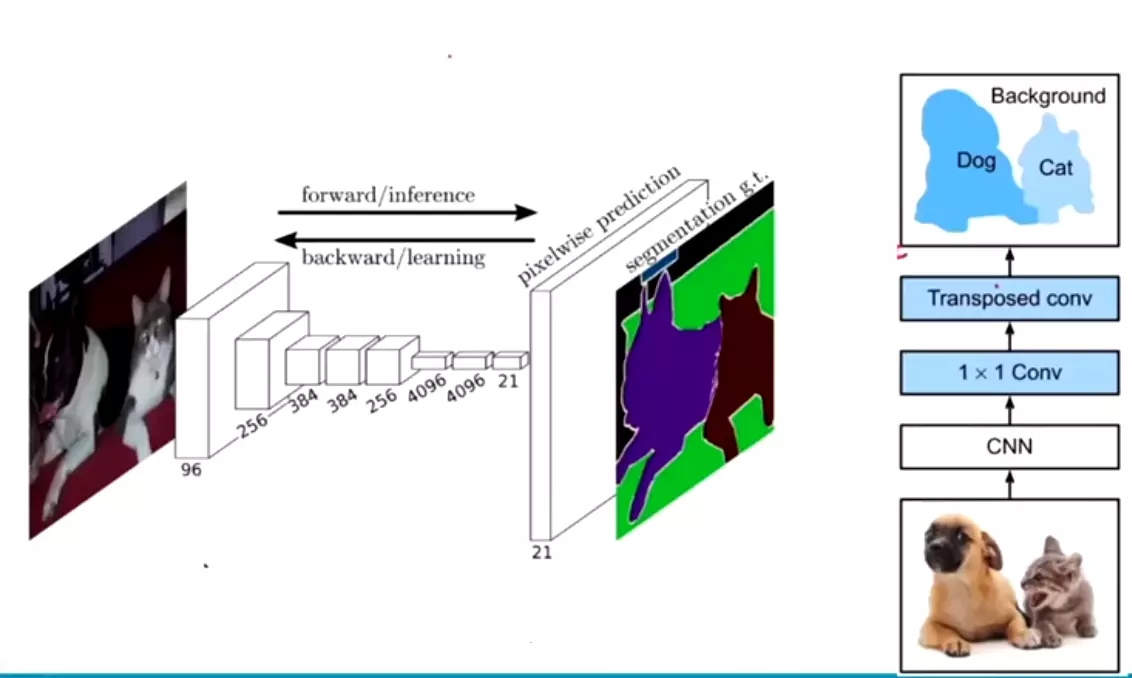
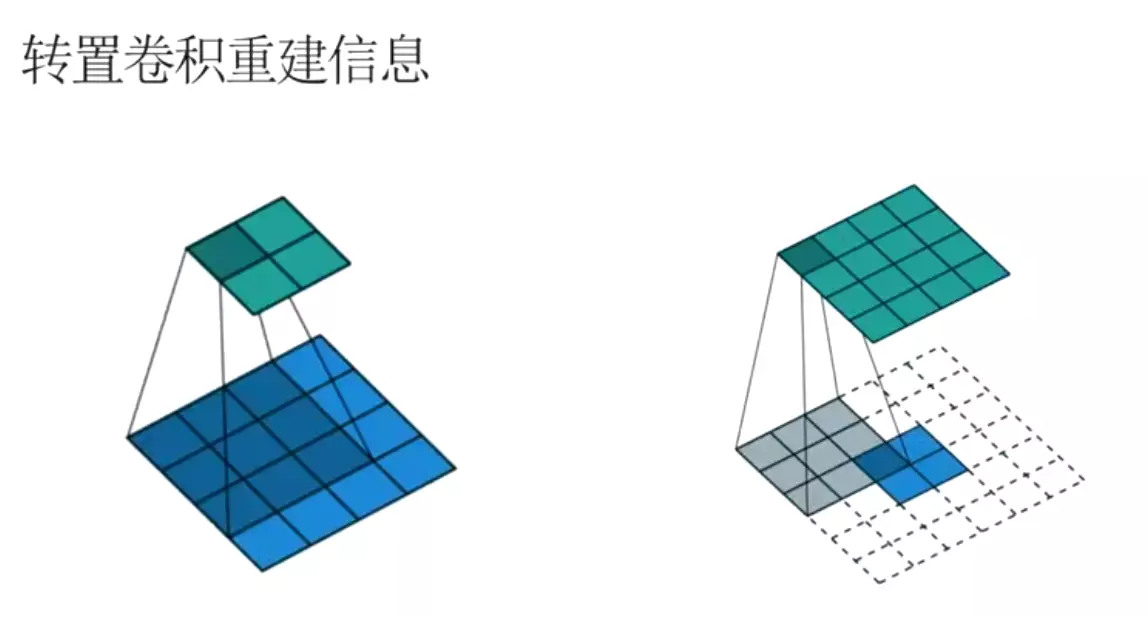
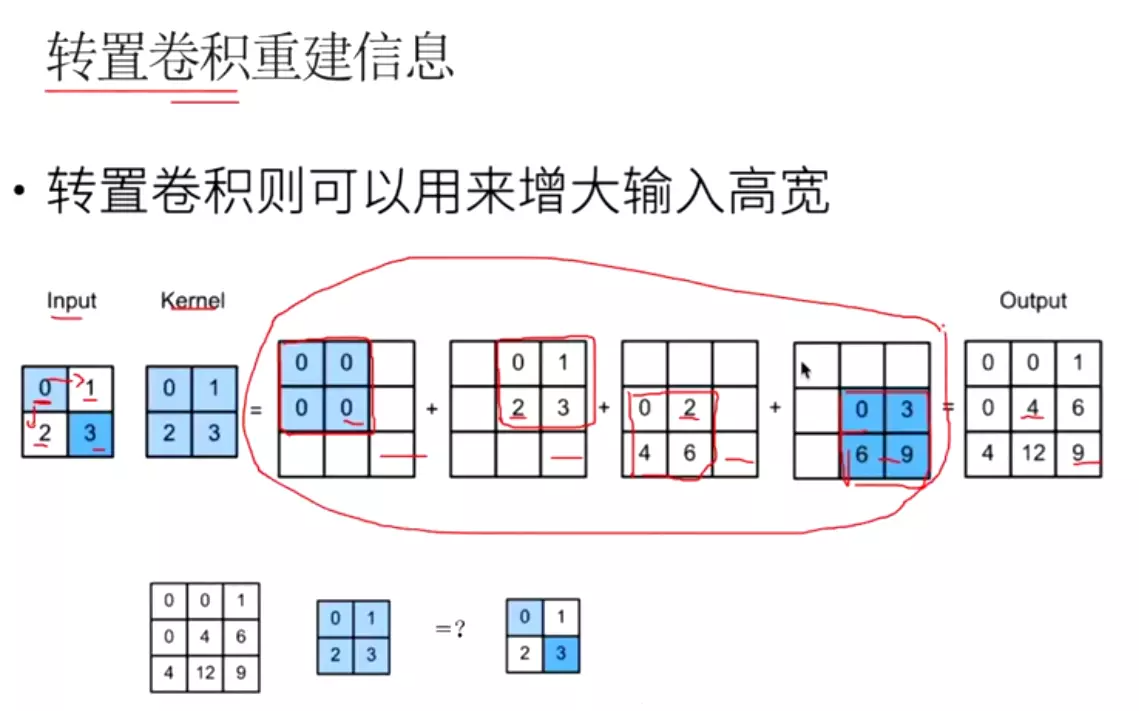


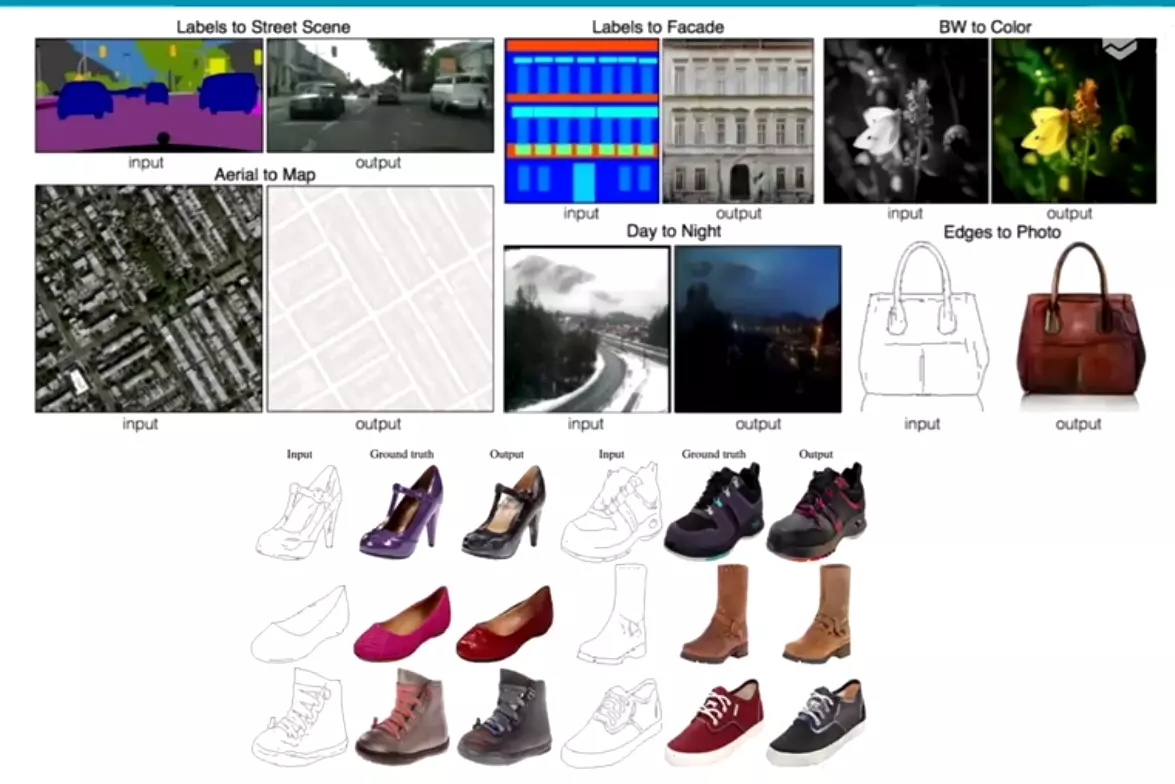 #首先GAN模型是做图像生成,图像生成分为很多子任务,例如风格迁移,生成人脸,改变发型,改变衣服等等。上图中展示的大部分是一些风格迁移的任务。可以看左上就是语音分割里面的一个迁移,就是会有一个模型输入是一些语音分割的这个结果,输出给你还原回真实的一个街景,现在我还能给他重建回去,重建回去用的就是一个干网络。左中图,,图像标注,这个地图是gan生成的,语言分割能做地图标注,其实干网络里边也可以用风格迁移的方法,把这个街景变成一个地图风格。中中图是白天转黑夜。中右图是草稿填色,gan网络都可以做。
#首先GAN模型是做图像生成,图像生成分为很多子任务,例如风格迁移,生成人脸,改变发型,改变衣服等等。上图中展示的大部分是一些风格迁移的任务。可以看左上就是语音分割里面的一个迁移,就是会有一个模型输入是一些语音分割的这个结果,输出给你还原回真实的一个街景,现在我还能给他重建回去,重建回去用的就是一个干网络。左中图,,图像标注,这个地图是gan生成的,语言分割能做地图标注,其实干网络里边也可以用风格迁移的方法,把这个街景变成一个地图风格。中中图是白天转黑夜。中右图是草稿填色,gan网络都可以做。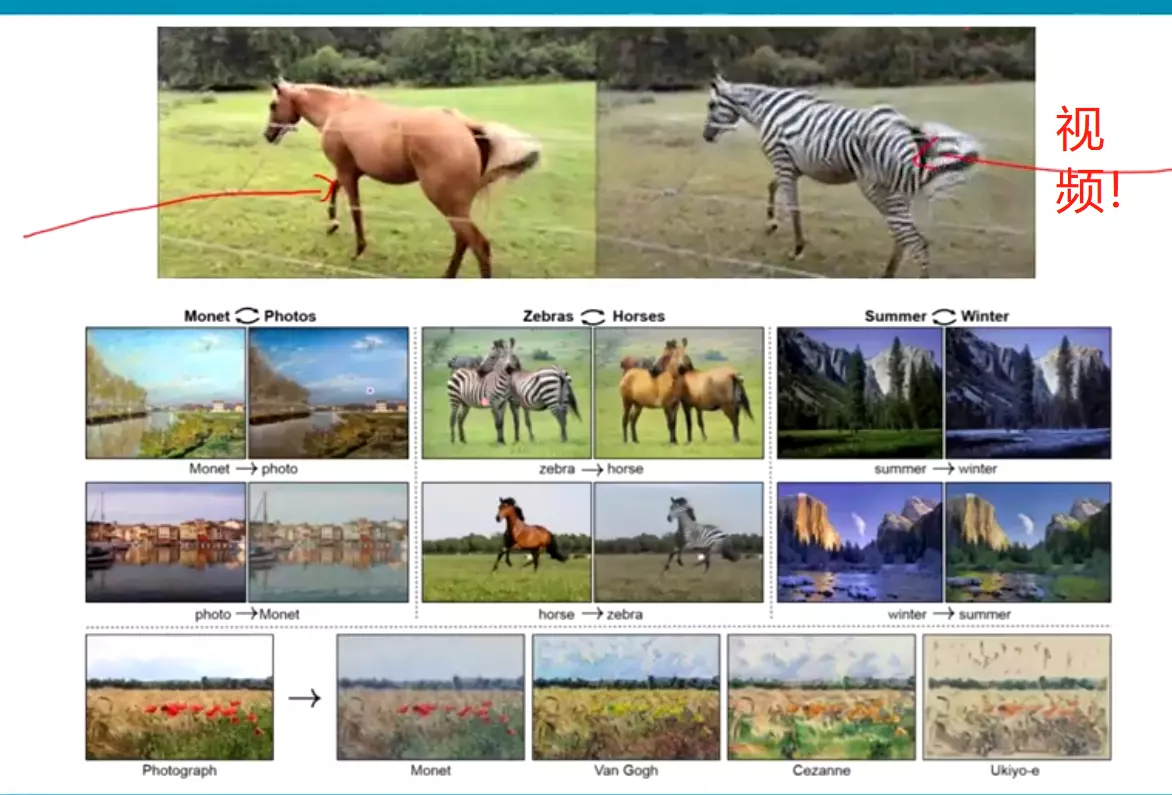




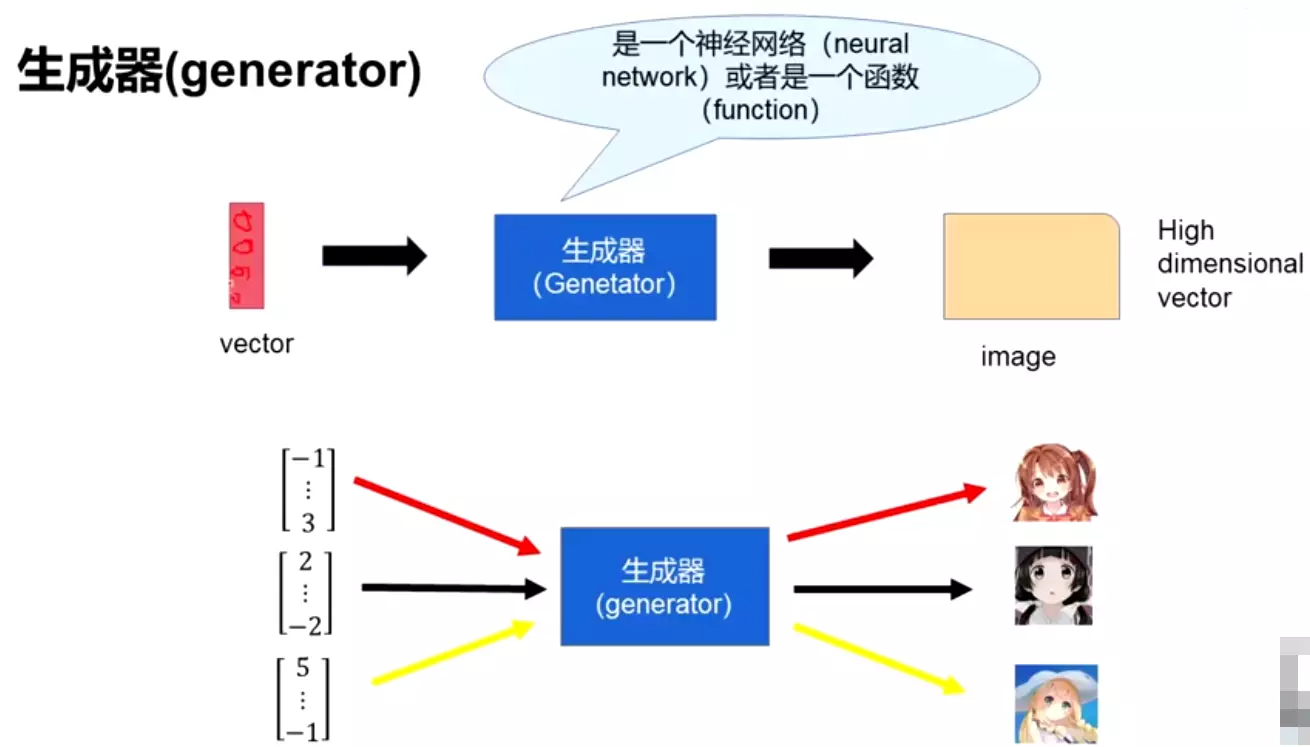
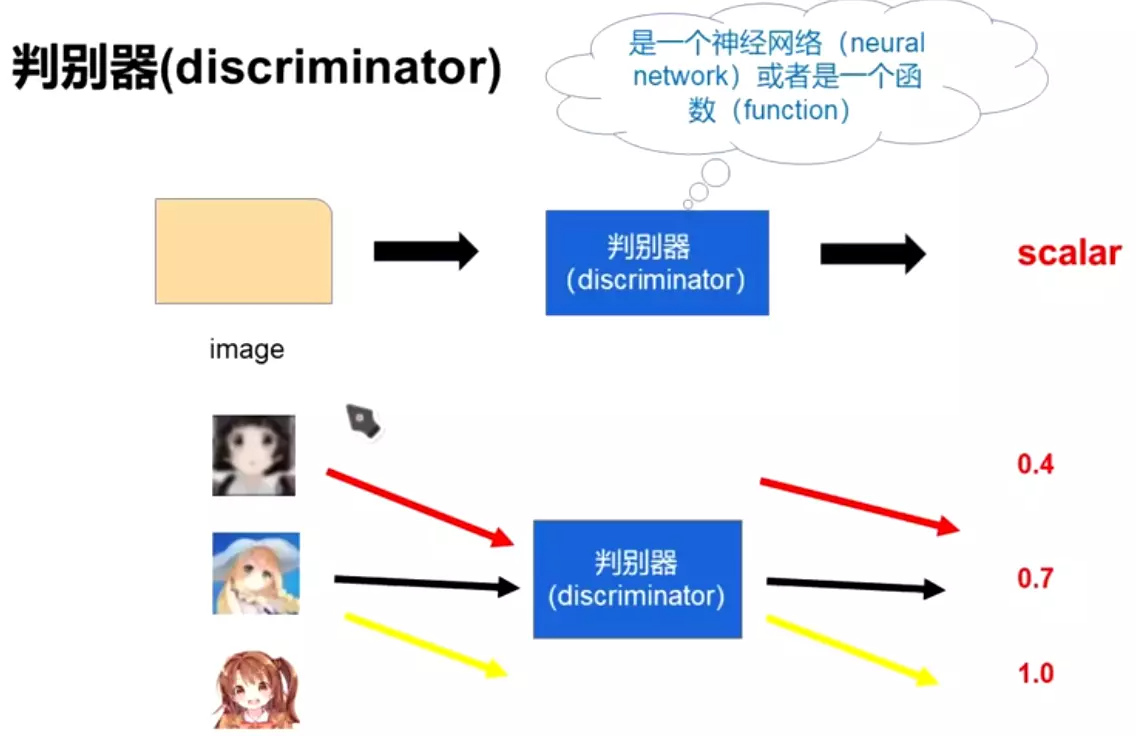 #判别器就是分类头,去接收到的这个图像。目的就是给当前接受到的图像打分。如果图像比较真,判决器就会给一个比较高的分值,如果这个图像不太真,就给他一个比较低的分值。可以看成一个分类任务。
#判别器就是分类头,去接收到的这个图像。目的就是给当前接受到的图像打分。如果图像比较真,判决器就会给一个比较高的分值,如果这个图像不太真,就给他一个比较低的分值。可以看成一个分类任务。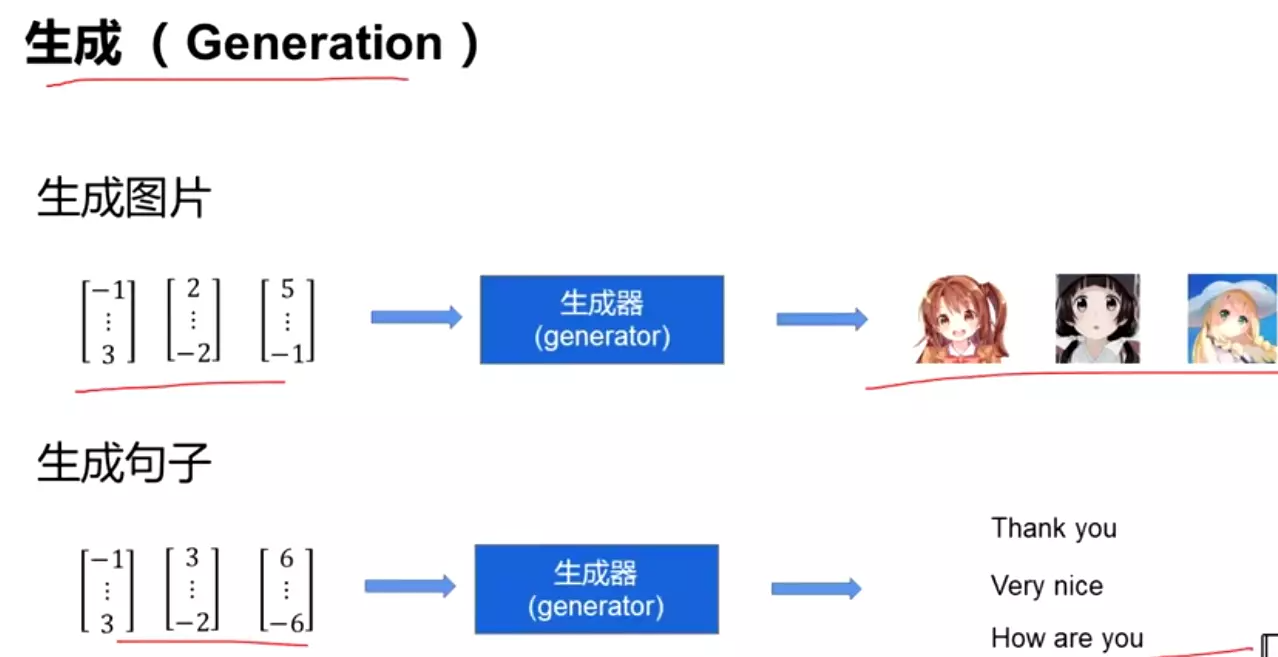
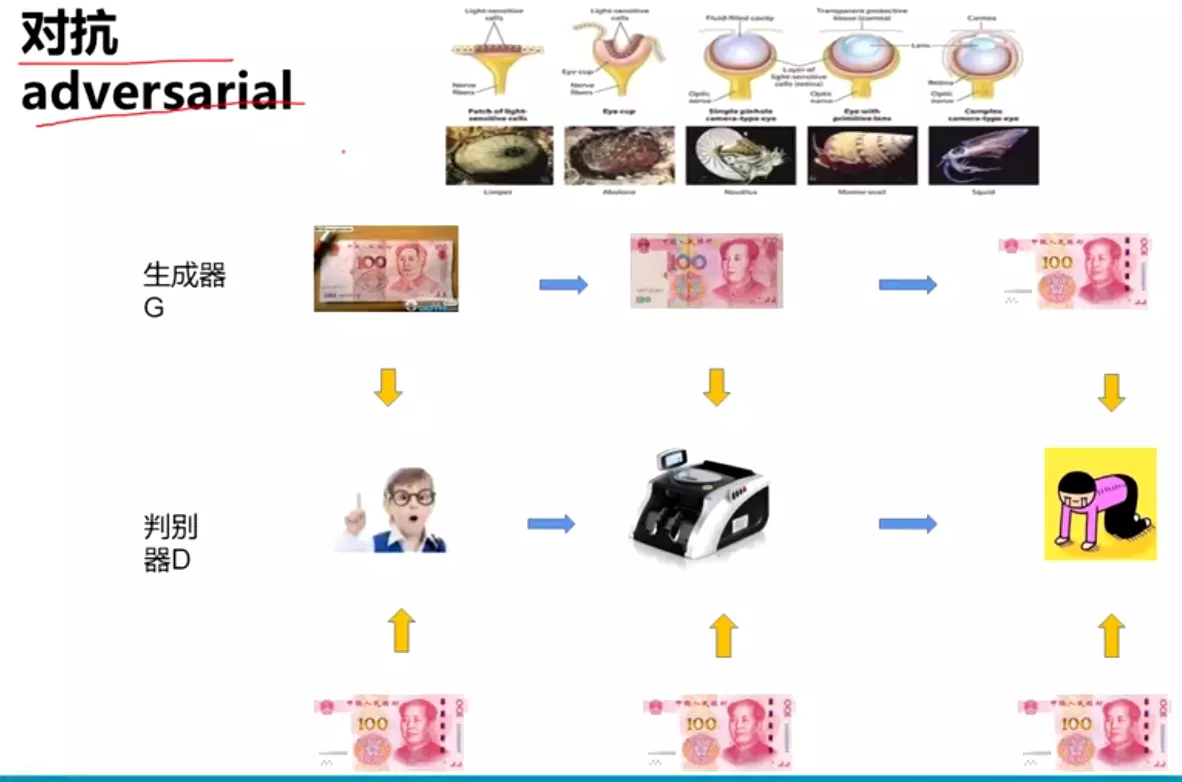



 ,看成是图像真实度的打分。
,看成是图像真实度的打分。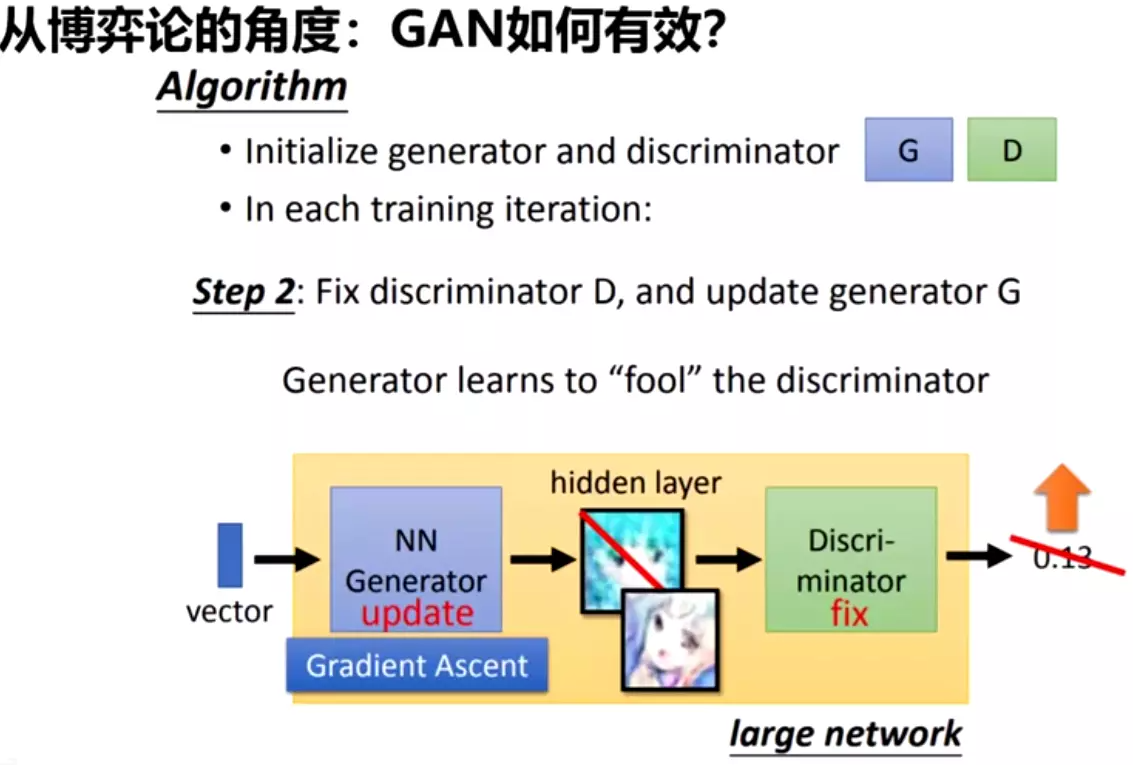 #
#
 这里只有数据集没有标签,从这个角度看GAN模型是无监督训练。但是从判别器角度看,因为会打上标签,所以是有监督任务。整体GAN,生成器是无监督,判别器是有监督。
这里只有数据集没有标签,从这个角度看GAN模型是无监督训练。但是从判别器角度看,因为会打上标签,所以是有监督任务。整体GAN,生成器是无监督,判别器是有监督。
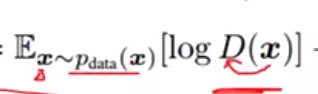 x是来自真实样本,希望打高分D(x);
x是来自真实样本,希望打高分D(x);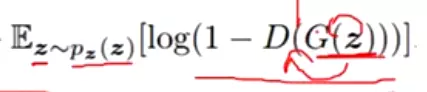 z是生成器生成的假样本,希望答低分。
z是生成器生成的假样本,希望答低分。






 浙公网安备 33010602011771号
浙公网安备 33010602011771号