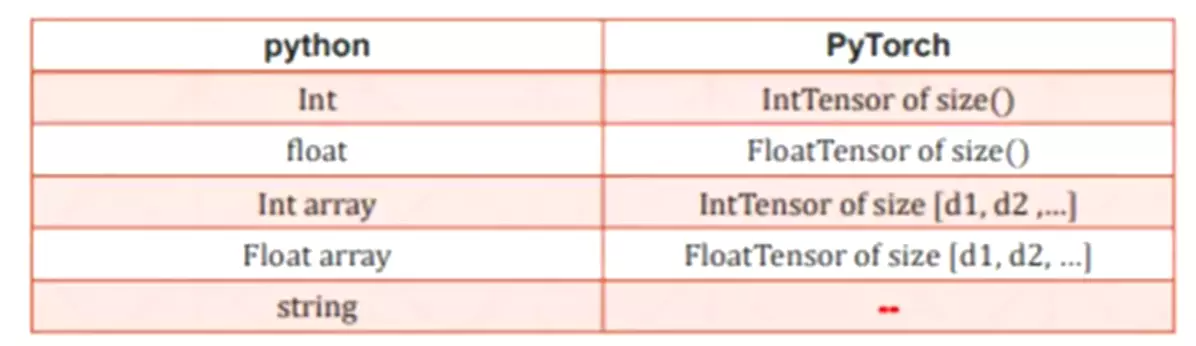
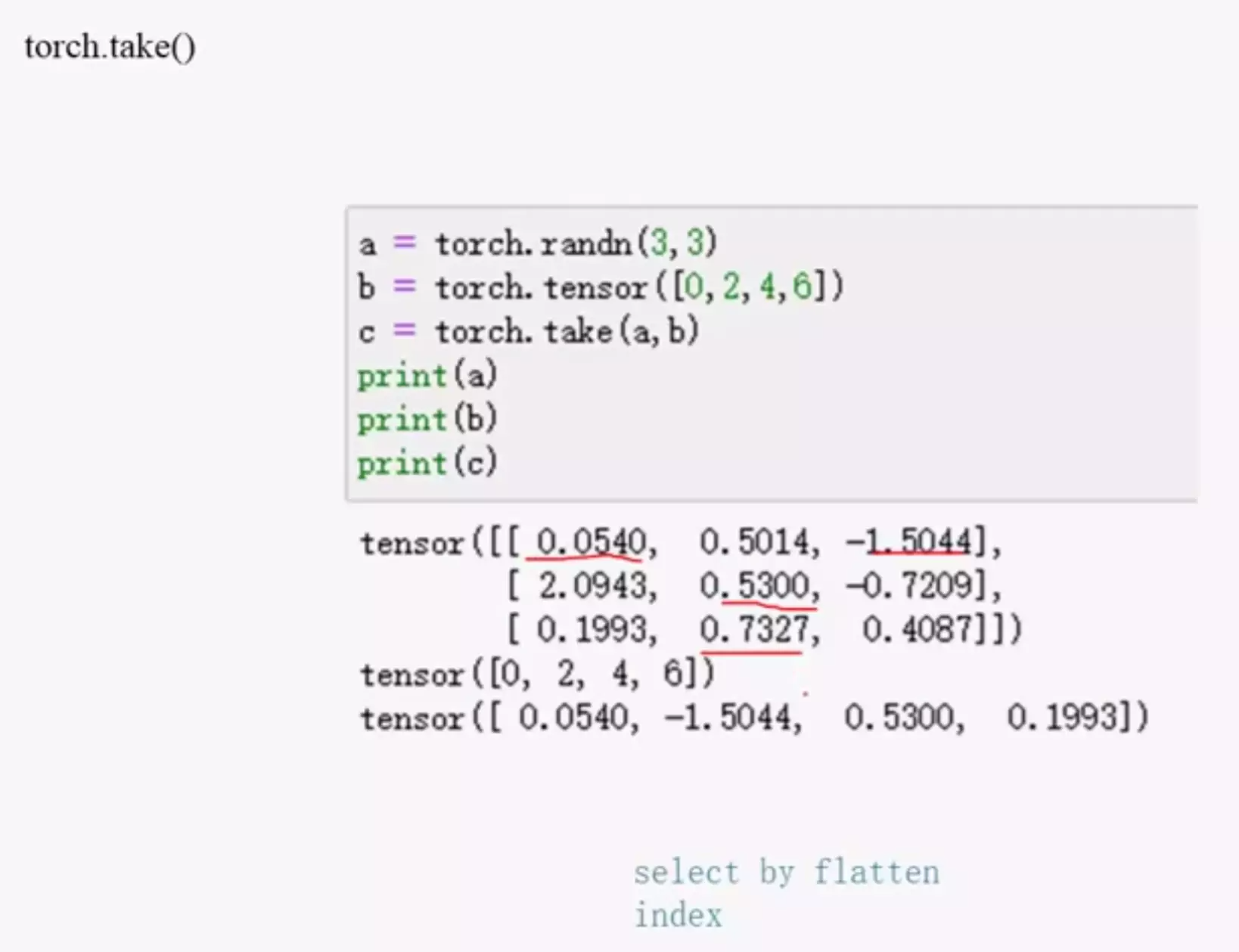
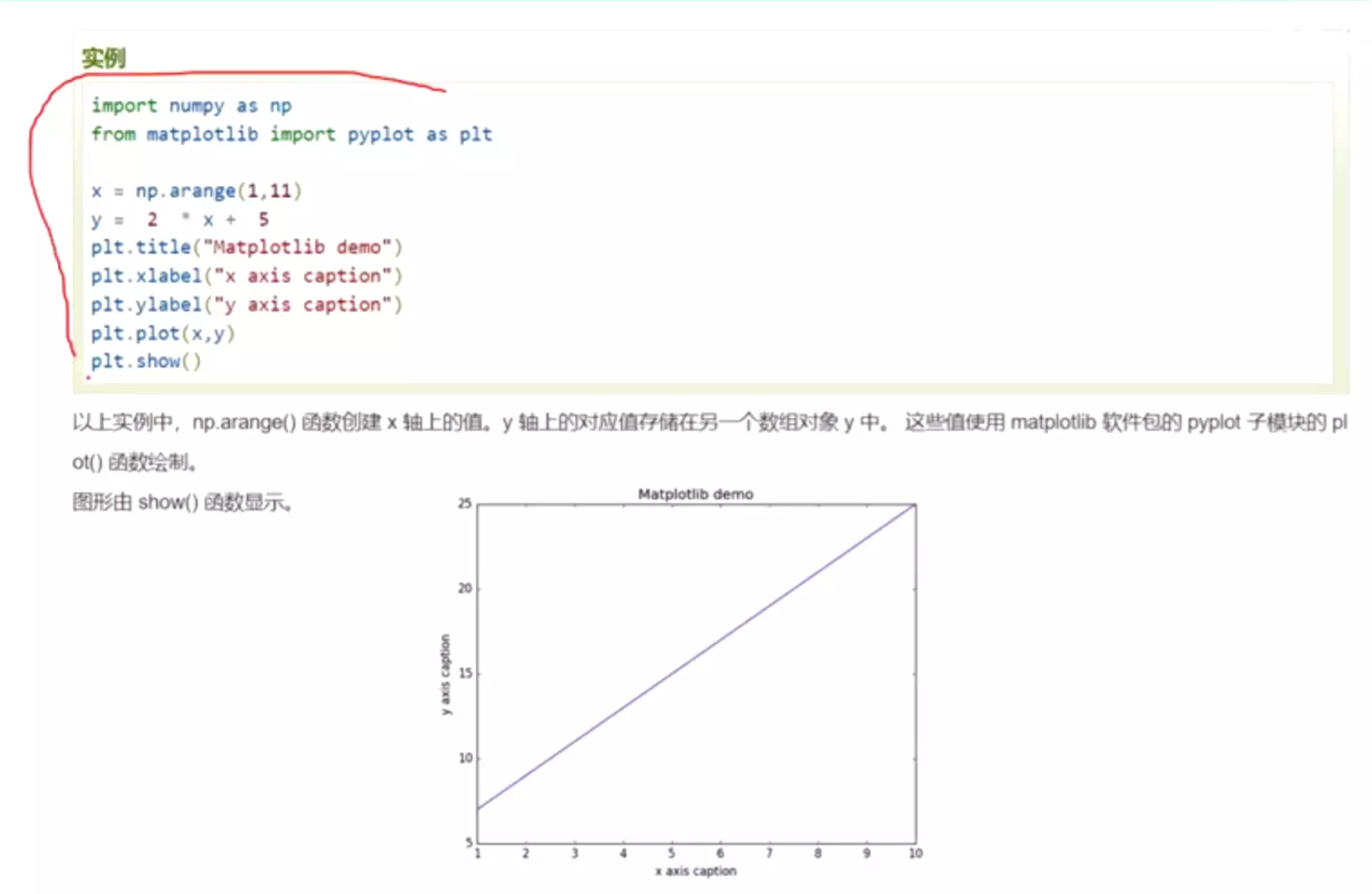
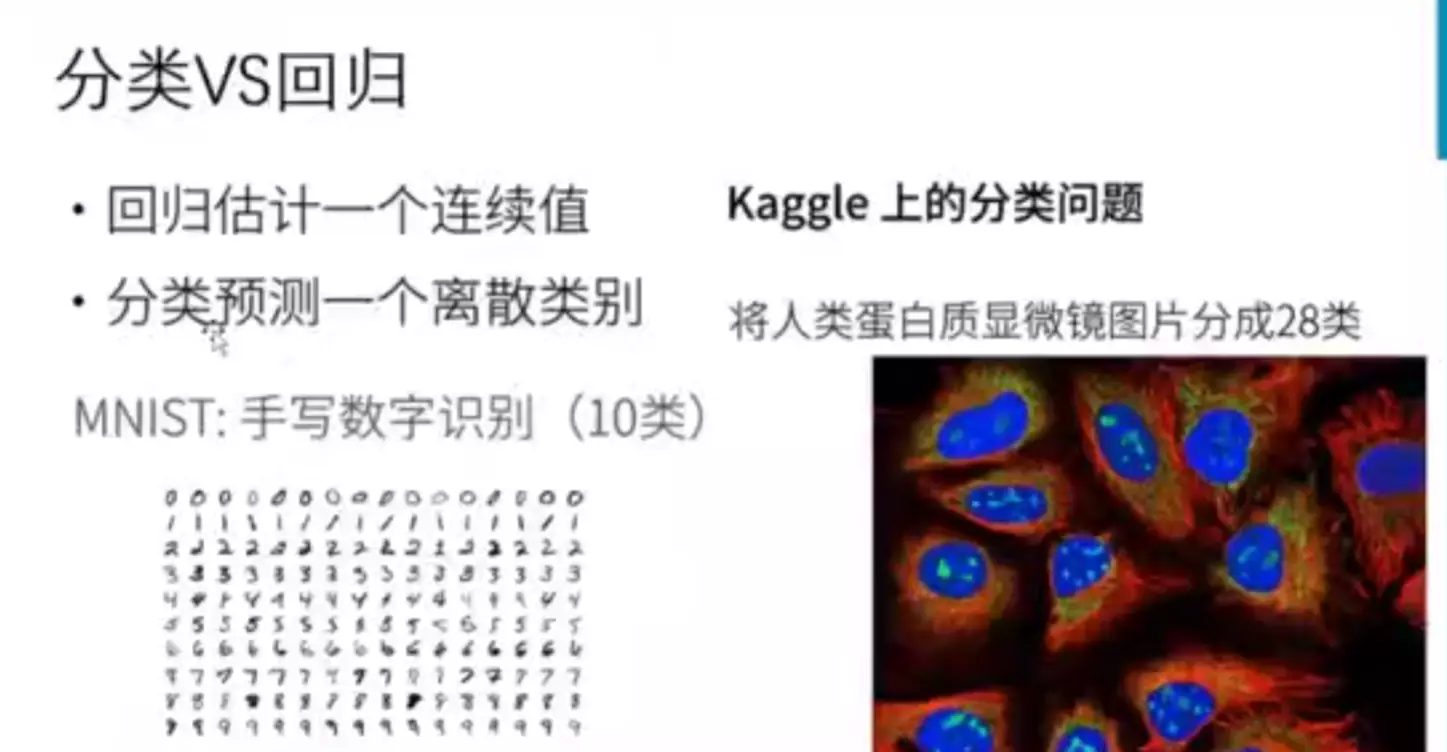
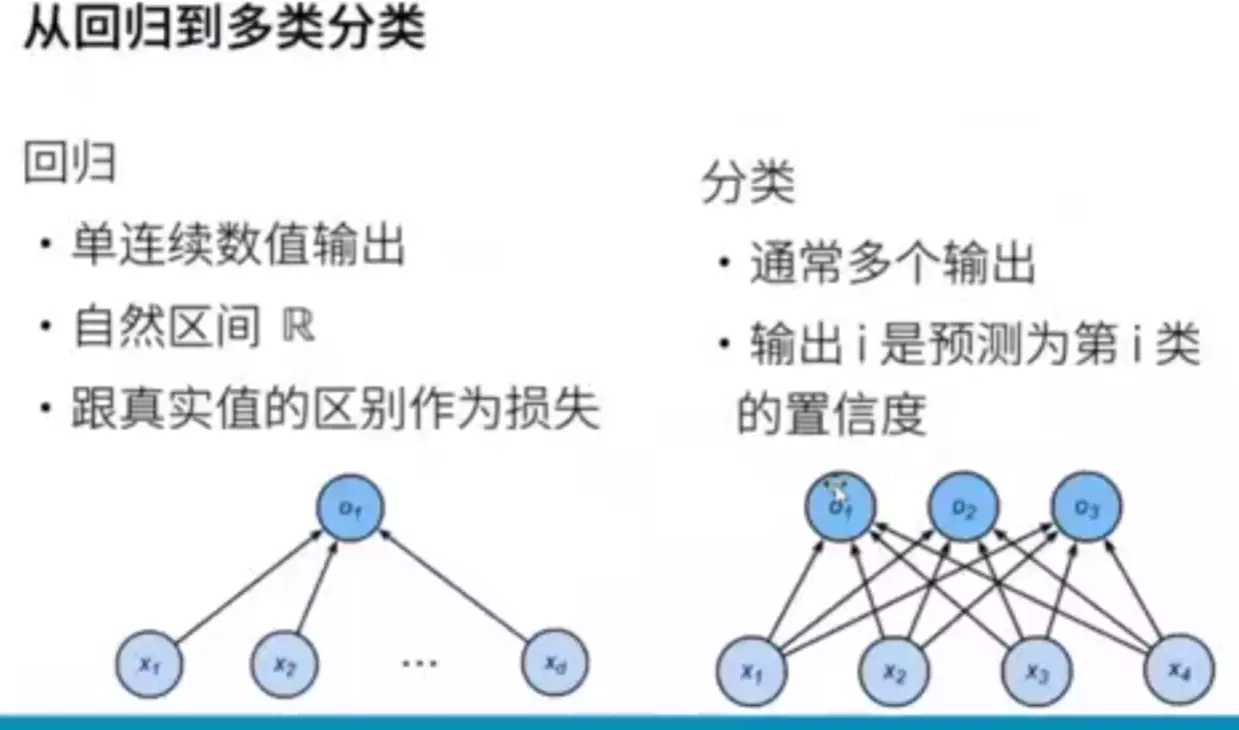
python与pytorch数据类型区别:
![]()
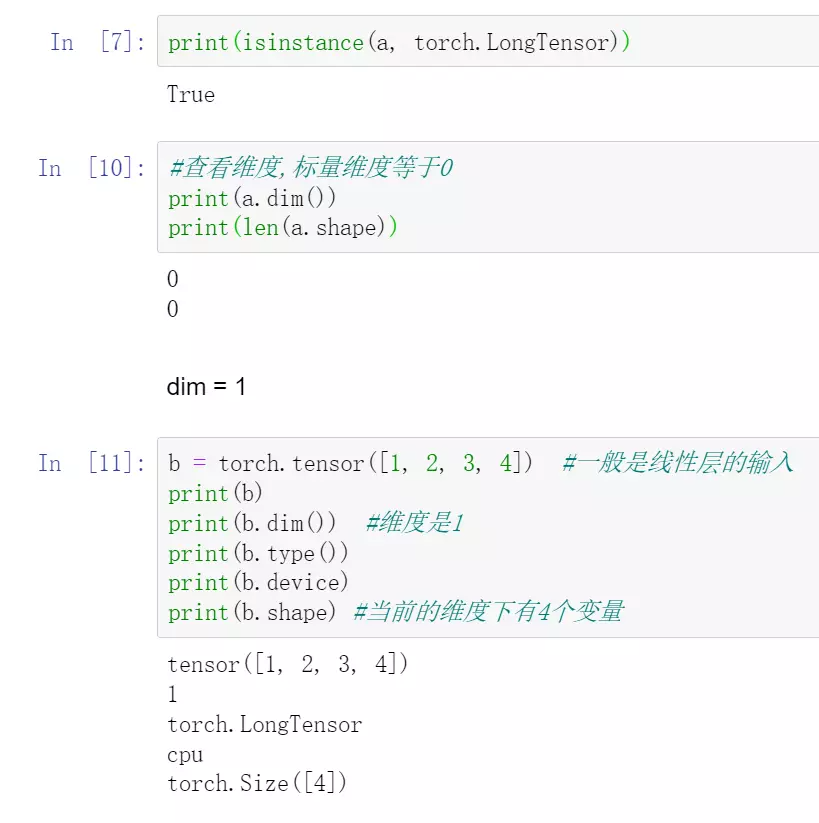
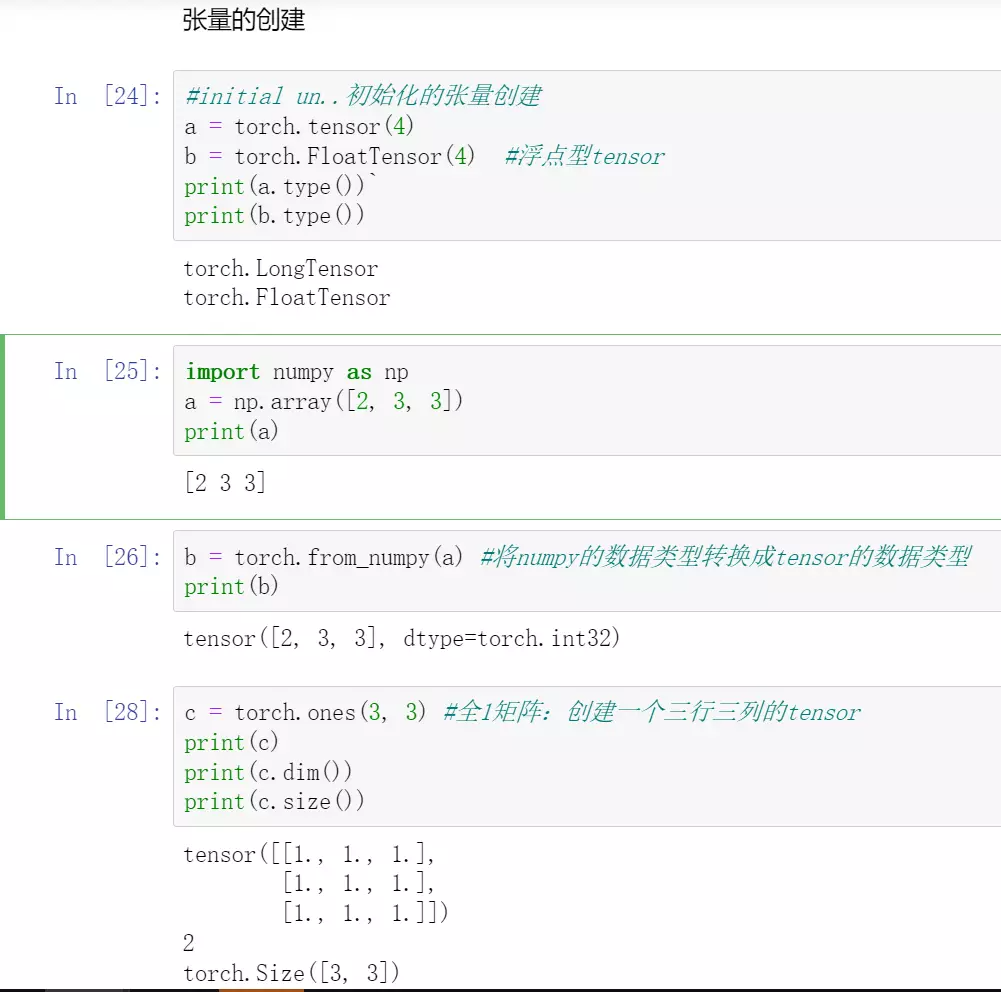
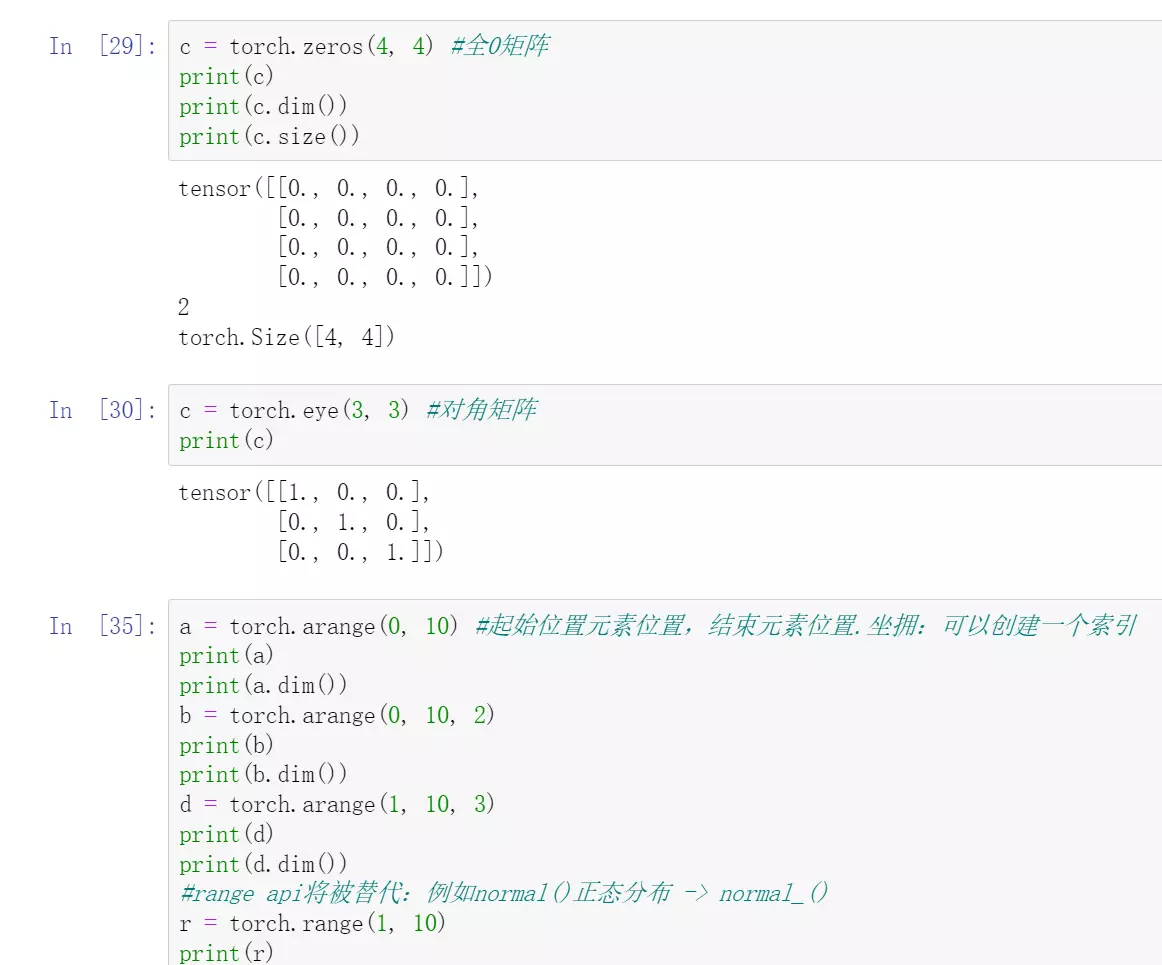
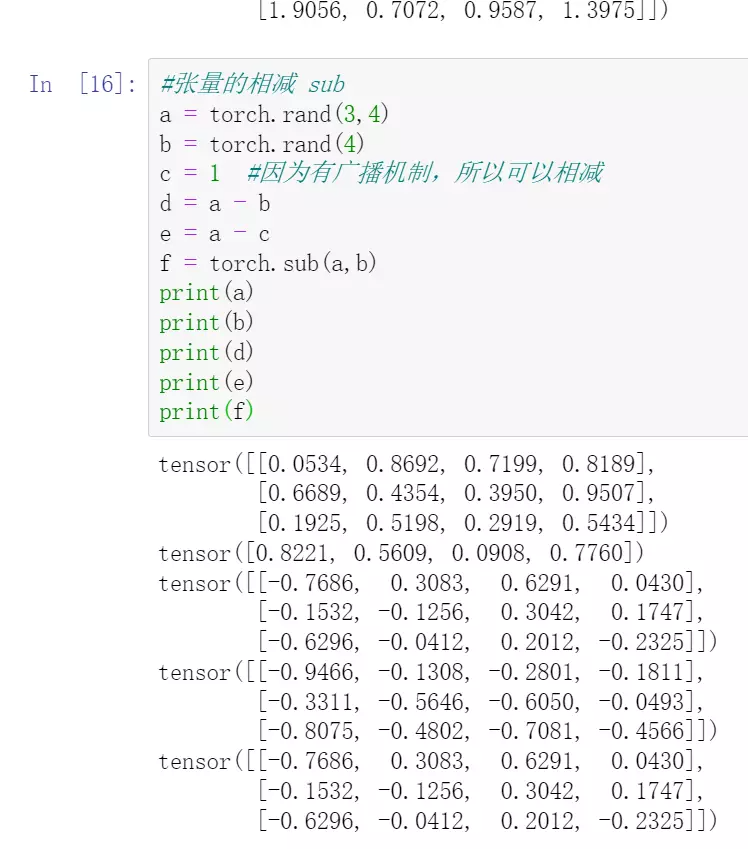
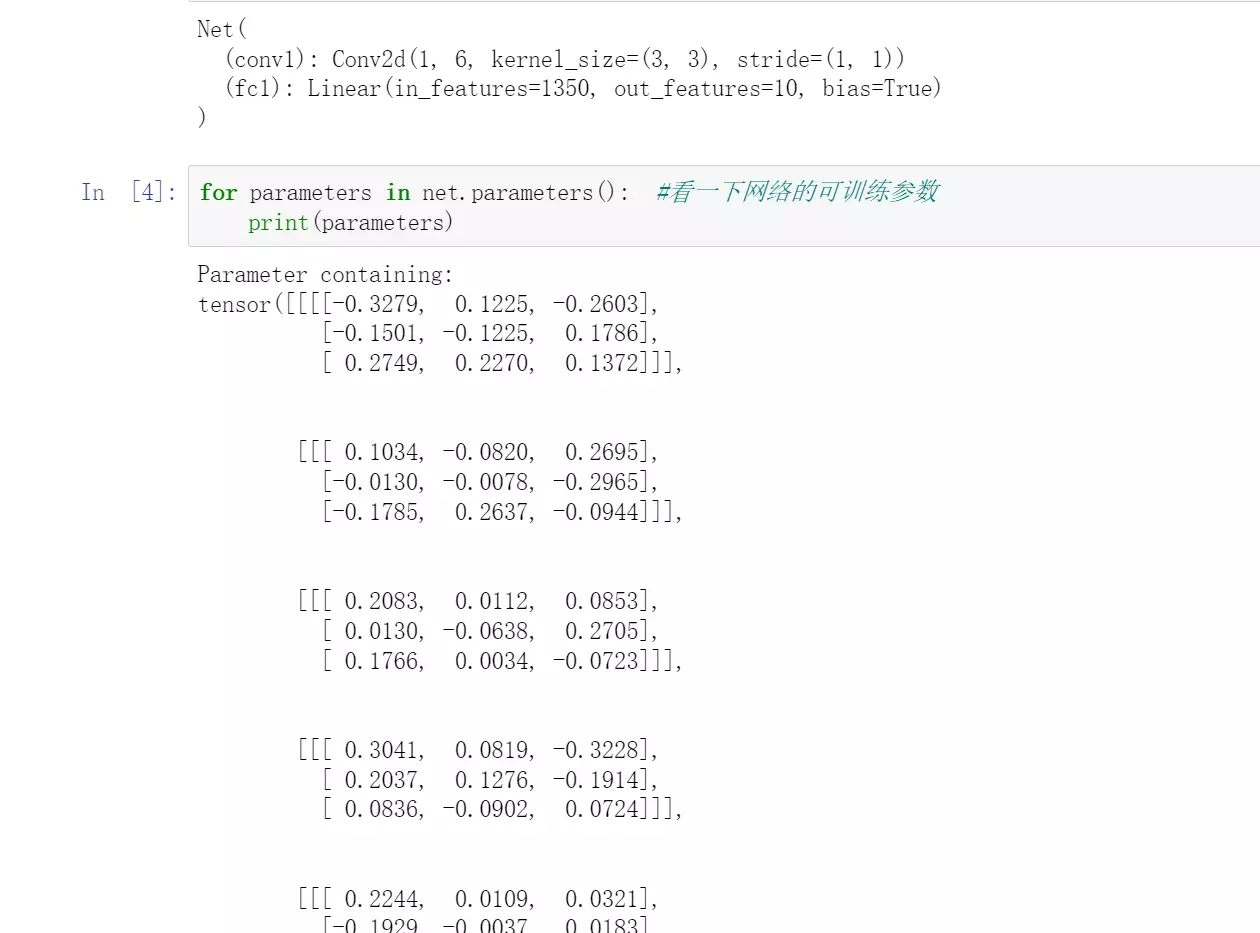
jupyter代码:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
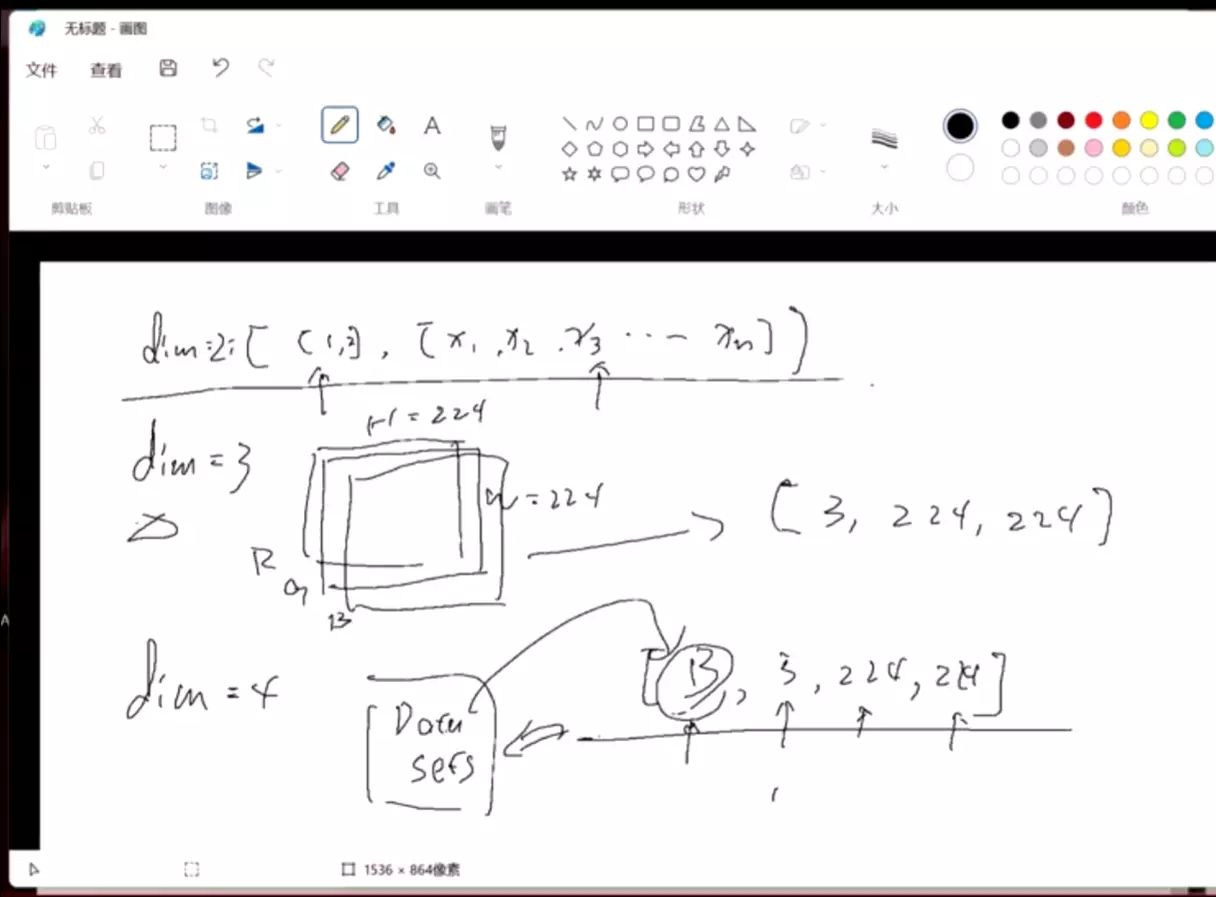
#图片:B表示第几个batch,就是数据集的数量。3是色彩通道,224、224高度和宽度。
![]()
#视频:有时间顺序,是一帧一帧的。224、224高度和宽度,3是彩色的,N=3000代表视频切分出了多少帧的图像。如果按照时间取的话,相当于将整个视频从头到尾播放一遍。
-----------new class----------
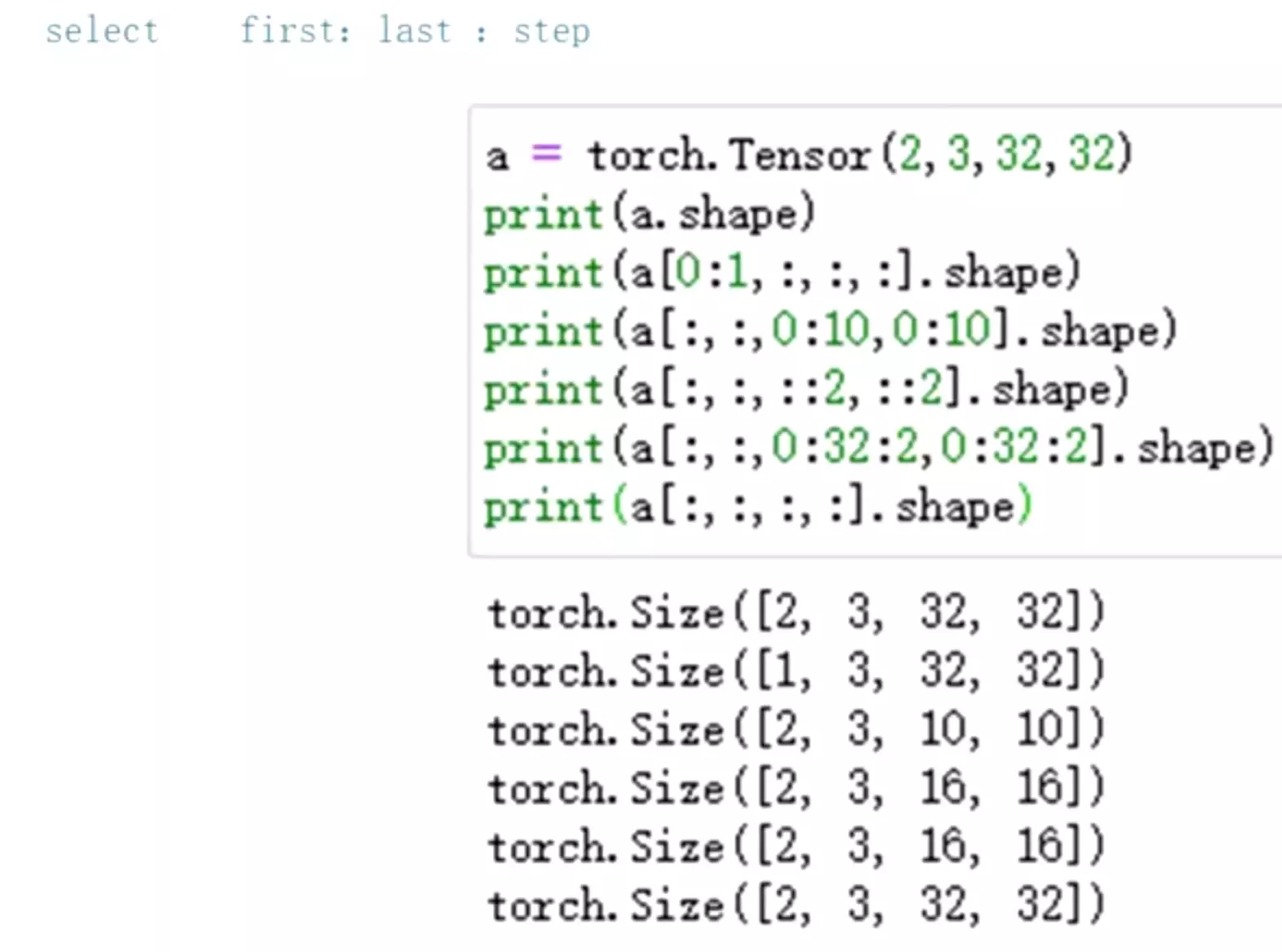
![]()
如果是图片,(2,3,32,32)代表什么?分别代表张数、颜色、长度、宽度。所以a[0].shape代表一张彩色图片
同理,a[0][0][0][0]第一张图像第一个颜色通道的第一个像素。
索引同python。
#切片:
![]()
![]()
#注意下采样!
![]()
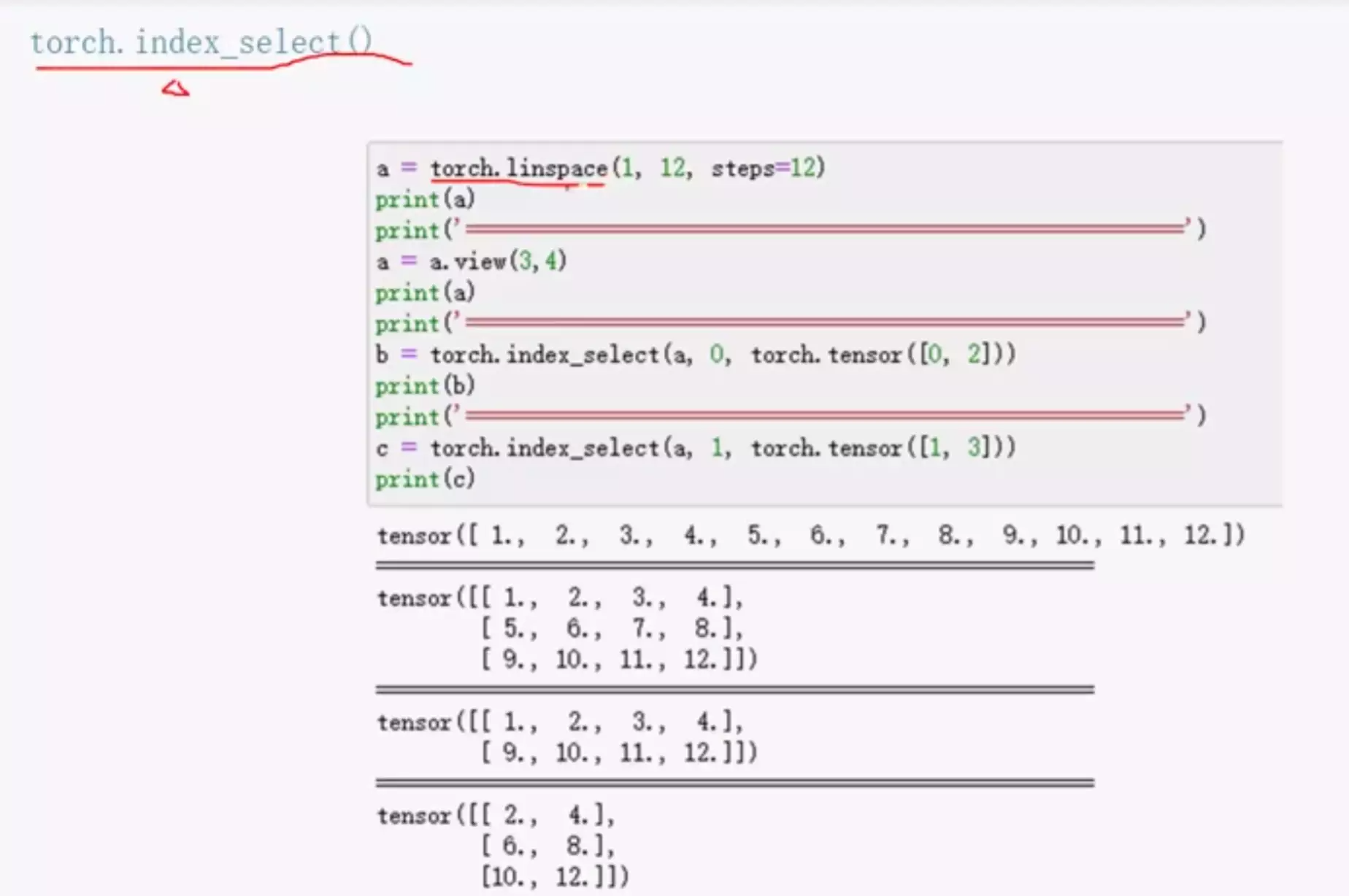
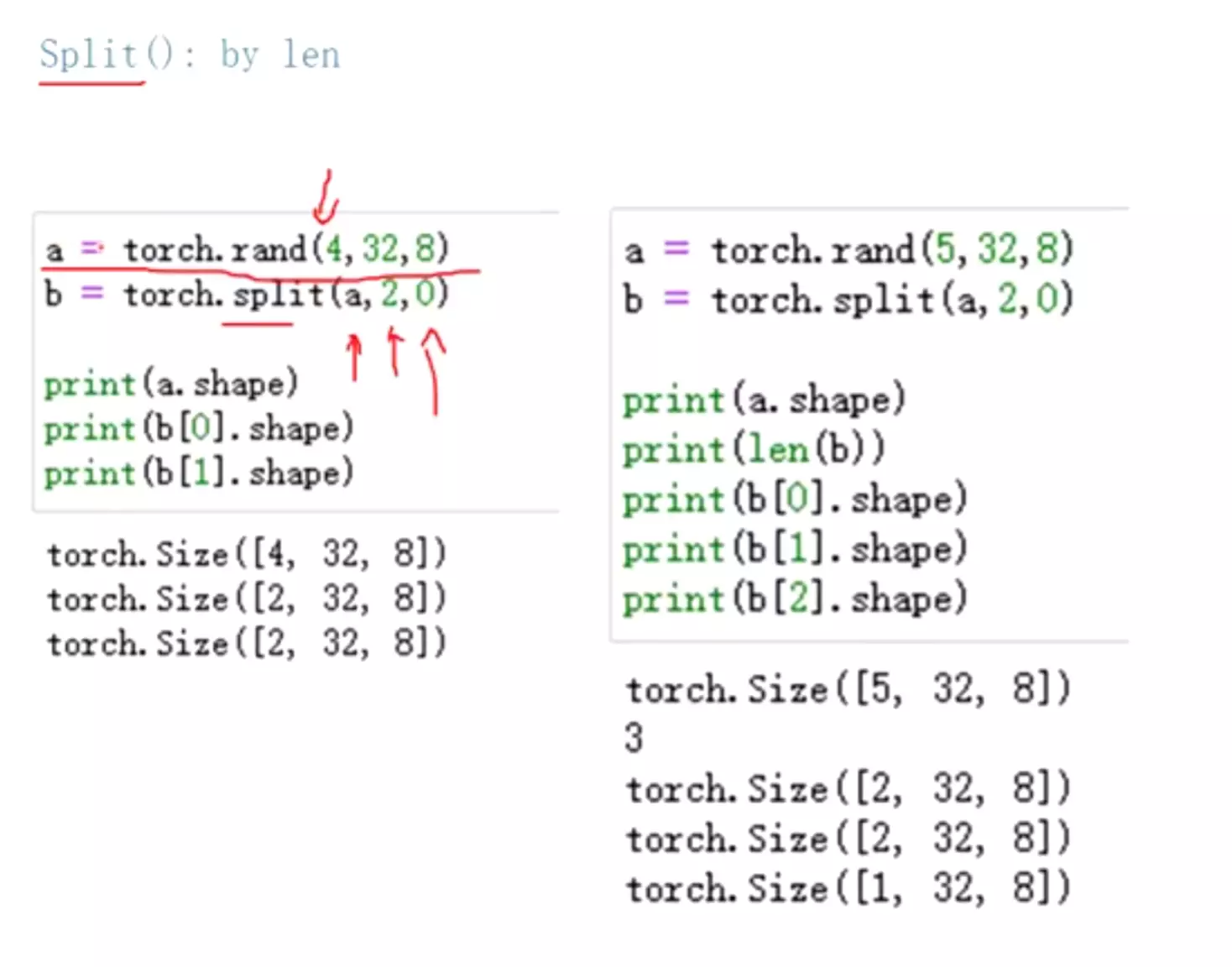
#steps表示多少步。view是变换成3行4列。index_select函数:!
![]()
![]()
#学会查看pytorch的官方文档API:google一下api
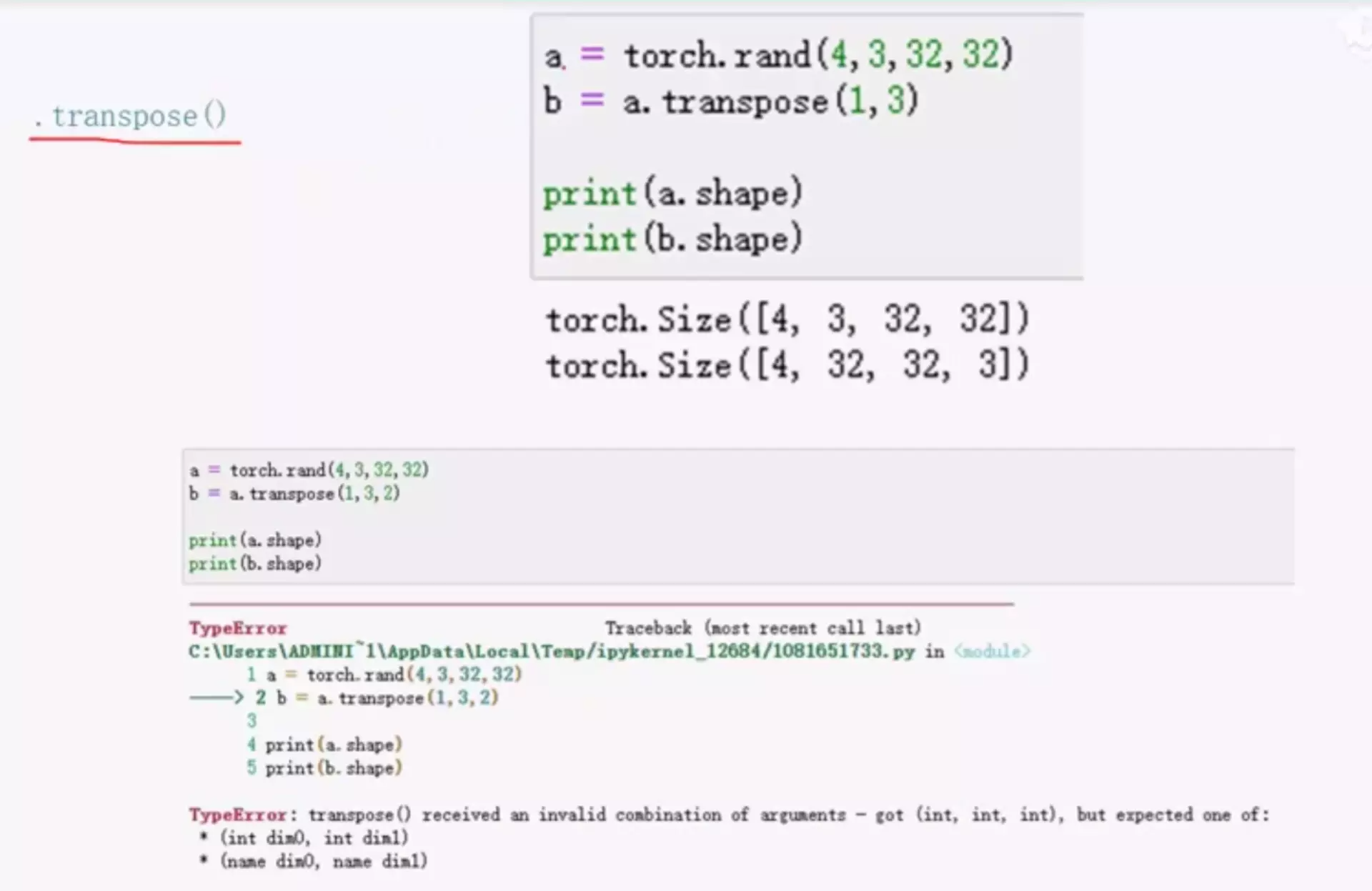
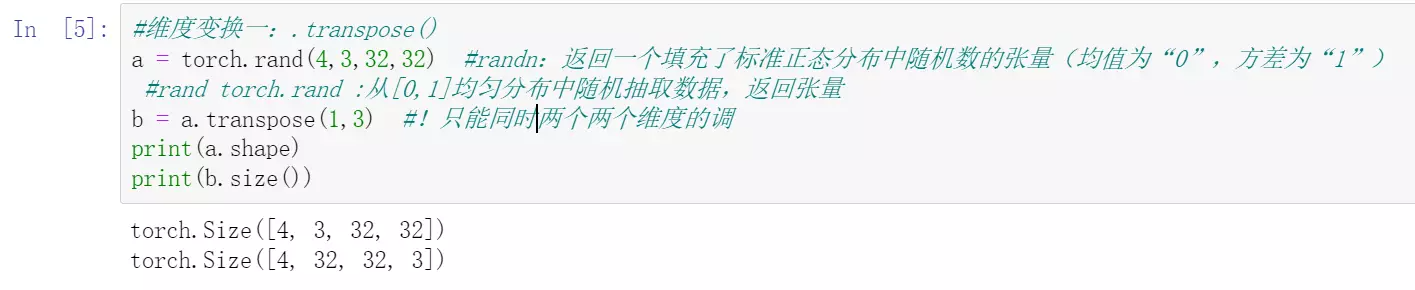
------------索引和张量的维度变换--------
![]()
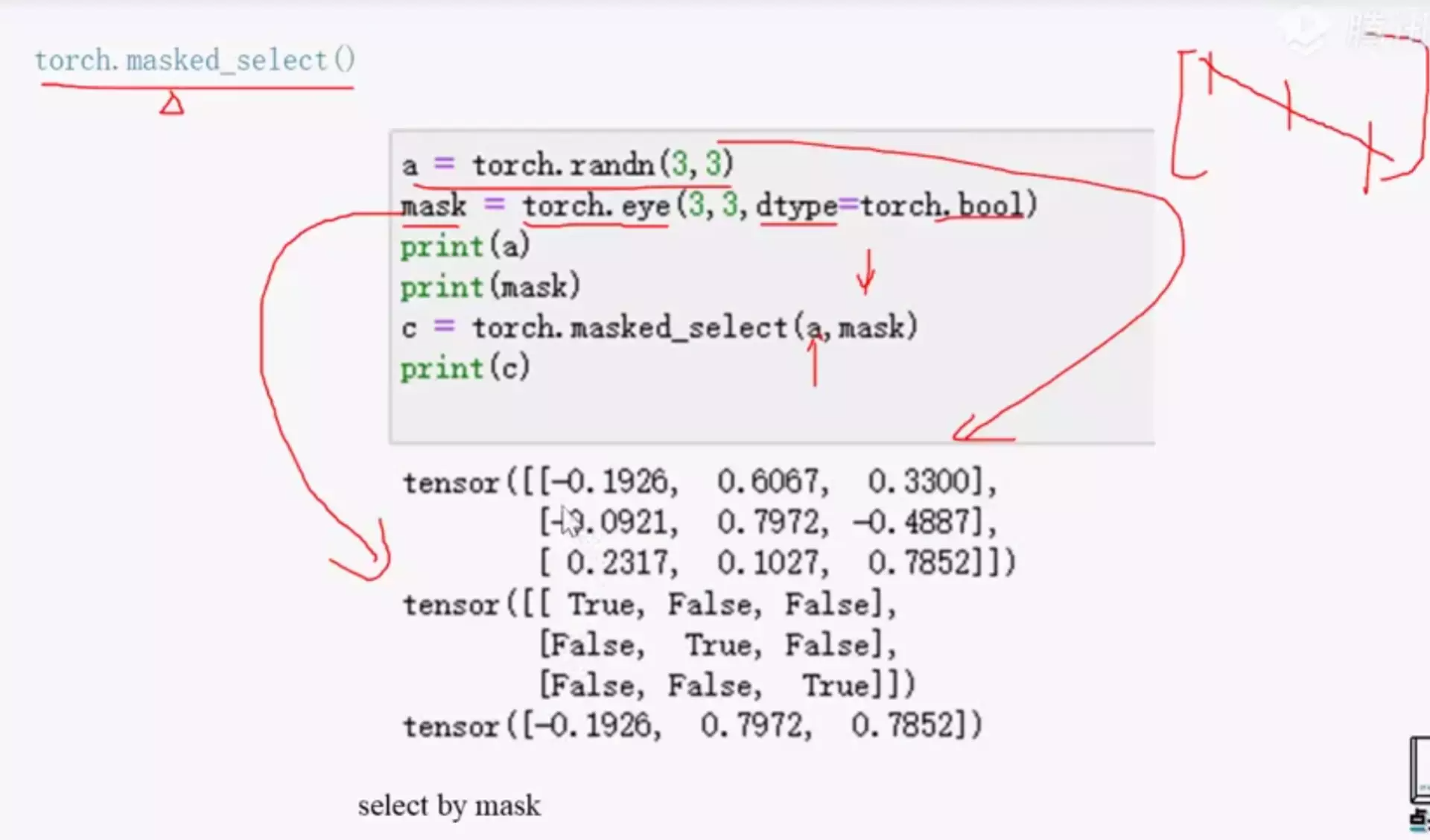
##torch.masked_select API:按模板取数
![]()
![]()
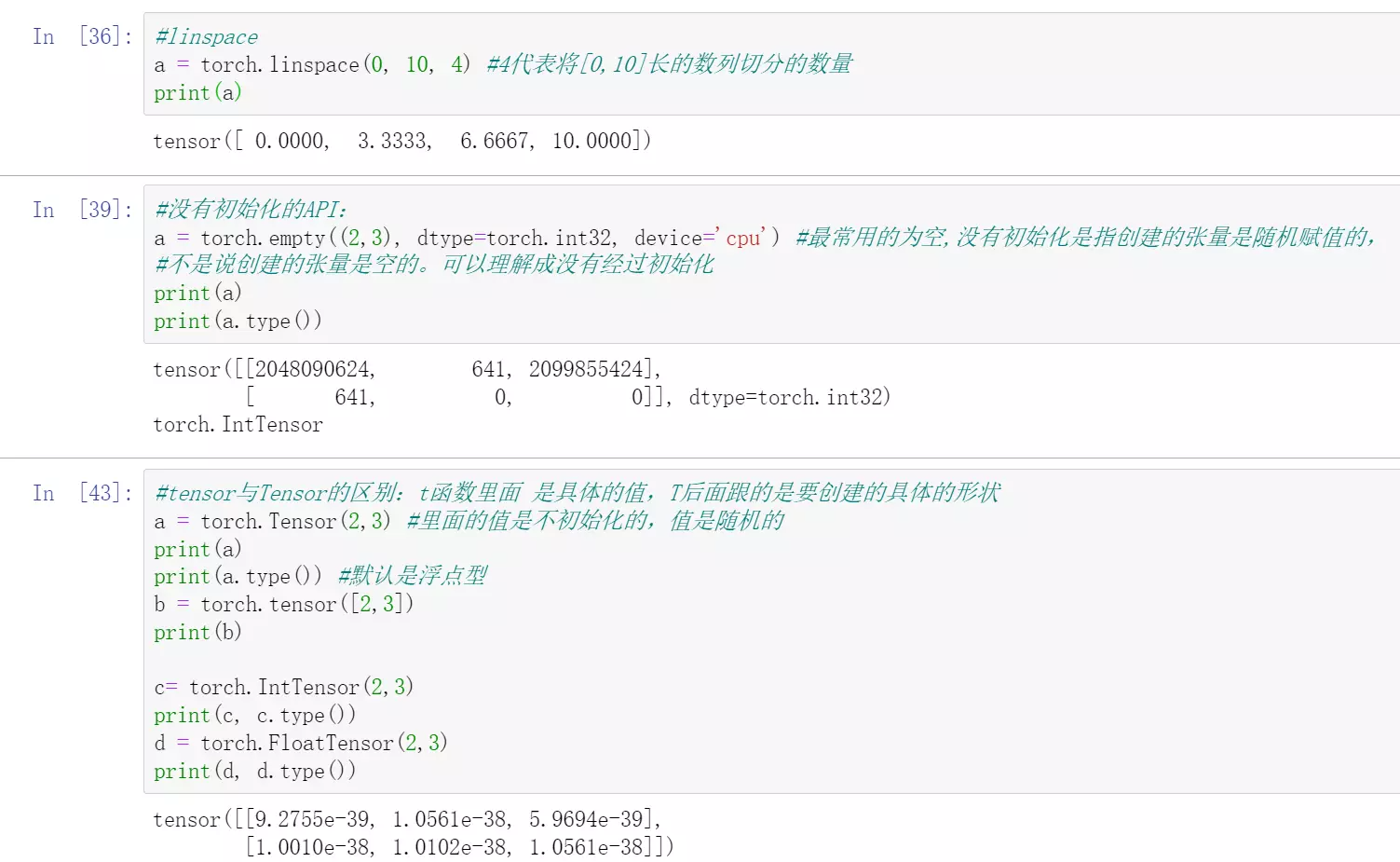
![]()
![]()
![]()
![]()
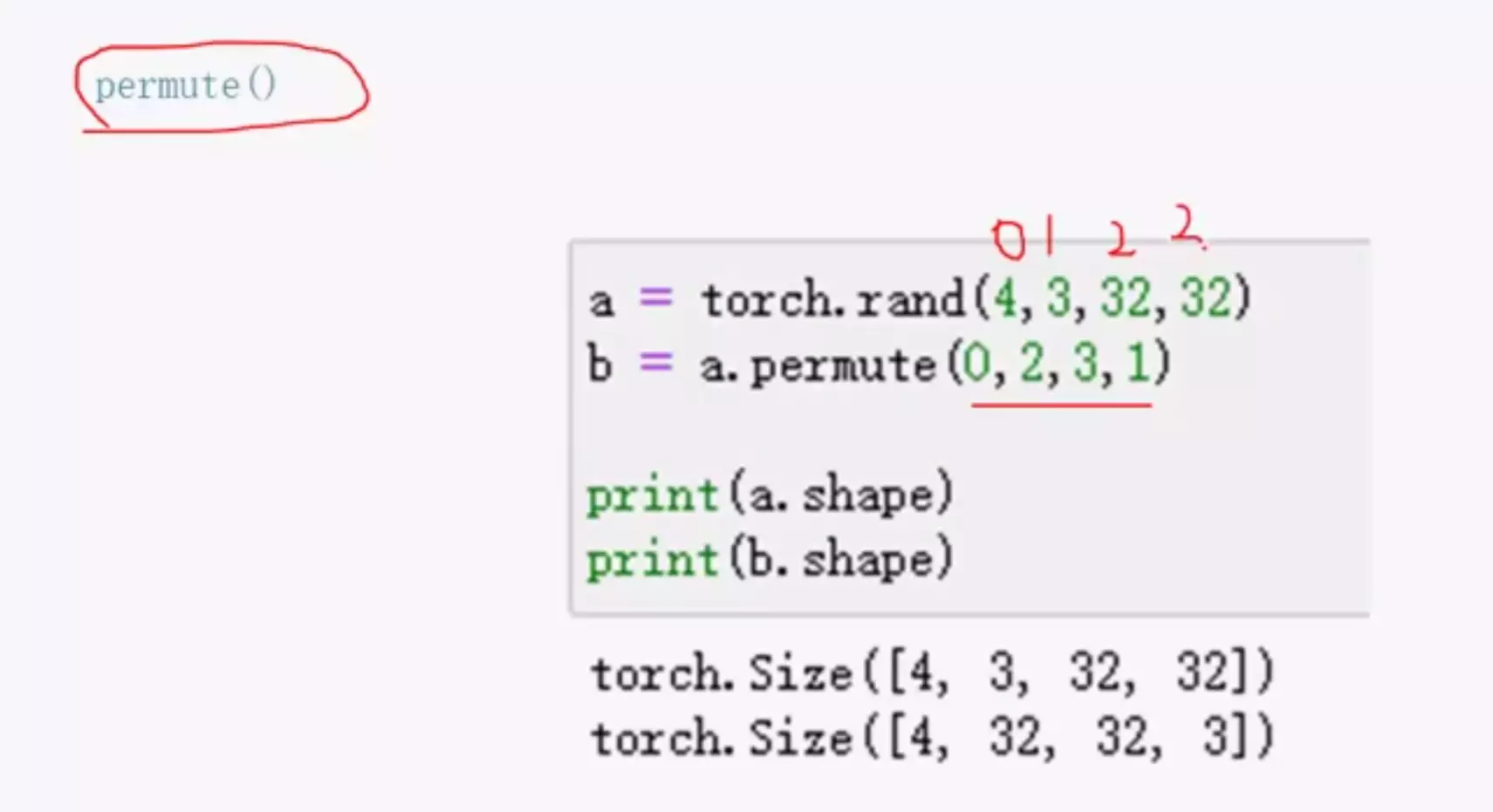
#想一次性多个维度调?
![]()
![]()
![]()
![]()
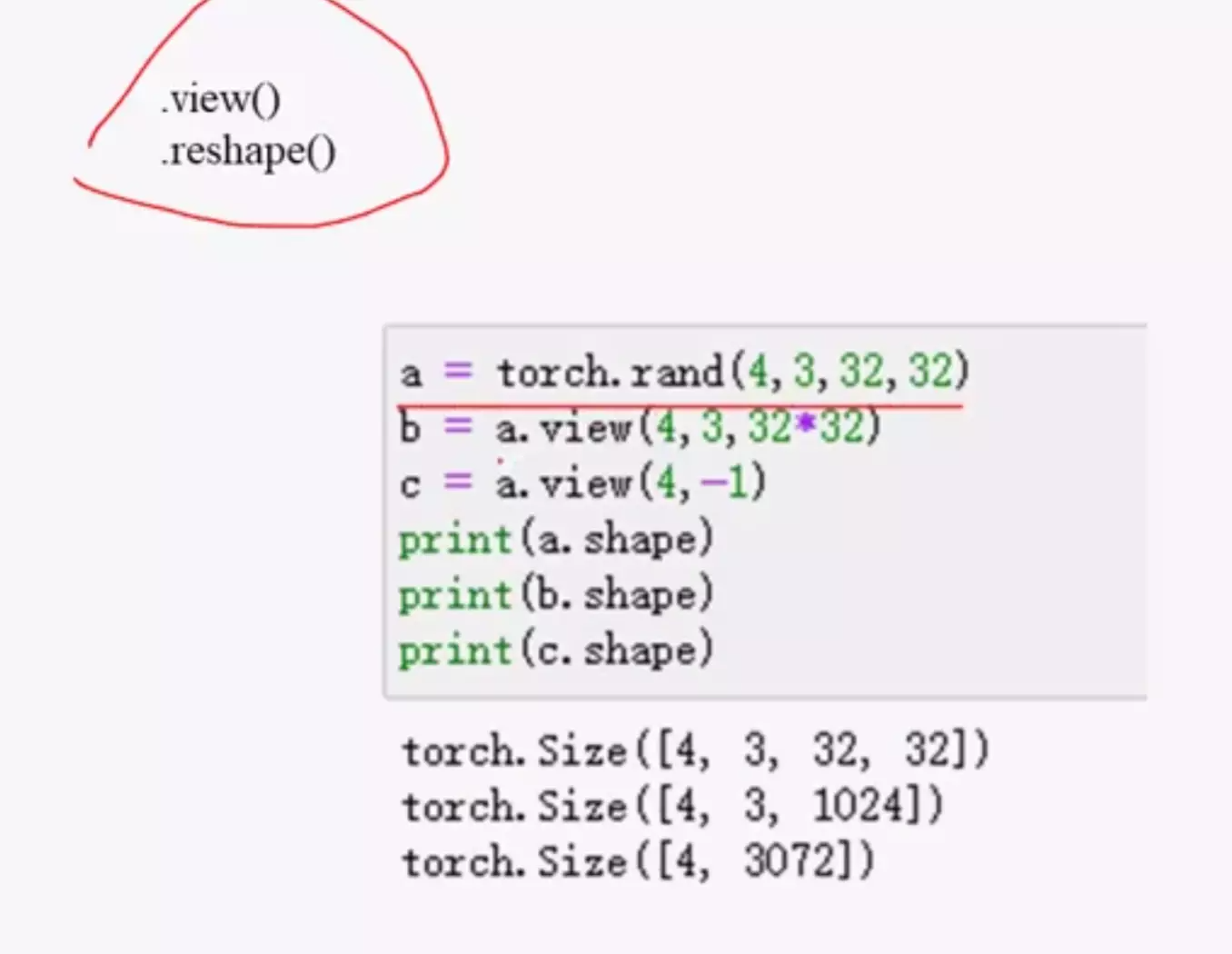
#维度变换三:view()
![]()
![]()
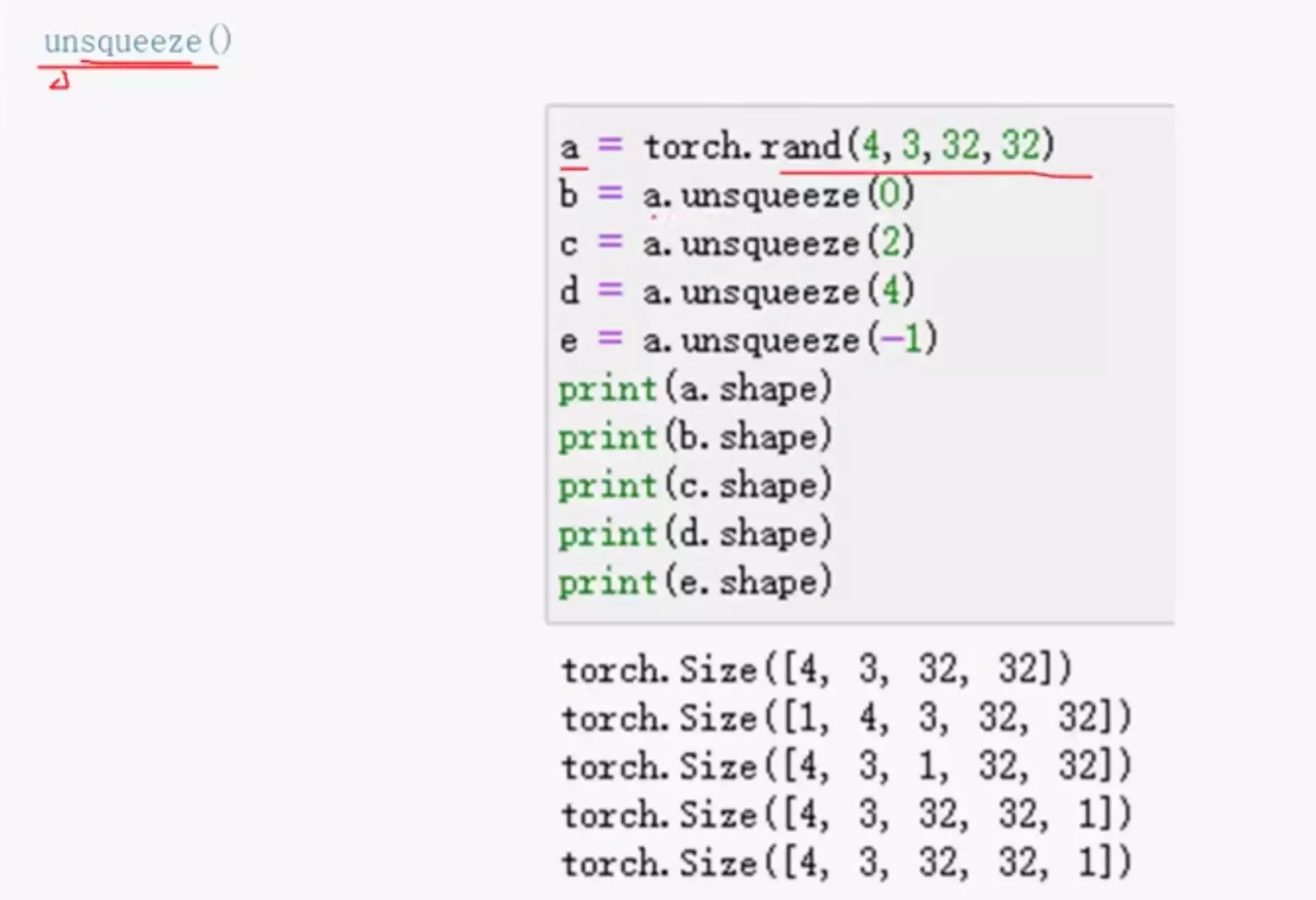
#维度变换四:unsqueeze() squeeze:压缩,unsqueeze扩张
![]()
![]()
#维度变换五:squeeze() 压缩,只能压缩维度值是1的维度!!!
![]()
#维度变换七:expand()复制扩张 、repeat()
![]()
![]()
![]()
![]()
#所以expand用的多一些,因为用repeat占内存,所以为了少占内存用expand多一些
![]()
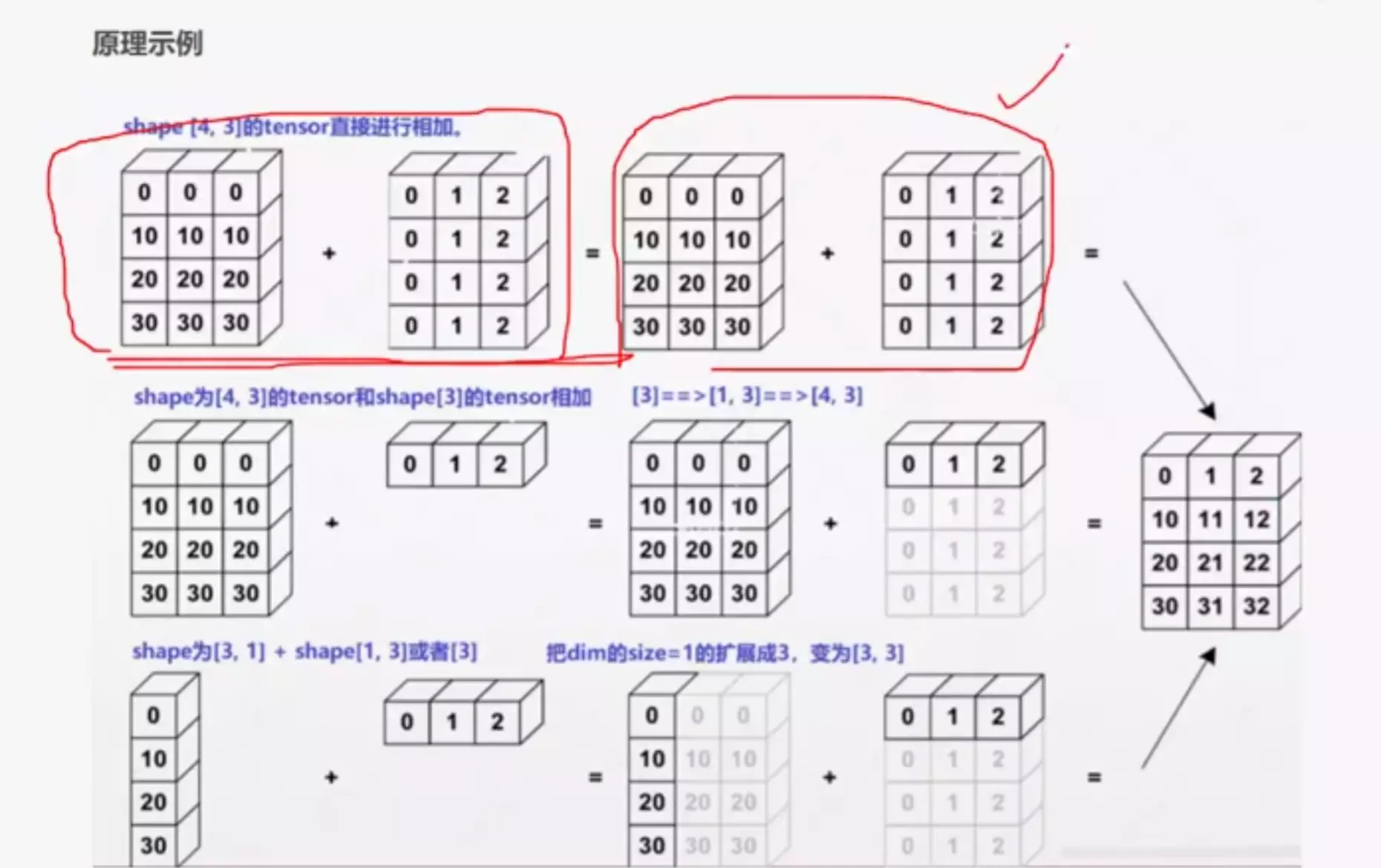
#广播机制:当两个数据的形状不一样时,可以自动扩展*****
![]()
一个特征图: [4,32,14,14]看成4张彩色图片,现在做一个偏置,给每一个像素点都做一个加1的操作。[32,1,1] 与[4,32,14,14]相加不会报错!!!
![]()
#也可以人为操作:
![]()
![]()
![]()
![]()
答:第4个
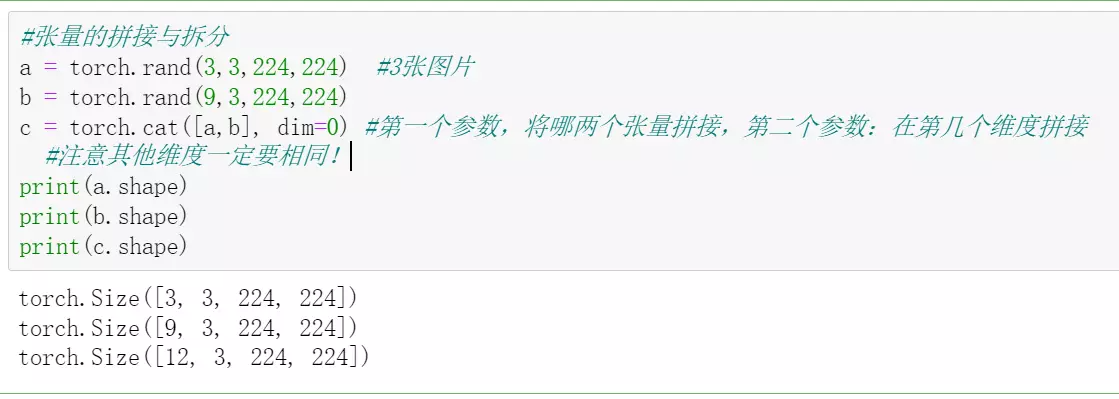
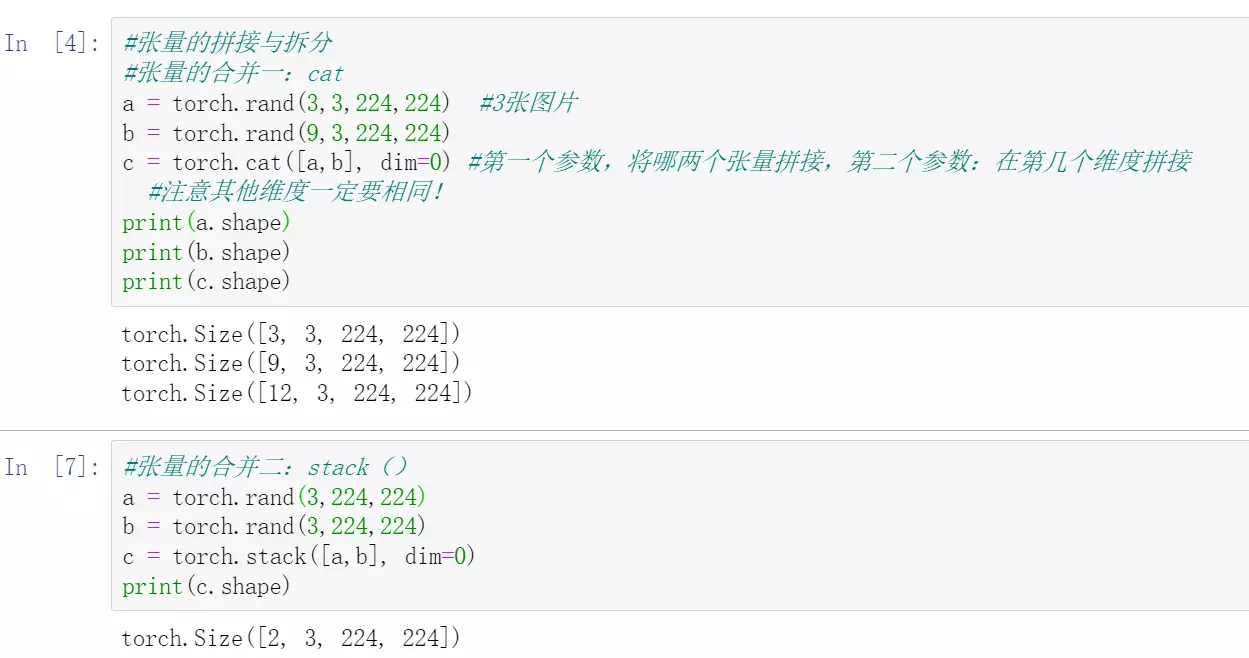
----------------张量的拼接与拆分---------
![]()
![]()
#ResNet捷径的链接用add、DenseNet用两个图拼接在一起用cat
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
-------pytorch运算与统计-------
![]()
![]()
![]()
![]()
![]()
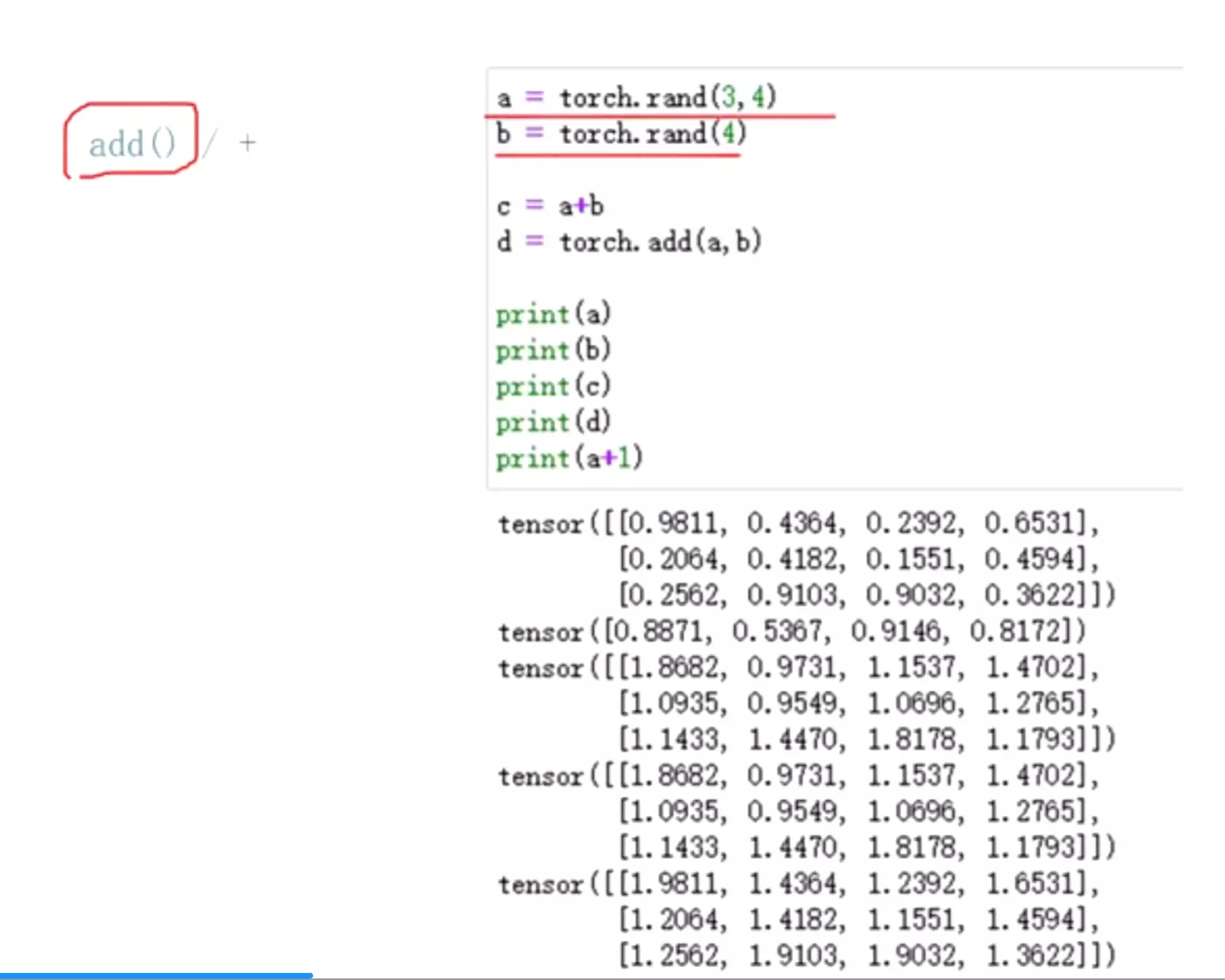
#matmul矩阵乘法;而mul是矩阵点乘
![]()
![]()
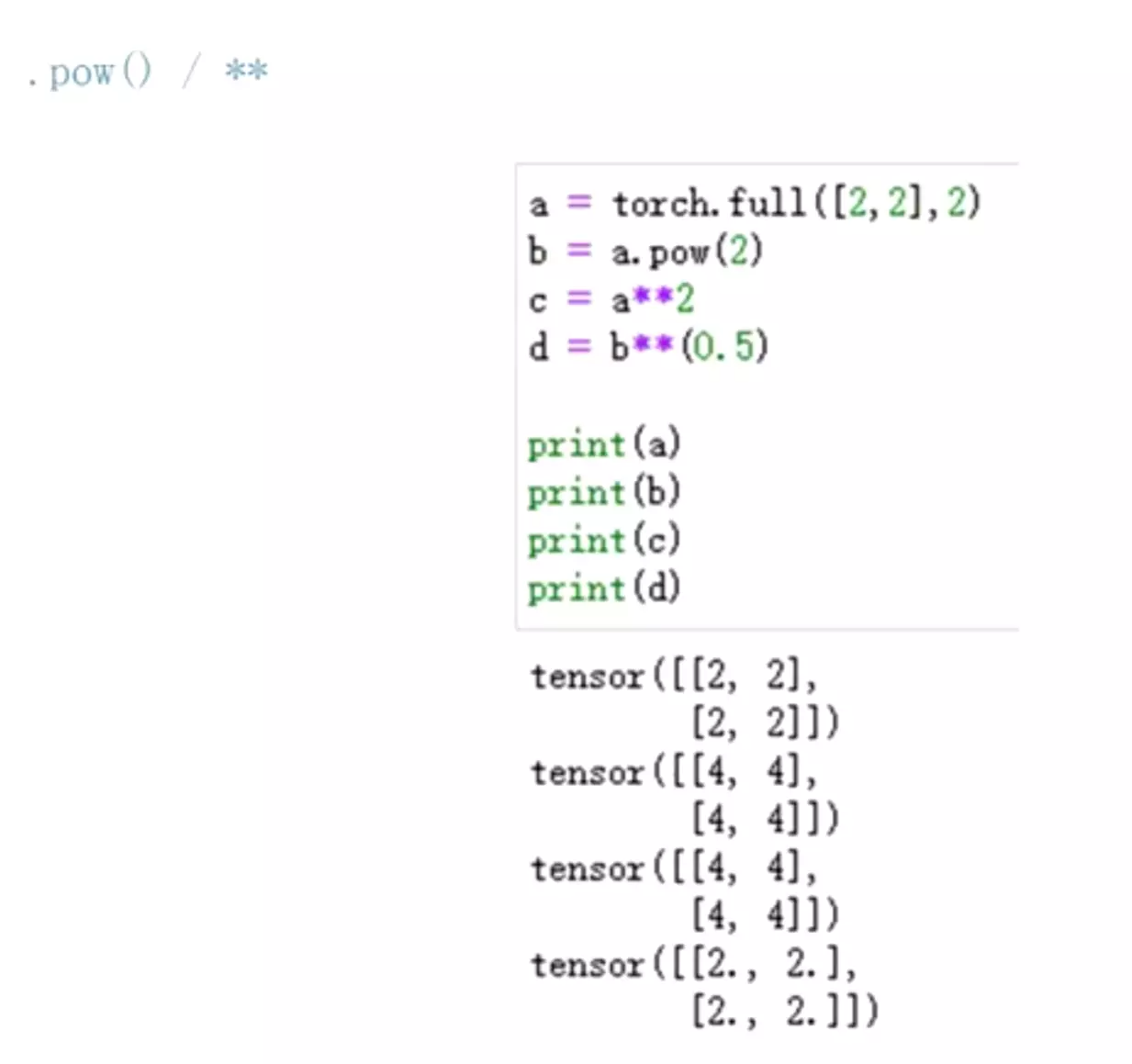
#共6个乘法API。
![]()
![]()
#矩阵的除法,full是填充
![]()
![]()
#sqrt是开方;rsqrt开方后倒数
#遇到不认识的API:去官网查接口文档
![]()
![]()
![]()
![]()
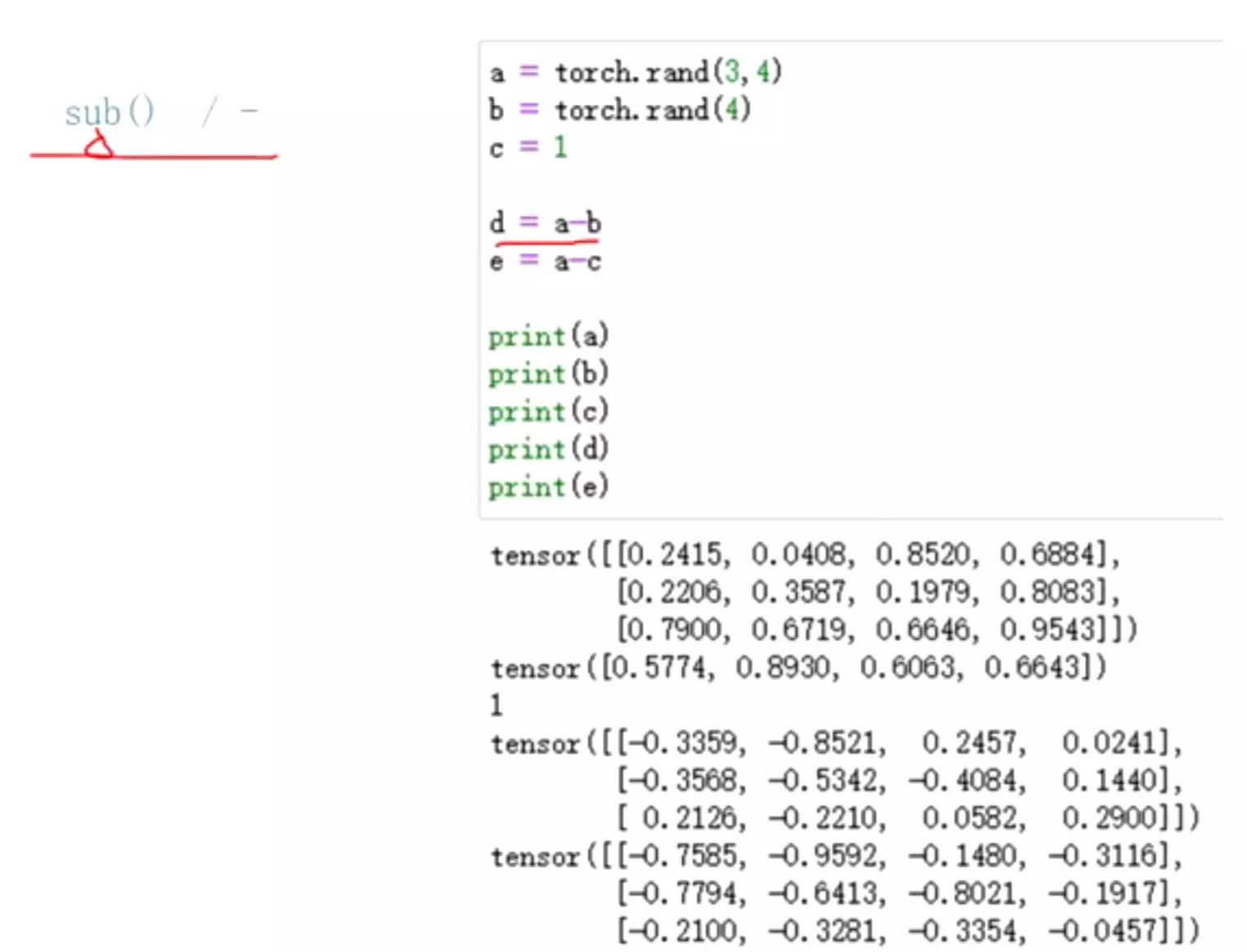
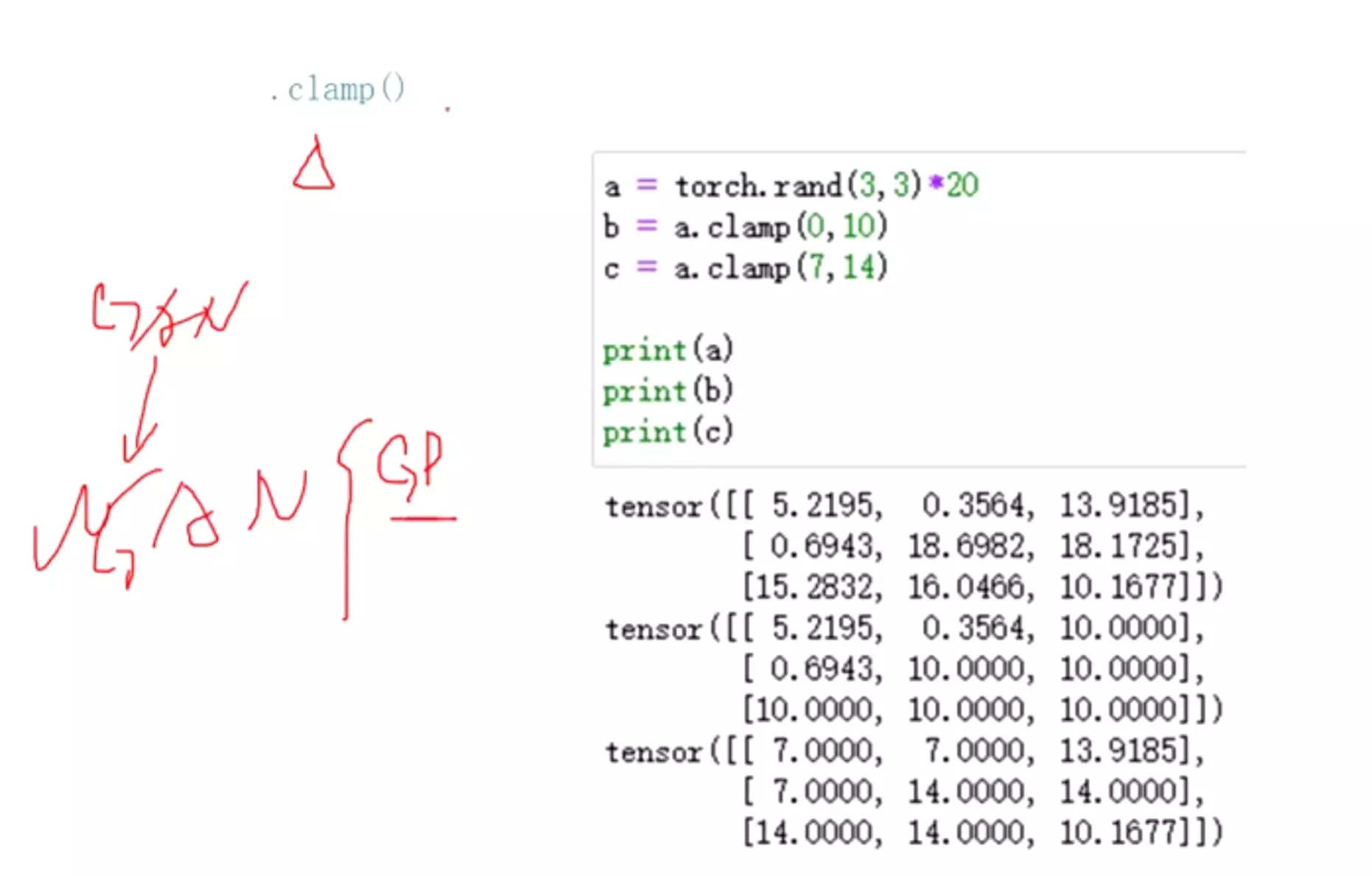
#两边裁剪:clamp
GAN生成对抗里的WGAN,里的GP就用的clamp
![]()
![]()
![]()
用普通就够了,25元三个月
#做了一个小程序,三个按钮,一个是上一个,一个是下一个,一个是保存的意思。这里涉及到Yeild,相当于next函数
![]()
![]()
它是python的图像化编辑器:
![]()
https://m.runoob.com/python/python-gui-tkinter.html在python没有流行前,会用javascript
![]()
python还可以做MySQL、多线程、网络编程等等
###
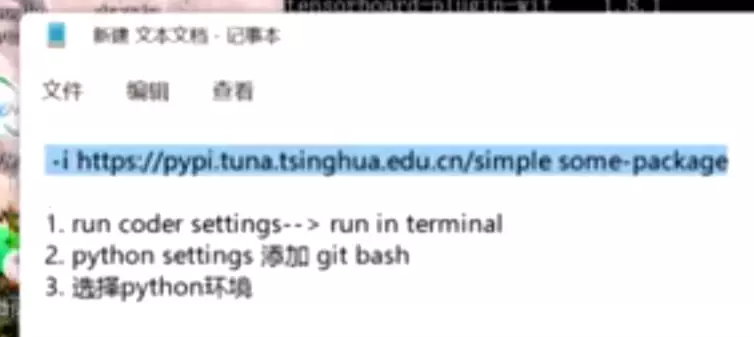
pip 换源,pip install jupyter +直接加下面的命令。注意换源时不要开VPN,防止网络冲突。
![]()
在base环境里,安装pip install nb_conda,再点new时可以切换环境
#退出:conda deactivate
![]()
#jupyter默认从c盘启动,如何改?
默认在c盘中:C:\Users\Administrator\.ipynb_checkpoints
![]()
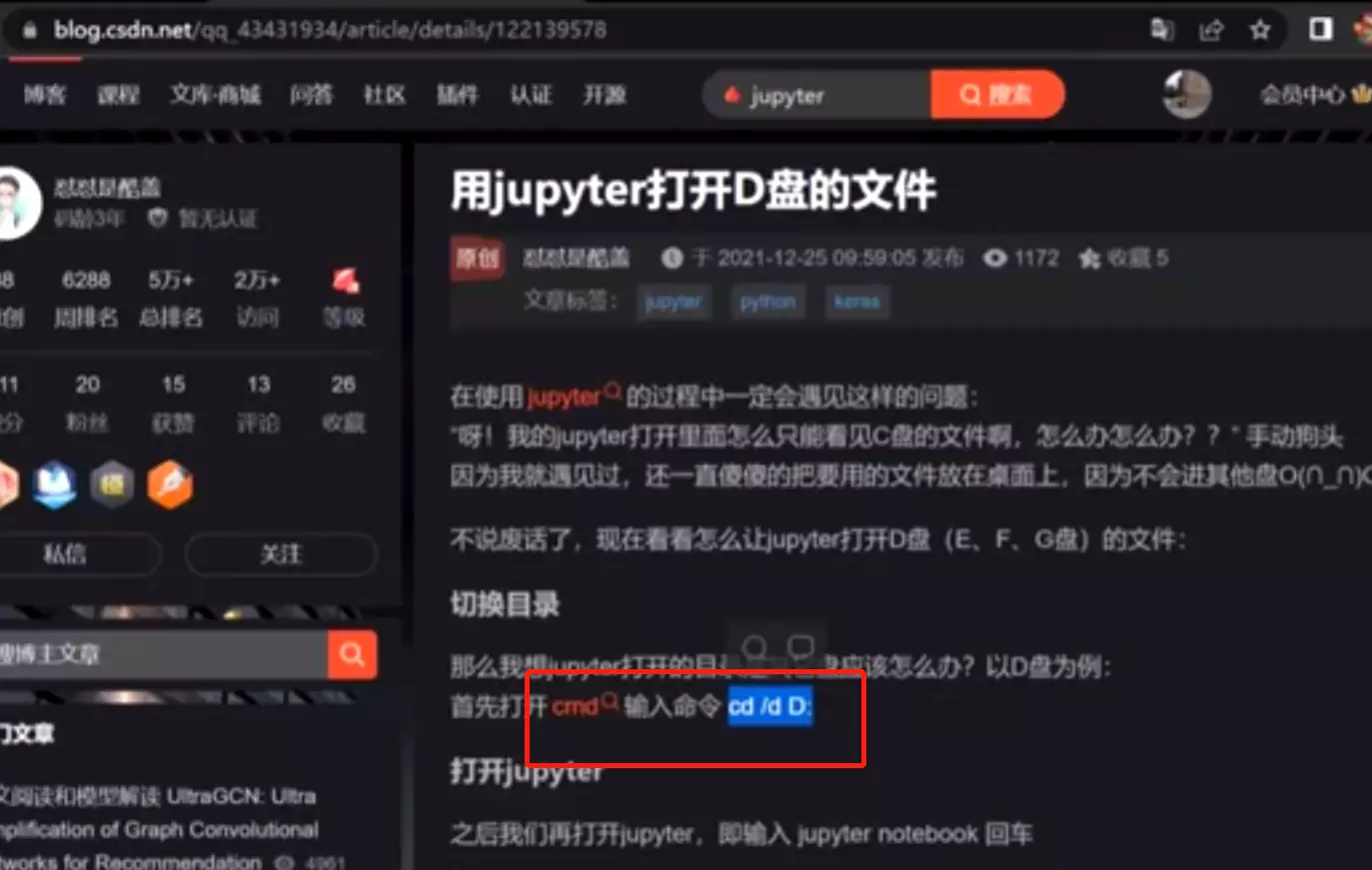
如何改到D盘?
1、在命令窗打开D盘,2、再启动jupyter![]()
![]()
![]()
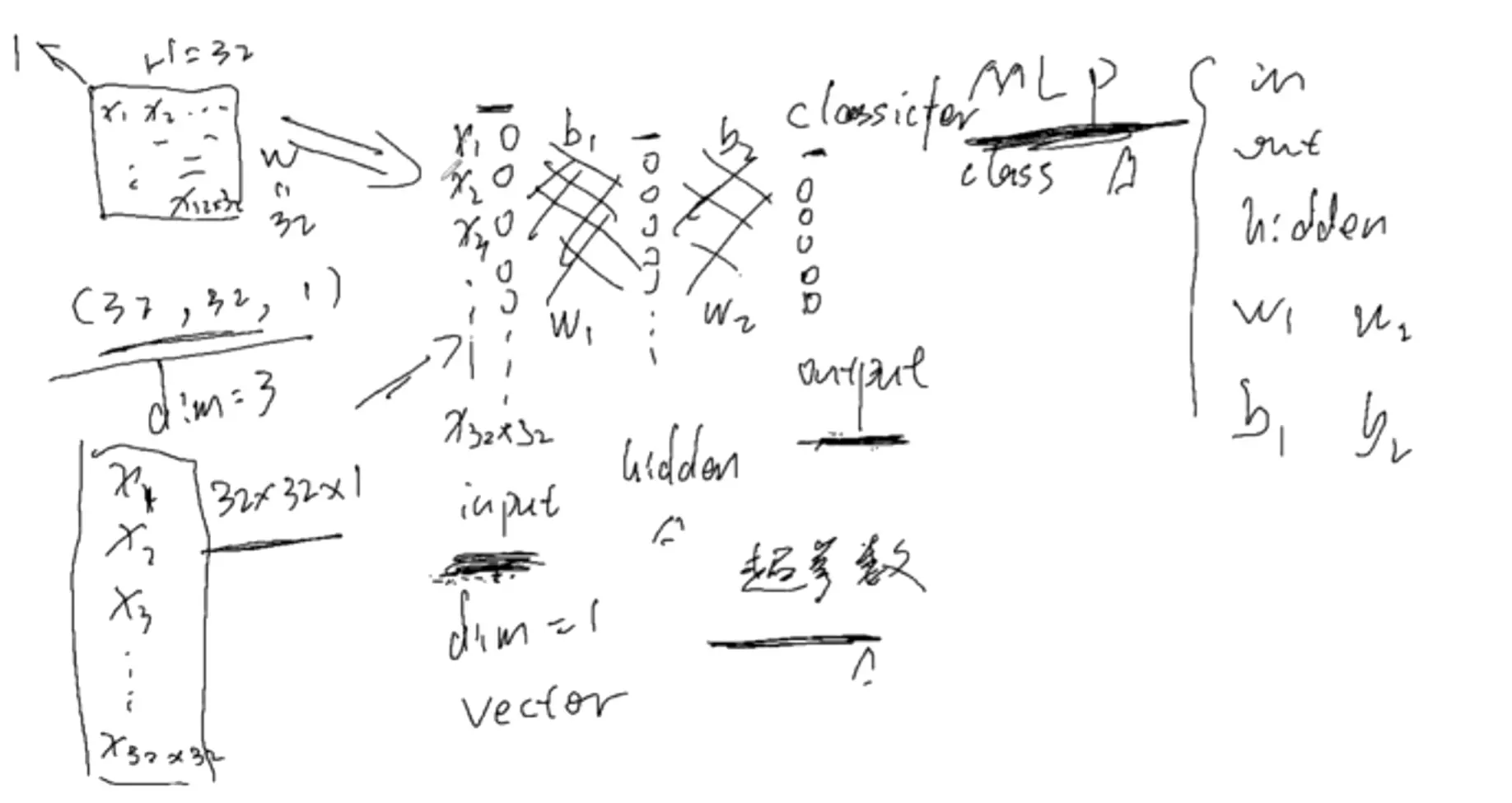
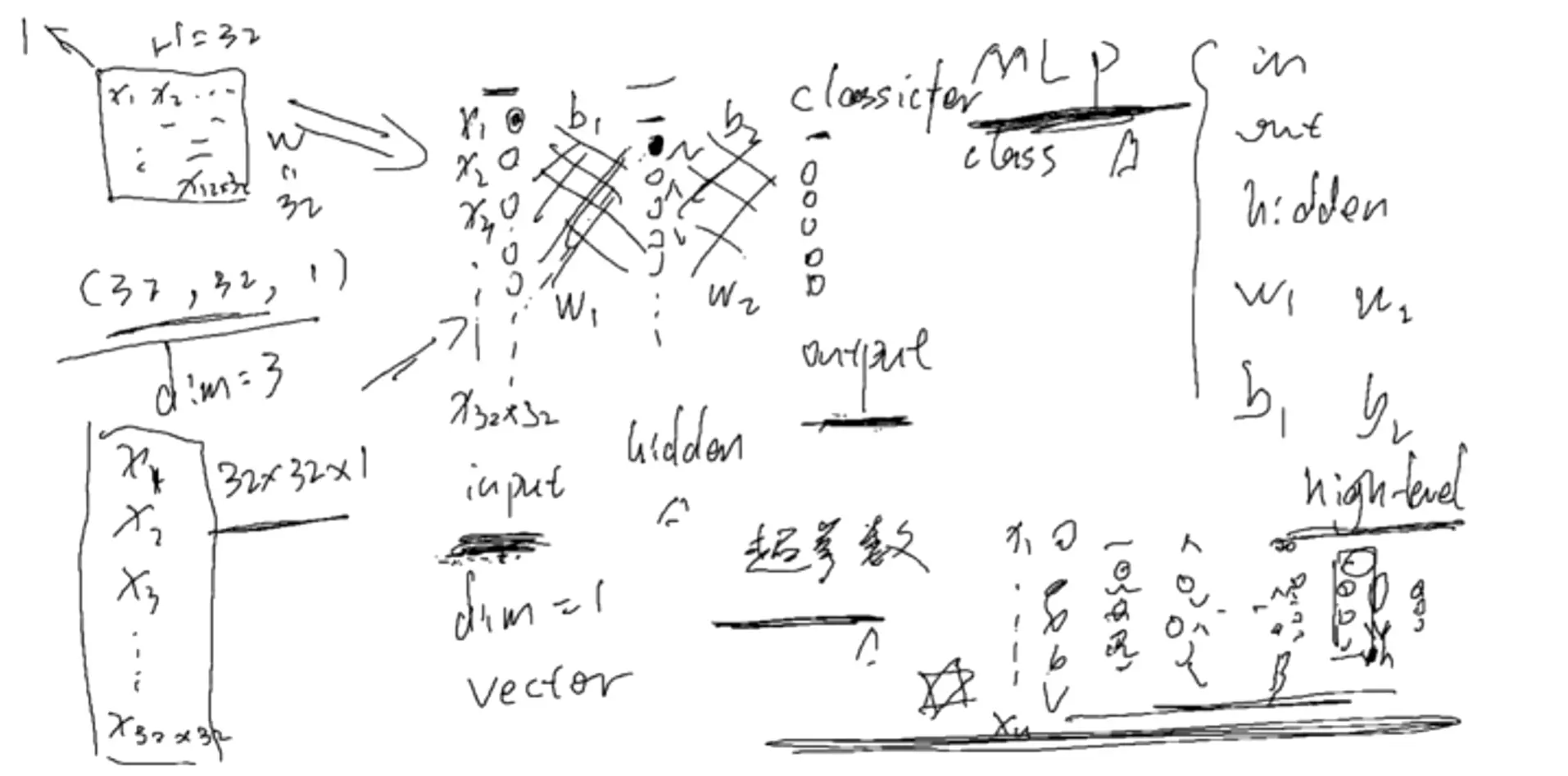
#认识科学计算库:torch.nn
![]()
![]()
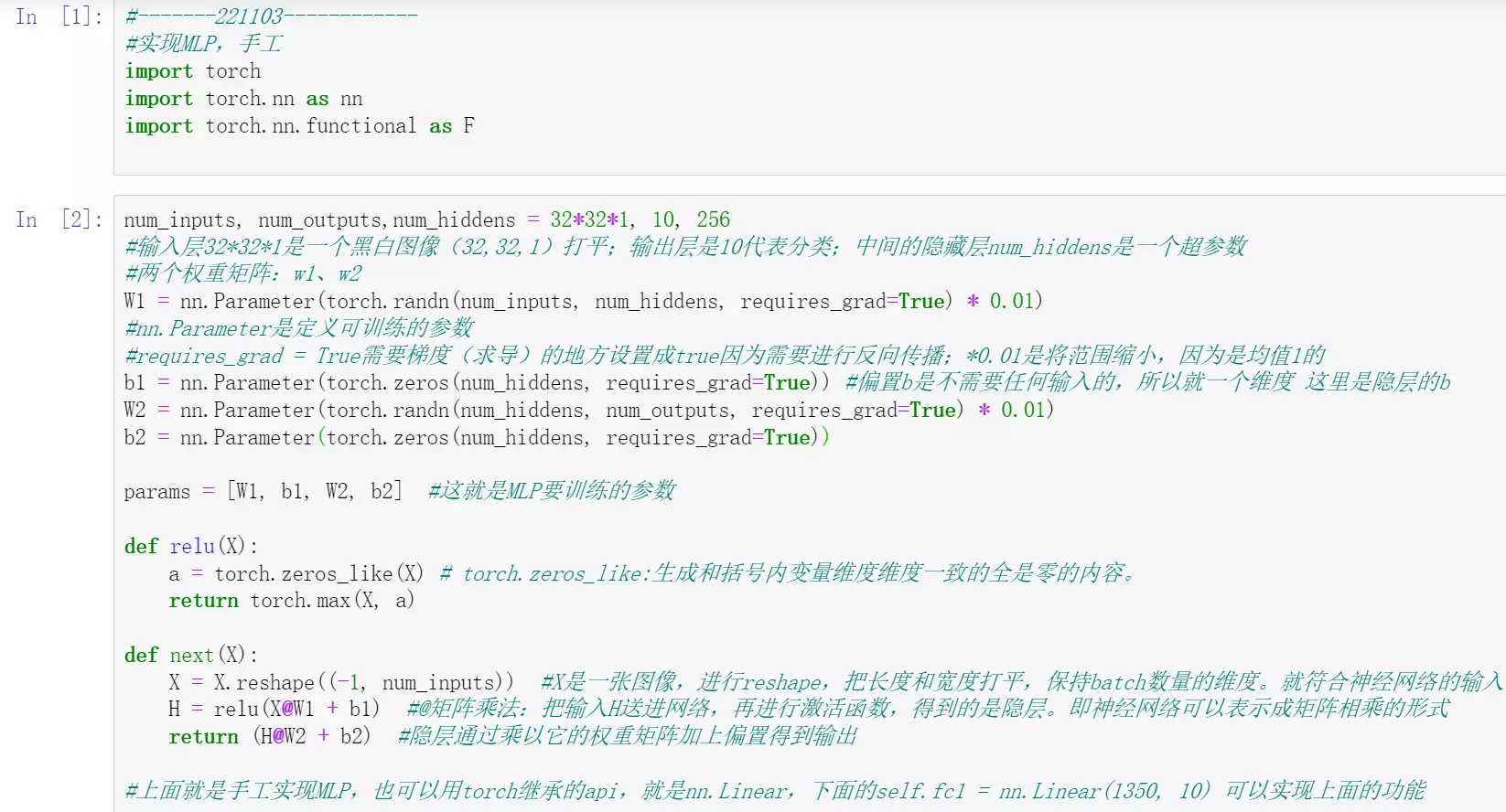
#手敲一下感知机模型,以后如果用包就不用敲了。
![]()
#神经元干的第一件事:把输入乘上相应的权重;第二件事,做一个求和,经过一个激活函数,得到一个输出。输入就是特征,权重代表更看重哪个特征,输出可以看出分数。
![]()
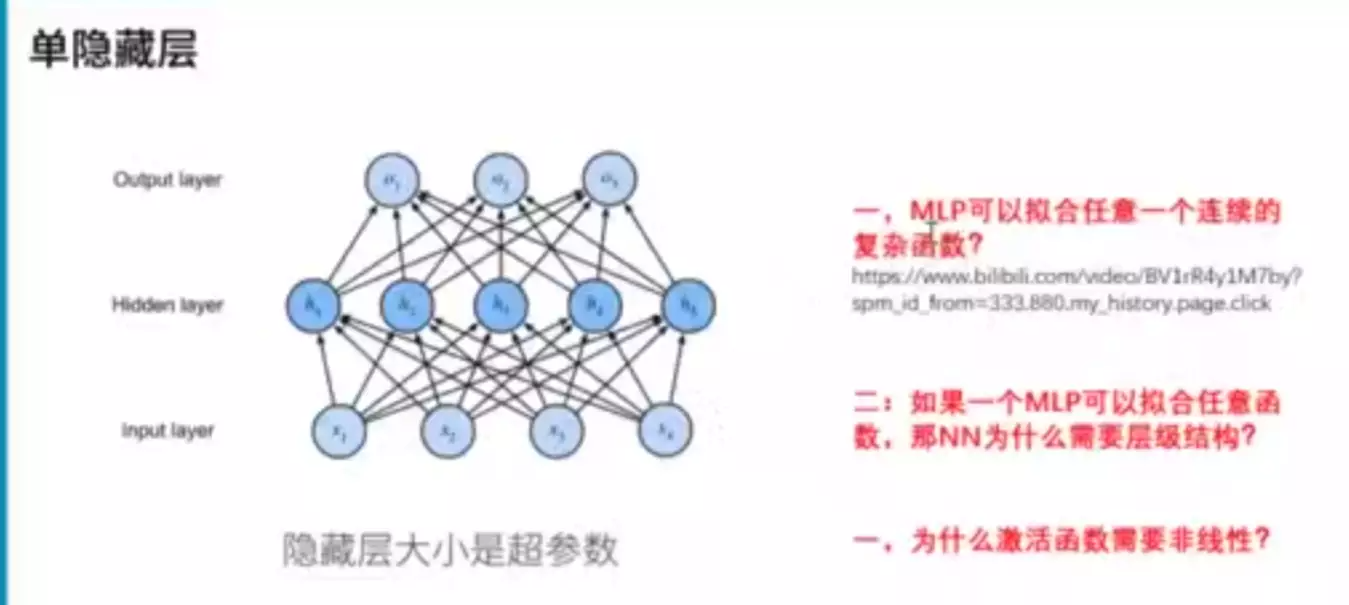
#当神经元扩展成两层时(input、hidden、output),就叫MLP(多层感知机)。当到了hidden隐藏层时维度有一个下降,就是说对前一层对浅层的特征做一个特征提取, 提取之后的特征语义信息变得更高级,这是神经网络一个非常重要的点,也是它的核心。w就是网络要学习的权重,一共有两个w矩阵要学习。bias是偏置,就是偏好的概念。例如小明找女朋友,眼界高,那么b可能是-0.2,如果眼界第,b可能是0.2,对于同一个结果,比如0.7,加上偏置,一个结果是0.5不及格,一个是0.9很好。 b与w的区别:b不接受输入,直接给到输出。例如对于hidden层的w,它接受输入,给到输出;但是b不接受输入,直接传到输出。
![]()
![]()
#单纯的一个像素点是没有意义的,它必须和周边的像素点一起去表示某个东西,比如一个眼睛、一个嘴巴,才有意义。一个隐层的神经元是综合考虑了所有的像素点 ,是对所有的像素点做了一个加权求和,抽取一些比较高层的概念。比如前面的神经元是一个个像素点,隐层的就是一个曲线、直线、一个边或一个角。同理,隐层如果越多的话,特征提取就越来越厉害。
#超参数:参数可调的意思。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
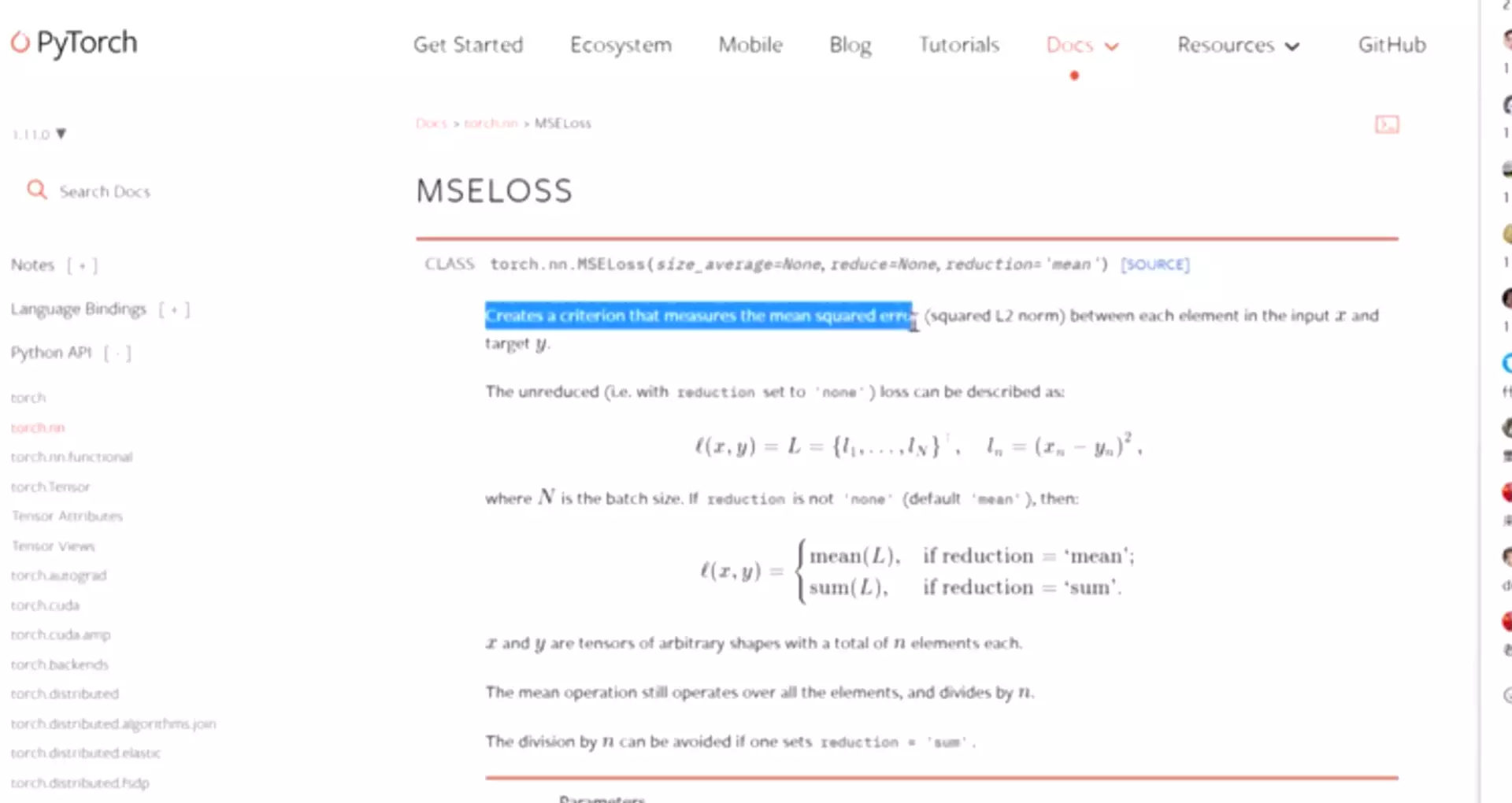
MSE:均方方差
![]()
![]()
![]()
![]()
![]()
![]()
![]()
#numpy有19个数据类型,是为了支持更多的数据计算。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
numpy是python自带的包。
![]()
![]()
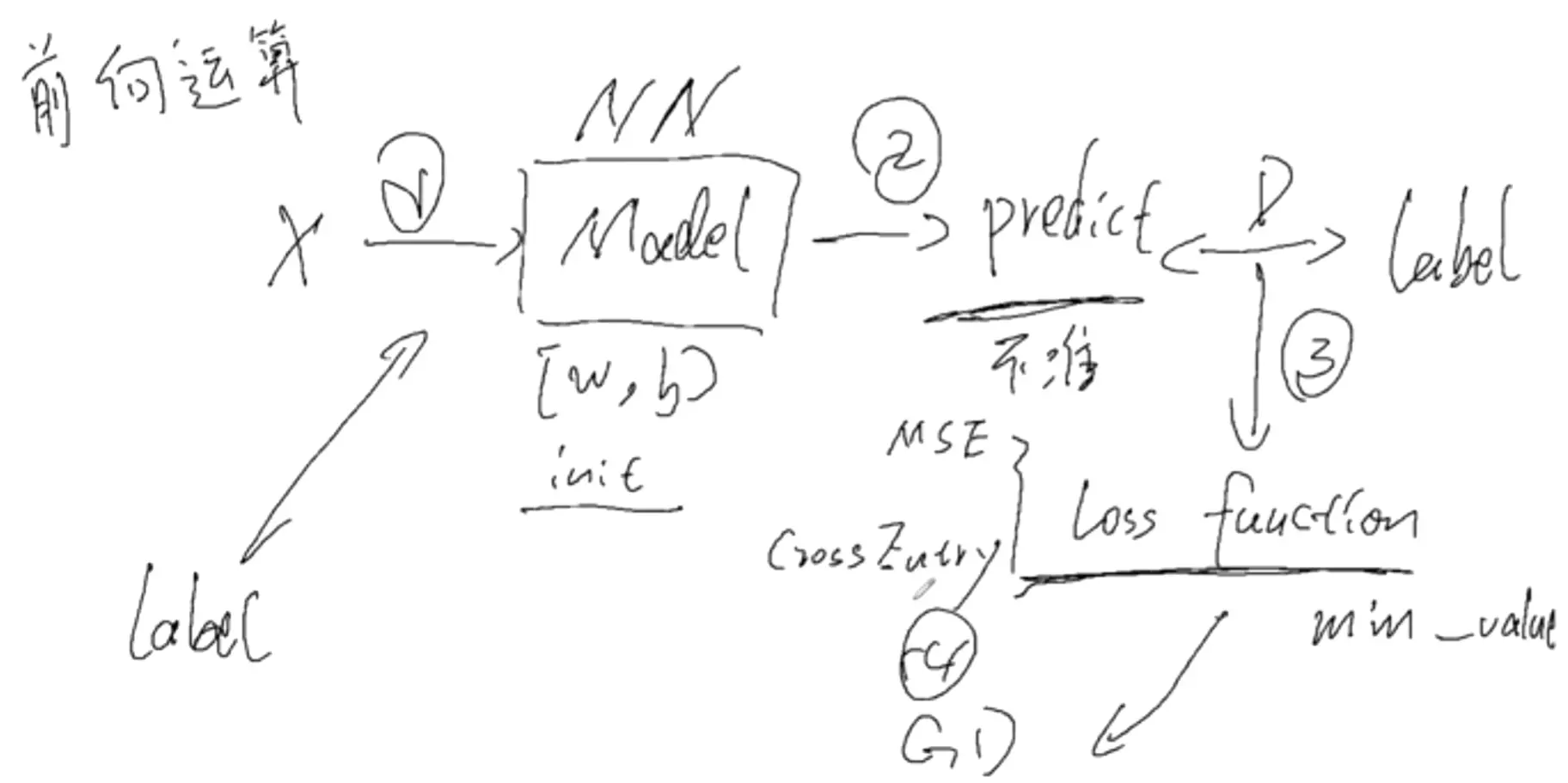
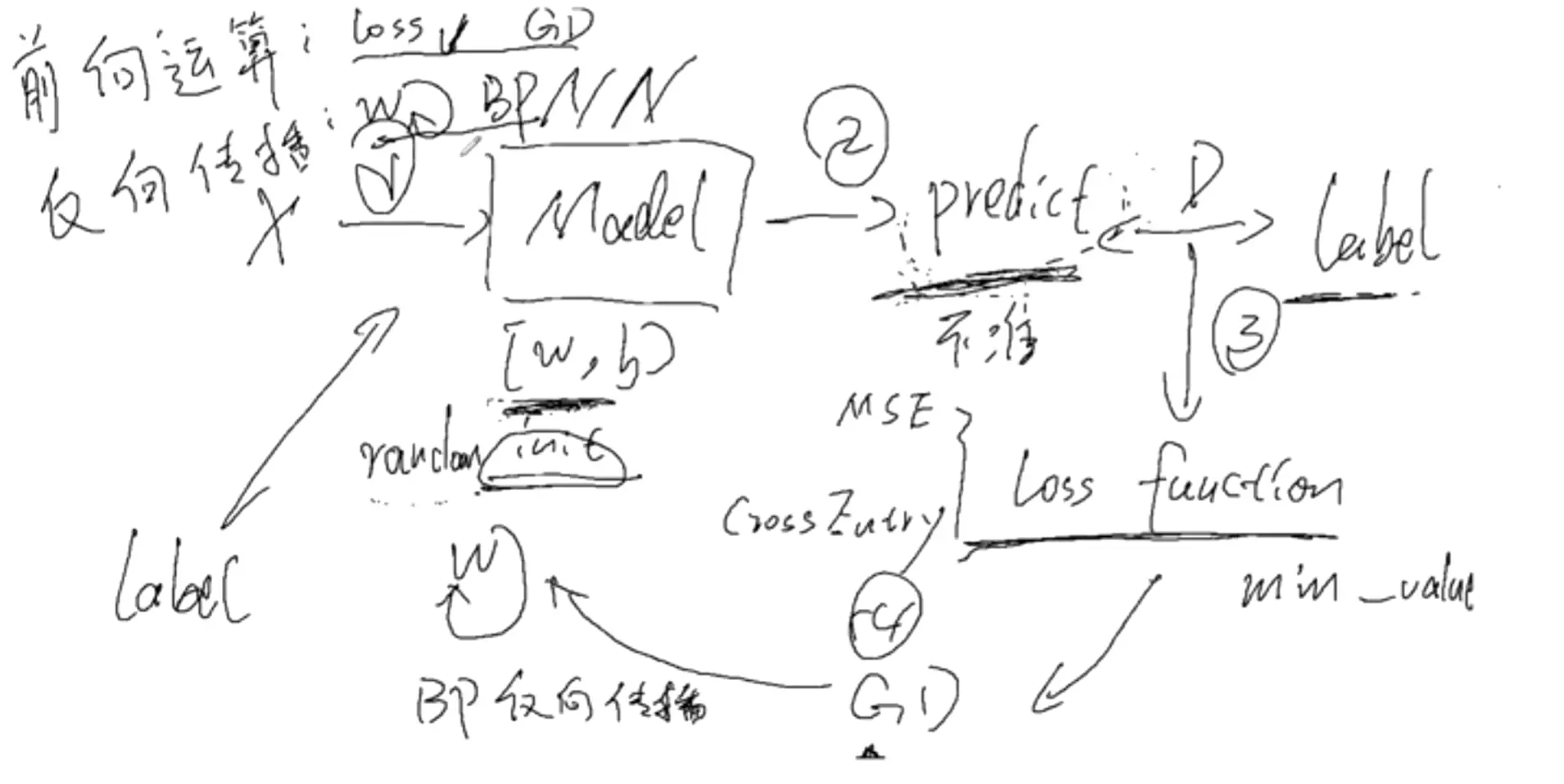
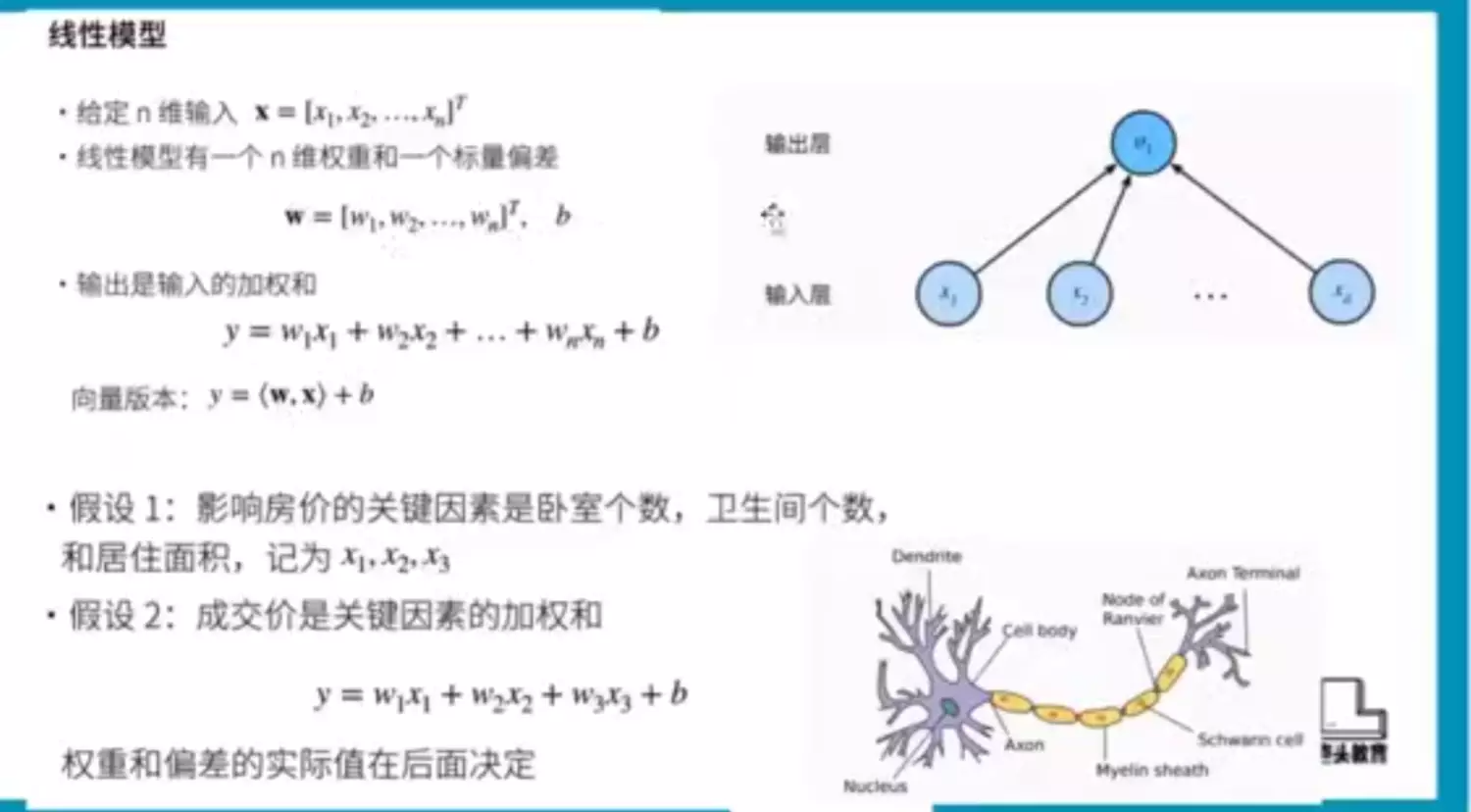
线性模型等于一个单词的神经网络
![]()
#距离是用函数来表示的,模型训练的目的是距离尽可能的减小。实际上是求模型的最小值。
![]()
#求导需要对全部数据集进行求导的计算,但是问题来了,对于DeepLearning的数据集一般都是很大的,一张图片都是上百万张,语言都是上百万数据量,在这么多的数据量进行求导,即便用计算机,计算量是很贵的。
#所以不用全部的数据,而是在数据集里进行一个随机的采样,用随机采样的b个样本用来近似原始的数据集。--》批训练,就是小批量的随机梯度下降
![]()
![]()
*** #首先,批量不能选择太小,因为1、本身这个批量是近似原始数据样本的,如果批量太小,这个误差就比较大,随机性太强了。2、如果批量太小,计算量就很小,只需要对几个样本进行损失计算,就不适合并行的计算资源,因为GPU是很强大的并行的矩阵计算单元,batch size设置太小,反而对计算速度有所降低的。
其次, 批量不能设置太大。1、显存不够用。显存就是GPU里的存储量;要求梯度、或者算损失的时候,如果根据比较大的批量进行计算,首先要把批量加载到显存。这就会导致显存不够用。2、太大也会浪费计算,因为比较合适的大小就能近似计算,太大没有必要。
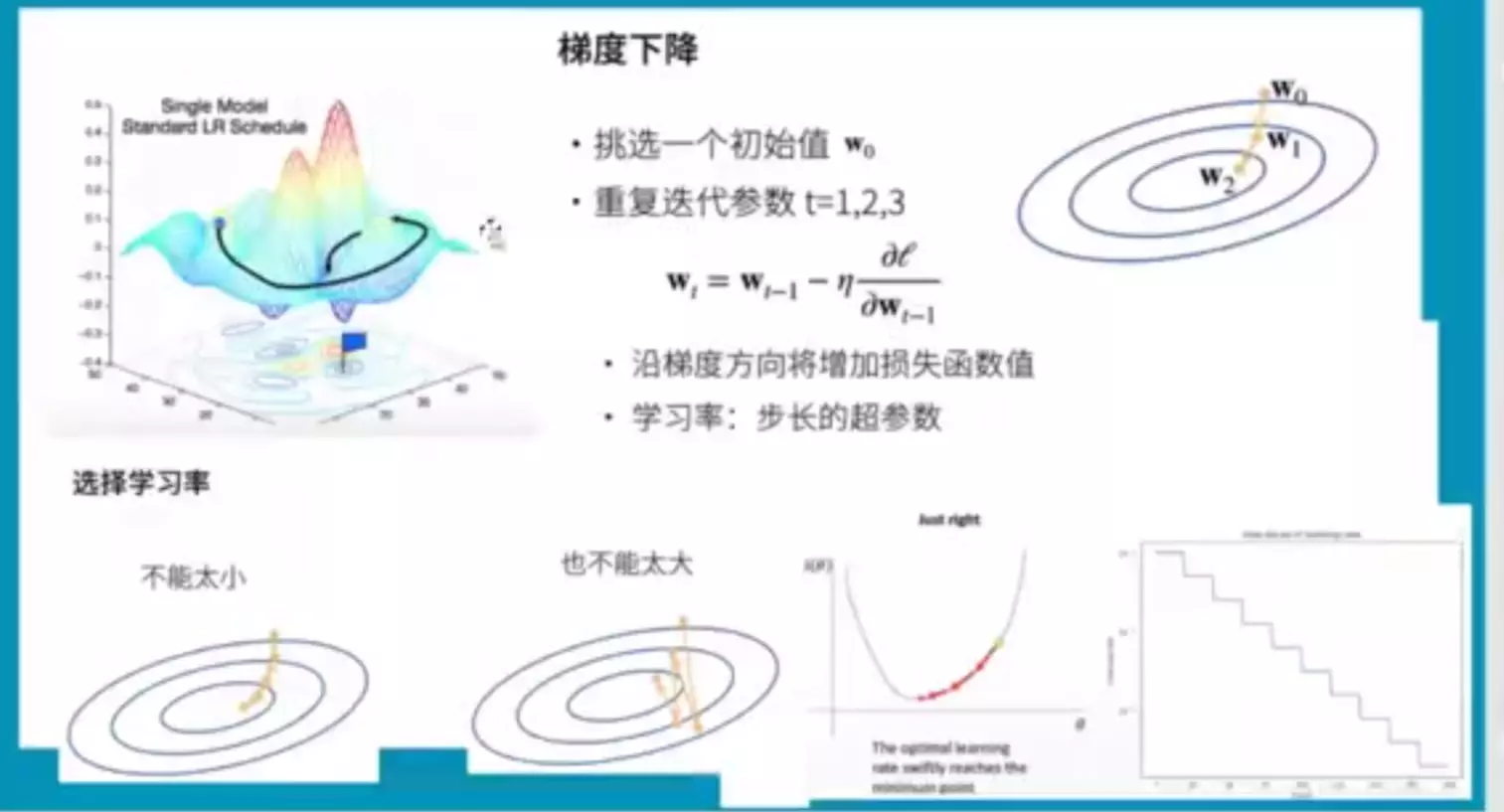
#关于反向传播:不要太纠结具体是怎么做的,为什么要做反向传播?其实为了求梯度,目的是为了广播训练,找到最小值。所以是为梯度服务的。
![]()
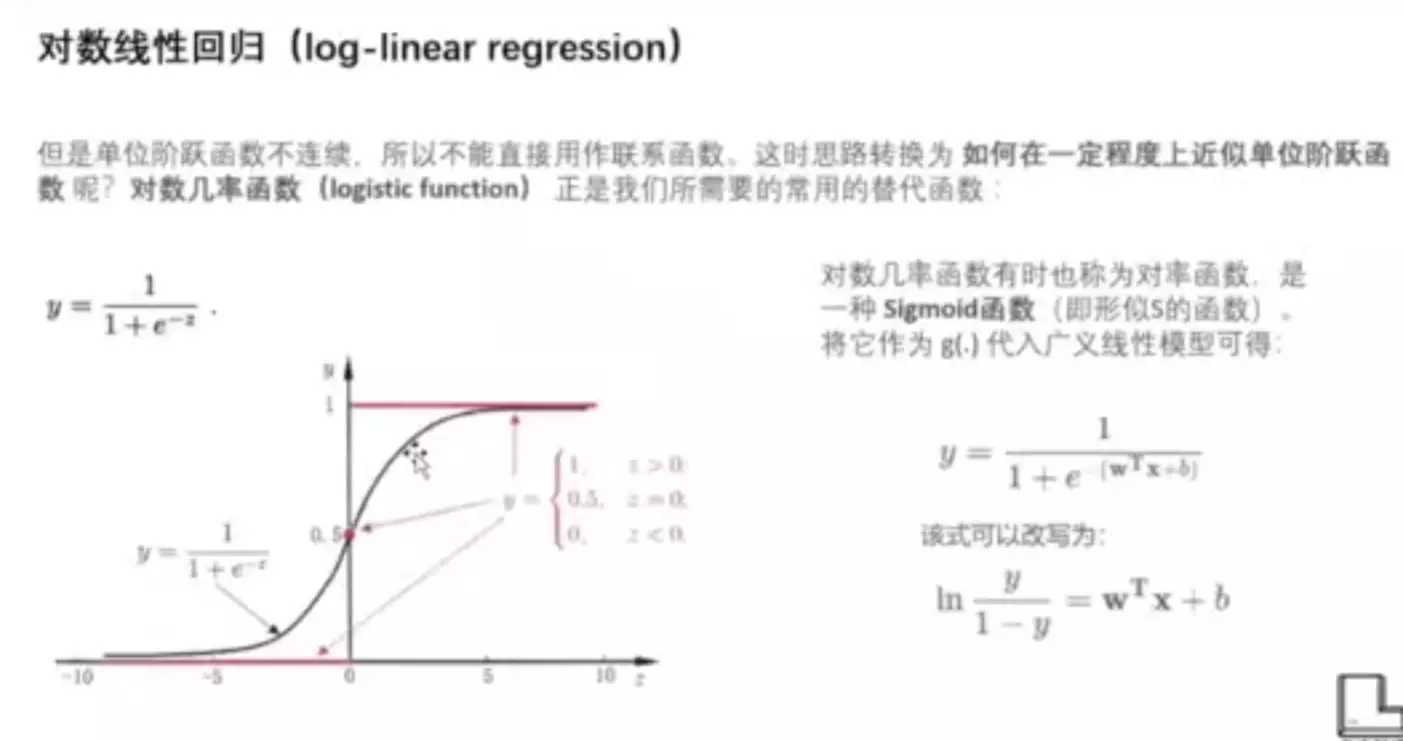
g是广义的,添加了g,就是联系函数,要求是单调可微的。就是做了个映射。可以解决非线性问题。非线性的经典问题:分类。
跃迁不能作为联系函数,但是可以改进一下:sigmoid
![]()
![]()
![]()
![]()
#需要找一个函数映射一下,就是softmax
![]()
![]()
![]()
可以作为解决二分类问题。
#感知机是一个线性模型?广义线性模型?
都不是。模糊讲可以是广义的线性模型。
#是线性回归还是逻辑回归?
不是回归。因为回归要求输出是连续值。
![]()
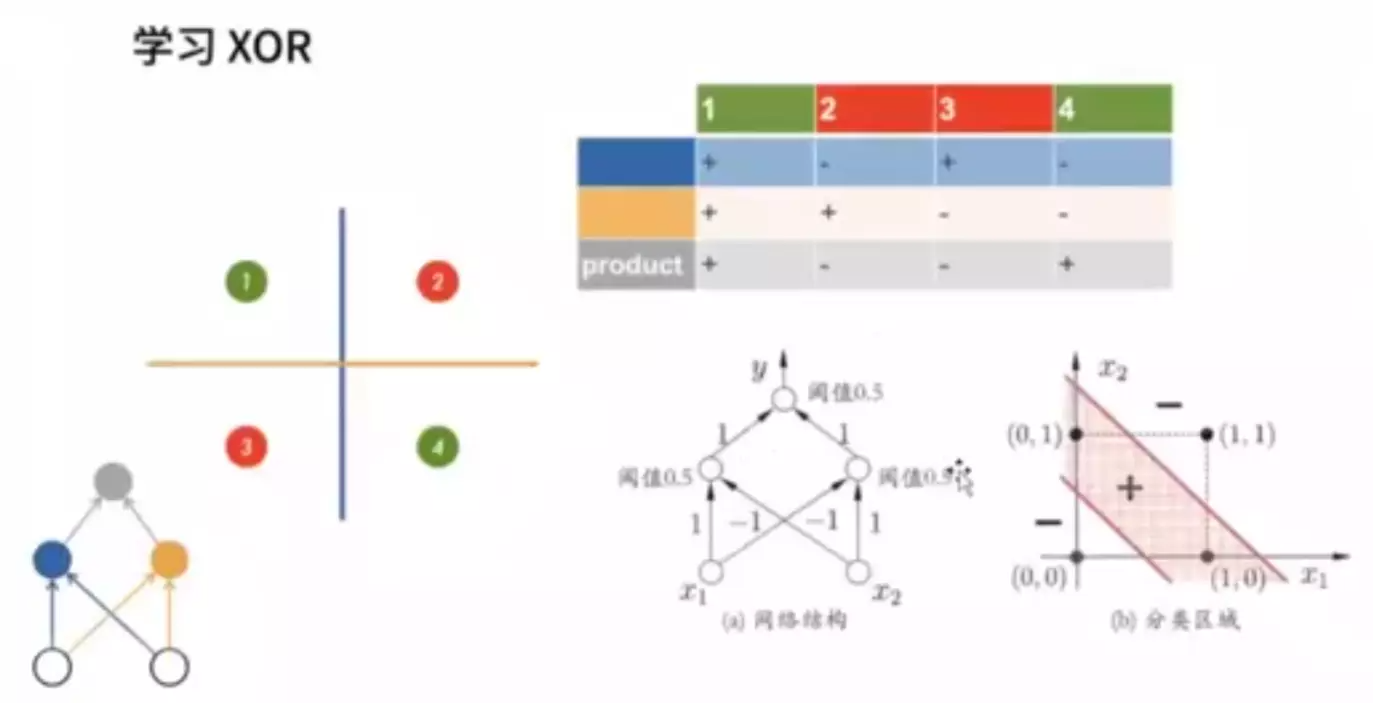
感知机无法解决异或问题。
![]()
多层感知机MLP:可以解决
![]()
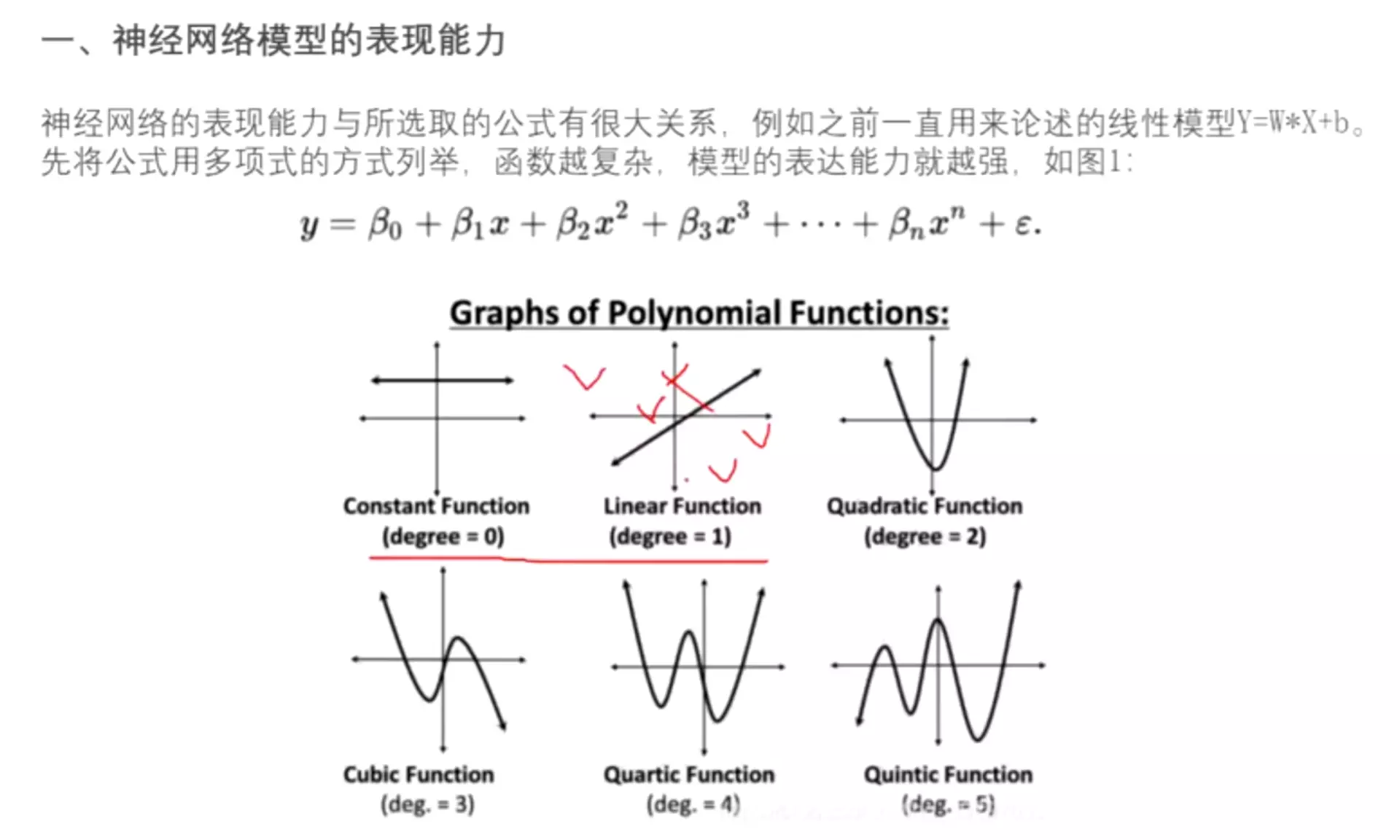
MLP和感知机相比,就是多了一个隐层。#MLP非常厉害:1、可以拟合任何一个复杂的连续函数 2、层级结构可以减少参数量。
![]()
![]()
![]()
![]()
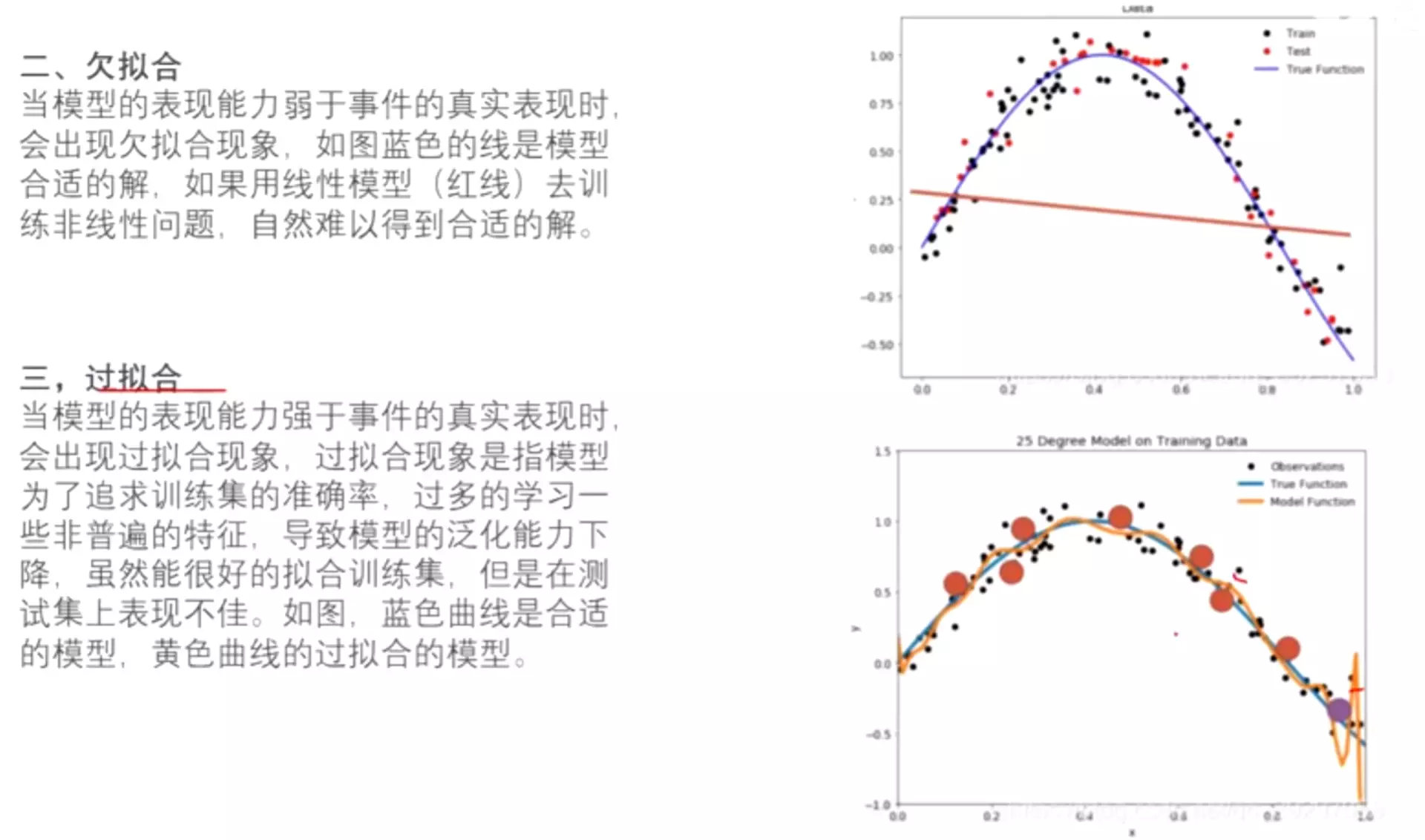
#问题的关键是会过拟合
![]()
![]()
![]()
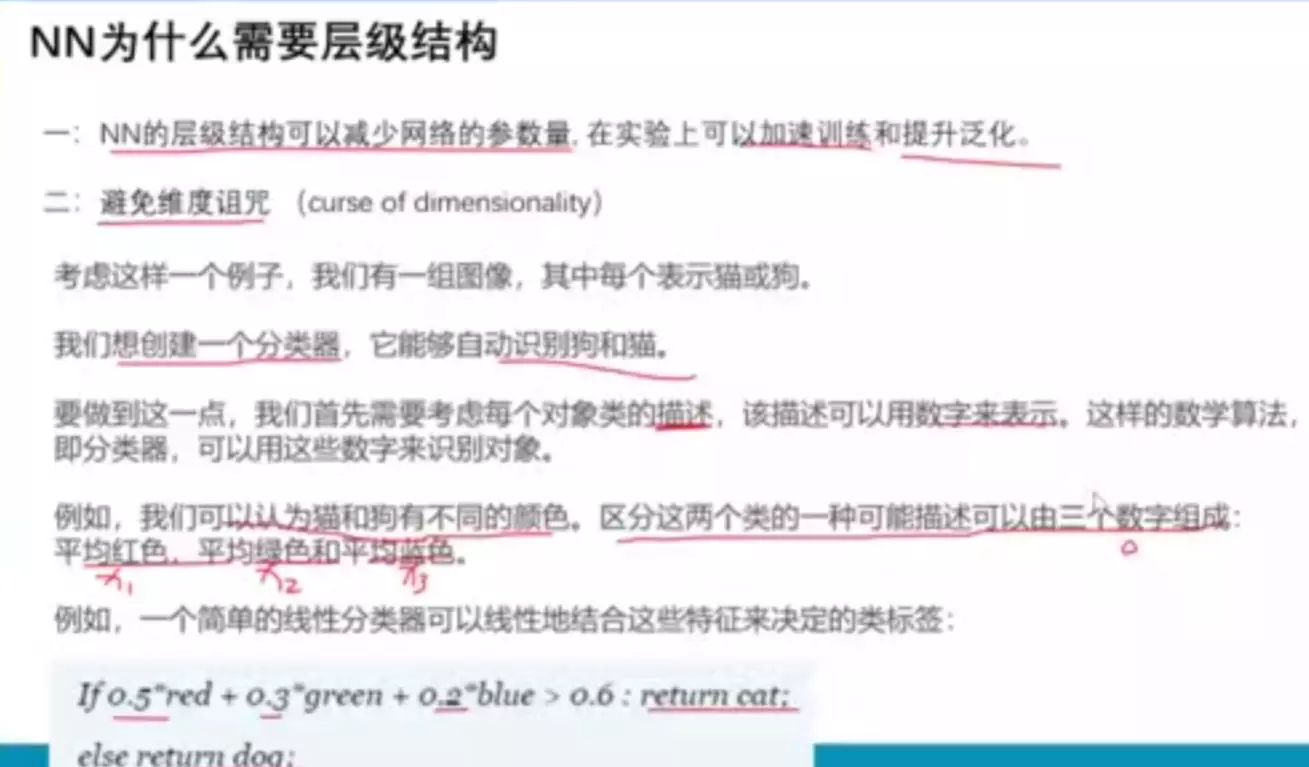
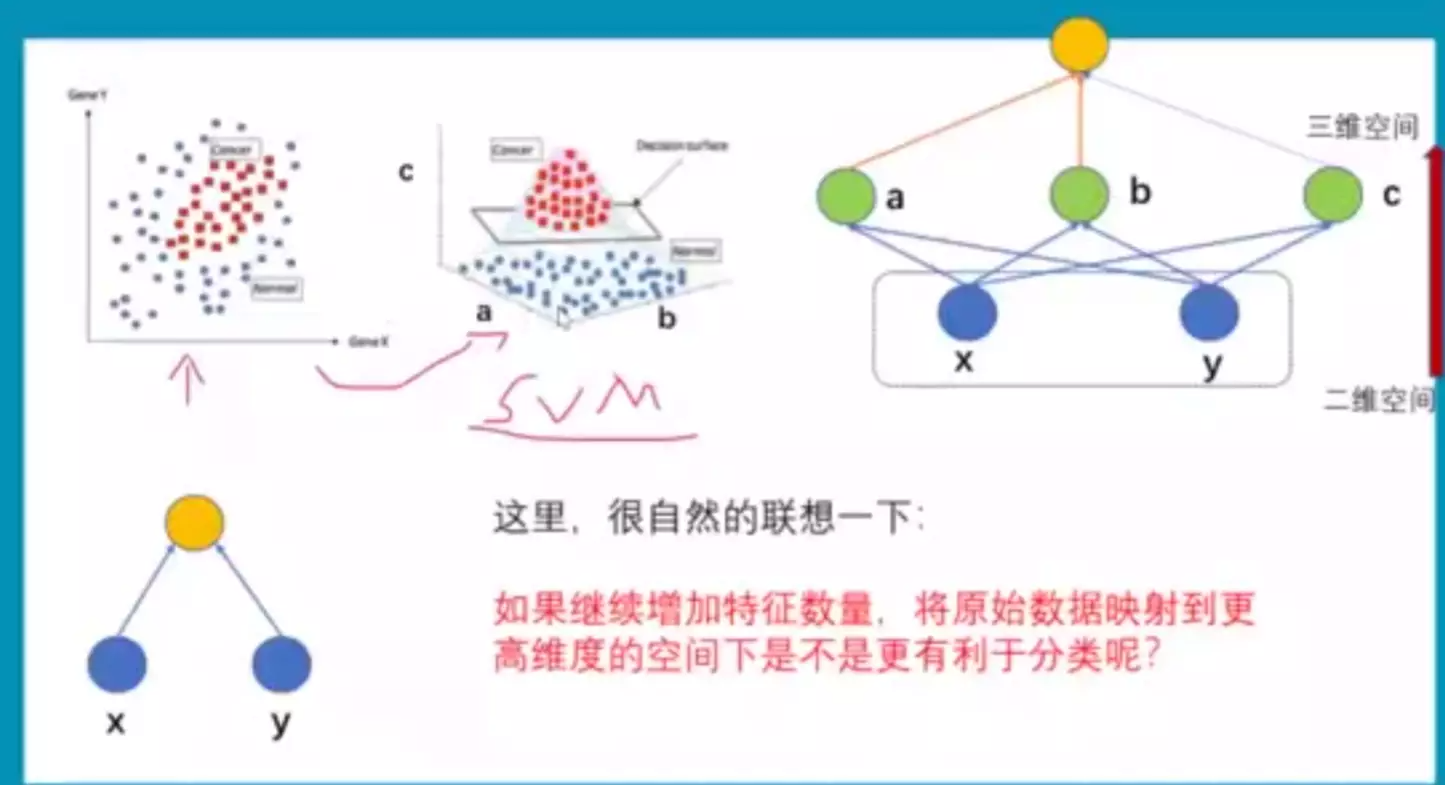
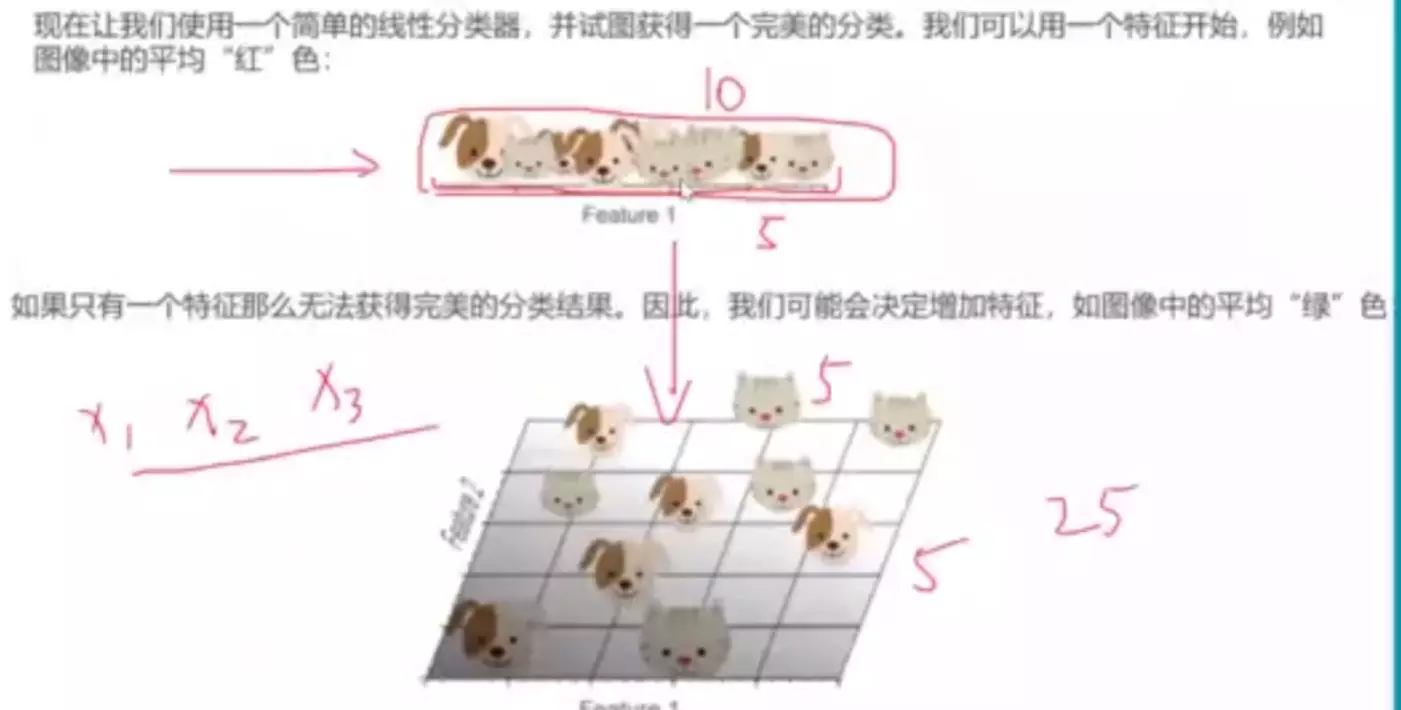
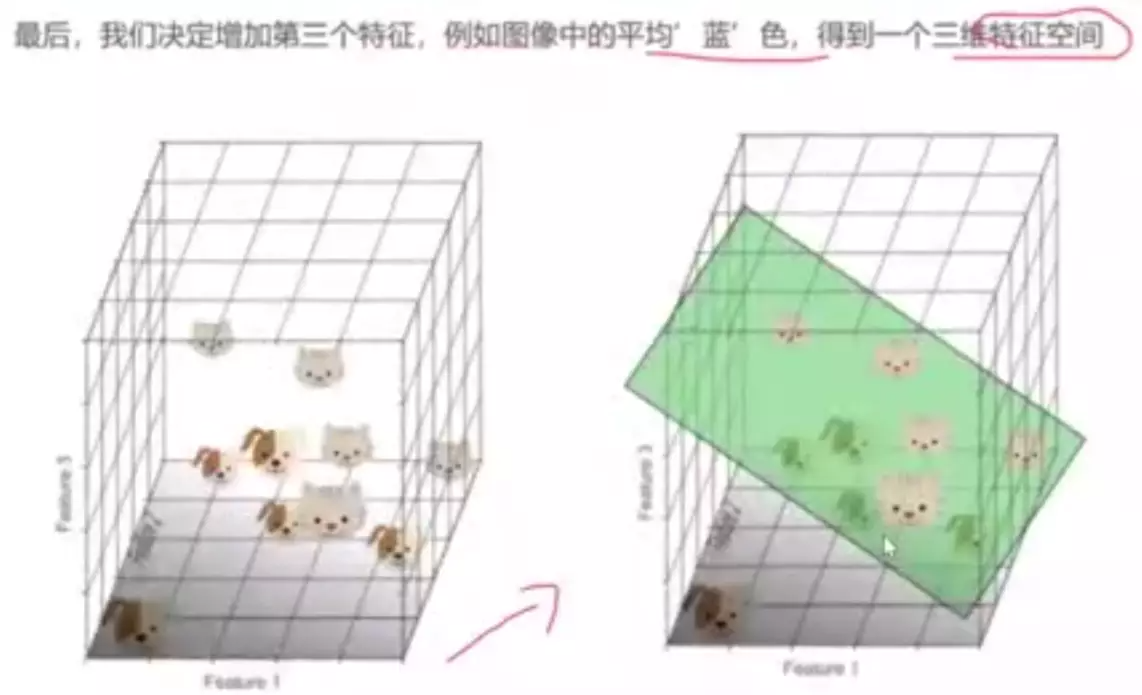
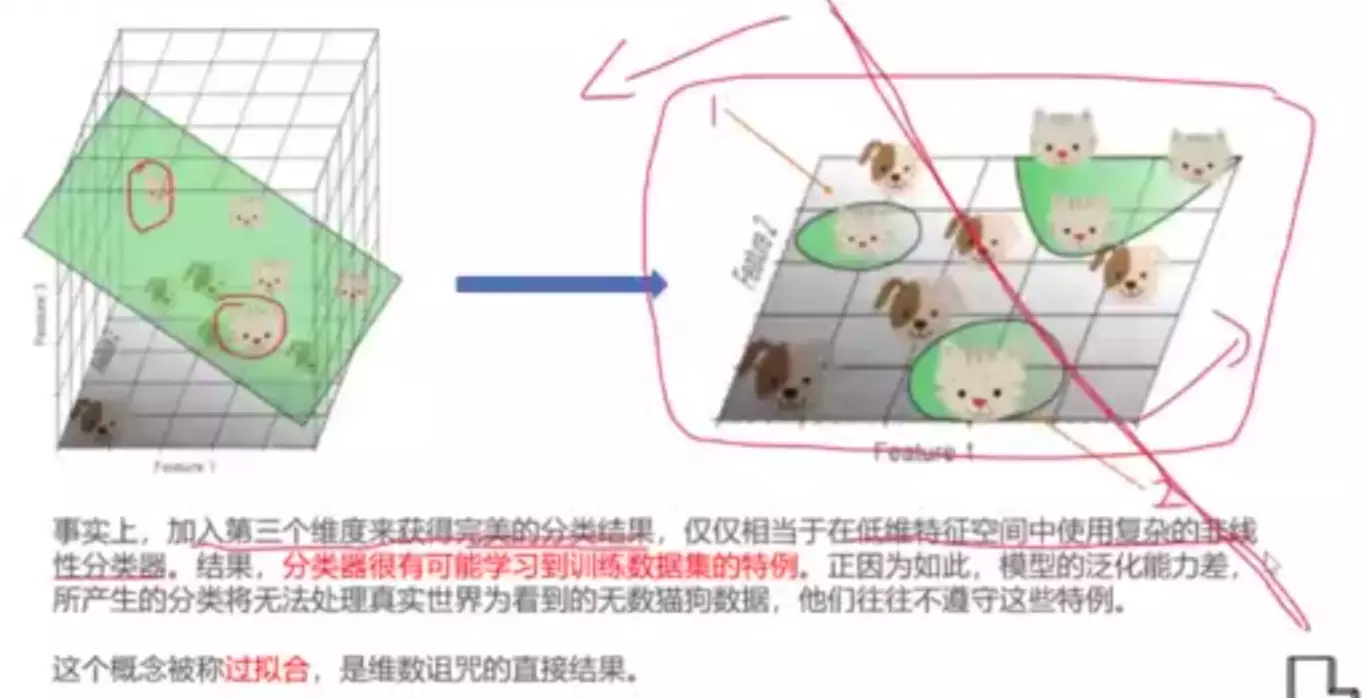
#为什么一维空间分不开?因为样本太密了
#为什么三维能分开?因为样本没那么密,可以很轻易的找到一个平面将猫和狗分开。
![]()
#过拟合:学习到了特例,并不具备泛化。
![]()
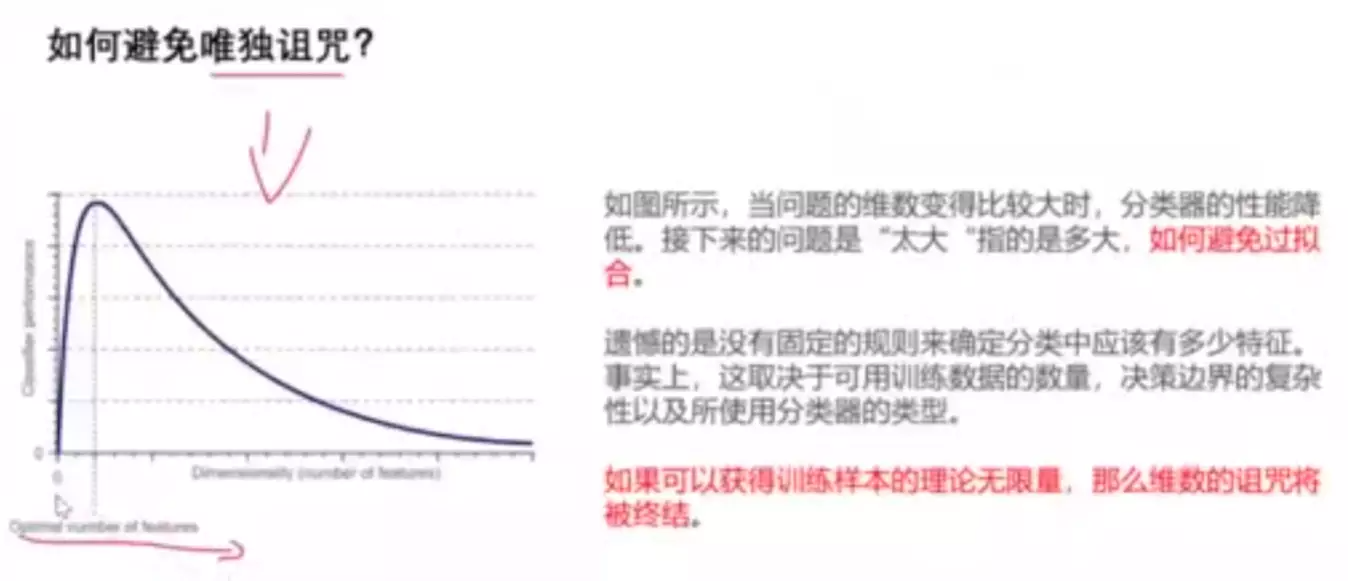
#当特征逐渐增加的时候,一开始会变好。维度诅咒的根本原因是数据量不够大。
#特征选择的多少跟数据容量有关系。如果训练样本无限大,那么维度诅咒就被终极。
![]()
#为什么喂不饱?--维度诅咒
#为什么NN的层级结果在开始时一般是降维趋势的? --1、输入一般是高维数据,2、高维样本之间的相似性难以挖掘,所以会对维度做一个压缩,是样本分布更稠密,便于分类。
![]()
#升维就是恢复一些数据。
![]()
#二维不可分的数据,可以将它数据所在的空间映射到更高维的空间,他在高维空间的分布可能就是可分的。或者增加模型的复杂度。![]()
![]()
#泛化:真实世界中所有的情况。
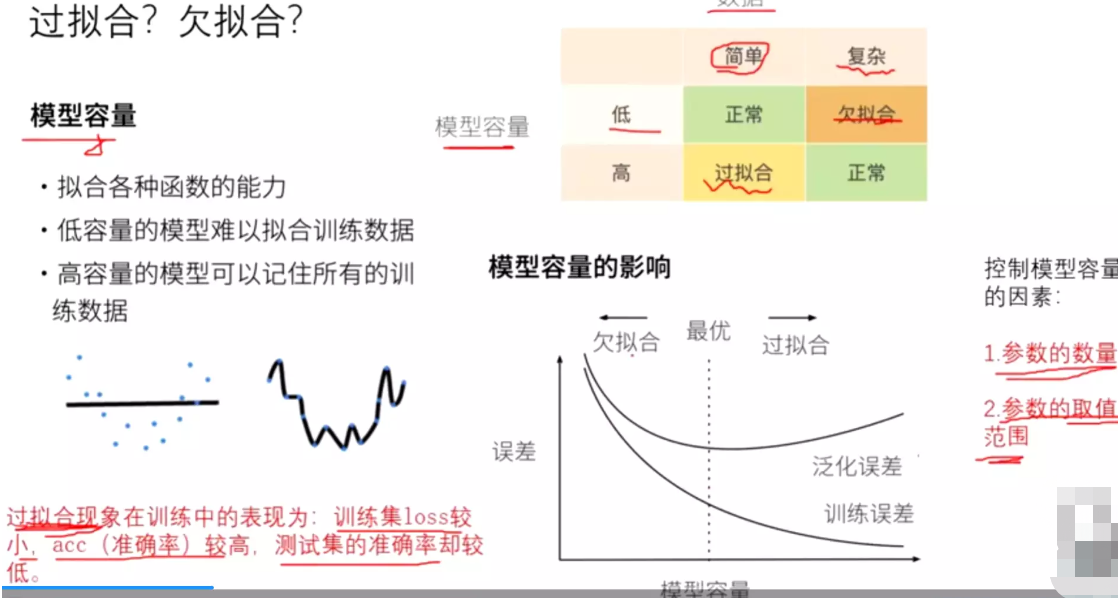
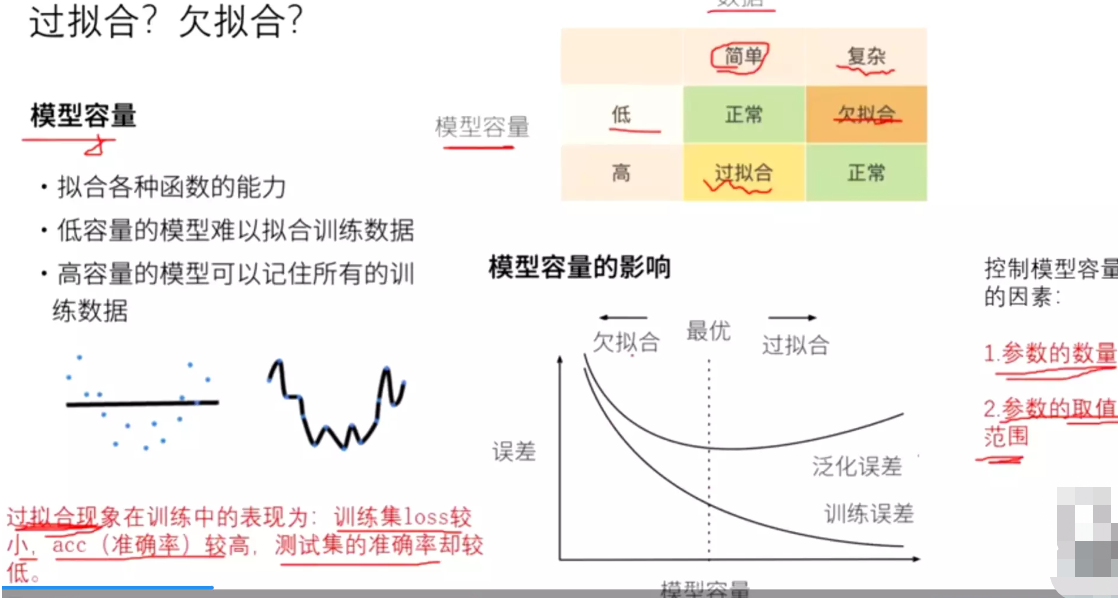
#模型参数的个数可以控制模型容量。
#控制模型容量的因素:一个是模型的参数个数;一个是参数的取值范围。
一直说的正则就是这个。
![]()
![]()
#过拟合:在训练集上loss较小、acc较高;测试集acc较低。
#理论上讲,一个模型的容量越大,理论上模型的表征能力会越来越强,他就会拟合现在的数据集的所有情况,它的误差就会越来越小。但是现在的数据集并不能代表真实世界的所有分布。 它在拟合真实数据时就会比较差,泛化误差高。所以在训练时希望达到什么效果?最优。既不过拟合又不欠拟合。
#技巧:早停法。一旦测试集上的acc出现下降的情况,就将它停掉。
#训练集和验证集,在DeepLearning中没有分的特别清。在数据比较少的情况可以把它两合并。一般训练集、验证集、测试集的比例是8:1:1,训练集相当于学习、验证集相当于摸底考试、测试集就是高考。所以严格讲,测试集只能用一次。训练集目的是学习参数;验证集目的是挑出那次成绩最高,这一次的思维方式和状态是比较好的,将模型的参数保留下来,作为选参--》确定超参;测试集目的是测试模型好坏。
![]()
![]()
#过拟合是因为模特太复杂了,模型的复杂程度是由模型容量决定的。模型容量是由模型的参数量和参数的取值范围决定的。只要对模型的容量产生约束都叫正则。
#范数:就是对模型参数的范围进行限制。
![]()
![]()
#L2范数惩罚,别名:权重衰减、岭回归。
数学原理:待搜索
![]()
#L2梯度为何叫梯度衰减? 因为权重的乘数小于1
![]()
![]()
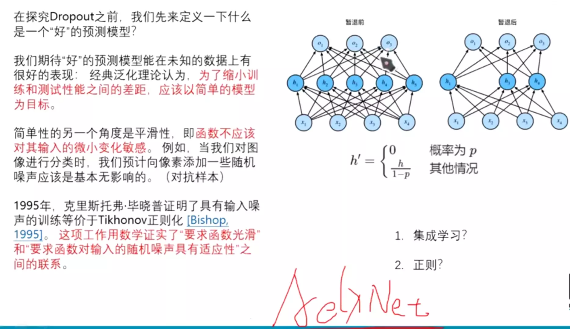
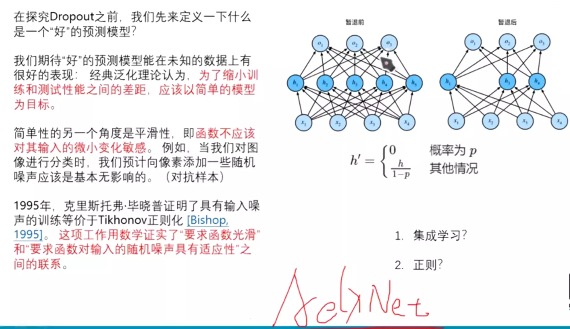
#dropout:准则:中国大道至简;外国:奥科姆的剃须刀--》奥卡姆剃刀原理.
就是说函数不应该对输入的微小变化过于敏感。
集成学习:dropout每一次训练都是训练一个子模型,但是最后整个模型进行验证的。
正则:dropout后模型容量是减少的,所以是正则。
dropout--》工业跑在了学术前面。
![]()
MSEloss平方损失:L2范数
![]()
去用dropout时直接实例化一个类。p=0.2
![]()
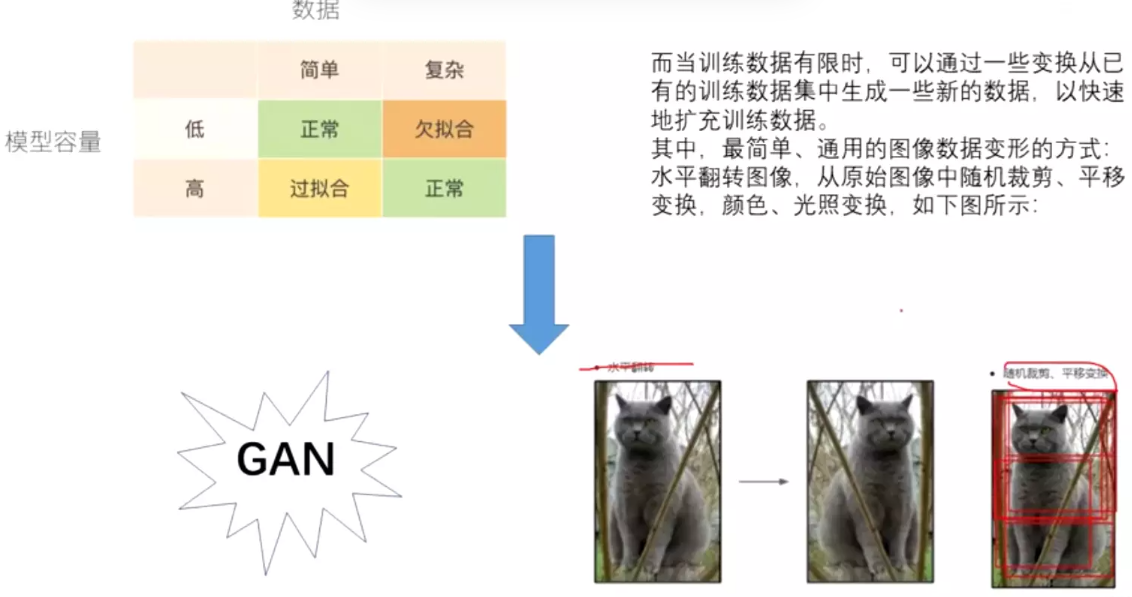
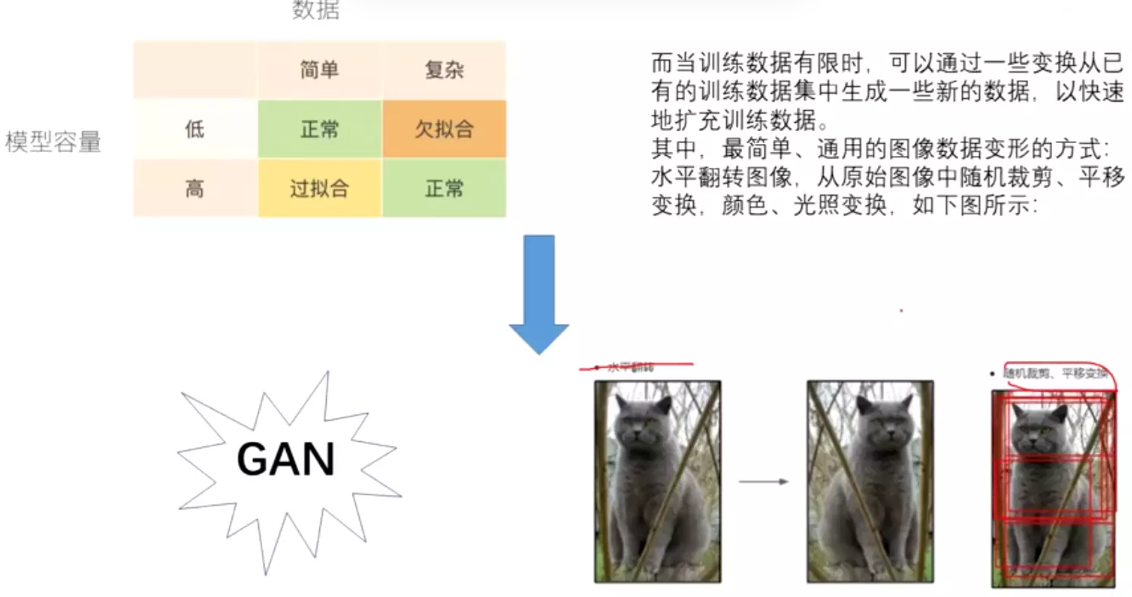
解决过拟合的另一个方式:数据增强
#正则是dropout,如果不改变模型容量,单纯增加数据,使数据更复杂,也可解决过拟合
![]()
![]()
传统的就是旋转,翻转。最先进的是生成对抗网络。
![]()
![]()
BP反向传播。![]()
![]()
#解决梯度爆炸/消失:
1、乘法变加法:ResNet,LSTM
2、归一化:梯度归一化、梯度裁剪 --->也可以看成一种正则,约束我的模型,万物皆正则
3、合理的权重初始化和激活函数,比如初始权重小一点、relu负值是0
![]()
硬性限制与柔性限制
![]()
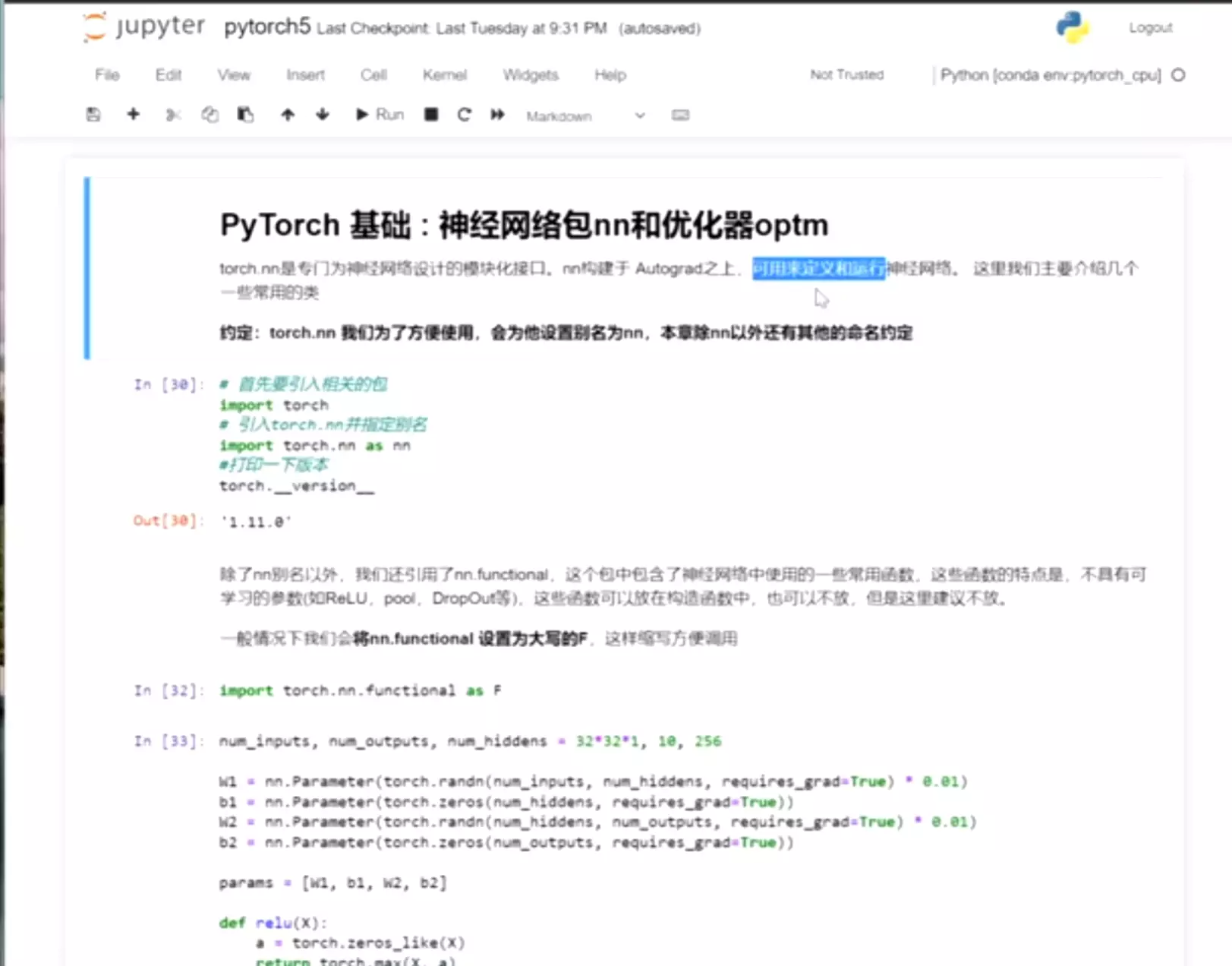
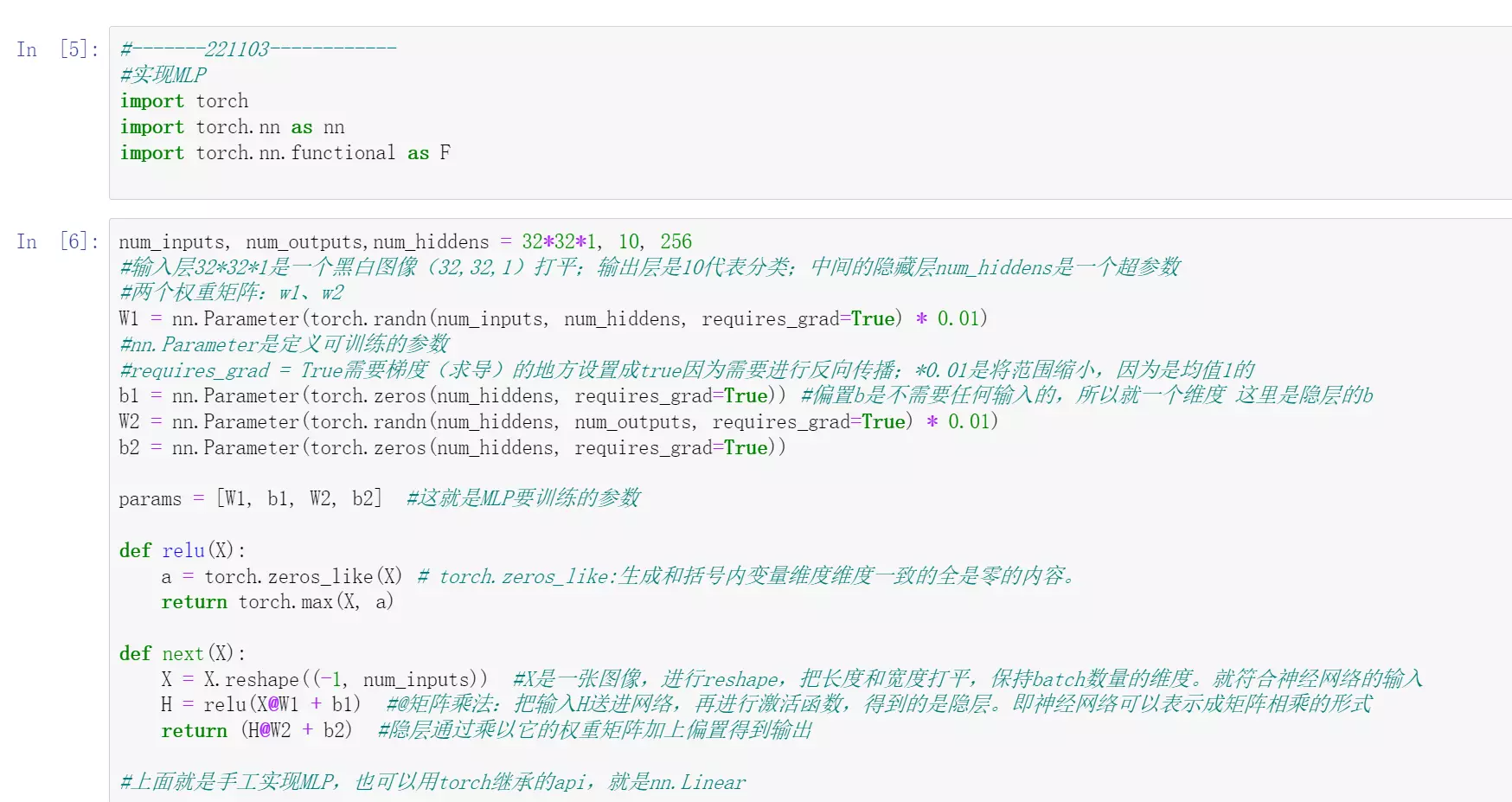
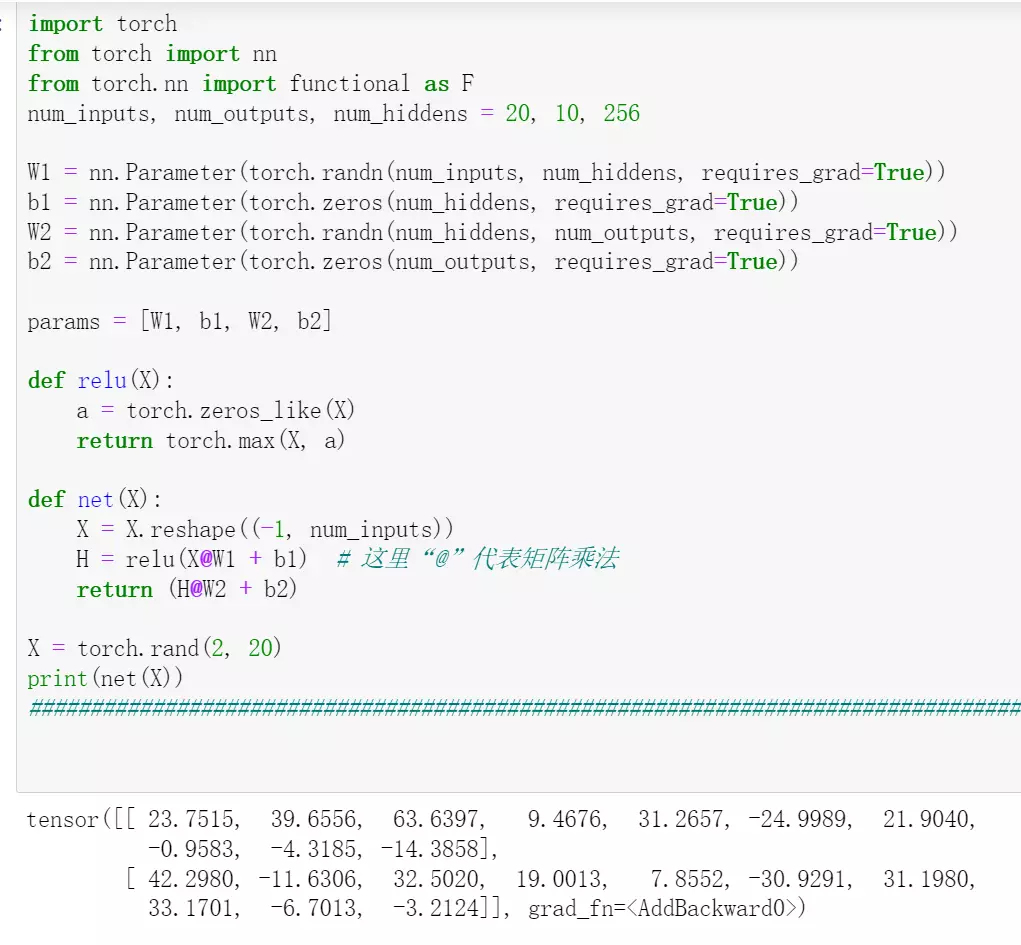
#如果自定义一个网络上面的代码。
nn.Parameter就是封装的可学习参数。
然后定义一个激活函数relu
然后进行前向传播,首先对输入进行一个reshape
是否记得minibatch?如果不记得翻课件。神经网络第一个参数就是batch,所以非常重要,需要reshape
H:第一个隐藏层的输出结果,经过激活函数,得到一个中间值。输出就是中间值乘上第二个参数矩阵加上第二个偏置,就得到了结果
#如果用pytorch去写:很简单
1、首先将神经网络定一个类:就有一个初始化函数__init__,这里面先调用一个super,因为这个类是继承自nn.Module(pytorch里面提供的模块这个类),所以先super一下调用父类的构造方法,就是通过super.__init__():这行代码写神经网络里都会调用的方法。
接下来定义一些成员变量:定义一个藏层,nn.Linear,这个隐层输入是20元素,输出是256
![]()
输出层out,接受是156,输出是10个分类。
再去定义前向传播。这样就写完一个神经网络。
再去实例net =MLP()
![]()
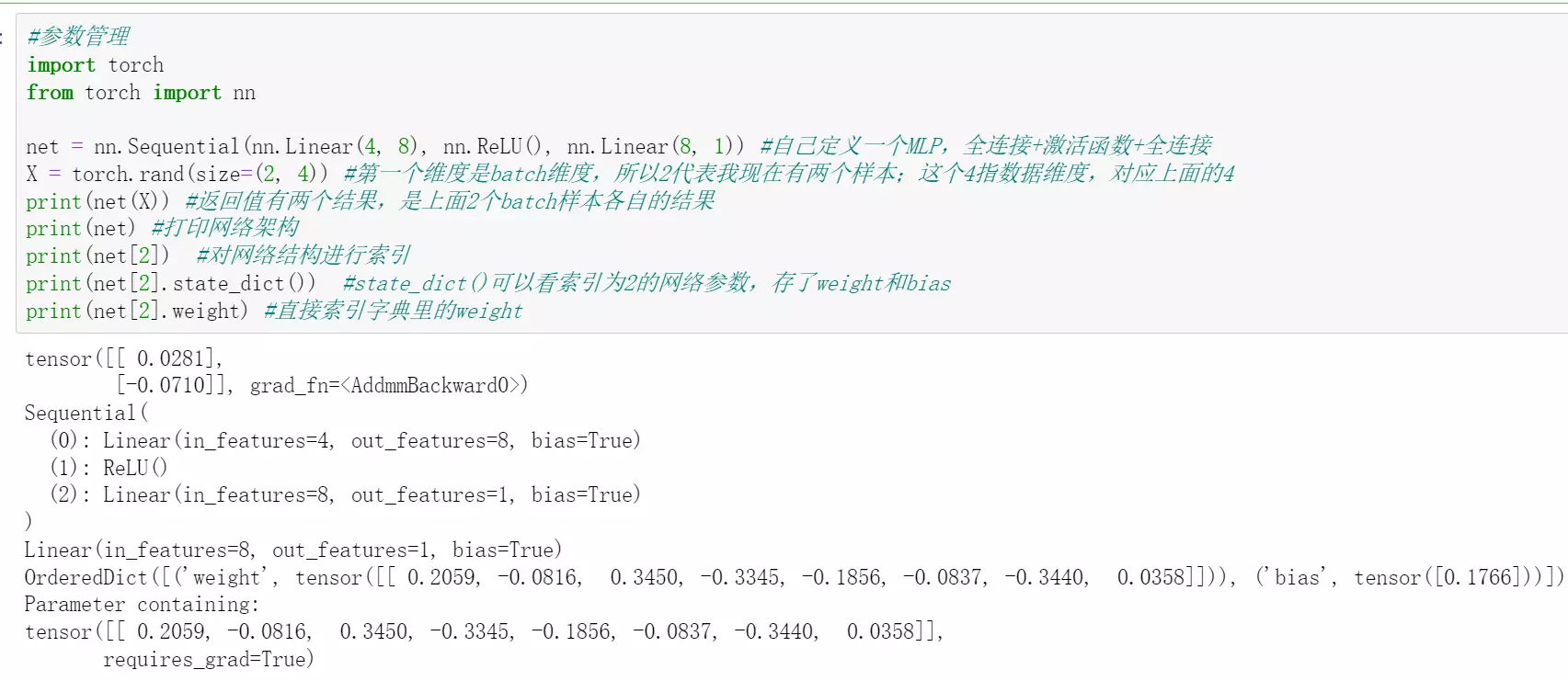
#最简单的写法:
直接实例化一个sequential类:给一个函数,他就可以给我们搭建一个网络
所以sequential就会给我们简化,它是一个顺序的执行过程
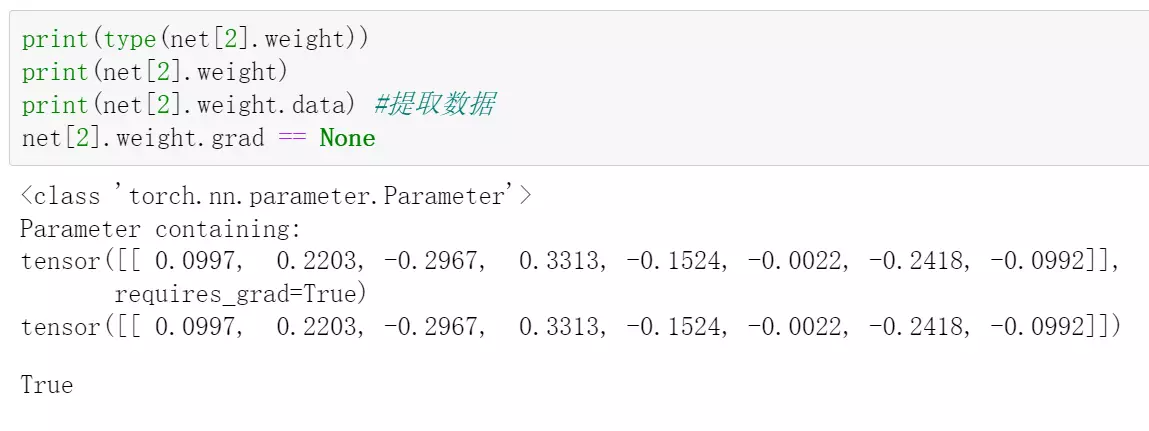
![]()
![]()
#用sequential还有一种方式:
用add_module(函数名字,函数),比上面多的一个功能就是可以指定名字
![]()
#第三种方式搭建网络:有序字典传参key是关键字,value是值
![]()
#课下看代码资料,TEACH用第一种多
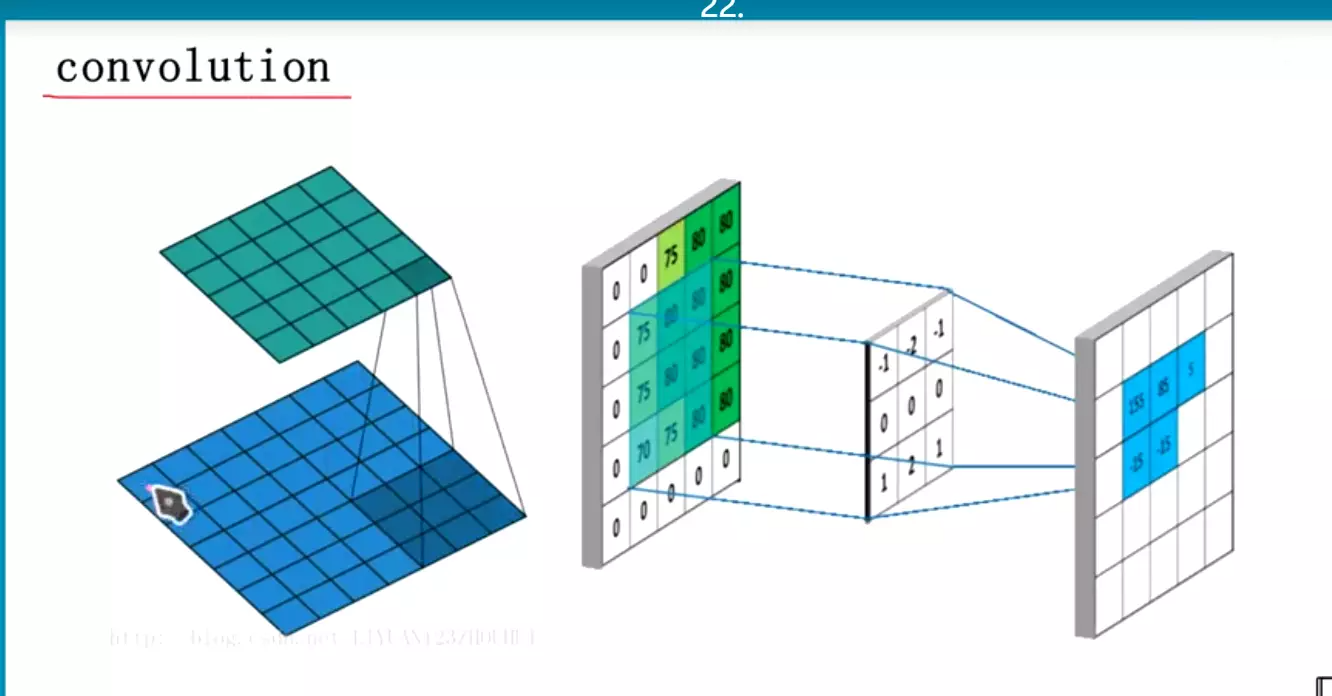
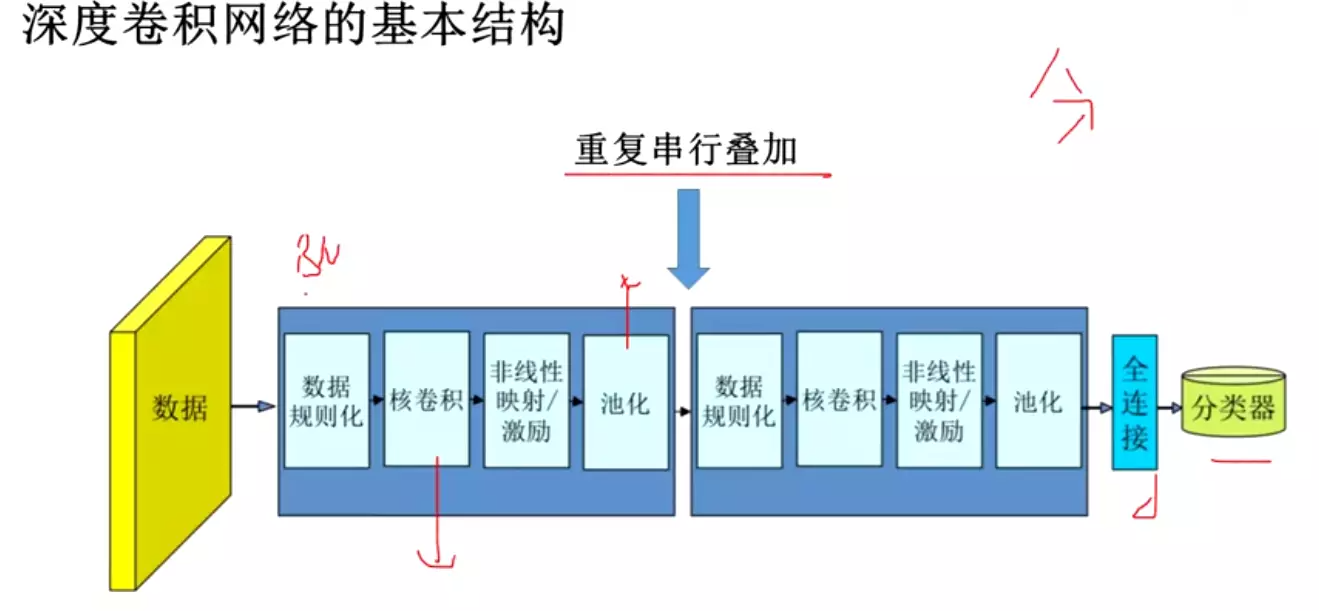
------------卷积---------
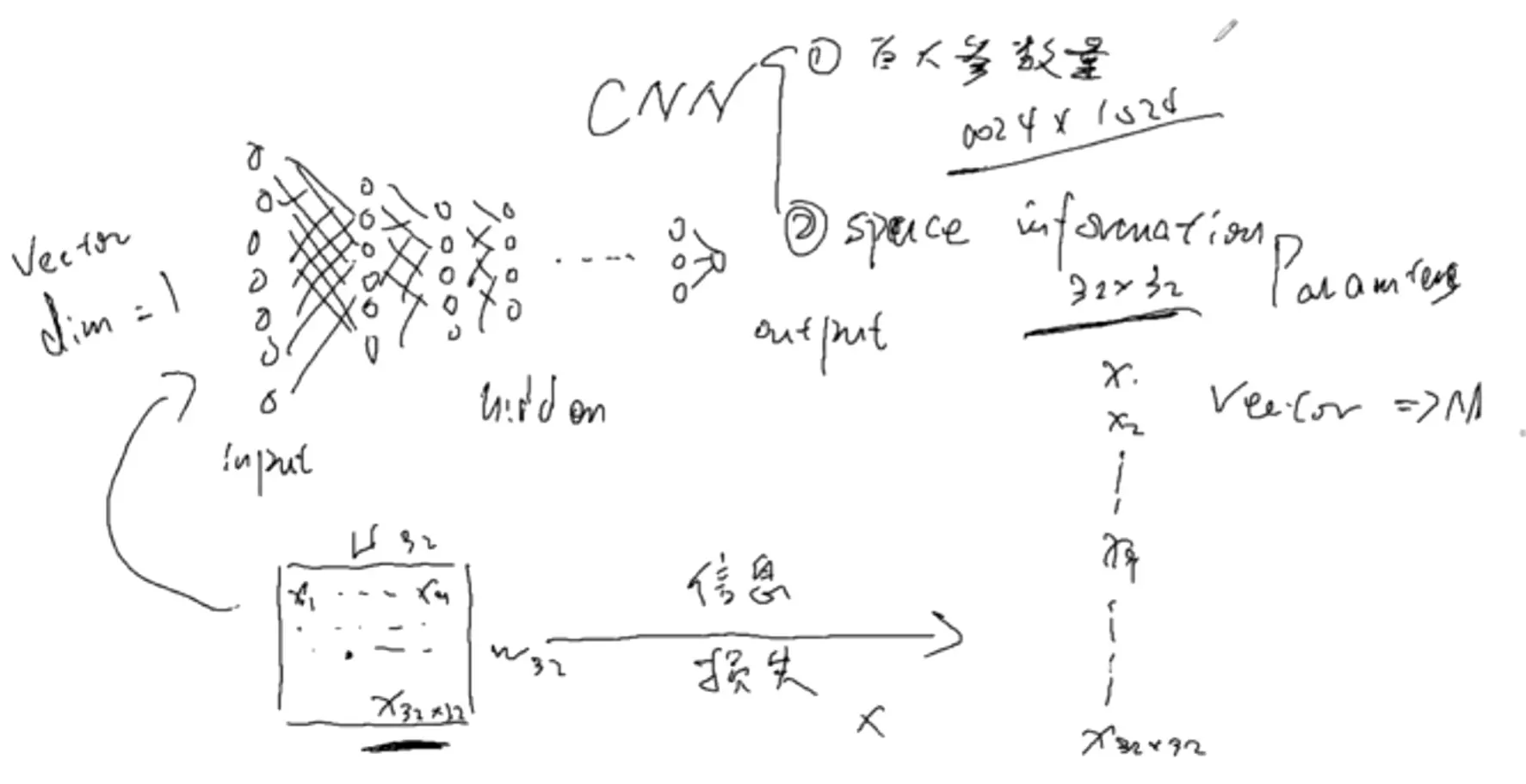
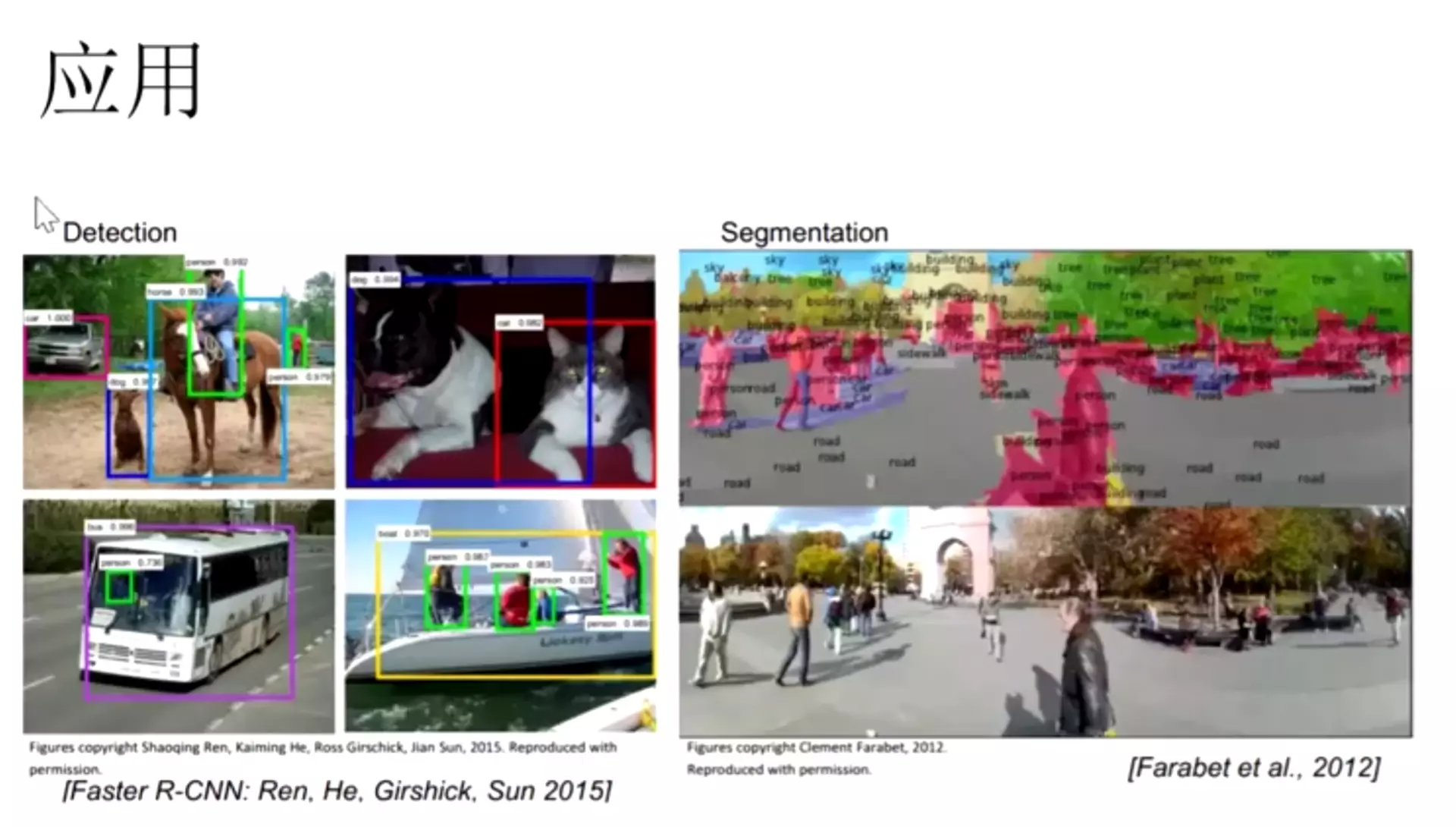
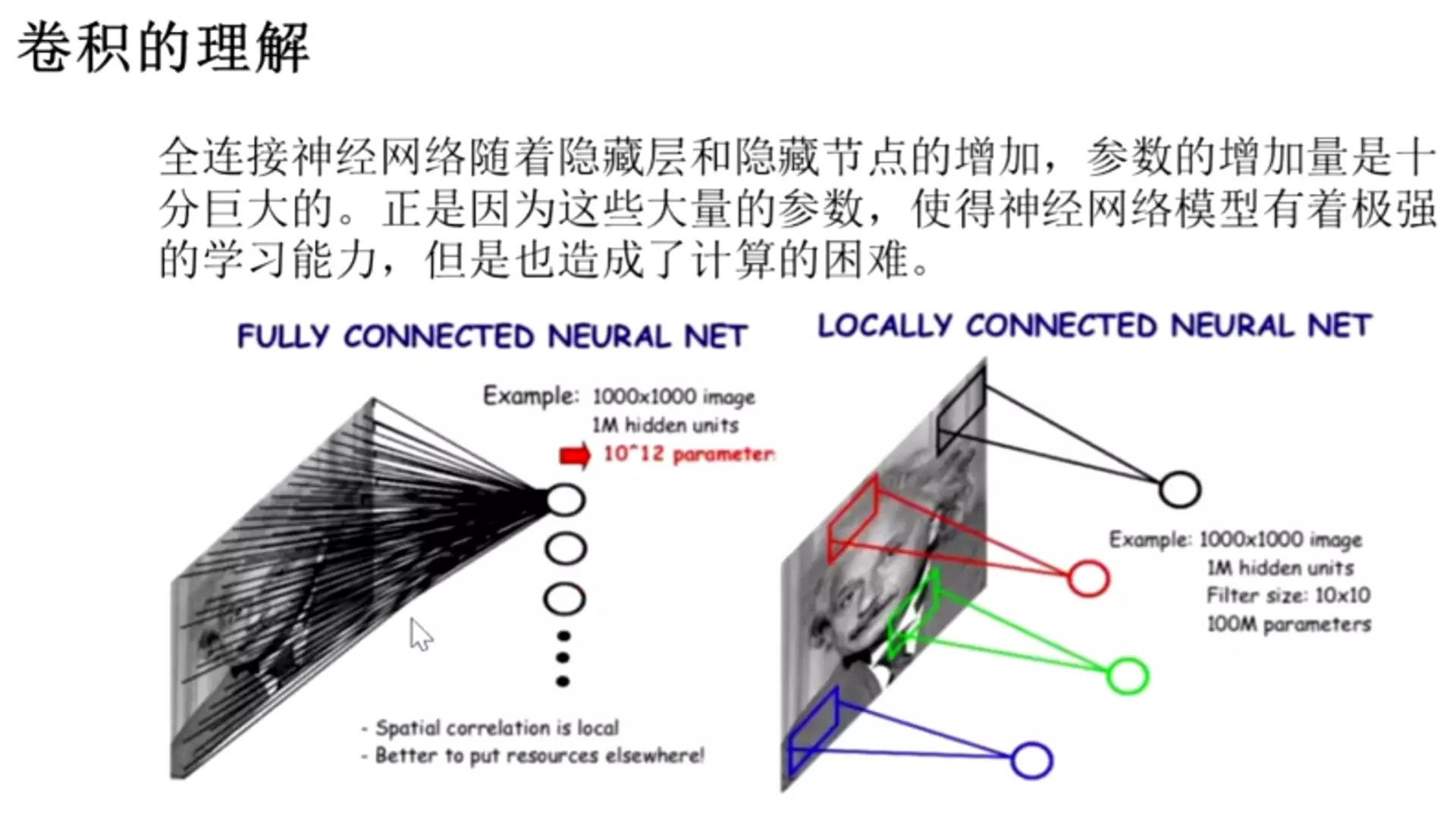
对于一个神经网络处理图像的缺点:
信息会损失,因为像素点上下左右是有信息关系的,给它打平就会损失
所以卷积是有作用的,第一个作用是处理大参数量,第二是处理信息损失的![]()
![]()
![]()
![]()
![]() 全连接神经网络-卷积神经网络-------
全连接神经网络-卷积神经网络-------![]()
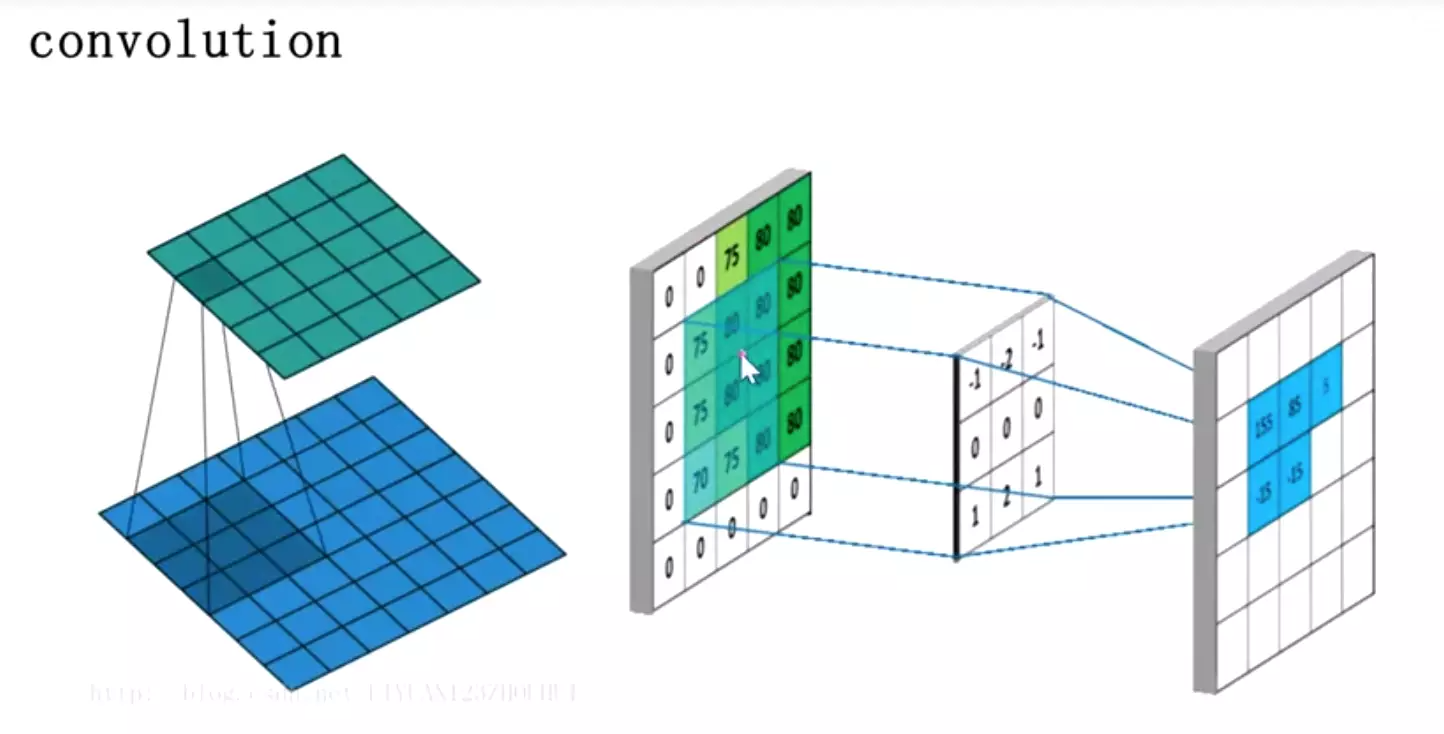
#卷积的重要概念:核概念kernel。由于kernel是一个小矩阵,需要滑动遍历,从左到右、从上到下,相乘求和。
为什么是3*3、5*5?习惯
![]()
![]()
kernel一开始叫滤波器。先验知识。
在深度学习里,不需要人为的赋值,是模型训练后最优得到。
![]()
首先是打平。然后在提取卷积。用局部相关性。相距比较远的像素点是没有关联的。卷积就是先看眼睛,再看其他部位。是模拟人的视觉的![]()
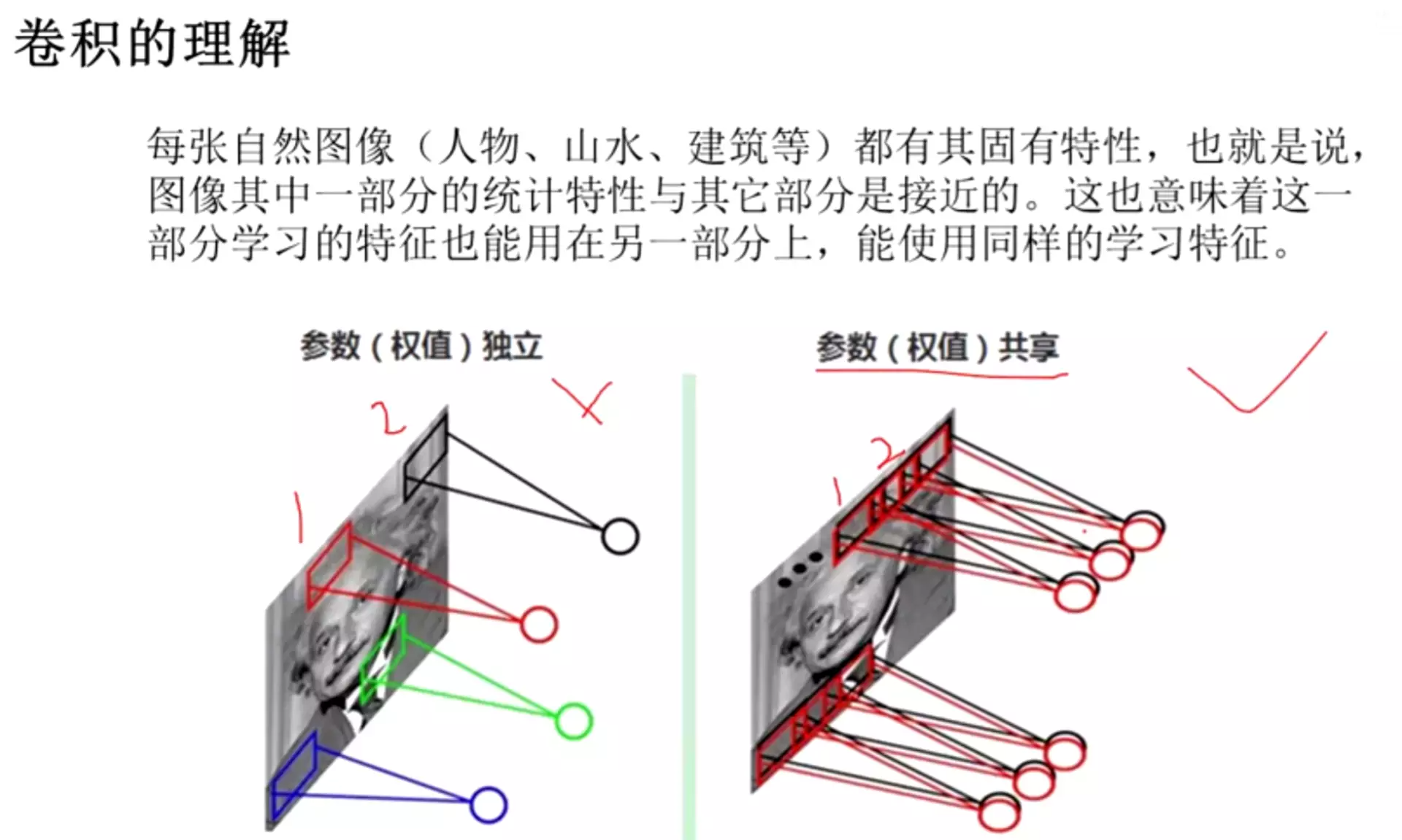
##***权值共享是权重不变;权值独立是权值不同,发生改变。卷积是权值共享的方式,就是
平移不变性:就是说如果是同一种特征,不管出现在图像中哪一个位置,都可以用同一种模式识别出来。例如如果是眼睛,无论出现在哪里,都能找出来。通过滑动遍历的方式找到。
但是:这个卷积核永远是找眼睛的,所以卷积核不应该改变。
同时,参数贡献也能降低参数量。![]()
和卷积算子一样的形状可以识别出来![]()
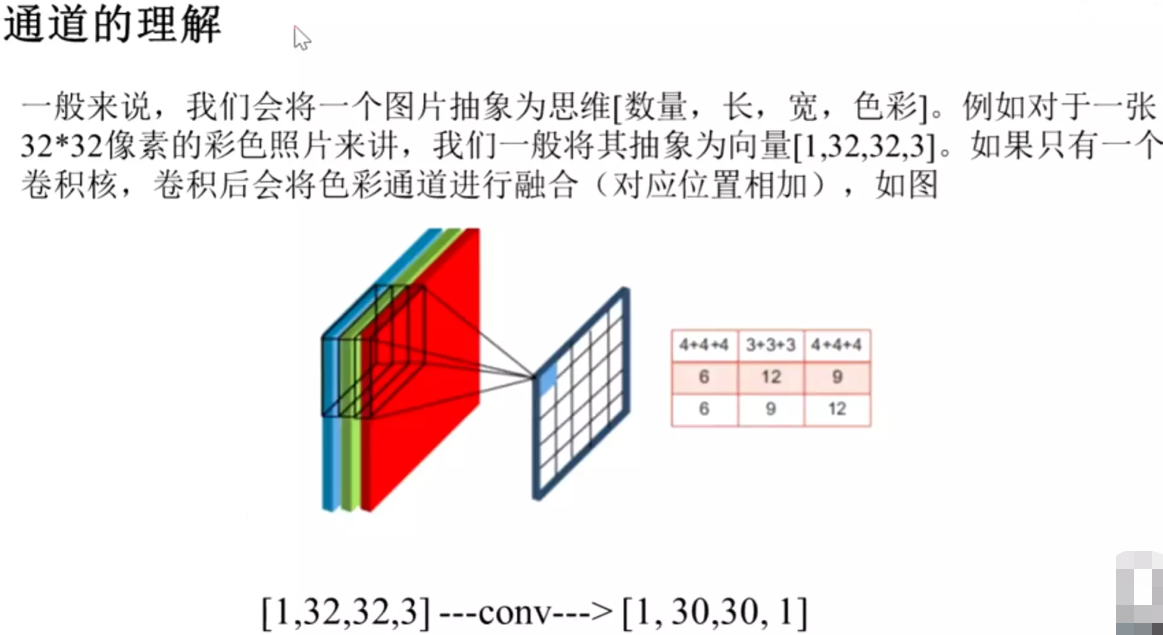
#卷积核是几维的?3维。因为他有自己的通道。严格意义上讲,做了3次卷积,但是只输出1个feature map,它是融合了3次卷积后的结果,不仅仅是求和。
卷积后:不会改变数量维度。改变高度、宽度和通道维度,通道变成1。【只是卷积的核心】
![]()
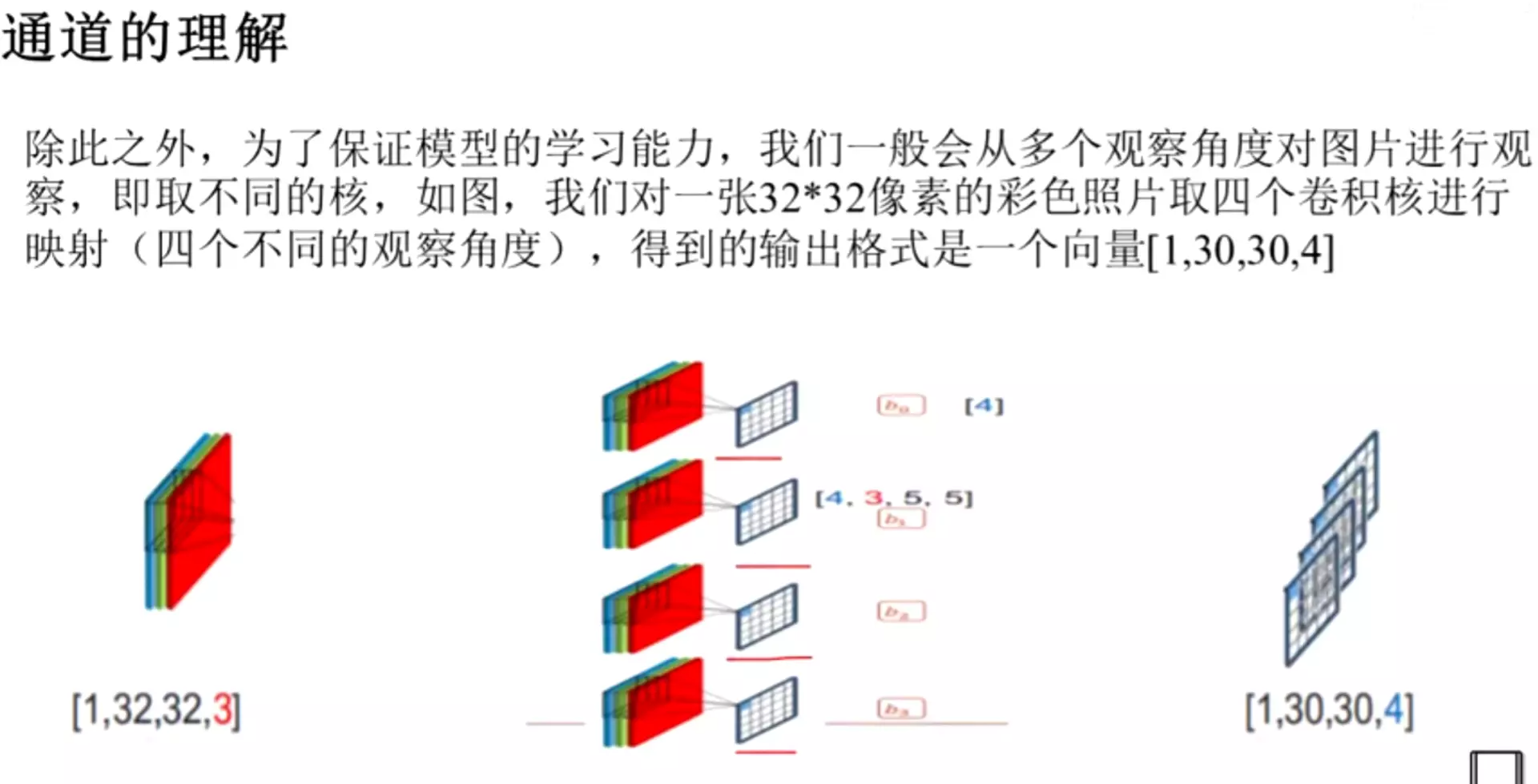
#用不同的卷积核:可以提取不同的特征。在真实的模型里至少有上百个卷积核、甚至有的有上千个。
![]()
![]()
一个卷积只能找一种特征,例如对角特征。所以用多个卷积识别,置信度更高一下。
![]() #卷积对于参数的减少:
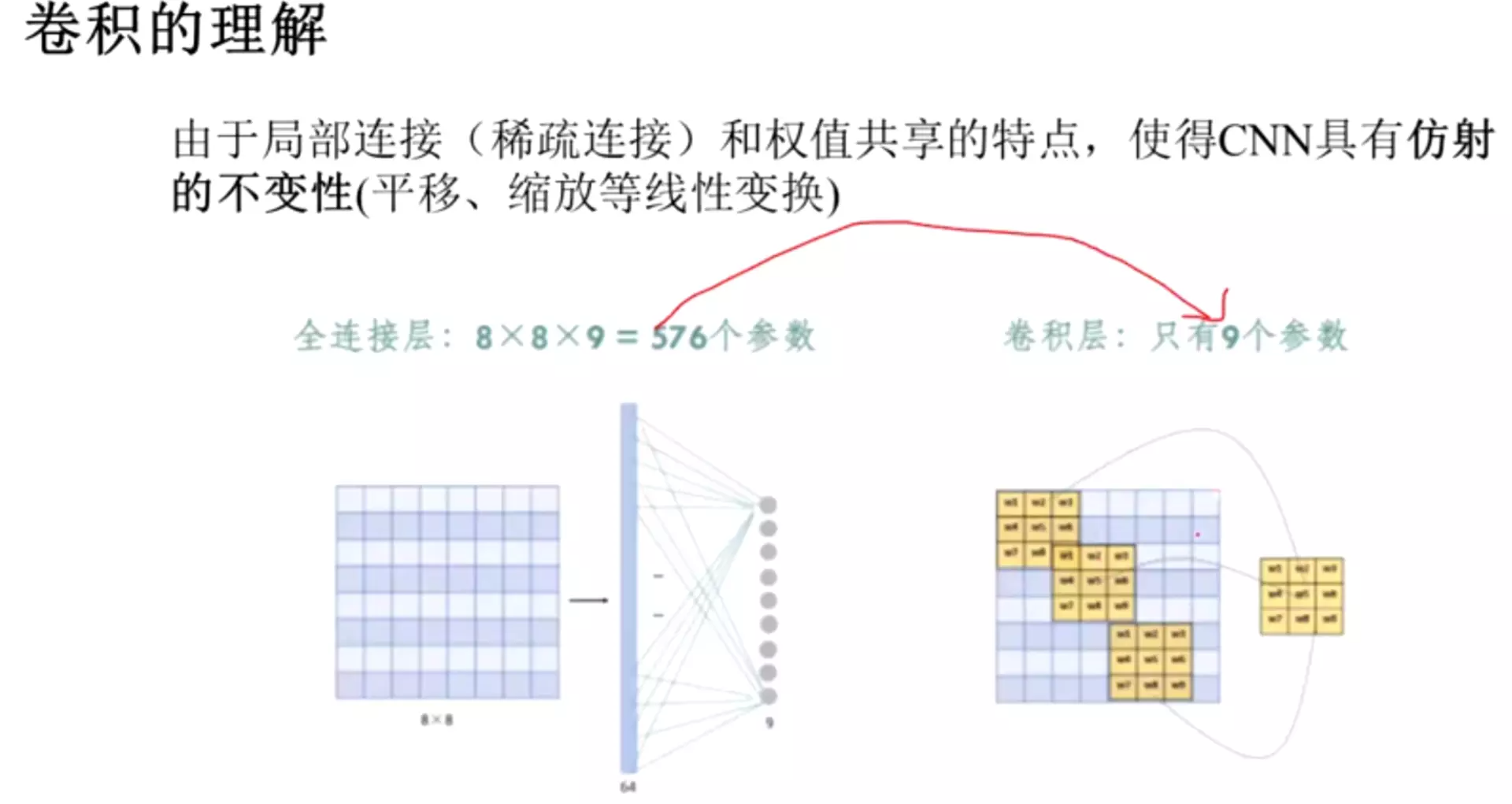
#卷积对于参数的减少:
全连接8*8*9,假设第二层的神经元有9个,这个9是和卷积核的九个参数对标的,这时的参数576个。但是对于卷积来讲,卷积核是只有9个参数量,所以卷积层只有9个参数。
![]()
#脆弱是指90%是从数据中学来的,只有不到10%是跟卷积核相关,学到的。
#缩放不变性:卷积的层级结构是有很多层的。
![]()
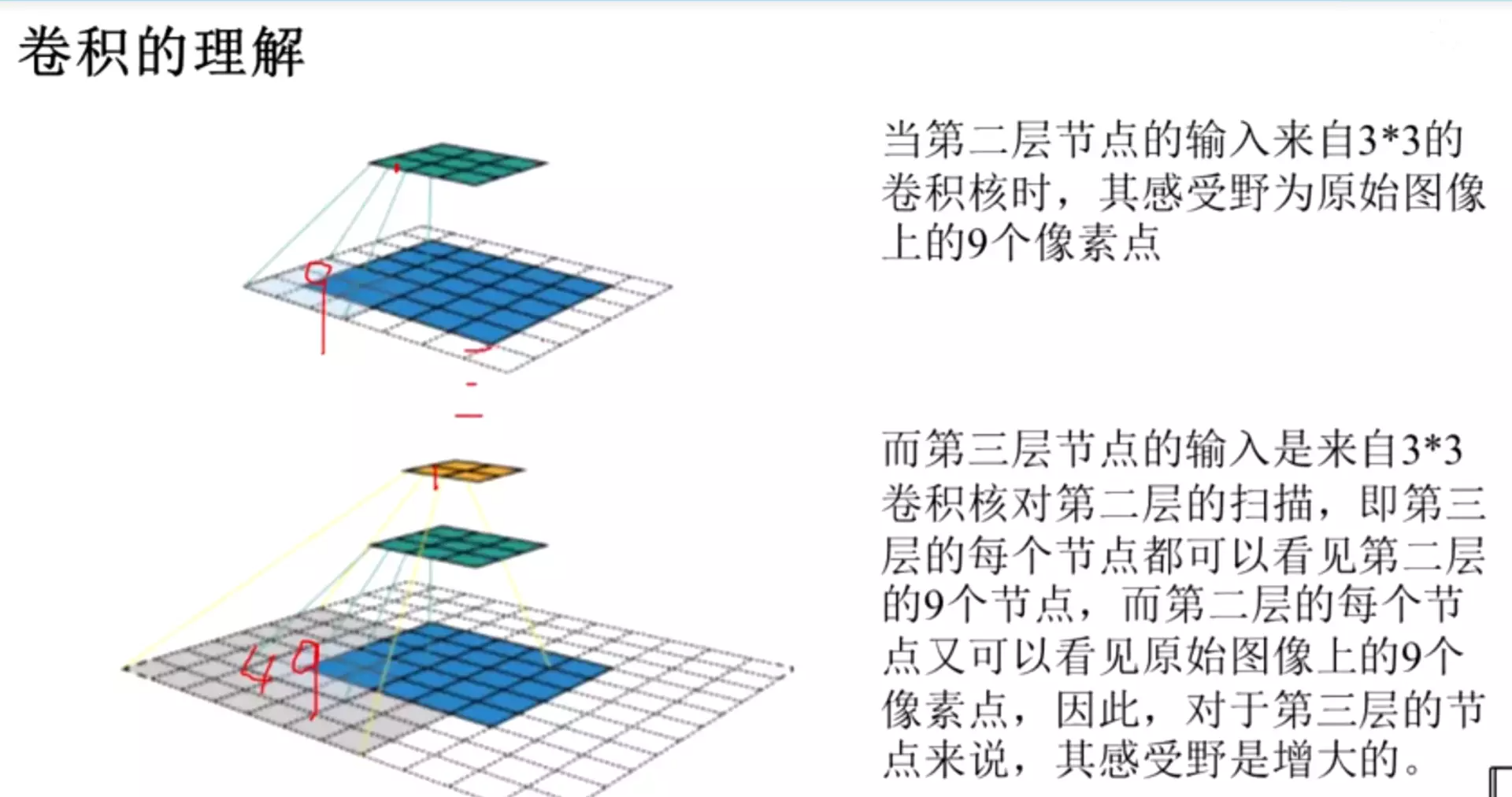
#感受野:指在原图中的计算范围。第一层的感受野是9,第二层的感受野是7*7=49
![]()
#卷积核划到哪里就和哪里做一个卷积。
![]()
![]()
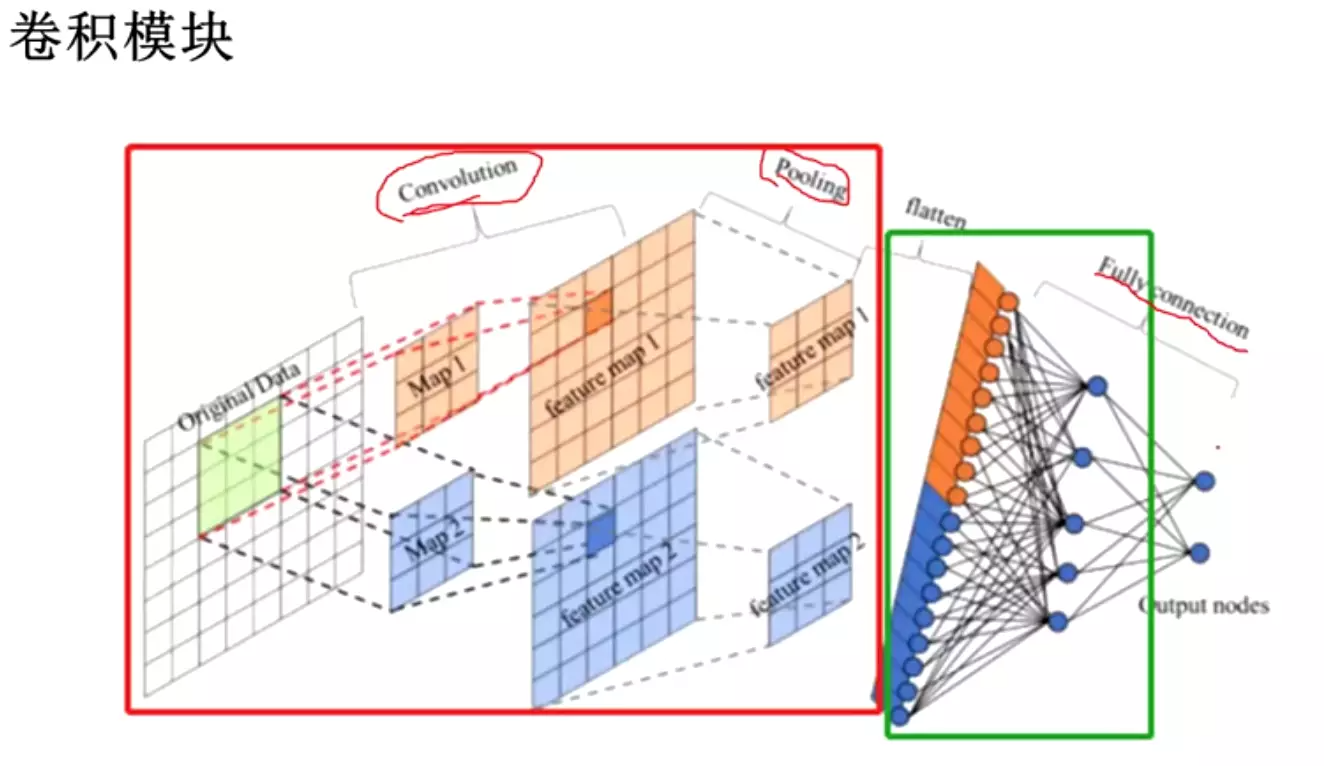
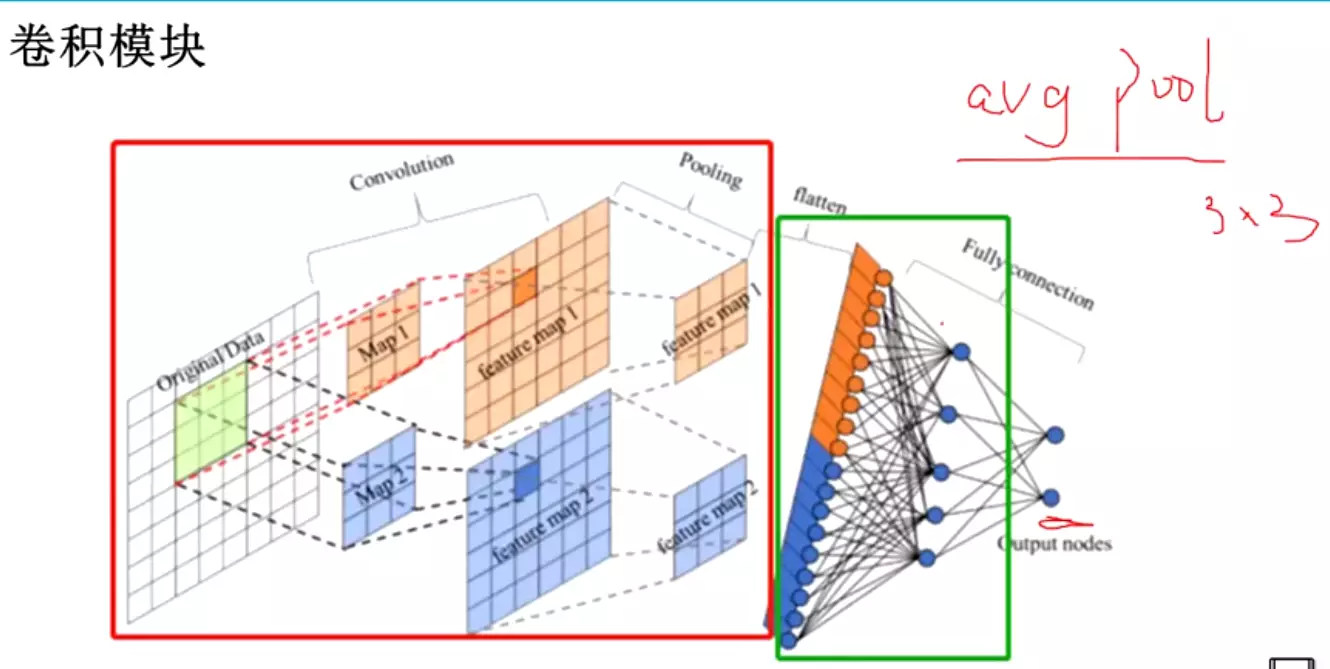
#feature map是表征在图像处理中找到的特征,然后进行flatten,链接一个分类头。
flatten是打平,经过打平后就是一个一维的。
#为什么要打平?--这里是解决问题的思路,这个思路是通用的。
因为最后的输出是一维的,要做一个分类的话,比如10分类,他的维度是等于1的,dim=1。但是上图经过卷积后他的feature map维度是2的,算上map数量,它的维度是3.他的维度是不匹配的,信息流就卡在这里了,传不下去了。因此需要打平变成1维送入全连接,让全连接对他进行降维,让全连接将18维降到5维,再降到2维。
所以打平是跟分类这个任务是相关的,如果不做分类可能不用打平。比如语义分割,最后输出一个图像和原图尺寸相同。因此语义分割是不会有打平操作的。
![]()
#但凡卷积核不是1*1的经过卷积处理后图像尺寸减少一圈
![]()
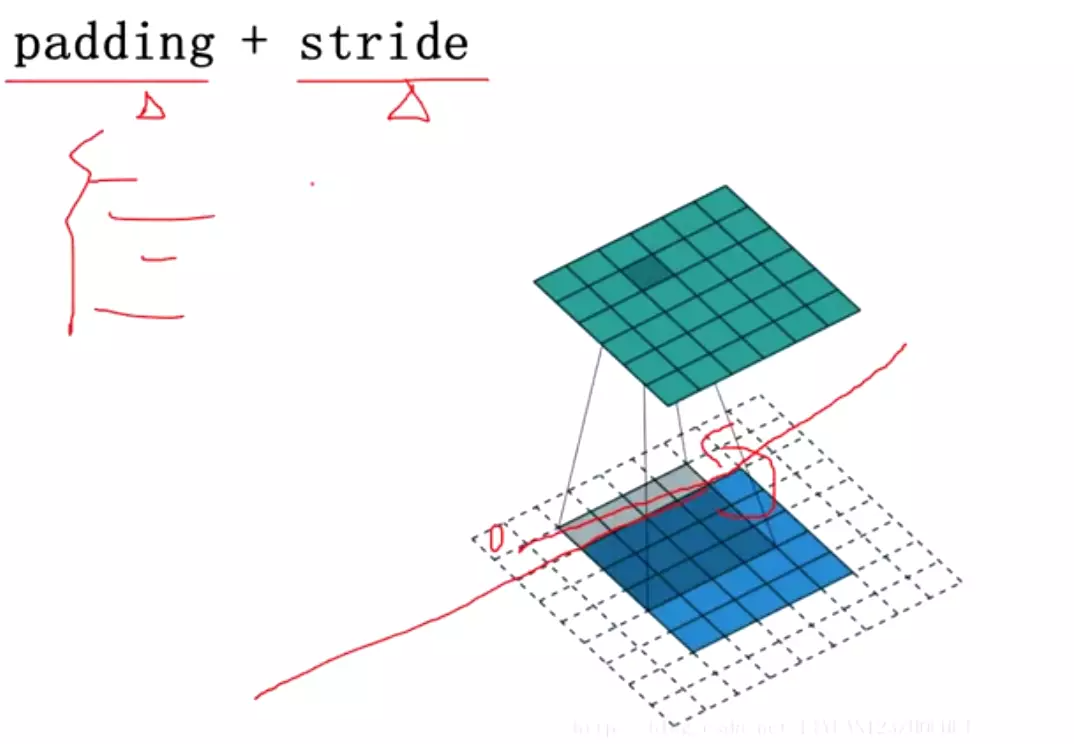
#不希望图像尺寸变化,就要填充padding
![]()
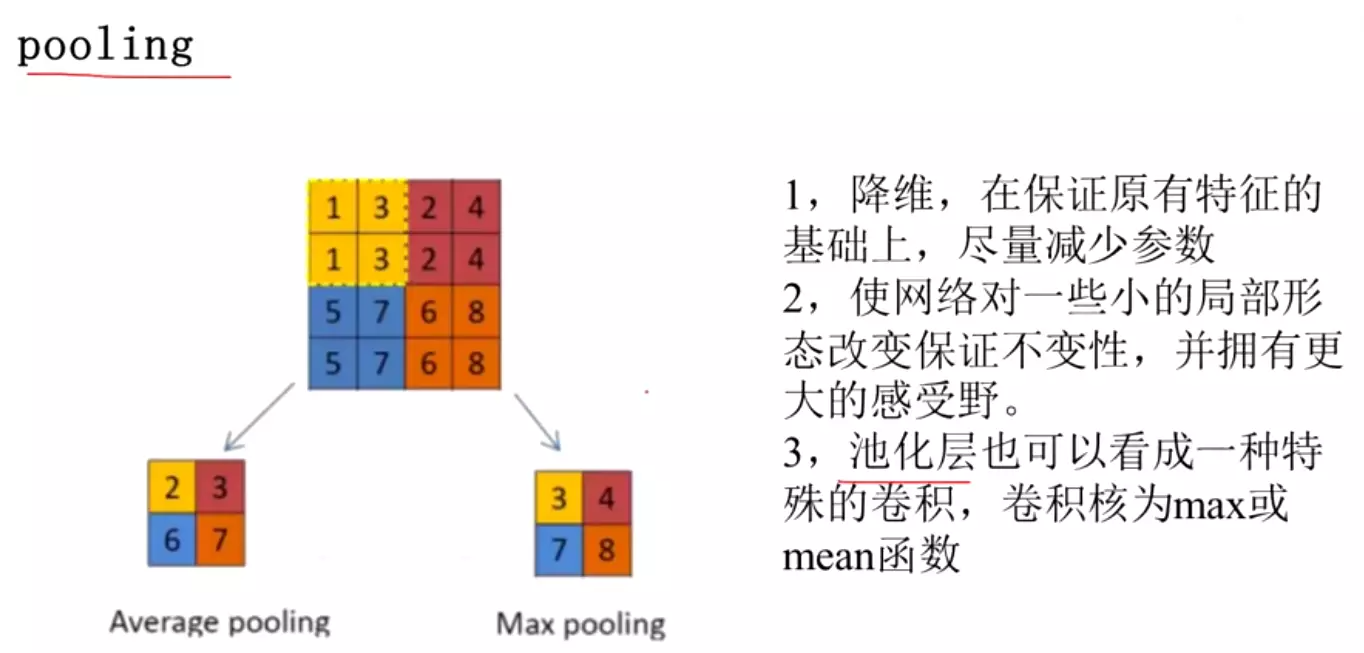
#池化:卷积有的它都有,池化核、求和、步长
特殊:要么平均、要么最大。甚至有人管他加下采样,因为池化后维度有降维,本来16个维度现在4个。只要做降维,信息就会有损失。池化厉害的地方是 降维后信息损失的是非常小的。
池化操作是保留卷积提取后的特征。
池化没有核。这个核是透明的,没有权重可以学习,是一个不可学习的层,所以没有必要有参数。池化只有一个范围。
![]()
#当用3*3的avg pool做池化时,这个feature map1(3*3的)还剩几维?1维的了,所以pool也可用来做数据降维。
![]()
#深蓝色负责特征提取,浅蓝色负责分类
![]()
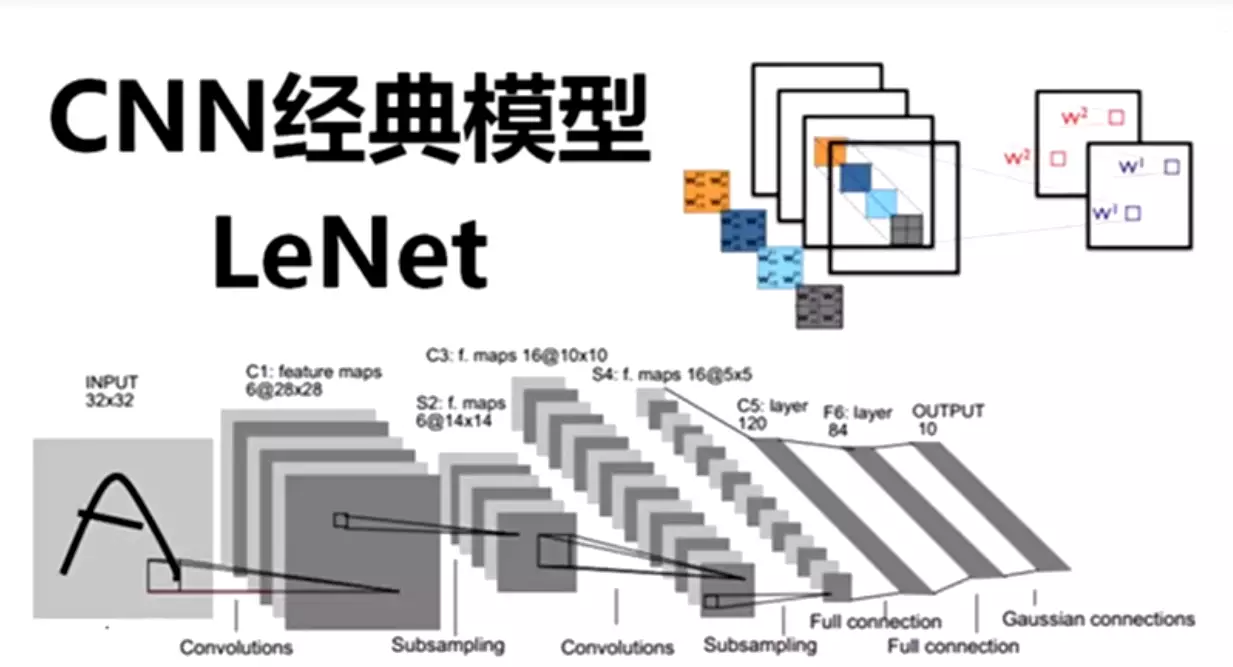
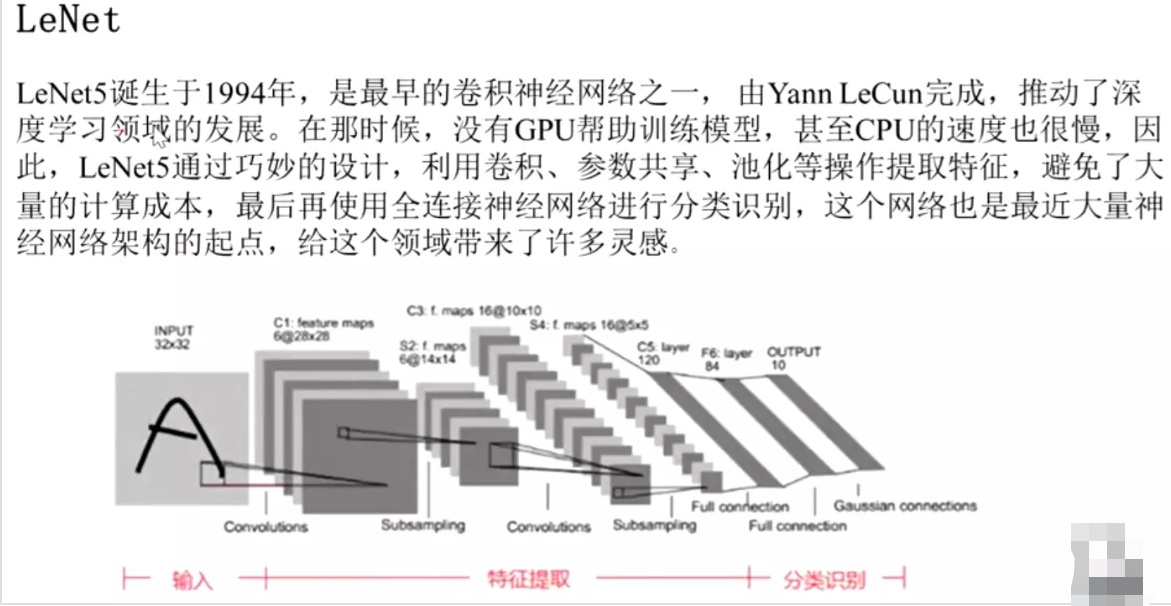
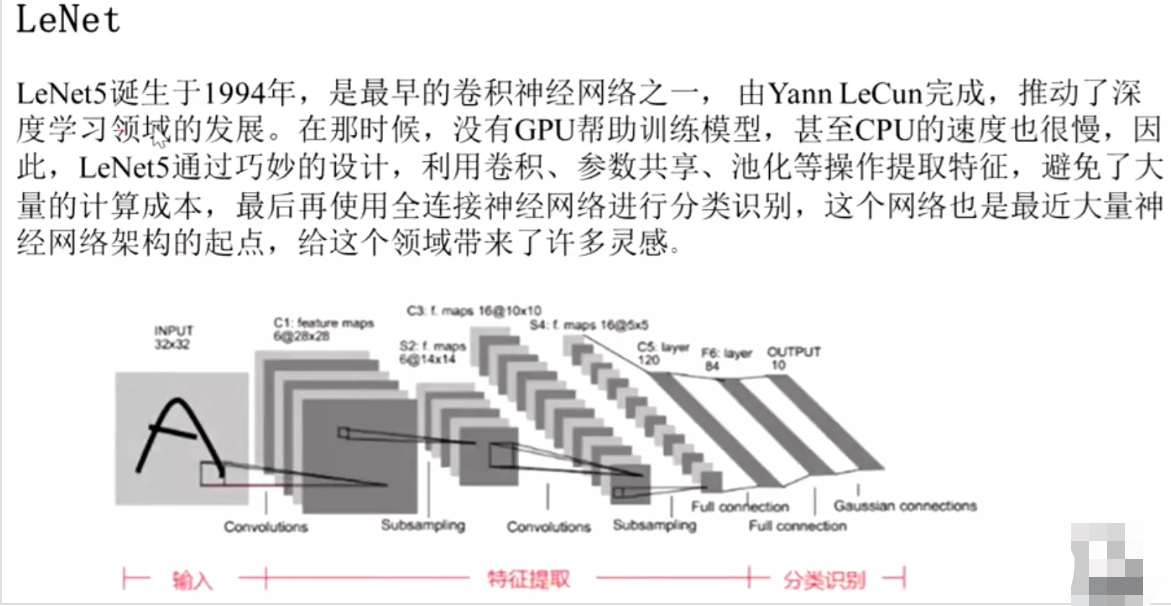
#经典模型:LeNet:需要知道输入和输出是定下来的,和任务相关的。大家要调整的超参就是中间的网络,中间的卷积层和池化层
![]()
![]()
#Yann LeCun深度学习领域大牛,1994年
![]()
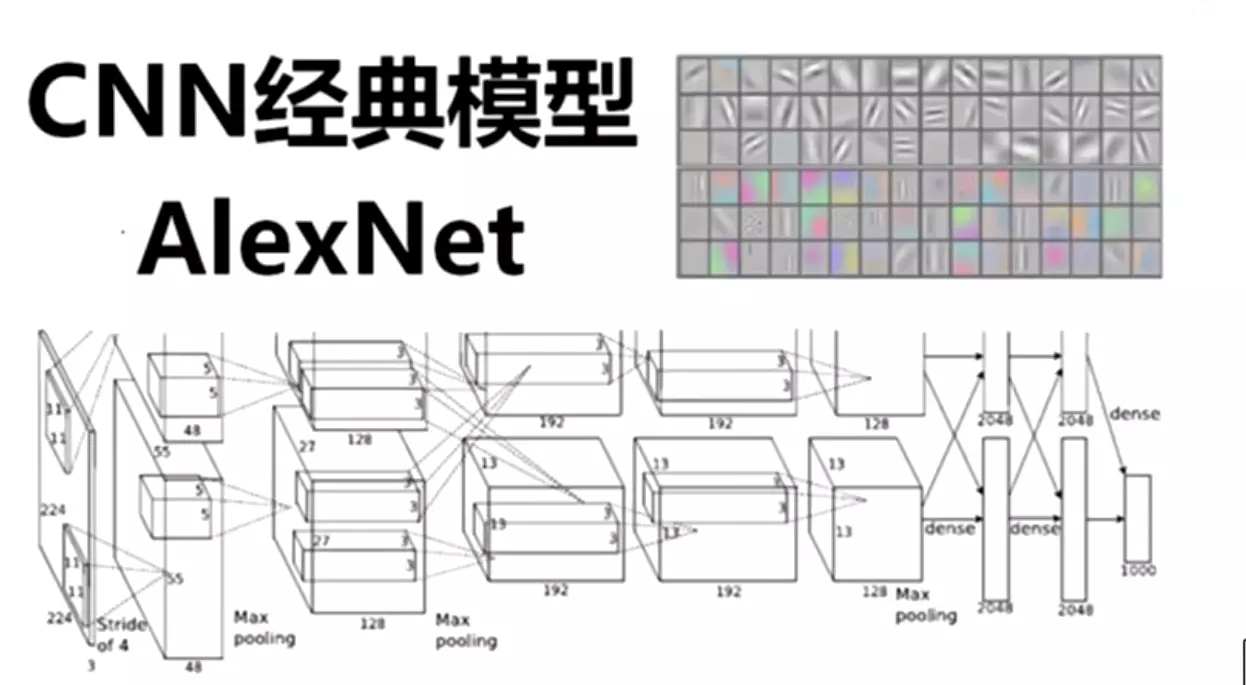
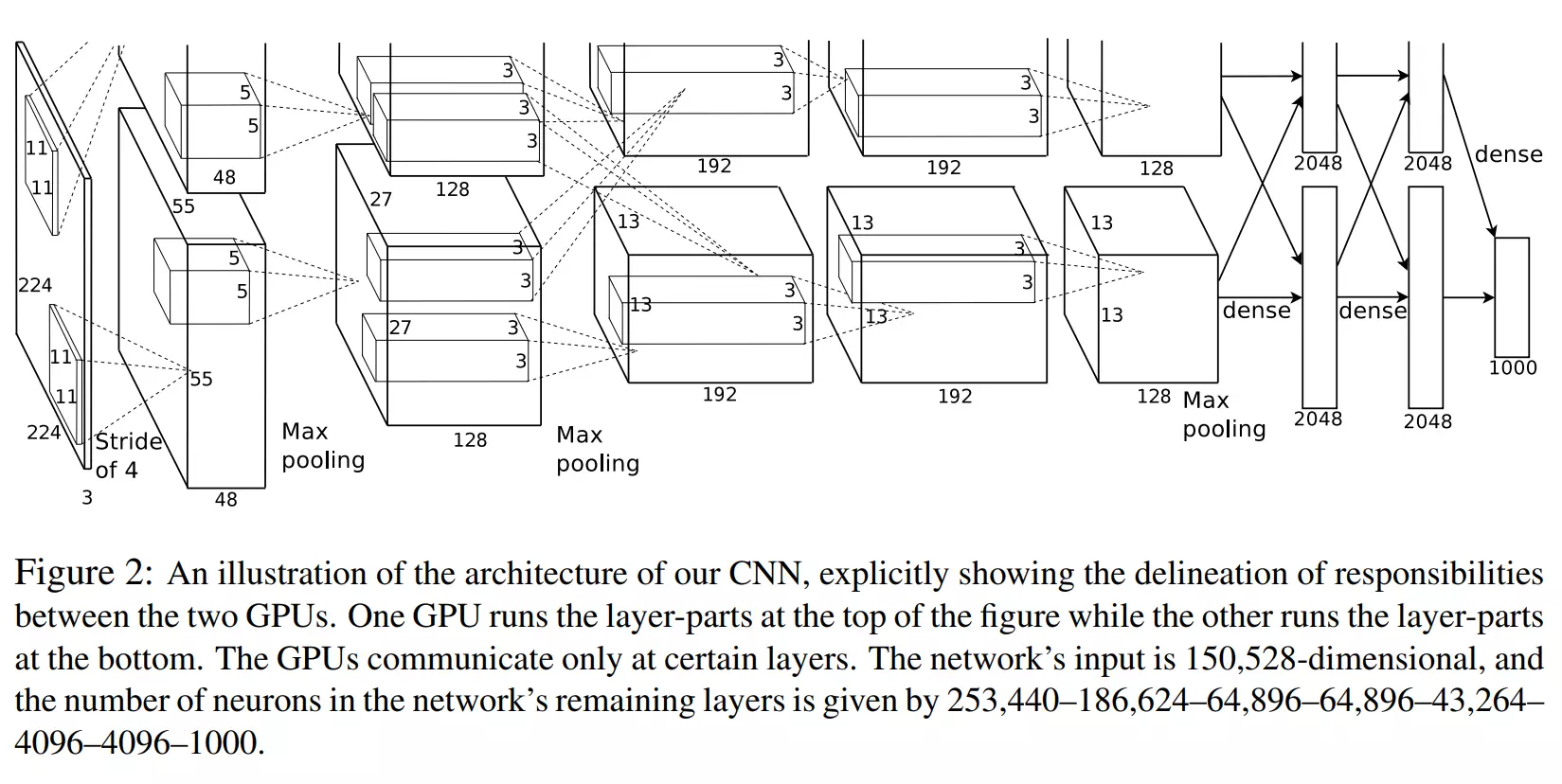
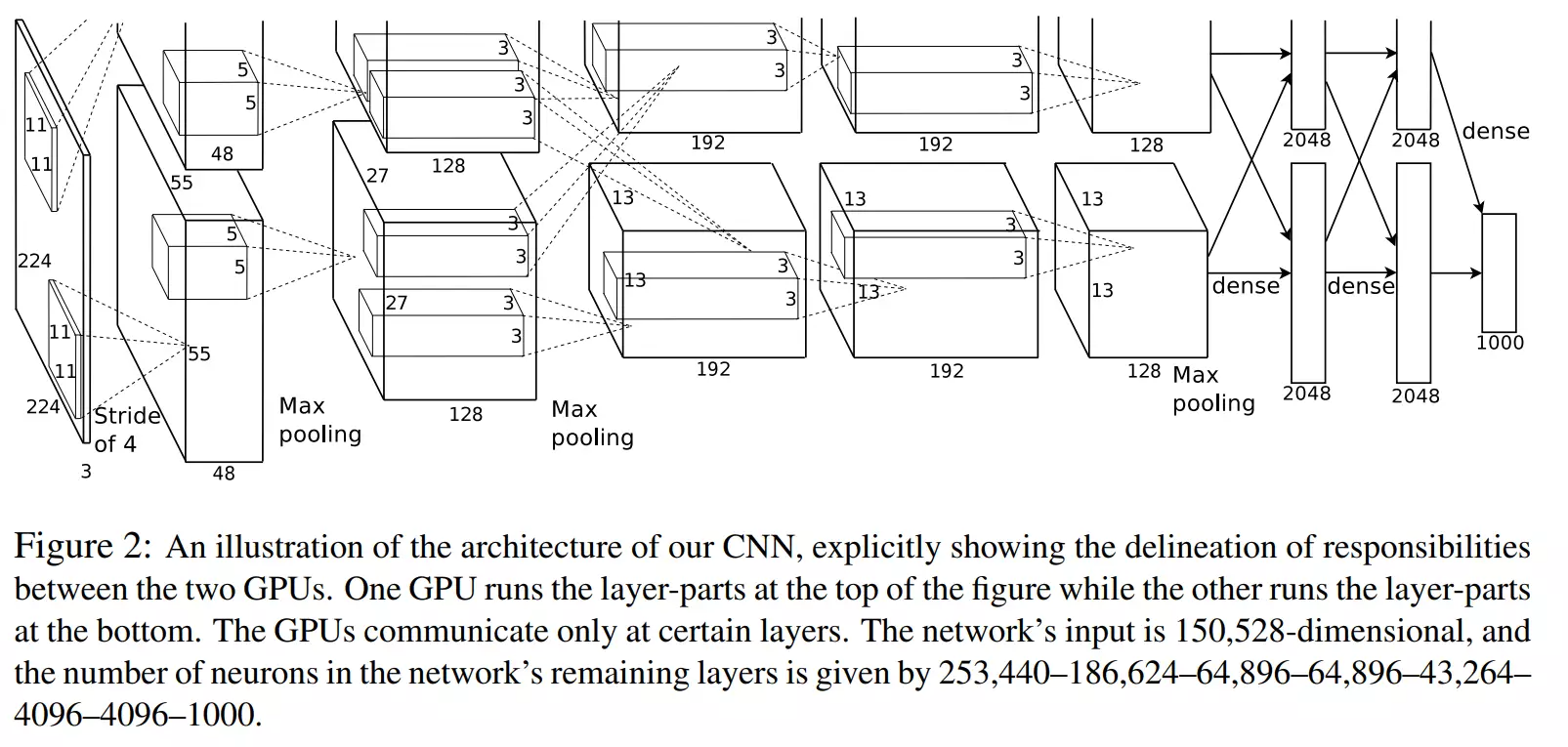
AlexNet
#AlexNet太重要了。2012年。里程碑式的模型。人工智能的第三次兴起,就是由于深度学习,深度学习是由哪一年兴起的呢?就是12年的AlexNet由它开启的深度学习
![]()
#自己先读一遍AlexNet的论文。过后老师讲解如何读论文。
![]()
![]()
#如果手工实现神经网络如上,需要指明一个前向传播,但是用sequential去搭建的时候,并没有指明数据流的传播方式,只需要搭建一个网络架构就可以了。所以sequential内部自动去完成了数据流的传播。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
#如果需要比较复杂的模型,需要嵌套的方式搭建,课下自己看
![]()
#moduleList不常用但是有些模型用了,像DenseNet。
![]()
#作业:完整的敲一遍代码!!!
自己敲:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
-
###ImageNet Classification with Deep Convolutional Neural Networks 2012
#一篇文章引领时代潮流。通过这篇文章如何阅读文献。你脑中有个新想法,搜一下相关文献,大多数情况有人研究过。读论文时要有怀疑、有自己独特的观点。
#一篇文章要读三遍:第一遍非常快,5分钟左右,看一下文章讲的是否和你相关。如果这篇和你的工作和研究相关就读第二遍。把模型、推导、结论都看一遍。第三遍,复现论文推导时,再读。
#第一遍:看标题、
、
![]()
state-of-the-art指比之前最好的效果还要好。多分类里top-1指必须要把类别分类正确、top-5在多分类里前五个置信度(最高的可能性)有我的分类。
reduce overfitting降低过拟合。
top-5的错误率是15.3%,比第二名高26.2%个百分点。写paper时注意参照。
在第一遍时看完摘要就直接看结论。![]()
purely supervised learning引领潮流了,指明了方向。再这之前是分监督学习。
So the depth really is important for achieving our results.指明了一个方向:深度是很重要的。
unsupervised pre-training 迁移学习或随机初始化。把B模型的权重直接加载到A模型就是迁移学习。
如果有更多的数据、更好的标签可以更好。
两个方向:一个是有监督可以达到不错的性能、另一个网络更深可以达到更好的效果。一个坑:可以处理视频数据。当然现在视频处理一直是一个很前沿的方向,但是一直没有达到很好的效果。
第二遍阅读:
看介绍:摘要的扩充版。
![]()
#第一段:可以解决之前的问题。
#make strong and mostly correct assumptions about the nature of images 天然适合图像。----注意!!!图像两大特点:平移不变性、局部相关性。
![]()
卷积有更少的链接和参数
#DeepLearning兴起的三个原因:1、数据集越来越大2、gpu算力越来越强2、算法不断提出和更新
![]()
#GPU implementation 实现了gpu版本的2D的卷积算子。(第二个贡献)
#unusual features which improve its performance and reduce its training time(第三个)
#如果数据集和GPU更快可以使模型提升。
![]()
#数据集:用了ImageNet,包含1千5百万个带标签图像。被分类为22000个类别。15 million labeled high-resolution images belonging to roughly 22,000 categories.
用于比赛的数据集是一个子类,常说的ImageNet1000。
没有使用图像的预处理,而直接使用生的RGB像素集。这里是和传统的机器学习做对比,传统的机器学习会进行特征工程,人为的设定一些特征,并将特征提取出来送进模型。而这里深度学习不需要提取特征,只需要把原始的像素点送进去就行,模型负责提取特征。所以常说的DeepLearning是endtoend端到端的。
#强调:在读第二遍的时候,不要太过于纠结细节问题。挑重点看。
![]()
#第三段:重点:novel or unusual 创新点features of our network’s architecture.
如果有基础可以先看图片,如果能把图片看懂,这些文字描述你不用看。但是你新学这个领域,你对着图把文字看一看。
如果发paper,需要注意两个点:1、模型的架构有创新的地方 2、模型没创新,解决了之前没有被解决的问题。或者这个问题被解决了但是我用来什么方法达到了更好的效果
#李飞飞、吴恩达
![]()
![]()
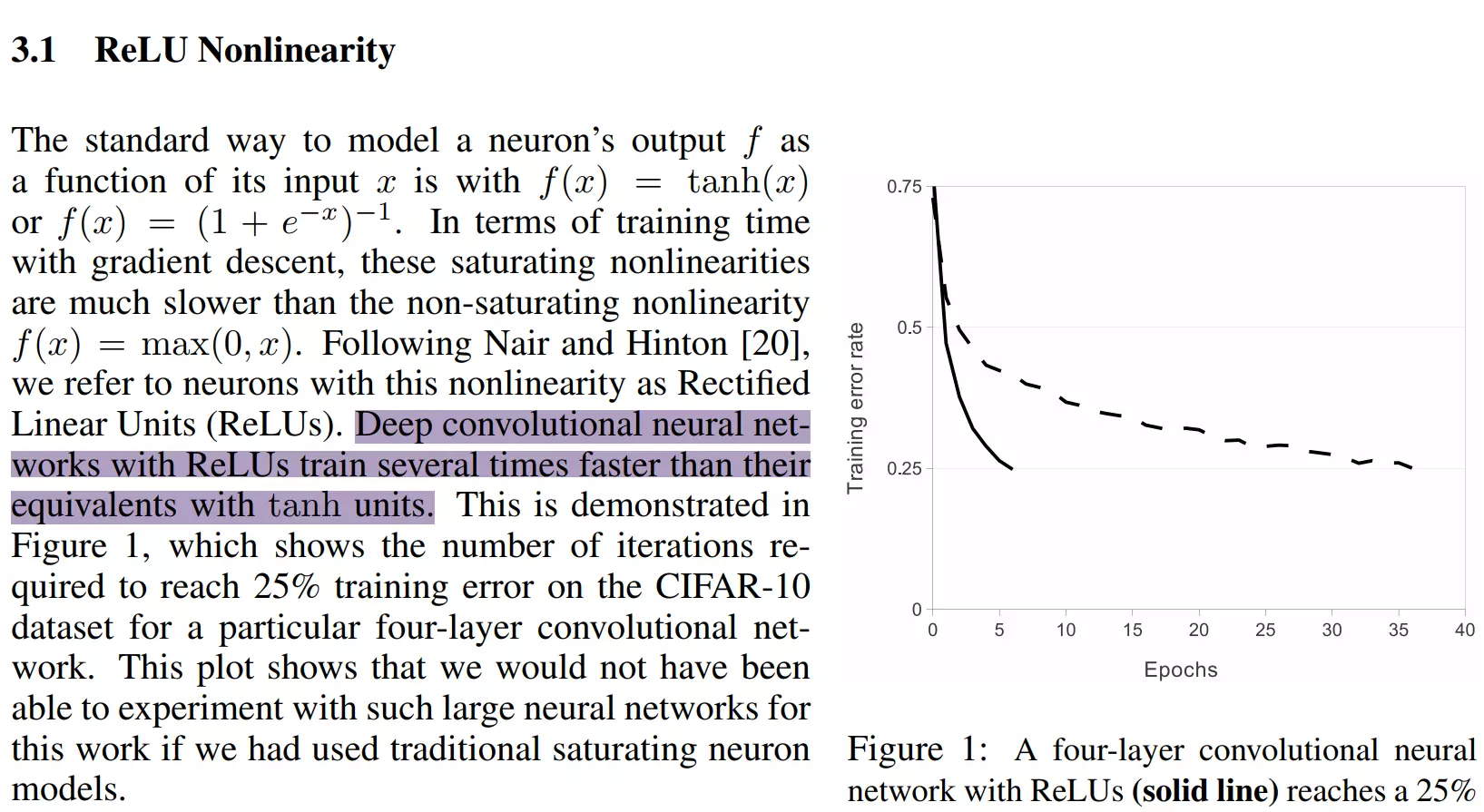
#新颖之处:一、用了ReLU。non-saturating nonlinearity不饱和非线性的激活函数f(x) = max(0; x).Deep convolutional neural networks with ReLUs train several times faster than their equivalents with tanh units。ReLU比tanh更快。
![]()
第二部分:有多GPU训练,具体如何配置第二遍阅读可以不看。
![]()
#他们不是第一个提出用多gpu训练的。在写论文时别人比你提出早都不要紧,你只需要把他列出来,然后你指出你和别人不一样的地方就行。千万不要觉得模型别人用过你再用就没有创新,或者不提别人用过,这样都是不好的。
![]()
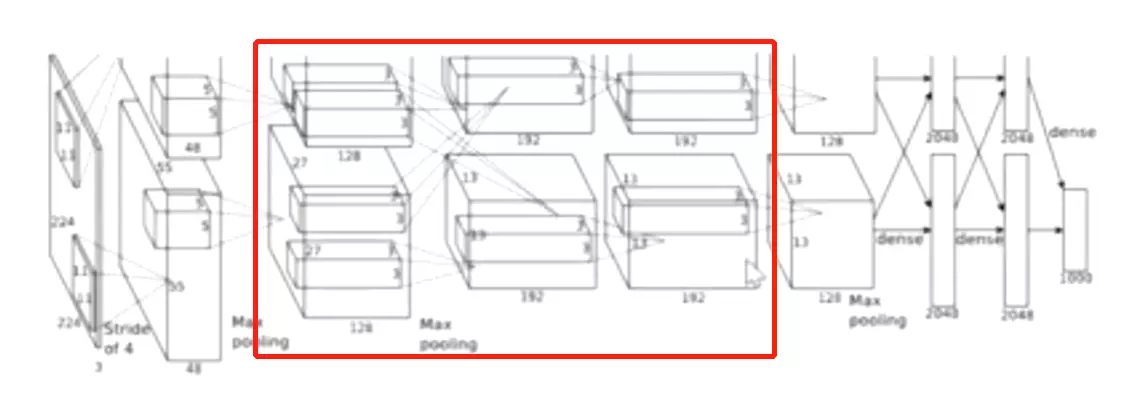
#先讲一下图:前人做法是两组卷积,两组各自提取不同的特征,让他们各自前向传播,最后到全连接层时再把信息做一个汇总。但是这篇文章不同之处:这两组在前向传播过程中也是有交流的,将不同组的卷积结果复制到GPU里。
#在当时看,用GPU进行训练是一个不常用的工程技巧。
![]()
#这一部分不讲:后人、包括VGG认为这一点正则是没有用的。
![]() #Overlapping Pooling 指卷积核的尺寸比步长大,比如3*3的卷积核,滑动窗口是2,滑动一次没有滑出卷积核。效果好,但是没有解释和严格的理论证明。这就体现了DeepLearning更注重工程实践。
#Overlapping Pooling 指卷积核的尺寸比步长大,比如3*3的卷积核,滑动窗口是2,滑动一次没有滑出卷积核。效果好,但是没有解释和严格的理论证明。这就体现了DeepLearning更注重工程实践。
![]()
#下面讲了如何实现框架的,这个图怎么做的信息流怎么流的,这部分在读第二遍时都不用细读的,到第三遍在仔细读。![]()
![]()
#我们的神经网络架构有6千万个参数,所以如果不用一些手段的话,模型是非常容易过拟合的。所以他们采取了两个方法:数据增强、随机失活
#防止过拟合的方向:样本的数量和参数的数量
![]()
#数据增强(在读第二遍时,如果你知道这个技术,可以不用细看):翻转和裁剪、对颜色增强
![]()
![]()
#集成学习:用不同的模型有助于减少错误率。但是消耗成本,时间成本贵。但是为了解决,有一个有效的方法,既考虑成本、训练时间和集成学习,就是随机失活。每次训练时都是训练一个子模型,等到我们预测是不做任何的dropout,所以用全部的子模型一起去预测,所以把dropout看做一个集成学习。这个dropout使神经元之间不能过度依赖。所以他们能学到更鲁棒的特征。--》more robust features--》例如眼睛和嘴巴,都是各自的神经元,如果一个失活了,另一个也能判断出来这是一个人。
最后,如果不做dropout的话网络可能过拟合和如果要收敛的话需要两倍的迭代。所以随机失活能加速训练。![]()
![]()
#第五部分,讲具体的实现。在读第二遍时可以略读,不用去看这些参数是怎么设计的。大概看一些有没有新的东西,都是参数怎么设计的,所以先不看。
![]()
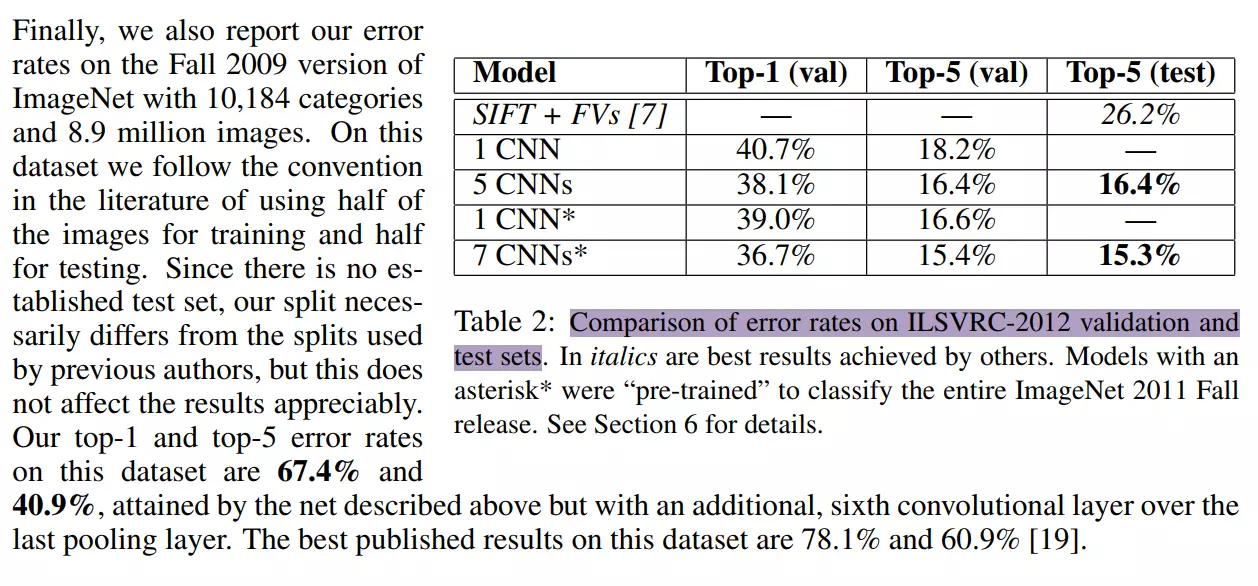
#直接看第六部分,结果:在2010年时,分类都是用机器学习去做的。像SIFT是一个非常有名的用来提取图像特征工程的。
![]()
#带*是预训练的模型,带*是经过迁移学习,它的精度是有提升的。并讨论了有几个卷积层对结果的影响。
![]()
#6.1贡献最大的地方:图三展示的第一次卷积后得到的卷积核。它表示的是两部分卷积核。通过图可以知道,上面组的卷积核偏向于找到黑白的特征,下面的卷积核偏向于找到彩色的特征。GPU1设备上的是color-agnostic;GPU2设备上的是color-specific;这个现象是彼此独立的和初始化没有关系。现在看来这个是Group Convolution组卷积。它是很有效的,既可以降低模型的参数,也可以让网络学到不同的模式。当然,当时作者 是不知道的。
![]()
#左边是结果展示,top-5出现的结果都是合理的。比如金钱豹,预测给的其他5个结果也是猫科动物,和金钱豹 是相关的。
#右边的:现在看是最重要的贡献,但当时作者没在回事。把4096维的向量都拿出来了,把哪些相似的向量的都拿出来看,发现这些图片都是相近的图片。发现神经网络确实可以提取深度特征。
现在看,这个事情可以做什么?可以做图像检索啊。比如现实中拍一个图片、去网上找图片看哪些图片的特征是和我们的拍的图片是相似的,那么它大概率就是一种
![]()
#然后读完了,第二遍大概用了1个小时。自己读可能会快一些。第三遍是你想把工作复现时,去搭建模型时,你直接读第3部分, 有几层啊,卷积核的尺寸、全连接等。
![]()
#怎么写论文?不要参照这个,因为这个人太牛了,因为这篇文章没有什么写作的方式。这篇文章更像是一个技术报告,因为对很多的现象,没有解释说明,甚至连假设都没有给。
在写文章时有一个现象最好给一个解释,而且最后的结论一定要有,不要只有一个讨论。
代码实现:读第三遍论文
![]()
#先看到这里,先把模型实现到这里:![]()
![]() 维度变化
维度变化
#torch.nn中的nn 就是neutral network;features是一个容器;conv2d里面参数就是用“=”传参。out_channels就是把空间的信息传到channel维度上
![]()
#classifier也是容器;一维是channel维度是128做了升维;后面的6*6指特征图的高度和宽度,做了降维,目的一是进行特征提取、二是防止参数量过大
![]()
![]()
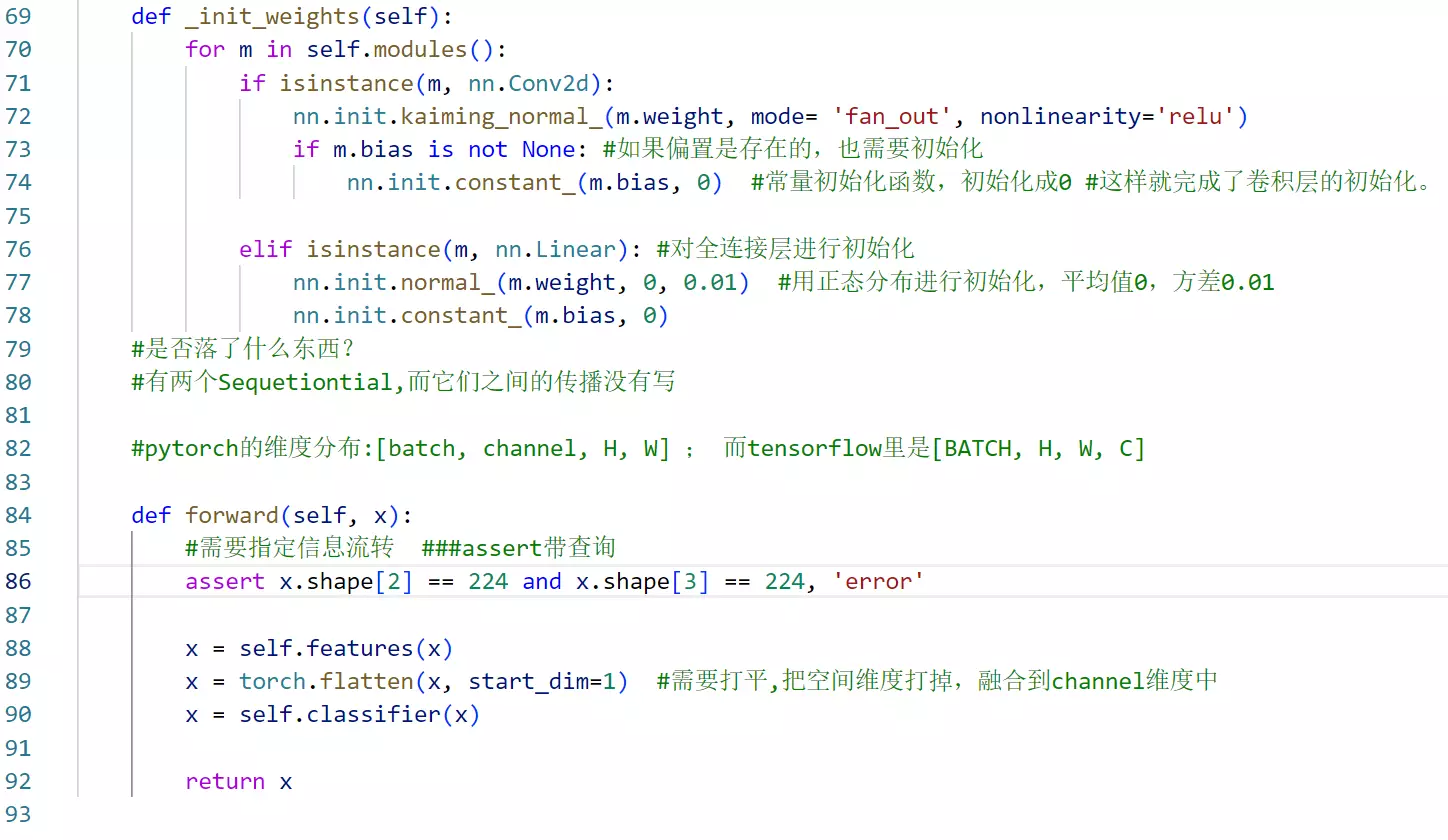
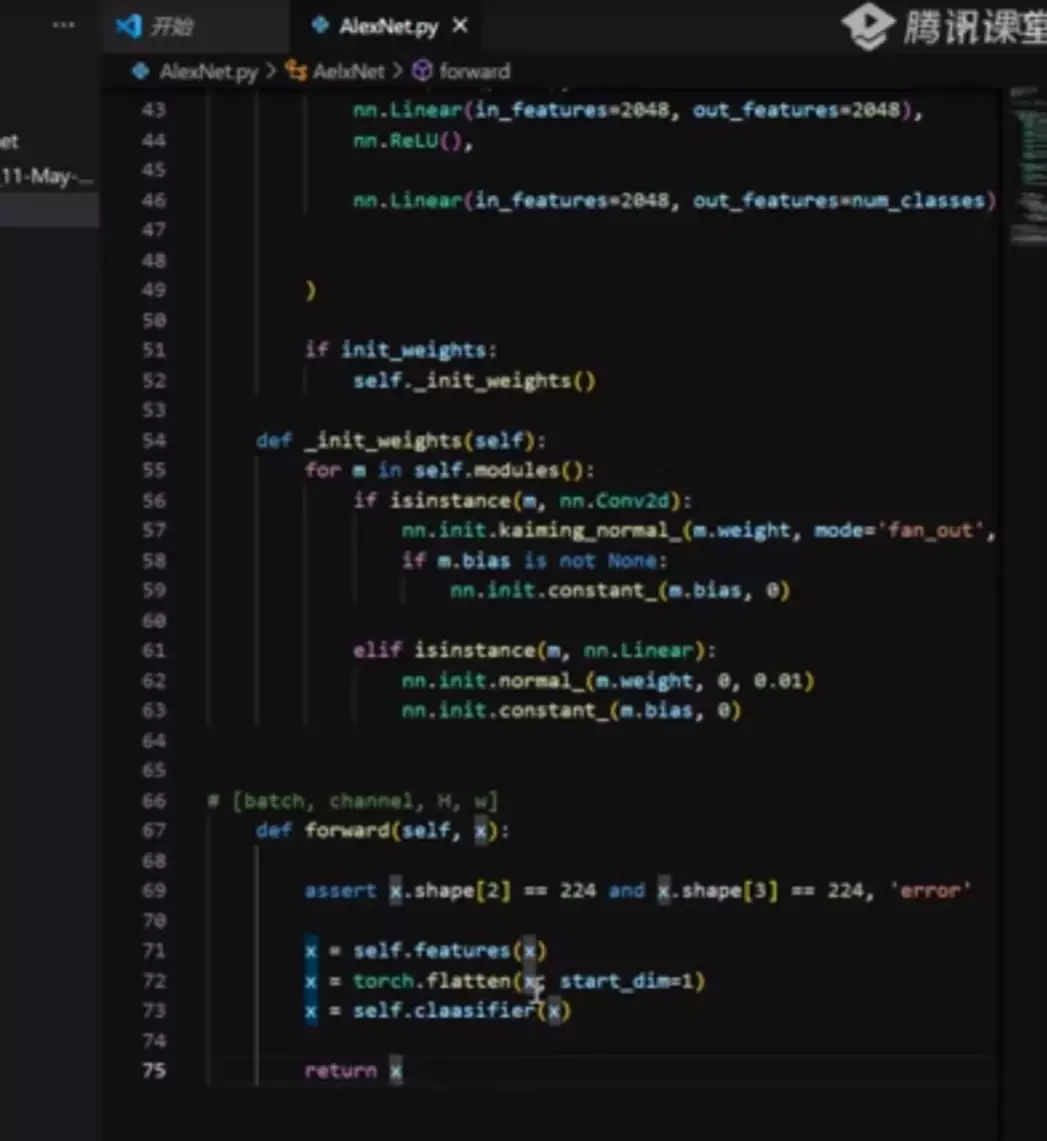
#70行 self.modules()这个函数会自动调用上面搭建的一系列结构,循环每一行nn.结构
#定义一个函数init_weights对权重初始化。isinstance是指后面两个是否相等。
#assert是判断语句x.shape的输出应该是[B, 3, 224, 224] B指每次送给模型多少张图片进行训练
#每一个卷积和全连接都要进行初始化。为什么不遍历最大池化层?池化不需要权重和参数
x = torch.flatten(x, start_dim=1)
#需要打平,把空间维度打掉,融合到channel维度中,所以从第1个维度开始做打平 --> [batch, channel * H * W]
![]()
![]()
训练数据脚本:可以接受
![]()
![]()
![]()
![]()
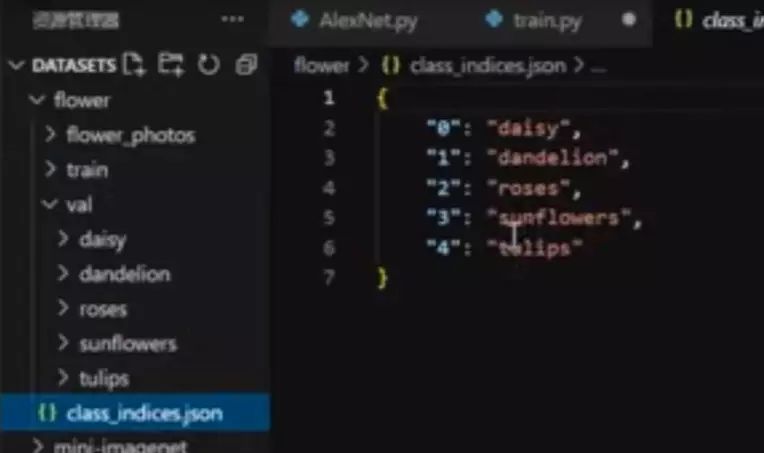
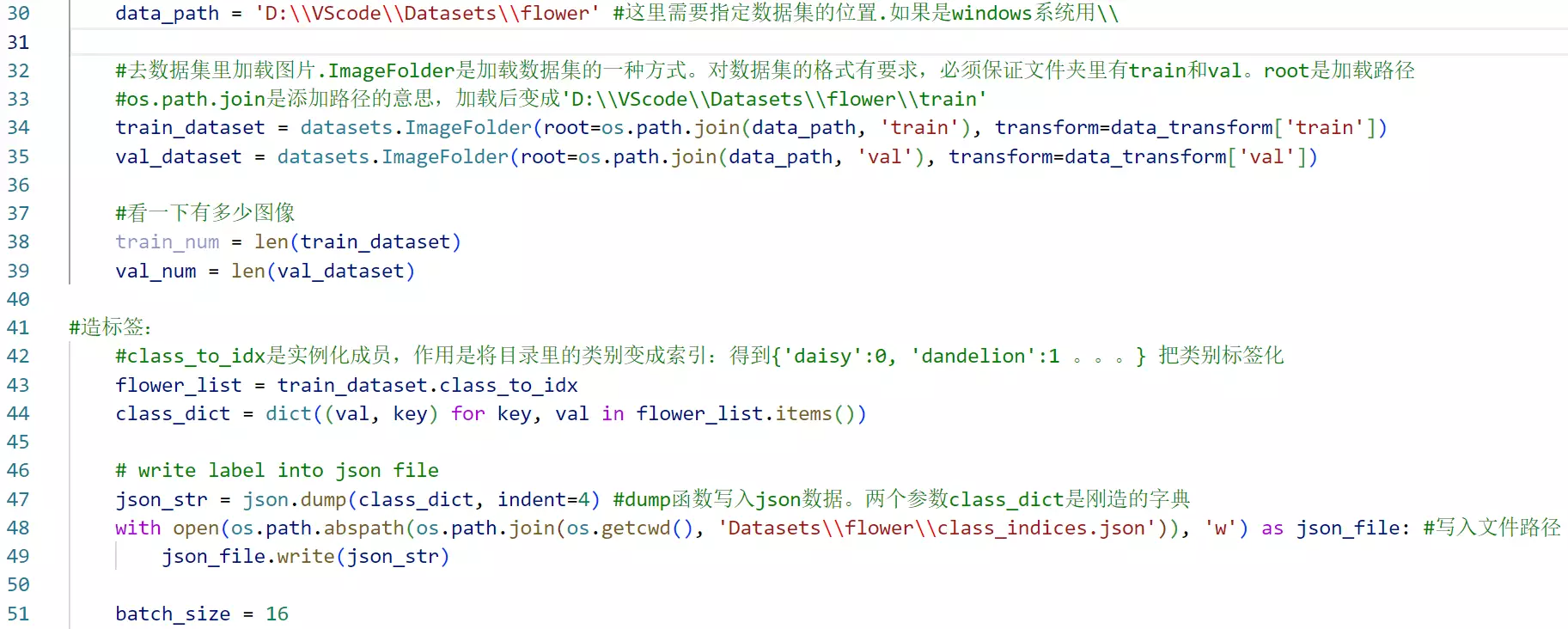
把类别和索引存成一个json文件,为了以后验证时预测出类别,做预测时找到类别,输出类别。![]()
![]()
![]()
![]()
![]()
#由于output是输入到设备中,labels开始是在cpu里,所以也要送到gpu里![]()
![]()
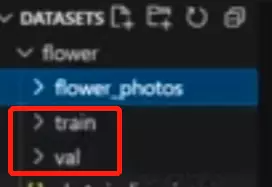
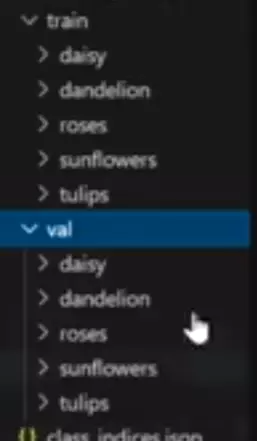
#通过ImageFolder加载图像的要求:1、加载的必须是图像 2、数据文件夹有要求:train、val![]()
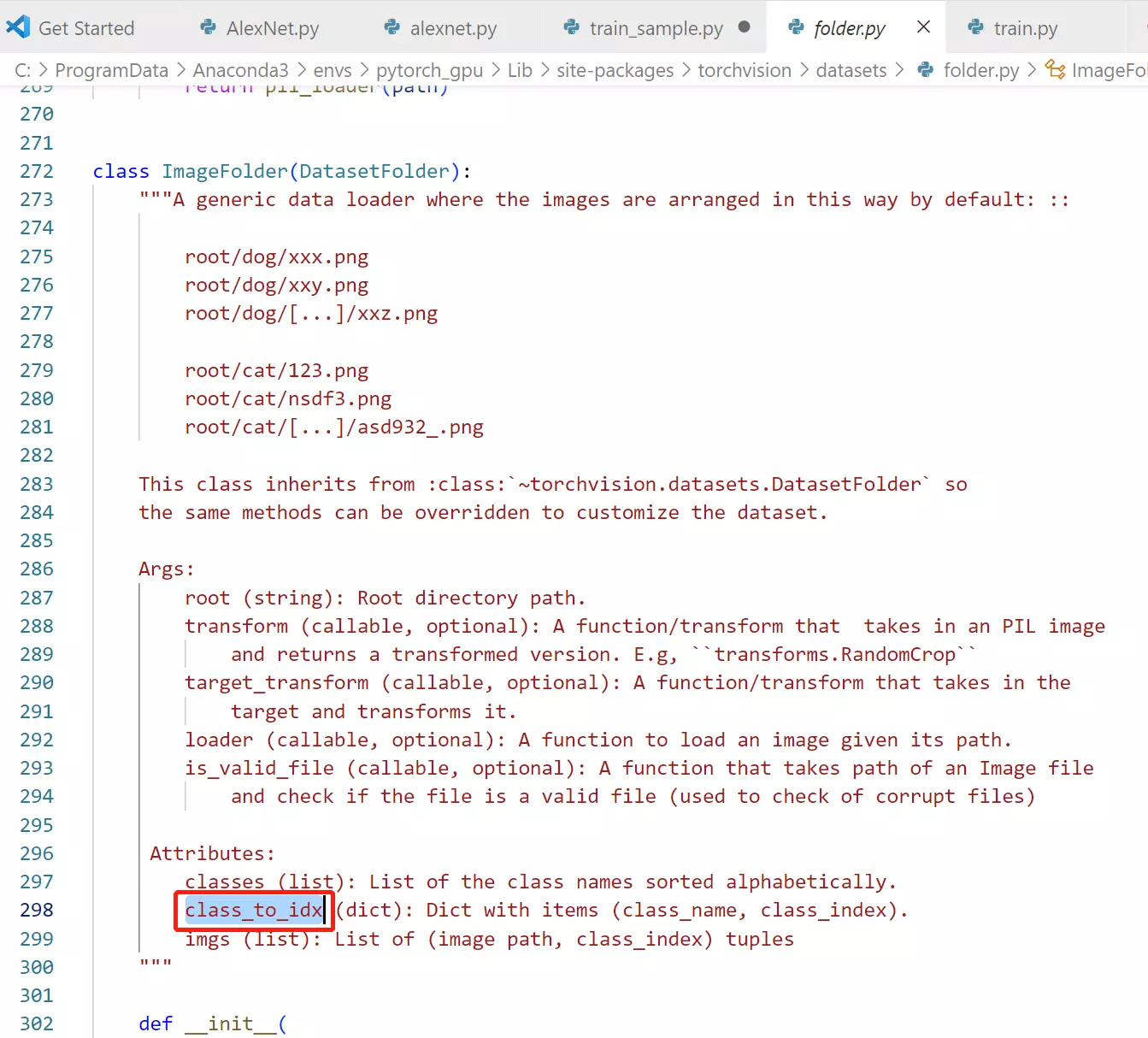
#里面的成员:class_to_idx
imgs 数据和标签捆绑在一起了
###新的模型脚本:
![]()
![]()
![]()
![]()
![]()
![]()
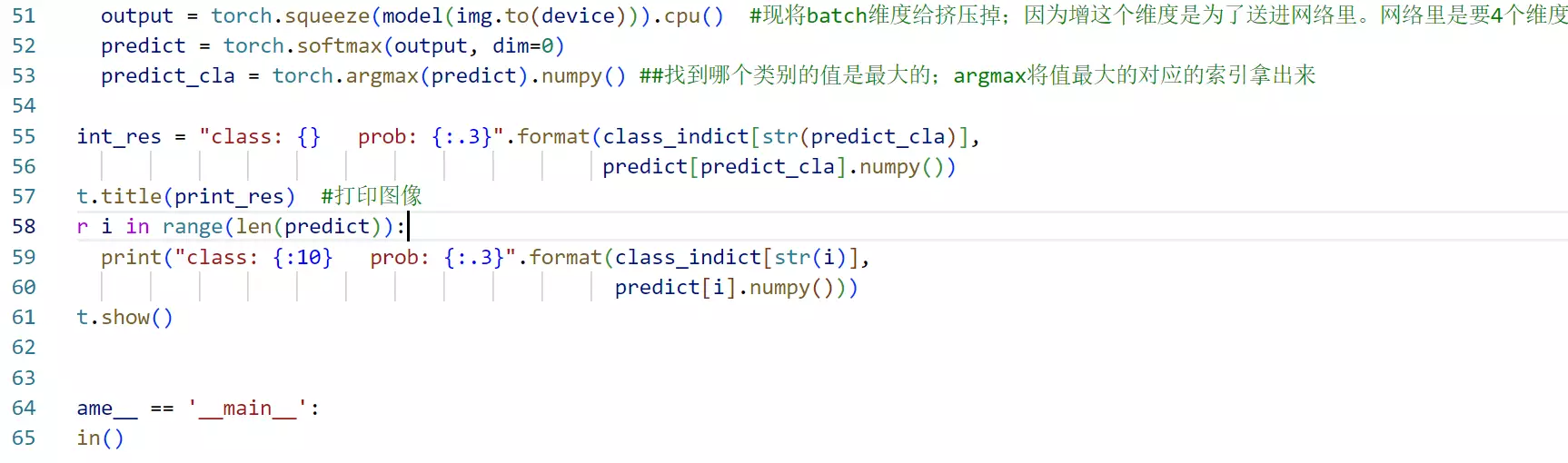
#预测代码。单独的test脚本:
![]()
#21行,随便加载一张图片
#22行,路径错误就报错![]()
#32行是加载标签,标签的样子![]()
#33行判断是否有这个标签
#39创建模型,实例化类
![]()
#42行:加载已经训练好的权重![]() 权重文件就是.pth的文件
权重文件就是.pth的文件
#46行:设置成推理状态,不会更新梯度
#49行:squeeze是降维
#predict是输出结果,有5个元素,是每一个类别的可能性
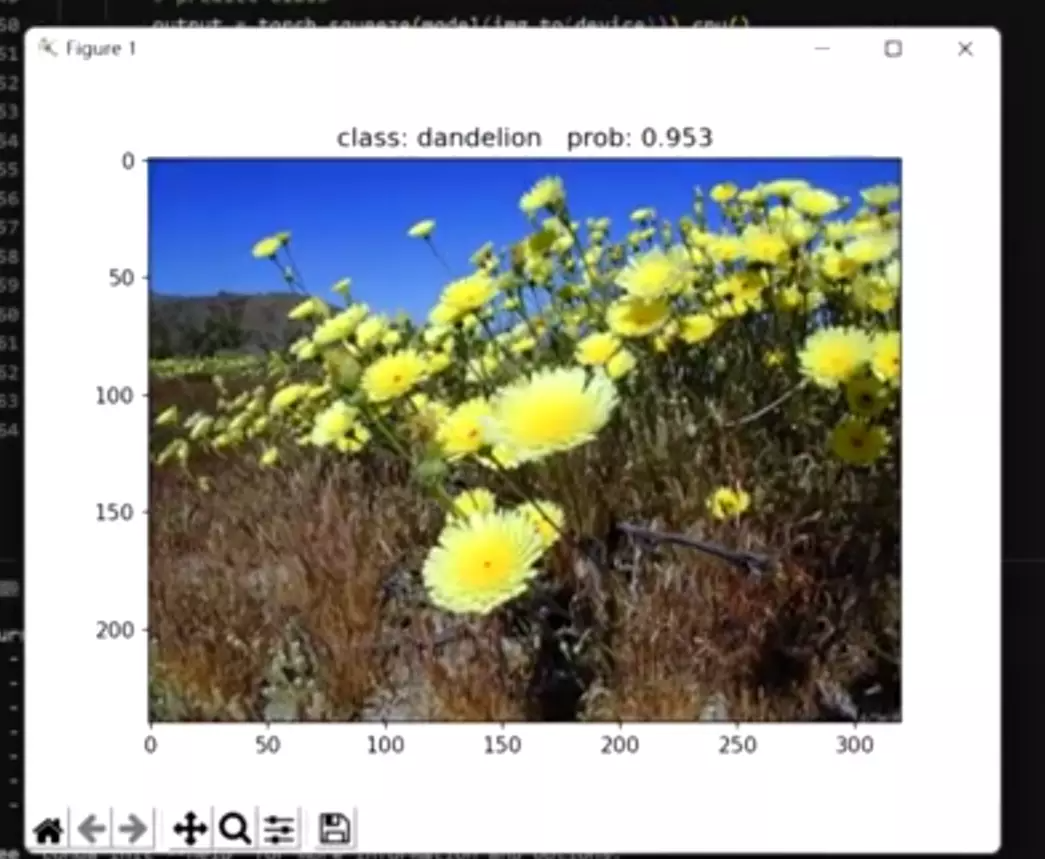
#51行:可能性最大的结果![]()
#输出小雏菊,分对了,给了置信度0.983![]() 5个分类的概率。
5个分类的概率。
![]()
#看训练脚本
#20随机裁剪
#21随机翻转 在做的数据增强
#test,做预测的时候并不需要做裁剪和翻转
![]()
#41行:进行类别的对应
#44~47:把标签写入json文件
#49行:每次训练32张图片![]()
#58行,传参,没有传input_channels、init_weight![]() ,因为有默认值
,因为有默认值
![]()
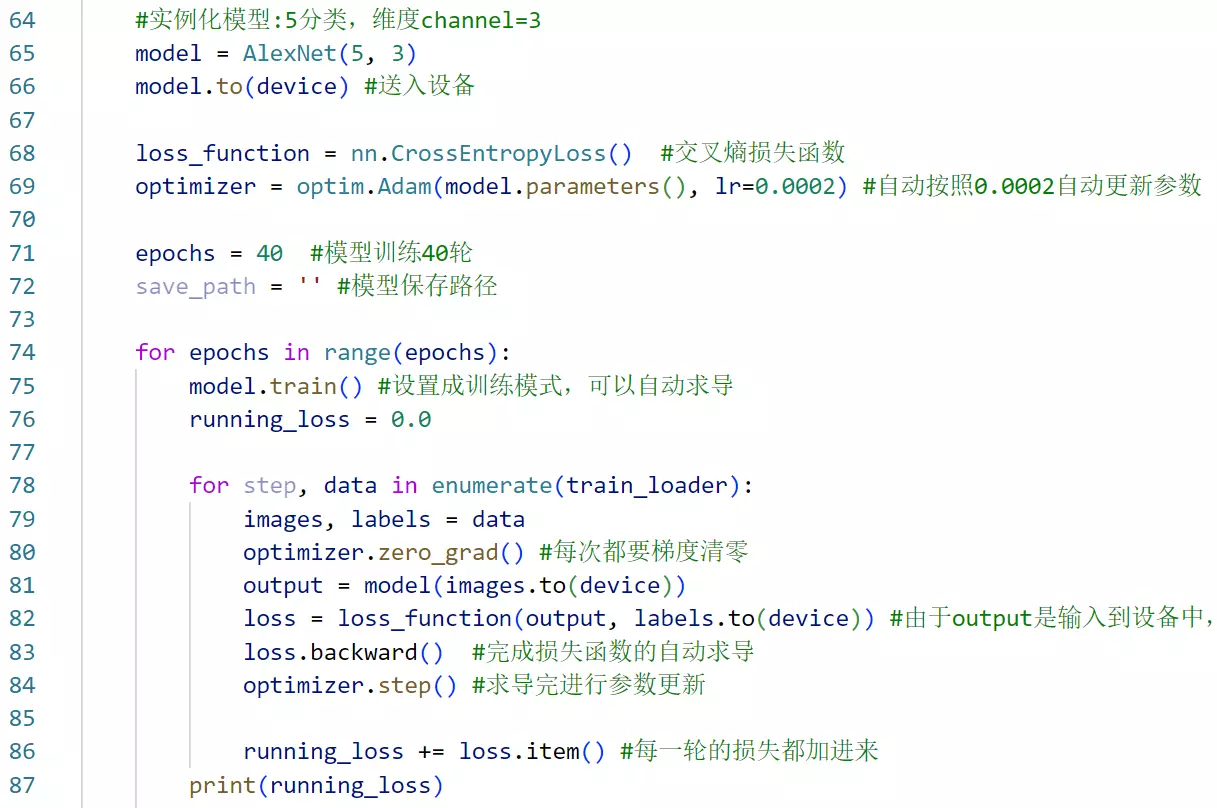
#76行 设置训练状态
#step,data 取出了 数据标号(为了打印用)和数据
#79行:数据里既有图像,又有label,因为![]() 这两行会自动给图像和标签打包
这两行会自动给图像和标签打包
#82:计算预测图片和真实图片的距离
#83行 做梯度下降
#84行:有优化器进行一个反向传播来更新网络参数
#88行 打印step步数
![]()
#91行:设置成验证状态,因为计算准确率时不希望更新模型梯度
#93行 也是不更新梯度的意思
#94行 去验证集中做验证
#98行:获得测试集中一共预测对多少张图片![]()
#输出是:用3306张图片进行训练,用364张图片进行检测;将训练的模型参数放到这个路径下![]() 70step就是用enumerate取到的step
70step就是用enumerate取到的step![]()
#完成第一轮,打印损失和准确率45.9%![]()
#第二轮完成,准确率提升对51%
#通过一次次训练逐步提升准确率
ZFNet论文_AlexNet模型可视化
![]()
![]()
对于网络的改进没法理解,模型为什么这么好也没有接受。但是我们可视化的技巧可以诊断网络结构哪里不好,针对模型做了改进,获得了13年的冠军。
他们发现不同的网络层的贡献是不一样的。
#用他们的网络ImageNet去训练别的数据集,得到当下最好的:state-of-the-art
#再看结论:没有结论只要discussion。自己写时一定要有结论,他们是大神。
![]()
![]()
#ablation study: 消融实验。在深度学习论文中,ablation study往往是在论文最终提出的模型上,减少一些改进特征(如减少几层网络等),以验证相应改进特征的必要性。
#都第一遍到里知道这个论文时讲卷积的,如果和自己相关,就再都第二遍。
#第二遍:网络实现略读。![]()
![]()
#深度学习的三驾马车:1、带标签的大数据集 2、硬件GPU支持 3、算法有很多改进,例如更好的模型带正则手段dropout
![]()
#trial-and-error:反复实验错误,跟炼丹一样,不理解模型,训练模型就是调参数,跟赌博一样。所以要探讨下,模型为什么这么有效。
#他们的手段叫deconvnet:将特征图重新映射回像素空间
![]()
#generalization ability 泛化能力:如何体现?训练别的数据,fit中间层,指去训练分类层,这个方法也叫做迁移学习。
#摘要也是先吹现在的现状怎么样,效果这么好,再however尽管这么好,还有一些问题,我的改进。。。
![]()
#相关工作:快速的略读。
先讲可视化现状,再讲我们的方法,有哪些不一样的地方,那些改进的地方。non-parametric view of invariance不需要参数的,只是对特征图进行简单的映射,映射成原像素空间。![]()
![]()
#4个像素的小图就是featuremap,再把这个featuremap重新映射回原来像素空间。
![]()
#实现:先将一下前人如何实现的,网络结构等。因为如果你做了改进,需要总结一些前人做了什么,不然看文章的人还要去翻前人的文章才能知道前人干了什么。这对读者来说是不友好的。![]()
![]()
![]()
#可视化的实现:这里讲卷积和池化是不可逆的。最大池化是扔掉了一些,保留一个。但是:
![]()
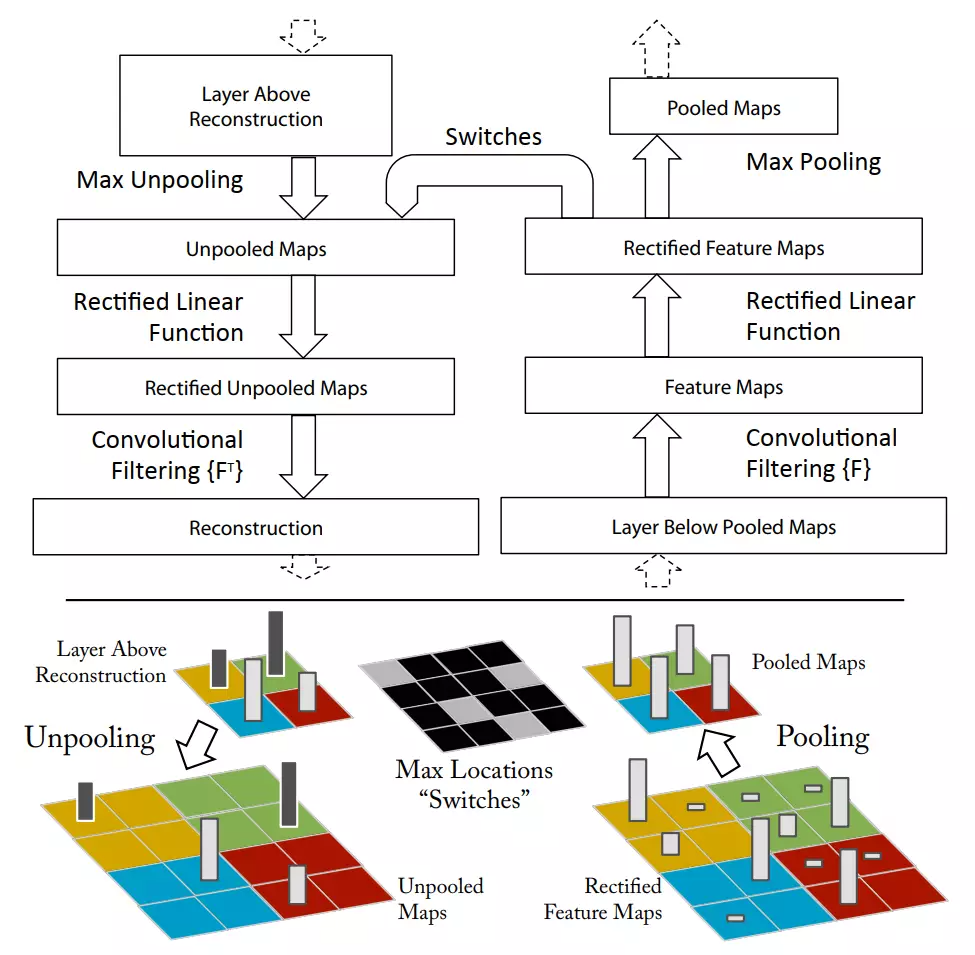
#他这里提出了一个方法是unpool可以将池化的结果进行恢复。
![]()
#记录做maxpooling时保留的位置,现在想重建回原来的样子,就会根据location重建。填到这里,剩下的三个值给一个值,不是和原始数据一模一样的,是有损的恢复。就是他做的反视化。![]()
#思想是反池化、反卷积,让feature map重新映射回原空间。
![]()
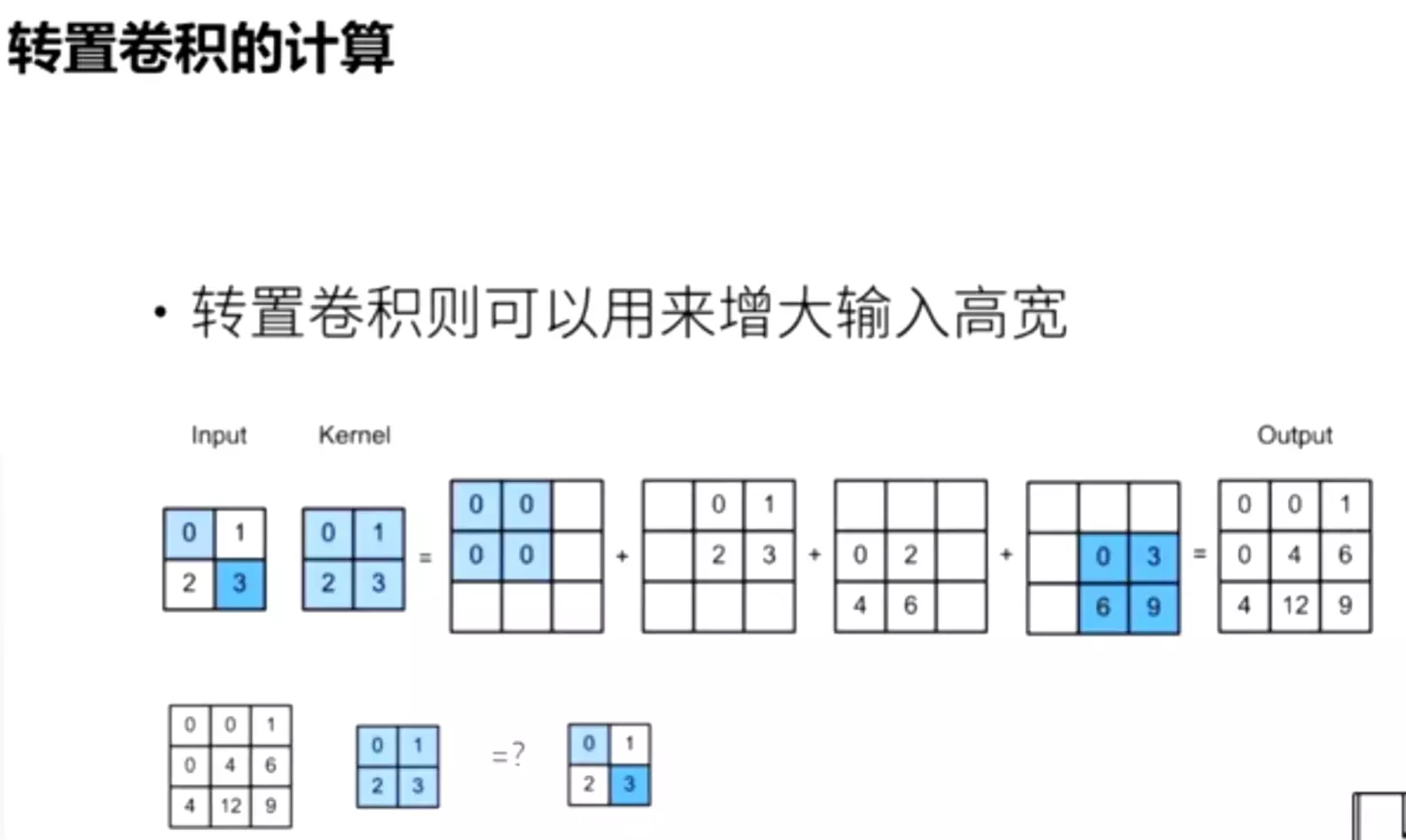
#激活 :在原始的卷积函数里面用的是relu,因此做反操作时保证值都是正的。这里就是做了一个转置卷积。
![]()
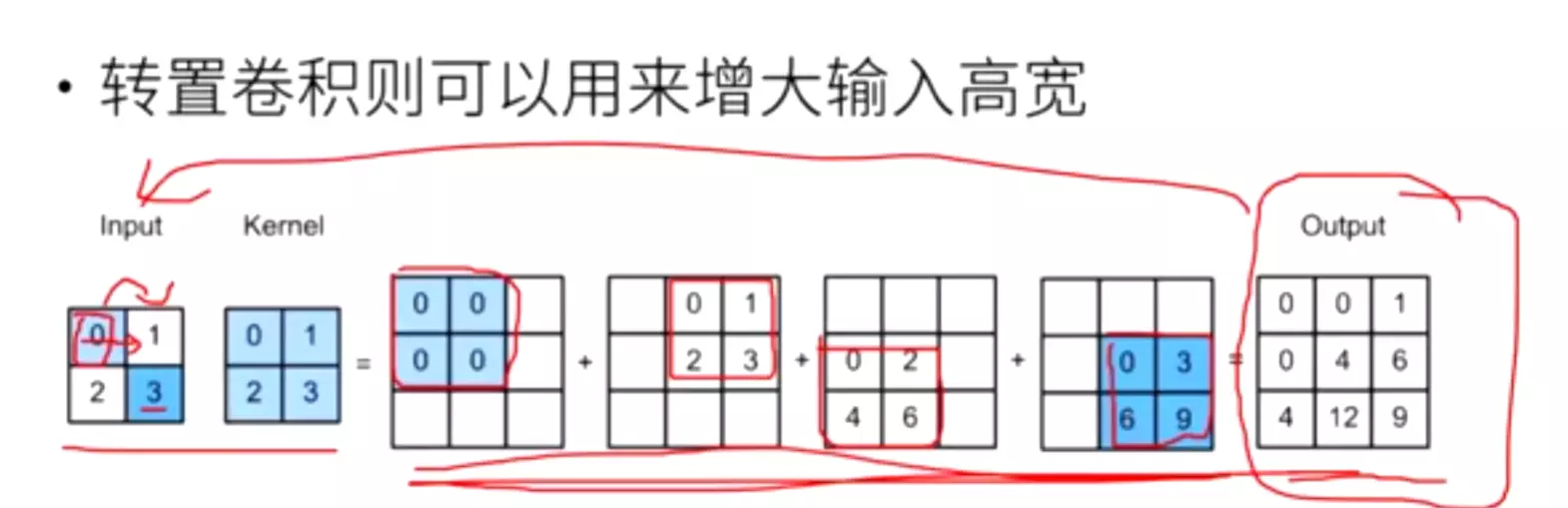
![]() 会增大图像的尺寸!!!·
会增大图像的尺寸!!!·![]()
![]()
![]()
#我们不再用2个gpu训练了,只用了一个。![]()
#再读第二遍时不用特别关心,如何实现,等第三遍细读时再都。![]()
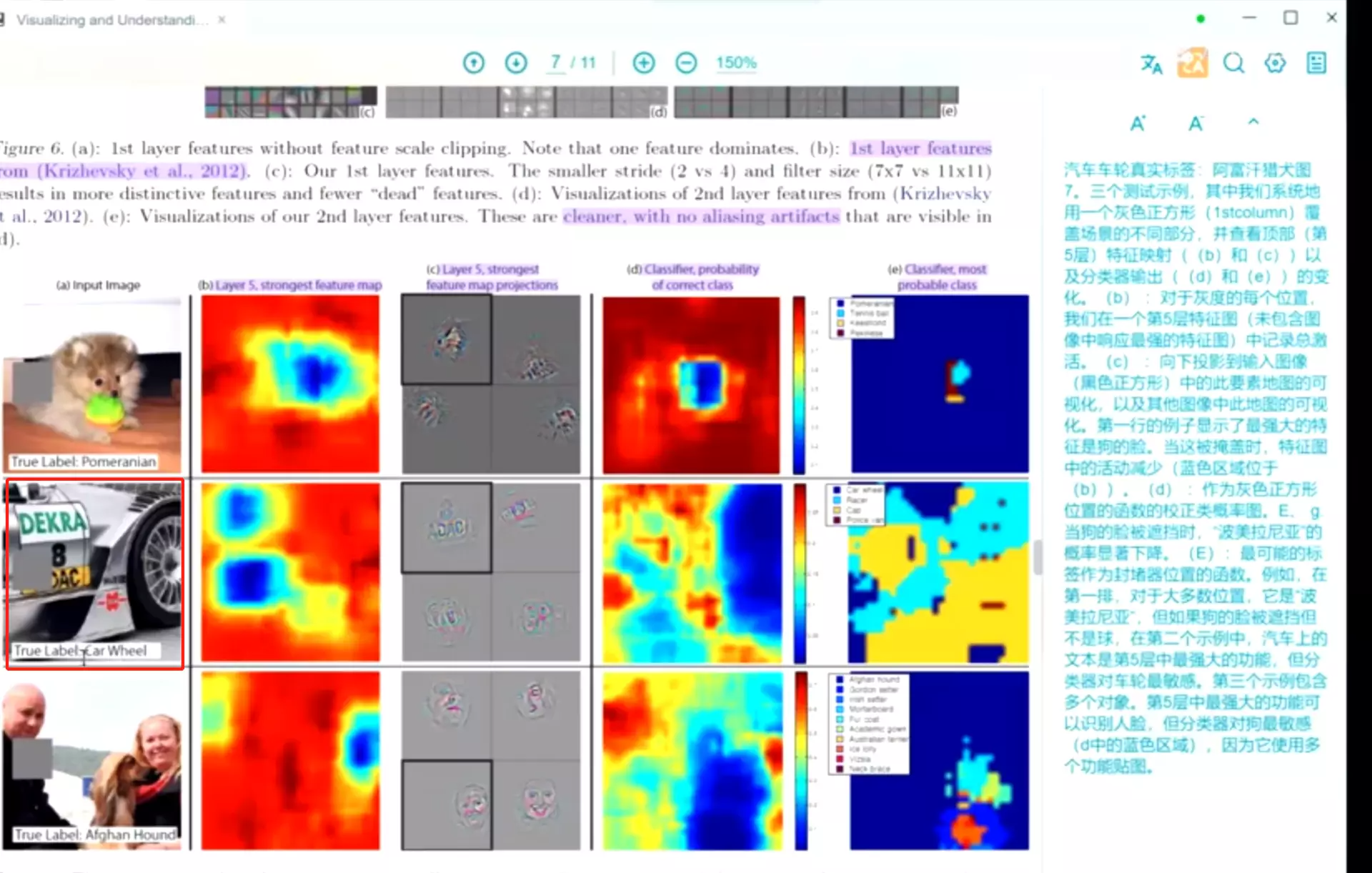
#可视化结果在图6a里![]()
![]()
feature map的可视化展示在图2里。如果大家能读懂图的话,文字可以不看,因为文字都是对图的描述。
#这里说越靠近后层图像的相关性就不那么明显了,例如第五层第一行第二列。这说明越靠近后层它关注的特征越高级。关注的高级的语义特征,目标层次的特征。模型能分辨草地和目标了,草地是背景,目标是前景,说明模型能理解图像了。
![]() layer1 左上这个图不是feature map 它每一个小图是feature map映射回原始空间后的样子。这里取卷积核输出里最大的9张拼成一张小图,然后将9张图重新映射回像素空间
layer1 左上这个图不是feature map 它每一个小图是feature map映射回原始空间后的样子。这里取卷积核输出里最大的9张拼成一张小图,然后将9张图重新映射回像素空间
下面的图不是feature map它是真实图像,它是可以使feature map的值时最大的。![]()
#下面的feature map关注的可能时颜色颜色信息,所以有绿色的小图像可以使feature map最大。
![]()
#第二组可视化的结果,同理。左边是卷积核得到的feature map映射回原始空间可视化结果;右边是原始图像,可以使feature map最大
![]()
比如中间第一个感兴趣的红色的特征,旁边的感兴趣的是圆形特征。
![]()
下面的感兴趣的是黄色特征。![]()
#第三组也是
![]()
#第五层:图像的相关性。这说明越靠近后层它关注的特征越高级。例如右上角关注的是草地。
![]()
![]()
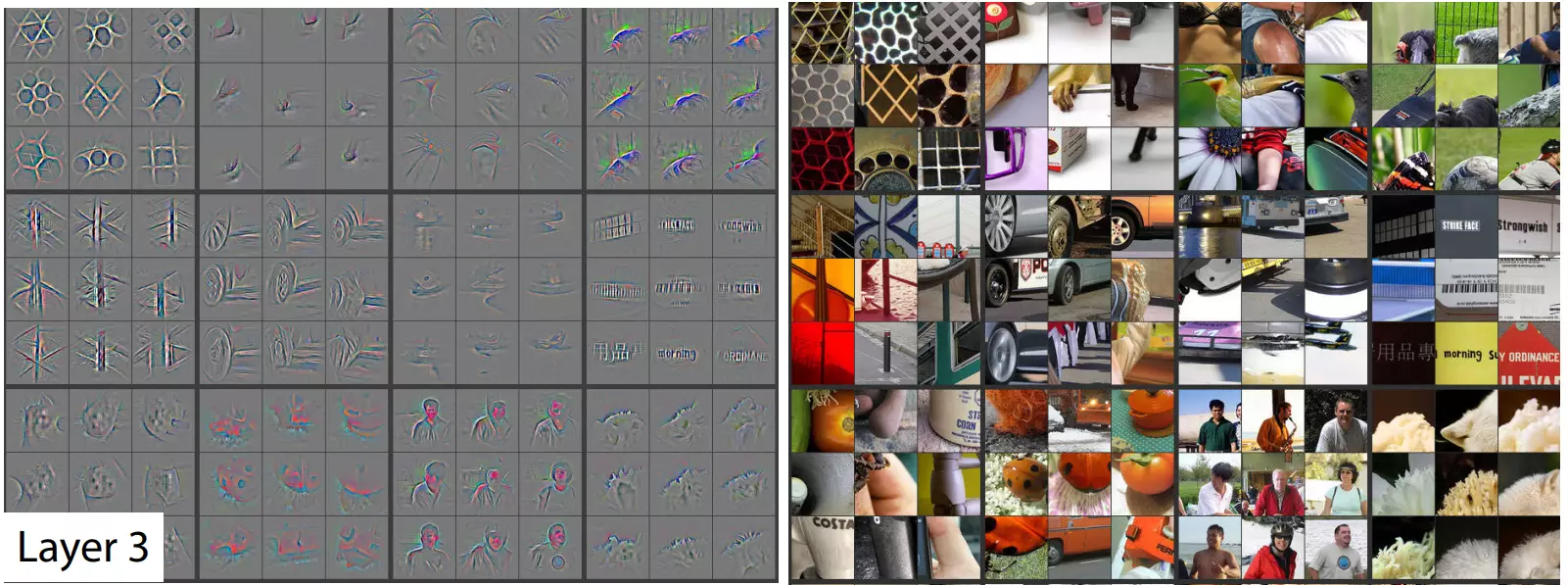
#描述:卷积得到的特征是hierarchical 分级的。而且是网络天然的特征。
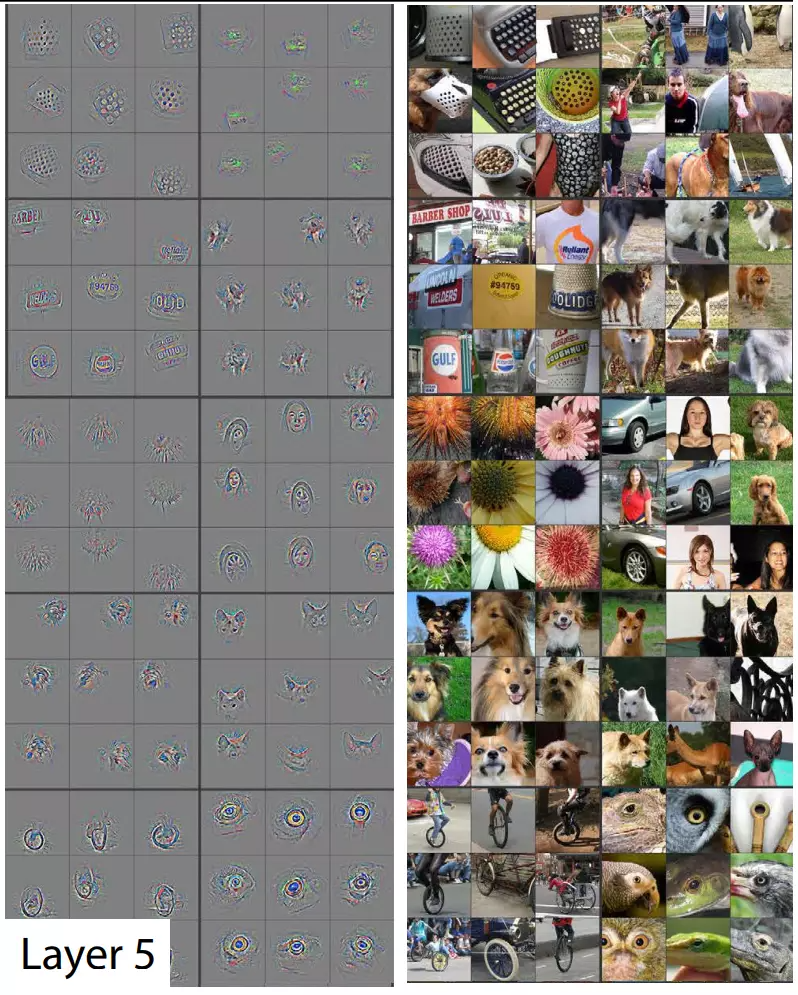
第二层更关注一些 edge/color边缘、颜色特征。第三层,关注的是complex invariances不变性特征,纹理特征。第4层抓一些目标级别的特征。第5层不再关注的是significant pose variation位置了,关注的是狗的属性特征。
Feature Evolution during Training:特征的进化。在图四里。在比较浅层里,网络可以快速的收敛,用很少的epoch。但是在深层,只有经过大量的训练,大概时40-50个epoch才能得到比较好的特征,才能收敛。所以高级的特征,需要学好久。![]()
#前几层就可以学到,刚开始训练时就可以学到特征图。但是在深层的网络里,慢慢才能学到特征图。![]()
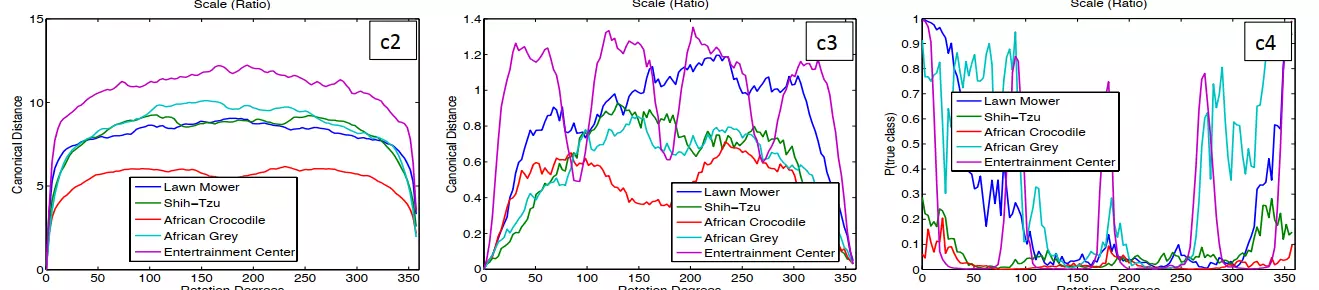
特征不变性。探讨图像的平移、旋转、缩放对结果是否有影响。这里说明:对平移和缩放有不变性,但是对旋转没有,除非我们的目标是中心对称的。![]()
#a1平移 b1缩放 c1旋转;右边的图是结果。前两个(第二列和第三列)是第一层卷积结果和最后一层卷积结果的图。最后一列是预测正确率的图。
看a2:横轴是平移的位移量,例如-20、-40等;纵轴是平移后送进网络里得到新的feature map和原feature map的差距。可以看到,在挪了一点时,变化比较大。但是在第7层,a3图,时准线性的变化,挪一点变化一点。这说明在网络的浅层我们更关注空间信息一个低语义的特征,不管是颜色、像素、空间也好,但是在深层关注的不是低级的特征了。平移的效果不明显。
![]() 这张图说明图像在平移到中间时效果比较好。
这张图说明图像在平移到中间时效果比较好。![]()
缩放也同理,在第一层时变化剧烈,在第7层时变化是准线性的了。
![]()
![]()
#再看旋转:紫色的是娱乐中心,酒吧。它是一个中心对称的。旋转90度,预测结果准确度高。但是旋转其他角度就预测准确度很低了。
#所以卷积有很好的平移和缩放不变性,但是对旋转和敏感.![]()
#问:层数越多越能抽象出的高级特征吗? 答:理论上是这个趋势,但是层数太多也不能说设置上千层都能学到高级的特征。
#问:这篇文章可视化结果代码复现?--不会。因为现在有更好的方法,来可视化。感兴趣老师可以发给你。
![]()
#他们发现两个问题:进行可视化发现第一层卷积后得到的feature map有些值特别大或者特别小,这说明没有学到特征,这些feature map没学到东西,是我们不想要的。第二个问题是第二层卷积可视化展示出,第二层的feature map出现了棋盘状的尾影![]()
这里将 a是第一层卷积得到的feature map映射为原始像素空间的表示。
![]() 第
第
第一层得到的feature map有些值特别大、显得特别不清。
![]()
d图:在第二层这里有尾影、像棋盘一样。他说这种情况是卷积核没有学到东西。他相当于学到了噪音。这个卷积核对网络的最后结果是没有贡献的。
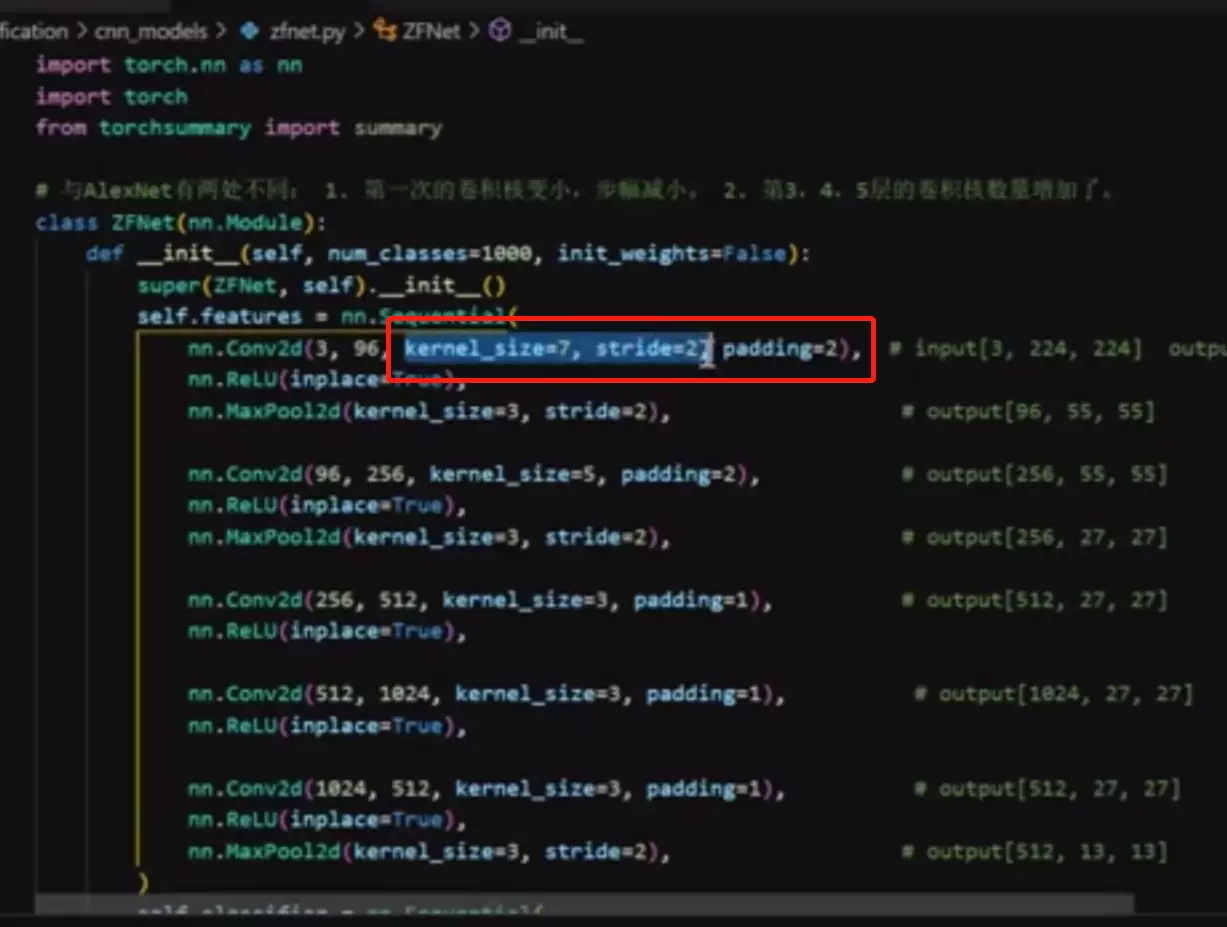
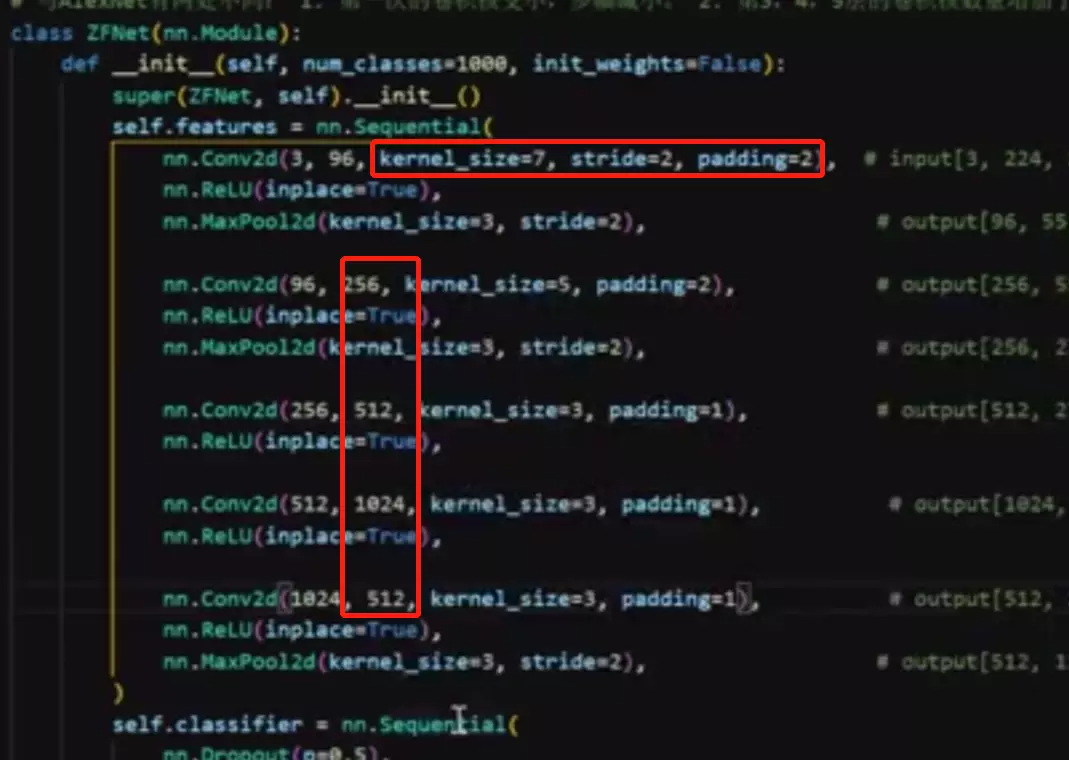
![]() c图:是作者改进后的feature map 他发现那种黑的卷积核不存在了。这是ZFNet的贡献。他改进的方法是:用更小的卷积核尺寸和更小的步长。所以ZFNet就做了这个贡献,他主要贡献是对卷积的解释。
c图:是作者改进后的feature map 他发现那种黑的卷积核不存在了。这是ZFNet的贡献。他改进的方法是:用更小的卷积核尺寸和更小的步长。所以ZFNet就做了这个贡献,他主要贡献是对卷积的解释。
![]()
![]()
#遮挡敏感性实验:当我们看一图时,是根据特定的位置,关注的地方去识别,还是要关注全局去识别,图7就尝试回答了这个问题。![]()
![]()
#首先它对图像做了随机遮挡,这个遮挡可以出现在任意位置。后面4列是他做的实验。
b列是卷积操作后得到一推特征图的,这个图是卷积后得到的一个feature map值的总和,就是特征图的值加到一起得到的图。 红色的代表这个值越大,蓝色区域代表这个值越小。可以看到当遮挡在四周的时候,得到的值是差不多的, 都挺大的。但是一旦遮挡出现在狗脸位置的时候,再将图像送进网络里做卷积,得到的feature map值相加得到的值就比较小。这说明我们的卷积核对狗脸这一块比较敏感,他输出的特征图的值比较大,如果把它挡住,再送进去后,值的总和就会有一个非常大的下降。 由这个也可也可以看出来卷积后得到的特征空间图也是保留了原始数据的空间信息的。 他知道这个狗脸在什么位置。
c列后看。
d列讲的是遮挡所在的位置对当前这个图像正确分类的影响,红色代表分类正确的可能性比较大,蓝色的代表分类正确的可能性比较小。所以当遮挡出现不是在狗脸的位置,在周边其他位置,对于分类正确的可能性没有影响。,他的分类准确度都挺高的。一但出现在狗脸的位置,准确都就一下子下来了。这就说明一个问题,我们的卷积神经网络关注的它感性趣的局部,而不是用的图像所有的信息。![]()
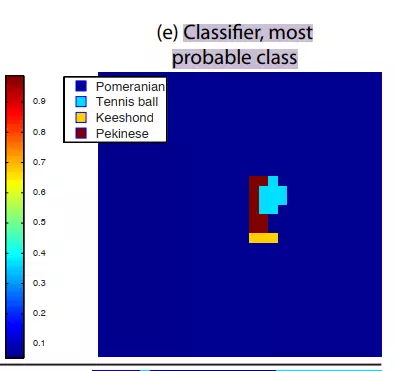
e列是一个探究,这个最有可能是一个什么类别。深蓝色的是博明犬、浅蓝色是网球、黄色的是~、紫色的是北京人。就是说当我的遮挡在不同位置的时候,会给我的图像做一个什么类的分类。结果表明,当遮挡出现在非狗脸的区域的时候,分类最大可能是博明犬,是正确的分类。当遮挡出现在狗脸的位置的时候,大概是浅蓝色的区域,最有可能的分类是网球,因为他把狗遮住了,现在的图像里面最明细的物体就是网球,自然就给了一个网球的分类。当遮挡出现在红色或黄色是射门分类。![]()
#再看c:第一张图的左上角,是第五个卷积后值最大的特征图映射回原像素空间之后的可视化结果。这说明这个特征图感兴趣的是个毛茸茸的狗脸,跟我们的目标是一致的,这也说明的我们的卷积核确实能提取到特征。而且是它感兴趣的目标级别的特征,在第五层的时候。
![]() 下面图左上角是值最大的feature map 它映射回原始的像素空间是这个样子。说明当前它感兴趣的是图像里的数字。剩下三个图是指将数据集里面其他的图像也送到当前的神经网络,然后它在第五层也会得到不同图像对应的featuremap,将这些不同图像得到的featuremap也拿出来,挑一个前三位,对这三个featuremap做一个可视化,发现是这些特征。
下面图左上角是值最大的feature map 它映射回原始的像素空间是这个样子。说明当前它感兴趣的是图像里的数字。剩下三个图是指将数据集里面其他的图像也送到当前的神经网络,然后它在第五层也会得到不同图像对应的featuremap,将这些不同图像得到的featuremap也拿出来,挑一个前三位,对这三个featuremap做一个可视化,发现是这些特征。
这说明,上面四个图像说明这个卷积核确实是在找毛茸茸的特征;中间四个图像说明 这个卷积核确实是在寻找文字的特征,像右上图有个中国必胜,说明原始数据集原图是跟中国必胜有关的图像,这说明第五层卷积核最关注的是文字包括gre、po什么。
下面4张就都是人脸。
##他这样做就是证明了我们卷积核确实是在提取它感兴趣的相关特征。比如果第一个卷积核感兴趣的是毛茸茸特征,它确实是到不同图像里去寻找毛茸茸的特征;中间卷积核感兴趣的是文字特征,它确实是到不同图像里去寻找文字特征;下面卷积核感兴趣的是人脸特征,它确实是到不同图像里去寻找人脸特征。
![]() 这个例子值最大的feature map 它映射回原始的像素空间是最感兴趣的是女人的脸。
这个例子值最大的feature map 它映射回原始的像素空间是最感兴趣的是女人的脸。
![]()
#看一个问题,第二个图像的标签是车轱辘,但是特征值最大的featuremap感兴趣的是文字。所以我们特征值最大的featuremap并不一定是对我当前分类最有帮助的、贡献最大的。为什么识别文字,也能正确的对车轱辘进行分类。答:因为能得到很多featuremap,虽然最大的是识别文字,但另一类就可能和车轱辘相关了,所以他能正确识别对车轱辘进行分析。
![]()
![]()
#相关性分析,先看图8
![]()
他探讨的是同一个特征在不同图像中的表现形式是不一样的。比如狗的眼睛在第一排图片和第二排图片中是不一样的。我们希望这种特征被识出来,他探究卷积神经网络能否有这个效果。
首先看第二列,他搞了一些遮挡块,将狗的左眼都遮住了。然后他将原图和遮挡之后的图像都送进神经网络里,这样他们各自得到各自的feature map,然后他去计算了一下这两张feature map 之间的距离,只是第一步。针对每一张狗图像都做了这个事情,然后得到5个结果,这5个结果分别代表着每一对图像feature map之间的差距![]()
![]()
![]()
#For each image i,
we then compute: �l i = xl i-x~l i, where xl i and ~ xl i are the
feature vectors at layer l for the original and occluded
images respectively.
第一步计算了经过卷积之后得到的特征向量,分别计算原图和遮挡之后的图像。第二步,用了汉明距离来识别这两个图像是否相似。分别对5对图像的汉明距离求了和。
这说明了如果你的卷积核能在不同图像提取同种特征的话,那么就说明我遮挡左眼的操作对5对狗的影响都是差不多的、就是featuremap之间的差值相似。
![]() 结合下面的表:
结合下面的表:![]()
#看表这个汉明距离求和是一个比较小的数。挡右眼、左眼、鼻子都是一个很小的值;但是当我随机生成的遮挡计算的汉明距离就很大。因为后面几列随机遮挡的地方是不一样的,所以是一个很大的值。
![]() 在第7层时,遮挡右眼、左眼、鼻子后的值是和第5层差不多,但是随机遮挡的值比第五层减小了很多。这是为什么?答:越往深层走,可以看图2,越往深层走提取的是目标基本的特征,而浅层如2层就是比较低级的特征、像色彩、边缘、位置、角点这些比较低级的特征,这些低级的特征是跟空间信息相关的。但是高级特征就不同了,像提取的犬,并不关系犬的位置。所以越往深层走,就不在关注空间信息了。
在第7层时,遮挡右眼、左眼、鼻子后的值是和第5层差不多,但是随机遮挡的值比第五层减小了很多。这是为什么?答:越往深层走,可以看图2,越往深层走提取的是目标基本的特征,而浅层如2层就是比较低级的特征、像色彩、边缘、位置、角点这些比较低级的特征,这些低级的特征是跟空间信息相关的。但是高级特征就不同了,像提取的犬,并不关系犬的位置。所以越往深层走,就不在关注空间信息了。
A lower value indicates greater consistency in the change resulting from
the masking operation, hence tighter correspondence
between the same object parts in different images
越小的值,代表着比较大的相关性在遮挡操作对结果改变的相关性。
![]()
#在读第二遍对实验不急于复现,所以略看![]()
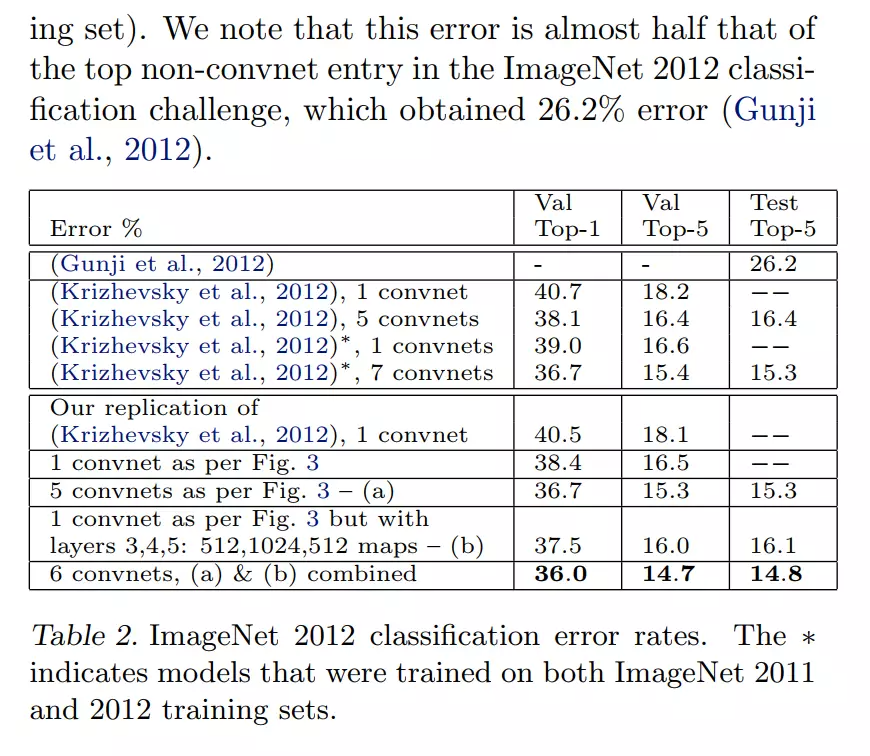
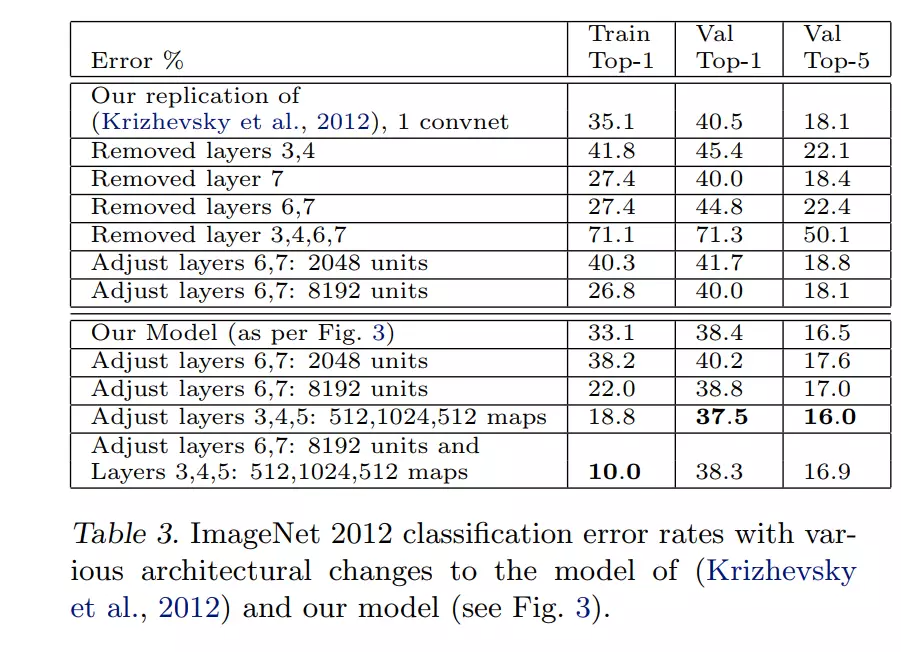
#在读第二遍时可以直接去读表格。因为文字都是对表格的叙述。第一行最后一列26.2是机器学习的结果,可以看到是最差的,和DeepLearning相比差了接近十个点。下面是本文作者复现的结果18.1,和上面就差了0.1个点。这说明Alex 小哥没有骗人,是一个正确的研究。下面就是对这个算法的改进,做了一些消融实验。 比如它改进后用来一个卷积、5个卷积后得到的结果:说他们最后的错误率是14.7%,也就是比15.4降低了7个点。所以通过表格可以知道,ZFNet比AlexNet效果还要好。这就可以了,不用往下看。
![]()
![]()
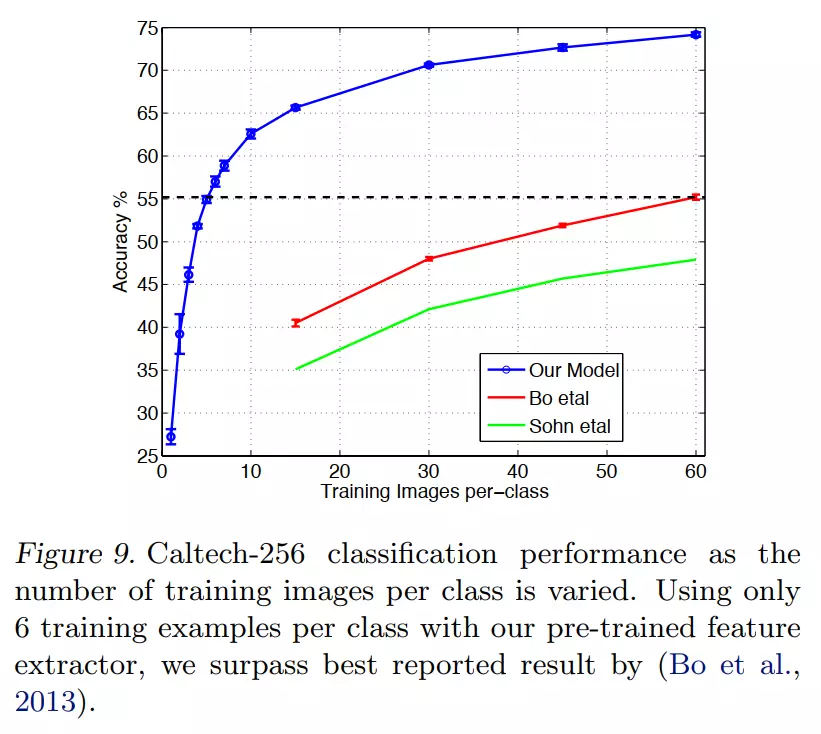
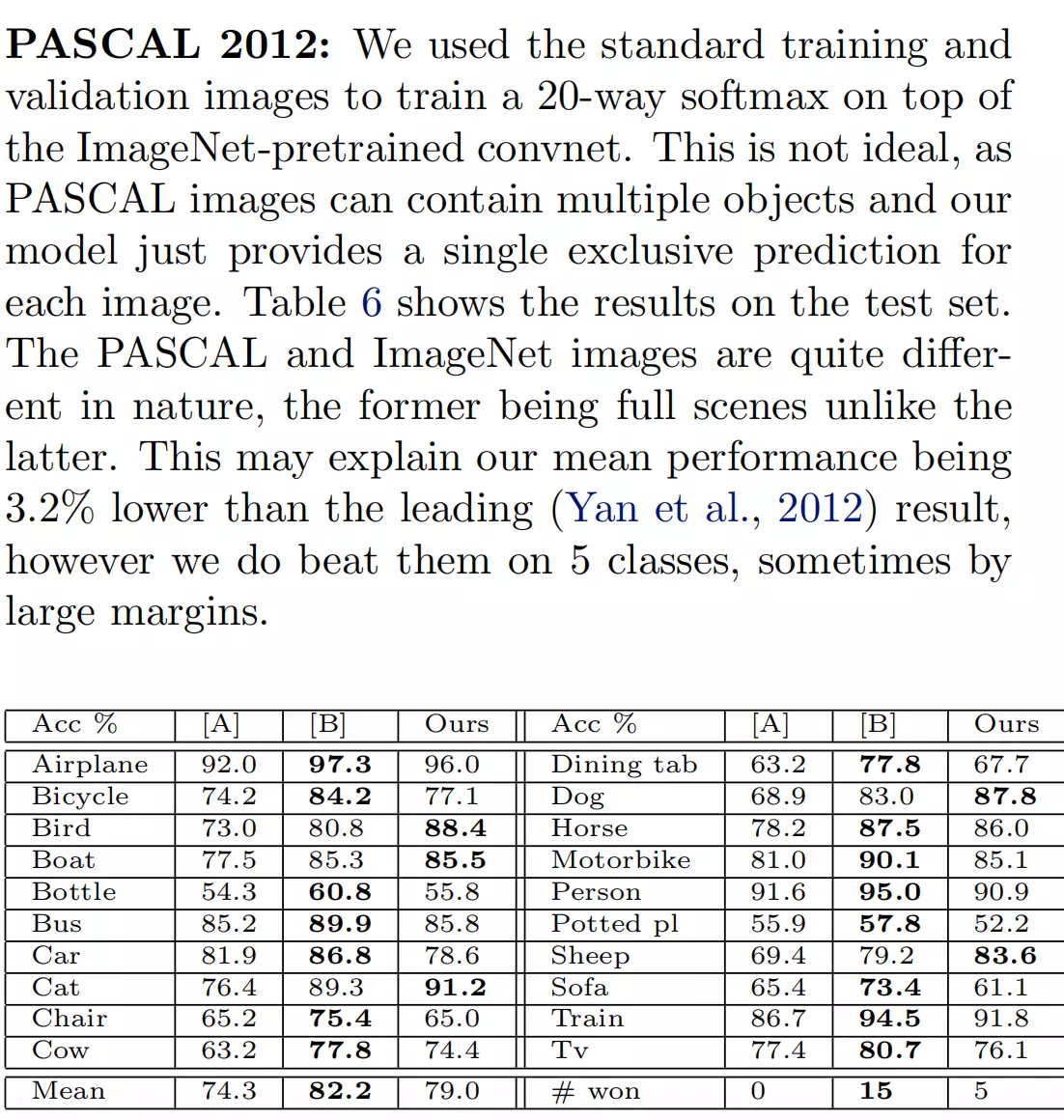
#这里讲的迁移学习,在ImageNet训练后保留权重后训练其他数据集—— PASCAL VOC 2012,如果本身好的话,说明ImageNet提取后的特征是通用的。通过图9 可以看出来。
![]()
这个蓝色的是通过迁移学习去训练的一个模型,红色和绿色的是之前的一个最佳模型。可以看出从ImageNet来的参数去训练其他数据集不仅是从训练速度来讲还是从准确率来讲,都有一个很大的提升。它就证明了模型的泛化能力是不错的。有一个卖点。
![]() 这个图做了一堆消融实验,做了一些改进。写了一个原版的。首先去掉了第三和第四层,发现错误率提升了5个点。又尝试去掉了第七层(一个全连接层、ps:一共有两个全连接,第6、7层都是),错误率40.0 不仅没有涨,还降了,就是精度有所提升,这说明了什么? 答:这说明全连接层是冗余的。【这里注意读论文时要待一个批判性的思想,不要以为写论文的人是大神,因为历史证明了就算是大神的论文也不是百分百正确的】
这个图做了一堆消融实验,做了一些改进。写了一个原版的。首先去掉了第三和第四层,发现错误率提升了5个点。又尝试去掉了第七层(一个全连接层、ps:一共有两个全连接,第6、7层都是),错误率40.0 不仅没有涨,还降了,就是精度有所提升,这说明了什么? 答:这说明全连接层是冗余的。【这里注意读论文时要待一个批判性的思想,不要以为写论文的人是大神,因为历史证明了就算是大神的论文也不是百分百正确的】
但是它去掉了第3、4、6、7层时,就是去掉两个卷积层、两个全连接层,错误率达到71.3%一下子上来了,这说明全连接和卷积都是有必要的。但是AlexNet之前设计成的结构并不是最优的模型。
|
Adjust layers 6,7: 2048 units
|
AlexNet是两个2048=4096的数量,它调整成了2048,发现错误率只有一点提升。这说明这么多节点是没有必要的,不是正比的提升。
|
Adjust layers 6,7: 8192 units
|
它调整成了8192.增加了这么多时,精度从增加了这么一点。
接下来调整了自己的模型:Adjust layers 3,4,5:就是三层卷积层,将他们的卷积核设置成512,1024,512 maps。
![]() 上面是原版,是128*2, 192*2, 192*2
上面是原版,是128*2, 192*2, 192*2
所以ZFNet就是改了卷积核数量,对AlexNet进行了小改。
![]()
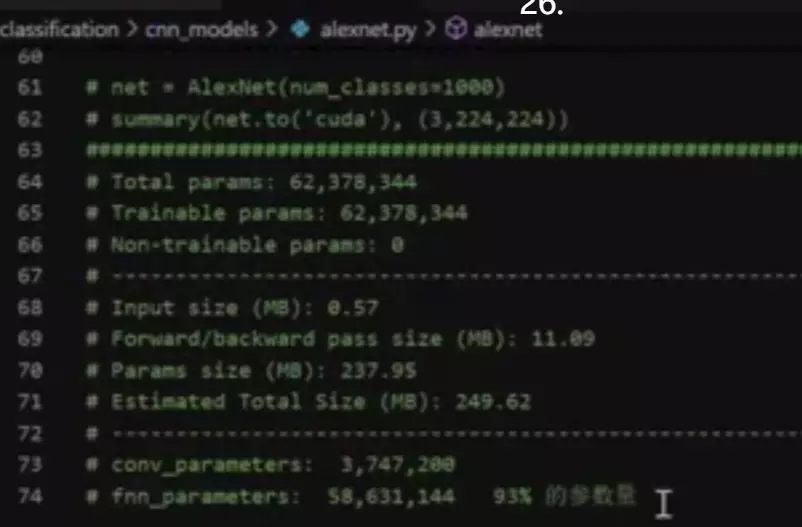
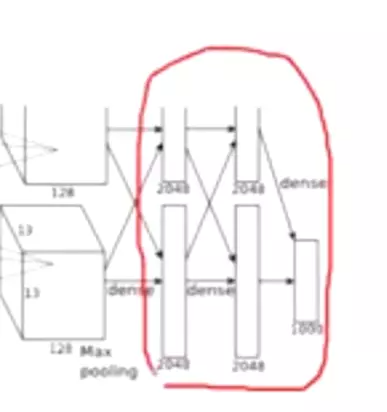
上节课展示的参数:对于AlexNet它的三个全连接占了整个模型93%的参数量,是非常夸张的。所以最后的几层是一个败笔。![]()
![]()
上面是ZFNet的改动。![]()
改动很小,其他的地方是和AlexNet是一样的,所以不讲了。
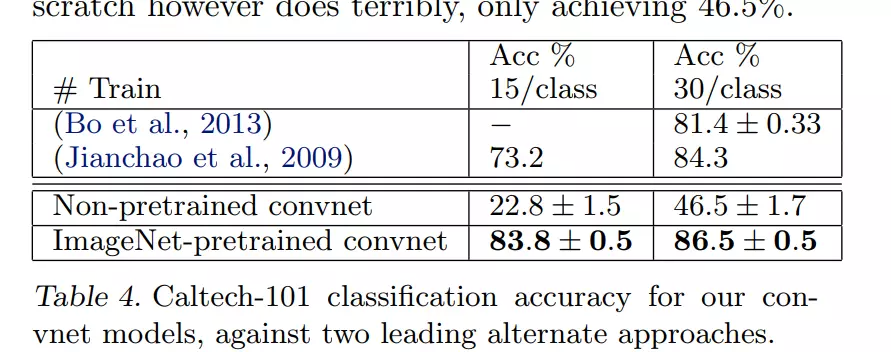
![]() #还有一个图,这个图就是去展示了一下预训练对模型的帮助。这就叫pretrained。预训练就是先在一个数据集上对模型去做训练,将训练好的参数作为模型的初始化参数。没有预训练和有预训练相比,所以说预训练帮助是很大的,尤其是当数据集比较小的情况。 例如每个类别是15个样本分类数据集比每个类别是30个样本小,预训练之后效果提升特别明显。
#还有一个图,这个图就是去展示了一下预训练对模型的帮助。这就叫pretrained。预训练就是先在一个数据集上对模型去做训练,将训练好的参数作为模型的初始化参数。没有预训练和有预训练相比,所以说预训练帮助是很大的,尤其是当数据集比较小的情况。 例如每个类别是15个样本分类数据集比每个类别是30个样本小,预训练之后效果提升特别明显。
![]()
![]()
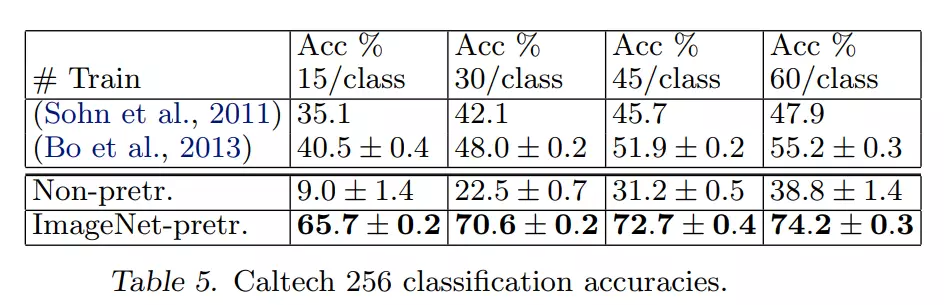
#这张图15、30、45、60说明数据集不断地变大。这说明数据集的不断增大即使不做预训练y模型的准确度也是不断地提到。这说明DeepLearning的三驾马车之一就是数据集的容量,提高后准确率也会提高。![]()
#目标检测方面的实验:还没讲过,先不看。
![]()
![]()
#第五小结特征分析:探究了不同层的特征对我们有什么批判性的帮助。SVM是模型里的分类器,可以根据一些特征对图进行分类。SVM(1)是第一次卷积得到的featuremap作为SVM的输入进行分类。。。发现越高层的卷积对我们模型的分类是有帮助的。
softmax第5层和第7层也是分类。
没了,discussion是第一遍读的。
#文章的第三遍不读了,因为就是实现代码。
#现在又比ZFNet更好的可视化手段,会提供给我们。
![]()
#讲没有讲完的test脚本
![]()
![]()
![]()
![]()
![]()
![]()
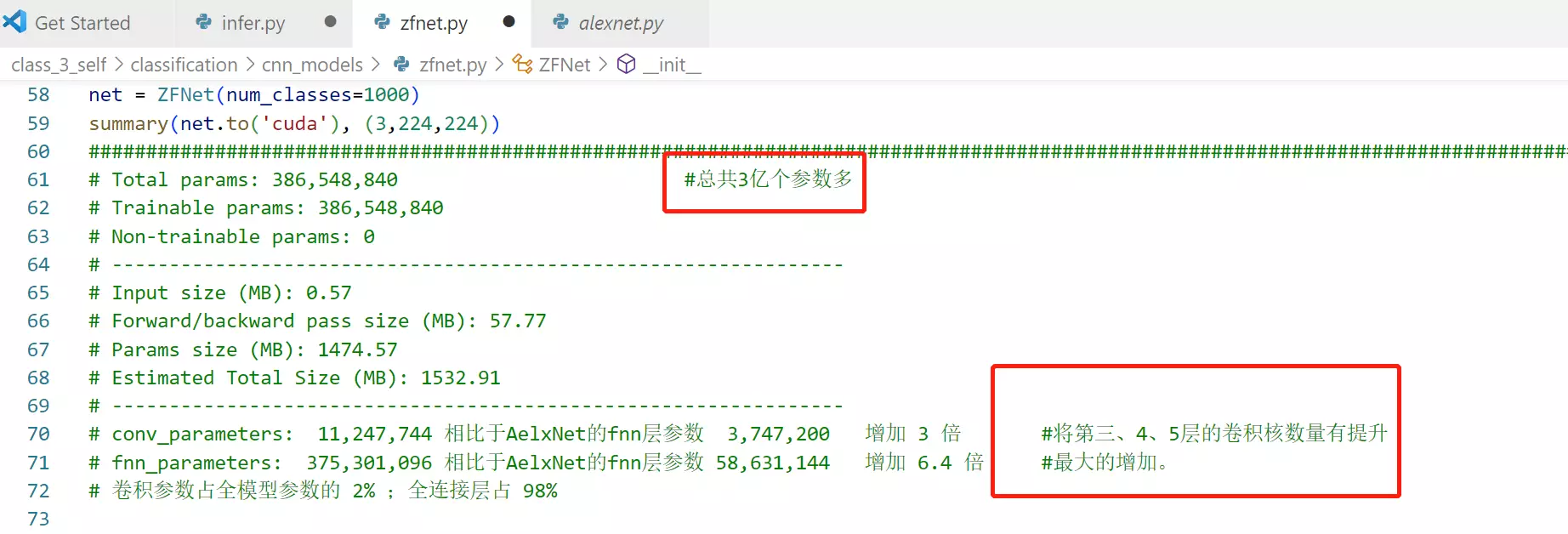
#看ZFNet和AlexNet的对比:
ZFNet是很大的,笔记本这个模型够呛能跑得起来。全连接占了98%,也是一个夸张的占比。在近期的模型很少有这么多的全连接参数了。
![]()
代码在github里,免费下载https://github.com/Arwin-Yu/Deep-Learning-Classification-Models-Based-CNN-or-Attention![]()
train_sample.py必须搞明白。
![]()
![]()
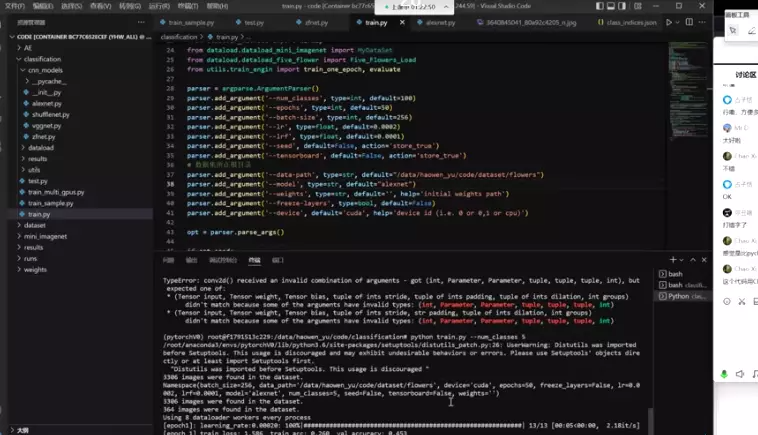
train.py是升级版:
![]()
可以通过
python train.py
![]()
![]()
通过指定模型的超参来实现分类数量。
![]()
![]()
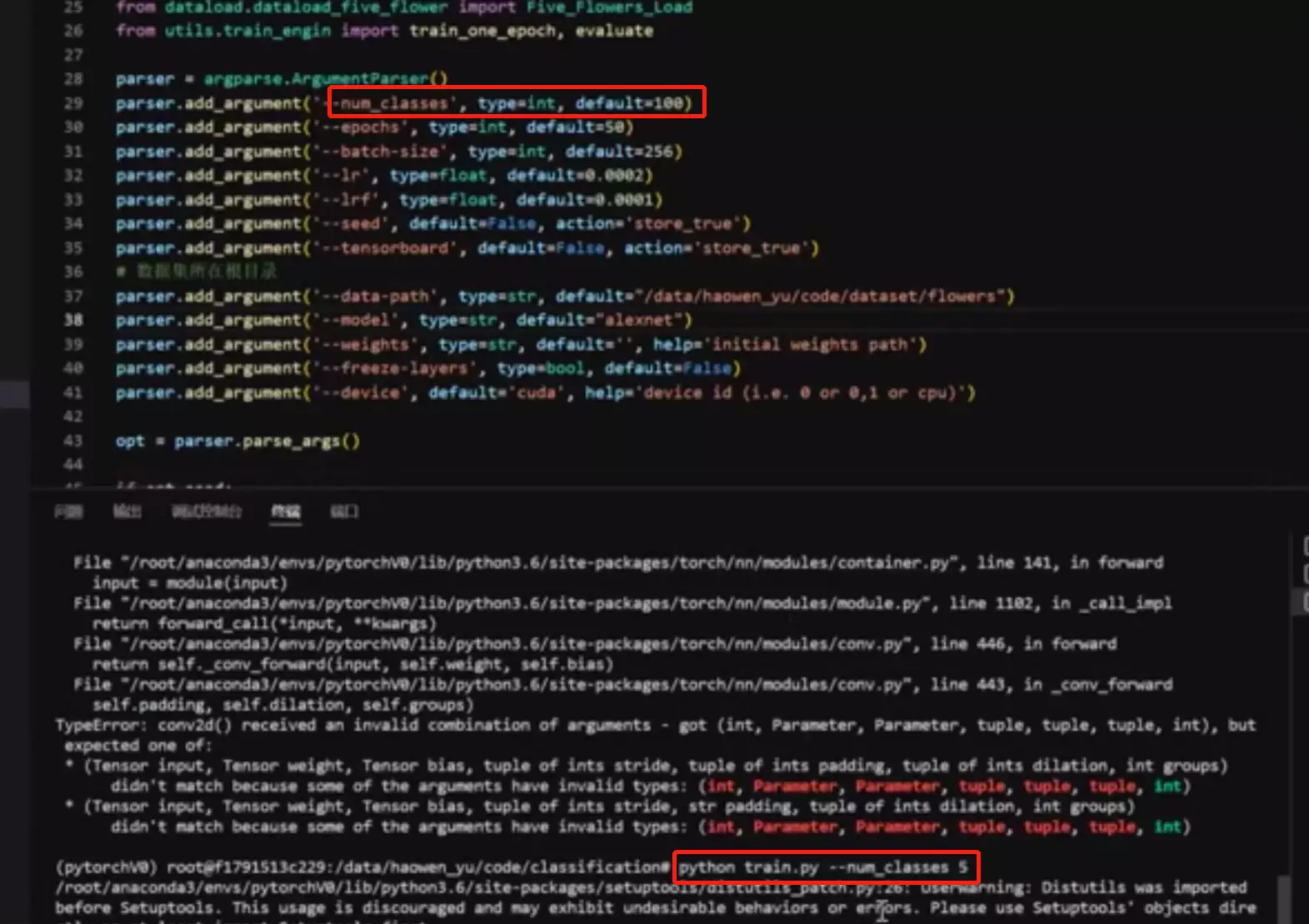
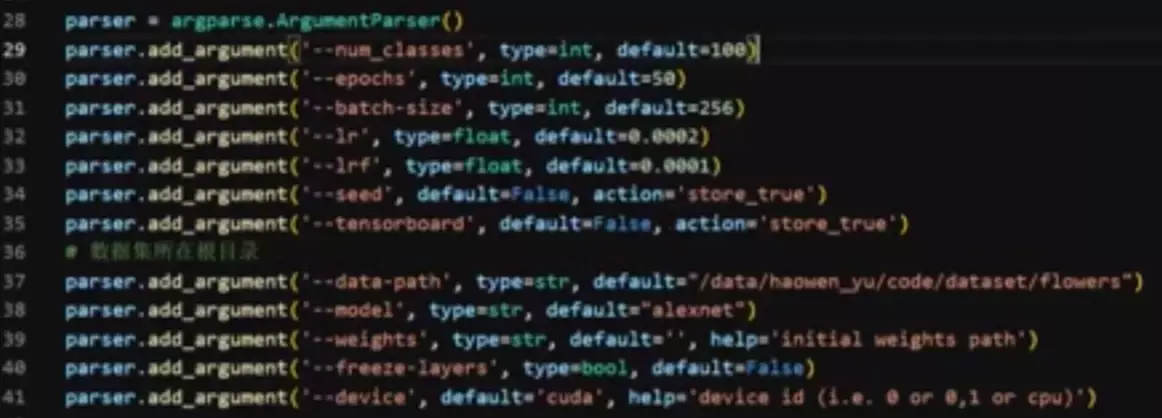
改进1:通过这个方式可以把超参放到前面,然后在命令行里改超参,比较省事和清晰。
![]()
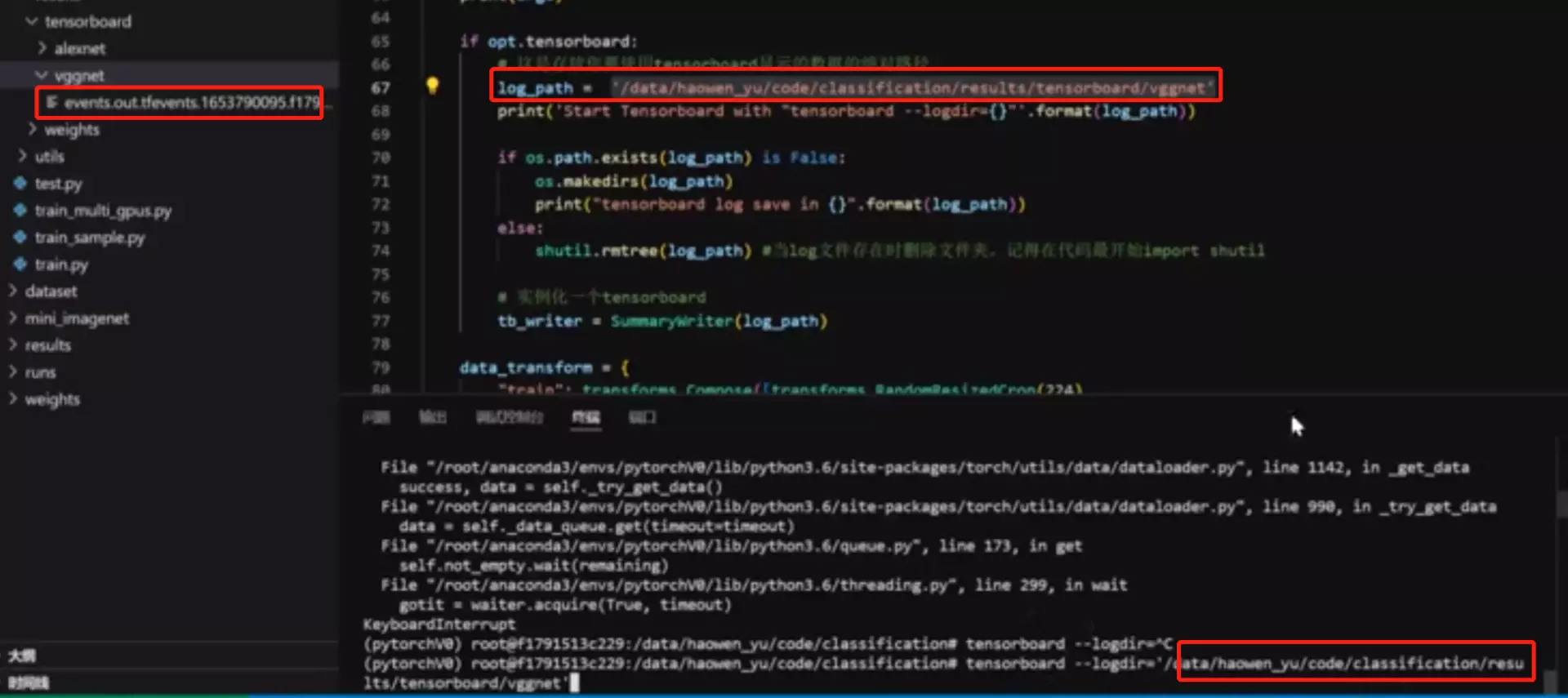
改进2:tensorboard 画图命令行
改进3:随着训练轮数递减的学习策略。刚开始lr=0.0002逐渐衰减到0.0001,这种策略可以帮助网络提升大概6-7个百分点
。
![]()
这个是升级版的train脚本.
#注:已下载。待训练--待学习
![]()
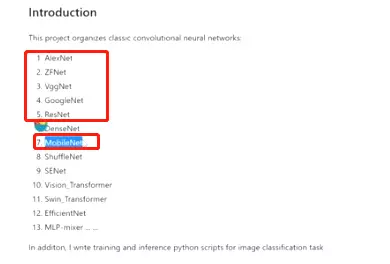
会将前五个和第7个mobilenet,其他的感兴趣可以自己去学!!









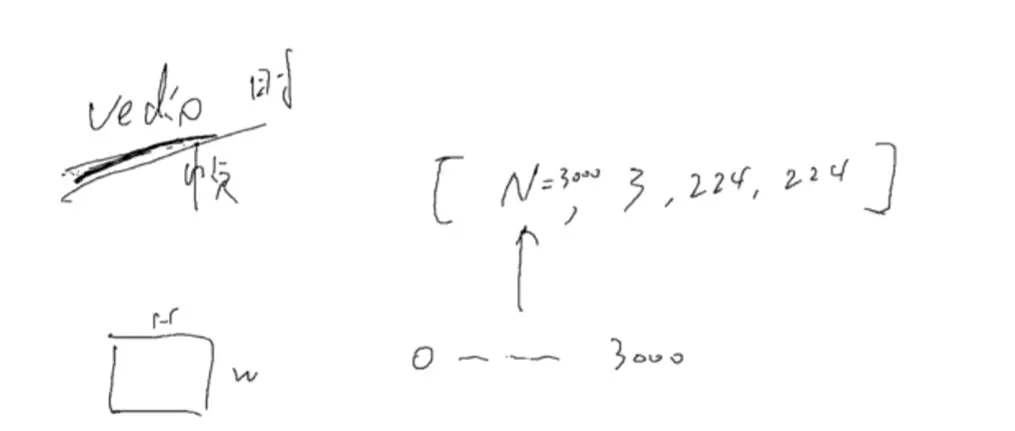










































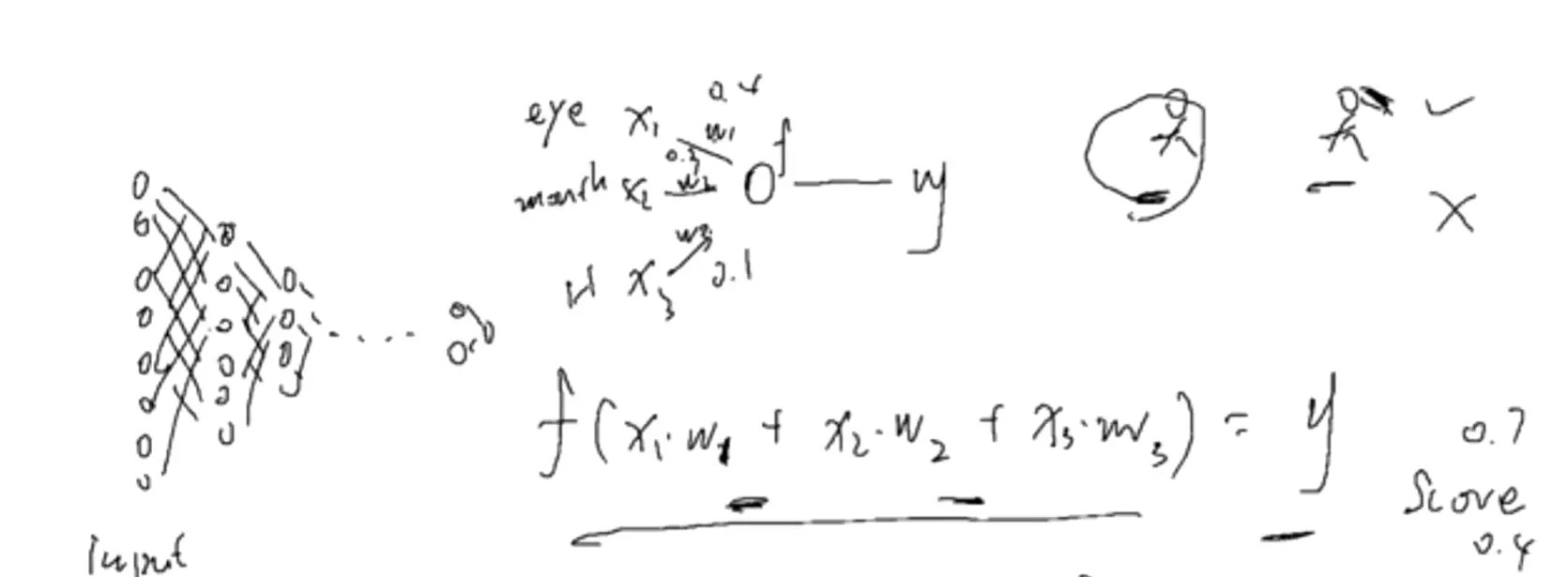
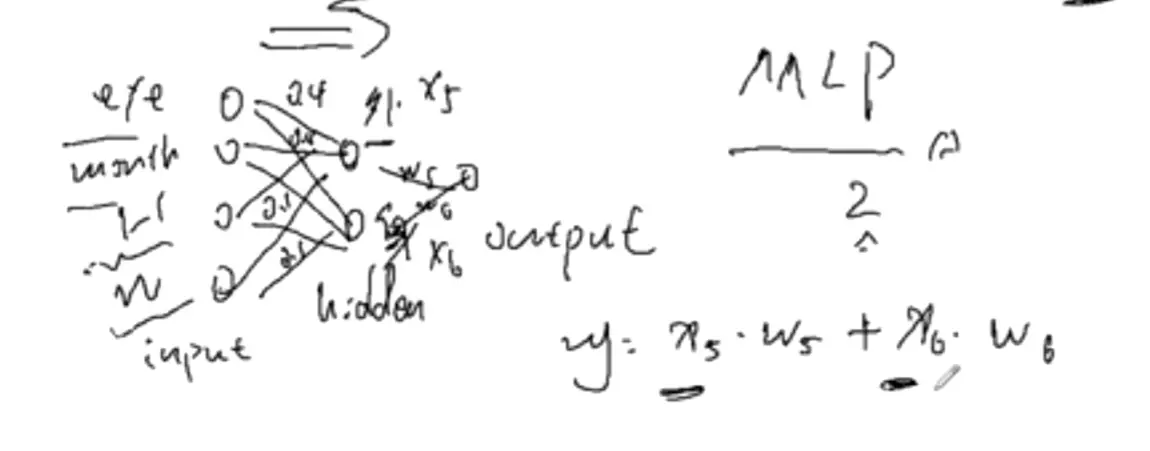





















































 全连接神经网络-卷积神经网络-------
全连接神经网络-卷积神经网络-------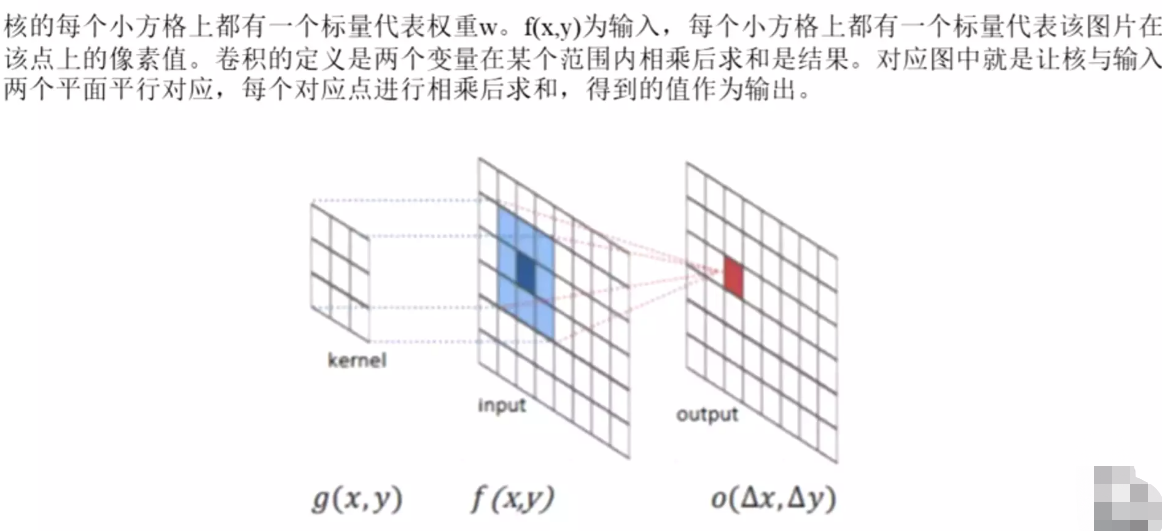

























































 维度变化
维度变化






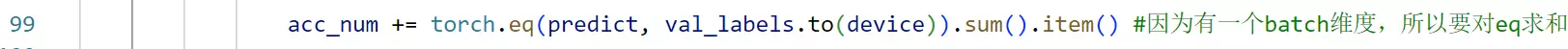










 权重文件就是.pth的文件
权重文件就是.pth的文件
 5个分类的概率。
5个分类的概率。


 ,因为有默认值
,因为有默认值
 这两行会自动给图像和标签打包
这两行会自动给图像和标签打包

 70step就是用enumerate取到的step
70step就是用enumerate取到的step


















 会增大图像的尺寸!!!·
会增大图像的尺寸!!!·






 layer1 左上这个图不是feature map 它每一个小图是feature map映射回原始空间后的样子。这里取卷积核输出里最大的9张拼成一张小图,然后将9张图重新映射回像素空间
layer1 左上这个图不是feature map 它每一个小图是feature map映射回原始空间后的样子。这里取卷积核输出里最大的9张拼成一张小图,然后将9张图重新映射回像素空间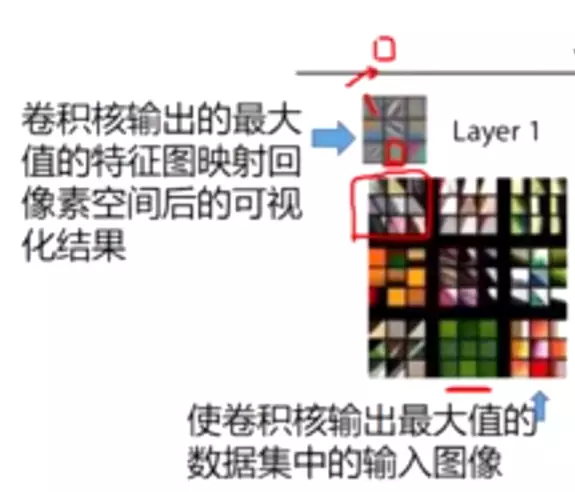








 这张图说明图像在平移到中间时效果比较好。
这张图说明图像在平移到中间时效果比较好。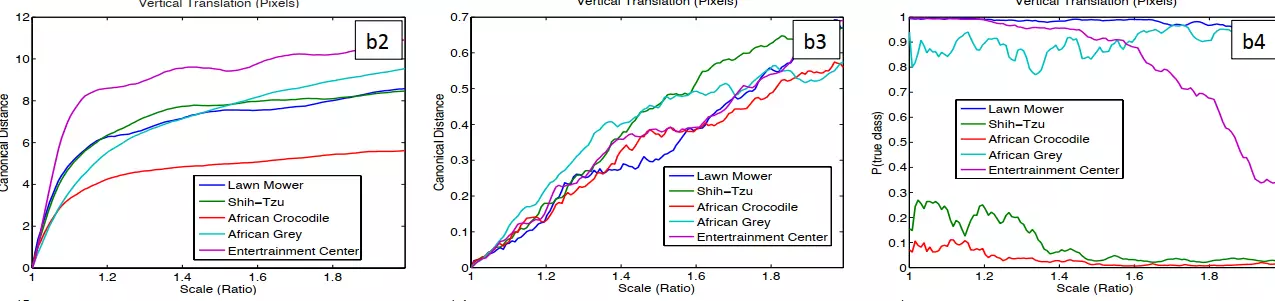



















 结合下面的表:
结合下面的表: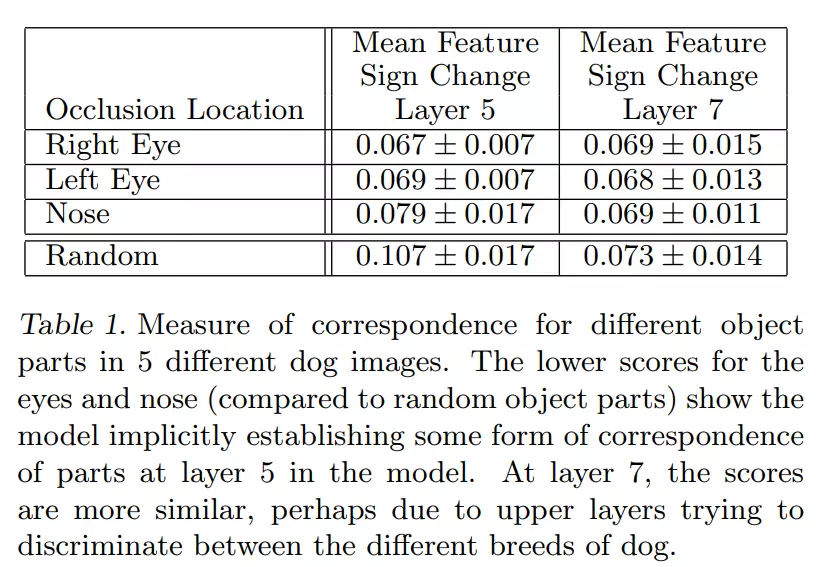











 浙公网安备 33010602011771号
浙公网安备 33010602011771号