


通过cookies跳过验证码登陆页面,直接访问网站的其它URL
之前写过一篇博客:自动化测试如何解决验证码的问题。
介绍了验证码的几种处理方式,最后一种就是通过Cookie跳转过验证码,但讲的不够详细。今天,就详细的介绍一下这种方式。
准备工具:
------------------
fiddler
Python+selenium
------------------
以百度登录为例。
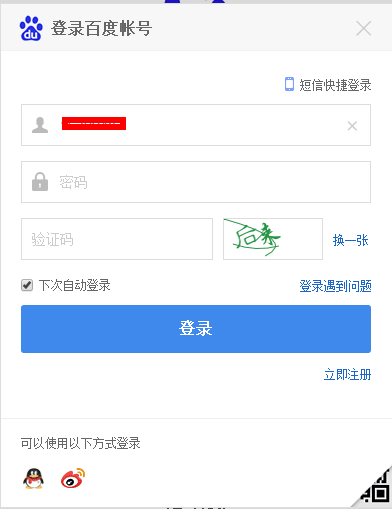
验证码是汉字的,我想通过程序识别起来有点难度,也会比较麻烦。
接下来开始动手。
1、开启Fiddler 工具,像这样!

2、通过浏览器登录正常登录百度账号。像这样!

3、通过Fiddler获取登录请求的Cookie。找到Host为“passport.baidu.com”的URL,在右侧窗口查看该请求的Cookie。

然后,找到重要的两个参数“BAIDUID”和“BDUSS”。
4、编写Selenium自动化测试脚本,跳过登录。

from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 添加Cookie
driver.add_cookie({'name':'BAIDUID','value':'AAAAAAAAAAAAAA:FG=1'})
driver.add_cookie({'name':'BDUSS','value':'AAAAAAAAAAAAAAAAAAAAAAAAAA'})
# 刷新页面
driver.refresh()
# 获取登录用户名并打印
username = driver.find_element_by_class_name("user-name").text
print(username)
#关闭浏览器
driver.quit()
首先,访问百度首页,处于未登录状态。
然后,通过Selenium所提供add_cookie()方法添加Cookie信息。
最后,刷新页面,现在已经是登录状态了,获取登录之后的用户名并打印。
可取到NN网的cookies之后,分不出哪两个是重要的参数,干脆就全部参数添加到cookies里面了,这样居然可以了。
但另一个问题出了,Firefox崩溃了,如下图
plugin container for firefox
转载链接:https://jingyan.baidu.com/article/3aed632e21d2c0701180916c.html
plugin-container引发火狐浏览器崩溃的解决方案
火狐浏览器是用户常用的浏览器之一,在使用过程中应该有用户遇到过plugin-container.exe异常导致的浏览器崩溃,这种崩溃往往是由Flash造成的。本文介绍一种解决方案,希望对需要的同学有所帮助,也希望可以交流其他更好的手段。
方法/步骤
-
我们先来看一下plugin-container.exe导致的异常信息:
![plugin-container引发火狐浏览器崩溃的解决方案]()
-
打开“我的电脑"->C盘->Program Files->Mozilla Firefox,知道到plugin-container.exe,并将该文件删除:
![plugin-container引发火狐浏览器崩溃的解决方案]()
-
关闭火狐浏览器并重启浏览器,这时候一般就能解决这种崩溃,但是为了从根本上避免,我们还需要修改浏览器配置。
![plugin-container引发火狐浏览器崩溃的解决方案]()
-
我们继续操作,在Firefox浏览器地址栏输入 about:config并回车:
![plugin-container引发火狐浏览器崩溃的解决方案]()
-
在搜索框中输入dom.ipc.plugins.enabled,找到“dom.ipc.plugins.flash.subprocess.crashreporter.enabled”将该值设置为false:
![plugin-container引发火狐浏览器崩溃的解决方案]()
-
到此就结束了
至此,通过cookies跳过验证码登陆页面,访问网站的其它URL就实现了。好开心………
可以改进的1)添加cookies参数较多,完全可以用脚本自动添加的,我一个一个复制粘贴的,效率低下。下次改进。
20230306
最近写了一个UI自动化的脚本,目的是提配我自考报名,用cookie跳过验证码登陆的方法,第一天晚上还行,第七天运行时,cookie过期了,就不能登陆了。这个脚本是要长期定时任务跑的,所以不适合用cookie跳过验证码登陆的方法。
跳过验证法有四种方法:
1. 添加cookie
2. 万能验证码
3. 验证码识别技术-tesseract、
4. 测试环境去掉验证码
我现在选择第三种方法:
准备条件
tesseract,下载地址:https://github.com/parrot-office/tesseract/releases/tag/3.5.1
python3.x,下载地址:https://www.python.org/downloads/
pillow(python3图像处理库)
安装好Python,通过pip install pillow安装pillow库。然后将tesseract中的tesseract.exe和testdata文件夹放到测试脚本所在目录下,testdata中默认有eng.traineddata和osd.traineddata,如果要识别汉语,请自行下载对应包。
以下是两个主要文件,TesseractPy3.py是通过python代码去调用tesseract以达到识别验证码的效果。code.py是通过selenium获取验证码图片,进而使用TesseractPy3中的函数得到验证码,实现网站的自动化登陆。
cmd命令行中:
F:\Program Files (x86)\Tesseract-OCR>tesseract F:\testProject\examination_warning\code.png output -l eng
Estimating resolution as 278
这样会要当前目录下生成一个output.txt文件,打开后还真的取出验证码是5pa2。
F:\Program Files (x86)\Tesseract-OCR>type output.txt
5pa2
终于成功了,部分代码如下:
from datetime import datetime
import time
from selenium import webdriver
from PIL import Image
import pytesseractdef img_to_str():
# 打开切出的验证码code.png
img = Image.open('code.png')
# 利用pytesseract识别出验证码
# -psm 8 为识别模式
# -c tessedit_char_whitelist=1234567890 的意思是 识别纯数字(0-9)
#code = pytesseract.image_to_string(img, config='-psm 8 -c tessedit_char_whitelist=1234567890')
config = r'-l chi_sim+eng --psm 6'
code = pytesseract.image_to_string(img,config=config)
print('验证码识别:{}'.format(code))
return code# 打开目标网站,并截取完整的图片
driver.get_screenshot_as_file('login.png')
# 找到输入账号的input,并输入账号
driver.find_element_by_xpath('//input[@name="xxxxx"]').send_keys('xxxxxxx')
# 找到输入密码的input,并输入密码
driver.find_element_by_xpath('//input[@name="xxxx"]').send_keys('xxxxxxx')
# 找到验证码img标签,切图
img_code = driver.find_element_by_xpath("//img[@id='xxxxx' and @alt='验证码']")
time.sleep(3)
# 算出验证码的四个点,即验证码四个角的坐标地址
left = img_code.location['x']
top = img_code.location['y']
right = img_code.location['x'] + img_code.size['width']
bottom = img_code.location['y'] + img_code.size['height']
print("验证码坐标::", left, top, right, bottom)
# 利用python的PIL图片处理库,利用坐标,切出验证码的图
im = Image.open('login.png')
im = im.crop((left, top, right, bottom))
im.save('code.png')
# 调用图片识别的函数,得到验证码
code = img_to_str()
# 找到验证码的input,并输入验证码
driver.find_element_by_xpath('//input[@name="xxxxxx"]').send_keys(code)
# 点击登录按钮
driver.find_element_by_xpath('//button[@onclick="login()" and text()="登录"]').click()
time.sleep(2)
问题又来了,有时遇到英文字母多的时候,由于验证码图片的分辩率低,所以就不能一次识别正确,本想导入CV2对验证码图片做灰度处理,但不知道安装哪个包
,最后python3.6下装的opencv-python。后来才找到正确的包是:
但在这之前,突然想到一个好的方法,一次识别不成功,再让它重新识别一次,开循环直至识别正确登陆进去为止,好方法。哈哈哈。成功了。
最后写了一个bat文件,将其加入开机自动中。@echo off
::start
f:echo *******runing exam_warning*******
cd ./
C:\Users\a\AppData\Local\Programs\Python\Python39\python.exe F:/testProject/examination_warning/main.py::sleep 8s
ping 127.0.0.1 -n 8::pause
exitwin10中开机自启动bat文件。
win+R -------》 shell:startup--------》 在启动文件夹下创建快捷方式指向写好的 bat文件即可。
大功告成,很开心。!!!
20230321由于我经常使用chatGPT,需要开启代理,导致有时候开机时,浏览器的代理是开着的,这里为了脚本的健壮性,需要增加浏览器代理是否开着的判断,如果开关就自行关闭了。
导下下面两个库就可以实现。import ctypes #和C混合编程
import winreg #操作注册表def set_key(self, name, value): # 修改键值 # 如果从来没有开过代理 有可能健不存在 会报错 INTERNET_SETTINGS = winreg.OpenKey(winreg.HKEY_CURRENT_USER, r'Software\Microsoft\Windows\CurrentVersion\Internet Settings', 0, winreg.KEY_ALL_ACCESS) _, reg_type = winreg.QueryValueEx(INTERNET_SETTINGS, name) winreg.SetValueEx(INTERNET_SETTINGS, name, 0, reg_type, value) def setBrowse(self): # 设置刷新 INTERNET_OPTION_REFRESH = 37 INTERNET_OPTION_SETTINGS_CHANGED = 39 internet_set_option = ctypes.windll.Wininet.InternetSetOptionW # 启用代理 self.set_key('ProxyEnable', 1) # 启用 self.set_key('ProxyOverride', u'*.local;<local>') # 绕过本地 self.set_key('ProxyServer', u'127.0.0.1:8080') # 代理IP及端口 internet_set_option(0, INTERNET_OPTION_REFRESH, 0, 0) internet_set_option(0, INTERNET_OPTION_SETTINGS_CHANGED, 0, 0) print("已启用代理,可点击查看") time.sleep(5) # 停用代理 self.set_key('ProxyEnable', 0) # 停用 internet_set_option(0, INTERNET_OPTION_REFRESH, 0, 0) internet_set_option(0, INTERNET_OPTION_SETTINGS_CHANGED, 0, 0) print("已关闭代理,可点击查看")






 浙公网安备 33010602011771号
浙公网安备 33010602011771号