
MySQL高级(上)
- MySQL 配置文件
- MySQL表结构及数据存储的位置
- MySQL常用命令
- MySQL逻辑架构简述
- SQL执行流程(以MySQL5.7为例)
- 数据库缓存池BufferPool
- 存储引擎(表处理器,表的类型)
- 索引(面试高频区)
- 为什么要使用索引?
- 索引的优点
- 索引的缺点
- 使用索引的小技巧
- 索引的数据结构(B+Tree)
- 常见索引概念
- InnoDB的B+Tree索引结构注意事项
- MyISAM中的索引方案
- InnoDB和MyISAM关于索引的对比
- 索引的代价
- hash结构的查找效率很高(尤其是等值查询),为什么InnoDB没有使用hash结构,而是使用树结构呢?
- InnDB本身不支持Hash索引,但提供自适应Hash
- InnoDB索引结构的选择演变
- 思考题:为了减少IO,索引树会一次性加载吗?
- 思考题:B+Tree的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO?
- 思考题: 为什么B+Tree比B-Tree更适合操作系统中文件索引和数据库索引?
- B+Tree和哈希索引的区别?
- 了解R树--优势在于范围查找
- InnoDB的数据存储结构
MySQL 配置文件
Windows环境 my.ini
Linux 环境 my.cnf
MySQL表结构及数据存储的位置
- InnoDB
- MySQL5.7
table_name.frm 结构
table_name.ibd 数据 - MySQL8.0
table_name.ibd 结构、数据及索引
- MySQL5.7
- MyISAM
- MySQL5.7
table_name.frm 结构
table_name.MYD 数据
table_name.MYI 索引 - MySQL8.0
table_name-363.sdi 结构
table_name.MYD 数据
table_name.MYI 索引
- MySQL5.7
MySQL常用命令
- 登录MySQL服务器
mysql -h hostname|hostIP -P port(默认3306) -u username -p DatabaseName -e "SQL语句"
简写
mysql -uusername -p - 查看当前服务器所有用户
select host,user form user - 用户管理
- 创建用户
create user 'username' @'hostname|hostIP(默认是%所有ip都可登录)' identified by 'password' - 删除用户
drop user 'user1,user2...'
也可以这样删除,但是不推荐,因为会有残留信息保留(比如用户权限)
delete form user where user='username' and @='hostName' - 修改当前用户密码
alter user user() identified by 'new_pwd'
或者
set password = 'new_pwd' - 修改其他用户的密码(修改者需要有对应权限,一般为root用户)
alter user 'user_name'@'host_name' identified by 'new_pwd'
或者
set password for 'user_name'@'hostname'='new_pwd'
- 创建用户
- 权限管理
- 添加权限(没有对应的用户会新建用户)
grant 权限1,权限2.. on database_name.table_name to user_name@hostName [identified by 'pwd']
授予某用户所有库有表的全部权限(select、update..)
grant all privileges on *.* to user1@'%'identified by '123456' - 收回权限
revoke 权限1,权限2.. on database_name.table_name from user_name@'用户地址'
收回全库全表的所有权限
revoke all privileges on *.* from user1@'%' - 查看权限
show grants
show grants for current_user
show grants for current_user()
查看某用户全局权限
show grants for 'user_name'@'主机地址'
- 添加权限(没有对应的用户会新建用户)
MySQL逻辑架构简述
- 连接层:客户端服务端建立连接,客户端发送SQL到服务器端。有连接池。
- 服务层(SQL层):对SQL语句进行处理。有SQL接口、解析器、优化器、缓存(8.0以后移除,原因:命中率低、存在脏数据、数据不准确)。
- 存储引擎层:有数据库文件交互,负责数据的存取。有MyIASM、InnoDB、CSV...
SQL执行流程(以MySQL5.7为例)
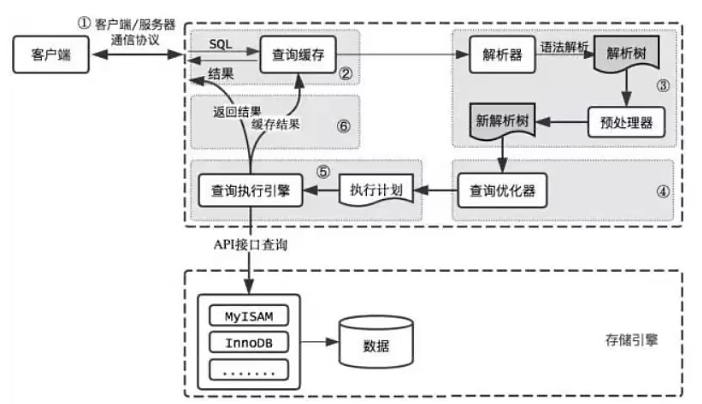

数据库缓存池BufferPool
解决访问数据时,磁盘速度与CPU速度不匹配的问题。在InnoDB存储引擎中,有部分数据会放到内存中,而缓存池则占用了这部分内存的大部分。当访问磁盘中的某个页(16KB)的数据时,将整页数据加载在缓存池中,在读取完成后将其缓存起来。但缓存池的大小是有限的,所以会优先对使用频次高的热数据进行加载。当我们执行更新操作时,并不会把数据马上同步到磁盘上,而是先更新缓存池中的数据,然后数据库以一定频率刷新到磁盘上,并不是每次更新都立刻回写磁盘。
存储引擎(表处理器,表的类型)
接收服务层(SQL层)传下来的指令(SQL执行计划),对表中的数据进行提取或写入操作。存储引擎决定着底层存储的文件的物理结构。
- InnoDB
- mysql 8.0默认存储引擎。
- 支持事务及分布式事务(崩溃后可以安全恢复),支持外键功能。
- 针对数据量和并发量更大及有很多更新、删除操作的表性能更优。
- 支持行锁。
- 缓存索引和数据,对内存要求较高,内存大小对性能有决定性影响。
- 缺点:写操作的处理效率差一些,会占用更多磁盘空间;由于不仅要缓存索引,还要缓存数据,所以对内存要求更高。
- MyISAM
- mysql 5.5之前默认存储引擎。
- 不支持事务(崩溃后不能安全恢复)和外键。
- 针对数据量小及大部分操作是增加、查询的表性能更优。
- 支持表锁。
- 只缓存索引。
- 优点:访问速度快;查询count(*)效率很高(针对数据统计有额外的常数存储);节省资源,消耗少。
- 应用场景:只读应用或者以读为主的业务。
- Archive 数据存档引擎,只支持插入和查询,有压缩机制。
- CSV 可作为一种数据交换机制,以逗号分隔各个数据项,不支持空列,xxx.csv可以直接用文本编辑器或excel读取。
- Memory 是基于内存的表,结构存储在磁盘,数据存储在内存,只能支持长度不变的数据格式,表的大小是基于参数设置受到限制的。使用哈希索引(默认)和B+Tree索引。虽然查询速度快,但是数据易丢失。
- NDB 主要应用于分布式集群环境。
- 补充:阿里巴巴使用自建存储引擎Xtradb.
索引(面试高频区)
索引是存储引擎用于快速找到数据记录的一种数据结构(排好序的),索引是在存储引擎中实现的,存储引擎还可以定义每个表的最大索引数(每个表最少16索引)和最大索引长度(每个表总索引长度至少为256字节),所以不同的存储引擎使用的索引结构可能不相同,这里以InnoDB使用的索引为例,InnoDB默认使用B+Tree索引。
为什么要使用索引?
不使用索引需要全表扫描,一条一条的比对数据,耗时长(O(n));
而使用索引可以有效减少磁盘I/O的次数,加快查询速率。
索引的优点
- 提高数据检索效率,降低数据库I/O成本。
- 创建唯一索引可以保证表中每一行数据的唯一性(参考唯一约束)。
- 数据的参考完整性方面,可以加速表和表之间的连接:对于有依赖关系的子表和父表联合查询时,可以提高查询速度。(参考外键)
- 在使用分组和排序子句进行查询时,可以显著减少分组和排序时间,降低CPU功耗。
索引的缺点
- 创建索引和维护索引要耗费时间,数据量越多,耗费的时间越多。
- 索引需要占据磁盘空间,如果有大量索引,索引文件就可能比数据文件更快达到最大尺寸文件。
- 会降低更新表的速度,当对表进行增删改操作时,索引也要动态维护,这样会降低数据的维护速度。
使用索引的小技巧
由于使用索引会影响插入记录的速率,这种情况下可以先删除表中索引,然后插入数据,插入完成后再创建索引。
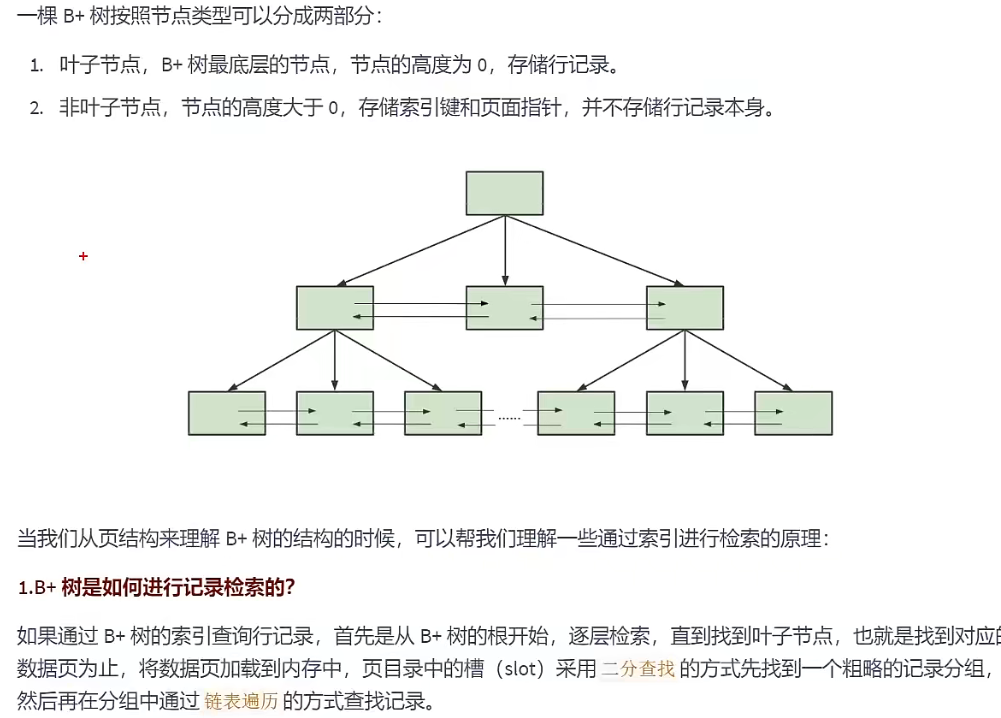
索引的数据结构(B+Tree)
-
索引单节点数据意义
![Compact行格式存储实际记录]()
![索引结构]()
![基本数据页模型]()
-
B+Tree的第3代迭代模型
![B+Tree迭代模型]()
-
一般情况下,我们用到的B+Tree的层次都不会超过4层?
![为什么B+Tree层次一般不会超过4层?]()
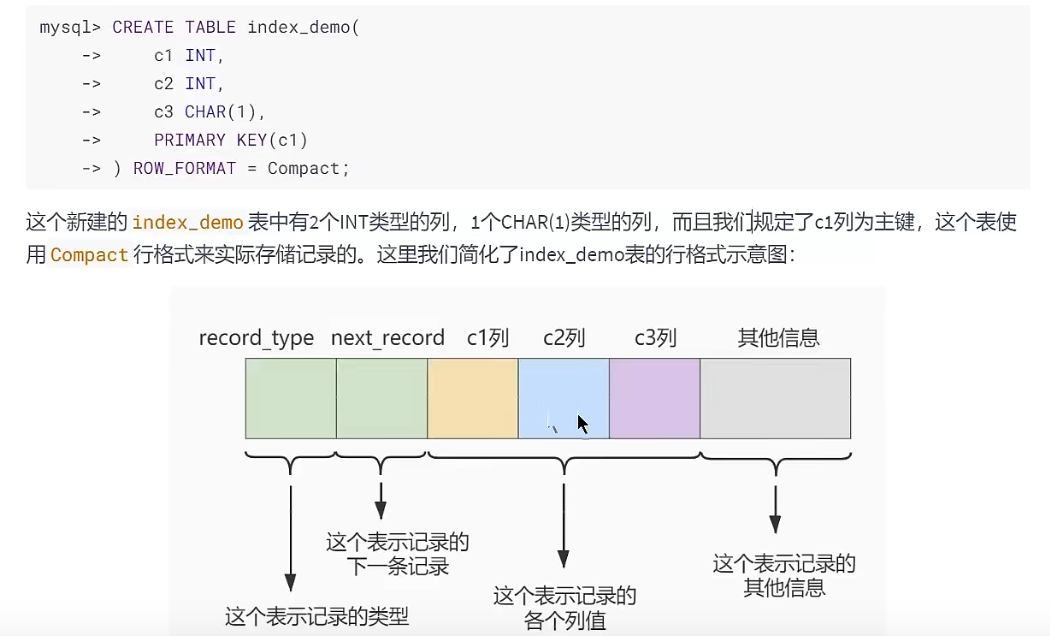
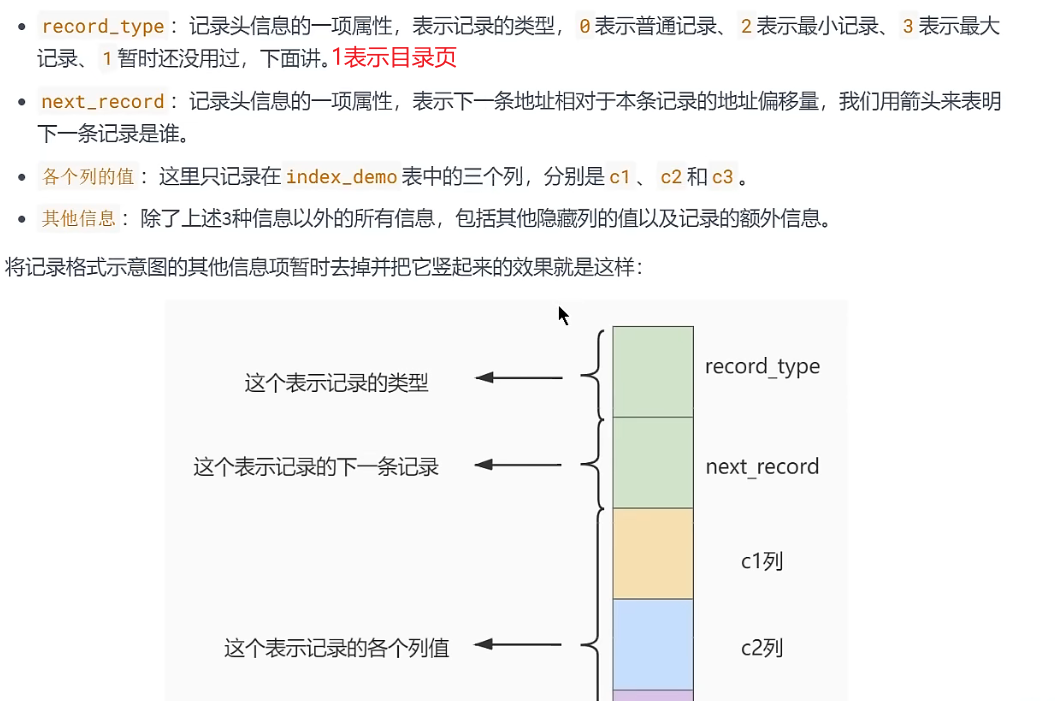
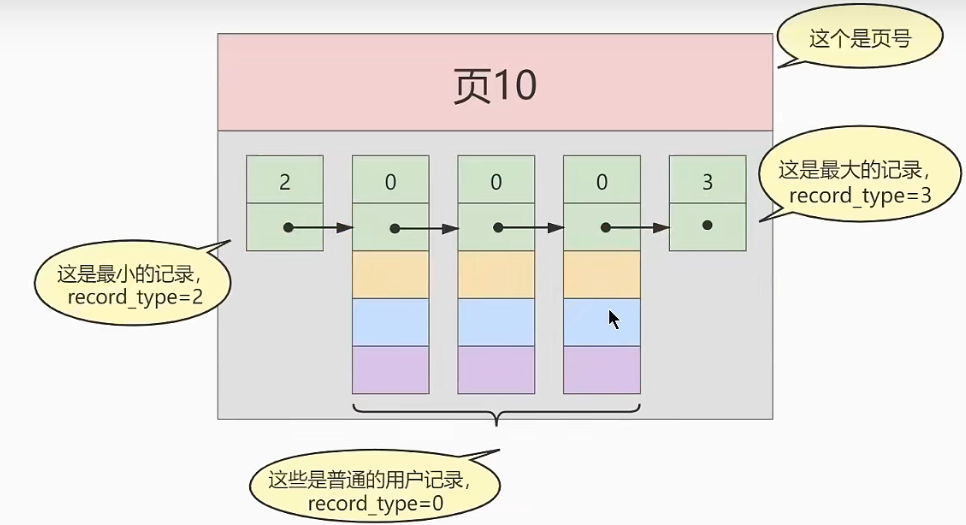
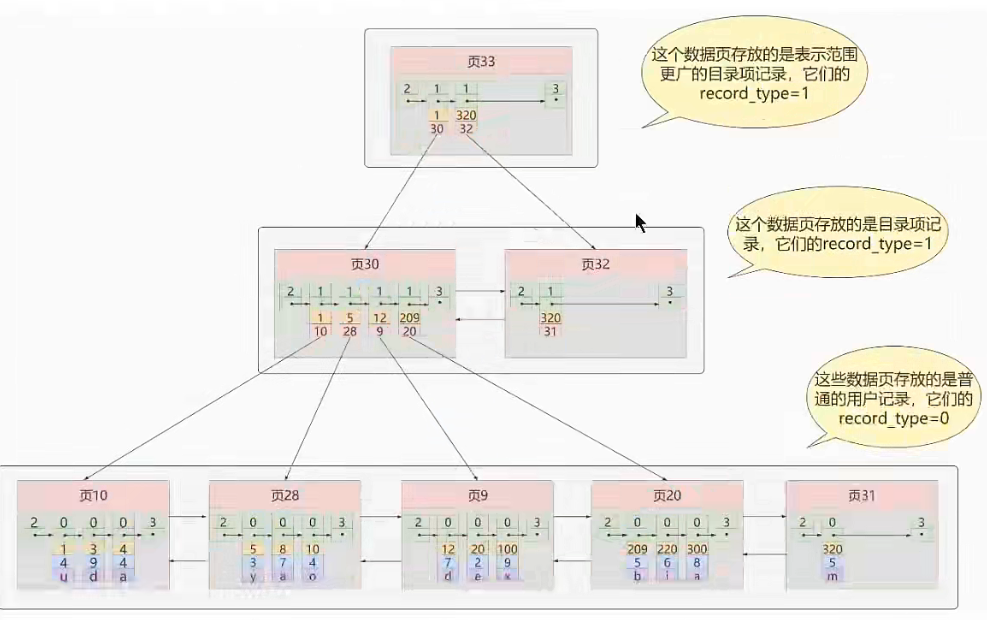

常见索引概念
-
聚簇索引 索引和数据存储在一起, 针对主键创建的索引。是一种数据存储方式,用户记录存储在叶子节点,索引即数据,数据即索引。不需要显示的创建改索引,InnoDB引擎会自动创建该类索引。
- 优点
- 比较非聚簇索引来说,数据访问更快。因为数据和索引在同一B+树,不需要回表。
- 对于主键的排序查找和范围查找速度非常快。
- 节省大量IO操作,因为按聚簇索引排列顺序,查询显示一定范围数据时,数据都是紧密相连,不用从多个数据块中提取数据,
- 缺点
![缺点]()
- 限制
![限制]()
- 优点
-
非聚簇索引 针对非主键列创建的索引,也称二级索引,辅助索引。表中不是完整的记录,叶子结点是记录主键的值和二级索引的值。
![非聚簇索引]()
-
联合索引 两列或两列以上组合成一个索引,叶子节点存储两列的值及主键的值,也属于非聚簇索引。
![联合索引]()


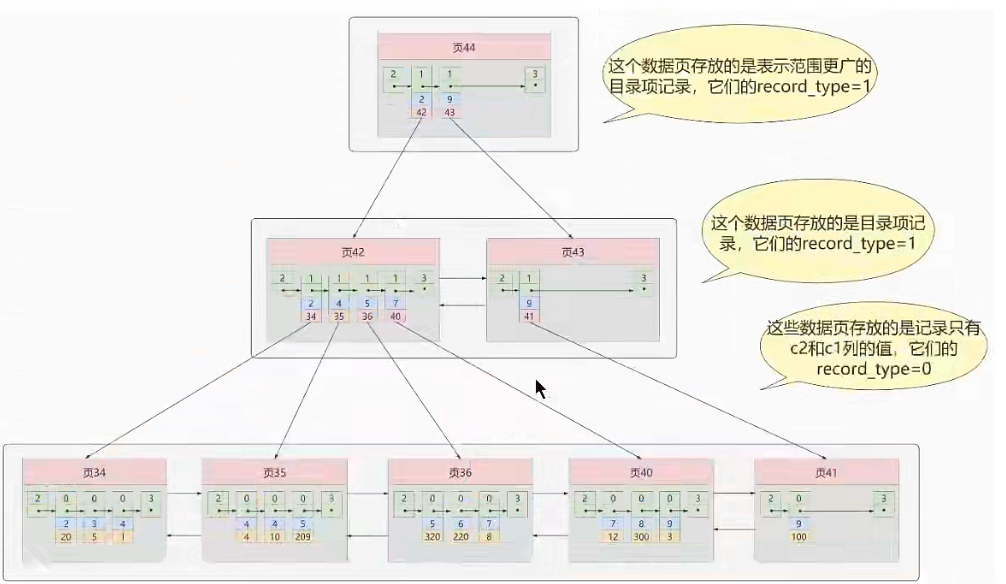
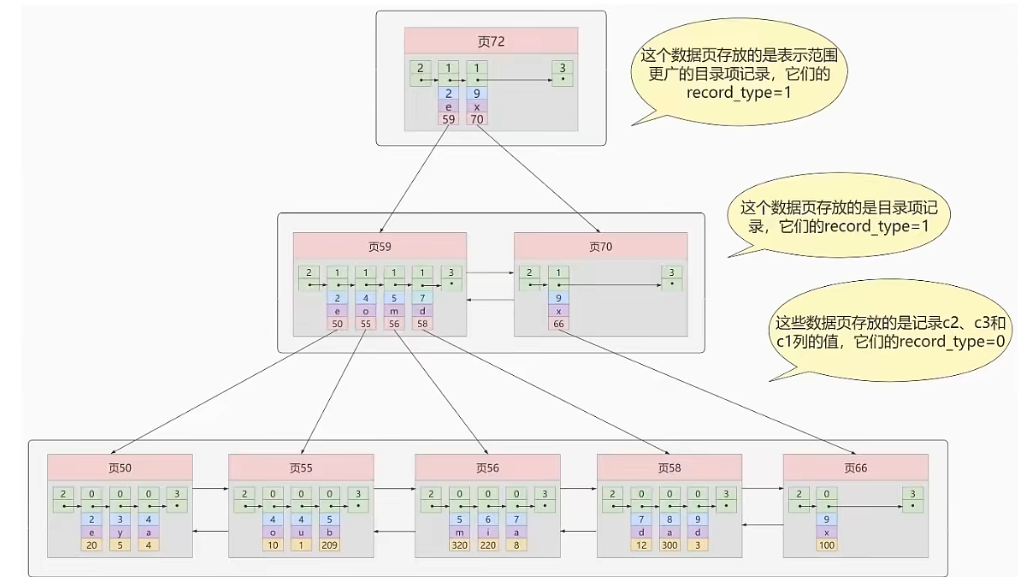
InnoDB的B+Tree索引结构注意事项
- 根页面位置不动,即实际存储时,根节点是叶子节点,存储数据,当数据越来越多时,根节点将数据复制一份作为叶子节点,根节点作为目录节点,以此类推,实际是由上而下的创建的方式。
- 内节点(非叶子节点)中目录项记录要保证唯一性,在实际存储时,当以非主键列创建索引时,会将主键列也存储在对应的内节点中,以保证其唯一性,便于查询时做比较。
- 一个页面最少存储2条记录,若只放一个,目录层级会非常多。
MyISAM中的索引方案
MyISAM使用B+Tree作为索引结构,叶子节点的data域存放数据记录的地址。数据及索引是分开存储的,即没有聚簇索引,都是二级索引。
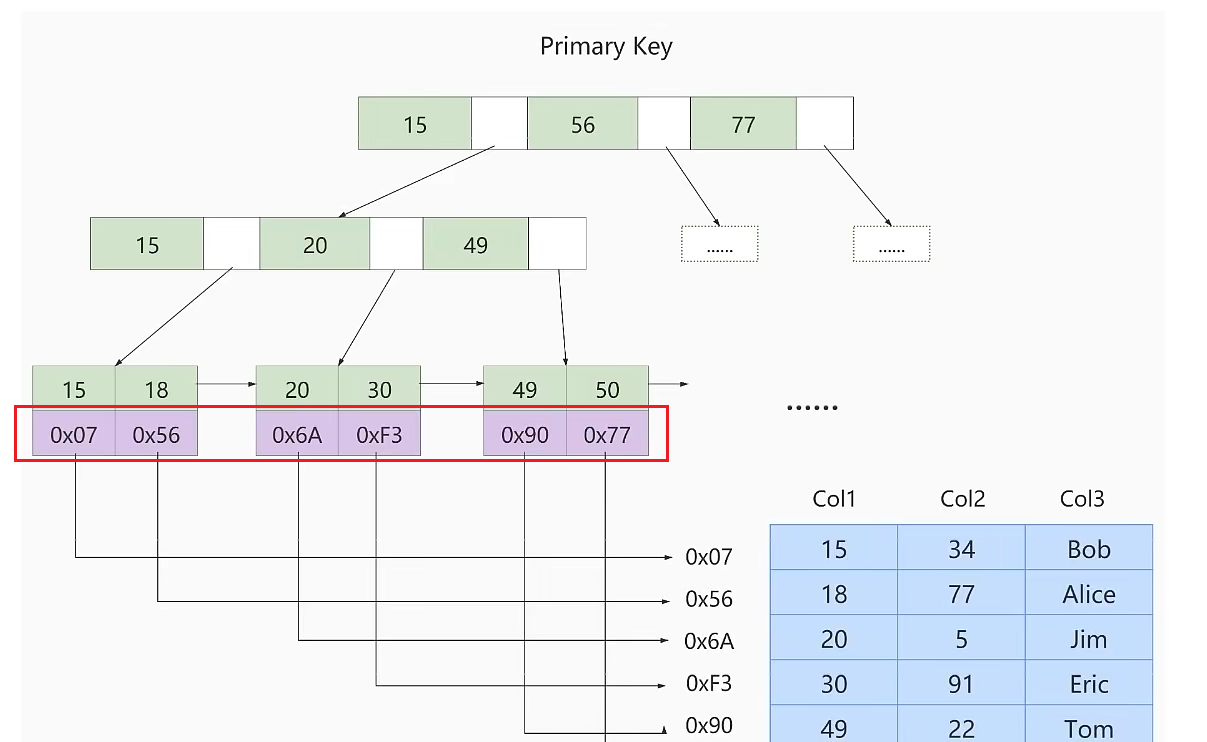
InnoDB和MyISAM关于索引的对比

索引的代价

hash结构的查找效率很高(尤其是等值查询),为什么InnoDB没有使用hash结构,而是使用树结构呢?

InnDB本身不支持Hash索引,但提供自适应Hash
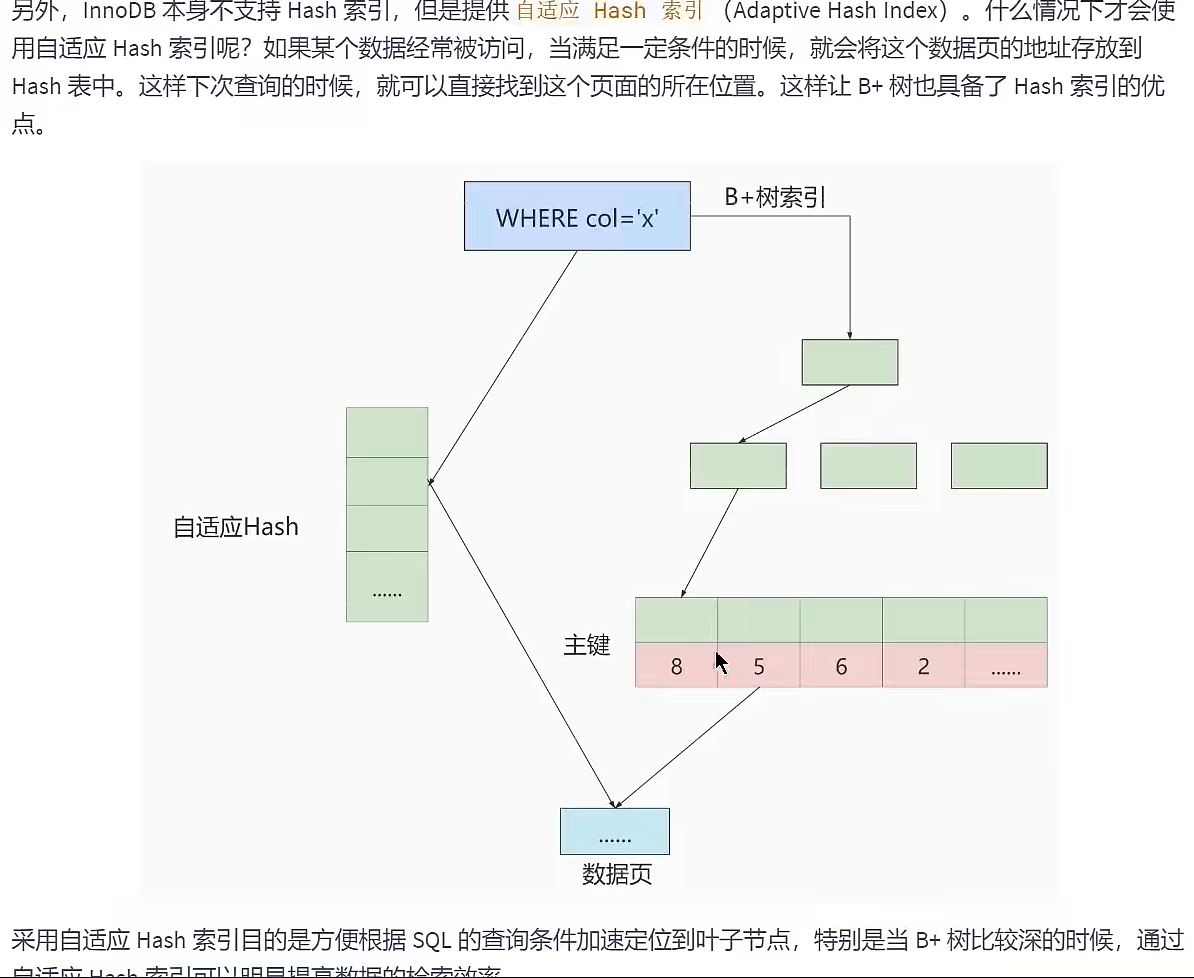
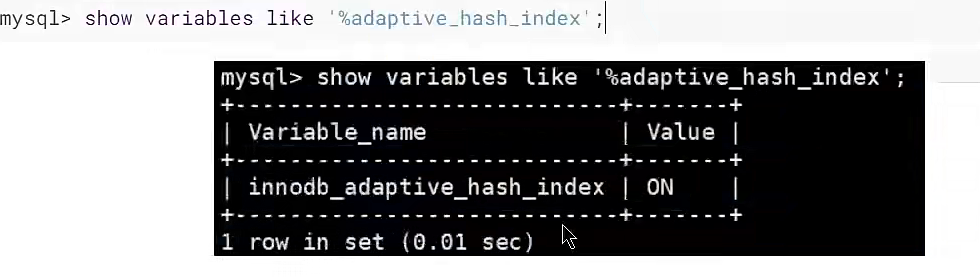
查看是否开启自适应Hash(默认开启)
InnoDB索引结构的选择演变
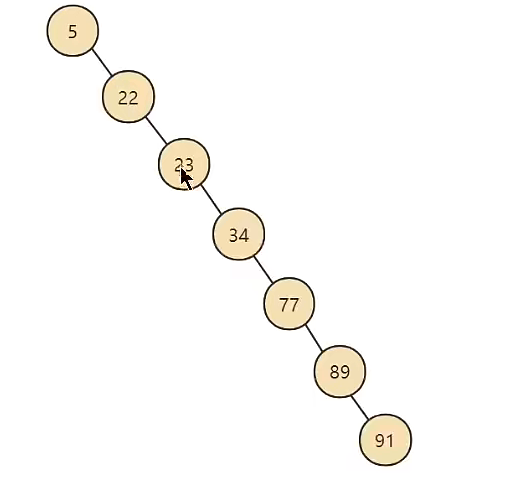
InnoDB为什么不使用二叉搜索树
二叉搜索树:左边的比我小,右边的比我大,
可能会出现极端情况如下,性能退化为链表,时间复杂度由O(log2n)变为O(n),磁盘IO次数增多(树的高度等于IO次数)。
从平衡二叉树(AVL)到平衡M(M>2)叉树的演变
平衡二叉树解决了二叉树极端情况的问题,但是当数据量很多时,树的高度还是很高,这样操作次数还是很多,当M越大时,数就会变得越“矮胖”。
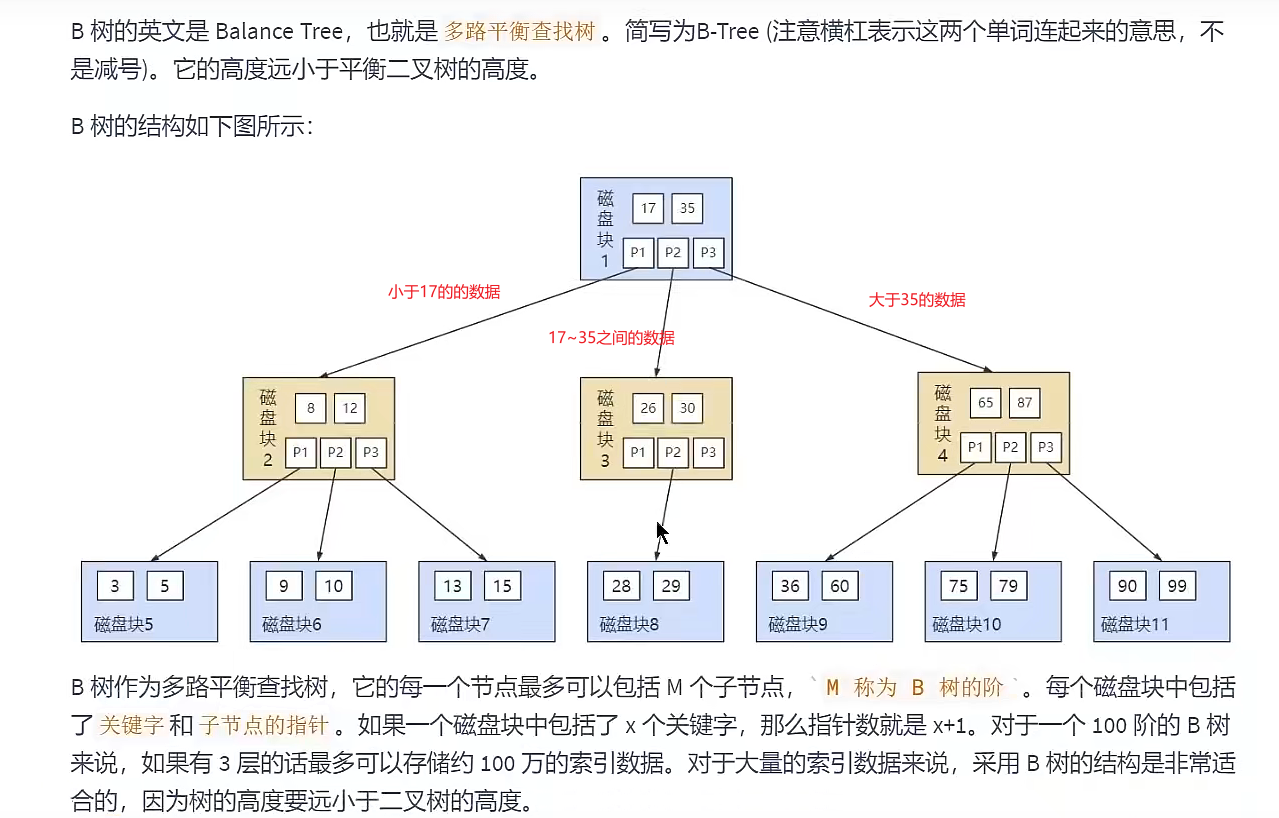
B-Tree 多路平衡二叉树
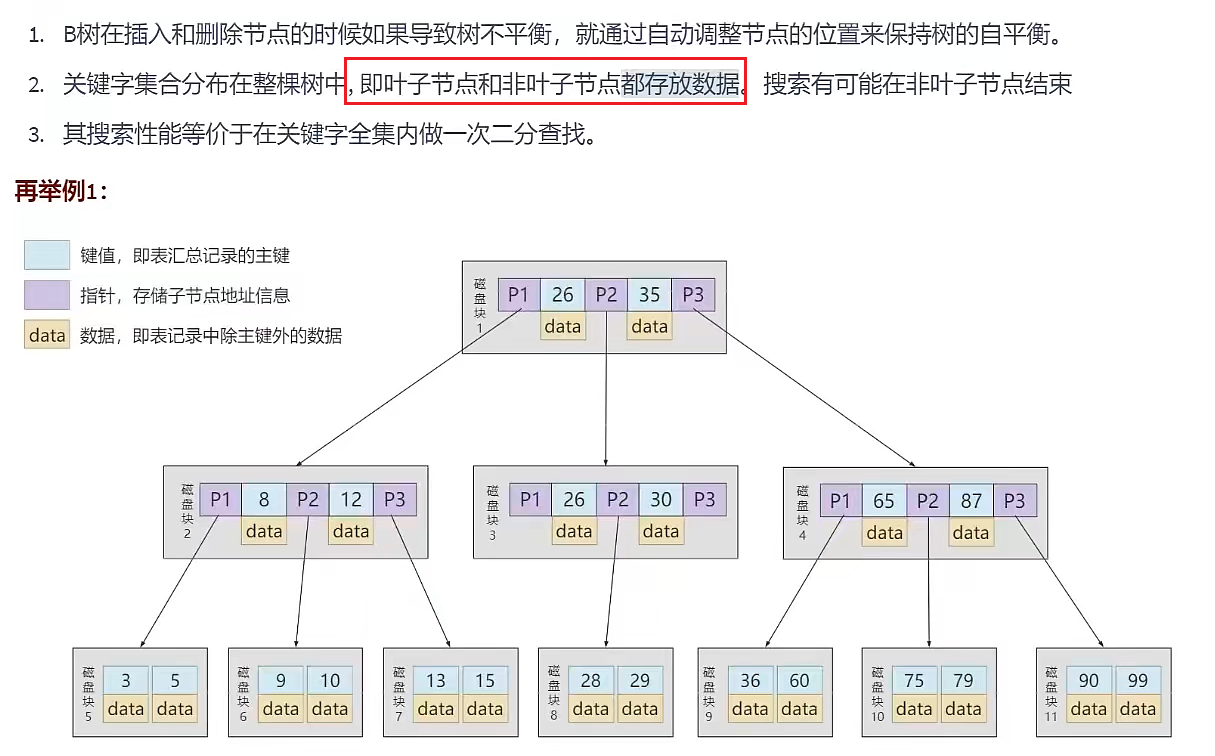
B+Tree 多路搜索树
B-Tree的改进,相较于B-Tree,B+Tree更适合文件索引系统。
- B+Tree的中间节点不直接存储数据有什么好处呢?
![B+Tree不直接存储数据的好处]()

思考题:为了减少IO,索引树会一次性加载吗?

思考题:B+Tree的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO?

思考题: 为什么B+Tree比B-Tree更适合操作系统中文件索引和数据库索引?

B+Tree和哈希索引的区别?

了解R树--优势在于范围查找

InnoDB的数据存储结构
数据库的存储结构——页
- 磁盘与内存交互基本单位——页(默认16KB)
![页结构概述]()
- 页的上层结构
![页的上层结构]()

页的内部结构(重点)
-
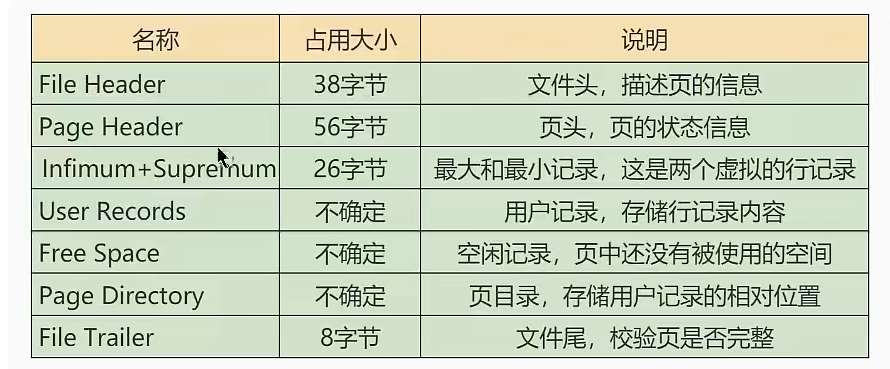
页的七部分组成
![页的七部分]()
详细讲解可参考“康师傅”的课程:https://www.bilibili.com/video/BV1iq4y1u7vj?p=122 -
为什么需要页目录?
加入页目录,可以使用二分法查找记录,提高查询效率。![页目录]()

从数据页的角度看B+Tree如何查询?
从页结构角度看普通索引和唯一索引在查询效率上有什么不同?

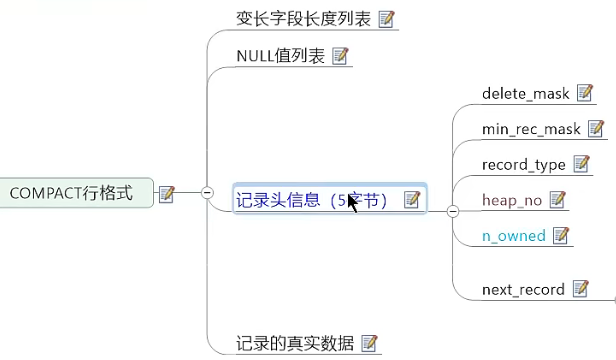
InnoDB行格式(记录格式)(重点)
-
MySQL8 默认行格式——Dynamic
![查看默认行格式]()
-
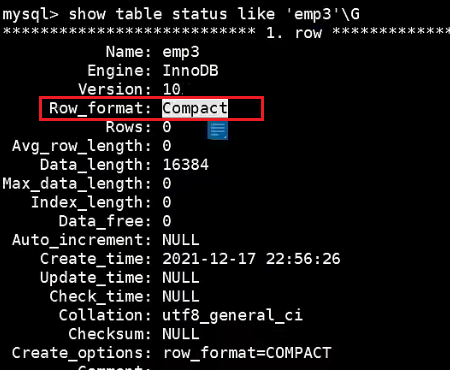
查看具体表使用的行格式
![查看具体表使用的行格式]()
-
MySQL5.1默认行格式——Compact

- Dynamic和Compact在处理行溢出时的区别
![Dynamic和Compact在处理行溢出时的区别]()

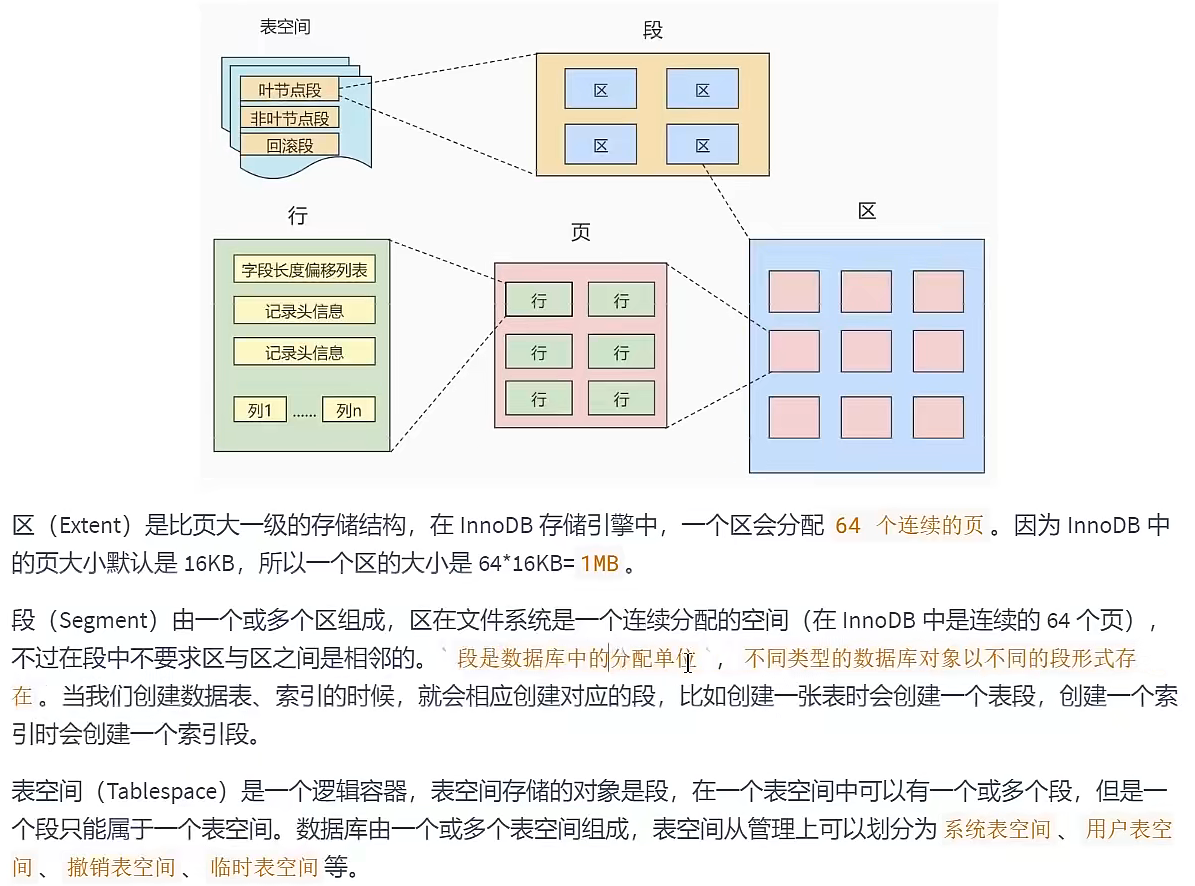
区、段、碎片区
- 为什么要有区?
![设置区的原因]()
- 为什么要有段?
![设置段的原因]()
- 为什么设置碎片区?
![设置碎片区的原因]()



表空间
-
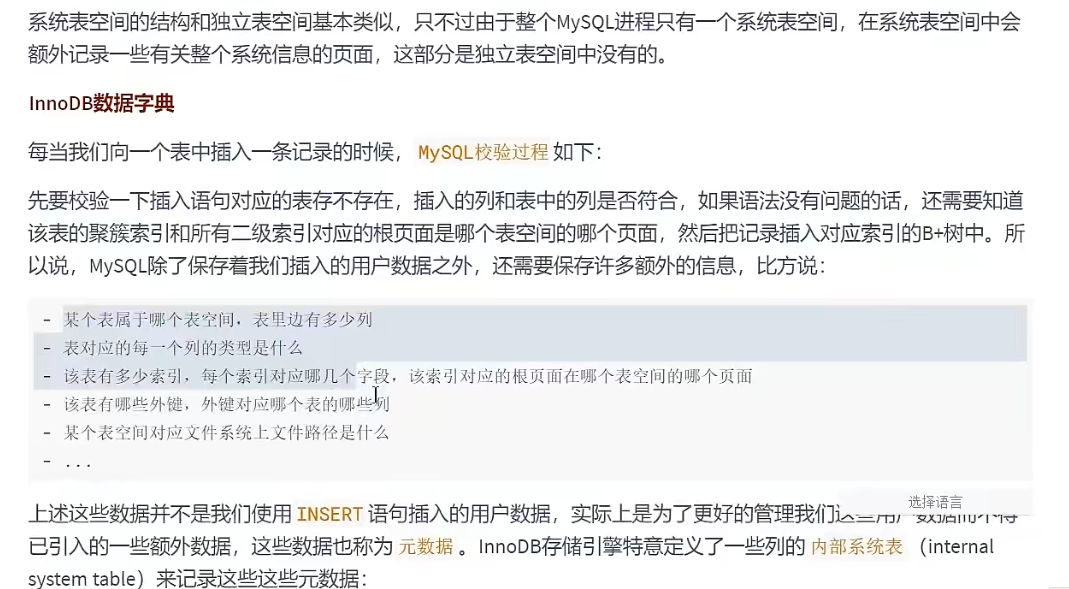
系统表空间
![系统表空间]()
-
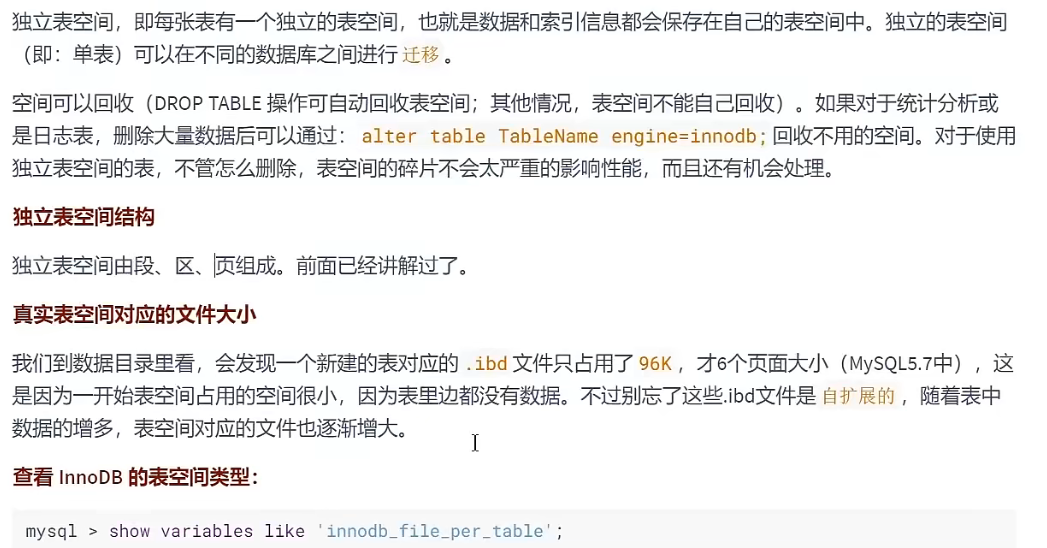
独立表空间
![独立表空间]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号