MySQL全连接(Full Join)实现,union和union all用法
2014-03-10 14:45 youxin 阅读(26649) 评论(0) 收藏 举报下面是一个简单测试,可以看看:
mysql> CREATE TABLE a(id int,name char(1));
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE TABLE b(id int,name char(1));
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO a VALUES(1,'a'),(2,'b');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> INSERT INTO b VALUES(2,'b'),(3,'c');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM a LEFT JOIN b ON a.id=b.id
-> UNION
-> SELECT * FROM a RIGHT JOIN b ON a.id=b.id;
+------+------+------+------+
| id | name | id | name |
+------+------+------+------+
| 1 | a | NULL | NULL |
| 2 | b | 2 | b |
| NULL | NULL | 3 | c |
+------+------+------+------+
3 rows in set (0.00 sec)
mysql>
MySQL UNION 语法
MySQL UNION 用于把来自多个 SELECT 语句的结果组合到一个结果集合中。语法为:
SELECT column,... FROM table1 UNION [ALL] SELECT column,... FROM table2 ...
在多个 SELECT 语句中,对应的列应该具有相同的字段属性,且第一个 SELECT 语句中被使用的字段名称也被用于结果的字段名称。
UNION 与 UNION ALL 的区别
当使用 UNION 时,MySQL 会把结果集中重复的记录删掉,而使用 UNION ALL ,MySQL 会把所有的记录返回,且效率高于 UNION。
MySQL UNION 用法实例
UNION 常用于数据类似的两张或多张表查询,如不同的数据分类表,或者是数据历史表等。下面是用于例子的两张原始数据表:
| aid | title | content |
|---|---|---|
| 1 | 文章1 | 文章1正文内容... |
| 2 | 文章2 | 文章2正文内容... |
| 3 | 文章3 | 文章3正文内容... |
| bid | title | content |
|---|---|---|
| 1 | 日志1 | 日志1正文内容... |
| 2 | 文章2 | 文章2正文内容... |
| 3 | 日志3 | 日志3正文内容... |
上面两个表数据中,aid=2 的数据记录与 bid=2 的数据记录是一样的。
使用 UNION 查询
查询两张表中的文章 id 号及标题,并去掉重复记录:
SELECT aid,title FROM article UNION SELECT bid,title FROM blog
返回查询结果如下:
| aid | title |
|---|---|
| 1 | 文章1 |
| 2 | 文章2 |
| 3 | 文章3 |
| 1 | 日志1 |
| 3 | 日志3 |
- 重复记录是指查询中各个字段完全重复的记录,如上例,若 title 一样但 id 号不一样算作不同记录。
- 第一个 SELECT 语句中被使用的字段名称也被用于结果的字段名称,如上例的 aid。
- 各 SELECT 语句字段名称可以不同,但字段属性必须一致。
使用 UNION ALL 查询
查询两张表中的文章 id 号及标题,并返回所有记录:
SELECT aid,title FROM article UNION ALL SELECT bid,title FROM blog
返回查询结果如下:
| aid | title |
|---|---|
| 1 | 文章1 |
| 2 | 文章2 |
| 3 | 文章3 |
| 1 | 日志1 |
| 2 | 文章2 |
| 3 | 日志3 |
显然,使用 UNION ALL 的时候,只是单纯的把各个查询组合到一起而不会去判断数据是否重复。因此,当确定查询结果中不会有重复数据或者不需要去掉重复数据的时候,应当使用 UNION ALL 以提高查询效率。
 我要投稿
我要投稿-
连接就是将两个表按照某个公共字段来拼成一个大表。
左连接就是在做连接是以左边这个表为标准,来遍历右边的表。
1、引子
左连接,自连接
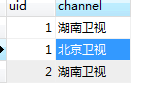
结果:
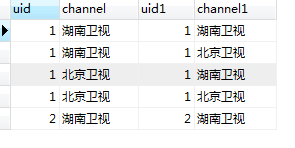
2、问题 例子:
用户访问记录:
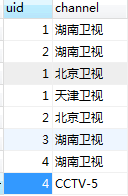
问题:查出看了湖南卫视但没有看北京卫视的用户信息
逻辑:先通过左连接将看了湖南卫视和北京卫视的查出来,然后再将看了湖南卫视但不在刚才查出的结果中的用户查出来。
123SELECT*FROMtest_visitWHEREchannel='湖南卫视'ANDuidNOTIN(SELECTDISTINCTt1.uidFROMtest_visit t1LEFTJOINtest_visit t2ONt1.uid = t2.uidWHEREt1.channel='湖南卫视'ANDt2.channel='北京卫视')SELECT语句中的自连接。
到目前为止,我们连接的都是两张不同的表,那么能不能对一张表进行自我连接呢?答案是肯定的。
有没有必要对一张表进行自我连接呢?答案也是肯定的。
表的别名:
一张表可以自我连接。进行自连接时我们需要一个机制来区分一个表的两个实例。
在FROM clause(子句)中我们可以给这个表取不同的别名, 然后在语句的其它需要使用到该别名的地方
用dot(点)来连接该别名和字段名。
我们在这里同样给出两个表来对自连接进行解释。
爱丁堡公交线路,
车站表:
stops(id, name)
公交线路表:
route(num, company, pos, stop)
一、对公交线路表route进行自连接。
SELECT * FROM route R1, route R2
WHERE R1.num=R2.num AND R1.company=R2.company
我们route表用字段(num, company)来进行自连接. 结果是什么意思呢?
你可以知道每条公交线路的任意两个可联通的车站。
二、用stop字段来对route(公交线路表)进行自连接。
SELECT * FROM route R1, route R2
WHERE R1.stop=R2.stop;
查询的结果就是共用同一车站的所有公交线。这个结果对换乘是不是很有意义呢。
从这两个例子我们可以看出,自连接的语法结构很简单,但语意结果往往不是
那么容易理解。就我们这里所列出的两个表,如果运用得当,能解决很多实际问题,
例如,任意两个站点之间如何换乘。
SELECT R1.company, R1.num
FROM route R1, route R2, stops S1, stops S2
WHERE R1.num=R2.num AND R1.company=R2.company
AND R1.stop=S1.id AND R2.stop=S2.id
AND S1.name='Craiglockhart'
AND S2.name='Tollcross'




 浙公网安备 33010602011771号
浙公网安备 33010602011771号