scrapy框架之生成存储文件json,xml、csv文件
以起点小说网举例子
网址
https://www.qidian.com/rank/yuepiao/
默认大家已经生成好scrapy项目了,如果不会请参考我之前的文章scrapy框架之创建项目运行爬虫
爬取网页
- 获取元素位置
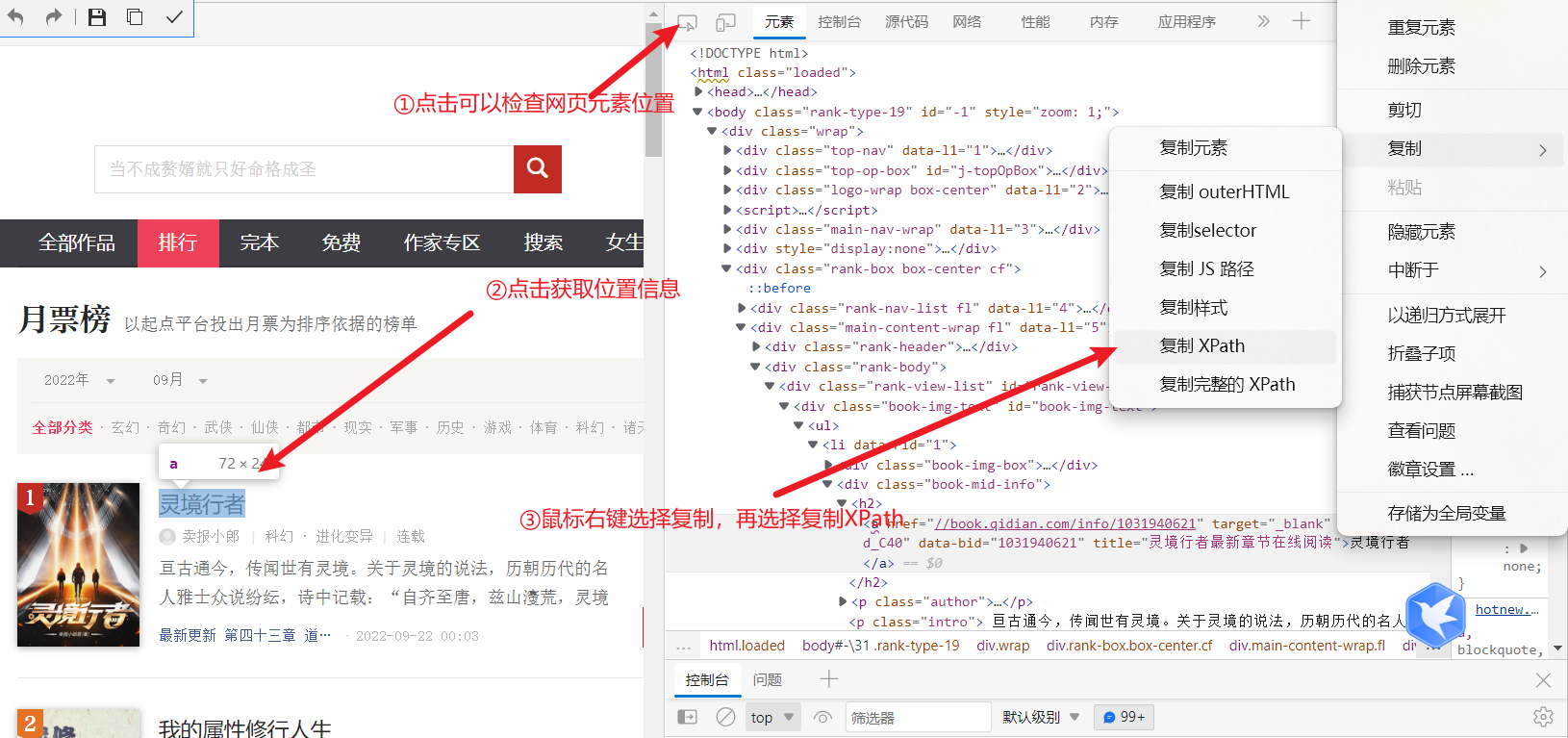
通过XPath Helper插件检查是否爬取成功

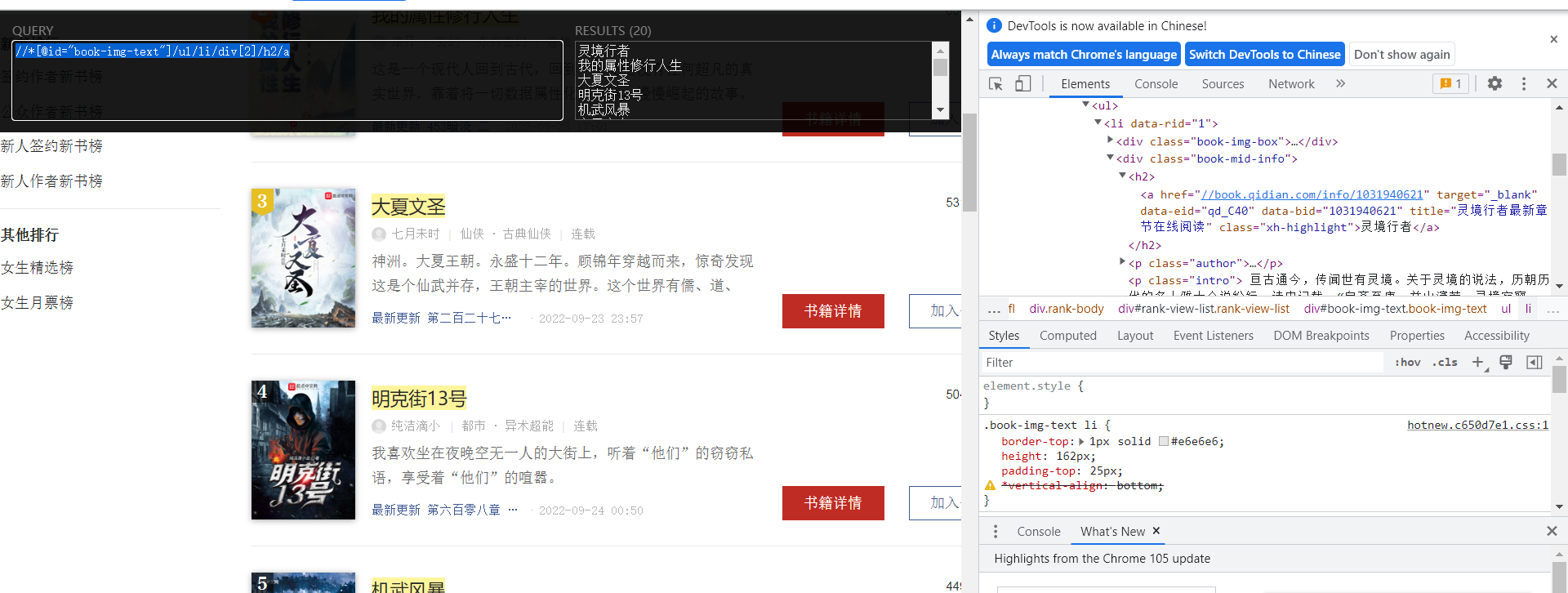
- 编写爬虫文件
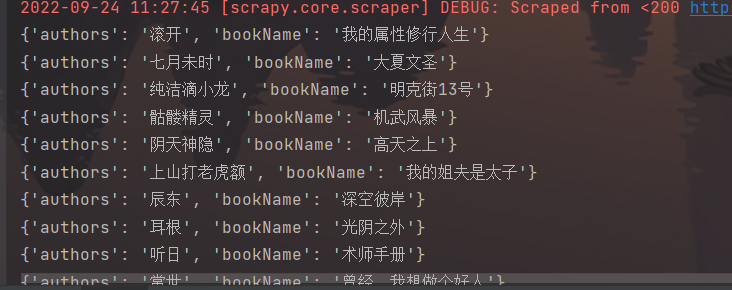
1.先在控制台打印一下,查看是否爬取成功
import scrapy
class QidianspiderSpider(scrapy.Spider):
name = 'qidianspider'
allowed_domains = ['www.qidian.com']
start_urls = ['https://www.qidian.com/rank/yuepiao/']
def parse(self, response):
names = response.xpath('//*[@id="book-img-text"]/ul/li/div[2]/h2/a/text()').extract()
authors = response.xpath('//*[@id="book-img-text"]/ul/li/div[2]/p[1]/a[1]/text()').extract()
print(names)
print(authors)
代码介绍:response.xpath()里写入xpath路径
extract()可以把返回数据取出杂余标签
2.循环取出数据并存到json文件中
import scrapy
class QidianspiderSpider(scrapy.Spider):
name = 'qidianspider'
allowed_domains = ['www.qidian.com']
start_urls = ['https://www.qidian.com/rank/yuepiao/']
def parse(self, response):
names = response.xpath('//*[@id="book-img-text"]/ul/li[1]/div[2]//a/text()').extract()
authors = response.xpath('//*[@id="book-img-text"]/ul/li[1]/div[2]//text()').extract()
book=[]
for name,author in zip(names,authors):
book.append({'name':name, 'author':author})
return book
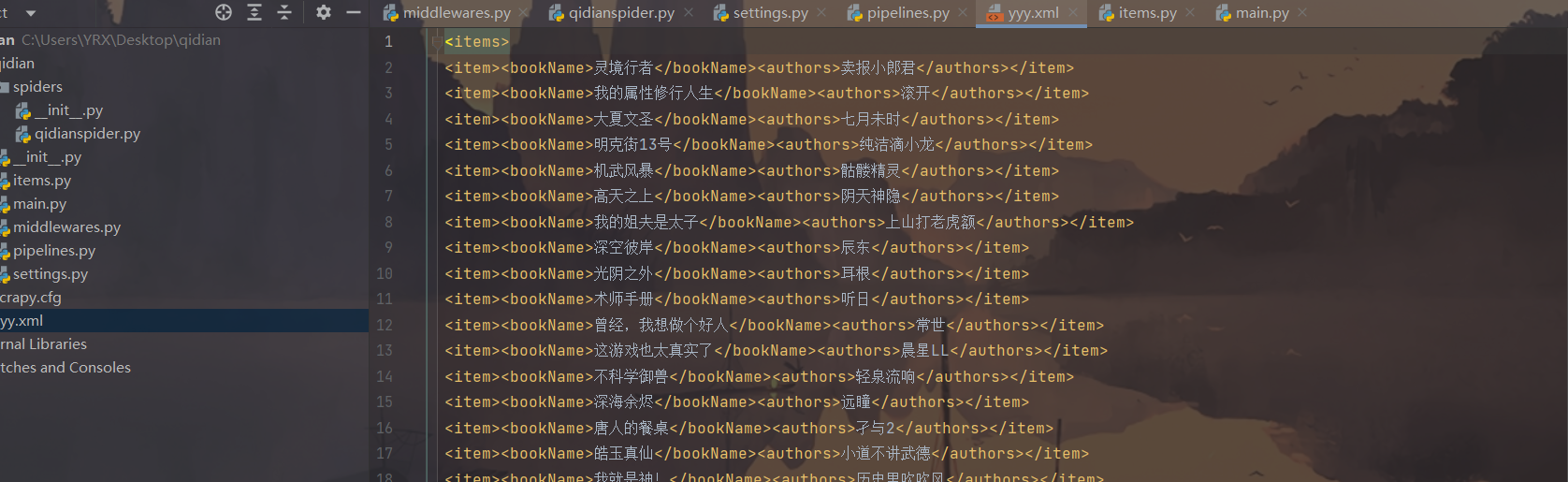
运行爬虫
scrapy crawl qidianspider -o yy.xml
代码介绍:-o 表示存储 后面更文件名,支持json,xml,csv文件存储
成果展示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号