正则表达式-Csharp
学习笔记:正则表达式
一. 正则表达式
正则表达式(Regex)是用来进行文本处理的技术,是语言无关的,在几乎所有语言中都有实现。
一个正则表达式就是由普通的字符及特殊字符(称为元字符符)组成的文字模式。该模式秒杀在查找文章主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
正则表达式的常用元字符(全为英文状态,注意可以代表的字符种类和个数):
|
元字符 |
含义 |
|
.(点) |
可以匹配除”\n”外的任意一个字符 |
|
[](中括号) |
可以匹配中括号内的任意一个字符 例如,"[abc]" 匹配"plain"中的"a" |
|
|(或符号) |
可以匹配或符号两边的任意一个字符,优先级比较低 匹配 x 或 y。例如 "z|food" 可匹配 "z" 或 "food"。 |
正则表达式的常用限定符(全为英文状态):
|
元字符 |
含义 |
|
*(星号) |
其限定的表达式出现次数等于或大于0次 例如,"zo*"可以匹配"z"、"zoo" |
|
+(加号) |
其限定的表达式至少出现1次 例如,"zo+"可以匹配"zoo",但不匹配"z" |
|
?(问号) |
其限定的表达式出现1次或0次 例如,"a?ve?"可以匹配"never"中的"ve" |
|
{n} |
其限定的表达式出现次数确定n次(n≥0) |
|
{n,} |
其限定的表达式至少出现n次 |
|
{n,m} |
其限定的表达式出现的次数为≥n次,≤m次(m>n) |
还有几个重要的符号:
|
符号 |
含义 |
|
^ (Shift+6) |
匹配输入的开始位置 非的意思。例如[^a-z],匹配非a-z的一个字符。 |
|
$ (Shift+4) |
匹配输入的结尾 |
|
\ |
将下一个字符标记为特殊字符或字面值 例如:想匹配”.”时或其他特殊字符时,需写为的”\.” |
|
()(小括号) |
1. 改变优先级 2. 分组,提取信息 |
需要熟记一些简写:
\d = [0-9]
\D=[^0-9]
\s =空字符,如\n tab space等
\S=非空字符
\w 能组成词的字符(字面、数字、中文或下划线等)
\W 非\w
正则表达式在.Net就是用字符串表示,这个字符串格式比较特殊,无论多么特殊,在C#语言看来都是普通的字符串,具体什么含义由Regex类内部进行语法分析。
正则表达式可以进行字符串的匹配、字符串的提取、字符串的替换。C#中分别对应正则表达式的三个重要方法。
1) IsMatch() 返回值为bool类型
格式:Regex.IsMatch("字符串", "正则表达式");
作用:判断字符串是否符合模板要求
例如:bool b =Regex.IsMatch("bbbbg","^b.*g$");判断字符串是否以b开头且以g结尾,中间可以有其他字符,若正确返回true,否则else。
2) Match() 返回值为Match类型,只能匹配一个
Matches() 返回值为MatchCollection集合类型,匹配所有符合的
格式:Match match = Regex.Match("字符串", "正则表达式");
或MatchCollection matches= Regex. Matches ("字符串", "正则表达式");
作用:
①提取匹配的子字符串
②提取组。Groups的下标由1开始,0中存放match的value。
例如:
Match match = Regex.Match("age=30", @"^(.+)=(.+)$"); if (match.Success){ Console.WriteLine(match.Groups[0] .Value);//输出匹配的子字符串 Console.WriteLine(match.Groups[1] .Value);//获取第一个分组的内容 Console.WriteLine(match.Groups[2] .Value);//获取第二个分组的内容 }
----------------------------------------------------------------------------------
 View Code
View Code

MatchCollection matches = Regex.Matches("2010年10月10日", @"\d+"); for (int i = 0; i < matches.Count; i++) { Console.WriteLine(matches[i].Value); }
3) Replace() 返回值为string
两种常用方式如下:
View Code
//将所有的空格替换为单个空格 string str = " aa afds fds f "; str = Regex.Replace(str, @"\s+", " "); Console.WriteLine(str); string str = "hello“welcome to ”beautiful “China”"; //hello"welcome to "beautiful "China" //$1表示引用第一组。$2表示用第二组。 string strresult = Regex.Replace(str, "“(.+?)”", "\"$1\""); Console.WriteLine(strresult);
贪婪模式与终结贪婪模式

实际应用有采集器(从某个网页上采集邮箱、图片或其他信息)、敏感词过滤、UBB翻译器。
采集邮箱:

保存图片:

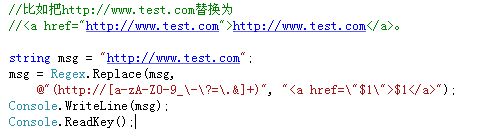
网址处理:
敏感词过滤:

UBB翻译:

一些常用的正则表达式
正则表达式用于字符串处理,表单验证等场合,实用高效,但用到时总是不太把握,以致往往要上网查一番。我将一些常用的表达式收藏在这里,作备忘之用。本贴随时会更新。
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
匹配双字节字符(包括汉字在内):[^\x00-\xff]
匹配空行的正则表达式:\n[\s| ]*
匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/
匹配首尾空格的正则表达式:(^\s*)|(\s*$)
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配网址URL的正则表达式:http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
补充:
^\d+$ //匹配非负整数(正整数 + 0)
^[0-9]*[1-9][0-9]*$ //匹配正整数
^((-\d+)|(0+))$ //匹配非正整数(负整数 + 0)
^-[0-9]*[1-9][0-9]*$ //匹配负整数
^-?\d+$ //匹配整数
^\d+(\.\d+)?$ //匹配非负浮点数(正浮点数 + 0)
^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$ //匹配正浮点数
^((-\d+(\.\d+)?)|(0+(\.0+)?))$ //匹配非正浮点数(负浮点数 + 0)
^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$ //匹配负浮点数
^(-?\d+)(\.\d+)?$ //匹配浮点数
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$ //匹配email地址
^[a-zA-z]+://匹配(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$ //匹配url

 浙公网安备 33010602011771号
浙公网安备 33010602011771号