Zookeeper-ZAB协议
接下来,记录下Zookeeper ZAB相关的内容,主要参考文末博文。
分布式一致性算法
分布式一致性算法可以保证多个数据节点上有一致的数据,目前有Paxos、Raft、Zab和Gossip几种,其中Zookeeper使用的是Zab,而Zab又和Raft比较类似,因此本文主要记录一下Raft和Zab。
Raft
Raft来自于Paxos共识算法,关于Paxos可以参考文末公众号文章或博文说明。Raft将分布式一致性问题分为Leader选举和Log复制,使用文末Raft动画网站说明,记录一下,基本是翻译一遍。
初识分布式一致性
如果是单个节点,如数据库服务器,想更新一个数据是比较简单的,只需要单个节点生效就行,但是如果有多个数据库服务器,如何保证数据一致性呢,这就需要用到Raft协议。如下图所示,绿色节点代表client,蓝色节点代表server,当服务端增加到3个,需要选举一个Leader来管事。
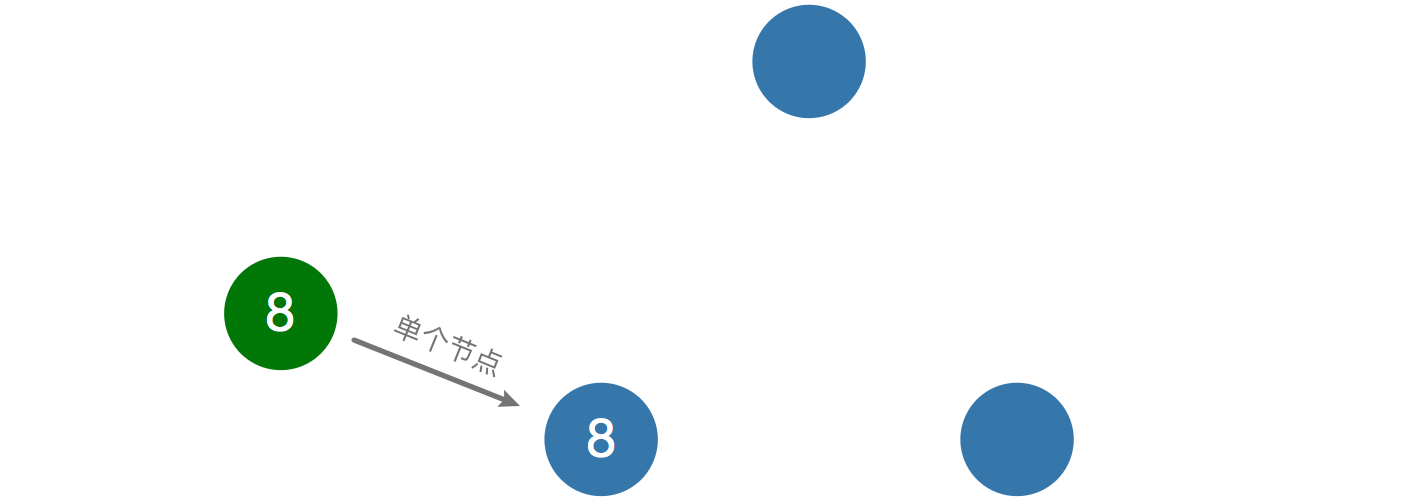
Raft里节点有三种角色,分别为Follower,Candidate和Leader,如图所示以不同外框线条款式标识,方便后面理解。

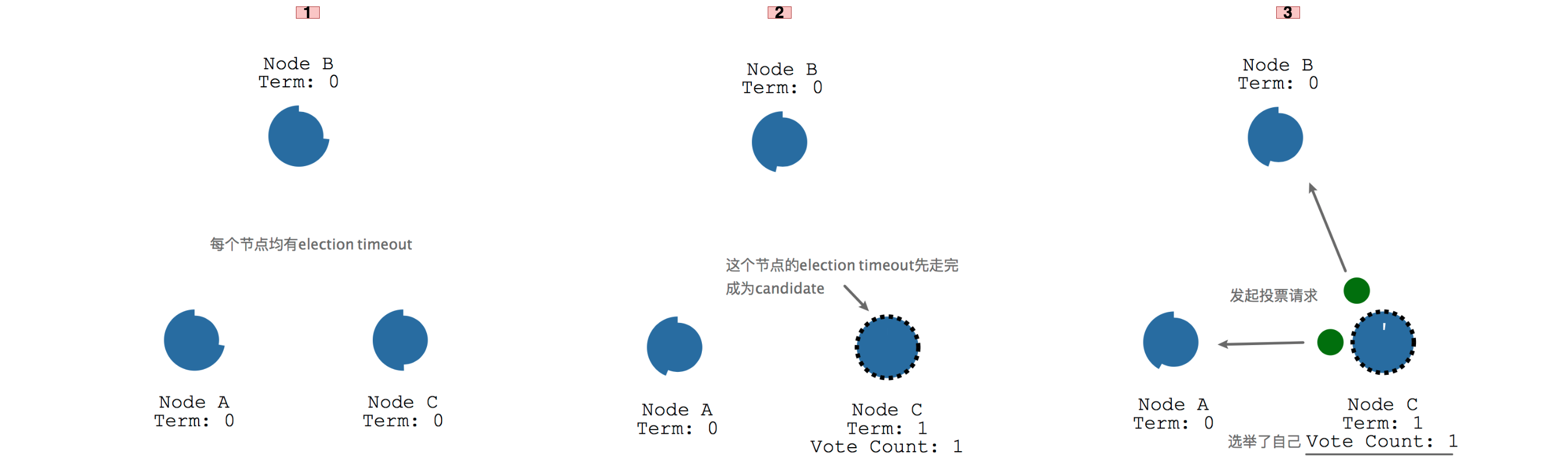
在三个节点的情况下,刚开始都是follower,当某个follower没有收到leader的信息(一般是心跳发来的信息),它可能会成为candidate,事实上每个follower都有机会成为candidate,需要看哪个follower先走完自己的等待时钟,后面Leader选举中有详细说明。

这个candidate会发出投票请求到其他节点,争求他们的投票,其他节点会返回投票结果返回到candidate。
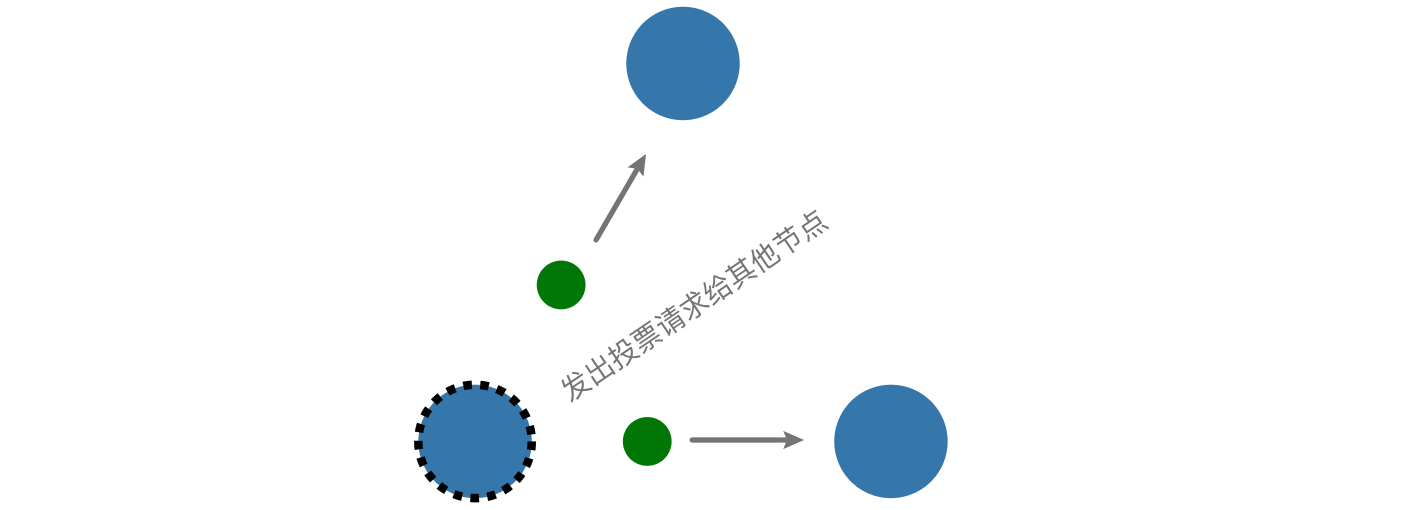
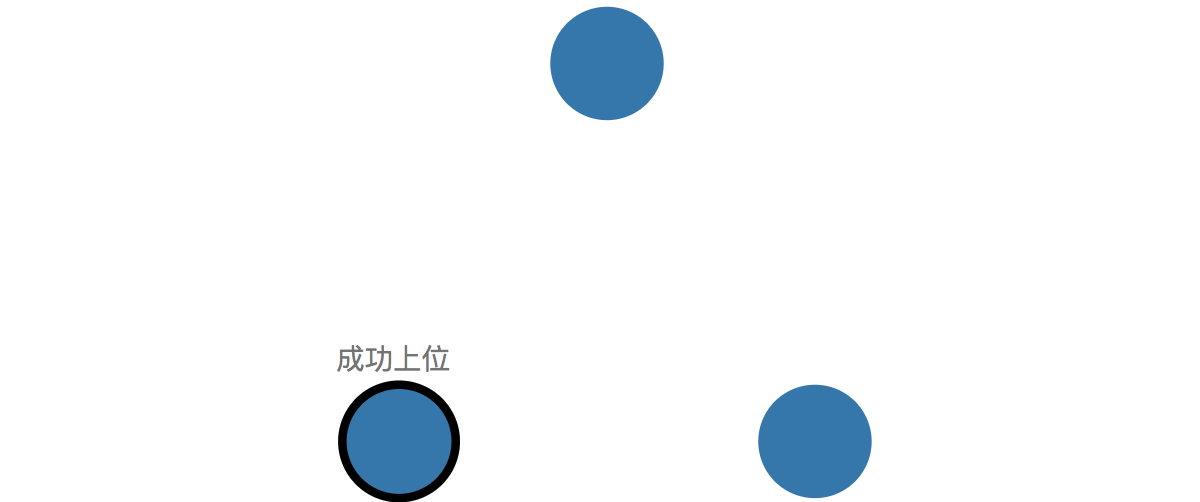
由于candidate获取到了超过半数(3/2+1)的投票,candidate会转正成为leader,随后跟client的沟通全部交给leader来负责,所有对系统的改变,均需要通过leader。
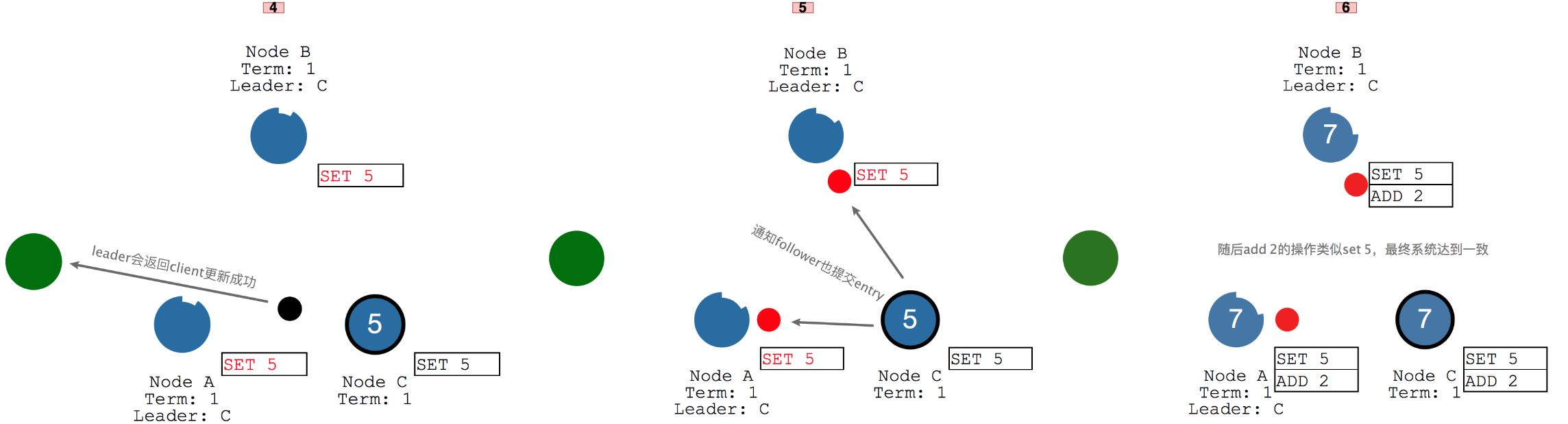
当client要更新一条数据为5,会先和leader通信,将动作写入log中记录,但是不立即提交更新,还需要将更新动作复制到follower。
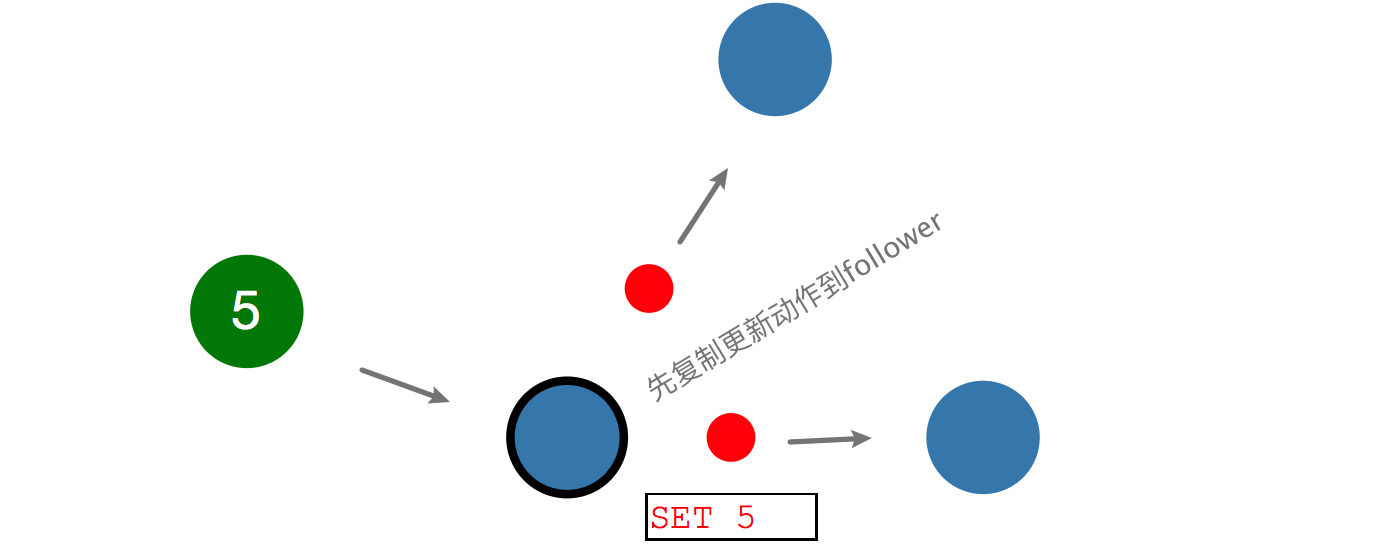
虽然都是"Set 5",但是均为红色字,说明都未提交。
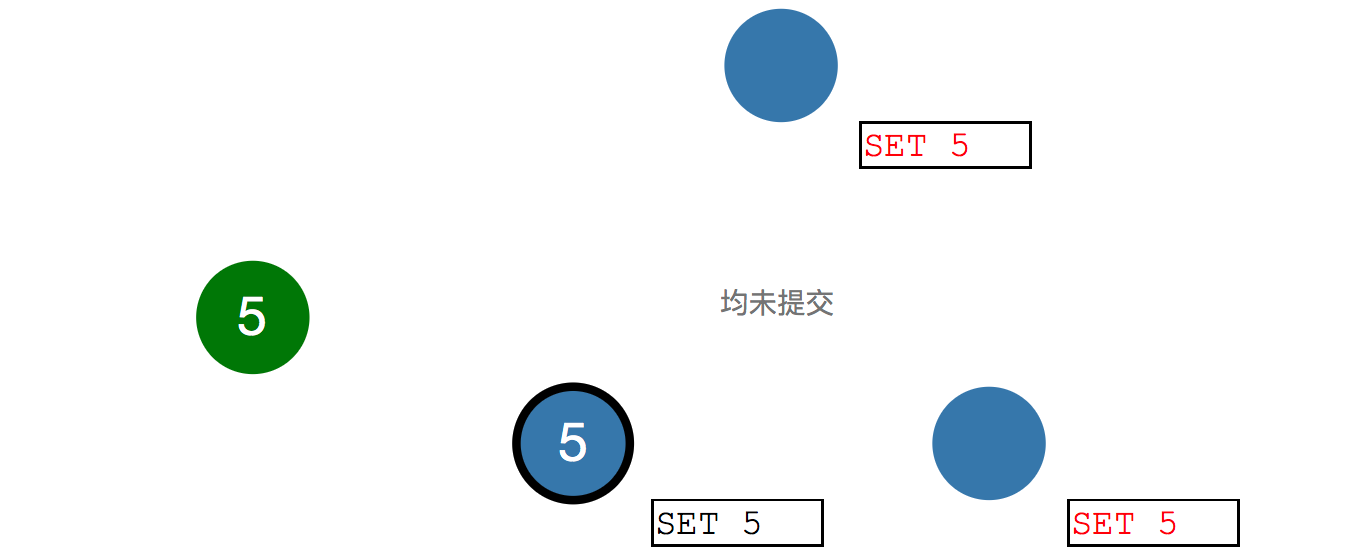
当过半的节点返回写入entry成功,leader会提交更新,并且告诉client,系统已经Set 5成功了,并随后通知其他节点提交更新,最后"Set 5"字样都变成了黑色,达到分布式一致。
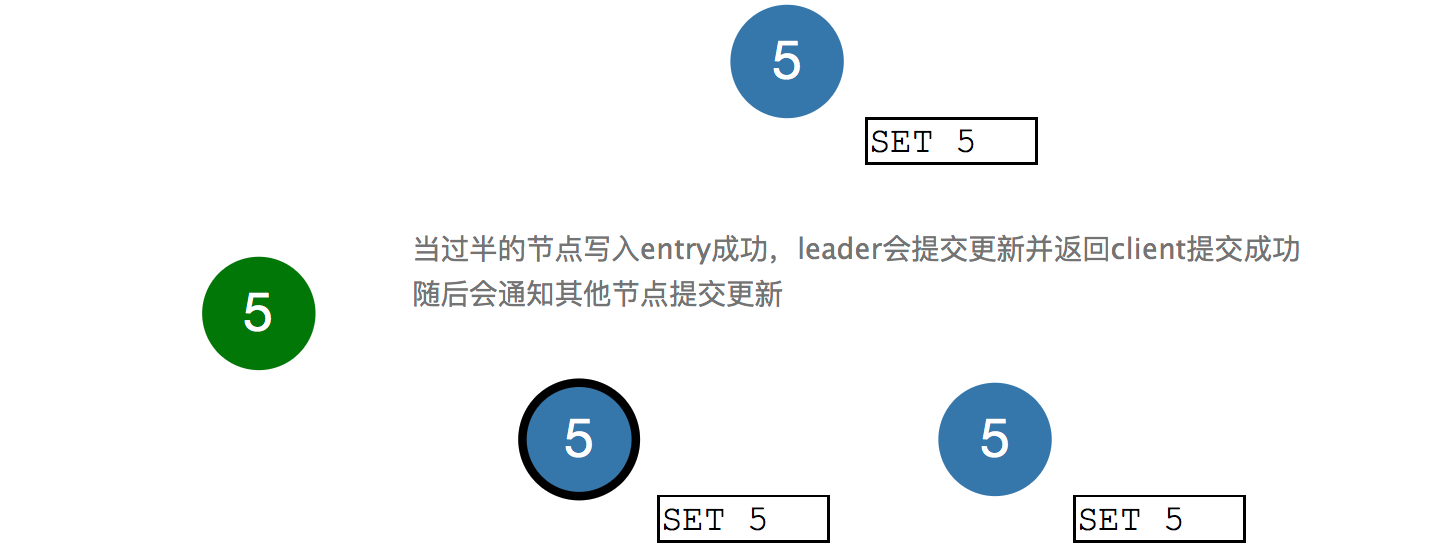
以上,就是分布式一致性实现过程的简单示意,包括leader选举和log复制。
Leader选举
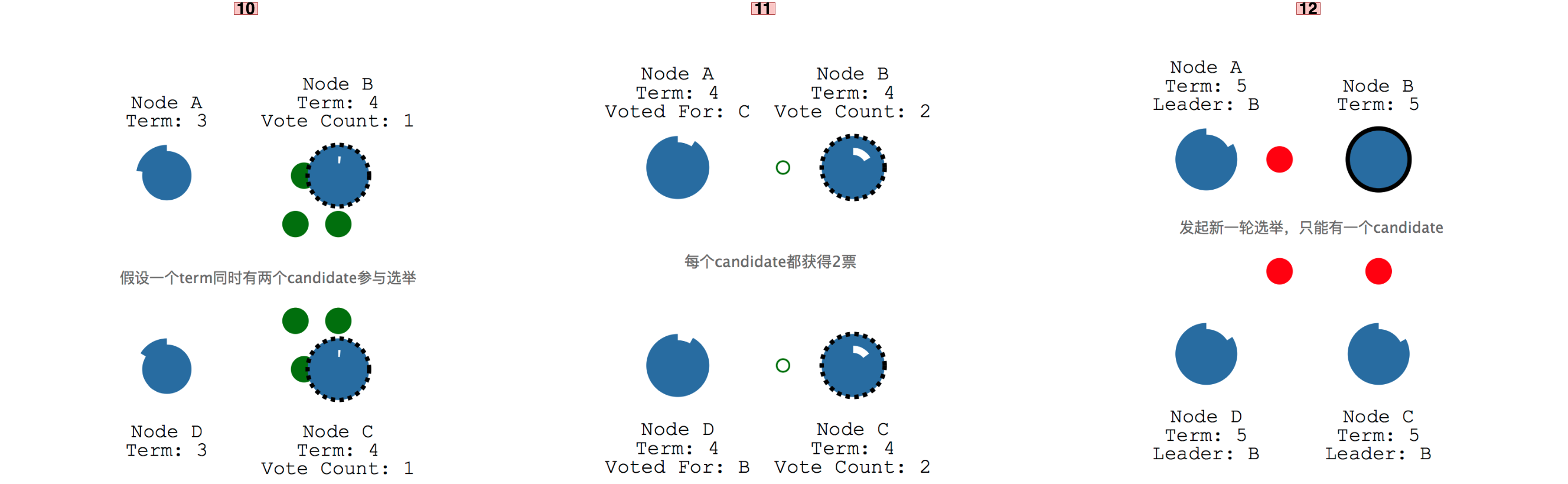
每个节点刚开始都有可能成为candidate,看谁先走完自己的时钟,每个时钟的timeout时长是随机的,默认是150~300ms。如下图所示先走完时钟的follower C先成为了candidate,然后开始向其他两个节点A和B发送投票选举请求,同时自己给自己投了一票。
A和B由于均不参与leader选举,因此都会将投票给C节点,由于C节点获取了集群中大部分的票数,就成为了leader,同时A和B节点会重置时钟,重新开始走。成为leader的C节点会不断发送心跳到A和B,心跳里包含Append Entries信息。
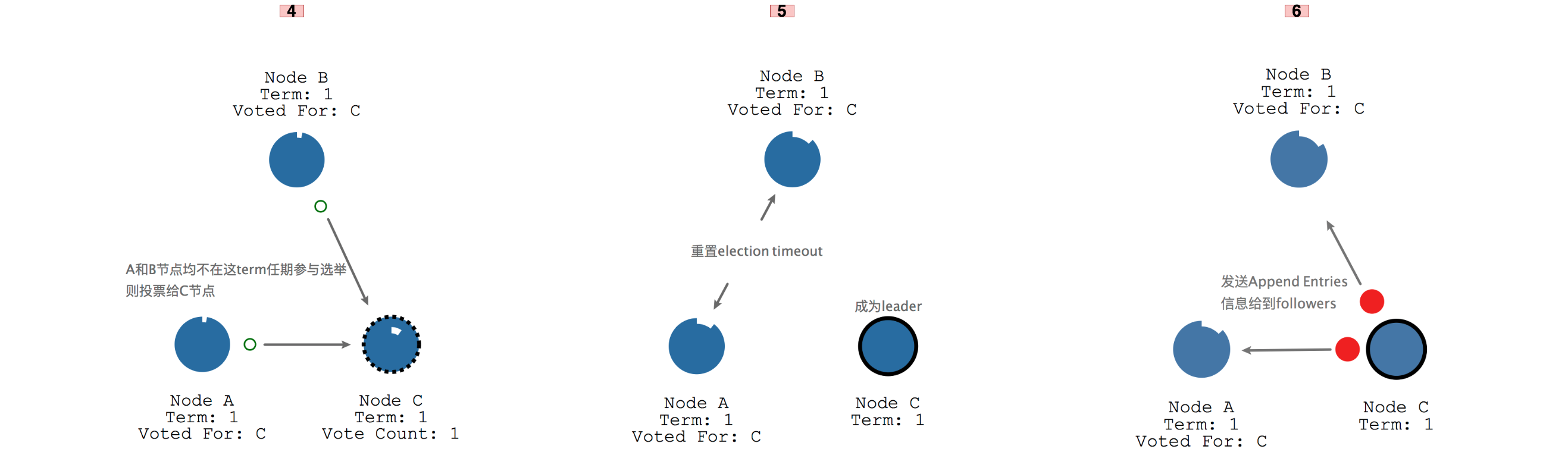
同时A和B每次都会响应结果给C,同时会重置自己的时钟,这种leader不断发送心跳,follower不断响应心跳的过程会一直持续,直到某个follower接收不到leader的心跳。这个时候就需要开始新一轮的leader选举了,由于A节点的时钟先走完因此成为了candidate,并且获取到了剩余2个节点的投票而成为term 2的leader。
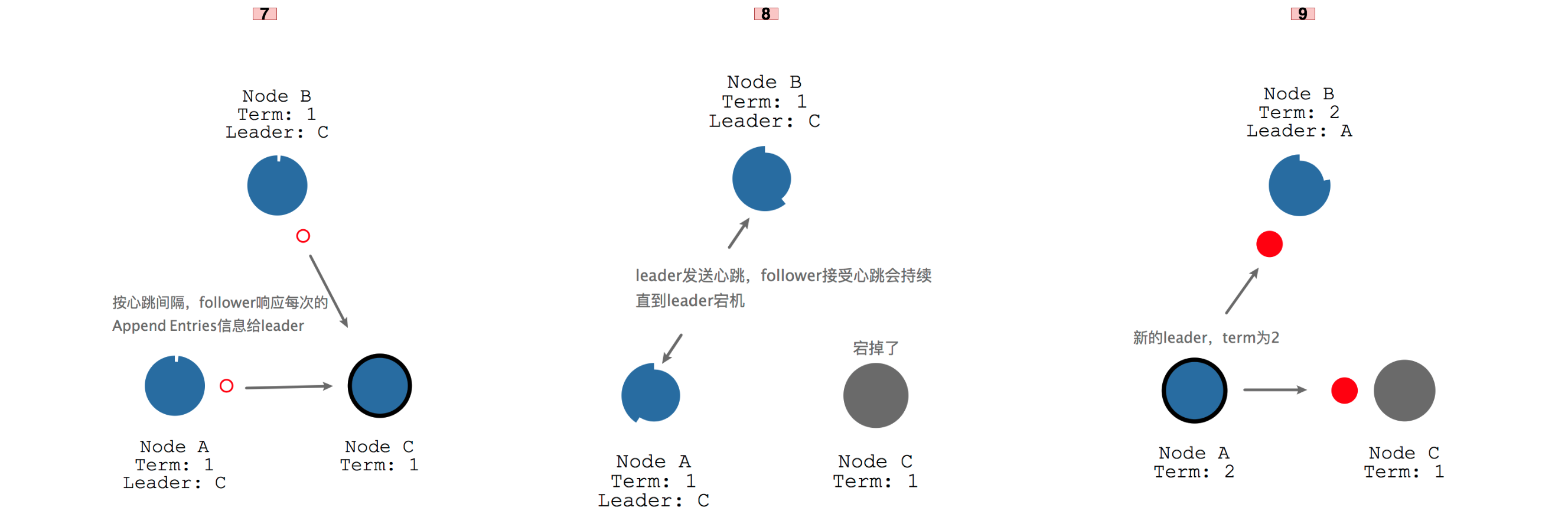
事实上一个term内,只能有一个candidate参与选举才能成功,如果有两个同时参与新一轮leader选举,则因为获取不到超过半数的票而被迫再进行一轮新的选举,这个时候两个candidate会随机推迟一段时间再发起投票,这样就只会有一个candidate参与选举。
以上是leader选举的细节。
Log复制
log复制也是基于append entries信息的,如图如果执行"set 5"的操作,会先将动作append到leader的log中,但暂时不提交。在下一次心跳中,leader会将更改内容发送给follower,当超过大多数的follower确认写入log后,leader才会提交这个entry。

随后leader会与client通信,告知更新成功,并且会通知所有follower也提交这个entry,这样所有的节点都完成"set 5"的操作,如果随后执行"add 2"的操作,也是一样的过程,先将操作写入到leader的log但是暂时不提交,当下次心跳大多数follower都写入成功它才提交,通知client集群"add 2"成功了,并且通知所有的follower也提交这个entry,这样整个集群都达成一致。
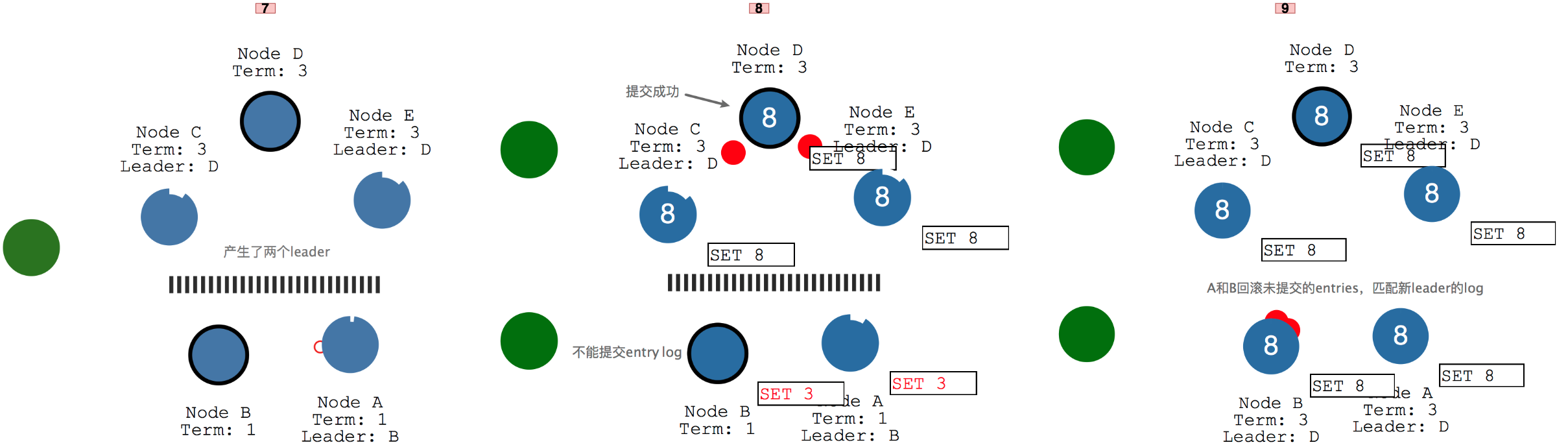
当集群中因为网络波动,产生了2个leader,并且有两个client都提交时,会发生什么呢,如图所示当靠下的client给集群发送"set 3"的动作,由于只有2个节点导致这个更新一直不能提交,leader B和follower A只能一直循环发送心跳。而靠上的client给集群发送"set 8"的动作时,可以满足过半的条件并提交成功。当网络恢复以后,就会出现"双主"的现象,这样两个leader B和D会比较term的大小,leader B发现自己的term比leader D的小,会选择回滚自己所有未提交的entries,并匹配上D的log,完成"set 8"的动作,最后整个集群都"set 8",达成一致。
以上就是log复制的细节。
ZAB协议
ZAB协议即Zookeeper原子广播协议(Zookeeper Automic Broadcast),可以保证分布式一致性,它和Raft比较类似,区别就是Raft的任期叫做term,ZAB叫做epoch,此外,Raft协议中,心跳是从leader到follower,而ZAB的心跳是从follower到leader。
广播模式(同步数据)
读数据
客户端先与某个zookeeper服务器建立session连接,然后直接从连接上的服务器读取数据,并返回客户端,无论连接的是哪个服务器,返回的结果都一样。读一致性是建立在写一致性基础上的,写保证了一致性,读取也就一致了。
写数据
参考文末博文,消息广播的大致步骤如下:
- 客户端发送给zookeeper的写请求,如果连接一个follower从节点,请求会转发给leader,如果连接的是leader直接自己处理。
- 请求到了leader后,先转化成事务proposal提案(如create /clyang "test"命令),并为proposal提供一个全局的txid,所有的proposal都有zxid。
- leader会将proposal提案发送给所有的follower,但是不是直接发送给follower,而是先让一个队列先接收着,其中每个follower都会有一个队列。队列采用FIFO的策略,先发给队列再处理可以实现异步解耦,提升性能。
- 当follower处理完proposal成功后会返回一个ack信号给leader,当quorum过半的follower都返回了ack,leader就认为可以commit这个proposal了,除了自己会提交事务会外,还会给每个follower广播这个commit信息,follower随后也都会在本地提交事务。
- zookeeper集群都提交完proposal后,follower或leader会响应客户端,写入成功。
有了消息广播还不能保证一致,还不够健壮,ZAB还有两个特征,可以保证一致性:
- 当leader提交了proposal,这样每个follower也需要完成commit提交。
- 当leader提出proposal后就挂掉了,这个proposal会被丢弃。
这样,就算leader挂掉了,可以做到"对应该提交的proposal不会漏过,对不该提交的proposal绝不留存"。
恢复模式(选取leader)
服务器有四种状态,刚开始都是looking状态,随着选举的进行会进行状态转换到leader或follower。如果是observer,需要在cfg配置文件中配置,observer不参与投票只接受投票结果,由于不参与投票,就没有写数据时多余的网络消耗,它的引入可以提高zookeeper集群服务的能力,具体参考文末博文:
# 告诉zookeeper这个节点是observer
peerType=observer
# 表明哪些节点指定为observer,在最后面添加observer
server.1=192.168.200.160:2888:3888:observer
- looking:服务器处于寻找leader的状态;
- leading:服务器作为leader时的状态;
- following:服务器作为follower跟随者时的状态;
- observing:服务器作为observer观察者时的状态。
不管是全新的leader选举,还是某个节点宕机新的leader选举,基本都是按照以下步骤来走,其中投票信息的结构为(sid,zxid)。

(1)集群刚开始建立,全新的leader选举
如果是刚开始建立的集群,按照zxid为0来处理,以三个节点为例,选举过程如下。
- 假设server1和server2先后启动,刚开始都投票给自己,投票信息后面还需要更新
- 然后server1将投票信息发送给server2,server2的就发送给server1
- 比较投票信息,先比较zxid,如果分不出高下就继续比较sid,这样server1和server2的信息都更新为(2,0)
- 更新后的投票信息,会发送给对方,告诉别人自己的选择,同时也知道别人的选择
- 最后投票统计,发现server1和server2都是投了2票给server2,server2就由looking状态变成了leader,而server1则变成了follower
- server3启动后,发现已经有了leader,自己直接从looking变成follower

(2)集群某节点宕机后,新的leader选举
类似上面全新leader选举过程,过程略。
以上,理解不一定正确,学习就是一个不断认识和纠错的过程。
参考博文:
(1)https://www.cnblogs.com/youngchaolin/p/12512565.html CAP ZAB
(2)http://thesecretlivesofdata.com/raft raft动画
(3)https://mp.weixin.qq.com/s/TSnsNVUD5rMFyaeEKrIJiQ Paxos、Raft、ZAB、Gossip
(4)https://www.jianshu.com/p/8e4bbe7e276c raft和paxos共识算法
(5)《从Paxos到Zookeeper-分布式一致性原理与实践》
(6)https://www.jianshu.com/p/2bceacd60b8a ZAB
(7)https://www.cnblogs.com/lytwajue/p/6943216.html observer

 浙公网安备 33010602011771号
浙公网安备 33010602011771号