Hadoop完全分布式安装
下面记录下hadoop完全分布式安装的过程,其中hadoop使用的版本是apache下的,不是cdh,linux版本为centos6。
完全分布式示意图
下面在三台节点上安装hadoop完全分布式,其中一个服务器节点上将有多个hadoop相关的节点,最后是压缩到三台的安装效果,正常来说至少13个服务节点。
(1)zookeeper用于管理namenode,用于故障转移主备切换,其中zookeeper通过failoverController进程来进行namenode主备切换。
(2)namenode主备之间通过journalNode来进行通信,进行数据同步。
(3)resourceManager也会有两个,一个挂了另外一个顶上。
(4)datanode上储存数据,MR计算有数据本地化策略,nodeManager一般和datanode在一起。

以上是最后安装的节点分布图,下面开始安装部署。
前置准备
前置准备包括关闭linux防火墙、修改主机名、ip映射、配置jdk和免密登录,可参考https://www.cnblogs.com/youngchaolin/p/11992600.html,其中这里使用的主机名分别为hadoop01、hadoop02和hadoop03。ip映射需修改/etc/hosts文件,添加三台ip和节点名的映射关系。以上操作三台都需要准备好,容易出现问题的就是免密登录,下面记录一下。
hadoop01节点生成公私钥对,并分发公钥到hadoop02和hadoop03,还包括自己hadoop01。
# ssh-keygen命令完成公私钥生成,这里省略了,具体参考上面博文记录
# 拷贝公钥到hadoop02 [root@hadoop01 ~]# ssh-copy-id root@hadoop02
# 直接回车 root@hadoop02's password: Now try logging into the machine, with "ssh 'root@hadoop02'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting. You have new mail in /var/spool/mail/root # 拷贝公钥到hadoop03 [root@hadoop01 ~]# ssh-copy-id root@hadoop03
# 直接回车 root@hadoop03's password: Now try logging into the machine, with "ssh 'root@hadoop03'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting. # 拷贝公钥到hadoop01自己 [root@hadoop01 ~]# ssh-copy-id root@hadoop01
完成这一步,所有节点~/.ssh目录下会在authorized_keys文件里保存hadoop01上的公钥。
# 第二个节点保存hadoop01上的公钥,第三个节点也是
[root@hadoop02 ~/.ssh]# ll total 8 -rw-------. 1 root root 395 Dec 28 23:11 authorized_keys
hadoop02和hadoop03节点都进行同样的操作后,就完成免密登录,查看authorized_keys文件,发现已经获取到三台的公钥。
# 任何一个节点上,都有三台节点的公钥信息
[root@hadoop03 ~/.ssh]# cat authorized_keys ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAwcYd1kp2gM0dszWemOTSYy7MpGAXcg9DQEDUxcr8x0oz3Wcm8iZs8i6EZj0GQtUAExKX8Y/6havVAfF6DF6HiszXB4P7CjJUVwrLJhNt1YtRj7e0gPe6/HMIsOkRzrDGQMoD3L5b5wmOP+0KBTTFWDNTNoIZlbttYLk5Ir0bW0VtfLlJhU2FJSYkcmqKAtZXKvsqclx1oQG1aKDQV6OIJA72/YVw0HvhFk82UPEZBoW9HYrmJcn6QOOH1AtR5eC9V2omrpXXsHrx71iXxDQesCvOlew6IOB3z6F2Zlll3ReNCjhP9RCr7ILJpfF3VKFbmwl8jnGJiEH56qMfwVesNQ== root@hadoop01 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEApyq6QsZvkHPkrOtTgmtsI365ZI8dV3DVgAs4ANWmPEaLb2j3GpJ8fLzml77HvX4oYO3fXIa9Nyg2oNgLGa3ipvmGCig58fR8P2wSGjQY0oHGowl5+Mt2BNRu6O+u7mBSIIn8Q2BR+K0AotfSGgQrw7U9fRUlA38dOU9qrWSuFNE+A8VgdzpLtV6Z5DgPJjzCbPZRCnHIex1CSg18X5Wg0jE1pbiumWvx2J9od36JheosEiJPljVTnbSYeCJnFJyyUsFeZq7nTwklifqeaY2RRUGSB72vrPXxLLaHT3tnwqV/DmcdIfIebLFsIUbzNeLQP03EmISLsJfLafYTCi0N/Q== root@hadoop02 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA3E+tThIDFezbq3qvPFFJDDGzKTSJBuRDl5dR1LdY5r38ODcEw7uslJMqiryXwlgSvLkzwEAQIE7FUiLMlOnmLJ+aiwdTHheEC1M9cPAYQZ6QMMkZp8Y6YQ9QeWqvMSfbtRPPpFrndEjaXML0+dJUh8Srgyzchu7zp1sSPu5wZXGuIbcTha8UNV7c0VjIQAimjQIdZSqA4zmTa2rt6MIVEwlGsq/RhzXnnaXopMLAyk97bVK8XWpWgIUJ/DSiKZBSDAa8usxaqTF8qw1AvxGf52Xuye5EV2WvpU5LeOaBj/XxmCnrtRRkqYrtvObEXvDRq1MG9wU90LFHeH68PRCrCQ== root@hadoop03
可以使用'ssh 节点名'来进行进行免密登录测试,第一次提示可能需要输入密码,这样会将登录信息保存在ssh目录下known_hosts中,后续不再提示需要密码,另外本次设置不需要密码。
安装zookeeper
三台节点安装zookeeper,参考博文https://www.cnblogs.com/youngchaolin/p/12113065.html。
安装完全分布式hadoop
完成以上配置后,就可以开始进入完全分布式hadoop的安装和部署,按照如下步骤傻瓜式安装就能完成。先在hadoop01节点上安装配置hadoop,然后将安装包分发到另外两台。
解压hadoop
解压apache版本的hadoop安装包。
[root@hadoop01 /home/software]# tar -zxvf hadoop-2.7.1.tar.gz
修改hadoop-env.sh
hadoop-env.sh是跟环境相关的,配置JAVA_HOME和HADOOP_CONF_DIR,JAVA_HOME就是前面配置好的jdk,后者就是指定hadoop配置文件的目录。
# 配置项
export JAVA_HOME=/home/software/jdk1.8.0_181 export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop
# 保存退出,source使其重新生效
[root@hadoop01 /home/software/hadoop-2.7.1/etc/hadoop]# source hadoop-env.sh
修改core-site.xml
使用zookeeper来管理hadoop节点,ns就是注册在zookeeper上节点的名字。
<configuration> <!--为集群起别名,以确定向Zookeeper注册的节点的名字--> <property> <name>fs.defaultFS</name> <value>hdfs://ns</value> </property> <!--指定Hadoop数据临时存放目录--> <property> <name>hadoop.tmp.dir</name> <value>/home/software/hadoop-2.7.1/tmp</value> </property> <!--指定zookeeper的连接地址--> <property> <name>ha.zookeeper.quorum</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property> </configuration>
修改hdfs-site.xml
配置hadoop高可用相关内容,配置两个namenode,指定节点位置,需要journalnode的支持,同样在里面配置。
<!--注意要和core-site.xml中的名称保持一致--> <property> <name>dfs.nameservices</name> <value>ns</value> </property> <!--ns集群下有两个namenode,分别为nn1, nn2--> <property> <name>dfs.ha.namenodes.ns</name> <value>nn1,nn2</value> </property> <!--nn1的RPC通信--> <property> <name>dfs.namenode.rpc-address.ns.nn1</name> <value>hadoop01:9000</value> </property> <!--nn1的http通信--> <property> <name>dfs.namenode.http-address.ns.nn1</name> <value>hadoop01:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns.nn2</name> <value>hadoop02:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.ns.nn2</name> <value>hadoop02:50070</value> </property> <!--指定namenode的元数据在JournalNode上存放的位置,这样,namenode2可以从journalnode集群里的指定位置上获取信息,达到热备效果--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/ns</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/software/hadoop-2.7.1/tmp/journal</value> </property> <!-- 开启NameNode故障时自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!--配置namenode存放元数据的目录,可以不配置,如果不配置则默认放到hadoop.tmp.dir下--> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/software/hadoop-2.7.1/tmp/hdfs/name</value> </property> <!--配置datanode存放元数据的目录,可以不配置,如果不配置则默认放到hadoop.tmp.dir下--> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/software/hadoop-2.7.1/tmp/hdfs/data</value> </property> <!--配置复本数量--> <property> <name>dfs.replication</name> <value>3</value> </property> <!--设置用户的操作权限,false表示关闭权限验证,任何用户都可以操作--> <property> <name>dfs.permissions</name> <value>false</value> </property>
修改mapred-site.xml
将MapReduce配置基于yarn来运行。
<!--mapreduce运行基于yarn,也可以调整为local--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
修改yarn-site.xml
主要配置resourcemanager的高可用,在节点1和节点3上配置,同样两个rm交给zookeeper管理。
<!--配置yarn的高可用--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--指定两个resourcemaneger的名称--> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!--配置rm1的主机--> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop01</value> </property> <!--配置rm2的主机--> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop03</value> </property> <!--开启yarn恢复机制--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--执行rm恢复机制实现类--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <!--配置zookeeper的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property> <!--执行yarn集群的别名--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>ns-yarn</value> </property> <!-- 指定nodemanager启动时加载server的方式为shuffle server --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定resourcemanager地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop03</value> </property>
修改slaves文件
# 添加三个节点信息
hadoop01
hadoop02
hadoop03
远程拷贝
将hadoop01上配置好的hadoop安装目录远程拷贝到hadoop02和hadoop03。
# $PWD就是/home/software,也可以写绝对路径
[root@hadoop01 /home/software]# scp -r hadoop2.7.1/ root@hadoop02:$PWD [root@hadoop01 /home/software]# scp -r haoop2.7.1/ root@hadoop03:$PWD
三节点配置hadoop环境变量
三个节点都需要配置hadoop环境变量,此外还包括前面准备阶段的java环境变量。配置完后需要source /etc/profile一下让环境变量生效。
export HADOOP_HOME=/home/software/hadoop-2.7.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
启动zookeeper
三个节点均需要启动zookeeper,并记得启动后查看状态是否为一主两从。
# 顺序启动后hadoop02上的zk就是leader,其他均为follower
[root@hadoop02 /home/software/zookeeper-3.4.8/bin]# ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /home/software/zookeeper-3.4.8/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@hadoop02 /home/software/zookeeper-3.4.8/bin]# ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /home/software/zookeeper-3.4.8/bin/../conf/zoo.cfg Mode: leader
第一个节点格式化zookeeper
使用hdfs zkfc -formatZK命令,这个操作将会在zk上注册节点。
# 格式化zookeeper
[root@hadoop01 /home/software]# hdfs zkfc -formatZK 19/12/29 01:16:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 19/12/29 01:16:20 INFO tools.DFSZKFailoverController: Failover controller configured for NameNode NameNode at hadoop01/192.168.200.140:9000 19/12/29 01:16:21 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 19/12/29 01:16:21 INFO zookeeper.ZooKeeper: Client environment:host.name=hadoop01 19/12/29 01:16:21 INFO zookeeper.ZooKeeper: Client environment:java.version=1.8.0_181 19/12/29 01:16:21 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation ...省略 19/12/29 01:16:21 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=hadoop01:2181,hadoop02:2181,hadoop03:2181 sessionTimeout=5000 watcher=org.apache.hadoop.ha.ActiveStandbyElector$WatcherWithClientRef@436813f3 19/12/29 01:16:21 INFO zookeeper.ClientCnxn: Opening socket connection to server hadoop02/192.168.200.150:2181. Will not attempt to authenticate using SASL (unknown error) 19/12/29 01:16:21 INFO zookeeper.ClientCnxn: Socket connection established to hadoop02/192.168.200.150:2181, initiating session 19/12/29 01:16:21 INFO zookeeper.ClientCnxn: Session establishment complete on server hadoop02/192.168.200.150:2181, sessionid = 0x26f4d75770d0000, negotiated timeout = 5000 19/12/29 01:16:21 INFO ha.ActiveStandbyElector: Session connected.
# 成功创建节点ns,ns就是前面配置的集群别名 19/12/29 01:16:21 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns in ZK. 19/12/29 01:16:21 INFO zookeeper.ZooKeeper: Session: 0x26f4d75770d0000 closed 19/12/29 01:16:21 INFO zookeeper.ClientCnxn: EventThread shut down You have new mail in /var/spool/mail/root
三个节点启动journalNode
三个节点均需要启动,命令在sbin目录下。
[root@hadoop01 /home/software/hadoop-2.7.1/sbin]# ./hadoop-daemon.sh start journalnode
第一个节点格式化namenode
注意只在第一个节点上使用如下命令格式化namenode,第二个节点还需要格式化namenode,使用的命令不一样,需要注意。
[root@hadoop01 /home/software/hadoop-2.7.1/sbin]# hadoop namenode -format DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. 19/12/29 01:22:26 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hadoop01/192.168.200.140 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.7.1 ...省略 STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a; compiled by 'jenkins' on 2015-06-29T06:04Z STARTUP_MSG: java = 1.8.0_181 ************************************************************/ 19/12/29 01:22:26 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 19/12/29 01:22:26 INFO namenode.NameNode: createNameNode [-format] 19/12/29 01:22:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Formatting using clusterid: CID-0deff869-4530-4fc5-a9e9-10babaaa7d48 19/12/29 01:22:26 INFO namenode.FSNamesystem: No KeyProvider found. 19/12/29 01:22:26 INFO namenode.FSNamesystem: fsLock is fair:true 19/12/29 01:22:26 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000 19/12/29 01:22:26 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true 19/12/29 01:22:26 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000 19/12/29 01:22:26 INFO blockmanagement.BlockManager: The block deletion will start around 2019 Dec 29 01:22:26 19/12/29 01:22:26 INFO util.GSet: Computing capacity for map BlocksMap 19/12/29 01:22:26 INFO util.GSet: VM type = 64-bit 19/12/29 01:22:26 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB 19/12/29 01:22:26 INFO util.GSet: capacity = 2^21 = 2097152 entries 19/12/29 01:22:26 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false 19/12/29 01:22:26 INFO blockmanagement.BlockManager: defaultReplication = 3 19/12/29 01:22:26 INFO blockmanagement.BlockManager: maxReplication = 512 19/12/29 01:22:26 INFO blockmanagement.BlockManager: minReplication = 1 19/12/29 01:22:26 INFO blockmanagement.BlockManager: maxReplicationStreams = 2 19/12/29 01:22:26 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false 19/12/29 01:22:26 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000 19/12/29 01:22:26 INFO blockmanagement.BlockManager: encryptDataTransfer = false 19/12/29 01:22:26 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 19/12/29 01:22:26 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE) 19/12/29 01:22:26 INFO namenode.FSNamesystem: supergroup = supergroup 19/12/29 01:22:26 INFO namenode.FSNamesystem: isPermissionEnabled = false 19/12/29 01:22:26 INFO namenode.FSNamesystem: Determined nameservice ID: ns 19/12/29 01:22:26 INFO namenode.FSNamesystem: HA Enabled: true 19/12/29 01:22:26 INFO namenode.FSNamesystem: Append Enabled: true 19/12/29 01:22:27 INFO util.GSet: Computing capacity for map INodeMap 19/12/29 01:22:27 INFO util.GSet: VM type = 64-bit 19/12/29 01:22:27 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB 19/12/29 01:22:27 INFO util.GSet: capacity = 2^20 = 1048576 entries 19/12/29 01:22:27 INFO namenode.FSDirectory: ACLs enabled? false 19/12/29 01:22:27 INFO namenode.FSDirectory: XAttrs enabled? true 19/12/29 01:22:27 INFO namenode.FSDirectory: Maximum size of an xattr: 16384 19/12/29 01:22:27 INFO namenode.NameNode: Caching file names occuring more than 10 times 19/12/29 01:22:27 INFO util.GSet: Computing capacity for map cachedBlocks 19/12/29 01:22:27 INFO util.GSet: VM type = 64-bit 19/12/29 01:22:27 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB 19/12/29 01:22:27 INFO util.GSet: capacity = 2^18 = 262144 entries 19/12/29 01:22:27 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 19/12/29 01:22:27 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0 19/12/29 01:22:27 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000 19/12/29 01:22:27 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 19/12/29 01:22:27 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 19/12/29 01:22:27 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 19/12/29 01:22:27 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 19/12/29 01:22:27 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 19/12/29 01:22:27 INFO util.GSet: Computing capacity for map NameNodeRetryCache 19/12/29 01:22:27 INFO util.GSet: VM type = 64-bit 19/12/29 01:22:27 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB 19/12/29 01:22:27 INFO util.GSet: capacity = 2^15 = 32768 entries 19/12/29 01:22:28 INFO namenode.FSImage: Allocated new BlockPoolId: BP-880978136-192.168.200.140-1577553748138
# 格式化成功 19/12/29 01:22:28 INFO common.Storage: Storage directory /home/software/hadoop-2.7.1/tmp/hdfs/name has been successfully formatted. 19/12/29 01:22:28 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 19/12/29 01:22:28 INFO util.ExitUtil: Exiting with status 0 19/12/29 01:22:28 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop01/192.168.200.140 ************************************************************/ You have new mail in /var/spool/mail/root
第一个节点启动namenode
[root@hadoop01 /home/software/hadoop-2.7.1/sbin]# ./hadoop-daemon start namenode
第二个节点格式化namenode
第二个节点也格式化namenode,其为standby状态。
[root@hadoop02 /home/software/hadoop-2.7.1/sbin]# hdfs namenode -bootstrapStandby 19/12/29 01:26:42 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hadoop02/192.168.200.150 STARTUP_MSG: args = [-bootstrapStandby] STARTUP_MSG: version = 2.7.1 ...省略 STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a; compiled by 'jenkins' on 2015-06-29T06:04Z STARTUP_MSG: java = 1.8.0_181 ************************************************************/ 19/12/29 01:26:42 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 19/12/29 01:26:42 INFO namenode.NameNode: createNameNode [-bootstrapStandby] 19/12/29 01:26:43 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable ===================================================== About to bootstrap Standby ID nn2 from: Nameservice ID: ns Other Namenode ID: nn1 Other NN's HTTP address: http://hadoop01:50070 Other NN's IPC address: hadoop01/192.168.200.140:9000 Namespace ID: 2053051572 Block pool ID: BP-880978136-192.168.200.140-1577553748138 Cluster ID: CID-0deff869-4530-4fc5-a9e9-10babaaa7d48 Layout version: -63 isUpgradeFinalized: true =====================================================
# 第二个nn格式化成功 19/12/29 01:26:43 INFO common.Storage: Storage directory /home/software/hadoop-2.7.1/tmp/hdfs/name has been successfully formatted. 19/12/29 01:26:44 INFO namenode.TransferFsImage: Opening connection to http://hadoop01:50070/imagetransfer?getimage=1&txid=0&storageInfo=-63:2053051572:0:CID-0deff869-4530-4fc5-a9e9-10babaaa7d48 19/12/29 01:26:44 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds 19/12/29 01:26:44 INFO namenode.TransferFsImage: Transfer took 0.00s at 0.00 KB/s 19/12/29 01:26:44 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 351 bytes. 19/12/29 01:26:44 INFO util.ExitUtil: Exiting with status 0 19/12/29 01:26:44 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop02/192.168.200.150 ************************************************************/
第二个节点启动namenode
[root@hadoop02 /home/software/hadoop-2.7.1/sbin]# ./hadoop-daemon.sh start namenode
三个节点启动datanode
[root@hadoop01 /home/software/hadoop-2.7.1/sbin]# ./hadoop-daemon.sh start datanode
第一个节点和第二个节点启动故障转移进程
启动故障转移进程后,web界面能查看到节点1上的hadoop为active,节点2上为standby。
[root@hadoop01 /home/software/hadoop-2.7.1/sbin]# ./hadoop-daemon.sh start zkfc [root@hadoop02 /home/software/hadoop-2.7.1/sbin]# ./hadoop-daemon.sh start zkfc
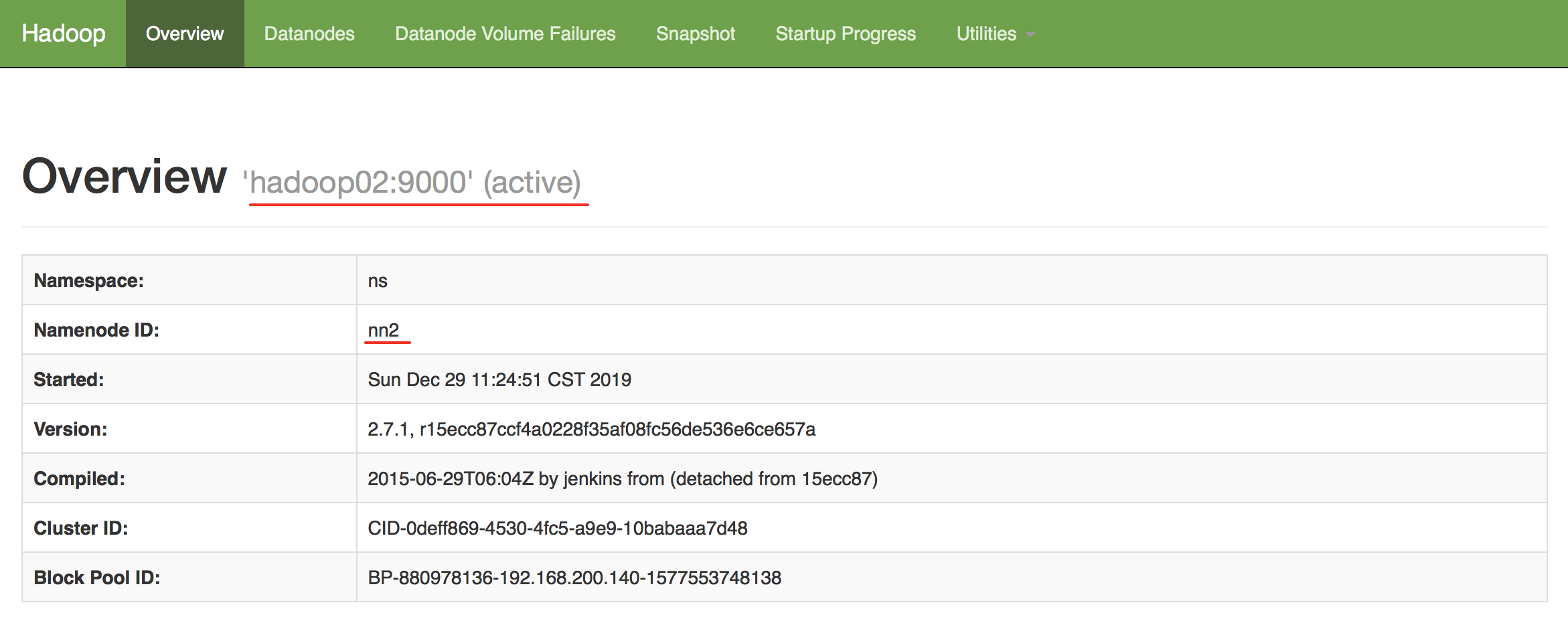
WEB界面查看效果,现在是节点2在对外提供服务,状态为active。
第三个节点启动yarn
第三个节点前面配置为resourcemanager的主节点,启动。
[root@hadoop03 /home/software/hadoop-2.7.1/sbin]# ./start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-resourcemanager-hadoop03.out hadoop01: starting nodemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-nodemanager-hadoop01.out hadoop02: starting nodemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-nodemanager-hadoop02.out hadoop03: starting nodemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-nodemanager-hadoop03.out
第一个节点单独启动resouceManager
[root@hadoop01 /home/software/hadoop-2.7.1/sbin]# ./yarn-daemon.sh start resourcemanager
检查最后节点信息
最后检查节点,如果三个节点信息如下,说明安装ok。
节点1
[root@hadoop01 /home/software/hadoop-2.7.1/sbin]# jps 2833 Jps 2756 ResourceManager 2548 NodeManager 2293 DataNode 1510 QuorumPeerMain 1879 JournalNode 2425 DFSZKFailoverController 2074 NameNode
节点2
[root@hadoop02 /home/software/hadoop-2.7.1/sbin]# jps 2388 DFSZKFailoverController 1526 QuorumPeerMain 2246 DataNode 1895 JournalNode 2106 NameNode 2668 Jps 2495 NodeManager
节点3
[root@hadoop03 /home/software/hadoop-2.7.1/sbin]# jps 2209 ResourceManager 1859 JournalNode 2311 NodeManager 1544 QuorumPeerMain 2041 DataNode 2655 Jps
关闭节点
在节点1上使用stop-all.sh来关闭节点。
[root@hadoop01 /home/software/hadoop-2.7.1/sbin]# stop-all.sh This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh 19/12/29 01:38:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Stopping namenodes on [hadoop01 hadoop02] hadoop02: stopping namenode hadoop01: stopping namenode hadoop02: stopping datanode hadoop01: stopping datanode hadoop03: stopping datanode Stopping journal nodes [hadoop01 hadoop02 hadoop03] hadoop02: stopping journalnode hadoop01: stopping journalnode hadoop03: stopping journalnode 19/12/29 01:39:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Stopping ZK Failover Controllers on NN hosts [hadoop01 hadoop02] hadoop02: stopping zkfc hadoop01: stopping zkfc stopping yarn daemons stopping resourcemanager hadoop01: stopping nodemanager hadoop03: stopping nodemanager hadoop02: stopping nodemanager no proxyserver to stop
关闭后三个节点的信息,zk的进程还保留,还有节点3上的rm进程保留。
# 节点1 [root@hadoop01 /home/software/hadoop-2.7.1/sbin]# jps 1510 QuorumPeerMain 3448 Jps # 节点2 [root@hadoop02 /home/software/hadoop-2.7.1/sbin]# jps 1526 QuorumPeerMain 2905 Jps # 节点3 [root@hadoop03 /home/software/hadoop-2.7.1/sbin]# jps 2817 Jps 2209 ResourceManager 1544 QuorumPeerMain
开启所有节点
在节点1上使用start-all.sh,可以将关闭的节点全部重新启动,无需单个命令启动。
[root@hadoop01 /home/software/hadoop-2.7.1/sbin]# start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh 19/12/29 01:43:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [hadoop01 hadoop02] hadoop02: starting namenode, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-namenode-hadoop02.out hadoop01: starting namenode, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-namenode-hadoop01.out hadoop02: starting datanode, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-datanode-hadoop02.out hadoop01: starting datanode, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-datanode-hadoop01.out hadoop03: starting datanode, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-datanode-hadoop03.out Starting journal nodes [hadoop01 hadoop02 hadoop03] hadoop03: starting journalnode, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-journalnode-hadoop03.out hadoop02: starting journalnode, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-journalnode-hadoop02.out hadoop01: starting journalnode, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-journalnode-hadoop01.out 19/12/29 01:43:31 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting ZK Failover Controllers on NN hosts [hadoop01 hadoop02] hadoop01: starting zkfc, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-zkfc-hadoop01.out hadoop02: starting zkfc, logging to /home/software/hadoop-2.7.1/logs/hadoop-root-zkfc-hadoop02.out starting yarn daemons starting resourcemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-resourcemanager-hadoop01.out hadoop01: starting nodemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-nodemanager-hadoop01.out hadoop02: starting nodemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-nodemanager-hadoop02.out hadoop03: starting nodemanager, logging to /home/software/hadoop-2.7.1/logs/yarn-root-nodemanager-hadoop03.out
这样所有关闭节点又重新启动,以上就是完全分布式hadoop集群在三个节点上的安装过程,尝试启动后上传一个文件到集群,发现上传到了active的节点里,standby的节点提示不可以访问。
[root@hadoop01 /home]# hadoop fs -put book.txt / 19/12/29 11:32:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable You have new mail in /var/spool/mail/root
# 上传到了节点2 [root@hadoop01 /home]# hadoop fs -ls / 19/12/29 11:32:39 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 1 items -rw-r--r-- 3 root supergroup 18 2019-12-29 11:32 /book.txt
standby的节点提示不可以访问,数据可以在active的节点上查看到。

以上就是安装和初步使用过程,记录下后面使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号