B-tree&哈夫曼算法
接下来学习B-tree和哈夫曼算法,只是浅显的了解一下。
B-Tree
B-tree就是balanced tree,即多路平衡查找树,其相比于上次学习的二叉查找树有很多优点,初步的映象就是能存储更多的数据,在做磁盘IO时一次读取一个page的数据时能返回更多有用的信息,而二叉查找树则比较浪费空间,一次IO返回的数据量太少,相比B-Tree,二叉查找树有如下缺陷和不足,部分参考了湖南泡咕学院seven老师的总结。
二叉树的不足
(1)搜索效率不足
二叉树一个结点存储的数据量有限,因此用二叉树保存同样体量数据会导致树深度很高,而在树结构中,数据所处的深度决定了它搜索时IO的次数。
(2)结点内容太少
每个磁盘块(结点/page)保存的关键字数据量太少了。没有很好的利用操作系统和磁盘的数据交换特性,以及磁盘的预读能力(空间局部性原理)。
以上缺陷导致二叉树没有成为MySql索引的选择,MySql索引选择B+Tree,B+Tree是B-Tree的一种变种,首先了解B-Tree对理解B+Tree会有帮助,后续再完善。
M阶B-Tree重要特性
(1)结点最多含有M棵子树(指针,指向子结点的引用),最多含有M-1个关键字(存的数据),M>=2,及至少是2阶B-Tree。
(2)除了根结点和叶子结点外,其余结点至少有Ceil(M/2)个子结点,Ceil为向上取整,如3阶B-Tree其余结点至少有2个子结点,4阶至少有2个子结点,5阶至少有3个子结点。
(3)若根结点不是叶子结点,则至少有2棵子树。
如下图为一个5阶的B-Tree,可以看出除了根结点和叶子结点外,中间的结点至少有3个子结点。
插入16后:
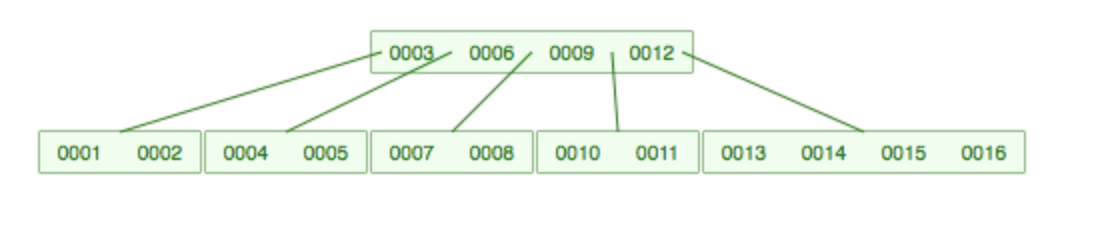
插入17,15上移,分裂:
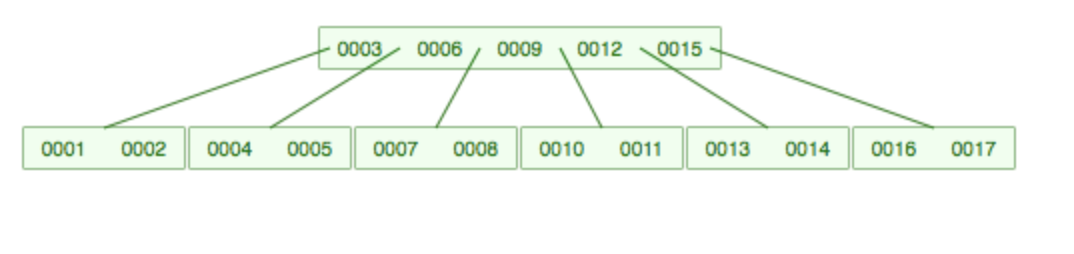
9上移,分裂,这样中间结点有3个子结点至少:
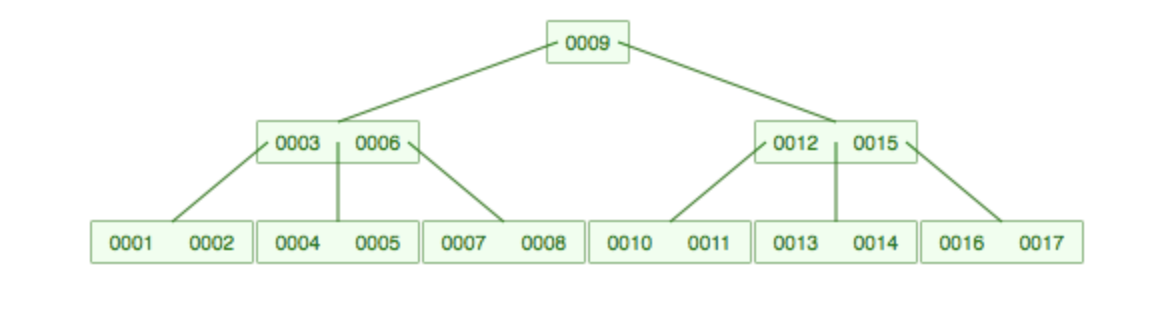
从上面的分裂可以看出来:
(1)如果M为奇数,中间某个结点在不断合并后,其最多有M个子路,当再次合并达到M+1条子路时,这个结点会分裂,其中一个数字上升到上层结点分成两路,因此左右各有(M+1)/2个子路,即等于Ceil(M/2)。
(2)如果M为偶数,同理分裂时,有M+1路等待2分,由于M+1是奇数,只能拆分一个偶数,一个奇数,因此一个为(M-1)/2条子结点,一个为(M+1)/2个子结点,至少为(M-1)/2个子路,即等于Ceil(M/2)。
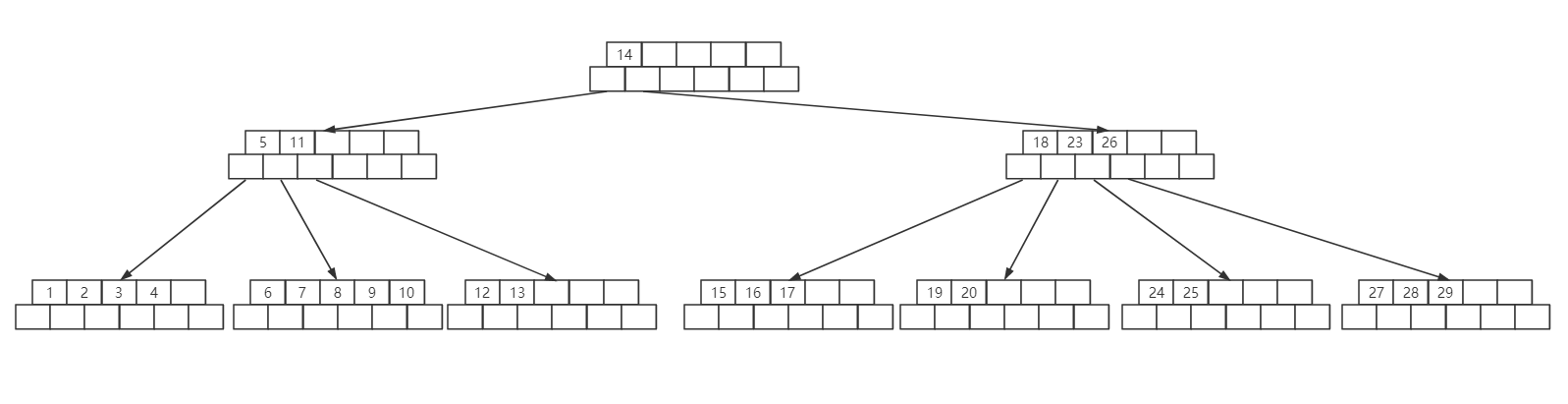
首先看下图一棵B-Tree,是一颗6阶的B-Tree简化样子,其跟二叉树类似,只是结点里的内容更多了,相比二叉树一个结点的只有一个数据,还有一个指向左子树的引用和右子树的引用后,就没有其他了。但如果是B-Tree,一个结点包含的内容更加的丰富。

如果要画上面6阶B-Tree的完整样子,简单就是如下的样子,这个图也是下面测试案例图,可以作为参考。
B-Tree构建
以下为将数字插入构建一颗B-Tree的代码,写的过程有参考子龙老师对结点属性的定义,但是构建思路基本完全不一样,过程有点痛苦花的时间也比较久,在不断修改调试中成功了,小小记录一下,大体思路如下:
(1)根据动画演示,可以看出数字插入时会先往下沉,直到达到最底端的子结点,因此写一个方法实现到达子结点。
(2)如果子结点(位置可能是最底端、中间、根都有可能)没有位置插入了,将会分裂,因此写一个方法实现子结点的分裂。
(3)分裂完成后,必然有一个数字会往上面父结点走,往父结点插入,如果能插入就直接插入,否则继续将父结点分裂,这里就需要迭代。
1 import java.util.Arrays; 2 import java.util.HashMap; 3 import java.util.Map; 4 5 /** 6 * B-Tree结点信息比较多,包含关键字,指向子结点的引用等 7 * @author yangchaolin 8 */ 9 class BtreeNode { 10 //属性 11 int M;//表示B-Tree的阶 12 int[] key;//关键字所在的数组 13 BtreeNode[] childs;//指向子结点的引用数组 14 int count;//一个结点中关键字的实际数量,因为一个结点不一定填满,所以这个数是变化的 15 boolean isLeaf;//是否是叶子结点 16 BtreeNode parent;//父结点 17 18 //构造方法 19 public BtreeNode(int m) { 20 this.M = m; 21 this.key = new int[m - 1]; 22 this.childs = new BtreeNode[m]; 23 this.count = 0; 24 this.isLeaf = true;//创建时默认为叶子结点 25 this.parent = null;//一个结点只有一个父结点 26 } 27 28 //重写测试用 29 @Override 30 public String toString() { 31 return "BtreeNode{" + 32 "M=" + M + 33 ", count=" + count + 34 ", isLeaf=" + isLeaf + 35 '}'; 36 } 37 } 38 39 /** 40 * 实现Btree插入数据功能 41 */ 42 public class BTree { 43 int M;//阶 44 BtreeNode root;//根结点 45 46 //构造方法 47 public BTree(int m) { 48 this.M = m; 49 root = new BtreeNode(m);//刚开始root结点是一个没有任何数据和子结点引用的空壳 50 } 51 52 //插入关键字数据到结点的过程中,寻找底层叶子结点,迭代过程 53 public BtreeNode insertKey(BtreeNode node, int key) { 54 //一种是插入到叶子结点 55 if (node.isLeaf) { 56 int sum = node.count; 57 int index = sum - 1;//最后的索引位置 58 //如果叶子结点没满 59 if (sum < M - 1) { 60 //平移比key大的数往后移动一位 61 while (index >= 0 && node.key[index] > key) { 62 node.key[index + 1] = node.key[index]; 63 index--; 64 } 65 //到了这里,说明目前index对应的数字比key小 66 node.key[index + 1] = key; 67 node.count++; 68 return null; 69 } 70 return node; 71 } else { 72 //先找到支路,再往下走 73 int index = 0;//key中的index 74 while (index <= node.count - 1 && key > node.key[index]) { 75 index++; 76 } 77 //此时的key[index]对应的数比key大,往左边走 78 if (node.childs[index].childs[0] == null) { 79 return node.childs[index]; 80 } else { 81 return insertKey(node.childs[index], key); 82 } 83 } 84 } 85 86 //根据子结点和插入的数进行插入,插入完成就返回null,否则返回必要信息,等待下一次插入 87 public Object[] splitNode(BtreeNode childNode, int key) { 88 Object[] returnObj = new Object[2]; 89 90 //如果childNode是根结点,并且插入key就满了 91 if (childNode.parent == null && childNode.count == M - 1) { 92 BtreeNode newBtreeNode = new BtreeNode(M); 93 newBtreeNode.isLeaf = false; 94 Object[] obj = getSplitResult(childNode, key); 95 BtreeNode leftNode = (BtreeNode) obj[0]; 96 BtreeNode rightNode = (BtreeNode) obj[1]; 97 newBtreeNode.childs[0] = leftNode; 98 newBtreeNode.childs[1] = rightNode; 99 newBtreeNode.key[0] = (int) obj[2]; 100 newBtreeNode.count = 1; 101 leftNode.parent = newBtreeNode; 102 rightNode.parent = newBtreeNode; 103 root = newBtreeNode; 104 return null; 105 } 106 107 //如果childNode非根结点,分析整段代码,能执行到这里,说明需要插入数字到叶子结点 108 if (childNode.count < M - 1 && childNode.isLeaf) { 109 int index = 0; 110 while (index <= childNode.count - 1 && key > childNode.key[index]) { 111 index++; 112 } 113 //System.out.println(index); 114 //到这里,key比childNode.key[index]小 115 int count = childNode.count; 116 childNode.count = count + 1; 117 for (int i = count - 1; i >= index; i--) { 118 childNode.key[i + 1] = childNode.key[i]; 119 } 120 childNode.key[index] = key; 121 childNode.count = count + 1; 122 return null; 123 } 124 //如果子结点满了 125 if (childNode.count == M - 1) { 126 Object[] obj = getSplitResult(childNode, key); 127 BtreeNode leftNode = (BtreeNode) obj[0]; 128 BtreeNode rightNode = (BtreeNode) obj[1]; 129 int newKey = (int) obj[2]; 130 BtreeNode parentNode = childNode.parent; 131 //遍历父结点,找到插入的位置 132 int index = 0; 133 for (int i = 0; i < M; i++) { 134 if (parentNode.childs[i] == childNode) { 135 index = i; 136 break; 137 } 138 } 139 //此时的parentNode.childs[index]对应的分支,将上来一个数字插入关键字&子结点 140 if (parentNode.count < M - 1) { 141 //关键字移动 142 for (int i = parentNode.count - 1; i >= index; i--) { 143 parentNode.key[i + 1] = parentNode.key[i]; 144 } 145 //右子结点移动 146 for (int i = parentNode.count; i >= index + 1; i--) { 147 parentNode.childs[i + 1] = parentNode.childs[i]; 148 } 149 parentNode.count = parentNode.count + 1; 150 parentNode.childs[index] = leftNode; 151 parentNode.childs[index + 1] = rightNode; 152 parentNode.key[index] = newKey; 153 leftNode.parent = parentNode; 154 rightNode.parent = parentNode; 155 parentNode.isLeaf = false; 156 return null; 157 } else if (parentNode.count == M - 1) { 158 //到了这里就越来越接近BTree,但有点问题,原来分裂后的两个子结点还没做处理,将其返回 159 returnObj = new Object[]{parentNode, newKey,leftNode,rightNode}; 160 } 161 } 162 return returnObj; 163 } 164 167 //得到分裂后的信息,包括两个字结点,以及新产生的关键字 168 public Object[] getSplitResult(BtreeNode childNode, int key) { 169 Object[] obj = new Object[3]; 170 //新建一个临时结点,保存分裂后右边的数据 171 BtreeNode tempNode = new BtreeNode(M); 172 //设置临时结点isLeaf属性 173 tempNode.isLeaf = childNode.isLeaf; 174 int position = M / 2 - 1;//分裂点选择索引M/2-1的位置 175 //分裂前先排序 176 int[] arr = new int[childNode.count + 1]; 177 System.arraycopy(childNode.key, 0, arr, 0, childNode.count); 178 arr[childNode.count] = key; 179 Arrays.sort(arr); 180 //取出需要上移动的数字 181 obj[2] = arr[arr.length / 2 - 1]; 182 int temp = arr[arr.length / 2 - 1]; 183 arr[arr.length / 2 - 1] = arr[arr.length - 1]; 184 arr[arr.length - 1] = temp; 185 int[] newArr = new int[childNode.count]; 186 System.arraycopy(arr, 0, newArr, 0, newArr.length); 187 Arrays.sort(newArr); 188 189 //newArr的0~arr.length/2-2的作为左子树,arr.length/2-1~newArr.length-1作为右子树 190 for (int i = 0; i < arr.length / 2 - 1; i++) { 191 childNode.key[i] = newArr[i]; 192 } 193 for (int i = arr.length / 2 - 1; i < M - 1; i++) { 194 childNode.key[i] = 0; 195 } 196 childNode.count = arr.length / 2 - 1; 197 for (int i = 0; i < newArr.length - arr.length / 2 + 1; i++) { 198 tempNode.key[i] = newArr[i + arr.length / 2 - 1]; 199 } 200 tempNode.count = newArr.length - arr.length / 2 + 1; 201 //如果子结点还有分支,将对应分支保存到临时结点 202 if (!childNode.isLeaf) { 203 for (int i = 0; i < M - position - 2; i++) { 204 tempNode.childs[i] = childNode.childs[i + position + 1]; 205 } 206 } 207 //将原来子结点的分裂出去的数据重置为默认 208 for (int i = position + 1; i < M; i++) { 209 childNode.childs[i] = null; 210 } 211 //判断子结点是否是叶子结点 212 if (childNode.childs[0] == null) { 213 childNode.isLeaf = true; 214 } else { 215 childNode.isLeaf = false; 216 } 217 obj[0] = childNode; 218 obj[1] = tempNode; 219 return obj; 220 } 221 222 //在B-Tree中寻找某个key,返回包含这个key的子结点,不包含子结点的树结点 223 public BtreeNode search(BtreeNode root, int key) { 224 int i = 0; 225 while (i < root.count && key > root.key[i]) { 226 i++; 227 } 228 //如果在root结点中找到 229 if (i <= root.count && key == root.key[i]) { 230 return root; 231 } 232 //如果到了叶子结点还没找到这个key,则返回null,说明没有对应结点 233 if (root.isLeaf) { 234 return null; 235 } else { 236 //没到叶子结点,则继续搜下一层,如果找到,从下面结点往上面逐一返回结果 237 return search(root.childs[i], key); 238 } 239 } 240 241 //插入数字到BTree 242 public void insertTree(BTree tree, int key) { 243 BtreeNode root = tree.root; 244 BtreeNode leafNode = insertKey(root, key); 245 if (leafNode != null) { 246 Object[] obj = splitNode(leafNode, key); 247 while (obj != null) { 248 BtreeNode newLeafNode = (BtreeNode) obj[0]; 249 int newKey = (int) obj[1]; 250 BtreeNode left=(BtreeNode) obj[2]; 251 BtreeNode right=(BtreeNode) obj[3]; 252 obj = splitNode(newLeafNode, newKey); 253 //关键部分:将未做处理的两个子结点插入到对应结点 254 BtreeNode node=search(tree.root,newKey); 255 int index=0; 256 while(index<=node.count-1&&newKey>node.key[index]){ 257 index++; 258 } 259 node.childs[index]=left; 260 node.childs[index+1]=right; 261 left.parent=node; 262 right.parent=node; 263 } 264 } 265 } 266 267 //打印BTree 268 public void print(BtreeNode node) { 269 for (int i = 0; i < node.count; i++) { 270 System.out.print(node.key[i] + " "); 271 } 272 if (!node.isLeaf) { 273 for (int j = 0; j <= node.count; j++) { 274 if (node.childs[j] != null) { 275 System.out.println(); 276 print(node.childs[j]); 277 } 278 } 279 } 280 } 281 }
再写插入的过程中,碰到了数字插入的当前结点满了,分裂后的数字往上父结点走时,父结点继续是满的情况。最开始的代码会导致丢失分裂的子结点。在最后插入29到子结点{24,25,26,27,28}时,26必然会上移动到父结点{5,11,14,18,23},这种情况下先分裂{24,25,26,27,28}将上移动26到父结点{5,11,14,18,23},然后继续分裂,最后的结果是{24,25}和{27,28,29}丢失了。后面修改了splitNode方法,将丢失的子结点作为方法的返回内容,在父结点{5,11,14,18,23}分裂完成后,用方法找到26对应的结点,然后将{24,25}和{27,28,29}添加到其左右子树才算解决这个问题。
以下为测试代码,将如下数组里的数字插入到B-Tree。
1 public class TestBtree { 2 3 public static void main(String[] args) { 4 5 Btree tree=new Btree(6); 6 int arr[ ] = {3,14,7,1,8,5,11,17,13,6,23,12,20,26,4,16,18,24,25,19,9,10,15,27,28,2,29}; 7 for (int i = 0; i < arr.length; i++) { 8 tree.insertTree(tree, arr[i]); 9 System.out.println(arr[i] + "插入后的Btree"); 10 tree.print(tree.root); 11 System.out.println(); 12 System.out.println("----------"); 13 } 14 } 15 }
控制台测试结果,可以看出构建出一颗和上图一样的B-Tree,测试OK。

最优二叉树
最优二叉树是带权路径长度总和最小的树,所谓带权路径,指的是叶子结点的权重乘以叶子结点到根结点所经过的路线(几条线到根结点),以下有三棵树,可以分别计算a,b,c,d的带权路径总和,其中a的权重为7,b的权重为5,c的权重为2,d的权重为4。
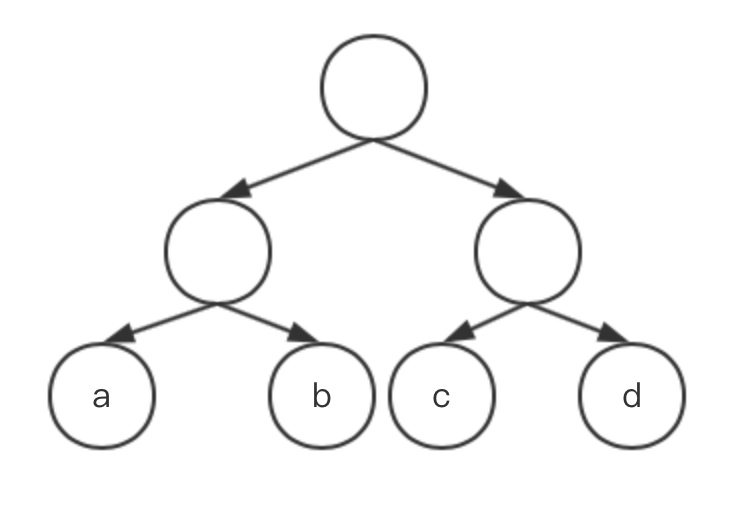
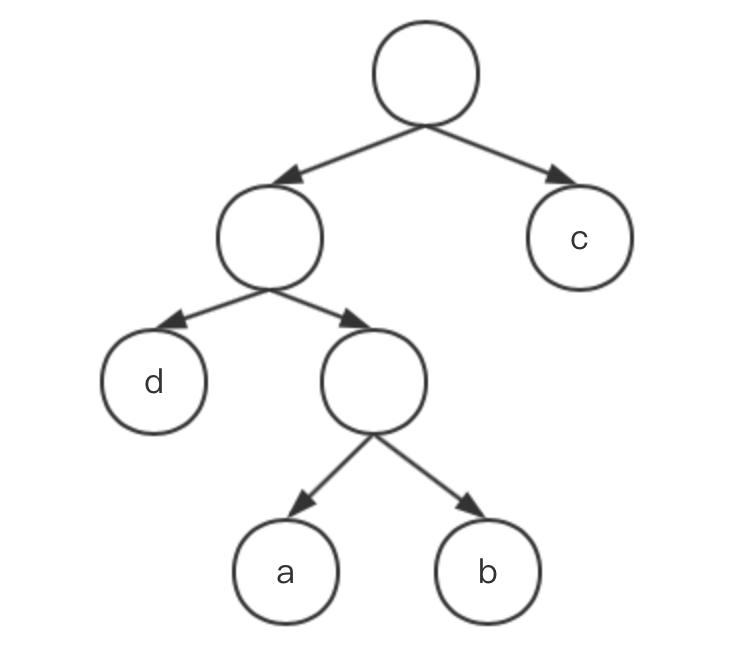

图1权重总和:WPL=7*2+5*2+2*2+4*2=36
图2权重总和:WPL=7*3+5*3+2*1+4*2=46
图3权重总和:WPL=7*1+5*2+2*3+4*3=35
图3的权重总和最小,其即为最优二叉树。
哈夫曼算法
什么是哈夫曼树
哈夫曼树其实就是一种最优二叉树,使用的构造算法叫做哈夫曼算法(也叫霍夫曼算法),主要用于编码和解码,由哈夫曼在1952年提出,其可以让字符变成更加节省空间的二进制数字,不需要字符原本那么多位,其为一种优秀的编码算法,可以应用于电报密文传输。一般以一本书的字分别出现的次数作为权重,构造出一颗哈夫曼树,然后使用哈夫曼树的编码来完成对字符的重新编码加密,如果改变树中某一个字符的权重,整颗哈夫曼树的结构就会进行调整。
哈夫曼树构建完成后,叶子结点到根结点的路径上,如果在左侧则为0,在右侧则为1,这样发现每个字符有不同的路径,则对应不同的码,哈夫曼树产生的编码,不会造成解码的二义性,即任何一个字符的编码,都不会以另外任意一个字符的编码作为前缀编码。比如下面控制台的例子先拿出来,随便拿一个B的编码0010,发现其他字符没有以0开头的,也没有以00开头的,也没有以001开头的,就是这个意思。

哈夫曼树构建
以下为实现构建一颗哈夫曼树,并完成编码和解码,其中解码是自己写的,编码是参考子龙老师的思路写的。
1 import java.util.ArrayList; 2 import java.util.HashMap; 3 import java.util.Iterator; 4 import java.util.List; 5 import java.util.Map; 6 import java.util.PriorityQueue; 7 import java.util.Set; 8 9 //创建结点类,实现Comparable接口,可以实现按照权重自然排序 10 class Node implements Comparable<Node>{ 11 //节点属性 12 private String chars="";//结点处对应字符 13 //weight为权重,一般代表这个字符出现的概率,越大代表权重越高,霍夫曼树构造完成后权重越高的字符编码越短,反之则越长 14 //这样的好处是,用的多的字符编码短,用的少的字符编码长,总的来看,在传输过程中提高了传输效率并节省空间 15 private int weight; 16 private Node leftNode;//左子结点 17 private Node rightNode;//右子结点 18 private Node parentNode;//父结点 19 20 //get set方法 21 public String getChars() { 22 return chars; 23 } 24 public void setChars(String chars) { 25 this.chars = chars; 26 } 27 public int getWeight() { 28 return weight; 29 } 30 public void setWeight(int weight) { 31 this.weight = weight; 32 } 33 public Node getLeftNode() { 34 return leftNode; 35 } 36 public void setLeftNode(Node leftNode) { 37 this.leftNode = leftNode; 38 } 39 public Node getRightNode() { 40 return rightNode; 41 } 42 public void setRightNode(Node rightNode) { 43 this.rightNode = rightNode; 44 } 45 public Node getParentNode() { 46 return parentNode; 47 } 48 public void setParentNode(Node parentNode) { 49 this.parentNode = parentNode; 50 } 51 52 //重写接口方法 53 @Override 54 public int compareTo(Node o) { 55 //自然排序 56 if(this.weight>o.weight){ 57 return 1; 58 } 59 if(this.weight<o.weight){ 60 return -1; 61 } 62 return 0; 63 } 64 } 65 /** 66 * 霍夫曼树的构造 67 * (1)如何创建一颗霍夫曼树 68 * (2)如何遍历叶子结点,得到对应字符的编码 69 * (3)如何根据给定编码,进行解码 70 */ 71 public class HuffmanTree { 72 //属性 73 private Node root;//根节点 74 private List<Node> leaves;//保存叶子结点的集合,在创建完树后会编织在一起,刚开始彼此独立,只包含字符和权重信息 75 private Map<Character,Integer> weight;//字符的权重信息,这里使用了包装类 76 //构造方法 77 public HuffmanTree(Map<Character, Integer> weight) { 78 this.leaves=new ArrayList<Node>(); 79 this.weight = weight; 80 } 81 //构建霍夫曼树,其实就是使用了贪心算法,先将结点按照权重从小到大排,然后将最小的两个拿出来,组合成一颗二叉树, 82 //父结点的权重值为这两个子结点之和,然后这个父结点作为新的'叶子结点',继续参与后面的比较和构建,继续组合二叉树。 83 public void createTree(){ 84 //先将结点存入最小优先队列:无论存入的顺序,最小的元素先出队列 85 PriorityQueue<Node> queue=new PriorityQueue<Node>(); 86 //遍历Map,返回key,即字符 87 Character[] keys=weight.keySet().toArray(new Character[0]);//参数作用是让set集合dump为一个Character类型数组,看注释应该是固定写法。 88 for(Character c:keys){ 89 Node node=new Node(); 90 node.setChars(c.toString());//key-字符 91 node.setWeight(weight.get(c));//value-权重 92 queue.add(node);//添加到队列 93 leaves.add(node);//添加到叶子结点集合 94 } 95 //然后遍历优先队列,每次取出2个最小权重的,组合成一颗二叉树,然后将新的结点放回队列,继续比较 96 int length=queue.size(); 97 for(int i=0;i<length-1;i++){ 98 //优先队列中有多少个结点,就比较结点数-1次,比较完就构建完 99 Node nodeLeft=queue.poll(); 100 Node nodeRight=queue.poll(); 101 Node fatherNode=new Node(); 102 fatherNode.setChars(nodeLeft.getChars()+nodeRight.getChars()); 103 fatherNode.setWeight(nodeLeft.getWeight()+nodeRight.getWeight()); 104 fatherNode.setLeftNode(nodeLeft); 105 fatherNode.setRightNode(nodeRight); 106 nodeLeft.setParentNode(fatherNode); 107 nodeRight.setParentNode(fatherNode); 108 queue.add(fatherNode); 109 } 110 System.out.println("霍夫曼树构建完成,leaves完成更新"); 111 root=queue.poll(); 112 } 113 114 //得到字符编码,保存到Map中 115 public Map<Character,String> getCharacterCode(){ 116 Map<Character,String> codeMap=new HashMap<Character,String>(); 117 for(Node leaf:leaves){ 118 Node currentNode=leaf; 119 Character c=new Character(leaf.getChars().charAt(0));//需保存到map中 120 String code="";//需保存到map中 121 do{ 122 //判断当前结点是左边还是右边 123 if(currentNode.getParentNode()!=null&¤tNode.getParentNode().getLeftNode()==currentNode){ 124 code="0"+code; 125 }else{ 126 code="1"+code; 127 } 128 //比较完一次后,结点上移动到父结点 129 currentNode=currentNode.getParentNode(); 130 }while(currentNode.getParentNode()!=null); 131 codeMap.put(c, code); 132 } 133 return codeMap; 134 } 135 136 //解码,默认用户输入的是'00010101010'这样的二进制数字,其他非法字符暂时不考虑,只考虑逻辑不考虑业务 137 public void decode(String code){ 138 String afterDecodeStr=""; 139 //得到编码Map 140 Map<Character,String> codeMap=getCharacterCode(); 141 //循环解码 142 char[] binaryCode=code.toCharArray(); 143 int index=0;//解码起始下标,如果一直往后遍历没找到匹配的,下标不变,否则下标更新到最新匹配到的位置 144 for(int i=1;i<=binaryCode.length;i++){ 145 if(index==binaryCode.length){ 146 return; 147 } 148 String buff=code.substring(index, i);//刚开始取待解码的第一个字符 149 //每个取出来的二进制字符,都和Map中的进行对比 150 Set keySet=codeMap.keySet(); 151 Iterator it=keySet.iterator(); 152 boolean flag=false; 153 while(it.hasNext()){ 154 Character c=new Character((Character) it.next()); 155 //如果匹配编码 156 if(codeMap.get(c).equals(buff)){ 157 afterDecodeStr+=c; 158 flag=true; 159 break; 160 } 161 } 162 //有匹配,更新index 163 if(flag){ 164 index=i; 165 } 166 } 167 System.out.println("解码后的结果为:"+afterDecodeStr); 168 } 169 170 //测试 171 public static void main(String[] args) { 172 Map<Character,Integer> weight=new HashMap<Character,Integer>(); 173 weight.put('L', 520); 174 weight.put('O', 912); 175 weight.put('V', 26); 176 weight.put('E', 30); 177 weight.put('B',22); 178 HuffmanTree tree=new HuffmanTree(weight); 179 tree.createTree(); 180 Map<Character,String> code=new HashMap<Character,String>(); 181 code=tree.getCharacterCode(); 182 //输出编码 183 System.out.println("L:"+code.get('L')); 184 System.out.println("O:"+code.get('O')); 185 System.out.println("V:"+code.get('V')); 186 System.out.println("E:"+code.get('E')); 187 System.out.println("B:"+code.get('B')); 188 //解码测试 189 String myCode="011001100000101000"; 190 tree.decode(myCode); 191 } 192 }
控制台输出情况,可以看到可以正确的对L,O,V,E,B五个字符进行编码,并对'011001100000101000'进行解码变成'LOVEBOE',如果是UTF-8的编码方式,一个英文字符占用1byte,即8bit,所以'LOVEBOE'应该是56个bit,但是使用霍夫曼编码得到的只有18个bit,这大大的节省了空间。
总结
(1)B-Tree类似二叉树,只是其度即分支更多,能储存更多的数据。在扫描磁盘同样区域大小的情况下能得到更多有用数据,因此B-Tree的变种B+tree一般作为MySql的索引。
(2)哈夫曼算法是一种优秀的算法,其主要理念就是将用得多的字符编码尽量变短,用得少的字符编码就变长,这样在传输的过程中可提高传输效率和节省空间。
参考博文:
(1)https://www.cnblogs.com/vianzhang/p/7922426.html B-tree
(2)https://blog.csdn.net/u013967628/article/details/84305511 B-tree
(3)https://blog.csdn.net/andyzhaojianhui/article/details/76988560 B-tree
(4)https://blog.csdn.net/kk55guang2/article/details/85223256 数据结构与算法
(5)https://blog.csdn.net/lanxu_yy/column/info/leetcode-solution LeetCode题解
(6)https://www.cs.usfca.edu/~galles/visualization/BTree.html BTree动画演示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号