Bigdata——Mapreduce编写
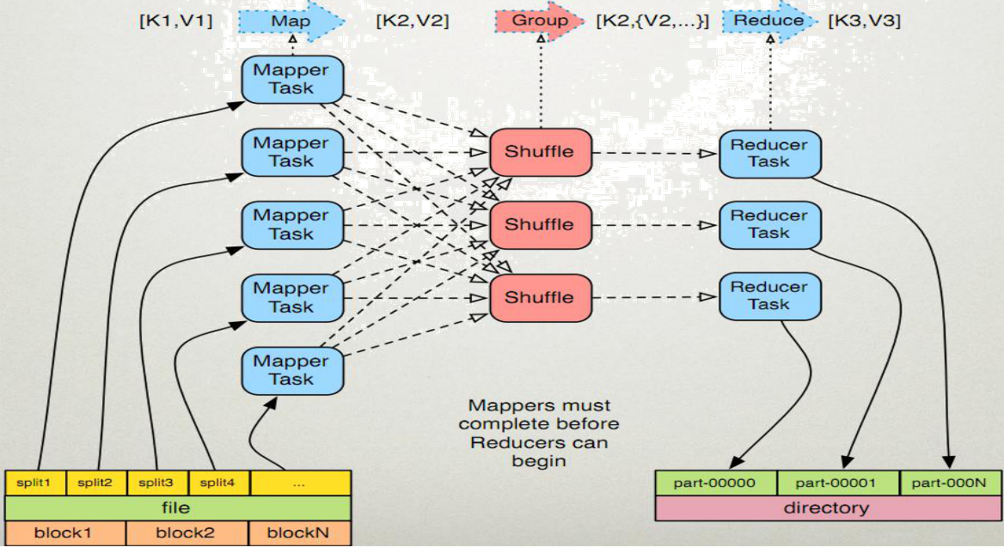
上图是MapReduce的任务处理过程
概述
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题. MapReduce是分布式运行的,由两个阶段组成:Map和Reduce,Map阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据。Reduce阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据【在这先把reduce理解为一个单独的聚合程序即可】。 MapReduce框架都有默认实现,用户只需要覆盖map()和reduce()两个函数,即可实现分布式计算,非常简单。 这两个函数的形参和返回值都是<key、value>,使用的时候一定要注意构造<k,v>。
Map
- 框架使用InputFormat类的子类把输入文件(夹)划分为很多InputSplit,默认,每个HDFS的block对应一个InputSplit。通过RecordReader类,把每个InputSplit解析成一个个<k1,v1>。默认,框架对每个InputSplit中的每一行,解析成一个<k1,v1>。
- 框架调用Mapper类中的map(...)函数,map函数的形参是<k1,v1>对,输出是<k2,v2>对。一个InputSplit对应一个map task。程序员可以覆盖map函数,实现自己的逻辑。
- (假设reduce存在)框架对map输出的<k2,v2>进行分区。不同的分区中的<k2,v2>由不同的reduce task处理。默认只有1个分区。 (假设reduce不存在)框架对map结果直接输出到HDFS中。
- (假设reduce存在)框架对每个分区中的数据,按照k2进行排序、分组。分组指的是相同k2的v2分成一个组。注意:分组不会减少<k2,v2>数量。
- (假设reduce存在,可选)在map节点,框架可以执行reduce归约。
- (假设reduce存在)框架会对map task输出的<k2,v2>写入到linux 的磁盘文件中。
Reduce
- 框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。这个过程称作shuffle。
- 框架对reduce端接收的[map任务输出的]相同分区的<k2,v2>数据进行合并、排序、分组。
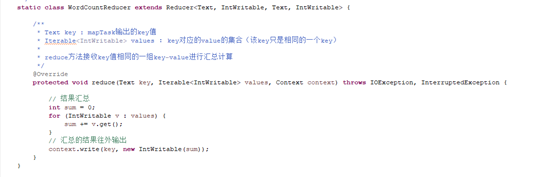
- 框架调用Reducer类中的reduce方法,reduce方法的形参是<k2,{v2...}>,输出是<k3,v3>。一个<k2,{v2...}>调用一次reduce函数。程序员可以覆盖reduce函数,实现自己的逻辑。
- 框架把reduce的输出保存到HDFS中。
Shuffle
- 每个map有一个环形内存缓冲区,用于存储map的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容溢写到(spill)磁盘的指定目录(mapred.local.dir)下的一个新建文件中。
- 写磁盘前,要partition,sort。如果有combiner,combine排序后数据。
- 等最后记录写完,合并全部文件为一个分区且排序的文件。
- Reducer通过Http方式得到输出文件的特定分区的数据。
- 排序阶段合并map输出。然后走Reduce阶段。
- reduce执行完之后,写入到HDFS中。
| Java基本类型 | Writable | 序列化大小(字节) |
|---|---|---|
| 布尔型(boolean) | BooleanWritable | 1 |
| 字节型(byte) | ByteWritable | 1 |
| 整型(int) | IntWritable | 4 |
| VIntWritable | 1-5 | |
| 浮点型(float) | FloatWritable | 4 |
| 长整型(long) | LongWritable | 8 |
| 双精度浮点型(double) | VLongWritable | 1-9 |
| DoubleWritable | 8 |
Demo:WordCount
1 public class WordCount { 2 /** 3 * 该main方法是该mapreduce程序运行的入口,其中用一个Job类对象来管理程序运行时所需要的很多参数: 4 * 比如,指定用哪个组件作为数据读取器、数据结果输出器 指定用哪个类作为map阶段的业务逻辑类,哪个类作为reduce阶段的业务逻辑类 5 * 指定wordcount job程序的jar包所在路径 .... 以及其他各种需要的参数 6 */ 7 public static void main(String[] args) throws Exception { 8 // 指定hdfs相关的参数 9 Configuration conf = new Configuration(); 10 11 // 手动设置,该MapReduce程序读取的数据来自于HDFS集群 12 conf.set("fs.defaultFS", "hdfs://master:9000"); 13 // 设置运行程序的用户是hadoop用户,就是安装hadoop集群的用户。如果该程序在Hadoop集群中使用hadoop用户进行运行,则可以去掉 14 System.setProperty("HADOOP_USER_NAME", "root"); 15 16 /** 17 * 以上的配置信息,事实上,在实际企业生产环境中,也可以使用conf.addResource方法进行加载。 18 * 当然如果配置文件的名字是core/hdfs/yarn/mapred-site/default.xml的话。 那么会自动加载的。 19 */ 20 // conf.addResource("hadoop_config/core-site.xml"); 21 // conf.addResource("hadoop_config/hdfs-site.xml"); 22 23 // 如果想让MR程序运行在特定的YARN集群之上,则可以使用一下代码,然后,这两信息,在安装集群的配置文件中都有配置的 24 // conf.set("mapreduce.framework.name", "yarn"); 25 // conf.set("yarn.resourcemanager.hostname", "node1"); 26 27 // 通过Configuration对象获取Job对象,该job对象会组织所有的该MapReduce程序所有的各种组件 28 Job job = Job.getInstance(conf); 29 30 // 设置jar包所在路径 31 job.setJarByClass(WordCount.class); 32 33 // 指定mapper类和reducer类 34 job.setMapperClass(WordCountMapper.class); 35 job.setReducerClass(WordCountReducer.class); 36 37 /** 38 * 指定maptask的输出类型 39 * Mapper的输入key-value类型,由MapReduce框架决定, 默认情况下就是 LongWritable和Text类型 40 * 41 * 假如 mapTask的输出key-value类型,跟reduceTask的输出key-value类型一致,那么,以上两句代码可以不用设置 42 */ 43 job.setMapOutputKeyClass(Text.class); 44 job.setMapOutputValueClass(IntWritable.class); 45 46 /** 47 * 指定reducetask的输出类型 48 * 如果reduceTask的输入key-value类型就是 mapTask的输出key-value类型。可以不需要指定 49 */ 50 job.setOutputKeyClass(Text.class); 51 job.setOutputValueClass(IntWritable.class); 52 53 // 为job指定输入数据的组件和输出数据的组件,以下两个参数是默认的,所以不指定也是OK的 54 job.setInputFormatClass(TextInputFormat.class); 55 job.setOutputFormatClass(TextOutputFormat.class); 56 57 // 为该mapreduce程序制定默认的数据分区组件。默认是 HashPartitioner.class 58 job.setPartitionerClass(HashPartitioner.class); 59 60 /** 61 * 指定该mapreduce程序数据的输入和输出路径: 62 * inputPath目录可以是文件,也可以是目录 63 * outputPath路径必须是不存在的目录 64 */ 65 Path inputPath = new Path("/bigdata/data.txt"); 66 Path outputPath = new Path("/output/wc"); 67 68 // 设置该MapReduce程序的ReduceTask的个数 69 // job.setNumReduceTasks(3); 70 71 // 该段代码是用来判断输出路径存在不存在,存在就删除,虽然方便操作,但请谨慎 72 FileSystem fs = FileSystem.get(conf); 73 if (fs.exists(outputPath)) { 74 fs.delete(outputPath, true); 75 } 76 77 // 设置wordcount程序的输入路径 78 FileInputFormat.setInputPaths(job, inputPath); 79 // 设置wordcount程序的输出路径 80 FileOutputFormat.setOutputPath(job, outputPath); 81 82 // job.submit(); 83 // 最后提交任务(verbose布尔值 决定要不要将运行进度信息输出给用户) 84 boolean waitForCompletion = job.waitForCompletion(true); 85 // 主线程程序根据MapReduce程序的运行结果成功与否退出。 86 System.exit(waitForCompletion ? 0 : 1); 87 } 88 89 /** 90 * Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 91 * 92 * KEYIN 是指框架读取到的数据的key的类型,在默认的InputFormat下,读到的key是一行文本的起始偏移量,所以key的类型是Long 93 * VALUEIN 是指框架读取到的数据的value的类型,在默认的InputFormat下,读到的value是一行文本的内容,所以value的类型是String 94 * KEYOUT 是指用户自定义逻辑方法返回的数据中key的类型,由用户业务逻辑决定,在此wordcount程序中,我们输出的key是单词,所以是String 95 * VALUEOUT 是指用户自定义逻辑方法返回的数据中value的类型,由用户业务逻辑决定,在此wordcount程序中,我们输出的value是单词的数量,所以是Integer 96 * 97 * 但是,String ,Long等jdk中自带的数据类型,在序列化时,效率比较低,hadoop为了提高序列化效率,自定义了一套序列化框架 98 * 所以,在hadoop的程序中,如果该数据需要进行序列化(写磁盘,或者网络传输),就一定要用实现了hadoop序列化框架的数据类型 99 * 100 * Long ----> LongWritable 101 * String ----> Text 102 * Integer ----> IntWritable 103 * Null ----> NullWritable 104 */ 105 static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { 106 107 /** 108 * LongWritable key : 该key就是value该行文本的在文件当中的起始偏移量 109 * Text value : 就是MapReduce框架默认的数据读取组件TextInputFormat读取文件当中的一行文本 110 */ 111 @Override 112 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 113 114 // 切分单词 115 String[] words = value.toString().split(","); 116 for (String word : words) { 117 // 每个单词计数一次,也就是把单词组织成<hello,1>这样的key-value对往外写出 118 context.write(new Text(word), new IntWritable(1)); 119 } 120 } 121 } 122 123 /** 124 * 首先,和前面一样,Reducer类也有输入和输出,输入就是Map阶段的处理结果,输出就是Reduce最后的输出 125 * reducetask在调我们写的reduce方法,reducetask应该收到了前一阶段(map阶段)中所有maptask输出的数据中的一部分 126 * (数据的key.hashcode%reducetask数==本reductask号),所以reducetaks的输入类型必须和maptask的输出类型一样 127 * 128 * reducetask将这些收到kv数据拿来处理时,是这样调用我们的reduce方法的: 先将自己收到的所有的kv对按照k分组(根据k是否相同) 129 * 将某一组kv中的第一个kv中的k传给reduce方法的key变量,把这一组kv中所有的v用一个迭代器传给reduce方法的变量values 130 */ 131 static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 132 133 /** 134 * Text key : mapTask输出的key值 135 * Iterable<IntWritable> values : key对应的value的集合(该key只是相同的一个key) 136 * 137 * reduce方法接收key值相同的一组key-value进行汇总计算 138 */ 139 @Override 140 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 141 142 // 结果汇总 143 int sum = 0; 144 for (IntWritable v : values) { 145 sum += v.get(); 146 } 147 // 汇总的结果往外输出 148 context.write(key, new IntWritable(sum)); 149 } 150 } 151 }
操作
创建项目
首先,需要将hadoop中的jar包导出来放到maven项目的库中,作为代码中类方法的引用。例如配置的读取、hdfs的读写接口、io输入输出流、mapreduce的相关类等。

主函数
主函数需要确定的很多。例如配置conf、jar调用时的主方法接口,map函数和reduce函数,以及文件输入输出的路径设置,还有key vlaue的类型。

Map函数
map函数很简单,主要做的就是切分的工作。

Reduce函数
reduce函数同样(但是并不是所有的编程都有reduce阶段,例如去重的过程中就没有reduce,shuffle对map的数据清洗生成的数据就不会有重复了)
打jar包


确定jar包名和位置 以及主类


运行
打完jar包传到虚拟机以后,这里需要注意的是,你在代码中是如何书写关于路径问题的,如果是直接写路径,并且jar中指出来主类,那么运行jar不需要任何参数。
如果路径的设置是以 args【1】或者args【2】输入的话,就需要你在运行jar时手动追加输入路径。此时输出路径需注意是个空文件夹或者未生成,不然就会提醒报错。(同样也可以在代码中利用api写删除路径)如果是idea的maven打包的话,还需要注意声明jar 的主方法。
hadoop 任务 提交命令(利用参数提交): hadoop jar WCdemo.jar /data/wc.txt /out1
有时会发现学习是一件很快乐的事情 比一直跑步容易多了 不是嘛

 浙公网安备 33010602011771号
浙公网安备 33010602011771号