UI自动化测试(1)
1、概述
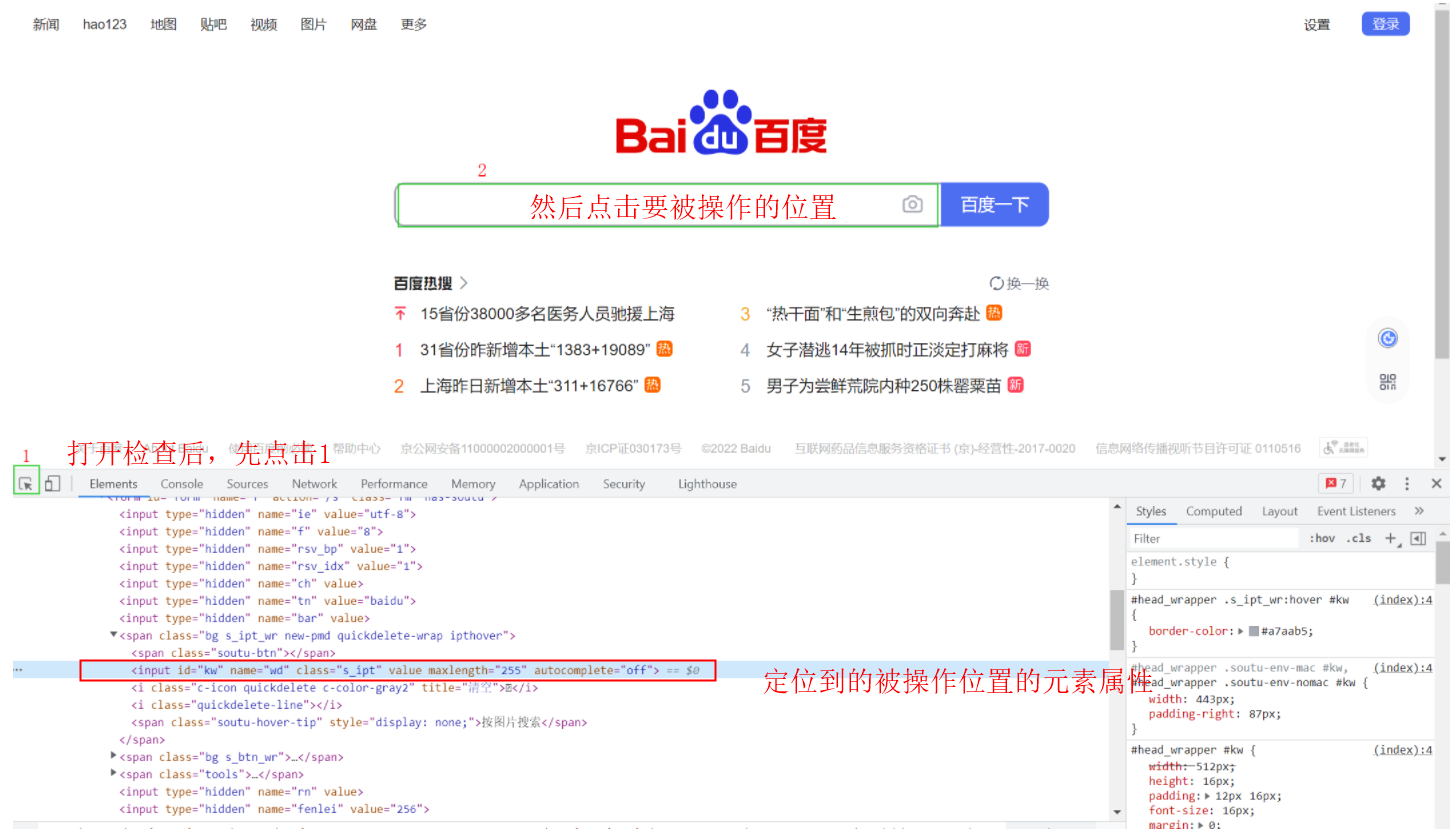
webdrive之所以能够操作浏览器,是因为他首先需要定位到被操作的元素属性,然后就可以对浏览器做各种操作。定位到被操作的元素属性的方法,以百度的输入框为例:
2、元素定位的分类
2.1单个元素定位
标签:
a标签下的都是超链接
2.1.1一般定位元素属性
2.2.1.1id
from selenium import webdriver
import time
#单个元素定位:
#1、常用元素属性定位:
#通过id元素属性定位
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
#find_element_by_id("kw")是通过id元素定位的关键字,send_keys("赵丽颖")是输入的关键字。
driver.find_element_by_id("kw").send_keys("赵丽颖")
time.sleep(5)
#退出浏览器,且关闭程序。
driver.quit()2.2.1.2name
from selenium import webdriver
import time
#通过name元素属性定位
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
#find_element_by_name("wd")是通过name元素定位的关键字,send_keys("冯绍峰")是输入的关键字。
driver.find_element_by_name("wd").send_keys("冯绍峰")
time.sleep(3)
driver.quit()2.2.1.3class_name
from selenium import webdriver
import time
#通过class_name元素属性定位
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
#find_element_by_class_name("s_ipt")是通过class_name元素定位的关键字,send_keys("赵丽颖")是输入的关键字。
driver.find_element_by_class_name("s_ipt").send_keys("赵丽颖")
time.sleep(3)
driver.quit()2.1.2超链接元素定位属性
超链接使用的前提是他的地址必须完整。
2.2.2.1link_text
from selenium import webdriver
import time
#2、处理超链接的元素属性:
#通过link text元素属性处理
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
#find_element_by_link_text("新闻")是通过link text元素处理超链接,click()是点击的意思。
driver.find_element_by_link_text("新闻").click()
time.sleep(3)
driver.quit()2.2.2.2partial link text
from selenium import webdriver
import time
#通过partial link text元素属性处理
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
#find_element_by_partial_link_text("闻")是通过partial link text元素模糊处理超链接,click()是点击的意思。
driver.find_element_by_partial_link_text("闻").click()
time.sleep(3)
driver.quit()2.2.3追加定位元素属性
当使用id、name、class_name都定位不到的时候,我们就是用css_selector和xpath,我习惯于把他们称为追加元素定位属性。
2.2.3.1xpath
from selenium import webdriver
import time
#3、当使用id、name、class_name都定位不到的时候,我们就是用css_selector和xpath。
#通过xpath元素属性定位
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
#find_element_by_xpath('//*[@id="kw"]')是通过xpath元素定位的关键字,send_keys("赵丽颖")是输入的关键字。
driver.find_element_by_xpath('//*[@id="kw"]').send_keys("赵丽颖")
time.sleep(3)
driver.quit()2.2.3.2css selector
from selenium import webdriver
import time
#通过css元素属性定位
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
#find_element_by_css_selector('#kw')是通过css元素定位的关键字,send_keys("杨紫")是输入的关键字。
driver.find_element_by_css_selector('#kw').send_keys("杨紫")
time.sleep(3)
driver.quit()2.2.3.2xpath和css的区别
(1)css:是依据页面的数据样式定位的, 有标签选择、类选择、id选择,或者他们的交并集,除此之外没有其他的辅助元素了 。xpath :是路径表达式,所有元素和内容都可以成为路径的一部分。两种定位方式功能基本一致,但是xpath明显更强大,只是xpath写起来较复杂,css写起来容易些。
(2)css表达式更简洁;
(3)css在chrom、火狐查找速度快一些,效率高一些,xpath在IE浏览器相对快一些(ie浏览器无论是css,xpath都比谷歌、火狐要慢)
(4)CSS不支持文本搜索,XPATH支持文本搜索text()
(5)xpath支持的函数特别多,CSS选择器支持的函数比较少,所以在复杂元素查找时候,xpath反而更加简洁,所以xpath功能更加强悍。
那么什么时候用css,什么时候xpath呢?当查找元素比较简单,用css没错,如果复杂,用xpath比较好。
2.2.4tag_name元素定位方法
from selenium import webdriver
import time
#tag_name元素属性定位和多元素定位:
#通过tag_name元素属性定位,tag_name获取到的是标签,当获取的标签有很多个时,就需要使用多个元素定位的方法。
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
#driver.find_elements_by_tag_name("input") #是通过tag_name元素定位的方法,由于input标签有很多,所以需要使用多个元素定位的方法。
list1=driver.find_elements_by_tag_name("input")
list1[7].send_keys("冯绍峰") #根据列表的索引来定位元素属性。
time.sleep(3)
driver.quit()2.3多个元素定位
多个元素定位,指的是元素的属性都一致,返回的是列表,可以根据列表的索引来定位元素属性。不管是单个元素定位还是多个元素定位,目前都有8种。
2.4实战
from selenium import webdriver
import time
#实战:以新浪邮箱登录为例:
#通过id元素属性定位:
driver=webdriver.Chrome()
driver.get("https://mail.sina.com.cn/")
driver.find_element_by_id("freename").send_keys("13762237226")
driver.find_element_by_id("freepassword").send_keys("123456")
time.sleep(3)
driver.find_element_by_link_text("登录").click()
time.sleep(3)
driver.quit()3、Webdriver类的常用方法
3.1获取当前测试地址
assert:是python原生的断言方法。
如:a==1 b==1 c==2
那么assert a=b是不会出错的。那么assert a=c是会出现asserterror的错误。
from selenium import webdriver
import time
#获取当前测试地址:
driver=webdriver.Chrome()
driver.get("https://mail.sina.com.cn/")
#current_url获取当前被测试WEB的地址
print(driver.current_url)
#assert:是python原生的断言方法。
assert driver.current_url.endswith("sina.com.cn/")
time.sleep(3)
driver.quit()
3.2获取当前页面代码
from selenium import webdriver
import time
#获取当前页面代码
driver=webdriver.Chrome()
driver.get("https://mail.sina.com.cn/")
#page_source:获取当前页面的代码。
print(driver.page_source)
driver.quit()3.3获取当前测试WEB的title
from selenium import webdriver
import time
#获取WEB的title
driver=webdriver.Chrome()
driver.get("https://www.baidu.com/")
driver.title
print(driver.title)
assert driver.title=="百度一下,你就知道"
driver.quit()
3.4页面的前进与后退
from selenium import webdriver
import time
#页面的前进与后退
driver=webdriver.Chrome()
driver.get("https://www.baidu.com/")
print(driver.current_url)
time.sleep(2)
driver.get("https://mail.sina.com.cn/")
print(driver.current_url)
time.sleep(2)
#页面后退
driver.back()
print(driver.current_url)
time.sleep(2)
#页面前进
driver.forward()
print(driver.current_url)
time.sleep(2)
driver.title
print(driver.title)
driver.quit()3.5浏览器页面最大化
from selenium import webdriver
import time
#浏览器页面的最大化
driver=webdriver.Chrome()
driver.get("https://mail.sina.com.cn/")
#maximize_window():浏览器页面最大化
driver.maximize_window()3.6多窗口解决思路
解决步骤:
(1)先打开当前页面;
(2)然后获取当前页面放在一个变量中;
(3)打开新的页面;
(4)获取所有页面并且放在一个变量中;
(5)循环所有页面,判断如果不是当前页面,那么就是在新的页面。
from selenium import webdriver
import time
#多窗口解决思路,以新浪邮箱为例:
driver=webdriver.Chrome()
driver.get("https://mail.sina.com.cn/")
#浏览器页面最大化
driver.maximize_window()
#获取当前页面放在一个变量中,current_window_handle:获取当前页面。
nowHandle=driver.current_window_handle
time.sleep(3)
#打开新的页面
driver.find_element_by_link_text("注册").click()
time.sleep(2)
#获取所有页面并且放在一个变量中,window_handles:获取所有页面。
allHandle=driver.window_handles
time.sleep(1)
#循环所有页面
for handle in allHandle:
#判断如果不是当前页面,那么就是在新的页面。
if handle!=nowHandle:
#从当前页面切换到新的页面
driver.switch_to.window(handle)
driver.find_element_by_name("email").send_keys("asd123")
time.sleep(2)
#关闭新的页面,但是不关闭程序。
driver.close()
#从新的页面切换到原来的页面
driver.switch_to.window(nowHandle)
time.sleep(1)
driver.find_element_by_id("freename").send_keys("qy12345")
time.sleep(2)
driver.quit()3.7清空
from selenium import webdriver
import time
#clear():清空
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
so=driver.find_element_by_id("kw")
so.send_keys("赵丽颖")
time.sleep(2)
so.clear()
time.sleep(2)
driver.quit()3.8获取元素属性的值
from selenium import webdriver
import time
#get_attribute()的方法是获取元素属性的值
driver=webdriver.Chrome()
driver.maximize_window()
driver.get("http://www.baidu.com")
time.sleep(2)
so=driver.find_element_by_id("kw")
time.sleep(1)
so.send_keys("赵丽颖")
#我们在输入框中输入的值都是键值中的value。
print(so.get_attribute("value"))
time.sleep(3)
driver.quit()3.9是否勾选
from selenium import webdriver
import time
#是否勾选:is_selected()
driver=webdriver.Chrome()
driver.get("https://mail.sina.com.cn/")
obj=driver.find_element_by_id("store1")
print(obj.is_selected())
time.sleep(3)
obj.click()
print(obj.is_selected())
time.sleep(3)
driver.quit()3.10是否可编辑
from selenium import webdriver
import time
#是否可编辑:is_enabled()
driver=webdriver.Chrome()
driver.get("https://mail.sina.com.cn/")
obj=driver.find_element_by_id("freepassword")
print(obj.is_enabled())
time.sleep(3)
driver.quit()3.11是否隐藏
from selenium import webdriver
import time
#是否隐藏:is_displayed()
driver=webdriver.Chrome()
driver.get("https://www.baidu.com")
obj=driver.find_element_by_link_text("关于百度")
print(obj.is_displayed())
time.sleep(3)
driver.quit()3.12页面刷新
#页面刷新
driver=webdriver.Chrome()
driver.get("https://www.baidu.com")
time.sleep(3)
driver.refresh()
time.sleep(3)
driver.quit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号