论文阅读记录-ACCL-EFLOPS
内容来源
-
Fast Multi-GPU collectives with NCCL | NVIDIA Technical Blog
-
EFLOPS: Algorithm and System Co-design for a High Performance Distributed Training Platform
-
TACCL: Guiding Collective Algorithm Synthesis using Communication Sketches
Collective Communication
-
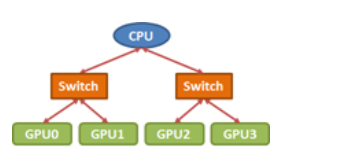
有许多有效实施集体通信的方法。但是,我们的实现必须考虑到处理器之间的互连拓扑结构,这一点很关键。例如,考虑将数据从GPU0广播到下图所示的PCIe树拓扑中的所有其他gpu。
-
在这种情况下,two-step tree算法是一种常见的选择。在第一步中,数据从GPU0发送到第二个GPU,在第二步中,两者都将数据发送到其余的处理器。这里我们可以在第一步将数据从GPU0发送到GPU1,然后在第二步将数据从GPU0发送到GPU2, GPU1发送到GPU3,或者我们可以在第二步执行从GPU0到GPU2的初始复制,然后GPU0到GPU1, GPU2到GPU3。
-
检查拓扑结构,很明显,第二个选项是首选的,因为同时从GPU0发送数据到GPU2,从GPU1发送数据到GPU3将导致上层PCIe链路争用,这一步的有效带宽减半。一般来说,实现良好的整体性能需要仔细关注互连拓扑。
-
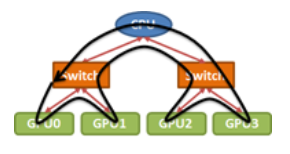
为了优化广播带宽,一个更好的方法是将上面的PCIe拓扑视为一个环。
-
通过将输入的小块围绕环从GPU0中继到GPU3来执行广播。环形算法为几乎所有标准的集合操作提供了接近最优的带宽,即使应用于“树状”PCIe拓扑。但请注意,选择正确的环顺序仍然很重要。
分布式通信算法
EFLOPS
Article:高性能分布式训练平台的算法与系统协同设计
Author:Jianbo Dong, Zheng Cao, Tao Zhang, Jianxi Ye, Shaochuang Wang, Fei Feng Li Zhao, Xiaoyong Liu, Liuyihan Song, Liwei Peng, Yiqun Guo, Xiaowei Jiang Lingbo Tang, Yin Du, Yingya Zhang, Pan Pan, Yuan Xie
Group:Alibaba Group
Publications:2020 IEEE International Symposium on High Performance Computer Architecture (HPCA)
Abstract
- 目前,DNN模型的训练变得具有挑战性,因为1)模型大小和数据量不断增加,通常需要更多的迭代来训练;2)深度神经网络算法发展迅速,这就要求训练阶段要短,以便快速部署。为了应对这些挑战,分布式培训平台被提出利用大量服务器节点进行培训,希望能显著减少培训时间。
- 但是分布式训练平台中,服务器内部的流量可能会导致严重的拥塞。服务器之间的通信在以太网上的流量拥塞也会对分布式训练性能造成严重影响。
- 文中,研究者设计了一种新的分布式训练平台EFLOPS,该平台采用算法和系统协同设计方法,具有良好的可扩展性。提出了一种新的服务器架构来缓解服务器内部的拥塞。此外,还提出了一种新的网络拓扑结构BiGraph,将网络划分为两个独立的部分,使得来自不同部分的任何节点之间始终存在直接连接。最后,结合BiGraph,提出了一种拓扑感知的allreduce算法来消除直连上的拥塞。
Introduction
- 减少训练时间,提高训练效率有两个方法:加速(scale-up)和扩大规模(scale-out)。加速侧重于单个设备的性能提升,比如开发专用处理器来加速神经网络,但是单个设备的性能进化速度较慢,远远不能满足人工智能应用的需求。因此,提出了数据并行和模型并行训练的分布式系统等规模扩大技术(scale-out)来提高训练性能。文中也主要关注于这种规模扩大化的横向扩展技术。
- 尽管数据中心的传统服务器集群可以直接用于训练,但它们受到服务器内外流量拥塞的影响。
- Nvidia的NVLink和NVSwitch部分解决了服务器内拥塞的问题,实现了一种内部无拥塞的网络来最大化提高训练效率。NVLink带宽可高达300GBps。然而,NVLink和NVSwitch专用于Nvidia的gpu,不支持其它厂商的专用加速器(GPU)。并且没有考虑服务器之间的通信问题,所以它不是大规模分布式机器学习的最终解决方案。
- 创新点 :
- 本文主要关注于PCie和以太网卡,并且修改了通用集群的系统架构,提出了一种高性能的分布式训练系统,即EFLOPS。在架构中,将安装相同数量的GPU和网卡,并在同一PCIe交换机下将一个GPU和一个网卡绑定为一对。我们将一个gpu-nic对表示为一个子节点。
- 对于服务器间通信,我们提出了一种新的网络拓扑BiGraph,其中交换机被均匀地分为两个独立的部分,这两个部分与CLOS网络互连。与Fat-Tree的是leaf-spain结构不同,我们将这两个部分表示为上部和下部。换句话说,来自不同部分的任意两个交换机之间总是存在直接链接。BiGraph背后的想法有两个方面。首先,在BiGraph的两个部分之间有大量的直接链接,这提供了更多的选项来为新的连接找到一些不那么拥塞(甚至无占用)的链接。其次,对于那些跨节点连接,最短路径是确定的。因此,可以在软件库中增强网络流量的可控性。
- 设计了Halving-Doubling with Rank Mapping (HDRM):一种拓扑感知的allreduce算法。在HDRM中,对子节点进行重新排序(Ranking),以确保一个连接占用一个链接。Ranking的目的是,保证一个连接占用一个物理链路,不产生争用,消除网络拥塞,提高通信性能。
BiGraph网络拓扑结构
- 希望通过设计一种新的网络拓扑结构和相应的连接控制算法来消除拥塞。
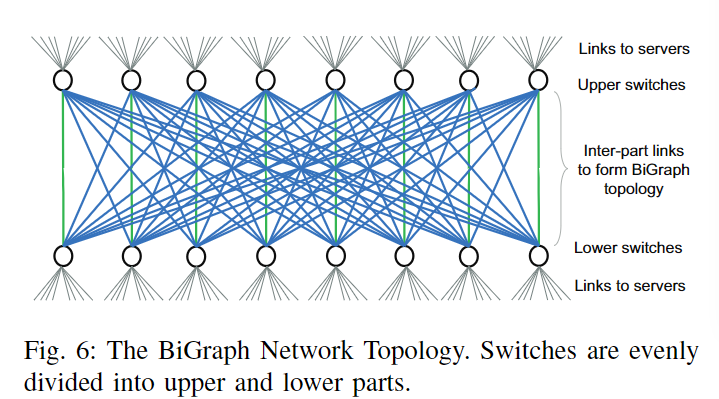
- 在BiGraph拓扑中,网络交换机分为上下两部分(如上图所示),与Fat-Tree类似,交换机的两个部分与CLOS架构互连。因此,BiGraph与Fat-Tree拓扑兼容,因此现有的Fat-Tree网络管理机制可以很容易地应用于BiGraph。最大的区别是Fat-Tree只允许通过leaf交换机进行网络访问,而BiGraph则允许从交换机的两个部分进行网络访问。
- 在BiGraph中,要求如果存在N个交换机(上下两层),每个交换机连接M个子节点(即M×N-BiGraph网络),如果网卡带宽与交换机带宽匹配,则满足\(M≤N/2\)的约束。
- BiGraph拓扑的特点
- 在P个子节点系统中,至少有P/2条双向链路可用。因此,当使用HD算法时,可用链路数等于所有reduce操作所需的连接数。因此,可以将这些连接一个接一个地映射到可用的直接链接,从而最终消除拥塞。
- 任意两个来自biggraph不同部分的子节点之间的最短路径是确定性的。这种确定性路径使我们能够完全控制库中跨部分连接的数据路径。例如,我们可以通过选择通信的源子节点和目的子节点来控制流量。

- 存在死锁的问题
- spine交换机负责重定向来自leaf交换机(在另一部分)的数据包。如果双方的多个spine交换机同时工作,则可能由于依赖循环而导致死锁。
- 如上图所示,四个并发流(flow1-flow4)在同一侧开始和结束,只在另一侧转发。因此,每个流都可以占用源交换机的输出端口,并在下一跳中竞争输出端口。例如,flow1占用sw1的输出端口(到sw2),并与flow2竞争sw2的输出端口(到sw3)。如果flow3和flow4具有相似的行为,则形成闭环依赖,产生死锁。
- 一种解决方案,将不同方向的流量划分为不同的优先级。因此,它们在不同的队列中处理,从而打破了依赖循环。
算法
-
Halving-Doubling with Rank Mapping (HDRM)
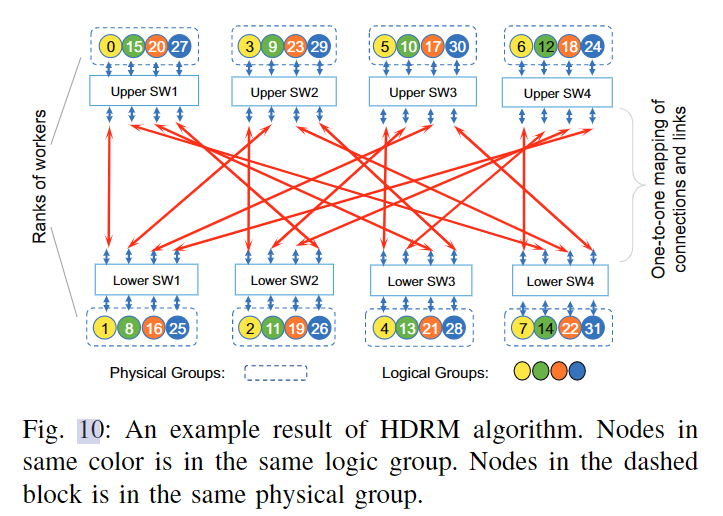
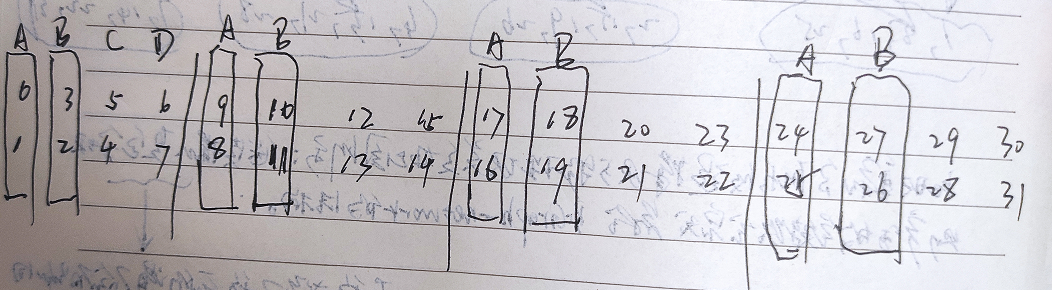
- 将连接到同一交换机的子节点表示为一个物理组。我们从每个物理组中选择一个子节点形成一个逻辑组。在M ×N系统中,应该有N个物理组和M个逻辑组。如上图所示物理组用虚线矩形表示。同一逻辑组中的子节点分散在物理组中,并用相同的颜色表示。

- 首先对一个逻辑组做排序映射。第一个逻辑组用作对其他逻辑组进行排序的基础。为了完成排序的基础,我们从有两个子节点的系统开始,其中只有[0;1],对于后续的子节点映射关系也就是[N-1;N-2]。如上图所示。对于ID号的二进制表达式为奇数个1时,子节点被强制交换。例如,我们应该重新排列对[2;3]-->[3;2]。其最终对应关系如下图所示。
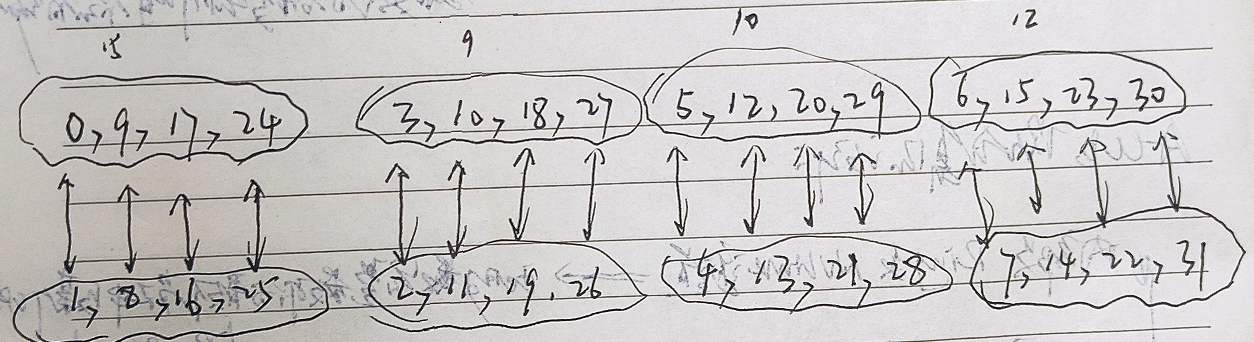
- 对于多个逻辑组,等级映射有一些小的变化。首先,我们从上一步生成的基数开始,而不是从[0;1]。这里我们将逻辑组的Rank定义为两个向量的集合,[X;Y],其中\(x =[0,3,5,6], Y =[1,2,4,7]\)。任何其他逻辑群的初始秩可以推广为\(Ri=[X +i × N;Y + i × N]\),其中i为逻辑组的序号。当序列号的二进制表达式有奇数个1时,我们交换向量X和向量Y。在这种情况下,\(Ri=[Y + i × N;X + i × N]\)。这一映射过程可以简单理解为,将第一步生成的两两对应的逻辑小组,再每4(4的来源是交换机数量的一半)个一组划分为大的逻辑组,这一大逻辑组中,每个具有相同索引的小逻辑组组成最终的映射逻辑组结果。最终结果如下图所示。
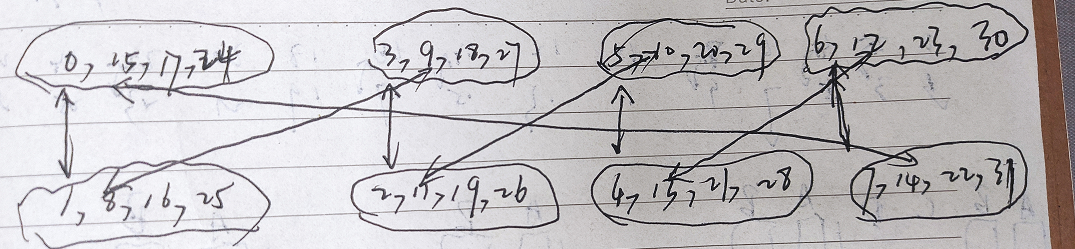
- 但是观察上述逻辑组映射会发现,会存在来自不同逻辑组的具有相同索引的子节点对会竞争相同的链接的问题,如上图的[0;1]和[9;8]会产生争用,原因是实际物理链路的架构导致的,如下图所示。为了解决这个问题,我们需要额外的步骤将这些冲突的连接映射到其他自由链接。在这项工作中,采用的方法是循环移动,循环移动向左或者向右,或移动的向量(第一个向量或者第二个向量)不会对最终HDRM的性能产生影响。因此对于[9,10,12,15]可以将[9]向右循环移动1位,变为[15,9,10,12]。其余组[17,18,20,23]、[24,27,29,30]做出相同操作,这样来自不同部分的任意两个物理组(即两个交换机)之间只有且仅有一个连接,因此,它们之间的链路被映射的连接独占使用,从而消除了拥塞。
ACCL
Article:用高效的集体通信库构建高可扩展的分布式训练系统
Author:Jianbo Dong , Shaochuang Wang, Fei Feng, Zheng Cao , Heng Pan, Lingbo Tang , Pengcheng Li, Hao Li, Qianyuan Ran, Yiqun Guo, Shanyuan Gao, Xin Long, Jie Zhang, Yong Li, Zhisheng Xia, Liuyihan Song , Yingya Zhang, Pan Pan, Guohui Wang, and Xiaowei Jiang。
Group:Alibaba Group, Hangzhou。
Publications:IEEE Computer Society
Abstract
-
分布式系统已被广泛用于深度神经网络模型训练。然而,分布式训练系统的可扩展性在很大程度上受到通信成本的限制。阿里设计了一个高效的集合通信库-->ACCL,以构建具有线性可扩展性的分布式训练系统。
-
允许多个算法共存于一个单一的集合操作中,以最大限度地提高单个类型fabric的通信效率。为了充分利用多轨网络,使多个设备同时进行节点间通信,并设计了一个两进程并行算法,启动两个并发进程和管道,以提高节点内和节点间互连的利用率。为了消除网络拥塞,提出了一种基于探测的路由控制机制,该机制生成从逻辑连接到物理数据路径的映射。基于这些映射,能够通过重新排序集合操作中的参与者来分散到不同聚合交换机的连接,从而将整个系统的流映射到专用的物理链路。
异构网络的算法
互连和通信算法分析
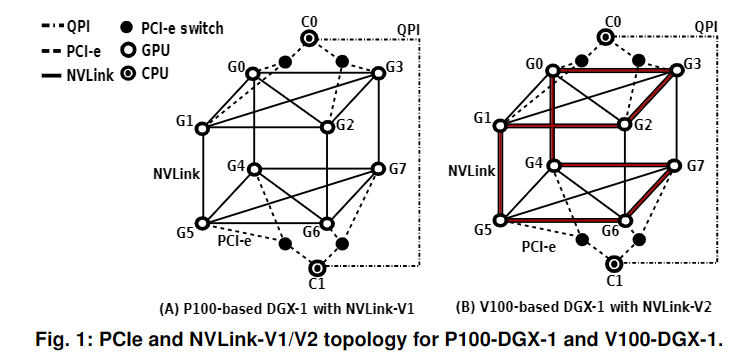
-
在服务器节点中,NVLink提供了比PCIe高得多的带宽容量。NVLink存在于“超立方体网格”拓扑中(如上图所示)。在该拓扑中,可以利用基于环的算法来饱和链路容量,而其他算法,如Halving–Doubling,不适用于此拓扑。
-
在服务器节点之外,Fat-Tree拓扑是事实上的数据中心网络标准,阿里之前的工作证明了如果网络拥塞可以消除,Halving–Doubling算法在这种网络中的性能将优于基于环的算法,因为前者只需要O(\(log_2 N\))开销,而后者需要O(N)的开销。
-
也就说目前没有一种已知的算法适合所有的互连架构。
混合算法设计
- 以AllReduce为例子,将环算法应用于服务器节点内(NVLink)通信,以及HD用于服务器节点间(以太网)。混合算法将AllReduce操作划分为多个微操作,并根据需要选择微操作,通过消除那些无意义的微操作,减小数据量。此外,ACCL解耦了算法和微操作,允许基于底层结构信息的微操作和算法之间的独立匹配。因此,可以在传输更少的数据的情况下,最大限度地利用整体带宽。
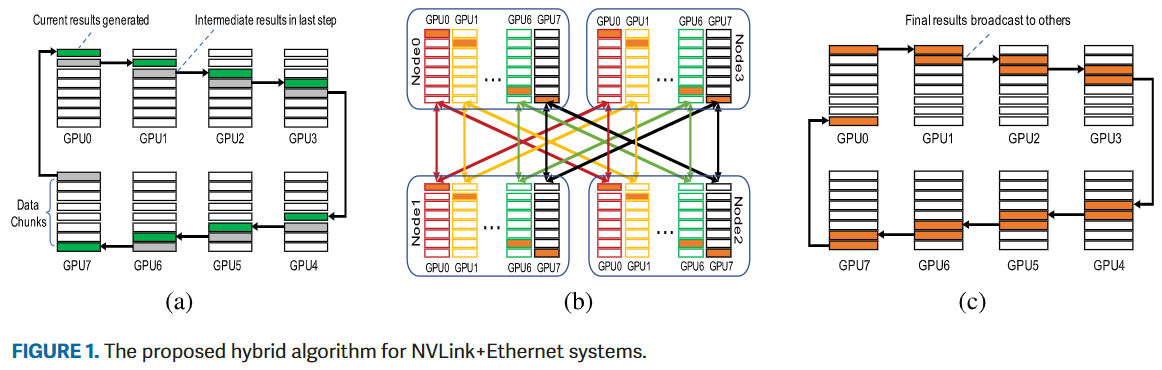
-
在第一阶段(上图a),通信发生在服务器节点内部,内部节点的reduce-scatter是基于Ring完成的,以最大化NVLink的带宽利用率。在每一步中,GPU: 1)从一侧接收下一个块的临时AllReduce结果;2) 计算当前块的AllReduce结果;3) 将结果发送到另一侧。在此阶段结束时,本地AllReduce结果分散在所有本地GPU上。
-
在第二阶段(上图b),通信发生在服务器节点之间,在节点间AllReduce是基于HD算法完成的,因为它的表现优于环(如果没有拥塞)。持有来自不同节点的相同本地reduce-scatter结果块的GPU被组成一个组,并与同一组中的其他GPU通信。注意,多个节点间AllReduce微操作是同时进行的。
-
在第三阶段(上图c),通信发生在服务器节点内部,第二阶段生成的分块AllReduce结果通过节点内allgather广播到本地GPU,也是基于Ring算法完成的。最后,所有GPU都可以拥有完整的结果。
- 在第一和第三阶段,环的使用能够充分利用NVLink的高速带宽,在第三阶段采用的是HD用于使以太网饱和,更重要的是,在第一阶段之后,中间结果分散在所有本地gpu上,这使得同时使用多个网卡来消除PCIe接口上的拥塞成为可能。
并行算法设计
- 虽然提出的混合算法可以提高通信的整体性能,但如果没有仔细的设计,整个系统的互连仍然可能无法充分利用。在最坏的情况下,内部节点和节点间通信的进程必须依次执行,使其中一个处于空闲状态,而另一个处于繁忙状态。
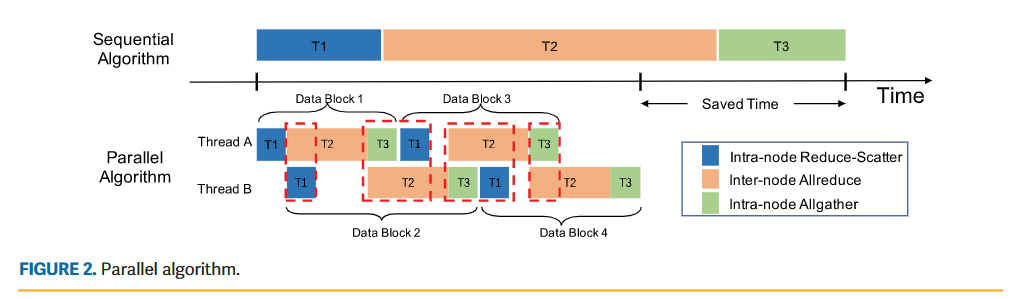
-
在这里,提出了一种并行算法,通过挖掘训练中的数据并行性,从而提高节点内和节点间的链路利用率。如上图所示,将整个消息划分为多个块,并将这些数据块均匀分布到两个并发线程中(例如图中的A和B)。通过这种方式,内部节点和节点间子操作可以被流水线化以供执行。
-
并行算法可以有效地提高节点内操作和节点间操作的并行性。理想情况下,当花在内部节点子操作上的通信时间等于节点间的通信时间时,两个子操作可以完美地并行运行。但是,聚合的节点间带宽通常低于内节点的带宽。因此,总通信时间将受到节点间带宽的限制。此外,由于拥塞的影响,实际的节点间带宽通常远低于峰值带宽。因此,并行算法的优势会被拥塞严重限制。
CLos网络中的拥塞避免
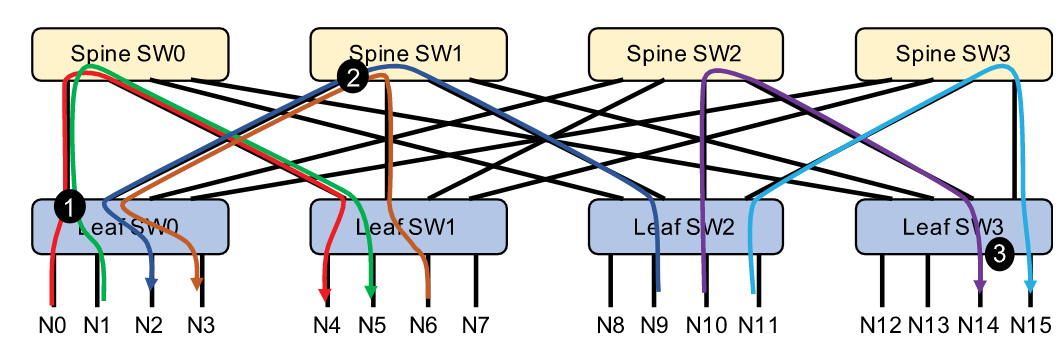
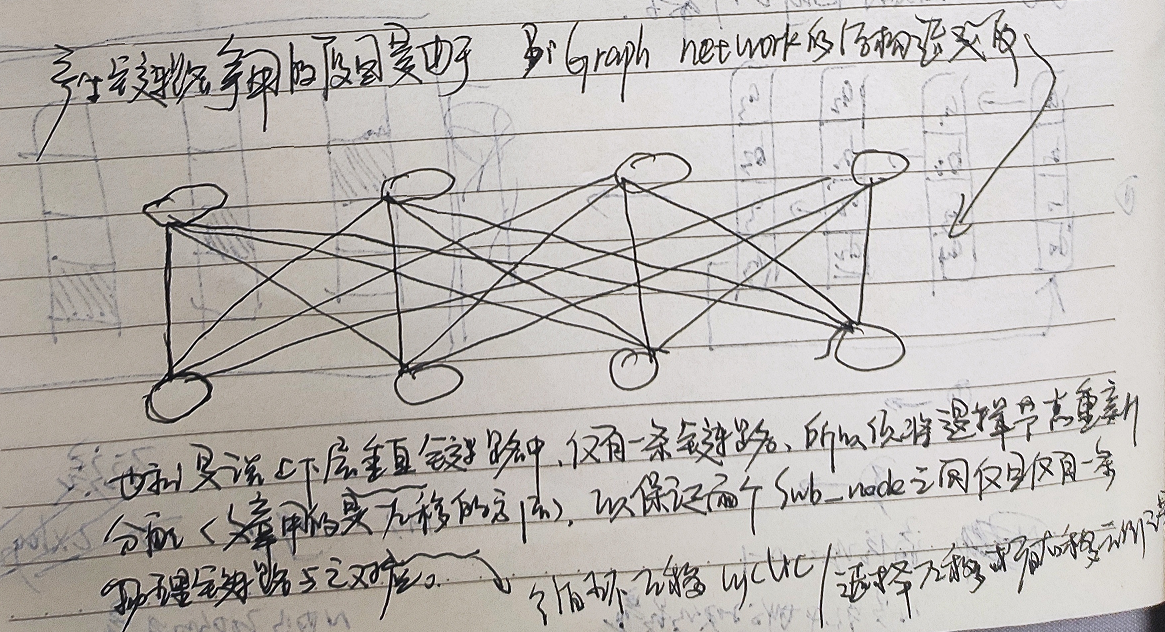
- 由于网络拥塞对通信性能产生不利影响,在本节中,我们将讨论如何在胖树网络中建立无拥塞集合通信。在这里,考虑全网状(full-mesh)拓扑中的两层Clos网络架构(也称为spine-leaf),如上图所示。
- 在之前的EPFLOPS中,提出了BiGraph网络拓扑。通过采用HDRM算法建立连接,消除了BiGraph中的拥塞问题。然而,将HDRM应用到传统的Fat-Tree网络是行不通的。首先,在Fat-Tree网络中,由于有多条候选的最短路径,因此失去了路径选择的可控性。在这项工作中,我们提出了基于探测的路由,以方便特定连接的路径选择。
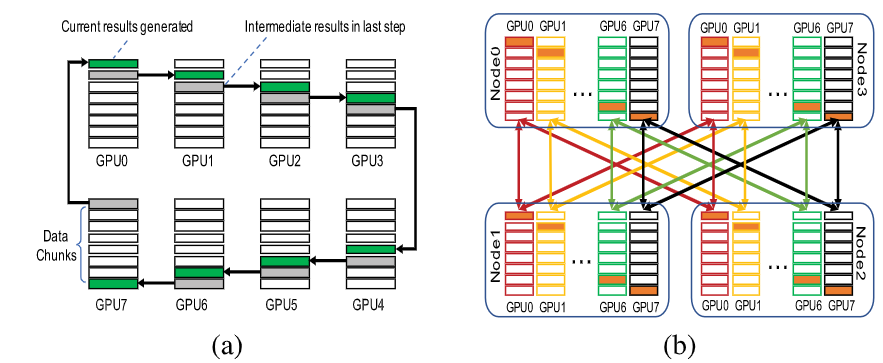
- 其次,节点间通信的行为不同于BiGraph。在BiGraph中,GPU拥有整个消息进行处理,并且都涉及相同的allreduce操作。因此,连接管理算法可以简化为基于Rank的算法。相反,上图(a)中所示的第一个子操作(即内部节点reduce-scatter)将本地allreduce结果分散到相关gpu,并且本地gpu保存本地结果的不同块。它要求具有相同本地Rank的gpu执行第二个子操作(即节点间allreduce),如上图(b)所示。
基于探测的路由控制
-
为了在spine-leaf网络中实现无拥塞的集合通信,我们提出了基于探测的路由机制来建立连接路径表,该表记录了通信连接与路由路径(即物理链路)之间的映射关系。在此基础上,我们提出了路径选择策略,将为通信算法建立的连接均匀分布到可用的物理链路上。
-
基于探测的路由机制的关键思想是,服务器通过改变源/目的端口向对等服务器发送多个探测数据包。因此,它们之间可能的通信连接可能会被耗尽。此外,每个探测数据包都需要记录它所经过的交换机,以便发送者可以知道映射的完整路由路径。最后,为这两台服务器构建一个连接路径表。
-
为了支持商用交换机上基于探测的路由机制,ACCL需要对传统的IP网络协议进行扩展,使交换机能够识别探测报文。为简单起见,我们将其表示为ACCL探测协议(ACPP)。ACPP报文封装为UDP (user datagram protocol)报文。下图显示了数据包格式,其中ACCL使用IP包报头中的差异化服务代码点(DSCP)字段来标记ACPP消息。
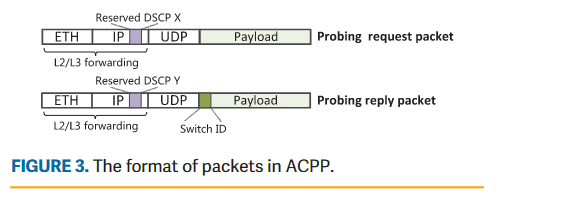
- 通常,ACPP消息分为两类:探测请求消息(DSCP=X)和探测回复消息(DSCP=Y)。探测请求消息的payload部分是没有意义的,但是探测应答消息的payload部分的前8位是指交换机ID。
- 使用DSCP字段的目的是为了区分ACPP报文和正常报文。
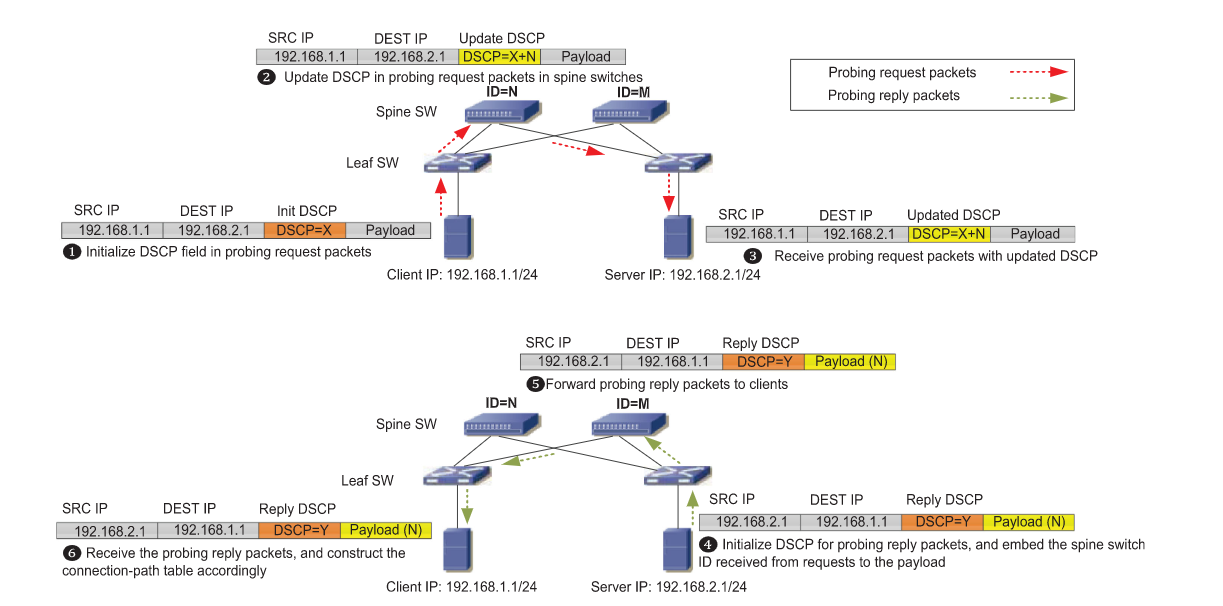
- 上图显示了一个示例:服务器192.168.1.1向另一个服务器192.168.2.1发送探测请求包。这个探测包的DSCP字段被初始化为X。当这个探测包经过ID为N的spine交换机时,DSCP字段将被更新为\(X+N\)。一旦目的服务器收到这个包,它就会认为这是一个探测请求包,因为DSCP值大于X。之后,服务器通过DSCP值减去X从收到的包中恢复交换机ID(N)。然后,它通过初始化DSCP为Y并将交换机ID嵌入payload中来构造应答数据包,并将其发送回源服务器。最后,源服务器接收到探测应答报文,解析报文的payload得到交换机ID。在此基础上,可以通过改变发起方的源端口来轻松地构建连接路径表。
Topology-Aware Ranking Algorithm
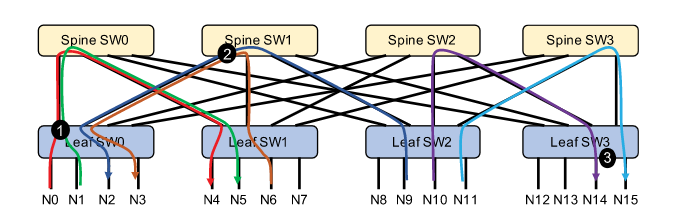
- 为了消除Fat-Tree网络中的网络拥塞,我们首先分析拥塞可能在哪里产生。如下图所示,流量拥塞一般会发生在3个点:①leaf交换机上行出端口;②Spine交换机下行出端口;③leaf交换机下行出端口。HD算法考虑到连接是成对建立的,在集体通信的每一步中,每对对等体只有一个连接是活动的。在这种交通模式下,只能在前两点看到拥堵。
-
为了消除Fat-Tree网络中的网络拥塞,我们首先分析可能产生拥塞的位置。如上图所示,流量拥塞一般有三个点:1)leaf交换机上行出端口;2)Spine交换机下行出端口;3)leaf交换机下行出端口。考虑到HD算法中的连接是成对建立的,在集合通信的每一步中,每对对等体只有一个连接处于活动状态。在这样的流量模式下,拥堵只能在前两点看到。
-
leaf交换机到spine的出口端口上的拥塞(在图5中突出显示为①)将在多个流(例如,N0→N4和N1→N5)从不同服务器发往同一spine交换机。因此,我们建议路由这些连接(从leaf里出来),根据使用基于探测的路由机制构建的连接路径表,发往不同的spine交换机。例如,如果我们路由流N0→N4到spine0和N1→N5到spine1,点①上的拥塞将被消除。
-
spine交换机到leaf的出口端口上的拥塞(在图5中突出显示为②)将发生在多个流(例如,N9→N2和N6→N3)从不同的leaf交换机定向到同一leaf交换机。通过将此类连接的总数限制在连接的服务器数量以下,并将连接(到同一leaf)分配到不同的spine,可以防止此类拥塞。其中,HD的成对连接已满足第一个条件(连接总数的限制),对于第二个条件(连接分流到不同的spine),我们将连接到同一leaf交换机的服务器视为一个集合,并按集合分配服务器的rank。假设每个集合中有M个节点,我们分配集合i的rank为:\(Rank[i]={i*M,...,(i+1)*M-1}\)。对于集合i中的每个节点,它与集合i+d中的每个节点相互对应(d为节点距离)。例如在下图中,对于来自两组服务器的节点,node0和node4,node1和node5认为是具有相同的距离,因此,这两个集合中的服务器通过HD连接逐一配对在一起。注意,集合中的rank序列是不相关的,因为它们扮演同等的角色。同样,集合的rank作为一个整体,是可以与其他集合交换的。
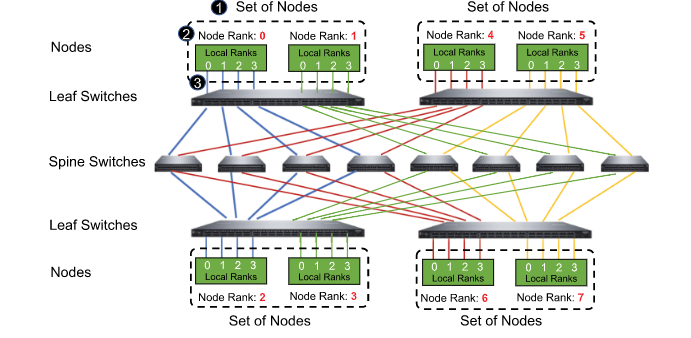
-
虽然上面讨论的方法只假定每台服务器有一个NIC,但当服务器上安装多个NIC时,它可以很容易地扩展。在这种情况下,我们只需将NIC与一定数量的GPU绑定,并将它们表示为子节点,如上图所示。因此,连接管理策略自然可以应用于这些子节点。
-
所以,为了构建无拥塞的Clos网络,连接管理算法分步骤阐述如下:
- 获取有关服务器位置及其连接到同一leaf交换机的对等设备(例如,服务器或多NIC系统的子节点)的信息。
- 根据收集到的信息,将节点(或子节点)相应地分组为多个集合。
- 为服务器(或子节点)分配连续的Rank,一组接一组。
- 根据基于探测的路由控制机制,从一组节点(或子节点)中选择不同的spine交换机。
TACCL
通过通信草图来指导集合通信算法的合成
Abstract
- 为了解决在大模型分布式训练过程中可能产生的通信瓶颈问题,微软设计了TACCL,这是一种使算法设计者能够指导合成器为给定的硬件和通信集体自动生成算法的工具。TACCL使用一种新颖的通信草图从设计者那里获得关键信息,从而显著减少搜索空间,并引导合成器获得更好的算法。TACCL还使用了一种新的问题编码,使其能够扩展到单节点拓扑之外。
Introduction
- GPU之间的通信瓶颈。 在P100GPU的100Gbps以太网集群上,使用BERT和Deeplight时,GPU有11%和63%的时间处于空闲状态。GPU的这种低效使用表明,通过优化GPU之间的通信可以显著提高的模型性能。
-
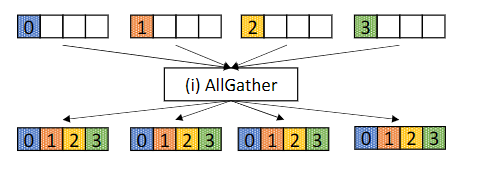
集合通信原语和算法 例如,ALLGATHER(所有GPU从所有GPU收集数据,如上图所示)的通用集合算法是Ring算法,其中所有GPU在逻辑上排列在一个环中,每个GPU从环中的前一个接收数据,并将先前接收的数据发送给其后一个。集合通信算法的效率低下会导致网络利用率低下,导致GPU在GPU间传输完成之前处于闲置状态,从而降低分布式训练和推理的总体效率。
-
GPU通信算法设计中的挑战 首先,需要在延迟和带宽优化之间做出取舍。例如,在使用基于Ring的AllReduce算法,对于小数据输入具有较高的延迟,效率较低。其次,GPU的拓扑存在异构性,节点/服务器内的GPU之间可能使用NVLink(双向带宽300GBps)连接,节点/服务器之间使用慢速的InfiniBand(每个NIC 12.5-25GBps)连接。此外,这些不同的设备供应商可能会使用不同的拓扑结构。最后,在路由和调度算法的整个空间中搜索以找到通信集体的最优空间,在计算上是令人望而却步的。并且以前合成集体通信算法的方法最多仅限于单节点拓扑或8个GPU(Blink中提到的算法)。
-
现有的集合算法方法 集合算法的设计必须考虑目标输入大小和目标拓扑的异质性。然而,今天用于分布式机器学习的大多数集合通信库,包括最先进的NCCL,使用叠加在目标拓扑上的集合算法的预定义模板。例如,对于ALLGATHER和REDUCESCATTER等集合,NCCL识别目标拓扑中的环并使用环算法。对于n个GPU,该算法需要每个数据块n个1链路传输步骤,对于链路传输延迟占主导地位的较小数据大小来说,该算法并不理想。此外,该算法类似地处理慢速节点间链路和快速节点内链路,在两者之间调度相等数量的数据传输。因此,当通过更快的节点内链路发送更多节点本地数据(即,节点本地GPU的数据)而获益时,通信在较慢的节点间链路上受阻。
-
管理自动化算法设计的规模 微软的设计目标是为给定的硬件配置和通信集体自动获得有效的算法,通过将寻找通信集体最优算法的问题编码到混合整数线性规划(MILP)中,目的是最小化总体执行时间。然而这个问题是NP-hard的。在这项工作中,微软提出了一种human-in-the-loop的方法,该方法结合了算法设计者的高级输入,以有效地合成异构GPU拓扑的集体通信算法。算法设计人员很容易提供一些简单的输入来约束算法的搜索空间,这允许合成引擎扩展到大型GPU拓扑。
-
通信草图作为用户输入 通信草图允许算法设计者提供限制算法搜索空间的高级参数(high-level intuitions)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号