比赛分析(完整版)
一、数据分析
该数据集采用COCO格式给出标注信息,即将所有训练图像的标注都存放到一个json文件中,数据以字典嵌套的形式存放。
检测数据集涉及3个场景,分别是“火灾检测”、“工业仪表检测”和“安全帽检测”
1.数据集分析
1.keys: dict_keys(['images', 'type', 'annotations', 'categories'])
2.物体类别: [{'supercategory': 'none', 'id': 1, 'name': 'fire'}, {'supercategory': 'none', 'id': 2, 'name': 'head'}, {'supercategory': 'none', 'id': 3, 'name': 'helmet'}, {'supercategory': 'none', 'id': 4, 'name': 'person'}, {'supercategory': 'none', 'id': 5, 'name': 'meter'}]
3.图像数量: 按8:2的比例划分为训练集:5691张,验证集1423张,共7114张
4.图像信息: {'file_name': '001772.jpg', 'height': 932.0, 'width': 1000.0, 'id': 0}
5.标注物体数量: 23053
6.查看一条目标物体标注信息: {'area': 472632.0, 'iscrowd': 0, 'bbox': [310.0, 58.0, 564.0, 838.0], 'category_id': 1, 'ignore': 0, 'image_id': 0, 'id': 1}
补充:


1.area:目标物体的面积,单位为像素平方,该值为 472632.0 像素平方。 2.iscrowd:一个布尔值,表示该目标是否是一个群体。当该值为 0 时,表示该目标为单个物体;当该值为 1 时,表示该目标为群体。 3.bbox:目标物体的边界框(bounding box)信息,由四个浮点数构成的列表,分别表示边界框的左上角点坐标 (x, y) 和宽度、高度。在这个例子中,边界框左上角点坐标为 (310.0, 58.0),宽度为 564.0,高度为 838.0。 4.category_id:目标物体所属的类别 ID,这里的值为 1,表示该目标属于 COCO 数据集中的第二个类别(通常情况下,ID 从 1 开始,而不是从 0 开始)。 5.ignore:一个布尔值,表示该目标是否被忽略。当该值为 0 时,表示该目标不被忽略;当该值为 1 时,表示该目标被忽略。 6.image_id:目标物体所在的图片 ID,该值为 0,表示该目标所在的图片在 COCO 数据集中的 ID 为 0。 7.id:该目标物体在注释文件中的唯一标识符,由整数值表示,该值为 1。
各类标签的数量分别为:
fire: 2683 head: 4487 helmet: 15141 person: 676 meter: 66
总的来说就是样本不均衡的问题比较严重。
思路:采用离线数据增强的方法,扩充数量少的样本
问题:怎样扩充样本比较合理,才不会导致过拟合
想法:
- 尝试将每个类别的样本数量增加到最小数量的两倍
- meter不是很重要,所以不需要扩充?
2.检测框高宽比分析
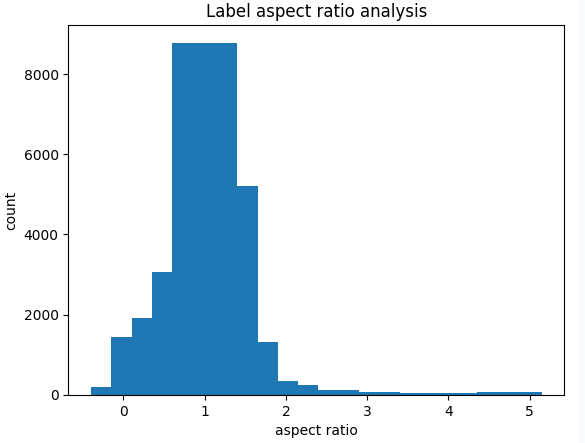
对高宽比的分析能够带来什么思路?
训练数据集中标注的检测框通常是由人工或者其他算法进行标注的,可能存在一些误差或者不完美的情况。而且,在实际应用中,检测目标物体的形状和大小可能会有所变化,这会对模型的检测结果产生影响。因此,为了提高模型的检测精度和鲁棒性,通常需要根据训练数据集中目标物体的形状和大小分布,选择最佳的检测框形状和大小。
在训练模型时,可以将选择的最佳检测框形状和大小作为超参数传入模型中进行训练。
3.尺寸,宽高度分析
数据集中,有1016种不同的尺寸 数据集中,高度最小为:120 数据集中,宽度最小为: 80
结论:数据集中,并不是所有图像的尺寸都是固定的
4.图像对比度分析
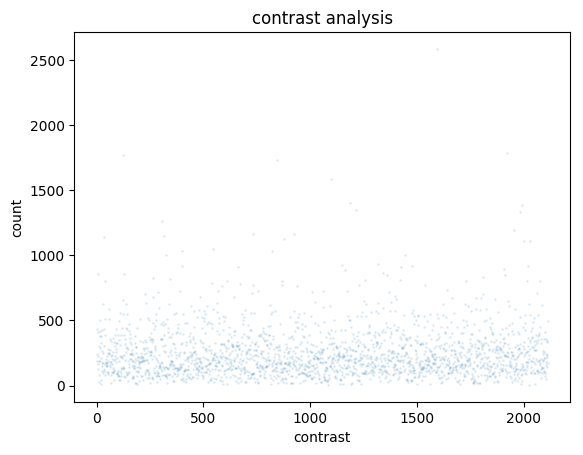
横轴表示图像的对比度值,纵轴表示该对比度值出现的图像数量。
对比度低的图像进行直方图均衡化来增加其对比度,或者对图像进行CLAHE(对比度受限的自适应直方图均衡化)操作,这样可以在不影响图像颜色分布的情况下增加对比度
将对比度高的图像添加高斯噪声、椒盐噪声等,这样可以在保持图像清晰度的同时,增加其噪声,从而使模型更加健壮。
实现这个功能比较困难,要自己写个transform,提升可能不是很明显,暂时先不做
5.图像亮度分析
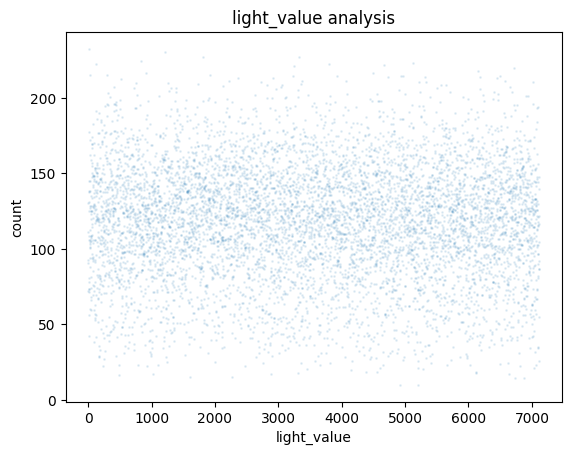
亮度低的图像通过调整图像的亮度、对比度或色温等参数来增加图像的亮度。还可以通过对图像进行Gamma校正或增加光源等方式来增加亮度,这样可以使模型更好地检测亮度较低的图像。
亮度高的图像通过添加阴影或调整图像的曝光度等方式来减少图像的亮度,这样可以使模型更好地检测亮度较高的图像。
同上
6.在线数据增强操作(待补充)
对每个样本:
- RandomCrop(随机裁剪)——针对画面有时候会出现遮挡的情况
- RandomDistort(随机扭曲图像的颜色)
- RandomExpand(随机扩展图像的大小)
- RandomFlip(随机水平翻转或垂直翻转图像)
- Mixup(将两个随机选取的样本混合成一个新的样本)
对每个batch:
- BatchRandomResize(随机调整 batch 中的图像尺寸)
- NormalizeImage(进行标准化处理)
7.数据清洁和处理
通过观察发现有大量脏数据,在推理时将BatchSize调整为1,将分数较低的图像单独拿出来进行分析,手动地将错标/漏标/误标的目标进行更正
脏数据该如何处理?数据清洗和处理 - yonuyeung - 博客园 (cnblogs.com)
二、模型分析
<1>目标检测
README:PaddleDetection/README_cn.md at release/2.6 · PaddlePaddle/PaddleDetection (github.com)
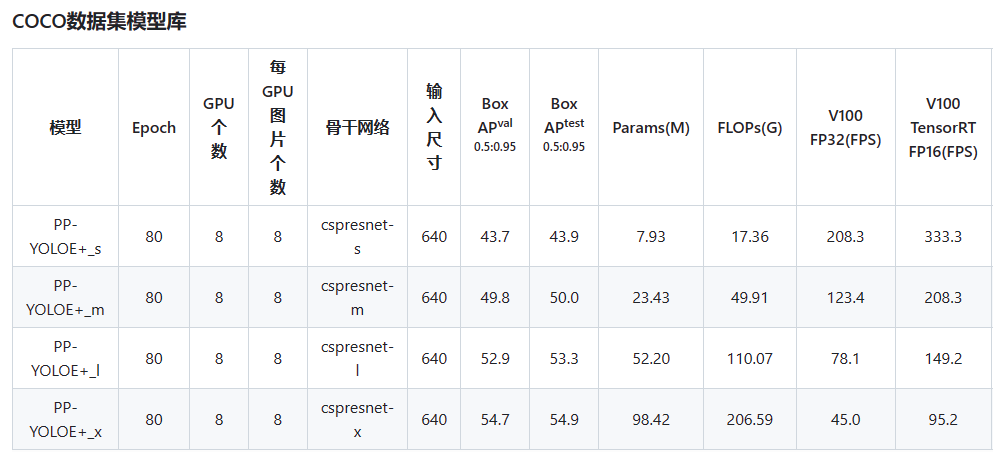
本次比赛使用的模型是PP-YOLOE+_l,骨干网络是CSPResNet
超参数调整
对优化器的调整没有什么思路:动量参数,正则化系数
epoch,batchsize,learningrate还没有经过多次测试寻找最合适的值
设置多进程
设置多进程可以提高FPS,但是没有什么思路
修改损失函数
在iou损失函数上面,尝试使用更新的diou,siou等损失函数,对比分析数据
<2>语义分割
更换模型
超参数的调整
三、其他
后处理:暂时先不弄
可视化
调整anchor尺寸

 浙公网安备 33010602011771号
浙公网安备 33010602011771号