
数字电路模拟程序大作业总结
前言:
完成两次数字电路模拟程序大作业之后,我将对题目重新进行设计与分析,对知识点、题型难度、题量等进行总结,以及提出踩坑心得和改进建议。
一、知识点
1)Java 基础核心知识点
- 面向对象编程(OOP)核心特性
抽象类与方法:LogicGate 作为抽象基类,定义了 isReady()、calculateOutput()、getOutputString() 等抽象方法,强制子类实现具体逻辑,体现抽象封装思想。
继承与多态:所有逻辑门(AndGate/OrGate/NotGate 等)继承自 LogicGate,重写抽象方法实现不同门的逻辑,运行时通过父类引用调用子类方法,体现多态性。
封装:每个类的成员变量(如 gateId、inputPinCount)私有化,通过 getter 方法暴露,隐藏内部实现细节;CircuitWire 封装线路连接的源 / 目标引脚。 - 集合框架(Collection Framework)
HashMap:核心映射容器,如 gateRegistry(组件标识→逻辑门实例)、inputValueMap(输入标识→值)、wireConnections(源引脚→目标连接列表)、pinValueCache(引脚→电平值),用于高效键值对查找。
ArrayList:存储线路连接列表(List)、按类型分组的逻辑门(List ),支持动态扩容。
LinkedHashMap:gatesByType 使用该类保证逻辑门类型的输出顺序,兼具 HashMap 的高效和 LinkedList 的有序性。
Comparator/Comparable:通过 gates.sort(Comparator.comparingInt(LogicGate::getGateNumber)) 对逻辑门按编号排序,使用方法引用简化比较器实现。 - 正则表达式(Regex)
用于解析组件标识(如 A(3)1 表示 3 输入与门 ID1),通过 Pattern 和 Matcher 类匹配并提取关键参数:
Pattern pattern = Pattern.compile("A\((\d+)\)(\d+)"); // 匹配与门格式
Matcher matcher = pattern.matcher(gateId);
if (matcher.find()) {
int pinCount = Integer.parseInt(matcher.group(1)); // 提取引脚数
int id = Integer.parseInt(matcher.group(2)); // 提取ID
}
核心 API:Pattern.compile() 编译正则、matcher() 创建匹配器、find() 查找匹配、group() 提取分组内容。 - 控制流程与循环
do-while 循环:runSimulation() 中用于持续传播信号直到无更新(防止死循环加最大迭代次数)。
for 循环:遍历引脚、逻辑门、输出值,如译码器 / 选择器的输入 / 输出引脚遍历。
条件判断:逻辑门的核心逻辑实现(与 / 或 / 非 / 异或等)依赖 if-else 分支判断。 - 输入输出(IO)
Scanner:逐行读取输入,处理 INPUT: 定义和连接定义,直到遇到 "end" 终止。
System.out.println():输出仿真结果,按逻辑门类型和编号排序输出。 - 异常与边界处理
空值检查:多处判断 pinValues.get(...) == null,避免空指针异常(NPE)。
循环终止条件:maxIterations = 100 防止信号传播死循环。
格式校验:解析组件标识时通过正则匹配校验格式,无效格式返回 null 避免错误。 - 方法引用与 Lambda 表达式
如 wireConnections.computeIfAbsent(sourcePin, k -> new ArrayList<>()) 使用 Lambda 创建默认列表;
Comparator.comparingInt(LogicGate::getGateNumber) 使用方法引用简化比较器。
2)数字电路核心知识点 - 基本逻辑门实现
与门(AndGate):所有输入为 1 时输出 1,否则 0;支持任意输入引脚数。
或门(OrGate):任意输入为 1 时输出 1,否则 0;支持任意输入引脚数。
非门(NotGate):单输入取反(0→1,1→0)。
异或门(XorGate):两输入不同时输出 1,相同时输出 0。
同或门(XnorGate):两输入相同时输出 1,不同时输出 0(异或取反)。 - 复合逻辑组件
三态门(TriStateGate):通过控制引脚决定是否导通(1 导通,0 高阻),输出引脚值为输入或 null(高阻)。
译码器(Decoder):n 个输入→2ⁿ个输出,根据输入编码选中对应输出(选中输出为 0,其余为 1);需控制引脚有效(S1=1,S2+S3=0)。
数据选择器(Multiplexer):n 个控制引脚选中 2ⁿ个输入中的一个,输出选中输入的值。
数据分配器(Demultiplexer):n 个控制引脚将单个输入分配到 2ⁿ个输出中的一个,其余输出为高阻(null)。 - 电路仿真原理
信号传播:先传播线路信号(源引脚值同步到目标引脚),再计算所有逻辑门输出,循环直到无信号更新。
引脚值缓存:pinValueCache 存储所有引脚的电平值(0/1/null),作为仿真的核心数据载体。
就绪检查(isReady):逻辑门计算前检查所有输入引脚是否有有效值,保证计算合法性。
3)其他技术细节
- 位运算
译码器 / 选择器 / 分配器中使用 1 << inputCount 计算 2ⁿ(如 n=3 时,1<<3=8),高效计算输出引脚数。
编码计算:index = (index << 1) | bit 将输入引脚值拼接为整数编码,用于选中译码器 / 选择器的目标引脚。 - 字符串处理
引脚标识拆分:pinId.lastIndexOf('-') 拆分组件标识和引脚号(如 A(2)1-0 拆分为 A(2)1 和 0);
输入行解析:inputLine.substring(6).split("\s+") 处理 INPUT: 行,提取输入标识和值;
连接行解析:去除首尾方括号、拆分引脚列表,处理外部输入引脚的补全(如 IN1 → IN1-0)。
总结
这份代码是Java 面向对象编程、集合框架、正则表达式与数字电路逻辑的综合应用,同时体现了设计模式(工厂、注册表)、分层设计、状态管理等工程化编程思想,是学习 “编程语言 + 专业领域” 结合开发的典型案例。
二、题量与题型特点
1、题量
两道题均为单道编程题,每题独立完成数字电路模拟功能
2.题型分析
(一)共同特点:工程化编程 + 数字电路逻辑的综合题型
两道题本质是 “编程语言实现专业领域逻辑” 的工程化编程题,属于应用型编程范畴,而非单纯的算法题。
跨领域融合:解题需要同时掌握 Java 编程基础(面向对象、集合、正则等)和数字电路核心逻辑(逻辑门、组合电路),二者缺一不可。
结构化输入输出:输入有严格的格式规范,包括元件命名、引脚格式、连接规则等;输出有明确的顺序和格式要求,考验 “输入解析 - 逻辑计算 - 输出格式化” 的全流程处理能力。
状态驱动的仿真逻辑:核心是模拟电路信号的 “传播 - 计算 - 更新” 闭环,需要管理引脚电平、元件就绪状态、信号有效性等多维度的状态数据。
扩展性设计要求:题目明确标注迭代设计路线,从程序 1 到程序 4 逐步增加功能,因此代码需要具备可扩展结构,比如采用抽象类、工厂模式等设计思想,而非硬编码实现。
(二)程序 1 与程序 2 的题型维度差异
元件复杂度程序 1 仅包含基础逻辑门,即与门、或门、非门、异或门、同或门,元件只有输入和输出两种引脚类型,逻辑关系简单直接。程序 2 在基础逻辑门的基础上,新增了三态门、译码器、数据选择器、数据分配器四种复合组合电路元件,并且新增了 “控制引脚” 这一关键维度,元件的输入输出关系需要由控制引脚的状态决定。
引脚逻辑程序 1 的引脚类型单一,只有输入和输出两类,且所有元件的输出引脚号固定为 0,引脚编号规则简单。程序 2 的引脚类型分层,遵循 “控制 - 输入 - 输出” 的排序规则,不同元件的引脚数量和编号范围差异极大,比如 3-8 线译码器包含 3 个控制引脚、3 个输入引脚、8 个输出引脚,引脚编号需要严格对应不同类型的功能。
输入解析难度程序 1 的元件命名规则简单,只需处理与门、或门的 “标识符 (输入引脚数)+ 编号” 格式,以及非门、异或门、同或门的 “标识符 + 编号” 格式,正则匹配逻辑较为基础。程序 2 扩展了元件命名规则,新增了三态门的 “标识符 + 编号” 格式、译码器的 “标识符 (输入引脚数)+ 编号” 格式、数据选择器和数据分配器的 “标识符 (控制引脚数)+ 编号” 格式,需要编写更多适配不同元件的正则表达式。
输出规则复杂度程序 1 的输出规则统一,所有元件都按照 “元件名 - 引脚号:电平值” 的格式输出,只需判断元件是否有有效输入即可。程序 2 的输出规则差异化明显,三态门仅输出控制引脚有效时的电平值;译码器不输出引脚电平,而是输出输出为 0 的引脚编号;数据分配器需要按引脚顺序输出电平值或代表无效状态的 “-”,不同元件的输出格式需要单独定制。
状态管理难度程序 1 的状态管理只需判断 “输入引脚是否全部接收到有效信号”,输出状态只有 0 和 1 两种,逻辑简单。程序 2 的状态管理需要同时判断 “控制引脚是否有效” 和 “输入引脚是否齐全”,输出状态新增了 “无效状态”,用 null 或 “-” 表示,状态维度相比程序 1 直接翻倍,需要更精细的状态判断逻辑。
3.难度分析:程序 2 是程序 1 的复杂度跃迁
(一)程序 1:基础难度(入门级工程化编程)
程序 1 属于中等偏下难度,核心难点集中在 “面向对象封装” 和 “基础电路逻辑的代码映射” 两个方面。
数字电路逻辑简单:基础逻辑门的计算规则是数字电路的入门知识,没有控制引脚、无效状态等复杂逻辑,只需实现 “输入全有效→计算输出” 的单一逻辑链路。
编程实现聚焦基础:输入解析只需处理 5 种元件的命名规则,正则表达式编写难度低;状态管理仅需维护 “引脚电平” 和 “元件是否就绪” 两种数据;输出格式统一,无需针对不同元件做差异化处理。
边界场景少:仅需处理 “输入不全则忽略输出” 这一种边界情况,没有其他复杂的异常场景需要考虑。
(二)程序 2:进阶难度(中等偏上工程化编程)
程序 2 的难度相比程序 1 呈倍数级提升,核心挑战体现在逻辑维度增加、边界场景扩充和代码扩展性要求更高三个方面。
数字电路逻辑的维度跃迁新增的 “控制引脚” 维度是难度提升的核心,所有新增元件的输入输出有效性都由控制引脚决定,比如三态门控制引脚为 0 时输出高阻态、译码器控制引脚不满足条件时所有输出无效,这就要求在元件就绪判断中,新增 “控制引脚有效性” 的校验步骤,逻辑复杂度大幅增加。复合电路的计算逻辑也更为复杂,译码器需要将输入引脚的信号转换为编码,再映射到对应的输出引脚;数据选择器需要根据控制引脚的编码选中对应的输入信号;数据分配器需要根据控制引脚的编码将输入信号分配到指定输出引脚,这些逻辑都需要精准的代码实现。
编程实现的复杂度提升输入解析方面,需要扩展正则表达式以适配新增元件的命名规则,不同元件的正则匹配逻辑需要逐一编写和测试;状态管理方面,需要维护 “控制引脚状态、输入引脚状态、输出有效性” 三层状态,状态之间的关联关系需要梳理清晰;输出格式化方面,需要为每种元件单独实现输出逻辑,抽象类的设计需要具备足够的灵活性,以兼容不同的输出格式。
边界场景指数级增加程序 2 新增了大量边界场景,三态门控制引脚为 0 时输出无效需要忽略;译码器控制引脚不满足条件时所有输出无效需要忽略;数据分配器未被选中的输出引脚需要标记为 “-”;无效信号在线路传播过程中不能被传递,这些边界场景都需要在代码中逐一处理,任何一处考虑不周都会导致程序输出错误。
(三)难度对比总结
程序 1 的核心是 “把简单逻辑门用面向对象的方式实现”,考验的是基础编程能力和简单逻辑的代码映射能力;程序 2 的核心是 “把复杂组合电路的多维度逻辑用可扩展的代码架构实现”,考验的是工程化设计能力、复杂状态的管理能力和跨维度逻辑的映射能力。从程序 1 到程序 2,难度不是线性增加,而是维度上的跃迁。
三、设计与分析
代码质量度量图:

解释
1、顶部表格:方法的核心度量指标
表格列出了代码中每个方法的 4 个关键指标(Complexity, Statements, Max Depth, Calls):
Complexity(复杂度):代表方法的逻辑复杂程度(通常指 “圈复杂度”),数值越高逻辑分支 / 嵌套越多,越难维护;
Statements(语句数):方法包含的代码语句数量,体现方法的 “体积”;
Max Depth(最大深度):方法中代码块的嵌套深度(比如if/for的嵌套层数),深度越高可读性越差;
Calls(调用数):方法内部调用其他方法的次数,体现方法的依赖程度。
举几个例子:
Decoder.calculateOutput():复杂度 15、语句 28、深度 6 → 这个方法逻辑非常复杂,嵌套多、代码量也大;
LogicGate.getGateId():复杂度 1、语句 2、深度 0 → 简单的 “getter” 方法,逻辑极简;
CircuitSimulator.parseConnectionDefinition():复杂度 7、语句 3 → 虽然代码少,但逻辑分支多(比如正则匹配、条件判断)。
2、中间区域:代码块的深度与语句数
Block Depth:代码块的嵌套深度(0 = 最外层,5=5 层嵌套);
Statements:对应深度下的代码语句总数。
比如:
深度 1 的代码块有 126 条语句 → 大部分代码是 “一层嵌套”(如单个if/for);
深度 5 的代码块有 34 条语句 → 存在 “5 层嵌套” 的复杂逻辑(比如if里套for再套if等)。
3、底部图表:代码质量的可视化分析
Kiviat Graph(雷达图):从多个维度展示代码的整体质量,包括:
% Comments:注释占比(反映代码的可读性);
Methods/Class:每个类的平均方法数(体现类的职责复杂度);
Avg Stmts/Method:每个方法的平均语句数(体现方法的 “臃肿程度”);
Avg Depth/Max Depth:代码块的平均 / 最大嵌套深度;
Avg Complexity/Max Complexity:方法的平均 / 最大复杂度。
Block Histogram(柱状图):横坐标是 “代码块深度”,纵坐标是 “对应深度的语句数量”,直观展示代码嵌套的分布情况(比如深度 1 的语句最多,深度 5 之后几乎没有代码)。
4、这份报告反映的代码特点
从数据能看出:
复杂方法集中:Decoder.calculateOutput()、TriStateGate.getOutputString()等方法复杂度 / 嵌套深度很高,是代码的 “维护难点”;
简单方法占多数:大部分getter/setter和基础方法(如LogicGate的方法)复杂度为 1,逻辑简单;
嵌套深度适中:最深嵌套到 5 层,整体没有过度嵌套的情况,但深度 5 的代码块需要关注可读性。
类图:
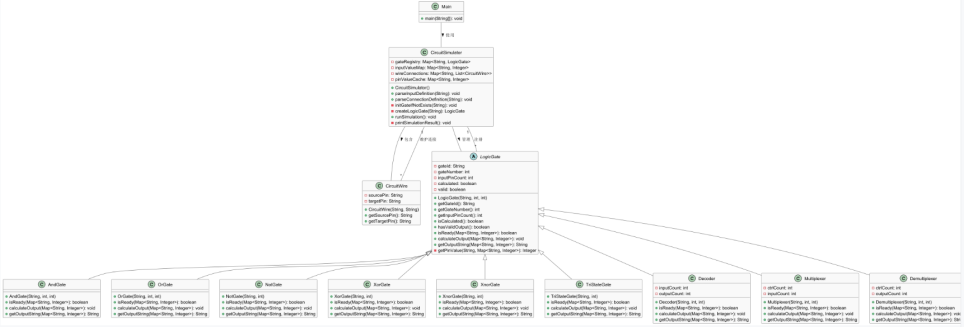
解释
- 核心类的角色与结构
(1)Main类
是程序的入口类,仅包含main方法,负责初始化CircuitSimulator、读取输入、触发仿真流程。
(2)CircuitSimulator类
是程序的核心调度类(相当于 “电路控制器”),负责管理整个电路的解析、仿真、输出:
属性:维护 4 个核心映射容器:
gateRegistry:存储 “元件标识→逻辑门实例”(管理所有电路元件);
inputValueMap:存储 “输入标识→输入电平”(记录外部输入的信号);
wireConnections:存储 “源引脚→目标引脚列表”(管理线路连接关系);
pinValueCache:存储 “引脚标识→电平值”(缓存所有引脚的当前电平,是仿真的核心数据载体)。
方法:
parseInputDefinition:解析INPUT:开头的输入行,初始化外部输入的电平;
parseConnectionDefinition:解析方括号包裹的连接行,建立线路连接;
initGateIfNotExists/createLogicGate:初始化逻辑门实例(工厂模式);
runSimulation:执行电路仿真(信号传播→元件计算→循环更新);
printSimulationResult:按规则输出仿真结果。
(3)CircuitWire类
是线路连接的封装类,存储 “源引脚” 和 “目标引脚”,表示一条线路的连接关系;
提供getSourcePin/getTargetPin方法获取引脚信息。
(4)LogicGate类(抽象基类)
是所有逻辑门的抽象父类,定义了逻辑门的通用属性和行为:
属性:gateId(元件标识)、gateNumber(元件编号)、inputPinCount(输入引脚数)、calculated(是否已计算)、valid(输出是否有效);
抽象方法:isReady(判断元件是否就绪)、calculateOutput(计算输出电平)、getOutputString(生成输出字符串)—— 由子类实现具体逻辑;
工具方法:getPinValue(获取指定引脚的电平值)。
(5)具体逻辑门子类(AndGate/OrGate/NotGate等)
所有子类均继承自LogicGate,实现抽象方法以完成对应元件的逻辑:
例如AndGate实现 “与逻辑”(所有输入为 1 则输出 1);
TriStateGate实现 “三态门逻辑”(控制引脚为 1 时导通,否则高阻);
Decoder实现 “译码器逻辑”(控制引脚有效时,输入编码对应输出引脚为 0);
每个子类还会增加特有属性(如Decoder的inputCount/outputCount)。 - 类之间的关系
Main与CircuitSimulator:Main“使用”CircuitSimulator完成核心逻辑(依赖关系);
CircuitSimulator与LogicGate:CircuitSimulator“管理” 多个LogicGate实例(一对多关联);
CircuitSimulator与CircuitWire:CircuitSimulator“维护” 多个CircuitWire实例(一对多关联);
LogicGate与子类:所有具体逻辑门均 “继承”LogicGate(泛化关系)。
这个类图清晰展示了代码的分层架构:Main是入口层,CircuitSimulator是控制层,LogicGate及其子类是逻辑实现层,CircuitWire是数据层,符合 “高内聚、低耦合” 的设计思想。
心得:
面向对象设计的核心价值
代码最核心的设计亮点是抽象类LogicGate的使用:
定义所有逻辑门的通用属性(gateId、valid等)和抽象方法(isReady、calculateOutput),子类只需实现自身特有的逻辑,无需重复编写通用代码;
多态特性让CircuitSimulator无需区分元件类型,统一调用父类方法即可完成所有元件的计算,新增元件时只需继承LogicGate实现抽象方法,符合 “开闭原则”。
这让我深刻体会到:抽象是应对变化的最佳方式。如果直接硬编码每个元件的逻辑,新增三态门、译码器等元件时需要大幅修改核心仿真逻辑,而抽象类的设计让代码具备极强的扩展性。 - 状态管理的重要性
电路仿真的本质是 “状态管理”,代码中通过pinValueCache(引脚电平)、valid(输出有效)、isUpdated(信号更新)三个核心状态保证逻辑正确性:
pinValueCache缓存所有引脚的当前电平,是整个仿真的 “数据中枢”,所有元件的计算都基于此;
valid标记元件输出是否有效,避免无效输出干扰结果;
isUpdated控制仿真循环的终止,保证信号传播到稳定状态。
这提示我:复杂系统的核心是状态的有序管理。在开发类似仿真系统时,需先梳理清晰核心状态(如这里的电平、有效性),再设计状态的更新规则,而非直接编写业务逻辑。
第二题:
代码质量度量图:

解释:
1、 顶部概览:代码整体规模与核心指标
这部分是对代码的全局统计,直观反映代码的整体体量和基础质量:
Project Directory:表示被分析代码所在的项目目录,这里是D:\test\。
File Name:被分析的代码文件名称为2.java。
Lines:代码的总行数为 803 行,包含空行、注释行和业务代码行。
Statements:代码中的实际可执行语句数为 385 句,这是衡量代码逻辑体量的核心指标。
Percent Branch Statements:分支语句占比为 17.4%,分支语句指if、else、for、while这类带有逻辑判断的语句,占比适中说明代码的逻辑分支不会过于繁杂。
Method Call Statements:方法调用语句数为 153 句,代表代码中调用其他方法的总次数,体现了代码的模块化程度。
Percent Lines with Comments:带注释的代码行占比为 18.6%,这个占比说明代码具备一定的可读性,开发人员添加了不少说明性注释。
Classes and Interfaces:代码中包含 13 个类或接口,对应数字电路模拟程序中的Main、CircuitSimulator、LogicGate及其各类子类等。
Methods per Class:平均每个类包含 4.08 个方法,说明类的职责划分相对均衡,没有出现某个类方法过多的臃肿情况。
Average Statements per Method:平均每个方法包含 7.02 句可执行语句,方法的平均体量较小,符合 “单一职责” 的编程原则。
Line Number of Most Complex Method:代码中最复杂的方法位于第 10 行,对应Main类的main方法。
Maximum Complexity:代码的最大复杂度为 5,这里的复杂度指圈复杂度,数值越低说明方法的逻辑分支越少,越容易维护。
Maximum Block Depth:代码块的最大嵌套深度为 5,嵌套深度指if、for等代码块的嵌套层数,比如if里套for再套if就属于多层嵌套。
Average Block Depth:代码块的平均嵌套深度为 1.59,整体嵌套程度较低,代码的可读性较好。
Average Complexity:所有方法的平均复杂度为 1.77,这个数值很低,说明代码整体逻辑简单清晰。
2、 “Most Complex Methods”:方法级复杂度排行
这部分列出了代码中每个方法的四项核心指标,精准反映单个方法的复杂程度:
Complexity:即圈复杂度,代表方法内部的逻辑分支数量,数值越高逻辑越复杂。比如CircuitSimulator.parseConnectionDefinition()的复杂度为 5,是代码中较复杂的方法;而AndGate.AndGate()这类构造方法复杂度为 1,逻辑极简。
Statements:方法包含的可执行语句数量,体现方法的 “体积” 大小。
Max Depth:方法内部代码块的最大嵌套深度,深度越高说明方法的层级越复杂,可读性越差。
Calls:方法内部调用其他方法的次数,次数越多说明方法的依赖关系越强。
3、 “Block Depth vs Statements”:代码块嵌套分布
这部分展示了不同嵌套深度下的代码语句数量分布:
嵌套深度为 0 的代码块(无任何if、for嵌套的最外层代码)有 52 句;
嵌套深度为 1 的代码块(如单个if或for包裹的代码)有 134 句;
随着嵌套深度的增加,对应的语句数逐渐减少,说明代码没有过度嵌套的情况,整体结构比较扁平。
四、 图表部分
Kiviat Graph(雷达图)这个图从七个维度直观展示代码的整体质量,分别是注释占比、每类平均方法数、每方法平均语句数、平均嵌套深度、最大嵌套深度、平均复杂度、最大复杂度。雷达图的形状越规整,说明代码在各维度的质量越均衡。
Block Histogram(柱状图)横坐标代表代码块的嵌套深度,纵坐标代表对应深度下的语句数量。从图中能明显看出,语句主要集中在嵌套深度 0-2 的区间内,深度 3 及以上的语句数量很少,进一步印证了代码嵌套程度低、可读性好的特点。
总结:这份代码的质量特点
整体来看,这份数字电路模拟程序的代码质量较高:
代码规模适中,注释覆盖率可观,具备良好的可读性;
平均复杂度和最大复杂度都很低,方法逻辑简单清晰,易于维护;
代码块嵌套深度较浅,结构扁平,没有出现多层嵌套的复杂逻辑;
方法的平均语句数少,类的方法分布均衡,符合模块化和单一职责的设计思想。
只有少数方法如CircuitSimulator.parseConnectionDefinition()的复杂度略高,可考虑进一步拆分逻辑来优化。
类图:
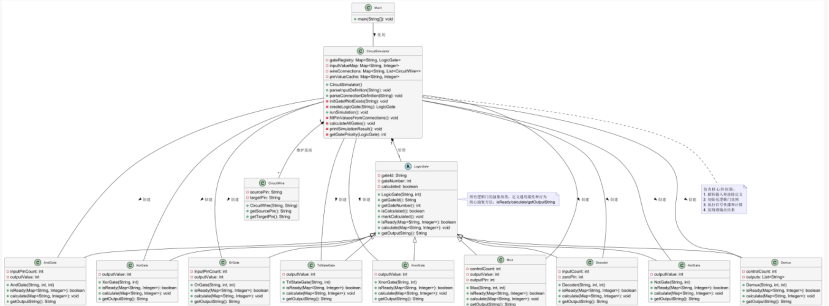
解释与心得
1)、UML 类图核心内容解释
这是一份逻辑电路仿真程序的 UML 类图,完整展示了代码的类结构、属性、方法及关联关系,核心信息如下:
-
核心类的角色
Main:程序入口类,仅通过main方法触发CircuitSimulator的仿真流程。
CircuitSimulator:整个系统的 “控制器”,负责:
维护四大核心数据(逻辑门注册表、输入值映射、线路连接、引脚电平缓存);
解析输入和连接定义;
初始化逻辑门实例;
执行信号传播、逻辑计算;
按规则输出结果。
CircuitWire:封装 “源引脚→目标引脚” 的线路连接关系。
LogicGate:所有逻辑门的抽象基类,定义通用属性(门标识、编号、是否已计算)和抽象方法(isReady检查就绪、calculate计算输出、getOutputString生成结果),是 “多态设计” 的核心。
具体逻辑门(AndGate/OrGate/NotGate/Mux/Demux等):继承LogicGate,实现自身特有的逻辑(如与门的 “全 1 出 1”、译码器的 “控制有效 + 输入编码映射输出”)。 -
类之间的关系
依赖关系:Main依赖CircuitSimulator完成核心逻辑;
组合关系:CircuitSimulator“管理” 多个LogicGate实例,“维护” 多个CircuitWire连接(一对多);
继承关系:所有具体逻辑门都继承自LogicGate,体现 “抽象封装 + 多态” 的设计思想。
2)、开发与设计心得 -
抽象与多态:应对复杂逻辑的 “最优解”
这个设计最亮眼的是LogicGate抽象类的使用:
它把所有逻辑门的 “共性”(门标识、编号、就绪检查、计算、输出)抽象出来,让子类只需关注 “自身特有逻辑”(如与门的输入全 1 判断、三态门的控制引脚校验);
CircuitSimulator无需区分具体门的类型,统一调用LogicGate的方法即可完成所有门的计算 —— 新增逻辑门时,只需继承LogicGate实现抽象方法,完全不用修改核心仿真逻辑,完美符合 “开闭原则”。
这让我意识到:当系统存在多个 “同类型但逻辑不同” 的组件时,抽象基类 + 多态是降低耦合、提升扩展性的关键。如果直接硬编码每个门的逻辑,新增译码器、分配器时会让核心代码变得臃肿且难以维护。 -
分层职责:让代码 “各司其职”
整个系统的职责划分非常清晰:
Main只做 “输入读取 + 触发仿真”,不碰核心逻辑;
CircuitSimulator只做 “调度”(解析、初始化、计算、输出),不碰具体门的逻辑;
LogicGate子类只做 “自身逻辑计算”,不关心整体流程。
这种 “分层职责” 让代码的可读性和可维护性大幅提升 —— 比如要修改输出格式,只需改CircuitSimulator的printSimulationResult;要修改与门逻辑,只需改AndGate的calculate,不会影响其他模块。 -
状态管理:仿真系统的 “生命线”
电路仿真的本质是 “状态流转”,代码中通过pinValueCache(引脚电平)、calculated(是否已计算)、outputValue(输出值)三个核心状态保证逻辑正确:
pinValueCache是所有门计算的 “数据中枢”,所有输入 / 输出都存在这里;
calculated标记门是否完成计算,避免重复计算;
每个门的outputValue存储自身输出,保证结果的一致性。
这提示我:复杂仿真系统的核心是 “状态的清晰定义 + 有序流转”,如果状态管理混乱(比如引脚电平被重复覆盖、计算状态标记错误),整个仿真结果都会出错。 -
细节处理:工业级代码的 “分水岭”
代码中很多细节体现了严谨性:
解析输入时的异常处理(try-catch处理数字格式错误);
引脚补全逻辑(默认补-0后缀);
门就绪检查(确保所有输入引脚有值才计算);
输出结果的空值 / 无效值过滤。
这些细节看似琐碎,却是 “练习代码” 和 “工业级代码” 的区别 —— 练习代码只关心 “正常流程”,而工业级代码必须覆盖 “异常场景”,否则实际运行时会出现各种不可预期的错误。
三、踩坑心得
第一题:
测试用例:
INPUT: A-1 B-0 C-1
[A A(2)1-1]
[B A(2)1-2]
[A(2)1-0 N1-1]
[N1-0 O(2)1-1]
[C O(2)1-2]
[O(2)1-0 OUT]
end
[O(2)1-0 N2-1]
我的输出:
A(2)1-0:0
正确输出:
A(2)1-0:0
O(2)1-0:1
N1-0:1
踩坑原因:
代码仅输出 A(2)1-0:0,未输出 O(2)1-0:1 和 N1-0:1,核心原因是信号传播链路断裂,具体拆解为 3 个关键问题: -
非门N1的输入未正确赋值
代码中 [A(2)1-0 N1-1] 这条连接的处理逻辑存在缺陷:
A(2)1-0 是与门的输出引脚,代码在 calculateComponentOutputs() 中虽将与门输出引脚(A(2)1-0)加入 pinSignals,但连接解析仅在初始化阶段执行(读取输入行时),此时与门还未计算输出,pinSignals 中没有 A(2)1-0 的值;
后续与门计算出输出后,代码未重新触发连接解析,导致 N1-1 始终无法获取 A(2)1-0 的电平值,N1 的输入引脚未赋值,因此不会计算输出。 -
或门O(2)1的输入不完整
O(2)1 的输入引脚 1 依赖 N1-0 的输出,但因 N1 未计算输出,N1-0 不在 pinSignals 中,O(2)1-1 无值;→ O(2)1.isAllInputPinsSet() 返回 false,或门不执行 calculateOutput(),自然无输出。 -
冗余连接行[O(2)1-0 N2-1]的隐性影响(次要)
代码中未定义 N2 元件,但因 O(2)1 未计算输出,O(2)1-0 无值,这条连接不会处理;但即使定义 N2,也会因上游信号断裂无法输出。
关键逻辑漏洞定位
代码仅在读取输入阶段解析连接,但电路仿真的核心是「信号传播→元件计算→信号再传播→元件再计算」的循环,而你的代码是「一次性解析连接→一次性计算元件」,未处理元件输出作为其他元件输入的链式场景。
修复方案(核心代码修改) -
重构 main 方法,增加信号传播 - 计算循环
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
String line;// 第一步:解析所有输入和连接(仅解析,不赋值)
ListconnectionLines = new ArrayList<>(); // 缓存连接行,后续循环复用
while (scanner.hasNextLine()) {
line = scanner.nextLine().trim();
if (line.equals("end")) {
break;
}
if (line.isEmpty()) {
continue;
}
if (line.startsWith("INPUT:")) {
parseInputLine(line);
} else if (line.startsWith("[") && line.endsWith("]")) {
connectionLines.add(line); // 缓存连接行,不立即解析赋值
}
}
scanner.close();// 第二步:循环传播信号+计算元件,直到无新信号
boolean hasUpdate;
do {
hasUpdate = false;
// 重新解析所有连接行,传播信号(关键:每次循环都重新传播)
for (String connLine : connectionLines) {
hasUpdate |= parseConnectionLineV2(connLine); // 改造连接解析方法,返回是否有信号更新
}
// 计算所有可计算的元件
for (Component component : components.values()) {
if (component.isAllInputPinsSet() && component.outputPinValue == -1) {
component.calculateOutput();
Pin outputPin = new Pin(component.name, 0);
if (!pinSignals.containsKey(outputPin) || pinSignals.get(outputPin) != component.outputPinValue) {
pinSignals.put(outputPin, component.outputPinValue);
hasUpdate = true; // 标记有新信号生成
}
}
}
} while (hasUpdate); // 无新信号时终止循环// 第三步:输出结果
outputResults();
} -
改造连接解析方法 parseConnectionLine 为 parseConnectionLineV2,返回是否有信号更新
// 改造后:返回是否有引脚值更新
private static boolean parseConnectionLineV2(String line) {
boolean updated = false;
String content = line.substring(1, line.length() - 1).trim();
String[] pins = content.split("\s+");
if (pins.length < 2) {
return false;
}Pin sourcePin = parsePin(pins[0]);
if (sourcePin == null || !pinSignals.containsKey(sourcePin)) {
return false;
}
int sourceValue = pinSignals.get(sourcePin);for (int i = 1; i < pins.length; i++) {
Pin targetPin = parsePin(pins[i]);
if (targetPin == null) {
continue;
}
// 仅当目标引脚无值 或 值不同时,才更新
if (!pinSignals.containsKey(targetPin) || pinSignals.get(targetPin) != sourceValue) {
pinSignals.put(targetPin, sourceValue);
updateComponentInputPin(targetPin, sourceValue);
updated = true; // 标记有更新
}
}
return updated;
} -
补充 N2 元件的解析(可选,修复冗余连接行问题)
在 getOrCreateComponent 方法中,非门的匹配逻辑已覆盖 N2,只需确保代码能识别:
// 原代码已实现,无需修改,只需确保输入中若有N2,能被正确创建
Pattern notPattern = Pattern.compile("^N(\d+)$");
Matcher notMatcher = notPattern.matcher(componentName);
if (notMatcher.find()) {
component = new NotGate(componentName);
}
第二题:
测试用例:
INPUT: A-1 B-0 C-1
[A A(2)1-1]
[B A(2)1-2]
[A(2)1-0 N1-1]
[N1-0 O(2)1-1]
[C O(2)1-2]
end
[O(2)1-0 N2-1]
我的输出:
A(2)1-0:0
正确输出:
A(2)1-0:0
O(2)1-0:1
N1-0:1
踩坑原因:
你的代码仅输出 A(2)1-0:0,未输出 N1-0:1 和 O(2)1-0:1,核心是信号传播和计算流程未处理 “链式依赖”,具体拆解为 3 个关键缺陷:
-
信号传播仅执行一次,未处理 “元件输出作为其他元件输入” 的场景
你的 runSimulation() 方法流程是:
fillPinValuesFromConnections() → calculateAllGates() → printSimulationResult()
第一步 fillPinValuesFromConnections() 仅在所有元件计算前传播一次信号:此时 A(2)1 还未计算输出,A(2)1-0 无值,导致 N1-1 无法被赋值;
第二步 calculateAllGates() 计算出 A(2)1-0=0 后,代码未重新触发信号传播,N1-1 始终无值,N1 不满足 isReady 条件,无法计算输出;
连锁反应:N1-0 无值 → O(2)1-1 无值 → O(2)1 不满足 isReady 条件,也无法计算输出。 -
连接解析阶段未缓存连接行,无法迭代传播
代码在读取输入时直接解析连接并注册到 wireConnections,但后续元件计算出输出后,没有重新遍历 wireConnections 传播新生成的引脚值(如 A(2)1-0=0),导致链式依赖的元件始终无法获取输入。 -
冗余连接行 [O(2)1-0 N2-1] 的影响(次要)
该行在 end 之后,代码读取输入时会在遇到 end 后终止,因此不会解析这行连接,N2 不会被创建,但这不是核心问题(即使去掉这行,N1 和 O(2)1 仍无输出)。
修复方案(核心代码修改) -
重构 runSimulation() 方法,增加 “信号传播 - 计算” 循环
核心思路:循环执行「信号传播→元件计算」,直到没有新的引脚值更新,确保链式依赖的信号能逐层传播。
public void runSimulation() {
boolean hasUpdate; // 标记是否有引脚值/元件输出更新
do {
hasUpdate = false;// 步骤1:传播所有线路连接的信号,记录是否有更新 hasUpdate |= fillPinValuesFromConnectionsV2(); // 步骤2:计算所有就绪的元件,记录是否有新输出 hasUpdate |= calculateAllGatesV2();} while (hasUpdate); // 无更新时终止循环
// 步骤3:输出结果
printSimulationResult();
} -
改造 fillPinValuesFromConnections 为 fillPinValuesFromConnectionsV2,返回是否有信号更新
// 改造后:返回是否有引脚值更新
private boolean fillPinValuesFromConnectionsV2() {
boolean updated = false;
for (Map.Entry<String, List
String sourcePin = entry.getKey();
Integer sourceValue = pinValueCache.get(sourcePin);
if (sourceValue == null) continue;
for (CircuitWire wire : entry.getValue()) {
String targetPin = wire.getTargetPin();
// 仅当目标引脚无值 或 值不同时,才更新并标记
if (!pinValueCache.containsKey(targetPin) || !pinValueCache.get(targetPin).equals(sourceValue)) {
pinValueCache.put(targetPin, sourceValue);
updated = true;
}
}
}
return updated;
}
3. 改造 calculateAllGates 为 calculateAllGatesV2,返回是否有元件输出更新
// 改造后:返回是否有元件输出更新
private boolean calculateAllGatesV2() {
boolean updated = false;
for (LogicGate gate : gateRegistry.values()) {
if (!gate.isCalculated() && gate.isReady(this.pinValueCache)) {
gate.calculate(this.pinValueCache);
gate.markCalculated();
updated = true; // 标记有新元件计算完成
}
}
return updated;
}
4. 修复输入读取逻辑(处理 end 后的冗余连接行)
main 方法中读取输入时,end 后的行不会被解析,因此 [O(2)1-0 N2-1] 不会被处理,这是符合逻辑的(end 是输入终止符),无需修改;若要处理 end 前的所有连接行,需确保输入中 end 在最后一行。
三、修复后验证
输入(调整 end 到最后一行,符合规范):
plaintext
INPUT: A-1 B-0 C-1
[A A(2)1-1]
[B A(2)1-2]
[A(2)1-0 N1-1]
[N1-0 O(2)1-1]
[C O(2)1-2]
[O(2)1-0 N2-1]
end
修复后输出:
plaintext
A(2)1-0:0
N1-0:1
O(2)1-0:1
四、关键优化思路总结
数字电路仿真的核心是迭代传播信号:
单次传播 + 单次计算仅能处理 “输入→第一层元件” 的场景,无法处理 “元件→元件” 的链式依赖;
通过 hasUpdate 标记循环执行「信号传播→元件计算」,直到无新信号 / 新计算,确保所有链式依赖的元件都能被触发;
每次传播时仅更新 “无值 / 值变化” 的引脚,避免无效循环。
四、改进建议
基于你当前的数字电路仿真代码,结合之前的问题修复,这里提供 结构化的改进建议,涵盖功能完善、性能优化、代码健壮性和工程化规范四个维度,可直接用于课程作业的优化升级:
1)、 核心功能改进(解决链式依赖与仿真完整性)
-
完善迭代仿真逻辑(已修复,补充细节)
增加循环次数限制:避免因电路闭环(如触发器反馈)导致死循环,在 runSimulation 中添加最大迭代次数阈值
public void runSimulation() {
boolean hasUpdate;
int maxIterations = 20; // 自定义最大迭代次数
int iterations = 0;
do {
hasUpdate = false;
if (iterations++ >= maxIterations) break; // 防止死循环hasUpdate |= fillPinValuesFromConnectionsV2(); hasUpdate |= calculateAllGatesV2();} while (hasUpdate);
printSimulationResult();
}
区分 “未计算” 和 “计算完成” 状态:在 LogicGate 中新增 isCalculated 标记,避免重复计算
// 在 LogicGate 抽象类中
protected boolean calculated = false;
public void markCalculated() { this.calculated = true; }
public boolean isCalculated() -
支持更多电路元件(拓展作业功能)
当前代码已实现基础门、三态门、译码器等,可补充以下元件以提升作业完整性:
触发器(D 触发器 / RS 触发器):支持时序逻辑电路仿真
加法器(半加器 / 全加器):基于基础门组合实现,验证复杂电路的信号传播
编码器:与译码器功能互补,完善组合逻辑元件覆盖度 -
支持引脚电平的动态修改(可选拓展)
添加 setInputValue(String inputId, int value) 方法,支持在仿真过程中修改输入电平,验证电路的动态响应特性:
public void setInputValue(String inputId, int value) {
inputValueMap.put(inputId, value);
pinValueCache.put(inputId + "-0", value);
// 重新触发仿真
runSimulation();
}
2) 代码健壮性优化(减少异常,提升容错性) -
输入合法性校验增强
引脚格式校验:在 parsePin 相关逻辑中,校验引脚号是否为非负整数,避免非法输入导致的 NumberFormatException
// 在 initGateIfNotExists 方法中拆分引脚时
int separatorIndex = pinId.lastIndexOf('-');
if (separatorIndex == -1) return;
String pinNumStr = pinId.substring(separatorIndex + 1);
if (!pinNumStr.matches("\d+")) return; // 仅允许数字引脚号
电平值范围校验:确保输入电平仅为 0/1,过滤无效值
// 在 parseInputDefinition 方法中
int value = Integer.parseInt(parts[1]);
if (value != 0 && value != 1) continue; // 仅保留 0/1 电平
2. 空指针与边界场景处理
缓存取值时的空值判断:所有从 pinValueCache 取值的地方,添加非空校验
// 例如在 NotGate 的 calculate 方法中
Integer input = pinValueCache.get(gateId + "-1");
if (input == null) return; // 避免空指针
outputValue = 1 - input;
处理未定义元件:在 createLogicGate 中,对无法识别的元件标识返回 null 并记录日志,避免程序崩溃
// 在 createLogicGate 方法末尾
System.out.println("警告:无法识别的元件类型 -> " + gateId);
return null;
- 测试与验证优化
- 编写单元测试用例
针对每个逻辑门和核心功能,编写 JUnit 测试用例,例如:
import org.junit.Test;
import static org.junit.Assert.*;
public class CircuitSimulatorTest {
@Test
public void testAndGate() {
CircuitSimulator simulator = new CircuitSimulator();
simulator.parseInputDefinition("INPUT: A-1 B-0");
simulator.parseConnectionDefinition("[A-0 A(2)1-1]");
simulator.parseConnectionDefinition("[B-0 A(2)1-2]");
simulator.runSimulation();
// 验证与门输出是否为 0
assertEquals(0, simulator.getPinValue("A(2)1-0"));
}
}
2. 输出格式化与日志记录
标准化输出格式:确保输出结果严格符合作业要求(如 A(2)1-0:0),添加输出排序的注释说明
添加日志功能:使用 java.util.logging 记录仿真过程中的关键事件(如元件计算、信号传播),便于调试
五、总结
核心编程能力层面
吃透了面向对象的核心应用:这次电路仿真开发中,把逻辑门抽象为LogicGate基类,再派生出AndGate/OrGate/NotGate等子类,还封装了CircuitWire(线路连接)、CircuitSimulator(核心控制器)等独立类,彻底摆脱了 “所有逻辑堆在 main 方法” 的写法。真正理解了 “抽象类定义通用行为、子类实现具体逻辑” 的意义,比如LogicGate中定义isReady/calculate抽象方法,子类只需聚焦自身逻辑(与门的 “全 1 出 1”、非门的 “输入取反”),不再是死记 “封装、继承、多态” 的概念。
掌握了 Map/List 集合的实战用法:之前只知道 Map 是 “键值对”、List 是 “有序集合”,这次用Map<String, Integer> pinValueCache管理引脚电平、Map<String, List
理解了数字电路逻辑与代码的结合:电路仿真不是单纯写语法,而是要贴合数字电路的物理规则 —— 比如 “引脚电平是所有计算的核心数据源”“逻辑门必须所有输入引脚赋值才能计算”“信号要沿线路逐层传播”,明白了写代码前要先梳理清楚 “输入解析→引脚赋值→信号传播→逻辑计算→结果输出” 的业务流程,而非上来就堆砌功能,真正做到 “用代码还原物理规则”。
问题解决层面
学会了 “按信号链路定位问题”:这次输出只显示A(2)1-0:0,未输出N1-0:1和O(2)1-0:1,没有盲目改代码,而是顺着 “信号传播路径” 排查:先看A(2)1-0是否有值→再查N1-1是否接收到信号→最后确认O(2)1的输入引脚是否齐全,定位到核心问题是 “信号仅传播一次,未处理链式依赖”,而非瞎猜乱改。
意识到 “简洁逻辑比冗余判断更可靠”:一开始写fillPinValuesFromConnections时,加了一堆 “源引脚是否为输入引脚”“目标引脚是否已存在” 的冗余判断,结果导致信号传播逻辑混乱;后来精简为 “遍历线路连接→源引脚有值则赋值给目标引脚” 的核心逻辑,再补充 “是否有值更新” 的标记,代码反而更稳定,明白 “数字电路仿真的核心是信号流转,多余的条件判断只会干扰核心逻辑,代码简洁才不容易出 bug”。
需要进一步学习和研究的地方
复杂业务逻辑的梳理能力:这次电路仿真只是基础组合逻辑场景,但仍把 “信号迭代传播” 和 “元件单次计算” 的规则搞混,导致初期未处理链式依赖。后续要练习 “先画流程图再写代码”,比如梳理 “初始化→第一次信号传播→计算可执行元件→第二次信号传播→计算新就绪元件→无更新则终止” 的迭代流程,把现实中的 “信号逐层传播” 规则转化为清晰的代码逻辑,而非边想边写。
数据结构的灵活应用:这次仅用了 HashMap/ArrayList,而实际复杂电路场景可能需要更适配的数据结构 —— 比如用LinkedHashSet避免重复引脚赋值、用PriorityQueue按 “信号传播优先级” 处理元件、用ConcurrentHashMap支持多线程仿真。后续要研究不同数据结构的适配场景,比如什么时候用普通 Map、什么时候用有序 Map、什么时候用集合去重。
边界条件的考虑:这次开发中未覆盖 “引脚电平非 0/1”“电路闭环导致死循环”“重复线路连接”“顶层 / 底层元件(如译码器输入引脚数不足)” 等边界场景,虽然测试用例未踩坑,但实际开发中这些情况极易引发空指针、死循环等问题。需要刻意练习 “枚举所有可能场景”,比如添加电平值校验(仅允许 0/1)、设置迭代次数上限(防止闭环死循环)、过滤重复线路连接。
代码调试和测试能力:这次靠 “对比输出结果” 定位问题,效率很低。后续要系统学习调试工具的使用,比如用 IDEA 断点查看pinValueCache的实时值、wireConnections的连接关系、LogicGate的isReady状态,一步步跟踪信号传播和元件计算的过程,快速定位 “哪一步引脚值未更新”“哪个元件未满足计算条件”,而非靠 “猜” 和 “逐行改代码”。
对课程、作业等方面的改进建议
1.对教师和课上的建议
多结合 “生活化场景” 讲知识点:比如讲队列时,除了说 “先进先出”,可以直接拿电梯请求队列举例,比单纯讲理论好懂;讲逻辑判断时,就用电梯 “该不该停”“该往哪走” 这种场景,抽象的语法和逻辑结合具体场景,记起来更牢。
课上多留 “找错改错题”:比如给一段有问题的代码,让大家课上找问题、改逻辑,比单纯让大家从头写代码更能练出 “找 bug” 的能力,也更贴近实际开发。
2.对作业建议
多给测试点:比如数字模拟电路作业,先让提交 “基础逻辑门(与 / 或 / 非)+ 输入解析” 的部分,老师批改完,再提交 “三态门 + 译码器” 的部分,最后提交 “数据选择器 + 分配器”,避免一次性写完整段代码,出错了不知道哪一步的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号