

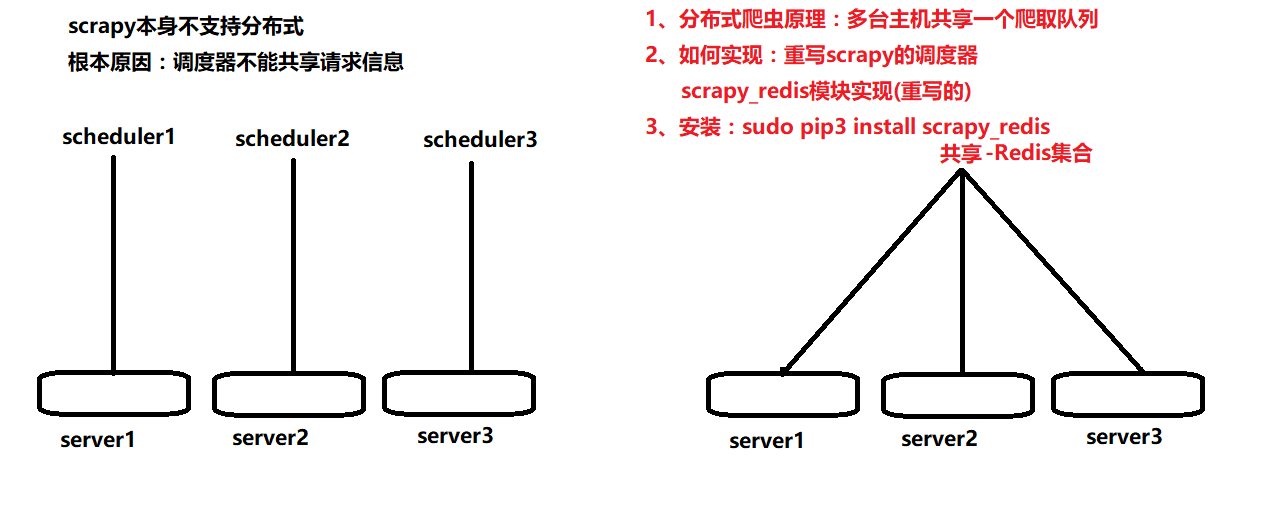
实现分布式爬虫
实现分布式爬虫:
1、原理:多台主机共享一个爬取队列
2、实现:利用redis中集合,重写scrapy的调度器,使用scrapy_redis模块实现
3、为什么使用redis
3.1》redis基于内存,快
3.2》redis中有集合数据类型,可以自动去重,存储每个请求的指纹
4、最终如何实现
4.1》先写普通的scrapy爬虫项目
4.2》设置为分布式爬虫 - settings.py中
SCHEDULER = ''
DUPEFILTER_CLASS = ''
REDIS_HOST = ''
REDIS_PORT = ''
SCHEDULER_PERSIST = True
中文解释: 重新指定调度器、去重机制,指定去重的redis的服务器,是否清楚请求指纹
python

 浙公网安备 33010602011771号
浙公网安备 33010602011771号