

Anytime Stereo Image Depth Estimation on Mobile Devices论文阅读笔记
这篇文章做了啥
ICRA2019的一篇文章,作者研究的主要问题是,现有的双目深度估计算法大多数都不能部署到移动端,作者提出了一个anynet,就是在任何时间限制下都能够得到一个深度估计,对fps要求比较高的话,可以用粗糙的结果,对fps要求比较低的话,可以用refine的结果,总之,可以在时间和精度之间进行权衡,如下图。
实际上作者训练的时长是真的很短,并且能够得到还比较能够接受的结果。后面我们会讲到这个。
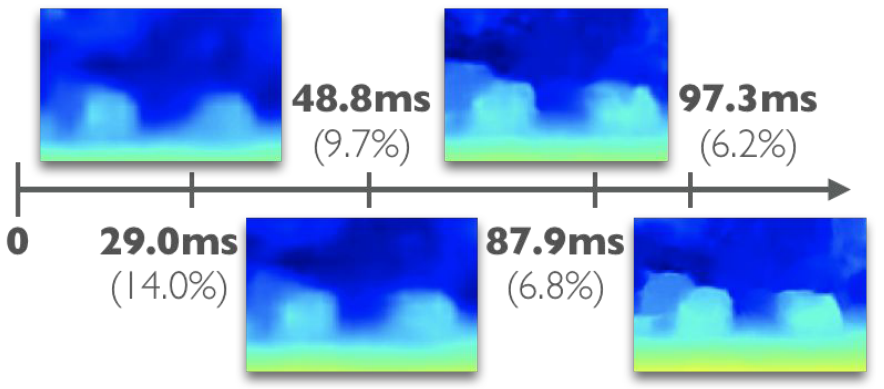
作者说,他们这个是第一个工作来进行实时双目深度估计优化的算法。
一些背景相关的工作介绍
作者说到,现有的深度估计的网络的计算的复杂度和图像分辨率的三次方成正比(长,宽,对应的max disparity也要缩小),并且和图像的maximum disparity一次成正比。所以作者想的是,既然和图像的尺寸成正比的话,那为何不缩小图像的尺寸进行预测呢?如果和最大视差也成正比的话,为何不减少视差(实际上改为预测残差)呢?
作者的网络结构图
如下图,
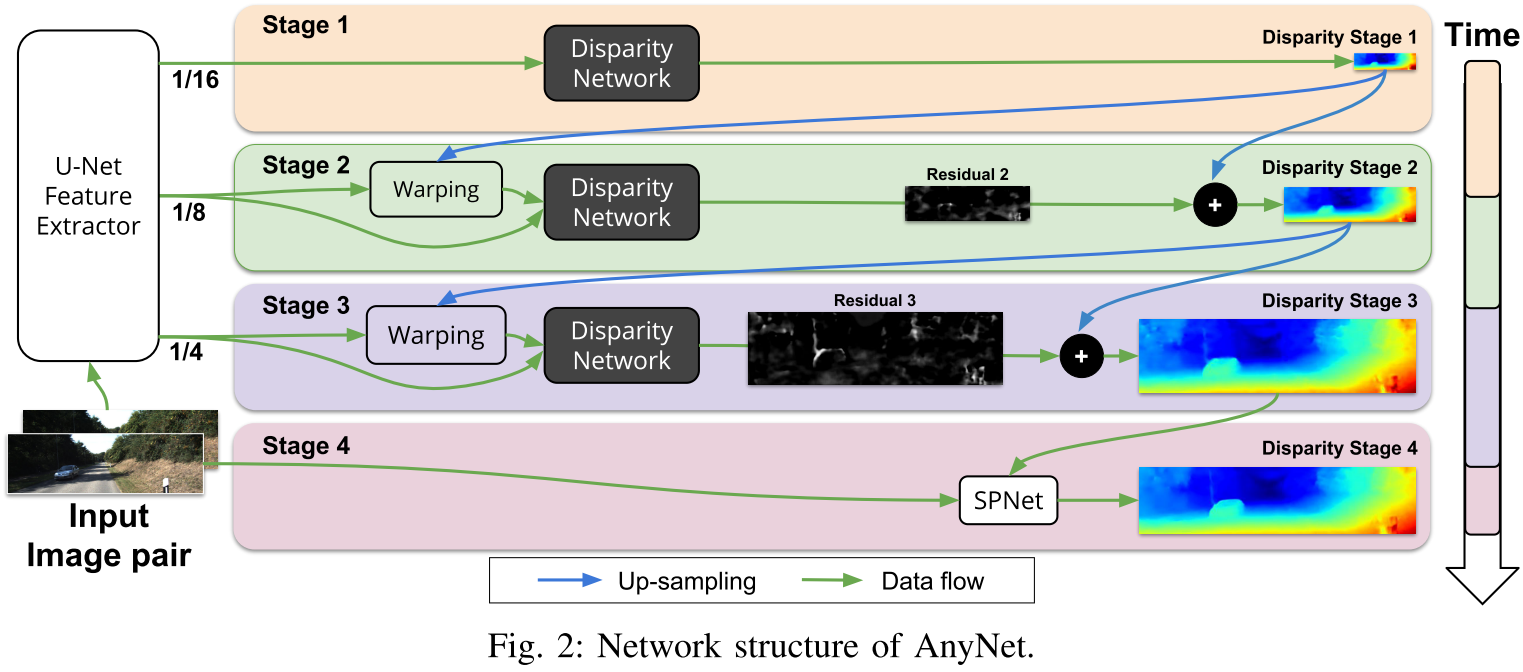
其中unet的feature extractor如下图

从上面第一张图可以看出,实际上有一个recursive的意思。大致的网络结构分为四个stage,无论是哪个stage,都是用的unet提取得到的feature,stage1用的是1/16的feature,经过视差网络,得到一个分辨率比较小的视差图。然后将这个视差图warp unet得到的1/8的分辨率的feature,所谓warp的意思是,将stage1得到的视差图先进行上采样,由1/16变为1/8,保持和stage2的unet输出的feature的尺寸一致;然后,由于视差图的每个pixel的value表示的是right image相对于left image像素的偏移量,所以可以直接进行warp,warp得到的结果这样的话,max disparity实际上就非常小了,比如如果第一次预测的比较准的话,第二次可能只需要进行微调,比如max disparity可能只为5这样,要知道,kitti上的max disparity为192,实际上,通过这种预测残差的方式,使得计算量大大的减少。stage3和stage2类似,stage4的话,用了一个现成的网络,叫SPNet,是使得边界更加清晰的网络,看代码,最终的输出是spnet处理之后的上采样得到的结果,和原图尺寸一样。网络的具体架构如下表格

干货其实就这么多,有几个要注意的点:
第一个是作者的unet网络实际上是共享的,disparity network也是,三个stage是三个视差网络,但是看代码stage1是单独的一个视差网络,stage2和stage3是共享了同一个网络,这个也比较好理解,就是stage的cost volume的max disparity实际上是192,但是经过warp之后,max disparity应该更小才对,所以stage1和stage2,3的三维卷积的设置是不一样的。
第二个要注意的就是,传统的方法都是用一个backbone来提取特征,比如resnet18这样,但是这种backbone有一个特点就是比较大,作者用了unet,相对轻量级(计算量和参数的话,有时间可以比较一下),然后因为stage的尺寸比较小,feature map的w和h不仅减小,对应的max disparity也减小,总的来讲,计算量一下减少了\((1/16)^3\),其实这个只是从3DCNN结构是一样的情况下来说的,但是比如psmnet或者gwcnet的话,用的是3D-hourglassnet的网络结构,非常的庞大的3D卷积,而作者这里只用了几层3D卷积。
第三个就是,作者在warp的时候用的是grid sample函数,来直接对feature map进行一个warp,这个函数可以用来对图像或者feature map进行变形。
实验结果
为了和其他的方法进行比较,作者对于原始的图像进行了4次分辨率降采样,使得具有对比意义,用其他的方法得到结果之后,再用双线性插值得到比较精确的实验结果,实验结果如下图

从上图可以看出,只有stereonet和作者的方法能够达到实时,而且作者的方法精度最高。在30fps-10fps之间,作者的方法最快,并且精度最高。实际上这里有几个问题,作者用低分辨率的图像,用psmnet结果竟然不尽如意,大概是因为作者的方法有高分辨率进行监督。而且如果能够实时运行的话,这里的精度实际上也并不高,3pixel error在kitti12或者kitti15已经刷的很高了。
ablation study
如下图
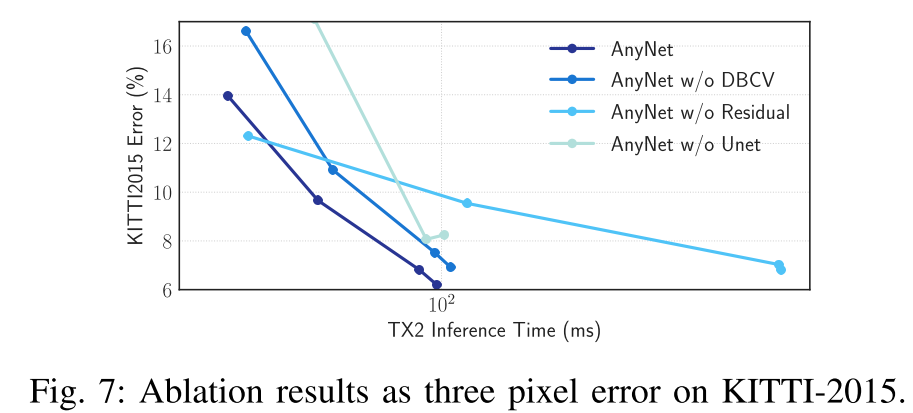
作者首先比较了不用一个unet extractor,而是用几层卷积分别处理(detail没有给出),作者想表达的意思是,低分辨率的时候,用unet效果仍然好。作者解释说,通过提取高层次的语义信息的约束,unet在提取低分辨率的时候仍然管用。
作者又对residual prediction进行了一个实验。作者不预测残差,而是直接预测一个完整的disparity map,也能够看出来,精度差别不大,但是耗时还挺大,一个有意思的现象是,在stage0的时候,不用残差约束的结果会好很多。
作者又对Distance-based Cost Volume做了一个ablation study,作者说,psmnet直接concate,没有计算距离,作者计算了距离,结果也如上图。关于这个的话gwcnet探究过,gwc用的一个是做concate,一个是相关,作者这里是两个对应的位置直接相减
论文阅读感受
感觉这两年双目深度估计发展的特别快,每年都有几篇文章讲如何提高精度,大致的pipline是提出一个网络,之前的gcnet开辟了引入3D CNN对cost volume进行约束,随之psmnet,gwcnet,层出不穷。不过大都是在kitti12或者kitti15上取得比较好的结果,不过现在kitti12或者kitti15已经不允许任何人随意提交结果。
但是,从网络压缩或者推理时间上来看的话,这方面的工作是比较少的,所以我觉得如果从网络压缩或者如何减少推理时间这个方向上去入手,做一下应该也是可以的。
作者的一个很好的idea就是利用全分辨率的来监督低分辨率的图像,深度估计预测结果,这样的话,如果单独拿出来第分辨率的结果,当然是最好的,而且,因为分辨率降低,所以实际上网络的容量和计算量都降低了很多。感觉这个idea实际上在很多任务中都能够用到,比如用来做分割等dense prediction的任务。
关于这个工作最后怎么follow,感觉并不是一件easy的事情,用网络压缩我感觉也不一定能pk过作者这篇文章。倒是可以试一试
posted on 2020-03-19 17:00 YongjieShi 阅读(869) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号