

阅读笔记之FastDepth: Fast Monocular Depth Estimation on Embedded Systems
这篇文章做了啥
对嵌入式,做了一个实时的单目深度估计框架。作者提出了一个efficient的encoder-decoder结构,精度可以和sota相媲美,并且推理时间非常短。作者主要集中在低延迟的decoder的设计上来
相关工作
作者回顾了一系列的单目深度估计的方法,说之前的方法主要集中在提升网络的精度上面,并没有太多考虑精度的信息。作者还回顾了mobilenet用1/30的参数达到了和vgg相类似的精度信息。SSD在检测方面也用到了更少的参数。
然而之前的网络都集中在优化encoder上面,实际上decoder在inference的时候占据了很大的时间,如下图
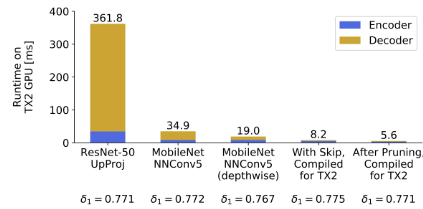
这篇文章主要就是针对decoder的推理时间进行优化,作者说他们所用到的depthwise separable convolution能够极大的减少他们的推理时间。
网络剪枝大部分都用于encoder网络结构,这篇文章作者用到了NetAdapt,来证明剪枝是可以同时优化encoder和decoder的。
方法
encoder & decoder & skip connection
作者提出的全卷积网络结构如下图

编码器常常被设计用来做图像的分类,vgg或者resnet已经具有很强的表达能力和高精度,但是这种encoder延迟比较大,以及比较复杂,在实时的嵌入式系统上跑根本不现实。
考虑到低延迟,所以encoder采用了mobilenet,在decoder上,作者说他们扥挖了过一共包含5层个上采样层,一个pointwise层。每个上采样层采用5*5的卷积来减少1/2输出的channel数目。最后用一个卷积层来输出最终的深度图。作者添加了一个skip connection来恢复图像的details,类似于unet或者deeper lab这种网络的short cut。feature map是相加的,而不是concate的,大概是为了减轻后续的计算压力。
网络编译
作者说我们提出的网络充分使用了depthwise分解,并且depth wise separable convolutional layers并没有在现有的深度学习框架上进行优化,所以这促使作者和需要对特定硬件来编译他们的代码,使得在硬件上减少运算的时间,作者在这里使用的是TVM complier。
网络剪枝
为了进一步减少网络的运行时间,作者用了一个sota的剪枝的方法来做后处理,叫做NetAdapt。从训练好的网络开始,NetAdapt可以从featuremap中自动地并且迭代地来鉴别和移除一些多余的channels,从而减轻计算的压力。在每一个迭代过程,NetAdapt产生一系列的从网络简化得到的network proposal。从这些proposal中,选出有着最好的accuracy-complexity trade-off的网络来作为下一次的简化的对象。直到目标的accuracy和complexity达到就停止迭代。网络的复杂度可以用MAC或者latency进行度量。
实验
作者 NYU dataset上进行了训练和测试。encoder在imagenet上进行预训练,误差用\(\delta_1\)进行衡量,指的是,relative error在25%以内的的pixel精度。测试的平台是jetson TX2。
和之前的方法相比较
如下图
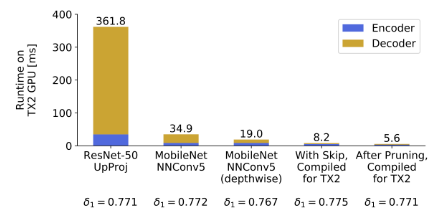
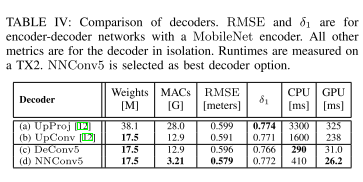
类似于一个ablation study,设计的网络结构极大的减少了网络运行时间,后来加的一些其他操作也减少不少。
下面这个是和其他的方法进行对比的结果
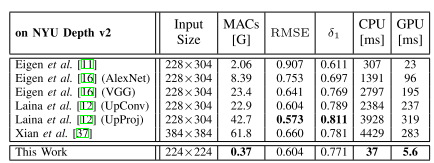
可以看出,精度有些指标会损失一些,但是时间却非常快。
随后,作者又切换了TX2的不同模式,比如max-Q是低功耗模式,如下图
 。
。
随后作者又可是花了一些误差估计的结果,如下图
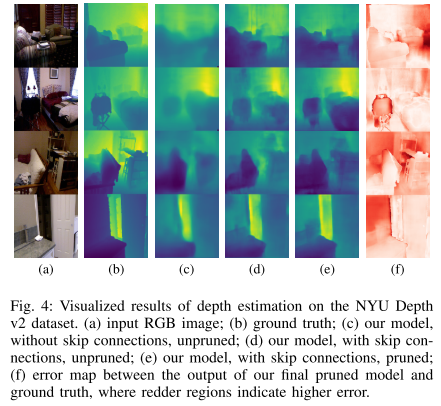
作者同时也用更大的网络来做训练,结果如下

cpu上mobilenet运行很慢,作者说这个是因为depthwise layer在cpu上没有优化
ablation study for decoder design space
作者探究了一下不同的encoder的影响是怎么样的,比如pooling层之后接一个residual b## 这篇文章做了啥
对嵌入式,做了一个实时的单目深度估计框架。作者提出了一个efficient的encoder-decoder结构,精度可以和sota相媲美,并且推理时间非常短。作者主要集中在低延迟的decoder的设计上来
相关工作
作者回顾了一系列的单目深度估计的方法,说之前的方法主要集中在提升网络的精度上面,并没有太多考虑精度的信息。作者还回顾了mobilenet用1/30的参数达到了和vgg相类似的精度信息。SSD在检测方面也用到了更少的参数。
然而之前的网络都集中在优化encoder上面,实际上decoder在inference的时候占据了很大的时间,如下图
这篇文章主要就是针对decoder的推理时间进行优化,作者说他们所用到的depthwise separable convolution能够极大的减少他们的推理时间。
网络剪枝大部分都用于encoder网络结构,这篇文章作者用到了NetAdapt,来证明剪枝是可以同时优化encoder和decoder的。
方法
encoder & decoder & skip connection
作者提出的全卷积网络结构如下图
编码器常常被设计用来做图像的分类,vgg或者resnet已经具有很强的表达能力和高精度,但是这种encoder延迟比较大,以及比较复杂,在实时的嵌入式系统上跑根本不现实。
考虑到低延迟,所以encoder采用了mobilenet,在decoder上,作者说他们扥挖了过一共包含5层个上采样层,一个pointwise层。每个上采样层采用5*5的卷积来减少1/2输出的channel数目。最后用一个卷积层来输出最终的深度图。作者添加了一个skip connection来恢复图像的details,类似于unet或者deeper lab这种网络的short cut。feature map是相加的,而不是concate的,大概是为了减轻后续的计算压力。
网络编译
作者说我们提出的网络充分使用了depthwise分解,并且depth wise separable convolutional layers并没有在现有的深度学习框架上进行优化,所以这促使作者和需要对特定硬件来编译他们的代码,使得在硬件上减少运算的时间,作者在这里使用的是TVM complier。
网络剪枝
为了进一步减少网络的运行时间,作者用了一个sota的剪枝的方法来做后处理,叫做NetAdapt。从训练好的网络开始,NetAdapt可以从featuremap中自动地并且迭代地来鉴别和移除一些多余的channels,从而减轻计算的压力。在每一个迭代过程,NetAdapt产生一系列的从网络简化得到的network proposal。从这些proposal中,选出有着最好的accuracy-complexity trade-off的网络来作为下一次的简化的对象。直到目标的accuracy和complexity达到就停止迭代。网络的复杂度可以用MAC或者latency进行度量。
实验
作者 NYU dataset上进行了训练和测试。encoder在imagenet上进行预训练,误差用\(\delta_1\)进行衡量,指的是,relative error在25%以内的的pixel精度。测试的平台是jetson TX2。
和之前的方法相比较
如下图
类似于一个ablation study,设计的网络结构极大的减少了网络运行时间,后来加的一些其他操作也减少不少。
下面这个是和其他的方法进行对比的结果
可以看出,精度有些指标会损失一些,但是时间却非常快。
随后,作者又切换了TX2的不同模式,比如max-Q是低功耗模式,如下图
。
随后作者又可是花了一些误差估计的结果,如下图
作者同时也用更大的网络来做训练,结果如下
cpu上mobilenet运行很慢,作者说这个是因为depthwise layer在cpu上没有优化
ablation study for decoder design space
作者探究了一下不同的encoder的影响是怎么样的,比如pooling层之后接一个residual block
或者是22的pooling接一个55的convolution
或者是55的转置卷积,又或者是55的卷积,然后接缩放两倍这样,实验结果如下图
后续
是否可以对于双目深度估计来做一个嵌入式的应用?模拟两个镜头拍摄得到的图像,只是针对目前主流的3D-CNN进行压缩或者加速?
posted on 2020-12-18 15:44 YongjieShi 阅读(1041) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号