

论文阅读笔记之Replacing Mobile Camera ISP with a Single Deep Learning Model
这篇文章做了啥
根据ccd或者cmos图像传感器获得的图像,要经过一系列的复杂的处理才能得到最终的图像,而且不同的cmos有不同的算法,作者这里的motivation是能不能有一个比较统一的框架来处理原始图像,而不是经过一系列复杂的ISP操作?
这个研究和我上一篇博客讲的很类似,(learning to see in the dark)[https://www.cnblogs.com/yongjieShi/p/12372729.html],只不过learning to see in the dark(LSD)这篇文章聚焦的部分不仅仅是通过,对原始的传感器得到的数据进行处理,更聚焦在时如何处理极低光图像,极低光图像的处理不仅仅是调整图像亮度这么简单,包含了去噪等step,作者在LSD这篇文章中重点突出了,如何处理极低光,网络没有创新性,很大的contribution来自于一个数据集合的建立。和LSD不一样,这篇文章也是对原始数据进行处理,而且对网络的创新性在一定程度上进行创新,这个我们后面再说
contributions
提出了第一个raw-to-rgb image的网络
一个新的PyNET CNN被提出,用于结合heavy global以及low-level fine grained信息
建立了一个10k的RAW–RGB image pairs数据集合,数据及在wild采集,用的两个设备,一个是华为p20,一个是cannon 5D Mark
做了大量的实验,来评估重建的图像的质量,同时,也和华为p20自己内部的isp处理结果进行了比较
数据集合建立
作者用了两台设备,一个是华为p20,另外一个是Canon,cannon拍摄的图片作为gt,就是图像经过isp处理之后的结果,因为单反拍摄的质量比较高,所以用单反拍摄的图片作为约束是合理的,同时在拍摄图片的时候,华为内部有自己内嵌的isp处理得到的结果,所以作者也把这个数据采集了下来,并且进行比较。华为p20的传感器用的是sony的拜耳传感器,同时作者还说华为有另外一个镜头,但是不能通过现有的api来获取其api,所以只能用sony的那个原始数据。
拍摄的过程是在一个空间点,朝向一致就行,比如放一台华为p20,采集两张,一个是raw的bayer数据,一个是built-in的isp处理得到的结果;同时把佳能放在这里,
因为是图像的处理,所以逐pixel对应是非常有必要的,作者在这里也说了需要用特征点匹配算法来进行图像匹配,作者展示了一组图片(如下图),仔细看的话确实是没有对齐的,后面还会详细讲,我觉得这个问题挺严重的,

上面的图片红色方框里面仔细看是不一样的
我觉得作者忽略了一个重要的问题,就是camera的focal length不一样,这种差距尤其在结构场景中体现更加明显,我想这就是为什么作者在wild采集图像,而不是结构场景中,相对于这个数据集合,SID dataset更加合理一些,SID dataset作者用的是两台不同的设备,但是cmos短曝光和长曝光是一对,一个是拿到原始的bayer或者x-trans数据,另外一个长曝光的是built-in isp处理得到的结果,maybe,(作者文中只说用了libraw库进行了处理,不确定原始的是不是isp-built in处理的结果)
网络结构
RAW to RGB 的mapping是一个涉及到global以及local图像modification的问题。这种直观的motivation是和isp处理的pipline有关系,比如,global modifications经常用来改变图像的内容,和一些higl-level的特性,比如亮度,白平衡,和色彩渲染;而low-level处理经常用于一些这种任务,比如纹理增强,锐化,噪声去除,去模糊等。而且更加重要的是,global和local信息应该进行交互,互相影响。比如,内容理解对于texture 处理或者local color correction是至关重要的。很很多deeplearning模型只focus其中一个step。比如vgg,resnet或者denesnet这种,不能很大的改变图像,而依赖于unet或者pixel的结构不具备改变局部区域的能力。为了解决这个问题,作者提出了他们的网络,如下图,叫PyNET,processing 图像在different scale以及把他们结合在一起。
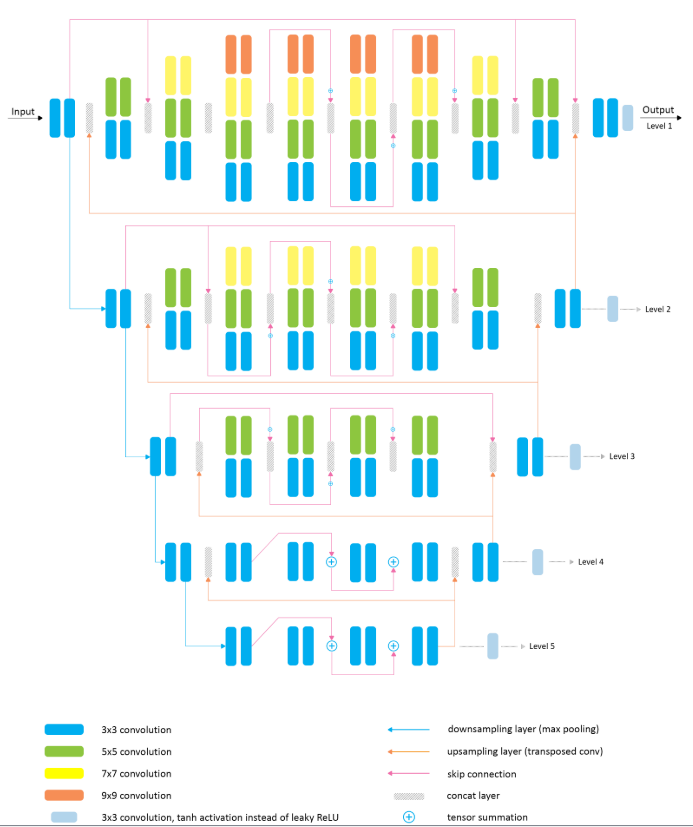
如上图,有五个不同的level,可以学习到不同的level的信息,lower scales的到的信息被上采样,然后和高层次的特征concate到一起,然由higier scales后继续处理,主要的就是这个,这就是结合了local以及global的信息。loss损失函数不同的level用不同的损失函数以及比例也不一样,level4-5的话,主要集中地global的信息上,比如亮度和gamma correction所以用了mse loss。level2-3主要用来refine 不同object的color和shape properties,用perceptual loss和mse loss
level1的话加了一个ssim loss,主要用来做local的调整,比如noise去除,特征增强,局部颜色处理
这个网络结构和zongwei zhou提出的unet++类似,都是倒三角形,unet++稍微复杂一些,先挖个坑
实验结果
实验主要围绕三个问题,作者提出的这个结果和经典的一些网络结构相比,结果怎么样?
第二个是,和华为的built-in的isp相比结果怎么样,
以及这种算法能不能apply到其他的设备上
作者首先和华为的built-in的isp处理结果比较了一下,如下图

仔细观察一下第二行图片,实际上房屋的大小并不是一样的,这种差异是由于焦距不同导致的
作者说他们的结果在local和global上面没有什么缺陷,唯独有一些光晕,和华为的isp比起来的话,作者的方法有更高的亮度,更自然的局部纹理,并且锐化程度并不是特别高。作者说这个可能和P20的另外一个相机有关系,作者说,我们的算法和华为的p20的built-in isp得到的结果是comparable的
作者和主流网络的定量比较结果如下
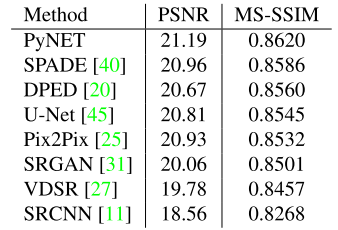
作者的方法在常见的网络结构式上达到了sota的结果
定性比较结果如下

针对这个结果,作者做了一些分析,VGG-19和SRCNN没有足够的能力来重建颜色,STGAN和UNET太暗了,有一些比较单调的颜色,pixel2pixel在精确颜色渲染上面有很大的问题,由于扭曲的色调使得看起来不真实。DPEDmodel得到的结果比较好,但是有一些yellowish的阴影,缺少生机。SPADE不能够处理任意size的input data,所以没有比较。
之后作者做了一个AMT test,

结果比p20还要好
之后又用BlackBerry KeyOne smartphone来看一下泛华能力,如下图

作者说,恢复了很多ISP处理之后不存在的阴影,我并没有看出来...相对于原图确实很赞

上图是一个细节图,作者说,结果不是特别好,但是相对于没有在这种型号的传感器进行训练的话,直接迁移得到的结果已经很好
后续
感觉对于raw的数据处理是一个大坑,我感觉可以踩一踩,实际上作者的这种local和global信息的获取不是那么的elegant
posted on 2020-02-29 11:05 YongjieShi 阅读(2074) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号