【数据仓库】|3 维度建模之维度表设计
维度是看待事情发生的角度,是维度建模的基础和灵魂。
维度设计基础
基本概念
我们在维度建模中,把度量称为事实,将环境称为维度。
举个例子,在电商业务中有这么个需求:我需要统计昨日所有店铺的成交金额。这里的维度就是:日期、店铺;度量(也就是事实)是:成交金额。
所以延伸下来,电商业务中的基础维度有:日期、店铺、买家、卖家、商品、类目、地区等;而事实有成交金额、购买人数、购买件数等。
维度表的主键有两种:代理键和业务主键(也叫自然键)。两者区别在之前的文章《DataVault建模》已经解释过。
维度属性指的就是维度的列。一般是我们在数据分析时用到的过滤条件、分组、排序等,所以维度属性越丰富,可以观察的角度就越多。
如果从SQL查询的角度上看,维度属性通常是放在where和group by、sort by后的列。
设计方法
维度的设计过程,就是维度属性的确定过程。
Kimball:“数仓的能力如何,跟维度属性的深度和质量成正比。”
下面我们用商品维度表的设计为例对维度设计的方法进行详细说明。
选择维度或者新建维度
在建设维度表中,要保证其在数仓中的唯一性,也就是说只允许有一个商品维表。
确定维度主来源表
在此处一般指的就是ODS层(与业务系统表结构一样)的商品表,如s_items_info,此表就是维度的主来源表。
确定相关维表
数据仓库的设计遵循数据的高度整合原则。在确定主来源表后,还需要根据实际需求,扩展商品的相关信息如:类目、所属卖家、所属店铺等
确定维度属性
在维度主来源表+相关维表的基础字段上,创建或补充维度属性:
- 尽可能地生成新的维度属性
- 尽可能给出一些包含文字描述的属性,这些属性不应该只有编码,更应该是真正的文字。如一级类目ID,一级类目名称
- 某些特殊的度量(数字)有可能也能作为维度属性。如商品单价,既在观察商品价格段时可以作为维度,也可以在求平均商品价格时作为事实。(区分数值型字段是维度还是度量的方法之一,就是看字段内容枚举值的多寡,多很可能是度量;少很可能是维度,但不绝对)
- 尽量沉淀出常用、公用的字段。如商品状态,需要通过上架时间判断
维度的层次结构
维度是有层次的,也是反范式的。拿商品维表举例,
【商品维表】(商品ID,商品名称,商品类目,一级类目ID,一级类目名称,二级类目ID,二级类目名称,三级类目ID,三级类目名称,上架时间)
类目层次:一级类目 》二级类目 》三级类目
时间层次:年 》月 》季度 》周 》天
这种层次结构常用在什么场景?数据钻取。
什么是数据钻取?
数据钻取分为上钻(维度减少)和下钻(维度增多)。简单来说就是想点开年份看详细的月份或者天数据,就叫下钻;如果由每天的维度变为看季度、年维度,那就是上钻。
常见的维度层次结构有以下几个:日期,地址,类目等。
星型模型和雪花模型
我们只要细心看上面商品表,会发现其实如果我们把类目当成一个单独的维度表抽离出来也是可行的。于是变成以下两张表:
【商品维表】(商品ID,商品名称,类目ID,上架时间)
【类目维表】(类目ID,一级类目ID,一级类目名称,二级类目ID,二级类目名称,三级类目ID,三级类目名称)
这种方法在维度建模中是允许存在的,当然我们更建议把类目维表的信息反规范化到商品维表中。这两种方法有个专业名称,叫星型模型和雪花模型。

星型模型和雪花模型中,都只有一个事实表,但是对于大多数业务而言都过于理想话,最后,由于事实表的增加,星型模型和雪花模型都会演化成最终的星座模型。
星座模型里会有多个事实表跟维度表公用。
一致性维度和交叉探查
交叉探查
将不同数据域(后面章节详细介绍,大概意思是不同业务模块的数据)的事实数据,根据同一个维度做合并的情况就叫交叉探查。
电商数据中最常见的是日志域和交易域的交叉探查。
假设有两张事实表:
【日志域.用户浏览商品行为事实表】(用户ID,商品ID,渠道ID,行为发生时间)- A表,三个维度外键
【交易域.用户购买商品事实表】(用户ID,商品ID,成交金额)- B表,两个维度外键
假设有两张上架时间格式不一样的商品维度表:
【商品维表A】(商品ID,商品名称,上架时间(格式:yyyy-MM-dd HH:mm:ss))
【商品维表B】(商品ID,商品名称,上架时间(格式:UNIX timestamp))
如:我想查询所有上架时间大于 2021-05-20 16:12:30 的每个商品的PV、UV和成交金额。
用一条伪SQL举例:
select 商品ID ,pv ,uv ,成交金额 from ( select 商品ID -- 交叉探查,同一个维度 ,count(*) as pv ,distinct(user_id) as uv from A group by 商品ID -- 日志域事实,维度上钻为商品ID ) as X1 join ( select 商品ID -- 交叉探查,同一个维度 ,sum(成交金额) as 成交金额 from B group by 商品ID -- 交易域事实,维度上钻为商品ID ) as X2 on xxx = xxx join 商品维表A/商品维表B on xxx = xxx -- 注意商品维表这个地方! where 上架时间>'2021-05-20 16:12:30'
OK,要想交叉探查数据是对的,也就是说想要上面SQL数据无误,前提必须是A表的商品和B表的商品维表属性(上架时间格式)一致。
如果不一致,将会导致数据出错,只能过滤掉部分数据。
如果觉得例子麻烦,那只需要记住一点即可,要想交叉探查数据无误,就一定要保证:一致性维度。
一致性维度
Kimball的数据仓库总线架构提供了种分解企业级数据仓库规划任务的合理方法,通过构建企业范围内一致性维度和事实来构建总线架构。 —— 《阿里巴巴大数据之路》
意思是维度建模要求必须有一致性维度。换句话说维度是统一设计的,每个维度表都是唯一不重复的,要做到全局通用。否则会导致数据查询的时候不一致甚至错误。
如何才能保证有一致性维度呢?有三种方法:
- 共享维度。每个维度全局都唯一(下面的复杂就只要做到这一点就好)
- 一致性上钻。其中一个维度的维度属性是另 一个维度的维度属性的子集,且两个维度的公共维度属性结构和内容相同。比如商品维度和类目维度,其中类目维度的维度属性是商品维度的维度属性的子集,且有相同的维度属性和维度属性值。这样基于类目维度进行不同业务过程的交叉探查也不会存在任何问题。
- 交叉属性 。两个维度具有部分相同的维度属性。比如在商品维度中具有类目属性,在卖家维度中具有主营类目属性,两个维度具有相同的类目属性,则可以在相同的类目属性上进行不同业务过程的交叉探查。
维度设计高级主题
什么维度需要整合
数据仓库的四大特性里面包含集成。维度的集成的过程可以概括为:将维度相关的维度属性做到统一。
- 来源系统多的情况下,表名、字段名要统一。如A系统用户ID是userid,B系统是user_id,维度表需要将这些统一
- 公共代码和编码值统一,如A系统男1,女0,B系统男M,女F;
- 业务含义相同的表统一
- 采用主从表方式,如商品维度可以拆成(商品主信息维表 + 商品扩展信息维表)
- 统一到一张表,如果表字段重合度比较低,会出现大量空值情况
- 不合并,如果源表表结构实在差异太大,可以不合并
什么维表需要拆分
当一张维度表中包含多个类别、加工逻辑十分困难、有部分维度属性可以单独处理或者不常用时,考虑将维度拆分。
无论是维表是分还是合,都需要从以下角度权衡:
- 当业务变化时,模型是否容易扩展
- 是否易用
- 查询效能问题
通常来说,拆分方法有以下几种:
水平拆分——数据层面
我们假设航旅的商品和普通的商品,都属于商品,都有商品价格、标题、类型、上架时间、类目等维度属性,但是航旅的商品除了有这些公共属性外,还有酒店、景点、门票、旅行等自己独特的维度属性。我们应该如何去设计维度?针对此问题,有两种解决思路:
- 方案1:提取航旅和普通商品的公共属性作为建一个维表【商品维表】,然后建立一个子维度表,【航旅商品维表】(公共属性,航旅特有属性)
- 方案2:只建一个维表,保存所有属性
当航旅类别的商品频繁更新、变化较大或者业务关联程度较低时,应当选择方案1,建单独的一张航旅商品维表进行维护。在大型系统中,基于这种思路,商品维表可能会被拆分成N个不同的子商品维表,而各个子维表的维度属性必定会比【商品维表】多。
啰嗦一句:【航旅商品维表】是【商品维表】的子维度表,它只存航旅相关的商品。
垂直拆分——维度属性层面
当某些维度属性的来源表产出时间较早,而某些维度属性的来表产出时间较晚;或者某些维度属性的热度高、使用频繁,而某些维度属性的热度低、较少使用,都可以使用主从表垂直拆分。
历史归档——无用数据层面
维度数据日积月累会有不少记录是废用的,我们应该给数据量大的维度表,新建一张历史维度表做数据归档。但如何去识别不用的数据进行历史归档?
《阿里巴巴大数据之路》中给出三个思路:
- 将商品状态为下架或删除的且最近 31 天未更新的商品归档至历史库,不推荐
- 数据仓库自定义归档,不推荐
- 通过binlog merge的delete标记(逻辑删除)进行归档,推荐
维度的变化
缓慢变化维
数据仓库中另一重要的特点是——反映历史变化。缓慢变化维度,这里的缓慢是跟(快速变化)事实表相对的。还是以商品维表举例,缓慢变化维一般就三种解决方法:
- 1. 重写维度,也就是覆盖历史数据,只保留最新一份
- 2. 新增维度列,【商品维表】(商品ID,商品名称)=> 【商品维表】(商品ID,商品历史名称,商品最新名称),这种只合适变化频率非常非常低的维度属性(毕竟频繁变化我们不可能会一直新增列来保存,特殊情况除外)
- 3. 插入新的维度行,保留历史数据,事实表和维度之变化前的维度值关联

快照维
阿里巴巴不建议用缓慢变化维处理维度的变化。
一方面是缓慢变化维需要生成全局唯一的代理键,对于阿里庞大的数据量来说,成本开销太高;二是加入了代理键后会增加ETL的复杂程度。基于这两点,阿里用的是快照维度,顾名思义就是一天生成一个表切片,每天的全量数据都存储到对应的历史分区。当我们取任意一天的事实时,可以通过时间对应到每一天的维度历史中进行关联即可。但是此方法最大的问题是太浪费存储!
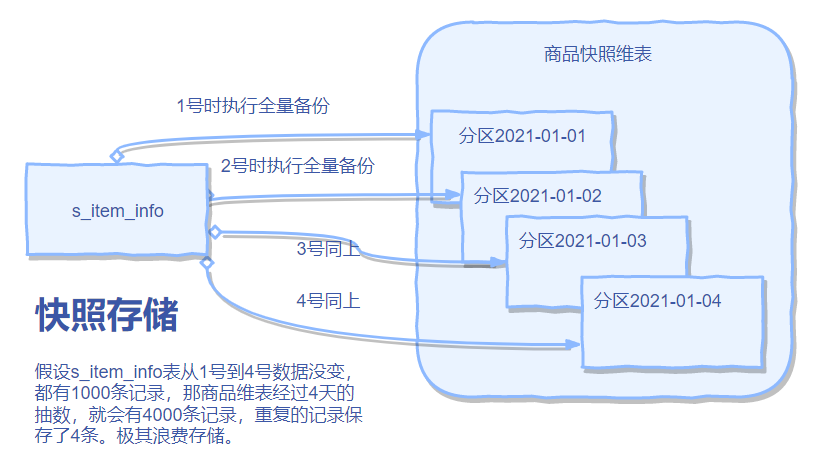
所以,阿里又推出了极限存储方案。不过需要注意的是,极限存储的底层是历史拉链存储,所以我们下面先讲讲什么是历史拉链,以及拉链表的优缺点,然后再介绍极限存储。
历史拉链存储
历史拉链存储是基于处理缓慢变化维的第三种方法来加工的,也就是:新建维度行。
但不同的是,拉链存储还特地用了两个时间键(生效时间和失效时间)来替代原有的代理键。
历史拉链一般用天作为一次记录变更的最细单位,新数据进来后,旧数据就置为历史状态,新数据打上最新标记。本质其实就是为了节省存储,其次才是为了反映历史变化。如果一天内变化多次,那就以当天最后一次变更记录为最新。但如果变化不太频繁,按天存储产生太多无用数据,也可以按周、月等做变更单位。
历史拉链存储一般应用场景:针对变化频率不频繁的维度表或者是周期性事实表(后面章节会介绍事实表的设计),如修改商品名称、修改身份证名称、订单状态变更、用户状态变更等。
举个例子:商品维度表
2021-01-01日向商品表新增加3个商品,结束时间 9999-12-31表示当前记录是最新的
|
商品ID
|
商品名称
|
生效时间
|
失效时间
|
|
1001
|
阿玛尼手表,新到货!
|
2021-01-01
|
9999-12-31
|
|
1002
|
香奈儿唇膏
|
2021-01-01
|
9999-12-31
|
|
1003
|
片仔癀
|
2021-01-01
|
9999-12-31
|
2021-01-02日,商品编号1002和1002更改了商品名称,除此之外又新增了1004商品苹果手机
绿色代表新品,红色代表修改
|
商品ID
|
商品名称
|
生效时间
|
失效时间
|
|
1001
|
阿玛尼手表,新到货!
|
2021-01-01
|
2021-01-02
|
|
1001
|
阿玛尼手表新名称
|
2021-01-02
|
9999-12-31
|
|
1002
|
香奈儿唇膏
|
2021-01-01
|
2021-01-02
|
|
1002
|
香奈儿唇膏新名称
|
2021-01-02
|
9999-12-31
|
|
1003
|
片仔癀
|
2021-01-01
|
9999-12-31
|
|
1004
|
苹果手机
|
2021-01-02
|
9999-12-31
|
这样一来,当我们需要查询商品最新记录时,只需要卡一下 结束时间='9999-12-31'
select * from 商品维表 where 结束时间='9999-12-31'
同样,如果我们想查商品在2021-01-01的所有商品状态
select * from 商品维表 where 开始时间 <='2021-01-01' and 结束时间 >= '2021-01-01'
查出来的结果就是2021-01-01日的三条商品记录。
所以最后会发现,如果每条数据每日都变化,天拉链会没有意义。反之,每天所有商品数据都不发生变化,此时,只需要存储一天的数据即可,也不需要拉链。
详细介绍可以参考我的另一篇文章《拉链表的创建、查询和回滚 - X.Jan - 博客园 (cnblogs.com)》
极限存储
其实阿里的极限存储底层依然还是历史拉链表,但是它按月做拉链,另外还封装了一层hook,当用户查询历史时,先从最近的历史快照中获取映射,再去历史拉链里面查。感觉就是历史拉链存储做了些许延伸,不细说。
特殊维度
递归层次
维度的递归层次,按照层级是否固定分为均衡层次结构和非均衡层次结构。比如类目,有固定数量的级别,分别是叶子类目、五级类 目、四级类目、三级类目、二级类目、 级类曰:地区,分别是乡镇/街道区县、城市、省份、国家。对于这种具有固定数量级别的递归层次,称为“均衡层次结构”。反之,对于数量级别不固定的递归层次,称为“非均衡层次结构”。
|
类目ID
|
类目名称
|
父类目ID
|
是否叶子结点
|
|
1001
|
A
|
无
|
N
|
|
1002
|
B
|
1001
|
N
|
|
1003
|
C
|
1001
|
N
|
|
1004
|
D
|
1003
|
Y
|
|
1005
|
E
|
1002
|
Y
|
|
1006
|
F
|
1002
|
Y
|
|
1007
|
G
|
1006
|
Y
|
其关系如下图:

对于递归层级维度,当树的高度不深的时候,我们只需要把它扁平化处理。
如生成下面的类目维度表:
【类目维度表】(类目ID,类目名称,类目层级,一级类目ID,一级类目名称,二级类目ID,二级类目名称,三级类目ID,三级类目名称... ... ,是否叶子类目)
其中如果只有高层级类目,没有低层级类目,就将低层级类目置空。
有些数据库或者数仓查询引擎是不支持递归查询的,递归的类目层级需要用语言特殊处理。
行为维度
通过事实表发生的事实计算出来的维度,称为行为维度或事实衍生维度。如按照交易金额划分的等级维度、卖家的信用度等。
按照加工方式,行为维度可以划分为以下几种:
- 另一个维度的过去行为,如买家最近一次访问淘宝的时间、 买家最近一次发生淘宝交易的时间等。
- 快照事实行为维度,如买家从年初截至当前的淘宝交易金额、买家信用分值 、卖家信用分值等。
- 分组事实行为维度 ,将数值型事实转换为枚举值。如买家从年初截至当前的淘宝交易金额按照金额划分的等级 买家信用分值按照分数划分得到的信用等级等。
- 复杂逻辑事实行为维度,通过复杂算法加工或多个事实综合加工得到。如卖家主营类目,商品热度根据访问、收藏、加人购物车、交易等情况综合计算得到。
对于行为维度,一般有两种处理方式,一是新建维表;二是冗余到现有的维度表中。
多值维度
如果一个事实表的某一条记录在维度表中找到多条记录对应,就成为多值维度。
如:电商系统一般会把订单分为大订单和小订单,一个大订单可以购买2个以上商品,小订单每单是1个商品。
如果从大订单事实表去关联商品维表,那明显是又问题的。
针对多值维度,可以通过以下两种思路解决:
- 降低事实表的粒度。本例中可以把大订单分摊为对应的小订单,再关联商品维表
- 在事实表中增加对应的维度ID字段(类似增加一个角色ID)。如:房屋共买,参考
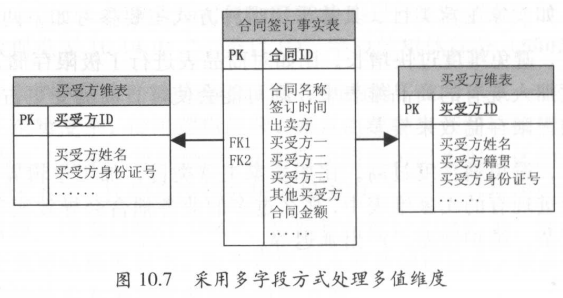
杂项维度
源业务系统中往往会有特别多的枚举值、指示符或者低基数标志字段、开关字段等。如:订单状态、微信场景、广告渠道、是否XXX(01标记)等。一般来说,如果这种维度少的话,可以在事实表中存储,但是如果特别多,建议剥离出事实表,单独存储到一张杂项维度表中,生成对应的代理键后,事实表只需保存维度的代理键即可。
例如,在销售订单中,可能存在有很多离散数据(yes-no这种开关类型的值),如:
- verification_ind(是否被审核,如果订单已经被审核,值为yes)
- credit_check_flag(是否信用状态被检查,表示此订单的客户信用状态是否已经被检查)
- new_customer_ind(是否新客首单,如果这是新客户的首个订单,值为yes)
- web_order_flag(是否线上,表示一个订单是在线上订单还是线下订单)
我们需要新增一个名为sales_order_attribute_dim的杂项维度表,该表包括四个yes-no列:verification_ind、credit_check_flag、new_customer_ind和web_order_flag。每个列可以有两个可能值中的一个,Y 或 N,因此sales_order_attribute_dim表最多有16(2^4=16)行。
注意:假设这16行已经包含了所有可能的组合,并且不考虑杂项维度修改的情况,则可以直接通过笛卡尔积生成记录后插入到杂项维度表中。但如果基数大,生成的笛卡尔积数量爆炸式增长,则不建议直接生成所有组合的完整的杂项维度表,我们只需要在抽取的过程中遇到新的组合就生成相应记录即可。
具体表结构如下图所示:
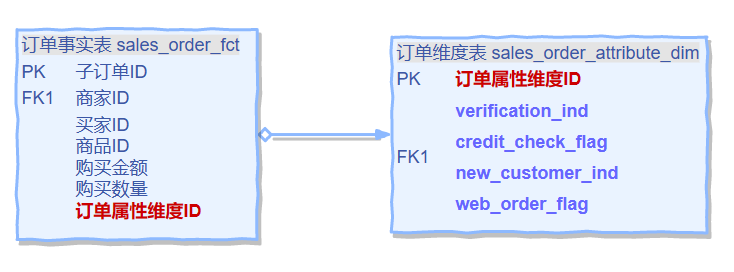
注意:上述的这种维表只归属于订单,针对公共性强(多个事实表都可用)的杂项维度,还是可以考虑单独给他建一个统一的维表存放的。
总结
本篇简单阐述了维度的概念,类型,设计维度的方法,模型等内容。可以说所有的内容都是奔着一个议题去的:
如何把维度设计规范化、简单易用、统一使用?如何尽可能地节省存储维度的空间?
维度建模中的维度表设计是在确定业务需求和数据粒度后开展的,而维度设计之后咱们将在下一篇继续讨论事实表的设计。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号