【数据仓库】|2 到底哪种数仓设计模型更合适
模型设计,通俗理解就是如何去设计表,使得表与表之间的关系组成一张有规律的大网。
在上一节《所以,什么是数据仓库》中提及数仓建模的方法论,其中点出了两位重要人物Kimball的维度建模和Inmon的3NF建模。在开始建设数据仓库前,模型的选择是最重要的一关之一,它是整个数仓中数据组织的基本骨架。在本节,我们整理了业界常用的四种建模方法详细讨论。
维度建模
Kimball提出的维度建模,是一种快速迭代和交付的模型建设方法。在目前众多建模方法中备受推崇,因为无论从数据理解、模型构建或者是BI分析等方面都相对于其他建模方式好。又因为现代数仓大部分是基于Hadoop构建,允许以空间换时间,维度建模就渐渐变成了首选 —— 我会在后面章节详细介绍这一建模方法。
特点
维度建模是通过高度冗余维度表,以此提升开发者对数据的理解能力、提高数据一致性。又因为关联少,可以减少下游ETL产生的I/O压力,但缺点是浪费存储。
概念
维度:看待事物的角度,如店铺、用户等
粒度:数据粒度,指结合多少个维度去看数据,如店铺商品粒度(细粒度)、店铺粒度(粗粒度)
事实:发生的某一件不可改变的事,如购买商品、订单退货等
度量:用来给事实发生的程度给定一个数字,如金额,长度,容量等
假设有这么个需求:领导想看所有店铺在昨天一天内成交的金额维度:店铺,日期事实:成交度量:金额
模型图
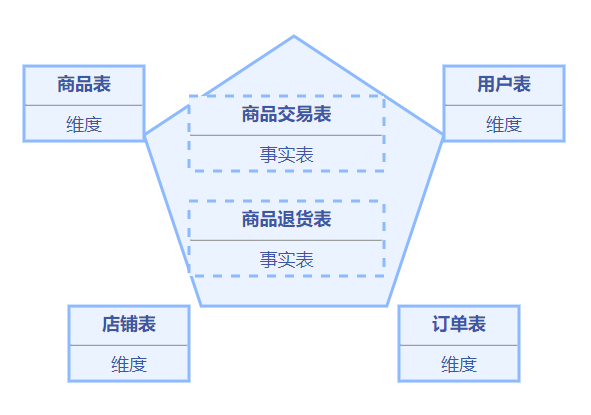
理想状态下,维度建模呈现的是一个标准的星型模型,多个维度围绕着事实表为中心。
一般来说,维度建模的设计过程如下:
- 选择业务过程,如上图的商品交易、商品退货过程
- 声明粒度
- 设计维度
- 设计事实
当新需求来时,我们都需要重走以上过程,来创建和丰富模型,如果业务过程不存在,则新建一套维度和事实与之对应;如果维度或者事实已经存在,请更新或者丰富表中的字段即可,所以维度建模方式是一个不断迭代,不断完善的建模方法。
实际设计中可能会从某个维度表中再分拆一个子维度表,如商品维度表,可以再拆分品类维度表,用外键依附于商品维度表,这种呈现方式称为雪花模型。
DataVault建模
Data Vault(下面称:DV)建模也是数据仓库建模的一种方法,在《Hadoop构建数据仓库实践》一书中有详细介绍。这种建模方式相对于维度建模来说,数据冗余度少,能自动适应未来不可预见的业务关系(表和表的关系)变化。如果你的公司比较注重历史数据的维护,或者是针对审计型(对资料作出证据搜集及分析)的业务,在数据进入模型的时候又不想过多对数据逻辑进行正确与否的判断的话,DV模型合适你。如果听不明白上面说啥很正常,我们可以先了解这种模型能解决什么问题!
其中重点摘录1. 这种模型能最大限度的适应业务系统关系和关系间的变化。如:订单-客户 以往是 N:1 关系,但是目前已经有了拼单玩法,就变成了 1:N,如果业务变化后,我们 只需要在Link表里增加记录或者列即可,不需推倒重来2. DV不推荐做脏数据处理,它仅仅反映上游系统数据的真实性,也就是说数据正确与否都应该记录到数仓里面并让他反映出来
特点
结构有点类似3NF,声明中心表和链接表来构建实体与实体之间的关系,把实体的描述信息全部放到卫星表中保存。这种建模方法适用于:要保存完完整整的历史数据更改记录的情况。所以基本上每一种表类型都有自己的代理键。
代理键:说白了就是通过数据加工方法,给表每一条记录生成一个唯一的ID,用来表示其每一次的变化。
假设我们有一张商品表:ID ITEM_ID ITEM_NAME0000001 20391 Iphone 11-新货上市!速购!0000002 20391 Iphone 11-双卡双待!来买!0000003 20391 Iphone 11-亏本卖!店主不要钱!这里的代理键就是ID,业务主键就是ITEM_ID。
概念
如果 Hub 是人的骨架,那么 Link 就是连接骨架的韧带,Satellite 就是骨架上的血肉。
维度建模有维度和事实的概念,相同的,DV模型也有自己的一套“表类型”,其中包含三种表
- Hub:中心表,每个实体单独建一个中心表,每个中心表只有代理键、业务主键、装载时间、数据来源四个字段。中心表与中心表之间是平等关系,不存在父子关系。
|
字段属性
|
描述
|
|
主键
|
系统生成的代理键,供内部使用
|
|
业务主键
|
唯一标识的业务单元,用于已知业务的源系统
|
|
装载时间
|
数据第一次装载到数据仓库时系统生成的时间戳
|
|
数据来源
|
定义了数据来源(例如源系统或表)
|
- Link:保存不同的Hub(两个或者以上)之间的关系,保存实体表的代理键、失效标记、装载时间、数据来源等。
|
属性
|
描述
|
|
主键
|
系统生成的代理键,供内部使用
|
|
外键{1-n}
|
引用中心表的代理键
|
|
装载时间
|
数据第一次装载到数据仓库时系统生成的时间戳
|
|
数据来源
|
定义了数据来源(例如源系统或表)
|
- Satelites:卫星表,保存Hub或者是Link的详细描述。
|
属性
|
描述
|
|
主键
|
系统生成的代理键,供内部使用
|
|
外键
|
引用中心表的链接表的代理键
|
|
装载时间
|
数据第一次装载到数据仓库时系统生成的时间戳
|
|
失效时间
|
数据失效时间的时间戳
|
|
数据来源
|
定义了数据来源(例如源系统或表)
|
|
属性{1-n}
|
属性自身
|
模型图
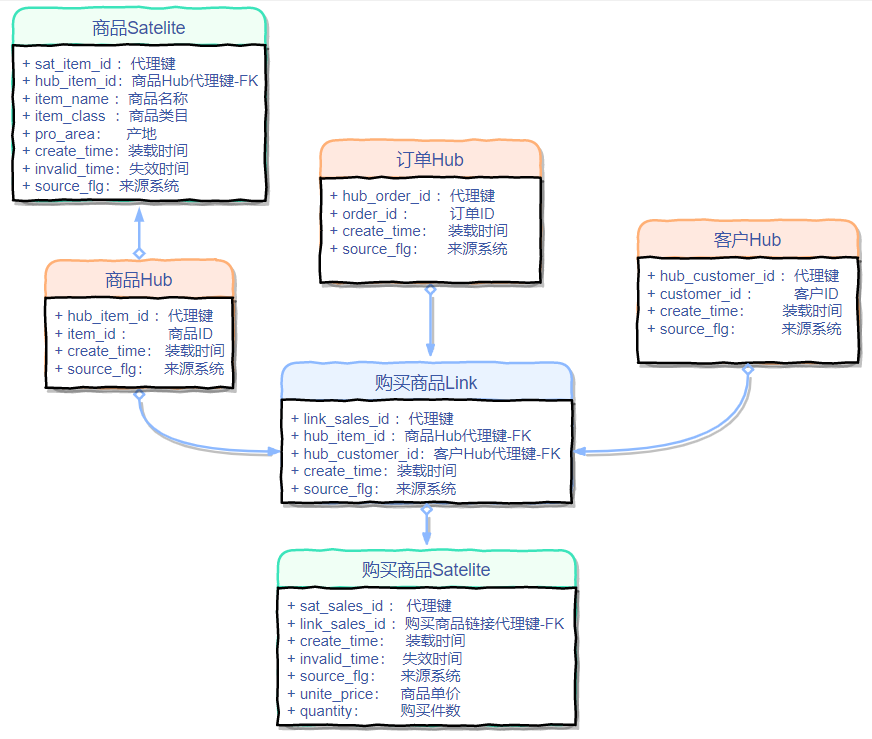
3NF建模
数据仓库之父 Bill INmon 提出的建模方法:从全企业的高度设计一个 3NF 模型,用实体关系(ER)模型描述企业业务,在范式理论上符合 3NF。
数据仓库中的 3NF 和 OLTP 系统中的 3NF 的区别:数据仓库的 3NF 是站在企业角度面向主题的抽象,而不是针对某个具体业务流程的实体对象关系的抽象。
数据仓库的 3NF 特点:
- 需要全面连接企业业务和数据;
- 实施周期非常长;
- 节省存储,数据高度精简;
- 对建模人员的要求较高;
- 采用 ER 模型建设数据仓库模型的出发点是整合数据,将各个系统中的数据以整个企业角度按主题进行相似性组合和合并,并进行一致性处理,为数据分析决策服务,但并不能直接用于分析决策;
由于三范式建模在企业中不常用,应用面不广而且没什么难度,所以这里就不展开讨论了。不过可以顺便回顾一下什么是3NF。
我们在设计OLTP系统时要遵循3NF,这是关系型数据库理论的基础和指导方法。
第一范式-1NF
强调列的原子性,要求列不能再切分。
例子:考虑这样一个表【联系人】(姓名,性别,电话)
|
姓名
|
性别
|
电话
|
|
张三
|
男
|
1376776352,(020)-97698769
|
在实际场景中,一个联系人有家庭电话和公司电话,那么这种表结构设计就没有达到 1NF。要符合 1NF 我们只需把列(电话)拆分,
即:【联系人】(姓名,性别,家庭电话,公司电话)
|
姓名
|
性别
|
个人电话
|
家庭电话
|
|
张三
|
男
|
1376776352
|
(020)-97698769
|
第二范式-2NF
在遵循1NF前提下,要求表必须有主键,且非主键列要完全依赖此主键,不能部分依赖。
例子:考虑订单明细表:【OrderDetail】(OrderID,ProductID,UnitPrice,Discount,Quantity,ProductName)
主键为(OrderID,ProductID),明显看出,标红的几个列是只依赖于主键之一的ProductID,所以(UnitPrice,ProductName)属于冗余字段,不符合2NF。
解决办法:【OrderDetail】表拆分为
【OrderDetail】(OrderID,ProductID,Discount,Quantity)和
【Product】(ProductID,UnitPrice,ProductName)
第三范式-3NF
在遵循2NF前提下,要求非主键列必须直接依赖于主键,不能存在传递依赖。
例子:考虑一个订单表【Order】(OrderID,OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity)主键是(OrderID),CustomerName,CustomerAddr,CustomerCity 直接依赖的是 CustomerID(非主键列),而不是直接依赖于主键,它是通过传递才依赖于主键,所以不符合 3NF。企业应该把这种外戚排除掉!
Anchor建模
太少人用了,这里不展开说。
Anchor模型由Lars. Rönnbäck提出,是DataVault模型的进一步范式化处理,核心思想是只添加、不修改的可扩展模型,Anchor模型构建的表极窄,类似于K-V结构化模型。它主要包括Anchors(实体且只有主键),Atributes(属性),Ties(关系),Knots(公用枚举属性))。Anchor是应用中比较少的建模方法,只有传统企业和少数几家互联网公司有应用,例如:蚂蜂窝等。
总结
数据仓库的建模方式大体来说就以上几种,在日益发展的技术水平、数据爆炸和存储成本降低的趋势中,维度建模是最多公司使用的。每个公司都需要按照实际情况选择合适的模型,不过,万变不离其宗,量体裁衣,从人力成本、数据使用成本、存储成本、加工复杂度等角度权衡,一定能找到适合自己的“大网”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号