

Spring三级缓存解决循环依赖
前提知识
1、解决循环依赖的核心依据:实例化和初始化步骤是分开执行的
2、实现方式:三级缓存
3、lambda表达式的延迟执行特性
spring源码执行逻辑

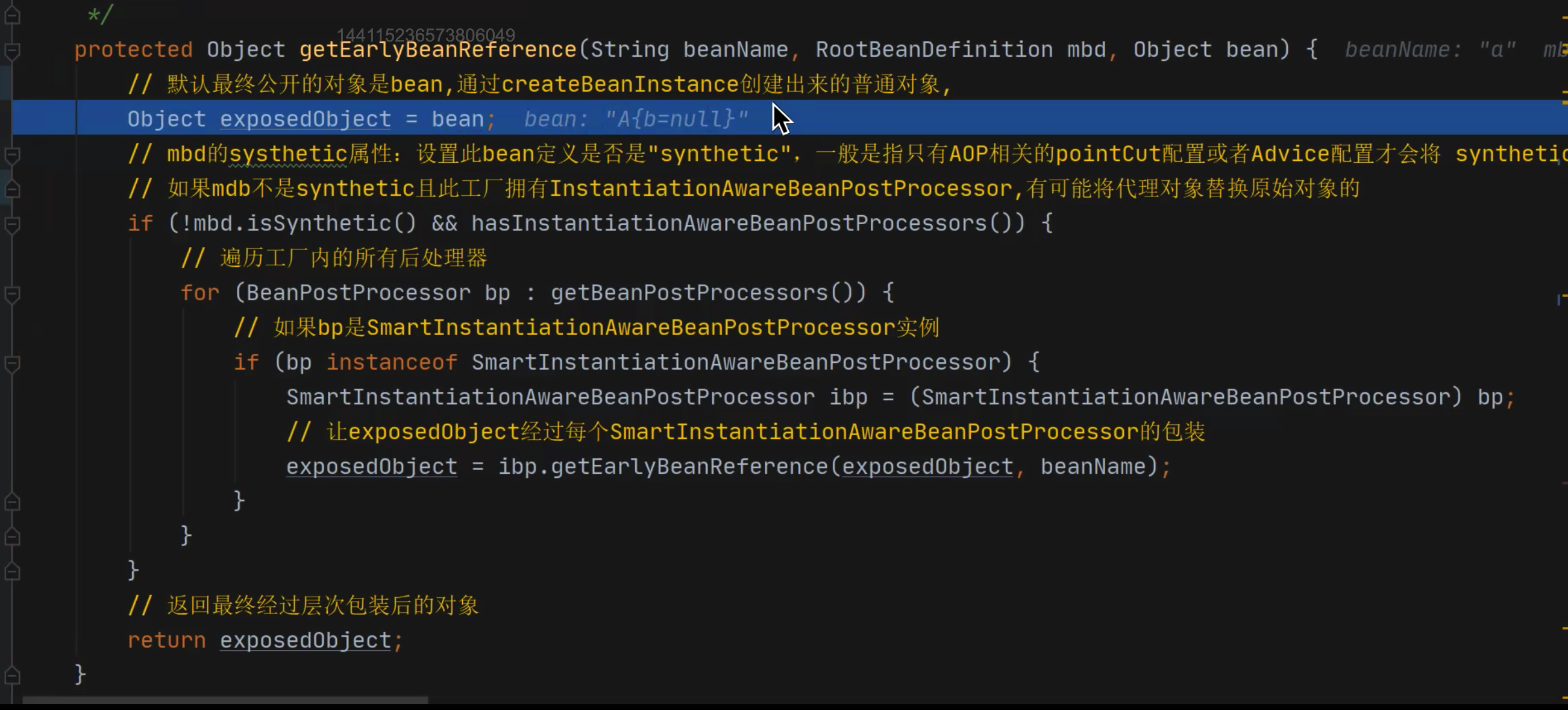
核心方法refresh(), populateBean()填充bean对象,设置属性值;
getEarlyBeanReference() 在未完成属性赋值之前,提前暴露代理对象,在赋值的时候才确定真实对象。
1、三个map结构分别存储什么类型的对象?
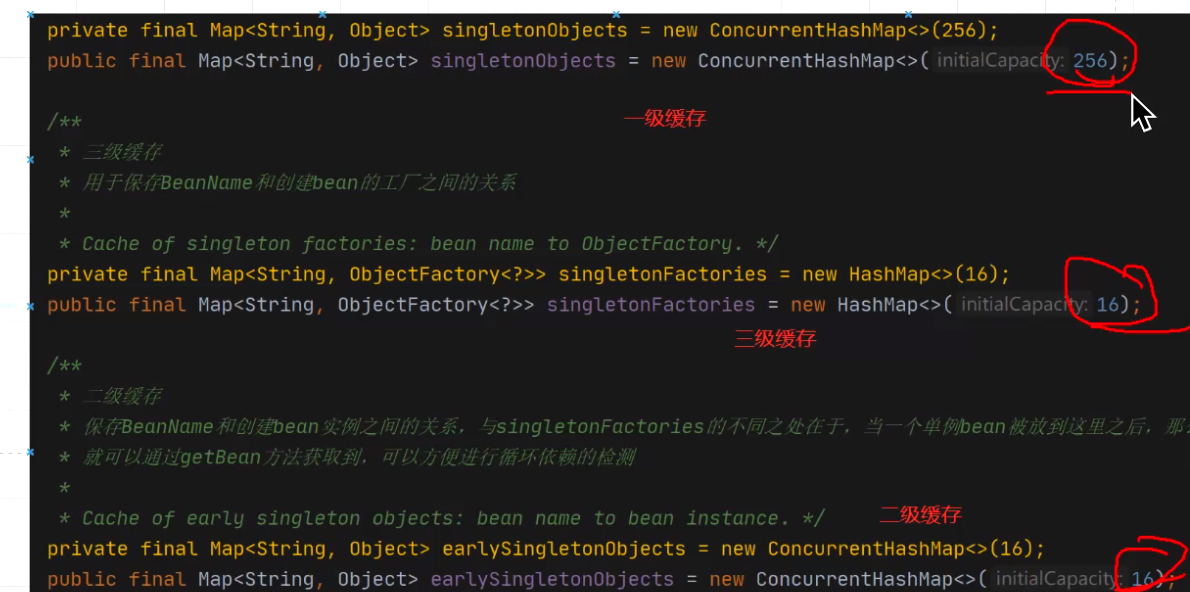
-级缓存:成品对象
级缓存:半成品对象
三级缓存:lambda表达式
2、三个map结构在进行对象查找的时候,查找的顺序是什么样的?
1, 2, 3
3、为什么一级缓存有对象之后就要把二级和三级给移除掉?
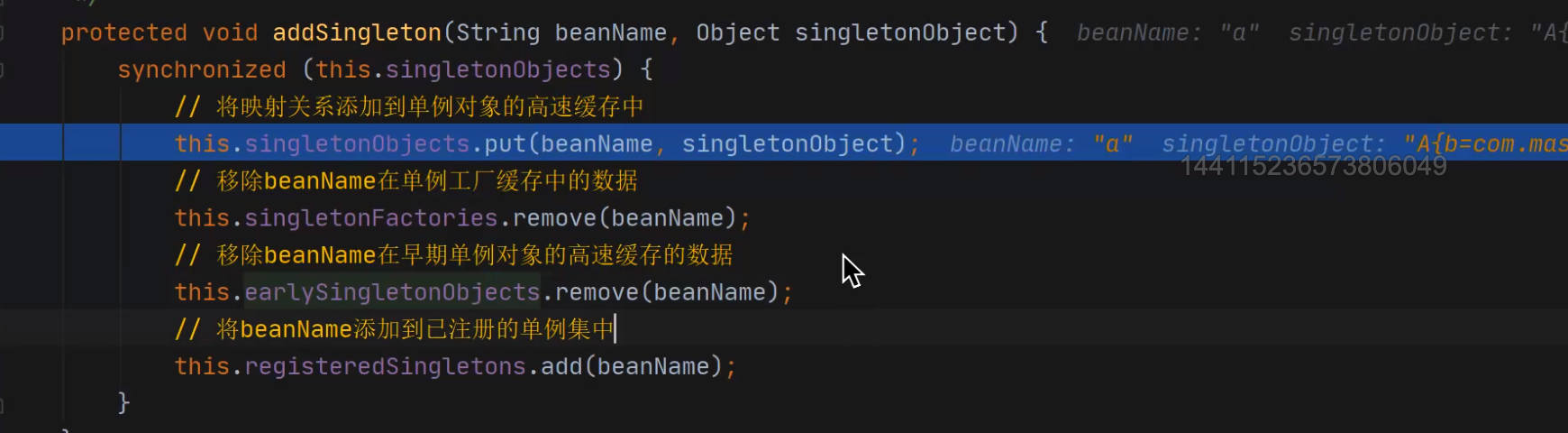
因为对象的查找顺序是1,2,3,如果在一级中找到了,那么二级永远也不会进行查找,以此类推
4、如果只有一个map结构,能否解决循环依赖问题?
原则上是可以的,但是操作起来比较麻烦,当只有一个map结构的时候就意味着成品对象和半成品对象要放到一起,而半成品对象是不能暴露给外部使用的,要不会报空指针异常,所以需要添加标识位,而容器中对象的名字都是固定的,所以标识位只能在value中,也就意味着每次在判断的时候都要获取到value然后判断完标志位之后才能进行下一步操作,比较麻烦,直接用两个map可以轻松解决这个问题
5、如果只有两个map结构,能否解决循环依赖问题?
原则上是可以的,但是有前提条件:整个代码的执行逻辑中不能包含代理对象的创建,否则会报错
6、为什么必须要使用三个map结构来解决循环依赖问题?三级缓存是如何解决循环依赖问题的?
(1)在创建代理对象的时候是否需要创建原始对象?
需要
(2)容器中能否同时存在两个同名的不同对象?
不能
(3)如果创建出了代理对象,那么原始对象应该怎么处理?
当创建出代理对象之后,需要将代理对象覆盖原始对象
(4)那么为什么要引入三级缓存呢?为什么要传入一个lambda表达式呢?
正常的bean的生命周期是先通过createBeanlnstance创建出原始对象,然后在populateBean的方法中完成对象属性的赋值工作,然后在BeanPostProcessor的后置处理方法中完成代理对象的创建工作,也就是说按照正常的执行逻辑,是完成属性的赋值之后才会创建出代理对象,那么意味着最后创建出的是代理对象,但是赋值的时候赋的是原始对象,所以会出现一个错误:that said other beans do not use the final version of the bean. 当引入lambda表达式之后相当于将生成代理对象的过程给提前了,也就是说在完成对象的属性赋值的时候必须要唯一性的确定好我需要的到底是代理对象还是原始对象,参考 (getEarlyBeanReference方法)也就是说我们在赋值的前一刻必须要确定好最终的结果,但是又因为我们没有办法确定什么时刻会给什么对象的属性赋值,所以采用lambda表达式的方法延迟执行,只有在对象赋值的最后一刻才确定出到底是什么对象。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号