202012-2期末预测之最佳阈值
题目
http://118.190.20.162/view.page?gpid=T122
思路
题目意思
题目的意思是,输入m个数以及这些成绩的挂科情况,然后依次以这些数为标准,在这些数中找一个数,使得它准确率最高,准确率可以这么理解:
低于这个标准的成绩不及格算作预判正确,高于或等于这个标准的成绩都及格了,也算预判正确,所以,正确率=低于这个标准的成绩不及格的成绩个数+高于或等于这个标准的成绩及格的个数。然后题目要求出这个准确率最高的标准成绩,如果准确率相同,那么就取成绩要求高的那个,用它来预判小明会不会挂科。
思路一:暴力法
用两个循环,外循环取的一个标准数,内循环用于比较数组中其他数和这个标准数的大小关系以及是否预判准确,顺便统计预判正确的数目,最后按要求排序,选出第一个就可以了。但是这种方法会超时,只得了70分。
#include <iostream>
using namespace std;
struct stu {
int y;
int result = -1;
int t = 0;
};
int cmp(const void* a, const void* b) {
if ((*(stu*)a).t == (*(stu*)b).t) {
if ((*(stu*)a).y > (*(stu*)b).y)
return -1;
else
return 1;
} else {
return (*(stu*)a).t < (*(stu*)b).t ? 1 : -1;
}
}
int main() {
ios::sync_with_stdio(false);
int m;
cin >> m;
stu s[m];
for (int i = 0; i < m; i++) {
cin >> s[i].y >> s[i].result;
}
int ant0[m]={0};
int ant1[m]={0};
for (int i = 0; i < m; i++) {
int index = s[i].y;
for (int j = 0; j < m; j++) {
if ((s[j].y >= index && s[j].result == 1) ||
(s[j].y < index && s[j].result == 0)) {
s[i].t++;
}
}
}
qsort(s, m, sizeof(s[0]), cmp);
cout << s[0].y;
return 0;
}
思路二:使用前缀和以及后缀和进行优化
思路一的方法中其实我们走了好多重复的步骤,比如每次选定一个标准数时,都要从头开始再一次遍历这个数组。那么我们可不可以尽量减少这样的重复,尽可能利用好前面循环得出的信息呢?是可以的。我们可以用前缀和以及后缀和来优化思路一的算法。我们可以先对数组进行升序排序,然后我们会发现,某个数的前面比他小的数的0的个数(即预判正确)是可以通过一个数组记录下来的,那么此时,这个数 比它小的数并且预判正确的个数就可以用他前一个数的预判正确数+它本身正确数(0/1),同样的,比它大的数并且预判正确的数也可以这么求出来。最后把预判正确的数相加就可以比较大小做出判断了。其实当中还是有坑的,先不说,先放上我的第一版代码
(有错:)
#include <bits/stdc++.h>
using namespace std;
const int N = 100005;
struct stu {
int y;
int result;
int zero;
int one;
int sum;
};
int cmp(stu a, stu b) { return a.y < b.y; }
int cmp2(stu a, stu b) {
if (a.sum != b.sum) {
return a.sum > b.sum;
} else {
return a.y > b.y;
}
}
int main() {
int m;
cin >> m;
stu s[N];
for (int i = 1; i <= m; i++) {
cin >> s[i].y >> s[i].result;
}
sort(s + 1, s + 1 + m, cmp);
s[0].zero = 0;
for (int i = 1; i <= m; i++) {
if (s[i].result == 0) {
s[i].zero = 1 + s[i - 1].zero;
} else
s[i].zero = s[i - 1].zero;
}
s[m + 1].one = 0;
for (int i = m; i >= 1; i--) {
if (s[i].result == 1) {
s[i].one = 1 + s[i + 1].one;
} else
s[i].one = s[i + 1].one;
s[i].sum = s[i].one + s[i-1].zero;
}
sort(s + 1, s + 1 + m, cmp2);
cout << s[1].y;
return 0;
}
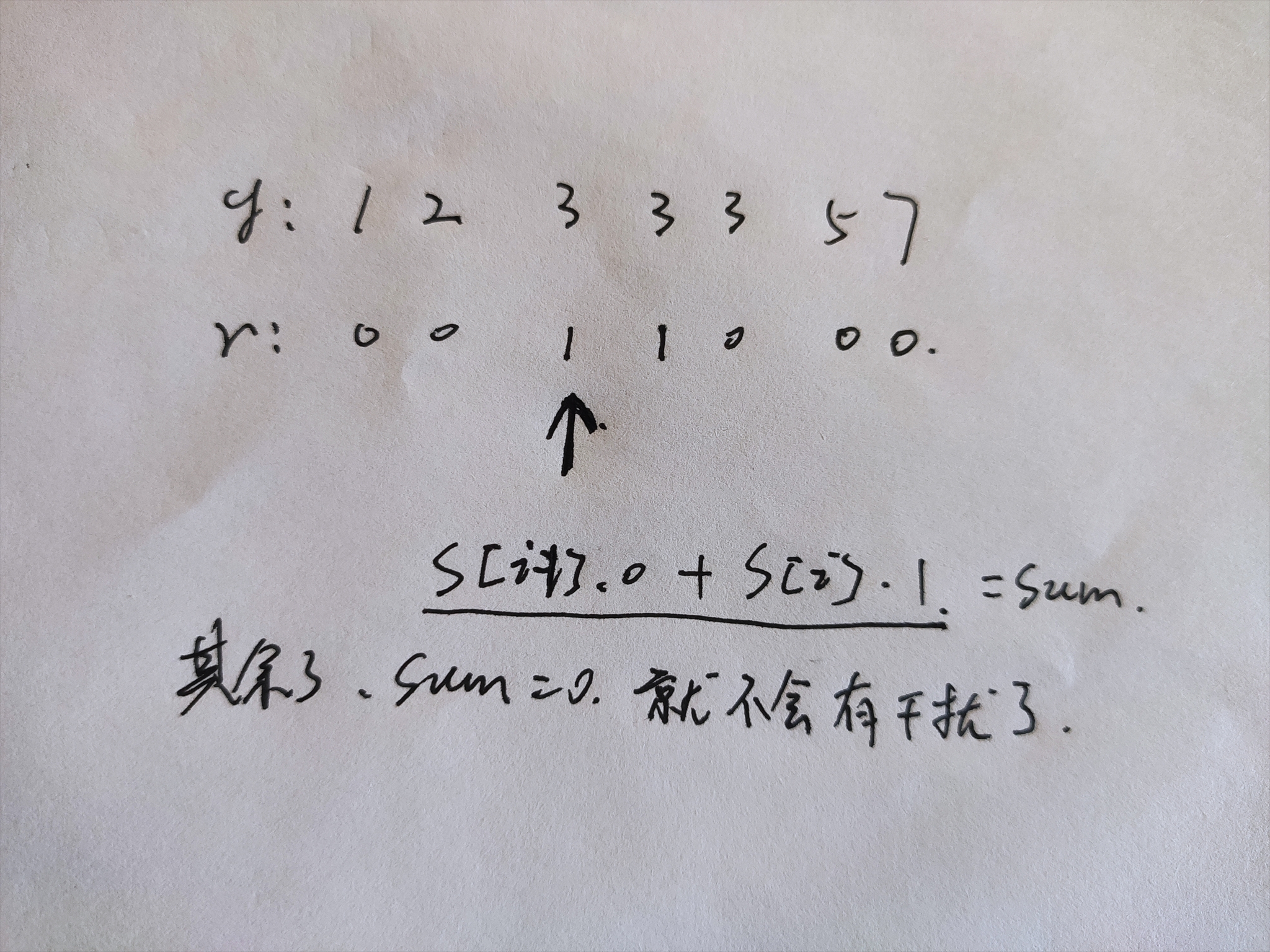
上面的代码其实是有错误的,我的做法是从头遍历一遍得到一个result为0的前缀和数组,从后往前遍历得到一个后缀数组,那么,预判成功的个数=0的个数+1的个数。再看一遍题目,其实我们预判成功的个数是=小于标准数的0的个数+>=标准数的1的个数,而我上面的代码则是:<=标准数的0的个数+>=标准数的1的个数,显然是和题意不一致的。这个bug其实会出现在,当某个数有多个并且他们都有0也有1时,例如下面所画:

这样,我们把相同的数按照result从大到小来排列,然后取其中一个数来计算sum值就可以了,当然是取第一个,因为这个数可以得到小于它的数的0的个数,也可以得到大于等于它的数的1的个数。其余的相同阈值只是用来统计0和1的个数,不参与sum的计算。
修改后代码
#include <bits/stdc++.h>
using namespace std;
const int N = 100005;
struct stu {
int y;
int result;
int zero;
int one;
int sum;
};
int cmp(stu a, stu b) {
if (a.y == b.y) return a.result > b.result;
return a.y < b.y;
}
int cmp2(stu a, stu b) {
if (a.sum != b.sum) {
return a.sum > b.sum;
} else {
return a.y > b.y;
}
}
int main() {
int m;
cin >> m;
stu s[N];
for (int i = 1; i <= m; i++) {
cin >> s[i].y >> s[i].result;
}
sort(s + 1, s + 1 + m, cmp);
s[0].zero = 0, s[0].y = -1;
for (int i = 1; i <= m; i++) {
if (s[i].result == 0) {
s[i].zero = 1 + s[i - 1].zero;
} else
s[i].zero = s[i - 1].zero;
}
s[m + 1].one = 0;
for (int i = m; i >= 1; i--) {
if (s[i].result == 1) {
s[i].one = 1 + s[i + 1].one;
} else
s[i].one = s[i + 1].one;
if (s[i].y != s[i-1].y) s[i].sum = s[i].one + s[i-1].zero;
else s[i].sum = 0;
}
sort(s + 1, s + 1 + m, cmp2);
cout << s[1].y;
return 0;
}
思路三:离散化(这个是大佬指点才学会的)
分析题目我们会发现,如果一个阈值出现很多次,我们要记录它以及它出现的次数,并且它对应的0和1的个数,那么我们可以怎么做呢?我们可以定义一个二维数组 sum[m][2] 数组的m为阈值,后面一个维度用于是0或者1,比如,阈值2出现两次,并且它对应的都是1,那么就可以这样子写:sum[2][1]++,最后就可以统计出阈值2出现的0和1的个数了。然后我们用前缀和和后缀和统计每一个阈值出现的0和1,代码如下:
for (int i = 1; i <= len; i++) {
sum[i][0] = sum[i-1][0] + sum[i][0];
sum[i][1] = sum[i-1][1] + sum[i][1];
}
然后一个阈值预判成功的个数为:
int s = sum[i-1][0] + (sum[len][1] - sum[i-1][1]);
最后比较就可以求出结果了。
可是,问题来了。我们的y(阈值)的数据范围为0~1e8,是开不了那么大的一个数组的。所以我们进行散列化处理。
我们对读进来的的数据进行处理,让它们存在另一个数组(t[i])中先,然后对他们进行去重处理,排好序。这样子我们就得到了m排好序的阈值。既然已经排好序了并且每个元素只出现一次,那我们就可以用数组t的下标一一对应他们每一个值,可以用二分查找查询某一个阈值在数组t中的位置,然后用这个下标代替他原来的值来执行sum中的前缀和操作,这样子我们sum数组所需的空间就能大大缩小。代码如下:
#include <algorithm>
#include <iostream>
using namespace std;
const int N = 1e5 + 10;
struct node {
int y, r;
} a[N];
int n, t[N];
int sum[N][2];
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> a[i].y >> a[i].r;
t[i] = a[i].y;
}
sort(t + 1, t + 1 + n);
int len = unique(t + 1, t + 1 + n) - t - 1;
for (int i = 1; i <= n; i++) {
int p = lower_bound(t + 1, t + 1 + len, a[i].y) - t;
sum[p][a[i].r]++;
}
for (int i = 1; i <= len; i++) {
sum[i][0] = sum[i-1][0] + sum[i][0];
sum[i][1] = sum[i-1][1] + sum[i][1];
}
int ans = 0, cnt = 0;
for (int i = 1; i <= len; i++) {
int s = sum[i-1][0] + (sum[len][1] - sum[i-1][1]);
if (s > cnt) ans = t[i], cnt = s;
else if(s == cnt) ans = max(ans, t[i]);
}
cout << ans;
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号