常用elk操作
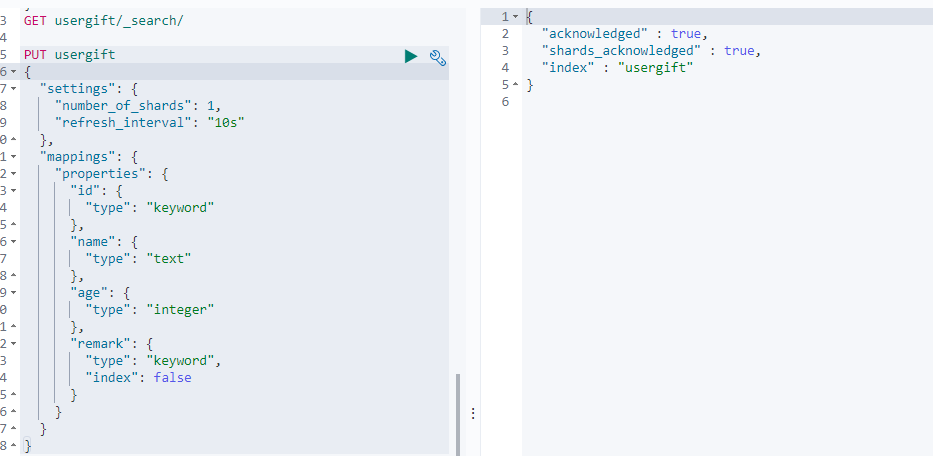
1.创建索引
PUT usergift
{
"settings": {
"number_of_shards": 1,
"refresh_interval": "10s"
},
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"remark": {
"type": "keyword",
"index": false
}
}
}
}
对于text模糊查询的字段,如果要精确查询,在字段中声明一个字段
PUT users_test1/ { "settings": { "number_of_shards": 2, "refresh_interval": "5s" }, "mappings" : { "properties" : { "ext" : { "type" : "text", "fields": { "keyword1": { "type": "keyword", "ignore_above": 10 } }, "store": true }, "id" : { "type" : "keyword" }, "nick" : { "type" : "text", "store": true }, "platform" : { "type" : "integer", "store": true }, "userId" : { "type" : "long" } } } }
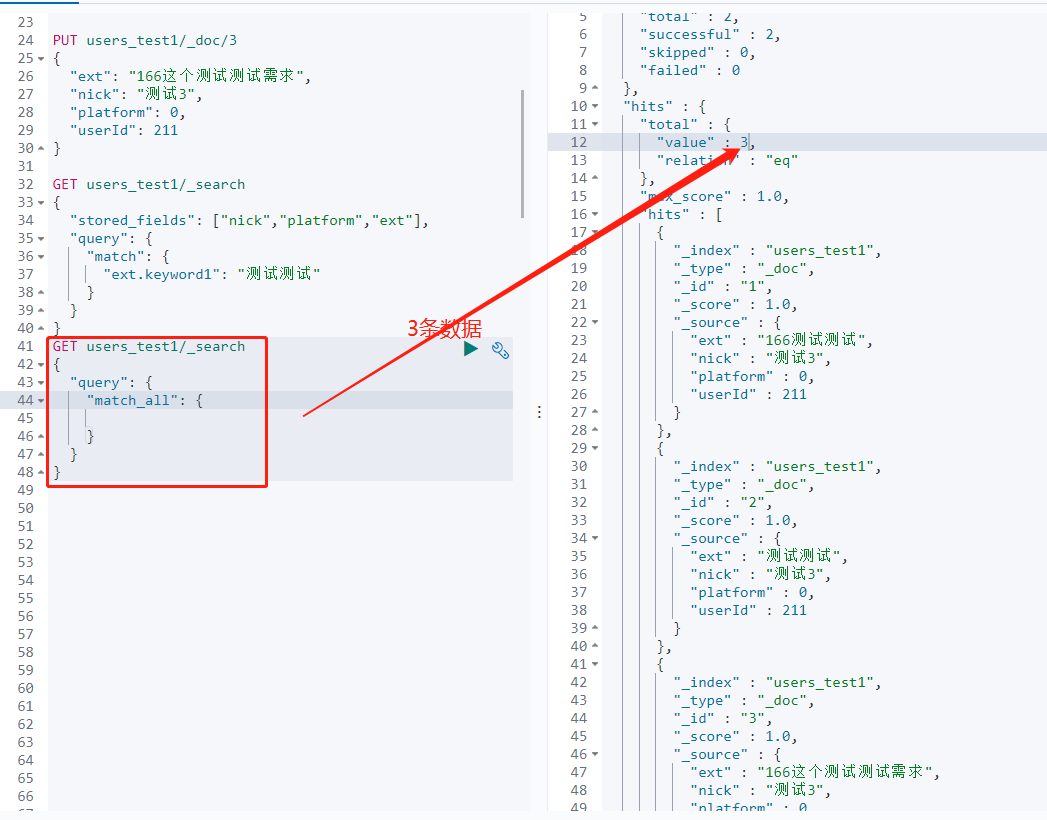
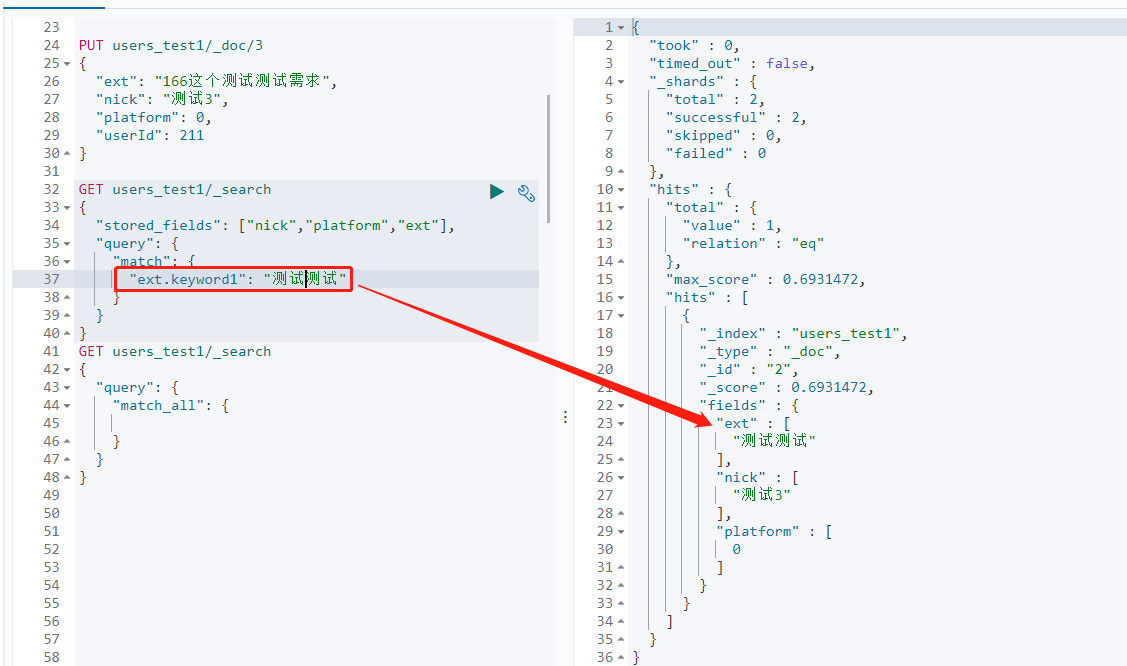
字段中的精确查询可以自定义名称,//TODO:还有其他用法没有去了解
2.数据迁移时设置写入阻塞会加快迁移速度
PUT usergift/_settings
{
"settings":{
"index.blocks.write": true
}
}
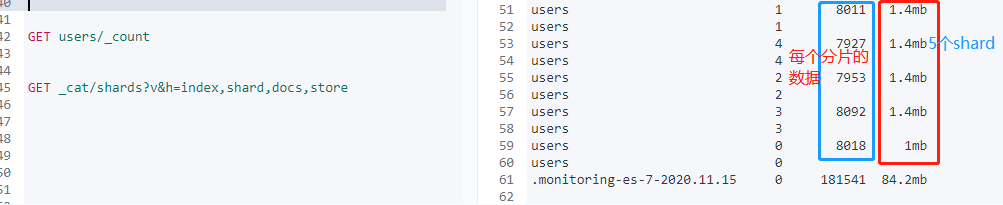
3.查看分片数据
GET _cat/recovery

GET _cat/shards?v&h=index,shard,docs,store
4.reindex
索引设定错误时,可以使用reindex将数据导到新建的索引库中(数据格式不会修改)
根据指定查询的数据导入到新的索引
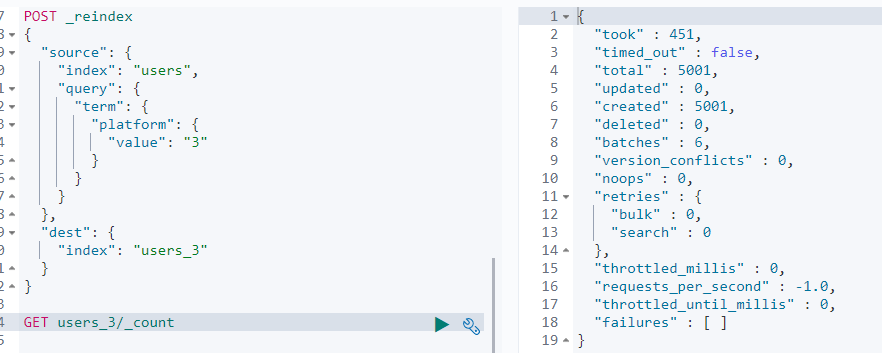
通过https://www.cnblogs.com/jajian/p/10152681.html学习到了别名和路由,后面再整理完善
上亿数据量聚合查询会很慢,处理方式选择在每一个agg下添加 "execution_hint": "map"
解决方案来自https://blog.csdn.net/laoyang360/article/details/79253294
数据迁移:
//设置刷新时间为不刷新,可以大大节省传输时间
PUT bk_test_20201127/_settings { "refresh_interval": "-1" } POST _reindex { "source": { "index": "test_20201127", "size": 8000 }, "dest": { "index": "bk_test_20201127" } } POST /_aliases { "actions": [ { "add": { "index": "bk_test_20201127", "alias": "tests" } },{ "remove": { "index": "test_20201127", "alias": "tests" } } ] } PUT bk_test_20201127/_settings { "refresh_interval": "10s" }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号