Python之路--Python基础13--异步IO、Redis\Memcached缓存、RabbitMQ队列
一、事件驱动与异步IO
回顾:同步、异步、阻塞、非阻塞
同步:
所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不会返回。按照这个定义,其实绝大多数函数都是同步调用。但是一般而言,我们在说同步、异步的时候,特指那些需要其他部件协作或者需要一定时间完成的任务。
举例:
1. multiprocessing.Pool下的apply #发起同步调用后,就在原地等着任务结束,根本不考虑任务是在计算还是在io阻塞,总之就是一股脑地等任务结束
2. concurrent.futures.ProcessPoolExecutor().submit(func,).result()
3. concurrent.futures.ThreadPoolExecutor().submit(func,).result()
异步:
异步的概念和同步相对。当一个异步功能调用发出后,调用者不能立刻得到结果。当该异步功能完成后,通过状态、通知或回调来通知调用者。如果异步功能用状态来通知,那么调用者就需要每隔一定时间检查一次,效率就很低(有些初学多线程编程的人,总喜欢用一个循环去检查某个变量的值,这其实是一 种很严重的错误)。如果是使用通知的方式,效率则很高,因为异步功能几乎不需要做额外的操作。至于回调函数,其实和通知没太多区别。
举例:
1. multiprocessing.Pool().apply_async() #发起异步调用后,并不会等待任务结束才返回,相反,会立即获取一个临时结果(并不是最终的结果,可能是封装好的一个对象)。
2. concurrent.futures.ProcessPoolExecutor(3).submit(func,)
3. concurrent.futures.ThreadPoolExecutor(3).submit(func,)
阻塞:
阻塞调用是指调用结果返回之前,当前线程会被挂起(如遇到io操作)。函数只有在得到结果之后才会将阻塞的线程激活。有人也许会把阻塞调用和同步调用等同起来,实际上他是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已。
举例:
1. 同步调用:apply一个累计1亿次的任务,该调用会一直等待,直到任务返回结果为止,但并未阻塞住(即便是被抢走cpu的执行权限,那也是处于就绪态);
2. 阻塞调用:当socket工作在阻塞模式的时候,如果没有数据的情况下调用recv函数,则当前线程就会被挂起,直到有数据为止。
非阻塞:
非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前也会立刻返回,同时该函数不会阻塞当前线程。
对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,该操作会经历两个阶段:
1)等待数据准备 (Waiting for the data to be ready)
2)将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
记住这两点很重要,因为这些IO模型的区别就是在两个阶段上各有不同的情况。
1、输入操作:read、readv、recv、recvfrom、recvmsg共5个函数,如果会阻塞状态,则会经理wait data和copy data两个阶段,如果设置为非阻塞则在wait 不到data时抛出异常
2、输出操作:write、writev、send、sendto、sendmsg共5个函数,在发送缓冲区满了会阻塞在原地,如果设置为非阻塞,则会抛出异常
3、接收外来链接:accept,与输入操作类似
4、发起外出链接:connect,与输出操作类似
1、事件驱动模型
在UI编程中,常常要对鼠标点击进行相应,首先如何获得鼠标点击呢?
方式一:创建一个线程,该线程一直循环检测是否有鼠标点击,那么这个方式有以下几个缺点:
1. CPU资源浪费,可能鼠标点击的频率非常小,但是扫描线程还是会一直循环检测,这会造成很多的CPU资源浪费;如果扫描鼠标点击的接口是阻塞的呢?
2. 如果是堵塞的,又会出现下面这样的问题,如果我们不但要扫描鼠标点击,还要扫描键盘是否按下,由于扫描鼠标时被堵塞了,那么可能永远不会去扫描键盘;
3. 如果一个循环需要扫描的设备非常多,这又会引来响应时间的问题;
所以,该方式是非常不好的。
方式二:就是事件驱动模型
目前大部分的UI编程都是事件驱动模型,如很多UI平台都会提供onClick()事件,这个事件就代表鼠标按下事件。事件驱动模型大体思路如下:
1. 有一个事件(消息)队列;
2. 鼠标按下时,往这个队列中增加一个点击事件(消息);
3. 有个循环,不断从队列取出事件,根据不同的事件,调用不同的函数,如onClick()、onKeyDown()等;
4. 事件(消息)一般都各自保存各自的处理函数指针,这样,每个消息都有独立的处理函数;
事件驱动编程是一种编程范式,这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制来触发相应的处理。另外两种常见的编程范式是(单线程)同步以及多线程编程。
让我们用例子来比较和对比一下单线程、多线程以及事件驱动编程模型。下图展示了随着时间的推移,这三种模式下程序所做的工作。这个程序有3个任务需要完成,每个任务都在等待I/O操作时阻塞自身。阻塞在I/O操作上所花费的时间已经用灰色框标示出来了。
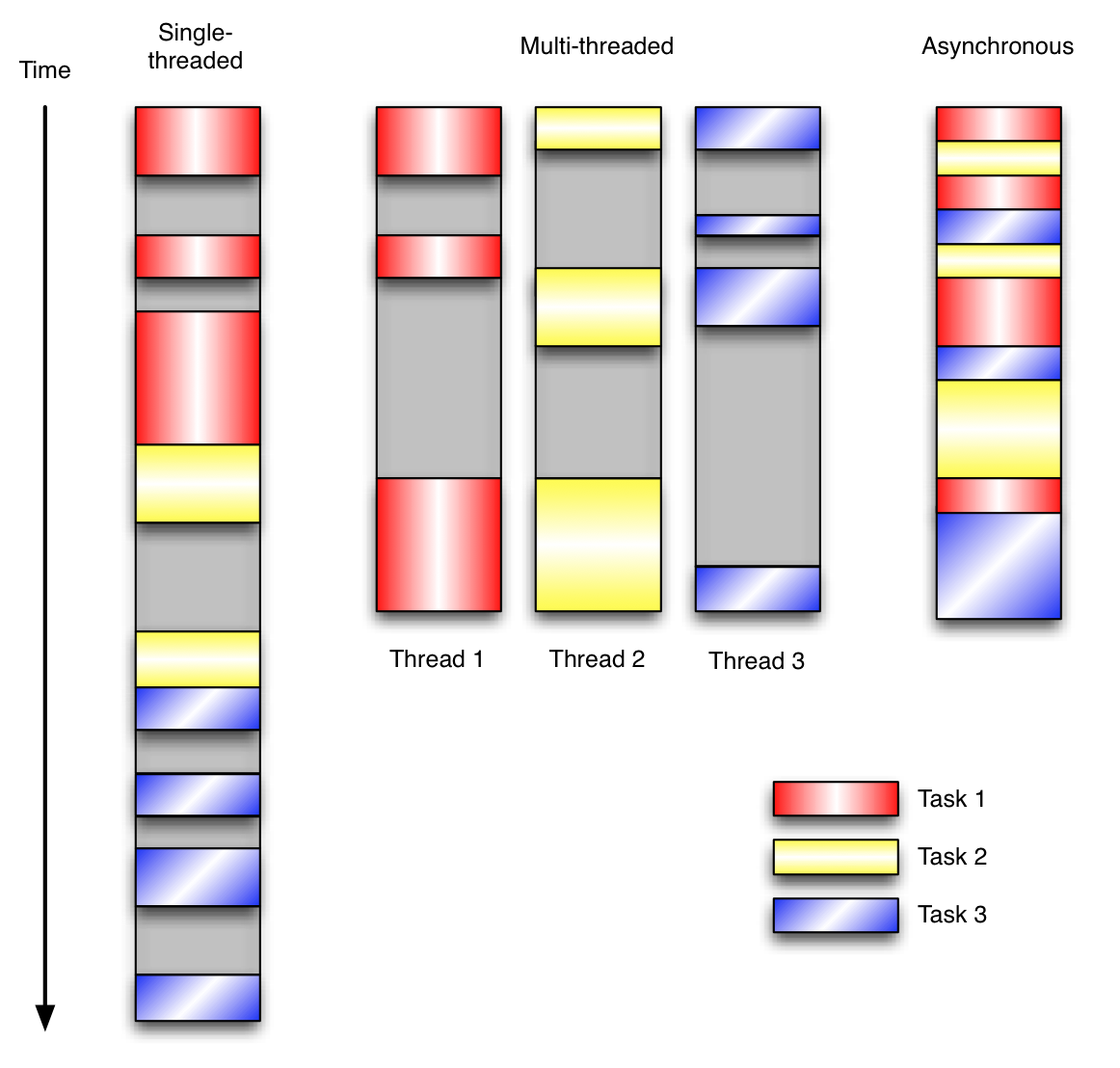
在单线程同步模型中,任务按照顺序执行。如果某个任务因为I/O而阻塞,其他所有的任务都必须等待,直到它完成之后它们才能依次执行。这种明确的执行顺序和串行化处理的行为是很容易推断得出的。如果任务之间并没有互相依赖的关系,但仍然需要互相等待的话这就使得程序不必要的降低了运行速度。
在多线程版本中,这3个任务分别在独立的线程中执行。这些线程由操作系统来管理,在多处理器系统上可以并行处理,或者在单处理器系统上交错执行。这使得当某个线程阻塞在某个资源的同时其他线程得以继续执行。与完成类似功能的同步程序相比,这种方式更有效率,但程序员必须写代码来保护共享资源,防止其被多个线程同时访问。多线程程序更加难以推断,因为这类程序不得不通过线程同步机制如锁、可重入函数、线程局部存储或者其他机制来处理线程安全问题,如果实现不当就会导致出现微妙且令人痛不欲生的bug。
在事件驱动版本的程序中,3个任务交错执行,但仍然在一个单独的线程控制中。当处理I/O或者其他昂贵的操作时,注册一个回调到事件循环中,然后当I/O操作完成时继续执行。回调描述了该如何处理某个事件。事件循环轮询所有的事件,当事件到来时将它们分配给等待处理事件的回调函数。这种方式让程序尽可能的得以执行而不需要用到额外的线程。事件驱动型程序比多线程程序更容易推断出行为,因为程序员不需要关心线程安全问题。
当我们面对如下的环境时,事件驱动模型通常是一个好的选择:
1、程序中有许多任务,而且…
2、任务之间高度独立(因此它们不需要互相通信,或者等待彼此)而且…
3、在等待事件到来时,某些任务会阻塞。
当应用程序需要在任务间共享可变的数据时,这也是一个不错的选择,因为这里不需要采用同步处理。
网络应用程序通常都有上述这些特点,这使得它们能够很好的契合事件驱动编程模型。
此处要提出一个问题,就是,上面的事件驱动模型中,只要一遇到IO就注册一个事件,然后主程序就可以继续干其它的事情了,只到io处理完毕后,继续恢复之前中断的任务,这本质上是怎么实现的呢?哈哈,下面我们就来一起揭开这神秘的面纱。。。。
2、Select\Poll\Epoll异步IO
select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
select
select(rlist, wlist, xlist, timeout=None)
函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述符就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以 通过遍历fdset,来找到就绪的描述符。
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。select的一 个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但是这样也会造成效率的降低。
select 多并发socket 例子
#select socket server
#_*_coding:utf-8_*_
__author__ = 'YL'
import select
import socket
import sys
import queue
server = socket.socket()
server.setblocking(0)
server_addr = ('localhost',10000)
print('starting up on %s port %s' % server_addr)
server.bind(server_addr)
server.listen(5)
inputs = [server, ] #自己也要监测呀,因为server本身也是个fd
outputs = []
message_queues = {}
while True:
print("waiting for next event...")
readable, writeable, exeptional = select.select(inputs,outputs,inputs) #如果没有任何fd就绪,那程序就会一直阻塞在这里
for s in readable: #每个s就是一个socket
if s is server: #别忘记,上面我们server自己也当做一个fd放在了inputs列表里,传给了select,如果这个s是server,代表server这个fd就绪了,
#就是有活动了, 什么情况下它才有活动? 当然 是有新连接进来的时候 呀
#新连接进来了,接受这个连接
conn, client_addr = s.accept()
print("new connection from",client_addr)
conn.setblocking(0)
inputs.append(conn) #为了不阻塞整个程序,我们不会立刻在这里开始接收客户端发来的数据, 把它放到inputs里, 下一次loop时,这个新连接
#就会被交给select去监听,如果这个连接的客户端发来了数据 ,那这个连接的fd在server端就会变成就续的,select就会把这个连接返回,返回到
#readable 列表里,然后你就可以loop readable列表,取出这个连接,开始接收数据了, 下面就是这么干 的
message_queues[conn] = queue.Queue() #接收到客户端的数据后,不立刻返回 ,暂存在队列里,以后发送
else: #s不是server的话,那就只能是一个 与客户端建立的连接的fd了
#客户端的数据过来了,在这接收
data = s.recv(1024)
if data:
print("收到来自[%s]的数据:" % s.getpeername()[0], data)
message_queues[s].put(data) #收到的数据先放到queue里,一会返回给客户端
if s not in outputs:
outputs.append(s) #为了不影响处理与其它客户端的连接 , 这里不立刻返回数据给客户端
else:#如果收不到data代表什么呢? 代表客户端断开了呀
print("客户端断开了",s)
if s in outputs:
outputs.remove(s) #清理已断开的连接
inputs.remove(s) #清理已断开的连接
del message_queues[s] ##清理已断开的连接
for s in writeable:
try :
next_msg = message_queues[s].get_nowait()
except queue.Empty:
print("client [%s]" %s.getpeername()[0], "queue is empty..")
outputs.remove(s)
else:
print("sending msg to [%s]"%s.getpeername()[0], next_msg)
s.send(next_msg.upper())
for s in exeptional:
print("handling exception for ",s.getpeername())
inputs.remove(s)
if s in outputs:
outputs.remove(s)
s.close()
del message_queues[s]
#select socket client
#_*_coding:utf-8_*_
__author__ = 'YL'
import socket
import sys
messages = [ b'This is the message. ',
b'It will be sent ',
b'in parts.',
]
server_address = ('localhost', 10000)
# Create a TCP/IP socket
socks = [ socket.socket(socket.AF_INET, socket.SOCK_STREAM),
socket.socket(socket.AF_INET, socket.SOCK_STREAM),
]
# Connect the socket to the port where the server is listening
print('connecting to %s port %s' % server_address)
for s in socks:
s.connect(server_address)
for message in messages:
# Send messages on both sockets
for s in socks:
print('%s: sending "%s"' % (s.getsockname(), message) )
s.send(message)
# Read responses on both sockets
for s in socks:
data = s.recv(1024)
print( '%s: received "%s"' % (s.getsockname(), data) )
if not data:
print(sys.stderr, 'closing socket', s.getsockname() )
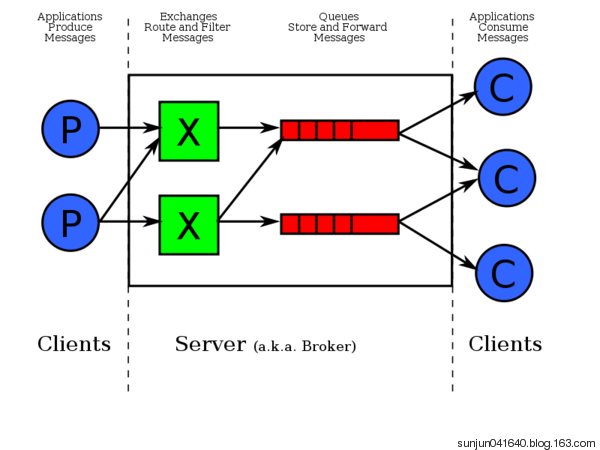
二、RabbitMQ队列
安装:http://www.rabbitmq.com/install-windows.html
安装 python rabbitMQ module :pip install pika
实现最简单的队列通信:
send端
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
#声明queue
channel.queue_declare(queue='hello')
#n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号