sql优化,原理减少回表操作
优化规则:
-- 优化前SQL SELECT 各种字段 FROM `table_name` WHERE 各种条件 LIMIT 0,10;
----->
-- 优化后SQL SELECT 各种字段 FROM `table_name` main_tale RIGHT JOIN ( SELECT 子查询只查主键 FROM `table_name` WHERE 各种条件 LIMIT 0,10; ) temp_table ON temp_table.主键 = main_table.主键
优化案例
首先我们执行以下脚本,创造测试数据;
CREATE TABLE `users` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) CHARACTER SET latin1 NOT NULL, `sex` char(1) CHARACTER SET latin1 DEFAULT NULL, `age` tinyint(4) DEFAULT NULL, `phone` varchar(16) CHARACTER SET latin1 DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_age` (`age`), KEY `idx_sex` (`sex`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=5000002 DEFAULT CHARSET=utf8;
delimiter //
-- 创建一个 名称为 p2 的存储过程
drop procedure if exists p2;
create procedure p2()
begin
declare sex varchar(1) character set utf8;
declare age,total int;
-- 初始化 变量
set total = 0;
-- loop 循环
xxx:
loop
IF mod(total,2) != 0 THEN
set sex = 'M';
ELSEIF mod(total,2) =0 THEN
set sex = 'F';
END IF;
set age = mod(total,100);
INSERT INTO `krisDB`.`users`(`id`, `name`, `sex`, `age`, `phone`) VALUES (total+1, 'tom'+total, sex, age, '10086');
if total = 5000000 then
leave xxx;
end if;
-- 累计
set total = total + 1;
end loop;
SELECT total;
end //
delimiter;
call p2();
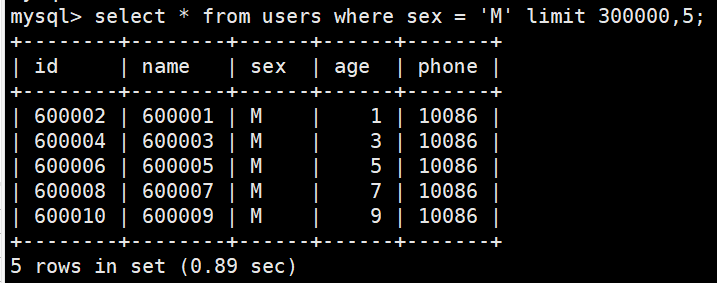
优化前:
优化后:
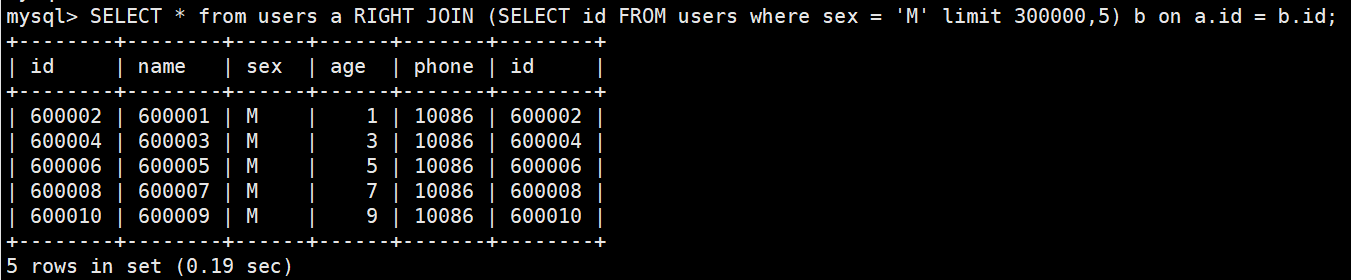
我们可以看到节省了很多时间了。
优化原理
select * from users where sex = 'M' limit 300000,5; 查询到索引叶子节点数据。根据叶子节点上的主键值,回表操作,也就是去聚簇索引上查询需要的全部字段值。
像上面这样,需要查询300005次索引节点,查询300005次聚簇索引的数据,最后再将结果过滤掉前300000条,取出最后5条。MySQL耗费了大量随机I/O在查询聚簇索引的数据上,而有300000次随机I/O查询到的数据是不会出现在结果集当中的,那么这部分时间是浪费的。这一点我们可以证实,因为information_schema.INNODB_BUFFER_PAGE表中有最近访问过的uk_sex,primary索引查询。
执行查询select * from users where sex = 'M' limit 300000,5之前

执行查询select * from users where sex = 'M' limit 300000,5之后

优化查询语句为SELECT * from users a RIGHT JOIN (SELECT id FROM users where sex = 'M' limit 300000,5) b on a.id = b.id;
执行查询语句之前

执行查询语句之后

至于什么是回表查看链接https://www.cnblogs.com/ykpkris/articles/15958768.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号