
index_merge索引合并优化导致的死锁问题
记录一个java操作mysql数据库出现死锁问题;
nested exception is com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction
建立一张表模仿与分析index_merge引起的死锁问题
CREATE TABLE `users` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) CHARACTER SET latin1 NOT NULL, `sex` char(1) CHARACTER SET latin1 DEFAULT NULL, `age` tinyint(4) DEFAULT NULL, `phone` varchar(16) CHARACTER SET latin1 DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_age` (`age`) USING BTREE, KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=219 DEFAULT CHARSET=utf8;
通过表结构可以看出,这张表一共有三个索引,id主键聚簇索引,普通的非聚簇索引索引index_age,index_name;
聚簇索引: 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据。
辅助索引: (非聚簇索引) 辅助索引叶子节点存储的是聚簇索引的键值,在这里也就是主键值。
主键索引 PRIMARY 就是聚簇索引,叶子节点中会保存行数据。idx_age,index_name为非聚簇索引,叶子节点中保存的是主键值,也就是id列值。当我们通过辅助索引查找行数据时,先通过辅助索引找到主键id,再通过主键索引进行二次查找(也叫回表),最终找到行数据。
话归正题,什么是索引优化:
MySQL5.0之前,一个表一次只能使用一个索引,无法同时使用多个索引分别进行条件扫描。但是从5.1开始,引入了 index merge 优化技术,对同一个表可以使用多个索引(一般是2个)分别进行条件扫描。简单的说,index merge 技术其实就是:对多个索引分别进行条件扫描,然后将它们各自的结果进行合并,合并方式分为三种:union, intersection, 以及它们的组合sort_union(先内部intersect然后在外部union);
查看数据库是否开启了index_merge:show variables like ‘%optimizer_switch%’;
关闭index_merge(重启才能生效):set @@global.optimizer_switch = ‘index_merge=off’ ;
开启index_merge(重启才能生效):set @@global.optimizer_switch = ‘index_merge=on’ ;
默认index_merge索引优化是开启的;
举个例子:
执行语句:EXPLAIN update users set phone = '10086' where name = 'tom' and age = 25;

这种情况用到了索引index_merge优化。对index_age,idx_name索引分别进行条件扫描;然后扫描结果出来的id列值进行交集;然后再二次查找(也叫回表);最终通过聚簇索引primary索引返回行数据;
index_merge索引优化的作用:
我们可以对比索引合并与普通利用单个索引的效率:
还是以EXPLAIN update users set phone = '10086' where name = 'tom' and age = 25为例子
单个索引:
- 根据 name = 'tom' 查询条件,利用idx_name索引找到叶子节点中保存的id值;
- 通过找到的id值,利用PRIMARY索引找到叶子节点中保存的行数据;
- 再通过 age = 25 条件对找到的行数据进行过滤。
索引合并:
- 根据 name = ‘tom’ 查询条件,利用idx_name索引找到叶子节点中保存的id值;
- 根据 age = 25 查询条件,利用idx_age索引找到叶子节点中保存的id值;
- 将1、2步中找到的id值取交集,然后利用PRIMARY索引找到叶子节点中保存的行数据
上边两种情况的主要区别在于,第一种是先通过一个索引把数据找到后,再用其它查询条件进行过滤;第二种是先通过两个索引查出的id值取交集,如果取交集后还存在id值,则再去回表将数据取出来。开启索引index_merge之后,不一定都会用到索引优化;只有当优化器认为索引合并比单个索引优势大的时候就会触发索引合并。
当表记录如下时:
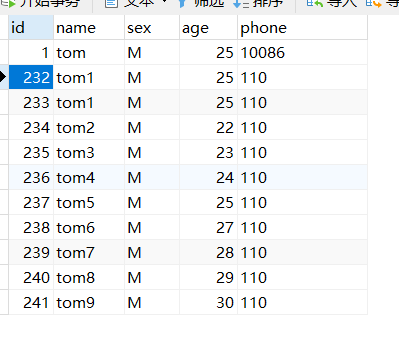
查看执行计划

当表记录如下时:
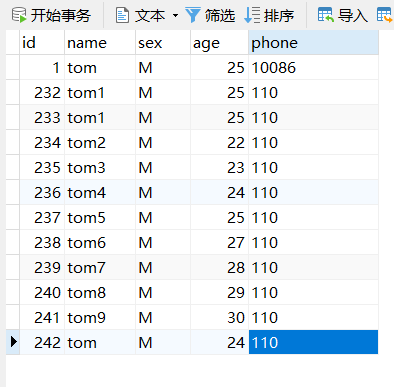
查看执行计划:

就是说当我们用idx_name索引查找到主键id之后,与使用另外一个index_age查到的id取交集可以减少回表的id数目的时候,就会用到索引优化技术。
为什么index_merge会导致死锁?
这里先简单介绍一下锁;
mysql的锁级别
MySQL有三种锁的级别:页级锁、表级锁、行级锁。
MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking);BDB存储引擎采用的是页面锁(page-level locking),但也支持表级锁;InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁。
MySQL这3种锁的特性可大致归纳如下:
页级锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度最高。
注意: 行级锁并不是直接锁记录,而是锁索引,如果一条SQL语句用到了主键索引,mysql会锁住主键索引;如果一条语句操作了非主键索引,mysql会先锁住非主键索引,再锁定主键索引。
而我们报错nested exception is com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction项目中用到的是行级锁;
导致死锁的情况;
比如来了两个update事务
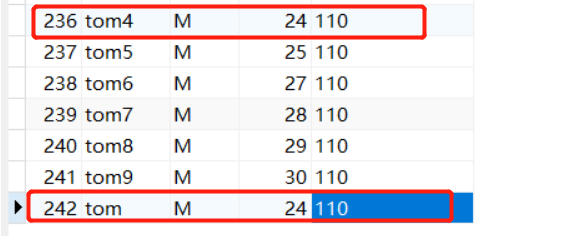
update users set phone = '10086' where name = 'tom4' and age = 24 事务一
update users set phone = '10086' where name = 'tom' and age = 24 事务二
| 事务一 | 事务二 |
| 锁住idx_name索引中的name为tom4的索引项 | |
| 锁住idx_name索引中的name为tom的索引项 | |
| 回表锁住Primary索引中的id为236的索引项 | |
| 回表锁住Primary索引中的id为242的索引项 | |
| 锁住idx_age索引中的age为24的索引项 | |
| 试图锁住idx_age索引中的age为24的索引项,发现该索引项目锁住了,等待事务一释放age为24的索引项 | |
| 试图回表锁住Primary索引中的id为242,236的索引项。发现242索引被事务二锁住了,等待释放。 | |
| 导致死锁了。 | |
解决方案
减去其中一个索引,避免索引合并;在业务代码里面过滤;
使用复合索引替代;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号