20192320 杨坤《python》实验四报告
20192320 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1923班
姓名: 杨坤
学号: 20192320
实验教师:王志强
实验日期:2022年5月30日
必修/选修: 公选课
1.实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
课代表和各小组负责人收集作业(源代码、视频、综合实践报告)
注:在华为ECS服务器(OpenOuler系统)和物理机(Windows/Linux系统)上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
批阅:注意本次实验不算做实验总分,前三个实验每个实验10分,累计30分。本次实践算入综合实践,打分为25分。
评分标准:
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)10分
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。10分。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。5分
(4)如果没有使用华为云服务(ECS或者MindSpore均可),本次实践扣10分。
注意:每个人的实验不能重复,课代表
2信息熵
随机变量\(P_k\)的熵定义为:
对于具体的、随机变量y生成的数据集\(D=\left\{y_1,.....,y_{N}\right\}\),在实际操作中通常利用经验熵来估计信息熵。
假设随机变量\(y\)的取值空间为\(\left\{c_1,......,c_k\right\}\),\(p_k\)表示\(y\)取\(c_k\)的概率:\(p_k=p(y=c_k)\);\(\left|C_k\right|\),代表变量\(y\)中类别为\(c_k\)的样本的个数,\(\left|D\right|\),代表D的总样本数。若对数的底数是2,信息熵的单位是比特(bit),若对数的底数是\(e\),信息熵的单位是纳特(nat)。
当:
\(p_1=p_2=...=p_k=1/K\)时,\(H(y)\)达到最大值\(-log\frac{1}{K}\),此时意味着随机变量\(y\)取每一个变量的概率是相等的,即\(y\)没有规律可循。
我们的目的是让\(y\)的不去定性减小,让\(y\)变得有规律方便我们预测。
3.条件熵
条件熵\(H(y|A)\)的概念来定义信息的增益:
- 条件熵就是根据A的不同取值\(\left\{a_1,...,a_m\right\}\)对\(y\)进行限制后,先对这些被限制的\(y\)分别计算信息熵,再把这些信息熵根据特征值本身的概率加权求和,从而得到总的条件熵。
所以条件熵\(H(y|A)\)越小,意味着\(y\)被A限制后的总的不确定性越小,从而意味着A更能帮助我们做出决策。
其中
即为:
特征A对训练数据集D的信息增益\(g(D,A)\),定义为集合D的经验熵\(H(D)\)与特征A给定条件下D的条件熵\(H(D|A)\)之差,即为:
代码:
def shannoEnt(dataSet):
labelCount = {}
numOfData = len(dataSet)
for data in dataSet:
classify = data[-1]
if classify not in labelCount.keys():
labelCount[classify] = 1
else:
labelCount[classify] += 1
H = 0.0
for value in labelCount.values():
pi = value / numOfData
H -= pi * log(pi, 2)
return H
def chooseBestFeatureSplit(dataSet):
HD = shannoEnt(dataSet)
bestGain = 0.0
bestFeature = -1
for i in range(len(dataSet[0]) - 1):
feat = [data[i] for data in dataSet]
prob = 0.0
for value in set(feat):
subData = splitData(dataSet, i, value)
prob += (len(subData) / len(dataSet)) * shannoEnt(subData)
Gain = HD - prob
if Gain > bestGain:
bestGain = Gain
bestFeature = i
# print('最优特征是:',label[bestFeature])
return bestFeature
4.ID3算法
- 从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点
- 再对子结点递归地调用以上方法,构建决策树
- 直到所有特征的信息增益均很小或没有特征可以选择为止
- 最后得到一个决策树
若\(D\)中所有实例属于同一类\(C_k\),则\(T\)为单结点树,返回\(T\)
若\(A=\emptyset\),则\(T\)为单结点树,并将\(D\)中实例数最大的类\(C_k\)作为该结点的类标记,返回\(T\)
否则,计算\(A\)中各特征对\(D\)的信息增益,选择信息增益最大的特征\(A_g\)
- 如果\(A_g\)的信息增益小于阈值\(\epsilon\),则\(T\)为单结点树,并将\(D\)中实例数最大的类\(C_k\)作为该结点的类标记,返回\(T\)
- 否则,依\(A_g=a_i\)将\(D\)分割为若干非空子集\(D_i\),递归地构建子树(训练集:\(D_i\),特征集:\(A-\{A_g\}\))
代码:
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if len(set(classList)) == 1:
return classList[0]
if len(dataSet[0]) == 0:
return majorityCnt(classList)
bestFeat = chooseBestFeatureSplit(dataSet)
bestFeatLabel = labels[bestFeat]
# 创建树:
myTree = {bestFeatLabel: {}}
del (labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
for value in set(featValues):
subLabels = labels[:]
subDataSet = splitData(dataSet, bestFeat, value)
myTree[bestFeatLabel][value] = createTree(subDataSet, subLabels)
for key, value in myTree.items():
print(key, value)
return myTree
总的代码:
# coding:utf-8
'''
**************************************************
@File :myPycharm -> ex_03
@IDE :PyCharm
@Author :20192320杨坤
@Date :2022/5/22 15:28
**************************************************
'''
from math import log
def loadDataSet():
dataSet = [['青年', '否', '否', '一般', '否'],
['青年', '否', '否', '好', '否'],
['青年', '是', '否', '好', '是'],
['青年', '是', '是', '一般', '是'],
['青年', '否', '否', '一般', '否'],
['中年', '否', '否', '一般', '否'],
['中年', '否', '否', '好', '否'],
['中年', '是', '是', '好', '是'],
['中年', '否', '是', '非常好', '是'],
['中年', '否', '是', '非常好', '是'],
['老年', '否', '是', '非常好', '是'],
['老年', '否', '是', '好', '是'],
['老年', '是', '否', '好', '是'],
['老年', '是', '否', '非常好', '是'],
['老年', '否', '否', '一般', '否']]
label = ['年龄', '有工作', '有自己的房子', '信贷情况']
return dataSet, label
def shannoEnt(dataSet):
labelCount = {}
numOfData = len(dataSet)
for data in dataSet:
classify = data[-1]
if classify not in labelCount.keys():
labelCount[classify] = 1
else:
labelCount[classify] += 1
H = 0.0
for value in labelCount.values():
pi = value / numOfData
H -= pi * log(pi, 2)
return H
def chooseBestFeatureSplit(dataSet):
HD = shannoEnt(dataSet)
bestGain = 0.0
bestFeature = -1
for i in range(len(dataSet[0]) - 1):
feat = [data[i] for data in dataSet]
prob = 0.0
for value in set(feat):
subData = splitData(dataSet, i, value)
prob += (len(subData) / len(dataSet)) * shannoEnt(subData)
Gain = HD - prob
if Gain > bestGain:
bestGain = Gain
bestFeature = i
# print('最优特征是:',label[bestFeature])
return bestFeature
def splitData(dataSet, axis, value):
retDataSet = []
for data in dataSet:
if data[axis] == value:
reducedData = data[:axis]
reducedData.extend(data[axis + 1:])
retDataSet.append(reducedData)
return retDataSet
def majorityCnt(classList):
classCount = dict([(i, classList.count(i)) for i in classList])
return max(classCount, key=lambda x: classCount[x])
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if len(set(classList)) == 1:
return classList[0]
if len(dataSet[0]) == 0:
return majorityCnt(classList)
bestFeat = chooseBestFeatureSplit(dataSet)
bestFeatLabel = labels[bestFeat]
# 创建树:
myTree = {bestFeatLabel: {}}
del (labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
for value in set(featValues):
subLabels = labels[:]
subDataSet = splitData(dataSet, bestFeat, value)
myTree[bestFeatLabel][value] = createTree(subDataSet, subLabels)
for key, value in myTree.items():
print(key, value)
return myTree
dataSet, label = loadDataSet()
mytree=createTree(dataSet, label)
# print(mytree)
# print('*' * 10)
def x(tree:dict, a,y,z):
print(a,y,z)
if type(tree) is not dict:
a=a+1
print(tree,a)
return
if len(tree) > 1:
for value in tree.values():
y=y+1
x(value,a,y,z)
else:
z=z+1
print(tree.keys())
x(list(tree.values())[0],a,y,z)
def y(tree:dict):
if type(tree) is not dict:
print(tree)
return
if len(tree)>1:
for value in tree.values():
y(value)
# print(value)
else:
# print(tree.values())
y(list(tree.values())[0])
print(tree.keys())
#
# print("先序遍历:")
# x(mytree,0,0,0)
# print("后序遍历:")
# y(mytree)
# coding:utf-8
'''
**************************************************
@File :myPycharm -> treePlotter
@IDE :PyCharm
@Author :20192320杨坤
@Date :2022/5/25 9:01
**************************************************
'''
import matplotlib.pyplot as plt
# 定义文本框和箭头格式
decisionNode = dict(boxstyle="round4", color='#3366FF') #定义判断结点形态
leafNode = dict(boxstyle="circle", color='#FF6633') #定义叶结点形态
arrow_args = dict(arrowstyle="<-", color='g') #定义箭头
#绘制带箭头的注释
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
#计算叶结点数
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
#计算树的层数
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
#在父子结点间填充文本信息
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
firstStr = list(myTree.keys())[0]
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt) #在父子结点间填充文本信息
plotNode(firstStr, cntrPt, parentPt, decisionNode) #绘制带箭头的注释
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW;
plotTree.yOff = 1.0;
plotTree(inTree, (0.5, 1.0), '')
plt.savefig('a.jpg')
plt.show()
# coding:utf-8
'''
**************************************************
@File :myPycharm -> main
@IDE :PyCharm
@Author :20192320杨坤
@Date :2022/5/25 9:02
**************************************************
'''
from pylab import *
from sympy.physics.quantum.tests.test_circuitplot import mpl
import treePlotter
from ex_03 import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像时负号'-'显示为方块的问题
##################################
# 测试决策树的构建
myDat, labels = loadDataSet()
myTree = createTree(myDat, labels)
# 绘制决策树
treePlotter.createPlot(myTree)
5.运行截图:
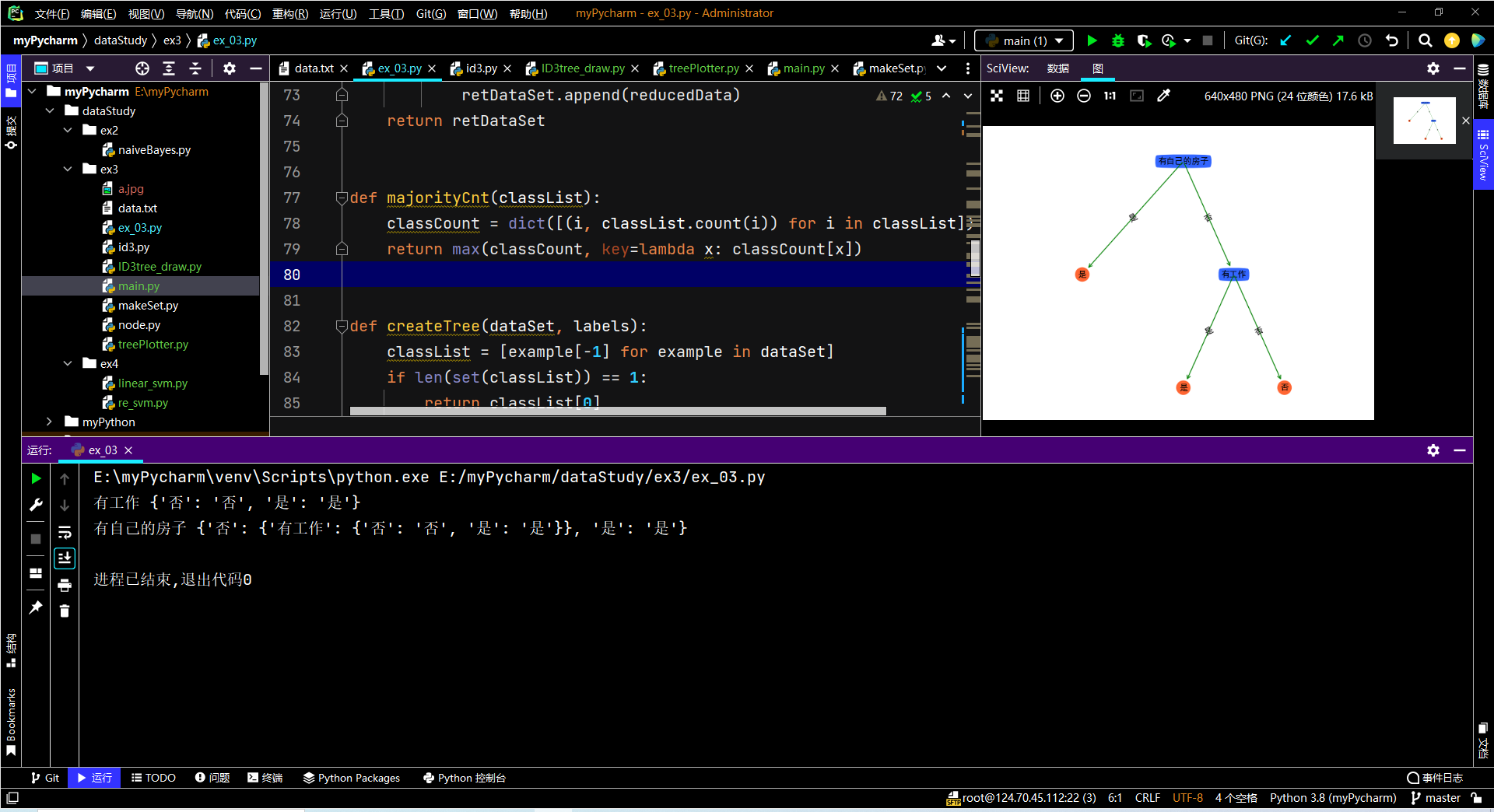
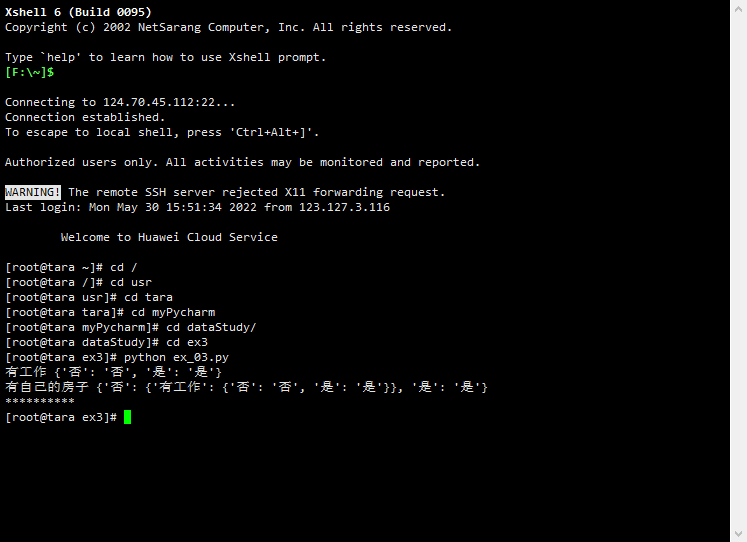
6.实验过程中遇到的问题和解决过程
- 问题1.云服务器配置python环境
- 解决办法:通过在云服务器配置anaconda软件来配置python环境3.8,同时需要修改环境变量。还可以在云服务器中创建虚拟环境,这样就可以在物理机pycharm中运行代码。
- 问题2.云服务器画图的图片没有字体,同时报错没有找到‘sans-serif’字体
- 解决办法:先找到python字体库的位置,下载对应字体后传到指定文件夹
- 问题3.云服务器不能运行rar压缩文件
- 解决办法:在云服务器下载rarlab软件即可。
7.课程感悟与思考
1.这学期的python课程,总体来说收获很多,感谢帅气的王老师的教学。
2.从第一节课初步认识python,我知道了python的优点:可读性强、编写简单、功能强大、扩展性良好。
3.再到后面详细学习python的基础语言规范:数据类型、循环、条件、序列、字典、异常等等,这些都让我收获很多。同时python强大的扩展库例如:numpy、matplotlib等等在机器学习上使用更加方便。这也让我对于python的学习更加感兴趣。
4.对于更高级的学习:正则表达式、网络编程、数据库操作,这些虽然都是只是简单初步的入门,但是程序的编写思想都是共通的,在课堂之外自己深入学习,也是收获满满。
5.python中最为经典的应用,爬虫。这是我第一次接触到爬虫,结合到学过的web的知识,学起来也是很容易上手。这一块可以在今后继续深入的理解学习。
8.课程的建议:
1.对于云服务器的使用可以在课程一开始就增加一节课详细介绍云服务器,这样也会使得整个课程更加饱满,同时这也会成为课程的一大特色。
2.课程中期的测评可以保留:既增加了课程的丰富程度又可以带来一些奖励。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号