【数据结构梳理04】串的模式匹配——KMP算法
一、串的模式匹配
设有两个串S和pat,若在S中查找是否有与pat相同的子串,则称串S为目标,称pat为模式,串的模式匹配即为查找模式串在目标串中的匹配位置的运算。
(1)朴素的模式匹配(B-F算法)
朴素的模式匹配想法十分简单粗暴:将pat中的每个字符依次与S中的字符比较,如果某一位匹配失败,则将pat右移一位,用pat中的字符从头开始与S中的字符比较,重复上述步骤,直到出现以下两种情况算法结束:
①在某一趟匹配中pat与S的某一子串匹配成功,则函数返回pat在当前串中第一次匹配的位置,匹配成功;
②pat已经移到最后可能与S比较的位置(即pat的最后一个字符已经对应到S的最后一个字符的位置)后pat仍不能与S匹配,则返回-1,表示匹配失败。
B-F算法匹配过程示意图:
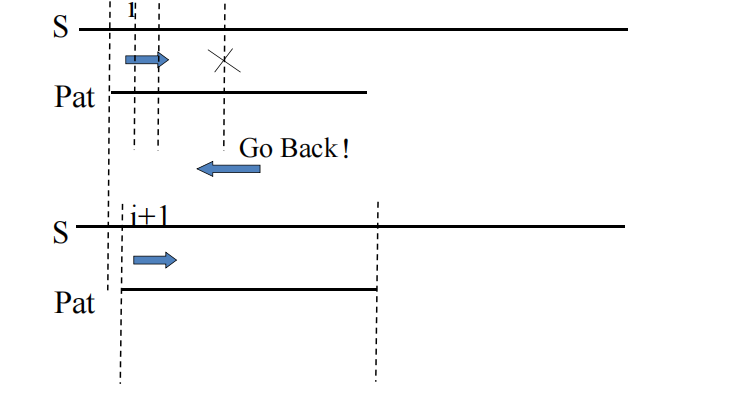
代码实现:
int String::Find(String& pat,int k)const{ //从*this的第k个位置开始寻找字串
int Posp;
int PosS;
for(PosS=k;PosS<=Length()-pat.Length();PosS++){
//检查从PosS开始的pat的str[PosP]
for(PosP=0;PosP<pat.Length()&&str[PosS+PosP]==pat.str[PosP];PosP++)
if(PosP==pat.Length())
return PosP;
}
return -1;性能分析:B-F算法是一种回溯算法,一旦产生失配,要将模式pat右移一位,从头开始比较。假如S的长度为m,pat的长度为n。那么在最坏情况下最多比较m-n+1趟,每一趟pat的指针需要移动n次,那么可见时间复杂度可以达到O(m*n)。
由B-F算法的基本思想可知,在朴素的匹配模式中有太多的重复比较,即rescannig,而这些比较中有绝大多数是无效的,所以要想降低时间复杂度,我们需要首先获取一些pat自身的特点,从而避免大量的重复扫描
(2)KMP算法
下面介绍三位大神提出的能在线性时间内实现字符串模式匹配的算法——KMP算法,该算法可以解决回溯问题,去除掉冗余的比较趟数,从而降低时间复杂度。
设目标串S=s1s2...sn-1,模式串pat=p1p2...pm-1。
在介绍KMP函数前,我们先来引入一个概念——失配(failure)函数
失配函数,有些地方也称作 next[]数组,是用来确定当某一趟匹配失败后,下一次匹配时pat中应当有哪一个字符与目标中刚失配的字符重新进行比较。
对于模式串pat,其失配函数f定义为:
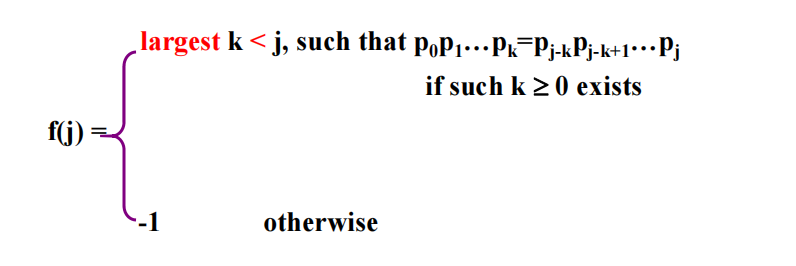
注意:(1)k取最大:防止出现串的漏匹配
(2)k<j:防止陷入死循环
其中p0p1...pk称作p0p1...pj的前缀子串,pj-k-1pj-k...pj-1称作p0p1...pj的后缀子串。假如pat = a b c a b c a c a b,那么我们有
j 0 1 2 3 4 5 6 7 8 9
pat a b c a b c a c a b
f -1 -1 -1 0 1 2 3 -1 0 1
f=-1时,表示下一趟匹配开始时,pat中的第-1个字符与目标串上次失配位置对齐,换句话说pat的起始位置字符p0与目标串上次失配位置的下一位置对齐。
f=k时,表示下一趟开始时,pat中的第k+1个字符pk与目标串的上次失配位置对齐。
示意图如下:
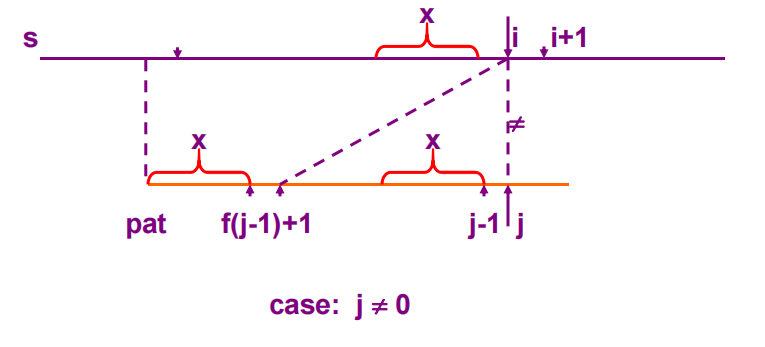
在匹配过程中,目标串的指针不回溯,pat的指针每失配一次就返回到f(j-1)+1处。
KMP算法的代码实现:
int String::KMP(String pat){
int PosP=0;
int PosS=0;
int LP=pat.Length();
int LS=Length();
while(PosP<LP&&PosS<LS){
if(str[PosP]==str[PosS]){
PosS++;
PosP++;
}
else
PosP=f[j-1]+1;
if(PosS==LS)
return -1; //匹配失败;
else
return PosS-LP;
}
}下面我们来计算f[ ]:(f[]已提前在自定义类String中声明)
void String::Failurefunction(){
int LengthP=Length();
f[0]=-1;
for(int i=1;i<LengthP;i++){
int temp=f[i-1];
while((*(str+i)!=*(str+temp+1))&&(temp>=0)) //前一个条件是判断第i个位置的字符是否与第f[i-1]+1处的字符相等,相等则跳出循环,得到 f[i]=f[i-1]+1,如果不相等
//则去比对f[f[i-1]]+1位置的字符,以此类推,直到temp<=0,则跳出循环
temp=f[temp];
if(*(str+i)==*(str+temp+1)) //当temp>=0时,直接加;当temp=-1时,*(str+temp+1)为pat的首字符;若条件满足,则f[i]=0;
f[i]=temp+1;
else
f[i]=-1;
}
}图解如下:

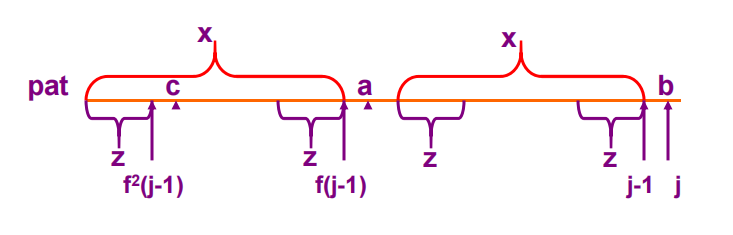
如果a=b,那么f[j]=f[j-1]+1;
如果a≠b,那么我们就需要在已经找到的两个相等的前缀和后缀子串中再去寻找更小的相同的前、后缀子串,就是上右图中的z,如果c=b,那么f[j]=f[f[j-1]]+1;如果c≠b,那么就要在z中继续找相同的前、后缀子串,重复上述步骤,直到所有的可能子串已经全部被找到,但仍然没有满足条件的子串,那么f[j]=-1。
转化为数学公式:
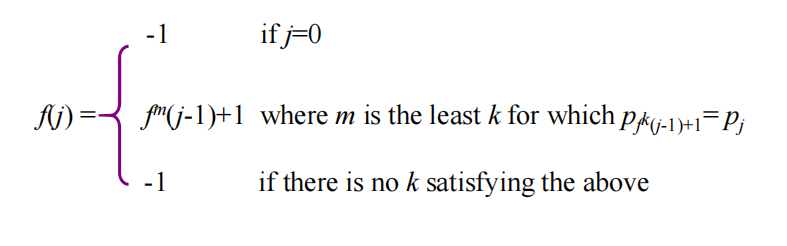
KMP性能分析:由于指针不回溯,目标串中的每一个字符最多扫描一遍,故时间复杂度为O(LengthP+LengthS)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号