

实验一、词法分析程序
实验一、词法分析实验
专业:商业软件工程二班 姓名 :颜杰文 学号:201506110150
一、 实验目的
编制一个词法分析程序
二、 实验内容和要求
实验内容:1.对字符串表示的源程序
2.从左到右进行扫描和分解
3.根据词法规则
4.识别出一个一个具有独立意义的单词符号
5.以供语法分析之用
6.发现词法错误,则返回出错信息
实验要求:输入:源程序字符串
输出:二元组(种别,单词符号本身)
三、 实验方法、步骤及结果测试
- 源程序名: yjw.c
可执行程序名:yjw.exe
- 原理分析及流程图
1、设置全局变量
1)char sum[] 把用户输入字符存到数组里面的
2)char ch 判断输入的字符的组成部分
3)char token[] 存放sum[]以及ch
4)*keyword[] 存放关键字
2、关键字表
*keyword[18]={"begin","and","const","long","float","double","void","main","if", "else","then","break","int","char","include","for","while","printf"}
3、关键函数
void scaner() 词法扫描及其判断程序
void main() 用户输入与输出

种别码表
|
单词符号 |
种别码 |
单词符号 |
种别码 |
单词符号 |
种别码 |
单词符号 |
种别码 |
|
begin |
1 |
int |
13 |
: |
28 |
} |
40 |
|
end |
2 |
char |
14 |
:= |
29 |
! |
41 |
|
const |
3 |
include |
15 |
< |
30 |
@ |
42 |
|
long |
4 |
for |
16 |
<= |
31 |
$ |
43 |
|
float |
5 |
while |
17 |
<> |
32 |
% |
44 |
|
double |
6 |
printf |
18 |
> |
33 |
^ |
45 |
|
void |
7 |
l(l|d)* |
21 |
>= |
34 |
& |
46 |
|
main |
8 |
dd* |
22 |
= |
35 |
# |
0 |
|
if |
9 |
+ |
24 |
; |
36 |
|
|
|
else |
10 |
- |
25 |
( |
37 |
|
|
|
then |
11 |
* |
26 |
) |
38 |
|
|
|
break |
12 |
/ |
27 |
{ |
39 |
|
|
- 主要程序段及其解释:
1、用于输入,直到用户输入#则跳出循环
void main()
{
printf("请输入一段你想测试的单词符号, 以‘#’号作为结束符号 !\n");
do
{
ch=getchar();//输入字符
sum[a++]=ch;//把字符存到数组里
}while(ch!='#');//以#为循环条件
a=0;
3、让token函数为空,判断标示符前的是否为空格,有则ch要进一位
void scaner()
{
for(n=0;n<100;n++)
{token[n]='\0';}
n=0;
ch=sum[a++];//全局变量p=0
while(ch==' '){ch=sum[a++];}//有空格就继续(判断标识符前是否存在空格)
4、判断输入的字符类型,若为英文字符则输出种别码zbm=21
if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))
{
do{
token[n++]=ch;
ch=sum[a++];
}while((ch>='a'&&ch<='z')||(ch>='a'&&ch<='z'));
zbm=21;
5、 判断英文是否和关键字完全一样,是则输出各关键字种别码
for(n=0;n<18;n++)
{
if(strcmp(token,keyword[n])==0)//判断英文是否和关键字完全一样
{
zbm=n+1;
}
}
a--;
}
6、判断用户输入是否为数字,若是则输出种别码zbm=22
else if(ch>='0'&&ch<='9')
{
a--;
do
{
token[n++]=sum[a++];
ch=sum[a];
}while(ch>='0'&&ch<='9');
zbm=22;
return;
}
7、判断其他字符的种别码
else
{
switch(ch)
{
case '+':zbm=24;token[0]=ch;break;
case '-':zbm=25;token[0]=ch;break;
case '*':zbm=26;token[0]=ch;break;
case '/':zbm=27;token[0]=ch;break;
case ':':zbm=28;token[0]=ch;
ch=sum[a++];
if(ch=='='){token[1]=ch;zbm++;}
else a--;
break;
case '<':zbm=30;token[0]=ch;
ch=sum[a++];
if(ch=='='){token[1]=ch;zbm++;}
else if(ch=='>'){token[1]=ch;zbm=zbm+2;}
else a--;
break;
case '>':zbm=33;token[0]=ch;
ch=sum[a++];
if(ch=='='){token[1]=ch;zbm++;}
else a--;
break;
case '=':zbm=35;token[0]=ch;break;
case ';':zbm=36;token[0]=ch;break;
case '(':zbm=37;token[0]=ch;break;
case ')':zbm=38;token[0]=ch;break;
case '{':zbm=39;token[0]=ch;break;
case '}':zbm=40;token[0]=ch;break;
case '!':zbm=41;token[0]=ch;break;
case '@':zbm=42;token[0]=ch;break;
case '$':zbm=43;token[0]=ch;break;
case '%':zbm=44;token[0]=ch;break;
case '^':zbm=45;token[0]=ch;break;
case '&':zbm=46;token[0]=ch;break;
case '#':zbm=0;token[0]=ch;break;
default: printf("词法分析出错! 请检查是否输入非法字符\n");zbm=-1;break;
8、对用户输入的字符进行判断,并输入各字符类型的种别码zmb。直到zmb为0,则跳出循环,循环结束。
do
{
scaner();
printf("<%d,%s>\n",zbm,token);
}while(zbm!=0);
printf("感谢使用该系统\n");
getchar();
}
- 运行结果及分析
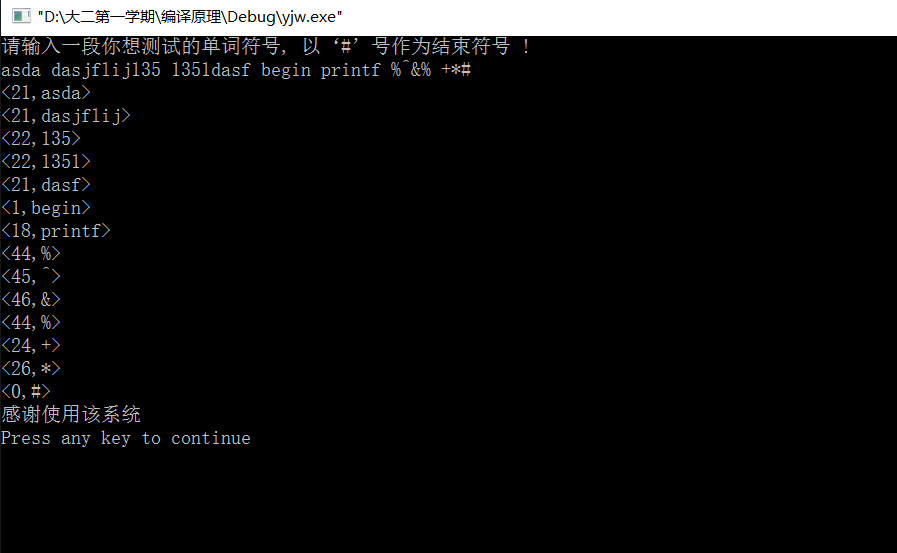
1.asda 是英文不是关键字,所以输出种别码为21
2.dasjflij 是英文不是关键字,所以输出种别码为21
3.135是数字,所以输出种别码为22
4.1351是数字,所以输出种别码为22
5.dasf 是英文不是关键字,所以输出种别码为21
6.Begin是英文且是关键字,所以输出对应种别码为1
7.Printf是英文且是关键字,所以输出对应种别吗为18
8.%是其他符号,所以输出对应种别码44
9.^是其他符号,所以输出对应种别码45
10.%是其他符号,所以输出对应种别码46
11.+是其他符号,所以输出对应种别码24
12.*是其他符号,所以输出对应种别码26
13.#是结束语,所以输出种别码为0
四、 实验总结
1.很有难度,在机房里憋了几个小时,还是搞不定,主要是在数字那一块
2.数字方面该程序是没有负数的,很多地方其实也都不算完美
3.通过与同学的交流,掌握了主要方法后发现其原理十分简单,把每一种类型都分开出来特殊处理就可以了
4.感觉像是复习了上学期C语言的内容,对这么课有了更深了理解
流程图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号