

DQN的第一次尝试 -- 软工结对编程第一次作业
DQN的第一次尝试
在本篇博客中将为大家形象地介绍一下我对DQN的理解,以及我和我的队友如何利用DQN进行黄金点游戏。最后我会总结一下基于我在游戏中看到的结果,得到的dqn使用的注意事项和这次游戏中我们应该改正的错误和改进的不足之处(可能只对黄金点有用,如果理解有误的话,可以指出,我立马改正)
问题定义
我的描述可能不太准确,这里直接使用参赛网站上对黄金点比赛的规则定义问题:
规则:N个玩家,每人写一个或两个0~100之间的有理数 (不包括0或100),提交给服务器,服务器在当前回合结束时算出所有数字的平均值,然后乘以0.618(所谓黄金分割常数),得到G值。提交的数字最靠近G(取绝对值)的玩家得到N分,离G最远的玩家得到-2分,其他玩家得0分。只有一个玩家参与时不得分。
我们本次比赛允许没人提交两个数,这就给了玩家很大的操作空间(提交一个大数或者小数进行扰动)
问题的难点,我认为主要在于选定合适的action和state,既能保证模型的更新速度,又能保证预测的action能起到得分的作用
方法建模
本次游戏中,每个玩家可拿到的信息有:之前的黄金点、每个玩家给出的数、每个玩家的得分。通过这些信息建模之后给出自己本轮认为可以得分的number1和number2。考虑到rl在游戏上的优异表现,我们本次采用的方法是DQN。下面介绍一下具体的建模方法。
Q Learning
这篇教程说得很好 --> 莫凡教程。 想要详细了解的小伙伴可以点开链接看一下。
提到dqn,必须要先介绍一下它的“前身” -- Q learning。dqn本质上是为了解决q learning的action-value表过大,有的状态更新不到的问题的。那什么是Q learning呢?我们在这里用石头剪刀布来举一下例子。
概念介绍
action
q learnig中的第一个核心是action。action指你未来可以进行的操作。在石头剪刀布中,action的定义就是我出石头、出剪刀或者是出布了。
value and reward
value则是q learning中的第二个核心。定义为你执行某一个action之后,在未来可以获得的收益值。
假设$value_t$为t时刻的value值。而你在t时刻选择了$action_i$,然后获得了$reward_t$(在石头剪刀布中,就是你每轮赢输或者平局)。那么你t时刻到未来可获得的收益值即为:你本轮获得收益加上你你未来获得收益。
$value_t = reward_t + value_{t+1}$
state
state则是q learning中的第三个核心。定义为你在当前的游戏状态,可以影响你下一步决策的游戏环境。在石头剪刀布中,state可以定义为你和你对手在之前的决策等。我们这里将state简化为上一轮你和对手的决策
流程
q learning维护了一张state-action的value表,这是什么意思呢?我们在这里虚构一张剪刀石头布中的q表:
| 剪刀 | 石头 | 布 | |
|---|---|---|---|
| 对手:布 你:石头 | 5 | 1 | 2 |
| 对手:布 你: 剪刀 | 4 | 2 | -1 |
| 对手:布 你:布 | 2 | -1 | 1 |
| 对手:石头 你:剪刀 | 3 | 0 | 4 |
| 。。。。 |
加设上一轮处于“对手:布 你: 剪刀”的状态。那么此时value值最大的action就是出剪刀(第三行),将这个值作为$value_{action}$。然后你下一轮出了剪刀之后,发现输了,因为对手出了石头。此时你需要更新自己的q表。
你拿到第二步的状态(对手:石头 你:剪刀),将这一状态下的max_value * gamma作为你未来的收益 ,再加上 你这一轮的收益(-1)。将这个值设为$value_{real}$, 更新$value_{action}$:
$value_{action_new} = value_{action} - lr * (value_{action} - value_{real})$
在上式中lr和gamma是人为设定的参数。
DQN
在上面石头剪刀布中,action相对较少,state我们也是用了一种简化的方式来模拟。在黄金点游戏中,action数比较多,state也很多。这种情况下是用一个神经网络代替q表,并周期的更新参数可以有效解决这个问题。
同时我们使用了Experience replay 和 Fixed Q-targets策略。
Experience replay:使用过去的状态acition对同时更新网络
Fixed Q-targte:使用两个net,一个(eval net)用于计算当前state下的value值,一个用于(target ney)计算使用action后未来的value。其中经常更新eval net。而target net 固定steps进行更新(与eval net 交换参数)。
由于我们第一轮的模型存在比较多的问题,现在就只给大家介绍一下第二轮的模型设置和流程
state
为了减小模型规模,我们只使用前10轮的黄金点作为状态。
action
有7个action:
- 使用上一轮的黄金点
- 使用上两轮黄金点的平均
- 使用前三轮黄金点的平均
- 使用周期为2的黄金点的平均
- 使用周期为3的黄金点的平均
- 使用最大的三个黄金点的平均
- 使用最小的三个黄金点的平均
model
我们的model为了减小参数和规模,只使用了全连接层。模型概念图如下
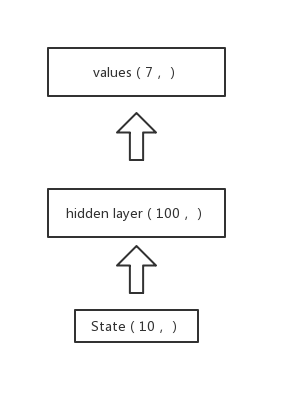
其他参数
memory size:最大记录前100轮的state1 action state2 reward
lr:0.1;在第50和500个step乘以0.1
batch size:8 ,在 50、100、 500、 1000个step成2
gamma:0.9
e_geedy:0.9
每20个step更新一次target net。
模型从15个step开始学习,从第50个step开始上线。
流程图
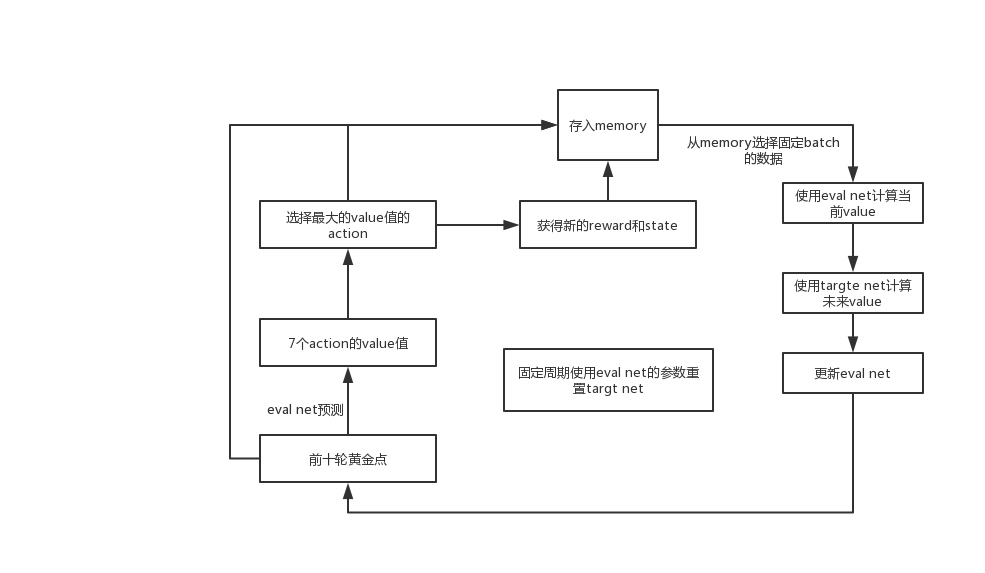
结果分析
我们第一轮的时候选择使用gru来选择action,同时state考虑了前20轮的user number、黄金点以及得分。action定义为选择的分数所在的区间。这导致了模型很难收敛,以及参数区间只要一预测错就会被扣分。最后的结果当然是分数惨淡,获得倒数第三名...
第二轮我们改进了策略,主要是改变了action,使每个action都是当前轮次中可能得分的action。简化模型,是的模型收敛速度加快。改变启动策略。
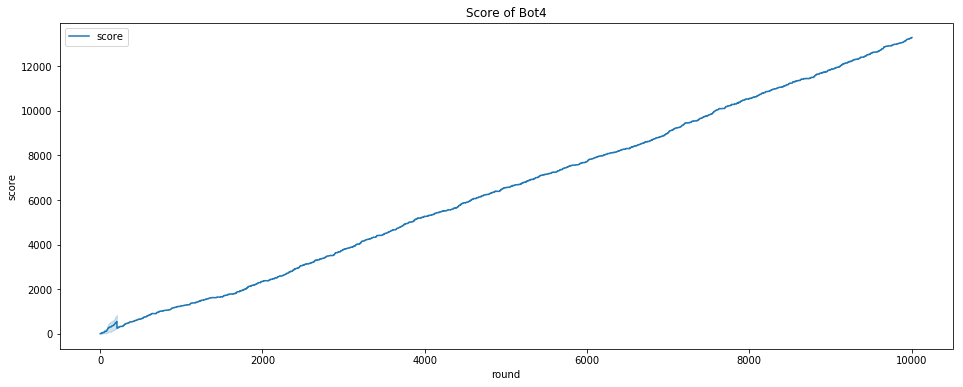
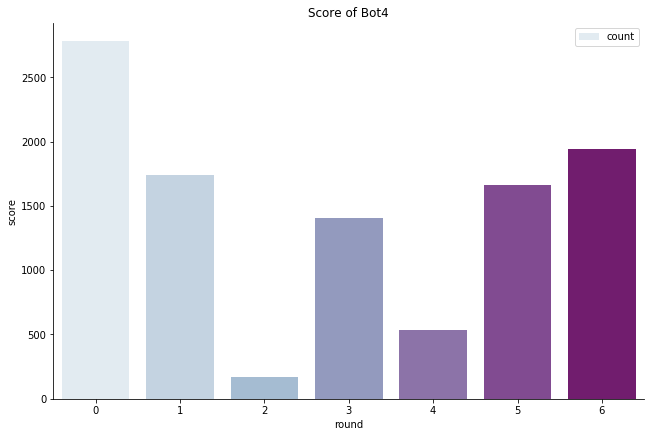
最后模型的效果如下,可以看到有的action还是很少使用的,而且我们目前阶段其实策略比较保守,没有像Bot8一样采用 扰动策略(来不及了)
分数趋势:
action1选择:
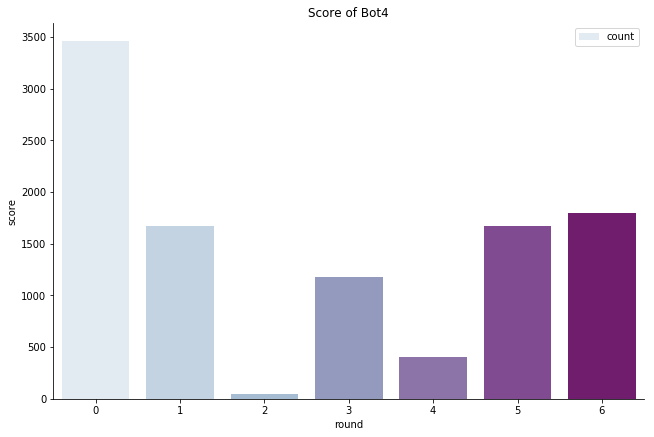
action2选择:
回答一下问题
- 我们其实没什么预期。。。第一轮有些失望,第二轮其实是超出了我们的预期的
- 比赛前,我们与其他选手进行了比赛,以及房间的ai进行了比赛,由此衡量模型的好坏
- 人数的多少并不影响我们方法的使用,但是效果是否会变好或者变差应该需要试验评估
- 我的队友真的是一个非常负责的队友,我本人其实在任务期间有mentor布置的工作要做,就很忙。很多时候事件的协调,debug等都是由我的队友负责的,非常感谢,而且最后队友提出的建议也在很大程度上改善了模型的效果!如果非要说什么不足的话,函数可以写短一点hhh, 主要是函数太长了hhh,debug比较麻烦。但是总体来说是非常好的,合作非常愉快~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号